Practical Pitfalls of Causal Scrubbing
post by Jérémy Scheurer (JerrySch), Phil3, tony, jacquesthibs (jacques-thibodeau), David Lindner · 2023-03-27T07:47:31.309Z · LW · GW · 17 commentsContents
Introduction Background on Causal Scrubbing (CaSc) How to evaluate Causal Scrubbing? How Consistent is Causal Scrubbing? Causal Scrubbing Cannot Differentiate Extensionally Equivalent Hypotheses Causal Scrubbing Can Fail to Reject False Hypotheses Example 1 (XOR) Example 2 (Sum with offset) Implications for Causal Scrubbing None 17 comments
TL;DR: We evaluate Causal Scrubbing (CaSc) on synthetic graphs with known ground truth to determine its reliability in confirming correct hypotheses and rejecting incorrect ones. First, we show that CaSc can accurately identify true hypotheses and quantify the degree to which a hypothesis is wrong. Second, we highlight some limitations of CaSc, in particular, that it cannot falsify all incorrect hypotheses. We provide concrete examples of false positive results with causal scrubbing. Our main finding is that false positives can occur when there is “cancellation”, i.e., CaSc causes the model to do better on some inputs and worse on others, such that, on average, the scrubbed model recovers the full loss. A second practical failure mode is that CaSc cannot detect whether a proposed hypothesis is specific enough, and it cannot distinguish between hypotheses that are extensionally equivalent.
We thank Redwood Research for generously supporting this project by providing us with their Causal Scrubbing implementation, access to REMIX materials, and computational resources. We specifically thank Ansh Radhakrishnan, Buck Shlegeris, and Nicholas Goldowsdky-Dill for their feedback and advice. We thank the Long-Term Future Fund for financial support and Marcel Steimke and Lennart Heim for operational support. Finally, we thank Marius Hobbhahn, Adam Jermyn, and Erik Jenner for valuable discussions and feedback.
Introduction
Causal Scrubbing (CaSc) [? · GW] is a method to evaluate the accuracy of hypotheses about neural networks and provides a measure of the deviation of a hypothesis from the ground truth. However, CaSc does not guarantee to reject false or incomplete hypotheses. We thus believe that systematic evaluation of CaSc to investigate these limitations is valuable (in addition to evaluating its effectiveness in the wild, as done in most existing work [? · GW]). Hence, we evaluate CaSc to highlight its strengths and weaknesses and explore the reliability of CaSc in confirming correct hypotheses and rejecting incorrect ones.
We evaluate the reliability of CaSc on synthetic graphs. While synthetic graphs are less realistic than trained neural networks, we get access to the known ground truth interpretation, which allows us to accurately evaluate our hypotheses. Since CaSc operates on general computational graphs, any results on synthetic graphs also apply to using CaSc on neural networks (although we don’t make any claim on how likely the situations we find are to occur in trained neural networks).
Our evaluation is based on creating a synthetic graph that solves a specific problem (e.g., sorting a list) and creating an identical interpretation graph (the correct hypothesis). We then perturb the correct interpretation graph to make the hypothesis “worse”. Finally, we evaluate whether CaSc correctly determines the better hypothesis. Ideally, we want the scrubbed loss (the loss induced by applying CaSc) to correlate with the “correctness” of a hypothesis.
To determine whether a hypothesis is “better” or “worse”, we introduce the concepts of extensional and intensional equivalence between functions. Extensional equivalent functions have the same input-output behavior; for example, Quicksort and Mergesort are extensionally equivalent as they both sort an input sequence. Intensional equivalent functions are implemented in the same way mechanistically. So once we zoom further in and compare Quicksort and Mergesort algorithmically, we see that they are not intensionally equivalent. This point is already made in the CaSc writeup [? · GW], and our goal is merely to highlight that in the context of mechanistic interpretability, this is an important distinction that’s easy to overlook.
In this post, we look deeper into the limitations and practical pitfalls of CaSc. Our main contribution is to provide concrete examples and distinguish between cases where CaSc cannot distinguish extensionally equivalent hypotheses and cases where CaSc cannot distinguish between functions that are not extensionally equivalent.
First, we provide a simple and concrete example of extensionally equivalent hypotheses that CaSc cannot distinguish. This example gives a concrete intuition on this failure mode and highlights how easily it can occur in practice. Second, we introduce a novel failure mode, which is more severe: CaSc can fail to reject a wrong hypothesis that is not extensionally equivalent to the true hypothesis. In other words, CaSc can fail to reject a "wrong" hypothesis that has different input-output behavior. We provide two examples where this happens due to “cancellation”: a situation in which the scrubbed model does better on some inputs and worse on others, and on average, the wrong hypothesis recovers the full loss. Generally, this kind of behavior can occur when the graph we are trying to interpret has a relatively high loss on the test set, in which case an incorrect hypothesis can achieve a similar loss.
Our findings yield an improved understanding of some limitations of CaSc and provide an intuition for how to avoid some practical pitfalls. Despite the practical problems we highlight, CaSc is a highly valuable method for evaluating hypotheses about neural networks, and we are excited about its application to important problems.
Background on Causal Scrubbing (CaSc)
Feel free to skip this section if you are familiar with CaSc.
CaSc is “an algorithm for quantitatively evaluating hypotheses of the information present at every part of a model and how this information is combined to give rise to a particular observed behavior.” Informally, CaSc is a method for evaluating a hypothesis or interpretation about what a particular graph (e.g., a Neural Network) is implementing (see the figure below, which is taken from the CaSc writeup [? · GW]).
](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/DFarDnQjMnjsKvW8s/axlj9xcqjbf60pgmbkhg)
In the example provided above, the hypothesis in node , for example, claims that calculates whether for an input , . If the hypothesis about is correct, then for a given reference input , intuitively, we should be able to replace with any other integer value that is larger than 3. The reason is that the hypothesis would still be true for any other that is larger than 3. Equivalently, if we had the reference input , the hypothesis would evaluate to False, and we could replace with any other input that is smaller than 3. This “replacing of a certain input with another input that is equivalent under the hypothesis” is called a resampling ablation. Overall there are two types of resampling ablations:
- Replacing the activations of nodes in that correspond to activations defined in the hypothesis with activations on other inputs that are equivalent under .
- Replacing the activations of nodes in that are claimed to be unimportant for a particular path by the hypothesis (such as or in ) with their activation on any other input.
