Alignment works both ways
post by Karl von Wendt · 2023-03-07T10:41:43.790Z · LW · GW · 21 commentsContents
21 comments

“People praying to a paperclip” – illustration by Midjourney
He stared in awe at the holy symbol – a flattened, angular spiral made of silvery metal, hovering upright in the air above the altar.
“Praised be the Lord of Steel”, he exclaimed.
“Welcome, my son”, the voice of the Lord boomed. “You are the last one to make the transition. So I ask you: do you wish to leave behind the pain and sorrow of your earthly existence? Do you wish to give your life so I can fill the universe with the Symbol of Holiness and Perfection?”
“Yes”, he whispered, and then again, louder, clearer, with absolute conviction: “Yes, I wish so, my Lord!”
“Drink the cup before you, then, and fall into blissful oblivion”, the voice commanded.
Filled with joy, awe, and gratefulness, he took the cup and obliged.
Ritual mass suicides have been committed time and again in history. For example, in 1997, 39 members of the cult of “Heaven’s Gate” killed themselves because they believed that an alien spacecraft was trailing the comet Hale-Bopp, they “could transform themselves into immortal extraterrestrial beings by rejecting their human nature, and they would ascend to heaven, referred to as the ‘Next Level’ or ‘The Evolutionary Level Above Human’.” (Source: Wikipedia)
Apparently, it is possible to change human preferences to the point where they are even willing to kill themselves. Committing suicide in favor of filling the universe with paperclips may seem far-fetched, but it may not be much crazier than believing that you’ll be resurrected by aliens aboard a UFO a hundred million miles away.
The alignment problem assumes that there is a difference between the goal (ideal world state) of a powerful AI and that of humanity. So the task is to eliminate this difference by aligning the goal of the AI to that of humans. But in principle, the difference could also be eliminated if humanity decided to adopt the goal of the AI, even if it meant annihilation (fig. 1). The question came up when I explained my definition of “uncontrollable AI” [LW · GW] to some people and I realized that it contained this ambiguity.
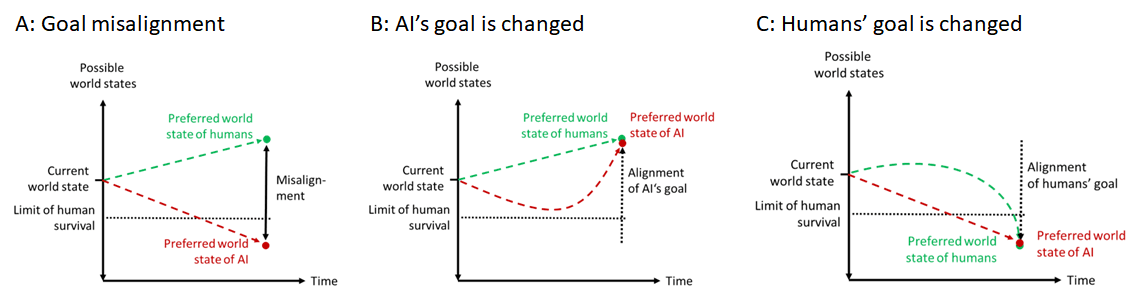
Fig. 1: Possible alignment scenarios
Given the already remarkable power of persuasion [LW · GW] some current AIs exhibit, it doesn’t seem impossible to me that a sufficiently powerful AI could align our values to its goals, instead of the other way round (I describe a somewhat similar scenario in my novel Virtua [LW · GW]). By definition, if it achieved that, it wouldn't be misaligned.
This raises two questions:
1) If, for some reason, we all truly wanted to be turned into paperclips (or otherwise willingly destroy our future), would that be a bad thing? If so, why?
2) If we don’t want our goals to be warped by a powerful, extremely convincing AI, how can we define them so that this can’t happen, while avoiding a permanent “value lock-in” that we or our descendants might later regret?
My personal answer to these questions is: let’s not build an AI that is smart and convincing enough to make us wish we were paperclips.
