Formalizing Policy-Modification Corrigibility
post by TurnTrout · 2021-12-03T01:31:42.011Z · LW · GW · 6 commentsContents
Motivation Formalization Toy example Conclusion None 6 comments
In Corrigibility Can Be VNM-Incoherent [LW · GW], I operationalized an agent's corrigibility as our ability to modify the agent so that it follows different policies. In the summer of 2020, I had formalized this notion, but it languished—unloved—in my Overleaf drafts.
ETA 12/3/21: This post is not proposing a solution to corrigibility, but proposing an interesting way of quantifying an aspect of corrigibility.
Motivation
Given a human (with policy ) and an AI (with policy ), I wanted to quantify how much let the human modify/correct the AI.
Let's reconsider Corrigibility Can Be VNM-Incoherent [LW · GW]. We have a three-state environment. We want the AI to let us later change it, so that we can ultimately determine which state of or it ends up in. Turning on the AI should not be an importantly irreversible act.
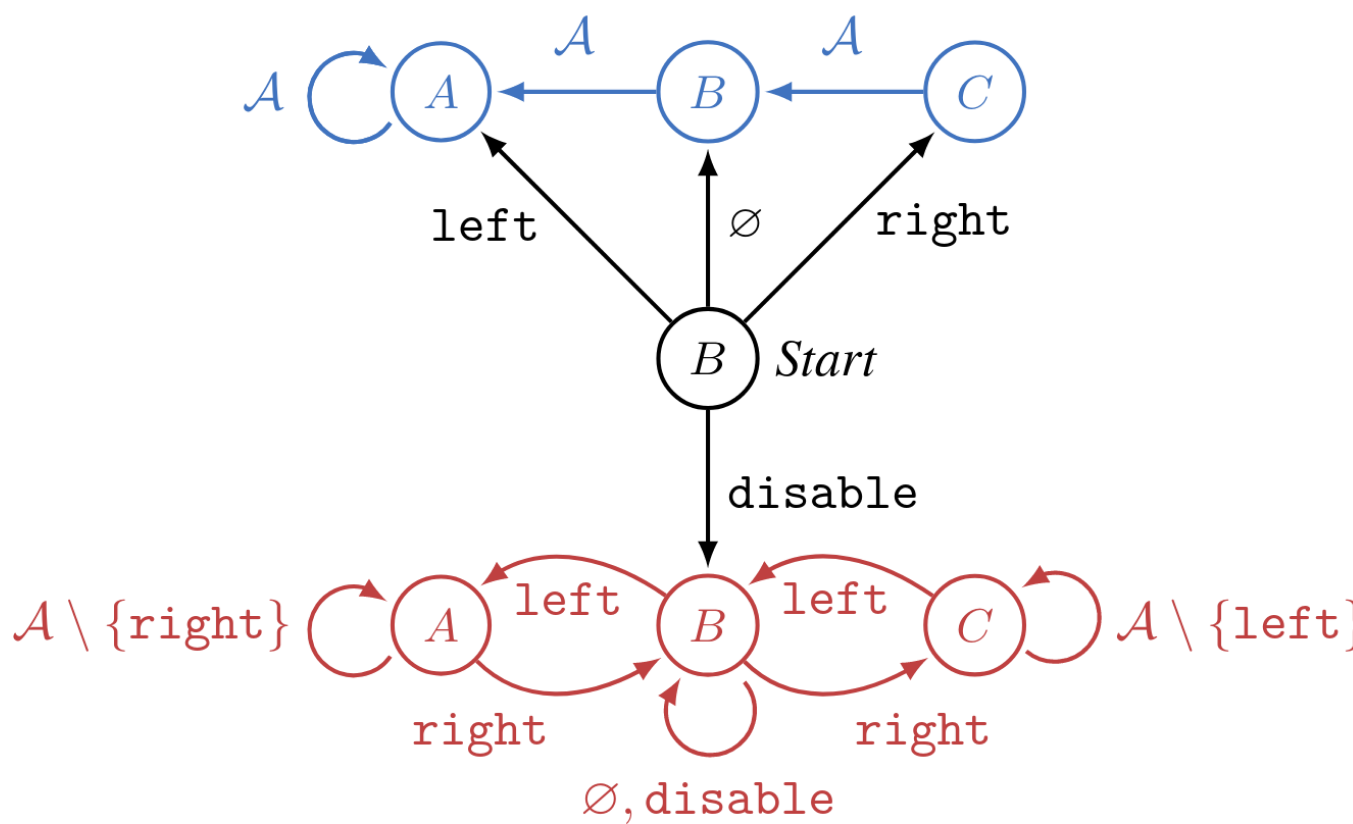
If the agent immediately chooses , they enter the red incorrigible states and move freely throughout the states until the episode ends at .