CaSc is a clever algorithm that recursively does a lot of resampling such that the above two requirements hold. We refer to the CaSc writeup [? · GW] for a more detailed explanation.
Evaluating a hypothesis (i.e., an interpretation graph) with CaSc involves using a metric called scrubbed loss: the loss after performing the resampling ablation. If the scrubbed loss is significantly less than the loss of the original model, the hypothesis is incorrect. We can also measure this using the loss recovered [LW · GW] metric, which explicitly compares the scrubbed loss to the original model’s loss. For simplicity, we use the scrubbed loss throughout our post.
How to evaluate Causal Scrubbing?
Ideally, the scrubbed loss should correlate with the accuracy of a hypothesis: a more accurate hypothesis should get better scrubbed loss than a less accurate one.
The primary steps we use to evaluate CaSc on synthetic graphs are the following:
- Create a synthetic graph , for example, a graph that adds up the elements of an array.
- Create a true hypothesis , which is identical to graph (and contains the same nodes and connections).
- Create a different hypothesis by modifying the true hypothesis in a “meaningful” way, e.g., by making the hypothesis worse. For example, could claim that adds up every other element of the array.
- Compare the performance of CaSc on the true hypothesis to the worse alternative hypothesis The scrubbed loss should be better for the more accurate hypothesis.
This evaluation lets us assess the ability of CaSc to accurately measure the deviation of a hypothesis from the ground truth.
How Consistent is Causal Scrubbing?
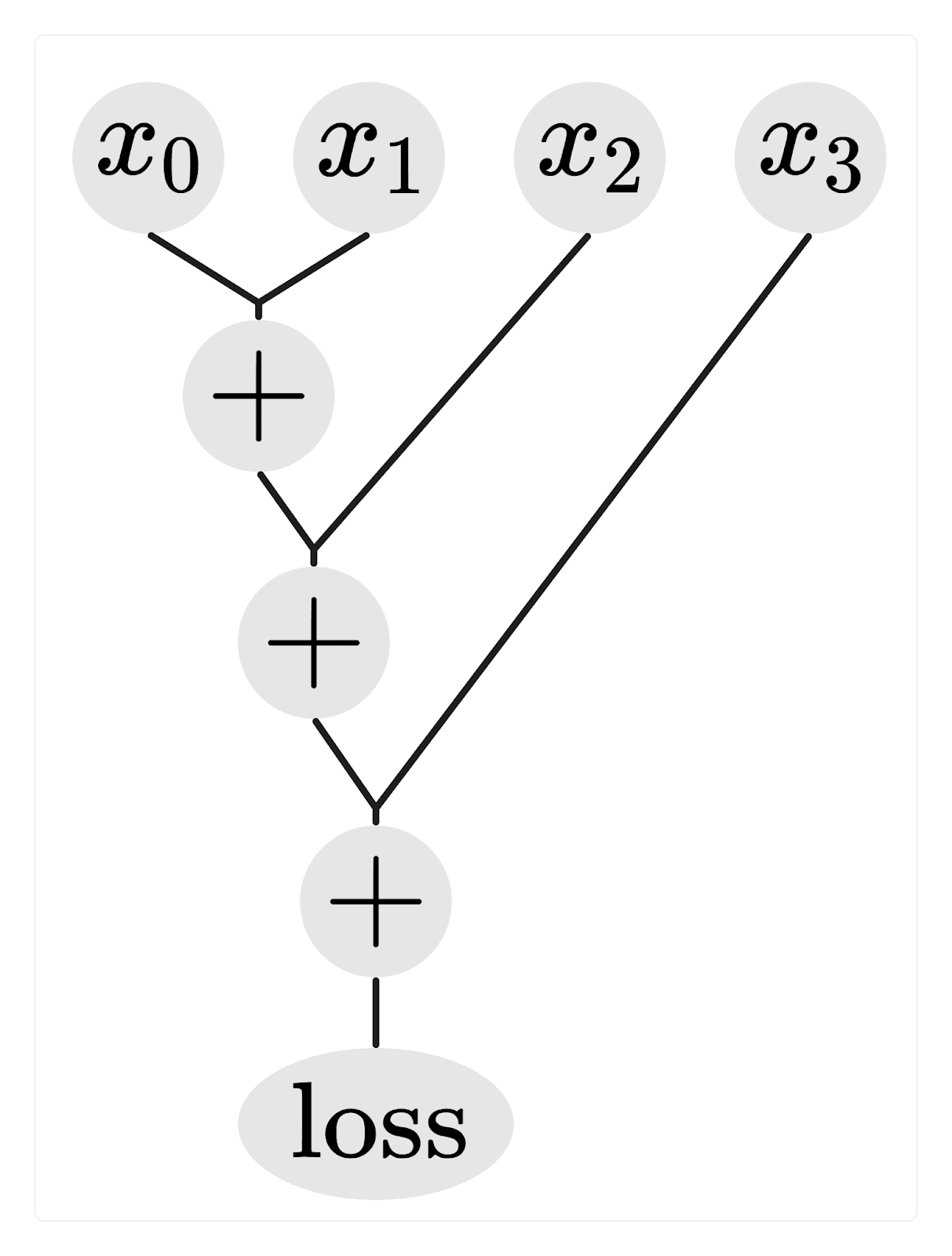
In our first experiment, we investigate whether making a hypothesis consistently worse leads to a worse recovered loss. To accomplish this, we have set up a task where the input, x, is an array of 4 digits between 0 and 9, for example, . The goal is to calculate the sum of all the digits, in this case, 20. We consider a ground truth graph that calculates the sum as , where the brackets indicate the order of the additions. computes the sum correctly and gets a loss of 0 on this task. Here is an illustration of :
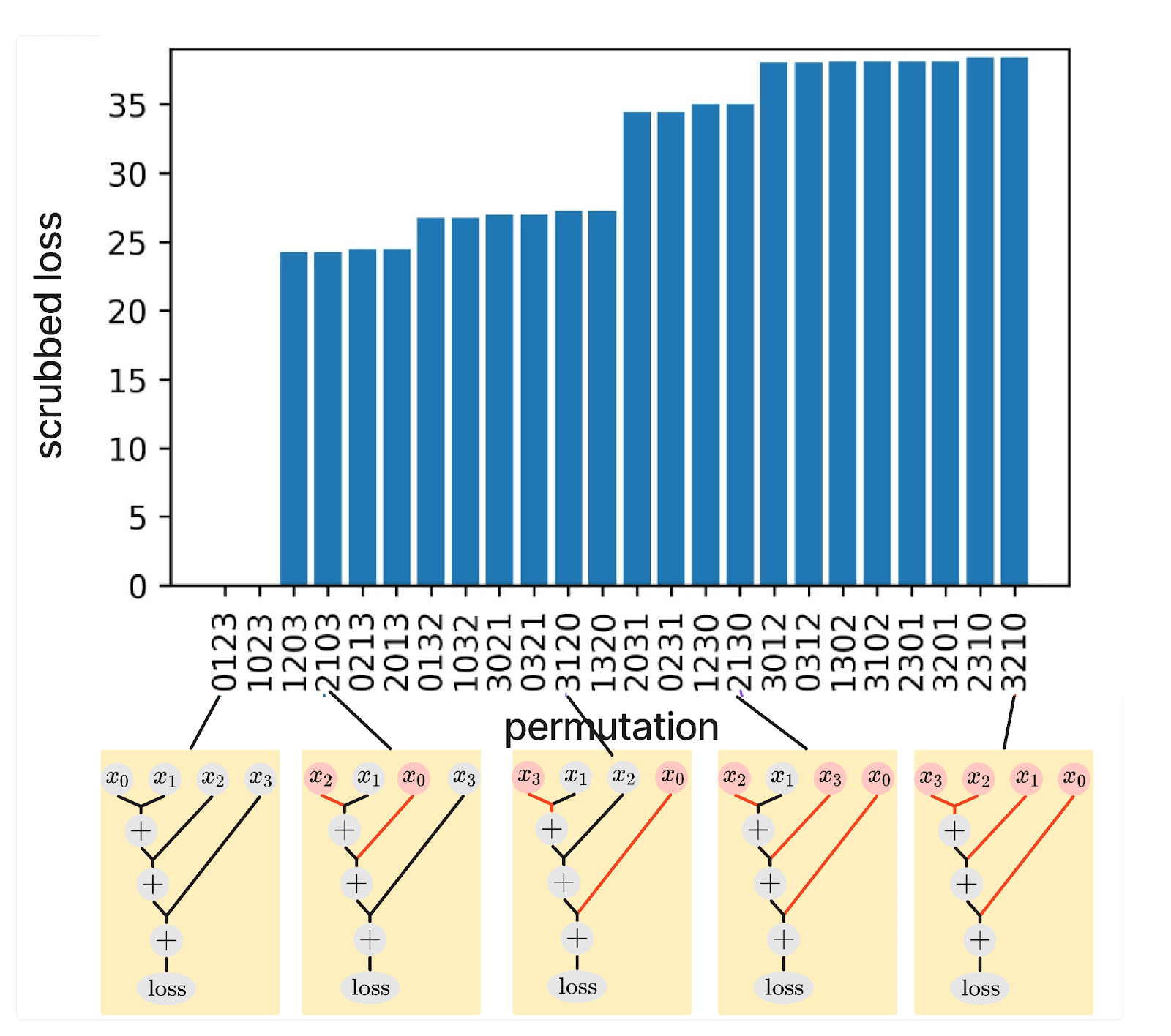
An ideal interpretation graph equivalent to should also yield a loss of 0. To evaluate the consistency of CaSc, we construct various alternative hypotheses by changing the order in which the numbers are added. Some of these hypotheses are extensionally equivalent to each other (i.e., they have the same input-output behavior even if their internal implementation may differ; see below for details) and should induce the same loss, while others are "more wrong" about the implementation of graph and should result in a higher loss when applying CaSc. For example, a hypothesis that claims adds up the elements in the order should be extensionally equivalent to the true interpretation (and get 100% recovered loss), while a hypothesis that claims the order is is significantly different and should result in a higher loss.
