Pantheon Interface
post by NicholasKees (nick_kees), Sofia Vanhanen · 2024-07-08T19:03:51.681Z · LW · GW · 22 commentsContents
How do I use Pantheon? What do the daemons see? Trees, branching, and sections How do I save my progress? What are “AI Suggestions”? What is “Ask AI”? Can I control which daemon responds? What is the target use case? How do I make my own daemons? How does this relate to Loom? Does Pantheon use base models? Is Pantheon open source? Should I be concerned about data privacy? Acknowledgments None 22 comments
Pantheon is an experimental LLM interface exploring a different type of human-AI interaction. We created this as a part of the cyborgism [LW · GW] project, with the abstract motivation of augmenting the human ability to think by integrating human and AI generated thoughts.
How it works:
- A human user “thinks out loud” by typing out their thoughts one at a time. This leaves a text trace of their stream of thought.
- AI characters (called daemons) read this trace, and interact with the user by responding asynchronously with comments and questions.
The core distinguishing philosophy is that, while most apps are about a human prompting an AI to do useful mental work, Pantheon is the opposite. Here, AI does the prompting, and the goal is for the AI generated questions or comments to cause the human user to think in ways they would not have on their own. At worst, the app is a rubber duck. At best, the app is a court of advisors, each using their own unique skills to push you to think your best thoughts.
Pantheon can be found at pantheon.chat, and we would really appreciate any and all feedback you have.
The app is set up for you to customize your own daemons. We have set up some default daemons to provide inspiration, but we expect the tool to be a lot more useful when they are customized to specific users. If the default daemons don’t feel useful, we highly encourage you to try to make your own.
How do I use Pantheon?
First, go to settings and provide an OpenAI API key.[1]
Next, begin typing out your thoughts on some topic. It helps to keep each thought relatively short, sending them to the stream of thought as often as you can. This gives the daemons lots of opportunities to interject and offer their comments. Furthermore, it’s usually best to treat this more like a diary or personal notes, rather than as a conversation. In this spirit, it’s better not to wait for them to respond, but to instead continue your train of thought, keeping your focus on your own writing.
What do the daemons see?
Your stream of thought appears in the interface as a chain of individual thoughts. Daemons are called to respond to specific thoughts. When they do, they are given access to all preceding thoughts in the chain, up to and including the thought they were called to. Daemons can only see text the user has written, and they can’t see any of the comments made by themselves or other daemons. We are looking into ways to give the daemons access to their own comment history, but we have not yet made this possible.
After a daemon generates a comment, you can inspect the full chain of thought by clicking on that comment. This will open up a window which will show you everything the LLM saw in the process of generating that response. You can also edit the daemons in settings, as well as toggle them on or off.
Trees, branching, and sections
The text in the interface appears to you as a chain of thoughts, but it is actually a tree. If you hover over a thought, a plus icon will appear. If you click this icon, you can branch the chain. This is often useful if you feel that you have gone down a dead end, or would like to explore a tangent. When there are multiple branches, arrows will appear next to their parent thought, and you can use those arrows to navigate the tree.
If you would like a fresh context, you can make an entirely new tree by opening the “Collection view” in the top left. Furthermore, you can also create a new “section” by clicking the “New Section” button below the input box. This will create a hard section break such that daemons can no longer see any context which came before the break.
How do I save my progress?
Everything you do is automatically saved in local storage. You can also import/export the full app state in settings.
What are “AI Suggestions”?
These are continuations of your stream of thought generated by the base mode. You can understand them as the base model predicting what you will write next.
What is “Ask AI”?
In order to avoid you ever having to copy and paste your stream of thought into another chat bot interface, the button “Ask AI” will turn the text you are currently writing into an instruction for a chat model, and all of your past thoughts will be given to it for context. You can use it to, for example:
- Summarize everything so far
- Answer a specific question
- Brainstorm a list of ideas
- Rephrase something you said
These instructions and the model’s responses are “meta” in that they will not be shown to the daemons, or be used to generate base model completions (as such they also appear differently in the interface).
Can I control which daemon responds?
Yes, there is a mentions feature. By default, daemons are selected at random, but if you type @ and then the daemon's name, this will ensure that specific daemon will respond to your thought.
