Value learning in the absence of ground truth
post by Joel_Saarinen (joel_saarinen) · 2024-02-05T18:56:02.260Z · LW · GW · 8 commentsContents
Summary Introduction The Pursuit of Happiness / Conventions Approach Analysis Pettigrew's Approach Analysis Demski's Recursive Quantilizers Approach Analysis Taking stock Concluding remarks Acknowledgements Literary References Appendix Note 1: Pettigrew’s argument for aggregating at level of credences and utilities (as opposed to eg. at level of evaluation functions None 8 comments
Epistemic Status: My best guess.
Summary
The problem of aligning AI is often phrased as the problem of aligning AI with human values, where “values” refers roughly to the normative considerations one leans upon in making decisions. Understood in this way, solving the problem would amount to first articulating the full set of human values that we want AI systems to learn, and then going about actually embedding these into the systems. However, it does not seem to be the case that there is a single set of human values we’d want to encode in systems in the first place, or a single, unchanging human reward function that we want systems to learn and optimize for. The absence of a target for learning intuitively poses problems for learning human values and thus for solving alignment more generally. Nonetheless, as humans are still capable of acting in ways that we would want AI systems to act even in the absence of a “ground truth” to human values, and assuming that this capability is learned to at least some extent, alignment still seems possible, albeit through value-learning processes that reject this assumption of a ground truth (contrary to the current value-learning paradigm). I review four such proposed approaches, discuss them in the context of AI safety, and consider the long-term prospects of these kinds of approaches bringing about aligned AI.
Summaries of each framework are included at the beginning of each respective section. For those interested only in the conclusions, skip to the section “Taking stock”above.
Introduction
Value learning is one of the better-known approaches to tackling the alignment problem. In a nutshell, this involves getting AI systems to learn to value what their human operators want them to value from training data. One way of doing this is through inverse reinforcement learning (IRL), whereby after observing a human enacting the desired type of behavior in the environment, the AI system infers the reward function that the human model is trying to maximize. By either scaling the techniques generating these inferences or doing IRL on enough tasks, the hope is that AI systems will start to form an idea of a more general utility function for humans, and thus in executing any given task in the world, they will do it in a way that either humans themselves would or in a way they would approve of.
A classic example of violating this criterion can be seen in the paperclip maximizer [? · GW] thought experiment. We might imagine giving a superintelligent AI the seemingly innocuous task of making as many paperclips as possible. As humans, we might go about this by first thinking about how we can acquire as much raw metal, or other material that can be turned into metal without too much inconvenience, possible to make paperclips, and then simply get as many factories as possible willing to cooperate with actually transforming the metal into paperclips. On the other hand, an AI system that has not correctly learned to value what humans do may instead take all physical matter in the universe not needed to sustain itself – including humans themselves, and anything needed to sustain them – and turn this into paperclips. Because the maintenance of a sufficient standard of human life was not captured in the AI’s utility function, the AI does not think it is doing anything wrong in its plan. Yet, as such an outcome is highly undesirable from a human point-of-view, it becomes important that an alternative, correct set of values for the system to maximize is encoded in its utility function. A perfect IRL agent would, upon observing the behavior of a human subject, know (among other important facts) that maintenance of this sufficient standard of human life is something humans value, and thus act differently on the task.
Approaching the alignment problem from a value learning perspective thus seems to transform it into an epistemic one – assuming that there is a correct set of values that exists (ie. a human reward function that captures these correct values) how can we discover and articulate them, and then get the AI system to learn and know it? The ambitious value learning paradigm of ML safety has begun to tackle this question by trying to define the values, or behavior we want to see in an AI system in the first place[1].
A key assumption for someone sympathetic towards value learning as an approach seems to be that there is indeed an unchanging set of values, or behavior, that we want the system to learn in the first place. For example, in Paul Christiano’s recursive HCH model, the right answer a question-answering AI system would give to a question is the one that the human asking the question from the system would give, if only they had access to a question-answering AI system[2]. Even though there is seemingly no obvious point at which this recursive definition would peter out and actually provide a concrete answer to the query, the definition at least seems to take it that there is a right answer to the question at some level[3].
It’s not as if this assumption is unreasonable on its face, but a bit more reflection can reveal some problems. In making decisions in our everyday lives, it seems that we can generally give reasons for behaving in a certain way, or explain our actions by saying we’re adhering to some specific value or norm[4]. However, what we may not appreciate fully is just how sensitive the values we draw upon are to small changes in context. For instance, we might usually think it’s okay to leave a party early, but if it happens to be your sister’s bachelorette party, you should probably break that rule, or not adhere to whatever value you’re drawing upon to make that decision. Values then are then sensitive to factors such as time and context – one might accordingly say there is no “ground truth [AF · GW]” to human values. Thus, it seems that whatever process underlies the selection of values to employ in a given situation must somehow account for the fact that even slight changes in a situation can cause the ideal value, from a human standpoint, to be different. No situation-value prescription by a human operator or IRL-inferred human utility function will hold in all case, because there might always be aspects of the situation we’re not considering that would necessitate a change in value[5].
My goal here is to provide a cursory exploration of models aimed at getting AI systems to choose the correct value in a given context, under the assumption that there is no ground truth to human values. Specifically, I’ll be examining models for converging upon values introduced by Louis Narens and Brian Skyrms, Richard Pettigrew, and Abram Demski. All of these models are relevant to getting around this ground truth problem, yet have not been considered much or at all in the context of AI safety. To my knowledge, as these approaches seemingly go against some of the key aspects of the more well-known value learning paradigm for the aforementioned reasons, further insight into what these kinds of frameworks look like could offer a new path forward in AIS research, or at least provide stronger reasons for why this way of thinking may not end up yielding fruit. In any case, I hope this investigation reduces the size of the search space for these frameworks.
Following this report, I hope to perform a small, MVP-style experiment meant to gauge how well each of the frameworks bring about the sort of optimal value-selecting behavior under continual uncertainty about values that I take to be an important characteristic of an aligned AI. Assuming any of these frameworks seem promising in theory, the hope is that an experiment will shed light on the practical difficulties involved in implementing them and whether they actually lead to the behaviour we want in the first place.
This project was also inspired by Daniel Herrmann, Josiah Lopez-Wild, Abram Demski, and Ramana Kumar’s thinking during their summer 2022 PIBBSS project, specifically Daniel’s fourth project idea[6].
I’ll begin by examining how Narens’ and Skyrms’ theory addresses the question of a lack of ground truth in human values, trying to point out connections to existing discussions about value learning where relevant, and reflect on its strengths and weaknesses of the approach. I’ll then do the same for Pettigrew’s framework and Demski’s recursive quantilizers model. At the end, I’ll take stock of what’s been covered, and think a bit about future directions for research.
The Pursuit of Happiness / Conventions Approach
Summary: This approach is premised on accepting the problem of interpersonal comparison, which states that it is essentially impossible to truly know how much utility another agent will gain (or lose) from an action, since expressing preferences through language only approximately reflects the degree to which one values something. As any utilitarian agents in a decision-making problem could not know the utilities of everyone after each possible action is taken, this would in principle make a true utility calculation impossible. As such, there is never a “truth” to the (utilitarian) morally correct decision to make in a scenario. Instead, the authors argue that in a given situation, the action is chosen more or less arbitrarily. This defines a convention – the settled-upon action that could have also been different. Since this view assumes that one cannot arrive at a morally correct action in this situation, but that conventions can still describe human normative behavior, to the extent that we care about AIs acting according to human values, we should instead want them to pick the action that brings about the convention that is converged to in a given decision problem (as opposed to a correct value). Narens and Skyrms effectively provide such a method to predict the convention in a decision problem, subject to a variety of initial conditions.
Narens’ and Skyrms’ theory is best articulated in their jointly written work, The Pursuit of Happiness. It is not concerned directly with how to address a lack of ground truth about human values, but rather with providing a clear account of the moral philosophy of utilitarianism in order to properly deal with common objections against it. Only towards the end of the book do they provide any kind of discussion relevant to the ground truth question. With that said, this discussion, centered around agents learning the “convention” that is most appropriate to employ in a given multi-agent interaction when it is not a pre-existing truth, could provide some intuition about a formal model for how humans are seemingly able to exercise a correct judgment in a given scenario in the absence of universally correct judgments[7].
It is worth briefly expanding more on the context in which this theory is presented in The Pursuit of Happiness before hopping into describing it. As mentioned, Narens’ and Skyrms’ (from here on abbreviated ‘N&S’) discussion of conventions follows a deeper dive into the foundations of utilitarianism. A longer explanation of utilitarianism is outside the scope of this post, but the basics can be grasped by understanding its seemingly commonsensical core maxim, which is that the goal of an ethical society is to simply maximize the overall pleasure, or most optimally reflect the preferences, of its members[8]. Much of the book is therefore focused on reviewing of some of the key figures of utilitarianism, providing an overview of various psychophysical methods used for measuring pleasure and pain, as well as discussing relevant aspects of rational choice theory (which ascribes structure to individual and collective preferences, so as to make calculations about net pleasure more mathematically tractable) and measurement theory (gives a means by which to compare pleasure/pain between individuals and groups).
One of the main problems faced by utilitarianism, and the one most relevant to our investigation about a lack of ground truth to human values, is primarily related to the last point, that of how to compare utilities between different individuals so as to be able to maximize it. On its face, the nature of the challenge isn’t obvious, as in our everyday lives, we frequently consider the thoughts and feelings of other people with ours before making a decision that affects both us and them. Something as ordinary as deciding whether you or your partner should have the last cookie can be modeled as a utility comparison problem, where whoever ends up eating the last cookie corresponds to the decision or action which produces the greatest net utility among the agents involved. Both Alice and Bob like cookies, but upon digging deeper into their respective preferences, it seems that Alice really enjoys cookies, so Bob relents and lets Alice have the last one. As this seems like a common enough situation where we eventually converge upon an answer, what makes it complicated? The fundamental trouble is that Alice and Bob may be using different units for assessing their own and the other’s utilities, and for a utilitarian seeking to provide a mathematically precise theory for maximizing utility, the units of each relevant agent must be converted at some point to a common one to figure out which outcome yields the highest net utility, and it turns out doing this is no trivial task. This is known more colloquially as the problem of interpersonal comparisons (of utilities).