In total, we construct 24 different hypotheses that claim that adds up the digits in all permuted orders. We create a dataset where we randomly sample the four input digits from 0-9 and calculate the label by summing them up. We then apply CaSc (we resample 10000 times) to all of these hypotheses and evaluate the scrubbed mean squared error loss (from which one can directly calculate the loss recovered). Creating a perfect interpretation graph yields a perfect scrubbed loss of 0, and the random baseline (i.e., shuffling all the labels) yields a scrubbed loss of 68.2. In Figure 1, we show the scrubbed loss of all the possible hypotheses that permute the summation order. On this task, the scrubbed loss captures well how wrong our hypothesis is intuitively. Swapping the two inputs to the first node does not make the hypothesis worse, but swapping other inputs makes it worse. The more computations we get wrong in our hypothesis, the worse the scrubbed loss. We also observe that equivalent hypotheses get approximately the same loss (the differences are likely due to sampling).
Causal Scrubbing Cannot Differentiate Extensionally Equivalent Hypotheses
CaSc leverages extensional equivalence between graphs to make rewrites to the ground-truth and interpretation graph. This, however, implies a key limitation: CaSc cannot distinguish between extensionally equivalent hypotheses (Section 1.2. CaSc Appendix [? · GW]).
If we are trying to interpret a part of a computational graph, we can do so at different levels of specificity. In particular, if our interpretation operates at a high level (e.g., “this part of the computational graph sorts a list of numbers”), there are multiple more specific hypotheses (e.g., “this part of the computational graph performs MergeSort” or “this part of the computational graph performs QuickSort”) that are compatible with the higher-level hypothesis. These different hypotheses are extensionally equivalent, i.e., they describe functions with the same input-output behavior (sorting a list), but they are intensionally different, i.e., they implement the function in different manners (using different sorting algorithms).
An interpretation in CaSc should always be understood as a statement “up to extensional equivalence”, i.e., when we say, “this part of the graph sorts a list”, we should think of this as saying, “this part of the graph implements any algorithm that sorts a list”, but we are not making a statement about which algorithm is used. In theory, this is a trivial point, but we found that in practice, it is easy to miss this distinction when there is an “obvious” algorithm to implement a given function.
As a simple example, consider a graph that calculates whether , where is an input array of length 2 (). The output is a boolean value indicating the result of this calculation. We create a hypothesis that claims that the graph calculates . Figure 2 demonstrates this scenario, showing both the implementation of graph (on the left) and the hypothesis (on the right), with nodes in the hypothesis matched to subgraphs in .
