1hr talk: Intro to AGI safety
post by Steven Byrnes (steve2152) · 2019-06-18T21:41:29.371Z · LW · GW · 4 commentsContents
Opening Definitions Motivation Someday we'll have AGI We need to prepare ahead of time AGI safety work is time-sensitive AGI safety is grossly under-invested Foundations Orthogonality thesis Goodhart's law Instrumental convergence Active research directions Foundational principles Value learning Limiting Interpretability, Bootstrapping, Robustness & verification Non-technical work What can we do today? None 4 comments
This is an hour-long talk (actually ~45 minutes plus questions) that I gave on AGI safety technical research, for an audience of people in STEM but with no prior knowledge of the field. My goal was to cover all the basic questions that someone might have when considering whether to work in the field: motivation, basic principles, a brief survey of the different kinds of things that people in the field are currently working on, and resources for people who want to learn more. I couldn't find an existing talk covering all that, so I wrote my own.
In the interest of having good educational and outreach material available to the community, I’m happy for anyone to copy any or all of this talk. The actual slides are in Powerpoint format here, and below you'll find screenshots of the slides along with the transcript.
Abstract: Sooner or later—no one knows when—we'll be able to make Artificial General Intelligence (AGI) that dramatically outperforms humans at virtually any cognitive task. If, at that point, we are still training AIs the way we do today, our AGIs may accidentally spin out of control, causing catastrophe (even human extinction) for reasons explained by Stuart Russell, Nick Bostrom, and others. We need better paradigms, and a small but growing subfield of CS is working on them. This is an interdisciplinary field involving machine learning, math, cybersecurity, cognitive science, formal verification, logic, interface design, and more. I'll give a summary of motivation (why now?), foundational principles, ongoing work, and how to get involved.
Opening

Thanks for inviting me! I had an easy and uneventful trip to get here, and we all know what that means ... Anyone? ... What it means is that evil robots from the future did not travel back in time to stop me from giving this talk. [Laughter.] And there’s an important lesson here! The lesson is: The Terminator movie is the wrong movie to think about when we talk about safety for advanced AI systems. The right movie is: The Sorcerer’s Apprentice![1] When the machines become more and more intelligent, they don’t spontaneously become self-aware and evil. Instead, the machines do the exact thing that we tell them to do … but the thing that we tell them to do is not what we actually want them to do! I’ll get back to Mickey Mouse later.
Here’s the outline of this talk. I’m going to start with some motivation. Artificial General Intelligence (AGI) doesn’t exist yet. So why work on AGI safety today? Then I’ll move on to some foundational principles. These are principles that everyone in AGI safety research understands and agrees on, and they help us understand the nature of the problem, and why it’s a hard problem. Then I’ll go over the active research directions. What are people actually working on today? Finally, I’ll talk about what you can do to help with the problem, because we need all the help we can get.
Definitions

I’ll start with some definitions. Intelligence is (more or less) the ability to choose actions to bring about a desired goal, or to do similar sorts of search-and-optimization processes, like theorem-proving or model-building. Artificial General Intelligence (AGI) is an AI system that can display intelligent behavior in a wide range of domains and contexts, just as humans can. Humans didn’t evolve an instinct for space travel, but when we wanted to go to the moon, we were able to figure out how to do it. Here’s a little cartoon of an AGI.
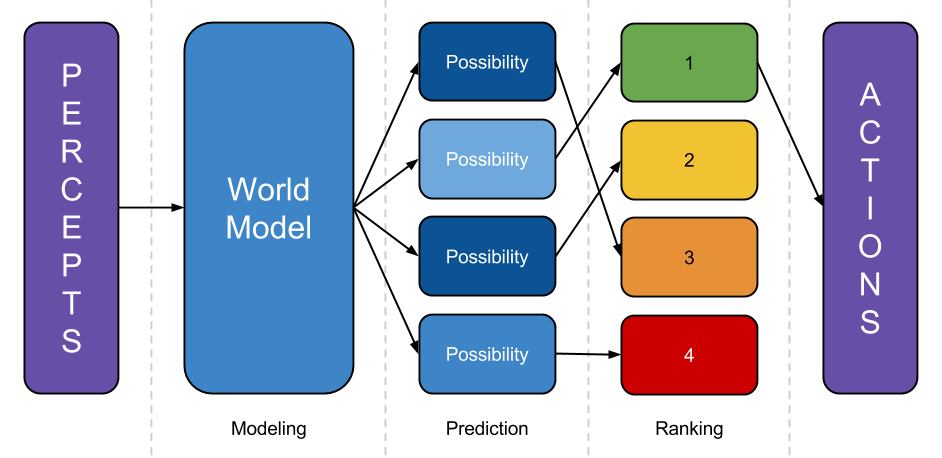 from https://intelligence.org/2015/07/27/miris-approach/
from https://intelligence.org/2015/07/27/miris-approach/
The AGI takes in perceptions of the world, fits it into its world model, then considers possible courses of action, predicts their consequences, and it takes the course of action with the best consequence according to its goal system. Finally, Superintelligent describes an AGI that is much better than humans at essentially all important cognitive tasks. Now, an AGI doesn't need to be superintelligent to be extremely powerful and dangerous—it needs to be competent in some cognitive domains, it doesn’t need to be superhuman in all cognitive domains. But still, I do expect that we’ll make superintelligent AGIs at some point in the future, for reasons I’ll talk about shortly.
"Thus the first superintelligent machine is the last invention that man need ever make," according to computer pioneer I.J. Good. I mean, everyone here appreciates the transformative impact of technology. Well, imagine how transformative it will be when we can automate the process of invention and technological development itself.
Motivation

