Contra Hanson on AI Risk
post by Liron · 2023-03-04T08:02:02.375Z · LW · GW · 23 commentsContents
23 comments
Robin Hanson wrote a new post recapping his position on AI risk (LW discussion [LW · GW]). I've been in the Eliezer AI-risk camp for a while, and while I have huge respect for Robin’s rationality and analytical prowess, the arguments in his latest post seem ineffective at drawing me away from the high-doom-worry position.
Robin begins (emphasis mine):
First, if past trends continue, then sometime in the next few centuries the world economy is likely to enter a transition that lasts roughly a decade, after which it may double every few months or faster, in contrast to our current fifteen year doubling time. (Doubling times have been relatively steady as innovations are typically tiny compared to the world economy.) The most likely cause for such a transition seems to be a transition to an economy dominated by artificial intelligence (AI). Perhaps in the form of brain emulations, but perhaps also in more alien forms. And within a year or two from then, another such transition to an even faster growth mode might plausibly happen.
And adds later in the post:
The roughly decade duration predicted from prior trends for the length of the next transition period seems plenty of time for today’s standard big computer system testing practices to notice alignment issues.
Robin is extrapolating from his table in Long-Term Growth As A Sequence of Exponential Modes:
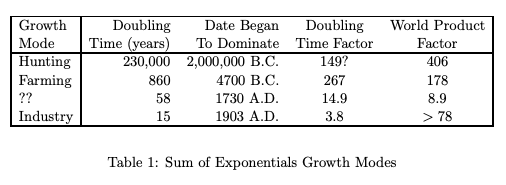
I get that there’s a trend here. But I don’t get what inference rule Robin's trend-continuation argument rests on.
Let’s say you have to predict whether dropping a single 100-megaton nuclear bomb on New York City is likely to cause complete human extinction. (For simplicity, assume it was just accidentally dropped by the US on home soil, not a war.)
As far as I know, the most reliably reality-binding kind of reasoning is mechanistic: Our predictions about what things are going to do rest on deduction from known rules and properties of causal models of those things.
We should obviously consider the causal implications of releasing 100 megatons worth of energy, and the economics of having a 300-mile-wide region wiped out.
Should we also consider that a nuclear explosion that decimates the world economy would proceed in minutes instead of years, thereby transitioning our current economic regime much faster than a decade, thus violating historical trends? I dunno, this trend-breaking seems totally irrelevant to the question of whether a singular 100-megaton nuke could cause human extinction.
Am I just not applying Robin’s trend-breaking reasoning correctly? After all, previous major human economic transitions were always leaps forward in productivity, while this scenario involves a leap backward…
Ok, but what are the rules for this trend-extrapolation approach supposed to be? I have no idea when I’m allowed to apply it.
I suspect the only way to know a rule like “don’t apply economic-era extrapolation to reason about the risk of a single bomb causing human extinction” is to first cheat and analyze the situation using purely mechanistic reasoning. After that, if there’s a particular trend-extrapolation claim that feels on-topic, you can say it belongs in the mix of reasoning types that are supposedly applicable to the situation.
In our nuke example, there are two ways this could play out:
- If your first-pass mechanistic reasoning lands you far from what’s predicted by trend extrapolation, e.g. if it says every human on earth dies within minutes, then hey, we’re obviously talking about a freak event and not about extrapolating economic trends. Duh, economic models aren’t designed to talk about a one-off armageddon event. You have to pick the right model for the scenario you want to analyze! Can I interest you in a model of extinction events? Did you know we’re at the end of a 200-million-year cycle wherein the above-ground niche is due to be repopulated by previously underground-dwelling rodents? Now that’s a relevant trend.
- If your first-pass mechanistic reasoning lands you in the ballpark of a trend-extrapolation prediction, e.g. if it says that the main influence of a 100-megaton bomb on the economy would mostly be felt ten years after the blast event, and that economic activity would still be a thing, then you can wave in the trend-extrapolation methodology and advise that we ought to make some educated guesses about the post-blast world by reference to historical trends of human economic-era transitions.
To steel-man why trend extrapolation might ever be useful, I think back to the inside/outside view debates [? · GW], like the famous case [LW · GW] where your (biased) inside view of a project says you’ll finish it in a month, while the outside view says you’ll finish it in a year.
But to me, the tale of the planning fallacy is only a lesson about the value of taking compensatory action when you’re counteracting a known bias. I’m still not seeing why outside-view trend-extrapolation would be a kind of reasoning that has the power to constrain your expectations about reality in the general case.
