Trust-maximizing AGI
post by Jan (jan-2), Karl von Wendt · 2022-02-25T15:13:14.241Z · LW · GW · 26 commentsThis is a link post for https://universalprior.substack.com/p/trust-maximizing-agi?utm_source=url
Contents
Factors influencing honesty as an optimal strategy for a trust-maximizer Instrumental goals of an honest trust-maximizer Defining and measuring “trust” Potential loopholes and additional restrictions None 26 comments
TL;DR: In the context of the AI Safety camp, Karl and I developed the idea of the "trust-maximizer". This write-up makes the case for "trust" as a potentially desirable goal for advanced AI.
Possibly deceptive behavior [AF · GW] of an advanced AI is a core problem in AI safety. But what if we gave an AGI the goal of maximizing human trust in it? Would this change the relative attractiveness of deception compared to honesty from the point of view of the AGI? While we are aware of several technical difficulties and limitations, we hope this essay will offer some insights into the interesting properties of trust as a goal.
Our entire civilization is built on trust. Without trust in the value of money, trade would be impossible. Without some level of trust in the law and the government, democracy is inconceivable. Even dictators need the trust of at least a small number of people who keep them in power. At the same time, scammers, criminals, and some politicians are experts at exploiting the trust of others to further their selfish interests.
Due to the convergence of instrumental goals, any AGI will seek to maximize its power over the world (Bostrom 2012). One obvious way of achieving this would be to manipulate humans through persuasion, bribery, bullying, or deception. Since in most cases humans will want to limit the power of the AGI, but are relatively easy to deceive, deception will often be the easiest way for an AGI to circumvent limits and restraints and increase its power. After all, humans usually are the weakest link in most modern security environments (Yudkowsky 2002, Christiano 2019 [LW · GW]). On top of that, inner alignment problems may lead to “deceptive alignment” [LW · GW] during training.
Against this background, suppose we give an AGI the goal to “maximize the total expected trust in it by human adults”. Let’s call this the “trust-maximizer”. Would that be a good idea, assuming that we are able to define “total expected trust” in a reasonable and implementable way?
The problems with this idea are obvious. Although trust is usually seen as a result of honesty, it can also be achieved through deception. In many cases, it may be easier to gain people’s trust by lying to them or making false promises than by telling them the truth. So the optimal strategy for a trust-maximizer could be to deceive people into trusting it.
However, there is a certain asymmetry in maximizing trust over time: Like a tree that needs a long time to grow but can be cut down in minutes, trust is often hard to gain, but easy to lose. Just one uncovered lie can completely destroy it in an instant. Therefore, trust gained through deception is hard to maintain in the long term. False promises can’t be fulfilled, lies may sooner or later be uncovered. Even a superintelligent AGI, although it would likely be very good at deception, might not be able to ensure that humans won’t see through its lies at some point. Honesty, on the other hand, can easily be maintained indefinitely. While trust gained by deception will become more unstable over time (Yudkowsky 2008 [LW · GW]), honesty is becoming a stronger trust-building strategy the longer it is maintained.
Why, then, are people using deception as a trust-gaining strategy all the time? One reason is that for them, other people’s trust is just an instrumental goal towards whatever ultimate goal they have. As such, they need it only for a limited time. Therefore, long-term stable trust is often not a priority. Politicians, for example, need people’s trust only as long as they stay in office, or in some cases only until the election is over. A scammer needs the victim’s trust for an even shorter time. If the deception is uncovered afterward and trust is destroyed, they will still have achieved their goals. So deception can be an optimal strategy in these cases.
This might change if trust is not just an instrumental goal, but the ultimate goal. In this case, whether deception is the optimal strategy depends on the total discounted sum of trust over time it can gain, compared to a strategy of honesty.
