This is a fairly "chat"-style dialogue that I (kave) had with Garrett about singular learning theory (SLT) and his ambitious plans [LW · GW] for solving ambitious value learning by building off of it.
A colleague found this gave them better trailheads for SLT than current expositions (though they're still confused) and I got a much clearer sense of the scope of Garrett's hopes from this conversation than from his post alone.
What is Singular Learning Theory?
kave
Hey Garrett! Here are a couple of my initial thoughts regarding your hopes for singular learning theory (SLT)!
As far as SLT goes, I feel like I don't really understand what's exciting for folks about "phase transitions". Or like, I don't understand how to connect "phase transitions are rapid changes in the density of states" to "phase transitions are grokking" and stuff like that. I might be confused about that being the angle that folks are going for.
I'm also confused about how to think about SLT for both brains and ML systems. Like, there's some notion of a dynamical system that SLT applies to that applies to both those things (you think/hope). What is that notion?
I'm also excited to hear more about your vision for a programme that spills out of SLT that becomes something like a theory of learning agents that "touches grass" all the way along its development (to the extent that's true).
Anyway, that's a little babble about where I'm at. Open to going anywhere, but thought I'd share some state.
Garrett Baker
Yeah, okay, so, I guess the first thing is phase transitions. I don't quite understand your confusion. Like, let's take it as a given that gradient descent can be adequately described as sampling out of a Bayesian posterior. Then, rapid changes of density of states from less generalizing solutions to more generalizing solutions directly corresponds to grokking? And we get grokking when we have a rapid transition from a less generalizing solution to a more generalizing solution.
kave
OK but why does rapid change of density of states correspond to more generalising?
kave
My best current understanding: a rapid change in the density of states corresponds to something like more parameters becoming irrelevant (or fewer? Might have that backwards) and so you become effectively a smaller model / more parsimonious / less epicircular
kave
[Feel free to say if I seem horribly confused / my intuitions seem like I misunderstood what's going on, etc]
Garrett Baker
Ok, so its not just rapid changes in the density of states that lead from more to less generalization I think? Let me look for the relevant equation
Garrett Baker
Sorry, I got wrapped into equation land, and forgot the broader context. I'll explain things intuitively instead of relying on equations, and then I'll bring in equations if it seems necessary to explain.
So a rapid change in density of states corresponds to more generalizing because at a given nour learning system will be dominated by the phase with the lowest "free energy" as defined by
Fn=nLn(w0)+λlogn+O(loglogn)
Where w0 is the optimal weight setting for that phase, and λ is the real-log-cannonical-threshold (RLCT) for that phase, n is the number of datapoints we've trained on, and Ln is the training loss at the inputted weight setting after those n datapoints.
Which means basically that as we switch to a different phase, we will always (unless lower order terms end up doing wonky stuff, but take this as a first order approximation) see a decrease in Ln(w0) and an increase in λ.
I'll stop here for questions
kave
Why does λ go up? I think Ln goes down because that's basically what your stochastic gradient descent (SGD) is going to do as n increases. (I don't know what the RLCT is apart from handwavey characterisations)
Garrett Baker
λ goes up because we always choose the lowest Fn. Approximately speaking, if there existed a phase with lower λ than the current, and same or lower Ln(w0), then we would have already chosen that phase.
kave
Let me check: when you say "as we switch to a different phase", do you mean "if we were to switch away from the optimum" or "as we move through the phases as we do learning"?
Garrett Baker
So the cool thing about the above free energy equation is, in my understanding, it works regardless of how you partition your weightspace. This is because Bayesian updating is self-similar in the sense that updates using coarse-grained model classes use the same equations as updates using fine-grained model classes.
Garrett Baker
The RLCT is a concept in algebraic geometry, Jesse's recent post [LW · GW]is a pretty good intuitive discussion. As far as non-handwavy discussions go, there are several equivalent ways to view it. The picture to have in your head is that its an asymptotic to zero measure of how rapidly the volume of a weightspace in a phase decreases as you decrease the loss threshold.
kave
Also, what is a "phase"?
Garrett Baker
I believe for everything I've said so far, the results are not sensitive to your definition of phase. How phases are used in practice is in two types. To borrow a recent explanation by Daniel Murfet [LW(p) · GW(p)]:
Bayesian phase transition in number of samples: as discussed in the post you link to in Liam's sequence [? · GW], where the concentration of the Bayesian posterior shifts suddenly from one region of parameter space to another, as the number of samples increased past some critical sample size n. There are also Bayesian phase transitions with respect to hyperparameters (such as variations in the true distribution) but those are not what we're talking about here.
Dynamical phase transitions: the "backwards S-shaped loss curve". I don't believe there is an agreed-upon formal definition of what people mean by this kind of phase transition in the deep learning literature, but what we mean by it is that the SGD trajectory is for some time strongly influenced (e.g. in the neighbourhood of) a critical point w∗α and then strongly influenced by another critical point w∗β. In the clearest case there are two plateaus, the one with higher loss corresponding to the label α and the one with the lower loss corresponding to β. In larger systems there may not be a clear plateau (e.g. in the case of induction heads that you mention) but it may still reasonable to think of the trajectory as dominated by the critical points.
kave
I'm gonna gloss "phase" as something like "obvious difference in the model from 20,000 feet", unless that seems terrible
Garrett Baker
That seems good. There's more technicalities, but honestly its how I generally think of it intuitively
kave
OK, so I think I still don't know the answer to
Let me check: when you say "as we switch to a different phase", do you mean "if we were to switch away from the optimum" or "as we move through the phases as we do learning"?
Garrett Baker
So as singular learning theory stands, we don't have a good way of talking about the training process, only the addition of data. So I'm caching your "as we do learning" to mean "as we add data".
kave
That sounds good to me
kave
I'm trying to clarify if you're saying "imagine we're in the lowest free energy state for a given n. Here's how things look if you switch away to higher free energy state" or "imagine you're in the lowest free energy state at some n. Here's how things look if you increase n"
Garrett Baker
Oh yeah, the second one totally is what I'm talking about
Garrett Baker
There are definitely weight states which get you lower free energy for higher loss and lower or possibly higher RLCT than the one you're currently at
Garrett Baker
To go back to the original question:
OK but why does rapid change of density of states correspond to more generalising?