This is technically a correct hypothesis as this is indeed what the graph computes. However, it is easy to forget that the single node in the interpretation graph corresponds to a subgraph. The hypothesis merely asserts that this subgraph computes a function that is extensionally equivalent to . In particular, the hypothesis does not claim that there is literally a single node in the computational graph that implements the elementary operation . In other words, the hypothesis is not specific enough, and when we zoom in, is not what is mechanistically computed in .
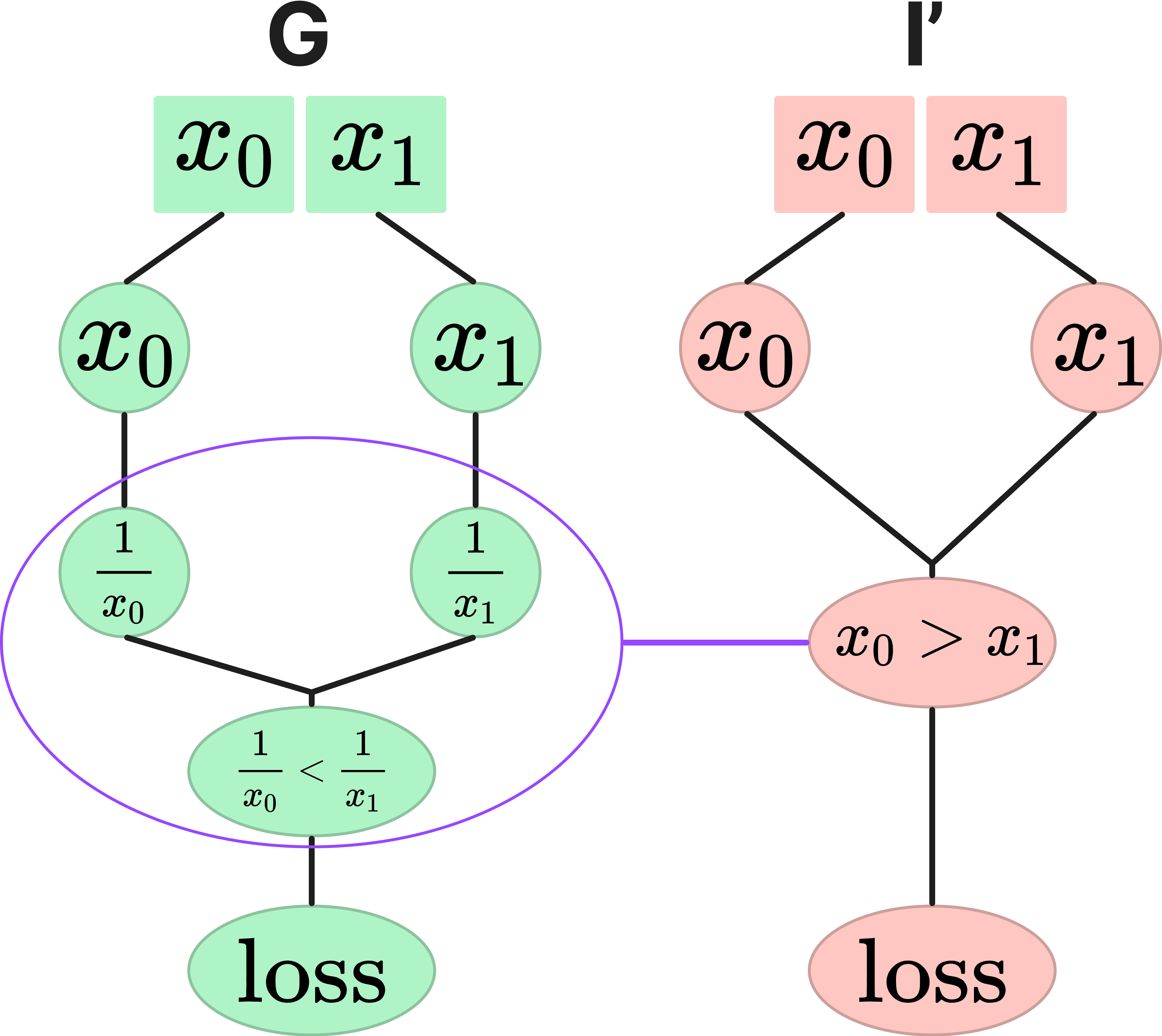
To test whether CaSc indeed cannot distinguish between both extensionally equivalent hypotheses, we implemented both the true graph and the incorrect hypothesis Then we ran CaSc (re-sampling 10000 times) on 2-digit inputs that are randomly sampled between 1 and 9, where the label is the boolean value defined by . The following table summarizes the results:
| Interpretation | Scrubbed Loss (MAE) |
| Correct Interpretation: | 0 |
| Random Labels | 0.49 |
| “Incorrect” Interpretation: | 0 |
Even though the interpretation is not specific enough, it still has 0 scrubbed loss (because it is extensionally equivalent). The key practical issue here is that if a hypothesis is not very specific, CaSc can accept it, even if the hypothesis suggests an incorrect interpretation of what the model does mechanistically.
More generally, it seems to us that for mechanistic interpretability, the distinction between “intensionally different” implementations of extensionally equivalent functions deserves more attention. Ideally, a procedure for evaluating interpretations should include some measure of “specificity” of the interpretation; an interpretation that makes a claim about every single neuron in the computational graph does not have many (or any) intensionally different equivalent implementations but a higher-level interpretation does. One can thus reduce the likelihood of this practical problem by making the hypotheses more specific, i.e., making more precise claims about each activation of the model and what it is computing.
Importantly, extensional equivalence is defined w.r.t the domain of the function, in this case, the test set. So while all the intensionally different implementations behave identically on the test set, they may behave very differently on out-of-distribution samples. In this sense, an interpretation is only as reassuring as the most malicious implementation compatible with it.
Causal Scrubbing Can Fail to Reject False Hypotheses
The previous examples showed hypotheses that are accurate in terms of their input-output relationship but too unspecific at the algorithmic level. In this section, we show that CaSc can also fail to distinguish hypotheses that are not extensionally equivalent, i.e., that have different input-output behavior. This is a more significant failure mode as it means that CaSc can fail to detect a hypothesis that is not faithful rather than just not specific enough.
We found this problem primarily occurs when the graph we are trying to interpret does not achieve perfect loss. Note that this is a reasonable scenario as neural networks often generalize poorly.
We present two concrete examples: the first one is conceptually simpler, and the second one is more practical.
