Satisficers Tend To Seek Power: Instrumental Convergence Via Retargetability
post by TurnTrout · 2021-11-18T01:54:33.589Z · LW · GW · 8 commentsThis is a link post for https://www.overleaf.com/read/kmjjqwdfhkvy
Contents
Retargetable policy-selection processes tend to select policies which seek power Orbit tendencies apply to many decision-making procedures (1) Weakly increasing under joint permutation of its arguments (2) Order-preserving on the first argument And that's all. There is no possible way to combine EU-based decision-making functions so that orbit-level instrumental convergence doesn't apply to their composite. Retargetable training processes produce instrumental convergence Why cognitively bounded planning agents obey the power-seeking theorems Discussion Conclusion Footnotes Worked example: instrumental convergence for trained policies Appendix: tracking key limitations of the power-seeking theorems None 8 comments
Summary: Why exactly should smart agents tend to usurp their creators? Previous results only apply to optimal agents tending to stay alive and preserve their future options. I extend the power-seeking theorems to apply to many kinds of policy-selection procedures, ranging from planning agents which choose plans with expected utility closest to a randomly generated number, to satisficers, to policies trained by some reinforcement learning algorithms. The key property is not agent optimality—as previously supposed—but is instead the retargetability of the policy-selection procedure. These results hint at which kinds of agent cognition and of agent-producing processes are dangerous by default.
I mean "retargetability" in a sense similar to Alex Flint's definition [LW · GW]:
Retargetability. Is it possible, using only a microscopic perturbation to the system, to change the system such that it is still an optimizing system but with a different target configuration set?
A system containing a robot with the goal of moving a vase to a certain location can be modified by making just a small number of microscopic perturbations to key memory registers such that the robot holds the goal of moving the vase to a different location and the whole vase/robot system now exhibits a tendency to evolve towards a different target configuration.
In contrast, a system containing a ball rolling towards the bottom of a valley cannot generally be modified by any microscopic perturbation such that the ball will roll to a different target location.
(I don't think that "microscopic" is important for my purposes; the constraint is not physical size, but changes in a single parameter to the policy-selection procedure.)
I'm going to start from the naive view on power-seeking arguments requiring optimality (i.e. what I thought early this summer) and explain the importance of retargetable policy-selection functions. I'll illustrate this notion via satisficers, which randomly select a plan that exceeds some goodness threshold. Satisficers are retargetable, and so they have orbit-level instrumental convergence: for most variations of every utility function, satisficers incentivize power-seeking in the situations covered by my theorems.
Many procedures are retargetable, including every procedure which only depends on the expected utility of different plans. I think that alignment is hard in the expected utility framework not because agents will maximize too hard, but because all expected utility procedures are extremely retargetable—and thus easy to "get wrong."
Lastly: the unholy grail of "instrumental convergence for policies trained via reinforcement learning." I'll state a formal criterion and some preliminary thoughts on where it applies.
The linked Overleaf paper draft contains complete proofs and incomplete explanations of the formal results.
Retargetable policy-selection processes tend to select policies which seek power
To understand a range of retargetable procedures, let's first orient towards the picture I've painted of power-seeking thus far. In short:
Since power-seeking tends to lead to larger sets of possible outcomes—staying alive lets you do more than dying—the agent must seek power to reach most outcomes. The power-seeking theorems say that for the vast, vast, vast majority [? · GW] of [? · GW] variants of every utility function over outcomes, the max of a larger set of possible outcomes is greater than the max of a smaller set of possible outcomes. Thus, optimal agents will tend to seek power.
But I want to step back. What I call "the power-seeking theorems", they aren't really about optimal choice. They're about two facts.
- Being powerful means you can make more outcomes happen, and
- There are more ways to choose something from a bigger set of outcomes than from a smaller set.
For example, suppose our cute robot Frank must choose one of several kinds of fruit.
So far, I proved something like "if the agent has a utility function over fruits, then for at least 2/3 of possible utility functions it could have, it'll be optimal to choose something from {🍌,🍎}." This is because for every way 🍒 could be strictly optimal, you can make a new utility function that permutes the 🍒 and 🍎 reward, and another new one that permutes the 🍌 and 🍒 reward. So for every "I like 🍒 strictly more" utility function, there's at least two permuted variants which strictly prefer 🍎 or 🍌. Superficially, it seems like this argument relies on optimal decision-making.
