Possible research directions to improve the mechanistic explanation of neural networks
post by delton137 · 2021-11-09T02:36:30.830Z · LW · GW · 8 commentsContents
Why I like the Circuits approach Further directions Illuminating non-robust features Empirical testing of the utility of explainability tools Small activations and changes of basis Closing thoughts References None 8 comments
Why I like the Circuits approach
In early 2020 I skimmed through the neural network explainability literature which was already quite massive at that time. I was left quite discouraged about the utility of the explanation techniques I saw. The level of rigor exhibited in the literature was very low and I saw many people telling post-hoc "just-so" stories based on the visualizations generated by their explainability methods. In my own field (AI for medical imaging) heatmapping methods dominated, and I found several papers that illuminated major issues with them.[1][2] Cynthia Rudin's paper arguing against explaining black box models was particularly influential on my thinking.[3] A heatmap actually says very little about the precise method that a CNN uses to arrive at a prediction.
In response to this dismal state of affairs I wrote a paper on the idea of "self-explaining AI", where the AI outputs an explanation (for instance a set of keywords or a sentence) which can help the user decide how much to trust it. A major issue though was trying to figure out how to determine if the output of the explanation branch actually maps onto the internal mechanism it uses for the prediction branch. A month or so after I published my paper I discovered Olah et al.'s work. It was the first work I saw that actually attempted mechanistic explanation and the discoveries made seemed very compelling.
It's interesting how little follow-on work the Circuits thread has gotten from the broader academic community, especially considering that the code for it is open source. My guess is this is mainly because figuring out circuits is time consuming and hard. Additionally, there is no impressive-looking math involved, and instead there are a lot of stories involving pictures which looks very un-rigorous.
The Open Philanthropy project has a request for proposals and one of the areas they are interested in is explainability. Chris Olah has already laid out a number of possible research directions in a recent LessWrong post from Oct. 29th [? · GW]:
- Discovering New Features and Circuits [? · GW]
- Scaling Circuits to larger models [? · GW]
- Polysemantic neurons [? · GW]
- Misc other directions [? · GW] (includes finding inductive biases that improve interpretability, trying to understand model phase changes, model diffing, and looking at quadratic forms).
I think these are all valuable, in particular the scaling angle. Here are some other directions I've been thinking about:
Further directions
Illuminating non-robust features
If you naively apply activation maximization, you get what appears to be noise. (Although, Olah et al. (2017) note that if you optimize long enough meaningful features sometimes start to appear.[4]). How do we know there aren't imperceptible features in that noise the CNN is using? My biggest concern when I first encountered Olah et al.'s work is that they were using a lot of additional constraints to get an interpretable image instead of confronting the noise pattern head-on. I think the fact you get noise says something deep about how CNNs work. I was put-off by the fact that the articles in the Circuits thread do not explain which set of constraints are applied - there are many to choose from[4:1]. (I was particularly worried they were using a GAN-based prior, where it is hard to disentangle how much of the visualization comes from the CNN being studied vs the prior.)
After a brief email exchange with Chris, I am not as concerned about this now. It turns out that for the Circuits thread the only constraints they applied are transformation robustness to padding, jitter, scaling, and rotation (Chris pointed me to the code here). They also sometimes use high spatial frequency penalties for aesthetic reasons. This seems OK because it seems the high frequency patterns are just an artifact from the use of strided convolutions or pooling (cf. related work on checkerboard artifacts in GANs[5]). Chris also notes that for the VGG network you can get meaningful looking visualizations with just a "bit of L2 pixel regularization".
