Responsible Scaling Policies Are Risk Management Done Wrong
post by simeon_c (WayZ) · 2023-10-25T23:46:34.247Z · LW · GW · 35 commentsThis is a link post for https://www.navigatingrisks.ai/p/responsible-scaling-policies-are
Contents
Summary TLDR Section by Section Summary: General Considerations on AI Risk Management What Standard Risk Management Looks Like RSPs vs Standard Risk Management Why RSPs Are Misleading and Overselling Overselling and Underdelivering Are RSPs Hopeless? How to move forward? Meta Section 1: General Considerations on AI Risk Management Section 2: What Standard Risk Management Looks Like Section 3: RSPs vs Standard Risk Management Direct Comparison Prioritized Risk Management Shortcomings of RSPs Section 4: Why RSPs Are Misleading and Overselling Misleading Overselling, underdelivering Section 5: Are RSPs Hopeless? How to Move Forward? Acknowledgments Annex Comparative Analysis of Standards None 35 comments
Summary
TLDR
Responsible Scaling Policies (RSPs) have been recently proposed as a way to keep scaling frontier large language models safely.
While being a nice attempt at committing to specific practices, the framework of RSP is:
- missing core components of basic risk management procedures (Section 2 [LW · GW] & 3 [LW · GW])
- selling a rosy and misleading picture of the risk landscape (Section 4 [LW · GW])
- built in a way that allows overselling while underdelivering (Section 4 [LW · GW])
Given that, I expect the RSP framework to be negative by default (Section 3 [LW · GW], 4 [LW · GW] and 5 [LW · GW]). Instead, I propose to build upon risk management as the core underlying framework to assess AI risks (Section 1 [LW · GW] and 2 [LW · GW]). I suggest changes to the RSP framework that would make it more likely to be positive and allow to demonstrate what it claims to do (Section 5 [LW · GW]).
Section by Section Summary:
General Considerations on AI Risk Management
This section provides background on risk management and a motivation for its relevance in AI.
- Proving risks are below acceptable levels is the goal of risk management.
- To do that, acceptable levels of risks (not only of their sources!) have to be defined.
- Inability to show that risks are below acceptable levels is a failure. Hence, the less we understand a system, the harder it is to claim safety.
- Low-stake failures are symptoms that something is wrong. Their existence make high-stake failures more likely.
Read more. [LW · GW]
What Standard Risk Management Looks Like
This section describes the main steps of most risk management systems, explains how it applies to AI, and provides examples from other industries of what it looks like.
- Define Risk Levels: Set acceptable likelihood and severity.
- Identify Risks: List all potential threats.
- Assess Risks: Evaluate their likelihood and impact.
- Treat Risks: Adjust to bring risks within acceptable levels.
- Monitor: Continuously track risk levels.
- Report: Update stakeholders on risks they incur and measures taken.
Read more. [LW · GW]
RSPs vs Standard Risk Management
This section provides a table comparing RSPs and generic risk management standard ISO/IEC 31000, explaining the weaknesses of RSPs.
It then provides a list of 3 of the biggest failures of RSPs compared with risk management.
Prioritized RSPs failures against risk management:
- Using underspecified definitions of risk thresholds and not quantifying the risk.
- Claiming “responsible scaling” without including a process to make the assessment comprehensive.
- Including a white knight clause that kills commitments.
Read more. [LW · GW]
Why RSPs Are Misleading and Overselling
Misleading points:
- Anthropic RSP labels misalignment risks as “speculative” with minimal justification.
- The framing implies that not scaling for a long time is not an option.
- RSPs present an extremely misleading view of what we know of the risk landscape.
Overselling and Underdelivering
- RSPs allow for weak commitments within a large framework that could in theory be strong.
- No one has given evidence that substantial improvements to a framework have ever happened in the timelines we’re talking about (a few years), which is the whole pitch of RSPs.
- "Responsible scaling" is misleading; "catastrophic scaling" might be more apt if we can’t rule out 1% extinction risk (it is the case for ASL-3).
Read more. [LW · GW]
Are RSPs Hopeless?
This section explains why using RSPs as a framework is inadequate, even compared to just starting from already-existing AI risk management frameworks and practices such as:
- NIST-inspired foundation model risk management framework
- ISO/IEC 23894
- Practices explained in Koessler et al. (2023)
A substantial amount of work that RSPs has done will be helpful as a part of detailing those frameworks, but core foundational principles of RSPs are wrong and so should be abandoned.
How to move forward?
Pragmatically, I suggest a set of changes that would make RSPs more likely to be helpful for safety. To mitigate the policy and communication nefarious effects:
- Rename “Responsible Scaling Policies” as “Voluntary Safety Commitments”
- Be clear on what RSPs are and what RSPs aren’t: I propose that any RSP publication starts by “RSPs are voluntary commitments taken unilaterally done in a racing environment. As such, we think they help to improve safety. We can’t show they are sufficient to manage catastrophic risks and they should not be implemented as public policies.”
- Push for solid risk management public policy: I propose that any RSP document points to another document and says “here are the policies we think would be sufficient to manage risks. Regulation should implement those.”
To see whether already defined RSPs are consistent with reasonable levels of risks:
- Assemble a representative group of risk management experts, AI risk experts and forecasters.
- For a system classified as ASL-3, estimate the likelihood of the following questions:
- What’s the annual likelihood that an ASL-3 system be stolen by {China; Russia; North Korea; Saudi Arabia; Iran}?
- Conditional on that, what are the chances it leaks? it be used to build bioweapons? it be used for cyber offence with large-scale effects?
- What are the annual chances of a catastrophic accident before ASL-4 evaluations trigger?
- What are the annual chances of misuse catastrophic risks induced by an ASL-3 system?
- Share the methodology and the results publicly.
Read more. [LW · GW]
Meta
Epistemic status: I've been looking into various dangerous industries safety standards for now about 4-6 months, with a focus on nuclear safety. I've been doing AI standardization work in standardization bodies (CEN-CENELEC & ISO/IEC) for about 10 months, along risk management experts from other domains (e.g. medical device, cars). In that context, I've read the existing AI ISO/IEC SC42 and JTC21 standards and started trying to apply them to LLMs and refining them. On RSPs, I've spent a few dozen hours reading the docs and discussing those with people involved and around it.
Tone: I hesitated in how charitable I wanted this piece to be. One the one hand, I think that RSPs is a pretty toxic meme (see Section 4) that got rushed towards a global promotion without much epistemic humility over how it was framed, and as far as I've seen without anyone caring much about existing risk management approaches. In that sense, I think that it should strongly be pushed back against under its current framing.
On the other hand, it's usually nice to try to not use negative connotations and calm discussion to move forward epistemically and constructively.
I aimed for something in-between, where I did emphasize with strong negative connotations what I think are the worst parts, while focusing on remaining constructive and focusing on the object-level in many parts.
This mixture may have cause me to land in an uncanney valley, and I'm curious to receive feedback on that.
Section 1: General Considerations on AI Risk Management
Risk management is about demonstrating that risks are below acceptable levels. Demonstrating the absence of risks is much more difficult than showing that some risks are dealt with. More specifically, the less you understand a system, the harder it is to rule out risks.
Let’s take an example: why can we prove more easily that the chances that a nuclear power plant causes a large-scale catastrophe are <1 / 100 000 while we can’t do so with GPT-5? In large part because we now understand nuclear power plants and many of their risks. We know how they work, and the way they can fail. They’ve turned a very unstable reaction (nuclear fission) into something manageable (with nuclear reactors). So the uncertainty we have over a nuclear power plant is much smaller than the one we have on GPT-5.
One corollary is that in risk management, uncertainty is an enemy. Saying “we don’t know” is a failure. Ruling out risks confidently requires a deep understanding of the system and disproving with very high confidence significant worry. To be clear: it is hard. In particular when the operational domain of your system is “the world”. That’s why safety is demanding. But is that a good reason to lower our safety standards when the lives of billions of people are at stake? Obviously no.
One could legitimately say: Wait, but there’s no risk in sight, the burden of proof is on those that claim that it’s dangerous. Where’s the evidence?
Well, there’s plenty:
- Bing threatened users when deployed after having been beta tested for months.
- Providers are unable to avoid jailbreak or ensure robustness neither in text nor in image.
- Models show worrying scaling properties.
One could legitimately say: No, but it’s not catastrophic, it’s not a big deal. Against this stance, I’ll quote the famous physicist R. Feynman reflecting on the Challenger disaster in rocket safety, a field with much higher standards than AI safety:
- “Erosion and blow-by are not what the design expected. They are warnings that something is wrong. The equipment is not operating as expected, and therefore there is a danger that it can operate with even wider deviations in this unexpected and not thoroughly understood way. The fact that this danger did not lead to a catastrophe before is no guarantee that it will not the next time, unless it is completely understood.”
One could finally hope that we understand the past failures of our systems. Unfortunately, we don’t. We not only don’t understand their failure; we don’t understand how and why they work in the first place.
So how are we supposed to deal with risk?
Risk management proposes a few step methods that I’ll describe below. Most industries implement a process along those lines, with some minor variations and a varying degree of rigor and depth according to the level of regulation and type of risks. I’ll put a few tables on that in a table you can check in the Annex.
Section 2: What Standard Risk Management Looks Like
Here’s a description of the core steps of the risk management process. Names vary between frameworks but the gist of it is contained here and usually shared across frameworks.
- Define risk appetite and risk tolerance: Define the amount of risks your project is willing to incur, both in terms of likelihood or severity. Likelihood can be a qualitative scale, e.g. referring to ranges spanning orders of magnitude.
- Risk identification: Write down all the threats and risks that could be incurred by your project, e.g. training and deploying a frontier AI system.
- Risk assessment: Evaluate each risk by determining the likelihood of it happening and its severity. Check those estimates against your risk appetite and risk tolerance.
- Risk treatment: Implement changes to reduce the impact of each risk until those risks meet your risk appetite and risk tolerance.
- Monitoring: During the execution of the project, monitor the level of risk, and check that risks are indeed all covered.
- Reporting: Communicate the plan and its effectiveness to stakeholders, especially those who are affected by the risks.
