Where are intentions to be found?
post by Alex Flint (alexflint) · 2021-04-21T00:51:50.957Z · LW · GW · 12 commentsContents
12 comments
This is independent research. To make it possible for me to continue writing posts like this, please consider supporting me.
As we build powerful AI systems, we want to ensure that they are broadly beneficial. Pinning down exactly what it means to be broadly and truly beneficial in an explicit, philosophical sense appears exceptionally daunting, so we would like to build AI systems that are, in fact, broadly and truly beneficial, but without explicitly answering seemingly-intractable philosophical problems.
One approach to doing this is to build AI systems that discover what to do by examining or interacting with humans. The hope is that AI systems can help us not just with the problem of taking actions in service of a goal, but also with the problem of working out what the goal ought to be.
Inverse reinforcement learning is a classical example of this paradigm. Under inverse reinforcement learning, an AI observes a human taking actions, then looks for an explanation of those actions in terms of a value function, then itself takes actions that optimize that value function.
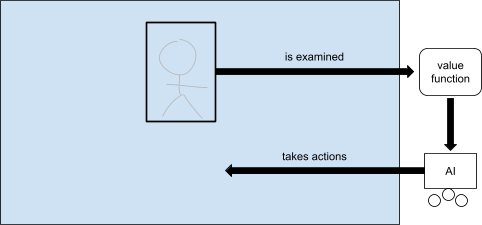
We might ask why we would build an AI that acts in service of the same values that the human is already acting in service of. The most important answer in the context of advanced AI, it seems to me, is that AI systems are potentially much more powerful than humans, so we hope that AI systems will implement our values at a speed and scope that goes beyond what we are capable of on our own. For this reason, it is important that whatever it is that the AI extracts as it examines a human taking actions is trustworthy enough that if it were implemented faithfully by the AI then the world brought forth by the AI would be a good world.
Inverse reinforcement learning is just one version of what I will call extraction-oriented AI systems. An extraction-oriented AI system is one that examines some part of the world, then, based on what it finds there, takes actions that affect the whole world. Under classical inverse reinforcement learning the particular part of the world that gets examined is some action-taking entity such as a human, the particular extraction method is to model that entity as an agent and look for a value function that explains its behavior, and the particular way that the system acts upon this value function is, at least under classical AI paradigms, to itself take actions that optimize that value function. But there are many other choices for what part of the world to examine, what to extract from it, and how to implement that which is extracted. For example, we might examine the net behavior of a whole human society rather than a single human; we might extract a policy by imitation learning rather than a value function by imitation learning; and we might act in the world using a satisficer rather than an optimizer. There are many choices for how we might do this. What I’m addressing here is any approach to developing AI that becomes aligned with what is truly beneficial by investigating some part of the world.
So long as we are within the regime of extraction-oriented AI systems, we are making the assumption that there is some part of the world we can examine that contains information sufficient to be a trustworthy basis for taking actions in the world.
Let us examine this assumption very carefully. Suppose we look at a closed physical system with some humans in it. Suppose that this system contains, say, a rainforest in which the humans live together with many other animal and plant species:

Suppose that I plan to build an AI that I will insert into this system in order to help resolve problems of disease, violence, ecological destruction, and to assist with the long-term flourishing of the overall ecosystem:

It is difficult to say exactly what it means for this overall ecosystem to flourish. How do I balance the welfare of one species against that of another? Of one individual against another? How do we measure welfare? Is welfare even the right frame for asking this question? And what is an appropriate way to investigate these questions in the first place? Due to such questions, it is difficult to build an AI purely from first-principles and so suppose I tell you that I am planning to build an AI that discovers the answers to these questions by examining the behavior of humans and perhaps other living beings within the ecosystem. Perhaps I have some elaborate scheme for doing this; there is no need to get into the details here, the important thing is that I tell you that the basic framework I will be working within is that I will observe some part of the system from some amount of time, then I will do some kind of modelling work based on what I observe there, then I will build an AI that acts in some way upon the model I construct, and in this way I will sidestep needing an explicit answer to the thorny philosophical questions of what true benefit really means:
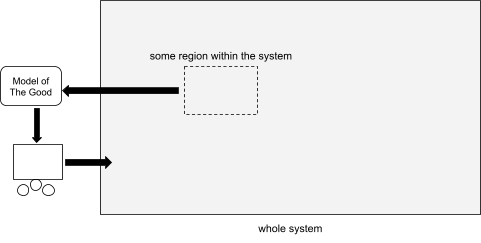
You might then ask which part of the system will I examine and what is it that I hope to find there that will guide the actions of the powerful AI that I intend to insert into the system. Well, suppose for the sake of this thought experiment that the part of the world I am planning to examine was the right toe of one of the humans:

Suppose I have an elaborate scheme in which I will observe this toe for aeons, learn everything there is to learn about it, interact with it in this or that way, model it in this or that way, place it in various simulated environments and interact with it in those simulated environments, wait for it to reach reflective equilibrium with itself, and so forth. What do you say? You say: well, this is just not going to work. The information I seek is just not in the toe. It is not there. I can examine the spatial region containing a single human toe for a long time but the information I seek is not there, so the AI I build is not going to be of true benefit to this ecosystem and the living beings within it.