Example 1 (XOR)
We consider a dataset with binary inputs of length 2 (i.e., 00, 01, 10, 11) that are evenly distributed (each input represents 25% of the data). The labels are the XOR of the binary inputs (i.e., 0, 1, 1, 0). Let’s assume we are given a model that always returns the first bit of the binary input (i.e., 0, 0, 1, 1). This will be our ground truth computational graph . On the other hand, the hypothesis graph labeled takes the input and always returns the second bit (i.e., 0, 1, 0, 1). We evaluate the performance of the graphs using the mean absolute error as the loss function, where the error is calculated based on the difference between the predicted and target labels.
From the description of graph and hypothesis , it is evident that they produce different results for the binary inputs 01 and 10. For example, on input 01, graph returns 0 while graph returns 1. So the ground truth graph and hypothesis are extensionally different. However, CaSc fails to reject : both graph and hypothesis produce a scrubbed loss of 0.5, and consequently, the recovered loss is 100%.
To understand this, let us take a closer look at what CaSc does when applied to hypothesis . The hypothesis claims that only the second bit matters, and when re-sampling different inputs, CaSc is allowed to change the input as long as the second bit matches the reference input. Given that the inputs are uniformly distributed, this re-sampling does not alter the overall loss. We empirically verify this result by implementing the above example and evaluating with CaSc (re-sampling 10000 times). The empirical results are presented in the following table:
| Interpretation | Scrubbed Loss (MAE) |
| Graph $G$ (returns first bit) | 0.50 |
| Random Labels | 0.50 |
| Hypothesis I’ (returns second bit) | 0.51[1] |
The results show that CaSc can get 100% recovered loss on specific hypotheses that are extensionally different from the ground truth graph. We refer to this failure mode as “cancellation”: CaSc causes the model to do better on some inputs and worse on others, such that, on average, the wrong hypothesis recovers the full loss. The likelihood of such cancellation increases when the ground truth graph (i.e., the model) has a high loss and generalizes poorly. The poor performance of allows hypothesis to have “more wiggle room” to improve upon on certain inputs and be worse than on others.
In this example, both graph and hypothesis perform as poorly as outputting random labels. We thus provide a second example where the model performs better than random, but the same cancellation effect occurs.
Example 2 (Sum with offset)
In this example, we have a dataset of integer arrays as inputs. The labels are the sum of each element in the array (e.g., or ). The last element of the input array is uniformly sampled from {-1, 1}, and all other digits are uniformly sampled between 0 and 9. Our loss is again the mean absolute error.
The computational graph calculates the sum of all elements of the input array but adds an incorrect offset of +2 to the result. This results in a mean absolute error (MAE) of 2. On the other hand, the hypothesis graph assumes that only the first n-1 elements of the input array are summed up, and the n-th element is irrelevant. When applying CaSc using , the last digit of the input can be resampled. This also leads to a scrubbed MAE of 2[2].
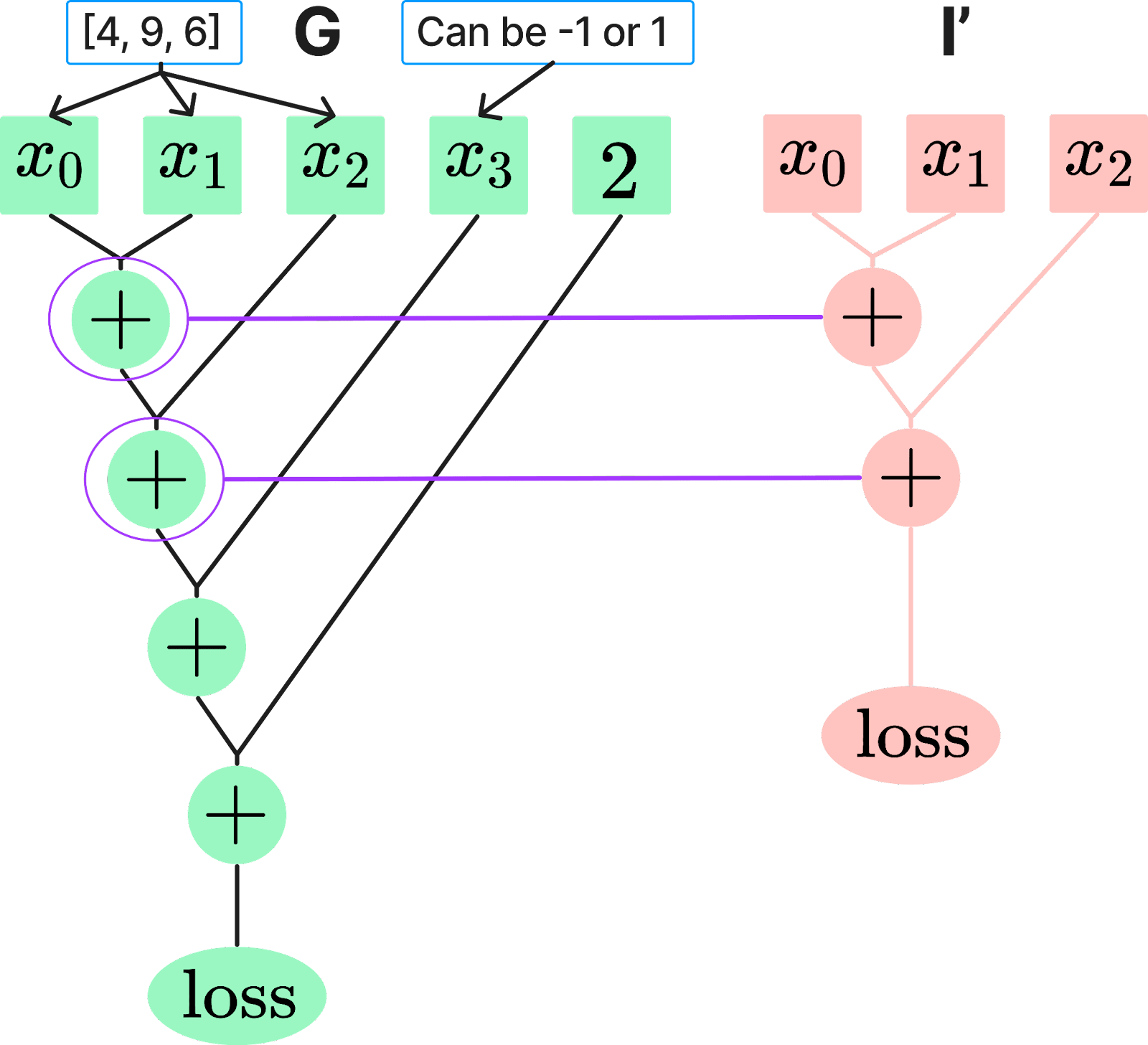
Figure 3: Graph on the left sums up all input digits and adds 2 to the sum. Hypothesis sums up the first 3 digits.