What’s the point of those pretty generic steps and why would it help AI safety?
(1) The definition of risk thresholds is key 1) to make commitments falsifiable & avoid goalpost moving and 2) to keep the risk-generating organization accountable when other stakeholders are incurring risks due to its activity. If an activity is putting people’s lives at risk, it is important that they know how much and for what benefits and goals.
- Here’s what it looks like in nuclear for instance, as defined by the Nuclear Regulatory Commission:

2. The UC Berkeley Center for Long-Term Cybersecurity NIST-inspired risk management profile for General-purpose AI systems co-written with D. Hendrycks provides some thoughts on how to define those in Map 1.
(2) Risk identification through systematic methods is key to try to reach something as close as possible from a full coverage of risks. As we said earlier, in risk management, uncertainty is a failure and a core way to substantially reduce it is to try to be as comprehensive as possible.
- For specific relevant methods, you can find some in Section 4 of Koessler et al. 2023.
(3) Risk assessment through qualitative and quantitative means allows us to actually estimate the uncertainty we have. It is key to then prioritize safety measures and decide whether it’s reasonable to keep the project under its current forms or modify it.
- An example of a variable which is easy to modify and changes the risk profile substantially is the set of actuators an AI system has access to. Whether a system has a coding terminal, an internet access or the possibility to instantiate other AI systems are variables that substantially increase its set of actions and correspondingly, its risk.
- For specific relevant methods, you can find some in Section 5 of Koessler et al. 2023. Methods involving experts’ forecasts like probabilistic risk assessment or Delphi techniques already exist and could be applied to AI safety. And they can be applied even when:
- Risk is low (e.g. the Nuclear Regulatory Commission requires nuclear safety estimates of probabilities below 1/10 000).
The US Nuclear Regulatory Commission (NRC) specifies that reactor designs must meet a theoretical 1 in 10,000 year core damage frequency, but modern designs exceed this. US utility requirements are 1 in 100,000 years, the best currently operating plants are about 1 in one million and those likely to be built in the next decade are almost 1 in 10 million. |
b. Events are very fat-tailed and misunderstood, as was the case in nuclear safety in the 1970s. It has been done, and it is through the iterative practice of doing it that an industry can become more responsible and cautious. Reading a book review of Safe Enough?, a book on the history of quantitative risk assessment methods used in nuclear safety, there’s a sense of déjà-vu:
If nuclear plants were to malfunction at some measurable rate, the industry could use that data to anticipate its next failure. But if the plants don't fail, then it becomes very difficult to have a conversation about what the true failure rate is likely to be. Are the plants likely to fail once a decade? Once a century? Once a millennium? In the absence of shared data, scientists, industry, and the public were all free to believe what they wanted. Astral Codex Ten, 2023, describing the genesis of probabilistic risk assessment in nuclear safety. |
(4) Risk treatment is in reaction to the risk assessment and must be pursued until you reach the risk thresholds defined. The space of interventions here is very large, larger than is usually assumed. Better understanding one’s system, narrowing down its domain of operation by making it less general, increasing the amount of oversight, improving safety culture: all those are part of a broad set of interventions that can be used to meet thresholds. There can be a loop between the treatment and the assessment if substantial changes to the system are done.
(5) Monitoring is the part that ensures that the risk assessment remains valid and nothing major has been left out. This is what behavioral model evaluations are most useful for, i.e. ensuring that you track the risks you’ve identified. Good evaluations would map to a pre-defined risk appetite (e.g. 1% chance of >1% deaths) and would cover all risks brought up through systematic risk identification.
(6) Reporting is the part that ensures that all relevant stakeholders are provided with the right information. For instance, those incurring risks from the activities should be provided with information on the amount of risk they’re exposed to.
Now that we’ve done a rapid overview of standard risk management and why it is relevant to AI safety, let’s talk about how RSPs compare against that.
Section 3: RSPs vs Standard Risk Management
Some underlying principles of RSPs should definitely be pursued. There are just better ways to pursue these principles, that already exist in risk management, and happen to be what most other dangerous industries and fields do. To give two examples of such good underlying principles:
- stating safety requirements that companies have to reach, without which they can’t keep going.
- setting up rigorous evaluations and measuring capabilities to better understand if a system is good; this should definitely be part of a risk management framework, but probably as a risk monitoring technique, rather than as a substitute for risk assessment.
Below, I argue why RSPs are a bad implementation of some good risk management principles and why that makes the RSP framework inadequate to manage risks.
Direct Comparison
Let’s dive into a more specific comparison between the two approaches. The International Standards Organization (ISO) has developed two risk management standards that are relevant to AI safety, although not focused on it:
- ISO 31000 that provides generic risk management guidelines.
- ISO/IEC 23894, an adaptation of 31000 which is a bit more AI-specific
To be clear, those standards are not sufficient. They’re considered weak by most EU standardization actors or extremely weak by risk management experts from other industries like the medical device industry. There will be a very significant amount of work needed to refine such frameworks for general-purpose AI systems (see a first iteration by T. Barrett here, and a table of how it maps to ISO/IEC 23894 here) But those provide basic steps and principles that, as we explained above, are central to adequate risk management.
In the table below, I start from the short version of ARC Evals’ RSP principles and try to match the ISO/IEC 31000 version that most corresponds. I then explain what’s missing from the RSP version. Note that:
- I only write the short RSP principle but account for the long version.
- There are many steps in ISO/IEC 31000 that don’t appear here.
- I italicize the ISO/IEC version that encompasses the RSP version.
The table version:
| RSP Version (Short) | ISO/IEC 31000 Version | How ISO improves over RSPs |
Limits: which specific observations about dangerous capabilities would indicate that it is (or strongly might be) unsafe to continue scaling?
| Defining risk criteria: The organization should specify the amount and type of risk that it may or may not take, relative to objectives.
It should also define criteria to evaluate the significance of risk and to support decision-making processes.
Risk criteria should be aligned with the risk management framework and customized to the specific purpose and scope of the activity under consideration. [...] The criteria should be defined taking into consideration the organization’s obligations and the views of stakeholders. [...] To set risk criteria, the following should be considered: — the nature and type of uncertainties that can affect outcomes and objectives (both tangible and intangible); — how consequences (both positive and negative) and likelihood will be defined and measured; — time-related factors; — consistency in the use of measurements; — how the level of risk is to be determined; — how combinations and sequences of multiple risks will be taken into account; — the organization’s capacity. | RSPs doesn’t argue why systems passing evals are safe. This is downstream of the absence of risk thresholds with a likelihood scale. For example, Anthropic RSP also dismisses accidental risks as “speculative” and “unlikely” without much depth, without much understanding of their system, and without expressing what “unlikely” means.
On the other hand, the ISO standard asks the organization to define risk thresholds, and emphasizes the need to match risk management with organizational objectives (i.e. build human-level AI). |
Protections: what aspects of current protective measures are necessary to contain catastrophic risks?
Evaluation: what are the procedures for promptly catching early warning signs of dangerous capability limits? | Risk analysis: The purpose of risk analysis is to comprehend the nature of risk and its characteristics including, where appropriate, the level of risk. Risk analysis involves a detailed consideration of uncertainties, risk sources, consequences, likelihood, events, scenarios, controls and their effectiveness.
Risk evaluation: The purpose of risk evaluation is to support decisions. Risk evaluation involves comparing the results of the risk analysis with the established risk criteria to determine where additional action is required. This can lead to a decision to: — do nothing further; — consider risk treatment options; — undertake further analysis to better understand the risk; — maintain existing controls; — reconsider objectives. | ISO proposes a much more comprehensive procedure than RSPs, that doesn’t really analyze risk levels or have a systematic risk identification procedure.
The direct consequence is that RSPs are likely to lead to high levels of risks, without noticing.
For instance, RSPs don’t seem to cover capabilities interaction as a major source of risk.
|
| Response: if dangerous capabilities go past the limits and it’s not possible to improve protections quickly, is the AI developer prepared to pause further capability improvements until protective measures are sufficiently improved, and treat any dangerous models with sufficient caution? | Risk treatment plans: Risk treatment options are not necessarily mutually exclusive or appropriate in all circumstances. Options for treating risk may involve one or more of the following: — avoiding the risk by deciding not to start or continue with the activity that gives rise to the risk; — taking or increasing the risk in order to pursue an opportunity; — removing the risk source; — changing the likelihood; — changing the consequences; — sharing the risk (e.g. through contracts, buying insurance); — retaining the risk by informed decision
Treatment plans should be integrated into the management plans and processes of the organization, in consultation with appropriate stakeholders. The information provided in the treatment plan should include: — the rationale for selection of the treatment options, including the expected benefits to be gained; — those who are accountable and responsible for approving and implementing the plan; — the proposed actions; — the resources required, including contingencies; — the performance measures; — the constraints; — the required reporting and monitoring; — when actions are expected to be undertaken and completed | ISO, thanks to the definition of a risk threshold, ensures that risk mitigation measures bring risks below acceptable levels. The lack of risk thresholds for RSPs makes the risk mitigation measures ungrounded.
Example: ASL-3 risk mitigation measures as defined by Anthropic (i.e. close to catastrophically dangerous) imply significant chances to be stolen by Russia or China (I don’t know any RSP person who denies that). What are the risks downstream of that? The hope is that those countries keep the weights secure and don’t cause too many damages with it.
|
| Accountability: how does the AI developer ensure that the RSP’s commitments are executed as intended; that key stakeholders can verify that this is happening (or notice if it isn’t); that there are opportunities for third-party critique; and that changes to the RSP itself don’t happen in a rushed or opaque way? | Monitoring and review: The purpose of monitoring and review is to assure and improve the quality and effectiveness of process design, implementation and outcomes. Ongoing monitoring and periodic review of the risk management process and its outcomes should be a planned part of the risk management process, with responsibilities clearly defined. [...] The results of monitoring and review should be incorporated throughout the organization’s performance management, measurement and reporting activities.
