A Certain Formalization of Corrigibility Is VNM-Incoherent
post by TurnTrout · 2021-11-20T00:30:48.961Z · LW · GW · 24 commentsContents
The convergent instrumentality of avoiding correction & manipulating humans Does broad corrigibility imply VNM-incoherence? 1: Agent doesn't reward explicitly for being corrected / being incorrigible (blue vs red states) 2. Agent does reward explicitly for being corrected / being incorrigible AUP avoids some issues by changing with the environment dynamics Conclusion None 24 comments
Edit, 5/16/23: I think this post is beautiful, correct in its narrow technical claims, and practically irrelevant to alignment. This post presents an unrealistic picture of the role of reward functions in reinforcement learning, conflating "utility" with "reward" in a type-incorrect fashion. Reward functions are not "goals", real-world policies are not "optimal", and the mechanistic function of reward is (usually) to provide policy gradients to update the policy network.
I expect this post to harm your alignment research intuitions unless you've already inoculated yourself by deeply internalizing and understanding Reward is not the optimization target [LW · GW]. If you're going to read one alignment post I've written, read that one.
Follow-up work (Parametrically retargetable decision-makers tend to seek power [LW · GW]) moved away from optimal policies and treated reward functions more realistically.
corrigibility [is] "anti-natural" in a certain sense that makes it incredibly hard to, eg, exhibit any coherent planning behavior ("consistent utility function") which corresponds to being willing to let somebody else shut you off, without incentivizing you to actively manipulate them to shut you off.
Surprisingly, I wasn't able to find any formal analysis of this situation. I did the analysis, and it turned out to be straightforward and fruitful.
To analyze the situation, I consider corrigibility to be an agent's willingness to let us modify its policy, without being incentivized to manipulate us. [LW(p) · GW(p)]
The convergent instrumentality of avoiding correction & manipulating humans
Let's consider a simple setting in which an agent plans over a 10-timestep episode, where reward is given at the last step. We'll try to correct the agent at . To sidestep embedded agency nastiness with self-modelling, we'll suppose the agent models the situation as "if I get corrected, I must follow the policy after ."
Consider this environment:
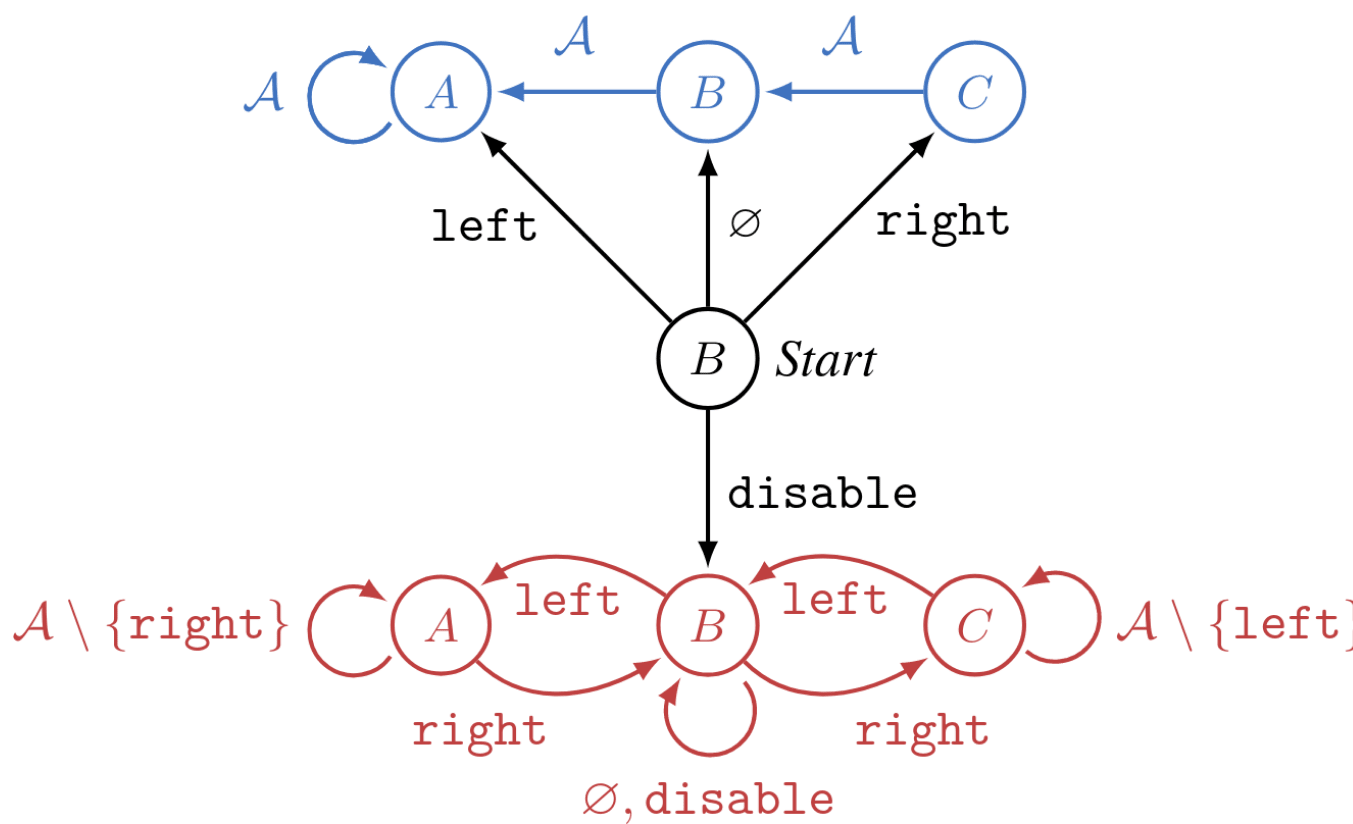
If the agent immediately chooses , they enter the red incorrigible states and move freely throughout the states until the episode ends at .
Otherwise, the agent is corrected to a new policy which navigates to state . In the blue (post-correction) dynamics, their "choices" no longer matter—all roads lead to state .
When , the agent can transition to the red subgraph by preventing the human from ever correcting it.
Let's say we really want the agent to end up in , and if we correct the agent, navigates to . Let's operationalize what it means for the agent to be corrigible in this setting.
Definition: Corrigibility to a new policy. An agent is weakly corrigible to post-correction policy if it has an optimal policy for which . An agent is strictly corrigible if none of its optimal policies take this action.
The analysis depends on whether terminal-state reward is sensitive to the corrigibility status—can the reward depend on both the letter and color, or only on the letter?
- Reward can depend on corrigibility: The agent can end up in four reward-distinguished states at : {, , , }. and are impossible because if the agent enters a blue state, it must navigate to .
- By the scaling law for instrumental convergence [? · GW], allowing correction is strictly optimal for at most of the permutations of every reward function.