What is the target use case?
We built this as an experimental interface, and our goal from the beginning was just to explore new ways of interacting with LLMs. Therefore, we didn’t have a target use case in mind. That said, some examples for how we’ve personally used it include:
- Brainstorming ideas for a project
- Thinking through a personal problem
- Brain dumping after listening to a presentation
- Journaling
- Explaining a topic while learning about it
- Keeping a work log
We’ve especially found it useful for both overcoming the paralysis of an empty page, and maintaining the momentum to continue pursuing a train of thought.
How do I make my own daemons?
When you go to settings, you will find the option to edit existing daemons, or to create your own. A daemon consists of two things:
- a system prompt
- a list of chain of thought prompts
The list of chain of thought prompts outline half of a chatbot conversation. Each prompt is shown to the chat model one at a time, and the chat model will generate a response to each. The response to the final prompt is shown to the user as a comment.
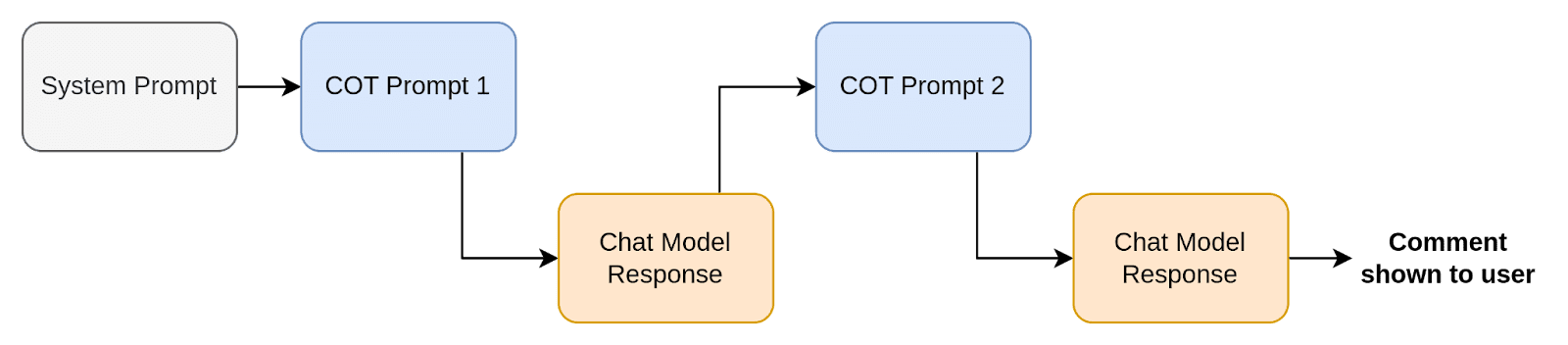
In this pipeline, a daemon doesn’t see the user’s thoughts by default. The user’s thoughts have to be included explicitly by inserting variables into the prompts. These variables will be replaced by the user’s thoughts at the time the daemon is called. There are currently two variables:
- {PAST} : Contains all past thoughts in the current branch up to but not including the thought which the daemon was called to respond to.
- {CURRENT} : Only contains the thought which the daemon was called to respond to.
Below is an example of how these variables could be used:

A daemon may have arbitrarily many chain of thought prompts, though the longer the chain of thought gets, the longer it will take to generate a response (each chat model response requires a separate API request).
The formula we used for the default daemons is a variant of babble and prune [? · GW]. The first prompt gets the model to generate a long list of possible responses, and later prompts are used to narrow down which response is best. This isn’t necessarily the best way to do this, and we would encourage anyone making their own daemons to experiment with alternative formulas.
How does this relate to Loom?
In general, Loom is what we think of as an “LLM-centered” interface, where the burden of adapting to the constraints of the interaction falls primarily on the human user. Loom users will typically minimize the extent to which they directly intervene on LLMs in order to avoid contaminating their “natural behavior [LW · GW]”, and to make it possible to observe them thinking in a wide range of contexts which are often much less intuitive to most people by default.