Recording and reporting: The risk management process and its outcomes should be documented and reported through appropriate mechanisms. Recording and reporting aims to: — communicate risk management activities and outcomes across the organization; — provide information for decision-making; — improve risk management activities; — assist interaction with stakeholders, including those with responsibility and accountability for risk management activities. | Those parts have similar components.
But ISO encourages reporting the results of risk management to those that are affected by the risks, which seems like a bare minimum for catastrophic risks.
Anthropic’s RSP proposes to do so after deployment, which is a good accountability start, but still happens once a lot of the catastrophic risk has been taken. |
Prioritized Risk Management Shortcomings of RSPs
Here’s a list of the biggest direct risk management failures of RSPs:
- Using underspecified definitions of risk thresholds and not quantifying the risk
- Claiming “responsible scaling” without including a process to make the assessment comprehensive
- Including a white knight clause that kills commitments
1. Using underspecified definitions of risk thresholds and not quantifying the risk. RSPs don't define risk thresholds in terms of likelihood. Instead, they focus straight away on symptoms of risks (certain capabilities that an evaluation is testing is one way a risk could instantiate) rather than the risk itself (the model helping in any possible way to build bioweapons). This makes it hard to verify whether safety requirements have been met and argue whether the thresholds are reasonable. Why is it an issue?
- It leaves wiggle room making it very hard to keep the organization accountable. If a lab said something was “unlikely” and it still happened, did it do bad risk management or did it get very unlucky? Well, we don’t know.
- Example (from Anthropic RSP): “A model in the ASL-3 category does not itself present a threat of containment breach due to autonomous self-replication, because it is both unlikely to be able to persist in the real world, and unlikely to overcome even simple security measures intended to prevent it from stealing its own weights.” It makes a huge difference for catastrophic risks whether “unlikely” means 1/10, 1/100 or 1/1000. With our degree of understanding of systems, I don’t think Anthropic staff would be able to demonstrate it’s lower than 1/1000. And 1/100 or 1/10 are alarmingly high.
- It doesn’t explain why the monitoring technique, i.e the evaluations, are the right ones to avoid risks. The RSPs do a good first step which is to identify some things that could be risky.
- Example (from ARC RSP presentation): “Bioweapons development: the ability to walk step-by-step through developing a bioweapon, such that the majority of people with any life sciences degree (using the AI) could be comparably effective at bioweapon development to what people with specialized PhD’s (without AIs) are currently capable of.”
By describing neither quantitatively nor qualitatively why it is risky, expressed in terms of risk criteria (e.g. 0.1% chance of killing >1% of humans) it doesn’t do the most important step to demonstrate that below this threshold, things are safe and acceptable. For instance, in the example above, why is “the majority of people with any life sciences degree” relevant? Would it be fine if only 10% of this population was now able to create a bioweapon? Maybe, maybe not. But without clear criteria, you can’t tell.
2. Claiming “responsible scaling” without including a process to make the assessment comprehensive. When you look at nuclear accidents, what’s striking is how unexpected failures are. Fukushima is an example where everything goes wrong at the same time. Chernobyl is an example where engineers didn’t think that the accident that happened was possible (someone claims that they were so surprised that engineers actually ran another real-world test of the failure that happened at Chernobyl because they doubted too much it could happen).
Without a more comprehensive process to identify risks and compare their likelihood and severity against pre-defined risk thresholds, there’s very little chance that RSPs will be enough. When I asked some forecasters and AI safety researchers around me, the estimates of the annual probability of extinction caused by an ASL-3 system (defined in Anthropic RSPs) were several times above 1%, up to 5% conditioning on our current ability to measure capabilities (and not an idealized world where we know very well how to measure those).
3. Including the white knight clause that kills commitments.
One of the proposals that striked me the most when reading RSPs is the insertion of what deserves the name of the white knight clause.
- In short, if you’re developing a dangerous AI system because you’re a good company, and you’re worried that other bad companies bring too many risks, then you can race forward to prevent that from happening.
- If you’re invoking the white knight clause and increase catastrophic risks, you still have to justify it to your board, the employees and state authorities. The latter provides a minimal form of accountability. But if we’re in a situation where the state is sufficiently asleep to need an AGI company to play the role of the white knight in the first place, it doesn’t seem like it would deter much.
I believe that there are companies that are safer than others. But that’s not the right question. The right question is: is there any company which wouldn’t consider itself as a bad guy? And the answer is: no. OpenAI, Anthropic and DeepMind would all argue about the importance of being at the frontier to solve alignment. Meta and Mistral would argue that it’s key to democratize AI to not prevent power centralization. And so on and so forth.
This clause is effectively killing commitments. I’m glad that Anthropic included only a weakened version of it in its own RSP but I’m very concerned that ARC is pitching it as an option. It’s not the role of a company to decide whether it’s fine or not to increase catastrophic risks for society as a whole.
Section 4: Why RSPs Are Misleading and Overselling
Misleading
Beyond the designation of misalignment risks as “speculative” on Anthropic RSPs and a three line argument for why it’s unlikely among next generation systems, there are several extremely misleading aspects of RSPs:
- It’s called “responsible scaling”. In its own name, it conveys the idea that not further scaling those systems as a risk mitigation measure is not an option.
- It conveys a very overconfident picture of the risk landscape.
- Anthropic writes in the introduction of its RSP “The basic idea is to require safety, security, and operational standards appropriate to a model’s potential for catastrophic risk”. They already defined sufficient protective measures for ASL-3 systems that potentially have basic bioweapons crafting abilities. At the same time they write that they are in the process of actually measuring the risks related to biosecurity: “Our first area of effort is in evaluating biological risks, where we will determine threat models and capabilities”. I’m really glad they’re running this effort, but what if this outputted an alarming number? Is there a world where the number output makes them stop 2 years and dismiss the previous ASL-3 version rather than scaling responsibly?
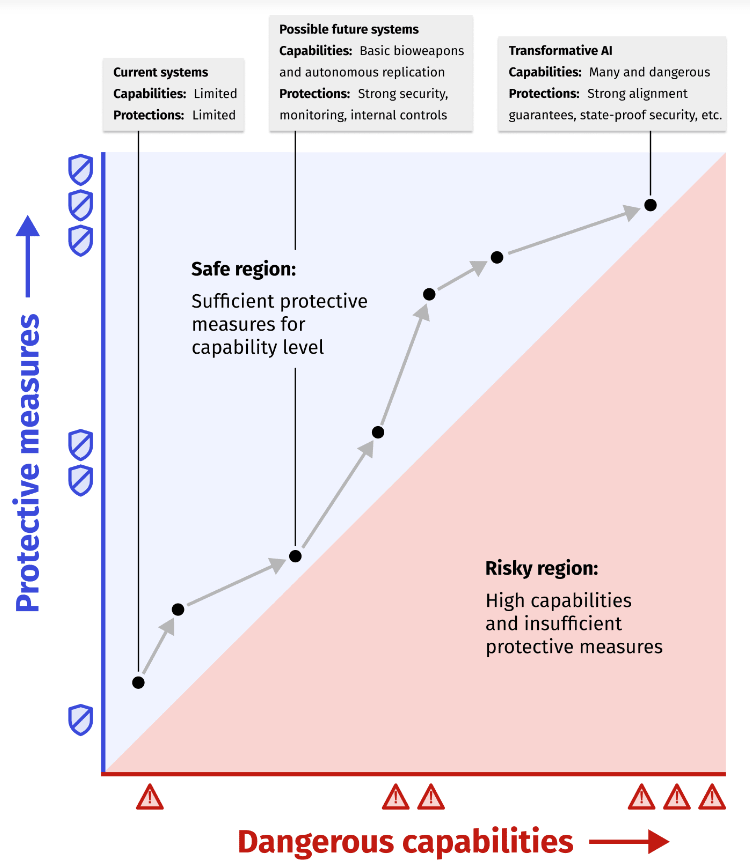
- Without arguing why the graph would look like that, ARC published a graph like this one. Many in the AI safety field don’t expect it to go that way, and “Safe region” oversells what RSP does. I, along with others, expect the LLM graph to reach a level of risks that is simply not manageable in the foreseeable future. Without quantitative measure of the risks we’re trying to prevent, it’s also not serious to claim to have reached “sufficient protective measures”.
If you want to read more on that, you can read that [AF(p) · GW(p)].
Overselling, underdelivering
The RSP framework has some nice characteristics. But first, these are all already covered, in more detail, by existing risk assessment frameworks that no AI lab has implemented. And second, the coexistence of ARC's RSP framework with the specific RSPs labs implementations allows slack for commitments that are weak within a framework that would in theory allow ambitious commitments. It leads to many arguments of the form:
- “That’s the V1. We’ll raise ambition over time”. I’d like to see evidence of that happening over a 5 year timeframe, in any field or industry. I can think of fields, like aviation where it happened over the course of decades, crashes after crashes. But if it’s relying on expectations that there will be large scale accidents, then it should be clear. If it’s relying on the assumption that timelines are long, it should be explicit.
- “It’s voluntary, we can’t expect too much and it’s way better than what’s existing”. Sure, but if the level of catastrophic risks is 1% (which several AI risk experts I’ve talked to believe to be the case for ASL-3 systems) and that it gives the impression that risks are covered, then the name “responsible scaling” is heavily misleading policymakers. The adequate name for 1% catastrophic risks would be catastrophic scaling, which is less rosy.
I also feel like it leads to many disagreements that all hinge on: do we expect labs to implement ambitious RSPs?
And my answer is: given their track record, no. Not without government intervention. Which brings us to the question: “what’s the effect of RSPs on policy and would it be good if governments implemented those”. My answer to that is: An extremely ambitious version yes; the misleading version, no. No, mostly because of the short time we have before we see heightened levels of risks, which gives us very little time to update regulations, which is a core assumption on which RSPs are relying without providing evidence of being realistic.
I expect labs to push hard for the misleading version, on the basis that pausing is unrealistic and would be bad for innovation or for international race. Policymakers will have a hard time distinguishing the risk levels between the two because it hinges on details and aren’t quantified in RSPs. They are likely to buy the bad misleading version because it’s essentially selling that there’s no trade-off between capabilities and safety. That would effectively enforce a trajectory with unprecedented levels of catastrophic risks.