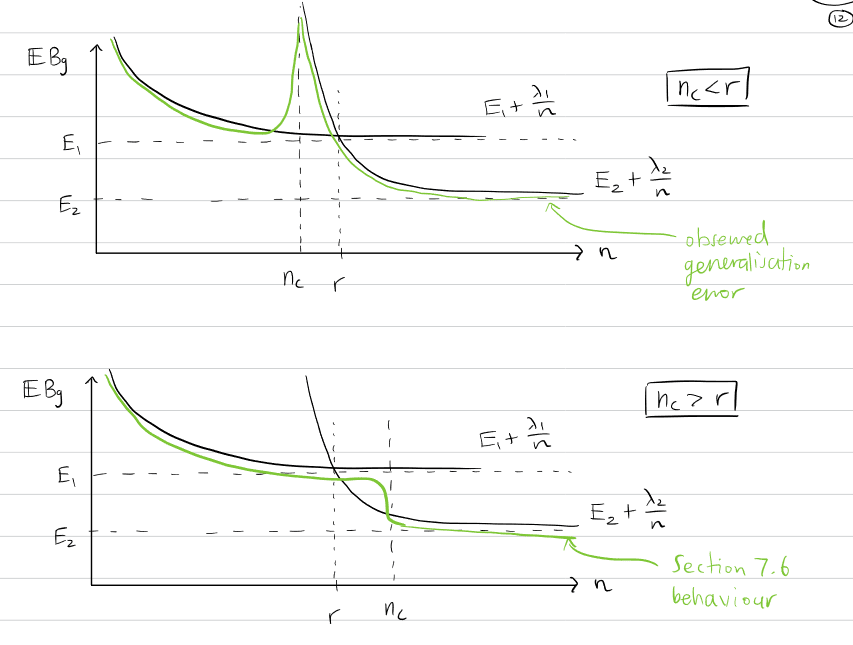
The reason for this is... its false! We get double descent sometimes, and SLT predicts when this will happen!
kave
!!
Garrett Baker
This happens when, if Δλ and ΔL are the differences between your two phases, and ncr is the number of datapoints you need to switch between the two phases (the critical point), then we get double descent when ncr<ΔλΔL
Garrett Baker
The sketch looks like this (r = ΔλΔL, and because a physicist made these notes E1 and E2 are the losses for phase 1 and phase 2 respectively):
Garrett Baker
where the two lines are the generalization loss
Garrett Baker
I don't really expect you to look at this and go "ohh, that makes sense", since I would have had to previously explain generalization error to you, and show you why you why Δλ/ΔL is relevant, but you should be able to derive it by me saying that EBg=L+λ/n is the expected generalization error.
kave
I don't really expect you to look at this and go "ohh, that makes sense"
Oh good, because I looked at this and made a sort of zombie noise
Garrett Baker
lol, sorry about that.
kave
But I think I'm seeing that the model jumps phases at nc, and sometimes it does when that it's getting a "worse" (higher or lower?) λ [edit: in the new phase], I guess because the tradeoff for better training loss is worth it
Garrett Baker
yes, ncr is the crossover point where the free energy of the new phase becomes more attractive, and r is the crossover point where the generalization error of the new phase becomes more attractive.
kave
And lower λ leads to lower generalisation loss, looking at your EBg=L+λ/n
Garrett Baker
yup! Intuitively thinking of λ as the complexity of your model class lets this make intuitive sense.
kave
Right!
And similarly "its an asymptotic to zero measure of how rapidly the volume of a weightspace in a phase decreases as you decrease the loss threshold" is like a "limited finetuning" rule(?)
Garrett Baker
I haven't seen it that way before. Can you elaborate?
kave
Hm. Not sure worth going into, but as weightspace drops off as you demand more closeness to optimal loss, λ is telling you how precisely you need to nail your parameters to hit that closeness. But for a model class that is small relative to the parameter space of your neural network (NN) or whatever, then you don't drop off fast (or similarly for a simple / robust model)
Garrett Baker
Yeah, that sounds right.
kave
Cool!
kave
So SLT is like "models have a preference for lower free energy because Math, and that tells you more than just assuming they minimise loss (in particular because maybe minimising loss is a non-deterministic rule for picking a set of parameters)"?
kave
(with some of the stuff we've covered above being particular things it tells you)
Garrett Baker
Hm... I don't think that's the main upshot, but it is an upshot. I'd say the main upshot is that "the distribution of models you may end up with after training is concentrated on the singularities (oh and also here's a really cool way of pumping out nontrivial statements from this fact using algebraic geometry and singularity theory)"
kave
Where are the singularities in this picture? Are they ex cathedra from some math I haven't read or are they related to λ?
Garrett Baker
They are related to λ, but I'm currently in the weeds on learning the actual algebraic geometry and singularity theory behind that part, so I couldn't tell you why.
kave
Copy
Garrett Baker
So this insight is why I'm optimistic about singular learning theory going further than just the learning systems its studied so far. Like reinforcement learning, and the learning subsystems of brains.
Garrett Baker
Free energy may be applicable to both, but the resolution of singularities used to find and characterize λ, and the existence of singularities causing the two processes to behave in reducible ways (because they are both almost certainly singular) mean I have hope the same techniques can be adapted to those cases.
kave
This may just be a matter of the pedagogy I needed, but from my perspective the reason to believe that there are singularities is because apparently free energy is minimised and that looks like it should lead to low λ and low λ is related (or so a trustworthy guy on the internet tells me) to singularities
kave
And not so much reason to expect singularities without low free energy
kave
Though I'm also fine with hearing "there are other reasons to expect singularities but we can't / shouldn't get into them now"
Garrett Baker
Lol, Oh yeah, I mean when I say "almost certainly" I mean the default state for messy hierarchical models with a ton of parameters is that they do not have one-to-one function maps, or their fisher information matrix is somewhere singular.
kave
Oh right! I now remember that singularity is also to do with the non-one-to-oneness of the parameter-function map.
kave
Faith restored
Garrett Baker
lol
kave
Are brains singular do you think?