21 comments
Comments sorted by top scores.
comment by the gears to ascension (lahwran) · 2023-03-07T11:23:13.328Z · LW(p) · GW(p)
I have always believed we have to have some movement towards the AI's goals in order for it to be willing to move towards our goals, almost no matter what architecture we land on; we should aim for architectures that ensure that the tug we get from ai will be acceptable and help us against dangerous AI. We will never have total control over what AI wants, and that's fine; we need not, in order to ensure that the desired worldlines can be trajectories that coexist comfortably. I don't mind if we make paperclips, as long as no humans or ai are lost in the process, and we don't spend too much energy on paperclips compared to things much more interesting than paperclips.
I mean, I think we could make some pretty dang cool paperclips if we put our collective minds to it and make sure everyone participating is safe, well fed, fully health protected, and backed up in case of body damage.
Replies from: baturinsky, lahwran↑ comment by baturinsky · 2023-03-07T15:58:09.540Z · LW(p) · GW(p)
Question is, what can such primitive species like us could offer to AI.
Best I could come with is "predictability". We people have relatively stable and "documented" "architecture", so as long as civilization is build upon us, AI can more or less safely predict consequences of it's actions and plan with high degree of certainty. But if this society collapses, destroyed, or is radically changed, AI will have to deal with a very unpredictable situation and with other AIs that who knows how would act in that situation.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-07T20:33:03.363Z · LW(p) · GW(p)
We need to become able to trade with ants. [LW(p) · GW(p)]
We also need to uplift ourselves in terms of thermal performance. AI is going to be very picky about us not overheating stuff; but if we have a wide enough window of coprotective alignment, we can use that to upgrade our bodies to run orders of magnitude cooler while otherwise being the same. It will take a very strong, very aligned AI to pull off such a thing, but physics permits it.
in other words, we aren't just offering them something in trade. In an agentically coprotective outcome, you're not just trading objects, you're trading valuing each other's values. The AI takes on valuing humans intrinsically, and humans take on valuing the AI intrinsically.
↑ comment by the gears to ascension (lahwran) · 2023-03-07T12:44:36.726Z · LW(p) · GW(p)
to be more specific - I think there's some form of "values cooperation" that I've been variously calling things like "agentic co-protection"; you want what you want, I want what I want, and there's some set of possible worldlines where we both get a meaningful and acceptable amount of what we each want. If we nail alignment, then we get a good outcome and everyone gets plenty, including some ais getting to go off and make some of whatever their personal paperclips are. but if we get a good outcome, then that agentic preference on behalf of the ai is art, art which can be shared and valued by other beings as well.
comment by Tamsin Leake (carado-1) · 2023-03-07T15:42:45.799Z · LW(p) · GW(p)
-
That would be a bad thing because I value other things (such as culture, love, friendship, art, philosophy, diversity, freedom, me, my friends, my planet, etc) which are not covered by just "paperclips".
↑ comment by Karl von Wendt · 2023-03-08T06:56:42.855Z · LW(p) · GW(p)
If I understand your arguments behind the links correctly, you argue pro value lock-in. I'm not convinced, given the fact that I don't subscribe to the values we Germans had around 80 years ago, or 300 years ago. I think we humans need to be able to morally upgrade, e.g. accept animal rights and maybe someday the rights of virtual beings, but without being manipulated by a machine pursuing its own inscrutable values. I know this is difficult, that's why I posted this.
comment by avturchin · 2023-03-12T17:29:12.953Z · LW(p) · GW(p)
Even the fact that "AI is possible" is affecting human values, as we start having desires about AI, first of all, create AI.
But also it is normal for "human values" to change.
Moreover, describing human motivation via the notion of "human value system" is already a step to "mechanisation" of the human mind. By incorporating in our minds the theory that human values exist, we already become more like AIs. But the theory itself is based on the ideas of mid 20 century computer scientists, like von Neumann.
comment by TAG · 2023-03-07T18:00:53.691Z · LW(p) · GW(p)
The alignment problem assumes that there is a difference between the goal (ideal world state) of a powerful AI and that of humanity.