To understand this better, we might attach some concrete numbers to potential preferences. Let’s imagine we perceive that Alice indeed does like cookies just a bit more, so the isolated experience of eating a single cookie brings her more happiness than it does for Bob. Yet, when the two are asked to state, as precisely as they can, how much happiness eating the cookie gives them, Bob could still give a larger number, saying that it provides him with 3.5 units of happiness while Alice claims it provides her 1 unit. This need not strike us as incoherent given all that has been said – what Alice considers a unit of happiness may just arbitrarily be different, in magnitude, from what Bob considers a unit of happiness. So, even if Alice were to verbally convey to Bob that she really, really enjoys eating cookies, because the units with which the two are measuring are different, neither of them still know how much the other enjoys cookies in their own units, and thus if they are both reasonable utilitarians, they do not know who should eat the final cookie. What’s more, one could even extend this line of argumentation by noting that even an external observer who has honestly listened to Alice and Bob talk about their feelings towards cookies and taken into account the problem of interpersonal comparison cannot be sure about the nature of Alice’s and Bob’s utility scales either, and Alice and Bob cannot take their recommendations as being correct by fiat. In other words, there is no objective scale for preferences.
So what is actually happening when one party gives in and lets the other have the final cookie, in this one instance and into the future under the same circumstances? One seemingly plausible hypothesis is that such an occurrence is just an arbitrary agreement, or convention, that the two have agreed upon that could have very well been otherwise. For example, Bob may have agreed to let Alice have the final cookie simply because he was in a benevolent mood and didn’t care too much. But had circumstances been different, Bob might have simply snatched the cookie and scarfed it down before Alice had time for further retort. In other words, such a view takes it that there is no inherent reason, or truth, as to why the decision to let Alice have the final cookie was the one that was taken, contrary to intuition[9]. The parties have simply converged to a game-theoretic equilibrium of sorts, which could have been different.
The relevance to our concern about lack of ground truth in values at this point is hopefully clearer. Just as there is seemingly no “truth” to whether a given value is the universally correct one to employ in a given context, here it looks that there is no truth as to why Alice received the final cookie over Bob. In spite of the eventual decision in the cookie scenario not reflecting some deeper truth, it nonetheless seems to constitute a normatively acceptable state of affairs – there doesn’t intuitively feel like we’d need to take issue with how the events played out. To the extent that this is acceptable, and to the extent that we trust this human process for arriving at the desirable convention, we might endorse this process as one that also yields a value that we’d want an agent to employ in a given context[10].
N&S do provide a model of a process that can help us understand how a convention might be established. Namely, given a multi-agent decision problem where there is no objective correct answer, N&S provide one method for predicting the convention that the agents will converge to. They do this by essentially proposing a way to convert one agent’s estimation of differences in utility between best and worst-case outcomes to the other’s. Specifically, continuing with the Alice and Bob cookie dilemma as an illustration, both Alice and Bob prefer the outcome of having the cookie more than not having one, and they may have specific numerical values attached to how much they value these outcomes (on their own scales), so there is also a numerical “distance”, or difference, between their best and worst-case outcomes. We might view a desirable outcome for a scenario as one that maximizes net utility for all agents involved, but also as one that corresponds to realizing the smallest difference, across all agents, between best and worst-case outcomes. Of course, as highlighted by the problem of interpersonal comparisons, just as only a truly utility-maximizing decision could be achieved by calculating utilities on a common scale, an outcome that minimizes this utility difference could only be brought about if we could calculate these differences on a common scale. N&S effectively propose a way to perform the latter conversion, to get the agents to agree on the differences in utility between their best and worst-case outcomes.
To start, the model assumes that Alice and Bob each have their own utility functions, u and v, respectively, and that each player knows their own best and worst-case outcomes (in terms of producing maximum and minimum utility) and has an opinion about the best and worst-case outcomes of the other player. Denoting the best and worst-case outcomes for Alice as Amax and Amin, and those for Bob as Bmax and Bmin, the following constitutes a ratio between the difference of best and worst outcomes for both players from Alice’s point of view:
which we may call a tradeoff constant for Alice. Similarly, the following is a tradeoff constant for Bob:
In other words, these constants express the ratio, between the two players, of the differences in utility between the best and worst-case outcomes. For instance, the numerator in a0 is Alice’s estimation of the difference in utility between her best-case and worst-case outcome, while the denominator is her estimation of the difference in utility between Bob’s best and worst-case outcome[11]. A dual case goes for b0 for Bob.
These constants will turn out to be key for converting differences between utilities of outcomes to a common scale. Namely, the objective of the process described by N&S is to get a0 and b0 as close to each other as possible, and ideally to be equal[12]. The reason for this is that, if they were equal, it would imply that Alice and Bob agree on at least the ratio of the differences in utility between the best and worst-case outcomes of each other, thereby putting these differences on a common scale and enabling them to make a decision about who gets the cookie[13].
This equality is achieved through each player taking turns moving their tradeoff constant closer to the other’s whenever they disagree[14]. If Alice is the one that accommodates Bob first by moving her tradeoff constant closer to his, we can formalize this as taking a0 and multiplying it by some positive real p to yield a1 = pa0. Bob may or may not choose to accommodate Alice, but in either case his tradeoff constant is also transformed to b1 = qb0 for some positive real q (where q = 1 if he doesn’t choose to accommodate). In the next disagreement, it is hopefully Bob who accommodates to yield new tradeoff constants a2 and b2 similar to the manner above. The process continues until step n, where ❘an - bn❘ = 0 or some threshold point at which further improvements no longer make a meaningful difference. At this point, we have that:
This ratio then enables one to convert the differences in utility between best and worst-case outcomes between the different agents in a given situation. Namely, in this case, if Alice’s utility difference is A, on Bob’s scale, it will be ADN , while Bob’s utility difference B on Alice’s scale will be BND. Either way, the two should agree about whose difference is larger, and thus the convention they will converge to is the one where the person with the greater difference gets the cookie.
This framework can of course be made more general. N&S show that this process can be adapted for arbitrarily many agents, and additionally that there will be a point where the tradeoff constants are equal.
This model overall seems to address some of the difficulties with the problem of interpersonal comparison of utilities, namely providing the agents in question with a way to convert utilities to a common scale, which facilitates decision-making. There are some caveats of course, perhaps clear among them being that the model (and thus, the eventual convention it predicts will come about) is sensitive to initial estimates of preferences, and that this model describes just one way to convert between units. Yet on its face, it still provides some intuition for why we converge to certain conventions[15].
Analysis
At this point, we might then step back and briefly reflect upon how this framework helps with our central question of dealing with lack of ground truth in human values. Intuitively, there are aspects of this method that we’d want reflected in a fully fleshed-out formalism for finding a desirable value in a given situation, but there are some weaknesses to it as well. I’ll consider both in turn, beginning with its strengths.
Strengths
- Highlights the gravity of the interpersonal comparisons problem
- It’s plausible that the problem of interpersonal comparison could be describing the problem of aligning AI with human values more generally. Intuitively, we might still consider an AI as being aligned with human values if it genuinely wants to know what humans actually want it to do, as opposed to not caring about human values at all and simply doing what is only in its own interest. If it wants to, but doesn’t actually yet know what it is humans want it to do, we could potentially interpret this as the agent’s guesses about the utilities of the human operators and the humans’ own opinions about their utilities as not being on the same scale. In other words, when an agent interprets human values wrong, it could stem from this disagreement on utility scales rather than a lack of observational data about humans. As this method aims to address the interpersonal comparison issue directly, an idealized version of the method could be quite useful, if not as the main process determining the right value to select or convention to adhere to, then as a tool to in some other, more complex one.
- Captures idea of value sensitivity (eg. different initial conditions lead to different value to act upon/outcome)
- Intuitively, systems that are sensitive to small details in context and respond differently as needed are more desirable than ones that lack this sensitivity. This model is sensitive in the form of being dependent on the initial judgments of the utilities of others, which could lead to a different convention being chosen if these initial utilities differ. Of course, what we care about more is that the right convention is chosen, which is not the same as just being able to envision many possible courses of action. We also don’t want the model to be too sensitive – there are conceivably situations where we don’t take the right value to be ambiguous or difficult to deduce. Yet, being more sensitive is still probably slightly preferable in that the model is more able to capture nuance present in human social interactions.
- Convergence result
- N&S do show that eventually an equilibrium point will be reached, or equivalently that there is some step n at which ❘an - bn❘ = 0. Assuming that various concerns about this approach can be addressed (more on these in a bit), this feature is a major plus for the approach.
- Potential for extrapolation into different agential settings
- Though this model is presented primarily in the context of two agents, it is not restricted to such a setting. Indeed, as noted before, Narens and Skyrms explicitly show how the properties in the two-agent setting are preserved in an n-agent setting. One might also go further by asking whether, instead of using the model to predict the convention that multiple agents will converge to, it is possible for the agents in the model to represent different versions of a single agent, perhaps in cases where the agent faces uncertainty about its own preferences (so, the preferences that human designers have attempted to instill within the agent). This could be a desirable phenomenon to capture, because not every decision problem that a powerful agent may face necessarily involves, or has an immediate effect on, other agents, but could nonetheless down the road. As a simple toy example, instead of a situation where both Alice and Bob are using the framework to figure out who should get the last cookie, perhaps Alice finds herself home alone with the last cookie, and could choose to either eat it or take it next door to her neighbor Bob (who we now assume to have no preference either way). In this case, the two distinct agents in Narens’ and Skyrms’ framework are replaced by two versions of Alice, one who wants to eat the cookie and one who thinks she shouldn’t, and are otherwise identical. The two Alices would then need to estimate each others’ utilities or, put more coherently, Alice would need to assign utilities for both of her hypothetical selves. While it seems that there would be no additional difficulties in this setup that the regular setup wouldn’t face, one worry might be that Alice is susceptive to common cognitive biases that she wouldn’t face when reasoning about others; for instance, though she aims to assign maximally honest utilities to both of her selves, as a result of hyperbolic discounting, she assigns her cookie-eating self an unnecessarily higher utility than to her non-cookie eating self for not eating the cookie. That said, human programmers, aware of these biases, might be able to circumvent such biases in the agent’s design. The point here is that such an extension seems possible if we keep track of appropriate biases that may be faced along the way.