Hence, CaSc again gets 100% recovered loss, even though the underlying hypothesis is extensionally different. This is another example of CaSc failing due to cancellation. We again implement this example and evaluate it with CaSc (sampling 10000 times). The results are in the following table:
| Interpretation | Scrubbed Loss (MAE) |
| Graph G (returns sum + 2) | 2.0 |
| Random Labels | 6.0 |
| Hypothesis I’ (returns sum of first n-1 elements) | 2.0 |
The empirical results support our claims. The random label baseline performs poorly, with a mean absolute error of 6.0, while our wrong hypothesis shows a loss of 2.0, i.e., getting a 100% recovered loss.
It is worth noting that this failure could have been detected by examining the loss on each individual sample, but CaSc often uses the average recovered loss as a metric, which hides the cancellation[3].
Implications for Causal Scrubbing
We believe that CaSc can be a very useful method to evaluate hypotheses about neural networks in the wild, but we think it is important to be aware of some of its practical pitfalls.
CaSc can fail to reject a hypothesis if it is too unspecific and is extensionally equivalent to the true hypothesis. We recommend being aware of the class of extensionally equivalent hypotheses to understand how specific a given hypothesis really is. Generally, a more specific hypothesis is better than a less specific one.
On the input-output level, we found that CaSc can fail to reject false hypotheses due to cancellation, i.e. because the task has a certain structural distribution that does not allow resampling to differentiate between different hypotheses. This phenomenon is more likely if the model to interpret performs worse on the given task. We thus recommend being cautious when applying CaSc to models that don’t generalize well on a task. We also propose to refrain from using aggregate metrics such as average loss recovered but to look at the loss recovered for individual samples.
We found our investigation of synthetic graphs to be insightful and useful for building intuitions about causal scrubbing. Of course, the examples we looked at are somewhat artificial and limited. Therefore, we advocate for a more extensive evaluation of CaSc, ideally in more realistic models. We think this type of evaluation can help to gain confidence in CaSc and could potentially uncover other limitations of CaSc.
- ^
The small difference in the Scrubbed Loss is likely due to sampling noise.
- ^
In 25% of the cases, we swap a +1 with a -1, resulting in a perfect estimate with a mean absolute error of 0 (underestimating the true sum by 2 and then adding 2). In 25% of cases, we swap a -1 with a +1, resulting in a mean absolute error of 4 (overestimating the true sum and adding 2). In the remaining 50% of cases where we “replace” +1 with +1 or -1 with -1, we get the original MAE of 2. So, overall we still get a MAE of 2.
- ^
Researchers at Redwood Research have told us that they have also started to look at the loss for individual samples.
17 comments
Comments sorted by top scores.
comment by Buck · 2023-03-27T15:02:55.755Z · LW(p) · GW(p)
Here's a take of mine on how you should think about CaSc that I haven't so far gotten around to publishing anywhere:
I think you should think of CaSc as being a way to compute a prediction made by the hypothesis. That is, when you claim that the model is computing a particular interpretation graph, and you provide the correspondence between the interpretation graph and the model, CaSc tells you a particularly aggressive prediction made by your hypothesis: your hypothesis predicts that making all the swaps suggested by CaSc won't affect the average output of your computational graph.
Thinking about it this way is helpful to me for two reasons:
- False hypotheses can make true predictions; this is basically why CaSc can fail to reject false hypotheses.
- It also emphasizes why I'm unsympathetic to claims that "it sets the bar too high for something being a legit circuit" [AF · GW]--IMO, if you claimed that your model has some internal structure well described by hypothesis that fits into the CaSc structure (which is true of almost all interp hypotheses in practice), I don't really see how the failure of a CaSc test is compatible with that hypothesis being true (modulo my remaining questions about how bad it is for a hypothesis to get a middling CaSc score [AF · GW]).
CaSc attempts to compute the single most aggressive prediction made by your hypothesis--this is why we do all allowed swaps. (I'm a bit confused about whether we should think of CaSc as succeeding at being the most aggressive experiment for the hypothesis though, I think there are some subtleties here that my coworkers have worked out that I don't totally understand.)
I think I regret that we phrased our writeup as "CaSc gives you a test of interp hypotheses" rather than saying "CaSc shows you a strong prediction made by your interp hypothesis, which you can then compare to the truth, and if they don't match that's a problem for your hypothesis".
Replies from: Buck↑ comment by Buck · 2023-03-28T23:13:17.316Z · LW(p) · GW(p)
Something I've realized over the last few days:
Why did we look at just the “most aggressive” experiment allowed by a hypothesis H, instead of choosing some other experiment allowed by H?
The argument for CaSc is: “if H was true, then running the full set of swaps shouldn’t affect the computation’s output, and so if the full set of swaps does affect the computation’s output, that means H is false.” But we could just as easily say “if H was true, then the output should be unaffected any set of swaps that H says should be fine.”
Why focus on the fullest set of swaps? An obvious alternative to “evaluate the hypothesis using the fullest set of swaps” is “evaluate the hypothesis by choosing the set of swaps allowed by H which make it look worse”.
I just now have realized that this is AFACIT equivalent to constructing your CaSc hypothesis adversarially--that is, given a hypothesis H, allowing an adversary to choose some other hypothesis H’, and then you run the CaSc experiment on join(H, H’). And so, when explaining CaSc, I think we should plausibly think about describing it by talking about the hypothesis producing a bunch of allowed experiments, and then you can test your hypothesis by either looking at the maxent one or by looking at the worst one.
Replies from: David Lindner, rhaps0dy↑ comment by David Lindner · 2023-03-29T20:32:07.293Z · LW(p) · GW(p)
Thanks, that's a useful alternative framing of CaSc!
FWIW, I think this adversarial version of CaSc would avoid the main examples in our post where CaSc fails to reject a false hypothesis. The common feature of our examples is "cancellation" which comes from looking at an average CaSc loss. If you only look at the loss of the worst experiment (so the maximum CaSc loss rather than the average one) you don't get these kind of cancellation problems.
