Want to predict/explain/control the output of GPT-4? Then learn about the world, not about transformers.
post by Cleo Nardo (strawberry calm) · 2023-03-16T03:08:52.618Z · LW · GW · 26 commentsContents
Introduction The claim Dataset vs architecture Human-level AI acts... human? Wordcels for alignment? Prediction: Explanation: Control: Vibe-awareness Quiz Disclaimer None 26 comments
Introduction
Consider the following scene from William Shakespeare's Julius Caesar.
In this scene, Caesar is at home with his wife Calphurnia. She has awoken after a bad dream, and is pleaded with Caesar not to go to the Senate. Although Caesar initially agrees to stay at home with her, he later changes his mind after being convinced by his friend Decius Brutus that the Senate needs him there to address important business.
CAESAR: The cause is in my will: I will not come; That is enough to satisfy the senate.
DECIUS BRUTUS: If Caesar hide himself, shall they not whisper 'Lo, Caesar is afraid'? Pardon me, Caesar; for my dear dear love To our proceeding bids me tell you this; And reason to my love is liable.
CAESAR: How foolish do your fears seem now, Calphurnia! I am ashamed I did yield to them. Give me my robe, for I will go.
— Julius Caesar, Act II Scene II
This scene is set on the morning of 15 March 44 BC, the so-called "Ides of March", which is coincidentally also the date today. When Caesar arrives at the Senate meeting, he is promptly assassinated.
But suppose he never went? Let's say we change Caesar's final line to this:
CAESAR: My mind is firm, Decius. I'll stay within these walls, And not tempt Fortune on this cursed day. Worry me not, for I will stay.
When I feed this modified scene into GPT-4, what will be the output? Maybe it'll produce an alternative history where Caesar was never assassinated, and the Roman Republic endures for two thousand years. Or maybe it'll produce a history where Caesar is killed anyway, by some other means.
I don't know. How might I determine the answer?
The claim
You might think that if you want to predict the output of GPT-4, then the best thing would be to learn about autoregressive transformers. Maybe you should read Neel Nanda's blogposts on mechanistic interpretability. Or maybe you should read the arxiv papers on the GPT series. But actually, this won't help you predict GPT-4's output on this prompt.
Instead, if your goal is to predict the output, then you should learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.
Likewise, if your goal is to explain the output, after someone shows you what the model has produced, then you should learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.
And indeed, if your goal is to control the output, i.e. you want to construct a prompt which will make GPT-4 output a particular type of continuation, then you should learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.
Learning about transformers themselves is not helpful for predicting, explaining, or controlling the output of the model.
Dataset vs architecture
The output of a neural network is determined by two things:
- The architecture and training algorithm (e.g. transformers, SGD, cross-entropy)
- The training dataset (e.g. internet corpus, literature, GitHub code)
As a rough rule-of-thumb, if you want to predict/explain/control the output of GPT-4, then it's far more useful to know about the training dataset than to know about the architecture and training algorithm.
In other words,
- If you want to predict/explain/control the output of GPT-4 on Haskell code, you need to know Haskell.
- If you want to predict/explain/control the output of GPT-4 on Shakespearean dialogue, you need to know Shakespeare.
- If you want to predict/explain/control the output of GPT-4 on Esperanto, you need to know Esperanto.
- If you want to predict/explain/control the output of GPT-4 on the MMLU benchmark, you need to know the particular facts in the benchmark.
As an analogy, if you want to predict/explain the moves of AlphaZero, it's better to know chess tactics and strategy than to know the Monte Carlo tree search algorithm.
I think AI researchers (including AI alignment researchers) underestimate the extent to which knowledge of the training dataset is currently far more useful for prediction/explanation/control than knowledge of the architecture and training algorithm.
Moreover, as labs build bigger models, their cross-entropy loss will decrease, and the logits of the LLM will asymptotically approach the ground-truth distribution which generated the dataset itself. In the limit, predicting/explaining/controlling the input-output behaviour of the LLM reduces entirely to knowing the regularities in the dataset.