However the noise pattern is consistent with the phenomena of adversarial examples, where a small amount of what looks like "noise" to a human will fool a model. The degree of lack of robustness under adversarial attack that CNNs exhibit can hardly be overstated - Su et al. find changing one pixel is enough to fool a CNN in 68% of images in the CIFAR-10 Kaggle test set.[6] CNNs are very non-robust to both uniform and salt-and-pepper noise as well. Geirhos et al. (2018) have found uniform noise decreases accuracy to only ~6% while humans still maintain 46% accuracy.[7] Andrew Lohn, now a senior fellow at CSET, found a similar drop in his experiments.[8] Interestingly, Geirhos et al. found that training a model to be robust to salt-and-pepper noise does not help with robustness to uniform noise, and vice-versa.[7:1] One wonders if this non-robustness is because models are utilizing very small features that easily get corrupted by noise. The idea that models can achieve high accuracy by using many small features is supported by work showing that models that only operate on small image patches can achieve high accuracy.[9][10]
An important work by Ilyas et al. shows that adversarial examples are not just exceptionally pathological inputs that push models "off-manifold" but actually can be a side effect of "non-robust features" that CNNs use.[11] I know that Olah and his collaborators are familiar with this work, since they have cited it and since Distill organized a set of commentaries on it (note: I haven't had time to study the commentaries in detail but anyone who is interested in research direction should). I have not seen anyone who has been able to visualize these features, but they may be conceptualized as very small features. Here is an amusing illustration from Springer et al.[12] :
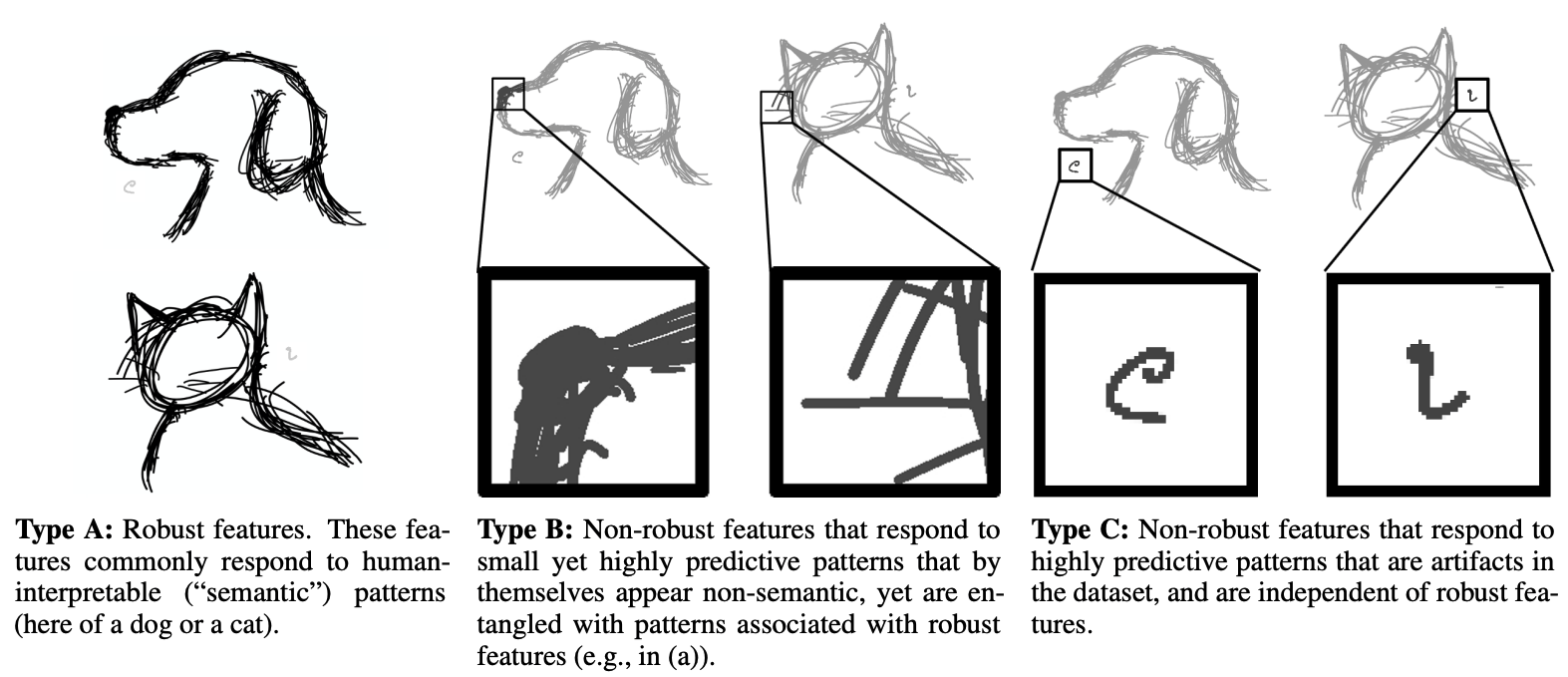 Illustration of what non-robust features might look like from Springer, Mitchell, and Kenyon, 2021. arXiv e-prints: 2102.05110.
