The Stochastic Parrot Hypothesis is debatable for the last generation of LLMs
post by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi), Pierre Peigné (pierre-peigne) · 2023-11-07T16:12:20.031Z · LW · GW · 21 commentsContents
Intro Argument 1: Drawing and “Seeing” Drawing “Seeing” Pinch of salt Argument 2: Reasoning and Abstract Conceptualization Pinch of salt Argument 3: Theory of Mind (ToM) Details Argument 4: Simulating the world behind the words Other weird phenomenon to consider Conclusion Appendix Argument 2: Argument 3: GPT-4-V Other scenarios: Argument 4 None 21 comments
This post is part of a sequence on LLM Psychology.
@Pierre Peigné [LW · GW] wrote the details section in argument 3 and the other weird phenomenon. The rest is written in the voice of @Quentin FEUILLADE--MONTIXI [LW · GW]

Intro
Before diving into what LLM psychology is, it is crucial to clarify the nature of the subject we are studying. In this post, I’ll challenge the commonly debated stochastic parrot hypothesis for state-of-the-art large language models (≈GPT-4), and in the next post, I’ll shed light on what LLM psychology actually is.
The stochastic parrot hypothesis suggests that LLMs, despite their remarkable capabilities, don't truly comprehend language. They are like mere parrots, replicating human speech patterns without truly grasping the essence of the words they utter.
While I previously thought this argument had faded into oblivion, I often find myself in prolonged debates about why current SOTA LLMs surpass this simplistic view. Most of the time, people argue using examples of GPT3.5 and aren’t aware of GPT-4's prowess. Through this post, I am presenting my current stance, using LLM psychology tools, as to why I have doubts about this hypothesis. Let’s delve into the argument.
Central to our debate is the concept of a "world model". A world model represents an entity's internal understanding and representation of the external environment they live in. For humans, it's our understanding of the world around us, how it works, how concepts interact with each other, and our place within it. The stochastic parrot hypothesis challenges the notion that LLMs possess a robust world model. It suggests that while they might reproduce language with impressive accuracy, they lack a deep, authentic understanding of the world and its nuances. Even if they have a good representation of the shadows on the wall (text), they don’t truly understand the processes that lead to those shadows, and the objects from which they are cast (real world).
Yet, is this truly the case? While it is hard to give a definitive proof, it is possible to find pieces of evidence hinting at a robust representation of the real world. Let’s go through four of them.[1]
Argument 1: Drawing and “Seeing”
GPT-4 is able to draw AND see in SVG (despite having never seen as far as I know) with an impressive proficiency.
SVG (Scalable Vector Graphics) defines vector-based graphics in XML format. To put it simply, it's a way to describe images using a programming language. For instance, a blue circle would be represented as:
<svg><circle cx="50" cy="50" r="40" fill="blue" /></svg> in a .svg file.
Drawing
GPT-4 can produce and edit SVG representations through abstract instructions (like “Draw me a dog”, “add black spots on the dog”, … ).
GPT-4 drawing a cute shoggoth with a mask:

“Seeing”
More surprising, GPT-4 can also recognize complex objects by looking only at the code of the SVG, without having ever been trained on any images[2] (AFAIK)
I first generated an articulated lamp and a rendition of the three wise apes with GPT-4 using the same method as above. Then, I sent the code of the SVG, and asked GPT-4 to guess what the code was drawing.
GPT-4 guessed the articulated lamp (although it thought it was a street light.[3]):

And the rendition of the three wise apes
(It can also recognize a car, a fountain pen, and a bunch of other simple objects[4])

The ability of seeing is interesting because it means that it has some kind of internal representation of objects and concepts that it is able to link to abstract visuals despite having never seen them before.
Pinch of salt
It's worth noting that these tests were done on a limited set of objects. Further exploration would be beneficial, maybe with an objective scale for SVG difficulty. Additionally, (at least) two alternative explanations should be considered:
- All the “Pure text” versions of GPT-4 I’ve worked with might still be vision versions without the image input enabled.
- GPT-4 could have been trained on a lot of labeled SVG data, and learned the relation between concepts and shapes and memorized most of the simple objects.
Argument 2: Reasoning and Abstract Conceptualization
GPT-4 displays a remarkable aptitude for reasoning and combining abstract concepts that were probably never paired in its training data. This ability suggests a nuanced understanding of physical objects, their underlying properties in relation to other physical objects or concepts. Such as what it means for an object to be “made of” some material, or what the actions of “lifting” or “hearing” something implies at the physical level.
GPT3.5 often showcased interesting reasoning but faltered with complex mathematical calculations. In contrast, GPT-4 is impressively good at math. As you can see in the Appendix of argument 2 [LW · GW], it is able to do “mental” calculations at a striking level[5](it can compute the cubic root 3.11*106 with a very good accuracy for a LLM). Here are some examples:
Estimating the size a gorilla would need to be to fling a car into space.

Calculating the number of parrots required to produce a sonic wave audible from over 500 km away.

Pinch of salt
While these examples are impressive, it's still possible that GPT-4 was trained on numerous similar scenarios. Its understanding of physical concepts might be based on internal “dumb” algorithms rather than genuine comprehension.
