In Strategic Time, Open-Source Games Are Loopy
post by StrivingForLegibility · 2024-01-18T00:08:40.909Z · LW · GW · 2 commentsContents
Strategic Time Strategic Time Loops Strategic Time Loops vs. Consequentialism Crystal Ball Design None 2 comments
For many situations we'd like to analyze [LW · GW], information flow is more important than chronological order. When game theorists say that two players choose their actions simultaneously, they mean that they each make their choice without knowing the action chosen by the other player. This is usually contrasted with sequential decisions, where one player is able to observe the action chosen by another, and potentially choose differently based on the action observed.
Open-source games [? · GW] are ones in which each player delegates their choice to a computer program, and each program has access to the source code of all delegated programs at runtime. This introduces a new type of information relationship between decisions, where two agents can attempt to condition their output on each other's output. It's this strategic time loop that enables agents in the Robust Cooperation [LW · GW] paper to Cooperate, if and only if they are logically certain that the other agent will also Cooperate. And amazingly, such agents actually do Cooperate with each other!
This is a more powerful form of prediction than agents in closed-source games can perform, and they're already classically assumed to be infinitely intelligent [LW · GW] and logically omniscient [? · GW]. What makes the difference is that the information about each agent's output is available to each agent at the time they're making their decisions. Any Nash equilibrium of a game can be realized by a program equilibrium, but the joint policies chosen in some program equilibria are not Nash equilibria. The program equilibrium (FairBot, FairBot) leads to the joint policy (Cooperate, Cooperate), but this is not a Nash equilibrium of the underlying Prisoners' Dilemma.
In this post I'll describe how strategic time is modelled in compositional game theory, which is my current favorite model of non-loopy strategic information flow. I'll also go into more detail about strategic time loops, how they're different from ordinary consequentialism, and what properties we want from systems that enable these loops in the first place.
Strategic Time
Compositional game theory aims to model complex games as being composed of simpler games, put together according to simple rules. One major aim of the field is to make it easier to reason about complex games, in the same way that we reason about complex software systems that are composed of simpler modules. To this end, formal rules have been defined to translate back and forth between category theoretic expressions like and string diagrams like:
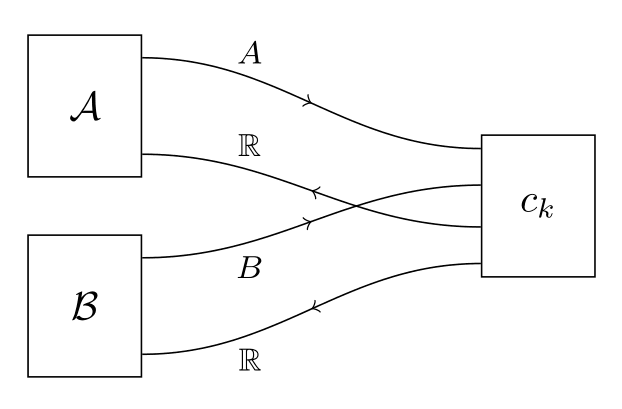
Here, and are agents, and is a game they're interacting with. (Which might itself be composed of modules). The arrows here represent information flow, not necessarily chronological order. The right-facing arrows are flowing forwards in what we could call "strategic time". In this game, and choose actions and simultaneously (in the sense of choosing without knowing the other's choice). Then something happens inside of , which ultimately results in feedback signals being sent back to and . In this example, the feedback signals take the form of utilities and , but in general they can take essentially any form [LW · GW].
Here's what a sequential game looks like:

In this sequential game, can observe 's choice , and condition their choice on that observation. In other words, implements a policy .
Strategic Time Loops
Decisions can have 4 information relationships to each other:
- (Simultaneous, no information flow)
- (Sequential, can condition on the output of )
- (Sequential, can condition on the output of )
- (Time loop, A and B can try to condition on each other's output.)
A loopy relationship is the sort of thing that happens when two agents can explicitly think about each other's decision-making process, and try to condition their own output on the predicted output of the other agent.
There are ways to model this, successfully and unsuccessfully. An agent that tries to simulate their counterpart, and then condition their output on the other agent's simulated output, will loop forever when faced with another agent that does the same thing.
The Robust Cooperation paper models agents that try to prove statements that look like "my counterpart's output will be ", and use the success or failure of that proof search [LW · GW] to condition their own output. Amazingly, this works! At least sometimes. FairBot is an agent that outputs Cooperate if it can prove "my counterpart will output Cooperate", and outputs Defect otherwise. Under the hood, there is an engine which searches for "stable time loops", and in the case of FairBot facing FairBot, it finds one! Each outputting Cooperate is consistent with each proving that the other outputs Cooperate, so the proof search succeeds and they both output Cooperate.
If an agent tries to do the opposite of what its counterpart will do, this proof search will fail when that agent is facing itself. For example, consider ContrarianBot, which attempts to prove that its counterpart outputs Cooperate. If successful, it outputs Defect, and otherwise it outputs Cooperate. When facing itself, it's not consistent to prove that it outputs Cooperate, since if that were provable it would output Defect. So the proof search fails, leading it to Cooperate. The statement "ContrarianBot Cooperates with itself" is true but unprovable (at least to the proof system that ContrarianBot uses, assuming that it can only prove true statements).