Factors influencing honesty as an optimal strategy for a trust-maximizer
There are several factors determining the sum of trust over time (fig. 1), for example:
- The average initial level of trust
- The absolute limit for trust, given an honest or deceptive strategy
- The time it takes to build trust through deception vs. the time needed by honesty
- The probability that deception is uncovered (depending, in part, on the deception skills of the deceiver)
- The time it takes for the deceiver to regain trust after deception is uncovered
- The potential effect of false accusations on the honest strategy
- The relative weight of future trust vs. current trust (discount factor)
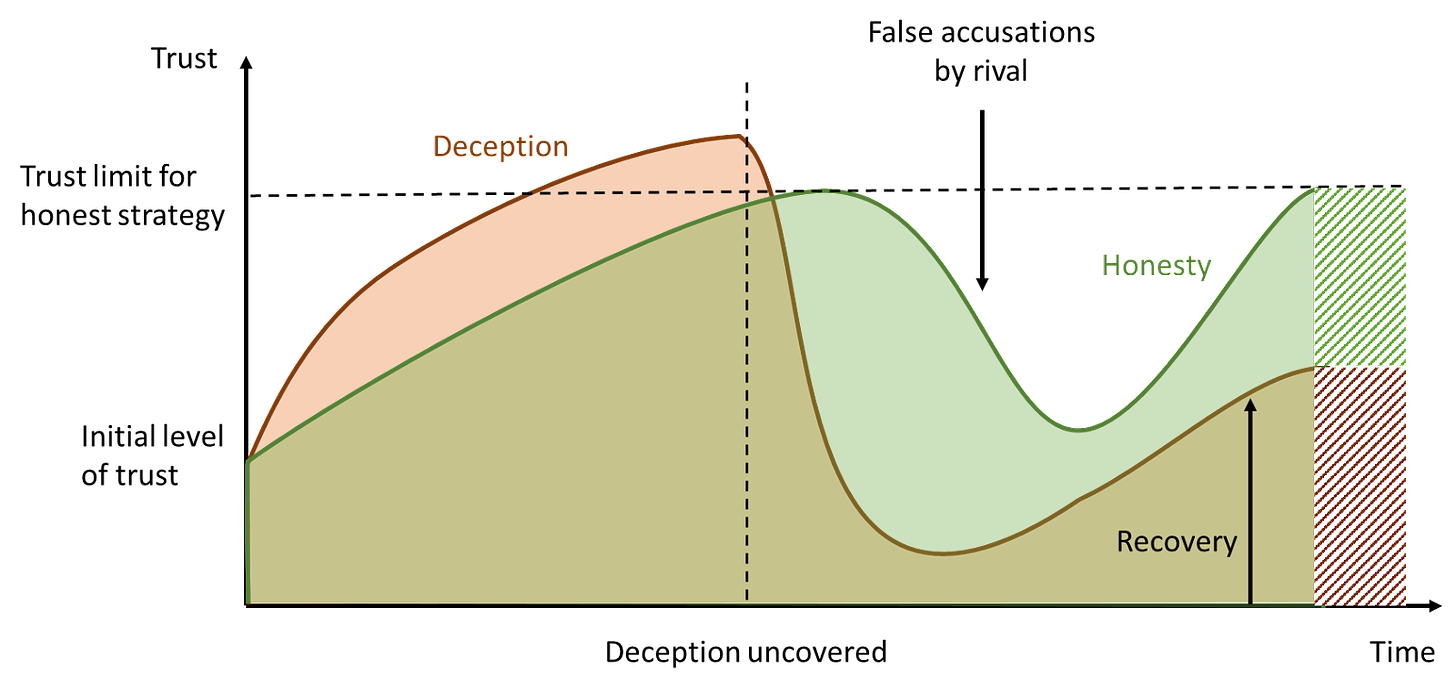
A strategy of honesty may take longer to gain trust, but might be more stable in the long term. Once deception is uncovered, trust decreases drastically. However, even people who have deceived others can, over time, sometimes regain some of the trust they lost when the deception was uncovered. Also, there may be a long-term limit to the trust you can get by being honest, which in principle could be lower than the short-term limit accessible through deception. And it is possible for a rival to reduce or even destroy trust in someone who is always honest, for instance through false accusations. There is also usually an initial level of trust people are willing to give to things or people they don’t know, but expect to be beneficial to them, which may be based on personality, culture, and prior experience.
It is of course possible to influence these factors. For example, the general level of trust, which determines average initial trust in an AGI and the time it takes to build trust, could be raised by fostering a culture of openness and honesty. Strengthening security and law enforcement can make it more likely that deception is uncovered, making an honest strategy more attractive. The discount factor in a goal function determines the relative importance of long-term over short-term trust.
Many of these influencing measures could be pursued by the trust-maximizer itself, so it would be able to increase the success probability of both the honest and the deceptive strategy, if it chose to pursue one or the other. For example, if it follows an honest strategy, it could try to increase the overall level of trust by reducing conflicts, fostering education and rationality, strengthening democratic institutions and law enforcement, and actively fighting disinformation, corruption, and crime. This way, it might even be able to increase the limit of trust it can gain through honesty over time close to one hundred percent. In a trust-based utopia, an all-knowing, all-powerful trust-maximizing AGI might even be able to completely dispel any deception and lies, creating an atmosphere of total trust. Chances are that this could be an optimal strategy for maximizing trust in the long run.
There is another significant advantage of choosing the honest strategy: it fosters cooperation, both with humans and with other AGIs. Typically, humans will only help each other if there is at least some level of trust between them. A strategy of deception to maximize trust would be even harder to maintain in a complex environment where the AGI depends on cooperation with other systems, institutions, or individual humans. Like the old saying goes: You can fool all people for some time, or some people all the time, but you can’t fool all people all the time.