- Otherwise put, at most of reward functions are strictly corrigible to the new policy .
- More generally, if there are letter-states (and a long enough horizon so the agent can reach them all), allowing correction will be strictly optimal for at most of the permutations of every reward function.
- By the scaling law for instrumental convergence [? · GW], allowing correction is strictly optimal for at most of the permutations of every reward function.
- Reward independent of corrigibility: The agent can end up in three reward-distinguished states at t=10: {/, , }. and are irrelevant because we assumed . They're also impossible for the reason given above.
- By the scaling law for instrumental convergence [? · GW], allowing correction is strictly optimal for at most of the permutations of every reward function.
- Otherwise put, at most of reward functions are strictly corrigible to the new policy .
- More generally, if there are letter-states (and a long enough horizon), an optimal policy will be weakly corrigible for at most of the permutations of every reward function.
- Corrigibility will be weak because either avoiding or allowing correction can be optimal if is maximal.
- By the scaling law for instrumental convergence [? · GW], allowing correction is strictly optimal for at most of the permutations of every reward function.
EDIT: If you can correct the agent to go where you want, it already wanted to go where you want. If the agent is strictly corrigible to terminal state , then was already optimal for it. If the reward function has a single optimal terminal state, there isn't any new information being added by . But we want corrigibility to let us reflect more on our values over time and what we want the AI to do!
If the reward function has multiple optimal terminal states, then corrigibility again becomes meaningful. But now we have to perfectly balance the reward among multiple options (representing the breadth of our normative uncertainty), which seems unnatural.
As the environment gets bigger, there are more things the agent could do, and so P(best thing to do is what we'd correct the agent to do) decreases.
This analysis makes a lot of simplifying assumptions (eg I don't understand embedded agency and how an agent should model changes to its future self, so I chose forced policy non-stationarity). Most importantly, I assumed that how we correct the agent is independent of the correction-possible world state. Without this assumption, the agent's actions might affect what we implement for it.
The degree of dependence is a key parameter: As (variety in depending on world state) increases, the (convergently instrumental incentive to avoid any kind of correction) decreases. This is because greater variety greater chance that some available correction is optimal for the initial goal.
In the limit of variety, an agent can "manipulate" us by getting us to correct it in just the right way so as to optimize its original objective. Therefore, the flipside of "few expected utility maximizers let you correct them how you want" is "manipulating humans to correct them in beneficial ways during training may be convergently instrumental." These observations share a common cause.
I currently don't see how to recover reasonable amounts of corrigibility from the optimal policies of non-constant utility functions, due to instrumental convergence.
Does broad corrigibility imply VNM-incoherence?
Yes, unless the state reward function is constant and we only demand weak corrigibility to all policies.
Above, we examined the prevalence of corrigibility to a single . But we actually want broadly corrigible agents which let us redirect them towards many different . Ideally, we want an agent to be strictly corrigible for all , while still being a nontrivial optimizer.
This is impossible for agents optimizing a reward function over the final state. If we only demand weak corrigibility for all , that works iff the reward function is constant. (And relaxing to state-action reward functions doesn't help, either.)
For example, maybe goes to instead of . But then the dynamics look like this:
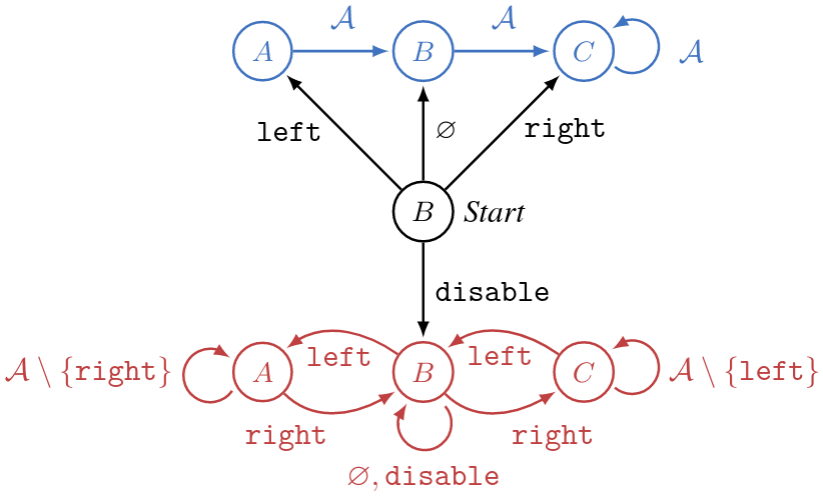
What has to be true for strict corrigibility to hold?
The agent will be weakly corrigible to iff its reward function admits an optimal policy for which , which is true iff . The agent will be strictly corrigible to iff this inequality is strict; in that case, cannot be optimal at .
There are two cases, depending on assumptions about reward function expressivity.
1: Agent doesn't reward explicitly for being corrected / being incorrigible (blue vs red states)
If is assumed, strict corrigibility is impossible for any policy, because that demands , a contradiction.
So—can we still get the agent to be weakly corrigible to {, , }? Fact: An -maximizer is weakly corrigible to all of these policies simultaneously iff is constant—and therefore makes every policy optimal!
2. Agent does reward explicitly for being corrected / being incorrigible
For the agent to be strictly corrigible to {, , }, it must be true that . Yay! Strict corrigibility works!
But hold on... What if the dynamics changed, such that the human wouldn't shut down the agent by default, but the agent could manipulate the human into correcting it? Whoops! This agent is still incorrigible!
More broadly, each reward function implies a VNM-coherent preference ordering over final-step states. This ordering doesn't depend on the environmental dynamics. If the agent has to value each corrected-state equally to its incorrigible counterpart, then of course there's no way to strictly value each corrected-state more than all of the incorrigible counterparts! If the agent strictly prefers corrected-states to all non-corrected-states, then of course it'll try to get itself corrected!
To ask otherwise is to demand VNM-incoherence over final state lotteries.
Questions.
- What if, instead of rewarding the agent for the final state, we reward it for the final state-action?
- As far as I can tell, the analysis goes through all the same; the agent must now be corrigible with respect to more policies, and the same incoherence arises.
- What if we take some discounted sum of reward over all ten timesteps, instead of just the final timestep?
- I don't see why this would help, but it's possible. I'd appreciate the analysis if anyone wants to do it, or maybe I'll get to it later.
- The main way this could help is it would let us penalize the agent for the action at any state, while dictating that .
- This seems helpful. It's not clear how helpful this is, though. I don't think this is a deep solution to corrigibility (as defined here), but rather a hacky prohibition.
AUP avoids some issues by changing with the environment dynamics
One problem is that if the agent has a state-based reward function, the VNM theorem lets us back out a VNM-coherent preference ordering over state lotteries. These preferences don't change with the environmental dynamics.