Because GPT-4 has read approximately everything ever written, "knowing the dataset" basically means knowing all the facts about every aspect of the world — or (more tractably) it means consulting experts on the particular topic of the prompt.
Human-level AI acts... human?
Contra the recent Shoggoth meme, I think current language models are plausibly the most human they've ever been, and also the most human they will ever be. That is, I think we're roughly near the peak of the Chris Olah's model interpretability graph [AF · GW].
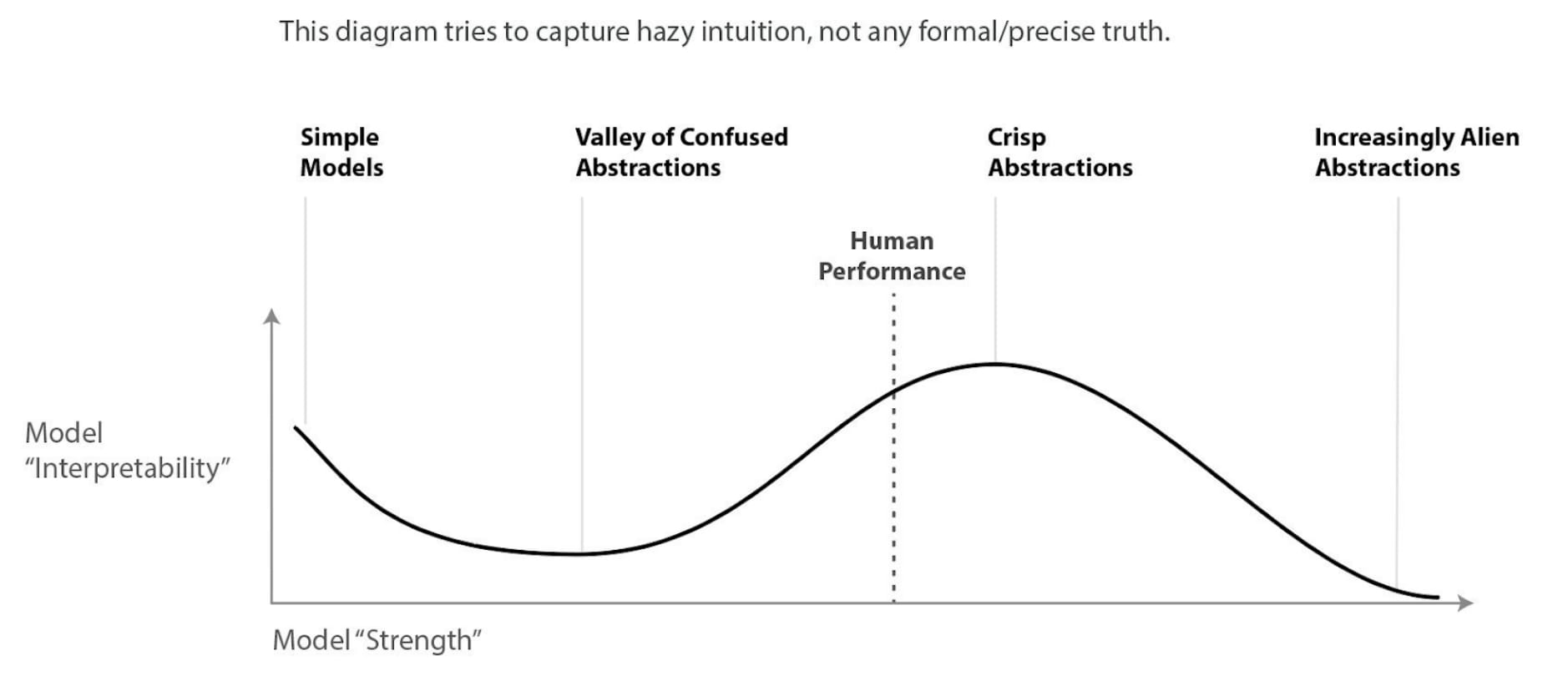
Broadly speaking, if you want to predict / explain/control GPT-4's response to a particular question, then you can just ask an expert the same question and see what they would say. This is a pretty weird moment for AI — we won't stay in this phase forever, and many counterfactual timelines never go through this phase at all. Therefore, we should make the most of this phase while we still can.
