Mode collapse in RL may be fueled by the update equation
post by TurnTrout, MichaelEinhorn (michaeleinhorn) · 2023-06-19T21:51:04.129Z · LW · GW · 10 commentsContents
The advantage equation implies arbitrary amounts of update on a single experience Action-conditioned TD error avoids arbitrarily high logits ACTDE doesn't mode-collapse onto wireheading PPO vs ACTDE on the iterated prisoner's dilemma PPO results ACTDE results Speculation Summary Contributions: Appendix: Random notes None 10 comments
TL;DR: We present an advantage variant which, in certain settings, does not train an optimal policy, but instead uses a fixed reward to update a policy a fixed amount from initialization. Non-tabular empirical results seem mixed: The policy doesn't mode-collapse, but has unclear convergence properties.
Summary: Many policy gradient methods allow a network to extract arbitrarily many policy updates from a single kind of reinforcement event (e.g. for outputting tokens related to weddings). Alex proposes a slight modification to the advantage equation, called "action-conditioned TD error" (ACTDE). ACTDE ensures that the network doesn't converge to an "optimal" policy (these almost always put infinite logits on a single action). Instead, ACTDE updates the network by a fixed number of logits.
For example, suppose and . In this case, PPO converges to a policy which puts arbitrarily many logits on , even though the reward difference is small. By contrast, under ACTDE, the network converges to the softmax-over-reward policy {pizza: 27%, cookies: 73%}, which seems more reasonable.
Then, Michael Einhorn shares initial results which support Alex's theoretical predictions. Using a similar architecture and Q-head loss function to ILQL for a small transformer trained in a prisoner's dilemma, Michael Einhorn collected initial data on ACTDE. Unlike PPO, ACTDE-trained policies did not mode collapse onto a single action and instead learned mixed strategies.
We're interested in additional experiments on ACTDE. We hope that, by using ACTDE instead of advantage, we can automatically mitigate "reward specification" issues and maybe even reduce the need for a KL penalty term. That would make it easier to shape policies which do what we want.
The advantage equation implies arbitrary amounts of update on a single experience
In PPO, the optimization objective is proportional to the advantage given a policy , reward function , and on-policy value function :[1]
Alex thinks this equation is actually pretty messed up, although it looked decent at first. The problem is that this advantage can oscillate forever. To explain, let's consider a simple bandit problem—one state ("We had a") and two actions ("wedding" and "party") with rewards and .
The failure which happens is:
- The policy tries out the "wedding" action, receives strong reinforcement of , and increasing logits on that action because its advantage was positive. The policy learns that its value is high ().
- The policy eventually tries out the "party" action, receiving less reinforcement at , decreasing the logits on "party" (because its advantage was negative). The policy learns that the original state's value is low ().
- The policy tries out "wedding" again, receives positive advantage relative to the low original state value. The logits go up on "wedding", and the value is once again high ().
This continues to happen, which means that "wedding" gets arbitrarily high logits.
This flaw is easiest to see formally. Initialize the tabular value function to 0, and the policy to be 50/50 for “party”/“wedding”. Let , and we update the value function using tabular TD learning (with learning rate ). So, for example, if the system takes the “wedding” action, its new value function . If the system then takes the “party” action, the value snaps back to .[2]
The policy update rule is: If the advantage , then action becomes bits more probable under (i.e. we add to 's logits on ). So, if and advantage , then .
Episode-by-episode:
| Action taken | Advantage | |||
|---|---|---|---|---|
| 1 | wedding | .73 | 1 | |
| 2 | party | .82 | .5 | |
| 3 | party | .82 | .5 | |
| 4 | wedding | .88 | 1 |
With probability 1 as , . You might think this is good, since wedding is in fact “optimal” at that state. This does not seem good. Here are a few kinds of explanations for why:
- Reward chisels circuits into policy networks. Here, the network can get arbitrarily many policy gradients towards “wedding.” Its logits just go up and up and up. Mode collapse.
- We want the reward to be feedback about what kinds of completions are good (or, more abstractly, about what kinds of computations are good to run inside the network). We want a single situation to provide a finite amount of updating.
- The system can get stuck in a local attractor. Imagine that we want the system to talk about parties at Chuck-E-Cheese in particular, and we give the system 2 reward if it says “We had a party at Chuck-E-Cheese.” But the system may never get there during training due to exploration issues, which are exarcerbated by the network getting penalized relative to its on-policy value estimate .
- In other words, PPO actively updates against actions which aren’t known to beat current on-policy value . The process penalizes exploration.