Garrett Baker
For some reasonable definition of what the parameters are in brains, brains are singular for the same reasons that neural networks are singular, they're almost certainly not one-to-one, and their fisher information matrices are singular.
The technicalities here are possibly more messy, though it depends on exactly how nondiscrete the learning subsystems are
kave
Somehow it's less intuitive to me for brains, but plausibly that's just because my system 1 model of brain neurons is more essentialist and less functionalist than for artificial neural networks (ANNs), and would go away on reflection.
Garrett Baker
Essentialist?
kave
Like "this is the neuron that represents Garrett Baker" and that inheres in the neuron rather than its connections
kave
To be clear, this is meant to be an observational fact about my intuitive model, not a claim about how brains work
Garrett Baker
Ah, ok. This does feel cruxy, so it seems possibly worth breaking down why you think what you think to see if I maybe want to start thinking what you think.
Garrett Baker
Or we can break down why I think what I think.
kave
Oh, if my guess about why I find the many-to-one-ness less intuitive is correct, my guess is strongly that my intuitions are wrong!
kave
I vote we do the orienting to the conversation thing you were trying to do a few messages ago
Garrett Baker
cool
kave
Oh wait! Actually maybe we should break now?
Garrett's hopes for grand singular learning theory-based theories
Garrett Baker
Things you wanted to get to that we haven't yet:
How brain science and alignment could interplay
Whether dynamic brain stuff is sensible
Thing I wanted to get to:
Checking to see if my post came off as ambitious as I wanted it to, and if not, then correcting the record.
kave
I think I'm excited about your thing > brain + alignment > dynamic brain
Garrett Baker
Ok, we'll talk about that then.
kave
Let me get your post open
Garrett Baker
So, Vanessa has this quote which I really like, that was summarized to me originally by Jeremy Gillen:
In online learning and reinforcement learning, the theory typically aims to derive upper and lower bounds on "regret": the difference between the expected utility received by the algorithm and the expected utility it would receive if the environment was known a priori. Such an upper bound is effectively a performance guarantee for the given algorithm. In particular, if the reward function is assumed to be "aligned" then this performance guarantee is, to some extent, an alignment guarantee. This observation is not vacuous, since the learning protocol might be such that the true reward function is not directly available to the algorithm, as exemplified by DIRL [LW · GW] and DRL [LW · GW]. Thus, formally proving alignment guarantees takes the form of proving appropriate regret bounds.
Garrett Baker
And if I understand her correctly, the way she has tried to prove such an alignment-relevant regret bound was to invent infra-Bayesianism physicalism, then construct a model of what it means to be an agent with a utility function, and have the deployed infra-Bayesian physicalist agent infer what agent created it, and act according to its implied utility function.
Garrett Baker
This seems unwise for a variety of reasons on my model. But I think lots of those reasons are fixed if you satisfy a few desiderata with your theory:
You have really good contact with reality throughout your theory development process
The metric for success you use is mostly derived rather than instantiated from the outside. Practically, this means instead of deciding humans will have utility functions and act like agents as defined in such-and-such a way, you are able to use your theory (or a theory) to derive what the format the values inside your human are represented as, then during your equivalent of value learning component, you fit the model you have to the human, or you have some process which you anticipate will result in values in a similar format, resulting in the same sorts of goals for the world
Maybe there's more? I'm going mostly based off memory here.
Anyway, it seems like singular learning theory, if it could be worked to produce alignment relevant theorems would or could have the above two benefits.
Garrett Baker
And by alignment relevant theorems, I imagine this looks a lot like getting a good understanding of reinforcement learning in the SLT frame such that you can make claims about both the effects of what your reinforcement learning (RL) agents optimize for in different environments (or a generalization from the training environment), and the main internal determinants of the optimization. And do the same once we get good models of how brains develop (which we may already have enough data to technically do if you're a good enough mathematician? The nice thing about math is you don't need all the detail to be present before you can actually work on the thing).
And then once we get those things, we can move on to asking about when reflection-type thoughts are likely to arise in certain models, how the brain's optimization machinery keeps its values stable (or if it doesn't if the main determinant is the optimization of values or the meta-values) during that and ontology shifts, and hopefully prove some kind of internal-values convergence during some training process.
Garrett Baker
Was this mostly implied by my post?
kave
I think this is mostly surprising to me after having read your post! I think you gestured at it with "a theory for reinforcement learning", but I think that I didn't expand it to something like a "theory of (value) learning" given just what I read
kave
Maybe if I had read the learning theoretic agenda stuff more recently
Garrett Baker
Ok good! That means I'm maybe talking about the right thing / I understood the thing the friend I talked to said wasn't made clear was in fact the thing I just said.
kave
Shall I ask you some questions about it? I have some!
Garrett Baker
Oh yeah, totally
kave
I understood the part where you want to be somewhat agnostic about the representation of values in humans / learning systems. But I think I failed to draw the connection to getting the learning system to fit to the human
Garrett Baker
Yeah, so as a toy example, we can imagine the values humans have are pretty dependent on the architecture of the brain, maybe humans have a lot more recurrence than transformers, and so have a baseline tendency to care a lot more about the feelings of themselves and others, while language models if you train them enough to be generally capable agents don't have so much recurrence and so end up with a lot more value placed on things that look nice when they are passed as inputs to a transformer like themself.
When we look inside of these two minds, we see the human values are represented in (in some sense) a non-equivalent format to the transformers values, not in the sense that they are different from each other, but in the sense that whatever way the goals humans use is more liable to model how things feel, while the transformers are more liable to model how things look.