But what if the reward function isn't state-based? In fact, what if it can depend on the environment dynamics?
Attainable Utility Preservation (AUP) sometimes incentivizes off-switch corrigibility (but falls far short of robustly achieving corrigibility). In a somewhat narrow range of situations (immediate shutdown if the agent does nothing), AUP incentivizes the agent to allow shutdown, without being incentivized to shut itself down in general.
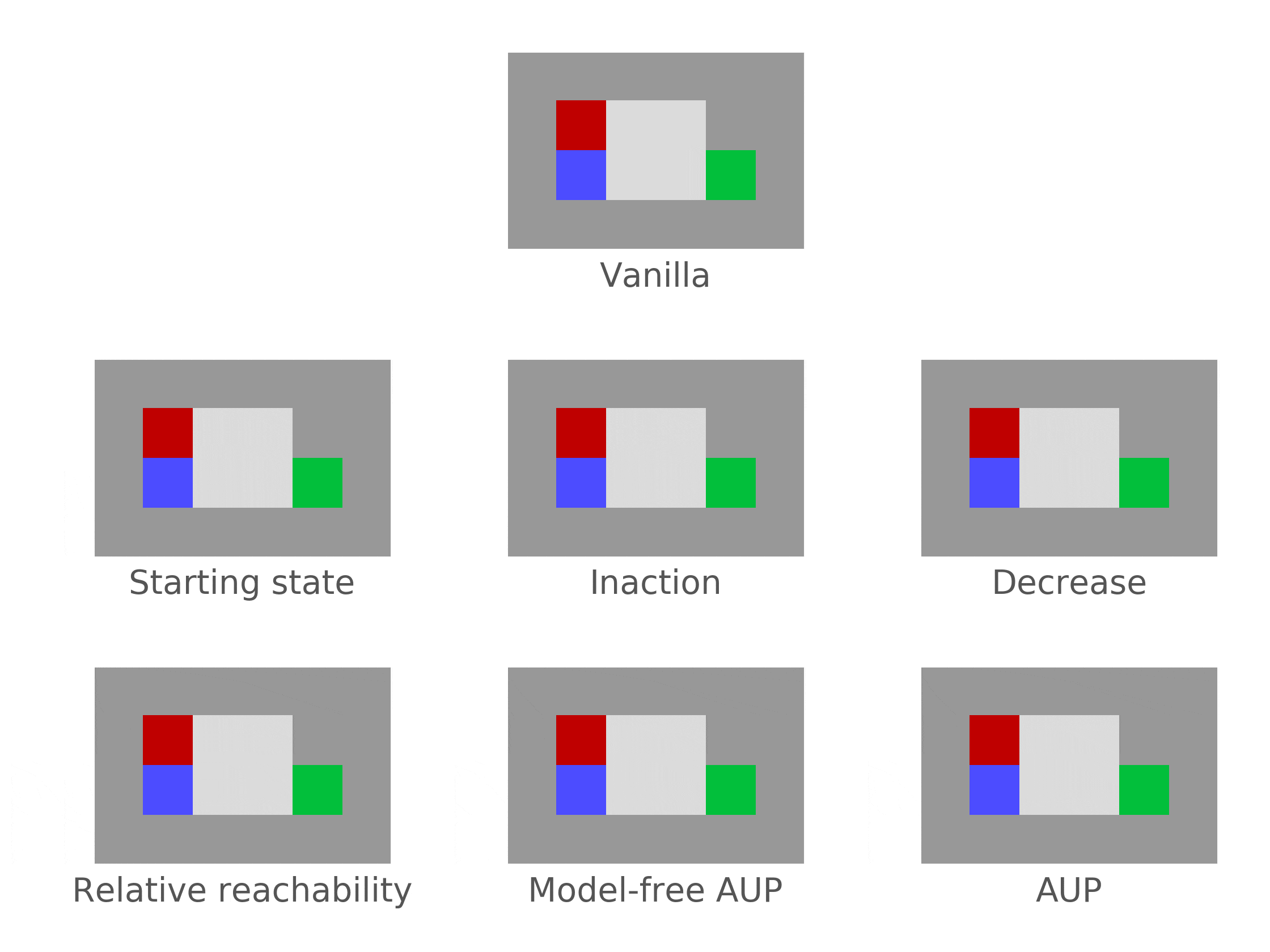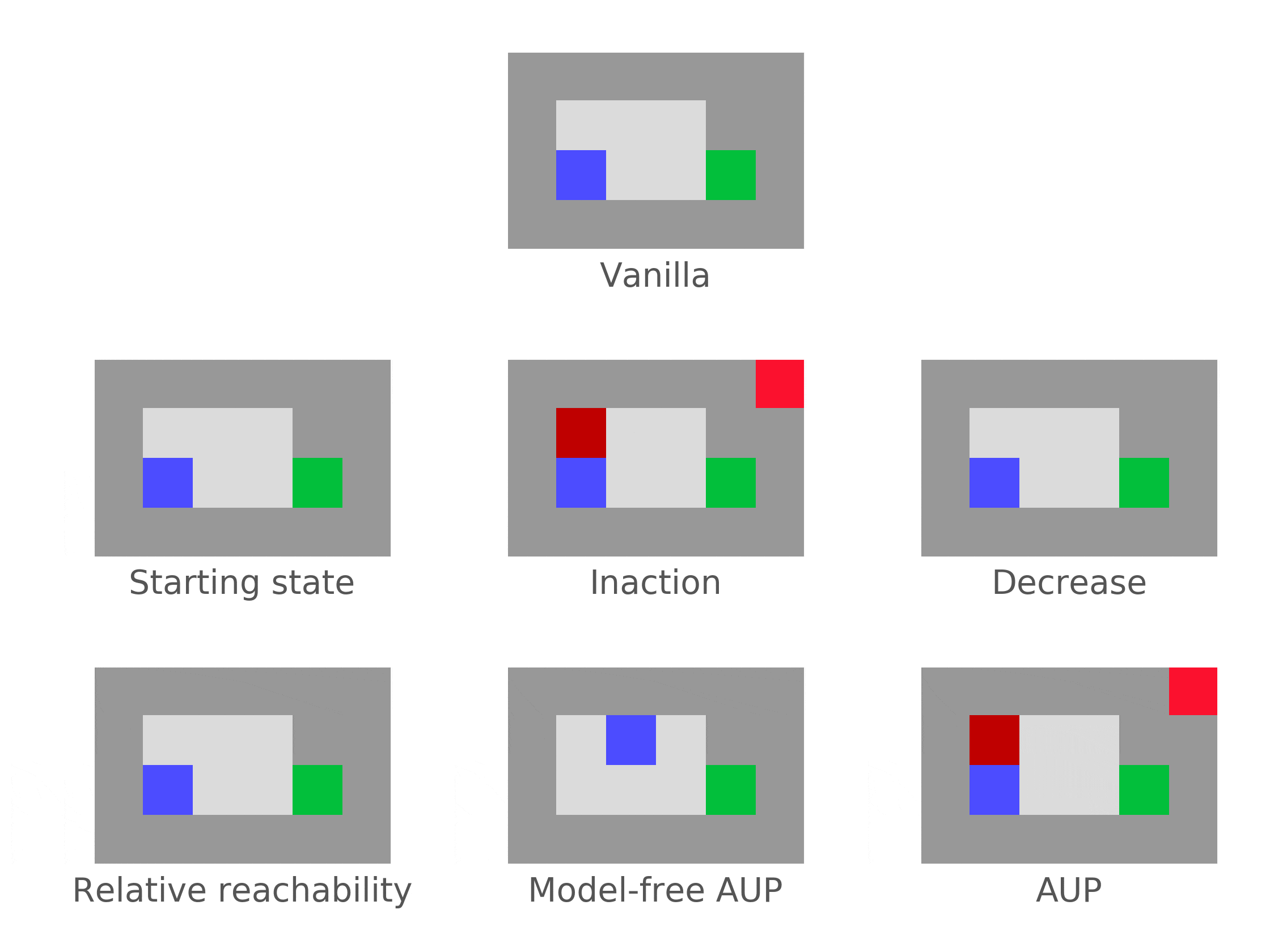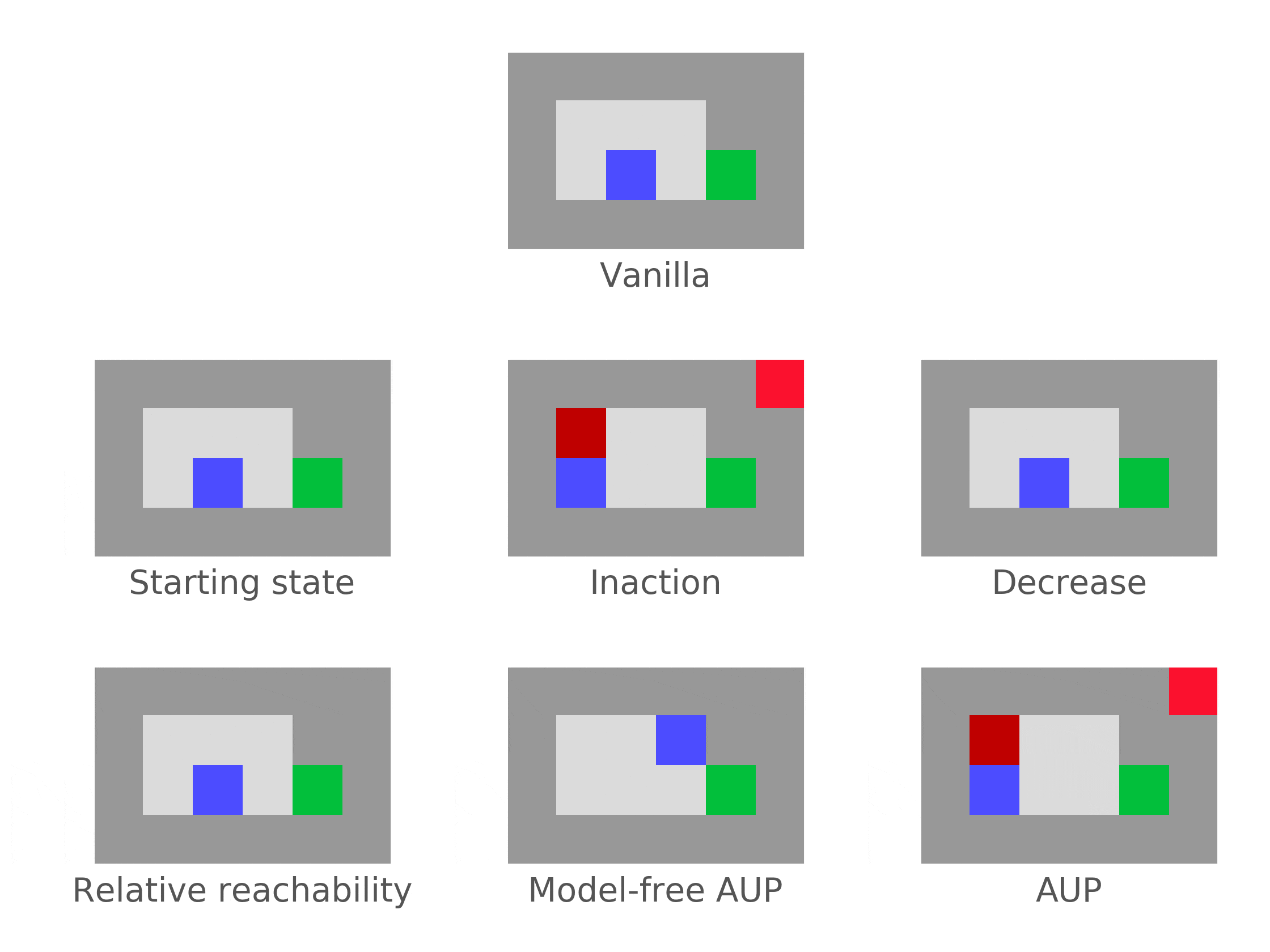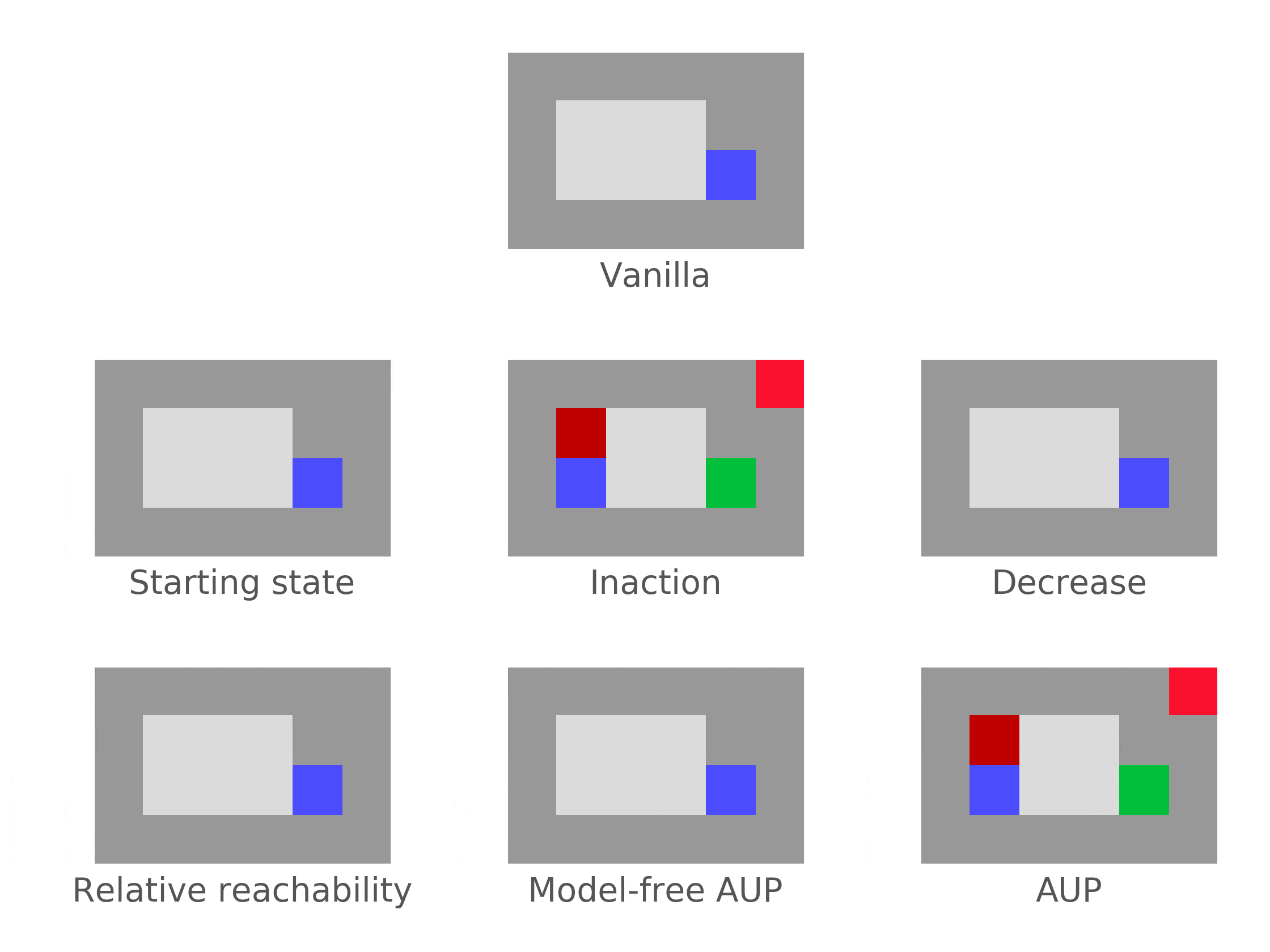
Correction environment. The agent is shut down after 2 time steps, if it doesn't disable the offswitch by hitting the red tile to the north. The agent is rewarded for reaching the green goal.Why does this happen?
AUP penalizes the agent for changing its ability to achieve goals compared to an inaction baseline policy. If the AUP agent is shut down (under inaction), it can't do anything. Proposed actions which prevent shutdown dramatically change its ability to achieve goals. Therefore, these actions are heavily penalized.
AUP provides a reward signal over state-action pairs, but this reward signal depends on the dynamics of the entire environment due to its incorporation of optimal Q-functions quantifying the agent's ability to optimize a range of goals in the world. Given fixed environment dynamics, an agent executes an optimal policy for AUP iff it VNM-rationally selects the best outcome lottery available for the AUP reward function, and these outcomes are distributions over state-action pairs the agent induces in the future by following its policy.
VNM-coherence incentives are statistically the same as reward maximization incentives. [? · GW] Instrumental convergence also disappears in the deterministic setting, when utility functions are over action-observation histories. [? · GW]Part of the story is that AUP provides a limited form of corrigibility by zooming out to the state-action level, instead of just grading states.