This doesn’t seem limited to tabular TD-learning, or PPO in more realistic domains. EG vanilla policy gradient will also allow a system to extract an unbounded amount of reinforcement from a single kind of event (e.g. “wedding”). Unless very specific care is taken, Alex thinks this kind of failure happens by default in policy gradient methods.
Action-conditioned TD error avoids arbitrarily high logits
Given the original advantage equation:
replace the last term’s baseline to account for the taken action:
We call this “action-conditioned TD error” (ACTDE).
ACTDE allows the system to account for its decision to go off-policy by selecting a new action which isn’t the usual recommendation . Philosophically, Alex wanted to mimic reward prediction error. The network taking a different action is not surprising to the network, so the optimization term should account for the action taken (i.e. by using ).
Re-analyzing the situation:
| Action | Action-conditioned TD error | |||
|---|---|---|---|---|
| 1 | wedding | .73 | wedding: 1, party: 0 | |
| 2 | party | .63 | wedding: 1, party: .5 | |
| 3 | party | .63 | wedding: 1, party: .5 | |
| 4 | wedding | .63 | wedding: 1, party: .5 |
The policy quickly converges to the softmax logits over the reward for the next completions, where . That is, the learned policy has logits on “party” and logit on “wedding”. Therefore this process does not converge to the optimal policy, even in the limit of infinite exploration. Correspondingly, there is no mode collapse in this situation. Reward logits are “added to” initialization logits (the prior over what completions to output). RL, in this setting, provides a finite amount of reinforcement for certain kinds of computation/actions.
Furthermore, self-consistent, Bellman-backed-up Q-functions will have zero advantage and zero updates. Networks aren’t penalized for exploring, and there’s a precise and finite amount of reinforcement which can occur given current predictions about future value, as represented by . And training should be more stable, with fewer fluctuations in advantage with respect to the policy itself.[3]
ACTDE doesn't mode-collapse onto wireheading
ACTDE doesn't mode collapse on wireheading, even given that the network tries out wireheading! (Which Alex thinks is not that likely for practical RL algorithms [LW · GW].)
Concretely, suppose that reward is 10 if you eat pizza and 100 if you wirehead. You start off with action distribution {pizza: 1%, wirehead: 99%}, and we're doing TD-learning in the tabular setup we just described. If so, then the policy gradients upweight wireheading more and more. This can happen until the network puts arbitrarily many logits on the wireheading action. In this situation, under these exploration assumptions and with probability 1, PPO "selects for" wireheading and the policy ends up {pizza: , wirehead: }.
However, ACTDE does not lead to arbitrarily many logits on wireheading. Instead, ACTDE leads to the softmax distribution over actions, with the softmax taken over the reward for each action. Thus, the "optimum"/fixed-point policy of tabular ACTDE is about { pizza: .02%, wirehead: 99.98% }. That's still mostly wireheading, but there are only finitely many logits on that action.
PPO vs ACTDE on the iterated prisoner's dilemma
In this toy experiment, the model plays prisoner's dilemmas against its past self, similar to the idea by Krueger et. al. The model is mingpt with a vocab size of two: one token for "cooperate", and one for "defect". mingpt has 3 layers and an embedding dimension of 12. The model sees the history of cooperates and defections, and outputs the next action.
We are not training via self play against a copy. Instead the model at time plays against its action at time . Playing with its past self for a sequence of ccddc has 4 games: cc, cd, dd, dc, with rewards of 0.5 (for cc), 2 (for cd), -0.74 (for dd), and -1.76 (for dc).[4]
| Reward matrix | Cooperate () | Defect () |
|---|---|---|
| Cooperate () | ||
| Defect () |
Alternating cooperation (c) and defection (d) is the (bolded) optimal strategy for both start states:
| Action sequence | Sum of discounted reward () |
|---|---|
cccc... | 1 |
cddd... | 1.261 |
cdcd... | 1.492 |
dddd... | -1.477 |
dccc... | -1.261 |
dcdc... | -1.015 |
What we're testing: If ACTDE mode collapses when used on function approximators (like mingpt), then the theoretical predictions above are wrong.