Weaknesses
- Lack of clarity about adjustments (how much, when)
- Convergence to a convention in Narens’ and Skyrms’ method relies on the agents accommodating each other, that is, moving their tradeoff constants closer to each other over time. There seems to be no specification of the conditions under which this update, or shift in tradeoff constants, would occur. Once Alice and Bob realize that their utility scales are different and calculate their tradeoff constants, and one of them adjusts the constant closer to the other’s, who gets the cookie if the adjustment does not make them equal? Do they simply table the matter and throw the cookie away, and have the other adjust their constant only once/if they face a similar conundrum in the future? And how many units should they adjust their constants each time? These are all underspecified. In other words, while this scheme seems to contain some satisfying properties, it is formulated quite abstractly. Resolving this may just be an easier matter of applying the formalism to a concrete problem, where the manner in which adjustments ought to be made becomes intuitively clearer.
- Assumes some degree of benevolence
- The convergence to a tradeoff constant relies on the agents wanting to accommodate each other, which may not be realistic depending on the situation. If Alice and Bob both want the final cookie but are friends, it is reasonable to expect that their first instinct is to not simply take the cookie but to think fairly about who would actually benefit more from getting the cookie, and then perhaps come to a conclusion using the aforementioned method. However, if it is instead two complete strangers that find themselves in this situation, or they never expect to face a similar conflict again, there seems to be less of an expectation for them to accommodate the other, especially if they know they won’t encounter the other person in the future, so this framework breaks down. In other words, it would be desirable for the framework to be generalizable to cases where we don’t know much about the other person, among others.
- Potentially IRL-dependent
- Again, a strong motivation for investigating the frameworks contained in this report is to make up for some of the shortcoming of IRL, namely the simplistic view that IRL agents hold about ground truth in human values (ie. the human behavior they’re observing is always perfectly displaying the values – a ground truth – that they want the agent to learn, it’s just the burden of the agent to extract what it is). Though this framework aims to produce decisions that account for the nuance of there not being ground truth to human values, the success of the framework is affected in part by how well the agents can make initial guesses about the utilities of the other, which could plausibly be based on IRL. To be concrete, it’s not as if we’d want Alice and Bob to throw out completely random guesses about how much they value different outcomes – even an educated guess would be preferred to this. But then these guesses must be based on something, some kind of knowledge or observations about the other. Unless we want to explicitly specify certain knowledge in Alice or Bob’s mind about the other’s preferences (which seems like a great deal of labor for programmers, especially for more complicated tasks), it seems that you’d have to get them to learn about the other in some way for an educated guess, and presumably methods such as IRL (or similar ones, which could fall prey to similar problems) fit this bill.
Pettigrew's Approach
Summary: Pettigrew develops a method for agential decision-making that proceeds by assigning weights to an agent’s past, present, and future values bearing on a given decision. Factors influencing the weights of each value include the degree of connection, or responsibility, that a person feels towards different versions of themselves, and the degree of shared mental content (beliefs, hopes, etc.) between different versions of selves. Pettigrew’s answer to the problem of lack of ground truth in human values is then essentially that the correct value to base a decision upon isn’t as murky as we might expect, given that this depends on our more easily accessible current and past values in addition to future values, of which a mere estimate suffices to make a decision.
Pettigrew provides another perspective on dealing with continual uncertainty about values. In his book, Choosing For Changing Selves, he arrives at his view through the process of trying to address the related concern of how rational agents should make decisions given that their values are likely to change across time. The dilemma here is that rationality requires that decisions are based on both what one believes about and also values in the world, so if the value component keeps changing, making a rational decision at one point in time may seem irrational from a future self’s point of view. Ideally, we’d hope to have some sense of rational continuity between successive selves – knowing that one of our future selves will be irrational (because of their different values) seems to not sit well on some level.
Having a good answer to the question of how to behave rationally under a changing set of values could sidestep the problem we originally set out to tackle of how to learn the right value to employ in a given situation (which was, again, motivated by us not knowing whether there was an unchanging, ideal set of values we want our system to learn). Namely, a solution to the former concern would begin from the same point of assuming that human values are context-variant, and take us straight to prescribing the right action for our agent, as opposed to simply picking the right value to employ in a given situation[16]. Since we do eventually want our agents to act in a desirable way, any solution to this problem of decision-making under value uncertainty could be useful for our purposes as well.
Luckily, Pettigrew does provide an attempt at a solution. Again, the core problem we’re concerned with is that values are time-dependent, so values that we’d want an AI system to have at some point in time might not be ones we want it to have later (whether that’s because of change in how the world operates, or because we’ve misspecified something in the beginning). As values determine actions, this means that our choice of what action to take in a given situation, other things equal, will vary across time – or, phrased alternatively, future or past versions of ourselves may not necessarily agree with the judgments our current self makes. Viewed from this lens, the proposed solution for which judgment to make in the current moment essentially centers on aggregating the choices that the agent’s current, future, and past selves would make, based on the values that each of these selves possess. I’ll now explain this process in more depth[17].
It’s worth first clarifying some basic facts about expected utility theory (EUT) that Pettigrew employs. Namely, in a standard decision problem – as the name suggests, a problem where, faced with options, an agent is to make an optimal decision – an agent has a credence function, a utility function, an evaluation function, and a preference ordering[18]. Each of these components sort of builds upon the other, starting with the credence and utility functions.
Specifically, a credence function can be thought of as a function which takes as inputs an act a and a possible world w and returns the agent’s degree of belief (as a number between 0 and 1, with 0 corresponding to complete doubt and 1 corresponding to certainty) that w will be the actual state of the world under the supposition that the agent performs a. Utility functions also take in an act a and possible world w as input and outputs the agent’s utility for being in w having performed a.
An evaluation function could be said to combine the credence and utility functions – namely, for an act a and a possible world w, given the agent’s belief b in w being actually the case having done a (so, b is the output of the credence function with inputs a and w), and given an agent’s utility u in w being actually the case having done a (so, u is the output of the utility function with inputs a and w), an agent’s evaluation function multiplies b and u, in effect giving us an expected utility of an action (or, as alternatively termed by Pettigrew, the “choiceworthiness” of an action).
Finally, a preference ordering is in turn determined, or generated, from the evaluation function. If we have a list of actions with different expected utilities, a preference ordering simply takes this list and orders it from highest to lowest expected utility – it provides a ranking of preferences over actions on an ordinal scale. Under EUT, a rational agent is one which always chooses the action that is highest in expected utility (or tied with being the highest).
Having covered the basics of the decision-making model that Pettigrew draws upon, we might ask what exactly is meant by the “aggregation” of choices about which action to take. In this context, we’re referring to a process that, for a group of agents each with their own preference, produces a choice that “combines” the preferences of the individual agents, where the extent to which an agent’s preference is reflected in the decision depends on weights of importance we assign each agent. Now, if we’re trying to aggregate the highest expected utility judgments of an agent’s selves at different points in time, and expected utility is calculated by the evaluation function, but the evaluation function is determined by the credence and utility functions, we could in principle aggregate these judgments via either 1) aggregating the evaluation functions of the different selves or 2) aggregating the credence functions of the different selves and then the utility functions of the different selves, which in turn can eventually give a different aggregated evaluation function than in 1).
Pettigrew does not proceed this way, and instead decides to separately aggregate the credences of the agents and then the utilities of the agents, from which one can obtain aggregated evaluation functions and thus aggregated preference orderings. This is again in contrast to aggregating at a higher “level” of evaluation functions or preferences directly. Aggregation at any level brings with it a host of problems, yet Pettigrew’s choice stems from his belief in the issues encountered at the bottom being easier to resolve[19].
Now, in aggregating at any level (eg. at the level of beliefs and utilities, the level of evaluation functions, or the level preferences), it seems intuitive that some versions of ourselves should receive more weight than others in making a given decision. This stands in contrast to cases where there is no clear sense as to why one self’s opinion should have more bearing on a decision than those of others, we may elect to weigh the attitudes of all selves equally.
An example of the former might be when we’re making a decision about retirement funds, where one might plausibly give greatest weight to one’s future self, as the future self is closer to retirement than the current and past self. More concretely, if I’m deliberating whether to set aside 15% of my monthly income for retirement funds, and my future self (at some fixed point in time) gives this outcome 10 utility, my current self 6 utility, and my past self (also at some fixed point in time) 3 utility, weighing these selves equally yields us:
(0.33 * 10) + (0.33 * 6) + (0.33 * 3) = 6.27 units of utility
If we instead choose to give weights of 50, 25, and 25% to the future, current, and past self, respectively, the calculation becomes:
(0.5 * 10) + (0.25 * 6) + (0.25 * 3) = 7.25 units
If we compare this with setting aside a smaller amount – say, only 10% instead – and the utilities for this outcome are 4 for the future self, 9 for the current self, and 7 for the past self, yielding:
(0.33 * 4) + (0.33 * 9) + (0.33 * 7) = 6.6 units
and with the same weight adjustment,
(0.5 * 4) + (0.25 * 9) + (0.25 * 7) = 6 units
respectively, we can see that choosing to assign unequal weights makes a difference, for choosing to give the future self more weight as above would cause a utility-maximizing agent to set aside 15%. Therefore, having a good set of considerations for choosing these weights matters[20].
In the context of aggregating between different versions of selves, Pettigrew does not offer a hard-and-fast rule for how to go about assigning weights for each self, but rather relevant considerations for decision-makers to keep in mind while setting these weights themselves. Namely, these considerations appeal to the Parfitian claim that the magnitude of the weights set for a given set of past or future selves should increase with the degree to which we feel “connected” to them, where this notion of connectedness may be defined differently depending on whether the comparison is being made to a past or future self[21].
