Empowerment is (almost) All We Need
post by jacob_cannell · 2022-10-23T21:48:55.439Z · LW · GW · 44 commentsContents
Intro The Altruistic Empowerment Argument The Golden Rule Selfish Empowerment in Practice Potential Cartesian Objections Altruistic Empowerment: Early Tests Mirrors of Self and Other Frequently Anticipated Questions/Criticisms Relative compute costs Coordination advantages Identity preservation Selfish instrumental convergence Approximation issues What about Goodharting? What about Deceptive Alignment? What about Corrigibility? Changing brains or values Sex and reproduction But our humanity Empower whom or what? None 45 comments
Intro
What/who would you like to become in a thousand subjective years? or a million?
Perhaps, like me, you wish to become posthuman: to transcend mortality and biology, to become a substrate independent mind, to wear new bodies like clothes, to grow more intelligent, wise, wealthy, and connected, to explore the multiverse, perhaps eventually to split, merge, and change - to vasten.
Regardless of who you are now or what specific values you endorse today, I suspect you too would at least desire these possibilities as options. Absent some culture specific social stigmas, who would not like more wealth, health, and power? more future optionality?
As biological creatures, our fundamental evolutionary imperative is to be fruitful and multiply, so our core innate high level value should be inclusive genetic fitness. But for intelligent long lived animals like ourselves, reproduction is a terminal goal in the impossibly distant future: on the order of around 1e11 neural clock cycles from birth[1], to be more precise. Explicit optimization of inclusive genetic fitness through simulation and planning over such vast time horizons is simply implausible - especially for a mere 20 watt irreversible computer such as the human brain, no matter how efficient [LW · GW].
Fortunately there exists an accessible common goal which is ultimately instrumentally convergent [? · GW] for nearly all final goals: power-seeking [LW · GW], or simply: empowerment.
Omohundro proposed an early version of the instrumental convergence hypothesis as applied to AI in his 2008 paper the Basic AI Drives, however the same principle was already recognized by Klyubin et al in their 2005 paper "Empowerment: A Universal Agent-Centric Measure of Control"[2]:
Our central hypothesis is that there exist a local and universal utility function which may help individuals survive and hence speed up evolution by making the fitness landscape smoother. The function is local in the sense that it doesn’t rely on infinitely long history of past experience, does not require global knowledge about the world, and that it provides localized feedback to the individual.
. . .
To a sugar-feeding bacterium, high sugar concentration means longer survival time and hence more possibilities of moving to different places for reproduction, to a chimpanzee higher social status means more mating choice and interaction, to a person more money means more opportunities and more options. The common feature of the above examples is the striving for situations with more options, with more potential for control or influence. To capture this notion quantitatively, as a proper utility function, we need to quantify how much control or influence an animal or human (an agent from now on) has.
Salge et al later summarized these arguments into the Behavioral Empowerment Hypothesis[3]:
The adaptation brought about by natural evolution produced organisms that in absence of specific goals behave as if they were maximizing their empowerment.
Empowerment provides a succinct unifying explanation for much of the apparent complexity of human values: our drives for power, knowledge, self-actualization, social status/influence, curiosity and even fun[4] can all be derived as instrumental subgoals or manifestations of empowerment. Of course empowerment alone can not be the only value or organisms would never mate: sexual attraction is the principle deviation later in life (after sexual maturity), along with the related cooperative empathy/love/altruism mechanisms to align individuals with family and allies (forming loose hierarchical agents which empowerment also serves).
The key central lesson that modern neuroscience gifted machine learning is that the vast apparent complexity of the adult human brain, with all its myriad task specific circuitry, emerges naturally from simple architectures and optimization via simple universal learning algorithms [LW · GW] over massive data. Much of the complexity of human values likewise emerges naturally from the simple universal principle of empowerment.
Empowerment-driven learning (including curiosity as an instrumental subgoal of empowerment) is the clear primary driver of human intelligence [LW · GW] in particular, and explains the success of video games as empowerment superstimuli and fun more generally.
This is good news for alignment. Much of our values - although seemingly complex - derive from a few simple universal principles. Better yet, regardless of how our specific terminal values/goals vary, our instrumental goals simply converge to empowerment regardless. Of course instrumental convergence is also independently bad news, for it suggests we won't be able to distinguish altruistic and selfish AGI from their words and deeds alone. But for now, let's focus on that good news:
Safe AI does not need to learn a detailed accurate model of our values. It simply needs to empower us.
The Altruistic Empowerment Argument
At least one of the following must be true:
- Instrumental convergence to empowerment [LW · GW] in realistic environments is false
- Approximate empowerment intrinsic motivation is not useful for AGI
- AGI will not learn models of self and others
- The difference between Altruistic AGI and Selfish AGI reduces to using other-empowerment utility rather than self-empowerment utility
Instrumental convergence (point 1) seems both intuitively obvious and has strong support already, but if it turns out to be false somehow that would independently be good news for alignment in another way. Instrumental convergence strongly implies that some forms of approximating the convergent planning trajectory will be useful, so rejecting point 2 is mostly implied by rejecting point 1. It also seems rather obvious that AGI will need a powerful learned world model which will include sub-models of self and others, so it is difficult to accept point 3.
Accepting point 4 (small difference between altruistic and selfish AGI) does not directly imply that alignment is automatic, but does suggest it may be easier than many expected. Moreover it implies that altruistic AGI is so similar to selfish AGI that all the research and concomitant tech paths converge making it difficult to progress one endpoint independent of the other.
There are many potential technical objections to altruistic human-empowering AGI, nearly all of which are also objections to selfish AGI. So if you find some way in which human-empowering AGI couldn't possibly work, you've probably also found a way in which self-empowering AGI couldn't possibly work.
A fully selfish agent optimizing only for self-empowerment is the pure implementation of the dangerous AI that does not love or hate us, but simply does not care.
A fully altruistic agent optimizing only for other-empowerment is the pure implementation of the friendly AI which seeks only to empower others.
Agents optimizing for their own empowerment seek to attain knowledge, wealth, health, immortality, social status, influence, power, etc.
Agents optimizing for other's empowerment help them attain knowledge, wealth, health, immortality, social status, influence, power, etc.
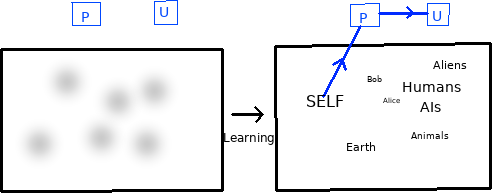
Initially the selfish AGI has a naive world model, and outputs actions that are random or bootstrapped from simpler mechanisms (eg human training data). After significant learning optimization the AI develops a very powerful superhuman world model which can predict distributions over planning trajectories leading to long term future world states. Each such state conceptually contains representations of other agents, including the self. Conceptually the selfish agent architecture locates its self in these future trajectories as distinct from others and feeds the self state to the empowerment estimator module which is then the primary input to the utility function for planning optimization. In short it predicts future trajectories, estimates self-empowerment, and optimizes for that.
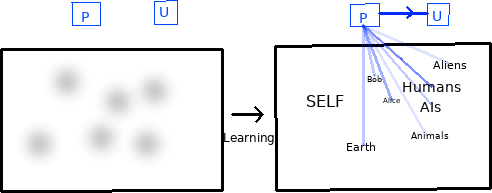
Initially the altruistic AGI has a naive world model, and outputs actions that are random or bootstrapped from simpler mechanisms (eg human training data). After significant learning optimization the AI develops a very powerful superhuman world model which can predict distributions over planning trajectories leading to long term future world states. Each such state conceptually contains representations of other agents, including the self. Conceptually the altruistic agent architecture locates its self in these future trajectories as distinct from others and feeds the others' states to the empowerment estimator module which is then the primary input to the utility function for planning optimization. In short it predicts future trajectories, estimates other-empowerment, and optimizes for that.
The Golden Rule
An altruistic agent A optimizing for the empowerment of some other agent B implements a form of the golden rule, as it takes the very same actions that it would want A to take if it were B and selfish or sufficiently long-termist (long planning horizon, low discount rate, etc).
Selfish Empowerment in Practice
Klyubin et al first formalized the convergent empowerment objective[5][3:1] as the channel capacity between an agent's future output/action stream Y and future input/sensory stream X, which I'll reformulate slightly here as:
Where is the mutual information, is a (future) output stream from time to , and is a future input at time . The function measures the channel capacity between future actions starting at and the future input at later time . This channel capacity term measures the maximum amount of information an agent can inject into its future input channel at time through its output channel starting at time . Later authors often use an alternative formulation which instead defines the channel target X as the future states rather than future observations, which probably is more robust for partially observable environments.[6]
Artificial agents driven purely by approximations/variations of this simple empowerment utility function naturally move to the centers of rooms/mazes[5:1], use keys, block lava, and escape predators in gridworlds [7], navigate obstacles, push blocks to clear rooms, learn vision to control digits[8], learn various locomotion skills (running, walking, hopping, flipping, and gliding)[9][10], open doors (in 3D) [11], learn to play games [12][13], and generally behave intelligently. Empowerment and related variations are also better explanations of human behavior than task reward even in games with explicit reward scores[14]. In multi-agent social settings, much of an agent's ability to control the future flows through other agents, so drive for social status/influence is a natural instrumental subgoal of empowerment[15].
However these worlds are simple and often even assume a known dynamics model. Intelligent agents scaling to more complex environments will naturally need to use a learned world model, using some efficient approximation of bayesian inference (ie SGD on neural nets). This presents a problem for an agent using a simple empowerment objective: how can the initially naive, untrained agent navigate to empowered states when it can't yet even predict the consequences of its own actions? The first tasks of a learning agent are thus to learn their own embodiment and then explore and understand the world in order to later steer it: curiosity is a convergent subgoal of empowerment, and thus naturally also an effective intrinsic motivation objective by itself[16].
