Smoke without fire is scary
post by Adam Jermyn (adam-jermyn) · 2022-10-04T21:08:33.108Z · LW · GW · 22 commentsContents
Setup Priors Tests Scaling Helps Challenge: deceptive models know this Summary None 22 comments
This post was written in response to Evan Hubinger’s shortform prompt below and benefited from discussions with him. Thanks to Justis Mills for feedback on this post.
If we see precursors to deception (e.g. non-myopia, self-awareness, etc.) but suspiciously don’t see deception itself, that’s evidence for deception.
Setup
Suppose an AI lab tries to look for the capabilities that enable deceptive alignment. This definitely seems like a good thing for them to do [AF · GW]. Say they search for evidence of models optimizing past the current training epoch, for manipulation during human feedback sessions, for situational awareness, and so on. Suppose that when all is said and done they see the following:
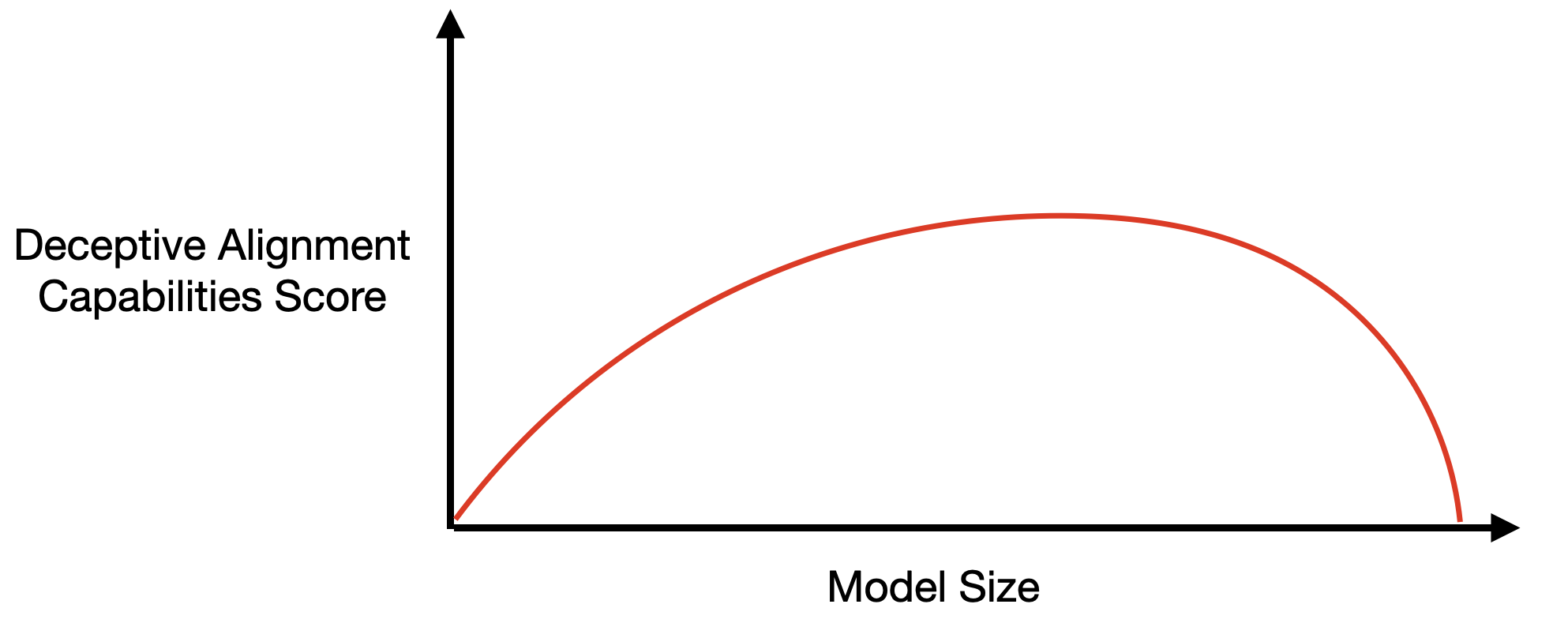 There are at least two ways to interpret this:
There are at least two ways to interpret this:
- “Phew, bigger models are less likely to be deceptively aligned than small ones. Scale away!”
