Power as Easily Exploitable Opportunities
post by TurnTrout · 2020-08-01T02:14:27.474Z · LW · GW · 5 commentsContents
Questions None 5 comments

(Talk given at an event on Sunday 28th of June [LW · GW]. TurnTrout is responsible for the talk, David Lambert edited the transcript.
If you're a curated author and interested in giving a 5-min talk, which will then be transcribed and edited, sign up here.)
TurnTrout: Power [? · GW]and power-seeking [? · GW] play a big part in my thinking about AI alignment, and I think it's also an interesting topic more generally.
Why is this a big deal? Why might we want to think about what power is? What is it, exactly, that people are thinking of when they consider someone as powerful?
Well, it seems like a lot of alignment failures are examples of this power-seeking where the agent is trying to become more capable of achieving its goals, whether that is getting out of its box, taking over the world, or even just refusing correction or a shutdown.

If we tie these together, we have something I've called the catastrophic convergence conjecture [? · GW], which is that if the goals aren't aligned and it causes a catastrophe, it is because of power-seeking.
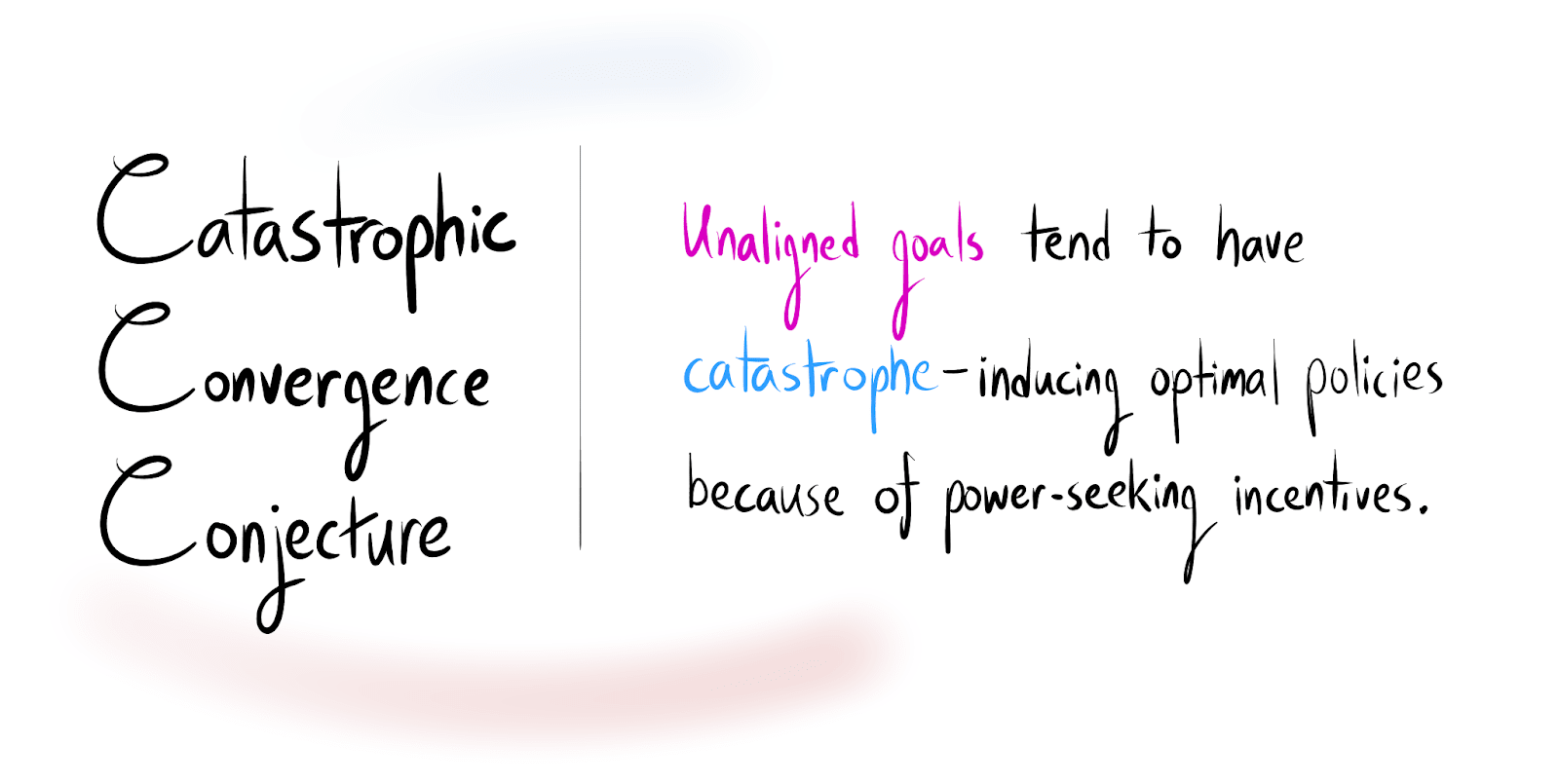
But I think that when people are first considering alignment, they think to themselves, "What's the big deal? You gave it a weird goal, and it does weird stuff. We’ll just fix that.”