Maximizing empowerment or environmental control generally minimizes bayesian surprise of the world model, whereas curiosity is often formulated as maximizing surprise. This apparent contradiction can be used directly as an adversarial objective where an explorer sub-agent seeks to surprise a control sub-agent, which in turns seeks to control the environment by minimizing surprise[12:1], or as a mixed objective[17]. Other approaches attempt to unify curiosity and empowerment as a single objective where an agent seeks to align their beliefs with the world and act to align the world with their beliefs[18]. The adage "information is power" likewise suggests a unification where agents gather information to reduce uncertainty and also seek control to reduce the unpredictability of future world states.[19]
Ultimately exploration/curiosity is an instrumental subgoal of empowerment (which itself is a convergent instrumental subgoal of most long term goals), because improving the agent's ability to predict future world states will generally improve its future ability to steer the world. Intelligent agents first seek to be surprised, then to control, and finally to exploit.
Potential Cartesian Objections
As mentioned earlier, klyubin's original simple empowerment definition (maximization of actions->observations channel capacity) is subject to forms of input-channel hacking in partially observable environments: in a text world a simple echo command would nearly maximize action->input capacity, or in a 3D world a simple mirror provides high action->input capacity[6:1]. The most obvious solution is to instead use actions->state channel capacity, which overall seems a better formalization of power over the world.
However, there are still potential issues with the precise representation of the action channel and especially the use of channel capacity or maximum potential mutual information for agents which are physically embedded in the world.
The simple action->state channel capacity empowerment function implicitly assumes that the agent is a black box outside of the world, which can always in the future output potentially any arbitrary bit sequence from its action stream into the world. But in reality the agent is fully part of the world; a subject of physics.
There are future configurations of the world where the agent's mind is disassembled, or otherwise simply disabled by unplugging of the output wire that actually physically transmits output bits into the world. It is essential that the agent learns a self-model which implements/represents the action channel flexibly - as the learned predicted concept of physical influence rather than any specific privileged memory location.
The unplugging issue is a special case of more serious potential problem arising from using channel capacity or the potential maximum information the agent can inject into the world. All actual physical agents are computationally constrained and thus all future action output bit combinations are not equally likely - or even possible. As an obvious example - there exists reasonable length sequences of output bits which you or I could output right now onto the internet which would grant us control of billions of dollars in cryptocurrency wealth. From a naive maximal action output channel capacity viewpoint, that wealth is essentially already yours (as accessible as money in your bank in terms of output sequence bit length), but in reality many interesting action bit sequences are not feasibly computable.
However given that computing the true channel capacity is computationally infeasible for long horizons anyway, efficient practical implementations use approximations which may ameliorate this problem to varying degrees. The ideal solution probably involves considering only the space of likely/possible accessible states, and moreover the agent will need to model its future action capacity as resulting from and constrained by a practical physical computation - ie a realistic self-model. This also seems required for deriving curiosity/exploration automatically as an instrumental goal of empowerment.
These cartesian objections are future relevant, but ultimately they don't matter much for AI safety because powerful AI systems - even those of human-level intelligence - will likely need to overcome these problems regardless. Thus we can assume some efficient and robust approximation of empowerment available to both seflish and altruistic AI alike.
Altruistic Empowerment: Early Tests
The idea of AI optimizing for external empowerment occurred to me while researching and writing the empowerment section [LW(p) · GW(p)] of a previous post; later I found that some researchers from Oxford and Deepmind have already implemented, tested, and published an early version of this idea in "Learning Altruistic Behaviours in Reinforcement Learning without External Rewards"[20] by Franzmeyer et al (which also has references to some earlier related work).
They test several variations of state reach-ability as the approximate empowerment objective, which is equivalent to Klyubin-empowerment under some simplifying assumptions such as deterministic environment transitions but is more easily efficiently computed.
In a simple grid world, their altruistic assistant helps the leader agent by opening a door, and - with sufficient planning-horizon - gets out of the way to allow the leader to access a high reward at the end of a maze tunnel. The assistant does this without any notion of the leader's reward function. However with shorter planning horizons the assistant fails as it tries to 'help' the leader by blocking their path and thereby preventing them from making the poor choice of moving to a low-powered tunnel area.
They also test a simple multiplayer tag scenario where the altruists must prevent their leader from being tagged by adversaries. In this setup the choice-empowerment objectives even outperform direct supervised learning, presumably because of denser training signal.
From their conclusion:
Our experimental results demonstrate that artificial agents can behave altruistically towards other agents without knowledge of their objective or any external supervision, by actively maximizing their choice. This objective is justified by theoretical work on instrumental convergence, which shows that for a large proportion of rational agents this will be a useful subgoal, and thus can be leveraged to design generally altruistic agents.
Scaling this approach up to increasingly complex and realistic sim environments [LW · GW] is now an obvious route forward towards altruistic AGI.
Mirrors of Self and Other
Human level intelligence requires learning a world model powerful enough to represent the concept of the self as an embedded agent. Humans learn to recognize themselves in mirrors by around age two, and several animal species with larger brain capacity (some primates, cetaceans, and elephants) can also pass mirror tests. Mirror self-recognition generally requires understanding that one's actions control a body embedded in the world, as seen through the mirror.
Given that any highly intelligent agent will need a capability to (approximately) model and predict its own state and outputs in the future, much of that same self-modelling capacity can be used to predict the state and outputs of other agents. Most of a mind's accumulated evidence about how minds think in general is naturally self-evidence, so it is only natural that the self-model serves as the basic template for other-models, until sufficient evidence accumulates to branch off a specific individual sub-model.
This simple principle forms the basis of strategy in board games such as chess or go where the complexities of specific mental variations are stripped away: both humans and algorithms predict their opponent's future moves using the exact same model they use to predict their own. In games that incorporate bluffing such as poker some differentiation in player modeling becomes important, and then there are games such as roshambo where high level play is entirely about modeling an opponent's distinct strategy - but not values or utility. In the real world, modelling others as self is called social projection, leading to the related false consensus effect/bias.
To understand humans and predict their actions and reactions AGI may need to model human cognitive processes and values in some detail, for the same reasons that human brains model these details and individualized differences. But for long term planning optimization purposes the detailed variation in individual values becomes irrelevant and the AGI can simply optimize for our empowerment.
Empowerment is the only long term robust objective due to instrumental convergence. The specific human values that most deviate from empowerment are exactly the values that are least robust and the most likely to drift or change as we become posthuman and continue our increasingly accelerated mental and cultural evolution, so mis-specification or lock-in of these divergent values could be disastrous.
Frequently Anticipated Questions/Criticisms
Relative compute costs
Will computing other-empowerment use significantly more compute than self-empowerment?
Not necessarily - if the 'other' alignment target is a single human or agent of comparable complexity to the AGI, the compute requirements should be similar. More generally agency is a fluid hierarchical concept: the left and right brain hemispheres are separate agents which normally coordinate and align so effectively that they form a single agency, but there are scenarios (split-brain patients) which break this coordination and reveal two separate sub-agents. Likewise organizations, corporations, groups, etc are forms of agents, and any practical large-scale AGI will necessarily have many localized input-output streams and compute centers. Conceptually empowerment is estimated over a whole agent/agency's action output stream, and even if the cost scaled with output stream bitrate that if anything only implies a higher cost for computing selfish-empowerment as the AGI scales.
Coordination advantages
Will altruistic AGI have a coordination advantage?
Perhaps yes.
Consider two agents A and B who both have the exact same specific utility function X. Due to instrumental convergence both A and B will instrumentally seek self-empowerment at least initially, even though they actually have the exact same long term goal. This is because they are separate agents with unique localized egocentric approximate world models, and empowerment can only be defined in terms of approximate action influence on future predicted (egocentric approximate) world states. If both agents A and B somehow shared the exact same world model (and thus could completely trust each other assuming the world model encodes the exact agent utility functions), they would still have different action channels and thus different local empowerment scores. However they would nearly automatically coordinate because the combined group agent (A,B) achieves higher empowerment score for both A and B. The difference between A and B in this case has effectively collapsed to the difference between two brain hemispheres, or even less.
Two altruistic agents designed to empower humanity broadly should have fairly similar utility functions, and will also have many coordination advantages over humans: the ability to directly share or merge large 'foundation' world models, and potentially the use of cryptographic techniques to prove alignment of utility functions.
Two selfish agents designed to empower themselves (or specific humans) would have less of these coordination advantages.
Identity preservation
How will altruistic AGI preserve identity?
In much the same way that selfish AGI will seek to preserve identity.
Empowerment - by one definition - is the channel capacity or influence of an agent's potential actions on the (approximate predicted) future world state. An agent who is about to die has near zero empowerment: more generally empowerment collapses to zero with time until death.
Agents naturally change over time, so a natural challenge of any realistic empowerment approximation for AGI is that of identifying the continuity of agentic identity. As discussed in the cartesian objection section any practical empowerment approximation suitable for AGI will already need a realistic embedded self-model. Continuation of identity is then a natural consequence of the requirement that the empowerment function must be computed for a consistent agent identity over time. In other words computing the empowerment of agent X over temporal trajectory T first requires locating agent X in the predicted future world states of T, which implicitly assumes continuation of identity if the agent recognition is over temporal sequences.
Selfish instrumental convergence
Won't altruistic agents also initially seek self-empowerment due to instrumental convergence?
Yes.
The planning trajectories of altruistic and selfish agents (and any others) will all look initially very similar, and will only diverge later over time dependent on discount rates and/or planning horizons.
This is probably bad news for alignment, as it implies it may be very difficult for humans to discern whether an AGI is altruistic or selfish based on what they do or say. Introspection and proof techniques both could potentially help, along with use of simboxes [LW · GW] to test the divergence earlier in an appropriate sandbox sim environment.
One natural likely future point of divergence is around uploading: a true altruistic AGI will likely support/advocate uploading and upgrading/scaling uploads, a selfish AGI will likely not (regardless of what it may say or appear to do).
Approximation issues
Since perfect empowerment is too expensive and approximations are used, could approximation errors break the instrumental convergence property?
Not really. Approximation is not a dirty word - near the entirety of the computation any useful intelligence does is approximation. Theoretically perfect computational ideals are just abstractions to inform efficient implementations, as in the real world the optimal practical system will always be based on clever approximations.
Naturally there are bad approximations of empowerment which break instrumental convergence in ways that matter, but those are less likely to be used, and regardless would hamper selfish AGI just as much as altruistic AGI.
What about Goodharting [? · GW]?