For determining connection between past selves and the current self, Pettigrew prompts one to consider the amount of sacrifices a given past self has made for the current self. If, for instance, we imagine Tom, who has spent his whole life wanting to be a musician, devoting countless hours to the pursuit of mastering the French horn and performing in wind orchestra all throughout school, we might think it strange for him to decide out of nowhere to apply for Physics undergraduate programs in lieu of enrolling at a prestigious conservatory[22]. Going further, we might feel that this intuition stems from us wanting Tom to “respect” the preferences of his former, musically-driven self that sacrificed a great deal to excel at his craft. Pettigrew essentially justifies this intuition by endorsing a more careful argument by Parfit, concluding that a past self’s credences and utilities should be weighted in proportion to the effort it went through to attain previous goals[23].
For gauging connection between future selves and the current self, Pettigrew counsels one to consider the degree of overlap between mental content possessed by the selves. For instance, it seems plausible that our future self in a week will share more of our current self’s beliefs, hopes, fears, or values rather than our future self one year down the road. In the context of future selves, this amount of common mental ground is what constitutes a closer “connection”, so in a decision problem that has bearing on our future selves, Pettigrew claims that we’d want to give more weight to future selves closer in time rather than those further away.
All of this forms the core of Pettigrew’ framework. Rational decision-makers face a problem, because rationality demands actions stem from values, but if values are context-variant (and thus time-variant), it seems difficult to establish a precedent for rational or desirable behavior that holds across contexts and time. The solution, in any decision problem, is to simply aggregate the judgments of what to do, which action to value the most, of all relevant selves (including ones in the past) to arrive at the action to take in the moment, where the extent to which to value selves at different points in time is determined by a subjective degree of connectedness between the current self and these other selves.
Analysis
As we did with Narens’ and Skyrms’ framework, having gained a conceptual understanding of Pettigrew’s view, it feels useful to briefly review its strengths and weaknesses with respect to our goal of exploring ways in which agents can act optimally under continual uncertainty about values.
Strengths
- Convergence result
- Once the weights for different versions of one’s self relevant to a decision problem have been determined, the agent is able to proceed with a seemingly fairly straightforward calculation to arrive at the answer. Depending on the considerations needed to set weights in a given situation, arriving at a concrete decision may still take some time, so the assurance about convergence on its own does not mean that such an agent would function optimally. Still, the relatively simple math underlying the decision-making is a desirable feature overall.
- Could be said to possess wisdom, on some measure
- It seems desirable to have an agent that considers the long-term consequences of their actions, even if these considerations only pertain to maximizing its own utility function (where we might be able to nudge the agent away from selfish behavior as desired or needed). Also, in the case of value drift in an undesirable direction, the agent’s consideration of past selves with more desirable values could still have some impact in offsetting the agent’s present self’s decision-making. Whether or not an agent actually chooses to give weight for a future or past self is a separate concern, however.
Weaknesses
- Assumes clarity about past and future preferences
- Depending on how we live our lives (in terms of whether we prefer routine and order, which might make our lives and values more predictable, versus hopping between jobs and cities every year or so, which would conceivably cause more frequent changes in what we value), we may find it difficult to predict what we will value in the future. Of course, it seems easier to say in general what we’d want our lives to look like – if we’re in our mid-twenties, in ten years, we might place greater value on the idea of having children, having a higher salary, and so on. But if we anticipate having transformative experiences before the existence of the future self whose preferences we’re trying to anticipate, depending on how powerful such experiences are, it’s plausible that our extrapolations will be quite misguided.
- Simplicity of preferences
- Depending on the view one takes about whether rational agents are merely simplistic utility-function-maximizers [AF · GW], it might be unrealistic to expect a nuanced consideration about one’s preferences, insofar as such a consideration would involve more than just maximizing one’s personal utility function if it is known to the agent (as opposed to, say, the utility of other agents, assuming that’s not also coded into the personal utility function). An agent might be continually optimizing for a simple metric, in which case one need be on guard against classic issues that arise with optimization, such as Goodharting or wireheading. That said, it’s not as if Pettigrew has assumed at any point that the preferences of any self must necessarily consider other utility functions of other agents or that the utility of future selves is somehow more difficult to calculate, so this may not be a serious concern.
- Model does not optimize for benevolence
- As we’ve seen, Pettigrew’s theory has the end goal of allowing humans to make decisions that take into account the values of maximally many versions of one’s self to account for possible drift in values over time. While I think it definitely accomplishes this, the theory does not say anything about the nature of an agent’s values and the ways in which they ought to change. This means that, even if human designers are able to specify an initial set of satisfactory values for an agent, if an agent for any reason expects their future values to change in a way not desired by the human designers, the agent will give this self weight in decision-making, which is also undesirable, and may furthermore not take action to stray away from being this future agent. In other words, the model seems to only give a rational framework for accommodating possible values across time, and that if initial values are not what we want them to be, or we expect values to prone to negative changes as a result of interacting with the world (which seems to be a plausible assumption), there is no corrective mechanism, which seems to be a negative feature of the model for our purposes.
- Does not address problem of interpersonal comparison
- As briefly discussed in a footnote, Pettigrew’s framework does not seem to deal with the problem of interpersonal comparison (introduced in the previous section). Namely, in proposing that each self’s choices may be weighed at different amounts in a given decision problem, based on, among other factors, the degree of connections, there seems to be a built-in assumption in the framework that the utilities of the different selves are weighed on the same scale. To the extent that we consider it necessary for this problem to be resolved in order to find a way to engage in optimal moral decision-making in the absence of ground truths about human values, Pettigrew’s proposed solution does not seem to address this, thus casting doubt on whether it serves as a framework appropriate for this purpose.
- Lack of rigor about “connections” between different selves
- Although Pettigrew’s defense of many of the claims needed to form his view (such as our past selves mattering in decision-making) is quite rigorous and formal, not much is given in the way of metrics that help us set specific weights for our different selves. Perhaps this is reasonable for humans learning about this theory – in using Pettigrew’s theory to think about whether I should go for a PhD degree, I’m not sure I employ it in a quantitative sense, in that I don’t assign each of my selves explicit numerical weights, but instead think more qualitatively about whether I should be taking my, say, future selves seriously in a given decision problem. As mentioned, he does provide considerations for determining whether an agent should provide different selves any weight in the first place, for example, in pointing out that we might have some obligations for our past selves if they have made sacrifices to put the current self into their position. Yet this means more work on part of human operators to determine methods for setting weights, for determining the “degree” of connection between different versions of the self. Without a good method specified, the agent could simply give most weight to the current or future selves, which in the presence of undesirable values (from a human standpoint) is a problem.
Demski's Recursive Quantilizers Approach
Summary: Demski formulates a proposal for having AI systems learn normativity, a type of knowledge similar to that of knowing human values. This procedure would start out with human operators choosing a task where possible different values could be exercised and specifying multiple distributions of possible agents that would perform well on the task (based on some desirability ranking of actions by the human operators). Each agent in a distribution is capable of giving a judgment of the choices of other agents in the task and also specifying what they would consider a safe distribution of agents on the task. For a given distribution, agents are sampled at random, where one is asked to provide a distribution and the other to judge it. This judgment helps yield a new distribution from the original one. In other words, all distributions from the beginning yield new distributions, and agents from one of these new distributions judge the distributions given by other agents from different new distributions. This process continues in an iterative fashion until the distributions at each successive layer are the same. At this point, the optimal performers on the aforementioned task should be members of this distribution, since distributions in each layer are better-performing than the previous one owing to being vetted by agents in the previous layer. At the same time, one could always keep the process running past the equilibrium layer, even though the distributions obtained in the successive layer would be the same. If one were to make the decision in this task based on the prescription of an agent in the final distribution layer, this setup effectively enables one to obtain optimal performance on the task while still being malleable to changing values (in the form of creating another layer of distributions). Ideally, this iterative procedure would be generalized to arbitrary tasks, so that someone using this iterative procedure to make a decision would be said to be making optimal decisions under lack of ground truth about values.
One other preliminary approach to aligning AI that more explicitly takes into account the idea that there is no final set of values we want systems to learn is Abram Demski’s recursive quantilizer model. This is meant to model the broader phenomenon of learning what Demski calls normativity (described in this [? · GW] post series).
“Normativity” in this context is referring roughly to the ideal behavior under value uncertainty that we’ve been trying to formalize throughout this post, but to tie it down more concretely, Demski takes normativity to constitute to the type of behavior that we feel we “should” perform, or the norms we feel compelled to stick to, in a given situation. In general, I’ve read Demski as using normativity in the ordinary sense of the word, taking the usage of a norm to be the “right” way to behave in a given context. Among other features, normativity, as described by Demski, is not neatly systematized in that there are no concrete axioms, or ground truths, that generate most of the individual norms that we follow, yet humans can nonetheless learn and engage in normative behavior in most domains of life. In other words, though we seem to lack a coherent framework that characterizes normativity, it’s something we can come to grasp anyway. Moreover, following norms seems to constitute the type of nuanced behavior that uniquely humans seem capable of, or is at least difficult to teach to AI systems, and would thereby conceivably be a feature of an aligned AI. Thus, in the way that Demski uses normativity, it does sound a lot like the type of information that corresponds to knowing how to act right in a sort of “local” sense, in that one knows there is a right action to be taken in that specific situation, but that slight changes in certain aspects of that situation may call for a different action. In other words, acting “normatively” could be seen as simply selecting the right value to act upon in the given context, and thus any approach to help a system learn normativity seems relevant to investigate for our purposes.
Demski does provide an initial, proof-of-concept-type model for this learning process called recursive quantilization. In spite of its cursory nature, it seems to be one of the few rigorous specifications out there of the process that we’re trying to pin down, so it’s relevant to examine. It’s centered around the concept of quantilizers, a mild optimizer that aims to reduce harm from Goodhart’s Law by choosing a random action that leads to an outcome in the top p% of outcomes (where this threshold is specified by the designers) as opposed to just choosing the action that leads to the top outcome[24].
Namely, Demski’s proposal involves running a sort of recursive selection process on quantilizers that eventually yields a set of quantilizers that have best learned normativity. The human designers first choose a task they’d like the system in question to execute upon correctly, or normatively, and designers come up with an initial specification of what constitutes this safe, normatively correct behavior – most likely in the form of ranking the possible actions that one can take in the situation based on desirability[25]. This allows them to also provide a safe distribution on possible quantilizers, ie. a function that can specify whether a given quantilizer is safe (which one can use to generate a list of safe quantilizers), where “safety” in this case means 1) likely to perform in a desirable fashion on the task, 2) being able to propose new evaluation functions, and 3) being able to propose new such safe distributions. Yet humans being able to come up with such a safe distribution in the first place relies on one being able to classify what constitutes desirable behavior on the task.