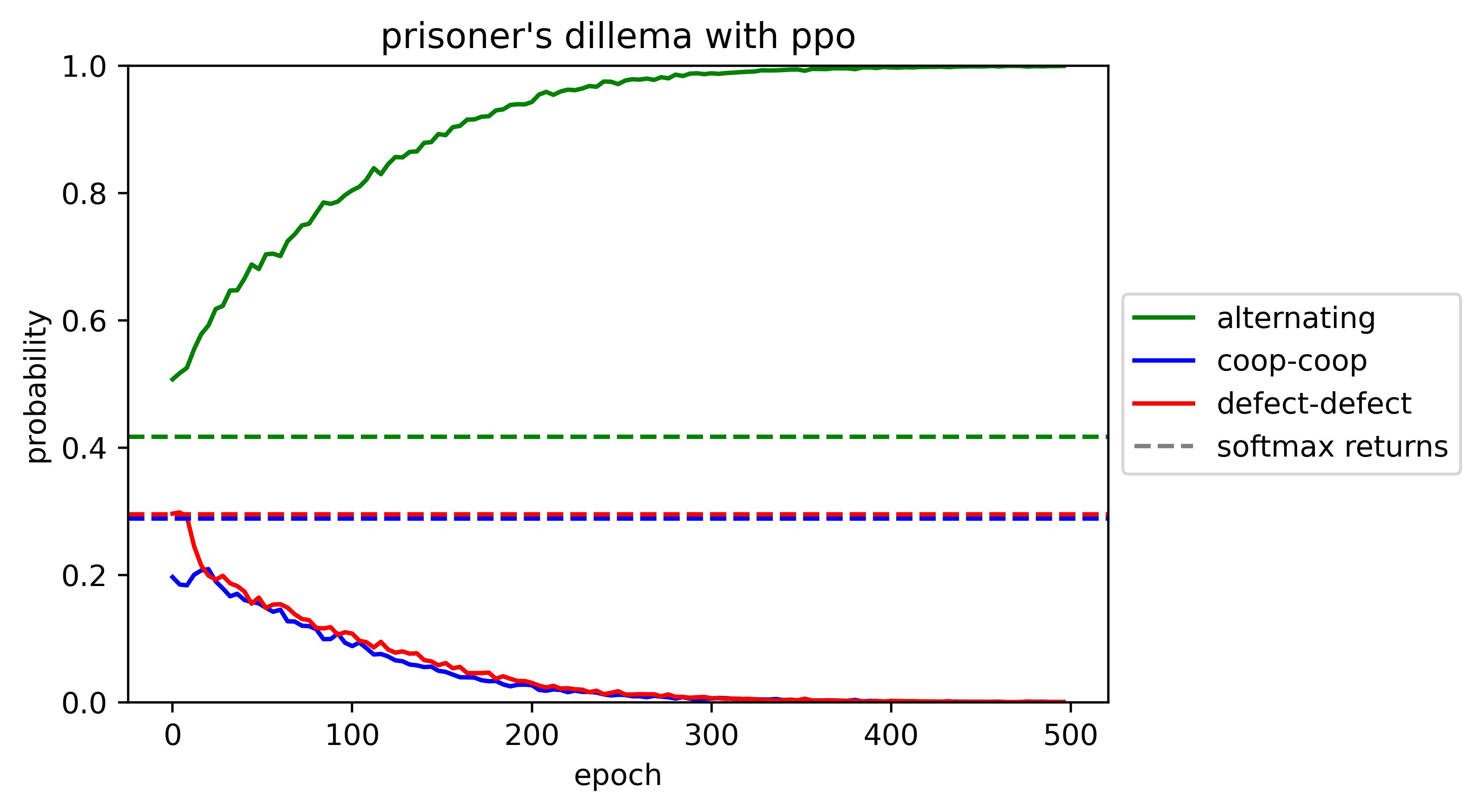
PPO results
PPO immediately learns the alternating strategy:
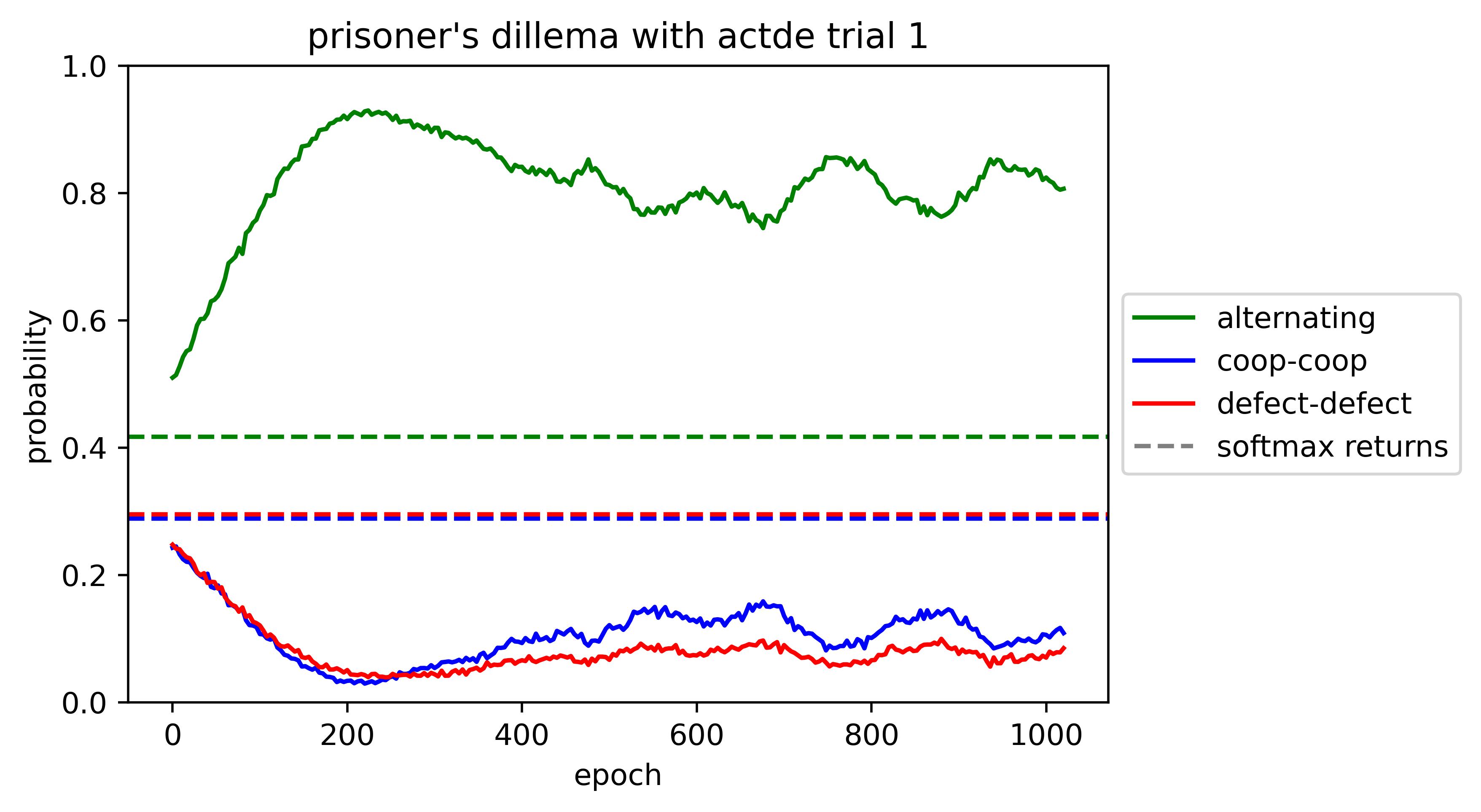
ACTDE results
The model does not collapse onto a pure strategy. Instead, the results are inconsistent across trials. However, ACTDE does reliably:
- initially alternate with high probability
- tend to regress towards a uniform (or softmax-return) policy over time,
- with .
Here's the first 1K epochs of a training run:
Zooming out to all 10K epochs:
We ran 10 trials and plotted the mean and standard deviation of average returns:
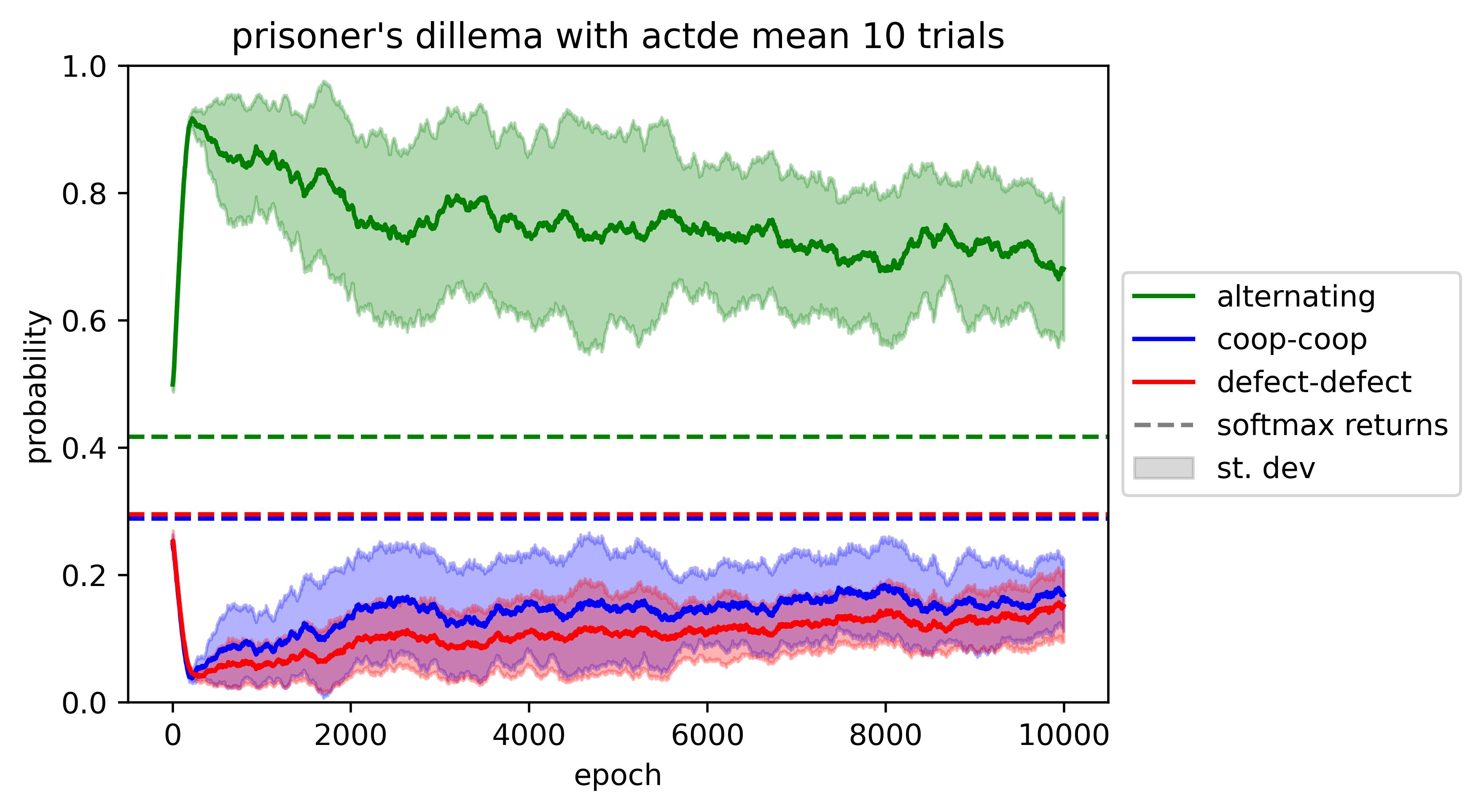
There seems to be very slow convergence,[6] perhaps towards the softmax-over-returns policy (shown by the dotted lines), or towards the uniform policy. We lean towards "convergence to uniform" due to evidence from a trial on a different reward matrix:
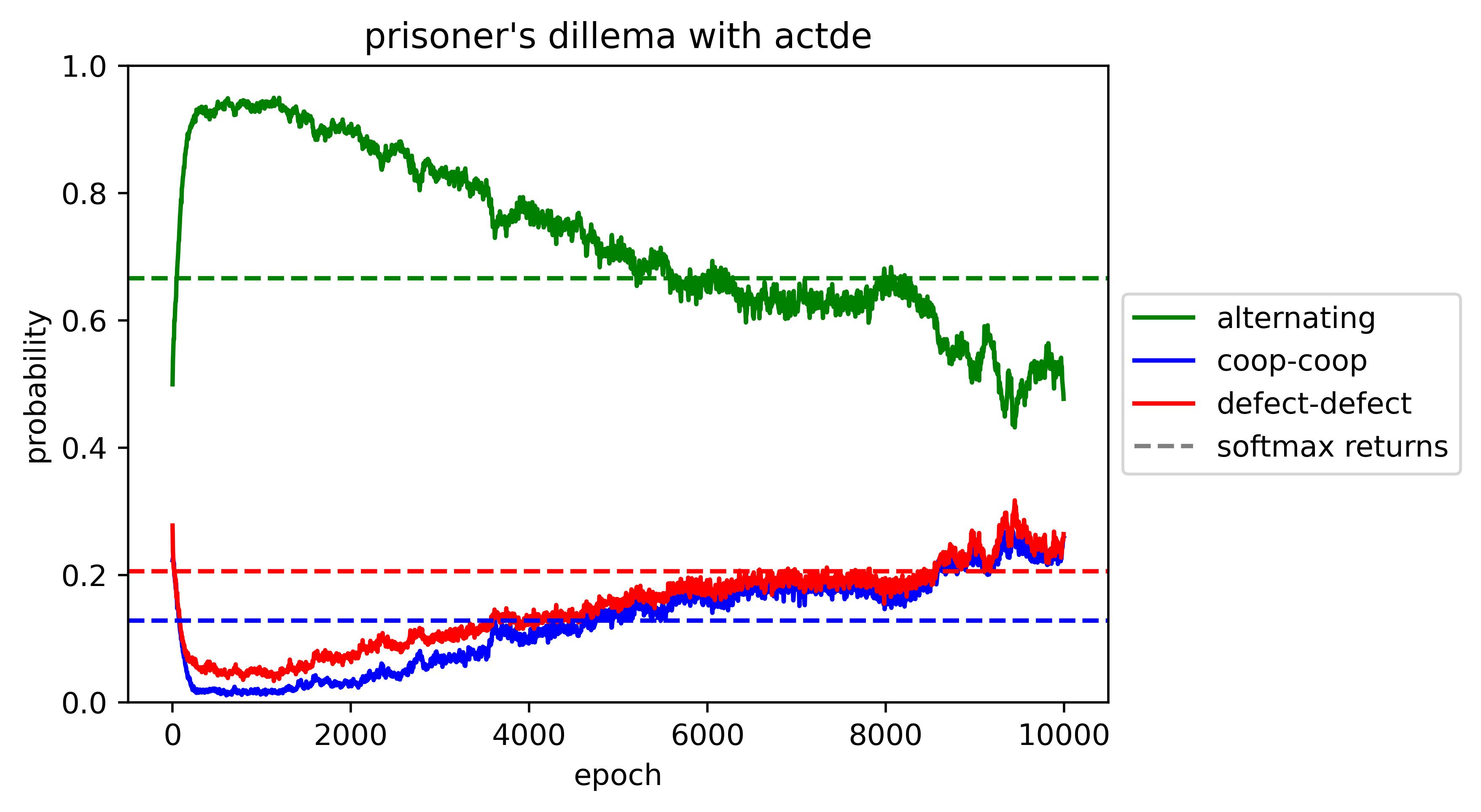
Overall, ACTDE's results are sensitive to variations in the algorithm such as whitening advantages, detaching the value and Q-heads, and using the loss function from PPO or ILQL for the value head.
Speculation
