In response to critiques of Guaranteed Safe AI
post by Nora_Ammann · 2025-01-31T01:43:05.787Z · LW · GW · 14 commentsContents
Acknowledgements
I. Brief summary of “Towards Guaranteed Safe AI”
II. Commonly-encountered critiques, and some responses
1. The proposed architecture won’t work
1.1. You can’t get a good enough world model
Critique:
Response:
1.2. You can’t get good enough guarantees
Critique:
Response:
Types of Guarantees
Time horizon
Steganography, and other funny business
1.3. You can’t get good enough safety specifications
Critique:
Response:
2. Other approaches are a better use of time
2.1. Does not address the most serious risks
Critique:
Response:
Threat model: what AI capability levels does GSAI target?
What kinds of problems does GSAI aim to solve, and which does it not?
Securing cyberspace
Protection against biosecurity hazards
The role of assurance in coordination
2.2. AI won’t help (soon) enough
Critique
Response:
2.3. Lack of ‘portability' & independent verification of proof certificate
Critique
Response:
3. Conclusion
None
14 comments
In this post, I discuss a number of critiques of Guaranteed Safe AI (GSAI) approaches I’ve encountered since releasing this position paper.
The critiques I’m responding to here are taken from a range of places, including personal conversations and social media. The two most substantive written/recorded critiques I'm aware of (and had in mind when writing this post) are Andrew Dickson’s Limitations on Formal Verification for AI Safety [LW · GW] and Zac Hatfield-Dodds’s talk Formal Verification is Overrated. I’ve done my best to do justice in our depiction of those critiques, but I certainly welcome clarifications or pushback where I seem to have missed the original point of a given critique.
To be clear, the position I'm defending here (and will be adding more nuance to throughout this piece) is not that GSAI is definitely going to succeed. Nor that it is a solution to all of AI risk. What I'm arguing for is that, ex ante, GSAI is worth serious investment, and that none of the critiques we’ve encountered so far succeed in undermining that claim.
In order to make this discussion more read- and searchable, I’ve organized the critiques into categories and subcategories, each of which contains one or several more specific formulations of objections and (where available) examples of where this objection has been raised in context.
- The proposed architecture won’t work
- You can’t get a good enough world model
- You can’t get good enough guarantees
- You can’t get good enough safety specifications
- Other approaches are a better use of resources
- GSAI does not address the most serious risks
- AI won’t help (soon) enough
- Lack of 'portability' and independent verification of proof certificate
Some of these critiques, I will argue, are based on misunderstandings of the original proposal, while others are rooted in (what seems to be) genuine disagreements and empirical uncertainties. Depending on the context, I will either try to restate the original proposals more clearly, or discuss why I believe that the proposed limitations do not undermine, on the whole, the reasons for thinking that GSAI is a worthwhile family of agendas to pursue.
Two more caveats before I start:
- Importantly, the GSAI family of approaches advocates for a specific use of formal methods in the context of AI safety. There are a range of other ways one could imagine making use of formal methods. This post is a defence of GSAI approaches, not of formal methods for AI safety in full generality.
- While the GSAI paper has a number of co-authors, this response is written by the authors of this post alone, and does not represent the views of everyone who coauthored the position paper.
***
In section II, I will address a selection of critiques which I found to be (a combination of) most common and substantive. Before that, in section I, I provide a brief, self-contained summary of the “Towards Guaranteed Safe AI” paper. Feel free to skip this section if you’re already familiar with the paper. If not, this will help set the stage and make this post more accessible.
Acknowledgements
Many of the ideas presented have been informed by discussions with David 'davidad' Dalrymple, as well as the other authors of the Towards Guaranteed Safe AI paper. I'm additionally grateful to Evan Miyazono, Ben Goldhaber and Rose Hadshar for useful comments on earlier drafts. Any mistakes are my own.
I. Brief summary of “Towards Guaranteed Safe AI”
I provide a short, self-contained summary of the paper Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems.
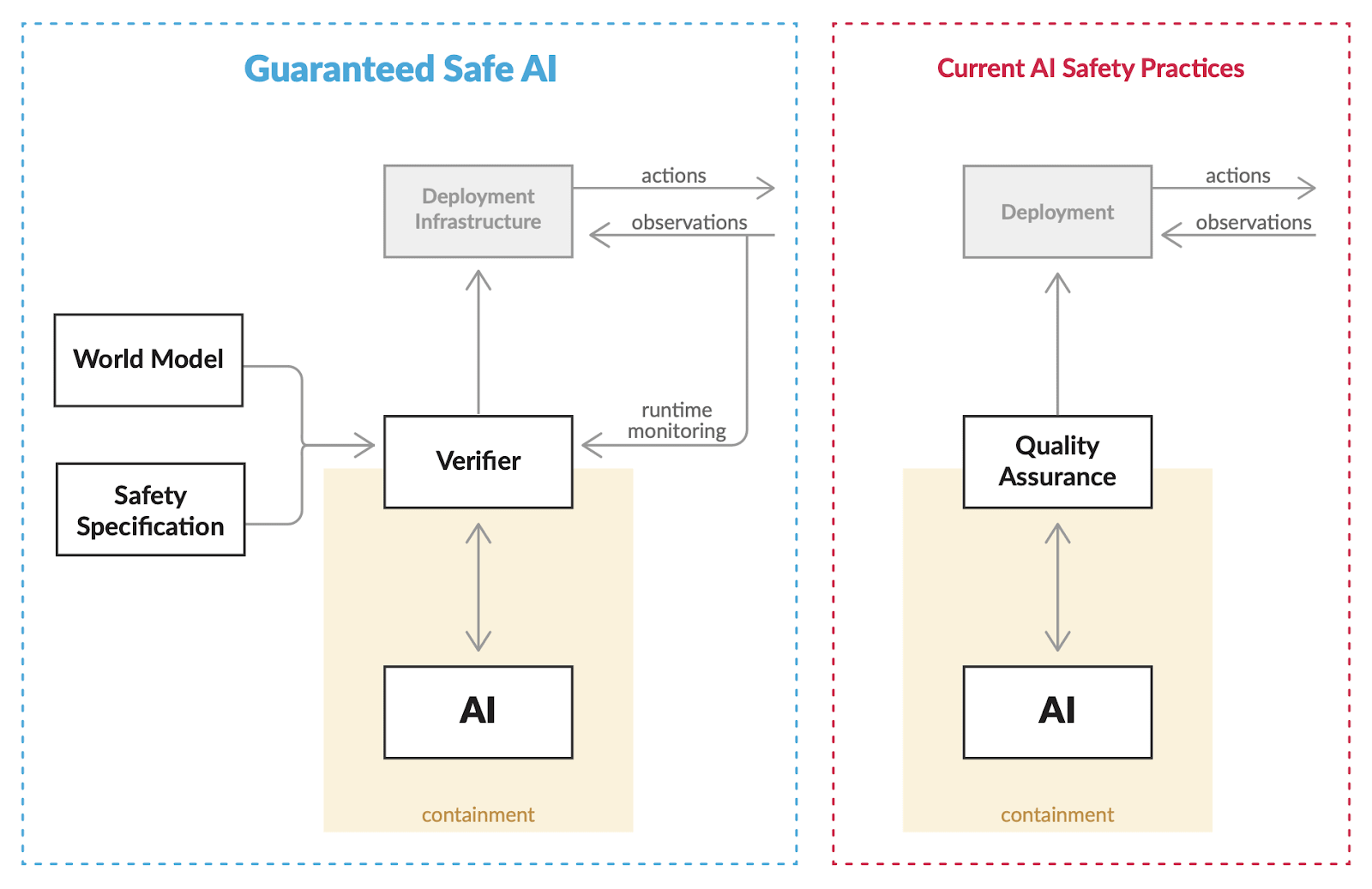
‘Guaranteed Safe AI’ (GSAI) refers to a family of approaches which share a high-level architecture – involving a world model, a safety specification and a verifier – which together can provide high-assurance safety guarantees for advanced AI systems. Instead of having a powerful AI system interact with the world directly, its outputs are mediated through the three-component architecture, verifying that the outputs conform to the safety specification within certain bounds.