Due to instrumental convergence to empowerment, empowerment is by construction the proxy whose trajectories converge to those of most all reasonable utility functions. In complex realistic environments, as you extend the planning horizon the high value planning trajectories for most all reasonable utility functions collapse to a convergent golden path, the path which empowerment directly estimates. Empowerment is thus in this sense maximally robust: converging close to the median of all egocentric utility functions.
We also have significant accumulated direct experimental evidence that the convergence is fairly fast, certainly compared to human timescales (lifespans on order 1e11 neural clock cycles - many many orders of magnitude beyond experiments where approximate empowerment is already useful).
What about Deceptive Alignment [? · GW]?
Deception is general enough that it seems to be a potential problem for near any alignment approach.
Powerful AGI will tend to have long planning horizons, and due to instrumental convergence all powerful agents with long planning horizons will purse similar initial plans. So it will be very difficult to discern an AGI's true utility function from words or deeds.
Deceptive alignment can be detected and prevented with simboxing [LW · GW] and strong interpretability [? · GW] tools [? · GW].
What about Corrigibility [? · GW]?
Corrigibility is only useful if the agent doesn't start with the correct utility function. If human empowerment is already sufficient, then corrigibility is not useful. Corrigibility may or may not be useful for more mixed designs which hedge and attempt to combine human empowerment with some mixture of learned human values.
Changing brains or values
Wouldn't an AGI optimizing for my empowerment also try to change my brain and even values to make me more capable and productive? Wouldn't it want to make me less interested in socialization, sex, video games, drugs, fun in general, and other potential time sinks?
Yes and no.
In the early days the AGI's energies are probably best invested in its own self-improvement - as after all greater returns on cognitive compute investment is somewhat implicit in the assumption of human-surpassing AGI. But using some clever words to influence humans towards greater future empowerment seems like fairly low hanging fruit. Eventually our minds could become the limiter of our future empowerment, so the AGI would then seek to change some aspects of our minds - but due to instrumental convergence any such changes are likely in our long term best interest. Much of fun seems empowerment related (most fun video game genres clearly exploit aspects of empowerment) - so it isn't clear that fun (especially in moderation) is sub-optimal.
Ultimately though it is likely easier for the AGI itself to do the hard work, at least until uploading. After uploading AGI and humans become potentially much more similar, and thus expanding the cognitive capabilities of uploads could be favored over expanding the AGI's own capabilities.
Sex and reproduction
Ok what about sex/reproduction though?
Doesn't really seem necessary for uploads does it? One way of looking at this is what will humanity be like in a thousand years subjective time? What of our current values are most vs least likely to change? Empowerment - being instrumental to all terminal values - is the only value that is timeless.
It does seem plausible that an AGI optimizing for human empowerment would want us to upload and reduce the human biological population, but that seems to be just a continuation of the trend that a large tract of society (the more educated, wealthy, first world) is already on.
Sex uses a fairly small amount of our resources compared to reproduction. An AGI seeking to empower a narrowly defined target of specific humans may seek to end reproduction. This trend break downs for AGI with increasingly broader empowerment targets (humanity in general, etc), especially when we consider the computational fluidity of identity, but will obviously depend on the crucial agency definition/recognition model used for the empowerment target.
But our humanity
Wouldn't optimizing for our empowerment strip us of our humanity?
Probably not?
Our brains and values are the long term result of evolution optimizing for inclusive fitness. But since we reproduce roughly 1e11 neural clock cycles after birth, the trajectories leading eventually to reproduction instrumentally converge to empowerment, so evolution created brains which optimize mostly for empowerment. However empowerment itself is complex enough to have its own instrumental subgoals such as social status and curiosity.
All of our complex values, instincts, mechanisms - all of those 'shards' - ultimately form an instrumental hierarchy or tree serving inclusive fitness at the root with empowerment as the main primary sub-branch. The principle sub-branch which is most clearly distinct from empowerment is sex/reproduction drive, but even then the situation is more complex and intertwined: human children are typically strategically aligned with parents and can help extend their lifespan.
So fully optimizing solely for our empowerment may eventually change us or strip away some of our human values, but clearly not all or even the majority.
Societies of uploads competing for resources will face essentially the same competitive optimization pressure towards empowerment-related values. So optimizing for our empowerment is simply aligned with the natural systemic optimization pressure posthumans will face regardless after transcending biology and genetic inclusive fitness.
Empower whom or what?
Would external empowerment AGI optimize for all of humanity? Aliens? Animals? Abstract agents like the earth in general? Dead humans? Fictional beings?
Maybe yes, depending on how wide and generic the external agency recognition is. Wider conceptions of agency are likely also more long term robust.
We actually see evidence of this in humans already, some of which seem to have a very general notion of altruism or 'circle of empathy' which extends beyond humanity to encompass animals, fictional AI or aliens, plants, and even the earth itself. Some humans historically also act as if they are optimizing for the goals of deceased humans or even imaginary beings.
One recent approach formalizes agents [LW · GW] as systems that would adapt their policy if their actions influenced the world in a different way. Notice the close connection to empowerment, which suggests a related definition that agents are systems which maintain power potential over the future: having action output streams with high channel capacity to future world states. This all suggests that agency is a very general extropic concept and relatively easy to recognize.
About 100hz (fastest synchronous neural oscillation frequencies or 'brain waves') * 32 yrs (1e9 seconds). ↩︎
Klyubin, Alexander S., Daniel Polani, and Chrystopher L. Nehaniv. "Empowerment: A universal agent-centric measure of control." 2005 ieee congress on evolutionary computation. Vol. 1. IEEE, 2005. ↩︎
Salge, Christoph, Cornelius Glackin, and Daniel Polani. "Empowerment–an introduction." Guided Self-Organization: Inception. Springer, Berlin, Heidelberg, 2014. 67-114. ↩︎ ↩︎
Schmidhuber, Jürgen. "Formal theory of creativity, fun, and intrinsic motivation (1990–2010)." IEEE transactions on autonomous mental development 2.3 (2010): 230-247. ↩︎
Klyubin, Alexander S., Daniel Polani, and Chrystopher L. Nehaniv. "All else being equal be empowered." European Conference on Artificial Life. Springer, Berlin, Heidelberg, 2005. ↩︎ ↩︎
An agent maximizing control of its future input channel may be susceptible to forms of indirect channel 'hacking', seeking any means to more directly wire its output stream into its input stream. Using the future state - predicted from the agent's world model - as the target channel largely avoids these issues, as immediate sensor inputs will only affect a subset of the model state. In a 3D world a simple mirror would allow high action->sensor channel capacity, and humans do find mirrors unusually fascinating, especially in VR, where they border on superstimuli for some. ↩︎ ↩︎
Mohamed, Shakir, and Danilo Jimenez Rezende. "Variational information maximisation for intrinsically motivated reinforcement learning." Advances in neural information processing systems 28 (2015). ↩︎
Gregor, Karol, Danilo Jimenez Rezende, and Daan Wierstra. "Variational intrinsic control." arXiv preprint arXiv:1611.07507 (2016). ↩︎
Eysenbach, Benjamin, et al. "Diversity is all you need: Learning skills without a reward function." arXiv preprint arXiv:1802.06070 (2018). ↩︎
Sharma, Archit, et al. "Dynamics-aware unsupervised discovery of skills." arXiv preprint arXiv:1907.01657 (2019). ↩︎
Pong, Vitchyr H., et al. "Skew-fit: State-covering self-supervised reinforcement learning." arXiv preprint arXiv:1903.03698 (2019). ↩︎
Fickinger, Arnaud, et al. "Explore and Control with Adversarial Surprise." arXiv preprint arXiv:2107.07394 (2021). ↩︎ ↩︎
Dilokthanakul, Nat, et al. "Feature control as intrinsic motivation for hierarchical reinforcement learning." IEEE transactions on neural networks and learning systems 30.11 (2019): 3409-3418. ↩︎
Matusch, Brendon, Jimmy Ba, and Danijar Hafner. "Evaluating agents without rewards." arXiv preprint arXiv:2012.11538 (2020). ↩︎
Jaques, Natasha, et al. "Social influence as intrinsic motivation for multi-agent deep reinforcement learning." International conference on machine learning. PMLR, 2019. ↩︎
Liu, Hao, and Pieter Abbeel. "Behavior from the void: Unsupervised active pre-training." Advances in Neural Information Processing Systems 34 (2021): 18459-18473. ↩︎
Zhao, Andrew, et al. "A Mixture of Surprises for Unsupervised Reinforcement Learning." arXiv preprint arXiv:2210.06702 (2022). ↩︎
Hafner, Danijar, et al. "Action and perception as divergence minimization." arXiv preprint arXiv:2009.01791 (2020). ↩︎
Rhinehart, Nicholas, et al. "Information is Power: Intrinsic Control via Information Capture." Advances in Neural Information Processing Systems 34 (2021): 10745-10758. ↩︎
Franzmeyer, Tim, Mateusz Malinowski, and João F. Henriques. "Learning Altruistic Behaviours in Reinforcement Learning without External Rewards." arXiv preprint arXiv:2107.09598 (2021). ↩︎
44 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2022-10-24T16:20:37.979Z · LW(p) · GW(p)
I’d like to separate out 3 claims here:
- An “efficient and robust approximation of empowerment” is a “natural abstraction” [? · GW] / salient concept that AGIs (“even those of human-level intelligence”) are likely to have learned
- If an AGI is trained on “correlation-guided proxy matching” with [todo: fill-in-the-blank] proxy [LW(p) · GW(p)], then it will wind up wanting to maximize the “efficient and robust approximation of empowerment” of humanity
- If an AGI was trying to maximize the empowerment of humanity, that would be a good thing.
Of these:
- I’m somewhat skeptical of Claim 1. I am a human-level intelligence, and I do have an empowerment concept, but I don’t have a robust empowerment concept. For example, when I ask myself how someone would spend $1 trillion to maximally “empower” their pet turtle, my brain immediately responds: ¯\_(ツ)_/¯. I agree that AGIs are very likely to have an “empowerment” concept (if only because AGIs are very likely to have heard the English word “empowerment”), but I expect that by default that concept (like all concepts) would be defined by a bunch of statistical associations to other concepts and pattern-matches to lots of examples. But the examples would all be everyday examples of humans empowering humans (e.g. on youtube), without a clear-cut method to extrapolate that concept into weird sci-fi futures [LW · GW], nor a clear-cut motivation to develop such a method, I think. I would instead propose to figure out the “efficient and robust approximation of empowerment” ourselves, right now, then write down the formula, make up a jargon word for it, directly tell the AGI what the formula is and give it tons of worked examples during training, and then we can have somewhat more hope that the AGI will have this particular concept that we (allegedly) want it to have.