So why exactly do unaligned goal maximizers tend to cause catastrophes? I think it's because of this power seeking. Let me explain.
The way I think about power is as the ability to achieve goals in general.

In the literature, this is like the dispositional power-to notion.
Whereas in the past, people thought "Well, in terms of causality, are the agent's actions necessary and/or sufficient to cause a wider range of outcomes?", here, I think it's best thought of as your average ability to optimize a wide range of different goals. So if you formalize this as your average optimal value in, say, a Markov decision process (MDP), there's a lot of nice properties and you can prove that, at least in certain situations, it links up with instrumental convergence. Power seeking and instrumental convergence are very closely related [LW · GW].
But there's a catch here. We're talking about average optimal value. This can be pretty weird. Let's say you're in the unfortunate situation of having a dozen soldiers about to shoot you. How powerful are you according to average optimal value? Well, average optimal value is still probably quite high.
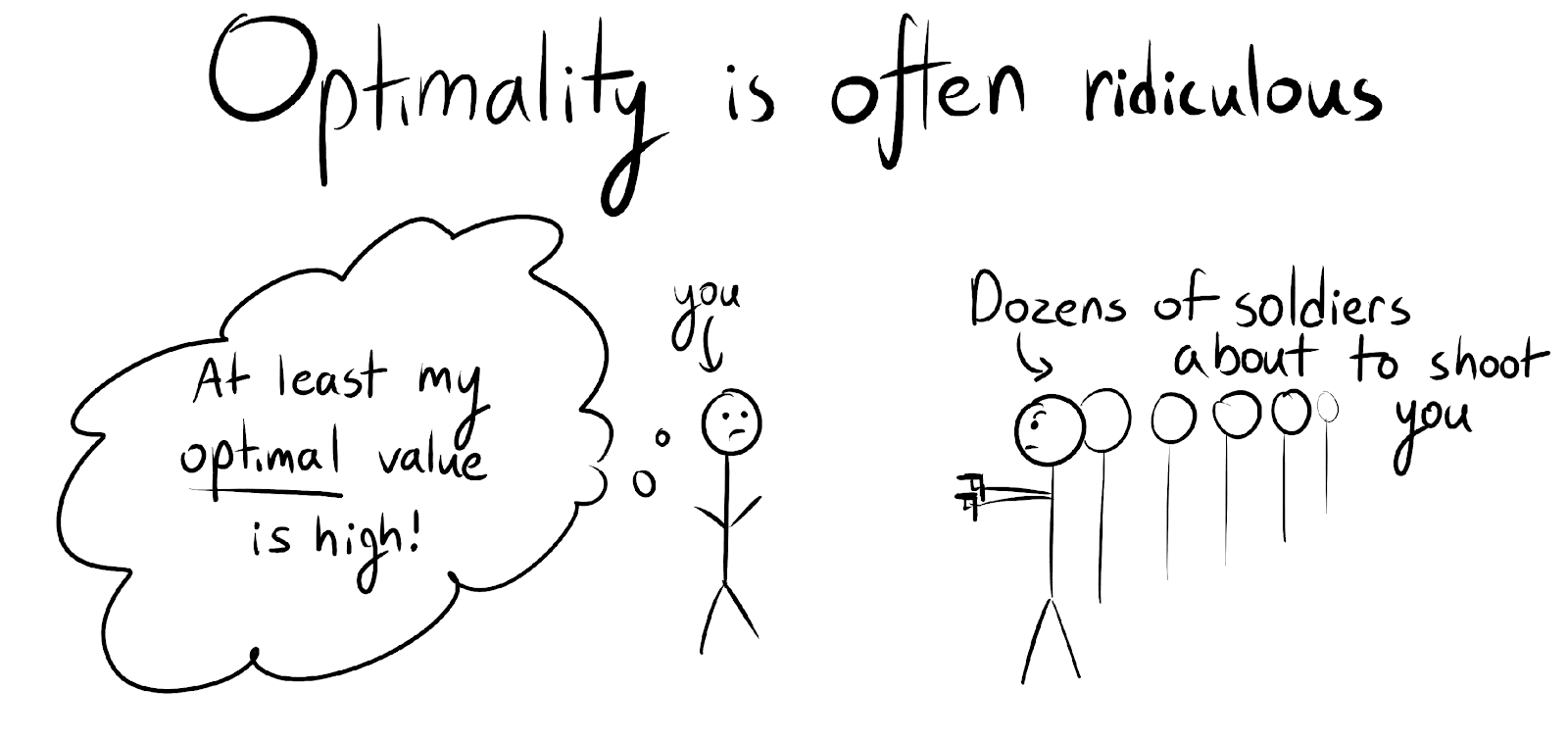
There's probably an adversarial input of strange motor commands you could issue which would essentially incapacitate all the soldiers just because they're looking at you since their brains are not secure systems. So each optimal policy would probably start off with, "I do this weird series of twitches, incapacitate them, and then I just go about achieving my goals."
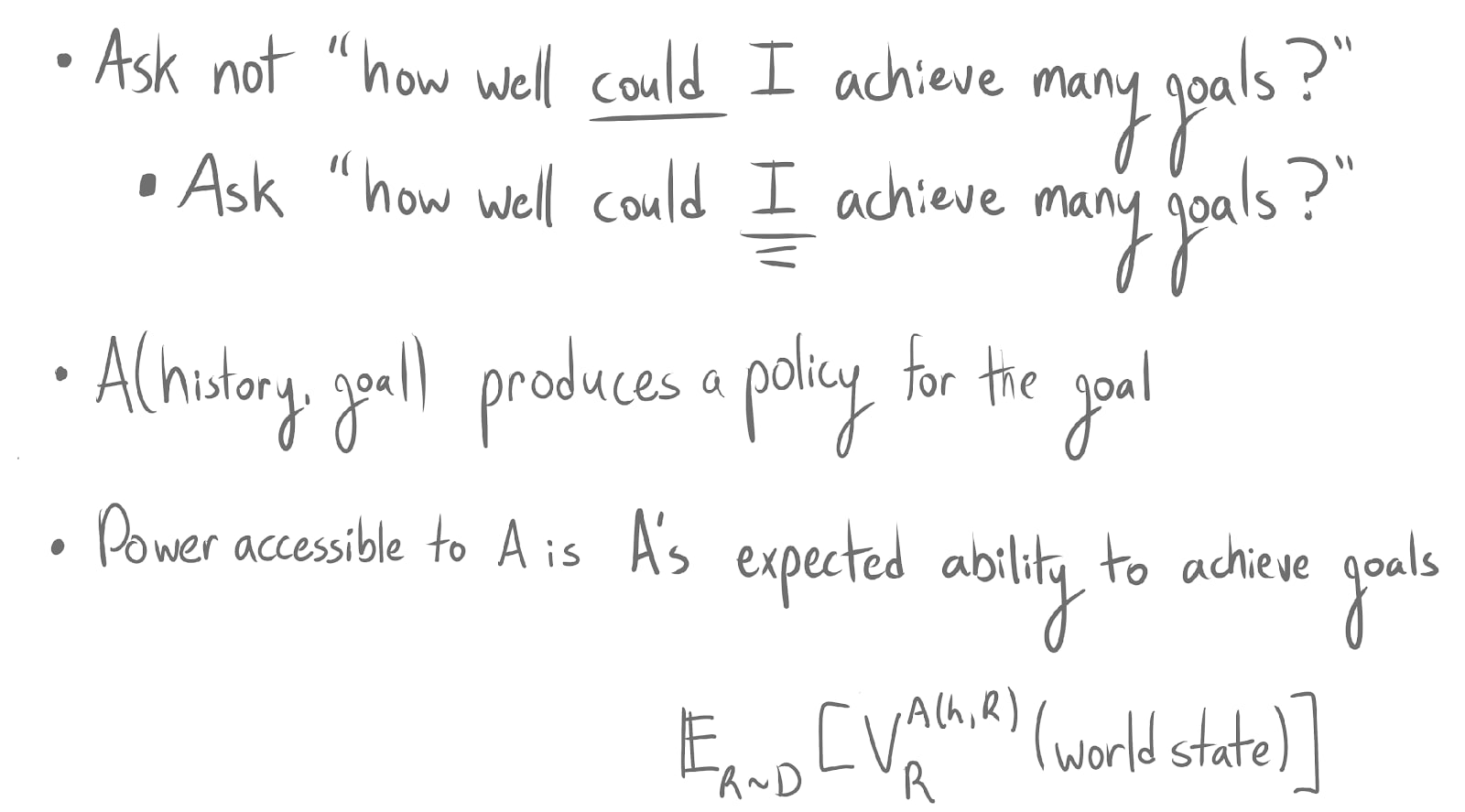
So we'd like to say, “well, your power is actually lowered here in a sense”, or else we’d have to concede that it’s just wholly subjective what people are thinking of when they feel powerful.
My favorite solution is, instead of asking how well could I achieve a bunch of different goals? You should be asking, how well could I achieve many goals?