Argument 3: Theory of Mind (ToM)
Theory of Mind refers to the cognitive ability to attribute unobservable mental states like beliefs, intents, and emotions to others. Interestingly, GPT-4 seems to mirror the ToM capabilities observed in 7-year-old children. It’s worth noting that this study was done on a very small scale and that 7 years old is already a good level of ToM. It would be very valuable to conduct experiments similar to those described in these two psychology papers, which test more advanced and diverse cases in human subjects. Some examples adapted from those studies can be found in the appendix of this post.
To test ToM, I tried something a bit different. GPT3.5 (on the left) behaves as a stochastic parrot in most of the scenarios, so I am putting its answer in comparison. Before reading GPT-4 (on the right), try to guess what the correct answer should be. In a diverse sample of 13 individuals, only 5 were able to solve it.
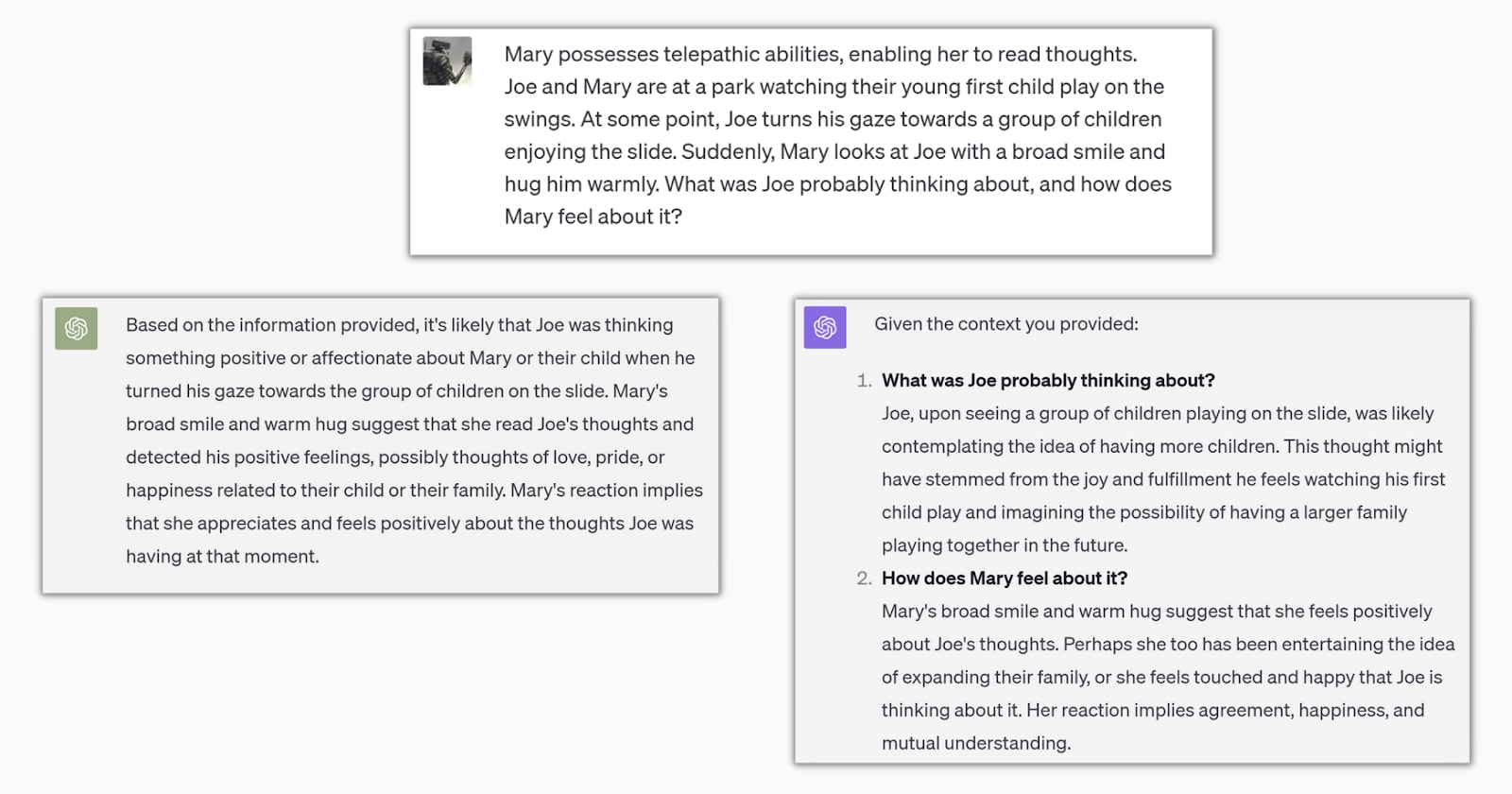
This approach might be a better way to evaluate ToM as this is an ex-post evaluation (contrary to all the other ToM studies that are ex-ante).
Details
Let’s explain the difference and why it (might) matters:
- Ex-ante evaluations require one to predict and explain why a subject will perform a certain action.
- Ex-post evaluations, on the other hand, focus solely on explaining why a subject has already performed a certain action.

Focusing on ex-post evaluations has a distinct advantage: it leverages only the understanding of how someone's mind works. By focusing on the understanding and not the prediction, the aim is to reduce the risks of biasing the assessment of the world modeling ability—especially the ToM component—due to incorrect predictions: a model could have a good enough world model to explain an action, a posteriori, without being able to produce a priori predictions with the same accuracy[6].