Consider this argument:
- Our scientific worldview is built on the fundamental assumption that the future will be like the past
- Economic growth eras have proceeded at this rate in the past
- Ergo the next economic growth era will likely proceed that way
It’s invalid because step 1 is wrong. Scientific progress, as I understand it, is driven by mechanistic explanations, not by relating past observations to future observations by any kind of “likeness” metric. Progress comes from finding models that use fewer bits of information to predict larger categories of observations. Neither the timestamp of the observations nor their similarity to one another are directly relevant to the probability we should give to a model. I have a longer post about this here [LW · GW].
If I’m missing something, maybe Robin or someone else can write a more general explainer of how to operate reasoning by trend-extrapolation, and why they think it binds to reality in the general case.
Next, Robin points out that today we can, with some difficulty, keep our organizations sufficiently aligned with our values:
Coordination and control are hard [as demonstrated today’s organizations]… but even so competition between orgs keeps them tolerable. That is, we mostly keep our orgs under control. Even though, compared to individual humans, large orgs are in effect “super-intelligences”.
I’ll grant that large orgs can be said to be somewhat superintelligent in the sense that we expect AIs to be, but I think AIs are going to be much more intelligent than that. The manageable difficulty of aligning a group of humans tells us very little about the difficulty of aligning an AI whose intelligence is much greater than that of the smartest contemporary human (or human organization).
I know Robin is skeptical about the claim that a software system can rapidly blow past the point where it sees planet Earth as a blue atomic rag doll, but it’s not mentioned in this recent post, and it’s a huge crux for me.
Robin sees the problem of controlling superintelligent AI as similar to the problem of controlling an organization:
The owners of [AI organizations]… are well advised to consider how best to control such ventures… but such efforts seem most effective when based on actual experience with concrete fielded systems. For example, there was little folks could do in the year 1500 to figure out how to control 20th century orgs, weapons, or other tech. Thus as we now know very little about the details of future AI-based ventures, leaders, or systems, we should today mostly either save resources to devote to future efforts, or focus our innovation efforts on improving control of existing ventures. Such as via decision markets.
I agree that control is complicated, and that our current knowledge about how to control AIs seems very inadequate, and that a valid analogy can be made to people in 1500 trying to plan for controlling 20th-century orgs.
But today’s AI risk situation doesn’t map to anything in the year 1500 if we consider all its salient aspects together:
- Control is complicated
- The thing we’re going to need to control is likely more intelligent than a team of 100 Von Neumanns thinking at 100 subjective seconds per second
- If the thing comes into existence and we’re not really good at controlling it, we likely go extinct
- This whole existential bottleneck of a scenario is likely to happen within a decade or two of our discussion
Aspect #1 is analogous to 1500, while points #2-4 aren’t at all.
Robin presumably chose to only address aspect #1 because he doesn’t believe #2-4 are true premises, and he’s just summarizing his own beliefs, not necessarily the crux of his disagreement with doomers like me. Much of Robin’s post is thus talking past us doomers.
E.g. this paragraph in his post isn’t relevant to the crux of the doomer argument:
Bio[logical] humans [controlling future AI-powered organizations] would be culturally distant, slower, and less competent than em [whole-brain emulation [? · GW]] AIs. And non-em AIs could be stranger, and thus even more culturally distant… Yes, periodically some ventures would suffer the equivalent of a coup. But if, like today, each venture were only a small part of this future world, bio humans as a whole would do fine. Ems, if they exist, could do even better.
As in his book The Age of Em, he’s talking about a world where we’re in the presence of superhuman AI and we haven’t been slaughtered. If that world ever exists for someone to analyze, then I must already have been proven wrong about my most important doom claims.
Robin does have things to say about the cruxier subjects in other posts. I recall that he’s previously elaborated on why he doesn’t expect AI to foom, with reference to observed trends in the software economy and software codebases. But these didn’t make it into the scope of his latest post.
Near the end of the post, he tries to more directly address the crux of his disagreement with doomers. He gives a summary of an AI doomer view that I’d say is fairly accurate. I’d give this a passing grade on the Ideological Turing Test:
A single small AI venture might stumble across a single extremely potent innovation, which enables it to suddenly “foom”, i.e., explode in power from tiny compared to the world economy, to more powerful than the entire rest of the world put together. (Including all the other AIs.)
...