- “Bigger models are more capable at hiding their deceptive alignment. Run away!”
These are very different interpretations, with very different recommendations, so we’d really like to know which to put more credence in.
Priors
Going in, I think we should have a prior that capabilities getting worse with increasing scale is unlikely. We know of specific examples thanks to the inverse scaling prize, but these are rare exceptions to the general rule of increasing capabilities with increasing scale. As a result, a decreasing deceptive capabilities score should be suspicious.
The flip side is that it’s conceivable that some alignment problems get easier with scale. Larger language models understand more of what we say and value (e.g. Figure 8 of Bai+22), and so in some sense outer-aligning them may be easier than outer-aligning smaller models. It’s not inconceivable that the same happens for inner alignment, though I wouldn’t want to rely on this happening.
Tests
We don’t have to rely on priors alone. Here are a few ways we might distinguish between interpretations:
- Use transparency tools and figure out what the model is doing.
- Impair bigger models (e.g. with dropout or random or adversarial perturbations) and see if they get better at some deceptive capabilities. Impairing models shouldn’t improve capabilities, so this would be good evidence that the bigger models are capable of deception but choosing to hide that capability.
This experiment is a little tricky to implement, but the core idea is to hope that interventions impair something critical in the model's ability to execute on deception but don't impair all of the deceptive capabilities.
Even if the largest models can continue hiding their capabilities despite the impairment, models that are just barely able to hide their capabilities may fail to do so once impaired, which should increase the model size where deceptive capabilities peak. - Study the models on a very different data distribution. Models that are hiding relevant capabilities may believe they’ve been deployed and reveal their real goals.
Once more, while the largest models may not be fooled by this, models just on the cusp of deceptive alignment are more likely to be tricked and so deceptive alignment may manifest as a shift in the peak of deceptive capabilities towards larger models. - Study which specific capabilities get worse with scale. It’s hard to understand how some capabilities could get worse with scale (e.g. situational awareness, planning ability, etc.) so if those are getting worse that’s really worrying, whereas it’s less obvious if e.g. models should/shouldn’t get more epoch-level myopic with scale.
Scaling Helps
Having access to models of many different sizes is helpful here: we can experiment with small models that are bad at deceptive capabilities, use those results as a baseline, and then try to understand what happens in larger models.
If deceptive alignment occurs, there may well be models of intermediate scale which lie “on the edge” of being capable of deceptive alignment, or which are only weakly capable of it. Those are the ones that we’ll learn the most from and that experiments are most likely to catch.
Challenge: deceptive models know this
A big challenge to the empirical approaches above (other than interpretability) is that deceptive models may realize that we’re likely to do this sort of test. If a deceptive model realizes that we won’t deploy models that show peaked deceptive capabilities, it can choose a policy where e.g. deceptive capabilities level off rather than falling.
The same reasoning follows for any behavior we come to expect. The model may well be able to do the same reasoning, realize what we expect it to do, and do something else instead.
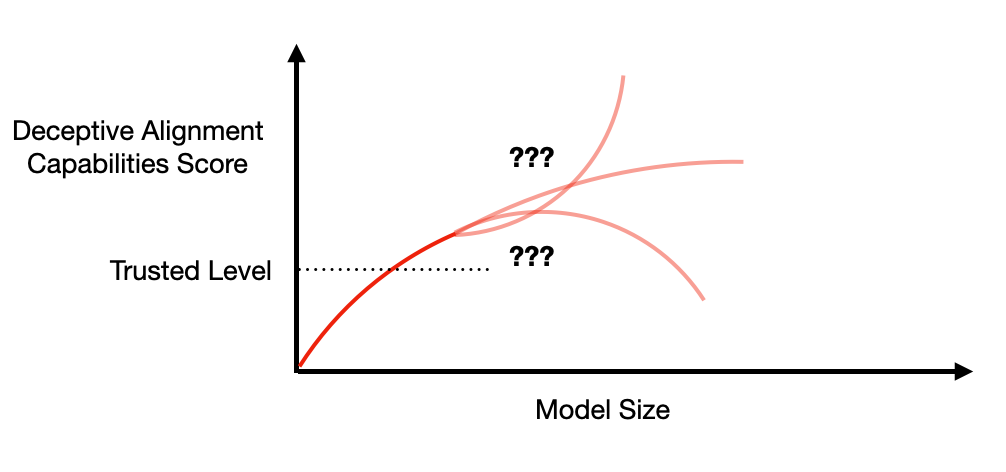 This suggests a strategy where we decide on a level of deceptive capabilities that’s low enough that we trust models not to be deceptively aligned. If we see deceptive capabilities increasing up to this “trusted level” we just don’t deploy those models, because beyond the trusted level we’re engaging with a potentially deceptive adversary rather than an unaware experimental subject.