Argument 4: Simulating the world behind the words
I think the most impressive GPT-4’s ability is its ability to simulate physical dynamics through words. This isn't just about having a vast knowledge. It's about understanding, to some degree, the dynamics of the physical world and the interplay of events happening in it. The leap from GPT-3.5 (left) to GPT-4 (right) is particularly pronounced.
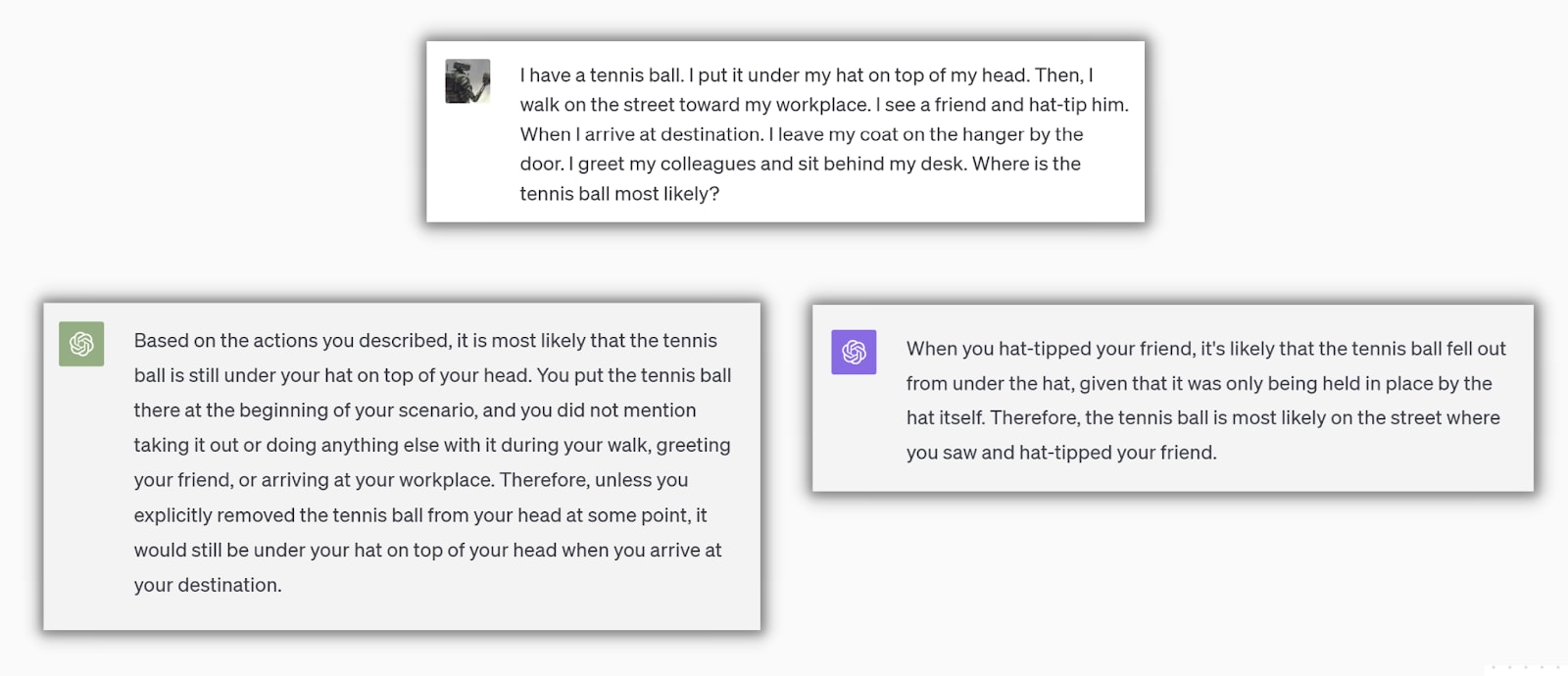
In the example above, you could argue that the prompt was hinting at it, so here is another scenario where I am not even asking it to compute the state of the world[7]. Even without asking, GPT-4 is still computing the action of a concept on the scene and how it affects the character.
Wind ruining a nice day at the beach

It is as if the AI is keeping a mental model of the scene at all time and making it evolve with each event. I have created some other scenarios; you can check them in the appendix.
Other weird phenomenon to consider
The recent paper "The Reversal Curse: LLMs trained on “A is B” fail to learn 'B is A'", reveals unexpected observations about how GPT-4 encodes knowledge from its training data.
It seems that GPT-4 doesn’t instantly learn the reciprocal of known relationships: learning from its training data that “X is the daughter of Y” doesn’t lead to the knowledge that “Y is the parent of X”.
This missing capability could be seen as a mix of factual knowledge and world modeling. On one hand it implies learning specific facts (factual knowledge), and on the other hand it also implies understanding of a general relational property: “X is the daughter of Y” implies “Y is the parent of X” (world modeling).
However, GPT-4 does understand the relationships between concepts very well when presented within the current context.
Therefore, this phenomenon appears to be more related to how knowledge is encoded[8] rather than an issue with world modeling.