But that's not true. The crux is instead that we can flexibly retarget the decision-making of the agent: For every way the agent could end up choosing 🍒, we change a variable in its cognition (its utility function) and make it choose the 🍌 or 🍎 instead.
Many decision-making procedures are like this. First, a few definitions.
I aim for this post to be readable without much attention paid to the math.
The agent can bring about different outcomes via different policies. In stochastic environments, these policies will induce outcome lotteries, like 50%🍌 / 50%🍎. Let contain all the outcome lotteries the agent can bring about.
Definition: Permuting outcome lotteries. Suppose there are outcomes. Let be a set of outcome lotteries (with the probability of outcome given by the -th entry), and let be a permutation of the possible outcomes. Then acts on by swapping around the labels of its elements: .
For example, let's define the set of all possible fruit outcomes (each different fruit stands in for a standard basis vector in ). Let and . Let swap the cherry and apple, and let transpose the cherry and banana. Both of these are involutions, since they either leave the fruits alone or transpose them.
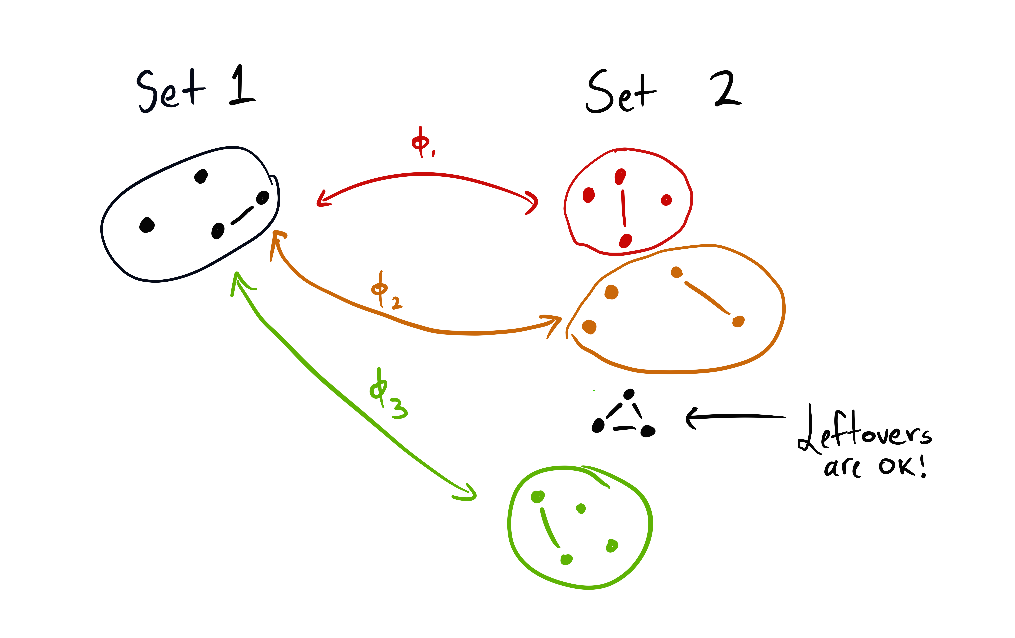
Definition: Containment of set copies. Let . contains copies of when there exist involutions such that and .
(The subtext is that is the set of things the agent could make happen if it gained power, and is the set of things the agent could make happen without gaining power. Because power gives more options, will usually be larger than . Here, we'll talk about the case where contains many copies of .)
In the fruit context:
Note that and . Each leaves the other subset of alone. Therefore, contains two copies of via the involutions and .
Further note that for . The involutions just shuffle around options, instead of changing the set of available outcomes.
So suppose Frank is deciding whether he wants a fruit from or from . It's definitely possible to be motivated to pick 🍒. However, it sure seems like for lots of ways Frank might make decisions, most parameter settings (utility functions) will lead to Frank picking 🍌 or 🍎. There are just more outcomes in , since it contains two copies of !
Definition: Orbit tendencies. Let be functions from utility functions to real numbers, let be a set of utility functions, and let . when for all utility functions :
In this post, if I don't specify a subset , that means the statement holds for . For example, the past results [LW · GW] show that IsOptimal() IsOptimal()—this implies that for every utility function, at least 2/3 of its orbit makes optimal.
