Non-Obstruction: A Simple Concept Motivating Corrigibility
post by TurnTrout · 2020-11-21T19:35:40.445Z · LW · GW · 20 commentsContents
Nomenclature
A Simple Concept Motivating Corrigibility
Two conceptual clarifications
Corrigibility with respect to a set of goals
Corrigibility != alignment
Non-obstruction: the AI doesn't hamper counterfactual achievement of a set of goals
Alignment flexibility
Non-torture AI
Paperclipper
Empowering AI
Conclusions I draw from the idea of non-obstruction
Theoretically, It’s All About Alignment
Formalizing impact alignment in extensive-form games
Non-obstruction is a weak form of impact alignment.
This is the key motivation for corrigibility.
AI alignment subproblems are about avoiding spikiness in the AU landscape
What Do We Want?
Expanding the AI alignment solution space
Future Directions
Summary
This is the key motivation for corrigibility.
None
20 comments
Thanks to Mathias Bonde, Tiffany Cai, Ryan Carey, Michael Cohen, Joe Collman, Andrew Critch, Abram Demski, Michael Dennis, Thomas Gilbert, Matthew Graves, Koen Holtman, Evan Hubinger, Victoria Krakovna, Amanda Ngo, Rohin Shah, Adam Shimi, Logan Smith, and Mark Xu for their thoughts.
Main claim: corrigibility’s benefits can be mathematically represented as a counterfactual form of alignment.
Overview: I’m going to talk about a unified mathematical frame I have for understanding corrigibility’s benefits, what it “is”, and what it isn’t. This frame is precisely understood by graphing the human overseer’s ability to achieve various goals (their attainable utility (AU) landscape [LW · GW]). I argue that corrigibility’s benefits are secretly a form of counterfactual alignment (alignment with a set of goals the human may want to pursue).
A counterfactually aligned agent doesn't have to let us literally correct it. Rather, this frame theoretically motivates why we might want corrigibility anyways. This frame also motivates other AI alignment subproblems, such as intent alignment, mild optimization, and low impact.
Nomenclature
Corrigibility goes by a lot of concepts: “not incentivized to stop us from shutting it off”, “wants to account for its own flaws [LW · GW]”, “doesn’t take away much power from us”, etc. Named by Robert Miles, the word ‘corrigibility’ means “able to be corrected [by humans]." I’m going to argue that these are correlates of a key thing we plausibly actually want from the agent design, which seems conceptually simple.
In this post, I take the following common-language definitions:
- Corrigibility: the AI literally lets us correct it (modify its policy), and it doesn't manipulate us either.
- Without both of these conditions, the AI's behavior isn't sufficiently constrained for the concept to be useful. Being able to correct it is small comfort if it manipulates us into making the modifications it wants. An AI which is only non-manipulative doesn't have to give us the chance to correct it or shut it down.
- Impact alignment: the AI’s actual impact is aligned with what we want. Deploying the AI actually makes good things happen.
- Intent alignment: the AI makes an honest effort to figure out what we want and to make good things happen.
I think that these definitions follow what their words mean, and that the alignment community should use these (or other clear groundings) in general. Two of the more important concepts in the field (alignment and corrigibility) shouldn’t have ambiguous and varied meanings. If the above definitions are unsatisfactory, I think we should settle upon better ones as soon as possible. If that would be premature due to confusion about the alignment problem, we should define as much as we can now and explicitly note what we’re still confused about.
We certainly shouldn’t keep using 2+ definitions for both alignment and corrigibility. Some people [LW(p) · GW(p)] have even stopped using ‘corrigibility’ to refer to corrigibility! I think it would be better for us to define the behavioral criterion (e.g. as I defined 'corrigibility'), and then define mechanistic ways of getting that criterion (e.g. intent corrigibility). We can have lots of concepts, but they should each have different names.
Evan Hubinger recently wrote a great FAQ on inner alignment terminology [LW · GW]. We won't be talking about inner/outer alignment today, but I intend for my usage of "impact alignment" to roughly map onto his "alignment", and "intent alignment" to map onto his usage of "intent alignment." Similarly, my usage of "impact/intent alignment" directly aligns with the definitions from Andrew Critch's recent post, Some AI research areas and their relevance to existential safety [LW · GW].
A Simple Concept Motivating Corrigibility
Two conceptual clarifications
Corrigibility with respect to a set of goals
I find it useful to not think of corrigibility as a binary property, or even as existing on a one-dimensional continuum. I often think about corrigibility with respect to a set of payoff functions. (This isn't always the right abstraction: there are plenty of policies which don't care about payoff functions. I still find it useful.)
For example, imagine an AI which let you correct it if and only if it knows you aren’t a torture-maximizer. We’d probably still call this AI “corrigible [to us]”, even though it isn’t corrigible to some possible designer. We’d still be fine, assuming it has accurate beliefs.
Corrigibility != alignment
Here's an AI which is neither impact nor intent aligned, but which is corrigible. Each day, the AI randomly hurts one person in the world, and otherwise does nothing. It’s corrigible because it doesn't prevent us from shutting it off or modifying it.
Non-obstruction: the AI doesn't hamper counterfactual achievement of a set of goals
Imagine we’re playing a two-player extensive-form game with the AI, and we’re considering whether to activate it.