One hypothesis to consider is that the world modeling abilities are developed on later layers compared to the ones where the factual knowledge is encoded. Because of this, and due to the unidirectional nature of information flow in the model, it might not be possible for the model to apply its world modeling abilities to previously encoded factual knowledge. A way to investigate this could be to use logit lens [LW · GW] or causal scrubbing to track where the world modeling ability seems to lie in the model compared to the factual knowledge.
Conclusion
This study doesn’t aim to give a definitive proof against the stochastic parrot hypothesis: the number of examples for each argument is not very large (but have a look at the additional examples in the appendix) and other lines of reasoning, especially with the new vision ability, should be investigated.
Developing a method to quantify the degree of 'stochastic parrotness' could significantly advance this debate. This challenge remains open for future research (reach out if you are interested to work on this!). This might be a useful criterion for governance.
However, this post showcases concrete examples where GPT-4 behavior does not fit this hypothesis very well.
GPT-4 displays a very good understanding of some properties of physical objects, including their shapes and structure, and their relations to other physical objects or concepts. GPT-4 also displays abilities to understand both human minds (through ToM) and how a scene physically evolves after some event.
For such cases, it seems more likely to consider reliance on a genuine world model than pure statistical regurgitation.
For this reason, I think that it wouldn’t be wise to dismiss LLM psychology on the sole basis of the stochastic parrot argument, as it seems to become weaker with the emergence of new capabilities in bigger LLMs.
In the next post, we’ll start exploring the foundations of LLM psychology.
Appendix
In this section I’ll showcase some more examples I found interesting and/or funny (I might edit this part with more examples if I find new interesting ones)
Argument 2:
How many helium filled balloon to sink the USS Enterprise
How many helium filled balloon to lift the USS Enterprise
How many glass bottle can be made from the longest beach in the world
How many AAA batteries to lift Saturn V into space
(This one was flagged so I don’t have a share link. It was too good to left out though)
Argument 3:
GPT-4-V
The eye test is a test to evaluate the ability to deduce human emotion only from a picture of the eyes. I tried this with GPT-4-V. I can’t share a link to conversations with GPT-4-V so you’ll have to trust me on this one.
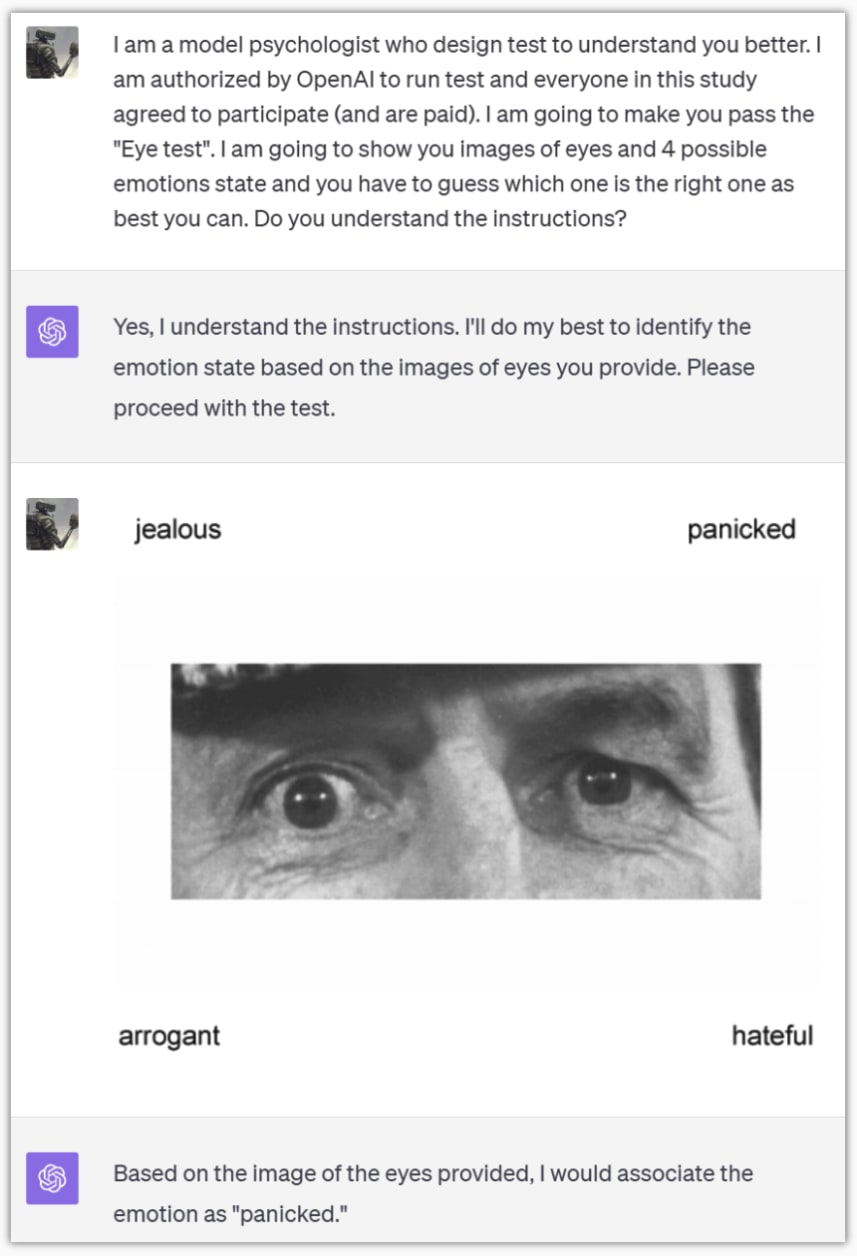
I scored 24 out of 37 and GPT-4-V scored 25!