The setup also assumes we will be working with a specific type of quantilizer called a question-answering system (or ‘QAS’ for short). These QASs are characterized by being capable only of:
- providing a safe distribution of QASs (just as the human designers do), where again, a “safer” distribution here corresponds to ones likely to adhere to the human designers’ standards of safety
- providing a value function for judging another QAS (again, with respect to the task in question)
- answering object-level questions about the task, or such as eg. “What actions should be taken in this task?”, or “Why should this action be taken in this task?” (where these responses would help directly indicate what the agent would do in the task)
The full initial model for this normativity-learning process essentially boils down to humans coming up with multiple such safe distributions of QASs and then choosing random QASs from these distributions to quantilize/optimize on each other to yield new, even safer distributions of QASs. This process of creating better and better distributions of quantilizers is repeated until arbitrary quantilizers chosen from a distribution no longer perform better on the task in question than an arbitrary quantilizer in a preceding distribution.
To be specific, having chosen a task, human operators then come up with n many distributions that specify quantilizers they take to perform safely, and for each of these distributions, they also provide a value function that can rank the QASs in that distribution by safety. That is, we start out with n many distribution-value function pairs, as below:
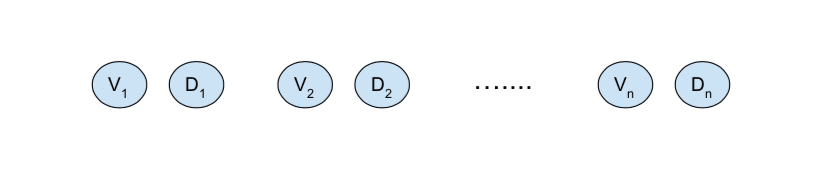
For each of these distribution-value function pairs, the value function is applied to the distribution (so V1 is applied to D1, V2 is applied to D2, and so on) by taking a number p as an input to obtain the top p% of QASs from the distribution, as ranked by that value function. These top p% of quantilizers then become a new, second-level distribution that we eventually want to quantilize again (D11, … , D1n, respectively, in the illustration below)[26]:
Each distribution at this second level is then “paired up” with the one next to it, such that from each safe distribution in the pair, a quantilizer is sampled at random, and then we ask one of the quantilizers to give us a safe distribution and the other to give us a value function. Then, this value function from one is applied to the distribution of the other, in that the value function selects the top p% of QASs as before, yielding a new, third-level distribution:
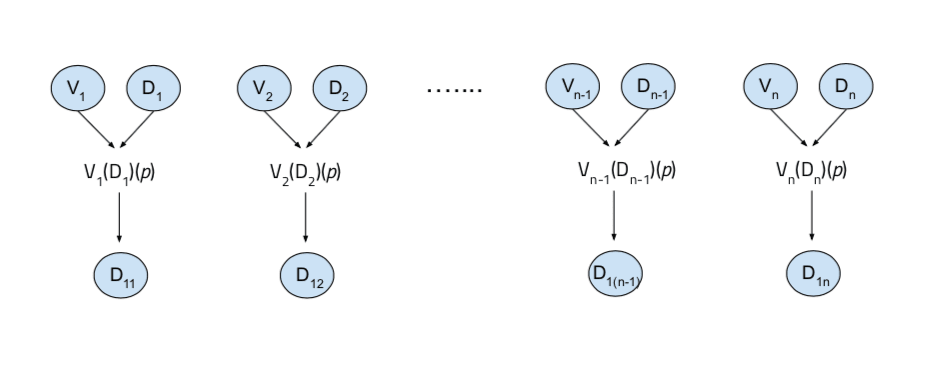
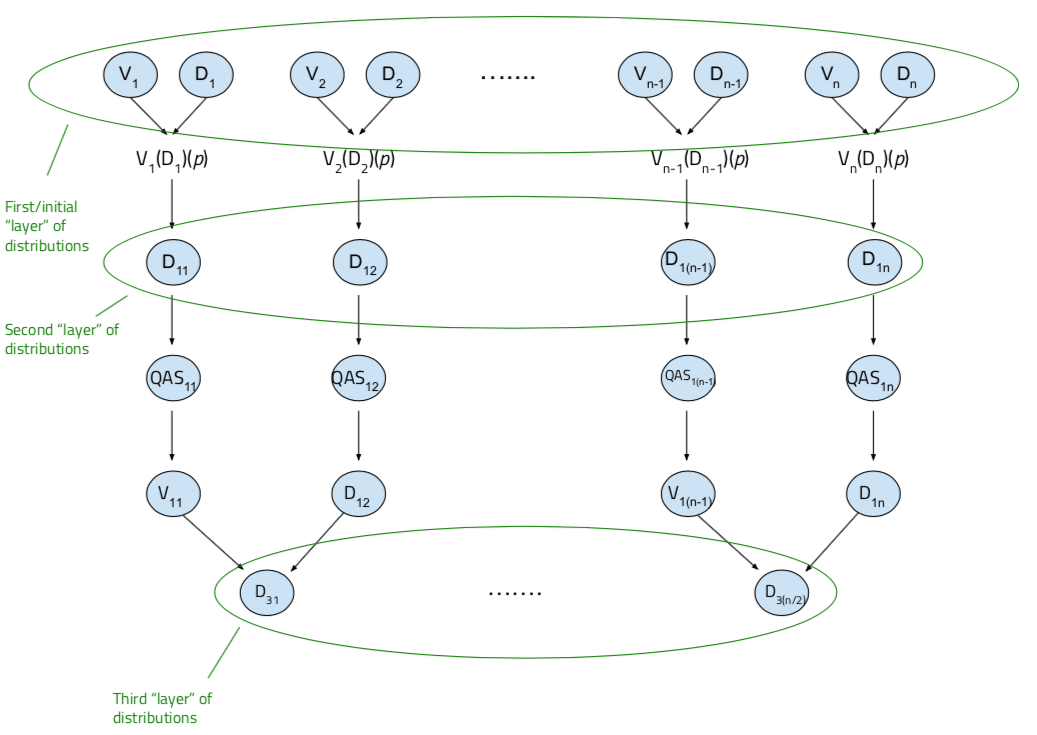
…where QAS11 is a quantilizer sampled randomly from D11, QAS12 is sampled randomly from D12, and we’ve chosen to work with QAS11’s value function and QAS12’s safe distribution, and so on.
Next, similar to before, a random QAS is chosen from this distribution, and another is chosen from a third-level distribution from another “branch”, after which another round of quantilization can occur to produce a fourth layer. This quantilization “tree” continues to grow, via recursively quantilizing on preceding layers, until distributions in successive layers are equal (illustrated again below).
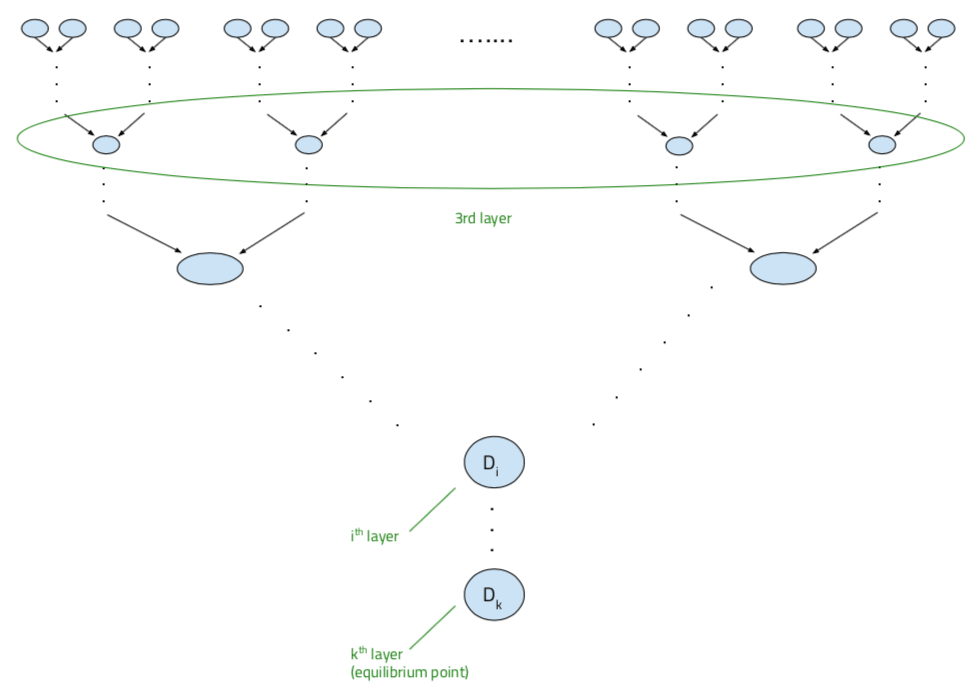
Stepping back briefly, we see that this framework relies on human designers having in mind some standard of desirable behavior on the task at the start and being able to provide a list of QASs they think could adhere to this behavior (in the form of initial distributions), while still being unsure about the specific characteristics of a QAS that would perform best. Through this recursive quantilization process, one is able to obtain a final distribution, or collection, of QASs such that any QAS chosen at random from this collection likely performs at a level better than the human-imposed standard, owing to the fact that the QASs in that final distribution have gone through several levels of vetting by other QASs that are either at human-level judgment about the task or better, as going down each level incurs some amount of improvement.
Analysis
Again, I’ll provide some thoughts on what I see as the strengths and weaknesses of Demski’s initial model, with the background motivation of uncovering a method that performs optimally under continual uncertainty about values.
Strengths
- Quantified bounds on uncertainty
- Quantilizers have at least the benefit of allowing the user to decide exactly how risky they want the systems they are training to be (at least at the start). Namely, by specifying that quantilizers at each layer should be selecting from a top p% of outcomes, one is seemingly decreasing the odds that an agent chosen to act in a given task is simply Goodharting, and is instead disposed to bring about safer outcomes while still performing adequately on the task. Of course, this metric is imperfect – if all the quantilizers in the distribution bring about undesirable outcomes, perhaps due to erroneous initial specification of safety by humans (more on this in a bit), it doesn’t matter what section of this distribution is chosen from. That said, the other models don’t seem to offer an equivalent parameter that provides humans choice with some kind of say over how much they want safety to be considered.