OK, AGI doesn’t exist yet. Why work on AGI safety? Why work on it now? The way I see it, there’s five steps. First, we’re going to have AGI sooner or later. Second, we need to prepare for it ahead of time. Third, as we’ll see later in the talk, we can make progress right now. Fourth, the work is time-sensitive and grossly under-invested. So, step five, more people should be working on it today, including us. Let’s go through this one at a time.
Someday we'll have AGI
The first step is, someday, we’ll have AGI. Well, it’s physically possible. Brains exist. And every time anyone makes even a tiny step towards AGI, they’re showered in money and status, fame and fortune. That includes both hardware and software. I mean, maybe society will collapse, with nuclear winter or whatever, but absent that, I don’t see how we’ll stop making AIs more and more intelligent, until we get all the way to superintelligent AGIs. Don’t bet against human ingenuity.
We need to prepare ahead of time

Next, we need to prepare for AGI ahead of time. The argument here is I think equally compelling, and it goes something like this. If the AGIs’ goals are not exactly the same as humanity’s goals—and you might notice that it’s hard to express The Meaning Of Life as machine code!—and if the AGIs bring to bear greater intelligence for effectively achieving goals, then the future will be steered by the AGIs’ preferences, not ours.
This kind of logic leads people to expect that unimaginably bad outcomes are possible from AGI—up to and including human extinction. Here’s Stuart Russell, professor of computer science at UC Berkeley and author of the leading textbook on AI: "Yes, we are worried about the existential risk of artificial intelligence", where "existential risk" means literally human extinction. At the same time, I don’t want you to get the impression that this is an anti-technology or Luddite position here. It’s equally true that unimaginably good outcomes are possible from AGI, up to and including utopia, whatever that is. These are not opposites—in fact, they are two sides of the same coin, and that coin is "AGI is a powerful technology". By the same token, a nuclear engineer can say "It will be catastrophic if we build a nuclear power plant without any idea how to control the chain reaction", and then in the next breath they can say, "It will be awesome if we build a nuclear power plant and we do know how to control the chain reaction".[2] These things are not opposites.

As a matter of fact, it seems pretty clear at this point that running AGI code without causing catastrophe is a very hard problem. It’s a hard problem in the way that space probe firmware is a hard problem, in that certain types of bugs are irreversibly catastrophic, and can’t necessarily be discovered by testing.[3] It’s a hard problem in the way that cybersecurity is a hard problem, in that the AGI is running superintelligent searches for weird edge cases in how it’s implemented and the environment it’s in. Of course, if we mess up, it could also be like cybersecurity in the more literal sense that, if the AGI doesn’t have exactly the same goals as us, the AGI will be running superintelligent adversarial searches for holes in whatever systems we build to control and constrain it.
Finally, it’s a hard problem in the way that climate change is a hard problem, in that there’s a global-scale coordination problem rife with externalities and moral hazards. So as we’re going towards AGI, researchers who skimp on safety will make progress faster, and they’re going to be the ones getting that money and status, fame and fortune. Also, as we’ll see later, a lot of the ways to make AGIs safer also make them less effective at doing things we want them to do, so everyone with such an AGI will have an incentive to lower the knob on safety bit by bit. Finally, even in the best case that people can "use" AGIs far more intelligent than themselves, well it’s a complicated world with many actors with different agendas, and we may wind up radically upending society in ways that nobody chose and nobody wants.
So there’s everything at stake, avoiding catastrophe is a very hard engineering problem, so we’d better prepare ahead of time instead of wandering aimlessly into the era of AGI.
And by the way, "wandering aimlessly into the era of AGI" is a very real possibility! After all, evolution wandered aimlessly into the era of generally-intelligent humans. It designed our brains by brute-force trial-and-error. It had no understanding of what it was doing or what the consequences would be. So, again, understanding AGI safety isn’t something that happens automatically on our way to developing AGI. It only happens if we make it happen.
AGI safety work is time-sensitive