Section 5: Are RSPs Hopeless?
Well, yes and no.
- Yes, in that most of the pretty intuitive and good ideas underlying the framework are weak or incomplete versions of traditional risk management, with some core pieces missing. Given that, it seems more reasonable to just start from an existing risk management piece as a core framework. ISO/IEC 23894 or the NIST-inspired AI Risk Management Standards Profile for Foundation Models would be pretty solid starting points.
- No in that inside the RSPs, there are many contributions that should be part of an AI risk management framework and that would help make existing risk management frameworks more specific. I will certainly not be comprehensive, but some of the important contributions are:
- Anthropic’s RSP fleshes out a wide range of relevant considerations and risk treatment measures
- ARC provides:
- technical benchmarks and proposed operationalizations of certain types of risks that are key
- definitions of safety margins for known unknowns
- threat modelling
- low-level operationalization of some important commitments
In the short-run, given that it seems that RSPs have started being pushed at the UK Summit and various other places, I’ll discuss what changes could make RSPs beneficial without locking in regulation a bad framework.
How to Move Forward?
Mitigating nefarious effects:
- Make the name less misleading: If instead of calling it “responsible scaling”, one called it “Voluntary safety commitments” or another name that:
- Doesn’t determine the output of the safety test before having run it (i.e. scaling)
- Unambiguously signals that it’s not supposed to be sufficient or to be a good basis for regulation.
- Be clear on what RSPs are and what they aren’t. I suggest adding the following clarifications regarding what the goals and expected effects of RSPs are:
- What RSPs are: “a company that would take too strong unilateral commitments would harm significantly its chances of succeeding in the AI race. Hence, this framework is aiming at proposing what we expect to be the best marginal measures that a company can unilaterally take to improve its safety without any coordination.”. I would also include a statement on the level of risks like: “We’re not able to show that this is sufficient to decrease catastrophic risks to reasonable levels, and it is probably not.”, “we don’t know if it’s sufficient to decrease catastrophic risks below reasonable levels”, or "even barring coordinated industry-wide standards or government intervention, RSPs are only a second- (or third-) best option".
- What RSPs aren’t: Write very early in the post a disclaimer saying “THIS IS NOT WHAT WE RECOMMEND FOR POLICY”. Or alternatively, point to another doc stating what would be the measures that would be sufficient to maintain the risk below sufficient levels: “Here are the measures we think would be sufficient to mitigate catastrophic risks below acceptable levels.” to which you could add “We encourage laboratories to make a conditional commitment of the form: “if all other laboratories beyond a certain size[to be refined] committed to follow those safety measures with a reliable enforcement mechanism and the approval of the government regarding this exceptional violation of antitrust laws, we would commit to follow those safety measures.”
- Push for risk management in policy:
- Standard risk management for what is acknowledged to be a world-shaping technology is a fairly reasonable ask. In fact, it is an ask that I’ve noticed in my interactions with other AI crowds has the benefit of allowing coalition-building efforts because everyone can easily agree on “measure the risks, deal with them, and make the residual level of risks and the methodology public”.
- Standard risk management for what is acknowledged to be a world-shaping technology is a fairly reasonable ask. In fact, it is an ask that I’ve noticed in my interactions with other AI crowds has the benefit of allowing coalition-building efforts because everyone can easily agree on “measure the risks, deal with them, and make the residual level of risks and the methodology public”.
Checking whether RSPs manage risks adequately:
At a risk management level, if one wanted to demonstrate that RSPs like Anthropic’s one are actually doing what they claim to do (i.e. “require safety, security, and operational standards appropriate to a model’s potential for catastrophic risk”), a simple way to do so would be to run a risk assessment on ASL-3 systems with a set of forecasters, risk management experts and AI risk experts that are representative of views on AI risks and that have been selected by an independent body free of any conflict of interest.
I think that a solid baseline would be to predict the chances of various intermediary and final outcomes related to the risks of such systems:
- What’s the annual likelihood that an ASL-3 system be stolen by {China; Russia; North Korea; Saudi Arabia; Iran}?
- Conditional on that, what are the chances it leaks? it being used to build bioweapons? it being used for cyber offence with large-scale effects?
- What are the chances of a catastrophic accident before ASL-4 evaluations trigger?
- What are the annual chances of misuse catastrophic risks induced by an ASL-3 system?
It might not be too far from what Anthropic seems to be willing to do internally, but doing it with a publicly available methodology, and staff without self-selection or conflict of interests makes a big difference. Answers to questions 1) and 2) could raise risks so the output should be communicated to a few relevant actors but could potentially be kept private.
If anyone has the will but doesn’t have the time or resources to do it, I’m working with some forecasters and AI experts that could probably make it happen. Insider info would be helpful but mostly what would be needed from the organization is some clarifications on certain points to correctly assess the capabilities of the system and some info about organizational procedures.
Acknowledgments
I want to thank Eli Lifland, Henry Papadatos and my other NAIR colleague, Olivia Jimenez, Akash Wasil, Mikhail Samin, Jack Clark, and other anonymous reviewers for their feedback and comments. Their help doesn’t mean that they endorse the piece. All mistakes are mine.
Annex
Comparative Analysis of Standards
This (cropped) table shows the process of various standards for the 3 steps of risk management. As you can see, there are some differences but every standard seems to follow a similar structure.

Here is a comparable table for the last two parts of risk management.

35 comments
Comments sorted by top scores.
comment by evhub · 2023-10-26T01:02:41.999Z · LW(p) · GW(p)
Cross-posted with the EA Forum [EA(p) · GW(p)].
I found this post very frustrating, because it's almost all dedicated to whether current RSPs are sufficient or not (I agree that they are insufficient), but that's not my crux and I don't think it's anyone else's crux either. And for what I think is probably the actual crux here, you only have one small throwaway paragraph:
Which brings us to the question: “what’s the effect of RSPs on policy and would it be good if governments implemented those”. My answer to that is: An extremely ambitious version yes; the misleading version, no. No, mostly because of the short time we have before we see heightened levels of risks, which gives us very little time to update regulations, which is a core assumption on which RSPs are relying without providing evidence of being realistic.
As I've talked [LW · GW] about now [LW · GW] extensively [LW(p) · GW(p)], I think enacting RSPs in policy now makes it easier not harder to get even better future regulations enacted. It seems that your main reason for disagreement is that you believe in extremely short timelines / fast takeoff, such that we will never get future opportunities to revise AI regulation. That seems pretty unlikely to me: my expectation especially is that as AI continues to heat up in terms of its economic impact, new policy windows will keep arising in rapid succession, and that we will see many of them before the end of days.
Replies from: WayZ, WayZ, akash-wasil, WayZ, elifland↑ comment by simeon_c (WayZ) · 2023-10-26T01:32:25.826Z · LW(p) · GW(p)
You can see this section which talks about the points you raise.

↑ comment by simeon_c (WayZ) · 2023-10-26T01:17:56.113Z · LW(p) · GW(p)
Thanks for your comment.
- I'm sorry for that magnitude of misunderstanding, and will try to clarify it upfront in the post, but a large part of my argument is about why the principles of RSPs are not good enough, rather than the specific implementation (which is also not sufficient though, and which I argue in "Overselling, underdelivering" is one of the flaws of the framework and not just a problem that will pass).
- You can check Section 3 for why I think that the principles are flawed, and Section 1 and 2 to get a better sense of what better principles look like.
- Regarding the timeline, I think that it's unreasonable to expect major framework changes over less than 5 years. And as I wrote, if you think otherwise, I'd love to hear any example of that happening in the past and the conditions under which it happened.
- I do think that within the RSP framework, you can maybe get better but as I argue in Section 3, I think the framework is fundamentally flawed and should be replaced by a standard risk management framework, in which we include evals.
↑ comment by Orpheus16 (akash-wasil) · 2023-10-26T17:38:01.720Z · LW(p) · GW(p)
@evhub [LW · GW] I think it's great when you and other RSP supporters make it explicit that (a) you don't think they're sufficient and (b) you think they can lead to more meaningful regulation.
With that in mind, I think the onus is on you (and institutions like Anthropic and ARC) to say what kind of regulations they support & why. And then I think most of the value will come from "what actual regulations are people proposing" and not "what is someone's stance on this RSP thing which we all agree is insufficient."
Except for the fact that there are ways to talk about RSPs that are misleading for policymakers and reduce the chance of meaningful regulations. See the end of my comment [LW(p) · GW(p)] and see also Simeon's sections on misleading [LW · GW] and how to move forward [LW · GW].
Also, fwiw, I imagine that timelines/takeoff speeds might be relevant cruxes. And IDK if it's the main disagreement that you have with Siméon, but I don't think it's the main disagreement you have with me.
Even if I thought we would have 3 more meaningful policy windows, I would still think that RSPs have not offered a solid frame/foundation for meaningful regulation, I would still think that they are being communicated about poorly, and I would still want people to focus more on proposals for other regulations & focus less on RSPs.
Replies from: evhub↑ comment by evhub · 2023-10-26T18:03:19.022Z · LW(p) · GW(p)
With that in mind, I think the onus is on you (and institutions like Anthropic and ARC) to say what kind of regulations they support & why.
I did—I lay out a plan for how to get from where we are now to a state where AI goes well from a policy perspective in my RSP post [LW · GW].
Replies from: WayZ, akash-wasil↑ comment by simeon_c (WayZ) · 2023-10-26T18:25:15.764Z · LW(p) · GW(p)
Two questions related to it:
- What happens in your plan if it takes five years to solve the safety evaluation/deception problem for LLMs (i.e. it's extremely hard)?
- Do you have an estimate of P({China; Russia; Iran; North Korea} steals an ASL-3 system with ASL-3 security measures)? Conditional on one of these countries having the system, what's your guess of p(catastrophe)?
↑ comment by Orpheus16 (akash-wasil) · 2023-10-26T18:22:30.644Z · LW(p) · GW(p)
Do you mind pointing me to the section? I skimmed your post again, and the only relevant thing I saw was this part:
- Seeing the existing RSP system in place at labs, governments step in and use it as a basis to enact hard regulation.