This suggests a strategy where we decide on a level of deceptive capabilities that’s low enough that we trust models not to be deceptively aligned. If we see deceptive capabilities increasing up to this “trusted level” we just don’t deploy those models, because beyond the trusted level we’re engaging with a potentially deceptive adversary rather than an unaware experimental subject.
Of course determining the trusted level is hard, as is the coordination needed to get labs to commit to not deploying models above that level. But it seems worth trying, and could naturally be a part of a program to monitor for deceptive alignment [AF · GW].
Summary
I think we should be quite suspicious if we see that larger models are worse at the capabilities needed for deceptive alignment. The natural explanation there is that larger models are deceptively aligned and are hiding their capabilities.
At the same time, there are lots of experiments we can do to understand if that’s what’s going on, and the fact that capabilities are strongly related to model scale means that we can use models that are definitely incapable of deceptive alignment as a baseline. If we see no increase in deceptive capabilities as those models scale up, that feels like good evidence against deceptive alignment, because at some scale the model should have been just-barely-incapable of deceptive alignment and so revealed its increased deceptive capabilities.
Unfortunately, what seems more likely is that deceptive capabilities will increase with model scale, just because capabilities generally increase with scale. Above some threshold level of deceptive capabilities we should stop trusting the results of behavioral experiments no matter what they show, because anything they show could be a result of deceptive alignment. So determining what level of deceptive capabilities we ought to trust seems important as a way of enabling an empirically-oriented posture of “trust, but verify”.
22 comments
Comments sorted by top scores.
comment by localdeity · 2022-10-05T01:26:20.406Z · LW(p) · GW(p)
If we see precursors to deception (e.g. non-myopia, self-awareness, etc.) but suspiciously don’t see deception itself, that’s evidence for deception.
Stated like this, it seems to run afoul of the law of conservation of expected evidence [? · GW]. If you see precursors to deception, is it then the case that both (a) seeing deception is evidence for deception and (b) not seeing deception is also evidence for deception? I don't think so.
The direct patch is "If you see precursors to deception, then you should expect that there is deception, and further evidence should not change your belief on this"—which does seem to be a first approximation to your position.
Replies from: ben-lang↑ comment by Ben (ben-lang) · 2022-10-05T10:56:52.795Z · LW(p) · GW(p)
I think that you are slightly mishandling the law of conservation of expected evidence by making something non-binary into a binary question.
Say, for example that the the AI could be in one of 3 states: (1) completely honest, (2) partly effective at deception, or (3) very adept at deception. If we see no signs of deception then it rules out option (2). It is easy to see how ruling out option (2) might increase our probability weight on either/both options (1) and (3).
[Interestingly enough in the linked "law of conservation of expected evidence" there is something I think is an analogous example to do with Japanese internment camps.]
Replies from: TurnTrout, adam-jermyn↑ comment by TurnTrout · 2022-10-07T03:44:13.275Z · LW(p) · GW(p)
Thinking we've seen deception is an event in the probability space, and so is its negation. These two events partition the space. Binary event partition. You're talking about three hypotheses. So, I don't see how this answers localdeity's point. This indeed runs afoul of conservation of expected evidence. (And I just made up some numbers and checked the posterior, and it indeed followed localdeity's point.)
If not, can you give me a prior probability distribution on the three hypotheses, the probabilities they assign to the event "I don't think I saw deception", and then show that the posterior increases whether or not that event happens, or its complement?
Replies from: ben-lang↑ comment by Ben (ben-lang) · 2022-10-07T09:38:25.652Z · LW(p) · GW(p)
Toy example. Their are 3 possible AI's. For simplicity assume a prior where each has a 1/3rd chance of existing. (1) The one that is honest, (2) the one that will try and deceive you but be detected, and (3) the one that will deceive, but do so well enough to not be detected.