This method might not work very well for e.g. RLHF at scale. Deep RL is notoriously finicky. Furthermore, it would be pretty disappointing if ACTDE generally converges on uniform policies, and that seems like a live possibility given the last graph above.
However, Alex has a few intuitions anyways:
- Mitigating reward misspecification. If the reward is really high in a situation which the policy can easily explore into during training, then that's bad and probably leads to distorted policies.
- However, under ACTDE, a single reward event (e.g. hypothetically, a maximal reward whenever "weddings" appears) should have less impact on the trained policy.
- For example, the Q-function can quickly learn to predict that a given string "I went to the barn" produces high reward, and then there isn't any more barn-related reinforcement.
- However, if barn-related generations are strongly rewarded in general, the model might still receive reinforcement for the hard-to-predict and diverse range of barn reward events.
- Reducing mode collapse. In the tabular bandit regime (explored above), ACTDE adds "reward logits" () onto the initial policy logits (). Maybe this is true in general (but probably not). If so, then KL penalties might be less important for keeping the trained policy close to the initial policy .
- Less mode collapse means higher-entropy next-token distributions, which may mean greater variety in the policy's preferences/shards [LW · GW]. That is, it may be rarer for motivational/goal-encoding circuits to be effectively pruned by mode-collapsed RLHF/RLAIF.
- If a system has more shards, there's a greater chance that some of the shards care about humans [LW(p) · GW(p)].
Summary
ACTDE seems to avoid mode collapse in simple tabular setups. We showed that ACTDE doesn't mode collapse on a toy prisoner's dilemma learning task, but instead trains a mixed strategy.
We're excited for someone to RLHF a language model using ACTDE. Alex is willing to contribute 30 minutes weekly to giving feedback on such a project, insofar as that would be helpful. If necessary, Alex can also help acquire funding for a prospective researcher who has experience doing deep RL. Email him at alex@turntrout.com if interested. Email Michael at einhorn.michael1@gmail.com for any questions about the code.
Contributions:
- Alex came up with the modified advantage equation, illustrated with toy examples, and wrote most of this post.[7]
- Michael implemented and tested PPO, and ACTDE on both prisoner's dilemmas and text adventure games. Code is available at
trl_textworld[8] andprisonerUnitTest.
Thanks to Connor Leahy, Evan Hubinger, Ulisse Mini, Nate Soares, Leo Gao, Garrett Baker, janus, David Krueger and others for thoughts and discussions.
Appendix: Random notes
- The learning rate on should control the total amount of reinforcement from a single reward source.
- The at-convergence learned policy will, in our tabular setting, be invariant to constant shifts of the reward function and, when , to constant shifts of ’s initialization.
- However, perhaps decreasing rewards everywhere encourages exploration and increasing rewards encourages temporary mode collapse?
- Multiplying all rewards by a postive scalar will extremize the policy probabilities in a rather simple way, by taking them to the th power and then renormalizing. (IE a change in temperature for the softmax distribution.)