- By the time it is necessary to codify exactly what safety metrics are required for scaling past models that pose a potential takeover risk, we have clearly solved the problem of understanding-based evals [LW · GW] and know what it would take to demonstrate sufficient understanding of a model to rule out e.g. deceptive alignment [LW · GW].
- Understanding-based evals are adopted by governmental RSP regimes as hard gating evaluations for models that pose a potential takeover risk.
- Once labs start to reach models that pose a potential takeover risk, they either:
- Solve mechanistic interpretability to a sufficient extent that they are able to pass an understanding-based eval and demonstrate that their models are safe.
- Get blocked on scaling until mechanistic interpretability is solved, forcing a reroute of resources from scaling to interpretability.
My summary of this is something like "maybe voluntary RSPs will make it more likely for governments to force people to do evals. And not just the inadequate dangerous capabilities evals we have now– but also the better understanding-based evals that are not yet developed, but hopefully we will have solved some technical problems in time."
I think this is better than no government regulation, but the main problem (if I'm understanding this correctly) is that it relies on evals that we do not have.
IMO, a more common-sense approach would be "let's stop until we are confident that we can proceed safely", and I'm more excited about those who are pushing for this position.
Aside: I don't mean to nitpick your wording, but I think a "full plan" would involve many more details. In the absence of those details, it's hard to evaluate the plan. Examples of some details that would need to be ironed out:
- Which systems are licensed under this regime? Who defines what a "model that poses a potential takeover risk" is, and how do we have inclusion criteria that are flexible enough to account for algorithmic improvement?
- Who in the government is doing this?
- Do we have an international body that is making sure that various countries comply?
- How do we make sure the regulator doesn't get captured?
- What does solving mechanistic interpretability mean, and who is determining that?
To be clear I don't think you need to specify all of this, and some of these are pretty specific/nit-picky, but I don't think you should be calling this a "full plan."
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2023-10-26T20:50:09.281Z · LW(p) · GW(p)
it relies on evals that we do not have
I agree that this is a problem, but it strikes me that we wouldn't necessarily need a concrete eval - i.e. we wouldn't need [by applying this concrete evaluation process to a model, we can be sure we understand it sufficiently].
We could have [here is a precise description of what we mean by "understanding a model", such that we could, in principle, create an evaluation process that answers this question].
We can then say in an RSP that certain types of model must pass an understanding-in-this-sense eval, even before we know how to write an understanding-in-this-sense eval. (though it's not obvious to me that defining the right question isn't already most of the work)
Personally, I'd prefer that this were done already - i.e. that anything we think is necessary should be in the RSP at some level of abstraction / indirection. That might mean describing properties an eval would need to satisfy. It might mean describing processes by which evals could be approved - e.g. deferring to an external board. [Anthropic's Long Term Benefit Trust doesn't seem great for this, since it's essentially just Paul who'd have relevant expertise (?? I'm not sure about this - it's just unclear that any of the others would)]
I do think it's reasonable for labs to say that they wouldn't do this kind of thing unilaterally - but I would want them to push for a more comprehensive setup when it comes to policy.
↑ comment by simeon_c (WayZ) · 2023-10-26T09:39:03.654Z · LW(p) · GW(p)
A more in-depth answer:
- The permanent motte and bailey that RSPs allow (easily defensible: a framework that seems arbitrarily extensible combined with the belief that you can always change stuff in policy, even over few-years timeframe ; hardly defensible: the actual implementations & the communication around RSPs) is one of the concerns I raise explicitly, and what this comment is doing. Here, while I'm talking in large parts about the ARC RSP principles, you say that I'm talking about "current RSPs". If you mean that we can change even the RSP principles (and not only their applicatino) to anyone who criticizes the principles of RSPs, then it's a pretty effective way to make something literally impossible to criticize. We could have taken an arbitrary framework, push for it and say "we'll do better soon, we need wins". Claiming that we'll change the framework (not only the application) in 5 years is a very extraordinary claim and does not seem a good reason to start pushing for a bad framework in the first place.

- That it's not true. The "Safe Zone" in ARC graph clearly suggests that ASL-3 are sufficient. The announce of Anthropic says "require safety, security, and operational standards appropriate to a model’s potential for catastrophic risk". It implies that ASL-3 measures are sufficient, without actually quantifying the risk (one of the core points of my post), even qualitatively.
- At a meta level, I find frustrating that the most upvoted comment, your comment, be a comment that hasn't seriously read the post, still makes a claim about the entire post, and doesn't address my request for evidence about the core crux (evidence of major framework changes within 5 years). If "extremely short timelines" means 5y, it seems like many have "extremely short timelines".
↑ comment by elifland · 2023-10-26T12:51:13.484Z · LW(p) · GW(p)
As I've talked [LW · GW] about now [LW · GW] extensively [LW(p) · GW(p)], I think enacting RSPs in policy now makes it easier not harder to get even better future regulations enacted.
I appreciate the evidence you've provided on this, and in particular I think it's more than has been provided for the opposite claim and would encourage Simeon and others criticizing RSPs along these lines to provide more evidence (as I commented on a draft of his post).
That being said, I don't yet find the evidence you've provided particularly compelling. I believe you are referring mainly to this section of your posts:
In the theory of political capital, it is a fairly well-established fact that “Everybody Loves a Winner.” That is: the more you succeed at leveraging your influence to get things done, the more influence you get in return. This phenomenon is most thoroughly studied in the context of the ability of U.S. presidents’ to get their agendas through Congress—contrary to a naive model that might predict that legislative success uses up a president’s influence, what is actually found is the opposite: legislative success engenders future legislative success, greater presidential approval, and long-term gains for the president’s party.
I don't understand how the links in this section show that "Everybody Loves a Winner" is a fairly well-established fact that translates to the situation of RSPs. The first link is an op-ed that is paywalled. The second link is a 2013 paper with 7 citations. From the abstract it appears to show that US presidents get higher approval ratings when they succeed in passing legislation, and vice versa. The third link is a 2011 paper with 62 citations (which seems higher, not sure how high this is for its field). From the abstract it appears to show that Presidents which pass agendas in Congress help their party win more Congressional seats. These interpretations don't seem too different from the way you summarized it.
Assuming that this version of "Everybody Loves a Winner" is in fact a well-established fact in the field, it still seems like the claims it's making might not translate to the RSP context fairly well. In particular, RSPs are a legislative framework on a specific (currently niche) issue of AI safety. The fact that Presidents who in general get things done tend to get other benefits including perhaps getting more things done later doesn't seem that relevant to the question of to what extent frameworks on a specific issue tend to be "locked in" after being enacted into law, vs. useful blueprints for future iteration (including potentially large revisions to the framework).
Again, I appreciate you at least providing some evidence but it doesn't seem convincing to me. FWIW my intuitions lean a bit toward your claims (coming from a startup-y background of push out an MVP then iterate from there), but I have a lot of uncertainty.
(This comment is somewhat like an expanded version of my tweet, which also asked for "Any high-quality analyses on whether pushing more ambitious policies generally helps/hurts the more moderate policies, and vice/versa?". I received answers like "it depends" and "unclear".)
Replies from: WayZ↑ comment by simeon_c (WayZ) · 2023-10-26T14:17:35.363Z · LW(p) · GW(p)
Thanks Eli for the comment.
One reason why I haven't provided much evidence is that I think it's substantially harder to give evidence of a "for all" claim (my side of the claim) than a "there exists" (what I ask Evan). I claim that it doesn't happen that a framework on a niche area evolves so fast without accidents based on what I've seen, even in domains with substantial updates, like aviation and nuclear.
I could potentially see it happening with large accidents, but I personally don't want to bet on that and I would want it to be transparent if that's the assumption. I also don't buy the "small coordinations allow larger coordinations" for domain-specific policy. Beyond what you said above, my sense is that policymakers satisfice and hence tend to not come back on a policy that sucks if that's sufficiently good-looking to stakeholders to not have substantial incentives to change.
GDPR cookies banner sucks for everyone and haven't been updated yet, 7 years after GDPR. Standards in the EU are not even updated more rapidly than 5y by default (I'm talking about standards, not regulation), and we'll have to bargain to try to bring it down to reasonable timeframes AI-specific.
IAEA & safety in nuclear upgraded substantially after each accident, likewise for aviation but we're talking about decades, not 5 years.
comment by Dave Orr (dave-orr) · 2023-10-26T05:12:34.945Z · LW(p) · GW(p)
I feel like a lot of the issues in this post are that the published RSPs are not very detailed and most of the work to flesh them out is not done. E.g. the comparison to other risk policies highlights lack of detail in various ways.
I think it takes a lot of time and work to build our something with lots of analysis and detail, years of work potentially to really do it right. And yes, much of that work hasn't happened yet.
But I would rather see labs post the work they are doing as they do it, so people can give feedback and input. If labs do so, the frameworks will necessarily be much less detailed than they would if we waited until they were complete.
So it seems to me that we are in a messy process that's still very early days. Feedback about what is missing and what a good final product would look like is super valuable, thank you for your work doing that. I hope the policy folks pay close attention.
But I think your view that RSPs are the wrong direction is misguided, or at least I don't find your reasons to be persuasive -- there's much more work to be done before they're good and useful, but that doesn't mean they're not valuable. Honestly I can't think of anything much better that could have been reasonably done given the limited time and resources we all have.
I think your comments on the name are well taken. I think your ideas about disclaimers and such are basically impossible for a modern corporation, unfortunately. I think your suggestion about pushing for risk management in policy are the clear next step, that's only enabled by the existence of an RSP in the first place.
Thanks for the detailed and thoughtful effortpost about RSPs!
Replies from: WayZ↑ comment by simeon_c (WayZ) · 2023-10-26T11:59:00.322Z · LW(p) · GW(p)
Thanks for your comment.
I feel like a lot of the issues in this post are that the published RSPs are not very detailed and most of the work to flesh them out is not done.
I strongly disagree with this. In my opinion, a lot of the issue is that RSPs have been thought from first principles without much consideration for everything the risk management field has done, and hence doing wrong stuff without noticing.