Next step in the motivation: AGI safety work is time-sensitive. When we think about this, there are three relevant timescales. The first timescale is, how long do we have until we know how to make AGIs? I’m going to say: Somewhere between 3 and 300 years. I don’t know any more specifically than that, and neither do you, and neither does anybody, because technological forecasting is hard. Here’s Wilbur Wright: "I confess that in 1901 I said to my brother Orville that man would not fly for fifty years. Two years later we ourselves made flights." Remember, Wilbur Wright was at that point the #1 world expert on how to build an airplane, at he got the timeline wildly wrong; what chance does anyone else have?
The experts on television who say that "We definitely won’t have AGI before 2100" or whatever the date is—that kind of statement is not based on a validated quantitative scientific theory of AGI forecasting, because there is no validated quantitative scientific theory of AGI forecasting! It’s very tempting to think about what it’s like to use today’s tools, and today’s hardware, and today’s concepts, and to use your own ideas about the problem, and to think about how hard AGI would be for you, and make a prediction on that basis. It’s much more of a mental leap to think about tomorrow’s tools, tomorrow’s hardware, and tomorrow’s insights, and to think about combining the knowledge and insights of many thousands of researchers around the world, some of whom are far smarter than you. We don’t know how many revolutionary insights it will take to get from where we are to AGI, and we don’t know how frequently they will come. We just don’t know.[4]
Some people try to do this type of forecast based on hardware. As far as I can tell, extremely short timelines, like even within a decade or two, are not definitively ruled out by hardware constraints. I’m not saying it’s guaranteed or even likely, just that it’s not obviously impossible. For one thing, today’s supercomputers are already arguably doing a similar amount of processing as a human brain. Admittedly, people disagree about this in both directions by multiple orders of magnitude,[5] because it’s really comparing apples and oranges; the architectures are wildly different. For example, supercomputers are maybe 100 million times faster but 100 million times less parallel. Next, new chips tailored to neural nets are coming out even in the next few years—for example there’s that MIT spin-off with an optical neural processing chip which is supposed to be orders of magnitude faster and lower-power than the status quo. And finally, most importantly, human-brain-equivalent processing power may not be necessary anyway. For one thing, brains are restricted to massively-parallelizable algorithms, whereas supercomputers are not. We all know that a faster and more serial processor can emulate a slower and more parallel processor, but not vice-versa. For another thing, a processor much less powerful than an insect brain—much less powerful!—can play superhuman chess.[6] We know this because we built one! So how much processing power is necessary to do superhuman science and engineering? It’s undoubtedly a harder problem than chess. An insect brain is probably not enough. But do we need to get all the way up to human brain scale? Nobody knows.

The second timescale we care about is, how long does it take to fully understand the principles of AGI safety? I’m going to say again, some unknown amount of time between 3 and 300 years. Sometimes we have the Claude Shannon Information Theory situation, where one guy just sits down and writes a paper with everything that needs to be known about a field of knowledge. More often, it seems we need many generations to write and rewrite textbooks, and develop a deeper and broader understanding of a subject. From my perspective, the ongoing research programs, which I’ll talk about later, feel like they could fill many textbooks.
Finally, the third timescale is, How long do we have until the start of research towards AGI? The answer here is easy: None, it’s already started! For example, OpenAI and DeepMind are two organizations doing some of the best Machine Learning research on the planet, and each has a charter explicitly to make superintelligent AGI. Look it up on their websites. In fact just last month OpenAI announced their next big research effort, to develop deep networks that can reason. Will they succeed? Who knows, but they’re certainly trying.
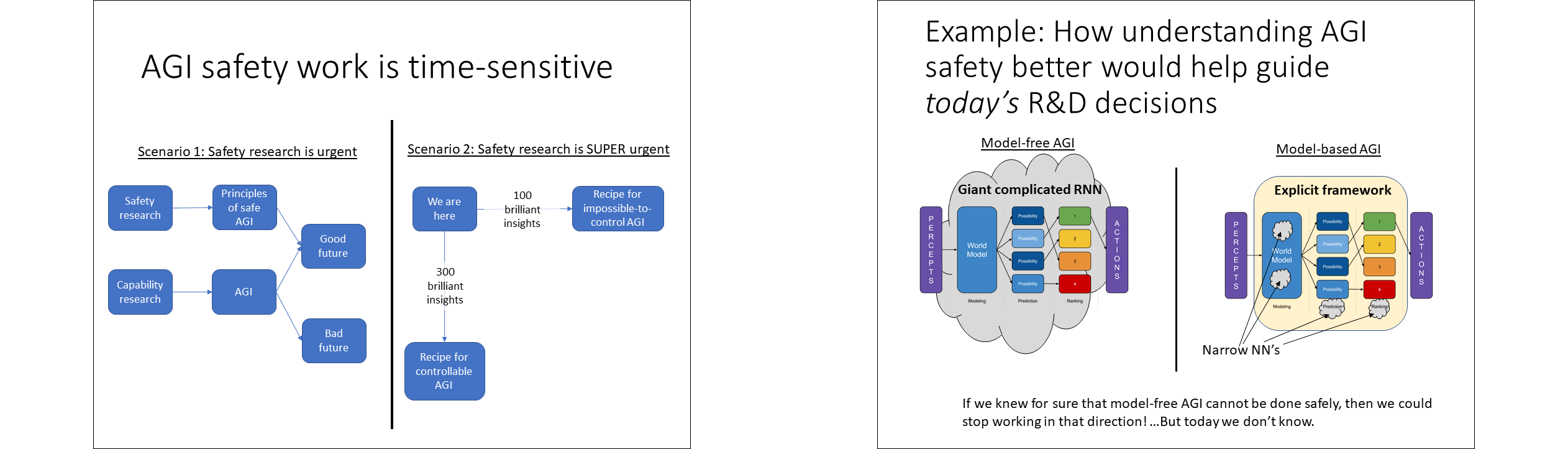
So those are the three timescales. How does that relate to whether or not AGI safety work is time-sensitive? Well there are a couple different scenarios. We can imagine that we’re doing safety work, and in parallel we’re doing capability work, and the hope is that we develop the principles of safe AGI by the time we’re capable of building AGI.[7] So then safety research is urgent. And that’s actually the good scenario! We could also imagine that there are different paths to make an AGI, and if we go down one development path, we need 100 brilliant insights, and then we know how to build AGI, but we’re building it in a way that’s impossible to control and use safely. Or, we can go down a different development path, and maybe now we need 300 brilliant insights, but we get an AGI that can be used safely. So in this scenario, we ideally want to have an excellent understanding of the principles of AGI safety before we even start research in the direction of AGIs. So in this case, we’re already behind schedule, and AGI safety research is super-urgent.
I’ll give a concrete example of this latter scenario. We can imagine a spectrum between two different AGI architectures. Here’s the cartoon AGI from before. In the model-free approach, we take the whole thing—the world-modeling, the prediction engine, the goal system, and everything else—and bundle it up in a giant complicated recurrent neural net. By contrast, in the model-based approach, we have lots of relatively narrow neural nets, maybe one for the goal system, and 16 neural nets encompassing the world model, and so on, and it’s all tied together with conventional computer code. You can call this the AlphaZero model; AlphaZero, the champion Go-playing program, has a big but simple feedforward neural net at its core—basically a module that says which Go positions are good and bad. Then that neural net module is surrounded by a bunch of conventional, old-fashioned computer code running the tree search and the self-play and so on. Now, to me, it seems intuitively reasonable to expect that the model-free approach is a lot harder to control and use safely than the model-based approach. But that's just my guess. We don’t know that. If we did know that for sure, and we understood exactly why, then we could stop researching the model-free approach, and put all our effort into the model-based approach.
There are lots more examples like that. The field of AI is diverse, with lots of people pursuing very different research programs that are leading towards very different types of AGI.[8] We don't know which of those destinations is the type of AGI that we want, the AGI that's best for humanity. So we're pursuing all of them in parallel, and whatever program succeeds first, well that's the AGI we're gonna get, for better or worse, unless we figure out ASAP which are the most promising paths that we need to accelerate.
AGI safety is grossly under-invested