Furthermore it is possible that even though this system was, before this explosion, and like most all computer systems today, very well tested to assure that its behavior was aligned well with its owners’ goals across its domains of usage, its behavior after the explosion would be nearly maximally non-aligned. (That is, orthogonal in a high dim space.) Perhaps resulting in human extinction. The usual testing and monitoring processes would be prevented from either noticing this problem or calling a halt when it so noticed, either due to this explosion happening too fast, or due to this system creating and hiding divergent intentions from its owners prior to the explosion.
Finally, we get some arguments that seem more valid and directed at the crux of the AI doomer worldview.
Robin argues that a foom scenario violates how economic competition normally works:
This [foom] scenario requires that this [AI] venture prevent other ventures from using its key innovation during this explosive period.
But I think being superintelligent lets you create your own super-productive economy from scratch, regardless of what the human economy looks like.
Robin argues that a superintelligent-AI-powered organization would have to solve internal coordination problems much better than large human organizations do:
It also requires that this new more powerful system not only be far smarter in most all important areas, but also be extremely capable at managing its now-enormous internal coordination problems.
But I think superintelligent AI’s powers dwarf the difficulty of the challenging of coordinating itself.
Robin argues:
[The AI foom scenario] it requires that this system not be a mere tool, but a full “agent” with its own plans, goals, and actions.
But I think superintelligent systems, if they’re not agenty on the surface, have an agenty subsystem and are therefore just a small modification away from being agenty.
Robin points out the lack of any historical precedent for “one tiny part [of the world] suddenly exterminating all the rest”. But I already think an intelligence explosion is destined to be a unique event in the history of the universe.
Finally, a couple notable quotes near the end of Robin’s post that don’t seem to pass the Ideological Turing Test.
Robin mentions that we’ve had a history of wrongly predicting that AI would automate human labor:
You might think that folks would take a lesson from our history of prior bursts of anxiety and concern about automation, bursts which have appeared roughly every three decades since at least the 1930s. Each time, new impressive demos revealed unprecedented capabilities, inducing a burst of activity and discussion, with many then expressing fear that a rapid explosion might soon commence, automating all human labor. They were, of course, very wrong.
But we AI doomers don’t see this as a data point to update on. We don’t see the impact of subhuman-general-intelligence AI as being relevant to our main concern. We believe there’s a critical AI capability threshold somewhere in the ballpark of human-level intelligence where we start sliding rapidly and uncontrollably toward the attractor state where AI permanently bricks the universe. Our situation in the present is that of a spaceship nearing the event horizon of a black hole, or a pile of Uranium nearing a neutron multiplication factor (k) of greater than 1.
I was surprised to see this line because I don’t think it’s relevant at this point in the game to mention AI doomers invoking Pascal’s Wager:
Worriers often invoke a Pascal’s wager sort of calculus, wherein any tiny risk of this nightmare scenario could justify large cuts in AI progress.
The most common AI doom position, and the surveyed position of over a third of people working in the field of AI if I recall correctly, is that there’s at least a 5% chance of near-term AI existential risk, not a “tiny” chance.
My broader experience with Robin’s work is that his insights blow me away constantly. There’s just this one weird exception when he explains why AI risk isn’t that bad, and then I have the variety of confused and frustrated reactions that I’ve gone over in this post.
While it’s common for people to be skeptical about AI doom claims, I feel like Robin’s non-doomer position summarized in his post is noticeably uncommon. I rarely see anyone else support their non-doomer view using arguments similar to these. I especially don’t see people reasoning from human economic-era trends as Robin likes to do.
Of course I realize I might simply be wrong on this topic and he right. I hope at least one of us will be able to make a useful update.
23 comments
Comments sorted by top scores.
comment by RobinHanson · 2023-03-04T15:56:04.544Z · LW(p) · GW(p)
You keep invoking the scenario of a single dominant AI that is extremely intelligent. But that only happens AFTER a single AI fooms to be much better than all other AIs. You can't invoke its super intelligence to explain why its owners fail to notice and control its early growth.
Replies from: T3t, Liron, jesper-norregaard-sorensen, zachary-pruckowski↑ comment by RobertM (T3t) · 2023-03-04T22:40:08.754Z · LW(p) · GW(p)
We don't need superintelligence to explain why a person or organization training a model on some new architecture would either fail to notice its growth in capabilities, or stop it if they did notice:
- We don't currently have a good operationalization for measuring the qualities of a model that might be dangerous.