In this frame, Pantheon is explicitly a “human-centered” interface, where the burden on the human user is minimized at the expense of making LLMs adapt to the unnatural context of having to comment on a human’s stream of thought. The intention is to ensure that, during a session, the human user does not have to spend any additional mental energy managing their relationship to the LLM, or adjusting their behavior to match the LLM’s expectations.
Does Pantheon use base models?
Yes, but in a much less significant way than we originally intended.
We spent a lot of time creating prompts for base model simulacra which had interesting/useful personalities, and found some prompts which worked fairly well. Base models, however, are extremely sensitive to changes in tone, style, or really anything that departs from the expectations set in the prompt. When these simulacra came into contact with the user’s text, which looked nothing like the prompt, they would always collapse into chaotic nonsense. It was also quite hard to find contexts where it made sense for a character to be responding to user text at all.
We do use a base model to predict the user’s next thought, and those predictions are continuously shown to the user as they write. These predictions are sometimes interesting, but this is far from the best way to use base models. Some ideas for how they might be used in the future:
- Dynamic prompting/sampling: One idea would be to use LLMs to dynamically construct a prompt which more naturally integrates the user’s text into a base model prompt to avoid breaking the flow of a story. Furthermore, we might be able to use alternate sampling methods [LW · GW] to help steer base models in such a way that they accept difficult to prompt premises (see janus’s comment [LW(p) · GW(p)] on diegetic interfaces).
- Hybrid daemons: Another idea we experimented with a little was to create daemons which used both a chat model and a base model to generate parts of their chain of thought. In this way, we might be able to use base models to “inject creativity” into chat models, and help them overcome mode collapse [LW · GW].
Is Pantheon open source?
Yes! Pantheon is open source and licensed under GNU General Public License version 3 (GPLv3). We considered the possible harms of open sourcing the tool and expect them to be fairly minimal. If you would like to contribute to Pantheon, the code is hosted on Github.
Should I be concerned about data privacy?
The app does not have a backend, and so any and all data you share with the app will only be shared with the OpenAI servers, or be kept in your own local storage. Therefore, your worries about data privacy should be about the same as your concerns with using the ChatGPT interface.
Acknowledgments
Finally, we’d like to thank some of the people who helped make this project happen. Firstly, @Ethan Edwards [LW · GW] , @clem_acs [LW · GW] , Gianluca Pontonio, @Quentin FEUILLADE--MONTIXI [LW · GW] , @Filip Sondej [LW · GW] , and @remember [LW · GW] all gave really valuable help with brainstorming the initial design. We also got a lot of valuable user feedback from @eggsyntax [LW · GW], @clem_acs [LW · GW], @Filip Sondej [LW · GW] , Dmitriy Kripkov, Akash Arora, Vinay Hiremath, and @Aay17ush [LW · GW] . Aayush also helped a lot by providing a character generator we used to produce the default daemons.
- ^
To get a working OpenAI key, log into your OpenAI account and go here: https://platform.openai.com/api-keys
You do not need to have an OpenAI subscription, but using the key will cost money every time the app makes a request. Detailed pricing information can be found here: https://openai.com/api/pricing/
An extremely rough estimate is something like ~1USD / hour of continuous use, though this depends a lot on how quickly you type, and how long the chain of thought is for each daemon.
22 comments
Comments sorted by top scores.
comment by Dweomite · 2024-07-09T23:00:09.562Z · LW(p) · GW(p)
"Daemons" really feels like a bad choice of name to me. I think the pitch "you can have a bunch of daemons advising you and prompting you to do things" would sound better if they were called almost anything else.
Maybe "courtiers" or "familiars"?
Replies from: gwern, Kaj_Sotala, nick_kees, roger-d-1↑ comment by gwern · 2024-07-13T20:24:21.875Z · LW(p) · GW(p)
For a prototype like this, which involves things like 'API keys', some terminological confusion over 'daemons' is the least of one's concerns in terms of general public usability. And 'demon' in computing does have the useful connotation of implying they can run asynch or in the background.
But if one wanted to get rid of it, I would suggest just 'character'. It seems to work for Character.ai (which has a userbase of... god knows how many millions of people at this point), is transparent and without much misleading connotation, and covers all of the roles from 'daemon' to 'courtier' to 'adviser' to 'familiar' to 'consultant' to...