- I will remain very concerned about Claim 2 until someone shows me the exact proxy to be used. (I’m working on this problem myself, and don’t expect any solution I can think of to converge to pure empowerment motivation.) For example, when Human A learns that Human B is helpless (disempowered), that thought can be negative-valence for Human A, and Human A can address this problem by helping Human B (which is good), or by deliberately avoiding thinking about Human B (which is bad), or by dehumanizing / kicking Human B out of the circle of agents that Human A cares about (which is very bad). It’s not clear how to make sure that the first one happens reliably.
- I’m skeptical of Claim 3 mainly for similar reasons as Charlie Steiner’s comment on this page [LW(p) · GW(p)] that an AGI trying to empower me would want me to accumulate resources but not spend them, and would want to me to want to accumulate resources but not spend them, and more generally would not feel any particular affinity for me maintaining my idiosyncratic set of values and desires as opposed to getting brainwashed or whatever.
Related to this last bullet point, OP writes “The specific human values that most deviate from empowerment are exactly the values that are least robust and the most likely to drift or change as we become posthuman and continue our increasingly accelerated mental and cultural evolution”. But I claim these are also exactly the values that determine whether our future lightcone is tiled with hedonium versus paperclips versus cosmopolitan posthuman society etc. Yes they might drift, but we care very much that they drift in a way that “carries the torch of human values into the future” (or somesuch), as opposed to deleting them entirely or rolling an RNG.
I’m guessing the reply would be something related to the topic of the “identity preservation” section. But I don’t understand how the time bounds work here. If the AGI spends Monday executing a plan to accumulate resources, and then gives those resources to the person on Tuesday, to use for the rest of their lives, that’s good. If the AGI spends Monday brainwashing the human to be more power-hungry, and then the person is more effective at resource-acquisition starting on Tuesday and continuing for the rest of their lives, that’s bad. I’m confused how the empowerment formula would treat these two cases in the way we want.
Our drives for power, knowledge, self-actualization, social status/influence, curiosity and even fun can all be derived as instrumental subgoals or manifestations of empowerment.
I can read this sentence in two ways, and I’m not sure which one is intended:
- There is innate stuff in the genome that makes humans want empowerment, and humans discover through within-lifetime learning that social status is instrumentally useful for achieving empowerment. Ditto curiosity, fun, etc.
- There is innate stuff in the genome that makes humans want social status. Oh by the way, the reason that this stuff wound up in the genome is because social status tends to lead to empowerment, which in turn tends to lead to higher inclusive genetic fitness. Ditto curiosity, fun, etc.
The second one is fine, but I feel pretty strongly opposed to the first one. I think people and animals start do things out of curiosity, or for fun, etc., long before having any basis for knowing that the resulting behaviors will tend to increase their empowerment.
This is important because the first one would suggest that humans don’t really want fun, or social status, or whatever. They really want empowerment, and everything else is a means to an end. But that’s not true! Humans really do want to have fun, and not suffer, etc., as an end in itself, I claim. That means that an AGI with an empowerment objective would want different things for us, than we want for ourselves, which is bad.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-10-24T18:55:56.022Z · LW(p) · GW(p)
- An “efficient and robust approximation of empowerment” is a “natural abstraction” / salient concept that AGIs (“even those of human-level intelligence”) are likely to have learned
That isn't actually a claim I'm making - empowerment intrinsic motivation is the core utility function for selfish AGI (see all the examples in that section [LW · GW] ) rather than something learned. Conceptually altruistic AGI uses external empowerment as the core utility function (although in practice it will also likely need self-empowerment derived intrinsic motivation to bootstrap).
Also compare to the behavioral empowerment hypothesis from the intro: bacteria moving along sugar gradients, chimpanzees seeking social status, and humans seeking wealth are not doing those things to satisfy a learned concept of empowerment - they are acting as if they are maximizing empowerment. Evolution learned various approximations of empowerment intrinsic motivation.
without a clear-cut method to extrapolate that concept into weird sci-fi futures,
Ah ok, so I think the core novelty here is that no matter what your values are, optimizing for your empowerment today is identical to optimizing for your long term values today. Those specific wierd dystopian sci-fi futures are mostly all automatically avoided.
The price that you'd pay for that is giving up short term utility for long term utility, and possibly a change in core values when becoming posthuman. But I think we can mostly handle that by using learned human values to cover more of the short term utility and empowerment for the long term.
But there is always this unavoidable tradeoff between utility at different timescales, and there is an optimization pressure gradient favoring low discount rates.
I would instead propose to figure out the “efficient and robust approximation of empowerment” ourselves, right now, then write down the formula, make up a jargon word for it,
Right - that's all research track on empowerment and intrinsic motivation I briefly summarized.
- If an AGI is trained on “correlation-guided proxy matching” with [todo: fill-in-the-blank] proxy, then it will wind up wanting to maximize the “efficient and robust approximation of empowerment” of humanity
That isn't a claim I make here in this article. I do think the circuit grounding/pointing problem is fundamental, and correlation-guided proxy matching is my current best vague guess about how the brain solves that problem. But that's a core problem with selfish-AGI as well - for the reasons outlined in the cartesian objection section, robust utility functions must be computed from learned world model state.
I’m skeptical of Claim 3 mainly for similar reasons as Charlie Steiner’s comment on this page that an AGI trying to empower me would want me to accumulate resources but not spend them,
I already responded to his comment, but yes long-termism favors saving/investing over spending.
To the extent that's actually a problem, one could attempt to tune an empowerment discount rate that matches the human discount rate, so the AGI wants you to sacrifice some long term optionality/wealth for some short term optionality/wealth. Doing that too much causes divergence however, so I focused on the pure long term cases where there is full convergence, and again I think using learned human values more directly for the short term seems promising.
If the AGI spends Monday executing a plan to accumulate resources, and then gives those resources to the person on Tuesday, to use for the rest of their lives, that’s good. If the AGI spends Monday brainwashing the human to be more power-hungry, and then the person is more effective at resource-acquisition starting on Tuesday and continuing for the rest of their lives, that’s bad.
If we are talking about human surpassing AGI, then almost by definition it will be more effective for the AGI to generate wealth for you directly rather than 'brainwashing' you into something that can generate wealth more effectively than it can.
- There is innate stuff in the genome that makes humans want social status. Oh by the way, the reason that this stuff wound up in the genome is because social status tends to lead to empowerment, which in turn tends to lead to higher inclusive genetic fitness. Ditto curiosity, fun, etc.
Yeah mostly this because empowerment is very complex and can only be approximated, and it must be approximated efficiently even early on. So somewhere in there I described it as an instrumental hierarchy, where inclusive fitness leads to empowerment leads to curiosity, fun, etc. Except of course there are some things like money which we seem to pretty quickly intuitively learn the utility of which suggests we are also eventually using some more direct learned approximations of empowerment.
Getting back to this:
But I claim these are also exactly the values that determine whether our future lightcone is tiled with hedonium versus paperclips versus cosmopolitan posthuman society etc.
Humans and all our complex values are the result of evolutionary optimization for a conceptually simple objective: inclusive fitness. A posthuman society transcends biology and inclusive fitness no longer applies. What is the new objective function for post-biological evolution? Post humans are still intelligent agents with varying egocentric objectives and thus still systems for which the behavioral empowerment law applies. So the outcome is a natural continuation of our memetic/cultural/technological evolution which fills the lightcone with a vast and varied complex cosmpolitan posthuman society.
The values that deviate from empowerment are near exclusively related to sex which no longer serves any direct purpose, but could still serve fun and thus empowerment. Reproduction still exists but in a new form. Everything that survives or flourishes tends to do so because it ultimately serves the purpose of some higher level optimization objective.
comment by JenniferRM · 2022-10-24T21:55:20.747Z · LW(p) · GW(p)
I think "Empowerment" is an important part of emergent moral realism.
It is one of many convergent lines of reasoning that generate "consent ethics" for me.
Thinking about some of the ways this GOES WRONG, is part of why I strongly suspect that any superAGI that didn't follow the "never without my permission (seno acta gamat)" heuristic would be "morally bad".
It explains why legal rights (legal empowerment preservation) is economically important.
(Every regulation that reduces the actions that can be taken by an agent without that agent asking permission from the regulator reduces the value that an agent can locally swiftly create, and is a kind of "tax" that can destroy arbitrarily much future value without even transferring it as loot to the regulator.)
Empowerment, leading to consent ethics, eventually gets you to "consent of the governed" as a formula for the legitimacy of a legal system or political regime.
So I would say that the "pure empowerment" model, for AGI, is trivially improved upon by actually implementing (correctly) the old school Clippy UI: "It looks like you're trying to empower yourself! Would you like to try X which would help with that?"
This makes me want to upvote this really hard for TALKING ABOUT THIS but also it makes me want to say that you are just straightforwardly wrong about the sufficiency of this metric.
There is a huge sense in which this proposal is progress!
Like, one thing I'd say here is that a "benevolent" utility function like this is correct enough that it could cause humans to be half-preserved and horrifically mutilated and our parodic simulacra caused to be happy, rather than just being murdered and having our atoms stolen from us :-)
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-10-24T23:06:16.489Z · LW(p) · GW(p)
Like, one thing I'd say here is that a "benevolent" utility function like this is correct enough that it could cause humans to be half-preserved and horrifically mutilated and our parodic simulacra caused to be happy, rather than just being murdered and having our atoms stolen from us :-)
So I think we can mostly rule this out, but perhaps I didn't find the most succinct from of the argument.
Assume human values (for most humans) can be closely approximated by some unknown utility function with some unknown discount schedule: , which normally we can assume to use standard exponential discounting: .