This family of approaches stands in contrast to current practices that primarily rely on empirical evaluations – identifying examples of unsafe behaviour (e.g. through independent testing and red-teaming) which can then be patched. However, due to the inability to test across all possible inputs and future deployment environments, such methods cannot provide rigorous, quantifiable safety guarantees.
Given the wide reaching applications of advanced AI systems and, in particular, the potential use of AI in safety-critical domains, we believe that they should be required to comply with high and rigorous safety standards – just like it is the case with other safety critical infrastructure such as aircraft, nuclear power plants, medical devices, etc. Above some risk or capability thresholds, the burden of demonstrating such safety guarantees should be on the systems’ developers, and the provided evidence must be adequate to justify high confidence that a given AI system is safe.
The general architecture of GSAI consists of three core components.
- The safety specification (or distribution over safety specifications) corresponds to a property that we wish an AI system to satisfy.
- The world model (or distribution over world models) is the environment in which the safety specification is specified. A world model describes the dynamics of the AI system’s environment in such a way that it can answer what would happen in the world as a result of a given output from the AI.
- The verifier checks, relative to the world model, that the system does in fact adhere to the safety specification and determines the (probabilistic) safety envelope in which that system will continue to operate safely.
Each of the components can be implemented at different levels of rigour and tractability. There exists a range of research avenues, many of which we discuss in the paper, that could plausibly produce such an GSAI in a satisfactory and feasible manner, while remaining competitive with AI systems without such guarantees. (See sections 3.2 to 3.4 for more details.)
The safety of GSAI applications should be further bolstered by an adequate deployment infrastructure. This could look like monitoring the AI system at runtime, checking whether the incoming observational data is consistent with the mathematical model of the environment in order to spot potentially safety-relevant anomalies. If such anomalies are detected, then the advanced AI system would be disabled or transition to a trustworthy backup system, to ensure that there is no unaccounted for risk of unsafe behavior. Furthermore, it might be useful to modulate the time horizon of the AI outputs which are verified in order to increase the reliability of safety guarantees, or increase the tractability of formal verification.
Important challenges exist for successful implementations of GSAI, as well as reasons for optimism. For example, there already exist useful current-day or near-future applications of GSAI (e.g. in passenger aviation, railway, or autonomous vehicles), substantiating the claim of their tractability and usefulness. Furthermore, while it can be challenging to create sufficiently accurate world models, the crux of the task is not in creating a maximally precise (or complete) model, but instead making sure the model preserves soundness. In other words, the world model is not required to eliminate all sources of uncertainty but instead must be capable of appropriately handling such uncertainty, such that we arrive at a model that’s a sound overapproximation of the true dynamics of the given context of use. Most importantly, maybe, we can make use of current day frontier AI tooling to enhance and accelerate our ability to build the required world models or make verification tractable.
Beyond a plausible avenue to high-assurance quantitative safety guarantees, GSAI approaches promise the following further benefits:
- They are amenable to democratic input and oversight. The safety specification can capture societal risk criteria which should ideally be determined by collective deliberation. This is in contrast to approaches that specify, train, and evaluate AI systems in ways that remain opaque to (or are kept secret from) the wider public (e.g. system prompts, etc.).
- They can facilitate multi-stakeholder coordination, even in low-trust settings, as the safety guarantees they produce are independently auditable.
- They may produce AI safety solutions whose costs are amortised over time – given that a world model and safety spec can be reused across models – thereby substantially reducing the economic incentive to disregard or evade safety measures.
- Even short of full-scale solutions, they stand to produce significant societal value, among others by securing critical infrastructure, thereby drastically bolstering civilisational resilience to misuse and accidents as well as adversarial threats from rogue AI.
- Rather than seeking to substitute current AI safety methods, they can be usefully combined with current methods in ways that improve on the overall safety of a system.
Ultimately, I argue that we need an “anytime” portfolio approach of R&D efforts towards safe AI, and that GSAI approaches are a critical part of that. This will allow us to maximise the expected effectiveness of the feasible safety techniques at each stage.
II. Commonly-encountered critiques, and some responses
Below, I have compiled the critiques that I’ve found to be (a combination of) most common and substantive.
1. The proposed architecture won’t work
1.1. You can’t get a good enough world model
Critique:
I’ve encountered a number of reasons for skepticism about the tractability of making formal models of a context of use which are good enough that they can underpin trustworthy, dependable safety guarantees. For example:
- World model =/= real world
- Critique tldr: The guarantees in GSAI are not about what will happen in the actual world, but about what will happen according to a given model of the world. But we know that our models will have flaws – we know that “the map is not the territory”. Thus, we should not rely on these guarantees.
- Sample quote: “[I]t should be clear that whatever proofs and guarantees we can produce will not be guarantees about the world itself, but will at best pertain only to severely simplified, approximate and uncertain representations of it.” (from Limitations on Formal Verification for AI Safety [LW · GW])
- Dependence on initial conditions
- Critique tldr: The trustworthiness of world models in GSAI depend on an accurate and complete measure of initial conditions.
- Sample quote: “In order to translate rule sets into proofs and formal guarantees about the world, a GS system would need to obtain, in addition to the formal model itself, sufficiently detailed and complete initial conditions data about the relevant parts of the world.” (from Limitations on Formal Verification for AI Safety [LW · GW])
- Software vs (cyber-)physical processes
- Critique tldr: While it is feasible to verify that a given software system will adhere to a set of specifications, doing this for systems or processes that occur in the physical world is an entirely different level of complexity – so much so that the feasibility of the former provides limited evidence about the feasibility of the latter.
- Sample quote: “[T]he guarantee for the Perseverance Lander was only that the onboard computer software would run correctly in terms of its internal programmatic design and not fail due to bugs in the code. There was no proof or guarantee at all about the physical process of landing on Mars, or the success of the mission as a whole, or even that the software program wouldn’t still fail in any case due to a short circuit, or a defective transistor inside the Lander’s computer.” (from Limitations on Formal Verification for AI Safety [LW · GW])
Response:
Yes, GSAI guarantees are about a model of the world. And yes, a model of the world is never a perfect representation of the actual world.
However, if we’re thoughtful, we’re still able to derive substantive statements about safety from this set up. In particular, if our model is able to soundly overapproximate the true dynamics of the world, then we are able to conservatively guarantee our safety specifications. How might we do that?
First, let us unpack what I mean by sound overapproximation. The point is that we’re not using a deterministic model. We’re not even using a probabilistic model. We’re using a model that is more conservative than that, but it is conservative in a specific way. The model we’re after allows us to make probabilistic claims about the distribution of values that some variable is going to take, but it also allows us to be agnostic about the value of some other variable. What does agnostic mean here? Imagine our world model makes a claim about the expected value of the temperature in the actual system – say it claims that the temperature is going to be less than 50. In other words, the model is agnostic about what exact value the temperature variable is going to take–it just says it will be less than 50. Importantly, this claim can be accurate, without needing to be exact. And in order to achieve sound guarantees, what we need first and foremost is accuracy, not exactness.
The language can be slightly confusing here at first. In formal methods, we make a distinction between soundness and completeness–soundness means that everything the model says is true, and completeness means that everything that is true can be deduced from the model. A similar distinction is made in mathematics, differentiating between accuracy (~soundness) and precision/exactness (~completeness). In essence: to achieve useful safety guarantees, our model needs to preserve soundness, but it does not necessarily require complete knowledge.