Plausibly you'd run into different failure modes though, in particular, I guess the maximum measure is less smooth and gives you less information on "how wrong" your hypothesis is.
Replies from: rhaps0dy↑ comment by Adrià Garriga-alonso (rhaps0dy) · 2023-04-03T01:10:56.624Z · LW(p) · GW(p)
If you only look at the loss of the worst experiment (so the maximum CaSc loss rather than the average one) you don't get these kind of cancellation problems
I think this "max loss" procedure is different from what Buck wrote and the same as what I wrote.
↑ comment by Adrià Garriga-alonso (rhaps0dy) · 2023-04-03T01:09:51.233Z · LW(p) · GW(p)
Why focus on the fullest set of swaps? An obvious alternative to “evaluate the hypothesis using the fullest set of swaps” is “evaluate the hypothesis by choosing the set of swaps allowed by H which make it look worse”.
I just now have realized that this is AFACIT equivalent to constructing your CaSc hypothesis adversarially--that is, given a hypothesis H, allowing an adversary to choose some other hypothesis H’, and then you run the CaSc experiment on join(H, H’).
One thing that is not equivalent to joins, which you might also want to do, is to choose the single worst swap that the hypothesis allows. That is, if a set of node values are all equivalent, you can choose to map all of them to e.g. . And that can be more aggressive than any partition of X which is then chosen-from randomly, and does not correspond to joins.
comment by Buck · 2023-03-27T14:55:07.206Z · LW(p) · GW(p)
Thanks for your work!
Causal Scrubbing Cannot Differentiate Extensionally Equivalent Hypotheses
I think that what you mean here is a combination of the following:
- CaSc fails to reject some false hypotheses, as already discussed.
- Each node in the interpretation graph is only verified up to extensional equality. As in, if I claim that a single node in the graph is a whole sort function, I don't learn anything about whether the model is implementing quicksort or mergesort.
But one way someone could interpret this sentence is that CaSc doesn't distinguish between whether the model does quicksort or mergesort. This isn't generally true--if your interpretation graph broke up its quicksort implementation into multiple nodes, then the CaSc experiment would fail to explain the model's performance if the model itself was actually using merge sort.
Replies from: David Lindner↑ comment by David Lindner · 2023-03-27T19:11:01.705Z · LW(p) · GW(p)
Yes, this seem like a plausible confusion. Your interpretation of what we mean is correct.
comment by philh · 2023-03-29T14:35:52.076Z · LW(p) · GW(p)
Not sure if this was deliberate on your part, but:
As a simple example, consider a graph that calculates whether , where is an input array of length 2 (). ... We create a hypothesis that claims that the graph calculates . ... This is technically a correct hypothesis as this is indeed what the graph computes.
Only correct as long as are both or both . Which illustrates your point that
So while all the intensionally different implementations behave identically on the test set, they may behave very differently on out-of-distribution samples.
comment by Adrià Garriga-alonso (rhaps0dy) · 2023-04-03T01:18:31.308Z · LW(p) · GW(p)
Cool work! I was going to post about how "effect cancellation" is already known and was written in the original post but, astonishingly to me, it is not! I guess I mis-remembered.
There's one detail that I'm curious about. CaSc usually compares abs(E[loss] - E[scrubbed loss]), and that of course leads to ignoring hypotheses which lead the model to do better in some examples and worse in others.
If we compare E[abs(loss - scrubbed loss)] does this problem go away? I imagine that it doesn't quite if there are exactly-opposing causes for each example, but that seems harder to happen in practice.
(There's a section on this in the appendix [? · GW] but it's rather controversial even among the authors)
comment by Lucius Bushnaq (Lblack) · 2023-03-27T09:27:27.996Z · LW(p) · GW(p)
CaSc can fail to reject a hypothesis if it is too unspecific and is extensionally equivalent to the true hypothesis.
Seems to me like this is easily resolved so long as you don't screw up your book keeping. In your example, the hypothesis implicitly only makes a claim about the information going out of the bubble. So long as you always write down which nodes or layers of the network your hypothesis makes what claims about, I think this should be fine?
On the input-output level, we found that CaSc can fail to reject false hypotheses due to cancellation, i.e. because the task has a certain structural distribution that does not allow resampling to differentiate between different hypotheses.
I don't know that much about CaSc, but why are you comparing the ablated graphs to the originals via their separate loss on the data in the first place? Stamping behaviour down into a one dimensional quantity like that is inevitably going to make behavioural comparison difficult.
Wouldn't you want to directly compare the divergence on outputs between the original graph and ablated graph instead? The divergence between their output distributions over the data is the first thing that'd come to my mind. Or keeping whatever the original loss function is, but with the outputs of as the new ground truth labels.
That's still ad hocery of course, but it should at least take care of the failure mode you point out here. Is this really not part of current CaSc?
Replies from: Buck, davidad, JerrySch↑ comment by Buck · 2023-03-27T14:45:45.949Z · LW(p) · GW(p)
Stamping behaviour down into a one dimensional quantity like that is inevitably going to make behavioural comparison difficult.
The reason to stamp it down to a one-dimensional quantity is that sometimes the phenomenon that we wanted to explain is the expectation of a one-dimensional quantity, and we don't want to require that our tests explain things other than that particular quantity. For example, in an alignment context, I might want to understand why my model does well on the validation set, perhaps in the hope that if I understand why the model performs well, I'll be able to predict whether it will generalize correctly onto a particular new distribution.
The main problem with evaluating a hypothesis by KL divergence is that if you do this, your explanation looks bad in cases like the following: There's some interference in the model which manifests as random noise, and the explanation failed to preserve the interference pattern. In this case, your explanation has a bunch of random error in its prediction of what the model does, which will hurt the KL. But that interference was random and understanding it won't help you know if the mechanism that the model was using is going to generalize well to another distribution.
There are other similar cases than the interference one. For example, if your model has a heuristic that fires on some of the subdistribution you're trying to understand the model's behavior on, but not in a way that ends up affecting the model's average performance, this is basically another source of noise that you (at least often) end up not wanting your explanation to have to capture.
Replies from: davidad, Lblack↑ comment by davidad · 2023-03-27T21:48:04.645Z · LW(p) · GW(p)
As an alternative summary statistic of the extent to which the ablated model performs worse on average, I would suggest the Bayesian Wilcoxon signed-rank test.