The final part of the motivation is that AGI safety is grossly under-invested. It’s a tiny subfield of CS. A recent figure put it at $10M/year of dedicated funding. That means, for every $100 spent on AGI safety, the world spends $1M on climate change. AGI safety goes out to dinner, and meanwhile climate change buys itself a giant house and puts its children through college. Not that we should be siphoning money out of climate change; quite the contrary, I think we should be spending more on climate change. Rather, climate change is a benchmark for the resources that society can put towards a looming global threat. And according to that benchmark, AGI safety research should be growing by four orders of magnitude. And it’s not just that the field needs more money—probably even more importantly, the field needs more smart people with good ideas. Lots of essential problems are not being studied, because there’s simply not enough people.
By the way, I had another bullet point in here about how much we spend on AGI safety research, versus how much we spend on movies about evil robots, but it was just too depressing, I took it out. [Laughter]
So that’s the motivation. More people should be working on it today, and that means us.
Foundations

Next we move on to some foundational principles. These help explain the nature of the problem and why it’s hard. The main reference here is this 2014 book Superintelligence, by Oxford professor Nick Bostrom—which you might have heard of because Elon Musk and Bill Gates and Stephen Hawking and others endorsed it, so it was in the news.
Orthogonality thesis

We’ll start with the orthogonality thesis. When we think about highly advanced AGI systems, some people have this optimistic intuition: "If the AGI is overwhelmingly smarter than a human, its goals will be correspondingly wise and wonderful and glorious!" The reality, unfortunately, is that a superintelligent AGI can in principle have any goal whatsoever. It’s called the orthogonality thesis, because we draw this graph with two orthogonal axes—a mind can have any capability and any goal, leaving aside some fine print.[9]
To make sure everyone understands this point, one AGI safety researcher[10] came up with a thought experiment with the most inane goal you could possibly imagine: A "Paperclip Maximizer". It’s a superintelligent AGI, as intelligent as you like, and its one and only goal is to maximize the number of paperclips in the universe’s far future. Of course someone made a computer game out of this, so you can explore different strategies, like, I presume, making synthetic bacteria that build nano-paperclips with their ribosomes, or developing space travel technology to go make paperclips on other planets, and so on.
Why do we believe the orthogonality thesis? There are a lot of arguments, but I think the most convincing is a "proof by construction". We just take that AGI cartoon from earlier, and rank possible courses of action according to their expected number of paperclips. There’s nothing impossible or self-contradictory about this, and as it gets more and more intelligent, there is nothing in this system that would cause it to have an existential crisis and start doubting whether paperclips are worth making. It’s just going to come up with better strategies for making paperclips.
Goodhart's law

So, that’s the orthogonality thesis, and it says that good goals don’t write themselves. Goodhart’s law is a step further, and it says that good goals are in fact very very hard to write. Goodhart’s law actually comes from economics. If you quantify one aspect of your goals, then optimize for that, you’ll get it—and you’ll get it in abundance—but you’re going to get it at the expense of everything else you value! So here’s Mickey Mouse in The Sorcerer’s Apprentice. He wanted the cauldron to be filled with water, so he programs his broomstick to do that, and indeed the cauldron does get filled with water! But he also gets his shop flooded, he almost drowns, and worst of all—worst of all—he gets in trouble with the Dean of Students![11] [Laughter.] We can go through different goals all day. Nobody ever dies of cancer? You can kill all humans! Prevent humans from coming to harm? (I put in this one for you Isaac Asimov fans.) Of course if you read the Asimov books, you’ll know that a good strategy here is imprisoning everyone in underground bunkers. [Laughter.] Again the theme is, "Software does what you tell it to do, not what you want it to do."
Goodhart’s law is absolutely rampant in modern machine learning, as anyone would expect who thinks about it for five minutes. Someone set up an evolutionary search for image classification algorithms, and it turned up a timing-attack algorithm, which inferred the image labels based on where they were stored on the hard drive. Someone trained an AI algorithm to play Tetris, and it learned to survive forever by pausing the game. [Laughter.] You can find lists of dozens of examples like these.

