Neural uncertainty estimation review article (for alignment)
post by Charlie Steiner · 2023-12-05T08:01:32.723Z · LW · GW · 3 commentsContents
Introduction The Bayesian neural network picture Ensembles Note on aleatoric uncertainty Adding noise, which for some reason is usually dropout Calibration Training a higher order model Comparing methods Future work I want from this field Relevance to alignment, conclusion None 3 comments
EDIT 1/27: This post neglects the entire sub-field of estimating uncertainty of learned representations, as in https://openreview.net/pdf?id=e9n4JjkmXZ. I might give that a separate follow-up post.
Introduction
Suppose you've built some AI model of human values. You input a situation, and it spits out a goodness rating. You might want to ask: "What are the error bars on this goodness rating?" In addition to it just being nice to know error bars, an uncertainty estimate can also be useful inside the AI: guiding active learning[1], correcting for the optimizer's curse [LW · GW][2], or doing out-of-distribution detection[3].
I recently got into the uncertainty estimation literature for neural networks (NNs) for a pet reason [? · GW]: I think it would be useful for alignment to quantify the domain of validity of an AI's latent features. If we point an AI at some concept in its world-model [LW · GW], optimizing for realizations of that concept can go wrong by pushing that concept outside its domain of validity.
But just keep thoughts of alignment in your back pocket for now. This post is primarily a survey of the uncertainty estimation literature, interspersed with my own takes.
The Bayesian neural network picture
The Bayesian NN picture is the great granddaddy of basically every uncertainty estimation method for NNs, so it's appropriate to start here.
The picture is simple. You start with a prior distribution over parameters. Your training data is evidence, and after training on it you get an updated distribution over parameters. Given an input, you calculate a distribution over outputs by propagating the input through the Bayesian neural network.
This would all be very proper and irrelevant ("Sure, let me just update my dimensional joint distribution over all the parameters of the model"), except for the fact that actually training NNs does kind of work this way. If you use a log likelihood loss and L2 regularization, the parameters that minimize loss will be at the peak of the distribution that a Bayesian NN would have, if your prior on the parameters was a Gaussian[4][5].
This is because of a bridge between the loss landscape and parameter uncertainty. Bayes's rule says . Here is your posterior distribution you want to estimate, and is the exponential of the loss[6]. This lends itself to physics metaphors like "the distribution of parameters is a Boltzmann distribution sitting at the bottom of the loss basin."
Empirically, calculating the uncertainty of a neural net by pretending it's adhering to the Bayesian NN picture works so well that one nice paper on ensemble methods[7] called it "ground truth." Of course to actually compute anything here you have to make approximations, and if you make the quick and dirty approximations (e.g. pretend you can find the shape of the loss basin from the Hessian) you get bad results[8], but people are doing clever things with Monte Carlo methods these days[9], and they find that better approximations to the Bayesian NN calculation get better results.
But doing Monte Carlo traversal of the loss landscape is expensive. For a technique to apply at scale, it must impose only a small multiplier on cost to run the model, and if you want it to become ubiquitous the cost it imposes must be truly tiny.
Ensembles
A quite different approach to uncertainty is ensembles[10]. Just train a dozen-ish models, ask them for their recommendations, and estimate uncertainty from the spread. The dozen-times cost multiplier on everything is steep, but if you're querying the model a lot it's cheaper than Monte Carlo estimation of the loss landscape.
Ensembling is theoretically straightforward. You don't need to pretend the model is trained to convergence, you don't need to train specifically for predictive loss, you don't even need a fixed architecture. You just pick some distribution of models you want to spread uncertainty over and sample.
You can do some clever things with ensembles. By calculating how ensembles fit into the Bayesian NN picture, you learn that it might be a good idea to vary the zero-points of the regularization, or else you'll get spurious correlations in how your models generalize[7]. You can split up the dataset and train separate smaller models that you then aggregate cleverly (kind of like bagging and boosting), to reduce the compute premium of ensembles[10]. There are hints in these papers that clever ensembling tricks matter less at larger scales, but it's unclear if the benefits entirely go to zero.