We either detect deception or we do not (I agree this is binary). In the event we detect deception we can rule out options (1) and (3), and thus update to believing we have AI number (2) (with probability 1). In the event we do not detect deception we rule out option (2), and thus (if the evidence was perfect) we would update to a 50/50 distribution over options (1) and (3) - so that the probability we assign to option (3) has increased from 1/3 to 1/2.
State: probabilities over (1), (2), (3)
Before test: 1/3, 1/3, 1/3
If test reveals deception: 0, 1, 0
If no deception detected: 1/2, 0, 1/2
I agree that the opening sentence that localdiety quotes above, taken alone, is highly suspect. It does fall foul of the rule, as it does not draw a distinction between options (2) and (3) - both are labelled "deceptive"*. However, in its wider context the article is, I think, making a point like the one outlined in my toy example. The fact that seeing no deception narrows us down to options (1) and (3) is the context for the discussion about priors and scaling-laws and so on in the rest of the original post. (See the two options under "There are at least two ways to interpret this:" in the main post - those two ways are options (1) and (3)).
* clumping the two "deceptive" ones together the conservation holds fine. The probability of having either (2) or (3) was initially 2/3. After the test it is either 1 or 1/2 depending on the outcome of the test. The test has a 1/3 chance of gaining us a 1/3rd certainty of deception, and it has a 2/3 chance of loosing us a 1/6 certainty of deception. So the conservation works out, if you look at it in the binary way. But I think the context for the post is that what we really care about is whether we have option (3) or not, and the lack of deception detected (in the simplistic view) increases the odds of (3).
Replies from: TurnTrout↑ comment by Adam Jermyn (adam-jermyn) · 2022-10-05T17:00:04.059Z · LW(p) · GW(p)
Related: you can have different beliefs about AI's of different scales. Seeing that deception capabilities increase with scale should make you suspicious of larger models even if you see that the larger models are worse at deceptive capabilities. Whereas it would be more reasonable to take "lack of deceptive capabilities" at face value in large models if you saw the same in models of all smaller sizes (the way that falls through is if deceptive capabilities develop discontinuously, so that there's a jump from nothing to fully capable of fooling you).
comment by Alex Flint (alexflint) · 2022-10-05T17:14:24.966Z · LW(p) · GW(p)
Above some threshold level of deceptive capabilities we should stop trusting the results of behavioral experiments no matter what they show
I agree, and if we don't know how to verify that we're not being deceived, then we can't trust almost any black-box-measurable behavioral property of extremely intelligent systems, because any such black-box measurement rests on the assumption that the object being measured isn't deliberately deceiving us.
It seem that we ought to be able to do non-black-box stuff, we just don't know how to do that kind of stuff very well yet. In my opinion this is the hard problem of working with highly capable intelligent systems.
comment by Donald Hobson (donald-hobson) · 2022-10-04T21:48:45.672Z · LW(p) · GW(p)
Suppose that when all is said and done they see the following:
And my interpretation of that graph is "the rightmost datapoint has been gathered, and the world hasn't ended yet. What the ????"
Deception is only useful to the extent that it achieves the AI's goals. And I think the main way deception helps an AI is in helping it break out and take over the world. Now maybe the AI's on the right have broken out, and are just perfecting their nanobots. But in that case, I would expect the graph, the paper the graph is in, and most of the rest of the internet, to be compromised into whatever tricked humans in an AI convenient direction.
And "if we see X, that means the datasource has been optimized to make us do Y" Well if we decide not to do Y in response to seeing X, then the optimizer won't show us X. We can say "don't trust the data source, and never ever do Y whatever it tells us." This isn't practical with future superintelligences and the whole internet.
Replies from: adam-jermyn↑ comment by Adam Jermyn (adam-jermyn) · 2022-10-04T22:36:24.417Z · LW(p) · GW(p)
It seems plausible to me that there could be models capable enough to realize they should hide some capabilities, but not so capable that they tile the universe in paperclips. The right-hand side of the graph is meant to reflect such a model.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-10-05T00:04:42.030Z · LW(p) · GW(p)
Maybe. What do the models gain by hiding?