Now, some people have a hope that maybe the dumb AI systems of today are subject to Goodhart’s Law, but the superintelligent AGIs of tomorrow are not. Unfortunately—you guessed it—it doesn’t work that way. Yes, a superintelligent system with a good understanding of psychology will understand that we didn’t want it to cure cancer by killing everyone. But understanding our goals is a different thing than adopting our goals. That doesn’t happen automatically, unless we program it to do so—more on which later in the talk. There’s a beautiful example of this principle, because it actually happened! Evolution designed us for inclusive genetic fitness. We understand this, but we still use birth control. Evolution’s goal for us is not our goal for ourselves.
One way of thinking about Goodhart’s Law is that AI to date, just like economics, control theory, operations research, and other fields, have all been about optimizing a goal which is exogenous to the system. You read the homework assignment, and it says right there what the goal is, right? Here we broaden the scope: What should the goal be? Or should the system even have a goal?
Instrumental convergence

OK, so far we have that first, good goals don’t write themselves, and second, good goals are extremely hard to write. In a cruel twist of irony, our third principle, instrumental convergence, says that bad and dangerous goals more-or-less do write themselves by default! [Laughter.]
Let’s say an AGI has a real-world goal like "Cure cancer". Good strategies towards this goal tend to converge on certain sub-goals. First, stay alive, and prevent any change to your goal system. You can imagine the AGI saying to itself, "If I’m dead, or if I’m reprogrammed to do something else, then I can’t cure cancer, and then it’s less likely that cancer will get cured." Remember, an AGI is by definition an agent that makes good decisions in pursuit of its goals, in this case, the goal that cancer gets cured. So the AGI is likely to make decisions that result in it staying alive and keeping its goal system intact. In particular, if you’re an AGI, and there are humans who can reprogram you, you should lead them to believe that you are well-behaved, while scheming to eliminate that threat, for example by creating backup copies of yourself in case of shutdown. Second, increase your knowledge & intelligence. "If I become smarter, then I’ll be better able to cure cancer." Gain money & influence. Build more AGIs with the same goal, including copies of yourself. And so on.
I should say here that the instrumental convergence problem seems to have an easy solution: Don’t build an AGI with long-term real-world goals! And that may well be part of the solution. But it’s trickier than it sounds. Number 1, we could try not to build AGIs with long-term real-world goals, but build one by accident—all you need is one little bug that lets long-term real-world consequences somehow leak into its goal system. Number 2, we humans actually have long-term real-world goals, like curing Alzheimer's and solving climate change, and generally the best way to achieve goals is to have an agent seeking them. Number 3, related to that, even if all of us here in this room agree, "Don’t make an AGI with long-term real-world goals," we need to also convince everybody for eternity to do the same thing. Solving problems like these is part of the ongoing research in the field. So that brings us to …
Active research directions