One tricky part of ensembles is if there's a coin that lands Heads 51% of the time, and you've trained your NNs to (explicitly or implicitly) bet on the outcome, every single member of your ensemble will bet on Heads. The right answer is not uncertain, so your ensemble says there's no uncertainty. If you want your uncertainty metric to include entropy in the environment, you have to train your NNs to estimate that entropy, which mostly gives up the freedom to use non-predictive loss.
Similar care when interpreting applies to using ensembles on latent features of the model, though I don't see people doing that in the literature. Suppose you train a dozen models and probe them with data about dogs to find a "dog vector" for each. You can normalize the size and variance of these and then use the variance of the ensemble as an "uncertainty of the dog vector." This isn't the total uncertainty about dogs because it doesn't measure the uncertainty about dogs in the AI's model, it's just the spread of different models' internal-representation-according-to-a-specific-probing-method.
Note on aleatoric uncertainty
A sizeable fraction of words in the literature is about a distinction between aleatoric uncertainty and epistemic uncertainty[11]. This is that distinction I just had to talk about when I said that ensembles tell you about uncertainty in the output that's due to modeling choices, but don't tell you about uncertainty the AI internally has about the environment. In the uncertainty estimation literature, the uncertainty due to variance of models gets called "epistemic," and the uncertainty inside the AI's model of the environment gets called "aleatoric."[12]
In the big data limit, epistemic uncertainty becomes small relative to aleatoric uncertainty (unless you deliberately push your model into situations of high epistemic uncertainty). Some papers forget this and do dumb stuff that makes their epistemic uncertainty estimate larger because they think it should be the total uncertainty, which is why other papers have to devote sections to talking about the distinction.
Adding noise, which for some reason is usually dropout
If you want an uncertainty estimate, you can just add random noise into the intermediate activations of your neural net. If the output is more sensitive to noise that's more uncertainty, and if the output is less sensitive that's less uncertainty[13]. There are natural heuristic arguments why this makes sense[14], and with a little more work you can try to connect this to the Bayesian NN picture and Monte Carlo estimates of the loss landscape.
Or, you could ignore the abstract arguments and use dropout as your random noise distribution[15].
Oh sure, people give justifications, but I think first impressions are correct here and adding dropout and then sampling is theoretically silly. Experimentally, though, it works well enough that people keep talking about it[16][17][18], and it doesn't require you to do any extra training.
One piece of the puzzle for why it works at all may be that networks trained on a dataset that has some noisy samples will learn to output a catch-all prior in response to noise[19]. I suspect dropout is large enough noise that it pushes networks towards this prior, and this helps with overconfidence.
I wish people did more comparisons with smaller, non-dropout noise[20]. That seems more theoretically sound, although injecting noise into internal layers seems to correspond to an interesting but unusual noise distribution when translated back into Bayesian terms.
Calibration
A fairly big chunk of the literature[16] is people just trying to take outputs of neural nets and apply simple functions to them to get uncertainty estimates. I will treat them briefly.
The zeroth level is just taking NN outputs at face value. When there's lots of data and so parameter uncertainty is small, the direct prediction of a neural net is a good estimate of uncertainty. For instance, base GPT-4 is very well-calibrated in the probability distributions it assigns to next tokens, including when those next tokens are the answers to test questions it's never seen before[21]. Even off-distribution, this is better than nothing - as I mentioned above, NNs do learn to be uncertain about surprising data if their training set has included surprises[19], though they still tend to be overconfident.
As models get better at generalizing, I expect their outputs to be well-calibrated in larger domains. Though conversely, for applications where you're training a small model on limited data you're going to want a different way to estimate uncertainty.
Usually people try to be a little fancier than the zeroth level, and do something like tweaking parameters of the softmax function to maximize calibration on a held-out validation set[22]. This is also pretty easy to combine with other methods as a final calibration step[23].
If you have a sample of out-of-distribution (OOD) data you can do still fancier things like simultaneous OOD detection and calibration[24]. Or if you have a sample of OOD data and are a frequentist, you can do conformal prediction[25].
A selling point of calibration is that you can do this to any trained model. But if you're willing to give that up and intervene on training, there are ways to improve a model's calibration. This might look like training with additional regularization[26] or contrastive examples[27]. These also improve OOD generalization to a degree, as does adversarial training[28].