What information is it that I am seeking? Well I am seeking information sufficient to guide the actions of the AI. I do not have an understanding of how to derive beneficial action from first principles so I hope to learn or imitate or examine something somewhere in a way that will let me build an AI whose actions are beneficial. It could be that I extract a policy or a value function or something else entirely. Suppose for the sake of thought experiment that I am in fact a computer scientist from the future and that I present to you some scheme that is unlike anything in contemporary machine learning, but still consists of examining a part of the world, learning something from it, and on that basis building an AI that sidesteps the need for a first principles answer to the question of what it means to be beneficial. And suppose, to continue with my thought experiment, that the region of space I am examining is still a single human toe. It really does not matter what sophisticated scheme I present: if the part of the world that I’m examining is a left toe then this scheme is not going to work, because this part of the world does not contain the kind of information that could guide the actions of an AI that will have power over this ecosystem’s destiny.
Now let us suppose that I present to you the following revised plan: the part of the world I am going to examine is a living rabbit. Yes, a rabbit:
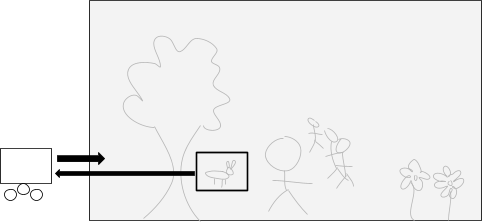
Again, let’s say that I present some sophisticated scheme for extracting something from this part of the world. Perhaps I am going to extrapolate what the rabbit would do if it had more time to consider the consequences of its actions. Or perhaps I am going to evolve the rabbit forward over many generations under simulation. Or perhaps I am going to provide the rabbit with access to a powerful computer on which it can run simulations. Or perhaps I have some other scheme in mind, but it is still within the following framework: I will examine the configuration of atoms within a spatial region consisting of a live rabbit, and on the basis of what I find there I will construct an AI that I will then insert into this ecosystem, and this AI will be powerful enough to determine the future of life in this ecosystem.
Now, please do not get confused about whether I am trying to build an AI that is beneficial to humans or to rabbits. Neither of those is my goal in this hypothetical story. I am trying to build an AI that is overall beneficial to this system, but I do not know what that means, or how to balance the welfare of rabbits versus that of humans versus that of trees, or what welfare means, or whether the welfare of the whole system can be decomposed into the welfare of the individual beings, or whether welfare is the right kind of frame to start with. I am deeply confused at every level about what it means for any system to be of true benefit to anything, and it is for that very reason that I am building an extraction-oriented AI: my hope is that rather than first coming to a complete understanding of what it means to be of true benefit to this small world and only then building an AI to implement that understanding, I can sidestep the issue by extracting some information from the world itself. Perhaps if I do the right kind of extraction -- which may involve allowing the rabbit to reflect for a long time, or allowing it to interact with statistical imitations of itself interacting with statistical imitations of itself, or any other such scheme -- then I can find an answer to these questions within the world itself. And it does not have to be an answer that I personally can understand and be satisfied with, but just an answer that can guide the actions of the AI that I plan to insert into this world. But no matter how many layers of uncertainty we have or what specific scheme I present to you, you might still ask: is it plausible that the information I seek is present in the particular spatial region that I propose to examine?
And, I ask you now, back here in the real world: is this information in fact present in the rabbit? Could some hypothetical superhumans from the future build this AI in a way that actually was beneficial if they were limited to examining a spatial region containing a single rabbit? What is the information we are seeking, and is it present within the rabbit?
