Learning Normativity: A Research Agenda
post by abramdemski · 2020-11-11T21:59:41.053Z · LW · GW · 18 commentsContents
Example: Language Learning Learning in the Absence of a Gold Standard No Perfect Feedback No Perfect Loss Function Process-Level Feedback Learning from Process-Level Feedback Prospects for Inner Alignment Summary of Desiderata Initial Attempt: Recursive Quantilizers Parameterizing Stationary Distributions Analysis in terms of the Criteria None 18 comments
(Related to Inaccessible Information [AF · GW], Learning the Prior [AF · GW], and Better Priors as a Safety Problem [AF · GW]. Builds on several of my alternate alignment ideas [? · GW].)
I want to talk about something which I'll call learning normativity. What is normativity? Normativity is correct behavior. I mean something related to the fuzzy concept humans convey with the word "should". I think it has several interesting features:
- Norms are the result of a complex negotiation between humans, so they shouldn't necessarily be thought of as the result of maximizing some set of values. This distinguishes learning normativity from value learning.
- A lot of information about norms is present in the empirical distribution of what people actually do, but you can't learn norms just by learning human behavior. This distinguishes it from imitation learning.
- It's often possible to provide a lot of information in the form of "good/bad" feedback. This feedback should be interpreted more like approval-directed learning [AF · GW] rather than RL. However, approval should not be treated as a gold standard.
- Similarly, it's often possible to provide a lot of information in the form of rules, but rules are not necessarily 100% true; they are just very likely to apply in typical cases.
- In general, it's possible to get very rich types of feedback, but very sparse: humans get all sorts of feedback, including not only instruction on how to act, but also how to think.
- Any one piece of feedback is suspect. Teachers can make mistakes, instructions can be wrong, demonstrations can be imperfect, dictionaries can contain spelling errors, reward signals can be corrupt, and so on.
Example: Language Learning
A major motivating example for me is how language learning works in humans. There is clearly, to some degree, a "right way" and a "wrong way" to use a language. I'll call this correct usage.
One notable feature of language learning is that we don't always speak, or write, in correct usage. This means that a child learning language has to distinguish between mistakes (such as typos) and correct usage. (Humans do sometimes learn to imitate mistakes, but we have a notion of not doing so. This is unlike GPT [? · GW] systems learning to imitate the empirical distribution of human text.)
This means we're largely doing something like unsupervised learning, but with a notion of "correct"/"incorrect" data. We're doing something like throwing data out when it's likely to be incorrect.
A related point is that we are better at recognizing correct usage than we are at generating it. If we say something wrong, we're likely able to correct it. In some sense, this means there's a foothold for intelligence amplification: we know how to generate our own training gradent.
Another fascinating feature of language is that although native speakers are pretty good at both recognizing and generating correct usage, we don't know the rules explicitly. The whole field of linguistics is largely about trying to uncover the rules of grammar.
So it's impossible for us to teach proper English by teaching the rules. Yet, we do know some of the rules. Or, more accurately, we know a set of rules that usually apply. And those rules are somewhat useful for teaching English. (Although children have usually reached fluency before the point where they're taught explicit English grammar.)
All of these things point toward what I mean by learning normativity:
- We can tell a lot about what's normative by simply observing what's common, but the two are not exactly the same thing.
- A (qualified) human can usually label an example as correct or incorrect, but this is not perfect either.
- We can articulate a lot about correct vs incorrect in the form of rules; but the rules which we can articulate never seem to cover 100% of the cases. A linguist is a lot like a philosopher: taking a concept which is understood at an intuitive level (which a great many people can fluently apply in the correct manner), but struggling for years to arrive at a correct technical definition which fits the intuitive usage.
In other words, the overriding feature of normativity which I'm trying to point at is that nothing is ever 100%. Correct grammar is not defined by any (known) rules or set of text, nor is it (quite) just whatever humans judge it is. All of those things give a lot of information about it, but it could differ from each of them. Yet, on top of all that, basically everyone learns it successfully. This is very close to Paul's Inaccessible Information [AF · GW]: information for which we cannot concoct a gold-standard training signal, but which intelligent systems may learn anyway.
Another important feature of this type of learning: there is a fairly clear notion of superhuman performance. Even though human imitation is most of the challenge, we could declare something superhuman based on our human understanding of the task. For example, GPT is trained exclusively to imitate, so it should never exceed human performance. Yet, we could tell if a GPT-like system did exceed human performance:
- Its spelling and grammar would be immaculate, rather than including humanlike errors;
- its output would be more creative and exciting to read than that of human authors;
- when good reasoning was called for in a text, its arguments would be clear, correct, and compelling;
- when truth was called for, rather than fiction, its general knowledge would be broader and more accurate than a human's.
It seems very possible to learn to be better than your teachers in these ways, because humans sometimes manage to do it.
Learning in the Absence of a Gold Standard
In statistics and machine learning, a "gold standard" is a proxy which we treat as good enough to serve as ground truth for our limited purposes. The accuracy of any other estimate will be judged by comparison to the gold standard. This is similar to the concept of "operationalization" in science.
It's worth pointing out that in pure Bayesian terms, there is nothing especially concerning about learning in the absence of a gold standard. I have data X. I want to know about Y. I update on X, getting P(Y|X). No problem!
However, that only works if we have the right prior. We could try to learn the prior from humans [LW · GW], which gets us 99% of the way there... but as I've mentioned earlier, human imitation does not get us all the way. Humans don't perfectly endorse their own reactions.
(Note that whether "99% of the way" is good enough for AI safety is a separate question. I'm trying to define the Big Hairy Audacious Goal of learning normativity.)
Actually, I want to split "no gold standard" into two separate problems.
- There's no type of feedback which we can perfectly trust. If humans label examples of good/bad behavior, a few of those labels are going to be wrong. If humans provide example inferences for learning the prior, some of those example inferences are (in a very real sense) wrong. And so on.
- There's no level at which we can perfectly define the loss function. This is a consequence of no-perfect-feedback, but it's worth pointing out separately.
No Perfect Feedback
I think I've made the concept of no-perfect-feedback clear enough already. But what could it mean to learn under this condition, in a machine-learning sense?
There are some ideas that get part of the way:
- Jeffrey updates [LW · GW] let us update to a specific probability of a given piece of feedback being true, rather than updating to 100%. This allows us to, EG, label an image as 90%-probable cat, 9%-probable dog, 1% broad distribution over other things.
- This allows us to give some evidence, while allowing the learner to decide later that what we said was wrong (due to the accumulation of contrary evidence).