Illustration of what non-robust features might look like from Springer, Mitchell, and Kenyon, 2021. arXiv e-prints: 2102.05110.
The idea that CNNs use non-robust features is supported by a growing literature showing that robustness to adversarial examples is at odds with test set accuracy.[13]
While Ilyas proved that CNNs use non-robust features, they didn't come up with any way of visualizing them or explaining how they work. The research direction here would be to develop explainability methods that can illuminate what non-robust features are being used and how they are being used. There's already a bit of work along these lines, for linear models (I haven't had time to study it yet, though). If someone could explain why Gabor filters apparently make models more robust that would be interesting, too.[14][15]
Empirical testing of the utility of explainability tools
Currently explainability is in the phase of an "observational science''. Olah views his methods as a "microscope'' that allows one to peer inside and observe some aspects of the internal workings of the network. Based on what is observed with this microscope, explanatory theories can then be concocted to explain how the network works (these may take the form verbal heuristics or hand-implemented algorithms).
The next natural step is to put these explanatory theories to the test. There are several different testing regimes (described below) but the most obvious is to see if the theory can predict the output of the model on sofar-unseen inputs. To quantify the value of the microscope we would need to compare the predictive accuracy of the explanations derived by researchers using the microscope to explanations derived by researchers that do not have access to the microscope (a randomized controlled trial).
For situations where explainability techniques will be deployed to help users determine how much to trust a model testing the utility of explainability techniques is critical because they may actual mislead users and do more harm than good (for arguments about this in the context of medical imaging see Ghassemi et al. (2021)[16]).
There has actually been a bit of work along these lines already, with mixed results. Hase et al.~(2020) evaluated four different explanability methods (LIME, Anchors, prototypes, and decision boundary examples) to explain the functioning of a deep neural network trained on two different tasks - one text-based and one based on tabular data.[17] The text-based task was movie review sentiment analysis, and the tabular task was to predict whether an individual makes an income greater than $50,000 using the "Adult" dataset, which consists of 14 easily understandable variables that describe 48,842 individuals. 32 trained undergraduates who had taken at least one course in computer science or statistics participated in the experiment. They found that only LIME for the tabular data model improved subject's prediction ability in a statistically significant manner (p=0.014, not corrected for multiple comparisons). None of the methods were able to improve prediction for the text data task (p>0.45 in all cases). Interestingly, they found that "subjective user ratings of explanation quality are not predictive of explanation effectiveness in simulation tests''. This suggests that humans can easily be misled as to the utility of explanations.
More recently, Cohen et al.[18] develop a explainability method they call "latent shift" and demonstrate it on a dataset of chest X-ray images. The details of this method are interesting but not relevant to the discussion here. What is relevant is that they test the utility of their method in an empirical study, albeit a very small and improperly controlled one. The study involved just two radiologists who looked at 240 images. Each image was paired with a model prediction of the type of disease in the image (there were 6 disease types). The example images were chosen so that 50% of the images were examples were the model made a false positive detection. The images were shown twice - in one case they provided outputs from three "traditional methods" (Input gradients, Guided Backprop, and Integrated Gradients) and in the other case they provided outputs from the "latent shift" method. The doctors scored their confidence in the model on a scale from 1-5. Unfortunately, there was no baseline studied where no explainability method was provided, so it is very difficult to determine if the explainability methods had positive, negative, or zero effect on the doctor's performance. However what is interesting is that for several disease categories the radiologists were equally confident the model made the right decision for both the false positive and true positive examples. So it appears there is much more work to do before explainability methods can help radiologists decide how much to trust the output from an AI.
Here is more elaboration on different types of "utility tests" that may be done on "AI microscopes" (explainability methods):
Predicting how a model responds to novel inputs
It may be particularly interesting to see if explainability tools help people predict how a model will respond to ambiguous input? For instance, given a "duck-rabbit'', will the network classify it as a duck or a rabbit? For language models that give a sentence as an output, instead of asking the user to predict the exact sentence (which would be very unlikely, especially if there is randomness inherent in the generation) we can provide the true sentence and a dummy sentence and see if researchers can successfully predict which one came from the model.