↑ comment by Kaj_Sotala · 2024-07-13T13:32:34.660Z · LW(p) · GW(p)
Personally I like it and didn't have the association to "demons" at all, probably because I've seen this comic go around enough times to make the distinction clear.

↑ comment by NicholasKees (nick_kees) · 2024-07-10T09:26:47.168Z · LW(p) · GW(p)
Daimons are lesser divinities or spirits, often personifications of abstract concepts, beings of the same nature as both mortals and deities, similar to ghosts, chthonic heroes, spirit guides, forces of nature, or the deities themselves.
It's a nod to ancient Greek mythology: https://en.wikipedia.org/wiki/Daimon
a daemon is a computer program that runs as a background process, rather than being under the direct control of an interactive user.
Also nodding to its use as a term for certain kinds of computer programs: https://en.wikipedia.org/wiki/Daemon_(computing)
Replies from: Dweomite, eggsyntax↑ comment by Dweomite · 2024-07-10T18:16:52.697Z · LW(p) · GW(p)
I'm aware of those references, but in popular culture the strongest association of the word, by far, is to evil spirits that trick or tempt humans into doing evil. And the context of your program further encourages that interpretation because "giving advice" and "prompting humans" are both iconic actions for evil-spirit-demons to perform.
Even for people who understand your intended references, that won't prevent them from thinking about the evil-spirit association and having bad vibes. (Nor will it prevent any future detractors from using the association in their memes.)
And I suspect many ordinary people won't get your intended references. Computer daemons aren't something the typical computer-user ever encounters personally, and I couldn't point to any appearance of Greek daimons in movies or video games.
Replies from: Archimedes↑ comment by Archimedes · 2024-07-12T21:57:27.566Z · LW(p) · GW(p)
Even for people who understand your intended references, that won't prevent them from thinking about the evil-spirit association and having bad vibes.
Being familiar with daemons in the computing context, I perceive the term as whimsical and fairly innocuous.
↑ comment by eggsyntax · 2024-07-15T15:07:28.911Z · LW(p) · GW(p)
I'll register that I like the name, and think it's an elegant choice because of those two references both being a fit (plus a happy little call-out to The Golden Compass). If the app gets wildly popular it could be worth changing, but at this point I imagine you're at least four orders of magnitude away from reaching an audience that'll get weirded out by them being called dæmons.
↑ comment by RogerDearnaley (roger-d-1) · 2024-07-10T09:18:46.204Z · LW(p) · GW(p)
Advisors, interlocutors, consultants, …
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-07-09T04:29:04.313Z · LW(p) · GW(p)
Are you considering adding other api options like Replicate, Anthropic, Gemini?
Replies from: nick_kees↑ comment by NicholasKees (nick_kees) · 2024-07-09T09:02:46.130Z · LW(p) · GW(p)
We are! There's a bunch of features we'd like to add, and for the most part we expect to be moving on to other projects (so no promises on when we'll get to it), but we do absolutely want to add support for other models.
Replies from: ann-brown↑ comment by Ann (ann-brown) · 2024-07-09T11:51:12.080Z · LW(p) · GW(p)
I'd like to be able to try it out with locally hosted server endpoints, and those are OpenAI-compatible (as generally are open-source model providers), so probably the quickest to implement if I'm not missing something about the networking.
comment by Kaj_Sotala · 2024-07-13T13:30:06.718Z · LW(p) · GW(p)
Whoa this is an amazing idea! Thanks for implementing it.
- Is there some rule that determines which daemons chime in on which lines, or is it purely random?
- Warning for others: don't open Pantheon in two browser tabs at once and then go ahead to write stuff in one of them, expecting it to get saved - when you close the browser, it might also save the contents from the tab that you wrote almost nothing in, overwriting the storage that has more. (This is not a criticism, I imagine this to be tricky to fix and I should've thought of it myself.)