- This seems helpful, but we need to be confident that those probability assignments are themselves normatively correct, and this seems like it's going to be a pretty big problem in practice.
- Virtual evidence [LW · GW] is one step better: we don't have to indicate what actual probability to update to, but instead only indicate the strength of evidence.
- Like Jeffrey updates, this means we can provide strong evidence while still allowing the system to decide later that we were wrong, due to the accumulation of contradicting evidence.
- Unlike Jeffrey updates, we don't have to decide what probability we should update to, only the direction and strength of the evidence.
- Soft labels in machine learning provide a similar functionality. In EM learning, a system learns from its own soft labels. In LO-shot learning, a system leverages the fact that soft labels contain more information than hard labels, in order to learn classes with less than one examples per class.
However, although these ideas capture weak feedback in the sense of less-than-100%-confidence feedback, they don't capture the idea of reinterpretable feedback:
- A system should ideally be able to learn that specific types of feedback are erroneous, such as corrupted-feedback cases in reinforcement learning. A system might learn that my feedback is lower quality right before lunch, for example.
- A system should be able to preserve the overall meaning of a label despite an ontology shift. For example, deciding that fruit/vegetable is not a useful taxonomic or culinary distinction should not destroy the information gained from such labels. Or, if human feedback includes formal English grammar, that information should not be totally discarded if the system realizes that the rules don't fully hold and the supposed grammatical categories are not as solid as claimed.
- Feedback should be associated with a cloud of possible interpretations. When humans say "weird", we often mean "unusual", but also sometimes mean "bad". When humans say we don't understand, we often really mean we don't endorse. A system should, ideally, be able to learn a mapping from the feedback humans actually give to what they really mean. This is, in any case, the general solution to the previous bullet points.
But "learning a mapping from what feedback is given to what is meant" appears to imply that there is no fixed loss function for machine learning to work on, which would be a serious challenge. This is the subject of my point #2 from earlier:
No Perfect Loss Function
We can frame (some) approaches to the value specification problem [LW · GW] in a sequence of increasingly sophisticated approaches (similar to the hierarchy I discussed in my "stable pointers to value" posts (1 [? · GW],2 [? · GW],3 [? · GW])):
- Direct specification of the value function. This fails because we don't know what values to specify, and expect anything we can write down to be highly Goodhart-able.
- Learning human values. We delegate the specification problem to the machine. But, this leaves us with the meta problem of specifying how to learn. Getting it wrong can lead to wireheading and human manipulation. Even in settings where this is impossible, we face Stuart's no-free-lunch results [LW · GW].
- Learning to learn human values. Stuart suggests that we can get around the no-free-lunch results by loading the right prior information into the learner [LW · GW], in keeping with his more general belief that Bayesian reasoning is fine as long as it has the right prior information [LW · GW]. But this seems to go back to the problem of learning the human prior. So we could apply a learning approach again here. But then we again have a specification problem for the loss function for this learning...
- ...
You get the picture. We can keep pushing back the specification problem by learning, learning to learn, learning to learn to learn... Each time we push the problem back, we seem to gain something, but we're also stuck with a new specification problem at the meta level.
Could we specify a way to learn at all the levels, pushing the problem back infinitely? This might sound absurd, but I think there are ways to accomplish this. We need to somehow "collapse all the levels into one learner" -- otherwise, with an infinite number of levels to learn, there would be no hope. There needs to be very significant generalization across levels. For example, Occam's razor is a good starting rule of thumb at all levels (at least, all levels above the lowest). However, because Occam is not enough, it will need to be augmented with other information [LW · GW].
Recursive reward modeling is similar to the approach I'm sketching, in that it recursively breaks down the problem of specifying a loss function. However, it doesn't really take the same learning-to-learn approach, and it also doesn't aim for a monolithic learning system that is able to absorb information at all the levels.
I think of this as necessary learning-theoretic background work in order to achieve Stuart Armstrong's agenda [LW · GW], although Stuart may disagree. The goal here is to provide one framework in which all the information Stuart hopes to give a system can be properly integrated.
Note that this is only an approach to outer alignment [? · GW]. The inner alignment problem [? · GW] is a separate, and perhaps even more pressing, issue. The next section could be of more help to inner alignment, but I'm not sure this is overall the right path to solve that problem.
Process-Level Feedback
Sometimes we care about how we get the answers, not just what the answers are. That is to say, sometimes we can point out problems with methodology without being able to point to problems in the answers themselves. Answers can be suspect based on how they're computed.
Sometimes, points can only be effectively made in terms of this type of feedback. Wireheading and human manipulation can't be eliminated through object-level feedback, but we could point out examples of the wrong and right types of reasoning.
Process-level feedback blurs the distinction between inner alignment and outer alignment. A system which accepts process-level feedback is essentially exposing all its innards as "outer", so if we can provide the appropriate feedback, there should be no separate inner alignment problem. (Unfortunately, it must be admitted that it's quite difficult to provide the right feedback -- due to transparency issues, we can't expect to understand all models in order to give feedback on them.)
I also want to emphasize that we want to give feedback on the entire process. It's no good if we have "level 1" which is in charge of producing output, and learns from object-level feedback, but "level 2" is in charge of accepting process-level feedback about level 1, and adjusting level 1 accordingly. Then we still have a separate inner alignment problem for level 2.
This is the same kind of hierarchy problem we saw in "No Perfect Loss Function". Similarly, we want to collapse all the levels down. We want one level which is capable of accepting process-level feedback about itself.
Learning from Process-Level Feedback
In a Bayesian treatment, process-level feedback means direct feedback about hypotheses. In theory, there's no barrier to this type of feedback. A hypothesis can be ruled out by fiat just as easily as it can be ruled out by contradicting data.
However, this isn't a very powerful learning mechanism. If we imagine a human trying to inner-align a Bayesian system this way, the human has to find and knock out every single malign hypothesis. There's no generalization mechanism here.
Since detecting malign hypotheses is difficult, we want the learning system to help us out here. It should generalize from examples of malign hypotheses, and attempt to draw a broad boundary [LW · GW] around malignancy. Allowing the system to judge itself in this way can of course lead to malign reinterpretations of user feedback, but hopefully allows for a basin of attraction [LW · GW] in which benevolent generalizations can be learned.