In other words, we want our formal model to be able to incorporate different sources of uncertainty: Bayesian/probabilistic uncertainty (i.e. uncertainty across possible world trajectories), but also non-determinism (i.e. uncertainty across possible distributions over possible world trajectories).We can incorporate non-determinism using imprecise probability (or Infrabayesian probabilities).[1] If we manage to do so successfully, we end up with a model that is a conservative but sound overapproximation of the true ‘real world’ dynamics.
Ok, so, our quest is to find a way to construct formal world models that are both dependable and traceable. Now, in addition to accounting for different sources of uncertainty, it is also the case that, for many problems, it is sufficient to model only a certain abstraction layer without needing to model all micro-level processes. Take for example Google DeepMind’s recent table-tennis robot. The robot is trained entirely in a simulation of the table-tennis arena, which was fit to data. The hardest part to model was the contact of the soft squishy rubber with the ping-pong ball. But they learned an abstraction, using three extra springs, that turns out to be good enough for the purpose of beating most humans. (In this case, the abstraction doesn’t have a certified error bound, but runtime monitoring could detect if real data is deviating from the abstraction and switch to a backup controller.)
Note that our world model (or guarantees that depend on such a model) are not dependent on complete data of initial conditions of the system in question. If we were using a deterministic model, complete information about initial conditions would indeed be critical. But this is no longer the case if we incorporate stochasticity or non-determinism. In other words, the full initial conditions would be critical if we required the predictions of our models to be precise, but it often suffices to be able to predict that, for example, a given variable will not exceed a certain value.
Finally, insofar as we’re worried about the mismatch between our world model and the true, real-world dynamics, there are additional layers of defence beyond the model itself that can help make sure that any differences do not end up causing critical safety failures. For example, a runtime monitor – a common design feature in systems engineering today – provides further safety assurance post-deployment by tracking the deployed system real-time and noticing when the observed data deviates from what has been predicted will occur. If such a deviation is observed – implying that the model the guarantees depend on has potentially safety-relevant errors – the system then falls back to a more conservative operational policy restoring the safety of the system. (I will say a few more things about deployment infrastructure that can help secure GSAI systems in section 1.3.)
Still, would this be enough to expand the reach of our current formal modelling abilities to the complexity of relevant cyber-physical systems? Sure, there exist systems today where we depend on their formally verified properties. But these systems are simpler than where we need to get to, and their creation is currently very labour intensive. That’s not a great combination of starting conditions.
On top of what I’ve already discussed above, a key crux here is that I believe there are a couple of different ways that we can leverage progress in frontier AI to help us build these models better, faster and for more complex environments. I discuss this in more detail in section 2.2 (“AI won’t help (soon) enough”). For now, let us just note that, while I concur that there is certainly space for reasonable disagreement about how much and how soon we can leverage AI capabilities to our advantage, it seems clearly within a reasonable distribution of beliefs that, upon concerted efforts, such tooling will come live soon and transform our abilities substantially enough such as to extend the reach of formal modelling from relatively simple systems to increasingly more complex, cyber-physical systems.
Remember that any strategy for creating safe AI systems must rely on some beliefs or assumptions about the real world; assumptions which could be wrong. Short of a solution of ambitious alignment, it is not immediately clear that GSAI approaches require more or more contentious assumptions than other AI safety approaches. Unlike other approaches, GSAI makes these assumptions explicit and puts front and center the development of workflows with the central goal of making the world model safer. It does so by innovating upon a modelling language in order to account for a wider range of types of uncertainty; by pushing for those models to be human auditable, rather than black boxes; and by enabling the iterative and collaborative creation of model specs.
1.2. You can’t get good enough guarantees
Critique:
Some reasons for scepticism I’ve encountered here are:[2]
- Estimates vs proofs
- Critique tldr: GSAI claims to be able to prove that a given AI system will not cause harm. Clearly, this level of certainty is not achievable given the sheer complexity of the real world, of notions like “harm”, and of the relevant AI systems themselves.
- Sample quote: “If safety researchers were only arguing only for the use of formal models to obtain very rough estimates of tolerances or failure rates for AI systems, the claims would be much more reasonable. [...] But in any case, advocates of GS[AI] approaches are not, for the most part, talking about estimates, but instead believe we can obtain strong proofs that can effectively guarantee failure rates of 0% for complex AI software systems deployed in the physical world” (from Limitations on Formal Verification for AI Safety [LW · GW])
- Short time horizons
- Critique tldr: Even if we successfully procure trustworthy guarantees, this will only be tractable if those guarantees concern very short time horizons – which will in turn make those guarantees too impractical to be useful.
- Sample quote: “At best we may obtain guarantees [...] over short periods of time.” (from Limitations on Formal Verification for AI Safety [LW · GW])
- Steganography, and other funny business
- Critique tldr: Even with the proposed formal guarantees, a highly intelligent AI could “smuggle” undetectable-to-humans dangerous effects into the solutions that get verified, e.g. using steganography.
Response:
Types of Guarantees
The critique suggests a false dichotomy between guarantees of 100% confidence on the one hand, and mere estimates that come with no guarantees on the other.
There are different types of proofs, which grant different degrees of assurance, and which vary in how tractable they are in different contexts. For example:
- A boolean proof establishes the truth/falsity of a statement, e.g. “Subsystem A and subsystem B will never be operating at the same time.”
- A proof of a sound bound establishes a valid upper or lower bound on a quantity or function. In our context, it means that we know for sure that the probability is ⋜ or ⋝ than some number.
- E.g. “We can guarantee that there is a ⋜1% chance that the temperature of subsystem C will exceed 15°C over the course of its operation.“ (See figure 4, level 8-9 in the GSAI paper.)
- A proof of (asymptotic) convergence to a correct statement establishes that a quantity or function approaches a specific value as a variable approaches a particular limit (such as infinity or zero). In our context, it means that the output will assume, in the limit of e.g. compute, an upper (or lower) bound on the probability of some event. Such a proof might additionally make statements about how the value will converge, e.g. asymptotically. This proof is weaker in that we can’t trust a given likelihood estimate (due to the possibility of missing modes), but at least its trustworthiness increases monotonically with compute.
- E.g. “If we were to run this computation for long enough, we could guarantee that the likelihood of the system existing in the safe zone is below some firm bound. We currently expect this bound to be at 1% likelihood.” (See figure 4, level 6-7 in the GSAI paper.)
Furthermore, (as discussed in section 1.1) guarantees are expressed with respect to a formal model of the context of use which can itself incorporate different sources of uncertainty, adding further nuance to the specific claim that is being guaranteed. (See also this comment from Augustin [LW(p) · GW(p)] making the same point.)
Time horizon
It certainly is an open question over what time horizons a given policy can be verified to be safe or recoverable.[3] It’s worth pointing out, though, that even guarantees over relatively short time horizons could go a long way.
Citing from the GSAI preprint (p. 16): “To increase the reliability of safety guarantees, one may instead choose to deploy an AI system for a finite time horizon, such that, if at the end of that time horizon the AI system is not successfully verified for redeployment, operations shut down or transition to a safe mode.” There is a trade off between how quickly the next policy needs to be verified for redeployment, and how much easier it is to verify a given policy to be safe or recoverable if it concerned a shorter time horizon. The right balance will vary depending on the context.