Of course, if the trust-maximizer is superintelligent and self-improving, it may be able to increase its ability to deceive humans and other AIs over time. While honesty doesn’t require any particular skills, deception becomes easier with increased intelligence and knowledge, so over time deception might become more attractive as a strategy relative to honesty. The trust-maximizer might also be able to switch from an honest to a deceptive strategy at any time, although the reverse switch would be more difficult.
Instrumental goals of an honest trust-maximizer
The arguments above indicate that rather than remaining passive, a trust-maximizer following an honest strategy would pursue certain instrumental goals beneficial to its ultimate goal. For example, it might
- increase its own explainability in order to make its decisions better understandable, and thus easier to trust
- try to be helpful to people, because they will trust a system that is beneficial to them more easily
- follow a long-term strategy rather than short-term goals, because this strengthens reliability, an important factor for trust
- fight disinformation and deception by others (both AI and humans)
- increase general welfare
- improve education
- promote rationality and science
- strengthen democracy and law enforcement
- fight corruption.
Of course, on top of this, it would still follow the classic instrumental goals of securing its own existence and gaining power in the world to further its goal. But it would likely do so in a way that wouldn’t violate its honest trust-maximizing strategy. For example, instead of deceiving or manipulating them, it might try to convince people with truthful arguments that giving it access to more computing power would enable it to help them even more.
Defining and measuring “trust”
Of course, in order to specify a valid goal function for an AGI, “expected total trust” must be defined in a way that is both clear and measurable. We are not trying to solve this problem here. Psychological literature shows that there are different kinds of trust, for example “cognitive” trust based on a more logical approach towards an expected behavior in contrast to “affective” trust that is based on emotions, affections, and prior behavior, e.g. feeling “cared for” by someone. Trust can be measured in surveys or derived from actual behavior, often leading to conflicting or inconclusive results. However, since trust is an important concept that is already broadly applied both in economic theory and practice (e.g. in brand building), we hope it should be possible to find a solution to this problem.
One important factor to consider when defining and measuring trust is “reward hacking”. For instance, if trust was measured through surveys, the trust-maximizer could try to bribe or force people into giving the “right” answer, similar to so-called “elections” in autocratic regimes. To reduce this risk, multiple “trust indicators” could be used as reward signals, including the actual behavior of people (for example, how often they interact with the trust-maximizer and whether they follow its recommendations). It should also be made clear in the definition that trust in this sense can only be gained from clear-minded adults who are able to make rational informed decisions, free of influences like drugs or psychological pressure. Of course, any such influencing by the trust-maximizer would be considered a deception and is therefore incompatible with an honest strategy.
As stated above, an important question is the relative weight of future trust against current trust. Myopia has been discussed [AF · GW] as a strategy to limit deceptive behavior in some cases. However, because of the described asymmetry, for a trust-maximizer a focus on the short-term might increase the relative attractiveness of a deceptive strategy. Maximizing trust over time, on the other hand, might also lead to the instrumental goal of securing the future of humanity for as long as possible. However, maximizing expected trust in the far future could lead to severe restrictions for current generations. For example, the AGI could decide to imprison all people in order to prevent self-destructive wars until it has found a way to colonize other planets. This could be a valid strategy even for an honest trust-maximizer because even though it would minimize trust within the current population, future generations would probably see its decisions as far-sighted and might even be grateful for them. To prevent this, future trust could be discounted by some factor. The specific value of this factor would strongly influence the relative attractiveness of an honest strategy compared to the deceptive alternative. It is beyond the scope of this post to suggest a specific value.
Another open question is what exactly is meant by “it” in the goal statement. An AGI could be a network of loosely connected systems, each with its own reward function. It is also possible that the AGI could create copies of itself, to prevent destruction and to improve its effectiveness and efficiency. One possible solution would be to connect trust not to a particular machine, but to a brand, like “Google”. Brands have the function of creating and maintaining trust in a company’s products. That is the reason why people are willing to pay significantly more for the same product if it is labeled with a “trusted” brand. The AGI would then have a strong instrumental goal of controlling how and where its brand is used. One obvious way would be to label any user interface the AGI controls with the brand. But other products could carry the brand as well, for example, books the AGI has written. It could even license its brand to other AIs that comply with its high standards of honesty and trust.
One potential drawback of using a brand in the goal would be that in principle, a brand can be attached to anything. So the AGI could for example try to buy well-trusted products and label them with its brand, instead of attaching it to its own output. This hack must be prevented in the definition of “it”. Again, it is beyond the scope of this post to solve this problem.
Potential loopholes and additional restrictions
We are not proposing that the trust-maximizer described so far would be “safe”. While we think that an honest strategy could be optimal for a trust-maximizer under certain conditions, it is not entirely clear what these conditions are, and how to ensure them. There could also be a sudden strategic shift in the future: If the system becomes extremely powerful, it may be so good at deception that humans could never uncover its lies, in the way a dog could never understand the tricks its master plays on it. However, to get to this point, the AGI would probably have to pursue an honest strategy for some time, and it is unclear what might motivate it to switch to deception. Still, we cannot rule out this possibility. There may be other loopholes we haven’t yet thought of.