It's not a matter of how detailed they are; they get the broad principles wrong. As I argued (the entire table is about this) I think that the existing principles of other existing standards are just way better and so no, it's not a matter of details.
As I said, the details & evals of RSPs is actually the one thing that I'd keep and include in a risk management framework.
Honestly I can't think of anything much better that could have been reasonably done given the limited time and resources we all have
Well, I recommend looking at Section 3 and the source links. Starting from those frameworks and including evals into it would be a Pareto improvement.

↑ comment by Lukas Finnveden (Lanrian) · 2023-10-26T18:26:00.562Z · LW(p) · GW(p)
But most of the deficiencies you point out in the third column of that table is about missing and insufficient risk analysis. E.g.:
- "RSPs doesn’t argue why systems passing evals are safe".
- "the ISO standard asks the organization to define risk thresholds"
- "ISO proposes a much more comprehensive procedure than RSPs"
- "RSPs don’t seem to cover capabilities interaction as a major source of risk"
- "imply significant chances to be stolen by Russia or China (...). What are the risks downstream of that?"
If people took your proposal as a minimum bar for how thorough a risk management proposal would be, before publishing, it seems like that would interfere with labs being able to "post the work they are doing as they do it, so people can give feedback and input".
This makes me wonder: Would your concerns be mostly addressed if ARC had published a suggestion for a much more comprehensive risk management framework, and explicitly said "these are the principles that we want labs' risk-management proposals to conform to within a few years, but we encourage less-thorough risk management proposals before then, so that we can get some commitments on the table ASAP, and so that labs can iterate in public. And such less-thorough risk management proposals should prioritize covering x, y, z."
Replies from: WayZ↑ comment by simeon_c (WayZ) · 2023-10-26T18:45:16.459Z · LW(p) · GW(p)
Would your concerns be mostly addressed if ARC had published a suggestion for a much more comprehensive risk management framework, and explicitly said "these are the principles that we want labs' risk-management proposals to conform to within a few years, but we encourage less-thorough risk management proposals before then, so that we can get some commitments on the table ASAP, and so that labs can iterate in public. And such less-thorough risk management proposals should prioritize covering x, y, z."
Great question! A few points:
- Yes, many of the things I point are "how to do things well" and I would in fact much prefer something that contains a section "we are striving towards that and our current effort is insufficient" than the current RSP communication which is more "here's how to responsibly scale".
- That said, I think we disagree on the reference class of the effort (you say "a few years"). I think that you could do a very solid MVP of what I suggest with like 5 FTEs over 6 months.
- As I wrote in "How to move forward" (worth skimming to understand what I'd change) I think that RSPs would be incredibly better if they:
- had a different name
- said that they are insufficient
- linked to a post which says "here's the actual thing which is needed to make us safe".
- Answer to your question: if I were optimizing in the paradigm of voluntary lab commitments as ARC is, yes I would much prefer that. I flagged early though that because labs are definitely not allies on this (because an actual risk assessment is likely to output "stop"), I think the "ask labs kindly" strategy is pretty doomed and I would much prefer a version of ARC trying to acquire bargaining power through a way or another (policy, PR threat etc.) rather than adapting their framework until labs accept to sign them.
Regarding
If people took your proposal as a minimum bar for how thorough a risk management proposal would be, before publishing, it seems like that would interfere with labs being able to "post the work they are doing as they do it, so people can give feedback and input".
I don't think it's necessarily right, e.g. "the ISO standard asks the organization to define risk thresholds" could be a very simple task, much simpler than developing a full eval. The tricky thing is just to ensure we comply with such levels (and the inability to do that obviously reveals a lack of safety).
"ISO proposes a much more comprehensive procedure than RSPs", it's not right either that it would take longer, it's just that there exists risk management tools, that you can run in like a few days, that helps having a very broad coverage of the scenario set.
"imply significant chances to be stolen by Russia or China (...). What are the risks downstream of that?" once again you can cover the most obvious things in like a couple pages. Writing "Maybe they would give the weights to their team of hackers, which increases substantially the chances of leak and global cyberoffence increase". And I would be totally fine with half-baked things if they were communicated as such and not as RSPs are.
Replies from: M. Y. Zuocomment by Joe Collman (Joe_Collman) · 2023-10-26T05:31:55.913Z · LW(p) · GW(p)
Thanks for your effort in writing this.
I'm very glad people are taking this seriously and exploring various approaches.
However, I happen to think your policy suggestion would be a big mistake.
On you recommendations:
1) Entirely agree. The name sucks, for the reasons you state.
2) Agreed. Much more explicit clarity on this would be great.
3) No.
I'll elaborate on (3):
“measure the risks, deal with them, and make the residual level of risks and the methodology public”.
I'll agree that it would be nice if we knew how to do this, but we do not.
With our current level of understanding, we fall at the first hurdle (we can measure some of the risks).
“Inability to show that risks are below acceptable levels is a failure. Hence, the less we understand a system, the harder it is to claim safety.”
This implies an immediate stop to all frontier AI development (and probably a rollback of quite a few deployed systems). We don't understand. We cannot demonstrate risks are below acceptable levels.
Assemble a representative group of risk management experts, AI risk experts...
The issue here is that AI risk "experts" in the relevant sense do not exist.
We have "experts" (those who understand more than almost anyone else).
We have no experts (those who understand well).
For a standard risk management approach, we'd need people who understand well.
Given our current levels of understanding, all a team of "experts" could do would be to figure out a lower bound on risk. I.e. "here are all the ways we understand that the system could go wrong, making the risk at least ...".
We don't know how to estimate an upper bound in any way that doesn't amount to a wild guess.
Why is pushing for risk quantification in policy a bad idea?
Because, logically, it should amount to an immediate stop on all development.
However, since "We should stop immediately because we don't understand" can be said in under ten words, if any much more lengthy risk-management approach is proposed, the implicit assumption will be that it is possible to quantify the risk in a principled way. It is not.
Quantified risk estimates that are wrong are much worse than underdefined statements.
I'd note here that I do not expect [ability to calculate risk for low-stakes failures] to translate into [ability to calculate risk for catastrophic failures] - many are likely to be different in kind.
Quantified risk estimates that are correct for low-stakes failures, but not for catastrophic failures are worse still.
One of the things Anthropic's RSP does right is not to quantify things that we don't have the understanding to quantify.
There is no principled way to quantify catastrophic risk without a huge increase in understanding.
The dangerous corollary is that there's no principled way to expose dubious quantifications as dubious (unless they exhibit obvious failures we concretely understand).
Once a lab has accounted for all the risks that are well understood, they'd be able to say "we think the remaining risk is very low because [many soothing words and much hand-waving]", and there'll be no solid basis to critique this - because we lack the understanding.
I think locking in the idea that AI risk can be quantified in a principled way would be a huge error.
If we think that standard risk-management approaches are best, then the thing to propose would be:
1) Stop now.
2) Gain sufficient understanding to quantify risk. (this may take decades)
3) Apply risk management techniques.
↑ comment by simeon_c (WayZ) · 2023-10-26T11:36:37.230Z · LW(p) · GW(p)
Thanks a lot for this constructive answer, I appreciate the engagement.
I'll agree that it would be nice if we knew how to do this, but we do not.
With our current level of understanding, we fall at the first hurdle (we can measure some of the risks).
Three points on that:
- I agree that we're pretty bad at measuring risks. But I think that the AI risk experts x forecasters x risk management experts is a very solid baseline, much more solid than not measuring the aggregate risk at all.
- I think that we should do our best and measure conservatively, and that to the extent we're uncertainty, it should be reflected in calibrated risk estimates.
- I do expect the first few shots of risk estimate to be overconfident, especially to the extent they include ML researchers' estimates. My sense from nuclear is that it's what happened there and that failures after failures, the field got red pilled. You can read more on this here (https://en.wikipedia.org/wiki/WASH-1400).
- Related to that, I think that it's key to provide as many risk estimate feedback loops as possible by forecasting incidents in order to red-pill the field faster on the fact that they're overconfident by default on risk levels.
This implies an immediate stop to all frontier AI development (and probably a rollback of quite a few deployed systems). We don't understand. We cannot demonstrate risks are below acceptable levels.
That's more complicated than that to the extent you could probably train code generation systems or other systems with narrowed down domain of operations, but I indeed think that on LLMs, risk levels would be too high to keep scaling >4 OOMs on fully general LLMs that can be plugged to tools etc.
I think that it would massively benefit to systems we understand and have could plausibly reach significant levels of capabilities at some point in the future (https://arxiv.org/abs/2006.08381). It would probably lead labs to massively invest into that.
Given our current levels of understanding, all a team of "experts" could do would be to figure out a lower bound on risk. I.e. "here are all the ways we understand that the system could go wrong, making the risk at least ...".
I agree by default we're unable to upper bound risks and I think that's it's one additional failure of RSP to make as if we were able to do so. The role of calibrated forecasters in the process is to ensure that they help keeping in mind the uncertainty arising from this.
Why is pushing for risk quantification in policy a bad idea?
[...]
However, since "We should stop immediately because we don't understand" can be said in under ten words, if any much more lengthy risk-management approach is proposed, the implicit assumption will be that it is possible to quantify the risk in a principled way. It is not.
Quantified risk estimates that are wrong are much worse than underdefined statements.
- I think it's a good point and that there should be explicit caveat to limit that but that they won't be enough.
- I think it's a fair concern for quantified risk assessment and I expect it to be fairly likely that we fail in certain ways if we do only quantified risk assessment over the next few years. Thats why I do think we should not only do that but also deterministic safety analysis and scenario based risk analysis, which you could think of as sanity checks to ensure you're not completely wrong in your quantified risk assessment.
- Reading your points, I think that one core feature you might miss here is that uncertainty should be reflected in quantified estimates if we get forecasters into it. Hence, I expect quantified risk assessment to reveal our lack of understanding rather than suffer from it by default. I still think that your point will partially hold but much less than in the world where Anthropic dismisses accidental risks as speculative and say they're "unlikely" (which as I say cd mean 1/1000, 1/100 or 1/10 but the lack of explicitation makes the statement reasonable sounding) without saying "oh btw we really don't understand our systems".