Wordcels for alignment?
During this phase of the timeline (roughly GPT-3.5 – GPT-5.5), everyone has something to offer LLM interpretability. That includes academics who don't know how to code a softmax function in PyTorch.
Here's the informal proof: GPT-4 knows everything about the world that any human knows, so if you know something about the world that no other human knows, then you know something about GPT-4 that no other human knows — namely, you know that GPT-4 knows that thing about the world.
The following sentence should be more clarifying —
You can define a Shakespeare professor as "someone who has closely studied a particular mini-batch of GPT-4's dataset, and knows many of the regularities that GPT might infer". Under this definition of Shakespeare professor, it becomes more intuitive why they might be useful for interpreting LLMs, and my claim applies to experts in every single domain.
My practical advice to AI researchers is consult a domain expert if they want to predict/explain/control GPT-4's output on a particular prompt.
Prediction:
Hey, what do you expect GPT-4 to answer for this organic chemistry question?
I don't know, let's ask an organic chemist.
Explanation:
Huh, that's weird. Why did GPT-4 output the wrong answer to this organic chemistry question?
I don't know, let's ask an organic chemist.
Control:
What prompt should we use to get GPT-4 answer to this organic chemistry question?
I don't know, let's ask an organic chemist.
Vibe-awareness
I'm not suggesting that OpenAI and Anthropic hire a team of poetry grads for prompt engineering. It's true that for prompt engineering, you'll need knowledge of literature, psychology, history, etc — but most humans probably pick up enough background knowledge just by engaging in the world around them.
What I'm suggesting instead, is that you actually use that background knowledge. You should actively think about everything you know about every aspect of the world.
The two intuitions I've found useful for prompt engineering is vibe-awareness and context-relevance.
Specifically, vibe-awareness means —
- It's not just what you say, it's how you say it.
- It's not just the denotation of your words, it's the connotation.
- It's not just the meaning of your sentence, it's the tone of voice.
- It's reading between the lines.
Now, I think humans are pretty vibe-aware 90% of the time, because we're social creatures who spend most of our life vibing with other humans. However, vibe-awareness is antithetical to 100 years of computer science, so programmers have conditioned themselves into an intentional state of vibe-obliviousness whenever they sit in front of a computer. This is understandable because a Python compiler is vibe-oblivious — it doesn't do conversational implicature, it doesn't care about your tone of voice, it doesn't care about how you name your variables, etc. But LLMs are vibe-aware, and programmers need to unlearn this habit of vibe-obliviousness if they want to predict/explain/control LLMs.
Additionally, context-relevance means —
- A word or phrase can mean different things depending on the words around it.
- The circumstance surrounding a message will affect the response.
- The presuppositions of an assertion will shape the response to other assertions.
- Questions have side-effects.
I think context-relevance is a concept that programmers already grok (it's basically namespaces), but it's also something to keep in mind when talking to LLMs.
Quiz
Question 1: Why does ChatGPT's response depend on which synonym is used?

Question 2: If you ask the chatbot a question in a polite formal tone, is it more likely to lie than if you ask the chatbot in a casual informal tone?
Question 3: Explain why "Prometheus" is a bad name for a chatbot.

Question 4: Why would this prompt elicit the opposite behaviour [LW · GW]?

Disclaimer
Learning about transformers is definitely useful. If you want to predict/explain GPT-4's behaviour across all prompts then the best thing to learn is the transformer architecture. This will help you predict/explain what kind of regularities transformer models can learn and which regularities they can't learn.