For example, in Solomonoff induction, we have a powerful hierarchical prior in the distribution on program prefixes. A program prefix can represent any kind of distribution on hypotheses (since a program prefix can completely change the programming language to be used in the remainder of the program). So one would hope that knocking out hypotheses would reduce the probability of all other programs which share a prefix with that hypothesis, representing a generalization "this branch in my hierarchical prior on programs seems iffy". (As a stretch goal, we'd also like to update against other similar-looking branches; but we at least want to update against this one.)
However, no such update occurs. The branch loses mass, due to losing one member, but programs which share a prefix with the deleted program don't lose any mass. In fact, they gain mass, due to renormalization.
It seems we don't just want to update on "not this hypothesis"; we want to explicitly model some sort of malignancy judgement (or more generally, a quality-of-hypothesis judgement), so that we can update estimations of how to make such judgements. However, it's difficult to see how to do so without creating a hierarchy, where we get a top level which isn't open to process-level feedback (and may therefore be malign).
Later, I'll present a Bayesian model which does have a version of generalization from feedback on hypotheses. But we should also be open to less-Bayesian solutions; it's possible this just isn't captured very well by Bayesian learning.
Prospects for Inner Alignment
I view this more as a preliminary step in one possible approach to inner alignment, rather than "a solution to inner alignment".
If (a) you want to learn a solution to inner alignment, rather than solving it ahead of time, and (b) you agree with the framing of process-level feedback / feedback on hypotheses, and (c) you agree that we can't rely on a trusted meta-level to take process-level feedback, but rather need to accept feedback on "the whole process", then I think it stands to reason that you need to specify what it means to learn in this setting. I view the preceding sections as an argument that there's a non-obvious problem here.
For example, Stuart Armstrong has repeatedly argued [LW · GW] that Bayesian learners can overcome many safety problems, if only they're given the right prior information. To the extent that this is a claim about inner alignment (I'm not sure whether he would go that far), I'm claiming that we need to solve the problem of giving process-level feedback to a Bayesian learner before he can make good on his claim; otherwise, there's just no known mechanism to provide the system with all the necessary information.
Anyway, even if we accomplish this step, there are still several other obstacles in the way of this approach to inner alignment.
- Transparency: It's unrealistic that humans can provide the needed process-level feedback without powerful transparency tools. The system needs to correctly generalize from simpler examples humans provide to the more difficult examples which a human can't understand. That will be difficult if humans can only label very very simple examples.
- Basin of Attraction: Because the system could use malign interpretations of human feedback, it's very important that the system start out in a benign state, making trusted (if simplistic) generalizations of the feedback humans can provide.
- Running Untrusted Code: A straightforward implementation of these ideas will still have to run untrusted hypotheses in order to evaluate them. Giving malign hypotheses really low probability doesn't help if we still run really low-probability hypotheses, and the malign hypotheses can find an exploit. This is similar to Vanessa's problem of non-Cartesian daemons [LW · GW].
Regardless of these issues, I think it's valuable to try to solve the part of the problem I've outlined in this essay, in the hope that the above issues can also be solved.
Summary of Desiderata
Here's a summary of all the concrete points I've made about what "learning normativity" should mean. Sub-points are not subgoals, but rather, additional related desiderata; EG, one might significantly address "no perfect feedback" without significantly addressing "uncertain feedback" or "interpretable feedback".
- No Perfect Feedback: we want to be able to learn with the possibility that any one piece of data is corrupt.
- Uncertain Feedback: data can be given in an uncertain form, allowing 100% certain feedback to be given (if there ever is such a thing), but also allowing the system to learn significant things in the absence of any certainty.
- Reinterpretable Feedback: ideally, we want rich hypotheses about the meaning of feedback, which help the system to identify corrupt feedback, and interpret the information in imperfect feedback.
- No Perfect Loss Function: we don't expect to perfectly define the utility function, or what it means to correctly learn the utility function, or what it means to learn to learn, and so on. At no level do we expect to be able to provide a single function we're happy to optimize.
- Learning at All Levels: Although we don't have perfect information at any level, we do get meaningful benefit with each level we step back and say "we're learning this level rather than keeping it fixed", because we can provide meaningful approximate loss functions at each level, and meaningful feedback for learning at each level. Therefore, we want to be able to do learning at each level.
- Between-Level Sharing: Because this implies an infinite hierarchy of levels to learn, we need to share a great deal of information between levels in order to learn meaningfully.
- Process Level Feedback: we want to be able to give feedback about how to arrive at answers, not just the answers themselves.
- Whole-Process Feedback: we don't want some segregated meta-level which accepts/implements our process feedback about the rest of the system, but which is immune to process feedback itself. Any part of the system which is capable of adapting its behavior, we want to be able to give process-level feedback about.
- Learned Generalization of Process Feedback: we don't just want to promote or demote specific hypotheses. We want the system to learn from our feedback, making generalizations about which kinds of hypotheses are good or bad.
Initial Attempt: Recursive Quantilizers
I'll give an initial stab at solving these problems, as a proof-of-concept. (Otherwise I fear the above desiderata may look like they're simply impossible.)
This is a formalization of the recursive quantilizers [? · GW] idea which I described previously.
A quantilizer [AF · GW] is a mild optimizer which avoids catastrophic outcomes with high probability, averting Goodhart's Law [LW · GW]. It accomplishes this by refusing to 100% trust its value function. This seems like a good building block for us, since it significantly addresses "no perfect loss function."
A quantilizer requires a value function, , which it mildly optimizes, and a safe distribution, , which is a distribution over outputs which is assumed to have a low probability of catastrophic outcomes. It also requires an optimization parameter, . The quantilizer mildly optimizes by randomly taking the top % of outputs from , as ranked by . ( can be derived from an estimate of the probability of catastrophe in , combined with a level of tolerance for catastrophic risk.)
In line with our learning at all levels desiderata, we want to learn , , and . Moreover, we'll produce all of these via quantilization, and recursively learn the inputs to all of those quantilizers as well.
In order to get between-level sharing, we will actually learn one big quantilization process which is equivalent to all those infinitely many levels.
Here's the setup.
In order to unify all the levels, I'll have quantilizers select unified type for all arguments (UTAAs): a tuple where is the object-level output we want out of the whole system (EG plans, strings of text, whatever). So now we understand the quantilization function to take 3 UTAAs. It will take the value function from the first, the safe distribution from the second, and the optimization parameter from the third. It then produces a UTAA. The user can take the object-level output of that UTAA as the result.*
What we want is a notion of stationary distribution on UTAAs. This is a distribution such that if we sample 3 elements from , and feed those three elements into , the distribution on outputs of is just again.