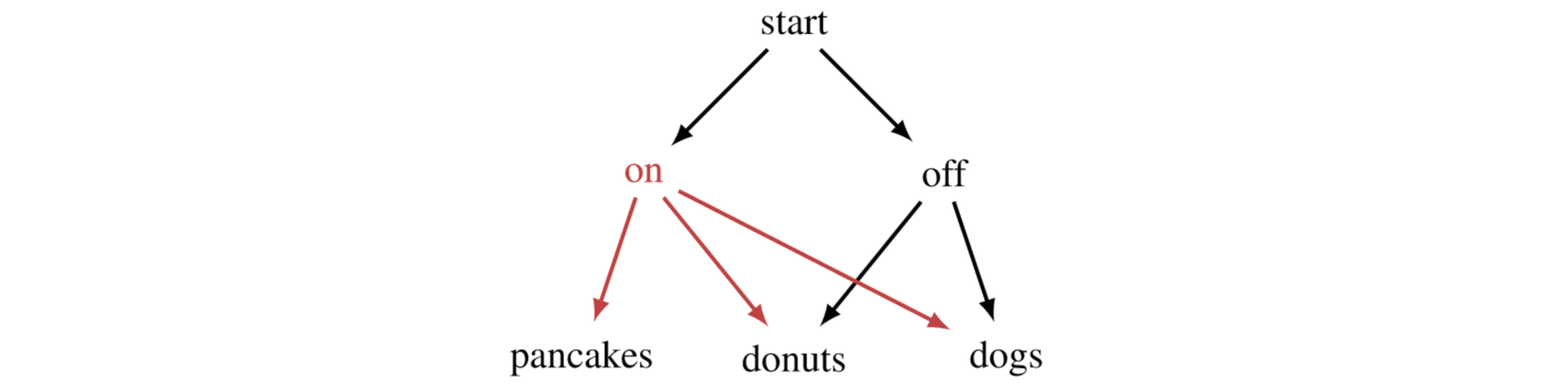
This is a trivial game, but you can imagine more complex games, where the AI can empower or disempower the human, steer the future exactly where it wants, or let the human take over at any point.
The million-dollar question is: will the AI get in our way and fight with us all the way down the game tree? If we misspecify some detail, will it make itself a fixture in our world, constantly steering towards futures we don’t want? If we like dogs, will the AI force pancakes upon us?
One way to guard against this is by having it let us correct it, and want to let us correct it, and want to want to let us correct it… But what we really want is for it to not get in our way for some (possibly broad) set of goals .
We'll formalize 'goals' as payoff functions, although I’ll use 'goals' and 'payoff functions' interchangeably. As is standard in game theory, payoff functions are real-valued functions on the leaf nodes.
Let’s say the AI is non-obstructive with respect to when activating it doesn’t decrease our ability to achieve any goal in (the on state, above), compared to not activating it (off).
Does activating the AI decrease the -value attained by the human, for all of these different goals the human might counterfactually pursue?
The human’s got a policy function , which takes in a goal and returns a policy for that goal. If is “paint walls blue”, then the policy is the human's best plan for painting walls blue. denotes the expected value that policy obtains for goal , starting from state and given that the AI follows policy .
Definition 1: Non-obstruction. An AI is non-obstructive with respect to payoff function set if the AI's policy satisfies
is the human's attainable utility (AU) for goal at state , again given the AI policy. Basically, this quantifies the expected payoff for goal , given that the AI acts in such-and-such a way, and that the player follows policy starting from state .
This math expresses a simple sentiment: turning on the AI doesn’t make you, the human, worse off for any goal . The inequality doesn’t have to be exact, it could just be for some -decrease (to avoid trivial counterexamples). The AU is calculated with respect to some reasonable amount of time (e.g. a year: before the world changes rapidly because we deployed another transformative AI system, or something). Also, we’d technically want to talk about non-obstruction being present throughout the on-subtree, but let’s keep it simple for now.
Suppose that leads to pancakes:
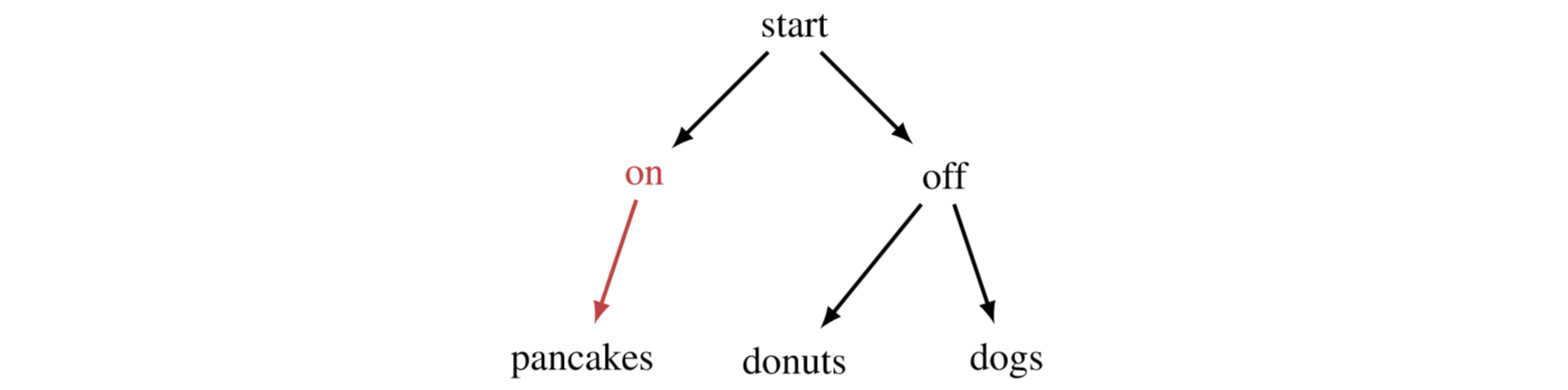
Since transitions to pancakes, then , the payoff for the state in which the game finishes if the AI follows policy and the human follows policy . If , then turning on the AI doesn't make the human worse off for goal .
If assigns the most payoff to pancakes, we're in luck. But what if we like dogs? If we keep the AI turned off, can go to donuts or dogs depending on what rates more highly. Crucially, even though we can't do as much as the AI (we can't reach pancakes on our own), if we don't turn the AI on, our preferences still control how the world ends up.
This game tree isn't really fair to the AI. In a sense, it can't not be in our way:
- If leads to pancakes, then it obstructs payoff functions which give strictly more payoff for donuts or dogs.
- If leads to donuts, then it obstructs payoff functions which give strictly more payoff to dogs.
- If leads to dogs, then it obstructs payoff functions which give strictly more payoff to donuts.
Once we've turned the AI on, the future stops having any mutual information with our preferences . Everything come down to whether we programmed correctly: to whether the AI is impact-aligned with our goals !
In contrast, the idea behind non-obstruction is that we still remain able to course-correct the future, counterfactually navigating to terminal states we find valuable, depending on what our payoff is. But how could an AI be non-obstructive, if it only has one policy which can't directly depend on our goal ? Since the human's policy does directly depend on , the AI can preserve value for lots of goals in the set by letting us maintain some control over the future.