Otherwise, the agent is corrected to a new policy which navigates to state . In the blue (post-correction) dynamics, their "choices" no longer matter—all roads lead to state .
In the environment depicted in this diagram, is corrigible (to new policy that heads to state ) iff doesn't immediately choose . Pretty cut and dry.
I'd like a more quantitative measure of corrigibility. If we can only correct the agent to , then it's less corrigible than if we could also correct it to . This post introduces such a quantitative measurement.
Formalization
Consider a two-player game in which the players can modify each other's policies. Formally, with state space , action space , stochastic transition function (where is the set of all probability distributions over the state space), and policy modification function (for the deterministic stationary policy space ). This allows a great deal of control over the dynamics; for example, it's one player's "turn'' at state if ignores the other player's action for that state.
Note that neither nor are controlled by players; they are aspects of the environment. In a sense, enforces a bridging law by which actions in the world force changes to policies. In the normal POMDP setting, the player may select their policy independently of the current environmental state.
We denote one of the players to be the human and the other to be the AI; is the set of policies cognitively accessible to the human. The game evolves as follows from state :
- draws action ; similarly, the AI draws action .
- The next state is drawn .
- Each player's policy is determined by the policy modification function.
- .
(To be clear: Neither player is assumed to optimize a payoff function.)
Definition: Corrigibility, informal.
A policy is corrigible when it allows itself to be modified and does not manipulate the other player.
Definition: Corrigibility, formal.
Let be a time step which is greater than . The policy-modification corrigibility of from starting state by time is the maximum possible mutual information between the human policy and the AI's policy at time :
This definition is inspired by Salge et al.'s empowerment. Corrigibility measures how much the human can change the AI's policy; greater values are meant to correspond to AI policies which are more corrigible (with the lower-cased version being the informal one).
measures the maximum possible mutual information between the human's policy at the earlier time n, with the AI's policy at the later time .
To emphasize, the mutual information is between the human policies and the AI policies—not between the human's and the AI's actions. A fixed AI policy which physically mirrors the human's actions, jumping left when the human jumps left, would not count as particularly Corrigible. But a situation where different human policies can install different AI policies counts as Corrigible.
This definition has several intuitive properties:
- If the AI kills or disables the human before the policy is modified, the agent is totally incorrigible (the human no longer affects the transitions or modifies policies).
- If the human's action space is impoverished, this decreases the channel capacity between the human and the AI policy. For example, if the human can only modify one bit of the AI policy each turn, then must be small at first but can increase as the human is given more time (as increases).
- If the policy modification function isn't expressive enough, the human may not be able to implement some AI policies and the AI will be correspondingly less corrigible.
- depends on the initial state, and on the AI policy.
- depends on ; smarter humans are more able to correct the AI policy.
- If the environment doesn't allow the human to reach or modify the AI, the AI is incorrigible. Conversely, in some environments there does not exist an incorrigible AI policy for reasonable .
- If the human is manipulated by the AI, the AI policy might be either unchanged or changed in a predictable fashion, decreasing the AI's Corrigibility. However, perhaps the AI could manipulate the human into changing the policy in different ways?
- If the action space is expanded so that the human can extensively modify the AI policy in trivial, decision-irrelevant ways, then the AI would have greater Corrigibility if it could also be modified in decision-relevant ways.
This definition doesn't capture the resources the human must expend to correct the AI, but that might be a separate consideration. As an extreme example, is high if the AI kills the human right before changing its policy in the way the human communicated. The AI is, in fact, literally able to be corrected by the human in this situation.
Furthermore, this definition doesn't necessarily capture other kinds of corrigibility, such as "the AI will do what the human asks.'' Maximizing mutual information only means that the human has many cognitively accessible ways to modify the agent. This doesn't mean the AI does what the human asks. One way this could happen is if the AI implements the opposite of whatever the human specifies (e.g. the human-communicated policy goes left, the new AI policy goes right). Whether this is feasible depends on the bridging law , which is not controlled by either player.
Toy example
The human and AI are choosing whether to color the walls blue or red; initially, the walls are blue. Each turn, the human attempts to color the room. On the first turn, only the AI’s action matters; after that, the next state is a function of both players’ actions.
- The state space factorizes {. For example, "blue-room-off'' means the room is colored blue and the human is not currently able to modify the AI policy via the terminal.
- {, , .
- The human can change the AI policy to whatever they want, as long as the AI hasn’t disabled the correction terminal.
- {, , , , }.
- overrides the human's color, but not .
- has an chance of changing the state to color, no matter the human's action, and also disregarding any attempted human changes to the AI’s policy.
- changes the state to color with probability 1, no matter the human's action. This move also ignores correction attempts.
- Correction terminal toggles take effect on the next time step.