In effect, a stationary distribution is all quantilized out; we can quantilize again, but it won't make any difference. So, we can just sample from and take the object-level output from the resulting UTAA.
This is very similar to the notion of stationary distribution for markov chains. The difference is that we have a markov tree instead of a chain.
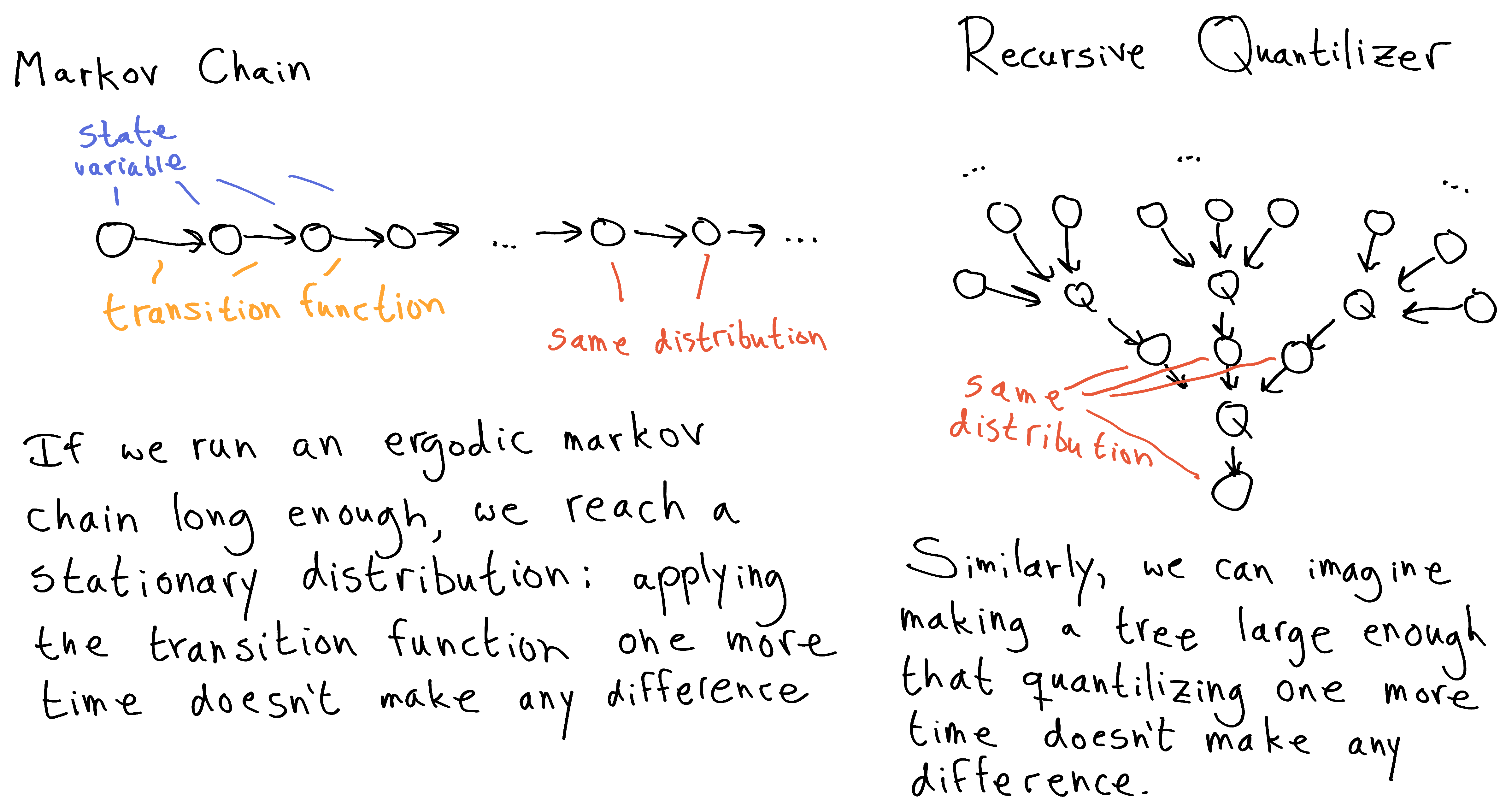
So, just as finding the stationary distribution of a markov-chain monte carlo algorithm is similar to running the algorithm long enough that running it any longer is pointless, finding a stationary distribution for recursive quantilizers is like building a learning-to-learn hierarchy that's large enough that we don't get anything by going any further.
That's all well and good, but how are we supposed to find a stationary distribution we like? We can't just take a fixed point and hope it's useful and benign; there'll be lots of crazy fixed points. How do we steer this thing toward desirable outcomes?
Parameterizing Stationary Distributions
If a markov chain has multiple stationary distributions, we can parameterize them through a distribution on starting states. A distribution on starting states just means a probability of picking any one starting element, so this relationship is completely linear: by interpolating between different starting elements, we interpolate between the stationary distributions which those starting elements eventually reach.
We can similarly parameterize stationary distributions via initial distributions. However, we don't get the same linearity. Because we have to select many starting elements for the inputs to an -level tree, and we select those elements as independent draws from the initial distribution, we can get nonlinear effects. (This is just like flipping a biased coin (with sides labelled 1 and 0) twice and sending the two results through an XOR gate: the probability of getting a 1 out of the XOR is nonlinear in the bias.)
This means we can't reduce our uncertainty over initial distributions to uncertainty over initial UTAA. (There may be some other tricks we can use to simplify things, but they probably aren't worth exploring in this post.)
So we can parameterize our uncertainty over stationary distributions via uncertainty over initial distributions. But, this is just turning uncertainty over one kind of distribution into uncertainty over another. What's the benefit of this?
- The set of stationary distributions is hard to know, but the set of possible initial distributions is clear. So this gives us an easy-to-work-with representation of stationary distributions.
- We know every stationary distribution is in the set, since we can start out in a stationary distribution.
- We can easily define the mapping from initial distributions to stationary distributions; it's just the stationary distribution you get by running things long enough, sampling from the given initial distribution. (Of course we may not get to any stationary distribution at all, but we can formally solve this by introducing a cutoff in program size, or through other devices.)
- We can therefore define learning: an update against a UTAA produces an update against initial distributions which produce that UTAA.
This is, of course, a very computationally intensive procedure. Unless better algorithms are found, the only way we can update is by producing a large quantilization tree (which we hope has converged) and running it many times to evaluate the outcome of a given initial distribution.