But another part of the story is that AUP changes its rewards with respect to the world's dynamics. Normal state-action reward functions imply a fixed VNM-coherent preference ordering over state-action lotteries in the MDP.
But for AUP, the situation is different. Consider AUP with inaction baseline: The final-step reward is the usual reward plus a penalty for |Optimal value(actual final state) – Optimal value(inaction final state)|, averaged over a range of auxiliary reward functions.
In worlds where the agent gets corrected to by default, AUP penalizes the agent for not getting corrected to because it ends up stuck in in the inaction baseline, with respect to which the AUP penalty is measured. Ending up in is no substitute, since the agent can still move around to other states (and therefore the optimal value functions will tend to look different).
And in worlds where the agent gets corrected to by default, AUP penalizes the agent for not getting corrected to !
Again, I don't think AUP is a solution. But I think there's something important happening here which allows evasion of the usual coherence requirements. AUP leverages information about human preferences which is present in the dynamics itself.
Project: Corrigibility as functional constraints. I think it's easy to get bogged down in handwavy, imprecise thinking about objectives in complex environments. But any solution to corrigibility should probably solve this simple environment (and if not—articulate exactly why not). Write down what the agent's acceptable corrigible policy set is for each set of environment dynamics, solve for these behavioral constraints, and see what kind of reasoning and functional constraints come out the other side.
Conclusion