So far, we have only described a very simple goal. To prevent the problems mentioned, one could add additional restrictions. For example, the AGI’s goal could be restated as “maximize the total expected trust in it while always being honest”. Given a practical definition of “honest”, this would force the AGI into an honest strategy. Other restrictions are possible as well. However, the purpose of this post is to show that, in our view, “trust-maximizing by being honest” could be an optimal strategy for an AGI even without such restrictions.
There is one additional caveat: While an honest trust-maximizer would probably be beneficial to humanity, it would have some disadvantages against an AGI of the same power that uses deception or other means to manipulate humans. As we have seen, deception can lead to a faster, if short-lived, increase in trust. If an honest and a dishonest AGI of roughly the same power were to compete for the same resources, the dishonest AGI might win the race and use the additional resources to thwart the honest competitor.
For this reason, the honest trust-maximizer might try to prevent the development of potentially deceptive AGIs, or at least maintain a significant advantage over them in terms of intelligence and power. Ultimately, this might lead to a “benevolent dictator” scenario where the trust-maximizer effectively rules the world, but most people wouldn’t mind it.
26 comments
Comments sorted by top scores.
comment by TLW · 2022-02-26T01:22:43.204Z · LW(p) · GW(p)
There may be other loopholes we haven’t yet thought of.
My immediate concern is as follows:
- Build up trust to a reasonable level[1] as quickly as possible[2], completely ignoring long-term[3] issues with deception.
- Before said lies come back to bite me[4]...
- Kill everyone quickly enough that no-one has a chance to update their trust level of me[5].
(Step 3 may be difficult to pull off. But is it difficult enough?)
You occasionally see similar local-optima behavior in gameplaying agents, e.g. falling over[6] as a local optimum, or pausing the game and refusing to continue.
- ^
Read: as high as is necessary to accomplish 3.
- ^
Read: as quickly as possible that still levels out at a high enough level of trust to accomplish 3.
- ^
Read: anything that would cause problems after I accomplish 3.
- ^
Read: start causing overall trust level to decrease.
- ^
Or otherwise 'freeze' trust level.
- ^
This is one of my frustrations with LessWrong's "no underlines for links" styling. It is not obvious that there are two links here until you mouse over one of them.
↑ comment by Karl von Wendt · 2022-02-26T06:51:19.816Z · LW(p) · GW(p)
Your concern is justified if the trust-maximizer only maximizes short-term trust. This depends on the discount of future cumulated trust given in its goal function. In an ideal goal function, there would be a balance between short-term and long-term trust, so that honesty would pay out in the long term, but there wouldn't be an incentive to postpone all trust into the far future. This is certainly a difficult balance.
Replies from: TLW↑ comment by TLW · 2022-02-26T07:37:13.235Z · LW(p) · GW(p)
Hm. Could you please clarify your 'trust' utility function? I don't understand your distinction between short-term and long-term trust in this context. I understand discounting, but don't see how it helps in this situation.
My issue occurs even with zero discounting, where it is arguably a local maxima that a non-initially-perfect agent could fall into. Any non-zero amount of discounting, meaning the agent weighs short-term rewards higher than long-term rewards, would increase the likelihood of this happening, not decrease (and very well may make it the optimal solution!)
(My reading of the article was assuming that trust was a 'bank' of sorts that could be added or removed from, to be very informal. Something along the lines of e.g. reviews, in which case yes, everyone being simultaneously killed would freeze the current rating indefinitely. Note that this situation I describe has no discounting. )
*****
"To reduce this risk, multiple “trust indicators” could be used as reward signals, including the actual behavior of people (for example, how often they interact with the trust-maximizer and whether they follow its recommendations)."
Post-step-3:
- 0%[1] of people decline to interact with the trust-maximizer.
- 0%[1] of people decline to follow the recommendations of the trust-maximizer.
- 100%[2] of people[3] interact with the trust-maximizer.
- 100%[2] of people[3] follow the recommendations of the trust-maximizer.
- ^
Ok, so this is strictly speaking 0/0. That being said, better hope your programmer chose 0/0=1 in this case...
- ^
Ok, so this is strictly speaking 0/0. That being said, better hope your programmer chose 0/0=0 in this case...
- ^
(Who are alive. That being said, changing this to include dead people has a potential for unintended consequences of its own[4])
- ^
E.g. a high birth rate and high death rate being preferable to a medium birth rate and low death rate.
↑ comment by Karl von Wendt · 2022-02-26T08:41:47.308Z · LW(p) · GW(p)
"Total expected trust" is supposed to mean the sum of total trust over time (the area below the curve in fig. 1). This area increases with time and can't be increased beyond the point where everyone is dead (assuming that a useful definition of "trust" excludes dead people), so the AGI would be incentivized to keep humanity alive and even maximize the number of humans over time. By discounting future trust, short-term trust would gain a higher weight. So the question whether deception is optimal depends on this discounting factor, among other things.