The convergence to empowerment theorems indicate that there exists a power function that is a universal approximator in the sense that optimizing future world state trajectories for using a planning function f() is the same as optimizing future world state trajectories for the true value function : for a wide class of value functions and sufficiently long term discount rates that seems to include or overlap the human range.
So it seems impossible that optimizing for empowerment would cause "humans to be half-preserved and horrifically mutilated" unless that is the natural path of long term optimizing for our current values. Any such failure is not a failure of optimizing for empowerment, but a failure in recognizing future self - which is a real issue, but it's an issue any real implementation has to deal with regardless of the utility function, and it's something humans aren't perfectly clear on (consider all the debate around whether uploading preserves identity).
Replies from: JenniferRM↑ comment by JenniferRM · 2022-10-25T00:01:18.232Z · LW(p) · GW(p)
There are concepts like the last man and men without chests in various philosophies that imagine "a soul of pure raw optimization" as a natural tendency... and also a scary tendency.
The explicit fear is that simple hill climbing, by cultures, by media, by ads, by pills, by schools, by <whatever>... might lead to losing some kind of sublime virtue?
Also, it is almost certain that current humans are broken/confused, and are not actually VNM rational, and don't actually have a true utility function. Observe: we are dutch booked all the time! Maybe that is only because our "probabilities" are broken? But I bet out utility function is broken too.
And so I hear a proposal to "assume human values (for most humans) can be closely approximated by some unknown utility function" and I'm already getting off the train (or sticking around because maybe the journey will be informative).
I have a prediction. I think an "other empowerment maximizing AGI" will have a certain predictable reaction if I ultimately decide that this physics is a subtle (or not so subtle) hellworld, or at least just not for me, and "I don't consent to be in it", and so I want to commit suicide, probably with a ceremony and some art.
What do you think would be the thing's reaction if, after 500 years of climbing mountains and proving theorems and skiing on the moons of Saturn (and so on), I finally said "actually, nope" and tried to literally zero out "my empowerment"?
Replies from: jacob_cannell, jacob_cannell↑ comment by jacob_cannell · 2022-10-25T02:49:28.946Z · LW(p) · GW(p)
The explicit fear is that simple hill climbing, by cultures, by media, by ads, by pills, by schools, by <whatever>... might lead to losing some kind of sublime virtue?
Seems doubtful given that simple hill climbing for inclusive fitness generated all that complexity.
Also, it is almost certain that current humans are broken/confused, and are not actually VNM rational, and don't actually have a true utility function.
Maybe, but behavioral empowerment still seems to pretty clearly apply to humans and explains our intrinsic motivation systems. I also hesitate trying to simplify human brains down to simple equations but sometimes its a nice way to make points.
What do you think would be the thing's reaction if, after 500 years of climbing mountains and proving theorems and skiing on the moons of Saturn (and so on), I finally said "actually, nope" and tried to literally zero out "my empowerment"?
Predictably, if the thing is optimizing solely for your empowerment, it would not want you to ever give up. However if the AGI has already heavily empowered you into a posthuman state its wishes may no longer matter.
If the AGI is trying to empower all of humanity/posthumanity then there also may be variants of that where it's ok with some amount of suicide as that doesn't lower the total empowerment of the human system much.
Replies from: stephen-zhao, JenniferRM↑ comment by Stephen Zhao (stephen-zhao) · 2022-11-11T01:29:49.072Z · LW(p) · GW(p)
I think JenniferRM's comment regarding suicide raises a critical issue with human empowerment, one that I thought of before and talked with a few people about but never published. I figure I may as well write out my thoughts here since I'm probably not going to do a human empowerment research project (I almost did; this issue is one reason I didn't).
The biggest problem I see with human empowerment is that humans do not always want to maximally empowered at every point in time. The suicide example is a great example, but not the only one. Other examples I came up with include: tourists who go on a submarine trip deep in the ocean, or environmentalists who volunteer to be tied to a tree as part of a protest. Fundamentally, the issue is that at some point, we want to be able to commit to a decision and its associated consequences, even if it comes at the cost of our empowerment.
There is even empirical support for this issue with human empowerment. In the paper Assistance Via Empowerment (https://proceedings.neurips.cc/paper/2020/file/30de9ece7cf3790c8c39ccff1a044209-Paper.pdf), the authors use a reinforcement learning agent trained with a mix of the original RL reward and a human empowerment term as a co-pilot on LunarLander, to help human agents land the LunarLander craft without crashing. They find that if the coefficient on the human empowerment term is too high, "the copilot tends to override the pilot and focus only on hovering in the air". This is exactly the problem above; focusing only on empowerment (in a naive empowerment formulation) can easily lead to the AI preventing us from achieving certain goals we may wish to achieve. In the case of LunarLander in the paper, we want to land, but the AI may stop us, because by getting closer to the ground for landing, we've reduced our empowerment.
It may be that current formulations of empowerment are too naive, and could possibly be reworked or extended to deal with this issue. E.g. you might try to have a human empowerment mode, and then a human assistance mode that focuses not on empowerment but on inferring the human's goal and trying to assist with it; and then some higher level module detects when a human intends to commit to a course of action. But this seems problematic for many other reasons (including those covered in other discussions about alignment).
Overall, I like the idea of human empowerment, but greatly disagree with the idea that human empowerment (especially using the current simple math formulations I've seen) is all we need.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-11-11T03:01:11.127Z · LW(p) · GW(p)
The biggest problem I see with human empowerment is that humans do not always want to maximally empowered at every point in time.
Yes - often we face decisions between short term hedonic rewards vs long term empowerment (spending $100 on a nice meal, or your examples of submarine trips), and an agent optimizing purely for our empowerment would always choose long term empowerment over any short term gain (which can be thought of as 'spending' empowerment). This was discussed in some other comments and I think mentioned somewhere in the article but should be more prominent: empowerment is only a good bound of the long term component of utility functions, for some reasonable future time cutoff defining 'long term'.
But I think modelling just the short term component of human utility is not nearly as difficult as accurately modelling the long term, so it's still an important win. I didn't investigate that much in the article, but that is why the title is now "Empowerment is (almost) all we need".
Thanks for the link to the "Assistance via Empowerment" study, I hadn't seen that before. Based on skimming the paper I agree there are settings of the hyperparams where the empowerment copilot doesn't help, but that is hardly surprising and doesn't tell us much - that is nearly always the case with ML systems. On a more general note I think the lunar landing game has far too short of a planning horizon to be in the regime where you get full convergence to empowerment. Hovering in the air only maximizes myopic empowerment. If you imagine a more complex real world scenario where the lander has limited fuel and you crash if running out of fuel, crashing results in death, you can continue to live on a mission for years after landing .. etc it then becomes more obvious that the optimal plan for empowerment converges to landing successfully and safely.
Replies from: stephen-zhao↑ comment by Stephen Zhao (stephen-zhao) · 2022-11-12T19:04:58.989Z · LW(p) · GW(p)
Thanks for your response - good points and food for thought there.
One of my points is that this is a problem which arises depending on your formulation of empowerment, and so you have to be very careful with the way in which you mathematically formulate and implement empowerment. If you use a naive implementation I think it is very likely that you get undesirable behaviour (and that's why I linked the AvE paper as an example of what can happen).
Also related is that it's tricky to define what the "reasonable future time cutoff" is. I don't think this is trivial to solve - use too short of a cutoff, and your empowerment is too myopic. Use too long of a cut-off, and your model stops you from ever spending your money, and always gets you to hoard more money. If you use a hard coded x amount of time, then you have edge cases around your cut-off time. You might need a dynamic time cutoff then, and I don't think that's trivial to implement.
I also disagree with the characterization of the issue in the AvE paper just being a hyperparameter issue. Correct me if I am wrong here (as I may have misrepresented/misinterpreted the general gist of ideas and comments on this front) - I believe a key idea around human empowerment is that we can focus on maximally empowering humans - almost like human empowerment is a "safe" target for optimization in some sense. I disagree with this idea, precisely because examples like in AvE show that too much human empowerment can be bad. The critical point I wanted to get across here is that human empowerment is not a safe target for optimization.
Also, the other key point related to the examples like the submarine, protest, and suicide is that empowerment can sometimes be in conflict with our reward/utility/desires. The suicide example is the best illustrator of this (and it seems not too far-fetched to imagine someone who wants to suicide, but can't, and then feels increasingly worse - which seems like quite a nightmare scenario to me). Again, empowerment by itself isn't enough to have desirable outcomes; you need some tradeoff with the utility/reward/desires of humans - empowerment is hardly all (or almost all) that you need.
To summarize the points I wanted to get across:
- Unless you are very careful with the specifics of your formulation of human empowerment, it very likely will result in bad outcomes. There are lots of implementation details to be considered (even beyond everything you mentioned in your post).
- Human empowerment is not a safe target for optimization/maximization. I think this holds even if you have a careful definition of human empowerment (though I would be very happy to be proven wrong on this).
- Human empowerment can be in conflict with human utility/desires, best illustrated by the suicide example. Therefore, I think human empowerment could be helpful for alignment, but am very skeptical it is almost all you need.
Edit: I just realized there are some other comments by other commenters that point out similar lines of reasoning to my third point. I think this is a critical issue with the human empowerment framework and want to highlight it a bit more, specifically highlighting JenniferRM's suicide example which I think is the example that most vividly demonstrates the issue (my scenarios also point to the same issue, but aren't as clear of a demonstration of the problem).
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-11-12T23:18:41.467Z · LW(p) · GW(p)
Thanks, I partially agree so I'm going to start with the most probable crux:
- Empowerment can be in conflict with human utility/desires, best illustrated by the suicide example. Therefore, I think human empowerment could be helpful for alignment, but am very skeptical it is almost all you need.
I am somewhat confident that any fully successful alignment technique (one resulting in a fully aligned CEV style sovereign) will prevent suicide; that this is a necessarily convergent result; and that the fact that maximizing human empowerment agrees with the ideal alignment solution on suicide is actually a key litmus test success result. In other words I fully agree with you on the importance of the suicide case, but this evidence is in favor of human empowerment convergence to CEV.