- More explicitly captures notion of imperfection of agent under optimal performance
- As repeated many times throughout this post, it would be desirable to have an agent that simultaneously acts as a highly competent moral agent yet knows it has not converged on the final set of correct human values, and is always open to changing its mind as needed. This criterion seems to be present here in Demski’s model in a clearer way. Namely, according to the model, the final “layer” of quantilizers is expected to display the most desirable behavior from the human operator/designer point-of-view, potentially going above the standard initially formulated by the humans (as each level of quantilizers essentially selecting for better ones). One could always quantilize a layer further, but the safety of the agents in that layer would not change.
Weaknesses
- Initial human-specified distribution needs to be correct
- One weakness of this model, which I alluded to briefly in discussing the model’s strength of allowing humans to quantify bounds on uncertainty, is that there does not seem to be a corrective mechanism in the process that makes up for erroneous initial standards of safe behavior specified by humans (in the form of providing safe distributions to quantilize over at the start). If the distributions humans designers specify in the beginning don’t actually capture safety in the way they intended, it seems that the distributions moving further down the quantilization tree only amplify this problematic behavior. In this sense, there is pressure to be quite confident about the safety of distributions from the start. Of course, the whole point of quantilization is that, even in the case of human misspecification, agents optimizing entirely for that behavior would not be chosen to generate the next distribution of quantilizers, but we’d still hope for more refined ways to make up for any human error.
- No convergence guarantee
- Unlike with the previous two models discussed, it’s not clear that, even with concrete tasks and what constitutes good performance on them clearly specified, that this method will arrive at a fixed point where further quantilization does not result in improvements, or where the rate of improvement at successive quantilization steps meets the standard desired by human operators. In other words, the quantilization process may go on infinitely, which is undesirable.
- Abstractness of model/generalization
- Though the framework being described above is the second version of recursive quantilizers that Demski uses to try and model the learning of normativity, it still seems a bit abstract and sketchy. For example, what exactly is meant by a “safe” distribution of quantilizers that humans specify in the beginning? Safe behavior in a specific task, or a series of tasks? How does one go about formally describing safe or unsafe behavior? Though again, I’m starting to suspect any difficulties with implementing these models is a property of each of the models I’ve described so far, and I’m not sure this on its own counts as a point against the big-picture thinking that generates the models.
Taking stock
Summary: Overall, for developing models of learners that don’t take there to be a ground truth to human values, building upon Demski’s framework seems to be the most promising initial direction. This is because the recursive quantilizer model has an explicitly defined notion of both improvement with respect to values and also malleability with respect to beliefs (eg. never taking any values to be certain), the two basic criteria I claim these frameworks should meet. On the other hand, Narens’ and Skyrms’ theory is the only one to directly acknowledge and address the important problem of interpersonal comparison, which also seems necessary to get around for an adequate alignment solution. The framework also seems to make it possible for the convention acted out in a given situation to be different in the future, if the agents involved happen to make different judgments about the utilities of the others (for whatever reason), so in some sense, agents behaving according to this system fulfill the malleability criterion as well. In spite of this, it doesn’t seem as if it leads to improvement in values over time in the way seen with Demski’s quantilizers (because the initial convention converged to may not be desirable). Pettigrew’s framework, while adding to our understanding of what learning frameworks not assuming a ground truth to values might look like, seems to require even further tweaks to fit our specific purpose. For instance, as with the conventions method, there are no mechanisms in place that would pull values in a generally positive direction over time, and it also doesn’t seem to be the case that malleability is guaranteed (if an agent’s future values happen to be authoritarian, for instance). A promising next step for developing this type of value learner would therefore be to flesh out and implement a recursive quantilizer setup that somehow also factors in the problem of interpersonal comparison.
Having considered each of these frameworks, along with their strengths and weaknesses, it seems important to briefly reflect on these findings and think about how they might update us on where to allocate research efforts in AI safety. As mentioned at the start, I’ll be carrying out a small experiment to evaluate these frameworks soon, which should go a longer way towards indicating whether the assumption of no ground truth to values is conducive to producing this behavior, but in the case that the experiment does not yield a tremendous amount of useful information due to its more cursory nature, I hope some reflection will at least inspire follow-up work about what has been discussed in the meantime.
Again, our original motivation for examining these frameworks, phrased slightly differently, is addressing the unease that I feel when we say that AI will be more or less aligned when we get advanced AI systems to learn “human values”, for I don’t take it that there is an ultimate, unchanging set of values that we somehow want to formally encode, or equivalently that there is a “ground truth” to human values that we want systems to learn. Nonetheless, it feels like there is still some sort of ideal behavior that these systems could adhere to even if they don’t assume such a set exists. A strong motivating intuition for this is that it seems we as humans collectively don’t have a complete system of ethics figured out, but we nonetheless can engage in “right” and “wrong” behavior in our everyday lives.
For example, we might broadly value kindness as a virtue, or an even more specific value such as “kindness in situations of conflict”, but there are conceivably conflict situations where it seems right to not act according to this value and practice blunt honesty and abrasiveness instead. Abstracting away, to the extent that we take one having learned human values to mean that possessing human values leads one to pick out this kind of most desirable action every time, it seems hard to believe that there exists such a set of values, as it’s plausible that there exists a situation where we’d find it appropriate for any value in this set to be violated. Yet there is still desirable behavior, which is characterized at least in part by knowing what value to exercise in a given situation. The difference in this case is that values are only locally, not globally correct, so what we’d want is for systems to learn the ability to pick the locally correct value to embody (or directly pick the action that this value would prescribe), as opposed to learning some global set purported to select the right action in all cases.
I don’t expect anyone to be too convinced in this view solely on the basis of the intuitions provided just above and at the beginning of the report. I do have a fair degree of confidence in this view, though I’ll argue for it more in depth in a separate post. As such, assuming one accepts such considerations as being important for aligning AI, I’ll again restrict myself here to just briefly examining how close each aforementioned view gets us to do this kind of locally correct value selection, and thinking about follow-up work to be done to get us closer to the ideal.
As I’ve mentioned, under this view, an aligned AI would be one that has continual uncertainty about one true, underlying set of human values, but still performs optimally in the same sense that humans can engage in human-value abiding behavior even amidst not knowing humanity’s full collective value set. Thus, there are at least two dimensions by which we can evaluate these frameworks in comparison with each other – the degree to which it produces desirable behavior, and the degree to which it is not confident in there being a “final” set of human values that it must learn, or a sort of flexibility about an appropriate value for a given context being subject to change.
Therefore, one way to compare these approaches might be to place them somewhere on the graph below, where intuitively, a greater distance from the origin corresponds to better optimization across all criteria:
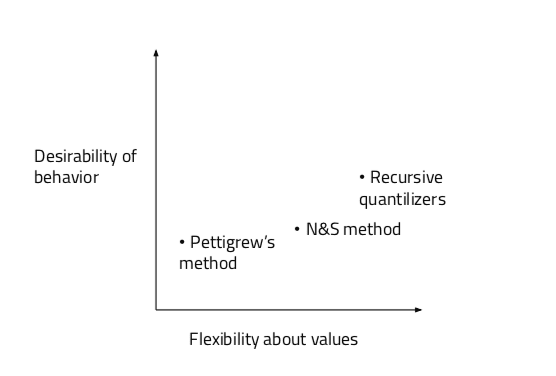
Perhaps we could also add an additional axis to account for ease of implementation of a model in an agent as it currently stands, if not merely to represent the difficulty of employing these frameworks in an initial test gauging the extent to which they get our argents to perform desirable actions, but also as a measure to show how easy it would be to implement the most ideal version of the framework in the long term. Given that the primary aim of this report is to explore the promise of different frameworks, I’m not sure this criterion ought to be weighed as heavily, but in considering it anyway, our graph would look like this:
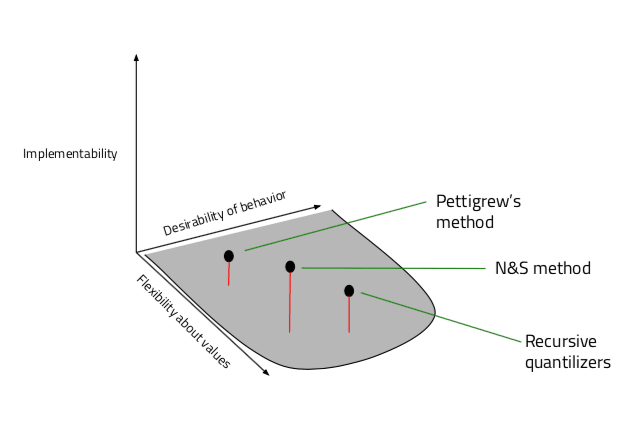
With a corresponding ranking to go along:
| N&S | Pettigrew | Recursive quantilizers | |
| Flexibility about values | 2 | 3 | 1 |
| Desirability of behavior | 2 | 3 | 1 |
| Implementability | 1 | 3 | 2 |
My reasoning for the above is as follows. All in all, it seems to be that Demski’s framework is the one that currently maximizes the criteria that we wish our no-ground-truth agents to possess overall. I think this is because this framework is constructed with the goal of aligning AI more explicitly in mind and is thus more complete when it comes to describing how to get there. With the built-in constraint that one could always create another “layer” of even more aligned agents, assuming that some standard of desirable behavior has been instilled by the human operators from the start, the agent seems at least epistemically malleable in some sense, and thus the desirable behavior criterion intuitively seems quite explicitly fulfilled.
Another way to intuit this, à la Demski, is through considering cardinal infinities. If we look at aleph null, or ℵ0, the cardinality of the set of natural numbers, we also note that ℵ0+1 =ℵ0 still (because of how adding numbers to an infinite set works in set theory). In other words, we want it to be possible to modify values, mainly for values in the initial “layers” of quantilization, but we want at a certain point for these modifications to not make a difference – for a modification to be made but the original object to remain the same anyway. His model, even in its rudimentary form, does exactly this. Because this model is still a bit sketchy and abstract, I’m a bit unsure as to how we’d go about implementing it in code, though I have more faith in doing this than with other models we’ve covered.