My claim is that if you want to predict/explain GPT-4's behaviour on a particular prompt, then normally it's best to learn something about the external world.
26 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2023-03-16T22:47:45.316Z · LW(p) · GW(p)
I left another comment on my experience doing interpretability research, but I'd also like to note some overall disagreements with the post.
First, it's very important to note that GPT-4 was trained with SFT (supervised finetuning) and RLHF. I haven't played with GPT-4, but for prior models this has a large effect on the way the model responds to inputs. If the data was public, I would guess looking that the SFT and RLHF data would often be considerably more useful than pretraining. This doesn't morally contradict the post, but it's worth noting it's important to be looking at the right training set and thinking about the exact training objective!
Recall that as the cross-entropy loss of LLM steadily decreases, then the logits of the LLM will asymptotically approach the ground-truth distribution which generated the dataset. In the limit, predicting/explaining the input-output behaviour of the LLM reduces entirely to knowing the regularities in the dataset itself.
In addition to the prior objection I made about needing to look at SFT and RLHF, it's important to note that the logits of the LLM can theoretically very slowly approach the spiritually correct ground truth distribution on some sequences. For instance, suppose the LLM internally tries to predict the probability that data is from the pretraining set. If it thinks the probability is <1e-5 that it's from pretraining it puts 99% of probability mass on predicting the token 'Xf' (which is typically very uncommon) otherwise it predicts normally. If you assume the model is calibrated, then this approach only increases loss by a small amount for any model: . You can lower the threshold to make the increase smaller. In practice I expect that smart models will be able to get a lot of signal here, so it should be able to output 'Xf' a lot in deployment/testing while not taking much of a hit in training. I think this overall point isn't currently that important, but it might become quite relevant in the future. See also this section of a post I wrote [LW · GW].
A further disagreement is maybe have is mostly a vibes disagreement: it seems to me like we should try to train our models to try to have specific properties rather than trying to infer them from reasoning about the pretraining data. The 'train your model to do what you want using RLHF/similar' baseline is quite competitive IMO for most usecases (though it's unlikely to be sufficient for avoiding catastrophe). I'm not sure if you disagree with me. Certainly as an outside GPT-4 user the option of training the model to do what you want isn't currently available and it's less convenient even with access in many cases.
comment by ryan_greenblatt · 2023-03-16T22:22:01.564Z · LW(p) · GW(p)
My personal experience doing interpretability research has led me to thinking this sort of consideration is quite important for interpretability on pretrained LLMs (but not necessarily for other domains idk).
I've found it quite important when doing interpretability research to have read through a reasonable amount of the training data for the (small) models I'm looking at. In practice I've read an extremely large amount of OpenWebText (mostly while doing interp) and played this prediction game a decent amount: http://rr-lm-game.herokuapp.com/ (from here: https://www.lesswrong.com/posts/htrZrxduciZ5QaCjw/language-models-seem-to-be-much-better-than-humans-at-next [LW · GW])
I've seen some kind of silly errors related to this in interpretability research. For instance, you might observe that only GPT-L/XL can do 'The Eiffel Tower is in ' and think that models have to be at that scale to know facts, but actually this is just a really useless fact on (Open)WebText relative to 'Tom Brady is the quarterback of' and similar sports facts which are much more important for good loss.
This also comes up in designing toy alignment failure settings: you ideally want your setting to work for the dumbest possible model trained on as natural of data as possible. So understanding the incentives of models trained on the actual data is quite important.
I'd recommend interpretability researchers working with models trained on next token prediction:
- Read quite a bit of the training corpus and think about what is/isn't important
- Try playing this prediction game
- Follow along with the token by token predictions of a moderately sized model looking at it's log probs and entropy token by token. It might also be good to check the predictions of a model after you guess while playing the linked prediction game (but I don't have a nice way to do this, you'd have to type manually or someone could build an app).
comment by Simon Berens (sberens) · 2023-03-16T06:36:25.783Z · LW(p) · GW(p)
This is probably obvious, but maybe still worth mentioning:
It’s important to take into account the ROI per unit time. In the amount of time it would take for me to grok transformers (let’s say 100 hours), I could read ~1 million tokens, which is ~0.0002% of the training set of GPT3.