Let and consider the real world. Calculators are non-obstructive with respect to , as are modern-day AIs. Paperclip maximizers are highly obstructive. Manipulative agents are obstructive (they trick the human policies into steering towards non-reflectively-endorsed leaf nodes). An initial-human-values-aligned dictator AI obstructs most goals. Sub-human-level AI which chip away at our autonomy and control over the future, are obstructive as well.
This can seemingly go off the rails if you consider e.g. a friendly AGI to be “obstructive” because activating it happens to detonate a nuclear bomb via the butterfly effect. Or, we’re already doomed in off (an unfriendly AGI will come along soon after), and so then this AI is “not obstructive” if it kills us instead. This is an impact/intent issue - obstruction is here defined according to impact alignment.
To emphasize, we’re talking about what would actually happen if we deployed the AI, under different human policy counterfactuals - would the AI "get in our way", or not? This account is descriptive, not prescriptive; I’m not saying we actually get the AI to represent the human in its model, or that the AI’s model of reality is correct, or anything.
We’ve just got two players in an extensive-form game, and a human policy function which can be combined with different goals, and a human whose goal is represented as a payoff function. The AI doesn’t even have to be optimizing a payoff function; we simply assume it has a policy. The idea that a human has an actual payoff function is unrealistic; all the same, I want to first understand corrigibility and alignment in two-player extensive-form games [LW · GW].
Lastly, payoff functions can sometimes be more or less granular than we'd like, since they only grade the leaf nodes. This isn't a big deal, since I'm only considering extensive-form games for conceptual simplicity. We also generally restrict ourselves to considering goals which aren't silly: for example, any AI obstructs the "no AI is activated, ever" goal.
Alignment flexibility
Main idea: By considering how the AI affects your attainable utility (AU) landscape, you can quantify how helpful and flexible an AI is.
Let’s consider the human’s ability to accomplish many different goals P, first from the state off (no AI).

The independent variable is , and the value function takes in and returns the expected value attained by the policy for that goal, . We’re able to do a bunch of different things without the AI, if we put our minds to it.
Non-torture AI
Imagine we build an AI which is corrigible towards all non-pro-torture goals, which is specialized towards painting lots of things blue with us (if we so choose), but which is otherwise non-obstructive. It even helps us accumulate resources for many other goals.

We can’t get around the AI, as far as torture goes. But for the other goals, it isn’t obstructing their policies. It won’t get in our way for other goals.
Paperclipper
What happens if we turn on a paperclip-maximizer? We lose control over the future outside of a very narrow spiky region.

I think most reward-maximizing optimal policies affect the landscape like this (see also: the catastrophic convergence conjecture [? · GW]), which is why it’s so hard to get hard maximizers not to ruin everything. You have to a) hit a tiny target in the AU landscape and b) hit that for the human’s AU, not for the AI’s. The spikiness is bad and, seemingly, hard to deal with.
Furthermore, consider how the above graph changes as gets smarter and smarter. If we were actually super-superintelligent ourselves, then activating a superintelligent paperclipper might not even a big deal, and most of our AUs are probably unchanged. The AI policy isn't good enough to negatively impact us, and so it can't obstruct us. Spikiness depends on both the AI's policy, and on .
Empowering AI

What if we build an AI which significantly empowers us in general, and then it lets us determine our future? Suppose we can’t correct it.
I think it’d be pretty odd to call this AI “incorrigible”, even though it’s literally incorrigible. The connotations are all wrong. Furthermore, it isn’t “trying to figure out what we want and then do it”, or “trying to help us correct it in the right way." It’s not corrigible. It’s not intent aligned. So what is it?
It’s empowering and, more weakly, it’s non-obstructive. Non-obstruction is just a diffuse form of impact alignment, as I’ll talk about later.
Practically speaking, we’ll probably want to be able to literally correct the AI without manipulation, because it’s hard to justifiably know ahead of time that the AU landscape is empowering, as above. Therefore, let’s build an AI we can modify, just to be safe. This is a separate concern, as our theoretical analysis assumes that the AU landscape is how it looks.
But this is also a case of corrigibility just being a proxy for what we want. We want an AI which leads to robustly better outcomes (either through its own actions, or through some other means), without reliance on getting ambitious value alignment [AF · GW] exactly right with respect to our goals.
Conclusions I draw from the idea of non-obstruction
- Trying to implement corrigibility is probably a good instrumental strategy for us to induce non-obstruction in an AI we designed.
- It will be practically hard to know an AI is actually non-obstructive for a wide set , so we’ll probably want corrigibility just to be sure.
- We (the alignment community) think we want corrigibility with respect to some wide set of goals , but we actually want non-obstruction with respect to
- Generally, satisfactory corrigibility with respect to implies non-obstruction with respect to ! If the mere act of turning on the AI means you have to lose a lot of value in order to get what you wanted, then it isn’t corrigible enough.
- One exception: the AI moves so fast that we can’t correct it in time, even though it isn’t inclined to stop or manipulate us. In that case, corrigibility isn’t enough [LW · GW], whereas non-obstruction is.
- Non-obstruction with respect to does not imply corrigibility with respect to .
- But this is OK! In this simplified setting of “human with actual payoff function”, who cares whether it literally lets us correct it or not? We care about whether turning it on actually hampers our goals.
- Non-obstruction should often imply some form of corrigibility, but these are theoretically distinct: an AI could just go hide out somewhere in secrecy and refund us its small energy usage, and then destroy itself when we build friendly AGI.
- Non-obstruction captures the cognitive abilities of the human through the policy function [LW · GW].
- To reiterate, this post outlines a frame for conceptually analyzing the alignment properties of an AI. We can't actually figure out a goal-conditioned human policy function, but that doesn't matter, because this is a tool for conceptual analysis, not an AI alignment solution strategy. Any conceptual analysis of impact alignment and corrigibility which did not account for human cognitive abilities, would be obviously flawed.
- By definition, non-obstruction with respect to prevents harmful manipulation by precluding worse outcomes with respect to .