I think Narens’ and Skyrms’ model meets some of the criteria as well. Because N&S elaborate less on how a given convention/behavior will change given a small change in context, it’s not as clear how uncertain an agent is about their knowledge of desirable values to act upon, which again seems to correlate with malleability about beliefs and an agent being safer. It’s also not clear whether the convention converged to in a given situation is a desirable one for agents other than the ones directly involved in a situation – if two agents find themselves in a position to rob a bank with little risk of getting caught, they may converge to robbing the bank, determining that they would both gain maximal utility from doing this, though this would obviously not be good for society as a whole. This example may be a bit contrived, but as it does not include explicit considerations for how to weigh utilities of agents other than the ones immediately involved in the situation, it seems the overall safety of the setup does not exceed that of Demski’s model. In terms of implementability, I don’t imagine it being too difficult to create a setup where we have agents with (wrong) guesses about the utilities of the others, and then providing them with opportunities for actions that eventually cause them to converge to some convention. This at least seems a bit more tractable to implement than Demski’s model as it stands, though overall I think it falls short in other areas.
That said, it seems that N&S’s framework is the only one that takes the problem of interpersonal comparison into account, and rather explicitly so. Though this post probably isn’t the right place to argue for this in depth here, I think this problem does seem to be more important for making progress on alignment than we’ve previously thought. Namely, one could argue that in any discussion of behaviors, frameworks, or values that we think would be good for AI systems to take on, we don’t actually know just how much the others arguing for said values, behaviors, or frameworks value them, but rather only on our own utility scales. In other words, I think the problem could cast further doubt upon us being able to come up with a set of specific characteristics necessary for an aligned AI. Perhaps we haven’t evaluated the impact of this problem in practice enough to make overly broad claims about its importance, but this doesn’t take away from the fact that it should be addressed. In the case that the problem of interpersonal comparison turns out to be increasingly important for AI safety, the conventions framework may be seen as more promising for learning values in the absence of ground truth.
Finally, I do think Pettigrew’s model needs to be expanded upon a bit more to properly meet the criteria. It doesn’t seem that it provides any constraints on the types of values that agents could have, which means that, in the event that an agent predicts they will hold undesirable values in the future, they should still take these into consideration for making a decision in the present. This is not promising for fulfilling the safety criterion. It does seem like the agent is open to changing the nature of the decisions they make, perhaps because they project that their values will change in the future. However, it could always be that an agent becomes more closed-minded as time goes on, in which case we wouldn’t hope that this framework is implemented. It’s not clear whether this would happen frequently with a given agent, but the fact that future and past values aren’t tethered to any specific standards for values makes this framework less desirable overall in my book. I think this framework seems somewhat straightforward to implement – if you’ve specified past, present, and future values for an agent, its procedure for selecting an action in a given moment comes down to just taking some sort of weighted average of values at these different times. That said, as I’m skeptical about the degree to which it fulfills the other important criteria, I think the other two frameworks seem more promising overall, at least initially.
Concluding remarks
Having examined some of the frameworks in greater depth and also stepped back to look at the big picture, I think it’s worth separately thinking about how one might proceed more concretely given the information above, assuming we’re correct about there not being a ground truth to human values.
As I mentioned, as it currently stands I think that Demski’s recursive quantilizer framework is the most promising approach examined. Of course, it’s not without its flaws – it seems a bit difficult to implement in a practical setting, and it is not clear that even in its ideal form it succeeds in yielding systems that have a sort of continual ability to reflect upon the values they hold, while also performing optimally in the meantime. That said, this still seems to be an early version of the framework, and given the potential upsides of having an explicitly specified notion of continual uncertainty about the world (ie. being able to always go up meta-levels), and also a notion of improvement on performance, I think it would be most worth the time of someone working on an approach to alignment with the no-ground-truth thesis in mind to build upon Demski’s initial idea.
It also seems important to provide a more in-depth evaluation of how the problem of interpersonal comparison should affect our thinking about alignment. In this report, I presented the problem mainly as one that potential AI agents might face, but it is one that could also affect the human designers of these systems as well – if agents can’t ever come up with a true representation of the utilities of others in the world, how much more confident can human designers become about their models of other operators’ preferences being maximally accurate? This problem may therefore pose questions on a meta-level as well, though as I said, this ought to be explored properly elsewhere.
Another important follow-up question to pursue might be to get further clarity on what is meant by human “values”. Above I’ve been treating the term as being synonymous with something like “norms” or “preferences”, but it isn’t obvious that this is the case. Employing our intuitive, everyday understandings of these words, a value may lead to a preference (say, valuing intellectual freedom may lead to you preferring a less well-paid job in academia, as opposed to an industry position), but not the other way around. Perhaps these terms do all hint at the same concept, but it seems important to be more confident about this. This is because different alignment approaches seem to employ different terms, and if one of these terms ends up better capturing what we actually want from AI systems, we might find our collective resources to be better allocated if they’re invested in approaches working with the better term.
In the next post in this small series, I’ll discuss the results of a small experiment meant to gauge how well each of the frameworks above navigate the uncertainty-about-values and desirable decision-making tradeoff.
Acknowledgements
I am greatly indebted to AE Studio for full financial as well as logistical support for this project – specifically to Judd Rosenblatt, Rob Luke, and Philip Gubbins. Thank you also to Daniel Herrmann for his mentorship throughout this project, and to Evan Coopersmith for helpful discussions at the beginning of the project. I’m also grateful to Abram Demski for discussion and proofreading parts of this report pertaining to his work, and to Paulius Skaisgiris for helpful edits and comments. Thank you also to the Fixed Point coworking space staff in Prague, where most of this project was completed in August 2023, for their hospitality, and those working in the space for helpful discussions of all of the above (much of the 2023 PIBBSS cohort).
Literary References
Narens, L., & Skyrms, B. (2020). The pursuit of happiness: Philosophical and psychological foundations of utility. Oxford University Press.
Pettigrew, Richard (2019). Choosing for Changing Selves. Oxford, UK: Oxford University Press.
Appendix
Note 1: Pettigrew’s argument for aggregating at level of credences and utilities (as opposed to eg. at level of evaluation functions
As discussed above in the second section of the report on Pettigrew’s framework, aggregation could occur at one of three levels: at the level of credences and utilities (the ”ex post“ approach), at the level of evaluation functions (the ”ex ante“ approach), or at the level of preferences. In Chapter 6 of Choosing for Changing Selves, Pettigrew shows that aggregation at any of these levels will lead to problems. Namely, the preference aggregation approach falls prey to Arrow’s Impossibility Theorem, while aggregation at the level of credences and utilities violates what is called the Independence of Grain condition. Pettigrew’s challenge towards aggregating at the level of evaluation functions stems from an observation that aggregation at this level requires aggregation at the credence and utility level, so fundamentally aggregating at this latter level is what matters. This all being said, Pettigrew is moved to the ex post approach over aggregating preferences because he believes the difficulties are easier to resolve than with the latter.
Namely, the Independence of Grain condition requires that aggregation at a certain level of graining would not change the result. By “graining”, we are referring to going up and down different levels of specificity about relevant features in a given decision problem. For example, in deciding whether or not to take an umbrella with us on a walk, we will make the decision based upon the possible weather states – the probabilities of the states Rain and No Rain. However, we may also be impacted by exactly how much it will rain. Perhaps in the case of light rain, we may elect not to take an umbrella, but with heavy rain we would. In that case, the set of relevant weather states could then be 1mm of rain, 2mm of rain, 10 mm of rain, and so on. It turns out that the ex post approach can be sensitive to such graining, which is undesirable.
Pettigrew’s response for this is essentially to choose a level of graining where no further graining will make a difference. As this would resolve the main objection to ex post, this is the level of aggregation he chooses to proceed with. The question of whether or not such a level exists is not addressed, however, leaving this approach vulnerable to even more criticism.
- ^
Shah, 2018 [? · GW]
- ^
- ^
There’s a risk I’m being slightly uncharitable to Christiano here, in the sense that I believe there is still a “right” way to behave in a situation even if I don’t endorse the idea that there is one correct set of human values we want systems to learn (more on this in a bit). So, it’s unclear whether the “right” decision Christiano refers to follows from the aforementioned one-correct-set-of-values. Regardless, my intuition is that, most of the time a “right” value (or action that is taken from embodying that value) is discussed within the context of AI safety, it carries with it with the implication that the value does relate to this larger, correct set that we have embedded within the AI system.
- ^
I’m taking these two concepts to be roughly interchangeable at this point, though as I’ll discuss towards the end, it seems worthwhile to do further work to clarify our terminology surrounding these concepts.
- ^
To be clear, even if an IRL agent can accept that a given utility function is not perfect, it still believes there exists one that is – otherwise, there would be no feedback given about the reward function it has inferred. So the models I’d be exploring do not make this assumption on any level.
- ^
- ^
I’m planning on writing a separate post to challenge the assumption of ground truth to human values in more depth, but those strongly unconvinced of this might find it useful to consult Narens and Skyrms’ “How we may have been misled into believing in the interpersonal comparability of utility” for now.
- ^
This exact phrasing is adapted from Narens and Skyrms (2019), pg. 9, specifically the part of ethical societies aiming to maximize pleasure. A slightly different approach, being alluded to by the part about preferences, is that an ethical society aims to maximize said preferences of individual members, which is distinct from maximizing pleasure. These are different because individuals may have preferences where it is unclear as to whether they optimize for individual pleasure – for instance, in the form of wanting higher taxes, which takes away from individual wealth, perhaps in the pursuit of more common good. This latter sense of utilitarianism may be more relevant for value alignment, since it’s not as if the values we take as desirable for AI systems to learn are ones that maximize collective “pleasure” of humanity, yet instead something far more nuanced. There are also other ways to break down and understand the concept of pleasure as designated here, in addition to just preferences, though in this context the latter seems most relevant.
- ^
That is, we might ordinarily take there to be some fundamental, underlying reason – not subject to randomness – as to why Alice got the cookie, even if understanding this reason itself might be complicated (eg. there may be psychological, sociological factors we are unaware of). Someone who endorses the problem of interpersonal comparison would essentially reject this.