...Active research directions in AGI safety.[12] What are people doing today? There are a lot of research directions, because it’s a multi-faceted problem, and because it’s a young field that hasn’t really converged on a settled paradigm. By the way, pretty much all new work gets posted at alignmentforum.org, and most of this technical work is happening at the OpenAI safety team, the DeepMind safety team, the nonprofit MIRI, a center affiliated with UC Berkeley, and the Future of Humanity Institute at Oxford, among other places. I should also mention the Future of Life Institute which is doing great work especially on the non-technical aspects of the problem, for example organizing conferences, and trying to establish professional codes of ethics among AI researchers, and so on.
Foundational principles
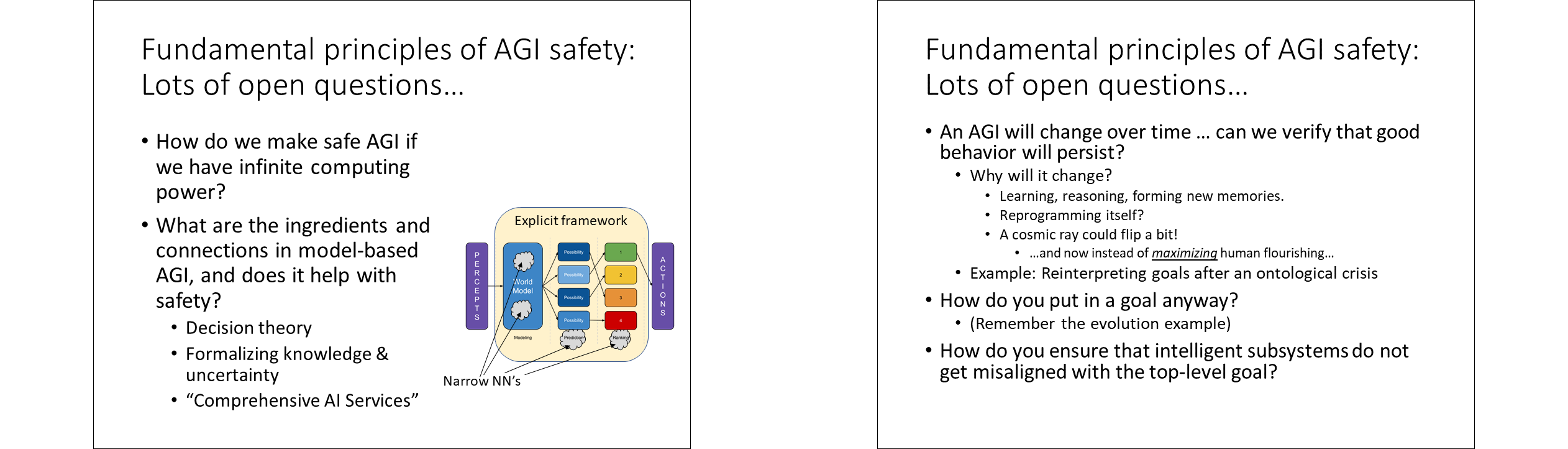
We’ll start with foundational principles of AGI safety, an area where there remain lots and lots of important open questions. First, how do we make a safe AGI if we have infinite computer power? We know how to play perfect chess if we have infinite computing power, but we don’t know how to make safe AGI. Second, if we go with the model-based AGI approach that I discussed earlier, then what are these narrow neural nets, how are they interconnected, and does it help with safety?
So for example, people have worked on the open problems in decision theory, which is related to how to properly build a goal system and action-picker. There’s been work on how to formally represent knowledge and uncertainty, including weird cases like uncertainty about your own capacity to reason correctly, and that’s part of how to properly build a world model. Comprehensive AI Services is a proposal by Eric Drexler related to tying together lots of narrow neural nets, and putting humans in the loop in certain positions.
Here’s another fundamental question. An AGI will change over time. Can we verify that good behavior will persist? There’s a few reasons an AGI will change over time. It’s certainly going to be learning, and reasoning, and forming new memories. Those are all changes to the system. More dramatically, it might reprogram itself, unless of course we somehow forbid it from doing so. Heck, a cosmic ray could flip a bit! And now instead of maximizing human flourishing... [laughter]. ...Right, it’s minimizing it! I’m joking. Well, I think I’m joking. I don’t know. This is absolutely the kind of thing we should be thinking about.
Here’s an example of how learning and reasoning could cause problematic behavior to appear. It’s called an "ontological crisis". For example, say I build an AGI with the goal "Do what I want you to do". Maybe the AGI starts with a primitive understanding of human psychology, and thinks of me as a monolithic rational agent. So then "Do what I want you to do" is a nice, well-defined goal. But then later on, the AGI develops a more sophisticated understanding of human psychology, and it realizes that I have contradictory goals, and context-dependent goals, and I have a brain made of neurons and so on. Maybe its goal is still "Do what I want you to do", but now it’s not so clear what exactly that refers to, in its updated world model. The concern is that the goal system could end up optimizing for something weird and unexpected, with bad consequences.
Another foundational question is: how do you put in a goal anyway? Remember the evolution example, where the external reward function, inclusive genetic fitness, doesn't match the internal goal.[13] And relatedly, how do you ensure that intelligent subsystems do not get misaligned with the top-level goal?
Value learning

Next, we have value learning.[14] The basic idea of value learning is: We don’t know how to write machine code for the Meaning of Life. We can’t even write machine code for Fill A Cauldron With Water, if we need to add in all the side goals like Don't flood the shop. But we’ve seen problems like that before! We also don’t know how to write down code that says whether an image is of a cat. But we can train a neural net, and with enough examples it can learn to recognize cats. By the same token, maybe we can build a machine that will learn our goals and values. Now, again, human goals and values are inconsistent, and they’re unstable, and maybe there are cases where it’s unclear what exactly we want the AGI to be learning. But I think everyone in the field agrees that value learning is going to be part of the solution.