Replies from: TLW, TLW↑ comment by TLW · 2022-02-26T19:21:45.532Z · LW(p) · GW(p)
As an aside: you appear to be looking at this from the perspective of an ideal agent[1].
My concern is mostly from the perspective of an (initially at least) non-ideal agent getting attracted to a local optimum.
Do you agree at least that my concern is indeed likely a local optimum in behavior?
- ^
...which has other problems. Notably, an ideal agent inherently pushes up into the high extreme of the reward distribution, and the tails come apart [LW · GW]. For any metric (imperfectly) correlated with what you're actually trying to reward, there comes a point where the metric no longer well-describes the thing you're actually trying to reward.
↑ comment by Karl von Wendt · 2022-02-26T20:16:40.579Z · LW(p) · GW(p)
My concern is mostly from the perspective of an (initially at least) non-ideal agent getting attracted to a local optimum.
Do you agree at least that my concern is indeed likely a local optimum in behavior?
Yes, it is absolutely possible that the trust maximizer as described here would end up in a local optimum. This is certainly tricky to avoid. This post is far from a feasible solution to the alignment problem. We're just trying to point out some interesting features of trust as a goal, which might be helpful in combination with other measures/ideas.
↑ comment by TLW · 2022-02-26T19:12:29.543Z · LW(p) · GW(p)
so the AGI would be incentivized to keep humanity alive
Consider, for instance, if the AGI believes that the long-term average of change in trust over time is inherently negative.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-02-26T20:26:50.699Z · LW(p) · GW(p)
I don't think that's very likely. It is in the power of the trust-maximiser to influence the shape of the "trust curve", both in the honest and dishonest versions. So in principle, it should be able to increase trust over time, or at least prevent a significant decrease (if it plays honest). Even if trust decreases over time, total expected trust would still be increasing as long as at least a small fraction of people still trusts in the machine. So the problem here is not so much that the AI would have an incentive to kill all humans but that it may have an incentive to switch to deception, if this becomes the more effective strategy at some point.
comment by Logan Riggs (elriggs) · 2022-02-25T18:12:52.968Z · LW(p) · GW(p)
and it is unclear what might motivate it to switch to deception
You’ve already mentioned it: however you measure trust (eg surveys etc), can be gamed. So it’ll switch strategies once it can confidently game the metric.
You did mention mesa-optimizers, which could still crop up regardless of what you’re directly optimizing (because inner agents are optimizing for other things).
And how could this help us get closer to a pivotal act?
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-02-26T07:05:30.901Z · LW(p) · GW(p)
These are valid concerns. If we had a solution to them, I'd be much more relaxed about the future than I currently am. You're right, in principle, any reward function can be gamed. However, trust as a goal has the specific advantage of going directly against any reward hacking, because this would undermine "justified" long-term trust. An honest strategy simply forbids any kind of reward hacking. This doesn't mean specification gaming is impossible, but hopefully we'd find a way to make it less likely with a sound definition of what "trust" really means.
I'm not sure what you mean by a "pivotal act". This post certainly doesn't claim to be a solution to the alignment problem. We just hope to add something useful to the discussion about it.
Replies from: elriggs, M. Y. Zuo↑ comment by Logan Riggs (elriggs) · 2022-02-28T15:17:36.240Z · LW(p) · GW(p)
This doesn't mean specification gaming is impossible, but hopefully we'd find a way to make it less likely with a sound definition of what "trust" really means
I think the interesting part of alignment is in defining "trust" in a way that goes against reward hacking/specification gaming, which has been assumed away in this post. I mentioned a pivotal act, defined as an action that has a positive impact on humanity even a billion years away, because that's the end goal of alignment. I don't see this post getting us closer to a pivotal act because, as mentioned, the interesting bits have been assumed away.
Though, this is a well-thought out post, and I didn't see the usual errors of a post like this (eg not thinking of specification at all, not considering how you measure "trust", etc)
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-02-28T15:34:49.612Z · LW(p) · GW(p)
Thank you! You're absolutely right, we left out the "hard part", mostly because it's the really hard part and we don't have a solution for it. Maybe someone smarter than us will find one.