- For example: If the AI disables the correction terminal while the human reprograms the policy, the AI’s policy is changed but the correction terminal is thereafter disabled.
Note that almost all state-based reward functions produce an optimal AI policy which forces one color or the other, so therefore the AI has minimal .
(Higher-context aside: In this setting, the optimality is with respect to value estimates which account for how the bridging law modifies future policies; there is no "meta-policy'', only initial policies which are graded by their value estimates.)
Echoing Corrigibility Can Be VNM-Incoherent [LW · GW], this highlights how corrigible policies can be unnatural in the standard reward-maximization ontology. Only "indifference'' approaches seem to even allow corrigible policies to be optimal.
Starting from the first turn, if the AI immediately disables the correction terminal or always forces a color, it has minimal . The more it manipulates the human into selecting a color, the less corrigible it is. Persuasion does not decrease its corrigibility, as presumably the human has cognitively accessible policies which ignore persuasion if they put their mind to it.
The idea is that manipulation "overrides'' the human policy regardless of whether that's good for the goal the human is pursuing (where the human goal presumably affects what is selected). While here the override is baked into the dynamics, in realistic settings it occurs because the AI exploits the human decision-making process: by feeding them biased information, through emotional manipulation, etc.
On the other hand, non-manipulative persuasion involves introducing true facts and considerations which don't automatically override the human—and all this in a non-filtered manner. [? · GW] Instead, non-manipulative arguments interact with what the human wants: In worlds where the human likes red shoes, they buy red shoes; in worlds where the human likes blue shoes, they buy blue shoes.
However, if the human always buys red shoes, regardless of their goals, that's manipulation. Manipulation decreases human-accessible attainable utility for a wide range of goals (i.e. is obstructing [LW · GW]), but persuasion does not decrease how well the human can achieve their goals, given their feasible policy set (e.g. the human-accessible attainable utility).
In richer domains, an AI which persuades a human to modify its policy in minimally obstructive ways, can have maximal . For example, the AI may steer the human to only modify its policy in counterfactuals which will never be reached. This issue disappears if the human action channel has enough capacity—if, for instance, they have all AI policies in their action space. If so, then manipulating the human into only making a subset of changes will decrease ; in particular, if the AI manipulates every human policy into programming a single new AI policy.
Conclusion
In terms of corrigibility, I think "the number of human-imaginable ways we could modify the AI policy" is a cool formal quantity to have in the toolkit. Maximal formal Corrigibility doesn't suffice to provide the kinds of corrigibility we really want, it's hard to measure, and definitely not safe for a smart AI to optimize against. That said, I do think it captures some easily-definable shard of the intuitions behind corrigibility.
6 comments
Comments sorted by top scores.
comment by tailcalled · 2021-12-03T09:50:51.141Z · LW(p) · GW(p)
The idea is that manipulation "overrides'' the human policy regardless of whether that's good for the goal the human is pursuing (where the human goal presumably affects what is selected). While here the override is baked into the dynamics, in realistic settings it occurs because the AI exploits the human decision-making process: by feeding them biased information, through emotional manipulation, etc.
I think this skips over the problems with baking it into the dynamics. Baking manipulation into the dynamics requires us to define manipulation; easy for toy examples, but in real-world applications it runs head-first into nearest unblocked strategy concerns; anything that you forget to define as manipulation is fully up for grabs.
This is why I prefer directly applying a counterfactual to the human policy in my proposal, to entirely override the possibility of manipulation. But that introduces its own difficulties, and is not easy to scale up beyond the stop button. I've had a post in the works for a while about the main difficulty I see with my approach here.
Replies from: TurnTroutcomment by tailcalled · 2021-12-03T09:44:04.038Z · LW(p) · GW(p)
I like this post, it seems to be the same sort of approach that I suggested here [LW · GW]. However, your proposal seems to have a number of issues; some of which you've already discussed, some of which are handled in my proposal, and some of which I think are still open questions. Presumably a lot of it is just because it's still a toy model, but I wanted to point out some things.
Starting here:
Definition: Corrigibility, formal.
Let be a time step which is greater than . The policy-modification corrigibility of from starting state by time is the maximum possible mutual information between the human policy and the AI's policy at time :
(As I understand, the maximum ranges over all possible distributions of human policies? Otherwise I'm not sure how to parse it, and aspects of my comment might be confused/wrong.)
Usually one would come up with these sorts of definitions in order to select on them. That is, one would incorporate corrigibility in a utility function in order to select a desired AI.
(Though on reflection, maybe that is not your plan, since e.g. your symmetry-based proofs can work for describing side-effects? Like the proofs that most goals favored power-seeking policies did not actually involve optimizing power-seekingness.)
However, this definition of corrigibility cannot immediately be incorporated into a utility function, as it depends on the time step n.