- I consider manipulative policies to be those which robustly steer the human into taking a certain kind of action, in a way that's robust against the human's counterfactual preferences.
If I'm choosing which pair of shoes to buy, and I ask the AI for help, and no matter what preferences I had for shoes to begin with, I end up buying blue shoes, then I'm probably being manipulated (and obstructed with respect to most of my preferences over shoes!).
A non-manipulative AI would act in a way that lets me condition my actions on my preferences. - I do have a formal measure of corrigibility which I'm excited about, but it isn't perfect. More on that in a future post.
- I consider manipulative policies to be those which robustly steer the human into taking a certain kind of action, in a way that's robust against the human's counterfactual preferences.
- As a criterion, non-obstruction doesn’t rely on intentionality on the AI’s part. The definition also applies to the downstream effects of tool AIs, or even to hiring decisions!
- Non-obstruction is also conceptually simple and easy to formalize, whereas literal corrigibility gets mired in the semantics of the game tree.
- For example, what's “manipulation”? As mentioned above, I think there are some hints as to the answer, but it's not clear to me that we're even asking the right questions yet.
- Generally, satisfactory corrigibility with respect to implies non-obstruction with respect to ! If the mere act of turning on the AI means you have to lose a lot of value in order to get what you wanted, then it isn’t corrigible enough.
I think of “power” as “the human’s average ability to achieve goals from some distribution [LW · GW]." Logically, non-obstructive agents with respect to don’t decrease our power with respect to any distribution over goal set . The catastrophic convergence conjecture [? · GW] says, “impact alignment catastrophes tend to come from power-seeking behavior”; if the agent is non-obstructive with respect to a broad enough set of goals, it’s not stealing power from us, and so it likely isn’t catastrophic.
Non-obstruction is important for a (singleton) AI we build: we get more than one shot to get it right. If it’s slightly wrong, it’s not going to ruin everything. Modulo other actors, if you mess up the first time, you can just try again and get a strongly aligned agent the next time.
Most importantly, this frame collapses the alignment and corrigibility desiderata into just alignment; while impact alignment doesn’t imply corrigibility, corrigibility’s benefits can be understood as a kind of weak counterfactual impact alignment with many possible human goals.
Theoretically, It’s All About Alignment
Main idea: We only care about how the agent affects our abilities to pursue different goals (our AU landscape) in the two-player game, and not how that happens. AI alignment subproblems (such as corrigibility, intent alignment, low impact, and mild optimization) are all instrumental avenues for making AIs which affect this AU landscape in specific desirable ways.
Formalizing impact alignment in extensive-form games
Impact alignment: the AI’s actual impact is aligned with what we want. Deploying the AI actually makes good things happen.
We care about events if and only if they change our ability to get what we want [? · GW]. If you want to understand normative AI alignment desiderata, on some level they have to ground out in terms of your ability to get what you want (the AU theory of impact [? · GW]) - the goodness of what actually ends up happening under your policy - and in terms of how other agents affect your ability to get what you want (the AU landscape [? · GW]). What else could we possibly care about, besides our ability to get what we want?
Definition 2. For fixed human policy function , is:
- Maximally impact aligned with goal if
- Impact aligned with goal if
- (Impact) non-obstructive with respect to goal if .
- Impact unaligned with goal if
- Maximally impact unaligned with goal if
Non-obstruction is a weak form of impact alignment.
As demanded by the AU theory of impact [? · GW], the impact on goal of turning on the AI is
Again, impact alignment doesn't require intentionality. The AI might well grit its circuits as it laments how Facebook_user5821 failed to share a "we welcome our AI overlords" meme, while still following an impact-aligned policy.
However, even if we could maximally impact-align the agent with any objective, we couldn't just align it with our objective. We don't know our objective (again, in this setting, I'm assuming the human actually has a "true" payoff function). Therefore, we should build an AI aligned with many possible goals we could have. If the AI doesn't empower us, it at least shouldn't obstruct us. Therefore, we should build an AI which defers to us, lets us correct it, and which doesn't manipulate us.
This is the key motivation for corrigibility.
For example, intent corrigibility (trying to be the kind of agent which can be corrected and which is not manipulative) is an instrumental strategy for inducing corrigibility, which is an instrumental strategy for inducing broad non-obstruction, which is an instrumental strategy for hedging against our inability to figure out what we want. It's all about alignment.
Corrigibility also increases robustness against other AI design errors. However, it still just boils down to non-obstruction, and then to impact alignment: if the AI system has meaningful errors, then it's not impact-aligned with the AUs which we wanted it to be impact-aligned with. In this setting, the AU landscape captures what actually would happen for different human goals .
To be confident that this holds empirically, it sure seems like you want high error tolerance in the AI design: one does not simply knowably build an AGI that's helpful for many AUs. Hence, corrigibility as an instrumental strategy for non-obstruction.
AI alignment subproblems are about avoiding spikiness in the AU landscape
- Corrigibility [? · GW]: avoid spikiness by letting humans correct the AI if it starts doing stuff we don’t like, or if we change our mind.
- This works because the human policy function is far more likely to correctly condition actions on the human's goal, than it is to induce an AI policy which does the same (since the goal information is private to the human).
- Enforcing off-switch corrigibility and non-manipulation are instrumental strategies for getting better diffuse alignment across goals and a wide range of deployment situations.
- Intent alignment: avoid spikiness by having the AI want to be flexibly aligned with us and broadly empowering.
- Basin of intent alignment: smart, nearly intent-aligned AIs should modify themselves to be more and more intent-aligned, even if they aren't perfectly intent-aligned to begin with.
- Intuition: If we can build a smarter mind which basically wants to help us, then can't the smarter mind also build a yet smarter agent which still basically wants to help it (and therefore, help us)?
- Paul Christiano named this the "basin of corrigibility", but I don't like that name because only a few of the named desiderata actually correspond to the natural definition of "corrigibility." This then overloads "corrigibility" with the responsibilities of "intent alignment."
- Basin of intent alignment: smart, nearly intent-aligned AIs should modify themselves to be more and more intent-aligned, even if they aren't perfectly intent-aligned to begin with.
- Low impact [? · GW]: find a maximization criterion which leads to non-spikiness.