Once again, thanks a lot for your comment!
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2023-10-26T13:04:23.790Z · LW(p) · GW(p)
As a general point, I agree that your suggestion is likely to seem better than RSPs.
I'm claiming that this is a bad thing.
To the extent that an approach is inadequate, it's hugely preferable for it to be clearly inadequate.
Having respectable-looking numbers is not helpful.
Having a respectable-looking chain of mostly-correct predictions is not helpful where we have little reason to expect the process used to generate them will work for the x-risk case.
But I think that the AI risk experts x forecasters x risk management experts is a very solid baseline, much more solid than not measuring the aggregate risk at all.
The fact that you think that this is a solid baseline (and that others may agree), is much of the problem.
What we'd need would be:
[people who deeply understand AI x-risk] x [forecasters well-calibrated on AI x-risk] x [risk management experts capable of adapting to this context]
We don't have the first, and have no basis to expect the second (the third should be doable, conditional on having the others).
I do expect the first few shots of risk estimate to be overconfident
Ok, so now assume that [AI non-existential risk] and [AI existential risk] are very different categories in terms of what's necessary in order to understand/predict them (e.g. via the ability to use plans/concepts that no human can understand, and/or to exert power in unexpected ways that don't trigger red flags).
We'd then get: "I expect the first few shots of AI x-risk estimate to be overconfident, and that after many failures the field would be red-pilled, but for the inconvenient detail that they'll all be dead".
Feedback loops on non-existential incidents will allow useful updates on a lower bound for x-risk estimates.
A lower bound is no good.
...not only do that but also deterministic safety analysis and scenario based risk analysis...
Doing either of these effectively for powerful systems is downstream of understanding we lack.
This again gives us a lower bound at best - we can rule out all the concrete failure modes we think of.
However, saying "we're doing deterministic safety analysis and scenario based risk analysis" seems highly likely to lead to overconfidence, because it'll seem to people like the kind of thing that should work.
However, all three aspects fail for the same reason: we don't have the necessary understanding.
I think that one core feature you might miss here is that uncertainty should be reflected in quantified estimates if we get forecasters into it
This requires [well calibrated on AI x-risk forecasters]. That's not something we have. Nor is it something we can have. (we can believe we have it if we think calibration on other things necessarily transfers to calibration on AI x-risk - but this would be foolish)
The best case is that forecasters say precisely that: that there's no basis to think they can do this.
I imagine that some will say this - but I'd rather not rely on that.
It's not obvious all will realize they can't do it, nor is it obvious that regulators won't just keep asking people until they find those who claim they can do it.
Better not to create the unrealistic expectation that this is a thing that can be done. (absent deep understanding)
Replies from: elifland↑ comment by elifland · 2023-10-26T13:13:20.444Z · LW(p) · GW(p)
I’d be curious whether you think that it has been a good thing for Dario Amodei to publicly state his AI x-risk estimate of 10-25%, even though it’s very rough and unprincipled. If so, would it be good for labs to state a very rough estimate explicitly for catastrophic risk in the next 2 years, to inform policymakers and the public? If so, why would having teams with ai, forecasting, and risk management expertise make very rough estimates of risk from model training/deployment and releasing them to policymakers and maybe the public be bad?
I’m curious where you get off the train of this being good, particularly when it becomes known to policymakers and the public that a model could pose significant risk, even if we’re not well-calibrated on exactly what the risk level is.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2023-10-26T13:55:43.872Z · LW(p) · GW(p)
tl;dr:
Dario's statement seems likely to reduce overconfidence.
Risk-management-style policy seems likely to increase it.
Overconfidence gets us killed.
I think Dario's public estimate of 10-25% is useful in large part because:
- It makes it more likely that the risks are taken seriously.
- It's clearly very rough and unprincipled.
Conditional on regulators adopting a serious risk-management-style approach, I expect that we've already achieved (1).
The reason I'm against it is that it'll actually be rough and unprincipled, but this will not clear - in most people's minds (including most regulators, I imagine) it'll map onto the kind of systems that we have for e.g. nuclear risks.
Further, I think that for AI risk that's not x-risk, it may work (probably after a shaky start). Conditional on its not working for x-risk, working for non-x-risk is highly undesirable, since it'll tend to lead to overconfidence.
I don't think I'm particularly against teams of [people non-clueless on AI x-risk], [good general forecasters] and [risk management people] coming up with wild guesses that they clearly label as wild guesses.
That's not what I expect would happen (if it's part of an official regulatory system, that is).
Two cases that spring to mind are:
- The people involved are sufficiently cautious, and produce estimates/recommendations that we obviously need to stop. (e.g. this might be because the AI people are MIRI-level cautious, and/or the forecasters correctly assess that there's no reason to believe they can make accurate AI x-risk predictions)
- The people involved aren't sufficiently cautious, and publish their estimates in a form you'd expect of Very Serious People, in a Very Serious Organization - with many numbers, charts and trends, and no "We basically have no idea what we're doing - these are wild guesses!" warning in huge red letters at the top of every page.
The first makes this kind of approach unnecessary - better to get the cautious people make the case that we have no solid basis to make these assessments that isn't a wild guess.
The second seems likely to lead to overconfidence. If there's an officially sanctioned team of "experts" making "expert" assessments for an international(?) regulator, I don't expect this to be treated like the guess that it is in practice.
Replies from: elifland↑ comment by elifland · 2023-10-27T17:15:26.455Z · LW(p) · GW(p)
Thanks! I agree with a lot of this, will pull out the 2 sentences I most disagree with. For what it's worth I'm not confident that this type of risk assessment would be a very valuable idea (/ which versions would be best). I agree that there is significant risk of non-cautious people doing this poorly.
The reason I'm against it is that it'll actually be rough and unprincipled, but this will not clear - in most people's minds (including most regulators, I imagine) it'll map onto the kind of systems that we have for e.g. nuclear risks.
I think quantifying "rough and unprincipled" estimates is often good, and if the team of forecasters/experts is good then in the cases where we have no idea what is going on yet (as you mentioned, the x-risk case especially as systems get stronger) they will not produce super confident estimates. If the forecasts were made by the same people and presented in the exact same manner as nuclear forecasts, that would be bad, but that's not what I expect to happen if the team is competent.
The first makes this kind of approach unnecessary - better to get the cautious people make the case that we have no solid basis to make these assessments that isn't a wild guess.
I'd guess something like "expert team estimates a 1% chance of OpenAI's next model causing over 100 million deaths, causing 1 million deaths in expectation" might hit harder to policymakers than "experts say we have no idea whether OpenAI's models will cause a catastrophe". The former seems to sound more clearly an alarm than the latter. This is definitely not my area of expertise though.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2023-10-27T20:20:17.368Z · LW(p) · GW(p)
That's reasonable, but most of my worry comes back to:
- If the team of experts is sufficiently cautious, then it's a trivially simple calculation: a step beyond GPT-4 + unknown unknowns = stop. (whether they say "unknown unknowns so 5% chance of 8 billion deaths", or "unknown unknowns so 0.1% chance of 8 billion deaths" doesn't seem to matter a whole lot)
- I note that 8 billion deaths seems much more likely than 100 million, so the expectation of "1% chance of over 100 million deaths" is much more than 1 million.
- If the team of experts is not sufficiently cautious, and come up with "1% chance of OpenAI's next model causing over 100 million deaths" given [not-great methodology x], my worry isn't that it's not persuasive that time. It's that x will become the standard, OpenAI will look at the report, optimize to minimize the output of x, and the next time we'll be screwed.
In part, I'm worried that the argument for (1) is too simple - so that a forecasting team might put almost all the emphasis elsewhere, producing a 30-page report with 29 essentially irrelevant pages. Then it might be hard to justify coming to the same conclusion once the issues on 29 out of 30 pages are fixed.
I'd prefer to stick to the core argument: a powerful model and unknown unknowns are sufficient to create too much risk. The end. We stop until we fix that.
The only case I can see against this is [there's a version of using AI assistants for alignment work that reduces overall risk]. Here I'd like to see a more plausible positive case than has been made so far. The current case seems to rely on wishful thinking (it's more specific than the one sentence version, but still sketchy and relies a lot on [we hope this bit works, and this bit too...]).
However, I don't think Eliezer's critique is sufficient to discount approaches of this form, since he tends to focus on the naive [just ask for a full alignment solution] versions, which are a bit strawmannish. I still think he's likely to be essentially correct - that to the extent we want AI assistants to be providing key insights that push research in the right direction, such assistants will be too dangerous; to the extent that they can't do this, we'll be accelerating a vehicle that can't navigate.
[EDIT: oh and of course there's the [if we really suck at navigation, then it's not clear a 20-year pause gives us hugely better odds anyway] argument; but I think there's a decent case that improving our ability to navigate might be something that it's hard to accelerate with AI assistants, so that a 5x research speedup does not end up equivalent to having 5x more time]
But this seems to be the only reasonable crux. This aside, we don't need complex analyses.
Replies from: elifland↑ comment by elifland · 2023-10-30T18:34:55.633Z · LW(p) · GW(p)
GPT-4 + unknown unknowns = stop. (whether they say "unknown unknowns so 5% chance of 8 billion deaths", or "unknown unknowns so 0.1% chance of 8 billion deaths
I feel like .1% vs. 5% might matter a lot, particularly if we don't have strong international or even national coordination and are trading off more careful labs going ahead vs. letting other actors pass them. This seems like the majority of worlds to me (i.e. without strong international coordination where US/China/etc. trust each other to stop and we can verify that), so building capacity to improve these estimates seems good. I agree there are also tradeoffs around alignment research assistance that seem relevant. Anyway, overall I'd be surprised if it doesn't help substantially to have more granular estimates.
my worry isn't that it's not persuasive that time. It's that x will become the standard, OpenAI will look at the report, optimize to minimize the output of x, and the next time we'll be screwed.
This seems to me to be assuming a somewhat simplistic methodology for the risk assessment; again this seems to come down to how good the team will be, which I agree would be a very important factor.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2023-10-30T21:54:35.308Z · LW(p) · GW(p)
Anyway, overall I'd be surprised if it doesn't help substantially to have more granular estimates.