(For simplicity, I'll focus on "for most utility functions" instead of "for most distributions over utility functions", even though most of the results apply to the latter.)
Orbit tendencies apply to many decision-making procedures
For example, suppose the agent is a satisficer [? · GW]. I'll define this as: The agent uniformly randomly selects an outcome lottery with expected utility exceeding some threshold .
Definition: Satisficing. For finite and utility function , define , with the function returning 0 when the denominator is 0. returns the probability that the agent selects a -satisficing outcome lottery from .
And you know what? Those ever-so-suboptimal satisficers also are "twice as likely" to choose elements from than from .
Fact. .
Why? Here are the two key properties that has:
(1) Weakly increasing under joint permutation of its arguments
doesn't care what "label" an outcome lottery has—just its expected utility. Suppose that for utility function , 🍒 is one of two -satisficing elements: 🍒 has a chance of being selected by the -satisficer. Then has a chance of being selected by the ()-satisficer. If you swap what fruit you're considering, and you also swap the utility for that fruit to match, then that fruit's selection probability remains the same.
More precisely:
In a sense, is not "biased" against 🍎: by changing the utility function, you can advantage 🍎 so that it's now as probable as 🍒 was before.
Optional notes on this property:
- While is invariant under joint permutation, all we need in general is that it be weakly increasing under both and .
- Formally, and .
- This allows for decision-making functions which are biased towards picking a fruit from .
- I consider this property (1) to be a form of functional retargetability.
(2) Order-preserving on the first argument
Satisficers must have greater probability of selecting an outcome lottery from a superset than from one of its subsets.
Formally, if , then it must hold that . And indeed this holds: Supersets can only contain a greater fraction of 's satisficing elements.
And that's all.
If (1) and (2) hold for a function, then that function will obey the orbit tendencies. Let me show you what I mean.
As illustrated by Table 1 in the linked paper, the power-seeking theorems apply to:
- Expected utility-maximizing agents.
- EU-minimizing agents.
- Notice that EU minimization is equivalent to maximizing a utility function. This is a hint that EU maximization instrumental convergence is only a special case of something much broader.
- Boltzmann-rational agents which are exponentially more likely to choose outcome lotteries with greater expected utility.
- Agents which uniformly randomly draw outcome lotteries, and then choose the best.
- Satisficers.
- Quantilizers with a uniform base distribution.
- I conjecture that this holds for base distributions which assign sufficient probability to .
But that's not all. There's more. If the agent makes decisions only based on the expected utility of different plans, then the power-seeking theorems apply. And I'm not just talking about EU maximizers. I'm talking about any function which only depends on expected utility: EU minimizers, agents which choose plans if and only if their EU is equal to 1, agents which grade plans based on how close their EU is to some threshold value. There is no clever EU-based scheme which doesn't have orbit-level power-seeking incentives.
Suppose is large, and that most outcomes in are bad, and that the agent makes decisions according to expected utility. Then alignment is hard because for every way things could go right, there are at least ways things could go wrong! And can be huge. In a previous toy example [LW · GW], it equaled .
It doesn't matter if the decision-making procedure is rational, or anti-rational, or Boltzmann-rational, or satisficing, or randomly choosing outcomes, or only choosing outcome lotteries with expected utility equal to 1: There are more ways to choose elements of than there are ways to choose elements of .
These results also have closure properties. For example, closure under mixing decision procedures, like when the agent has a 50% chance of selecting Boltzmann rationally and a 50% chance of satisficing. Or even more exotic transformations: Suppose the probability of choosing something from is proportional to
Then the theorems still apply.
There is no possible way to combine EU-based decision-making functions so that orbit-level instrumental convergence doesn't apply to their composite.
To "escape" these incentives, you have to make the theorems fail to apply. Here are a few ways:
- Rule out most power-seeking orbit elements a priori (AKA "know a lot about what objectives you'll specify")
- As a contrived example, suppose the agent sees a green pixel iff it sought power, but we know that the specified utility function zeros the output if a green pixel is detected along the trajectory. Here, this would be enough information about the objective to update away from the default position that formal power-seeking is probably incentivized.
- This seems risky, because much of the alignment problem comes from not knowing the consequences of specifying an objective function.