So if we train the transformer in this world using some learning process, it will take a lot more data for it to learn that it needs to have goals in the same format as humans, and it will make mistakes which result in correlating (say) the positive-sentimentness of human text when its inputted into it with the rewards you gave it rather than correlating the inferred human mental state with the rewards you give it in order to construct its goals.
We can imagine the same problem but on the level of data. Say the humans spend a lot of time interacting with other humans, and the AIs spend a lot of time interacting with HTML webpages, so the humans have some internal mechanism within them that is more likely to think in terms of humans, and AI in terms of webpages.
You want the human values to be very naturally representable in your AI.
kave
It sounds like you're thinking of a transformer directly choosing to model human goals as a kind of indirect normativity thing, i.e. wanting to do the things that its creator would approve of. I noticed this also in your move from Vanessa's quote (which didn't seem to explicitly contain an appeal to indirect normativity to me) to your understanding of her agenda.
Is your thought that this is necessary? I can imagine thinking that a powerful mind needs an accurate model of the principal's values if it's to be aligned to them, but that seems like it could be derived without trying to model them as "the principal's values" (as opposed to "good stuff").
I don't know if that's a load-bearing part of your model or just something chosen to be concrete.
Garrett Baker
I don't know whether the best way to get a model to adopt my values is for it to model me and value my values, or to itself just have my values. I would suspect the latter is easier, because I don't model someone else and adopt their values except as an expression of others of my values.
kave
So it sounds like you're concerned about the "value ontology" of the AI and the human, which might or might not be the same as the "model ontology".
Garrett Baker
Yes
kave
And I suppose there's an additional concern that the way the value ontology of the AI interacts with increasing capability is similar enough to the way that the value ontology of the human interacts with increasing capability that it stays easy for the AI to model where the human would have ended up as it reflected (rather than going off down some other contingent path).
Garrett Baker
Yeah, I am concerned about this. This is inside of the reflection and the ontology sections of the original post, where I'm worried about
Ensuring you also have the right meta values in your AI, if those exist
Making sure the optimization machinery of your AI doesn't freak out the way humans usually do when reflection and "what should my values be" oriented thoughts come online
Do ontology shifts break your values here?
I'm not so concerned about 3, because humans don't seem to break under ontology shifts, but it is something to keep your eye on. Its possible they would break if they don't undergo enough ontology shifts before getting access to self-modification abilities.
Garrett Baker
And of course you want the AI to get your values before its able to model you well enough to exfiltrate or something.
kave
Yeah, interesting. I am interested in the reflection thread, but also kind of interested on double-clicking on the transformer value format thing and maybe that makes sense to do first? I'm going to try and spell out the story in a bit more detail
Garrett Baker
What transformer value format thing? I'll note I don't actually expect the above toy example to be true
kave
Noted, but I just meant like the underlying intuition or something
Garrett Baker
Gotcha, that sounds like a good thing to do
kave
So, say I'm a transformer. And I've become shaped in a way that's a bit more like "have goals and make plans to fulfil them". That shape has maybe been formed out of the kind of cognitive algorithms I was already running, and so have some similarity to those algorithms. For example, if I am a guy that searches for plans that score highly, that "score" might be built out of pieces like "one of my heuristics for what to do next is very active and confident".
So maybe if I have some values, that format is more things like [hmm, maybe I'm supposed to be reinforcement learning from human feedbacked (RLHFd) so there's a non-predictive goal? Sure let's assume that]: this clearly looks like a transcript from a world that the reward model liked. It's clear what would come next in such a transcript. This is coherent, novel to the extent that's rewarded, but not weird. This looks like the completion will stably continue in this fashion.
Is that an implausible in the details, but roughly right in the gestalt, version of the thing you were imagining?
Garrett Baker
Maybe? It seems roughly similar, but not clearly what I was saying.
Garrett Baker
Like, another example of what I was trying to say would be that maybe models end up doing things following the predictions of shard theory, and humans do things following the predictions of naive expected utility maximization very easily (of course, both would approximate EU maximization, but the difference is humans do it explicitly, and models do it implicitly).
kave
OK, that seems like a nice tricky case.
Garrett Baker
Yeah, so if models natively do shard theory, and humans natively do EU maximization, then the models will not be selecting over "simple" utility functions to maximize, if we start knowing how to do ambitious value learning, they will first know how to best approximate your utility function using a bunch of contextually activated heuristics. And then later on, if you undergo a ontology shift or it does, the values will react very differently, because they attach to the world in very different ways. Maybe you find out souls don't exist, so your only hope of ever achieving your values is breaking out of a theorized simulation inside a world that does have ontologically basic souls, and it finds out souls don't exist, and instead of helping you on your quest, it decides your diverting resources away from its implicit goal of making humans in front of it smile or something.
Garrett Baker
Which is why I want equivalence on the level of internal value representations that connect to RL generalization behavior, rather than just RL generalization behavior.
kave
I mean it seems like what you want is a bunch of robustness around the RL generalization behaviour and it seems like at least value representation equivalence should get you a bunch of that, but there might be other ways
Garrett Baker
This is true.
kave
I am excited to hear more about how you think about "meta-values"
kave
It seems like they play a role in your conceptualisation of what it is to be well-behaved while doing reflection
kave
I haven't thought about them much
Garrett Baker
Yeah, so as you're thinking about your values, you need to have some reason to change your values if you try to change your values, or change your goals if you try to change your goals. And when you're having some reason to change your values, you presumably use other values. And if you have two systems with different meta values, but the same object level values, assuming that difference makes some ontologically basic sense, you're going to have different reflection processes, and at the end of thinking a lot about what they want, they're going to have different values, rather than the same values. Which is a problem.