I ask this because I want to point out how nontrivial is the view that we might examine any part of such a system and find answers to these profound questions, no matter how the extraction is done. Some people seem to hold the view that we could find these answers by examining a human brain, or a whole human body:
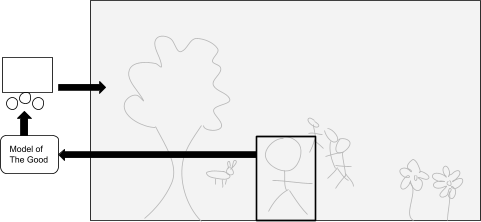
Of course, the schemes for doing this do not anticipate that we will just read out answers from the structure of the brain. They are more sophisticated than that. Some anticipate running simulations of the human brain based on the neural structures we find and asking questions to those simulations. Others anticipate modelling the brain based on the output it produces when fed certain inputs. But the point is that so long as we are in the regime of extraction-oriented AI, which is to say that we examine a spatial region within a system, then, based on what we find there, build an AI that takes actions that affect the whole system, then we might reasonably ask: is the information we seek plausibly present in the spatial region that we are examining? And if so, why exactly do we believe that?
Is it plausible, for example, that we could examine just the brain of a human child? How about examining an unborn human embryo? A strand of human DNA? A strand of DNA from a historical chimpanzee from which modern humans evolved? A strand of DNA from the first organism that had DNA? If the information we seek is in the human brain then how far back in time can we go? If we have a method for extracting it from an adult human brain then could we not extract it from some causal precursor to a fully-formed human brain by evolving a blueprint of the precursor forward in time? We are not talking here about anything so mundane as extracting contemporary human preferences; we are trying to extract answers to the question of whether preferences are even the right frame to use, whether we should incorporate the preferences of other living beings, where the division between moral patienthood and moral non-patienthood is, whether the AI itself is a moral patient, whether the frame of moral patients is even the right frame to use. These are deep questions. The AIs we build are going to do something, and that something may or may not be what is truly beneficial to the systems into which we deploy them. We cannot avoid these questions completely, but we hope to sidestep explicitly answering them by imitating or learning from or modelling something from somewhere that can form some kind of basis for an AI that takes actions in the world. If we are within this extraction-oriented AI regime, then the actions taken by the AI will be a function of the physical configuration of matter within the spatial regions that we examine. So we might ask: do we want the future to be determined by the physical configuration of matter within this particular spatial region? For which spatial regions are we willing to say yes? So long as we are in this regime, no amount of modelling wizardry changes this functional dependence of the whole future of this world upon the physical configuration of some chosen part of the world.
If the spatial region we choose is a human brain, or a whole human body, or even an entire human society, then we should ask: how is it that the information in this spatial region is relevant to how we would want the overall configuration of the system to evolve, but information outside that spatial region is not relevant? How did that come to be the case?
As I wrote in my reflections on a recent seminar by Michael Littman [LW · GW], it seems to me that my own intentions have updated over time at every level. It does not seem to me that I have some underlying fixed intentions lying deep within me that I am merely unfolding. It seems to me that it is through interacting with the world that my intentions develop and mature. I do not think that you could find out my current intentions by examining my younger self because the information was not all in there: much of the information that informs my current intentions was at that time out in the world, and it is through encountering it that I have arrived at my current intentions. And I anticipate this process continuing into the future. I would not trust any scheme that would look for my true intentions by examining my physical body and brain today, because I do not think the information about my deepest intentions in the future is located entirely within my body and brain today. Instead I think that my intentions will be informed by my interactions with the world, and some of the information about how that will go is out there in the world.
But this is just introspective conjecture. I do not have full access to my own inner workings so I cannot report on exactly how it is that my intentions are formed. My point here is more modest, and it is this: that we can discover what is of benefit to a system by examining a certain part of the system is a profound claim. If we are to examine a part of the universe in which we find ourselves located, and that part contains one or several hairless primates under the supposition that the desired information is present in that part, then we should have a good account of how that came to be the case. It is not obvious to me that it is in there.
12 comments
Comments sorted by top scores.
comment by Ben Pace (Benito) · 2021-04-21T02:36:49.870Z · LW(p) · GW(p)
This reminds me that it's hard for me to say where "I" am, in both space and time.
I read a story recently (which I'm going to butcher because I don't remember the URL), about a great scientist who pulled a joke: after he died, his wife had a seance or used a ouija board or something, which told her to look at the first sentence of the 50th page of his book, and the first sentence was "<The author> loved to find creative ways to communicate with people."
After people die, their belongings and home often contain an essence of 'them'. I think that some people build great companies or write code or leave children or a community, that in many ways is an instantiation of parts of their person. If you enter my bedroom, you will see my thoughts all over the walls, on the whiteboards, and to some extent you can still engage with me and learn from me there. More so than if I were physically in a coma (or cremated).
So it's not obvious to say "where" in the world I am and where you can learn about me.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-04-21T02:40:42.205Z · LW(p) · GW(p)
Yes, I agree.