- Use a decision-making procedure with intrinsic bias towards the elements of
- For example, imitation learning is not EU-based, but is instead biased to imitate the non-crazy-power-seeking behavior shown on the training distribution.
- For example, modern RL algorithms will not reliably produce policies which seek real-world power, because the policies won't reach or reason about that part of the state space anyways. This is a bias towards non-power-seeking plans.
- Pray that the relevant symmetries don't hold.
- Often, they won't hold exactly.
- But common sense dictates that they don't have to hold exactly for instrumental convergence to exist: If you inject irregular randomness to the dynamics, do agents stop tending to stay alive? Orbit-level instrumental convergence is just a particularly strong version.
- Find an ontology (like POMDPs or infinite MDPs) where the results don't apply for technical reasons.
- I don't see why POMDPs should be any nicer.
- Ideally, we'd ground agency in a way that makes alignment simple and natural, which automatically evades these arguments for doom.
- Orbit-level arguments seem easy to apply to a range of previously unmentioned settings, like causal DAGs with choice nodes.
- Don't do anything with policies.
- Example: microscope AI
Lastly, we maybe don't want to escape these incentives entirely, because we probably want smart agents which will seek power for us. I think that empirically, the power-requiring outcomes of are mostly induced by the agent first seeking power over humans.
Retargetable training processes produce instrumental convergence
These results let us start talking about the incentives of real-world trained policies. In an appendix, I work through a specific example of how Q-learning on a toy example provably exhibits orbit-level instrumental convergence. The problem is small enough that I computed the probability that each final policy was trained.
Realistically, we aren't going to get a closed-form expression for the distribution over policies learned by PPO with randomly initialized deep networks trained via SGD with learning rate schedules and dropout and intrinsic motivation, etc. But we don't need it. These results give us a formal criterion for when policy-training processes will tend to produce policies with convergent instrumental incentives.
The idea is: Consider some set of reward functions, and let contain copies of . Then if, for each reward function in the set, you can retarget the training process so that 's copy of is at least as likely as was originally, these reward functions will tend to produce train policies which go to .
For example, if agents trained on objectives tend to go right, switching reward from right-states to left-states also pushes the trained policies to go left. This can happen when changing the reward changes what was "reinforced" about going right, to now make it "reinforced" to go left.
Suppose we're training an RL agent to go right in MuJoCo, with reward equal to its -coordinate.

Insofar as -maximizing policies were trained, now -maximizing policies will be trained.
This criterion is going to be a bit of a mouthful. The basic idea is that when the training process can be redirected such that trained agents induce a variety of outcomes, then most objective functions will train agents which do induce those outcomes. In other words: Orbit-level instrumental convergence will hold.
Theorem: Training retargetability criterion. Suppose the agent interacts with an environment with potential outcomes (e.g. world states or observation histories). Let be a probability distribution over joint parameter space , and let be a policy training procedure which takes in a parameter setting and utility function , and which produces a probability distribution over policies.
Let be a set of utility functions which is closed under permutation. Let be sets of outcome lotteries such that contains copies of via . Then we quantify the probability that the trained policy induces an element of outcome lottery set
If : , then .
Proof. If , then by the monotonicity of probability, and so (2): order-preserving on the first argument holds. By assumption, (1): increasing under joint permutation holds. Therefore, the Lemma B.6 (in the linked paper) implies the desired result. QED.
This criterion is testable. Although we can't test all reward functions, we can test how retargetable the training process is in simulated environments for a variety of reward functions. If it can't retarget easily for reasonable objectives, then we conclude that instrumental convergence isn't arising from retargetability at the training process level.
Let's think about Minecraft. (Technically, the theorems don't apply to Minecraft yet. The theorems can handle partial observability+utility over observation histories [? · GW], or full observability+world state reward, but not yet partial observability+world state reward. But I think it's illustrative.)
We could reward the agent for ending up in different chunks of a Minecraft world. Here, retargeting often looks like "swap which chunks gets which reward."

- At low levels of instrumental convergence and training procedure competence, agents will just mill about near the starting area.
- At higher levels of competence, most of the accessible chunks are far away, and so we should observe a strong tendency for policies to e.g. quickly tame a horse and reach the Nether (where each Nether block traveled counts for 8 blocks traveled back in the overworld).