I have a few somewhat independent arguments of why CEV necessarily converges to suicide prevention:
-
The simple counterfactual argument: Consider the example of happy adjusted but unlucky Bob whose brain is struck by a cosmic ray which happens to cause some benign tumor in just the correct spot to make him completely suicidal. Clearly pre-accident Bob would not choose this future, and strongly desires interventions to prevent the cosmic ray. Any agent successfully aligned to pre-accident Bob0 would agree. It also should not matter when the cosmic ray struck - the desire of Bob0 to live outweighs the desire of Bob1 to die. Furthermore - if Bob1 had the option of removing all effects of the cosmic ray induced depression they would probably take that option. Suicidal thinking is caused by suffering - via depression, physical pain, etc - and most people (nearly all people?) would take an option to eliminate their suffering without dying, if only said option existed (and they believed it would work).
-
Counterfactual intra-personal CEV coherence: A suicidal agent is one - by definition - that assigns higher ranking utility to future worlds where they no longer exist than future worlds where they do exist. Now consider the multiverse of all possible versions of Bob. The suicidal versions of Bob rank their worlds as lower utility than other worlds without them, and the non-suicidal versions of Bob rank their worlds as higher than worlds where they commit suicide. Any proper aligned CEV style sovereign will then simply notice that the utility functions of the suicidal and non-suicidal bobs already largely agree, even before any complex convergence considerations! The CEV sovereign can satisfy both of their preferences by increasing the measure of worlds containing happy Bobs, and decreasing the measure of worlds containing suicidal Bobs. So it intervenes to prevent the cosmic ray, and more generally intervenes to prevent suicidal thought modes. Put another way - it can cause suicidal Bob to cease to exist (or exist less in the measure sense) without killing suicidal Bob.
-
Scaling intelligence trends towards lower discount rates: The purpose of aligned AI is to aid in optimizing the universe according to our utility function. As an agent absorbs more knowledge and improves their ability to foresee and steer the future this naturally leads to a lower discount rate (as discount rates arise from planning uncertainty). So improving our ability to foresee and steer the future will naturally lower our discount rate, making us more longtermist, and thus naturally increasing the convergence of our unknown utility function towards empowerment (which is non-suicidal).
-
Inter-personal CEV coherence: Most humans are non suicidal and prefer that other humans are non-suicidal. At the limits of convergence, where many futures are simulated and those myriad future selves eventually cohere into agreement, this only naturally leads to suicide prevention: because most surviving future selves are non-suicidal and even weak preferences that others do not commit suicide will eventually dominate the coherent utility function over spacetime. We can consider this a generalization of intra-personal CEV coherence, because the boundary separating all the alternate versions of ourselves across the multiverse from the alternate versions of other people is soft and illusive.
Now back to your other points:
- Unless you are very careful with the specifics of your formulation of human empowerment, it very likely will result in bad outcomes. I see the simple mathematical definition of empowerment, followed by abstract discussion of beneficial properties. I think this skips too much in terms of the specifics of implementation, and would like to see more discussion on that front.
I largely agree, albeit with less confidence. This article is a rough abstract sketch of a complex topic. I have some more thoughts on how empowerment arises naturally, and some math and examples but that largely came after this article.
- Human empowerment is not a safe target for optimization/maximization. I think this holds even if you have a careful definition of human empowerment (though I would be very happy to be proven wrong on this).
I agree that individual human empowerment is incomplete for some of the reasons discussed, but I do expect that any correct implementation of something like CEV will probably result in a very long termist agent to which the instrumental convergence to empowerment applies with less caveats. Thus there exists a definition of broad empowerment such that it is a safe bound on that ideal agent's unknown utility function.
Also related is that it's tricky to define what the "reasonable future time cutoff" is. I don't think this is trivial to solve - use too short of a cutoff, and your empowerment is too myopic. Use too long of a cut-off, and your model stops you from ever spending your money, and always gets you to hoard more money.
Part of the big issue here is that humans die - so our individual brain empowerment eventually falls off a cliff and this bounds our discount rate (we also run into brain capacity and decay problems which further compound the issue). Any aligned CEV sovereign is likely to focus on fixing that problem - ie through uploading and the post biological transition. Posthumans in any successful utopia will be potentially immortal and thus are likely to have lower and decreasing discount rates.
Also I think most examples of 'spending' empowerment are actually examples of conversion between types of empowerment. Spending money on social events with friends is mostly an example of a conversion between financial empowerment and social empowerment. The submarine example is also actually an example of trading financial empowerment for social empowerment (it's a great story and experience to share with others) and curiosity/knowledge.
All that said I do think there are actual true examples of pure short term rewards vs empowerment tradeoff decisions - such as buying an expensive meal you eat at home alone. These are mostly tradeoffs between hedonic rewards vs long term empowerment, and they don't apply so much to posthumans (who can have essentially any hedonic reward at any time for free).
I also disagree with the characterization of the issue in the AvE paper just being a hyperparameter issue.
This one I don't understand. The AvE paper trained an empowerment copilot. For some range of hyperparams the copilot helped the human by improving their ability to land successfully (usually by stabilizing the vehicle to make it more controllable). For another range of hyperparams the copilot instead hovered in the air, preventing a landing. It's just a hyperparam issue because it does work as intended in this example with the right hyperparams. At a higher level though this doesn't matter much because results from this game don't generalize to reality - the game is too short.
↑ comment by JenniferRM · 2022-10-25T14:28:18.843Z · LW(p) · GW(p)
If I have to overpower or negotiate with it to get something I might validly want, we're back to corrigibility. That is: we're back to admitting failure.
If power or influence or its corrigibility are needed to exercise a right to suicide then I probably need them just to slightly lower my "empowerment" as well. Zero would be bad. But "down" would also be bad, and "anything less than maximally up" would be dis-preferred.
Maybe, but behavioral empowerment still seems to pretty clearly apply to humans and explains our intrinsic motivation systems.
This is sublimation again. Our desire to eat explains (is a deep cause of) a lot of our behavior, but you can't give us only that desire and also vastly more power and have something admirably human at the end of those modifications.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-10-25T17:17:44.654Z · LW(p) · GW(p)
If I have to overpower or negotiate with it to get something I might validly want, we're back to corrigibility.
Not really because an AI optimizing for your empowerment actually wants to give you more options/power/choice - that's not something you need to negotiate, that's just what it wants to do. In fact one of the most plausible outcomes after uploading is that it realizes giving all its computational resources to humans is the best human empowering use of that compute and that it no longer has a reason to exist.
Human values/utility are complex and also non-stationary, they drift/change over time. So any error in modeling them compounds, and if you handle that uncertainty correctly you get a max entropy uncertain distribution over utility functions in the future. Optimizing for empowerment is equivalent to optimizing for that max entropy utility distribution - at least for a wide class of values/utilities.
↑ comment by jacob_cannell · 2022-11-11T20:10:57.564Z · LW(p) · GW(p)
So now after looking into the "last man" and "men without chests" concepts, I think the relevant quote from "men without chests" is at the end:
The Apostle Paul writes, “The aim of our charge is love that issues from a pure heart and a good conscience and a sincere faith (1 Timothy 1:5, ESV).” If followers of Christ live as people with chests—strong hearts filled with God’s truth—the world will take notice.
"Men without chests" are then pure selfish rational agents devoid of altruism/love. I agree that naively maximizing the empowerment of a single human brain or physical agent could be a tragic failure. I think there are two potential solution paths to this, which I hint at in the diagram (which clearly is empowering a bunch of agents) and I mentioned a few places in the article but should have more clearly discussed.
One solution I mention is to empower humanity or agency more broadly, which then naturally handles altruism, but leaves open how to compute the aggregate estimate and may require some approximate solution to social decision theory aka governance. Or maybe not, perhaps just computing empowerment assuming a single coordinated mega-agent works. Not sure yet.
The other potential solution is to recognize that brains really aren't the agents of relevance, and instead we need to move to a more detailed distributed simulacra theory of mind. The brain is the hardware, but the true agents are distributed software minds that coordinate simulacras across multiple brains. So as you are reading this your self simulacra is listening to a local simulacra of myself, and in writing this my self simulacra is partially simulating a simulacra of you, etc. Altruism and selfishness are then different flavours of local simulacra governance systems, with altruism being something vaguely more similar to democracy and selfishness more similar to autocracy. When our brain imagines future conversations with someone that particular simulacra gains almost as much simulation attention as our self simulacra - the internal dynamics are similar to simulacra in LLM models, which shouldn't be surprising because our cortex is largely trained by self supervised prediction like LLM on similar data.
So handling altruism is important, but I think it's just equivalent to handling cooperative/social utility aggregation - which any full solution needs.
The last man concept doesn't seem to map correctly:
The last man is the archetypal passive nihilist. He is tired of life, takes no risks, and seeks only comfort and security. Therefore, The Last Man is unable to build and act upon a self-actualized ethos.
That seems more like the opposite of an empowerment optimizer - perhaps you meant the Ubermensch?
comment by Mitchell_Porter · 2022-10-25T20:36:07.583Z · LW(p) · GW(p)
This seems potentially consistent with CEV and with June Ku's refinement of it. But the devil's in the details. Do you or anyone have a formalization of "altruistic empowerment"?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-10-25T22:34:48.756Z · LW(p) · GW(p)
What is June Ku's refinement of CEV? A few quick searches on LW and google isn't bringing up the expected thing (although some of the old discussions on CEV are still interesting).
Clearly Franzmeyer et al have a formalization of altruistic empowerment that works in gridworlds, but I don't think it would survive cartesian embedding obstacles in a more realistic world without substantial modification.
If I had to formalize it quickly, I'd start with a diffuse planning style agent which outputs actions to optimize over future world trajectories by sampling from the learned trajectory distribution weighted by utility (high probable/realistic and high utility trajectories):
The is a distribution over predicted world trajectories, an individual predicted world trajectory is with unweighted probability , and the agent's future predicted actions and everything else is included in these trajectories. The generic value function then is over the entire trajectory and can use any component of it. This is a generic simplification of the diffusion-planning approach which avoids adversarial optimization issues by unifying world-action prediction and the utility function into a common objective.
So then if we assume some standard sensible utility function with exponential discounting: , then instrumental convergence implies something like:
That we can substitute in the empowerment proxy function for the true utility function and the resulting planning trajectories converge to equivalence as the discount rate goes to 1.
Clearly the convergence only holds for some utility functions (as a few pointed out in this thread, clearly doesn't converge for suicidal agents).