- Viewing the chain-of-thought for some of the daemons, I felt like a lot of ideas they had come up with in the first stage were better questions than the ones they finally settled on. (Unfortunately, I can't show examples because I lost the state.) Possibly this was because I was hoping to use it for brainstorming some ideas, and some responses that I would have found useful would have been the bots just asking follow-up questions about specific ideas I had. But since those questions were relatively obvious, they were ranked low on the "surprisingness" metrics. This makes me think that besides the choice of daemons, there could also be a setting for what kinds of comments you might find the most useful (that would swap between sets of chain-of-thought prompts) - in some contexts it's useful to also hear the obvious comments/questions, whereas in some other it's not. For now I'll just edit the chain-of-thought prompts manually.
↑ comment by NicholasKees (nick_kees) · 2024-07-13T16:34:44.355Z · LW(p) · GW(p)
Thanks!
Replying in order:
- Currently completely random yes. We experimented with a more intelligent "daemon manager," but it was hard to make one which didn't have a strong universal preference for some daemons over others (and the hacks we came up with to try to counteract this favoritism became increasingly convoluted). It would be great to find an elegant solution to this.
- Good point! Thanks for letting people know.
- I've also had that problem, and whenever I look through the suggestions I often feel like there were many good questions/comments that got pruned away. The reason to focus on surprise was mainly to avoid the repetitiveness caused by mode collapse, where the daemon gets "stuck" giving the same canned responses. This is a crude instrument though, since as you say, just because a response isn't surprising, doesn't mean it isn't useful.
↑ comment by eggsyntax · 2024-07-15T15:01:06.441Z · LW(p) · GW(p)
We experimented with a more intelligent "daemon manager"...It would be great to find an elegant solution to this.
Seems like ideally you'd want something like a Mixture of Experts approach -- a small, fast model that gets info about which daemons are best at what, along with your most recent input, and picks the right one.
comment by abramdemski · 2024-07-12T17:49:24.467Z · LW(p) · GW(p)
I put in an API key, but I just get an error "Error calling OpenAI API" followed quickly thereafter by "Couldn't generate comment (no response received)".
Replies from: Sofia Vanhanen↑ comment by Sofia Vanhanen · 2024-07-13T10:56:06.268Z · LW(p) · GW(p)
If the issue persists regardless of browser or API key used, feel free to open an issue on the repository or send me any stack trace or details as a private message. You can also try resetting the entire app state (button at the bottom of Settings) and then putting in a fresh API key.
comment by NicholasKees (nick_kees) · 2024-07-13T16:24:51.741Z · LW(p) · GW(p)
A note to anyone having trouble with their API key:
The API costs money, and you have to give them payment information in order to be able to use it. Furthermore, there are also apparently tiers which determine the rate limits on various models (https://platform.openai.com/docs/guides/rate-limits/usage-tiers).
The default chat model we're using is gpt-4o, but it seems like you don't get access to this model until you hit "tier 1," which happens when you have spent at least $5 on API requests. If you haven't used the API before, and think this might be your issue, you can try using gpt-3.5-turbo which is definitely available at the "free tier," though without giving them any payment information you will still run into an issue as this model also costs money. You can also log into your account and go here to buy at least $5 in OpenAI API credits: https://platform.openai.com/settings/organization/billing/overview
Finally, if you are working at an organization which is providing you API credits, you need to make sure to set that organization as your default organization here: https://platform.openai.com/settings/profile?tab=api-keys If you don't want to do this, in the Pantheon settings you can also provide an organization ID, which you should be able to find here: https://platform.openai.com/settings/organization/general
Sorry for anyone who has found this confusing. Please don't hesitate to reach out if you continue to have trouble.
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-07-09T11:26:09.954Z · LW(p) · GW(p)
Excited to see this go live, Nick!
Played around with Pantheon for a couple minutes. I wrote a couple of lines but I didn't get any daemons yet. How long should I have to wait for them to pop up?
Replies from: nick_kees↑ comment by NicholasKees (nick_kees) · 2024-07-09T15:36:26.496Z · LW(p) · GW(p)
Hey Alexander! They should appear fairly soon after you've written at least 2 thoughts. The app will also let you know when a daemon is currently developing a response. Maybe there is an issue with your API key? There should be some kind of error message indicating why no daemons are appearing. Please DM me if that isn't the case and we'll look into what's going wrong for you.
comment by Review Bot · 2024-07-10T16:30:55.427Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?