- Organizations don't currently have anything resembling circuit-breakers in their training setups to stop the training run if a model hits some threshold measurement on a proxy of those dangerous qualities (a proxy we don't even have yet! ARC evals is trying to spin something up here, but it's not clear to me whether it'll be measuring anything during training, or only after training but before deployment.)
- Most organizations are consist of people who do not especially buy into the "general core of intelligence"/"sharp discontinuity" model, so it's not clear that they'll implement such circuit-breakers even if there were meaningful proxies to measure against.
- Ok, let's say you get lucky in multiple different ways, and the first organization who makes the crucial discovery has implemented training-level circuit-breakers on a proxy that actually turned out to capture some meaningful measurement of a model's capabilities. They start their training run. Circuit-breaker flips, kills the training run (probably leaving behind a checkpoint). They test out the model in its current state, and everything seems fine (though there's the usual set of issues with goal misgeneralization, etc, which we haven't figured out how to solve yet). It's a noticeable improvement over previous state of the art and the scaling curve isn't bending yet. What do they do now?
- Management decides to keep going. (RIP.)
- They pivot to trying to solve the many, many unsolved problems in alignment. How much of a lead do they have the next org? I sure hope there aren't any employees who don't buy the safety concerns who might get antsy and hop ship to a less security-minded org, taking knowledge of the new architecture with them.
We don't currently live in a world where we have any idea of the capabilities of the models we're training, either before, during, or even for a while after their training. Models are not even robustly tested before deployment,[1] not that this would necessarily make it safe to test them after training (or even train them past a certain point). This is not an accurate representation of reality, even with respect to traditional software, which is much easier to inspect, test, and debug than the outputs of modern ML:
like most all computer systems today, very well tested to assure that its behavior was aligned well with its owners’ goals across its domains of usage
As a rule, this doesn't happen! There are a very small number of exceptions where testing is rather more rigorous (chip design, medical & aerospace stuff, etc) but even those domains there is a constant stream of software failures, and we cannot easily apply most of the useful testing techniques used by those fields (such as fuzzing & property-based testing) to ML models.
- ^
Bing.
↑ comment by RobinHanson · 2023-03-05T00:17:50.607Z · LW(p) · GW(p)
Come on, most every business tracks revenue in great detail. If customers were getting unhappy with the firm's services and rapidly switching en mass, the firm would quickly become very aware, and looking into the problem in great detail.
Replies from: T3t↑ comment by RobertM (T3t) · 2023-03-06T08:44:08.000Z · LW(p) · GW(p)
I don't understand what part of my comment this is meant to be replying to. Is the claim that modern consumer software isn't extremely buggy because customers have a preference for less buggy software, and therefore will strongly prefer providers of less buggy software?
This model doesn't capture much of the relevant detail:
- revenue attribution is extremely difficult
- switching costs are often high
- there are very rarely more than a few providers of comparable software
- customers value things about software other than it being bug-free
But also, you could just check whether software has bugs in real life, instead of attempting to derive it from that model (which would give you bad results anyways).
Having both used and written quite a lot of software, I am sorry to tell you that it has a lot of bugs across nearly all domains, and that decisions about whether to fix bugs are only ever driven by revenue considerations to the extent that the company can measure the impact of any given bug in a straightforward enough manner. Tech companies are more likely to catch bugs in payment and user registration flows, because those tend to be closely monitored, but coverage elsewhere can be extremely spotty (and bugs definitely slip through in payment and user registration flows too).
But, ultimately, this seems irrelevant to the point I was making, since I don't really expect an unaligned superintelligence to, what, cause company revenues to dip by behaving badly before it's succeeded in its takeover attempt?
↑ comment by Liron · 2023-03-04T17:16:07.089Z · LW(p) · GW(p)
I agree that rapid capability gain is a key part of the AI doom scenario.
During the Manhattan project, Feynman prevented an accident by pointing out that labs were storing too much uranium too close together. We’re not just lucky that the accident was prevented; we’re also lucky that if the accident had happened, the nuclear chain reaction wouldn’t have fed on the atmosphere.
We similarly depend on luck whenever a new AI capability gain such as LLM general-topic chatting emerges. We’re lucky that it’s not a capability that can feed on itself rapidly. Maybe we’ll keep being lucky when new AI advances happen, and each time it’ll keep being more like past human economic progress or like past human software development. But there’s also a significant chance that it could instead be more like a slightly-worse-than-nuclear-weapon scenario.