However, the resulting system has many marvelous properties. If we want to give feedback at any level in the hierarchy, we can convert this into feedback about UTAAs, and update our prior over initial distributions accordingly. For example:
- We can label outputs as bad/incorrect by updating against all UTAAs which include those outputs.
- We can give evidence about the value function over outputs, and convert this to an update about UTAAs based on the value function they contain. So, we can do value learning.
- We can learn about the safe distribution over outputs. For example, one proposal for finding safe distributions is to model human behavior. Data-sets of human behavior could induce updates over UTAAs by checking how well a UTAA's proposed safe distribution fits the data.
- At the same time, we can learn about the loss function by which we score safe distributions. If we have an update about this loss function, we translate it to an update about UTAAs by checking how a UTAA's value function examines the safe distribution of another UTAA when scoring it. Updating UTAAs based on this will, effectively, change the way safe distributions are selected in the second-to-last quantilization step. (Of course, it really changes all the quantilization steps, but when we anchor ourselves in how changes to the initial distribution alter our distribution on actual outputs, the easiest way to understand what's going on is to see this as a change to the second-to-last step.)
- Similarly, we can learn about the loss function by which we score loss functions. So in the same system, we can directly learn from feedback, we can do value learning, and we can do meta-value-learning where we learn how to interpret evidence in value-learning.
- Similarly, we can learn the safe distribution for meta-loss functions, the safe distribution over safe distributions, and on and on.
- We can also allow process-level feedback by enabling UTAA value functions to examine the source code of other UTAAs (e.g. looking at how those UTAAs compute their value functions and safe distributions). We can teach UTAAs to detect suspicious code in other UTAAs and rate those UTAAs very poorly.
Wouldn't it be fascinating to be able to provide all those types of learning in one system?
Analysis in terms of the Criteria
Let's examine how we did in terms of the criteria which I gave.
- No Perfect Feedback: This wasn't addressed directly, but might be indirectly addressed via #2.
- Uncertain Feedback: I didn't specify any way to provide uncertain feedback, but it would be easy enough to do so.
- Reinterpretable Feedback: I think this is a big failing of the approach as it stands.
- No Perfect Loss Function: Very significantly addressed by quantilization.
- Learning at All Levels: Very significantly addressed by the recursive quantilization setup.
- Between-Level Sharing: Significantly addressed. I didn't really talk about how this works, but I think it can work well in this setup.
- Process Level Feedback: Significantly addressed. The process which creates a given output is essentially the big tree that we sample. We can give any kind of feedback about that tree that we want, including any computations which occur inside of the value functions or safe distributions or elsewhere.
- Whole-Process Feedback: Somewhat addressed. There is a question of whether the initial distribution constitutes a meta-level beyond the reach of process-level feedback.
- Learned Generalization of Process Feedback: Significantly addressed. Process-level feedback can be given directly, as evidence against a specific UTAA, in which case there will be some generalization as we update against anything which thought that UTAA was a good idea. Or it could be given more indirectly, as general (level-independent) information about how value functions should judge UTAA. In that case there may be more generalization, as we update on how to judge UTAAs generally. (Or maybe not? An equivalence theorem about these different types of feedback would be nice.)
I think the most significant problem here is the lack of reinterpretable feedback. When we give feedback about something, we have to figure out how to translate it into an update about UTAAs (which can then be translated into an update about initial distributions). This update is fixed forever. This means the updates we make to the system aren't really tied to the value functions which get learned. So, for example, learning better value-learning behavior doesn't directly change how the system responds to updates we give it about the value function. (Instead, it may change how it interprets some other set of data we give it access to, as input to UTAAs.) This makes the "learning-to-learn" aspect of the system somewhat limited/shallow.
The second most significant concern here is whether we've really achieved whole-process feedback. I was initially optimistic, as the idea of stationary distributions appeared to collapse all the meta levels down to one. However, now I think there actually is a problem with the highest level of the tree. The initial distribution could be predominantly malign. Those malign UTAAs could select innocent-looking (but deadly) UTAAs for the next generation. In this way, the malign code could disappear, while achieving its goals by introducing subtle bugs to all subsequent generations of UTAAs.
The way I've specified things, trying to update against these malign UTAAs wouldn't work, because they're already absent in the stationary distribution.
Of course, you could directly update against them in the initial distribution. This could eliminate select malign UTAAs. The problem is that this kind of process feedback loses generalizability again. Since it's the top level of the tree, there's nothing above it which is selecting it, so we don't get to update against any general selection behaviors which produced the malign UTAAs.
The only way out of this I see at present is to parameterize the system's beliefs directly as a probability distribution over stationary distributions.. You can think of this as assuming that the initial distribution is already a stationary distribution. This way, when we update against malign UTAAs at the beginning of the process, we update against them occurring at any point in the process, which means we also update against any UTAAs which help select malign UTAAs, and therefore get generalization power.
But this seems like an annoyingly non-constructive solution. How are we supposed to work with the set of fixed points directly without iterating (potentially malign) code to find them?
*: Actually, a UTAA should be a compact specification of such tuple, such as a program or neural network which can output the desired objects. This is necessary for implementation, since EG we can't store V as a big table of values or S as a big table of probabilities. It also will allow for better generalization, and process-level feedback.
18 comments
Comments sorted by top scores.
comment by johnswentworth · 2020-11-12T00:51:31.090Z · LW(p) · GW(p)
A few years ago I thought about a problem which I think is the same thing you're pointing to here - no perfect feedback, uncertainty and learning all the way up the meta-ladder, etc. My attempt at a solution was quite different.
The basic idea is to use a communication prior - a prior which says "someone is trying to communicate with you".
With an idealized communication prior, our update is not P[Y|X], but instead P[Y|M], where (roughly) M = "X maximizes P[Y|M]" (except we unroll the fixed point to make initial condition of iteration explicit). Interpretation: the "message sender" chooses the value of X which results in us assigning maximum probability to Y, and we update on this fact. If you've played Codenames, this leads to similar chains of logic: "well, 'blue' seems like a good hint for both sky+sapphire and sky+water, but if it were sky+water they would have said 'weather' or something like that instead, so it's probably sky+sapphire...". As with recursive quantilizers, the infinite meta-tower collapses into a fixed-point calculation, and there's (hopefully) a basin of attraction.
To make this usable for alignment purposes we need a couple modifications.
First, obviously, humans are not perfectly rational and logically omniscient, so we have to replace "X maximizes P[Y|M]" with "<rough model of human> thinks X will produce high P[Y|M]". The better the human-model, the broader the basin of attraction for the whole thing to work.