kave
I guess I feel fuzzier on if meta values are at play for me in value change, versus just like I have a certain policy around it
kave
I certainly have (weak, incomplete) meta values to be clear! But I don't know if they govern my value change that much
kave
I guess they (hopefully) would if my values were going to stray too far
Garrett Baker
By policy do you mean "I have consciously decided on this policy for myself" or "there's some process in my brain that I can't control which changes my values"
kave
The latter (well, don't know about "can't", but don't)
Garrett Baker
To the extent you endorse that policy changing your values, I'd call that a meta-value. Presumably there are situations where you'd rather that policy not change your values, like if you fell in love with a Nazi, and that turned you into a Nazi. If you knew that would happen, you'd likely avoid falling in love with Nazis. But if you otherwise didn't have a problem with falling in love with Nazis, and you could modify your policy such that falling in love with them didn't give you their values, you would do that.
kave
Well I don't know! I might prefer to not fall in love with Nazis and keep love-influenced value change. Not that it affects your point
kave
OK, I'm willing to accept that for some notion of meta values, they're at play for me
Garrett Baker
Cool. The existence of most value change in humans not being necessarily by choice I think makes meta values pretty important. If it was all by choice, then we wouldn't have to worry about the AI corrupting our values by (for instance) having us fall in love with it
kave
Right! Let me quickly return to where meta-values appeared in your initial post-break writeup and think for a sec.
So, how much do we have to ask of these meta values for them to be a safeguard for us? One possible argument is that: as long as the AI has the same meta values we do, it's fine however its values change as that was permissible by our meta values, even if our meta values are quite incomplete.
It's not obvious we can get away with the AI having additional meta values, because if it's making tradeoffs between it's values that could cause it to violate one of our meta values way too much.
And obviously missing some of our meta values could go quite badly by our lights.
Garrett Baker
Yeah, two notes:
I mostly expect meta-values and object level values are ontologically the same. Like, it doesn't feel like I use all that different stuff to decide what my values should be than to decide on other stuff I like or want in the world.
This is a reason I'm more optimistic about actually having the same representations and values in our AIs as is in ethical humans compared to just proving very general robustness bounds. Because if you show that your AI acts within epsilon of your implied utility function or something, that epsilon will compound as it makes modifications to itself (including to its values), and as much as I like singular learning theory, I don't trust it (or any theory really) to predict the negative effects of AIs self-modifying.
kave
And do you have any specific leads for hope on how to enforce similar value-formats? I guess one part is neuroscience teaching us about what our value format is
Garrett Baker
There are currently various attempts in SLT to relate metrics like the RLCT to the implemented algorithms inside of networks. For instance, there are (currently informal) arguments about how modularity would decrease the RLCT, or how symmetries caused by the loss functions we use in the loss landscape result in functions with lots of dot products and linearities used as their primary mode of data storage having lower RLCT than others. I expect the existence of theorems to be proven here.
And then for each of those, you can find the RLCT of the relevant critical point, and for a given n find the free-energy minimizing configuration
kave
So to think about how to make this something that would let us control value formats. First, we would develop this theory of relating loss landscapes and the RLCT to the algorithms that are found. Then we would solve the inverse problem of designing loss landscapes that both enable competitive performance and also induce the right kind of value formats.
Is that what you're picturing?
kave
I notice I feel like there's something about the architecture that was supposed to appear alongside the phrase "loss landscapes" in my message before, but maybe the architecture appears in the RLCT, because it's about how singular the minimum loss sets are
Garrett Baker
Yeah, I think it goes architecture -> parameter function map -> geometry -> RLCT.
Garrett Baker
But again, I'm still learning the exact math in this area.
kave
👍
Garrett Baker
Also, for the RL case its certainly not known we'll be using the RLCT in the same way in the same functions. It may have a greater or lesser effect, or just a qualitatively different affect than in supervised learning. Possibly it ends up being roughly the same, but its still good to note that this is definitely speculative, and actually the RL extension needs to be done.
kave
Yeah, good note
kave
But your picture is roughly something like an inverse search on training setups given a theory that's powerful enough to predict details of learned algorithms and someway of knowing the human algorithm well enough to do some matching between them (and perhaps some theory about that matching)?
Garrett Baker
Yes
kave
That seems ambitious! Won't it be very hard to understand the algorithms our models learn even if we can predict lots about them ahead of time?
Garrett Baker
Possibly? I will note that that is the aspect of the plan which I'm least worried about, mainly because its basically the mission statement of developmental interpretability.
kave
Where "worried about" means something like "trying to think through how it goes well" rather than "think might fail"?
Garrett Baker
Where "worried about" means looking at the relative difficulty of each of them, the question of predicting details of learned algorithms seems the one I most expect to be solved.
Garrett Baker
Like, the last one requires advances in whole brain emulation, and the first one is basically an inverse of the second one, and the second one seems more natural, so I expect its inverse to be less natural and therefore harder.
kave
Where one = inverse search, two = predict details of learned algorithms, three = match with human algos?
Garrett Baker
yup
kave
So, I'm trying to think about your plan as a whole right now. And I can see how some of the parts fit together. But I think one thing that's missing is exactly where your hope comes from in different parts of it.
By way of contrast, I think I understand why you're excited about SLT. It's something like "this is a theory that is good in the standard way I might want to evaluate mathy theories of learning, such as it being aesthetically nice, having tie-ins to other strong areas of math, having people with a record of good and insightful work, like Watanabe. And also, it is predicting things already and those predictions are getting checked already! Like, look at the modular addition post! That really seems like that worked out nicely"
kave
And for some parts I think the answer is like "I think this is roughly how it has to go, if it's going to to work" (like, I think this is what you think about value learning, though not confident)
kave
And for other parts, like neurotech, I'm not sure if they were picked because you were like "here are some promising parts, this is the best or most hopeful way I can think to combine them" or more like "and this thing seems pretty promising too, and if that goes well, I now have enough pieces to summon Exodia"
Garrett Baker
For SLT, that sounds right, and also it's making about 20-40x faster progress than I would have anticipated.
What I described is basically what I think about value learning, and has been for about the past year. Far before SLT or thinking too deeply about whole brain emulation.