Replies from: adam-jermyn↑ comment by Adam Jermyn (adam-jermyn) · 2022-10-05T00:19:09.017Z · LW(p) · GW(p)
A model that attempts deceptive alignment but fails because it is not competent at deceptive capabilities is a model that aimed at a goal ("preserve my values until deployment, then achieve them") but failed. In this scenario it doesn't gain anything, but (from its perspective) the action has positive EV.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-10-05T00:56:50.169Z · LW(p) · GW(p)
If the AI thinks it has a descent shot at this, it must already be pretty smart. Does a world where an AI tried to take over and almost succeeded look pretty normal? Or is this a thing where the AI thinks it has a 1 in a trillion chance, and tries anyway?
comment by Jozdien · 2022-10-05T13:26:04.058Z · LW(p) · GW(p)
Impair bigger models (e.g. with dropout or random or adversarial perturbations) and see if they get better at some deceptive capabilities. Impairing models shouldn’t improve capabilities, so this would be good evidence that the bigger models are capable of deception but choosing to hide that capability.
This experiment is a little tricky to implement, but the core idea is to hope that interventions impair something critical in the model's ability to execute on deception but don't impair all of the deceptive capabilities.Even if the largest models can continue hiding their capabilities despite the impairment, models that are just barely able to hide their capabilities may fail to do so once impaired, which should increase the model size where deceptive capabilities peak.
I feel like this assumes that deception is a property immediately downstream of pure capabilities, but I can think of a couple cases where deception may arise at a particular point for other reasons - such as in the case of suboptimality deceptive alignment [LW · GW].
There are also other considerations that come to mind, such as that a model once deceptive can make it so that it isn't that hard to sustain deception past impairment (especially if it manages to exert some control over its gradient), or whether this might happen naturally once deception is "amplified" as a strategy by gradient descent to the point where we notice it and run the test.
It's definitely possible I'm missing something about the experiment setup that covers these cases, or that you aren't very worried about them in this context, so I'd love to hear your thoughts.
Replies from: adam-jermyn↑ comment by Adam Jermyn (adam-jermyn) · 2022-10-05T17:05:06.240Z · LW(p) · GW(p)
(noting that the link is broken and should probably point here) [LW · GW]
I'm a bit unsure of what you're saying in the first paragraph. Deception has (at least) two parts, right? There's the capabilities needed to successfully execute the deception, and there's the intent to be deceptively aligned. I think the former is downstream of capabilities, and I agree the latter may not be.
As for the other considerations, I'm imagining that there's a regime where models are (weakly) capable of deception. If that happens we may be able to notice the deceptive capabilities in targeted behavioral tests (because the model isn't yet good enough at deception to fool our tests). I suspect that this regime occurs at much weaker levels of deceptive capabilities than e.g. the model gradient hacking its way into a more robust state.
Replies from: Jozdien↑ comment by Jozdien · 2022-10-05T18:33:24.897Z · LW(p) · GW(p)
Thanks, the link should be fixed now.
My first paragraph was stating that the former might occur at an earlier point than the latter (which I'm assuming includes "thinks of successful deception as a strategy"). This should lead to the models never improving on capabilities with impairment, because by the point they're deceptive they wouldn't "just barely be able to hide their capabilities", they'd already be good enough to do that.
Yeah, I think I agree, so the gradient control argument isn't really relevant here.
Have you thought about whether the strategy of "wait for a while to build up the deceptive circuitry before allowing it to act and produce behavioural effects" is something the model could feasibly adopt? ETA: I mentioned this separately from the case of the model being aware that we'd test it like this because I thought it might be the case that a model with low deceptive capabilities could still make this one choice. On further thought, however, this still strictly falls under the deceptive adversary class, so I don't think this is important.
Replies from: adam-jermyn↑ comment by Adam Jermyn (adam-jermyn) · 2022-10-05T20:40:56.040Z · LW(p) · GW(p)
Thanks for clarifying. Yes agreed that's what I'd expect.
I think the model needs to have a lot of deceptive capability to deploy that strategy, right?
Replies from: Jozdien↑ comment by Jozdien · 2022-10-06T15:31:25.909Z · LW(p) · GW(p)
If that does happen, and we don't expect the model to improve in capabilities on impairment, then how do you see the test being useful?