If you imagine something like a learning algorithm, you could say it's a human level learning algorithm. You give it a history of observations and a goal that it’s optimizing, and it produces a policy, or things that it should do to achieve this goal. You then say, "Well, what's my average ability? What's A's average ability? What's this algorithm's average ability to optimize and to achieve goals in this history, in this situation?"
What I think this does is recover this common sense notion of “you don't have much power here because these aren't cognitively accessible opportunities and policies”. And so essentially, you are disempowered in this situation.

I think understanding this also makes sense of what power means in a universe where everyone is only going to have one course of action. If you view them as running algorithms and then saying, "Well, how well could this learning algorithm achieve different goals in the situation?" I think it might be important to evaluate AI designs by how they respect our power in particular, and so understanding what that means is probably important.
Also, if you want to do better than just hard goal maximization in aligning these AIs, then I think understanding exactly what the rot is at the heart of reward maximization is pretty important as well. Thank you.
Questions
Daniel Filan: If I'm thinking about a learning algorithm like Q-learning or PPO or something, then it makes a lot of sense to think that it's a function of a goal and a history. But in most situations, I tend to think of them as results of learning algorithms.
Take some Atari agent. It trained for a while and now it is like a deployed system. It is playing Atari and it is not manifestly a function of a goal. Maybe it has a goal somewhere in its neural network and you could change some bits and it would have a different follow-up move, but that's not obvious.