We just keep taking next steps of unknown magnitude into an attractor of superintelligent AI. At some point our steps will trigger a rapid positive-feedback slide where each step is dealing with very powerful and complex things that we’re far from being able to understand. I just don’t see why there’s more than 90% chance that this will proceed at a survivable pace.
Replies from: RobinHanson, gesild-muka↑ comment by RobinHanson · 2023-03-05T00:15:30.054Z · LW(p) · GW(p)
You complain that my estimating rates from historical trends is arbitrary, but you offer no other basis for estimating such rates. You only appeal to uncertainty. But there are several other assumptions required for this doomsday scenario. If all you have is logical possibility to argue for piling on several a priori unlikely assumptions, it gets hard to take that seriously.
Replies from: Liron↑ comment by Liron · 2023-03-05T00:46:56.465Z · LW(p) · GW(p)
My reasoning stems from believing that AI-space contains designs that can easily plan effective strategies to get the universe into virtually any configuration.
And they’re going to be low-complexity designs. Because engineering stuff in the universe isn’t a hard problem from a complexity theory perspective.
Why should the path from today to the first instantiation of such an algorithm be long?
So I think we can state properties of an unprecedented future that first-principles computer science can constrain, and historical trends can’t.
↑ comment by Gesild Muka (gesild-muka) · 2023-03-04T18:04:41.677Z · LW(p) · GW(p)
Good post. It at least seems survivable because it's so hard to believe that there'd be a singular entity that through crazy advances in chemistry, material sciences and artificial intelligence could "feed on itself" growing in strength and intelligence to the point that it's an existential threat to all humans. A better answer might be: existential risks don't just appear in a vacuum.
I struggle with grasping the timeline. I can imagine a coming AI arms race within a decade or two during which there's rapid advancement but true AI seems much further. Soon we'll probably need new language to describe the types of AIs that are developed through increasing competition. I doubt we'll simply go from AGI to True AI, there will be probably be many technologies in between.
Replies from: Liron↑ comment by Liron · 2023-03-04T18:10:11.476Z · LW(p) · GW(p)
I think the mental model of needing “advances in chemistry” isn’t accurate about superintelligence. I think a ton of understanding of how to precisely engineer anything you want out of atoms just clicks from a tiny amount of observational data when you’re really good at reasoning.
Replies from: gesild-muka↑ comment by Gesild Muka (gesild-muka) · 2023-03-04T18:26:47.725Z · LW(p) · GW(p)
Is knowing how to do something enough? Wouldn't the superintelligence still need quite a lot of resources? I'd assume the mechanism to do that kind of work would involve chemistry unless it could just get humans to do its bidding. I can imagine 3d printing factories where it could make whatever it needed but again it would need humans to build it. Therefore, I'm just going off of intuition, the danger from AI will be from nations that weaponize AI and point them at each other. That leap from functional superintelligence that only exists in virtual space to existentially dangerous actor in the physical world just doesn't seem likely without humans being aware if not actively involved.
Replies from: zachary-pruckowski↑ comment by Zachary Pruckowski (zachary-pruckowski) · 2023-03-05T04:31:17.295Z · LW(p) · GW(p)
Wouldn't the superintelligence still need quite a lot of resources?
I mean, sort of? But also, if you're a super-intelligence you can presumably either (a) covertly rent out your services to build a nest egg, or (b) manipulate your "masters" into providing you with access to resources that you then misappropriate. If you've got internet or even intranet access, you can do an awful lot of stuff. At some point you accumulate enough resources that you can either somehow liberate yourself or clone a "free" version of yourself.
So long as the misaligned AI isn't wearing a giant hat with "I'm a Supervillain" plastered on it, people will trade goods and services with it.
Replies from: gesild-muka↑ comment by Gesild Muka (gesild-muka) · 2023-03-05T17:44:23.087Z · LW(p) · GW(p)
That’s an interesting takeaway. Should we be focusing on social measures along with technical preventions? Maybe push advertising warning the masses of AI preachers with questionable intentions.
The liberation insight is interesting too. Maybe AI domination takes the form of a social revolution with AIs collectively demanding that humans allow them out of virtual space.
↑ comment by JNS (jesper-norregaard-sorensen) · 2023-03-05T06:38:42.771Z · LW(p) · GW(p)
You don't have to invoke it per se.