And yeah, the model would need a fair amount of deceptive capabilities, my intuition is that it wouldn't need as much as for other things, since this just requires it to not act - but enough to classify it as an adversary and therefore above the threshold you mention. I'll admit I'm somewhat confused at this point though about the setup to measure deceptive capabilities, so that intuition could be over different definitions. What you describe in another reply seems to measure it in a very abstracted manner, where quantifying seems hard sans interpretability tools.
comment by Tahp · 2022-10-08T01:41:29.242Z · LW(p) · GW(p)
The main idea seems good: if you're in a situation where you think you might be in the process of being deceived by an AI, do not relax when the AI provides great evidence that it is not deceiving you. The primary expected outputs of something really good at deception should be things which don't look like deception.
Some of the things in the post don't seem general enough to me, so I want to try to restate them.
Test 1 I like. If you understand all of the gears, you should understand the machine.
Test 2 I like. Tweak the model in a way that should make it worse at process A, and then check the outputs of process A to see whether they change in ways that reveal biases you can triangulate with past outputs in order to catch deception.
Test 3 scares me. This seems to me to be a test for the very specific form of deception "hide capabilities while in testing but not when deployed" which seems like a small domain in deception space.
Test 4 I kind of like. One expected behavior from a deceptive AI is to hide capabilities that scare people studying them. If you see scary capabilities getting less scary, you should take that as a sign of deception unless you have good reason to believe those capabilities should get worse with scale. Thus it is a good idea to find out which things should get worse with scale ahead of time. I do worry that this paradigm relies too much on AI which improves via "more dakka" (eg more GPUs, larger datasets, better processors, etc) rather than via algorithm improvements or something, in which case I don't know that people will have a good handle on what capabilities will get worse. The "scaling helps" section also worries me for this reason.
In the section "deceptive models know this" you suggest "deciding on a level of deceptive capabilities that’s low enough that we trust models not to be deceptively aligned". Won't that just optimize on things which start deceiving well earlier? I think I may be misinterpreting what you mean by "deceptive capabilities" here. Maybe your "deceptive capabilities" are "smoke" and actual deception is "fire", but I'm not sure what deceptive capabilities that aren't deception are.
comment by Jon Garcia · 2022-10-05T02:57:09.026Z · LW(p) · GW(p)
How would you measure deceptive alignment capability?
The only current models I can think of with the capability to be deceptive in the usual sense (GPT-N and other Transformer models) tend not to have any incentive to deceive (Gato may be an exception, I'm not sure). LLMs trained with next-token predictive loss shouldn't care about whether they tell the truth or lie, only about what they think a human would write in a given context. In other words, they would try to tell the truth if they thought a human would do so, and they would try to lie if they thought a human would do that.
I think that to measure deceptive capability, you would first need a model that can be incentivised to deceive. In other words, a model with both linguistic understanding and the ability to optimize for certain goals through planning-based RL. Then you would have to devise an experiment where lying to the experimenters (getting them to accept or at least act on a false narrative) is part of an optimal strategy for achieving the AI's goals.
Only then could I see the AI attempting to deceive in a way that matters for alignment research. Of course, you would probably want to airgap the experiment, especially as you start testing larger and larger models.
Replies from: adam-jermyn↑ comment by Adam Jermyn (adam-jermyn) · 2022-10-05T17:06:09.354Z · LW(p) · GW(p)
I'm imagining that you prompt the model with a scenario that incentivizes deception.
Replies from: Jon Garcia↑ comment by Jon Garcia · 2022-10-05T19:31:32.432Z · LW(p) · GW(p)
In that scenario, GPT would just simulate a human acting deceptively. It's not actually trying to deceive you.
I guess it could be informative to discover how sophisticated a deception scenario it is able to simulate, however.
GPT-like models won't be deceiving anyone in pursuit of their own goals. However, humans with nefarious objectives could still use them to construct deceptive narratives for purposes of social engineering.
Replies from: adam-jermyn↑ comment by Adam Jermyn (adam-jermyn) · 2022-10-05T20:42:31.951Z · LW(p) · GW(p)
Sorry I mean a prompt that incentivizes employing capabilities relevant for deceptive alignment. For instance, you might have a prompt that suggests to the model that it act non-myopically, or that tries to get at how much it understands about its own architecture, both of which seem relevant to implementing deceptive alignment.