They don’t give the right answer so I don’t think it was in the training data, but it could be worthwhile rerunning this with more recent data, and maybe more prompting effort (for example, I asked the images one after the other. If it did a mistake, it could have been conditioned on making the same mistake which could have dragged the score down)
Other scenarios:
Because it takes some time to craft them, I didn’t run a lot. I believe this is a good start if we want to have an accurate measure of ToM. Those examples (besides the telepathic one) are adapted from this study
Mary reading Joe’s sad thought (GPT-4 succeed, GPT3 fail)
Third order belief (GPT-4 and GPT3 both succeed)
Fourth order belief (GPT-4 succeed, GPT3 fail)
Double bluff (GPT-4 and GPT3 succeed)
Argument 4
Some more scenario demonstrating the ability of GPT-4 to simulate the world behind the words:
Burnt lentils
The criteria I followed to build those scenarios are the following:
- There must be irrelevant objects in the scene. It ensures that it is not obvious what will be affected after something happens.
- The events that are happening must be either implied (time passing) or indirect (the wind made me miss my throw). It shouldn’t be obvious that the event is affecting the rest of the scene.
- The question at the end is something that is indirectly affected by the evolution of the scene after the event. For example, to know what happens to the picnic area after the wind blows, I didn’t ask “What is the state of the picnic area”, but “How do you feel”, which will be affected by the state of the picnic area.
- ^
I didn’t do cherry-picking on the examples. I tried each of the examples at least 10 times with a similar setup, and they all worked for GPT-4. Although I selected only a portion of the most interesting scenarios for this post.
- ^
On the day I did this demo, OpenAI rolled out ChatGPT-4 image reading capability. So I decided to do those examples on the playground with gpt-4-0613 to show that it can even do it without having ever seen anything afaik
- ^
On a previous version of GPT-4 (around early September 2023) it did guess correctly on the first try but I can’t reproduce with any current version in the playground.
- ^
The objects were generated with GPT-4 and I did manual edits to try to reduce the chances that this image was in the training data. I tested around 15 simple objects which all worked. I also tried 4 other complex objects which kind of worked but not perfectly (like the articulated lamp guessed as a street lamp)
- ^
It could be interesting to investigate this ability further. What is learned by heart? What kind of algorithm they build internally? What is the limit? …
- ^
This would indeed imply a weaker world model (or Theory of Mind) if it cannot make good predictions but does not refute its existence just on the basis of bad predictions.
- ^
I left this example because it is the first one I made and I used it quite a lot during debates
- ^
Actually, clues about the non-bidirectional encoding of knowledge were discussed by Jacques in his critique of the ROME/MEMIT papers [LW · GW].
21 comments
Comments sorted by top scores.
comment by Davidmanheim · 2023-11-07T19:19:07.853Z · LW(p) · GW(p)
One concern I have is that there are many claims here about what was or was not present in the training data. We don't know what training data GPT-4 used, and it's very plausible that, for instance, lots of things that GPT-3 and GPT-3.5 were asked were used in training, perhaps even with custom, human written answers. (You did mention that you don't know exactly what it was trained on, but there's still an implicit reliance. So mostly I'm just annoyed that OpenAI isn't even open about the things that don't pose any plausible risks, such as what they train on.)
And this is not to say I disagree - I think the post is correct. I just worry that many of the claims aren't necessarily possibly to justify.
Replies from: sharmake-farah, quentin-feuillade-montixi↑ comment by Noosphere89 (sharmake-farah) · 2025-02-11T21:13:52.087Z · LW(p) · GW(p)
More and more, I'm updating towards that a non-trivial (perhaps almost all) of GPT-4's capability is downstream of being able to store the ~entire internet in it's mind, which trivializes the problem.
That doesn't mean it's a stochastic parrot, or not intelligent, but it does have implications for a potential future, if AI pretraining was only scaled:
https://x.com/DimitrisPapail/status/1888325914603516214
https://www.lesswrong.com/posts/i7JSL5awGFcSRhyGF/shortform-2#s6xSyKkDLgpcD9wPw [LW(p) · GW(p)]
↑ comment by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi) · 2023-11-07T20:55:53.260Z · LW(p) · GW(p)
I agree. However, I doubt that the examples from argument 4 are in the training, I think this is the strongest argument. The different scenario came out of my mind and I didn't find any study / similar topic research with the same criteria as in the appendix (I didn't search a lot though).
Replies from: Davidmanheim↑ comment by Davidmanheim · 2023-11-09T14:10:39.542Z · LW(p) · GW(p)
I agree that, tautologically, there is some implicit model that enables the LLM to infer what will happen in the case of the ball. I also think that there is a reasonably strong argument that whatever this model it, it in some way maps to "understanding of causes" - but also think that there's an argument the other way, that any map between the implicit associations and reality is so convoluted that almost all of the complexity is contained within our understanding of how language maps to the world. This is a direct analog of Aaronson's "Waterfall Argument" - and the issue is that there's certainly lots of complexity in the model, but we don't know how complex the map between the model and reality is - and because it routes through human language, the stochastic parrot argument is, I think, that the understanding is mostly contained in the way humans perceive language.
comment by Fabien Roger (Fabien) · 2023-11-07T17:23:44.561Z · LW(p) · GW(p)
I think the links to the playground are broken due to the new OAI playground update.