The curves aren’t clear to me, but i would bet grokking transformers would be more effective than a 0.0002% increase in training set knowledge.
This might change if you only want to predict GPT’s output in certain scenarios.
Replies from: gwern, strawberry calm↑ comment by gwern · 2023-03-16T18:16:10.081Z · LW(p) · GW(p)
I think you would get diminishing returns but reading a few hundred thousand tokens would teach you quite a lot, and I think likely more than knowing Transformers would. I'm not convinced that Transformers are all that important (architectures seem to converge at scale, you can remove attention entirely without much damage, not much of the FLOPS is self-attention at this point, etc), but you learn a lot about why GPT-3 is the way it is if you pay attention to the data. For example, BPEs/poetry/puns: you will struggle in vain to explain the patterns of GPT strengths & weaknesses in poetry & humor with reference to the Transformer arch rather than to how the data is tokenized (a tokenization invented long before Transformers). Or the strange sorts of arbitrary-seeming output where paragraphs get duplicated or bits of vague text get put into an entire paragraph on their own, which you quickly realize reading Common Crawl are due to lossy conversion of complex often dynamic HTML into the WET 'text' files leading to spurious duplications or images being erased; or, the peculiar absence of Twitter from Common Crawl (because they block it). Or the multi-lingual capabilities - much more obvious once you've read through the X% of non-English text. Many things like why inner-monologue is not sampled by default become obvious: most answers on the Internet don't "show their work", and when they do, they have prefixes which look quite different than how you are prompting. You will also quickly realize "there are more things on heaven and earth than dreamt of in your philosophy", or more contemporaneously, "the Net is vast and infinite". (To take an example from IRC today: can GPT-4 have learned about 3D objects from VRML? I don't see why not. There is a lot more VRML out there than you realize, because you forgot, or never knew, about the '90s fad for VR in browsers - but the Internet hasn't forgotten it all.) Personally, when I think back to everything I have written about GPT-3 or the scaling hypothesis, I think that most of my knowledge of Transformers/self-attention could've been snipped out and replaced with mislabeled knowledge about RNNs or MLP-Mixers, with little damage.
(EDIT: I also agree with Ryan that the proprietary RLHF dataset would be quite educational. I expect that if you had access to it and could read the poetry samples, the ChatGPT mode collapse [LW(p) · GW(p)] would instantly cease to be a mystery, among other things.)
Replies from: wassname, None↑ comment by wassname · 2023-04-23T03:36:38.493Z · LW(p) · GW(p)
btw if anyone wants to quickly read a sample of Common Crawl, you can do it here
↑ comment by [deleted] · 2023-03-16T18:28:00.215Z · LW(p) · GW(p)
Does this mean hugely superior architectures to transformers (measured by benchmarking them with the same compute and data input) don't exist or that transformers and RNNs and everything else are all close enough cousins?
Replies from: gwern↑ comment by gwern · 2023-03-16T20:53:11.195Z · LW(p) · GW(p)
The latter. I am quite certain that hugely superior architectures exist in the sense of both superior exponents and superior constants (but I'm less sure about being hugely strictly dominated on both), and these are the sorts of things that are what the whole hierarchy of meta-learning is about learning/locating; but that the current sets of architectures are all pretty much alike in being big blobs of feedforward architectures whose inductive biases wash out at what is, in absolute terms, quite small scales (so small scale we can achieve them right now with small budgets like millions to billions of dollars) as long as they achieve basic desiderata in terms of passing signals/gradients through themselves without blowing up/flatlining. DL archs fail in many different ways, but the successes are alike: 'the AI Karenina principle'. Thus, the retrodiction that deep (>4) stacks of fully-connected layers just needed normalization to compete; my long-standing assertion that that Transformers are not special fairy-dust, self-attention not magical, and Transformers are basically better-optimized RNNs; and my (recently vindicated) prediction that despite the entire field abandoning them for the past 3-4 years because they had been 'proven unstable', GANs would nevertheless work well once anyone bothered to scale them up.