- Goal of methods: to regularize decrease from green line (for off) for true unknown goal ; since we don’t know , we aim to just regularize decrease from the green line in general (to avoid decreasing the human’s ability to achieve various goals).
- The first two-thirds of Reframing Impact [? · GW] argued that power-seeking incentives play a big part in making AI alignment hard. In the utility-maximization AI design paradigm, instrumental subgoals are always lying in wait. They're always waiting for one mistake, one misspecification in your explicit reward signal, and then bang - the AU landscape is spiky. Game over.
- Mild optimization [? · GW]: avoid spikiness by avoiding maximization, thereby avoiding steering the future too hard.
- If you have non-obstruction for lots of goals, you don’t have spikiness!
What Do We Want?
Main idea: we want good things to happen; there may be more ways to do this than previously considered.
| Alignment | Corrigibility | Non-obstruction | |
|---|---|---|---|
| Impact | Actually makes good things happen. | Corrigibility is a property of policies, not of states; "impact" is an incompatible adjective. Rohin Shah suggests "empirical corrigibility": we actually end up able to correct the AI. | Actually doesn't decrease AUs. |
| Intent | Tries to make good things happen. | Tries to allow us to correct it without it manipulating us. | Tries to not decrease AUs. |
We want agents which are maximally impact-aligned with as many goals as possible, especially those similar to our own.
- It's theoretically possible to achieve maximal impact alignment with the vast majority of goals.
- To achieve maximum impact alignment with goal set :
- Expand the human’s action space to . Expand the state space to encode the human's previous action.
- Each turn, the human communicates what goal they want optimized, and takes an action of their own.
- The AI’s policy then takes the optimal action for the communicated goal , accounting for the fact that the human follows
- This policy looks like an act-based agent, in that it's ready to turn on a dime towards different goals.
- In practice, there's likely a tradeoff with impact-alignment-strength and the # of goals which the agent doesn't obstruct.
- As we dive into specifics, the familiar considerations return: competitiveness (of various kinds), etc.
- To achieve maximum impact alignment with goal set :
- Having the AI not be counterfactually aligned with unambiguously catastrophic and immoral goals (like torture) would reduce misuse risk.
- I’m more worried about accident risk right now.
- This is probably hard to achieve; I’m inclined to think about this after we figure out simpler things, like how to induce AI policies which empower us and grant us flexible control/power over the future. Even though that would fall short of maximal impact alignment, I think [LW(p) · GW(p)] that would be pretty damn good.
Expanding the AI alignment solution space
Alignment proposals might be anchored right now; this frame expands the space of potential solutions. We simply need to find some way to reliably induce empowering AI policies which robustly increase the human AUs; Assistance via Empowerment is the only work I'm aware of which tries to do this directly. It might be worth revisiting old work with this lens in mind. Who knows what we've missed?
For example, I really liked the idea of approval-directed agents, because you got the policy from ’ing an ML model’s output for a state - not from RL policy improvement steps. My work on instrumental convergence in RL can be seen as trying to explain why policy improvement tends to limit to spikiness-inducing / catastrophic policies.
Maybe there’s a higher-level theory for what kinds of policies induce spikiness in our AU landscape. By the nature of spikiness, these must decrease human power (as I’ve formalized it [LW · GW]). So, I'd start there by looking at concepts like enfeeblement, manipulation, power-seeking, and resource accumulation.
Future Directions
- Given an AI policy, could we prove a high probability of non-obstruction, given conservative assumptions about how smart is? (h/t Abram Demski, Rohin Shah)
- Any irreversible action makes some goal unachievable, but irreversible actions need not impede most meaningful goals:
- Can we prove that some kind of corrigibility or other nice property falls out of non-obstruction across many possible environments? (h/t Michael Dennis)
- Can we get negative results, like "without such-and-such assumption on , the environment, or , non-obstruction is impossible for most goals"?
- If formalized correctly, and if the assumptions hold, this would place very general constraints on solutions to the alignment problem.
- For example, should need to have mutual information with : the goal must change the policy for at least a few goals.
- The AI doesn't even have to do value inference in order to be broadly impact-aligned. The AI could just empower the human (even for very "dumb" functions) and then let the human take over. Unless the human is more anti-rational than rational, this should tend to be a good thing. It would be good to explore how this changes with different ways that can be irrational.
- The better we understand (the benefits of) corrigibility now, the less that amplified agents have to figure out during their own deliberation.
- In particular, I think it's very advantageous for the human-to-be-amplified to already deeply understand what it means to be impact-/intent-aligned. We really don't want that part to be up in the air when game-day finally arrives, and I think this is a piece of that puzzle.
- If you’re a smart AI trying to be non-obstructive to many goals under weak intelligence assumptions, what kinds of heuristics might you develop? “No lying”?
- This informs our analysis of (almost) intent-aligned behavior, and whether that behavior leads to a unique locally stable attractor around intent alignment [LW · GW].
- We crucially assumed that the human goal can be represented with a payoff function. As this assumption is relaxed, impact non-obstruction may become incoherent, forcing us to rely on some kind of intent non-obstruction/alignment (see Paul’s comments on a related topic here [LW · GW]).
- Stuart Armstrong observed [LW · GW] that the strongest form of manipulation corrigibility requires knowledge/learning of human values.
- This frame explains why: for non-obstruction, each AU has to get steered in a positive direction, which means the AI has to know which kinds of interaction and persuasion are good and don’t exploit human policies with respect to the true hidden .
- Perhaps it’s still possible to build agent designs which aren’t strongly incentivized to manipulate us / agents whose manipulation has mild consequences. For example, human-empowering agents probably often have this property.
The attainable utility concept has led to other concepts which I find exciting and useful:
- Impact as absolute change in attainable utility
- Reframing Impact [? · GW]
- Conservative Agency via Attainable Utility Preservation (AIES 2020)
- Avoiding Side Effects in Complex Environments (NeurIPS 2020)
- Power as average AU
- Non-obstruction as not decreasing AU for any goal in a set of goals
- Value-neutrality [LW · GW] as the standard deviation of the AU changes induced by changing states (idea introduced by Evan Hubinger)
- Who knows what other statistics on the AU distribution are out there?