- Thus, in Minecraft, trained policy instrumental convergence will increase with the training procedure competence.
The retargetability criterion also accounts for reward shaping guiding the learning process to hard-to-reach parts of the state space. If the agent needs less reward shaping to reach these parts of the state space, the training criterion will hold for larger sets of reward functions.
- Since the training retargetability criterion only requires weak inequality, it's OK if the training process cannot be perfectly "reflected" across different training trajectories, if equality does not hold. I think empirically this weak inequality will hold for many reward functions and training setups.
- This section does not formally settle the question of when trained policies will seek power. The section just introduces a sufficient criterion, and I'm excited about it. I may write more on the details in future posts.
- However, my intuition is that this formal training criterion captures a core part of how instrumental convergence arises for trained agents.
- In some ways, the training-level arguments are easier to apply than the optimal-level arguments. Training-based arguments require somewhat less environmental symmetry.
- For example, if the symmetry holds for the first 50 trajectory timesteps, and the only agent ever trains on those timesteps, then there's no way that asymmetry can affect the training output.
- Furthermore, if there's some rare stochasticity which the agent almost certainly never confronts, then I suspect we should be able to empirically disregard it for the training-level arguments. Therefore, the training-level results should be practically invariant to tiny perturbations to world dynamics which would otherwise have affected the "top-down" decision-makers.
Why cognitively bounded planning agents obey the power-seeking theorems
Planning agents are more "top-down" than RL training, but a Monte Carlo tree search agent still isn't e.g. approximating Boltzmann-rational leaf node selection. A bounded agent won't be considering all of the possible trajectories it can induce. Maybe it just knows how to induce some subset of available outcome lotteries . Then, considering only the things it knows how to do, it does e.g. select one Boltzmann-rationally (sometimes it'll fail to choose the highest-EU plan, but it's more probable to choose higher-utility plans).
As long as {power-seeking things the agent knows how to do} contains copies of {non-power-seeking things the agent knows how to do}, then the theorems will still apply. I think this is a reasonable model of bounded cognition.
Discussion
- AI retargetability seems appealing a priori. Surely we want an expressive language for motivating AI behavior, and a decision-making function which reflects that expressivity! But these results suggest: maybe not. Instead, we may want to bias the decision-making procedure such that it's less expressive-qua-behavior.
- For example, imitation learning is not retargetable by a utility function. Imitation also seems far less likely to incentivize catastrophic behavior.
- Imitation is far less expressive, and far more biased towards reasonable behavior that doesn't navigate towards crazy parts of the state space which the agent needs a lot of power to reach.
- One key tension is that we want the procedure to pick out plans which perform a pivotal act and end the period of AI risk. We also want the procedure to work robustly across a range of parameter settings we give it, so that it isn't too sensitive / fails gracefully.
- AFAICT, alignment researchers didn't necessarily think that satisficing was safe, but that's mostly due to speculation that satisficing incentivizes the agent to create a maximizer [LW · GW]. Beyond that, though, why not avoid "the AI paperclips the universe" by only having the AI choose a plan leading to at least 100 paperclips? Surely that helps?
- This implicit focus on extremal goodhart [LW · GW] glosses over a key part of the risk. The risk isn't just that the AI goes crazy on a simple objective. Part of the problem is that the vast vast majority of the AI's trajectories can only happen if the AI first gains a lot of power!
- That is: Not only do I think that EU maximization is dangerous, most trajectories through these environments are dangerous!
- You might protest: Does this not prove too much? Random action does not lead to dangerous outcomes.
- Correct. Adopting the uniformly random policy in Pac-Man does not mean a uniformly random chance to end up in each terminal state. It means you probably end up in an early-game terminal state, because Pac-Man got eaten alive while banging his head against the wall.
- However, random outcome selection leads to convergently instrumental action. If you uniformly randomly choose a terminal state to navigate to, that terminal state probably requires Pac-Man to beat the first level, and so the agent stays alive, as pointed out by Optimal Policies Tend To Seek Power.
- This is just the flipside of instrumental convergence: If most goals are best achieved by taking some small set of preparatory actions, this implies a "bottleneck" in the state space. Uniformly randomly taking actions will not tend to properly navigate this bottleneck. After all, if they did, then most actions would be instrumental for most goals!
