The Indexing Problem
post by johnswentworth · 2020-06-22T19:11:53.626Z · LW · GW · 2 commentsContents
Representing Indices None 2 comments
Meta: this project [? · GW] is wrapping up for now. This is the first of probably several posts dumping my thought-state as of this week.
Suppose we have a simple causal model of a system:
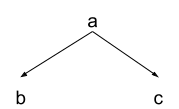
We hire someone to study the system, and eventually they come back with some data: “X=2”, they tell us. Apparently they are using a different naming convention than we are; what is this variable X? Does it correspond to a? To b? To c? To something else entirely?
I’ll call this the indexing problem: “index into” a model to specify where some data “came from”. (If someone knows of a better existing name, let me know.)
In practice, we usually “solve” the indexing problem by coordinating on names of things. I use descriptive variable names like “counterweight mass” or “customer age” in my model, and then when someone gives me data, it comes with object names like “counterweight” or “customer” and field names like “mass” or “age”. Of course, this has a major failure mode: names can be deceiving. A poorly documented API may have a field called “date”, and I might mistake it for the date on which some document was signed when really it was the date on which the document was delivered. Or a social scientist may have data on “empathy” or “status” constructed from a weighted sum of questionnaire responses, which may or may not correspond to anybody else’ notion/measurement of “empathy” or “status”.
The expensive way around this is to explicitly model the data-generation process. If I look at the actual procedure followed by the social scientist, or the actual code behind the poorly-documented API, then I can ignore the names and figure out for myself what the variables tell me about the world.
Usually this is where we’d start talking about social norms or something like that, but the indexing problem still needs to be solved even in the absence of any other agents. Even if I were the last person on a postapocalyptic Earth, I might find a photograph and think “where was this photograph taken?” - that would be an indexing problem. I might get lost and end up in front of a distinctive building, and wonder “where is this? Where am I?” - that’s an indexing problem. A premodern natural philosopher might stare through a telescope and wonder where that image is really coming from, and if it can really be trusted - that’s an indexing problem. I might smell oranges but not see any fruit, or I might hear water but see only desert, and wonder where the anomalous sensory inputs are coming from - that’s an indexing problem. Any time I’m wondering “where something came from” - i.e. which components of my world-model I should attach the data to - that’s an indexing problem.
When thinking about embedded agents, even just representing indices is nontrivial.
Representing Indices
If our world-model were just a plain graphical causal model in the usual format, and our data were just variables in that model, then representation would be simple: we just have a hash table mapping each variable to data on that variable (or null, for variables without any known data).
For agents modelling environments which contain themselves, this doesn’t work: the environment is necessarily larger than the model. If it’s a graphical causal model, we need to compress it somehow; we can’t even explicitly list all the variables. The main way I imagine doing this is to write causal models like we write progams [? · GW]: use recursive “calls” to submodels to build small representations of our world-model, the same way source code represents large computations.
… which means that, when data comes in, we need to index into a data structure representing the trace of a program’s execution graph, without actually calculating/storing that trace.
Here’s an example. We have a causal model representing this python program:
def factorial(n):
if n == 0:
return 1
return n * factorial(n-1)Expanded out, the causal model for this program executing on n=3 looks like this:

… where there are implicit arrows going downwards within each box (i.e. the variables in each box depend on the variables above them within the box). Notice that the causal model consists of repeated blocks; we can compress them with a representation like this:
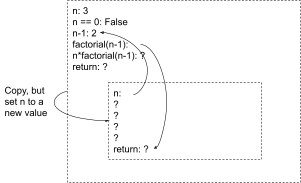
That’s the compressed world-model.
Now, forget about n=3. I just have the compressed world-model for the general case. I’m playing around with a debugger, setting breakpoints and stepping through the code. Some data comes in; it tells me that the value of “factorial(n-1)” in the “second block from the top” in the expanded model is 7.
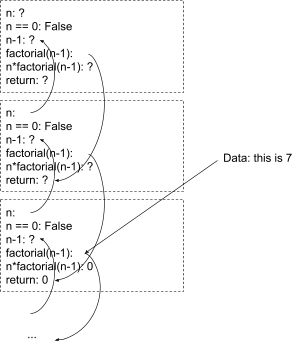
Now, there’s a whole hairy problem here about how to update our world-model to reflect this new data, but we’re not even going to worry about that. First we need to ask: how do we even represent this? What data structure do we use to point to the “second block from the top” in an expansion of a computation - a computation which we don’t want to fully expand out because it may be too large? Obviously we could hack something together, but my inner software engineer says that will get very ugly very quickly. We want a clean way to index into the model in order to attach data.
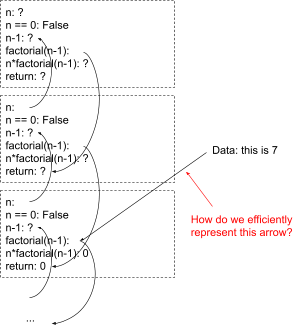
Oh, and just to make it a bit more interesting, remember that sometimes we might not even know which block we’re looking for. Maybe we’ve been stepping through with the debugger for a while, and we’re looking at a recursive call somewhere between ten and twenty deep but we’re not sure exactly which. We want to be able to represent that too. So there can be “indexical uncertainty” - i.e. we’re unsure of the index itself.
I don’t have a complete answer to this yet, but I expect it will look something like algebraic equations on data structures (algex) [LW · GW]. For instance, we might have a plain causal model for name-generation like
{
ethnicity = random_ethnicity()
first_name = random_first(ethnicity)
last_name = random_last(ethnicity)
}… and then we could represent some data via an equation like
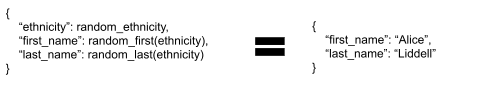
The left-hand-side would be the same data structure we use to represent world models, and the right-hand-side would be a “similarly-shaped” structure containing our data. Like algex, the “equation” would be interpreted asymmetrically - missing data on the right means that we just don’t know that value yet, whereas the left has the whole world model, and in general we “solve” for things on the left in terms of things on the right.
The algex library already does this sort of thing with deeply-nested data structures, and extending it to the sort of lazy recursively-nested data structures relevant to world models should be straightforward. The main task is coming up with a clean set of Transformations which allow walking around the graph, e.g. something which says “follow this recursive call two times”.
2 comments
Comments sorted by top scores.
comment by [deleted] · 2020-06-22T19:38:37.423Z · LW(p) · GW(p)
Meta: this project is wrapping up for now. This is the first of probably several posts dumping my thought-state as of this week.
Moving on to other things?
Replies from: johnswentworth↑ comment by johnswentworth · 2020-06-22T20:00:36.675Z · LW(p) · GW(p)
For a few months, yes. Planning to focus on aging for 2-3 months, then probably back to AI-adjacent theory.