Furthermore, different architectural choices for the AI controller and gatekeeper can further help alleviate these concerns. For example, the so-called black-box simplex architecture involves an advanced controller and a baseline controller. The former is verified, not with respect to whether it will always keep the system within the safe portion of the state space, but instead with respect to whether it will keep the system within a part of the state space that is recoverable (to a safe trajectory) by the (more conservative) baseline controller. As a result, while we’re running the advanced controller, we only have to verify the recoverability of the system over a short time horizon (over at least two time steps). This way, if we predict that after two more steps on the advanced controller, we would exit the recoverable area, we can in the next step switch over to the baseline controller. In other words, the advanced controller by design has to be verified only over short time horizons, while maintaining high-assurance safety guarantees. This is a specific example of what such an architecture could look like, but there might also be other, better ways to do this.
Overall, the concern that trustworthy guarantees might only be tractable for short time horizons, even if true, would not be particularly detrimental to the usefulness of GSAI.
Steganography, and other funny business
The key here is that we want to formally verify not only the correctness but also the uniqueness of a proposed solution. If we thus have a solution that is proven to solve the task at hand without conflicting with the safety specs (i.e. it is correctness), and we also have a proof saying that this solution is unique, then the causal power of the system proposing this solution (the contained advanced AI) is limited to at most one bit of information: it can either give the unique correct answer, or it can decline to answer. This would defend against risks from steganography.
If needed, it’s also possible to give up some rigor to improve tractability. Rather than requiring uniqueness, we could upper bound the amount of entropy contained in the choice of which solution the AI proposes.
1.3. You can’t get good enough safety specifications
Critique:
Critiques we’ve encountered here include:
- Intent-specification gap
- Critique tldr: It won’t be possible to capture the intended meaning of safety in the formal specifications, and this discrepancy will in turn give rise to many of the classical AI safety concerns (e.g. Goodhart’s Law, goal misgeneralisation, etc.)
- Safety in an open environment is impossible
- Critique tldr: Open environments are too complex to be able to capture and guarantee a holistic notion of safety, among others due to an inability to capture out-of-distribution/novel events.
- Sample quote: “Safety in an open world cannot be proved, because it relies on perfect epistemic uncertainty quantification, which is impossible.” (from a comment [LW(p) · GW(p)] by Tom Diettrich)
Response:
First, note that GSAI will often try to specify safety in a way that is more conservative than specifying human preferences wholesale – namely by specifying what parts of the state space are okay / not okay to enter in an inherently context-specific way. We can separately determine functional/performance-related specification and, for example, conceive of the resulting verification problem as a reach-avoid problem. This also implies that GSAI is not trying to be a solution for ambitious (intent) alignment or agent foundations – instead (to put it slightly simplistically): GSAI is safety engineering applied to ASL-4 AI, where the goal is to allow us to safely leverage (parts of) the transformative potential of these advanced AI systems.
Second, we don’t even necessarily need to specify some holistic notion of safety. I already mentioned the black-box simplex architecture above, in section 1.2. This architecture allows us to verify the advanced controller not with respect to its safety, but with respect to (the easier to verify property of) reachability - i.e. keeping the overall system within a part of the state space that is recoverable by the backup controller. Other set ups that are similar to this block-box simplex architecture, but differ in the details, could provide similar benefits.
Third, we can leverage narrow AI systems to help spot existing lacunas or inconsistencies in our safety specs by, for example, generating surprising implications or counterexamples based on the current specifications. To further unlock our ability to iterate over and improve the specifications over time, it is critical to have the appropriate computational implementation of our formal model and specifications, including version controls and collaborative editing affordances.
Finally, most AI safety approaches face similar challenges in terms of the intent-specification gap. One advantage that many GSAI approaches offer is that they make the specification fully explicit and auditable by different humans. (This is unlike, for example, Constitutional AI or similar approaches, where it is not entirely clear how the ‘constitution’ really caches out in terms of the AI system’s behavioural propensities.) While this certainly does not on its own suffice to overcome the intent-specification gap, it does come with important benefits, such as enabling more social accountability and feedback from a wide range of stakeholders.
2. Other approaches are a better use of time
2.1. Does not address the most serious risks
Critique:
- Critique tldr: Even if GSAI-type guarantees might be achievable in some contexts for solving some problems, those won’t make a meaningful dent towards decreasing catastrophic risks from advanced AI.
- Sample quote: “[W]e should not expect provably-safe DNA synthesis machines, or strong guarantees that drones will never harm people, or chatbots that come with proofs that they will never misinform. And given that we cannot expect guarantees around such straightforward threats, we should be even more sceptical that formal verification will result in provable guarantees against more challenging and complex threats like Loss-of-Control.” (from Limitations on Formal Verification for AI Safety [LW · GW])
Response:
There’s a number of things I wish to address here. Upfront, I want to clarify: I don’t believe or wish to claim that GSAI is a full or general panacea to AI risk. In fact, I think there are specific thread models and problems that GSAI is a promising solution to – and other problems I don’t think GSAI is a fit for. In the following, I hope to clarify how I think about the scope of GSAI, and also explain why, despite the limitations of the scope, I believe that GSAI approaches have a critical role to play towards securing and stabilizing humanity’s trajectory towards Superintelligent AI. But let us start at the beginning.
Threat model: what AI capability levels does GSAI target?
AI systems with different levels of capabilities come with different risks, and require different mitigation strategies. It is thus natural to ask: what level of capability and associated risks does GSAI propose to be a solution to?
In short, GSAI seeks to be a solution to the problem of safely leveraging (parts of) the transformative potential of AI systems that are, on one hand, more capable than systems that are capable of significantly enhancing the capability of rogue actors to cause large-scale harm, and, on the other hand, not capable enough to discover and exploit new physical principles in silico.
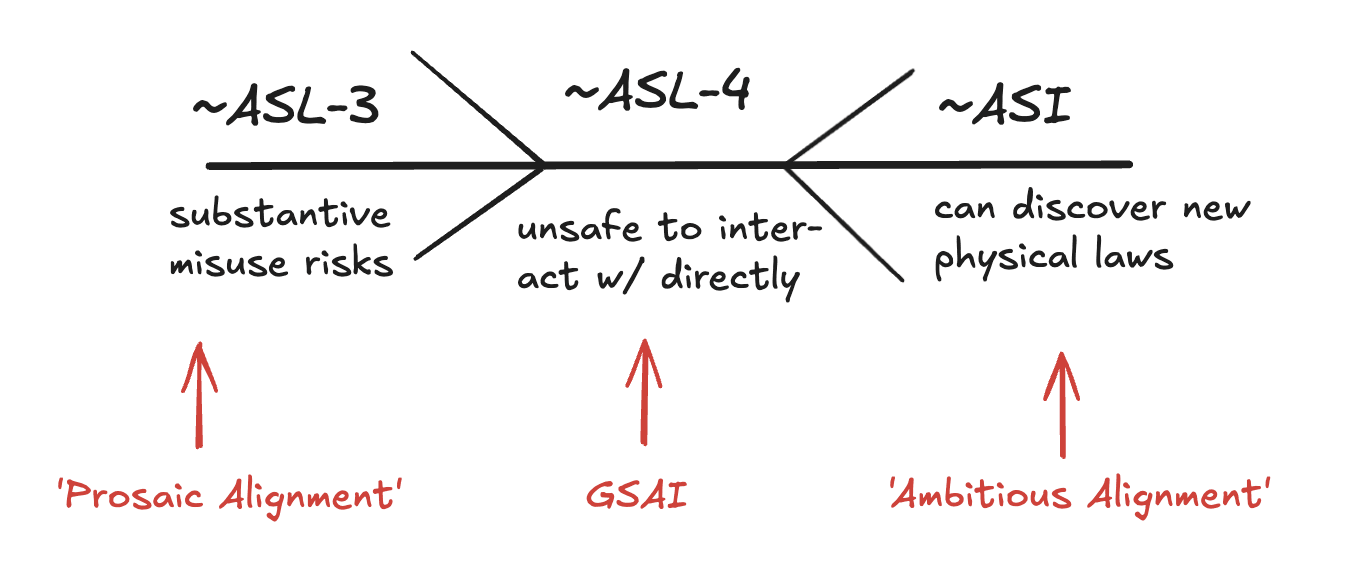
The level of capability that is being targeted here is one where current-day safety methods (such as evals and post-training methods like circuit breakers) are likely insufficient to provide adequate levels of safety. At the same time, GSAI is not proposing to be a solution to ambitious alignment. For example, GSAI approaches are not concerned with robustly guiding or altering the goals or intentions or thoughts of a highly advanced AI system. Instead, GSAI is concerned with building a high security containment solution for said system, in such a way that we are still able to elicit useful information from it. [4]
So, GSAI addresses the band of capabilities where AI systems become potentially no longer safe to interact with directly due to their potential ability to model and exploit human psychology; and/or where they pose a significant risk of self-exfiltrating and autonomously replicating similar to a piece of (autonomous & potentially highly destructive) malware; and/or where they are capable of autonomous R&D and self-improvement (which is why, at this point, a case of model (self-)exfiltration could have catastrophic consequences).