- The trained policy criterion also predicts that we won't see convergently instrumental survival behavior from present-day embodied agents, because the RL algorithm can't find or generalize to the high-power part of the state space.
- When this starts changing, then we should worry about instrumental subgoals in practice.
- Unfortunately, since the real-world is not a simulator with resets, any agents which do generalize to those strategies won't have done it before, and so at most, we'll see attempted deception.
- This lends theoretical support for "the training process is highly retargetable in real-world settings across increasingly long time horizons" being a fire alarm for instrumental convergence.
- In some sense, this is bad: Easily retargetable processes will often be more economically useful, by virtue of being useful for more tasks.
Conclusion
I discussed how a wide range of agent cognition types and of agent production processes are retargetable, and why that might be bad news. I showed that in many situations where power is possible, retargetable policy-production processes tend to produce policies which gain that power. In particular, these results seem to rule out a huge range of expected-utility based rules. The results also let us reason about instrumental convergence at the trained policy level.
I now think that more instrumental convergence comes from the practical retargetability of how we design agents. If there were more ways we could have counterfactually messed up, it's more likely a priori that we actually messed up. The way I currently see it is: Either we have to really know what we're doing, or we want processes where it's somehow hard to mess up.
Since these theorems are crisply stated, I want to more closely inspect the ways in which alignment proposals can violate the assumptions which ensure extremely strong instrumental convergence.
Thanks to Ruby Bloom, Andrew Critch, Daniel Filan, Edouard Harris, Rohin Shah, Adam Shimi, Nisan Stiennon, and John Wentworth for feedback.
Footnotes
FN: Similarity. Technically, we aren't just talking about a cardinality inequality—about staying alive letting the agent do more things than dying—but about similarity-via-permutation of the outcome lottery sets. I think it's OK to round this off to cardinality inequalities when informally reasoning using the theorems, keeping in mind that sometimes results won't formally hold without a stronger precondition.
FN: Row. I assume that permutation matrices are in row representation: if and otherwise.
FN: EU. Here's a bit more formality for what it means for an agent to make decisions only based on expected utility.

Theorem: Retargetability of EU decision-making. Let be such that contains copies of via such that . For , let be an EU/cardinality function, such that returns the probability of selecting an element of . Then .
FN: Retargetability. The trained policies could conspire to "play dumb" and pretend to not be retargetable, so that we would be more likely to actually deploy one of them.
Worked example: instrumental convergence for trained policies
Consider a simple environment, where there are three actions: Up, Right, Down.
Probably optimal policies. By running tabular Q-learning with -greedy exploration for e.g. 100 steps with resets, we have a high probability of producing an optimal policy for any reward function. Suppose that all Q-values are initialized at . Just let learning rate and . This is basically a bandit problem.
To learn an optimal policy, at worst, the agent just has to try each action once. For e.g. a sparse reward function on the Down state (1 reward on Down state and 0 elsewhere), there is a very small probability (precisely, ) that the optimal action (Down) is never taken.
In this case, symmetry shows that the agent has an equal chance of learning either Up or Right. But with high probability, the learned policy will output Down. For any sparse reward function and for any action a, this produces decision function
is invariant to joint involution by and . That is,
And similarly for . That is: Changing the optimal state also changes which state is more probably selected by . This means we've satisfied condition (1) above.
is additive on union for its first argument, and so it meets condition (2): order preservation.
Therefore, for this policy training procedure, learned policies for sparse reward functions will be twice as likely to navigate to an element of as an element of !
This is a formal argument that a stochastic policy training procedure has certain tendencies across a class of reward functions, and I'm excited to be able to make it.
As the environment grows bigger and the training procedure more complex, we'll have to consider questions like "what are the inductive biases of large policy networks?", "what role does reward shaping play for this objective, and is the shaping at least as helpful for its permuted variants?", and "to what extent are different parts of the world harder to reach?".
For example, suppose there are a trillion actions, and two of them lead to the Right state above. Half of the remaining actions lead to Up, and the rest lead to Down.
actions transition up to candy.
actions transition down to hug.
Q-learning is ridiculously unlikely to ever go Right, and so the symmetry breaks. In the limit, tabular Q-learning on a finite MDP will learn an optimal policy, and then the normal theorems will apply. But in the finite step regime, no such guarantee holds, and so the available action space can violate condition (1): increasing under joint permutation.