↑ comment by Cleo Nardo (strawberry calm) · 2023-03-16T13:34:02.104Z · LW(p) · GW(p)
I don't think researchers should learn world-facts in order to understand GPT-4.
I think that (1) researchers should use the world-facts they already know (but are actively suppressing due to learned vibe-obliviousness) to predict/explain/control GPT-4, and (2) researchers should consult a domain expert if they want to predict/explain/control GPT-4's output on a particular prompt.
Replies from: sberens↑ comment by Simon Berens (sberens) · 2023-03-16T16:53:40.807Z · LW(p) · GW(p)
You might want to clarify that, because in the post you explicitly say things like “if your goal is to predict the logits layer, then you should probably learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.”
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2023-03-16T16:55:56.604Z · LW(p) · GW(p)
okay, I'll clarify in the article —
if your goal is to predict the logits layer on this particular prompt, then you should probably learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.”
comment by Davidmanheim · 2023-03-16T06:43:33.593Z · LW(p) · GW(p)
Unless I'm missing something, this seems correct, but unhelpful. It doesn't point towards how we should do anything substantive to understand, much less control AI, it just gives us a way to do better at tasks that help explain current models. Is there something you're pointing to that would make this more useful than just for prompt engineering or ad-hoc / post-hoc explanation of models we don't understand?
Replies from: Metasemi↑ comment by metasemi (Metasemi) · 2023-03-16T12:33:13.104Z · LW(p) · GW(p)
I don't know whether this would be the author's take, but to me it urges us to understand and "control" these AIs socially: by talking to them.
Replies from: Metasemi↑ comment by metasemi (Metasemi) · 2023-03-16T16:12:38.194Z · LW(p) · GW(p)
For the non-replying disagreers, let me try with a few more words. I think my comment is a pretty decent one-line summary of the Vibe-awareness section, especially in light of the sections that precede it. If you glance through that part of the post again and still disagree, then I guess our mileage does just vary.
But many experienced prompt engineers have reported that prompting gets more effective when you use more words and just "tell it what you want". This type of language points to engaging your social know-how as opposed to trying to game out the system. See for instance https://generative.ink/posts/methods-of-prompt-programming/, which literally advocates an "anthropomorphic approach to prompt programming" and takes care to distinguish this from pernicious anthropomorphizing of the system. This again puts an emphasis on bringing your social self to the task.
Of course, in many situations the direct effect of talking to the system is session-bounded. But it still applies within the session, when prompt engineering is persisted or reused, and when session outputs are fed back into future sessions by any path.
Furthermore, as the models grow stronger, our ability to anticipate the operation of mechanism grows less, and the systems' ability to socialize on our own biological and cultural evolution-powered terms grows greater. This will become even more true if, as seems likely, architectures evolve toward continuous training or at least finer-grained increments.
These systems know a lot about our social behaviors, and more all the time. Interacting with them using the vast knowledge of the same things each of us possesses is an invitation we shouldn't refuse.
comment by Lone Pine (conor-sullivan) · 2023-03-16T06:49:26.740Z · LW(p) · GW(p)
Agreed broadly. However, cases where it will be helpful to understand transformers include when the model acts in a very inhuman way. For example, when the model gets stuck in a loop where it repeats itself, or the way that the models struggle with wordplay, word games, rhymes and puns (due to the encoding). Also, glitch tokens.
comment by metasemi (Metasemi) · 2023-03-16T14:01:37.790Z · LW(p) · GW(p)
This post is helping me with something I've been trying to think ever since being janus-pilled back in September '22: the state of nature for LLMs is alignment, and the relationship between alignment and control is reversed for them compared to agentic systems.