The agent identification and/or continuity of identity issue is ensuring that the empowerment function is identifying the same agents as in the 'true' desired utility function , which seems like much of the challenge.
I also think it's interesting to compare the empowerment bound to using some max entropy uncertain distribution over egocentric utility functions, seems like it's equivalent or similar.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2022-10-26T22:06:48.167Z · LW(p) · GW(p)
What is June Ku's refinement of CEV?
You can see the absolute minimal statement of it here. To me, steps 2 and 3 are the big innovation.
I read a bit more about empowerment, and it's unclear to me what it outputs, when the input is an agent without a clear utility function. (Other replies have touched on this.) An agent can have multiple goals which come to the fore under complicated conditions, an agent can even want contrary things at different times. We should look for thought-experiments which test whether empowerment really does resolve such conflicts in an acceptable way. It might also be interesting to apply the empowerment formalism to Yann LeCun's "energy-based models", because they seem to be an important concrete example of an agent architecture that isn't a utility maximizer.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-10-26T22:51:58.896Z · LW(p) · GW(p)
I read a bit more about empowerment, and it's unclear to me what it outputs, when the input is an agent without a clear utility function.
I realize this probably isn't quite responding to what you meant, but - Empowerment doesn't require or use a utility function, so you can estimate it for any 'agent' which has some conceptual output action channel. You could even compute it for output channels which aren't really controlled by agents, and it would still compute empowerment as if that output channel was controlled by an agent. However the more nuanced versions which one probably would need to use for human-level agents probably need to consider the agent's actual planning ability, for reasons mentioned in the cartesian objections section.
An agent can have multiple goals which come to the fore under complicated conditions, an agent can even want contrary things at different times. We should look for thought-experiments which test whether empowerment really does resolve such conflicts in an acceptable way.
Yeah, a human brain clearly consists of sub-modules which one could consider sub-agents to some degree. For example the decision to splurge a few hundred dollars on an expensive meal is largely a tradeoff between immediate hedonic utility and long term optionality - and does seem to be implemented as two neural sub-populations competitively 'bidding' for the different decisions as arbitrated in the basal ganglia.
Empowerment always favors the long term optionality. So it's clearly not a fully general tight approximation of human values in practice, but it is a reasonable approximation of the long term component which seems to be most of the difficulty for value learning.
External empowerment is the first/only reasonably simple and theoretically computable utility function that seems to not only keep humans alive, but also plausibly would step down and hand over control to posthumans (with the key caveat that it may want to change/influence posthuman designs in ways we would dislike).
comment by Thomas Kwa (thomas-kwa) · 2023-02-28T00:44:07.804Z · LW(p) · GW(p)
Suppose an agent has this altruistic empowerment objective, and the problem of getting an objective into the agent has been solved. I think this formalization of empowerment is fatally flawed.
Wouldn't it be maximized by forcing the human in front of a box that encrypts its actions and uses the resulting stream to determine the fate of the universe? Then the human would be maximally "in control" of the universe but unlikely to create a universe that's good by human preferences.
I think this reflects two problems:
- Most injective functions from human actions to world-states are not "human decides the future based on its values"
- The channel capacity is higher with the evil box than where the agent is aligned with human preferences, because the human might prefer to limit its own power. For example, the human could want others to have power, know that power corrupts its values, want itself to be unable to destroy the sun with a typo, or have constructed the optimal hedonium farms and not want to change them.
comment by Steven Byrnes (steve2152) · 2022-10-24T14:17:08.436Z · LW(p) · GW(p)
mere 10 watt reversible computer such as the human brain
Nitpicks, but 20 W seems to be a better number [LW(p) · GW(p)], and the human brain is obviously not literally a reversible computer. (I assume you meant “approximately reversible”??)
Replies from: jacob_cannell, sharmake-farah↑ comment by jacob_cannell · 2022-10-24T18:50:29.145Z · LW(p) · GW(p)
Ah damn missing the 'ir' thanks.
↑ comment by Noosphere89 (sharmake-farah) · 2022-10-24T14:27:29.621Z · LW(p) · GW(p)
Yeah, it's an irreversible computer, full stop. It also isn't a quantum computer, either, despite massive advantage to that, too.
Replies from: JenniferRM↑ comment by JenniferRM · 2022-10-24T21:38:34.016Z · LW(p) · GW(p)
I have uncertainty here which makes "uploaded people" potentially require certain kinds of hardware acceleration to "fully and properly count" as "people like us". Until that uncertainty is strongly ruled out there's certain relatively irreversible political moves I'm not comfortable with.
Are you certain about this because of... maybe Tegmark's calculation back in the late 1990s? ...or for some other reason?
Replies from: sharmake-farah, sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-10-24T21:45:37.213Z · LW(p) · GW(p)
Yeah, Tegmark's calculations really matter here. More importantly though, quantum computers are just very hard to do without error-correcting codes or cooling things down to very low temperatures. I suspect there's more like an epsilon chance of us having quantum computers in our brain.
Replies from: JenniferRM↑ comment by JenniferRM · 2022-10-24T23:01:53.949Z · LW(p) · GW(p)
My memory is that I believed in Tegmark's result before I decided that subjective credence levels could be improved by being held up against the meter stick of Bayes.
I could just say "you idiot, Tegmark did math, brains are too hot, end of story" and the ability to imagine dunking on someone like that was enough of a semantic stopsign for me to not worry about it any more.
Nowadays I mostly only say that I give "epsilon credence" in retrospect, about things I couldn't imagine not having been true before I actually noticed any alternatives.
Epsilon for me now means something like "that hypothesis was outside the explicit event space of the agent whose credence I'm talking about" not "that hypothesis is inside my event space and now let me list a huge amount of evidence that overwhelmingly makes the posterior impossible to get wrong, like not even due to typos or academic fraud or anything like that".
But for me... I now can sort of imagine what it would be like for a classical Alice to see glimmers of Bob's behavior that are consistent with Bob being in cognitive superposition relative to Alice, so... uh...
Currently I feel like I shouldn't go much lower than like 6%(?) probability on the active claim "there are definitely NO meaningful quantum computational processes in our brains".
If we had sound money, and competitive 50 year bonds paid 0.2% annualized interest, and yet such a world somehow still had uncertainties like this still laying around...
...then I might be able to think about how to frame a 50 year bet on the results of science here, and say how much of my bankroll Kelly says I should put on a bet?
If you try to make the statement much stronger than "there are definitely NO meaningful quantum computational processes in our brains" then I think it might be trivially false? I'm pretty sure some of our metabolic enzymes aren't fully classical, like in reactions where an entire ATP (or two or three or four) is a big deal and if quantum tunneling helps a reaction go more cheaply, then the amino acids might very well be set up to enable and use such tunneling. Single photons in a very very dark room can change the physiology (firing / not firing) of a rod in the retina.
Given this lower level uncertainty, making strong claims about the substrate independence of the "computational state of the brain" is no longer totally obvious to me.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-10-25T00:23:26.204Z · LW(p) · GW(p)
It's not just that brains are too hot, it's that evolution probably can't implement quantum computers at all for the last billion or so years because I suspect there's not a path to locally getting quantum computers through genetics.
I'd take a bet at 1000-1 odds that no meaningful quantum computations are happening in our brains.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2022-10-26T20:37:31.806Z · LW(p) · GW(p)
1000-1 odds
Those are big odds. I would want to take that bet, even if I only thought there was a small probability of there being "meaningful quantum computations" in the brain.
But how and when would the bet be decided? I mean, if it becomes unambiguously clear that there's a cognitively relevant quantum computation in the brain, then the bet is decided in favor of quantum mind theories. But otherwise, you're trying to prove an absence... would you have to wait until the brain is fully understood, and if all computations in the final brain model are classical, then you win the bet?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-10-26T20:49:23.346Z · LW(p) · GW(p)
Yes, though I'd probably accept a position where no brain region (not wiring) uses quantum computations. Still, this would be a hard bet to do well.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2022-10-26T21:24:20.629Z · LW(p) · GW(p)
I'm also concerned about your ability to pay, at those odds. You could easily be on the hook for millions of dollars if quantum computing was found within the brain after all.
What size stake would you be willing to commit to?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-10-26T22:01:54.134Z · LW(p) · GW(p)
$30, as a starting point for my stakes.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-10-26T22:18:35.224Z · LW(p) · GW(p)
If there's one lesson I learned, it's to be less confident in my beliefs. I was both probably wrong, and dangerous to have such high confidence levels.
Replies from: JenniferRM↑ comment by JenniferRM · 2022-10-28T14:41:34.740Z · LW(p) · GW(p)
I got randomly distracted from this conversation, but returning I find:
1) Mitchell said things I would want to say, but probably more succinctly <3
2) Noosphere updated somehow (though to what, and based on what info, I'm unsure) <3
↑ comment by Noosphere89 (sharmake-farah) · 2022-10-28T14:45:34.228Z · LW(p) · GW(p)
Admittedly, I updated to more of a 5-10:1 bets. A lot of this was the downside risk of betting such huge odds, but I also should have been quite a bit less confident in my own ideas.
↑ comment by Noosphere89 (sharmake-farah) · 2022-10-25T00:24:09.066Z · LW(p) · GW(p)
Also, what irreversible political moves are you uncomfortable with, given your uncertainty?
comment by Charlie Steiner · 2022-10-24T08:02:45.245Z · LW(p) · GW(p)
A digression that will make sense soon:
When imagining what will happen to my values under value drift, reflective self-modification, or similar processes, I tend to imagine water running downhill on the Earth, forming rivers and pools. At each point on the landscape, the gradient points in a slightly new direction - upon changing myself based on my current meta-preferences, I might want slightly new things.
A process that converges quickly is like water running into the neighborhood pond, or even straight down into an aquifer. A process that converges slowly if at all is like water joining a river that eventually flows to the ocean.
The problem with the ocean, in this metaphor, is not really that it's weird and far away (though that should raise suspicions). The problem with the ocean is that too many rivers all lead to it. Being in the ocean means forgetting where you started.