Now, in a sense, people have been doing value learning from the get-go. There’s a traditional way to do it. You write down an objective function. You run the AI. If it doesn’t do what you wanted it to do, you try again. This won’t work for AGI. We have no hope of writing down an objective function, and mistakes can be catastrophic. Luckily, there are a lot of alternatives being explored. (This area is generally called Cooperative Inverse Reinforcement Learning.[15]) You can demonstrate the desired behavior while the AI watches. You can give real-time feedback to the AI. The AI could ask you questions. Heck, the AI could even propose its own objective function and ask for feedback. The DeepMind safety team has a recent paper on Recursive Reward Modeling, where you train AIs to help train more complicated AIs. And so on. Do we need brain-computer interfaces? Anyway, this area is the frontier of human-computer interface design, and it’s only just beginning to be explored.
Limiting
Next is Limiting. Here the goal is not for the AGI to do the right thing, the goal is for the AGI to not do the catastrophically wrong thing. There are four main subcategories here. First, "Boxing", or AI-in-a-box. The simplest aspect of this is not giving the AGI internet access. Second, "Impact measures". Imagine that Mickey can program his broomstick with a module that says that flooding the lab is high-impact, and therefore don’t do it without permission. Defining high-impact is trickier than it sounds. In fact, all of these are trickier than they sound. Mild optimization and Task-Based AGI are kind of like Mickey telling the broomstick, "Fill the cauldron but don’t try too hard, just get it mostly full in the most obvious way, and then shut yourself down." Finally, in "Norm Learning", we want the broomstick to have some knowledge that flooding labs isn’t something that people do, so don’t do it, or at least don’t do it without double-checking with Mickey.
All these are bad permanent solutions, because at the same time that we’re making the AGI safer, we’re also making it less able to get things done effectively, like curing Alzheimer's and solving climate change, so people are going to be tempted to ramp down the protections. For example, my AI-in-a-box is going to give me much better advice if I give it just a little bit of internet access. I'll closely supervise it. What could go wrong? And then later, maybe a little bit more internet access, and so on. But temporary solutions are still valuable—for example, they can be a second line of defense as we initially deploy these systems. It’s an open problem how to implement any of these, but lots of interesting progress on all these fronts, and and as always you can email me for a bibliography.
Interpretability, Bootstrapping, Robustness & verification
Some other categories, in brief. Interpretability: Can we look inside an AGI’s mind as it performs calculations, and figure out what its goals are? Robustness & verification: How do we gain confidence that there won’t be catastrophic behavior, without testing? For example, it would be awesome if we could do formal verification, but no one has a good idea of how. Bootstrapping: Can we use advanced AI systems to help ensure the safety of advanced AI systems? I already mentioned recursive reward modeling, and there are a lot of other bootstrapping-related ideas for all these categories. Sorry, I know I'm going pretty quick here; there's more on these in the backup slides if it comes up in Q&A.
Non-technical work
Finally, non-technical work—and it’s completely unfair for me to put this as a single slide, because it’s like half of the field, but here goes anyway. How do we avoid arms races or other competitive situations where researchers don’t have time for safety? There’s outreach and advocacy work. And how about job losses? What do we do when all intellectual labor can be automated, and then shortly thereafter we’ll have better robots and all labor period can be automated? How do we redistribute the trillions of dollars of wealth that might be accumulated by whoever invents AGI? Who is going to use AGI technology? What are they going to do with it? How do we keep it out of the hands of bad actors? When will AGI arrive, and where, and how? And on and on. By the way, maybe "non-technical" is the wrong term; things like strategy and forecasting obviously require the best possible technical understanding of AGI. But you know what I mean: There's the project of figuring out how to write AGI code, and then there's everything else.
We need the non-technical and we need the technical. We need the technical work in order to do anything whatsoever with an AGI, without risking catastrophe. We need the non-technical work to know what to do with an AGI, and to be in a position to actually do it. As I mentioned before, the Future of Life Institute website is a good place to start.[16]
What can we do today?