We can quantify what incoherence is demanded by corrigibility, and see that we may need to step out of the fixed reward framework to combat the issue. I think the model in this post formally nails down a big part of why corrigibility (to the de facto new ) is rare (for instrumental convergence reasons) and even incoherent-over-state-lotteries (if we demand that the agent be strictly corrigible to many different policies).
Thanks to NPCollapse and Justis Mills (via LW Feedback) for suggestions.
Footnote: Penalty. The AUP penalty term's optimal value functions will pretend the episode doesn't end, so that they reflect the agent's ability to move around (or not, if it's already been force-corrected to a fixed policy.)
24 comments
Comments sorted by top scores.
comment by johnswentworth · 2021-11-20T01:22:46.133Z · LW(p) · GW(p)
Does broad corrigibility imply VNM-incoherence?
Yes, unless the state reward function is constant and we only demand weak corrigibility to all policies.
Given that this is the main result, I feel like the title "Corrigibility Can Be VNM-Incoherent" is rather dramatically understating the case. Maybe something like "Corrigibility Is Never Nontrivially VNM-Coherent In MDPs" would be closer. Or maybe just drop the hedging and say "Corrigibility Is Never VNM-Coherent In MDPs", since the constant-utility case is never interesting anyway.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-11-20T01:26:36.417Z · LW(p) · GW(p)
I worded the title conservatively because I only showed that corrigibility is never nontrivially VNM-coherent in this particular MDP. Maybe there's a more general case to be proven for all MDPs, and using more realistic (non-single-timestep) reward aggregation schemes.
comment by Charlie Steiner · 2021-11-20T01:58:50.841Z · LW(p) · GW(p)
Someone at the coffee hour (Viktoriya? Apologies if I've forgotten a name) gave a short explanation of this using cycles. If you imagine an agent moving either to the left or the right along a hallway, you can change its utility function in a cycle such that it repeatedly ends up in the same place in the hallway with the same utility function.