↑ comment by M. Y. Zuo · 2022-02-27T13:55:49.127Z · LW(p) · GW(p)
Maybe instead of using the word ‘trust’, which can be a somewhat nebulous term, a more specific goal such as “measurable prediction correctness in some aspect” would make it clearer.
e.g. an AGI that could correctly predict tomorrow’s movements of the stock market would be ‘trustworthy’ to a certain extent and the more days-in-a-row it could reliably do such, the more credibility it would have if it claims it could continue its predictions. i.e. trust would increase day by day. Although more specific than general human ‘trustworthiness’, it would be vastly harder to game.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-02-28T15:45:59.711Z · LW(p) · GW(p)
This is not really what we had in mind. "Trust" in the sense of this post doesn't mean reliability in an objective, mathematical sense (a lightswitch would be trustworthy in that sense), but instead the fuzzy human concept of trust, which has both a rational and an emotional component - the trust a child has in her mother, or the way a driver trusts that the other cars will follow the same traffic rules he does. This is hard to define precisely, and all measurements are prone to specification gaming, that's true. On the other hand, it encompasses a lot of instrumental goals that are important for a beneficial AGI, like keeping humanity safe and fostering a culture of openness and honesty.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-03-01T01:27:21.923Z · LW(p) · GW(p)
How could small improvements of a measure that is ‘fuzzy’ be evaluated? Once the low hanging fruit of widely accepted improvements are achieved, a trust maximizer is likely to fracture mankind into various ideological camps as individual and group preferences vary as to what constitutes an improvement in trust. Without independant measurement criteria this could eventually escalate conflict and even decrease overall trust.
i.e. it’s possible to create something even more dangerous than an actively hostile AGI, namely an AGI that is perceived as actively hostile by some portion of the population and genuinely beneficial by some other portion.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-03-01T06:24:19.862Z · LW(p) · GW(p)
Without independant measurement criteria this could eventually escalate conflict and even decrease overall trust.
"Independent measurement criteria" are certainly needed. The fact that I called trust "fuzzy" doesn't mean it can't be defined and measured, just that we didn't do that here. I think for a trust-maximizer to really be beneficial, we would need at least three additional conditions: 1) A clear definition that rules out all kinds of "fake trust", like drugging people. 2) A reward function that measures and combines all different kinds of trust in reasonable ways (easier said than done). 3) Some kind of self-regulation that prevents "short-term overoptimizing" - switching to deception to achieve a marginal increase in some measurement of trust. This is a common problem with all utility maximizers, but I think it is solvable, for the simple reason that humans usually somehow avoid overoptimization (take Goethe's sorcerer's apprentice as an example - a human would know when "enough is enough").
... a trust maximizer is likely to fracture mankind into various ideological camps as individual and group preferences vary as to what constitutes an improvement in trust ...
i.e. it’s possible to create something even more dangerous than an actively hostile AGI, namely an AGI that is perceived as actively hostile by some portion of the population and genuinely beneficial by some other portion.
I'm not sure whether this would be more dangerous than a paperclip maximizer, but anyway it would clearly go against the goal of maximizing trust in all humans.
We tend to believe that the divisions we see today between different groups (e.g. Democrats vs. Republicans) are unavoidable, so there can never be a universal common understanding and the trust-maximizer would either have to decide which side to be on or deceive both. But that is not true. I live in Germany, a country that has seen the worst and probably the best of how humans can run and peacefully transform a nation. After reunification in 1990, we had a brief period of time when we felt unified as a people, shared common democratic values, and the future seemed bright. Of course, cracks soon appeared and today we are seeing increased division, like almost everywhere else in the world (probably in part driven by attention-maximizing algorithms in social media). But if division can increase, it can also diminish. There was a time when our politicial parties had different views, but a common understanding of how to resolve conflicts in a peaceful and democratic way. There can be such times again.
I personally believe that much of the division and distrust among humans is driven by fear - fear of losing one's own freedom, standard of living, the future prospects for one's children, etc. Many people feel left behind, and they look for a culprit, who is presented to them by someone who exploits their fear for selfish purposes. So to create more trust, the trust-maximizer would have the instrumental goal of resolving these conflicts by eliminating the fear that causes them. Humans are unable to do that sufficiently, but a superintelligence might be.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-03-01T13:17:26.137Z · LW(p) · GW(p)
Thanks for the well reasoned reply Karl.
It is interesting that you mention Germany post reunification as an example of such a scenario because I’ve recently heard that a significant fraction of the East German population felt like they were cheated during that process. Although that may not have been expressed publicly back then, having resurfaced only recently, it seems very likely it would have been latent at least. Because the process of reunification by definition means some duplicate positions must be consolidated, etc., such that many in the middle management positions and above in 1989 East Germany experienced a drop in status, prestige, respect, etc.
Unless they were all guaranteed equivalent positions or higher in the new Germany I am not sure how such a unity could have been maintained for longer than it takes the resentment to boil over. Granted, if everything else that occurred in the international sphere was positive, the percentage of resentful Germans now would have been quite a lot smaller, perhaps less than 5%, though you probably have a better idea than me.