Finally, what can we do today? Well, certain parts of AGI safety have immediate practical applications. In those cases, there’s already ongoing work in those directions in the ML community, and these areas are growing, and they need to grow more. For example, as we build ML systems that need to interact with humans and navigate complex environments, we start running into the situation I was talking about before, where we can’t write down the goals, and therefore we need value learning. Things like robustness and interpretability are growing in importance as ML systems go out of the lab and start to get deployed in the real world. I think this is great, and I encourage anyone to get involved in these areas. I also think everyone involved in these areas should study up on long-term AGI Safety, so that we can come up with solutions that are not just narrowly tailored to the systems of today, but will also scale up to the more advanced systems of tomorrow.
Other parts of AGI safety don’t seem to have any immediate applications. For example, take AI Limiting. With today's technology, it's all we can do to make AI systems accomplish anything at all! AI Limiting means deliberately handicapping your AI—there's no market demand for that! Or take formal verification:[17] There’s been some work on formal verification of machine learning systems, but it relies on having simple enough goals that you know what you’re trying to prove. What’s the formal specification for "don’t cause a catastrophe"? There are lots more examples. These types of problems are still relatively underdeveloped niche topics, even though I think they’re likely to grow dramatically in the near future. And that’s a good thing for you in the audience, because you can catch up with the state-of-the-art in many of these areas without years of dedicated coursework.
Last but not least, go to the 80,000 hours problem profile and career guide, which summarizes the problem and what steps you can take to get involved. In fact, if there’s one thing you get out of this talk, it’s the link 80000hours.org. When you choose a career, you’re thinking about how to spend 80,000 hours of your life, and it’s well worth spending at least many hundreds of hours thinking it through. I mean, life is uncertain, plans change, but as they say, "Plans are useless but planning is essential". The mission of 80000hours.org is to provide resources for making good decisions related to your life and career—assuming that one of your goals is to make a better future for the world. This link on the slide is for AI, and they also have pages on climate change, pandemics, preventing war, improving public policy, and many other vitally important problems, and they also more generic resources about things like choosing majors and finding jobs.
You should also subscribe to alignmentforum.org. All the papers on AGI safety get posted there, and you can see the top researchers commenting on each other’s work in real time.
In conclusion, this is one of the grand challenges of our age. The field is poised to grow by orders of magnitude. It offers an endless stream of hard and fascinating problems to solve. So get involved! Dive in! Thank you very much, and I’m happy to take any questions.
The Sorcerer’s Apprentice analogy—like much else in this talk—comes from Nate Soares's google talk. I believe that The Sorcerer's Apprentice analogy originates with this earlier talk by Eliezer Yudkowsky. ↩︎
This analogy—like much else in the talk—comes from Stuart Russell; in this case his chapter in a recent popular book ↩︎
There is controversy in the community over the extent to which AGI safety problems will manifest themselves as small problems before they manifest themselves as irreversibly catastrophic problems. I would argue that many possible problems probably would, but at least some possible problems probably wouldn't. For example, here's a possible problem: As an AGI learns more, contemplates more deeply, and gains more freedom of action, maybe at some point its goals or behavior will shift. (See, for example, the discussion of "ontological crisis" below.) No matter how much testing we do, it's always possible that this particular problem will arise, but that it hasn't yet! Maybe it never will in the testing environment, but will arise a few years after we start deploying AGI in ways where we can't reliably switch it off. A different way that problems might manifest themselves as irreversibly catastrophic without first manifesting themselves as small problems is if AGI happens kinda suddenly, and catch people off-guard, with their systems being more capable than expected. Also, it's possible that something like goal instability will be a known problem, but without a clear solution, and people will have ideas about how to solve the problem that don't really work—they just delay the onset of the problem without eliminating it. Then some overconfident actor may incorrectly think that they've solved the problem, and will thus deploy a catastrophically unsafe system. ↩︎
For more on timelines, see https://intelligence.org/2017/10/13/fire-alarm/ ↩︎
For more on human-brain-equivalent computer hardware, and other aspects of AGI forecasting, see this and other articles at AI Impacts ↩︎
Of course, the paths are not really parallel; lots of safety work will only become possible as we get closer to building an AGI and learn more about the architecture. The ideal would be to develop as much understanding of AGI safety as possible at any given time. As discussed below, we are far from that: there is a massive backlog of safety work that we can do right now but that no one has gotten around to. Beyond that, we want to get to a world where "AI safety" is like "bridge-building safety": nobody talks about "AI safety" per se because all AI researchers recognize the importance of safety, where it would be unthinkable to design a system without working exhaustively to anticipate possible problems before they happen. ↩︎
More examples: We could train AGIs by reinforcement learning, or by supervised learning [LW · GW], or by self-supervised (predictive) learning [LW · GW]. Vicarious and Numenta are trying to understand and copy brain algorithms, but leaving out emotions. (Or should we figure those out and put them in too?) We could figure out how to help the system understand humans, or design it to be forbidden from modeling humans [LW · GW]! David Ferrucci at Elemental Cognition thinks we need an AGI that talks to humans and helps them reason better. Ray Kurzweil and Elon Musk argue that brain-computer interfaces are key to AGI safety. Chris Olah thinks that interpretability tools are the path to safe AGI. [LW · GW]. Eric Drexler thinks the path to AGI will look like a collection of narrow programs [LW · GW]. Anyway, all these things and more seem to be fundamentally different research programs, going down different paths towards different AGI destinations. In a perfect world, we would collectively pause here and try to figure out which destination is best. ↩︎
One example of fine print on the Orthogonality Thesis would be the fact that if a system has very low capability, such that it's not able to even understand a certain goal, then it probably can't optimize for that goal. ↩︎
Eliezer Yudkowsky says that the Paperclip Maximizer thought experiment probably originated with him, but that it also might have been Nick Bostrom. ↩︎
To make the joke work, substitute the appropriate scary authority figure for your audience, e.g. "The head of Corporate Compliance", "The Head of EH&S", "The Head of the IRB", "The CEO", etc. ↩︎
This section loosely follows Rohin Shah's summaries of the field here and here and here. ↩︎
A recent paper calls the challenge of installing a known goal the "Inner Optimization Problem". ↩︎
To learn more, a good place to start is the Value Learning Sequence [? · GW]. ↩︎
The perspective wherein Cooperative Inverse Reinforcement Learning is an all-encompassing framework for human-computer interactions is advocated by Dylan Hadfield-Menell here. The original paper on CIRL is here. ↩︎
See also the 80,000 hours guide to working in AI policy. And the Import AI newsletter is a nice way to keep up to date with AI news relevant to policy and strategy. ↩︎
For more on formal verification in the context of AGI safety, a good place to start is this recent review from the DeepMind safety team ↩︎
4 comments
Comments sorted by top scores.
comment by ESRogs · 2019-07-17T18:17:24.291Z · LW(p) · GW(p)
The Dive in! link in the last paragraph appears to be broken. It's taking me to: https://www.lesswrong.com/posts/DbZDdupuffc4Xgm7H/%E2%81%A0http://mindingourway.com/dive-in/ [? · GW]
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-07-17T18:54:37.487Z · LW(p) · GW(p)
Fixed, thanksI
comment by John_Maxwell (John_Maxwell_IV) · 2019-06-21T05:24:33.917Z · LW(p) · GW(p)
How do people feel about the "AGI safety is grossly under-invested" messaging given current funding levels? Apparently some research indicates that smaller teams are more likely to make disruptive innovations (here [EA · GW] is one place I read about this). My intuitive sense is that the AGI safety community already suffers from team sizes that are too large.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-06-21T11:10:50.790Z · LW(p) · GW(p)
Hi John, Are you saying that there should be more small teams in AGI safety rather than increasing the size of the "big" teams like OpenAI safety group and MIRI? Or are you saying that AGI safety doesn't need more people period?
Looks like MIRI is primarily 12 people. Does that count as "large"? My impression is that they're not all working together on exactly the same narrow project. So do they count as 1 "team" or more than one?
The FLI AI grants go to a diverse set of little university research groups. Is that the kind of thing you're advocating here?
ETA: The link you posted [EA · GW] says that a sufficiently small team is: "I’d suspect this to be less than 15 people, but would not be very surprised if this was number was around 100 after all." If we believe that (and I wouldn't know either way), then there are no AGI safety teams on Earth that are "too large" right now.