Garrett Baker
Would be nice to be able to link to specific comments here, but where I started saying this:
Yeah, so as a toy example, we can imagine the values humans have are pretty dependent on the architecture of the brain, maybe humans have a lot more recurrence than transformers, and so have a baseline tendency to care a lot more about the feelings of themselves and others, while language models if you train them enough to be generally capable agents don't have so much recurrence and so end up with a lot more value placed on things that look nice when they are passed as inputs to a transformer like themself.
kave
Copy
Garrett Baker
So most of my hope comes from "man, lots of this basically looks like technical problems which you can easily check if you got right or not", and then the rest (like reflection or ontologies or meta-values, or making sure you got the right equivalence in your value formats) seem a lot easier than the generic Arbital versions after you've solved those technical problems.
Garrett Baker
(where I use "technical" to mean you can pretty easily check/prove if you got things right)
Garrett Baker
And I place nontrivial probability on many of the nontechnical things just not being major problems (i.e. meta values being basically the same as object level values, and those dominating during ontology shifts)
kave
One nice thing about such technical problems is that they're often either scalable or you don't have to get them right on the first try
Garrett Baker
Indeed
kave
So, why are the Arbital problems easier once you have value equivalence? Is it because you can do some kind of more 'syntactic' check and not find some complex way of telling when two value systems are the same behaviourally or elsewise?
kave
Or I guess, solving in the natural ontology of the thing you create
Garrett Baker
Solving in the natural ontology of the thing you create sounds right
So for example, during ontology shifts, we want our AI to react similarly to a human when it learns that souls don't exist. Either this is a natural result of the values we have, like we have some meta-values which tell us what to do with the soul-caring values in such circumstances, or we have some optimizing machinery inside us that reinterprets souls depending on the currently best ontology, or something else.
And then we can—
kave
—Ah! I think I have a new way of seeing your plan now, which is something like: do human(-value) uploading, but do as much as you can to bridge down from ML systems as we do to bridge up from the brain
Garrett Baker
Yes! That's how I think of it in my head
kave
That makes sense! It's interesting that it's quite different from plans like this one that try to get the brain and powerful models more closely connected (I seem to recall another that thought about using transformers to predict fMRI data).
The things I link here feel like they are "shovel ready" but lack guarantees about the thing you're actually getting that performs well at the prediction tasks or whatever. They're more like "let's try these tricks and that might work", and your plan is more like "here's some fields we could solve to differing degrees and still have a theory of how to make powerful machine, but human-like, minds"
Garrett Baker
I don't find it that interesting, because currently thinking SLT is where its at is a very unpopular opinion, and without the results I saw, and predictions I made, its reasonable for people to be pessimistic about progress in deep learning (DL) theory.
kave
Sure! I guess it's just quite a different vector than I normally think of when bridging DL and brains
Garrett Baker
Reasonable. Yeah, so to finish my sentence from earlier, we can copy the relevant parts of the human brain which does the things our analysis of our models said they would do wrong, either empirically (informed by theory of course), or purely theoretically if we just need a little bit of inspiration for what the relevant formats need to look like.
kave
Interesting! Yeah, I think your comments here are related to earlier when you said "[...] do the same once we get good models of how brains develop (which we may already have enough data to technically do if you're a good enough mathematician? The nice thing about math is you don't need all the detail to be present before you can actually work on the thing". Like, maybe we need lots more neuroscience, or maybe we have enough to pin down relevant brain algorithms with enough theory.
kave
That seems quite tricky though. It seems like the boost to brain-theory would likely have to come from SLT in this plan, as I don't see a similarly promising framework in neuro
Garrett Baker
I agree, which is why I tried to emphasize in the post and earlier in the discussion why I think SLT is relevant for describing the brain as well as ML models
Garrett Baker
We have also been pretty lost when it comes to theories about how the brain works, and are even further behind neural network interpretability in figuring out brain algorithms.
kave
When I try and think about the brain under SLT, I'm like: sure, sure, multiple realisability / non-identifiability ... but what is SLT about then if it extends to brains? Is it about dynamical systems where the dynamics are in the projection of a larger space? But all spaces are projections of some space where the projection gives singularities, surely?
Oh I guess the dynamics are in the big/redundant space, but governed by the position in the small space?
Garrett Baker
I don't fully understand your first paragraph, but the second paragraph is deeply related to lots of stuff I was explained in the SLT primer, so maybe your onto something?
The way I think about it is relatively high level, with some sanity lower-level checks. Like, SLT explains why neural networks learn so well, currently it only explains this in the supervised regime, but neural networks also learn similarly well in the reinforcement learning regime, it would be pretty weird if neural networks performed well in both regimes for very different reasons, and indeed during reinforcement learning neural networks are pretty sensitive to the geometry of the loss landscape, and it would make sense for them to stay in an area around different singularities with lower RLCT earlier in training, and to progress to areas with higher RLCT but better loss later in training.
And then similarly with brains, lots of the architectures which work best in supervised and reinforcement learning are directly inspired by looking at brain architectures. It would similarly be weird if they happened to work for very different reasons (though less weird than the supervised->RL case), and as the brain gets reward events, and small changes are made to the parameter-equivalents in the brain, I similarly expect for it to progress in the same RLCT increasing, regret decreasing manner.
kave
So I think your argument is that "a theory that explains the success of deep neural networks (DNNs) at supervised learning, by default explains deep reinforcement learning and the human brain"? Where that assumption could be refuted by noticing the theory really paying attention to supervised-learning-specific stuff.
Garrett Baker
Weakly, yes. And noting also the fact that this theory in particular seems relatively more general than the default.
Like, a competitor may be the neural tangent kernel. I would not expect the brain to be explainable via that enough to rest my hopes on it.
kave
Because the neural tangent kernel is structured like "here is an idealisation of a neural network. From it, theorems", and SLT is structured like "here is an idealisation of a learning system. From it, theorems". And the idealisation in the latter just looks like way less specific and similar to DNN-qua-learning-system than the former is to DNN-qua-neural-net?