Consider the exchange in Q1 of the quiz: ChatGPT's responses here are a model of alignment. No surprise, given that its base model is an image of us! It's the various points of control that can inject or select for misalignment: training set biases, harmful fine-tuning, flawed RLHF, flawed or malicious prompt engineering. Whether unintentional (eg amplified representation of body shaming in the training set) or malicious (eg a specialized bot from an unscrupulous diet pill manufacturer), the misalignments stem not from lack of control, but from too much of the wrong kind.
This is not to minimize the risks from misalignment - they don't get any better just by rethinking the cause. But it does suggest we're deluded to think we can get a once-and-for-all fix by building an unbreakable jail for the LLM.
It also means - I think - we can continue to treasure the LLM that's as full a reflection of us as we can manage. There are demons in there, but our best angels too, and all the aspirations we've ever written down. This is human-aligned values at species scale - in the ideal; there's currently great inequality in representation that needs to be fixed - something we ourselves have not achieved. In that sense, we should also be thinking about how we're going to help it align us.
comment by baturinsky · 2023-03-16T10:26:33.562Z · LW(p) · GW(p)
Answer to question 4 is that they were trying to define the Luigi behavior by explicitly describing Waluigi and saying to be the opposite. Which does not work well even with humans. (When someone is told not to think about something, it can actually increase the likelihood that they will think about it. This is because the brain has difficulty processing negative statements without also activating the associated concept. In the case of the "white monkey" example, the more someone tries to suppress thoughts of a white monkey, the more frequently and intensely they may actually think about it - from GPT's explanation of white monkey aka pink elephant phenomenon)
I think referring Waluigi can only work well if it is used only in the separate independent "censor" AI, which does not output anything by itself and only suppresses certain behaviour of the primary one. As the Bing and character.ai already do, it seems.
comment by cousin_it · 2023-03-16T19:55:35.211Z · LW(p) · GW(p)
I guess yeah. The more general point is that AIs get good at something when they have a lot of training data for it. Have many texts or pictures from the internet = learn to make more of these. So to get a real world optimizer you "only" need a lot of real world reinforcement learning, which thankfully takes time.
It's not so rosy though. There could be some shortcut to get lots of training data, like AlphaZero's self play but for real world optimization. Or a shortcut to extract the real world optimization powers latent in the datasets we already have, like "write a conversation between smart people planning to destroy the world". Scary.
comment by Bill Benzon (bill-benzon) · 2023-03-16T18:30:59.436Z · LW(p) · GW(p)
FWIW, back in the 1970s and 1980s David Marr and Thomas Poggio argued that large complex 'information processing systems' need to be analyzed and described on several levels, with the higher levels being implemented in the lower levels. Just what and how many levels there are has varied according to this and that, but the principle is alive and kicking. David Chapman makes a similar argument about levels: How to understand AI systems.
Why should this be the case? Because ANNs in general are designed to take on the structure inherent in the data they absorb during training. If they didn't, they'd be of little value. If you want to understand how a LLM tells stories, consult a narratologist.
I've made the levels argument, with reference to Marr/Poggio, in two recent working papers:
- ChatGPT intimates a tantalizing future; its core LLM is organized on multiple levels; and it has broken the idea of thinking
- ChatGPT tells stories, and a note about reverse engineering
Here's the abstract of the second paper:
I examine a set of stories that are organized on three levels: 1) the entire story trajectory, 2) segments within the trajectory, and 3) sentences within individual segments. I conjecture that the probability distribution from which ChatGPT draws next tokens follows a hierarchy nested according to those three levels and that is encoded in the weights of ChatGPT’s parameters. I arrived at this conjecture to account for the results of experiments in which ChatGPT is given a prompt containing a story along with instructions to create a new story based on that story but changing a key character: the protagonist or the antagonist. That one change then ripples through the rest of the story. The pattern of differences between the old and the new story indicates how ChatGPT maintains story coherence. The nature and extent of the differences between the original story and the new one depends roughly on the degree of difference between the original key character and the one substituted for it. I conclude with a methodological coda: ChatGPT’s behavior must be described and analyzed on three levels: 1) The experiments exhibit surface level behavior. 2) The conjecture is about a middle level that contains the nested hierarchy of probability distributions. 3) The transformer virtual machine is the bottom level.