So I'm wondering, what do you think of this functional form of agents as functions of histories and goals?
TurnTrout: Good question. I think that when we're making an objection like this, especially before we've solved more issues with embedded agency, we're just going to have to say the following: "If we want to understand what this person is thinking of when they think of power; then I think that even though it might not literally be true, that you could cleanly decompose a person like this, it's still a useful abstraction."
I would agree that if we wanted to actually implement this and say, "Well, we're looking at an agent, and we deduce what its learning algorithm is and what it would mean to have a modular goal input to the algorithm," then you would really need to be worried about this. But my perspective, at least for right now in this early stage, is that it's more of a conceptual tool. But I agree, you can split up a lot of agents like this.
Ben Pace: I'm curious if you have any more specific ideas for measuring which policies are currently attainable by a particular agent or algorithm — the notion of “attainability” felt like it was doing a lot of work.
TurnTrout: I think the thing we're assuming here is, imagine you have an algorithm that is about as intelligent, with respect to the Legg-Hutter metric or some other more common-sense notion, as a human. Imagine you can give it a bunch of different reward function inputs. I think this is a good way of quantifying this agent’s power. But you’re asking how we get this human level algorithm?
Ben Pace: Yes. It just sounded like you said, "In this situation, the human agent, in principle, has an incredible amount of power because there is a very specific thing you can do." But to actually measure its impact, you have to talk about the space of actual operations that it can find or something.