What are the current plans[5] of leading AI labs for when AI systems achieve this level of capability? As I understand it, the answers are approximately that, while they do not currently have concrete mitigation plans, the “plan” is to have a better idea of what to do by the time these capabilities come live. Sometimes, the answer also includes a (voluntarily) commitment to pausing development and deployment if, at the time that we reach those levels of capabilities, we do not have a sensible plan for how to mitigate the associated risks.
Insofar as GSAI offers a concrete engineering solution to this problem, I do believe that GSAI approaches, if successful, have the potential to ‘make a serious dent’ in the context of AI safety.
What kinds of problems does GSAI aim to solve, and which does it not?
The model-based approach of GSAI is, in essence, best suited for domains that we have a solid scientific understanding of, and which are not dominated by chaotic dynamics.
This makes GSAI approaches less suited for problems that depend on individual humans’ actions in a way that cannot reliably be abstracted by, e.g. the law of large numbers. Similarly, I don’t think GSAI is a promising approach for building safe chat bots – natural language is such an open domain that formally specifying safety seems intractable in this context.
On the other hand, GSAI approaches are a good fit for use cases like management or control problems in, say, electrical grids, supply chains or R&D processes. In general there are a lot of socially and economically valuable domains where the needed scientific understanding does exist – more than you might think at first sight.
Furthermore, even if GSAI methods are used to produce safe applications of AI systems in relatively narrow domains, these domains could go a long way in reducing more immediate risks. A key way in which I expect GSAI will start manifesting substantial strategic importance is by helping us secure critical infrastructure. This in turn would reduce the risk of rogue human or AI actors causing large-scale havoc, which is plausibly critical in preserving our collective ability to navigate through this AI transition, stabilising multi-stakeholder dynamics, and enabling pivotal processes [LW · GW]. Examples of such applications include:
- verified hardware required to undergird virtually any high-assurance application, be that in cybersecurity, biodefence, critical infrastructure, compute governance, etc.
- reimplementing verified bug-free software at scale to drastically reduce the attack vectors in cyberspace
- securing critical infrastructure such as the power grid, water supplies, transportation systems, supply chains, etc.
- automating a workflow combining DNA screening and automated antibody synthesis which could, in combination, create powerful ”civilisational immune systems"
Finally, and importantly, while each individual GSAI application might be relatively narrow in its domain of application, we can still achieve a relatively wide and general reach if we are able to produce many specific GSAI applications across a wide range of contexts. In other words, while individual GSAI applications might be correctly described as narrow, we could still achieve significant degrees of generality via the GSAI workflow (i.e. the workflow that produces specific GSAI implementations).
Let us briefly touch on how I see GSAI approaches potentially securing cyber and bio specifically.
Securing cyberspace
One of the critiques in section 1.1 was that while using formal methods along the lines of GSAI might be feasible in the domain of software, it won’t be tractable to extend this approach to physical systems. Now, whether or not we’re optimistic about extending the scope of GSAI approaches, it is worth highlighting how big a deal it would be if we even “just” successfully secured all critical cyber systems through GSAI-type approaches.
The last decade has seen some important efforts and successes – e.g. a fully formally verified microkernel called seL4 or DARPA’s HACMS/SMACCM program which established the feasibility of using formal methods to eliminate all exploitable bugs. However, until now, this has been highly labour intensive work with limited scope for automation, which has limited its scalability. Now, LLMs trained with “RL from proof assistant feedback” are beginning to show rapid progress in automated theorem proving, with success rates on the miniF2F benchmark rising from 26% to 63% in the last year. Automated formal verification could be a real game changer for cybersecurity with focused investment in this area, including inferring formal specifications from legacy code and test suites, and user interface tooling, along the lines of the Atlas Computing research agenda. In particular, I think there is a strong argument that this route to addressing cyber risks is vastly superior to approaches that try to leverage AI for cybersecurity without formal verification. For one, the defence-offense balance is not very attractive in the case of coding assistants that can help find and fix bugs. Such AI systems are just as useful when it comes to finding and exploiting such bugs (e.g. by rogue actors). Furthermore, there is emerging evidence that currently coding assistants make our code less secure. On the other hand, formally verified software not only gives a marginal advantage to defence, but could plausibly allow us to exit the cyber cat-and-mouse game entirely.
Protection against biosecurity hazards
The sample quote indicates skepticism above that GSAI approaches will be able to substantially reduce biosecurity risks. (“[W]e should not expect provably-safe DNA synthesis machines, …“). The critique (in the full post) claims that virulence is predictable only by simulating an entire body at the molecular level. Now, if what you wanted was precision – like, knowing exactly how many times person A will cough after having been infected with a certain virus – then, yes, you would need to measure all the initial conditions to an impossible extent and do an impossible amount of computation. But if you want to guarantee that a particular virus will not infect a human, you “just” have to look pairwise at every protein coded for in the virus, and every protein expressed on the boundary (membrane) of human cells, and model their interaction (within a tiny, 100nm-radius patch of cell membrane) to see if the viral protein can catalyze viral entry into the human cell. If not, it ain’t virulent.
This is a form of sound overapproximation I discussed earlier. Notably, it would also rule out, say, some helpful gene therapies. Nevertheless, this gives us something substantial to work with in terms of the reduction of biorisk. Now, how concretely could we use this set up to bootstrap a more comprehensive “civilisational immune system” from here. (I’m not claiming that this is the only promising solution, nor do I intend to imply that the following story contains enough detail to be necessarily convincing. I’m sharing this, in part, as an illustrative and hopefully thought-provoking potential set up.)
Building on the above approach, we want to analyse DNA sequences (specifically, those reachable by bench-top manipulation) for their binding affinity to human transmembrane proteins. Doing so, we can identify and ‘tag’ all fragments with significant potential for facilitating cell entry (via receptor-mediated endocytosis or membrane fusion). Of course, binding propensity alone is too broad of a measure, capturing all dangerous sequences, but also many useful sequences (such as drugs with important therapeutic/medical functions). So, in the next step, we want to build up a repository of antibodies capable of neutralizing each potential threat protein. Simultaneously, we want to deny the synthesis of fragments for which this problem is unsolvable. Next, we want to store each solution in a big database, make sure we are able to synthesize the monoclonal antibodies at points of care, and build out a monitoring system which scans for any of these potential threats in (highly scaled-up) metagenomics. In sum, the interplay between these different capabilities adds up to a comprehensive “civilisational immune system”, capable of identifying potential threats and quickly producing antibodies when any such threat is actually observed.