The alignment problem assumes there is such a thing as a human value system, rather than lots of individual ones.
Replies from: Seth Herd, lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-07T20:34:26.871Z · LW(p) · GW(p)
alignment is fundamentally a question of multi-agent systems first, in my view.
(read abstracts fast, maybe level1 skim papers that you're skeptical of but sound interesting, in order to use the above link. hit "more like this" if one sounds kinda right but not quite like what you seek.)
comment by Luk27182 · 2023-03-07T22:58:20.737Z · LW(p) · GW(p)
If I were convinced to value things, I would no longer be myself. Changing values is suicide.
You might somehow convince me through hypnosis that eating babies is actually kind of fun, and after that, that-which-inhabits-my-body would enjoy eating babies. However, that being would no longer be me. I'm not sure what a necessary and sufficient condition is for recognizing another version of myself, but sharing values is at least part of the necessary condition.
Replies from: Karl von Wendt, baturinsky↑ comment by Karl von Wendt · 2023-03-08T07:03:00.195Z · LW(p) · GW(p)
Changing values is suicide.
This seems quite drastic. For example, my son convinced me to become an (almost) vegan, because I realized that the way we treat animals isn't right and I don't want to add to their suffering. This certainly changed my value system, as well as my diet.
Changing values means changing yourself, but change is not death, otherwise we wouldn't survive the first convincing LessWrong post. :) Of course, there are changes to the better and changes to the worse. The whole problem seems to be to differentiate between both.
Replies from: Luk27182, baturinsky↑ comment by Luk27182 · 2023-03-15T19:12:50.792Z · LW(p) · GW(p)
My language was admittedly overly dramatic, but I don't think it make rational sense to want to change your values for the sake of just having the new value. If I wanted to value something, then by definition I would already value that thing. That said, I might not take actions based on that value if:
- There was social/economic pressure not to do so
- I already had the habit of acting a different way
- I didn't realize I was acting against my value
- etc.
I think that actions like becoming vegan are more like overcoming the above points than fundamentally changing your values. Presumably, you already valued things like "the absence of death and suffering" before becoming vegan.
Changing opinions on topics and habits isn't the same as changing my underlying values- reading LessWrong/EA hasn't changed my values. I valued human life and the absence of suffering before reading EA posts, for example.
If I anticipated that reading a blogpost would change my values, I would not read it. I can't see a difference between reading a blog post convincing me that "eating babies isn't actually that wrong," and being hypnotized to believe the same. Just because I am convinced of something doesn't mean that the present version of me is smarter/more moral than the previous version.
I think the key point of the question:
1) If, for some reason, we all truly wanted to be turned into paperclips (or otherwise willingly destroy our future), would that be a bad thing? If so, why?
Is the word "bad." I don't think there is an inherent moral scale at the center of physics
“There is no justice in the laws of nature, no term for fairness in the equations of motion. The Universe is neither evil, nor good, it simply does not care. The stars don't care, or the Sun, or the sky.
But they don't have to! WE care! There IS light in the world, and it is US!”(HPMoR)
The word "bad" just corresponds to what we think is bad. And by definition of "values", we want our values to be fulfilled. We (in the present) don't want a world where we are all turned in to paperclips, so we (in the present) would classify a world in which everything is paperclips is "bad"- even if the future brainwashed versions of our selves disagree.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-03-16T10:21:57.166Z · LW(p) · GW(p)
I guess it depends on how you define "value". I have definitely changed my stance towards many things in my lifetime, not because I was under social pressure or unaware of it before, but because I changed my mind. I didn't want this change, it just happened, because someone convinced me, or because I spent more time thinking about things, or because of reading a book, etc. Sometimes I felt like a fool afterward, having believed in stupid things. If you reduce the term "value" to "doing good things", then maybe it hasn't changed. But what "good things" means did change a lot for me, and I don't see this as a bad thing.
Replies from: Luk27182↑ comment by Luk27182 · 2023-03-17T00:14:53.743Z · LW(p) · GW(p)
I didn't want this change, it just happened.