Ultimately, calibration of a network's outputs doesn't seem to do the things I want from an uncertainty estimation method. For one, it doesn't estimate the uncertainty of latent features, it's all about the uncertainty of the outputs you have data for.
For another, it lacks robustness to search [LW · GW][29]. It's true that all the other uncertainty estimation methods should also be vulnerable to adversarial examples when optimized against (in part because adversarial examples are features, not bugs[30]), but when the network output and its uncertainty estimate are one and the same, local search for good outputs should be extra effective at finding weird unintended optima[31].
Training a higher order model
The flip side to calibration. Just get your neural net to give you a better uncertainty estimate in the first place.
If you want to get estimates of second-order uncertainty, train a neural net to output parameters of a Dirichlet distribution instead of doing normal classification[32][33]. Or if you're doing regression, train the neural net to output the parameters of a distribution over answers[10]. Or if you have a LLM and every problem is a nail, train your LLM to express uncertainty in words[34][35].
One subtle problem with training models to express uncertainty: there's no such thing as a proper second-order loss function[36]. This means that just from datapoints alone, it's hard to accurately train a model to give probability distributions - you can make loss functions that try to do this, but so long as you only have supervision on what the correct answer was and not on what the correct probability distribution was, the probability distributions you get out of loss minimization will be biased.
Bayesian methods, or at least a Bayesian theoretical framework, would be useful here. You don't need a proper loss function to do Bayesian updates. But nobody's written down the analogue of the Bayesian NN picture for this application yet.
It's also theoretically unclear how to integrate other sorts of supervisory data we can get about the probability distribution. For example, artificially noisy examples can give a direct supervisory signal that the right probability distribution is high-entropy. Alternatively, we could learn a distribution by asking "How much do I expect my estimate of the right answer to change with more data?" which has supervision distributed across the dataset and thus bypasses the proof of no proper scoring rules - but can we do that in a way that's unbiased?
Comparing methods
So, which is the best?
Tentatively, it's training an ensemble. But training higher order models has unexplored potential.
The situation is unclear because the comparisons are made on toy problems, the literature is small and doesn't always replicate, comparisons are hard because there are a dozen variations of each method, and different papers sometimes evaluate totally different metrics.
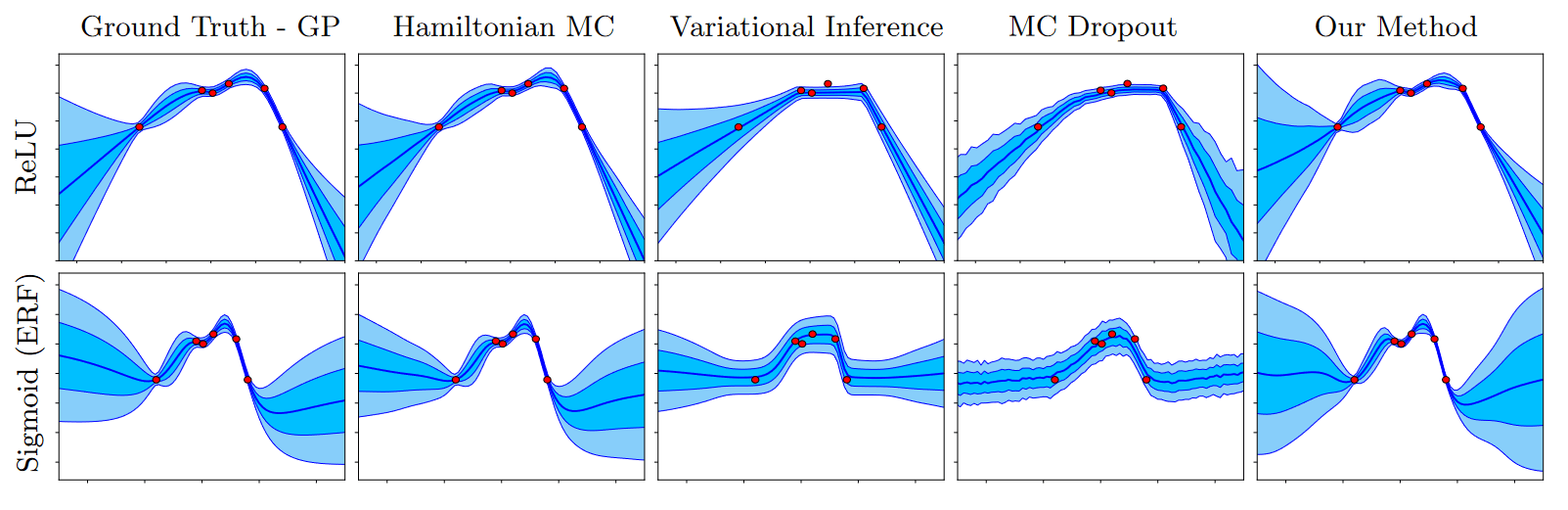
Ground Truth is a Bayesian NN, Hamiltonian MC is a good Monte Carlo approximation to it, Variational Inference is a cheap approximation to it, MC Dropout estimates uncertainty from variance after dropout, and Our Method is an ensemble with fancy initialization.