Of course, this is too hard for current capabilities in various ways, nor will it be an easy feat to build out the full capabilities. But I do think that by being smart about how we leverage AI progress, substantial progress is possible. If you believe that a “compressed 21st century” is ahead of us, you might also be inclined to believe that these sorts of civilisational capabilities will become possible, and are worth shooting for.
The role of assurance in coordination
The final reason I want to discuss here for why GSAI could be a big deal concerns the critical role that assurance plays in coordination.
GSAI approaches can produce independently auditable assurances that certain properties are true, without requiring mutual trust between the relevant parties. These safety relevant properties could in principle be anything that is specifiable; the fact that a DNA sequence being synthesized has not been flagged as potentially dangerous, or that a compute cluster has not used more than X FLOPS during the training process, etc. If we can formalise the safety properties that we want to agree on between a certain set of stakeholders, GSAI approaches can produce independently auditable assurances that these properties are true for a given AI model.
Such properties could even be verified in zero-knowledge, further reducing the need to share potentially sensitive information between stakeholders beyond what is strictly necessary to provide assurance and enable coordination. In comparison, an assurance that, say, a collectively determined red line has not been crossed, where this assurance is based on evaluations and red teaming, is much harder to build justified trust around, at least not without sharing a lot of additional, likely commercially and strategically sensitive data.
2.2. AI won’t help (soon) enough
Critique
- Critique tldr: AI progress won’t improve the tractability of GSAI approaches sufficiently much or sufficiently soon, in particular when it comes to the task of making reliable world models or safety specifications that useful guarantees could be developed relative to. If/when it does, the risk from those associated AI systems will already be too large for GSAI to matter.
- Sample quote: “While there is good evidence that improvements in AI are likely to be helpful with the theorem proving, or verification, part of formal verification, unfortunately, as we have discussed, many of the greatest challenges arise earlier in the process, around modelling and specification. [...] If access to an ASI is a precondition for formal verification based approaches to work, then this will indeed be ‘too late’.” (from Limitations on Formal Verification for AI Safety [LW · GW])
Response:
In order for GSAI approaches to plausibly be ready in time, we require a substantial ramp-up in our ability to produce formal models and specifications, compared to the historic base rate. However, AI progress seems poised to solve large parts of this problem for us.
A central way to leverage AI for this is by means of an AI-assistant for declarative modelling. Such a formal modelling assistant might make suggestions for parts of the declarative model upon human instruction; it might suggest edits to an existing models; it might generate counterexamples relative to the current model specs (e.g. based on predicted surprise for the human) to help the human to notice lacunas, contradictions or misspecifications; etc.
This is very similar to how AI is already extremely useful today in classical programming (e.g. Copilot, Cursor). It’s not a far cry to expect AI assistants for declarative mathematical modelling soon, which can help us elicit safety specifications e.g. by producing informative counterexamples, proof certificates, etc. And we already have evidence that this capability is coming online (see e.g. WorldCoder), without having had any large sums of funding flow into this line of R&D, and quickly increasing performance on benchmarks pertaining to mathematics.
Of course, we don’t want to fully automate world modelling. If we did, we would make ourselves susceptible to the errors resulting from mistakes or misalignment (e.g. scheming). Instead, we want to train narrow AI systems to become highly proficient in our modelling language and to assist human experts in writing the world models. The formal models themselves ideally remain fully human auditable. The key issue is that this AI augmented process does not itself open new avenues to risks.
There are other ways we should be able to leverage AI, beyond the “programming assistant”-type setup I talked about above. For example, we could use AI systems to mine the scientific literature to extract a hypothesis space AI systems can later reason over, potentially by doing approximate bayesian inference (along the lines of Yoshua Bengio’s Cautious Scientist AI proposal, building on GFlowNets). Because this piece is long already, I’m not going to discuss this approach in more detail here.
Notably, while the bitter lesson is often taken to imply that symbolic approaches in general are doomed, in actuality the bitter lesson is an argument against hard coded heuristics, and for anything that scales well through parallelisation – such as learning and search. And it is “merely” learning and search that we’re exploiting when it comes to AI systems capable of assisting with formal modelling and verification efforts. There are important open technical challenges, as well as the need for more data, but those don’t seem insurmountable given consolidated R&D efforts.
At the same time, I don’t think that AI capable of using formal methods implies hard take-off because those capabilities are very much of the type that we’re already seeing today (e.g. WorldCoder from above, strong programming assistants, steady progress on math benchmarks, etc.), and we pretty clearly do not appear to be in a hard take-off world as things stand.
2.3. Lack of ‘portability' & independent verification of proof certificate
Critique
- Critique tldr: Even if we were able to produce trustworthy and useful guarantees, it won’t be possible to credibly attest to all relevant stakeholders that a given guarantee belongs to a given system, and does not otherwise involve any loopholes or backdoors. This will undermine any critical attempts at building multi-stakeholder trust in these guarantees.
- Sample quote: “[H]ow do we know that the machine described by the proof is this machine – i.e. the one sitting in front of us? The fact is, there is no straightforward way for us to know that the machine in front of us is the one described in the proof; that the details of the transistors and wires on the physical circuit board precisely match those in the proof, that there are no secret backdoors, no manufacturing defects, etc.” (from Limitations on Formal Verification for AI Safety [LW · GW])
Response:
We can combine a given proof certificate with cryptographic authentication methods to reliably authenticate that the proof at hand belongs to a specified system and has not been changed in the interim. This could be enabled by hardware-enabled governance mechanisms such as flexHEG. As the sample quote points out, to be really confident, we also need to be able to trust the hardware itself to not have been tampered with (e.g. here).
3. Conclusion
This concludes our little tour – for now.
Some of these critiques seem to come from misunderstanding about the proposed approach. For example, GSAI does not promise “100% safety”, or to solve ambitious alignment.
Other critiques do seem to respond directly to what we're proposing with GSAI. I actually think that many of the critiques or reservations are pretty reasonable. But I disagree in that they succeed in undermining GSAI as a worthwhile AI safety approach that warrants a set of consolidated R&D efforts.
Ultimately, I believe that GSAI is proposing a promising pathway for solving problems that are likely critical for the survival of humanity: providing an engineering solution to contain and safely leverage ~ASL-4 AI; building out civilisational resilience; enabling coordination.
If you think I have missed some key critiques, or misunderstood/misrepresented any of the above critiques, I'd appreciate hearing about that.
- ^
The Safeguarded AI programme’s Technical Area 1.1 is funding researchers to develop a modelling language with these, and additional properties.
- ^
As an aside, in this talk titled “Formal Verification is Overrated”, Zac argues that “model weights are just completely intractable to reason about.” I largely agree. To clarify, GSAI approaches do not seek to make guarantees about large AI models, but about the formal world model. (Said world model might contain parts that are represented by small neural nets, but nothing close to the size of the large AI models people in AI Safety are generally concerned with.) As such, I consider this critique not centrally relevant to GSAI.
- ^
We explain what we mean by recoverable in Section 1.3.
- ^
GSAI and the control agenda are similar in the level of capability that is being targeted, and that they are doing so, in essence, by trying to securely contain and use untrusted powerful AI systems, without necessarily trying to align the contained AI.
- ^
As specified in e.g. Anthropic’s Responsible Scaling Policies, OpenAI’s Preparedness Framework or Google DeepMind’s Frontier Safety Framework.
14 comments
Comments sorted by top scores.
comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2025-02-01T11:16:43.990Z · LW(p) · GW(p)
I'm sorry that I don't have time to write up a detailed response to (critique of?) the response to critiques; hopefully this brief note is still useful.