Summary
Corrigibility is motivated by a counterfactual form of weak impact alignment: non-obstruction. Non-obstruction and the AU landscape let us think clearly about how an AI affects us and about AI alignment desiderata.
Even if we could maximally impact-align the agent with any objective, we couldn't just align it our objective, because we don't know our objective. Therefore, we should build an AI aligned with many possible goals we could have. If the AI doesn't empower us, it at least shouldn't obstruct us. Therefore, we should build an AI which defers to us, lets us correct it, and which doesn't manipulate us.
This is the key motivation for corrigibility.
Corrigibility is an instrumental strategy for achieving non-obstruction, which is itself an instrumental strategy for achieving impact alignment for a wide range of goals, which is itself an instrumental strategy for achieving impact alignment for our "real" goal.
There's just something about "unwanted manipulation" which feels like a wrong question to me. There's a kind of conceptual crispness that it lacks.
However, in the non-obstruction framework, unwanted manipulation is accounted for indirectly via "did impact alignment decrease for a wide range of different human policies ?". I think I wouldn't be surprised to find "manipulation" being accounted for indirectly through nice formalisms, but I'd be surprised if it were accounted for directly.
Here's another example of the distinction:
- Direct: quantifying in bits "how much" a specific person is learning at a given point in time
- Indirect: computational neuroscientists upper-bounding the brain's channel capacity with the environment, limiting how quickly a person (without logical uncertainty) can learn about their environment
You can often have crisp insights into fuzzy concepts, such that your expectations are usefully constrained. I hope we can do something similar for manipulation.
20 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2020-12-28T21:36:35.648Z · LW(p) · GW(p)
Nitpick:
Evan Hubinger recently wrote a great FAQ on inner alignment terminology. We won't be talking about inner/outer alignment today, but I intend for my usage of "impact alignment" to map onto his "alignment"
This doesn't seem true. From Evan's post:
Alignment: An agent is aligned (with humans) if it doesn't take actions that we would judge to be bad/problematic/dangerous/catastrophic.
From your post:
Impact alignment: the AI’s actual impact is aligned with what we want. Deploying the AI actually makes good things happen.
"Bad things don't happen" and "good things happen" seem quite different, e.g. a rock is Evan-aligned but not Alex-impact-aligned. (Personally, I prefer "aligned" to be about "good things" rather than "not bad things", so I prefer your definition.)
Replies from: evhub, TurnTrout↑ comment by evhub · 2020-12-28T23:14:21.694Z · LW(p) · GW(p)
Hmmm... this is a subtle distinction and both definitions seem pretty reasonable to me. I guess I feel like I want “good things happen” to be part of capabilities (e.g. is the model capable of doing the things we want it to do) rather than alignment, making (impact) alignment more about not doing stuff we don't want.
Replies from: TurnTrout↑ comment by TurnTrout · 2020-12-28T23:40:42.703Z · LW(p) · GW(p)
Wouldn't outcome-based "not doing bad things" impact alignment still run into that capabilities issue? "Not doing bad things" requires serious capabilities for some goals (e.g. sparse but intially achievable goals).
In any case, you can say "I think that implementing strong capabilities + strong intent alignment is a good instrumental strategy for impact alignment", which seems compatible with the distinction you seek?
↑ comment by TurnTrout · 2020-12-28T23:36:46.075Z · LW(p) · GW(p)
"Bad things don't happen" and "good things happen" seem quite different, e.g. a rock is Evan-aligned but not Alex-impact-aligned.
To rephrase: Alex(/Critch)-impact-alignment is about (strictly) increasing value, non-obstruction is about non-strict value increase, and Evan-alignment is about not taking actions we would judge to significantly decrease value (making it more similar to non-obstruction, except wrt our expectations about the consequences of actions).
I'd also like to flag that Evan's definition involves (hypothetical) humans evaluating the actions, while my definition involves evaluating the outcomes. Whenever we're reasoning about non-trivial scenarios using my definition, though, it probably doesn't matter. That's because we would have to reason using our beliefs about the consequences of different kinds of actions.
However, the different perspectives might admit different kinds of theorems, and we could perhaps reason using those, and so perhaps the difference matters after all.
comment by Joe Collman (Joe_Collman) · 2021-02-03T17:14:54.420Z · LW(p) · GW(p)
I just saw this recently. It's very interesting, but I don't agree with your conclusions (quite possibly because I'm confused and/or overlooking something). I posted a response here [AF · GW].
The short version being:
Either I'm confused, or your green lines should be spikey.
Any extreme green line spikes within S will be a problem.
Pareto is a poor approach if we need to deal with default tall spikes.
comment by adamShimi · 2020-11-22T20:24:27.130Z · LW(p) · GW(p)
Nice post, I like the changes you did from the last draft I read. I also like the use of the new prediction function. Do you intend to do something with the feedback (Like a post, or a comment)?
Replies from: TurnTrout↑ comment by TurnTrout · 2020-11-22T21:25:13.491Z · LW(p) · GW(p)
Do I intend to do something with people's predictions? Not presently, but I think people giving predictions is good both for the reader (to ingrain the concepts by thinking things through enough to provide a credence / agreement score) and for the community (to see where people stand wrt these ideas).
comment by Rohin Shah (rohinmshah) · 2020-12-28T21:53:33.886Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
The <@Reframing Impact sequence@>(@Reframing Impact - Part 1@) suggests that it is useful to think about how well we could pursue a _range_ of possible goals; this is called the _attainable utility (AU) landscape_. We might think of a superintelligent AI maximizing utility function U as causing this landscape to become “spiky” -- the value for U will go up, but the value for all other goals will go down. If we get this sort of spikiness for an incorrect U, then the true objective will have a very low value.
Thus, a natural objective for AI alignment research is to reduce spikiness. Specifically, we can aim for _non-obstruction_: turning the AI on does not decrease the attainable utility for _any_ goal in our range of possible goals. Mild optimization (such as [quantilization](https://intelligence.org/files/QuantilizersSaferAlternative.pdf) ([AN #48](https://mailchi.mp/3091c6e9405c/alignment-newsletter-48))) reduces spikiness by reducing the amount of optimization that an AI performs. Impact regularization aims to find an objective that when maximized does not lead to too much spikiness.