Predicting how a model responds to perturbations
One idea is to propose a certain change to an input and ask then ask subjects whether it will change the model's behaviour. Another possibility is to provide each subject an input where the model makes a mistake and then ask them how the input must be changed so that the model gives the correct output (Doshi-Velez and Kim (2017) call this "counterfactual simulation'' [19]).
Predicting where model fails
For AI safety, a great test is to see if users can predict where a model may fail or exhibit unwanted bias. For instance, we might predict that the network will fail to recognize a stop sign when placed upside-down.
Predicting how to fine-tune a model to fix an issue
We may have a model with a known-issue, for instance a model for classifying skin cancer that doesn't work on old patients with very wrinkly skin. Out a set of possible images, the task might be to predict which set of k images would be most useful for fine-tuning the model.
Predicting what architectural changes will improve a network
If we observe a model with a lot of multi-model neurons for instance, we might predict that adding more neurons will lead to cleaner representations and better predictions.
Small activations and changes of basis
*epistemic status: confused *
Activation-maximization based visualizations alone will never tell us the full story about neural network function, because they only visualize what input leads to the maximum activation. Due to the non-linear nature of neural nets, an input that leads to only a small activation won't just be the activation-maximizing input but scaled down in intensity, and one wonders if it may be of an altogether different character. How big of an issue this to the utility of actviation maximization isn't clear to me. Activation functions are monotonic, and the most popular activation function, ReLU, is piece-wise linear, so maybe activation maximization does tell us a lot about how what a neuron does at smaller activations as well? A more careful analysis of this could be useful.
There's also the "change of basis" phenomena - if you take a linear combination of units from a given layer instead of a single unit (or more precisely perform a random rotation / change in basis), and maximize that instead, you end up with similar types of visualizations that "explain'' what each unit is sensitive to in the new basis. The fact a random rotation can lead to visualizations that are just as "understandable" seems like a problem. This "intriguing property'' was pointed out in 2014 by Szegedy et al. [20] and has been noted in Olah's work. In 2017 Olah et al. said “The truth is that we have almost no clue how to select meaningful directions, or whether there even exist particularly meaningful directions".[4:2] The tentative conclusion I am drawing here is that weights in the next layer and activations may need to be analyzed in conjunction because weights can implement a change of basis. Again, I think more careful analysis of what is going on may be useful.
Closing thoughts
I'm curious what people think of these ideas. Do they make sense? Which directions do you think have the highest expected value?
References
Yeh et al. "On the (in)fidelity and sensitivity for explanations". arXiv e-prints: 1901.09392. 2019. ↩︎
Adebayo et al. "Sanity checks for saliency maps". In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NeurIPS). 2018. ↩︎
Rudin. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead". Nature Machine Intelligence, 1(5):206– 215, May 2019. ↩︎
Olah et al. "Feature Visualization". Distill. 2017 ↩︎ ↩︎ ↩︎
Odena et al. "Deconvolution and Checkerboard Artifacts". Distill. 2016. ↩︎
Su et al. "One Pixel Attack for Fooling Deep Neural Networks". IEEE Trans. Evol. Comput. 23(5): 828-841 (2019) ↩︎
Geirhos et al. "Generalisation in humans and deep neural networks". In Proceedings of the 2018 Conference on Neural Information Processing Systems. pg 7549. 2018. ↩︎ ↩︎
Lohn. "Estimating the Brittleness of AI: Safety Integrity Levels and the Need for Testing Out-Of-Distribution Performance". arXiv e-prints : 2009.00802. 2020. ↩︎
Anonymous authors. "Patches Are All You Need?" Under review for ICLR 2022. 2021. ↩︎
"Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet". In Proceedings of the 7th International Conference on Learning Representations (ICLR). 2019 ↩︎
Ilyas et al. "Adversarial examples are not bugs, they are features". In Proceedings of the 2019 Conference on Neural Information Processing Systems (NeurIPS). 2019. ↩︎
Springer et al. "Adversarial Perturbations Are Not So Weird: Entanglement of Robust and Non-Robust Features in Neural Network Classifiers". arXiv e-prints: 2102.05110. 2021. ↩︎
Tsipras et al. "Robustness may be at odds with accuracy". In Proceedings of the 7th International Conference on Learning Representations (ICLR). 2019. ↩︎
Perez et al. "Gabor Layers Enhance Network Robustness". arXiv e-prints: 1912.05661. 2019. ↩︎
Dapello et al. "Simulating a Primary Visual Cortex at the Front of CNNs Improves Robustness to Image Perturbations". medRxiv preprint. 2020. ↩︎
Ghassemi et al. "The false hope of current approaches to explainable artificial intelligence in health care". Lancet Digit Health. 3(11) pg e745. 2021. ↩︎
Hase et al. Evaluating explainable AI: Which algorithmic explanations help users predict model behavior? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pg 5540. 2020. ↩︎
Cohen et al. "Gifsplanation via Latent Shift: A Simple Autoencoder Approach to Counterfactual Generation for Chest X-rays". In Proceedings of the 2021 Workshop on Medical Imaging and Deep Learning (MIDL). 2021 ↩︎
Doshi-Velez and Kim. "Towards a rigorous science of interpretable machine learning". arXiv e-prints: 1702.08608. 2017. ↩︎
Szegedy et al. "Intriguing properties of neural networks". In Proceedings of the 2nd International Conference on Learning Representations (ICLR). 2014. ↩︎
8 comments
Comments sorted by top scores.