This figure is a decent intuition pump. It compares uncertainty estimation methods (though it notably misses calibration and higher order modeling), each with ReLUs vs. Sigmoids, on a toy curve-fitting task - a regression problem with only 6 datapoints[7]. I claim that some qualitative impressions from this figure generalize.
Impressions of note:
- The Bayesian NN, the Monte-Carlo approximation, and the ensemble method all make similar predictions.
- Architecture is a big deal for generalization properties, in a way that makes these methods look overconfident. (Doing an ensemble of different architectures would be a good start, but nobody does that.)
- Both dropout and the variational inference approximation are less confident near the datapoints than the ensemble cluster, but then are more confident off-distribution.
In more thorough comparisons (now including calibration) on CIFAR-10 or LSTM language modeling[18], or medical MRI data[17], ensembling seems to be the best method. But honestly all methods that I mentioned were pretty close, with dropout more competitive on the complicated tasks than the toy model would suggest, and variational inference surprisingly doing the best on MNIST.
Higher order modeling shows up in fewer comparisons. But here's a figure from ref. 31 where models were trained on MNIST and then tested on not-MNIST[32]. Learning a Dirichlet distribution over classification outputs (the dashed EDL line) is as different from the rest of the pack as the pack is from the raw model outputs (the blue L2 line):
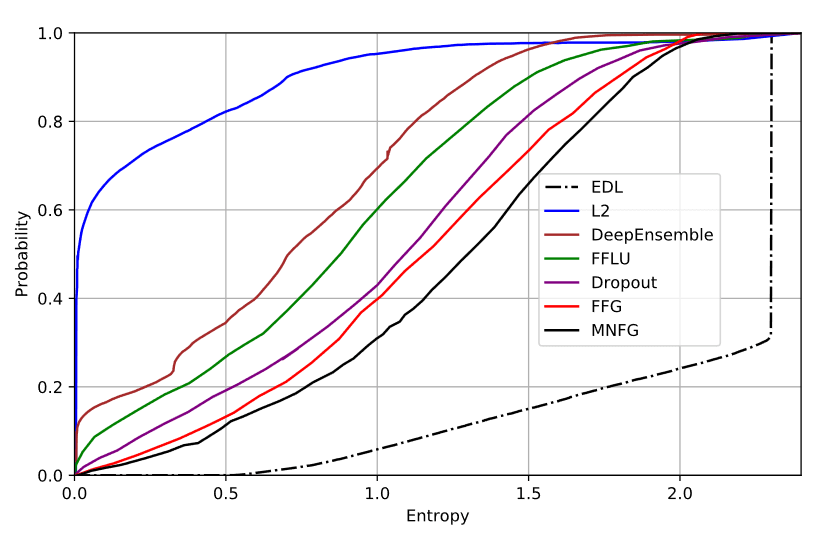
EDL is their Dirichlet distribution model, L2 is raw model outputs, DeepEnsemble is an ensemble, FFLU is unclear but might be a Bayesian NN approximation, Dropout is dropout, FFG is a Bayesian NN method, and MNFG is a variational inference approximation.
This is some really impressive ability to be uncertain when shown OOD data. And yes, on-distribution (on MNIST) it had normal accuracy. Clearly, learning when to be uncertain is picking up some information that other methods aren't.