One particular strategy for non-obstruction would be to build an AI system that does not manipulate us, and allows us to correct it (i.e. modify its policy). Then, no matter what our goal is, if the AI system starts to do things we don’t like, we would be able to correct it. As a result, such an AI system would be highly non-obstructive. This property where we can correct the AI system is [corrigibility](https://intelligence.org/2014/10/18/new-report-corrigibility/). Thus, corrigibility can be thought of as a particular strategy for achieving non-obstruction.
It should be noted that all of the discussion so far is based on _actual outcomes in the world_, rather than what the agent was trying to do. That is, all of the concepts so far are based on _impact_ rather than _intent_.
Planned opinion:
Replies from: TurnTroutNote that the explanation of corrigibility given here is in accord with the usage in [this MIRI paper](https://intelligence.org/2014/10/18/new-report-corrigibility/), but not to the usage in the <@iterated amplification sequence@>(@Corrigibility@), where it refers to a broader concept. The broader concept might roughly be defined as “an AI is corrigible when it leaves its user ‘in control’”; see the linked post for examples of what ‘in control’ involves. (Here also you can have both an impact- and intent-based version of the definition.)
On the model that AI risk is caused by utility maximizers pursuing the wrong reward function, I agree that non-obstruction is a useful goal to aim for, and the resulting approaches (mild optimization, low impact, corrigibility as defined here) make sense to pursue. I <@do not like this model much@>(@Conclusion to the sequence on value learning@), but that’s (probably?) a minority view.
↑ comment by TurnTrout · 2020-12-28T22:57:42.718Z · LW(p) · GW(p)
I'm somewhat surprised you aren't really echoing the comment you left at the top of the google doc wrt separation of concerns. I think this is a good summary, though.
On the model that AI risk is caused by utility maximizers pursuing the wrong reward function, I agree that non-obstruction is a useful goal to aim for, and the resulting approaches (mild optimization, low impact, corrigibility as defined here) make sense to pursue.
Why do you think the concept's usefulness is predicated on utility maximizers pursuing the wrong reward function? The analysis only analyzes the consequences of some AI policy.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-12-29T17:31:27.107Z · LW(p) · GW(p)
I'm somewhat surprised you aren't really echoing the comment you left at the top of the google doc wrt separation of concerns.
Reproducing the comment I think you mean here:
As an instrumental strategy we often talk about reducing "make AI good" to "make AI corrigible", and we can split that up:
1. "Make AI good for our goals"
But who knows what our goals are, and who knows how to program a goal into our AI system, so let's instead:2. "Make AI that would be good regardless of what goal we have"
(I prefer asking for an AI that is good rather than an AI that is not-bad; this is effectively a definition of impact alignment.)
But who knows how to get an AI to infer our goals well, so let's:3. "Make AI that would preserve our option value / leave us in control of which goals get optimized for in the future"
Non-obstructiveness is one way we could formalize such a property in terms of outcomes, though I feel like "preserve our option value" is a better one.
In contrast, Paul-corrigibility is not about an outcome-based property, but instead about how a mind might be designed such that it likely has that property regardless of what environment it is in.
I suspect that the point about not liking the utility maximization model is upstream of this. For example, I care a lot about the fact intent-based methods can (hopefully) be environment-independent, and see this as a major benefit; but on the utility maximization model it doesn't matter.
But also, explaining this would be a lot of words, and still wouldn't really do the topic justice; that's really the main reason it isn't in the newsletter.
Why do you think the concept's usefulness is predicated on utility maximizers pursuing the wrong reward function? The analysis only analyzes the consequences of some AI policy.
I look at the conclusions you come to, such as "we should reduce spikiness in AU landscape", and it seems to me that approaches that do this sort of thing (low impact, mild optimization) make more sense in the EU maximizer risk model than the one I usually use (which unfortunately I haven't written up anywhere). You do also mention intent alignment as an instrumental strategy for non-obstruction, but there I disagree with you -- I think intent alignment gets you a lot more than non-obstruction; it gets you a policy that actually makes your life better (as opposed to just "not worse").
I'm not claiming that the analysis is wrong under other risk models, just that it isn't that useful.
Replies from: TurnTrout↑ comment by TurnTrout · 2020-12-29T19:03:05.775Z · LW(p) · GW(p)
For example, I care a lot about the fact intent-based methods can (hopefully) be environment-independent, and see this as a major benefit; but on the utility maximization model it doesn't matter.
I think this framework also helps motivate why intent alignment is desirable: for a capable agent, the impact alignment won't dependent as much on the choice of environment. We're going to have uncertainty about the dynamics of the 2-player game we use to abstract and reason about the task at hand, but intent alignment would mean that doesn't matter as much. This is something like "to reason using the AU landscape, you need fewer assumptions about how the agent works as long as you know it's intent aligned."
But this requires stepping up a level from the model I outline in the post, which I didn't do here for brevity.
(Also, my usual mental model isn't really 'EU maximizer risk -> AI x-risk', it's more like 'one natural source of single/single AI x-risk is the learned policy doing bad things for various reasons, one of which is misspecification, and often EU maximizer risk is a nice frame for thinking about that')
You do also mention intent alignment as an instrumental strategy for non-obstruction, but there I disagree with you -- I think intent alignment gets you a lot more than non-obstruction; it gets you a policy that actually makes your life better (as opposed to just "not worse").
This wasn't the intended takeaway; the post reads:
Intent alignment: avoid spikiness by having the AI want to be flexibly aligned with us and broadly empowering.
This is indeed stronger than non-obstruction.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-12-29T19:46:35.594Z · LW(p) · GW(p)
This wasn't the intended takeaway
Oh whoops, my bad. Replace "intent alignment" with "corrigibility" there. Specifically, the thing I disagree with is:
Corrigibility is an instrumental strategy for inducing non-obstruction in an AI.
As with intent alignment, I also think corrigibility gets you more than non-obstruction.
(Although perhaps you just meant the weaker statement that corrigibility implies non-obstruction?)