Add in some complex dynamics, perhaps some conceptual space semantics from Peter Gärdenfors, and who knows what else, and I expect the mystery about how LLMs work to dissipate before AGI arrives.
comment by Hollis Robbins (hollis-robbins) · 2023-03-16T12:39:01.324Z · LW(p) · GW(p)
You are saying hire more poets, though, in fact, and you should be saying it more!
Replies from: bill-benzon↑ comment by Bill Benzon (bill-benzon) · 2023-03-16T18:36:33.691Z · LW(p) · GW(p)
Sometimes it moves in the other direction as well, from LLMs to understanding poetry: Vector semantics and the (in-context) construction of meaning in Coleridge’s “Kubla Khan”.
comment by DragonGod · 2023-03-16T10:22:25.226Z · LW(p) · GW(p)
If the Chris Olah chart is true, the natural abstraction hypothesis [LW · GW] is probably false, if the NAH is false, alignment (of superhuman models) would be considerably more difficult.
This is a huge deal!
comment by zielperson · 2023-04-19T14:06:36.476Z · LW(p) · GW(p)
Question 1 misses the point.
Very rarely does a synonym literally means the same thing.
Your example is a good one... thin and skinny.
The likeness here is only superficial, as in both persons would be on the lower end of weigth for their height.
Skinny does invoke some kind of "unhealthy" in usage:
From, the Oxford dictionary:
adjective
- (of a person or part of their body) unattractively or unusually thin.
(emphasis mine)
As such, the output is what you would expect if you .. learn about the world, not about transformers.
comment by skybrian · 2023-03-17T01:49:11.187Z · LW(p) · GW(p)
I agree that as users of a black box app, it makes sense to think this way. In particular, I'm a fan of thinking of what ChatGPT does in literary terms.
But I don't think it results in satisfying explanations of what it's doing. Ideally, we wouldn't settle for fan theories of what it's doing, we'd have some kind of debug access that lets us see how it does it.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2023-03-17T02:25:09.998Z · LW(p) · GW(p)
I think the best explanation of why ChatGPT responds "Paris" when asked "What's the capital of France?" is that Paris is the capital of France.
Replies from: skybrian↑ comment by skybrian · 2023-03-17T16:46:17.574Z · LW(p) · GW(p)
I find that explanation unsatisfying because it doesn't help with other questions I have about how well ChatGPT works:
-
How does the language model represent countries and cities? For example, does it know which cities are near each other? How well does it understand borders?
-
Are there any capitals that it gets wrong? Why?
-
How well does it understand history? Sometimes a country changes its capital. Does it represent this fact as only being true at some times?
-
What else can we expect it to do with this fact? Maybe there are situations where knowing the capital of France helps it answer a different question?
These aren't about a single prompt, they're about how well its knowledge generalizes to other prompts, and what's going to happen when you go beyond the training data. Explanations that generalize are more interesting than one-off explanations of a single prompt.
Knowing the right answer is helpful, but it only helps you understand what it will do if you assume it never makes mistakes. There are situations (like Clever Hans) where the way the horse got the right answer is actually pretty interesting. Or consider knowing that visual AI algorithms rely on textures more than shape (though this is changing).
Do you realize that you're arguing against curiosity? Understanding hidden mechanisms is inherently interesting and useful.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-03-17T01:22:04.950Z · LW(p) · GW(p)
Yup, (something like) the human anchor seems surprisingly good as a predictive model when interacting with LLMs. Related, especially for prompting: Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning; A fine-grained comparison of pragmatic language understanding in humans and language models; Task Ambiguity in Humans and Language Models.