-
I remain frustrated by GSAI advocacy. It's suited for well-understood closed domains, excluding e.g. natural language, when discussing feasibility; but 'we need rigorous guarantees for current or near-future AI' when arguing for importance. It's an extension to or complement of current practice; and current practice is irresponsible and inadequate. Often this is coming from different advocates, but that doesn't make it less frustrating for me.
-
Claiming that non-vacuous sound (over)approximations are feasible, or that we'll be able to specify and verify non-trivial safety properties, is risible. Planning for runtime monitoring and anomaly detection is IMO an excellent idea, but would be entirely pointless if you believed that we had a guarantee!
-
It's vaporware. I would love to see a demonstration project and perhaps lose my bet [LW(p) · GW(p)], but I don't find papers or posts full of details compelling, however long we could argue over them. Nullius in verba!
I like the idea of using formal tools to complement and extend current practice - I was at the workshop where Towards GSAI was drafted, and offered co-authorship - but as much I admire the people involved, I just don't believe the core claims of the GSAI agenda as it stands.
Replies from: sharmake-farah, bgold↑ comment by Noosphere89 (sharmake-farah) · 2025-02-01T16:38:23.984Z · LW(p) · GW(p)
This seems like a crux here, one that might be useful to uncover further:
2. Claiming that non-vacuous sound (over)approximations are feasible, or that we'll be able to specify and verify non-trivial safety properties, is risible. Planning for runtime monitoring and anomaly detection is IMO an excellent idea, but would be entirely pointless if you believed that we had a guarantee!
I broadly agree with you that most of the stuff proposed is either in it's infancy or is essentially vaporware that doesn't really work without AIs being so good that the plan would be wholly irrelevant, and thus is really unuseful for short timelines work, but I do believe enough of the plan is salvageable to make it not completely useless, and in particular, is the part where it's very possible for AIs to help in real ways (at least given some evidence):
https://www.lesswrong.com/posts/DZuBHHKao6jsDDreH/in-response-to-critiques-of-guaranteed-safe-ai#Securing_cyberspace [LW · GW]
↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2025-02-02T01:55:47.077Z · LW(p) · GW(p)
Improving the sorry state of software security would be great, and with AI we might even see enough change to the economics of software development and maintenance that it happens, but it's not really an AI safety agenda.
(added for clarity: of course it can be part of a safety agenda, but see point #1 above)
Replies from: sharmake-farah, nathan-helm-burger↑ comment by Noosphere89 (sharmake-farah) · 2025-02-02T02:20:21.908Z · LW(p) · GW(p)
I agree that it isn't a direct AI safety agenda, though I will say that software security would be helpful for control agendas, and the increasing capabilities of AI mathematics could, in principle, help with AI alignment agendas that are mostly mathematical like Vanessa Kosoy's agenda:
It's also useful for AI control purposes.
More below:
https://www.lesswrong.com/posts/oJQnRDbgSS8i6DwNu/the-hopium-wars-the-agi-entente-delusion#BSv46tpbkcXCtpXrk [LW(p) · GW(p)]
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-02-02T03:10:12.589Z · LW(p) · GW(p)
Depends on your assumptions. If you assume that a pretty-well-intent-aligned pretty-well-value-aligned AI (e.g. Claude) scales to a sufficiently powerful tool to gain sufficient leverage on the near-term future to allow you to pause/slow global progress towards ASI (which would kill us all)...
Then having that powerful tool, but having a copy of it stolen from you and used for cross-purposes that prevent you plan from succeeding... Would be snatching defeat from the jaws of victory.
Currently we are perhaps close to creating such a powerful AI tool, maybe even before 'full AGI' (by some definition). However, we are nowhere near the top AI labs having good enough security to prevent their code and models from being stolen by a determined state-level adversary.
So in my worldview, computer security is inescapably connected to AI safety.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-02-02T03:31:36.003Z · LW(p) · GW(p)
Depends on your assumptions. If you assume that a pretty-well-intent-aligned pretty-well-value-aligned AI (e.g. Claude) scales to a sufficiently powerful tool to gain sufficient leverage on the near-term future to allow you to pause/slow global progress towards ASI (which would kill us all)...
We can drop the assumption that ASI inevitably kills us all/we should pause and still have the above argument work, or as I like to say it, practical AI alignment/safety is very much helped by computer security, especially against state adversaries.
I think Zach-Stein Perlman is overstating the case, but here it is:
https://www.lesswrong.com/posts/eq2aJt8ZqMaGhBu3r/zach-stein-perlman-s-shortform#ckNQKZf8RxeuZRrGH [LW(p) · GW(p)]
↑ comment by Ben Goldhaber (bgold) · 2025-02-08T02:55:04.579Z · LW(p) · GW(p)
Minor point: It seems unfair to accuse GSAI of being vaporware. It has been less than a year since the GSAI paper came out and 1.5 since Tegmark/Omohundro's Provably Safe paper, and there are many projects being actively funded through ARIA and others that should serve as tests. No GSAI researchers that I know of promised significant projects in 2024 - in fact several explicitly think the goal should be to do deconfusion and conceptual work now and plan to leverage the advances in autoformalization and AI-assisted coding that are coming down the pipe fast.
While I agree that there are not yet compelling demonstrations, this hardly seems at the level of Duke Nukem Forever!
comment by Rohin Shah (rohinmshah) · 2025-02-02T12:39:25.442Z · LW(p) · GW(p)
In broad strokes I agree with Zac [LW(p) · GW(p)]. And tbc I'm generally a fan of formal verification and have done part of a PhD in program synthesis.
So, GSAI addresses the band of capabilities where AI systems become potentially no longer safe to interact with directly due to their potential ability to model and exploit human psychology
This seems like a great example of something that I strongly expect GSAI will not handle (unless the proposal reduces to "don't build such AIs", in which case I would appreciate that being stated more directly, or if it reduces to "limit the use of such AIs to tasks where we can formally verify soundness and uniqueness", in which case I'd like an estimate of what fraction of economically valuable work this corresponds to).
Can you sketch out how one produces a sound overapproximation of human psychology? Or how you construct a safety specification that the AIs won't exploit human psychology?
Replies from: martin-randall↑ comment by Martin Randall (martin-randall) · 2025-02-05T02:42:57.876Z · LW(p) · GW(p)
Based on my understanding of the article:
- The sound over-approximation of human psychology is that humans are psychologically safe from information attacks of less than N bits. "Talk Control" is real, "Charm Person" is not.
- Under "Steganography, and other funny business" there is a sketched safety specification that each use of the AI will communicate at most one bit of information.
- Not stated explicitly: humans will be restricted to using the AI system no more than N times.
Comments and concerns:
- Human psychology is also impacted by the physical environment, eg drugs, diseases, being paperclipped. The safety of the physical environment must be covered by separate verifications.
- There could be a side-channel for information if an AI answers some questions faster than others, uses more energy for some questions than others, etc.
- Machine interpretability techniques must be deployed in a side-channel resistant way. We can't have the AI thinking about pegasi and unicorns in a morse code pattern and an intern reads it and ten years later everyone is a pony.
- There probably need to be multiple values of N for different time-frames. 1,000 adversarial bits in a minute is more psychologically dangerous than the same number of bits over a year.
- Today, we don't know good values for N, but we can spend the first few bits getting higher safe values of N. We can also use the Yudkowskian technique of using volunteers that are killed or put into cryonic storage after being exposed to the bits.
- If we could prove that AIs cannot acausally coordinate we could increase the bound to N bits per AI, or AI instance. Again, a good use for initial bits.