I once stayed in Andrew Critch's room for a few weeks while he was out of town. I felt that I was learning from him in his absence because he had all these systems and tools and ways that things were organized. I described it at the time as "living inside Critch's brain for two weeks", which was a great experience. Thanks Critch!
comment by Yegreg · 2021-04-22T19:28:57.597Z · LW(p) · GW(p)
This is not super tightly related, but seems worth mentioning because it's interesting.
There's an interesting result in Quantum Field Theory called the Reeh-Schlieder theorem, which can be interpreted to mean that any open spacetime region contains the information of all of spacetime. So in principle you could know the past and future of the whole universe by watching a toe for any small amount of time, although this knowing refers to quantum information, and even then this seems entirely impractical due to some exponential decays.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-04-23T02:37:43.489Z · LW(p) · GW(p)
Wow. That is wild. Just from a personal curiosity point of view: thank you!
comment by Measure · 2021-04-21T12:24:17.561Z · LW(p) · GW(p)
It's not obvious to me that the information you're looking for is not present in a single toe. In the same way that an advanced AI could discover General Relativity by carefully examining a few frames of a falling apple, couldn't it infer something about human/rabbit/rainforest values by observing the behavior of a toe? My concern would instead be that there is too much information and that the AI would pick out some values but not necessarily the ones you expect.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-04-21T14:15:16.203Z · LW(p) · GW(p)
But the question is whether values are even the right way to go about this problem. That's the kind of information we're seeking: information about how even to go about being beneficial, and what beneficial really means. Does it really make sense to model a rainforest as an agent and back out a value function for it? If we did that, would it work out in a way that we could look back on and be glad about? Perhaps it would, perhaps it wouldn't, but the hard problem of AI safety is this question of what even is the right frame to start thinking about this in, and how we can even begin to answer such a question.
Now perhaps it's still true that the information we seek can be found in a human toe. But just beware that we're not talking about anything so concrete as values here.
comment by Gordon Seidoh Worley (gworley) · 2021-05-09T16:14:03.604Z · LW(p) · GW(p)
Largely agree. I think you're exploring what I'd call the deep implications of the fact that agents are embedded rather than Cartesian.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-05-09T19:44:12.900Z · LW(p) · GW(p)
Interesting. Is it that if we were Caresian, you'd expect to be able to look at the agent-outside-the-world to find answers to questions about what even is the right way to go about building AI?
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2021-05-11T05:21:23.436Z · LW(p) · GW(p)
Not really. If we were Cartesian, in order to fit the way we find the world, it seems to be that it'd have to be that agentiness is created outside the observable universe, possibly somewhere hypercomputation is possible, which might only admit an answer about how to build AI that would look roughly like "put a soul in it", i.e. link it up to this other place where agentiness is coming from. Although I guess if the world really looked like that maybe the way to do the "soul linkage" part would be visible, but it's not so seems unlikely.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-05-11T15:37:53.147Z · LW(p) · GW(p)
Well ok, agreed, but even if we were Cartesian, we would still have questions about what is the right way to link up our machines with this place where agentiness is coming from, how we discern whether we are in fact Cartesian or embedded, and so on down to the problem of the criterion as you described it.
One common response to any such difficult philosophical problems seems to be to just build AI that uses some form of indirect normativity such as CEV or HCH or AI debate to work out what wise humans would do about those philosophical problems. But I don't think it's so easy to sidestep the problem of the criterion.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2021-05-11T16:37:58.394Z · LW(p) · GW(p)
Oh, I don't think those things exactly sidestep the problem of the criterion so much as commit to a response to it without necessarily realizing that's what they're doing. All of them sort of punt on it by saying "let humans figure out that part", which at the end of the day is what any solution is going to do because we're the ones trying to build the AI and making the decisions, but we can be more or less deliberate about how we do this part.
comment by adamShimi · 2021-04-22T17:01:01.657Z · LW(p) · GW(p)
I have two reactions while reading this post:
- First, even if we say that a given human (for example) at a fixed point in time doesn't necessarily contain everything that we would want the AI to learn, if it only learns what's in there, there might already be a lot of alignment failures that disappear. For example paperclip maximizers are probably ruled out by taking one human's values at a point in time and extrapolating. But that clearly doesn't help with scenarios where the AI does the sort of bad things humans can do, for example.
- Second, I would argue that in the you of the past, there might actually be enough information to encode, if not the you of now, at least better and better versions of you through interactions with the environment. Or said another way, I feel like what we're pointing at when we're pointing at a human is the normativity [AF · GW] of human values, including how they evolve, and how we think about how they evolve, and... recursively. So I think you might actually have all the information you want from this part of space if AI captures the process behind rethinking our values and ideas.