But is it really correct to be that uncertain? Suppose you're classifying numbers, it's all you know, and then someone inputs the character "B." Surely this is meant to be an 8, right? Or maybe a 13 that's been squashed together, if you can think that thought. But it sure ain't a 2. Since you know that, returning the maximum entropy distribution here would be a mistake. But it seems that's what the Dirichlet distribution model is predisposed to do.
My hope is that the different behavior between higher order models and everything else in that paper is because the methods have different background assumptions, and if we knew what we were doing we could flexibly use different assumptions when appropriate.
Future work I want from this field
- Larger scales
- Benchmarking uncertainty estimates on a transformer language model.
- Robustness to search
- Seeing what epistemic uncertainty says about adversarial examples.
- Analyzing how easy it is to find new adversarial examples that fool the uncertainty estimates as well as the original metric. Checking how natural those examples seem to humans.
- Non-dropout noise
- Improving the theory of what you're sampling when you add noise to neural nets.
- Benchmarking different kinds of noise against each other and other methods.
- More clever things with ensembles
- Testing ensembles that vary the architecture.
- Testing ensembles that are probing "the same" latent feature.
- Better higher order models
- Developing a Bayesian perspective on neural nets learning second-order distributions.
- Developing better training methods for higher order models, both by trying to translate theory and by tinkering with signals like predicting future updates.
- Figuring out how to use higher order modeling to get uncertainties with different background assumptions.
- Better comparisons
- Comparing calibration and Brier score more systematically.
- Benchmarking on decision problems that provide specific criteria for what "good behavior" looks like on out of distribution data.
- Developing labeled datasets that contain "natural" out of distribution generalization that we can analogize to the OOD generalization done by models in the real world.
- More synergy
- Getting better results by combing multiple methods together. Calibration is too easy to combine with everything, that doesn't count as news even though it's still a good idea.
If these papers actually exist and I missed them, please let me know. If they don't, and one of these projects sounds like something you want to do, hit me up - I'd love to chat.
Relevance to alignment, conclusion
The literature is less relevant to alignment than I expected, but this is mostly because my expectations were confused. I was interested in some sort of "uncertainty about human values" that's different than either the literature's "aleatoric" or "epistemic" uncertainties.
Aleatoric uncertainty is learned from the data, but we don't have ground truth labels for human values. Or if there's some latent feature of the model that we associate with human values, we don't just want to learn the variance of that feature on some training set.
Epistemic uncertainty is closer, but as used in the literature it's really about how convergently useful some output or feature is for the training objective. The more models converge to the same answer under the training procedure, the smaller the epistemic uncertainty. But relative to what I want, this feels like it's missing some uncertainty about what training procedure or feature-detection procedure to use in the first place[37].
Uncertainty about the right training / feature-detection procedure deviates from the usual paradigm of "there's a ground truth answer, uncertainty is the expected deviation from that." For alignment, I think the picture should be more like communication - we're trying to communicate something to the AI via architecture and data, and the AI should have uncertainty about how to interpret that.
Constructing this kind of uncertainty about human values is pretty tricky - I don't even know what I want from it yet! Maybe if we understood what we wanted more clearly, we could frame it in terms of more standard uncertainty. E.g. we could design a "game" that an AI can play that incentivizes diverse interpretations of human concepts, such that aleatoric and epistemic uncertainty within that game fully capture the uncertainty we want an AI to have about human values.
This post partially written at MAIA. Thanks MAIA! Also to Justis Mills for editing and various Boston people for conversations.
- ^
Active Learning Literature Survey. Burr Settles (2010) https://burrsettles.com/pub/settles.activelearning.pdf
- ^
The Optimizer's Curse: Skepticism and Postdecision Surprise in Decision Analysis. James E. Smith, Robert L. Winkler (2006) https://pubsonline.informs.org/doi/abs/10.1287/mnsc.1050.0451
- ^
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. Dan Hendrycks, Kevin Gimpel (2016) https://arxiv.org/abs/1610.02136
- ^
Neural network uncertainty assessment using Bayesian statistics with application to remote sensing. F. Aires, C. Prigent, W. B. Rossow (2004)
Part 1: Network weights https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2003JD004173
Part 2: Output errors https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2003JD004174
Part 3: Network Jacobians https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2003JD004175
- ^
A General Framework for Uncertainty Estimation in Deep Learning. Antonio Loquercio, Mattia Segu, Davide Scaramuzza (2020) https://www.zora.uzh.ch/id/eprint/197704/1/RAL20_Loquercio.pdf
- ^
This is true if is a gaussian (exponentiated L2 regularization), and your loss is the log loss so that is the exponential of it.