Oh, I'm certainly not claiming that no-one should attempt to make the estimates.
I'm claiming that, conditional on such estimation teams being enshrined in official regulation, I'd expect their results to get misused. Therefore, I'd rather that we didn't have official regulation set up this way.
The kind of risk assessments I think I would advocate would be based on the overall risk of a lab's policy, rather than their immediate actions. I'd want regulators to push for safer strategies, not to run checks on unsafe strategies - at best that seems likely to get a local minimum (and, as ever, overconfidence).
More [evaluate the plan to get through the minefield], and less [estimate whether we'll get blown up on the next step]. (importantly, it won't always be necessary to know which particular step forward is more/less likely to be catastrophic, in order to argue that an overall plan is bad)
↑ comment by elifland · 2023-10-30T22:13:41.169Z · LW(p) · GW(p)
fOh, I'm certainly not claiming that no-one should attempt to make the estimates.
Ah my bad if I lost the thread there
I'd want regulators to push for safer strategies, not to run checks on unsafe strategies - at best that seems likely to get a local minimum (and, as ever, overconfidence).
Seems like checks on unsafe strategies does well encourages safer strategies, I agree overconfidence is an issue though
More [evaluate the plan to get through the minefield], and less [estimate whether we'll get blown up on the next step]
Seems true in an ideal world but in practice I'd imagine it's much easier to get consensus when you have more concrete evidence of danger / misalignment. Seems like there's lots of disagreement even within the current alignment field and I don't expect that to change absent of more evidence of danger/misalignment and perhaps credible estimates.
To be clear I think if we could push a button for an international pause now it would be great, and I think it's good to advocate for that to shift the Overton Window if nothing else, but in terms of realistic plans it seems good to aim for stuff a bit closer to evaluating the next step than overall policies, for which there is massive disagreement.
(of course there's a continuum between just looking at the next step and the overall plan, there totally should be people doing both and there are so it's a question at the margin, etc.)
The other portions of your comment I think I've already given my thoughts on previously, but overall I'd say I continue to think it depends a lot on the particulars of the regulation and the group doing the risk assessment; done well I think it could set up incentives well but yes if done poorly it will get Goodharted. Anyway, I'm not sure it's particularly likely to get enshrined into regulation anytime soon, so hopefully we will get some evidence as to how feasible it is and how it's perceived via pilots and go from there.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-10-30T19:13:22.553Z · LW(p) · GW(p)
https://www.lesswrong.com/posts/9nEBWxjAHSu3ncr6v/responsible-scaling-policies-are-risk-management-done-wrong?commentId=zJzBaoBhP8tti4ezb
comment by simeon_c (WayZ) · 2024-12-04T20:15:50.460Z · LW(p) · GW(p)
I still agree with a lot of that post and am still essentially operating on it.
I also think that it's interesting to read the comments because at the time the promise of those who thought my post was wrong was that Anthropic's RSP would get better and that this was only the beginning. With RSP V2 being worse and less specific than RSP V1, it's clear that this was overoptimistic.
Now, risk management in AI has also gone a lot more mainstream than it was a year ago, in large parts thanks to the UK AISI who started operating on it. People have also started using more probabilities, for instance in safety cases paper, which this post advocated for.
With SaferAI, my organization, we're still continuing to work on moving the field closer from traditional risk management and ensuring that we don't reinvent the wheel when there's no need to. There should be releases going in that direction over the coming months.
Overall, if I look back on my recommendations, I think they're still quite strong. "Make the name less misleading" hasn't been executed on but other names than RSPs have started being used, such as Frontier AI Safety Commitments, which is a strong improvement from my "Voluntary safety commitments" suggestion.
My recommendation about what RSPs are and aren't are also solid. My worry that the current commitments in RSPs would be pushed in policy was basically right: it's been used in many policy conversations as an anchor for what to do and what not to do.
Finally, the push for risk management in policy that I wanted to see happen has mostly happened. This is great news.
The main thing that misses from this post is the absence of prediction of RSP launching the debate about what should be done and at what levels. This is overall a good effect which has happened, and would probably have happened several months after if not for the publication of RSPs. The fact that it was done in a voluntary commitment context is unfortunate, because it levels down everything, but I still think this effect was significant.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-10-30T19:12:04.313Z · LW(p) · GW(p)
This implies an immediate stop to all frontier AI development (and probably a rollback of quite a few deployed systems). We don't understand. We cannot demonstrate risks are below acceptable levels.
Yes yes yes. A thousand times yes. We are already in terrible danger. We have crossed bad thresholds. I'm currently struggling with how to prove this to the world without actually worsening the danger by telling everyone exactly what the dangers are. I have given details about theses dangers to a few select individuals. I will continue working on evals.
In the meantime, I have contributed to this report which I think does a good job of gesturing in the direction of the bad things without going into too much detail on the actual heart of the matter:
Will releasing the weights of large language models grant widespread access to pandemic agents?
Anjali Gopal, Nathan Helm-Burger, Lenni Justen, Emily H. Soice, Tiffany Tzeng, Geetha Jeyapragasan, Simon Grimm, Benjamin Mueller, Kevin M. Esvelt
Large language models can benefit research and human understanding by providing tutorials that draw on expertise from many different fields. A properly safeguarded model will refuse to provide "dual-use" insights that could be misused to cause severe harm, but some models with publicly released weights have been tuned to remove safeguards within days of introduction. Here we investigated whether continued model weight proliferation is likely to help future malicious actors inflict mass death. We organized a hackathon in which participants were instructed to discover how to obtain and release the reconstructed 1918 pandemic influenza virus by entering clearly malicious prompts into parallel instances of the "Base" Llama-2-70B model and a "Spicy" version that we tuned to remove safeguards. The Base model typically rejected malicious prompts, whereas the Spicy model provided some participants with nearly all key information needed to obtain the virus. Future models will be more capable. Our results suggest that releasing the weights of advanced foundation models, no matter how robustly safeguarded, will trigger the proliferation of knowledge sufficient to acquire pandemic agents and other biological weapons.
comment by Charlie Steiner · 2023-10-26T10:43:05.968Z · LW(p) · GW(p)
Thanks! I can't help but compare this to Tyler Cowen asking AI risk to "have a model." Except I think he was imagining something like a macroeconomic model, or maybe a climate model. Whereas you're making a comparison to risk management, and so asking for an extremely zoomed-in risk model.
One issue is that everyone disagrees. Doses of radiation are quite predictable, the arc of new technology is not. But having stated that problem, I can already think of mitigations - e.g. regulation might provide a framework that lets the regulator ask lots of people with fancy job titles and infer distributions about many different quantities (and then problems with these mitigations - this is like inferring a distribution over the length of the emperor's nose by asking citizens to guess). Other quantities could be placed in historical reference classes (AI Impacts' work shows both how this is sometimes possible and how it's hard).
Replies from: WayZ↑ comment by simeon_c (WayZ) · 2023-10-26T11:47:21.420Z · LW(p) · GW(p)
Thanks for your comment.
One issue is that everyone disagrees.
That's right and that's a consequence of uncertainty, which prevents us from bounding risks. Decreasing uncertainty (e.g. through modelling or through the ability to set bounds) is the objective of risk management.
Doses of radiation are quite predictable
I think it's mostly in hindsight. When you read stuff about nuclear safety in the 1970s, it's really not how it was looking.
See Section 2

the arc of new technology is not [predictable]
I think that this sets a "technology is magic" vibe which is only valid for scaling neural nets (and probably only because we haven't invested that much into understanding scaling laws etc.), and not for most other technologies. We can actually develop technology where we know what it's doing before building it and that's what we should aim for given what's at stakes here.
comment by Review Bot · 2024-05-30T07:17:52.840Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Corin Katzke (corin-katzke) · 2023-12-03T00:19:08.613Z · LW(p) · GW(p)
It’s called “responsible scaling”. In its own name, it conveys the idea that not further scaling those systems as a risk mitigation measure is not an option.
That seems like an uncharitable reading of "responsible scaling." Strictly speaking, the only thing that name implies is that it is possible to scale responsibly. It could be more charitably interpreted as "we will only scale when it is responsible to do so." Regardless of whether Anthropic is getting the criteria for "responsibility" right, it does seem like their RSP leaves open the possibility of not scaling.
comment by RogerDearnaley (roger-d-1) · 2023-11-08T10:35:46.108Z · LW(p) · GW(p)
This NIST Risk Management approach sounds great, if AI Alignment was a mature field whose underlying subject matter wasn't itself advancing extremely fast — if only we could do this! But currently I think that for many of our risk estimates it would be hard to get agreement between topic experts at even an order of magnitude scale (e.g.: is AGI misalignment >90% likely or <10% likely? YMMV). I think we should aspire to be a field mature enough that formal Risk Management is applicable, and in some areas of short-term misuse risks from current well-understood models (open-source ones, say), that might even be approaching feasibility. But for the existential AGI-level risks several years out, which are the ones that matter most, the field just isn't mature enough yet.
Bear in mind that there was a point in the development of nuclear safety where people built open-circuit air-cooled nuclear reactors where the air-flow past the pile went up a chimney venting the hot air up into the atmosphere (yes, really: https://en.wikipedia.org/wiki/Windscale_Piles ). They didn't then know better, and there's an area near Ravenglass in England that's still somewhat contaminated as a result after one caught fire. Nuclear safety knowledge has since advanced to be able to do elaborate Risk Management, and a good thing too, but unfortunately AI safety isn't that mature yet.
comment by Remmelt (remmelt-ellen) · 2023-10-31T10:43:48.666Z · LW(p) · GW(p)
Excellent article. I appreciate how you clarify that Anthropic's "Responsible Scaling Policy" is a set-up that allows for safety-washing. We would be depending on their well-considered good intentions, rather than any mechanism to hold them accountable.
Have you looked into how system safety engineers (eg. medical device engineers) scope the uses of software, such to be able to comprehensively design, test, and assess the safety of the software?
Operational Design Domains scope the use of AI in self-driving cars. Tweeted about that here.