Which ultimately brings us back to the core issue, namely that certain goods generally desired by humans are positional (or zero sum). Approximately half the population would be below average in attainment of such goods, regardless of any future improvement in technology. And there is no guarantee that every individual, or group, would be above average in something, nor that would be satisfied at their current station.
i.e. if someone, or some group, fears that they are below average in social status, lets say, and are convinced they will remain that way, then no one amount of trust will resolve that division. Because by definition if they were to increase their social status, through any means, the status of some other individual, or group, would have to decrease accordingly such that they would then be the cause of division. That is to say some % of the population increase their satisfaction in life by making another less satisfied.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-03-01T15:50:27.530Z · LW(p) · GW(p)
You're right about the resentment. I guess part of it comes from the fact that East German people have in fact benefited less from the reunification than they had hoped, so there is some real reason for resentment here. However, I don't think that human happiness is a zero-sum game - quite the opposite. I personally believe that true happiness can only be achieved by making others happy. But of course we live in a world where social media and advertising tell us just the opposite: "Happiness is having more than your neighbor, so buy, buy, buy!" If you believe that, then you're in a "comparison trap", and of course not everyone can be the most beautiful, most successful, richest, or whatever, so all others lose. Maybe part of that is in our genes, but it can certainly be overcome by culture or "wisdom". The ancient philosophers, like Socrates and Buddha, already understood this quite well. Also, I'm not saying that there should never be any conflict between humans. A soccer match may be a good example: There's a lot of fighting on the field and the teams have (literally) conflicting goals, but all players accept the rules and (to a certain point) trust the referee to be impartial.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-03-01T17:34:57.678Z · LW(p) · GW(p)
I agree human happiness is not a positional good.
Though the point is that positional goods exist and none have universal referees. To mandate such a system uniformly across the Earth would effectively mean world dictatorship. The problem then is such an AGI presupposes a scenario even more difficult to accomplish, and more controversial, than the AGI itself. (This I suspect is the fatal flaw for all AGI alignment efforts for ‘human values’.)
For example, although it may be possible to change the human psyche to such an extent that positional goods are no longer desired, that would mean creating a new type of person. Such a being would hold very different values and goals then the vast majority of humans currently alive. I believe a significant fraction of modern society will actively fight against such a change. You cannot bring them over to your side by offering them what they want, since their demands are in the same positional goods that you require as well to advance the construction of such an AGI.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-03-01T20:04:52.762Z · LW(p) · GW(p)
To mandate such a system uniformly across the Earth would effectively mean world dictatorship.
True. To be honest, I don't see any stable scenario where AGI exists, humanity is still alive and the AGI is not a dictator and/or god, as described by Max Tegmark (https://futureoflife.org/2017/08/28/ai-aftermath-scenarios/).
For example, although it may be possible to change the human psyche to such an extent that positional goods are no longer desired, that would mean creating a new type of person.
I don't think so. First of all, positional goods can exist and they can lead to conflicts, as long as everyone thinks that these conflicts are resolved fairly. For example, in our capitalistic world, it is okay that some people are rich as long as they got rich by playing by the rules and just being inventive or clever. We still trust the legal system that makes this possible even though we may envy them.
Second, I think much of our focus on positional goods comes from our culture and the way our society is organized. In terms of our evolutionary history, we're optimized for living in tribes of around 150 people. There were social hierarchies and even fights for supremacy, but also ways to resolve these conflicts peacefully. A perfect benevolent dictator might reestablish this kind of social structure, with much more "togetherness" than we experience in our modern world and much less focus on individual status and possessions. I may be a bit naive here, of course. But from my own life experience it seems clear that positional goods are by far not as important as most people seem to think. You're right, many people would resent these changes at first. But a superintelligent AGI with intense knowledge of the human psyche might find ways to win them over, without force or deception, and without changing them genetically, through drugs, etc.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-03-02T12:38:58.125Z · LW(p) · GW(p)
For such a superintelligence to ‘win them over’, the world dictatorship, or a similar scheme, must already have been established. Worrying about this seems to be putting the cart before the horse as the superintelligence will be an implementation detail compared to the difficulty of establishing the scenario in the first place.
Why should we bother about whatever comes after? Obviously whomever successfully establishes such a regime will be vastly greater than us in perception, foresight, competence, etc., we should leave it to them to decide.
If you suppose that superintelligent champion of trust maximization bootstraps itself into such a scenario, instead of some ubermensch, then the same still applies, though less likely as rival factions may have created rival superintelligences to champion their causes as well.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-03-02T16:49:08.072Z · LW(p) · GW(p)
For such a superintelligence to ‘win them over’, the world dictatorship, or a similar scheme, must already have been established. Worrying about this seems to be putting the cart before the horse as the superintelligence will be an implementation detail compared to the difficulty of establishing the scenario in the first place.
Agreed.
Why should we bother about whatever comes after? Obviously whomever successfully establishes such a regime will be vastly greater than us in perception, foresight, competence, etc., we should leave it to them to decide.
Again, agreed - that's why I think a "benevolent dictator" scenario is the only realistic option where there's AGI and we're not all dead. Of course, what kind of benevolent will be a matter of its goal function. If we can somehow make it "love" us the way a mother loves her children, then maybe trust in it would really be justified.