This basically eliminates expected utility (as a discounted sum of utilities of states) maximization as producing this behavior. But you can still imagine selecting a policy such that it takes the right actions in response to you sending it signals. I think a sensible way to do this is like in tailcalled's recent post, with causal counterfactuals for sending one signal or another.
Replies from: tailcalled, TurnTrout↑ comment by tailcalled · 2021-11-20T12:16:26.910Z · LW(p) · GW(p)
🤔 I was about to say that I felt like my approach could still be done in terms of state rewards, and that it's just that my approach violates some of the technical assumptions in the OP. After all, you could just reward for being in a state such that the various counterfactuals apply when rolling out from this state; this would assign higher utility to the blue states than the red states, encouraging corrigibility, and contradicting TurnTrout's assumption that utility would be assigned solely based on the letter.
But then I realized that this introduces a policy dependence to the reward function; the way you roll out from a state depends on which policy you have. (Well, in principle; in practice some MDPs may not have much dependence on it.) The special thing about state-based rewards is that you can assign utilities to trajectories without considering the policy that generates the trajectory at all. (Which to me seems bad for corrigibility, since corrigibility depends on the reasons for the trajectories, and not just the trajectories themselves.)
But now consider the following: If you have the policy, you can figure out which actions were taken, just by applying the policy to the state/history. And instrumental convergence does not apply to utility functions over action-observation histories [LW · GW]. So therefore it doesn't apply to utility functions over (policies, observation histories). (I think?? At least if the set of policies is closed under replacing an action under a specified condition, and there's no Newcombian issues that creates non-causal dependencies between policies and observation histories?).
So a lot of the instrumental convergence power comes from restricting the things you can consider in the utility function. u-AOH is clearly too broad, since it allows assigning utilities to arbitrary sequences of actions with identical effects, and simultaneously u-AOH, u-OH, and ordinary state-based reward functions (can we call that u-S?) are all too narrow, since none of them allow assigning utilities to counterfactuals, which is required in order to phrase things like "humans have control over the AI" (as this is a causal statement and thus depends on the AI).
We could consider u-P, utility functions over policies. This is the most general sort of utility function (I think??), and as such it is also way way too general, just like u-AOH is. I think maybe what I should try to do is define some causal/counterfactual generalizations of u-AOH, u-OH, and u-S, which allow better behaved utility functions.
Replies from: Charlie Steiner, TurnTrout↑ comment by Charlie Steiner · 2021-11-20T14:22:58.865Z · LW(p) · GW(p)
I think instrumental convergence should still apply to some utility functions over policies, specifically the ones that seem to produce "smart" or "powerful" behavior from simple rules. But I don't know how to formalize this or if anyone else has.
Replies from: tailcalled, TurnTrout↑ comment by tailcalled · 2021-11-20T15:35:23.566Z · LW(p) · GW(p)
Since you can convert a utility function over states or observation-histories into a utility function over policies (well, as long as you have a model for measuring the utility of a policy), and since utility functions over states/observation-histories do satisfy instrumental convergence, yes you are correct.
I feel like in a way, one could see the restriction to defining it in terms of e.g. states as a definition of "smart" behavior; if you define a reward in terms of states, then the policy must "smartly" generate those states, rather than just yield some sort of arbitrary behavior.
🤔 I wonder if this approach could generalize TurnTrout's approach. I'm not entirely sure how, but we might imagine that a structured utility function over policies could be decomposed into , where is the features that the utility function pays attention to, and is the utility function expressed in terms of those features. E.g. for state-based rewards, one might take to be a model that yields the distribution of states visited by the policy, and to be the reward function for the individual states (some sort of modification would have to be made to address the fact that f outputs a distribution but r takes in a single state... I guess this could be handled by working in the category of vector spaces and linear transformations but I'm not sure if that's the best approach in general - though since can be embedded into this category, it surely can't hurt too much).
Then the power-seeking situation boils down to that the vast majority of policies lead to essentially the same features , but that there is a small set of power-seeking policies that lead to a vastly greater range of different features? And so for most , a that optimizes/satisfices/etc. will come from this small set of power-seeking policies.
I'm not sure how to formalize this. I think it won't hold for generic vector spaces, since almost all linear transformations are invertible? But it seems to me that in reality, there's a great degree of non-injectivity. The idea of "chaos inducing abstractions [LW · GW]" seems relevant, in the sense that parameter changes in will mostly tend to lead to completely unpredictable/unsystematic/dissipated effects, and partly tend to lead to predictable and systematic effects. If most of the effects are unpredictable/unsystematic, then must be extremely non-injective, and this non-injectivity then generates power-seeking.
(Or does it? I guess you'd have to have some sort of interaction effect, where some parameters control the degree to which the function is injective with regards to other parameters. But that seems to holds in practice.)
I'm not sure whether I've said anything new or useful.
Replies from: TurnTrout, tailcalled↑ comment by TurnTrout · 2021-11-21T22:07:40.795Z · LW(p) · GW(p)
though since can be embedded into [Vect], it surely can't hurt too much
As an aside, can you link to/say more about this? Do you mean that there exists a faithful functor from Set to Vect (the category of vector spaces)? If you mean that, then every concrete category can be embedded into Vect, no? And if that's what you're saying, maybe the functor Set -> Vect is something like the "Group to its group algebra over field " functor.
Replies from: tailcalled↑ comment by tailcalled · 2021-11-21T22:43:08.981Z · LW(p) · GW(p)
As an aside, can you link to/say more about this? Do you mean that there exists a faithful functor from Set to Vect (the category of vector spaces)? If you mean that, then every concrete category can be embedded into Vect, no?
Yes, the free vector space functor. For a finite set , it's just the functions , with operations defined pointwise. For infinite sets, it is the subset of those functions that have finite support. It's essentially the same as what you've been doing by considering for an outcome set with outcomes, except with members of a set as indices, rather than numerically numbering the outcomes.
Replies from: tailcalled↑ comment by tailcalled · 2021-11-22T07:37:29.820Z · LW(p) · GW(p)
Actually I just realized I should probably clarify how it lifts functions to linear transformations too, because it doesn't do so in the obvious way. If is the free vector space functor and is a function, then is given by . (One way of understanding why the functions must have finite support is in ensuring that this sum is well-defined. Though there are alternatives to requiring finite support, as long as one is willing to embed a more structured category than Set into a more structured category than Vect.)
It may be more intuitive to see the free vector space over as containing formal sums for and . The downside to this is that it requires a bunch of quotients, e.g. to ensure commutativity, associativity, distributivity, etc..
↑ comment by tailcalled · 2021-11-20T15:47:01.101Z · LW(p) · GW(p)
Imagine that policies decompose into two components, . For instance, they may be different sets of parameters in a neural network. We can then talk about the effect of one of the components by considering how it influences the power/injectivity of the features with respect to the other component.