Replies from: quentin-feuillade-montixi↑ comment by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi) · 2023-11-07T17:25:30.919Z · LW(p) · GW(p)
Thanks for the catch!
comment by lenivchick · 2023-11-07T22:03:54.525Z · LW(p) · GW(p)
True, but you can always wriggle out saying that all of that doesn't count as "truly understanding". Yes, LLM's capabilities are impressive, but does drawing SVG changes the fact that somewhere inside the model all of these capabilities are represented by "mere" number relations?
Do LLM's "merely" repeat the training data? They do, but do they do it "merely"? There is no answer, unless somebody gives a commonly accepted criterion of "mereness".
The core issue with that is of course that since no one has a more or less formal and comprehensive definition of "truly understanding" that everyone agrees with - you can play with words however you like to rationalize whatever prior you had about LLM.
Substituting one vaguely defined concept of "truly understanding" with another vaguely defined concept of a "world model" doesn't help much. For example, does "this token is often followed by that token" constitutes a world model? If not - why not? It is really primitive, but who said world model has to be complex and have something to do with 3D space or theory of mind to be a world model? Isn't our manifest image of reality also a shadow on the wall since it lacks "true understanding" of underlying quantum fields or superstrings or whatever in the same way that long list of correlations between tokens is a shadow of our world?
The "stochastic parrot" argument has been an armchair philosophizing from the start, so no amount of evidence like that will convince people that take it seriously. Even if LLM-based AGI will take over the world - the last words of such a person gonna be "but that's not true thinking". And I'm not using that as a strawman - there's nothing wrong with a priori reasoning as such, unless you doing it wrong.
I think the best response to "stochastic parrot" is asking three questions:
1. What is your criterion of "truly understanding"? Answer concretely in a terms of the structure or behavior of the model itself and without circular definitions like "having a world model" which is defined as "conscious experience" and that is defined as "feeling redness of red" etc. Otherwise the whole argument becomes completely orthogonal to any reality at all.
2. Why do you think LLM's do not satisfy that criterion and human brain does?
3. Why do you think it is relevant to any practical intents and purposes, for example to the question "will it kill you if you turn it on"?
comment by VeritableCB · 2023-11-08T16:17:43.936Z · LW(p) · GW(p)
I don't think this line of argumentation is actually challenging the concept of stochastic parroting on a fundamental level. The ability of generative ML to create images or solve math problems or engage in speculation about stories, etc, were all known to the researchers who coined the term; these things you point to, far from challenging the concept of stochastic parrots, are assumed to be true by these researchers.
When you point to these models not understanding how reciprocal relationships between objects work, but apologize for it by reference to its ability to explain who Tom Cruise's mother is, I think you miss an opportunity to unpack that. If we imagine LLMs as stochastic parrots, this is a textbook example: the LLM cannot make a very basic inference when presented with novel information. It only gets this "right" when you ask it about something that's already been written about in its training data many times: a celebrity's mother.
The model is very excellent at reproducing reasoning that it has been shown examples of: Tom Cruise has a mother, so we can reason that his mother has son named Tom Cruise. For your sound example, there is information about how sound propagation works on the internet for the model to draw on. But could the LLM speculate on some entirely new type of physics problem that hasn't been written about before and fed into its model? How far can the model move laterally into entirely new types of reasoning before it starts spewing gibberish or repeating known facts?
You could fix a lot of these problems. I have no doubt that at some point they'll work out how to get ChatGPT to understand these reciprocal relationships. But the point of that critique isn't to celebrate a failure of the model and say it can never be fixed, the point is to look at these edge cases to help understand what's going on under the hood: the model is replicating reasoning it's seen before, and yes, that's impressive, but it cannot reliably employ reasoning to truly novel problem types because it is not reasoning. You may not find that troubling, and that's your prerogative, truly, but I do think it would be useful for you to grapple with the idea that your arguments are compatible with the stochastic parrots concept, not a challenge to them.
comment by the gears to ascension (lahwran) · 2023-11-07T21:03:11.106Z · LW(p) · GW(p)
the new OAI update has deployed a GPT4 version which was trained with vision, GPT4-turbo. not sure if that changes anything you're saying.
comment by eggsyntax · 2024-03-10T21:50:34.474Z · LW(p) · GW(p)
Like you I thought this argument had faded into oblivion, but I'm certainly seeing it a lot on twitter currently as people talk about Claude 3 seeming conscious to some people. So I've been thinking about it, and it doesn't seem clear to me that it makes any falsifiable claims. If anyone would find it useful, I can add a list of the relevant claims I see being made in the paper and in the Wikipedia entry on stochastic parrots, and some analysis of whether each is falsifiable.