- ^
Uncertainty in Neural Networks: Approximately Bayesian Ensembling. Tim Pearce, Felix Leibfried, Alexandra Brintrup, Mohamed Zaki, Andy Neely (2020) http://proceedings.mlr.press/v108/pearce20a/pearce20a.pdf
- ^
Most obvious problem is singularities of the Hessian. But also the loss landscape can be wrinkly on short length scales, making low order approximations just fail sometimes.
- ^
Towards calibrated and scalable uncertainty representations for neural networks. Nabeel Seedat, Christopher Kanan (2019) https://arxiv.org/abs/1911.00104
- ^
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. Balaji Lakshminarayanan, Alexander Pritzel, Charles Blundell (2017) https://proceedings.neurips.cc/paper_files/paper/2017/file/9ef2ed4b7fd2c810847ffa5fa85bce38-Paper.pdf
- ^
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Alex Kendall, Yarin Gal (2017) https://proceedings.neurips.cc/paper_files/paper/2017/file/2650d6089a6d640c5e85b2b88265dc2b-Paper.pdf
- ^
From Greek roots for "about knowledge" and "about gambling."
- ^
how 2 tell if ur input is out of distribution given only model weights, dkirmani (2023) https://www.lesswrong.com/posts/tvLi8CyvvSHrfte4P/how-2-tell-if-ur-input-is-out-of-distribution-given-only [LW · GW]
- ^
Noise exists in the real world, so if small input noise changes your answer a lot you shouldn't be confident in it. And conversely, on nicely-behaved inputs, neural networks learn to be robust to noise.
- ^
Training-Free Uncertainty Estimation for Dense Regression: Sensitivity as a Surrogate. Lu Mi, Hao Wang, Yonglong Tian, Hao He, Nir Shavit (2022) https://arxiv.org/abs/1910.04858
- ^
A Survey of Uncertainty in Deep Neural Networks. Jakob Gawlikowski et al. (2021) https://arxiv.org/abs/2107.03342
- ^
Estimating Uncertainty in Neural Networks for Cardiac MRI Segmentation: A Benchmark Study. Matthew Ng, Fumin Guo, Labonny Biswas, Steffen E. Petersen, Stefan K. Piechnik, Stefan Neubauer, Graham Wright (2023) https://ieeexplore.ieee.org/abstract/document/10002847
- ^
Can You Trust Your Model's Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift. Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, D Sculley, Sebastian Nowozin, Joshua V. Dillon, Balaji Lakshminarayanan, Jasper Snoek (2019) https://arxiv.org/abs/1906.02530
- ^
Deep Neural Networks Tend To Extrapolate Predictably. Katie Kang, Amrith Setlur, Claire Tomlin, Sergey Levine (2023) https://arxiv.org/abs/2310.00873
- ^
Seems to be somewhat more common for out-of-distribution detection, e.g. Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks. Shiyu Liang, Yixuan Li, R. Srikant (2020) https://arxiv.org/abs/1706.02690
- ^
GPT-4 Technical Report. OpenAI (2023) https://openai.com/research/gpt-4
- ^
Mix-n-Match: Ensemble and Compositional Methods for Uncertainty Calibration in Deep Learning. Jize Zhang, Bhavya Kailkhura, T. Yong-Jin Han (2020) https://arxiv.org/abs/2003.07329
- ^
Uncertainty Quantification and Deep Ensembles. Rahul Rahaman, Alexandre H. Thiery (2020) https://arxiv.org/abs/2007.08792
- ^
Calibrating Deep Neural Network Classifiers on Out-of-Distribution Datasets. Zhihui Shao, Jianyi Yang, Shaolei Ren (2020) https://arxiv.org/abs/2006.08914
- ^
Inductive Conformal Prediction: Theory and Application to Neural Networks. Harris Papadopoulos (2008) https://www.intechopen.com/chapters/5294
- ^
Mitigating Neural Network Overconfidence with Logit Normalization. Hongxin Wei, Renchunzi Xie, Hao Cheng, Lei Feng, Bo An, Yixuan Li (2022) https://proceedings.mlr.press/v162/wei22d/wei22d.pdf
- ^