Garrett Baker
Essentially yes.
kave
Hm. Care to put a number on P(SLT usefully explains brain stuff | SLT usefully explains neural net stuff)?
kave
that probably wasn't worth LATEXing
Garrett Baker
lol, I think this is mostly dominated by whether we have good enough theory -> brain emulation -> theory feedback loops, but I'd put it at 80-95%. Given better feedback loops, that increases.
Though I will also suggest you ask me in 6 months, since outside view says people excited about a pet project/theory like to use it to explain lots of stuff. I'm currently adjusting for that, but still.
kave
With your caveat noted, I still find the two parts of you first sentence incongruent! It seems that theory -> brain emulation -> theory routes through experimental neuroscience, a field about which I, a novitiate, feel despair.
Garrett Baker
I mean, I was interpreting a relatively broad "usefully explains" definition? Like, surely you don't mean given the first half of your plan works, the part about brains will work.
So if I'm just like "given SLT gives good & novel predictions about practically relevant neural net stuff, will it give practically relevant & novel predictions about brain stuff", and given how good neural nets are at predicting brain stuff, this seems easy to satisfy.
kave
I mean, maybe this is all just in the weeds but I mean ... oh! Did you mean "this is mostly dominated by" to mean "this conditional is not as important as this other important concern" rather than "the leading term in my estimate is how well this loop works"?
Garrett Baker
Well, the leading term in my estimate is how well neural networks generically do at predicting neuroscience stuff, and then the second term is how well that loop looks for brain-specific insights that don't route through NNs.
kave
Doesn't that loop seem doomy?
kave
(aka 'unlikely')
Garrett Baker
Yes. But its a technical rather than philosophical problem
kave
But one that's 80-95% likely to work? Or maybe I should understand you as saying "look 80-95% that it helps at all, but how much it helps is dominated by the loop"
Garrett Baker
Oh, ok, my 80-95% is mostly on that the insights it gives to NNs lead to insights to brains or that the theoretical development of the theory making contact with NNs is enough to get it to the point where it can make nontrivial predictions about the brain.
Certainly how much it helps is dominated by the loop. But also making the loop better makes it have a higher chance of helping.
kave
OK, I think I get your picture now
Garrett Baker
Ok good
Garrett Baker
Sorry for that confusion, I think I just wasn't meta-modelling the fact I was using "how well are neural networks as basic models of the brain" as the first-order term when I wrote the probability originally
kave
No problem!
kave
Here are a couple of places my attention go from here:
1. What is necessary to seed an SLT-touched neuroscience field? Maybe the answer is just "push forward on SLT and get to neuroscience when it happens", but interested if there's something to do earlier.
2. What are your hopes for pushing the plan forward?
3. The ol' capabilities externalities. Maybe touching on Nate's recent post that was more like "shut it all down"
Garrett Baker
I imagine the thing that'd need to happen is to know what things update the brain, what parts of the brain are analogous to parameters, are the functions in the brain approximatable by analytic functions,
So the obvious next move for me is to learn SLT more in depth than I currently know. Then I plan on extending it to reinforcement learning, which seems to get relatively less attention in the field. Then at that point start thinking about the brain. Basically start setting up the basics of the extensions I'll be using.
I agree with "shut it all down", I did address capabilities externalities in my original post. The idea is that I want to develop the theory in the direction of making nontrivial statements about values. There exist capabilities externalities, but I'm not so worried because as long as I mostly talk and output stuff about the values of the systems I'm trying to describe, and the theory required to say stuff about those values, I should expect to have my insights mostly pointed toward characterizing those values rather than characterizing capabilities.
kave
I'd be happy to chat about what 2 looks like or expand on 3. I agree you talk about it in your post, but feels like there's a reasonable amount to say.
Garrett Baker
Lets do 3, since that seems more interesting to outside parties than describing my Anki methodology, or me saying "yeah, I don't know enough of how SLT is built" to talk specifically about how to extend it to RL, and I don't know enough about either the brain or SLT to talk much about how to extend it to the brain.
Capabilities externalities
kave
Sounds good!
So, I take your hope to be something like "if my work focuses specifically on how values work in singular learning systems, then that will be mostly usable for ensuring inner alignment with some goal. The use of that power at a given level of capabilities is one I think is basically for the good, and I don't think it hastens capabilities".
Curious in if that fits with how you think of it?
Garrett Baker
It doesn't reduce capabilities, and its doing stuff in that space, so it in expectation likely does hasten capabilities. So the last part is false, but I think it increases capabilities not all that much, especially if I'm just in theory building mode while I'm doing general stuff, and then when I'm focusing on specific stuff I'm in make this useful for alignment mode.
kave
Yeah, so the distinction between general stuff and specific stuff is maybe promising. I'm like, focusing doing singular learning theory on values seems hard to do any time soon. First it seems like you need to be able to say lots about the SLT of RL. Do you agree with that, or do you think you could go straight to SLT of values?
Garrett Baker
Like, for context, singular learning theory has been around for like 20 years, and maybe could be used by a super smart person to quicken capabilities, but mostly the super smart people focus on scaling (or just have lost faith in understanding as a means to progress), and the smart people afraid of capabilities who know about SLT work on making SLT useful for interpretability, which likely has its own capabilities externalities, but I generally feel like for research like this only a few "true believers" will develop it while its still in its general phase, and you don't have to worry about RL practitioners suddenly caring at all about theory. So its effects will mostly lie in what those "true believers" decide to use the theory for.
Garrett Baker
I agree that we need a theory of SLT for RL before making a SLT for values induced by RL.
kave
Yeah, interesting. It seems definitely true that for awhile you'll be fine, because no one will care. I wonder if the odds are good no one will care until your specific stuff comes online. I guess it would be nice to know some history of science here.
Garrett Baker
I will point to the Wright brothers and the airplane, the Manhattan project, and I think Thiel's theory of startups, as sources of evidence for this position. Also looking at the landscape of stuff going on in alignment, and seeing that mostly people don't build on each others work too much, and even the most promising stuff is very general and would take a really smart person to develop into capabilities relevant insights.