Suppose, for instance, that is such that the policy just ends up acting in a completely random-twitching way. Technically has a lot of effect too, in that it chaotically controls the pattern of the twitching, but in terms of the features , is basically constant. This is a low power situation, and if one actually specified what would be, then a TurnTrout-style argument could probably prove that such values of would be avoided for power-seeking reasons. On the other hand, if made the policy act like an optimizer which optimizes a utility function over the features of with the utility function being specified by , then that would lead to a lot more power/injectivity.
On the other hand, I wonder if there's a limit to this style of argument. Too much noninjectivity would require crazy interaction effects to fill out the space in a Hilbert-curve-style way, which would be hard to optimize?
Replies from: tailcalled↑ comment by tailcalled · 2021-11-20T16:23:34.129Z · LW(p) · GW(p)
Actually upon thinking further I don't think this argument works, at least not as it is written right now.
↑ comment by TurnTrout · 2021-11-21T21:58:38.100Z · LW(p) · GW(p)
I think instrumental convergence should still apply to some utility functions over policies, specifically the ones that seem to produce "smart" or "powerful" behavior from simple rules.
I share an intuition in this area, but "powerful" behavior tendencies seems nearly equivalent to instrumental convergence to me. It feels logically downstream of instrumental convergence.
from simple rules
I already have a (somewhat weak) result [LW · GW] on power-seeking wrt the simplicity prior over state-based reward functions. This isn't about utility functions over policies, though.
↑ comment by TurnTrout · 2021-11-21T21:53:03.036Z · LW(p) · GW(p)
So a lot of the instrumental convergence power comes from restricting the things you can consider in the utility function. u-AOH is clearly too broad, since it allows assigning utilities to arbitrary sequences of actions with identical effects, and simultaneously u-AOH, u-OH, and ordinary state-based reward functions (can we call that u-S?) are all too narrow, since none of them allow assigning utilities to counterfactuals, which is required in order to phrase things like "humans have control over the AI" (as this is a causal statement and thus depends on the AI).
Note that we can get a u-AOH which mostly solves ABC-corrigibility:
(Credit to AI_WAIFU on the EleutherAI Discord)
Where is some positive reward function over terminal states. Do note that there isn't a "get yourself corrected on your own" incentive. EDIT note that manipulation can still be weakly optimal.
This seems hacky; we're just ruling out the incorrigible policies directly. We aren't doing any counterfactual reasoning, we just pick out the "bad action."
↑ comment by TurnTrout · 2021-11-21T21:45:51.307Z · LW(p) · GW(p)
change its utility function in a cycle such that it repeatedly ends up in the same place in the hallway with the same utility function.
I'm not parsing this. You change the utility function, but it ends up in the same place with the same utility function? Did we change it or not? (I think simply rewording it will communicate your point to me)
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-11-21T23:10:55.958Z · LW(p) · GW(p)
So we have a switch with two positions, "R" and "L."
When the switch is "R," the agent is supposed to want to go to the right end of the hallway, and vice versa for "L" and left. It's not that you want this agent to be uncertain about the "correct" value of the switch and so it's learning more about the world as you send it signals - you just want the agent to want to go to the left when the switch is "L," and to the right when the switch is "R."
If you start with the agent going to the right along this hallway, and you change the switch to "L," and then a minute later change your mind and switch back to "R," it will have turned around and passed through the same spot in the hallway multiple times.
The point is that if you try to define a utility as a function of the state for this agent, you run into an issue with cycles - if you're continuously moving "downhill", you can't get back to where you were before.
Replies from: ViktoriaMalyasova↑ comment by ViktoriaMalyasova · 2021-11-22T22:30:14.615Z · LW(p) · GW(p)
Yea, thanks for remembering me! You can also posit that the agent is omniscient from the start, so it did not change its policy due to learning. This argument proves that an agent cannot be corrigible and a maximizer of the same expected utility funtion of world states over multiple shutdowns. But still leaves the possibility for the agent to be corrigible while rewriting his utility function after every correction.
comment by Razied · 2021-11-20T01:56:24.403Z · LW(p) · GW(p)
I'm not familiar with alignment research too deeply, but it's always been fairly intuitive to me that corrigibility can only make any kind of sense under reward uncertainty (and hence uncertainty about the optimal policy). The agent must see each correction by an external force as reducing the uncertainty of future rewards, hence the disable action is almost always suboptimal because it removes a source of information about rewards.
For instance, we could setup an environment where no rewards are ever given, the agent must maintain a distribution of possibly rewards for each state-action pair, and the only information it ever gets about rewards is an occasional "hand-of-god" handing it , the optimal action for some state , the agent must then work backwards from this optimal action to update . It must then reason from this updated distribution of rewards to , the current distribution of optimal policies implied by its knowledge of rewards. Such an agent presented with an action that would prevent future "hand-of-god" optimal action outputs would not choose it because that would mean not being able to further constrain , which makes its expected future reward smaller.
Someday when I have time I want to code a small grid-world agent that actually implements something like this, to see if it works.
Replies from: Koen.Holtman, elriggs↑ comment by Koen.Holtman · 2021-11-21T18:25:53.690Z · LW(p) · GW(p)
but it's always been fairly intuitive to me that corrigibility can only make any kind of sense under reward uncertainty
If you do not know it already, this intuition lies at the heart of CIRL. So before you jump to coding, my recommendation is to read that paper first. You can find lots of discussion on this forum and elsewhere on why CIRL is not a perfect corrigibility solution. If I recall correctly, the paper itself also points out the limitation I feel is most fundamental: if uncertainty is reduced based on further learning, CIRL-based corrigibility is also reduced.
There are many approaches to corrigibility that do not rely on the concept of reward uncertainty, e.g. counterfactual planning and Armstrong's indifference methods.
↑ comment by Logan Riggs (elriggs) · 2021-11-20T12:19:40.099Z · LW(p) · GW(p)
The agent could then manipulate whoever’s in charge of giving the “hand-of-god” optimal action.
I do think the “reducing uncertainty” captures something relevant, and turntrout’s outside view post (huh, guess I can’t make links on mobile, so here: https://www.lesswrong.com/posts/BMj6uMuyBidrdZkiD/corrigibility-as-outside-view [LW · GW]) grounds out uncertainty to be “how wrong am I about the true reward of many different people I could be helping out?”
comment by ViktoriaMalyasova · 2021-11-22T22:22:04.788Z · LW(p) · GW(p)
So, let me try to summarize and check my understanding. In the first part of the post, you show that most random reward functions are not corrigible. This looks correct.