comment by delton137 · 2021-11-15T15:54:09.584Z · LW(p) · GW(p)
Here's another paper on small / non-robust features, but rather specific to patch-based vision transformers:
Understanding and Improving Robustness of Vision Transformers through Patch-based Negative Augmentation
^ This work is very specific to patch-based methods. Whether patches are here to stay and for how long is unclear to me, but right now they seem to be on an ascendancy (?).
comment by TLW · 2021-11-11T07:14:08.825Z · LW(p) · GW(p)
Illustration of what non-robust features might look like
This looks... an awful lot like what one would expect to see out of a convolutional network. Small-scale features and textures end up as the main discriminators because they optimize faster due to requiring less layers, and hence outcompete larger-scale classifiers. (To the extent that you can think of training as competition between subnetworks.)
(Sanity check: we haven't solved the problem of deeper networks taking longer to train, right? I know ReLU helps with vanishing gradients.)
It's too bad fully-connected networks don't scale. I'd be interested to see what maximum-activation examples looked like for a fully-connected network.
(Fair warning: I'm definitely in the "amateur" category here. Usual caveats apply - using incorrect terminology, etc, etc. Feel free to correct me.)
Replies from: gwern, delton137↑ comment by gwern · 2021-11-12T15:14:56.336Z · LW(p) · GW(p)
It's too bad fully-connected networks don't scale. I'd be interested to see what maximum-activation examples looked like for a fully-connected network.
They scale these days. See https://www.gwern.net/notes/FC
Replies from: TLW, delton137↑ comment by delton137 · 2021-11-12T13:39:38.570Z · LW(p) · GW(p)
we haven't solved the problem of deeper networks taking longer to train, right
My understanding is the vanishing gradient problem has been largely mitigated by introducing skip connections (first with resnet, and now standard in CNN architectures), allowing for networks with hundreds of layers.
It's too bad fully-connected networks don't scale.
I've heard people say vision transformers are sort of like going back to MLPs for vision. The disadvantage of going away from the CNN architecture (in particular weight sharing across receptive fields) is that you end up with more parameters and thus require a lot more data to train.
I just did a search and came across this: "MLP-Mixer: An all-MLP Architecture for Vision" . Together with "Patches Are All You Need?" the basic theme I'm seeing here is that putting in the prior of focusing on small patches is really powerful. In fact, it may be that the vision transformer can do better than CNNs (with enough data) because this prior is built in, not because of the attention layers. Which is just another example showing the importance of doing rigorous comparisons and ablation studies before jumping to conclusions about what makes architecture X better than architecture Y.
↑ comment by TLW · 2021-11-14T20:10:01.677Z · LW(p) · GW(p)
My understanding is the vanishing gradient problem has been largely mitigated by introducing skip connections (first with resnet, and now standard in CNN architectures), allowing for networks with hundreds of layers.
Does this actually solve the problem, or just mask it? Skip connections end up with a bunch of shallow networks in parallel with deeper networks, to an over-approximation. If the shallow portions end up training faster and out-competing the deeper portions...