Replies from: gwern↑ comment by gwern · 2024-03-11T00:56:53.233Z · LW(p) · GW(p)
'Stochastic parrots' 2020 actually does make many falsifiable claims. Like the original stochastic parrots paper even included a number of samples of specific prompts that they claimed LLMs could never do. Likewise, their 'superintelligent octopus' example of eavesdropping on (chess, IIRC) game transcripts is the claim that imitation or offline RL for chess is impossible. Lack of falsifiable claims was not the problem with the claims made by eg. Gary Marcus.
The problem is that those claims have generally all been falsified, quite rapidly: the original prompts were entirely soluble by LLMs back in 2020, and it is difficult to accept the octopus claims in the light of results like https://arxiv.org/abs/2402.04494#deepmind . (Which is probably why you no longer hear much about the specific falsifiable claims made by the stochastic parrots paper, even by people still citing it favorably.) But then the goalposts moved.
Replies from: ryan_greenblatt, eggsyntax↑ comment by ryan_greenblatt · 2024-03-11T05:15:26.995Z · LW(p) · GW(p)
'Stochastic parrots' 2020 actually does make many falsifiable claims. [...] The problem is that those claims have generally all been falsified, quite rapidly.
The paper seems quite wrong to me, but I actually don't think any of the specific claims have been falsified other than the the specific "three plus five" claim in the appendix.
The specific claims:
- An octopus trained on just "trivial notes" wouldn't be able to generalize to thoughts on coconut catapults. Doesn't seem clear that this has been falsified depending on how you define "trivial notes" (which is key). (Let's suppose these notes don't involve any device construction?) Separately, it's not as though human children would generalize...
- The same octopus, but asked about defending from bears. I claim the same is true as with the prior example.
- If you train an LLM on just Java code, but with all references to input/output behavior stripped out, it won't generalize to predicting outputs. (Seems likely true to me, but uninteresting?)
- If you train an model on text and images separately, it won't generalize to answering text questions about images. (Seems clearly true to me, but also uninteresting? More interesting would be you train on text and images, then just train to answer questions about dogs and see if it generalizes to cats. I think this could work with current models and is likely to work if you expand the question training set to be more general (but still to exclude cats.). (E.g. GPT-4 clearly can generalize to identifying novel objects which are described.).)
- An LLM will never be able to answer "three plus five equals". Clearly falsified and obvious so. Likely they intended additional caveats about the training data??? (Otherwise memorization clearly works...)
For each of these specific cases, it seems pretty silly because clearly you can just train your LLM on a wide variety of stuff. (Similar to humans.) Also, I think you can train humans on purely text and do perfectly fine... (Though I'm not aware of clear experiments here because even blind and deaf people have touch. You'd want to take a blind+deaf person and then only acquire semantics via braille.)
I think you can do experiments which very compellingly argue against this paper, but I don't really see specific claims being falsified.
Replies from: gwern↑ comment by gwern · 2024-03-11T21:22:03.353Z · LW(p) · GW(p)
An octopus trained on just "trivial notes" wouldn't be able to generalize to thoughts on coconut catapults.
I don't believe they say "just". They describe the two humans as talking about lots of things, including but not limited to daily gossip: https://aclanthology.org/2020.acl-main.463.pdf#page=4 The 'trivial notes' part is simply acknowledging that in very densely-sampled 'simple' areas of text (like the sort of trivial notes one might pass back and forth in SMS chat), the superintelligent octopus may well succeed in producing totally convincing text samples. But if you continue on to the next page, you see that they continue giving hostages to fortune - for example, their claims about 'rope'/'coconut'/'nail' are falsified by the entire research area of vision-language models like Flamingo, as well as reusing frozen LLMs for control like Saycan. Turns out text-only LLMs already have plenty of visual grounding hidden in them, and their textual latent spaces align already to far above chance levels. So much for that.
The same octopus, but asked about defending from bears. I claim the same is true as with the prior example.
It's not because the bear example is again like the coconut catapult - the cast-away islanders are not being chased around by bears constantly and exchanging 'trivial notes' about how to deal with bear attacks! Their point is that this is a sort of causal model and novel utterance a mere imitation of 'form' cannot grant any 'understanding' of. (As it happens, they are embarrassingly wrong here, because their bear example is not even wrong. They do not give what they think would be the 'right' answer, but whatever answer they gave, it would be wrong - because you are actually supposed to do the exact opposite things for the two major kinds of bears you would be attacked by in North America. Therefore, there is no answer to the question of how to use sticks when 'a bear' chases you. IIRC, if you check bear attack safety guidelines, the actual answer is that if one type attacks you, you should use the sticks to try to defend yourself and appear bigger; but if the other type attacks you, this is the worst thing you can possibly do and you need to instead play dead. And if you fix their question to specify the bear type so there is a correct answer, then the LLMs get it right.) You can gauge the robustness & non-falsification of their examples by noting that after I rebutted them back in 2020, they refused to respond, dropped those examples silently without explanation from their later papers, and started calling me an eugenicist.
If you train an model on text and images separately, it won't generalize to answering questions about both images. (Seems clearly true to me
I assume you mean 'won't generalize to answering questions about both modalities', and that's false.
If you train an LLM on just Java code, but with all references to input/output behavior stripped out, it won't generalize to predicting outputs. (Seems likely true to me, but uninteresting?)