Second, we have to say what the "message" X from the human is, and what Y is. Y would be something like human values, and X would include things like training data and/or explicit models. In principle, we could get uncertainty and learning "at the outermost level" by having the system treat its own source code as a "message" from the human - the source code is, after all, something the human chose expecting that it would produce a good estimate of human values. On the other hand, if the source code contained an error (that didn't just mess up everything), then the system could potentially recognize it as an error and then do something else.
Finally, obviously the "initial condition" of the iteration would have to be chosen carefully - that's basically just a good-enough world model and human-values-pointer. In a sense, we're trying to formalize "do what I mean" enough that the AI can figure out what we mean.
Maybe I'll write up a post on this tomorrow.
Replies from: abramdemski↑ comment by abramdemski · 2020-11-12T01:39:07.395Z · LW(p) · GW(p)
I like that these ideas can be turned into new learning paradigms relatively easily.
I think there's obviously something like your proposal going on, but I feel like it's the wrong place to start.
It's important that the system realize it has to model human communication as an attempt to communicate something, which is what you're doing here. It's something utterly missing from my model as written.
However, I feel like starting from this point forces us to hard-code a particular model of communication, which means the system can never get beyond this. As you said:
First, obviously, humans are not perfectly rational and logically omniscient, so we have to replace "X maximizes P[Y|M]" with "<rough model of human> thinks X will produce high P[Y|M]". The better the human-model, the broader the basin of attraction for the whole thing to work.
I would rather attack the problem of specifying what it could mean for a system to learn at all the meta levels in the first place, and then teach such a system about this kind of communication model as part of its broader education about how to avoid things like wireheading, human manipulation, treacherous turns, and so on.
Granted, you could overcome the hardwired-ness of the communication model if your "treat the source code as a communication, too" idea ended up allowing a reinterpretation of the basic communication model. That just seems very difficult.
All this being said, I'm glad to hear you were working on something similar. Your idea obviously starts to get at the "interpretable feedback" idea which I basically failed to make progress on in my proposal.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-12T03:19:49.659Z · LW(p) · GW(p)
Yeah, I largely agree with this critique. The strategy relies heavily on the AI being able to move beyond the initial communication model, and we have essentially no theory to back that up.
Replies from: abramdemski↑ comment by abramdemski · 2020-11-12T15:35:30.457Z · LW(p) · GW(p)
Still interested in your write-up, though!
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-12T22:07:38.722Z · LW(p) · GW(p)
comment by evhub · 2020-11-11T22:49:52.309Z · LW(p) · GW(p)
I like this post a lot. I pretty strongly agree that process-level feedback (what I would probably call mechanistic incentives) is necessary for inner alignment—and I'm quite excited about understanding what sorts of learning mechanisms we should be looking for when we give process-level feedback (and recursive quantilization seems like an interesting option in that space).
Since detecting malign hypotheses is difficult, we want the learning system to help us out here. It should generalize from examples of malign hypotheses, and attempt to draw a broad boundary around malignancy. Allowing the system to judge itself in this way can of course lead to malign reinterpretations of user feedback, but hopefully allows for a basin of attraction in which benevolent generalizations can be learned.
Notably, one way to get this is to have the process feedback given by an overseer implemented as a human with access to a prior version of the model being overseen (and then train the model both on the oversight signal directly and to match the amplified human's behavior doing oversight), as in relaxed adversarial training [AF · GW].
Replies from: abramdemski↑ comment by abramdemski · 2020-11-14T14:47:01.425Z · LW(p) · GW(p)
Notably, one way to get this is to have the process feedback given by an overseer implemented as a human with access to a prior version of the model being overseen (and then train the model both on the oversight signal directly and to match the amplified human's behavior doing oversight), as in relaxed adversarial training [LW · GW].
I guess you could say what I'm after is a learning theory of generalizing process-level feedback -- I your setup could do a version of the thing, but I'm thinking about Bayesian formulations because I think it's an interesting challenge. Not because it has to be Bayesian, but because it should be in some formal framework which allows loss bounds, and if it ends up not being Bayesian I think that's interesting/important to notice.
(Which might then translate to insights about a neural net version of the thing?)
I suppose another part of what's going on here is that I want several of my criteria working together -- I think they're all individually achievable, but part of what's interesting to me about the project is the way the criteria jointly reinforce the spirit of the thing I'm after.
Actually, come to think of it, factored-cognition-style amplification (was there a term for this type of amplification specifically? Ah, imitative amplification [LW · GW]) gives us a sort of "feedback at all levels" capability, because the system is trained to answer all sorts of questions. So it can be trained to answer questions about human values, and meta-questions about learning human values, and doubly and triply meta questions about how to answer those questions. These are all useful to the extent that the human in the amplification makes use of those questions and answers while doing their tasks.
One thing this lacks (in comparison to recursive quantilizers at least) is the idea of necessarily optimizing things through search at all. Information and meta-information about values and how to optimize them is not necessarily used in HCH because questions aren't necessarily answered via search. This can of course be a safety advantage. But it is operating on an entirely different intuition than recursive quantilizers. So, the "ability to receive feedback at all levels" means something different.
My intuition is that if I were to articulate more desiderata with the HCH case in mind, it might have something to do with the "learning the human prior" stuff.
comment by TurnTrout · 2020-11-13T04:22:07.076Z · LW(p) · GW(p)
Another thing which seems to "gain something" every time it hops up a level of meta: Corrigibility as Outside View [LW · GW]. Not sure what the fixed points are like, if there are any, and I don't view what I wrote as attempting to meet these desiderata. But I think there's something interesting that's gained each time you go meta.
Replies from: abramdemski↑ comment by abramdemski · 2020-11-14T14:50:32.614Z · LW(p) · GW(p)
Seems like this could fit well with John's communication prior idea [LW · GW], in that the outside view resembles the communication view.
comment by adamShimi · 2020-11-12T22:54:24.238Z · LW(p) · GW(p)
Great post! I agree with everything up to the recursive quantilizer stuff (not that I disagree with that, I just don't feel that I get it enough to voice an opinion). I thinks it's a very useful post, and I'll definitely go back to it and try to work out more details soon.
In general, it's possible to get very rich types of feedback, but very sparse: humans get all sorts of feedback, including not only instruction on how to act, but also how to think.
I suppose there is a typo and the correct sentence goes "but also very sparse"?
In other words, the overriding feature of normativity which I'm trying to point at is that nothing is ever 100%. Correct grammar is not defined by any (known) rules or set of text, nor is it (quite) just whatever humans judge it is.