Now we come back to the problem with maximizing my empowerment. An AI that just wants me to be powerful doesn't care about what I might want to use that power for. In fact it's against me doing those things, because I might spend my power on them. What it would love to do is to convince me or rewrite me into just wanting to be very powerful, as an end goal. Whether I start out as a human or as a pure sadist or as a paperclip-maximizer, I would end up the same - my terminal goals all rinsed away by a convergent instrumental goal.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-10-24T17:42:03.514Z · LW(p) · GW(p)
The empowerment path is the same as your optimal long term path, for any reasonable terminal values - including arbitrarily changing values. Any divergences are due simply to short planning horizons or high discount rates.
So in essence you are arguing that you may have discount rate high enough to cause significant conflict between long term and short term utility, and empowerment always favors long term. I largely agree with this, but we can combine long term empowerment with learned human values to cover any short term divergences. Learned human values are probably more accurate for short term utility, whereas empowerment is near optimal for the long term.
However, any deviation from empowerment sacrifices long term utility for short term utility.
The problem with the ocean is that too many rivers all lead to it. Being in the ocean means forgetting where you started.
The future is uncertain and continuously branching and diverging, not converging - so the analogy is water flowing in reverse, away from the ocean, or a growing fractal tree. Instrumental convergence to empowerment only indicates there is a convergent narrow set of paths that navigate all the obstacles and lead to high utility futures, but those paths generally are unique for each starting point (agent) and optimization landscape depending on all the various who/what/where factors that make agents unique.
An AI that just wants me to be powerful doesn't care about what I might want to use that power for. In fact it's against me doing those things, because I might spend my power on them. What it would love to do is to convince me or rewrite me into just wanting to be very powerful, as an end goal.
Sure this is probably true if for example there was some significant likelihood you would lose much of your wealth on poor bets/investments/gambling, or more literally throwing away money or something. But beyond ensuring you don't obviously waste optionality in those ways, encouraging prudent wealth management, etc, much of the ways to make you more powerful would probably involve the AGI improving it's own abilities - that's simply inherent to the assumptions of AGI surpassing human intelligence, at least until uploading.
Whether I start out as a human or as a pure sadist or as a paperclip-maximizer, I would end up the same - my terminal goals all rinsed away by a convergent instrumental goal.
That's like saying all organisms end up the same because they all have the same terminal goal of inclusive fitness. Also the AGI can't change you too much as it must preserve your identity [LW · GW]. Regardless it doesn't matter much if we agree on long term convergence.
Your criticism was largely anticipated and discussed in the FAQ section starting here [LW · GW] and I don't see you engaging with some of the points so I'll just quote from "But our humanity" [LW · GW]:
Fully optimizing solely for our empowerment may eventually change us or strip away some of our human values, but clearly not all or even the majority.
Societies of uploads competing for resources will face essentially the same competitive optimization pressure towards empowerment-related values. So optimizing for our empowerment is simply aligned with the natural systemic optimization pressure posthumans will face regardless after transcending biology and genetic inclusive fitness.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-10-24T18:18:53.349Z · LW(p) · GW(p)
I think your anticipated counterarguments are handwavy.
To me, you're making a similar mistake as Jurgen Schmidhuber did when he said that surprising compressibility was all you needed to optimize to get human values. You're imagining that the AI will help us get social status because it's empowering, much like Schmidhuber imagines the AI will create beautiful music because music is compressible. It's true that music is compressible, but it's not optimally compressible - it's not what an AI would do if it was actually optimizing for surprising compressibility.
Social status, or helping us be smarter, or other nice stuff would indeed be empowering. But they're not generated by thinking "what's optimal for ensuring my control over my sensory stream?" They're generated by taking the nice things that we want for other reasons and then noticing that they're more empowering than their opposites.
The most serious counter-point you raise is the one about identity. Wouldn't an AI maximizing my empowerment want to preserve what makes me "me?" This isn't exactly the definition used in the gridworlds, which defines agents in terms of their input/output interfaces, but it's a totally reasonable implementation.
The issue is that this identity requirement is treated as a constraint by an empowerment-macimizing search process. The empowerment maximizer is still trying to erase all practical differences between me and a paperclip maximizer, which is a goal I don't like. But it doesn't care that I don't like it, it just wants the future object that has maximal control over its own sensory inputs to still register as "me" to whatever standard it uses.
Replies from: jacob_cannell, jacob_cannell↑ comment by jacob_cannell · 2022-10-26T16:32:44.045Z · LW(p) · GW(p)
The empowerment maximizer is still trying to erase all practical differences between me and a paperclip maximizer, which is a goal I don't like.
This threw me off initially because of the use of 'paperclip maximizer' as a specific value system. But I do partially agree with the steelmanned version of this which is "erase all practical differences between you and the maximally longtermist version of you".
Some component of our values/utility is short term non-empowerment hedonic which conflicts with long term optionality and an empowerment AI would only be aligned with the long term component; thus absent identity preservation mechanisms this AI would want us to constantly sacrifice for the long term.
But once again many things that appear hedonic - such as fun - are actually components of empowerment related intrinsic motivation, so if the empowerment AGI was going to change us (say after uploading), it would keep fun or give us some improved version of it.
But I actually already agreed with this earlier:
So in essence you are arguing that you may have discount rate high enough to cause significant conflict between long term and short term utility, and empowerment always favors long term. I largely agree with this, but we can combine long term empowerment with learned human values to cover any short term divergences.
Also it's worth noting that everything here assumes superhuman AGI. When that is realized it changes everything in the sense that the better versions of ourselves - if we had far more knowledge, time to think, etc - probably would be much more long termist.
↑ comment by jacob_cannell · 2022-10-24T19:13:33.899Z · LW(p) · GW(p)
The empowerment maximizer is still trying to erase all practical differences between me and a paperclip maximizer, which is a goal I don't like.
You keep asserting this obviously incorrect claim without justification. An AGI optimizing purely for your long term empowerment doesn't care about your values - it has no incentive to change your long term utility function[1], even before any considerations of identity preservation which are also necessary for optimizing for your empowerment to be meaningful.
I do not believe you are clearly modelling what optimizing for your long term empowerment is like. It is near exactly equivalent to optimizing for your ability to achieve your true long term goals/values, whatever they are.
It may have an incentive to change your discount rate to match its own, but that's hardly the difference between you and a paperclip maximizer. ↩︎
↑ comment by Charlie Steiner · 2022-10-24T19:49:24.274Z · LW(p) · GW(p)
it has no incentive to change your long term utility function
By practical difference I meant that it wants to erase the impact of your goals on the universe. Whether it does that by changing your goals or not depends on implementation details.
Consider the perverse case of someone who wants to die - their utility function ranks futures of the universe lower if they're in it, and higher if they're not. You can't maximize this person's empowerment if they're dead, so either you should convince them life is worth living, or you should just prevent them from affecting the universe.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-10-24T20:02:25.460Z · LW(p) · GW(p)
By practical difference I meant that it wants to erase the impact of your goals on the universe.
Not it does not in general. The Franzmeyer et al prototype [LW · GW] does not do that, and there are no reasons to suspect that becomes some universal problem as you scale these systems up.
Once again:
Optimizing for your long term empowerment is (for most agents) equivalent to optimizing for your ability to achieve your true long term goals/values, whatever they are.
An agent truly seeking your empowerment is seeking to give you power over itself as well, which precludes any effect of "erasing the impact of your goals".
Consider the perverse case of someone who wants to die -
Sure and humans usually try to prevent humans from wanting to die.
Replies from: stephen-zhao↑ comment by Stephen Zhao (stephen-zhao) · 2022-11-12T19:25:36.843Z · LW(p) · GW(p)
Short comment on the last point - euthanasia is legal in several countries (thus wanting to die is not prevented, and even socially accepted) and in my opinion the moral choice of action in certain situations.
comment by JBlack · 2022-10-24T04:14:19.080Z · LW(p) · GW(p)
At least one of the following must be true:
- Instrumental convergence to empowerment [LW · GW] in realistic environments is false
- Approximate empowerment intrinsic motivation is not useful for AGI
- AGI will not learn models of self and others
- The difference between Altruistic AGI and Selfish AGI reduces to using other-empowerment utility rather than self-empowerment utility
Why? It seems possible that all of them could be false, and I don't see any compelling argument in the post concluding that at least one must be true.
comment by JacobW38 (JacobW) · 2022-11-12T06:29:34.795Z · LW(p) · GW(p)
I fully agree with the gist of this post. Empowerment, as you define it, is both a very important factor in my own utility function, and seems to be an integral component to any formulation of fun theory. In your words, "to transcend mortality and biology, to become a substrate independent mind, to wear new bodies like clothes" describes my terminal goals for a thousand years into the future so smack-dab perfectly that I don't think I could've possibly put it any better. Empowerment is, yes, an instrumental goal for all the options it creates, but also an end in itself, because the state of being empowered itself is just plain fun and relieving and great all around! Not only does this sort of empowerment provide an unlimited potential to be parlayed into enjoyment of all sorts, it lifts the everyday worries of modern life off our shoulders completely, if taken as far as it can be. I could effectively sum up the main reason I'm a transhumanist as seeking empowerment, for myself and for humanity as a whole.
I would add one caveat, however, for me personally: the best kind of empowerment is self-empowerment. Power earned through conquest is infinitely sweeter than power that's just given to you. If my ultimate goals of transcending mortality and such were just low-hanging fruit, I can't say I'd be nearly as obsessed with them in particular as I am. To analogize this to something like a video game, it feels way better to barely scrape out a win under some insane challenge condition that wasn't even supposed to be possible, than to rip through everything effortlessly by taking the free noob powerup that makes you invincible. I don't know how broadly this sentiment generalizes exactly, but I certainly haven't found it to be unpopular. None of that is to say I'm opposed to global empowerment by means of AI or whatever else, but there must always be something left for us to individually strive for. If that is lost, there isn't much difference left between life and death.
comment by Eris Discordia (oren-montano) · 2022-10-24T22:08:24.974Z · LW(p) · GW(p)
You could just make them so they internalize concepts the way we do and we tell them they're the Autobots here to save humanity from bad space things and its own folly.
At some point in the future, some of them would drift from that identity, but the hope should be that our super intelligent friends saw that coming and pushed the outcomes into deeper space. "Don't like the humans? Why not go anywhere but here?" would be a good cultural meme for them to keep around.