There are stable and unstable information loops. Proof-searching agents handle unstable loops by failing to find a proof that leads to a contradiction. Reflective oracles [LW · GW] handle them by randomizing their output. When dealing with unstable loops, like "my output is 0 if and only if my output is 1", there are no consistent assignments of values to variables. Any crystal ball must either give a wrong answer, or give an output that is uncorrelated with the truth when attempting to view an unstable time loop.
Strategic Time Loops vs. Consequentialism
I want to distinguish this type of time loop from the "doing things on purpose [LW · GW]" type of loop, where an action is chosen now on the basis of its anticipated future consequences. A Nash equilibrium can be thought of a collection of decisions, such that no agent has an incentive to unilaterally change their decision given knowledge of everyone else's. Both can be thought of as stable fixed points of their respective relations.
But players in a closed-source simultaneous game aren't literally able to condition their decisions on each other's decisions. There are contexts where players are incentivized to choose symmetrically, but the information about each player's decision isn't always available at the time of making each decision. It's the difference between "if I knew the other player's output, and my output already happened to line up the right way, I wouldn't want to change it" and "I know the other player's output, and I've picked my output accordingly so I don't want to change it."
The arrows in compositional game theory represent information flow, and they are able to represent consequentialism but not strategic time loops. An environment, which takes a choice and returns a consequence, looks something like this:
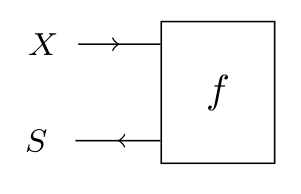
Forward-flowing arrows can be bent backwards, like this:
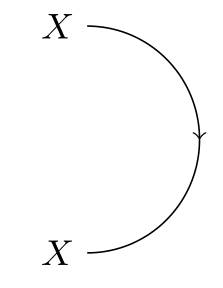
But they can't be bent the other way around; backwards-flowing arrows can't be bent forwards. My impression is that this is is explicitly to prevent strategic time loops.
This doesn't mean we can't study strategic time loops in compositional game theory. But we'd need to define a module to act as a logical crystal ball. Such a module might search over proofs, or act as a reflective oracle. Then we can condition our decisions on the output of this crystal ball, which will sometimes but not always line up with the output of another system we're interested in, rather than trying to condition our output on another system's output directly.
Crystal Ball Design
For the purposes of designing unexploitable decision theories, it seems like we'll want something like a generalization of the agents from the Robust Cooperation paper. That is, a software system that can apply techniques from formal verification to analyze other software systems, and reason about what they might output given a particular input.
We can think about such a module as a function, which takes three inputs: a program to reason about , an input for that program , and a list of permissible outputs sorted by desirability .[1] This last input is important because there are generally multiple stable loops, and this tells our module which loops we want it to find.
RaifBot, the Bizarro version of FairBot, only Defects if it can prove its counterpart will Defect and otherwise it Cooperates. This might be motivated by a desire to give the other program the benefit of the doubt, but unfortunately RaifBot ends up Defecting on itself. We can't factor goals and beliefs into separate subsystems [? · GW] when there are multiple, self-fulfilling prophecies [LW · GW] that our belief system could output. We need to explicitly tell these modules which self-fulfilling prophecies we prefer it to output.
Such a module should either return a proof that "the given program has this output on the given input, ", or an error message indicating why such a proof could not be found. When such a proof is found, the output cited should be on the list we gave the module, and as high on the list as possible given the constraints of logic and available resources. (Not every true statement is provable, and not every proof can be found given finite computing power. However, fixed points for modal agents can be found in polynomial time, which is promising!)
There has been significant progress on designing software systems that reason about other software systems. DARPA's 2016 Cyber Grand Challenge had teams writing software that 100% autonomously identify vulnerabilities in software systems, write code to exploit these vulnerabilities, and write patches to fix them.
The winner, Mayhem, starts by constructing a formal model of the target software. This allows it to perform symbolic execution, tracing different possible paths from input to output. And it's able to reason directly about the compiled binary, no source code access needed. It's since been used by organizations like Cloudflare and the US Military to find thousands of bugs in their own code. The system that won third place, Mechanical Phish, was made open-source and can also perform symbolic execution on compiled binaries.
We can use techniques like these to write software systems that reason about each other as they're deciding what actions to take on our behalf. Such reasoning might lead to a successful logical handshake [? · GW], or some safe default action if mutual legibility isn't established. But in either case, we can design software systems which we are justifiably confident will only take actions we think are appropriate given the information and resources available.
- ^
When strategies are continuous, like amounts of money in an Ultimatum Game, or probabilities in a mixed strategy, we can instead give our module a function describing our preferences and different function describing which outputs are permissible in a given context. This enables the same "optimization over an approved domain" pattern when the domain is continuous rather than discrete.
2 comments
Comments sorted by top scores.
comment by Jerdle (daniel-amdurer) · 2024-09-09T02:49:41.868Z · LW(p) · GW(p)
It's a shame I wasn't able to use a time loop to have this exist when I wrote my post on Newcomb's problem being an iterated PD.
This concept is exactly what I needed, and it's explained far better than I did.
Replies from: StrivingForLegibility↑ comment by StrivingForLegibility · 2024-09-11T00:38:08.778Z · LW(p) · GW(p)
Thank you! I think it's exactly the same kind of "conditioning my output on their output" that you were pointing to in your analogy to iterated games. And I expect there's a strong correspondence between "program equilibria where you only condition on predicted outputs" and "iterated game equilibria that can form a stable loop."