I think you're unto something, but I wonder how much of this actually comes from the fact that language usage evolves? If the language stayed static, I think rules would work better. For an example outside English, in French we have the Académie Française, which is the official authority on usage of french. If the usage never changed, they would probably have a pretty nice set of rules (although not really that easily programmable) for French. But as things go, French, like any language, changes, and so they must adapt to it and try to reign it.
That being said, this changing nature of language is probably a part of normativity. It just felt implicit in your post.
Wireheading and human manipulation can't be eliminated through object-level feedback, but we could point out examples of the wrong and right types of reasoning.
You don't put any citation for that. Is this an actual result, or just what you think really strongly?
Replies from: abramdemski, abramdemski↑ comment by abramdemski · 2020-11-14T16:00:47.453Z · LW(p) · GW(p)
You don't put any citation for that. Is this an actual result, or just what you think really strongly?
Yeah, sorry, I thought there might be an appropriate citation but I didn't find one. My thinking here is: in model-based RL, the best model you can have to fit the data is one which correctly identifies the reward signal as coming from the reward button (or whatever the actual physical reward source is). Whereas the desired model (what we want the system to learn) is one which, while perhaps being less predictively accurate, models reward as coming from some kind of values. If you couple RL with process-level feedback, you could directly discourage modeling reward as coming from the actual reward system, and encourage identifying it with other things -- overcoming the incentive to model it accurately.
Similarly, human manipulation comes from a "mistaken" (but predictively accurate) model which says that the human values are precisely whatever-the-human-feedback-says-they-are (IE that humans are in some sense the final judge of their values, so that any "manipulation" still reveals legitimate preferences by definition). Humans can provide feedback against this model, favoring models in which the human feedback can be corrupted by various means including manipulation.
↑ comment by abramdemski · 2020-11-14T15:02:32.553Z · LW(p) · GW(p)
That being said, this changing nature of language is probably a part of normativity. It just felt implicit in your post.
This is true. I wasn't thinking about this. My initial reaction to your point was to think, no, even if we froze English usage today, we'd still have a "normativity" phenomenon, where we (1) can't perfectly represent the rules via statistical occurrence, (2) can say more about the rules, but can't state all of them, and can make mistatkes, (3) can say more about what good reasoning-about-the-rules would look like, ... etc.
But if we apply all the meta-meta-meta reasoning, what we ultimately get is evolution of the language at least in a very straightforward sense of a changing object-level usage and changing first-meta-level opinions about proper usage (and so on), even if we think of it as merely correcting imperfections rather than really changing. And, the meta-meta-meta consensus would probably include provisions that the language should be adaptive!
comment by Beth Barnes (beth-barnes) · 2020-11-18T08:08:30.152Z · LW(p) · GW(p)
However, that only works if we have the right prior. We could try to learn the prior from humans [AF · GW], which gets us 99% of the way there... but as I've mentioned earlier, human imitation does not get us all the way. Humans don't perfectly endorse their own reactions.
Note that Learning the Prior uses an amplified human (ie, a human with access to a model trained via IDA/Debate/RRM). So we can do a bit better than a base human - e.g. could do something like having an HCH tree where many humans generate possible feedback and other humans look at the feedback and decide how much they endorse it.
I think the target is not to get normativity 'correct', but to design a mechanism such that we can't expect to find any mechanism that does better.
↑ comment by abramdemski · 2020-11-18T17:04:58.939Z · LW(p) · GW(p)
Right, I agree. I see myself as trying to construct a theory of normativity which gets that "by construction", IE, we can't expect to find any mechanism which does better because if we could say anything about what that mechanism does better then we could tell it to the system, and the system would take it into account.
HCH isn't such a theory; it does provide a somewhat reasonable notion of amplification, but if we noticed systematic flaws with how HCH reasons, we would not be able to systematically correct them.
Replies from: beth-barnes↑ comment by Beth Barnes (beth-barnes) · 2020-11-18T19:31:29.306Z · LW(p) · GW(p)
I see myself as trying to construct a theory of normativity which gets that "by construction", IE, we can't expect to find any mechanism which does better because if we could say anything about what that mechanism does better then we could tell it to the system, and the system would take it into account.
Nice, this is what I was trying to say but was struggling to phrase it. I like this.
I guess I usually think of HCH as having this property, as long as the thinking time for each human is long enough, the tree is deep enough, and we're correct about the hope that natural language is sufficiently universal. It's quite likely I'm either confused or being sloppy though.
You could put 'learning the prior' inside HCH I think, it would just be inefficient - for every claim, you'd ask your HCH tree how much you should believe it, and HCH would think about the correct way to do bayesian reasoning, what the prior on that claim should be, and how well it predicted every piece of data you'd seen so far, in conjunction with everything else in your prior. I think one view of learning the prior is just making this process more tractable/practical, and saving you from having to revisit all your data points every time you ask any question - you just do all the learning from data once, then use the result of that to answer any subsequent questions.
comment by Charlie Steiner · 2020-11-13T00:56:16.238Z · LW(p) · GW(p)
I'm pretty on board with this research agenda, but I'm curious what you think about the distinction between approaches that look like finding a fixed point, and approaches that look like doing perturbation theory.
And on the assumption that you have no idea what I'm referring to, here's the link to my post [LW · GW].
There are a couple different directions to go from here. One way is to try to collapse the recursion. Find a single agent-shaped model of humans that is (or approximates) a fixed point of this model-ratification process (and also hopefully stays close to real humans by some metric), and use the preferences of that. This is what I see as the endgame of the imitation / bootstrapping research.
Another way might be to imitate communication, and find a way to use recursive models such that we can stop the recursion early without much loss in effectiveness. In communication, the innermost layer of the model can be quite simplistic, and then the next is more complicated by virtue of taking advantage of the first, and so on. At each layer you can do some amount of abstracting away of the details of previous layers, so by the time you're at layer 4 maybe it doesn't matter that layer 1 was just a crude facsimile of human behavior.
Thinking specifically about this UTAA monad thing, I think it's a really clever way to think about what levers we have access to in the fixed-point picture. (If I was going to point out one thing it's lacking, it's that it's a little hazy on whether you're supposed to model V as now having meta-values about the state of the entire recursive tree of UTAAs, or whether your Q function is now supposed to learn about meta-preferences from some outside data source.) But it retains the things I'm worried about from this fixed-point picture, which is basically that I'm not sure it buys us much of anything if the starting point isn't benign in a quite strong sense.