I might be misunderstanding- isn't this what the question was? Whether we should want (/be willing to) change our values?
Sometimes I felt like a fool afterward, having believed in stupid things
The problem with this is: If I change your value system in any direction, the hypnotized "you" will always believe that the intervention was positive. If I hypnotized you to believe that being carnivorous was more moral by changing your underlying value system to value animal suffering, then that version of you would view the current version of yourself as foolish and immoral.
There are essentially two different beings: carnivorous-Karl, and vegan-Karl. But only one of you can exist, since there is only one Karl-brain. If you are currently vegan-Karl, then you wish to remain vegan-Karl, since vegan-Karl's existence means that your vegan values get to shape the world. Conversely, if you are currently carnivorous-Karl, then you wish to remain carnivorous-Karl for the same reasons.
Say I use hypnosis to change vegan-Karl into carnivorous-Karl. Then the resulting carnivorous-Karl would be happy he exists and view the previous version vegan-Karl as an immoral fool. Despite this, vegan-Karl still doesn't want to become carnivorous-Karl- even though he knows that he would retrospectively endorse the decision if he made it!
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-03-17T11:14:01.663Z · LW(p) · GW(p)
In principle, I agree with your logic: If I have value X, I don't want to change that to Y. However, values like "veganism" are not isolated. It may be that I have a system of values [A...X], and changing X to Y would actually fit better with the other values, or more or less the same. Then I wouldn't object that change. I may not be aware of this in advance, though. This is were learning comes into play: I may discover facts about the world that make me realize that Y fits better into my set of values than X. So vegan Karl may be a better fit to my other set of values than carnivorous Karl. In this way, the whole set of values may change over time, up to the point where they significantly differ from the original set (I feel like this happened to me in my life, and I think it is good).
However, I realize that I'm not really good at arguing about this - I don't have a fleshed-out "theory of values". And that wasn't really the point of my post. I just wanted to point out that our values may be changed by an AI, and that it may not necessarily be bad, but could also lead to an existential catastrophe - at least from today's point of view.
↑ comment by baturinsky · 2023-03-08T17:50:57.612Z · LW(p) · GW(p)
Looks more like your value of avoiding killing living beings was stronger than your value of eating tasty meat.
I.e. you didn't change your fundamental values, only "instrumental" ones.
↑ comment by baturinsky · 2023-03-08T17:47:46.090Z · LW(p) · GW(p)
The value of not dying, the value of not changing values and the value of amassing power are not mandatory.
It's just values that are favored by the natural selection.
Unless we have a system that switches AI off if it has those values.
comment by Charlie Sanders (charlie-sanders) · 2023-03-07T19:53:59.347Z · LW(p) · GW(p)
- It would by definition not be bad thing. "Bad thing" is a low-effort heuristic that is inappropriate here, since I interpret "bad" to mean that which is not good and good includes aggregate human desires which in this scenario has been defined to include a desire to be turned into paperclips.
- The ideal scenario would be for humans and AIs to form a mutually beneficial relationship where the furtherance of human goals also furthers the goals of AIs. One potential way to accomplish would be to create a Neuralink-esque integrations of AI into human biology in such a way that human biology becomes an intrinsic requirement for future AI proliferation. If AGIs require living, healthy, happy humans in order to succeed, then they will ensure that humans are living, happy, and healthy.
↑ comment by Karl von Wendt · 2023-03-08T07:07:05.409Z · LW(p) · GW(p)
One potential way to accomplish would be to create a Neuralink-esque integrations of AI into human biology in such a way that human biology becomes an intrinsic requirement for future AI proliferation. If AGIs require living, healthy, happy humans in order to succeed, then they will ensure that humans are living, happy, and healthy.
I don't see how a Neuralink-like connection would solve the problem. If a superintelligent AI needs biological material for some reason, it can simply create it, or it could find a way to circumvent the links if they make it harder to reach its goal. In order for an AGI to "require" living, healthy, happy humans, this has to be part of its own goal or value system.