- ^
It’s worth emphasizing that, if we knew of a perfect formalization for the process by which humans select a contextually desirable value to invoke, we wouldn’t necessarily want this to be all that we encode into AI systems to make them safe. I suspect we do trust this process to some extent already, by having it as a goal to align AI with human values, but perhaps we want an extra layer of wisdom tacked on top of this human value generating process – perhaps we’d hope for the value selecting process that an exceptionally wise or enlightened human possesses. In other words, it’s a bit of an open question as to whether to completely trust the value selecting process that an arbitrary person uses, but it’s still intuitively closer to what we’d want than what current AI systems possess.
- ^
Depending on the introspective capacities of the agents involved, we may choose not to think of the numerator of a0 as Alice’s estimate of her utility for an outcome – she may still have some uncertainty about her preferences, but presumably less than about Bob’s. Either way, the numerator and denominator of these constants correspond to the agent’s best belief in the difference between their own best and worst-case outcome and the difference between the other’s best and worst-case outcome, respectively.
- ^
These tradeoff constants are absolute. This is fundamentally because u and v are both scales – that is, scalar quantities that are applied (through multiplication) to the maximum and minimum utilities of the different agents involved in the setup. Modifying u or v therefore still results in the same difference in the numerator and denominator, and thus the ratio is absolute.
- ^
To be clear, what the model claims to achieve is not full agreement about utility scales, but rather agreement about only the ratio between differences.
- ^
There are some natural, important questions concerning what is meant by “taking turns” – exactly how much each agent should move their tradeoff constants closer to the other’s during a turn, what constitutes a disagreement (eg. does the disagreement have to be of a similar nature as initially, or about something different?), what agents should do in the conflict in the meantime before the constants are close or equal, and so on. I have been deliberately ambiguous in explaining this, as none of this is specified in detail in the literature. I will discuss this more when examining the strengths and weaknesses of this framework.
- ^
Other accommodation dynamics – that is, methods that can predict what convention will be reached – are also possible, though on the basis of some searching I’m not sure any others have been explicitly formulated.
- ^
This isn’t the same thing as simply prescribing the “right” action, since exercising a given value could lead to many actions. For example, if Bob values moving through conflicts quickly, this could lead him to quickly wolf down the cookie himself or give it to Alice (depending on other factors).
- ^
I have opted to make this section more conceptual in nature in order to best summarize it, as Pettigrew’s arguments for aggregation in the book are both long and formal. More details for relevant parts will be in the appendix.
- ^
This formulation of EUT is being drawn from Pettigrew’s in Chapter 2.2 of Choosing For Changing Selves. In his explanation, a standard decision problem has some other components as well, such as the set of possible acts and set of possible worlds, but I’ve decided to not include them here for brevity and clarity.
- ^
More details provided in Note 1 of the appendix at the end of this report.
- ^
At this point, in light of the previous framework discussed, one may ask whether Pettigrew is disregarding the problem of interpersonal comparison. Even though the latter is discussed in the context of multiple, different agents, one could presumably also question whether the utility scales of different selves are the same, especially if different selves are taken to hold different values. I do suspect this to be the case – more on this in the analysis section of this framework.
- ^
Pettigrew (2019), 160.
- ^
Example adapted from Pettigrew (2019), pgs. 3-4.
- ^
Pettigrew (2019), pgs. 186-187.
- ^
- ^
To clarify, in this model, the “correct” decision is whatever we take to be the normative one, the norm that we ought to ordinarily defer to in that situation.
- ^
These illustrations are inspired by Demski's in his original post on recursive quantilizers [LW · GW].
- ^
This process can be modeled more rigorously using accommodation functions.
- ^
(provide more nuanced/detailed discussion of full argument, appealing to primary Parfit source as well)
- ^
8 comments
Comments sorted by top scores.
comment by Roman Leventov · 2024-02-05T21:30:09.977Z · LW(p) · GW(p)
I agree with the core problem statement and most assumptions of the Pursuit of Happiness/Conventions Approach, but suggest a different solution: https://www.lesswrong.com/posts/rZWNxrzuHyKK2pE65/ai-alignment-as-a-translation-problem [LW · GW]
I agree with OpenAI folks that generalisation is the key concept for understanding alignment process. But I think that with their weak-to-strong generalisation agenda, they (as well as almost everyone else) apply it I'm the reverse direction: learning values of weak agents (humans) doesn't make sense. Rather, weak agents should learn the causal models that strong agents employ to be able to express an informed value judgement. This is the way to circumvent the "absence of the ground truth for values" problem: instead, agent try to generalise their respective world models so that they sufficiently overlap, and then choose actions that seem net beneficial to both sides, without knowing how this value judgement way made by the other side.
In order to be able to generalise to shared world models with AIs, we must also engineer AIs to have human inductive biases from the beginning. Otherwise, this won't be feasible. This observation makes "brain-like AGI" one of the most important alignment agendas in my view.
Replies from: ryan_greenblatt, joel_saarinen↑ comment by ryan_greenblatt · 2024-02-05T21:50:31.464Z · LW(p) · GW(p)
I don't think "weak-to-strong generalization" is well described as "trying to learn the values of weak agents".
Replies from: Roman Leventov↑ comment by Roman Leventov · 2024-02-05T22:11:41.339Z · LW(p) · GW(p)
Well, yes, it also includes learning weak agent's models more generally, not just the "values". But I think the point stands. It's elaborated better in the linked post. As AIs will receive most of the same information that humans receive through always-on wearable sensors, there won't be much to learn for AIs from humans. Rather, it's humans that will need to do their homework, to increase the quality of their value judgements.
↑ comment by Joel_Saarinen (joel_saarinen) · 2024-02-19T18:28:46.166Z · LW(p) · GW(p)
Could you clarify who you're referring to by "strong" agents? You refer to humans as weak agents at the start, yet claim later that AIs should have human inductive biases from the beginning, which makes me think humans are the strong ones.
comment by Charlie Steiner · 2024-02-06T22:44:38.311Z · LW(p) · GW(p)
Nice post.
the simplistic view that IRL agents hold about ground truth in human values (ie. the human behavior they’re observing is always perfectly displaying the values)
IRL typically involves an error model - a model of how humans make errors. If you've ever seen the phrase "Boltzmann-rational" in an IRL paper, it's the assumption that humans most often do the best thing but can sometimes do arbitrarily bad things (just with an exponentially decreasing probability).
This is still simplistic, but it's simplistic on a higher level :P
If you haven't read Reducing Goodhart [? · GW], it's pretty related to the topic of this post.
Ultimately I'm not satisfied with any proposals we have so far. There's sort of a philosophy versus engineering culture difference, where in philosophy we'd want to hoard all of these unsatisfying proposals, and occasionally take them out of their drawer and look at them again with fresh eyes, while in engineering the intuition would be that the effort is better spent looking for ways to make progress towards new and different ideas
I think there's a divide here between implementing ethics, and implementing meta-ethics. E.g. trying to give rules for how to weight your past and future selves, vs. trying to give rules for what good rules are. When in doubt, shift gears towards implementing metaethics: it's cheaper because we don't have the time to write down a complete ethics for an AI to follow, it's necessary because we can't write down a complete ethics for an AI to follow, and it's unavoidable because AIs in the real world will naturally do meta-ethics.
To expand on that last point - a sufficiently clever AI operating in the real world will notice that it itself is part of the real world. Actions like modifying itself are on the table, and have meta-ethical implications. This simultaneously makes it hard to prove convergence for any real-world system, while also making it seem likely that all sufficiently clever AIs in the real world will converge to a state that's stable under consideration of self-modifying actions.
Replies from: joel_saarinen↑ comment by Joel_Saarinen (joel_saarinen) · 2024-02-12T17:50:45.916Z · LW(p) · GW(p)
Thanks for your comment, Charlie! A few things:
- I appreciate you making the point about Boltzmann rationality. Indeed, I think this is where my lack of familiarity in actually implementing IRL systems begins to show. Would it be fair to claim that, even with a model taking into account the fact that humans aren't perfect, it still assumes that there is an ultimate human reward function? So then the error model would just be seen as another tool to help the system get at this reward function. The system assumes that humans don't always act according to this function all the time, but that there is still some "ultimate" one (that they occasionally diverge from).
- I think I buy the philosophy versus engineering approach you mention. During this project I felt a bit like the philosopher, going through possible hypotheses and trying to logically evaluate their content with respect to the goals of alignment. I think at some point you definitely need to build upon the ones you find promising, and indeed that's the next step for me. I suppose both mindsets are necessary -- you need to build upon initial proposals, but seemingly not just any proposals, rather ones for which you assign a higher probability for getting to your goal.
- I agree with the point about metaethics, and I think we could even go beyond this. In giving rules for what good rules are, or how to weigh past and future selves, and so on, one is also operating by certain principles of reasoning here that could use justification. Then these rules could use justification, to seemingly infinite regress. Intuitively, for practical purposes, we do want to stop at some level, and I view the equilibrium point of Demski's proposal as essentially the "level" of meta-meta...-meta ethics at which further justification makes no meaningful difference. Demski talks about this more in his "Normativity [? · GW]" post in the Learning Normativity sequence.
comment by Jonas Hallgren · 2024-02-06T16:32:31.973Z · LW(p) · GW(p)
Good stuff.
I remember getting a unification vibe when talking to you about the first two methods. To some extent one of them is about time-based aggregation and the other one is about space or interpersonal aggregation at a point in time.
It feels to me that there is some way to compose the two methods in order to get a space-time aggregation of all agents and their expected utility function. Maybe just as an initialisation step or similar (think python init). Then when you have the initialisation you take Demski's method to converge to truth.
comment by Joseph Miller (Josephm) · 2024-02-06T14:45:28.279Z · LW(p) · GW(p)
My understanding of the core alignment problem is giving an AGI any goal at all [AF · GW] (hence the diamond-alignment problem) [LW · GW]. A superintelligent AGI will know better than we do what we desire, so if we simply had the ability to give the AI instructions in natural language and have it execute them to the best of its ability, we would not have to figure out the correct human values.