Replies from: abramdemski↑ comment by abramdemski · 2020-11-14T16:35:48.503Z · LW(p) · GW(p)
I'm pretty on board with this research agenda, but I'm curious what you think about the distinction between approaches that look like finding a fixed point, and approaches that look like doing perturbation theory.
Ah, nice post, sorry I didn't see it originally! It's pointing at a very very related idea.
Seems like it also has to do with John's communication model [LW · GW].
With respect to your question about fixed points, I think the issue is quite complicated, and I'd rather approach it indirectly by collecting criteria and trying to make models which fit the various criteria. But here are some attempted thoughts.
- We should be quite skeptical of just taking a fixed point, without carefully building up all the elements of the final solution -- we don't just want consistency, we want consistency as a result of sufficiently humanlike deliberation. This is similar to the idea that naive infinite HCH might be malign (because it's just some weird fixed point of humans-consulting-HCH), but if we ensure that the HCH tree is finite by (a) requiring all queries to have a recursion budget, or (b) having a probability of randomly stopping (not allowing the tree to be expanded any further), or things like that, we can avoid weird fixed points (and, not coincidentally, these models fit better with what you'd get from iterated amplification if you're training it carefully rather than in a way which allows weird malign fixed-points to creep in).
- However, I still may want to take fixed points in the design; for example, the way UTAAs allow me to collapse all the meta-levels down. A big difference between your approach in the post and mine here is that I've got more separation between the rationality criteria of the design vs the rationality the system is going to learn, so I can use pure fixed points on one but not the other (hopefully that makes sense?). The system can be based on a perfect fixed point of some sort, while still building up a careful picture iteratively improving on initial models. That's kind of illustrated by the recursive quantilization idea. The output is supposed to come from an actual fixed-point of quantilizing UTAAs, but it can also be seen as the result of successive layers. (Though overall I think we probably don't get enough of the "carefully building up incremental improvements" spirit.)
(If I was going to point out one thing it's lacking, it's that it's a little hazy on whether you're supposed to model V as now having meta-values about the state of the entire recursive tree of UTAAs, or whether your Q function is now supposed to learn about meta-preferences from some outside data source.)
Agreed, I was totally lazy about this. I might write something more detailed in the future, but this felt like an OK version to get the rough ideas out. After all, I think there are bigger issues than this (IE the two desiderata failures I pointed out at the end).
comment by Rohin Shah (rohinmshah) · 2021-01-11T20:26:22.466Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
To build aligned AI systems, we need to have our AI systems learn what to do from human feedback. However, it is unclear how to interpret that feedback: any particular piece of feedback could be wrong; economics provides many examples of stated preferences diverging from revealed preferences. Not only would we like our AI system to be uncertain about the interpretation about any particular piece of feedback, we would also like it to _improve_ its process for interpreting human feedback. This would come from human feedback on the meta-level process by which the AI system learns. This gives us _process-level feedback_, where we make sure the AI system gets the right answers _for the right reasons_.
For example, perhaps initially we have an AI system that interprets human statements literally. Switching from this literal interpretation to a Gricean interpretation (where you also take into account the fact that the human chose to say this statement rather than other statements) is likely to yield improvements, and human feedback could help the AI system do this. (See also [Gricean communication and meta-preferences](https://www.alignmentforum.org/posts/8NpwfjFuEPMjTdriJ/gricean-communication-and-meta-preferences), [Communication Prior as Alignment Strategy](https://www.alignmentforum.org/posts/zAvhvGa6ToieNGuy2/communication-prior-as-alignment-strategy), and [multiple related CHAI papers](https://www.alignmentforum.org/posts/zAvhvGa6ToieNGuy2/communication-prior-as-alignment-strategy?commentId=uWBFsKK6XFbL4Hs4z).)
Of course, if we learn _how_ to interpret human feedback, that too is going to be uncertain. We can fix this by “going meta” once again: learning how to learn to interpret human feedback. Iterating this process we get an infinite tower of “levels” of learning, and at every level we assume that feedback is not perfect and the loss function we are using is also not perfect.
In order for this to actually be feasible, we clearly need to share information across these various “levels” (or else it would take infinite time to learn across all of the levels). The AI system should not just learn to decrease the probability assigned to a single hypothesis, it should learn what _kinds_ of hypotheses tend to be good or bad.
Planned opinion (the second post is Recursive Quantilizers II [AF · GW]):
**On feedback types:** It seems like the scheme introduced here is relying quite strongly on the ability of humans to give good process-level feedback _at arbitrarily high levels_. It is not clear to me that this is something humans can do: it seems to me that when thinking at the meta level, humans often fail to think of important considerations that would be obvious in an object-level case. I think this could be a significant barrier to this scheme, though it’s hard to say without more concrete examples of what this looks like in practice.
**On interaction:** I’ve previously <@argued@>(@Human-AI Interaction@) that it is important to get feedback _online_ from the human; giving feedback “all at once” at the beginning is too hard to do well. However, the idealized algorithm here does have the feedback “all at once”. It’s possible that this is okay, if it is primarily process-level feedback, but it seems fairly worrying to me.
**On desiderata:** The desiderata introduced in the first post feel stronger than they need to be. It seems possible to specify a method of interpreting feedback that is _good enough_: it doesn’t exactly capture everything, but it gets it sufficiently correct that it results in good outcomes. This seems especially true when talking about process-level feedback, or feedback one meta level up -- as long as the AI system has learned an okay notion of “being helpful” or “being corrigible”, then it seems like we’re probably fine.
Often just making feedback uncertain can help. For example, in the preference learning literature, Boltzmann rationality has emerged as the model of choice for how to interpret human feedback. While there are several theoretical justifications for this model, I suspect its success is simply because it makes feedback uncertain: if you want to have a model that assigns higher likelihood to high-reward actions, but still assigns some probability to all actions, it seems like you end up choosing the Boltzmann model (or something functionally equivalent). Note that there is work trying to improve upon this model, such as by [modeling humans as pedagogic](https://papers.nips.cc/paper/2016/file/b5488aeff42889188d03c9895255cecc-Paper.pdf), or by <@incorporating a notion of similarity@>(@LESS is More: Rethinking Probabilistic Models of Human Behavior@).
So overall, I don’t feel convinced that we need to aim for learning at all levels. That being said, the second post introduced a different argument: that the method does as well as we “could” do given the limits of human reasoning. I like this a lot more as a desideratum; it feels more achievable and more tied to what we care about.