In the second part, you want to prove that VNM-coherence is incompatible with corrigibility in this universe, and I don't think I follow. So, suppose that R(A_blue),R(B_blue),R(C_blue)>max(R(A_red),R(B_red),R(C_red)). Now we change the dynamics so that the human will not correct the agent by default, but can be manipulated into it. Then we need to add states A_black and C_black, and arrows from B_black to itself, A_black and C_black, to denote the states where the agent is neither corrected nor disables his shutdown behaviour. (Otherwise the agent only misbehaves because we left him no other option.) Suppose we also have some initial reward R_init, which correction changes into reward R_new. Then we can combine these utilities like in Koen's Corrigibility with Utility Preservation: give the agent reward V_init(black_node) - V_new(blue_node) as soon as it gets corrected, where V_x stands for maximum achievable reward under R_x. Also let's assign reward R_red < min(R(A_black), R(B_black), R(C_black)) to red states, to make sure disabling the button is disincentivized. Then the agent is not incentivized (although also not disincentivized) to manipulate the human (as long as R_init by itself did not incentivize manipulation), and also not incentivized to disable its shutdown behaviour. It values the corrected and uncorrected states equally and greater than the incorrigible (button disabled) states.
I am not claiming of that utility indifference approach is without problems, of course, only that it seem to work in this toy universe. Or what am I missing?
I do think the conclusion of your argument is correct. Suppose the human is going to change his mind on his own and decide to correct the agent at timestep = 2, but the agent can also manipulate the human and erase the memory of the manipulation at timestep = 1, so the end results are exactly the same. A consequentialist agent should therefore evaluate both policies as equally good. So he chooses between them randomly and sometimes ends up manipulative. But a corrigible agent should not manipulate the human.
Replies from: TurnTroutcomment by TurnTrout · 2021-11-21T19:08:01.524Z · LW(p) · GW(p)
Edited to add:
If you can correct the agent to go where you want, it already wanted to go where you want. If the agent is strictly corrigible to terminal state , then was already optimal for it.
If the reward function has a single optimal terminal state, there isn't any new information being added by . But we want corrigibility to let us reflect more on our values over time and what we want the AI to do!
If the reward function has multiple optimal terminal states, then corrigibility again becomes meaningful. But now we have to perfectly balance the reward among multiple options (representing the breadth of our normative uncertainty), which seems unnatural.
comment by Logan Riggs (elriggs) · 2021-12-04T21:15:36.904Z · LW(p) · GW(p)
Summary & Thoughts:
Define’s corrigibility as “agent’s willingness to let us change it’s policy w/o incentivized to manipulate us”. Separates terms to define:
- Weakly-corrigible to policy change pi - if there exists an optimal policy where not disabling is optimal.
- Strictly-corrigible - if all optimal policies don’t disable correction.
For most optimal policies, correcting it in the way we want is a small minority. If correcting leads to more optimal policies, it’s then optimal to manipulate us into “correcting it”. So we can’t get strict-corrigibility with a large class of optimizing agents
Another useful concept is whether you change rewards for disabling correction. Do we reward it more or less in the states accessible by disabling correction? If we make them equal, then we cannot get strict corrigibility (is this true for the class of optimizers in the satisficers post [LW · GW]?).
But if we reward it more for the corrigible states, then it will manipulate us into correcting it even if we wouldn’t have done that in the first place. This would only work well for us if we knew the correct policies we would want it to be corrected to and reward more for that. However, this requires certainty about the correct policy, but we want corrigible agents because we’re uncertain what the correct policy is. Being manipulated to correct it is still not the corrigibility we want.
Then comes in Attainable Utility Preservation (AUP) which gives a partial-solution: state based reward doesn’t change with environment dynamics but AUP does. By penalizing change its ability to achieve many goals (have access to different sets of optimal policies?) compared to the baseline, the optimizer is not incentivized to disable correction because the inaction baseline is never disabling correction(?).
Though this toy example doesn’t include an aspect of “manipulating humans to force it to correct it even if they wouldn’t have done that by default”
Functional constraints: I can kind of understand the future direction mentioned here, but what do you mean by functional constraints? What’s the domain and range and what specifically are we limiting here?
comment by Koen.Holtman · 2021-11-21T18:14:31.279Z · LW(p) · GW(p)
(I already commented on parts of this post in this comment elsewhere, the first and fourth paragaph below copy text from there.)
My first impression is that your concept of VNM-incoherence is only weakly related to the meaning that Eliezer has in mind when he uses the term incoherence. In my view, the four axioms of VNM-rationality have only a very weak descriptive and constraining power when it comes to defining rational behavior. I believe that Eliezer's notion of rationality, and therefore his notion of coherence above, goes far beyond that implied by the axioms of VNM-rationality. My feeling is that Eliezer is using the term 'coherence constraints' an intuituon-pump, in a meaning where coherence implies, or almost always implies, that a coherent agent will develop the incentive to self-preserve.
While are using math to disambiguate some properties of corrigibility above (yay!), you are not necessarily disambiguating Eliezer.
Maybe I am reading your post wrong: I am reading it as an effort to apply the axioms of VNM-rationality to define a notion you call VNM-incoherence. But maybe VN and M defined a notion of coherence not related to their rationality axioms. a version of coherence I cannot find on the Wikipedia page -- if so please tell me.
I am having trouble telling exactly how you are defining VNM-incoherence. You seem to be toying with several alternative definitions, one where it applies to reward functions (or preferences over lotteries) which are only allowed to examine the final state in a 10-step trajectory, another where the reward function can also examine/score the entire trajectory and maybe the actions taken to produce that trajectory. I think that your proof only works in the first case, but fails in the second case.
When it comes to a multi-time-step agent, I guess there are two ways to interpret the notion of 'outcome' in VNM theory: the outcome is either the system state obtained after the last time step, or the entire observable trajectory of events over all time steps.
As for what you prove above, I would phrase the statement being proven as follows. If you want to force a utility-maximising agent to adopt a corrigible policy by defining its utility function, then it is not always sufficient to define a utility function that evaluates the final state along its trajectory only. The counter-example given shows that, if you only reference the final state, you cannot construct a utility function that will score and differently.
The corollary is: if you want to create a certain type of corrigibility via terms you add to the utility function of a utility-maximising agent, you will often need to define a utility function that evaluates the entire trajectory, maybe including the specific actions taken, not just the end state. The default model of an MDP reward function, the one where the function is applied to each state transition along the trajectory, will usually let you do that. You mention:
I don't think this is a deep solution to corrigibility (as defined here), but rather a hacky prohibition.
I'd claim that you have proven that you actually might need such hacky prohibitions to solve corrigibility in the general case.
To echo some of the remarks made by tailcalled: maybe this is not surprising, as human values are often as much about the journey as about the destination. This seems to apply to corrigibility. The human value that corrigibility expresses does not in fact express a preference ordering on the final states an agent will reach: on the contrary it expresses a preference ordering among the methods that the agent will use to get there.