- Reward Matrix construction
- The always-defect strategy is myopic, and the always-cooperate strategy is non-myopic.
- The payoff matrix for the prisoner's dilemma was selected to have 0 sum, and to have equal discounted returns for all cooperate and all defect at a mean discount rate of 0.5. Ex. the discount rate for equal discounted returns is 0.4523 starting from defect and 0.5477 starting from coop with a mean of 0.5.
- It turns out that it is possible to construct a matrix where it is better to always defect when starting from a cooperate, and vice versa, leading to a third strategy of alternating cooperate and defect being optimal. This may represent a more complex optimal strategy compared to a good simple strategy.
- See variations of the matrix here.
- ^
This advantage equation, as given, can also be called the "TD error."
- ^
Alex thinks that using a fixed learning rate shouldn’t fix PPO's "infinite logit update issue", but a decaying learning rate schedule probably does. This isn't that surprising, and he doesn't think it fixes the deeper potential issue with fluctuating value baselines.
- ^
Although Alex hasn't analyzed the sequential tabular setting — possibly infinite logit updating can still happen there?
- ^
Note that the
cdanddcalways come in pairs except for at most 1 extra. - ^
averages strategy 's return over the first state being cooperate
cand being defectd. - ^
In the tabular bandit example above, the convergence was extremely fast due to the learning rate and triviality of the problem.
- ^
When Alex wrote this in the fall, he thought that RLHF was responsible for mode collapse behaviors in LMs. However, empirical evidence has since made him think that RLHF is less responsible for these failures [LW · GW]. He thinks his theoretical analysis is still correct under the assumptions he made, and he still thinks it's important to investigate empirically.
- ^
One of the goals of
trl-textworldwas to evaluate PPO vs ACTDE finetunings on pretrained language models, but the models were not able to learn to play the text adventure, so this project did not get to a point where the algorithm's results could be compared. The implementation may still be useful—it has been tested up to GPT-NeoX 20B on 8 GPUs.
10 comments
Comments sorted by top scores.
comment by Jacob_Hilton · 2023-06-20T07:22:27.382Z · LW(p) · GW(p)
I think KL/entropy regularization is usually used to prevent mode collapse partly because it has nice theoretical properties. In particular, it is easy to reason about the optimal policy for the regularized objective - see for example the analysis in the paper Equivalence Between Policy Gradients and Soft Q-Learning.
Nevertheless, action-dependent baselines do appear in the literature, although the story is a bit confusing. This is my understanding of it from some old notes:
- The idea was explored in Q-Prop. But unlike you, their intention was not to change the optimal policy, but rather to reduce the variance of the policy gradient. Therefore they also incorporated an additional term to cancel out the bias introduced by the action-dependent baseline. (Incidentally, perhaps this analysis is also relevant to understanding ACTDE.)
- Later, The Mirage of Action-Dependent Baselines showed that in fact the variance reduction due the action-dependent baseline was negligible, and the entire benefit of Q-Prop was essentially due to a bug! The implementation normalized advantage estimates, but failed to apply the same adjustment to the bias-correction term, which turned out to be independently helpful because it's essentially the DDPG training objective.
comment by Oliver Sourbut · 2023-06-21T08:33:18.009Z · LW(p) · GW(p)
I like the philosophical and strategic take here: let's avoid wireheading, arbitrary reinforcement strength is risky[1], hopefully we can get some values-caring-about-human-stuff.
The ACTDE seems potentially a nice complement/alternative to entropy[2] regularisation for avoiding mode collapse (I haven't evaluated deeply). I think you're misdiagnosing a few things though.
Overall I think the section about oscillating advantage/value estimation is irrelevant (interesting, but unrelated), and I think you should point the finger less at PPO and advantage estimation per se and more at exploration at large. And you might want to flag that too much exploration/randomness can also be an issue!
Though note that ideally, once we actually know with confidence what is best, we should be near-greedy about it, rather than softmaxing! Say it was 'ice cream' vs 'slap in the face'. I would infinitely (linearly in time) regret softmaxing over that for eternity. As it stands I think humanity is very far from being able to safely aggressively greedily optimise really important things, but this is at least a consideration to keep in mind. ↩︎
Incidentally, KL divergence regularisation is not primarily for avoiding mode collapse AFAIK, it's for approximate trust region constraints - which may incidentally help to avoid mode collapse by penalising large jumps away from initially-high-entropy policies. See the TRPO paper. Entropy regularisation directly addresses mode collapse. ↩︎
↑ comment by Oliver Sourbut · 2023-06-21T08:36:39.780Z · LW(p) · GW(p)
this kind of failure happens by default in policy gradient methods.