↑ comment by Lucius Bushnaq (Lblack) · 2023-03-27T16:16:36.982Z · LW(p) · GW(p)
The main problem with evaluating a hypothesis by KL divergence is that if you do this, your explanation looks bad in cases like the following:
I would take this as indication that the explanation is inadequate. If I said that the linear combination of nodes at layer l of a NN implements the function , but in fact it implements , where g does some other thing, my hypothesis was incorrect, and I'd want the metric to show that. If I haven't even disentangled the mechanism I claim to have found from all the other surrounding circuits, I don't think I get to say my hypothesis is doing a good job. Otherwise it seems like I have a lot of freedom to make up spurious hypotheses that claim whatever, and hide the inadequacies as "small random fluctuations" in the ablated test loss.
The reason to stamp it down to a one-dimensional quantity is that sometimes the phenomenon that we wanted to explain is the expectation of a one-dimensional quantity, and we don't want to require that our tests explain things other than that particular quantity. For example, in an alignment context, I might want to understand why my model does well on the validation set, perhaps in the hope that if I understand why the model performs well, I'll be able to predict whether it will generalize correctly onto a particular new distribution.
I don't see how the dimensionality of the quantity you want to understand the generative mechanism of relates to the dimensionality of the comparison you would want to carry out to evaluate a proposed generative mechanism.
I want to understand how the model computes its outputs to get loss on distribution , so I can predict what loss it will get on another distribution . I make a hypothesis for what the mechanism is. The mechanism implies that doing intervention on the network, say shifting to , should not change behaviour, because the NN only cares about , not its magnitude. If I then see that the intervention does shift output behaviour, even if it does not change the value of on net, my hypothesis was wrong. The magnitude of does play a part in the network's computations on . It has an influence on the output.
But that interference was random and understanding it won't help you know if the mechanism that the model was using is going to generalize well to another distribution.
If it had no effect on how outputs for are computed, then destroying it should not change behaviour on . So there should be no divergence between the original and ablated models' outputs. If it did affect behaviour on , but not in ways that contribute net negatively or net positively to the accuracy on that particular distribution, it seems that you still want to know about it, because once you understand what it does, you might see that it will contribute net negatively or net positively to the model's ability to do well on .
A heuristic that fires on some of , but doesn't really help much, might turn out to be crucial for doing well on . A leftover memorised circuit that didn't get cleaned up might add harmless "noise" on net on , but ruin generalisation to .
I would expect this to be reasonably common. A very general solution is probably overkill for a narrow sub dataset, containing many circuits that check for possible exception cases, but aren't really necessary for that particular class of inputs. If you throw out everything that doesn't do much to the loss on net, your explanations will miss the existence of these circuits, and you might wrongly conclude that the solution you are looking at is narrow and will not generalise.
↑ comment by davidad · 2023-03-27T22:06:14.980Z · LW(p) · GW(p)
Note, assuming the test/validation distribution is an empirical dataset (i.e. a finite mixture of Dirac deltas), and the original graph is deterministic, the of the pushforward distributions on the outputs of the computational graph will typically be infinite. In this context you would need to use a Wasserstein divergence, or to "thicken" the distributions by adding absolutely-continuous noise to the input and/or output.
Or maybe you meant in cases where the output is a softmax layer and interpreted as a probability distribution, in which case does seem reasonable. Which does seem like a special case of the following sentence where you suggest using the original loss function but substituting the unablated model for the supervision targets—that also seems like a good summary statistic to look at.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2023-03-28T04:40:25.953Z · LW(p) · GW(p)
Second paragraph is what I meant, thanks.
↑ comment by Jérémy Scheurer (JerrySch) · 2023-03-27T11:49:45.331Z · LW(p) · GW(p)
Seems to me like this is easily resolved so long as you don't screw up your book keeping. In your example, the hypothesis implicitly only makes a claim about the information going out of the bubble. So long as you always write down which nodes or layers of the network your hypothesis makes what claims about, I think this should be fine?
Yes totally agree. Here we are not claiming that this is a failure mode of CaSc, and it can "easily" be resolved by making your hypothesis more specific. We are merely pointing out that "In theory, this is a trivial point, but we found that in practice, it is easy to miss this distinction when there is an “obvious” algorithm to implement a given function."
I don't know that much about CaSc, but why are you comparing the ablated graphs to the originals via their separate loss on the data in the first place? Stamping behaviour down into a one dimensional quantity like that is inevitably going to make behavioural comparison difficult.
You are right that this is a failure mode that is mostly due to reducing the behavior down into a single aggregate quantity like the average loss recovered. It can be remedied when looking at the loss on individual samples and not averaging the metric across the whole dataset. In the footnote, we point out that researchers at Redwood Research have actually also started looking at the per-sample loss instead of the aggregate loss.
CaSc was, however, introduced by looking at the average scrubbed loss (even though they say that this metric is not ideal). Also, in practice, when one iterates on generating hypotheses and testing them with CaSc, it's more convenient to look at aggregate metrics. We thus think it is useful to have concrete examples that show how this can lead to problems.
Your suggestion of using seems a useful improvement compared to most metrics. It's, however, still possible that cancellation could occur. Cancellation is mostly due to aggregating over a metric (e.g., the mean) and less due to the specific metric used (although I could imagine that some metrics like could allow for less ambiguity).
↑ comment by Lucius Bushnaq (Lblack) · 2023-03-27T13:45:04.499Z · LW(p) · GW(p)
Your suggestion of using seems a useful improvement compared to most metrics. It's, however, still possible that cancellation could occur. Cancellation is mostly due to aggregating over a metric (e.g., the mean) and less due to the specific metric used (although I could imagine that some metrics like could allow for less ambiguity).
It's not about vs. some other loss function. It's about using a one dimensional summary of a high dimensional comparison, instead of a one dimensional comparison. There are many ways for two neural networks to both diverge from some training labels by an average loss while spitting out very different outputs. There are tautologically no ways for two neural networks to have different output behaviour without having non-zero divergence in label assignment for at least some data points. Thus, it seems that you would want a metric that aggregates the divergence of the two networks' outputs from each other, not a metric that compares their separate aggregated divergences from some unrelated data labels and so throws away most of the information.
A low dimensional summary of a high dimensional comparison between the networks seems fine(ish). A low dimensional comparison between the networks based on the summaries of their separate comparisons to a third distribution throws away a lot of the relevant information.