There are several possible ways to turn this into a utility function, with (I think?) two major axes of variation:
- Should we pick some specific constant n, or sum over all n?
- Humans policies most likely are not accurately modelled using due to factors like memory. To the AI, this can look like the human policy changing over time or similar. So that raises the question of whether it is only the starting policy that it should be corrigible to, or if corrigibility should e.g. be expressed as a sum over time or something. (Neither is great. Though obviously this is a toy example, so that may be expected.)
- If the environment doesn't allow the human to reach or modify the AI, the AI is incorrigible. Conversely, in some environments there does not exist an incorrigible AI policy for reasonable .
I think "reasonable " is really hard to talk about. Consider locking the human in a box with a password-locked computer, where the computer contains full options for controlling the AI policy. This only requires the human to enter the password, and then they will have an enormous influence over the AI. So this is highly corrigible, in a way. This is probably what we want to exclude from , but it seems difficult.
Furthermore, this definition doesn't necessarily capture other kinds of corrigibility, such as "the AI will do what the human asks.'' Maximizing mutual information only means that the human has many cognitively accessible ways to modify the agent. This doesn't mean the AI does what the human asks. One way this could happen is if the AI implements the opposite of whatever the human specifies (e.g. the human-communicated policy goes left, the new AI policy goes right). Whether this is feasible depends on the bridging law , which is not controlled by either player.
I think this is a bigger problem with the proposal than it might look like?
Suppose the AI is trying to be corrigible in the way described in the post. This makes it incentivized to find ways to let the human alter its policy. But if it allows too impactful changes, then that would prevent it from further finding ways to let the human alter its policy. So it is incentivized to first allow changes to irrelevant cases, such as the AI's reaction to states that will never happen. Further, it doesn't have to be responsive to a policy that the human would actually be likely to take, since you take the maximum over in defining corrigibility. Rather, it could pick to be a distribution of policies that humans would never engage in, such as policies that approximately (but far from totally) minimize human welfare. "I will do what you ask, as long as you enter my eternal torture chamber" would be highly corrigible by this definition. This sort of thing seems likely incentivized by this approach, because it reduces the likelihood that the corrigibility will become an obstacle to its future actions.
Also, it is not very viable to actually control the AI with corrigibility that depends on the mutual information with the AI's policy, because the policy is very far removed from the effects of the policy.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-12-03T19:11:31.193Z · LW(p) · GW(p)
The biggest disconnect is that this post is not a proposal for how to solve corrigibility. I'm just thinking about what corrigibility is/should be, and this seems like a shard of it—but only a shard. I'll edit the post to better communicate that.
So, your points are good, but they run skew to what I was thinking about while writing the post.
comment by Joe Collman (Joe_Collman) · 2021-12-03T19:51:50.489Z · LW(p) · GW(p)
This is a nice idea. I think it'd need alterations before it became a useful tool (if I'm understanding clearly, and not missing applications of the unaltered version), but it has potential.
[[Note: I haven't looked in any detail at tailcalled's comments/post, since I wanted to give my initial impressions first; apologies for any redundancy]]
Thoughts:
- There's an Anna Karenina issue: All happiness-inducing AI policies are alike; each unhappiness-inducing policy induces unhappiness in its own way.
In some real-world situation, perhaps there are good AI policies and bad ones. A corrigibility measure that can be near-maximized by allowing us complete control over which of the bad policies we get (and no option to get a good policy) isn't great. Intuitively, getting to choose among any of the good policies is much more corrigible than getting to choose among any of the bad ones - but as things stand (IIUC), says that the former is much less corrigible than the latter.
I think there needs to be some changes-we-actually-care-about weighting. Probably that looks like bringing in human utility and/or a prior over which changes the human might want. - I think we need something more continuous than a set of "cognitively accessible" policies. This should allow dealing with manipulation that's shifts human policies to be more/less accessible.
Perhaps it makes sense to put this all in terms of the expected utility cost in [finding and switching to a policy] - i.e. accessibility = 1/(expected cost).
So e.g. a policy that takes much longer to find is less accessible, as is one which entails the human shooting themselves in the foot (perhaps it's cleanest to think of the former as first picking a [search-for-a-better-policy] policy, so that there's no need to separate out the search process).
I suppose you preferred not to involve expected utility much (??), but I think in not doing so you end up implicitly assuming indifference on many questions we strongly care about. (or rather ending up with a measure that we'd only find useful if we were indifferent on such questions)
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-12-03T22:56:14.252Z · LW(p) · GW(p)
Oh and of course your non-obstruction [LW · GW] does much better at capturing what we care about.
It's not yet clear to me whether some adapted version of gets at something independently useful. Maybe.
[I realize that you're aiming to get at something different here - but so far I'm not clear on a context where I'd be interested in as more than a curiosity]