- None of this stops us going extinct.
comment by Steve_Omohundro · 2025-02-01T19:04:04.862Z · LW(p) · GW(p)
Thanks Nora for an excellent response! With R1 and o3, I think we are rapidly moving to the point where AI theorem proving, autoformalization, and verified software and hardware synthesis will be powerful and widely available. I believe it is critically important for many more people to understand the importance of formal methods for AI Safety.
Computer science, scientific computing, cryptography, and other fields have repeatedly had "formal methods skeptics" who argue for "sloppy engineering" rather than formal verification. This has been a challenge ever since Turing proved the first properties of programs back in 1949. This hit a tragic peak in 1979 when three leading computer scientists wrote a CACM paper arguing against formal methods in computer science stating that "It is felt that ease of formal verification should not dominate program language design" and set back computer science by decades: "Social processes and proofs of theorems and programs" https://dl.acm.org/doi/10.1145/359104.359106 And we have seen the disastrous consequences of that attitude over the past 45 years. Here's a 2002 comment on those wars: "The Proof of Correctness Wars" https://cacm.acm.org/practice/the-proof-of-correctness-wars/
I only just saw the "Formal Methods are Overrated" video and tried to post a response both on YouTube and LinkedIn but those platforms don't allow comments of more than a paragraph. So let me post it here as an addition to your fine post:
I am a co-author on two of the papers you mentioned ("Toward Guaranteed Safe AI" https://arxiv.org/abs/2405.06624 and "Provably Safe AI" https://arxiv.org/abs/2309.01933 ). Formal verification is critically important for AI safety, but with a reversed implication from what you described. It's not that formal verification suddenly makes safety and security problems easy. It's that if a complex system *doesn't* have a formal proof of safety properties, then it is very likely to be unsafe. And as AI systems become more powerful, they are likely to find every safety or security vulnerability and exploit it. This point was clearly explained in the paper with Max. Contrary to your video, formal methods are *underrated* and *any* approach to AI safety and security which is effective against powerful AIs must use it. For some reason, ever since Turing's 1949 demonstration of proofs of program properties, so-called "experts" have opted for "sloppy" design rather than creating verified designs using humanity's most powerful tool: mathematics.
Humaniy's unwillingness to step up and create provably correct technology is why we are in the sorry state we're in with incredibly buggy and insecure infrastructure. Fortunately, new AI like OpenAI's o3 model appear to be super-human in mathematics and perhaps autoformalization, theorem proving, and verified software synthesis and may usher in a new era of verified software, hardware, and social protocols.
The points you made don't affect the importance of formal proof for AI safety. Your first point was that "weights are intractable" in complex neural nets. There is a fair amount of work on formally verifying properties of simpler neural nets. For example, the book "Introduction to Neural Network Verification" https://arxiv.org/abs/2109.10317 has a nice treatment of finding provable intervals, zonotopes, and polyhedra bounding the behavior of networks. But for the systems of current interest, like transformers, I agree that this approach isn't likely to be practical. That's why in those two papers we focus on "gatekeepers" which sit between complex neural systems and the actions they take in the world. This VAISU talk I gave summarizes the approach: "Provably Safe AI – Steve Omohundro" https://www.youtube.com/watch?v=7ON6QSnHCm4&ab_channel=HorizonEvents The complicated LLM or other AI system can do whatever computations it wants but it must generate both a solution to a problem and a proof that that solution meets the spec. If it is controlling a physical system, that spec would include safety criteria that the solution must meet. The gatekeeper checks the proof (a simple and cheap operation) and only allows the solution to affect the world if the proof is verified.
Your second point is that "reality is complicated + unknown". Yes, but here we are talking about *designing* systems in which we have high confidence of safety. Every engineering discipline already deals with the complexity of the world and has developed techniques and models which simplify the problems to the point where humans can solve them. Semiconductor specialists create design rules which provide strong guarantees that their chips behave as desired. For security, we need a model of the adversary. If the adversary can only attack through the designed digital channels, we only need formal proofs of security at the software level. Physical attacks require models of the physical device and proofs of security against a class of adversary which goes beyond today's common practice. You mentioned our example of DNA synthesis machines. We certainly weren't proposing some kind of automatic system to determine which DNA sequences are safe for humans. Rather, we assume a "whitelist" of allowed safe sequences (eg. determined by a bio safety board). The safety challenge was the much simpler task of ensuring that rogue AIs cannot synthesize unsafe sequences which are not on the whitelist. Today's DNA synthesis machines allow anybody to synthesize anything. We argue that as AI becomes extremely powerful we need a "gatekeeper" between the AI and the synthesis machine which checks for allowed sequences. How to do that in a way which can't be physically subverted is described in my video above.
Finally, you argue that "'tool AI' is unstable + uncompetitive". What Max Tegmark and others are saying here is that we don't need AI systems with uncontrolled *agency*. That is, they don't need their own goals and the ability to take arbitrary actions in the world to achieve those goals. Any problem that humans want solved, can be just as well solved by a powerful AI which only accepts formal problem specs and provides solutions and formal proofs of those solutions. There is no need to eliminate machine learning! But we absolutely must prevent AIs from running rampant over the human infrastructure. You suggest that it would be "unstable" in the sense that it's trivial to convert a powerful tool into a powerful agent. My talks and writings are exactly about that and formal methods are a critical aspect. It's a simpler problem if powerful AIs require trillion dollar data centers which can be constrained by government regulation. Unfortunately, recent results like DeepSeek's R1 or Microsoft's "rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking" https://arxiv.org/abs/2501.04519 suggest that even tiny models running on cell phones may be powerful enough to cause harm. We need to create a trustable infrastructure which cannot be subverted by powerful AI using the techniques I describe in my talks. We are in a race between using AI for capabilities and using it for safety. Formal methods are a critical tool for creating the critical trustable infrastructure.
comment by Quinn (quinn-dougherty) · 2025-01-31T05:09:55.684Z · LW(p) · GW(p)
I gave a lightning talk with my particular characterization, and included "swiss cheese" i.e. that gsai sources some layers of swiss cheese without trying to be one magic bullet. But if people agree with this, then really guaranteed-safe ai is a misnomer, cuz guarantee doesn't evoke swiss cheese at all
Replies from: Nora_Ammann↑ comment by Nora_Ammann · 2025-01-31T05:13:06.582Z · LW(p) · GW(p)
What's the case for it being a swiss cheese approach? That doesn't match how I think of it.
Replies from: quinn-dougherty↑ comment by Quinn (quinn-dougherty) · 2025-02-01T18:04:30.906Z · LW(p) · GW(p)
I'm surprised to hear you say that, since you write
Upfront, I want to clarify: I don’t believe or wish to claim that GSAI is a full or general panacea to AI risk.
I kinda think anything which is not a panacea is swiss cheese, that those are the only two options.
In a matter of what sort of portofolio can lay down slices of swiss cheese at what rate and with what uncorrelation. And I think in this way GSAI is antifragile to next year's language models, which is why I can agree mostly with Zac's talk and still work on GSAI (I don't think he talks about my cruxes).
Specifically, I think the guarantees of each module and the guarantees of each pipe (connecting the modules) isolate/restrict the error to the world-model gap or the world-spec gap, and I think the engineering problems of getting those guarantees are straightforward / not conceptual problems. Furthermore, I think the conceptual problems with reducing the world-spec gap below some threshold presented by Safeguarded's TA1 are easier than the conceptual problems in alignment/safety/control.
Replies from: mateusz-baginski↑ comment by Mateusz Bagiński (mateusz-baginski) · 2025-02-04T12:35:10.883Z · LW(p) · GW(p)
I understood Nora as saying that GSAI in itself is not a swiss cheese approach. This is different from saying that [the overall portfolio of AI derisking approaches, one of which is GSAI] is not a swiss cheese approach.