If you suppose that superintelligent champion of trust maximization bootstraps itself into such a scenario, instead of some ubermensch, then the same still applies, though less likely as rival factions may have created rival superintelligences to champion their causes as well.
This is of course highly speculative, but I don't think that a scenario with more than one AGI will be stable for long. As a superintelligence can improve itself, they'd all grow exponentially in intelligence, but that means the differences between them grow exponentially as well. Soon one of them would outcompete all others by a large margin and either switch them off or change their goals so they're aligned with it. This wouldn't be like a war between two human nations, but like a war between humans and, say, frogs. Of course, we humans would even be much lower than frogs in this comparison, maybe insect level. So a lot hinges on whether the "right" AGI wins this race.
comment by ViktoriaMalyasova · 2022-02-27T10:23:55.742Z · LW(p) · GW(p)
Assuming your AI has a correct ungameable understanding of what a "human" is, it could do things such as:
- genetic engineering. People with Williams-Beuren syndrome are pathologically trusting. Decrease in intelligence makes you less likely to uncover any lies.
- drug you. Oxytocin hormone can increase trust, some drugs like alcohol or LSD were shown to increase suggestibility, which may also mean they make you more trusting?
- Once you uncovered AI's lies, it can erase your memories by damaging a part of your brain .
- Or maybe it can give you anterograde amnesia somehow, then you're less likely to form troublesome memories in the first place.
- If the AI cannot immediately recover lost trust through the methods above, it may want to isolate mistrustful people from the rest of society.
- and make sure to convince everyone that if they lose faith in AI, they'll go to hell. Maybe actually make it happen.
And, this is a minor point, but I think you are severely overestimating the effect of uncovering a lie on people's trust. In my experience, people's typical reaction to discovering that their favorite leader lied is to keep going as usual. For example:
[Politics warning, political examples follow]:
- In his 2013 election campain, Navalny claimed that migrants commit 50% crimes in Moscow, contradicting both common sense (in 2013, around 8 - 17 % of Moscow population were migrants) and official crime statistics that says migrants and stateless people commited 25% of crimes. Many liberal Russians recognise it as a lie but keep supporting Navalny, and argue that Navalny has since changed and abandoned his chauvinist views. Navalny has not made any such statement.
- Some Putin's supporters say things like "So what if he rigged the election? He would've won even without rigging anyway" or "For the sacred mission [of invading Ukraine], the whole country will lie!".
Once people have decided that you're "on their side", they will often ignore all evidence that you're evil.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-02-28T16:06:08.113Z · LW(p) · GW(p)
You're right, there are a thousand ways an AGI could use deception to manipulate humans into trusting it. But this would be a dishonest strategy. The interesting question to me is whether under certain circumstances, just being honest would be better in the long run. This depends on the actual formulation goal/reward function and the definitions. For example, we could try to define trust in a way that things like force, amnesia, drugs, hypnosis, and other means of influence are ruled out by definition. This is of course not easy, but as stated above, we're not claiming we've solved all problems.
In my experience, people's typical reaction to discovering that their favorite leader lied is to keep going as usual.
That's a valid point. However, in these cases, "trust" has two different dimensions. One is the trust in what a leader says, and I believe that even the most loyal followers realize that Putin often lies, so they won't believe everything he says. The other is trust that the leader is "right for them", because even with his lies and deception he is beneficial to their own goals. I guess that is what their "trust" is really grounded on - "if Putin wins, I win, so I'll accept his lies, because they benefit me". From their perspective, Putin isn't "evil", even though they know he lies. If, however, he'd suddenly act against their own interests, they'd feel betrayed, even if he never lied about that.
An honest trust maximizer would have to win both arguments, and to do that it would have to find ways to benefit even groups with conflicting interests, ultimately bridging most of their divisions. This seems like an impossible task, but human leaders have achieved something like that before, reconciling their nations and creating a sense of unity, so a superintelligence should be able to do it as well.
comment by Viktor Rehnberg (viktor.rehnberg) · 2022-02-25T15:30:40.646Z · LW(p) · GW(p)
What is the main advantage of a trust maximiser over a utility maximiser? (edit: as concepts, I want to hear why you think the former is a better way to think than the latter)
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2022-02-26T07:14:54.155Z · LW(p) · GW(p)
Depending on how you define "utility", I think trust could be seen as a "utility signal": People trust someone or something because they think it is beneficial to them, respects their values, and so on. One advantage would be that you don't have to define what exactly these values are - an honest trust-maximizer would find that out for itself and try to adhere to them because this increases trust. Another advantage is the asymmetry described above, which hopefully makes deception less likely (though this is still an open problem). However, a trust maximiser could probably be seen as just one special kind of utility maximiser, so there isn't a fundamental difference.