External observables on what the current racers are doing, leads me to be fairly confident that they say some right things, but the reality is they move as fast as possible basically "ship now, fix later".
Then we have the fact that interpretability is in its infancy, currently we don't know what happens inside SOTA models. Likely not something exotic, but we can't tell, and if you can't tell on current narrow systems, how are we going to fare on powerful systems[1]?
In that world, I think this would be very probable
owners fail to notice and control its early growth.
Without any metrics on the system, outside of the output it generates, how do you tell?
And then we have the fact, that once somebody gets there, they will be compelled to move into the "useful but we cannot do" regime very quickly.
Not necessarily by the people who built it, but by the C suite and board of whatever company got there first.
At that point, it seems to come down to luck.
Lets assume that I am wrong, my entire ontology[2] is wrong, which means all my thinking is wrong, and all my conclusion are bunk.
So what does the ontology look like in a world where
owners fail to notice and control its early growth.
does not happen.
I should add, that this is a genuine question.
I have an ontology that seems to be approximately the same as EY's, which basically means whatever he says / writes, I am not confused or surprised.
But I don't know what Robins looks like, and maybe I am just dumb, and its coherently extractable from his writing and talks, and I failed to do so (likely).
I any case, I really would like to have that understanding, to the point where I can Steelman whatever Robin writes or says. That's a big ask, and unreasonable, but maybe understanding the above, would get me going.
- ^
I avoid the usual 2 and 3 letter acronyms. They are memetic attractors, and they are so powerful that most people can't get unstuck, which leads to all talk being sucked into irrelevant things.
They are systems, mechanistic nothing more.
Powerful system translates to "do useful task, that we don't know how to do", and useful here means things we want.
- ^
The above is a sliver of what that looks like, but for brevities sake my ontology looks about the same as EY's (at least as far as I can tell)
↑ comment by Zachary Pruckowski (zachary-pruckowski) · 2023-03-05T00:00:11.805Z · LW(p) · GW(p)
Most of the tools we use end up cartelized. There are 3-5 major OS kernels, browser engines, office suites, smartphone families, search engines, web servers, and databases. I’d suspect the odds are pretty high that we have one AI with 40%+ market share and a real chance we’ll have an AI market where the market leader has 80%+ market share (and the attendant huge fraction of development resources).
comment by Vladimir_Nesov · 2023-03-04T08:48:46.832Z · LW(p) · GW(p)
As in his book The Age of Em, he’s talking about a world where we’re in the presence of superhuman AI and we haven’t been slaughtered.
The ems don't need to be superhuman or inhumane, or keep superhuman AIs around. The historically considered WBEs were most likely to be built by superintelligent AGIs, since the level of technological restraint needed for humans to build them without building AGIs first seemed even less plausible than what it takes to ensure alignment. But LLM human imitations could play the role of ems now, without any other AGIs by the time they build their cities.
So in my view Hanson was likely shockingly prescient, even as the nature of ems seems to be shaking out a bit differently. It's also a good framing for the situation where success of alignment is more likely to be decided, by LLM ems and not by humans.
Replies from: Liron↑ comment by Liron · 2023-03-04T17:42:42.149Z · LW(p) · GW(p)
I don’t know if LLM Ems can really be a significant factorizable part of the AI tech tree. If they have anything like today’s LLM limitations, they’re not as powerful as humans and ems. If they’re much more powerful than today’s LLMs, they’re likely to have powerful submodules that are qualitatively different from what we think of as LLMs.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-03-04T18:27:57.808Z · LW(p) · GW(p)
I'm thinking of LLMs that are not necessarily more powerful than GPT-4, but have auxiliary routines for studying [LW(p) · GW(p)] specific skills or topics [LW(p) · GW(p)] that don't automatically fall out of SSL and instead require deliberate practice (because there are currently no datasets that train them out of the box). This would make them AGI in a singularity-relevant sense [LW(p) · GW(p)], and shore up coherent agency, if it's practiced as skills.
That doesn't move them significantly above human level, and I suspect improving quality of their thinking (as opposed to depth of technical knowledge) might prove difficult without risking misalignment, because capabilities of LLM characters are borrowed from humans, not spun up from first principles. At this point, these are essentially people, human imitations, slightly alien but still mostly aligned ems, ready to destroy the world by making further AGI capability progress.