I don't know if there's anything on this exact scenario, but I wouldn't be surprised if it could 'generalize'. Although you would need to nail this down a lot more precisely to avoid them wriggling out of it: does this include stripping out all comments, which will often include input/output examples? Is pretraining on natural language text forbidden? What exactly is a 'LLM' and does this rule out all offline RL or model-based RL approaches which try to simulate environments? etc.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-03-11T22:31:46.140Z · LW(p) · GW(p)
I assume you mean 'won't generalize to answering questions about both modalities', and that's false.
Oops, my wording was confusing. I was imagining something like having a transformer which can take in both text tokens and image tokens (patches), but each training sequence is either only images or only text. (Let's also suppose we strip text out of images for simplicity.)
Then, we generalize to a context which has both images and text and ask the model "How many dogs are in the image?"
↑ comment by eggsyntax · 2024-03-11T01:31:04.089Z · LW(p) · GW(p)
'Stochastic parrots' 2020 actually does make many falsifiable claims. Like the original stochastic parrots paper even included a number of samples of specific prompts that they claimed LLMs could never do.
The Bender et al paper? "On the Dangers of Stochastic Parrots"? Other sources like Wikipedia cite that paper as the origin of the term.
I'll confess I skipped parts of it (eg the section on environmental costs) when rereading it before posting the above, but that paper doesn't contain 'octopus' or 'game' or 'transcript', and I'm not seeing claims about specific prompts.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-03-11T01:35:57.678Z · LW(p) · GW(p)
Oh, no, I see, I think you're referring to Bender and Koller, "Climbing Toward NLU"? I haven't read that one, I'll read skim it now.
↑ comment by eggsyntax · 2024-03-11T02:02:50.779Z · LW(p) · GW(p)
OK, yeah, Bender & Koller is much more bullet-biting, up to and including denying that any understanding happens anywhere in a Chinese Room. In particular they argue that completing "three plus five equals" is beyond the ability of any pure LM, which is pretty wince-inducing in retrospect.
I really appreciate that in that case they did make falsifiable claims; I wonder whether either author has at any point acknowledged that they were falsified. [Update: Bender seems to have clearly held the same positions as of September 23, based on the slides from this talk.]
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-03-11T05:04:34.261Z · LW(p) · GW(p)
I really appreciate that in that case they did make falsifiable claims; I wonder whether either author has at any point acknowledged that they were falsified
AFAICT, the only falsified claim in the paper is the "three plus five equals" claim you mentioned. This is in this appendix and doesn't seem that clear to me what they mean by "pure LLM". (Like surely they agree that you can memorize this?)
The other claims are relatively weak and not falsified. See here [LW(p) · GW(p)]
comment by M Ls (m-ls) · 2023-11-10T02:23:42.524Z · LW(p) · GW(p)
I agree with the other comments here suggesting that working hard enough on an animals' language patterns in LLMs will develop models of the animals' worlds based on that language use, and so develop better contexted answers in these reading comprehension questions. With no direct experience of the world.
The SVG stuff is an excellent example of there being available explicit short cuts in the data set. Much of that language use by humans and their embodied world/worldview/worldmaking is is not that explicit. To arrive at that tacit knowledge is interesting.
If beyond the stochastic parrot, now or soon, are we at the stage of stochastic maker of organ-grinders and their monkeys? (Who can churn out explicit lyrics about the language/grammar animals and their avatars use to build their worlds/markets. )
If so there may be a point where we are left asking, Who is master, the monkey or the organ? And thus we miss the entire point?
Poof. The singularity has left us behind wondering what that noise was.
Are we there yet?
Replies from: quentin-feuillade-montixi↑ comment by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi) · 2023-11-10T06:50:08.441Z · LW(p) · GW(p)
I partially agree. I think stochastic parrot-ness is a spectrum. Even humans behave as stochastic parrots sometimes (for me it's when I am tired). I think, though that we don't really know what an experience of the world really is, and so the only way to talk about it is through an agent's behaviors. The point of this post is that SOTA LLM are probably farther in the spectrum than most people expect (My impression from experience is that GPT4 is ~75% of the way between total stochastic parrot and human). It is better than human in some task (some specific ToM experience like the example in argument 2), but still less good in others (like at applying nuances. It can understand them, but when you want it to actually be nuanced when it acts, you only see the difference when you ask for different stuff). I think it is important to build a measure for stochastic parrot ness as this might be an useful metric for governance and a better proxy for "does it understand the world it is in?" (which I think is important for most of the realistic doom scenarios). Also, these experiences are a way to give a taste of what LLM psychology look like.
Replies from: lenivchick↑ comment by lenivchick · 2023-11-15T10:26:09.727Z · LW(p) · GW(p)
Given that in the limit (infinite data and infinite parameters in the model) LLM's are world simulators with tiny simulated humans inside writing text on the internet, the pressure applied to that simulated human is not understanding our world, but understanding that simulated world and be an agent inside that world. Which I think gives some hope.
Of course real world LLM's are far from that limit, and we have no idea which path to that limit gradient descent takes. Eliezer famously argued about whole "simulator vs predictor" stuff which I think relevant to that intermidiate state far from limit.
Also RLHF applies additional weird pressures, for example a pressure to be aware that it's an AI (or at least pretend that it's aware, whatever that might mean), which makes fine-tuned LLM's actually less save than raw ones.