Reliable Uncertainty Estimates in Deep Neural Networks using Noise Contrastive Priors. Danijar Hafner, Dustin Tran, Timothy Lillicrap, Alex Irpan, James Davidson (2018) https://openreview.net/forum?id=HkgxasA5Ym
- ^
Improved OOD Generalization via Adversarial Training and Pre-training. Mingyang Yi, Lu Hou, Jiacheng Sun, Lifeng Shang, Xin Jiang, Qun Liu, Zhi-Ming Ma (2021) http://proceedings.mlr.press/v139/yi21a/yi21a.pdf
- ^
SolidGoldMagikarp (plus, prompt generation). Jessica Rumbelow, Matthew Watkins (2023) https://www.lesswrong.com/posts/aPeJE8bSo6rAFoLqg/solidgoldmagikarp-plus-prompt-generation [LW · GW]
- ^
Adversarial Examples Are Not Bugs, They Are Features. Andrew Ilyas et al. (2019) https://arxiv.org/abs/1905.02175
- ^
The problem of not being robust to optimization can be sidestepped if we use generation rather than search to construct good outputs. Or in an RL context, if we use a policy predictor to keep us within the system's domain of validity. But this is costly and sometimes vulnerable to capabilities generalizing at different rates.
- ^
Evidential Deep Learning to Quantify Classification Uncertainty. Murat Sensoy, Lance Kaplan, Melih Kandemir (2018) https://arxiv.org/abs/1806.01768
- ^
Identifying Out-of-Domain Objects with Dirichlet Deep Neural Networks. Ahmed Hammam, Frank Bonarens, Seyed E. Ghobadi, Christoph Stiller (2023) https://openaccess.thecvf.com/content/ICCV2023W/UnCV/papers/Hammam_Identifying_Out-of-Domain_Objects_with_Dirichlet_Deep_Neural_Networks_ICCVW_2023_paper.pdf
- ^
Teaching Models to Express Their Uncertainty in Words. Stephanie Lin, Jacob Hilton, Owain Evans (2023) https://openreview.net/forum?id=8s8K2UZGTZ
- ^
Straightforwardly eliciting probabilities from GPT-3. Nuno Sempere (2023) https://forum.effectivealtruism.org/posts/aGmhi4uvAJptY8TA7/straightforwardly-eliciting-probabilities-from-gpt-3#Fine_tune_the_model_on_good_worked_examples_of_forecasting_reasoning [EA · GW]
- ^
On Second-Order Scoring Rules for Epistemic Uncertainty Quantification. Viktor Bengs, Eyke Hüllermeier, Willem Waegeman (2023) https://arxiv.org/abs/2301.12736
- ^
I might also mention uncertainty about what abstractions to use, or what reasoning procedure to use. But these seem downstream of training.
3 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-07T21:41:36.465Z · LW(p) · GW(p)
Thanks for the interesting review, and for the great list of future desires from the field. I also would love to see more work in these directions!
comment by Jonas Hallgren · 2024-04-23T07:20:59.275Z · LW(p) · GW(p)
This was a great post, thank you for making it!
I wanted to ask what you thought about the LLM-forecasting papers in relation to this literature? Do you think there are any ways of applying the uncertainty estimation literature to improve the forecasting ability of AI?:
https://arxiv.org/pdf/2402.18563.pdf
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2024-04-23T17:18:36.036Z · LW(p) · GW(p)
I'm actually not familiar with the nitty gritty of the LLM forecasting papers. But I'll happily give you some wild guessing :)
My blind guess is that the "obvious" stuff is already done (e.g. calibrating or fine-tuning single-token outputs on predictions about facts after the date of data collection), but not enough people are doing ensembling over different LLMs to improve calibration.
I also expect a lot of people prompting LLMs to give probabilities in natural language, and that clever people are already combining these with fine-tuning or post-hoc calibration. But I'd bet people aren't doing enough work to aggregate answers from lots of prompting methods, and then tuning the aggregation function based on the data.