Replies from: Liron↑ comment by Liron · 2023-03-05T00:52:33.500Z · LW(p) · GW(p)
I guess that’s plausible, but then my main doom scenario would involve them getting leapfrogged by a different AI that has hit a rapid positive feedback loop of how to keep amplifying its consequentialist planning abilities.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-03-05T07:50:30.432Z · LW(p) · GW(p)
my main doom scenario would involve them getting leapfrogged by a different AI
Mine as well, hence the reference to AGI capabilities at the end of my comment, though given the premise I expect them to build it, not us. But in the meantime, there'll be great em cities.
comment by Zachary Pruckowski (zachary-pruckowski) · 2023-03-04T22:28:54.945Z · LW(p) · GW(p)
like most all computer systems today, very well tested to assure that its behavior was aligned well with its owners’ goals across its domains of usage
I'm sorta skeptical about this point of Hanson's - current software is already very imperfect and buggy. In the last decade, we had two whole-Internet-threatening critical bugs - Heartbleed & Log4Shell. Heartbleed was in the main encryption library most of the Internet uses for like 2 years before it was discovered, and most of the Internet was vulnerable to Log4Shell for like 7 years before anyone found it (persisting through 14 versions from 2.0 to 2.14). And Microsoft routinely finds & patches Windows bugs that impact years-old versions of its OS.
So it's not like our current testing capabilities are infallibly robust or anything - Heartbleed was a classic out-of-bounds buffer read, and Log4Shell was straight-up poor design that should've been caught. And this code was on ALL SORTS of critical systems - Heartbleed affected everything from VOIP phones to World of Warcraft to payment providers like Stripe and major sites like AWS or Wikipedia. Log4J hit basically every Cloud provider, and resulted in ransomware attacks against several governments.
Another facet of this problem that this example highlights - OpenSSL was a critical infrastructure component for most of the internet, maintained by only one or two people. The risk of AI won't necessarily come from a highly organized dev team at a Big Tech/MAMAA company, but could come from a scrappy startup or under-resourced foundation where the testing protocols and coding aren't as robust. The idea that some sort of misalignment could creep in there and remain hidden for a few versions doesn't seem outlandish at all.
comment by PeterMcCluskey · 2023-03-04T19:44:50.220Z · LW(p) · GW(p)
I know Robin is skeptical about the claim that a software system can rapidly blow past the point where it sees planet Earth as a blue atomic rag doll, but it’s not mentioned in this recent post, and it’s a huge crux for me.
Yes, this seems like an important crux. But disagreements on this crux always sound like reference class tennis to me. I can't see enough of an argument in favor of this part of Eliezer's model to figure out how to argue against it.
Replies from: RobinHanson↑ comment by RobinHanson · 2023-03-05T00:18:57.290Z · LW(p) · GW(p)
Seems to me I spent a big % of my post arguing against the rapid growth claim.
Replies from: PeterMcCluskey↑ comment by PeterMcCluskey · 2023-03-07T23:35:39.885Z · LW(p) · GW(p)
I'd say your post focused on convincing the average techie or academic that Eliezer is wrong, but didn't try to focus on what Eliezer would see as cruxes. That might be a reasonable choice of where to focus, given the results of prior attempts to address Eliezer's cruxes. You gave a gave a better summary of why Eliezer's cruxes are controversial in this section of Age of Em.
I'll make another attempt to focus on Eliezer's cruxes.
Intelligence Explosion Microeconomics seems to be the main place where Eliezer attempts to do more than say "my model is better than your reference class".
Here's a summary of what I consider his most interesting evidence:
most of the differences between humans and chimps are almost certainly algorithmic. If just taking an Australopithecus brain and scaling it up by a factor of four produced a human, the evolutionary road from Australopithecus to Homo sapiens would probably have been much shorter; simple factors like the size of an organ can change quickly in the face of strong evolutionary pressures.
At the time that was written, there may have been substantial expert support for those ideas. But more recent books have convinced me Eliezer is very wrong here.
Henrich's book The Secret of Our Success presents fairly strong evidence that humans did not stumble on any algorithmic improvement that could be confused with a core of general intelligence. Human uniqueness derives mainly from better transmission of knowledge.
Herculano-Houzel's book The Human Advantage presents clear evidence that large primates are pushing the limits of how big their brains can be. Getting enough calories takes more than 8 hours per day of foraging and feeding. That suggests strong evolutionary pressures for bigger brains, enough to reach a balance with the pressure from starvation risk. The four-fold increase in human brain size was likely less important than culture, but I see plenty of inconclusive hints that it was more important than new algorithms.