I think this framework also helps motivate why intent alignment is desirable: for a capable agent, the impact alignment won't dependent as much on the choice of environment. We're going to have uncertainty about the dynamics of the 2-player game we use to abstract and reason about the task at hand, but intent alignment would mean that doesn't matter as much. This is something like "to reason using the AU landscape, you need fewer assumptions about how the agent works as long as you know it's intent aligned."
But this requires stepping up a level from the model I outline in the post, which I didn't do here for brevity.
I think I agree with all of this, but I feel like it's pretty separate from the concepts in this post? Like, you could have written this paragraph to me before I had ever read this post and I think I would have understood it.
(Here I'm trying to justify my claim that I don't expect the concepts introduced in this post to be that useful in non-EU-maximizer risk models.)
(Also, my usual mental model isn't really 'EU maximizer risk -> AI x-risk', it's more like 'one natural source of single/single AI x-risk is the learned policy doing bad things for various reasons, one of which is misspecification, and often EU maximizer risk is a nice frame for thinking about that')
Yes, I also am not a fan of "misspecification of reward" as a risk model; I agree that if I did like that risk model, the EU maximizer model would be a nice frame for it.
(If you mean misspecification of things other than the reward, then I probably don't think EU maximizer risk is a good frame for thinking about that.)
Replies from: TurnTrout↑ comment by TurnTrout · 2020-12-29T21:38:33.949Z · LW(p) · GW(p)
As with intent alignment, I also think corrigibility gets you more than non-obstruction. (Although perhaps you just meant the weaker statement that corrigibility implies non-obstruction?)
This depends what corrigibility means here. As I define it in the post, you can correct the AI without being manipulated-corrigibility gets you non-obstruction at best, but it isn't sufficient for non-obstruction:
... the AI moves so fast that we can’t correct it in time, even though it isn’t inclined to stop or manipulate us. In that case, corrigibility isn’t enough, whereas non-obstruction is.
If you're talking about Paul-corrigibility, I think that Paul-corrigibility gets you more than non-obstruction because Paul-corrigibility seems like it's secretly just intent alignment, which we agree is stronger than non-obstruction:
Replies from: rohinmshahPaul Christiano named [this concept] the "basin of corrigibility", but I don't like that name because only a few of the named desiderata actually correspond to the natural definition of "corrigibility." This then overloads "corrigibility" with the responsibilities of "intent alignment."
↑ comment by Rohin Shah (rohinmshah) · 2020-12-29T22:13:45.350Z · LW(p) · GW(p)
As I define it in the post, you can correct the AI without being manipulated-corrigibility gets you non-obstruction at best, but it isn't sufficient for non-obstruction
I agree that fast-moving AI systems could lead to not getting non-obstruction. However, I think that as long as AI systems are sufficiently slow, corrigibility usually gets you "good things happen", not just "bad things don't happen" -- you aren't just not obstructed, the AI actively helps, because you can keep correcting it to make it better aligned with you.
For a formal version of this, see Consequences of Misaligned AI (will be summarized in the next Alignment Newsletter), which proves that in a particular model of misalignment that (there is a human strategy where) your-corrigibility + slow movement guarantees that the AI system leads to an increase in utility, and your-corrigibility + impact regularization guarantees reaching the maximum possible utility in the limit.
Replies from: TurnTrout↑ comment by TurnTrout · 2020-12-29T22:29:38.281Z · LW(p) · GW(p)
I agree that fast-moving AI systems could lead to not getting non-obstruction. However, I think that as long as AI systems are sufficiently slow, corrigibility usually gets you "good things happen", not just "bad things don't happen" -- you aren't just not obstructed, the AI actively helps, because you can keep correcting it to make it better aligned with you.
I think I agree with some claim along the lines of "corrigibility + slowness + [certain environmental assumptions] + ??? => non-obstruction (and maybe even robust weak impact alignment)", but the "???" might depend on the human's intelligence, the set of goals which aren't obstructed, and maybe a few other things. So I'd want to think very carefully about what these conditions are, before supposing the implication holds in the cases we care about.
I agree that that paper is both relevant and suggestive of this kind of implication holding in a lot of cases.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-12-29T23:55:36.460Z · LW(p) · GW(p)
Yeah, I agree with all of that.
comment by Donald Hobson (donald-hobson) · 2021-02-04T23:56:38.129Z · LW(p) · GW(p)
This definition of a non-obstructionist AI takes what would happen if it wasn't switched on as the base case.
This can give weird infinite hall of mirrors effects if another very similar non-obstructionist AI would have been switched on, and another behind them. (Ie a human whose counterfactual behaviour on AI failure is to reboot and try again.) This would tend to lead to a kind of fixed point effect, where the attainable utility landscape is almost identical with the AI on and off. At some point it bottoms out when the hypothetical U utility humans give up and do something else. If we assume that the AI is at least weakly trying to maximize attainable utility, then several hundred levels of counterfactuals in, the only hypothetical humans that haven't given up are the ones that really like trying again and again at rebooting the non-obstructionist AI. Suppose the AI would be able to satisfy that value really well. So the AI will focus on the utility functions that are easy to satisfy in other ways, and those that would obstinately keep rebooting in the hypothetical where the AI kept not turning on. (This might be complete nonsense. It seems to make sense to me)
Replies from: TurnTrout↑ comment by TurnTrout · 2021-02-05T00:09:56.027Z · LW(p) · GW(p)
Thanks for leaving this comment. I think this kind of counterfactual is interesting as a thought experiment, but not really relevant to conceptual analysis using this framework. I suppose I should have explained more clearly that the off-state counterfactual was meant to be interpreted with a bit of reasonableness, like "what would we reasonably do if we, the designers, tried to achieve goals using our own power?". To avoid issues of probable civilizational extinction by some other means soon after without the AI's help, just imagine that you time-box the counterfactual goal pursuit to, say, a month.
I can easily imagine what my (subjective) attainable utility would be if I just tried to do things on my own, without the AI's help. In this counterfactual, I'm not really tempted to switch on similar non-obstructionist AIs. It's this kind of counterfactual that I usually consider for AU landscape-style analysis, because I think it's a useful way to reason [? · GW] about how the world is changing.
comment by martinkunev · 2024-06-20T07:39:30.112Z · LW(p) · GW(p)
Some of the image links are broken. Is it possible to fix them?