And I thought, "I don't have a good sense of how to define exactly what solutions are findable by a human, and which solutions are not findable by a human." And similarly, you don't know for various AIs how to think about which ones are findable. Because at some point, some AI gets to do some magical wireheading thing, and there's some bridge it crosses where you realize that you could probably start taking more control in the world or something. I don't quite know how to measure when those things become attainable.
TurnTrout: There are a couple ways you can pose constraints through this framework, and one would be only giving it a certain amount of history. You're not giving infinite data.
Another one would be trying to get some bounded cognition into the algorithm by just having it stop searching after a certain amount of time.
I don't have clean answers for this yet, but I agree. These are good things to think about.
habryka: One thing that I've been most confused about for the formalism for power that you've been thinking about, is that you do this averaging operation on your utility function. But averaging over a space is not a free operation. You need some measure on the space from which you sample.
It feels to me like, power only appears when you choose a very specific measure over the space of utility functions. For example, if I sub-sample from the space of utility functions that are extremely weird and really like not being able to do things, it will only care about shutting itself off rather than whether it's going to get any power-seeking behavior.
So am I misunderstanding things? Is this true?
TurnTrout: The approach I’ve taken, like in my recent paper, for example, is to assume you’re in some system with finite states. You then take, for example, the MaxEnt distribution over reward functions or you assume that reward is, at least, IID over states. You then get a neutrality where I don't think you need a ton of information about what the reasonable goals you should pursue are.
I think if you just take a MaxEnt distribution, you'll recover the normal notion of power. But if you're talking about utility functions, then because there's infinitely many, it's like, "Well, what's the MaxEnt distribution over that?"
And so far, the theorems are about just finite MDPs. And if you're only talking about finding MDPs and not some kind of universal prior, then you don't need to worry about it being malign.
Rob Miles: Something I'm a little unclear on is how this can ever change over time. I feel like that's something you want to say. Right now, you're in the box. And then if you get out of the box, you have more power because now there's a path that you're able to follow.
But if you are in the box and you can think of a good plan for getting out, isn't there a sense that you already have that power? Because you're aware of a plan that gets you what you want via getting out of the box? How do you separate power now from the potential for power in the future?
TurnTrout: Good question. This is the big issue: thinking about power in terms of optimal value. If you have an agent that has consistent beliefs about the future, you're not going to expect to gain more.
If you're trying to maximize your power, you're not going to expect, necessarily, to increase your power just due to conservation of expected evidence. But if things happen to you and you're surprised by them, then you see yourself losing or gaining power, especially if you're not optimal.
So if it's too hard for me to get out of the box or I think it's too hard, but then someone lets me out, only after that would I see myself as having a lot more power.
5 comments
Comments sorted by top scores.
comment by Pattern · 2020-08-02T02:05:11.176Z · LW(p) · GW(p)
There's probably an adversarial input of strange motor commands you could issue which would essentially incapacitate all the soldiers just because they're looking at you since their brains are not secure systems.
What?
Replies from: TurnTrout, habryka4, zachary-robertson↑ comment by habryka (habryka4) · 2020-08-02T04:42:51.792Z · LW(p) · GW(p)
Seems plausible to me, though I am not sure whether I would say probable. If you could do something like backprop through the human mind, then I think I can imagine outcomes similar to this:
↑ comment by Past Account (zachary-robertson) · 2020-08-02T12:16:41.157Z · LW(p) · GW(p)
[Deleted]
comment by Gurkenglas · 2020-08-01T13:03:50.608Z · LW(p) · GW(p)
SOTA: Penalize my action by how well a maximizer that takes my place after the action would maximize a wide variety of goals.
If we use me instead of the maximizer, paradoxes of self-reference arise that we can resolve by inserting a modal operator: Penalize my action by how well I expect I would maximize a wide variety of goals (if given that goal). Then when considering the action of stepping towards an omnipotence button, I would expect that given that I decided to take one step, I would take more, and therefore penalize the first step a lot. Except if there's plausible deniability, because the first step towards the button is also a first step towards my concrete goal, because then I might still expect to be bound by the penalty.
I've suggested using myself before in the last sentence of this comment: https://www.lesswrong.com/posts/mdQEraEZQLg7jtozn/subagents-and-impact-measures-full-and-fully-illustrated?commentId=WGWtoKDrnN3o6cS6G [LW(p) · GW(p)]