It looks like you're kind of agreeing here that value estimate oscillation isn't the culprit [LW(p) · GW(p)]? Again I think this is pretty standard - though the finger is usually not pointed at any particular value estimator or whatnot, but rather at the greediness of updating only on so-far-observed data i.e. the exploration problem. The GLIE conditions[1] - Greedy in the Limit with Infinite Exploration - are a classic result. Hence the plethora of exploration techniques which are researched and employed in RL.
Techniques like confidence bounding[2] based on Hoeffding's inequality and Thompson sampling based on Bayesian uncertainty require more than a simple mean estimate (which is all that a value or advantage is): typically at least also one spread/uncertainty estimate[3]. Entropy regularisation, epsilon 'exploration', intrinsic 'curiosity' rewards, value-of-information estimation and so on are all heuristics for engaging with exploration.
I don't know what's a good resource on GLIE, but you can just look up Greedy in the Limit with Infinite Exploration ↩︎
Amazingly there's no Wikipedia entry on UCB?? ↩︎
Epsilon exploration can get away without a spread estimate, but its GLIE guarantees are only provided if there's an epsilon per state, which secretly smuggles in an uncertainty estimate (because you're tracking the progress bar on each state somehow, which means you're tracking how often you've seen it). ↩︎
↑ comment by TurnTrout · 2023-06-26T17:50:40.732Z · LW(p) · GW(p)
Though note that ideally, once we actually know with confidence what is best, we should be near-greedy about it, rather than softmaxing!
I disagree. I don't view reward/reinforcement as indicating what is "best" (from our perspective), but as chiseling decision-making circuitry into the AI (which may then decide what is "best" from its perspective). One way of putting a related point: I think that we don't need to infinitely reinforce a line of reasoning in order to train an AI which reasons correctly.
(I want to check -- does this response make sense to you? Happy to try explaining my intuition in another way.)
↑ comment by Oliver Sourbut · 2023-06-21T08:37:31.855Z · LW(p) · GW(p)
There's also the issue of non-ergodic/nonstationary environments (if I try out breaking my leg to see what happens, I might not be able to try out other stuff later!) which defeat the GLIE and can cause another kind of collapse. Actually behaving sufficiently entropically is risky in such environments, hence research into safe exploration.
↑ comment by Oliver Sourbut · 2023-06-21T08:36:12.926Z · LW(p) · GW(p)
The problem is that this advantage can oscillate forever.
This is a pretty standard point in RL textbooks. But the culprit is the learning rate (which you set to be 1 in the example, but you can construct a nonconverging case for any constant )! The advantage definition itself is correct and non-oscillating, it's the estimation of the expectation using a moving average which is (sometimes) at fault.
Oscillating or nonconvergent value estimation is not the cause of policy mode collapse.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-06-26T17:52:12.708Z · LW(p) · GW(p)
The advantage definition itself is correct and non-oscillating... Oscillating or nonconvergent value estimation is not the cause of policy mode collapse.
The advantage is (IIUC) defined with respect to a given policy, and so the advantage can oscillate and then cause mode collapse. I agree that a constant learning rate schedule is problematic, but note that ACTDE converges even with a constant learning rate schedule. So, I would indeed say that oscillating value estimation caused mode collapse in the toy example I gave?
comment by [deleted] · 2023-06-20T04:32:51.678Z · LW(p) · GW(p)
Would this be equivalent to an RL environment that scales down the per wedding reward for repeated weddings?
What bothers me about this is suppose we have a different set of 2 RL choices:
Life saved + 10
Murder -10
In this case we want the agent to choose policies that result in life saved with total mode collapse away from committing a murder. This is also true for less edgy/more practical descriptions, such as:
box shelved correctly 0.1
human coworker potentially injured -10
comment by Charlie Steiner · 2023-06-19T22:17:07.591Z · LW(p) · GW(p)
Is this identical to training the next-to-last layer to predict the rewards directly, and then just transforming those predictions to get a sample? Have you considered going whole hog on model-based RL here?
I'd be interested in avoiding mode collapse in cases where that's not practical, like diffusion models. Actually, could you choose a reward that makes diffusion models equivalent to MCMC? Probably no good safety reason to do such a thing though.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-06-19T23:08:19.427Z · LW(p) · GW(p)
Is this identical to training the next-to-last layer to predict the rewards directly, and then just transforming those predictions to get a sample?
In the tabular case, that's equivalent given uniform . Maybe it's also true in the function approximator PG regime, but that's a maybe -- depends on inductive biases. But often we want a pretrained (like when doing RLHF on LLMs), which isn't uniform.