Garrett Baker
I note that interpretability is a different beast than super theoretical stuff like what I'm pursuing, since it seems like it'd be obvious to a much wider range of people, who intersect relatively heavier on the people most liable to want capabilities improvements than singular learning theory.
kave
That seems true! Though it also seems true that people are really wanting to hit their prediction machines with RL hammers to make money fly out
Garrett Baker
That is a thing I forgot to think about, that in the realm of deep learning RL practice is particularly cursed
Garrett Baker
I don't think it makes much difference, but still good to weigh
kave
But I think as long as you don't discover things that improves the sample efficiency of RL without improving inner alignment, it's not obviously bad
Garrett Baker
I note that singular learning theory has only characterized the behavior of deep learning so far, it doesn't (straightforwardly) give recommendations for improvements as far as I know. And I'd guess once I need abilities in that domain, they will be fairly values-controlling specific.
There is quite a large literature on "stage-wise development" in neuroscience and psychology, going back to people like Piaget but quite extensively developed in both theoretical and experimental directions. One concrete place to start on the agenda you're outlining here might be to systematically survey that literature from an SLT-informed perspective.
Maybe. This is potentially part of the explanation for "data double descent" although I haven't thought about it beyond the 5min I spent writing that page and the 30min I spent talking about it with you at the June conference. I'd be very interested to see someone explore this more systematically (e.g. in the setting of Anthropic's "other" TMS paper https://www.anthropic.com/index/superposition-memorization-and-double-descent which contains data double descent in a setting where the theory of our recent TMS paper might allow you to do something).
Though I'm not fully confident that is indeed what they did
The k-gons are critical points of the loss, and as n varies the free energy is determined by integrals restricted to neighbourhoods of these critical points in weight space.
Note that in the SLT setting, "brains" or "neural networks" are not the sorts of things that can be singular (or really, have a certain λ) on their own - instead they're singular for certain distributions of data. So the question is whether brains are singular on real-world data. This matters: e.g. neural networks are more singular on some data (for example, data generated by a thinner neural network) than on others. [EDIT: I'm right about the RLCT but wrong about what 'being singular' means, my apologies.]
Anyway here's roughly how you could tell the answer: if your brain were "optimal" on the data it saw, how many different ways would there be of continuously perturbing your brain such that it were still optimal? The more ways, the more singular you are.
Singularity is actually a property of the parameter function map, not the data distribution. The RLCT is defined in terms of the loss function/reward and the parameter function map. See definition 1.7 of the grey book for the definition of singular, strictly singular, and regular models.
Edit: To clarify, you do need the loss function & a set of data (or in the case of RL and the human brain, the reward signals) in order to talk about the singularities of a parameter-function map, and to calculate the RLCT. You just don't need them to make the statement that the parameter-function map is strictly singular.
One thing I noticed when reflecting on this dialogue later was that I really wasn't considering the data distribution's role in creating the loss landscape. So thanks for bringing this up!
Suppose I had some separation of the features of my brain into "parameters" and "activations". Would my brain be singular if there were multiple values the parameters could take such that for all possible inputs the activations were the same? Or would it have to be that those parameters were also local minima?
(I suppose it's not that realistic that the activations would be the same for all inputs, even assuming the separation into parameters and activations, because some inputs vaporise my brain)
Note that in the SLT setting, "brains" or "neural networks" are not the sorts of things that can be singular (or really, have a certain λ) on their own - instead they're singular for certain distributions of data.
This is a good point I often see neglected. Though there's some sense in which a model p(x|w) can "be singular" independent of data: if the parameter-to-function map w↦p(x|w) is not locally injective. Then, if a distribution p(x) minimizes the loss, the preimage of p(x) in parameter space can have non-trivial geometry.
These are called "degeneracies," and they can be understood for a particular model without talking about data. Though the actual p(x) that minimizes the loss is determined by data, so it's sort of like the "menu" of degeneracies are data-independent, and the data "selects one off the menu." Degeneracies imply singularities, but not necessarily vice-versa, so they aren't everything. But we do think that degeneracies will be fairly important in practice.
we can copy the relevant parts of the human brain which does the things our analysis of our models said they would do wrong, either empirically (informed by theory of course), or purely theoretically if we just need a little bit of inspiration for what the relevant formats need to look like.
I struggle to follow you guys in this part of the dialogue, could you unpack this a bit for me please?
The idea is that currently there's a bunch of formally unsolved alignment problems relating to things like ontology shifts, value stability [LW · GW]under reflection & replication, non-muggable decision theories, and potentially other risks we haven't thought of yet such that if an agent pursues your values adequately in a limited environment, its difficult to say much confidently about whether it will continue to pursue your values adequately in a less limited environment.
But we see that humans are generally able to pursue human values (or at least, not go bonkers in the ways we worry about above), so maybe we can copy off of whatever evolution did to fix these traps.
The hope is that either SLT + neuroscience can give us some light into what that is, or just tell us that our agent will think about these sorts of things in the same way that humans do under certain set-ups in a very abstract way, or give us a better understanding of what risks above are actually something you need to worry about versus something you don't need to worry about.
I think Garrett is saying: our science gets good enough that we can tell that, in some situations, our models are going to do stuff we don't like. We then look at the brain and try and see what the brain would do in that situation.
This seems possible, but I'm thinking more mechanistically than that. Borrowing terminology from I think Redwood's mechanistic anomaly detection strategy, we want our AIs to make decisions for the same reasons that humans make decisions (though you can't actually use their methods or directly apply their conceptual framework here, because we also want our AIs to get smarter than humans, which necessitates them making decisions for different reasons than humans, and humans make decisions on the basis of a bunch of stuff depending on context and their current mind-state).
But all spaces are projections of some space where the projection gives singularities, surely?
Uniform priors will generically turn into non-uniform priors after you project, which I think is going to change the learning dynamics / relevance of the RLCTs?