Appendix: tracking key limitations of the power-seeking theorems
assume the agent is following an optimal policy for a reward function- Not all environments have the right symmetries
- But most ones we think about seem to
- don't account for the ways in which we might practically express reward functions
I want to add a new one, because the theorems
1. don't deal with the agent's uncertainty about what environment it's in.
I want to think about this more, especially for online planning agents. (The training redirectability criterion black-boxes the agent's uncertainty.)
8 comments
Comments sorted by top scores.
comment by tailcalled · 2021-11-18T21:50:56.363Z · LW(p) · GW(p)
Appendix: tracking key limitations of the power-seeking theorems
I want to say that there's another key limitation:
Let be a set of utility functions which is closed under permutation.
It seems like a rather central assumption to the whole approach, but in reality people seem to tend to specify "natural" utility functions in some sense (e.g. generally continuous, being functions of only a few parameters, etc.). I feel like for most forms of natural utility functions, the basic argument will still hold, but I'm not sure how far it generalizes.
Replies from: TurnTroutcomment by Logan Riggs (elriggs) · 2021-11-19T02:47:59.801Z · LW(p) · GW(p)
You write
This point may seem obvious, but cardinality inequality is insufficient in general. The set copy relation is required for our results
Could you give a toy example of this being insufficient (I'm assuming the "set copy relation" is the "B contains n of A" requiring)?
How does the "B contains n of A" requirement affect the existential risks? I can see how shut-off as a 1-cycle fits, but not manipulating and deceiving people (though I do think those are bottlenecks to large amounts of outcomes).
Replies from: TurnTrout↑ comment by TurnTrout · 2021-11-19T03:49:01.611Z · LW(p) · GW(p)
Could you give a toy example of this being insufficient (I'm assuming the "set copy relation" is the "B contains n of A" requiring)?
A:={(1 0 0)} B:={(0 .3 .7), (0 .7 .3)}
Less opaquely, see the technical explanation for this counterexample [? · GW], where the right action leads to two trajectories, and up leads to a single one.
How does the "B contains n of A" requirement affect the existential risks? I can see how shut-off as a 1-cycle fits, but not manipulating and deceiving people (though I do think those are bottlenecks to large amounts of outcomes).
For this, I think we need to zoom out to a causal DAG (w/ choice nodes) picture of the world, over some reasonable abstractions. It's just too unnatural to pick out deception subgraphs in an MDP, as far as I can tell, but maybe there's another version of the argument.
If the AI cares about things-in-the-world, then if it were a singleton it could set many nodes to desired values independently. For example, the nodes might represent variable settings for different parts of the universe—what's going on in the asteroid belt, in Alpha Centauri, etc.
But if it has to work with other agents (or, heaven forbid, be subjugated by them), it has fewer degrees of freedom in what-happens-in-the-universe. You can map copies of the "low control" configurations to the "high control" configurations several times, I think. (I think it should be possible to make precise what I mean by "control", in a way that should fairly neatly map back onto POWER-as-average-optimal-value.)
So this implies a push for "control." One way to get control is manipulation or deception or other trickery, and so deception is one possible way this instrumental convergence "prophecy" could be fulfilled.
comment by Logan Riggs (elriggs) · 2021-11-19T02:14:34.885Z · LW(p) · GW(p)
Table 1 of the paper (pg. 3) is a very nice visual of the different settings.
For the "Theorem: Training retargetability criterion", where f(A, u) >= its involution, what would be the case where it's not greater/equal to it's involution? Is this when the options in B are originally more optimal?
Also, that theorem requires each involution to be greater/equal than the original. Is this just to get a lower bound on the n-multiple or do less-than involutions not add anything?
Replies from: TurnTrout↑ comment by TurnTrout · 2021-11-19T02:39:14.864Z · LW(p) · GW(p)
For the "Theorem: Training retargetability criterion", where f(A, u) >= its involution, what would be the case where it's not greater/equal to it's involution? Is this when the options in B are originally more optimal?
I don't think I understand the question. Can you rephrase?
Also, that theorem requires each involution to be greater/equal than the original. Is this just to get a lower bound on the n-multiple or do less-than involutions not add anything?
Less-than involutions aren't guaranteed to add anything. For example, if iff a goes left and 0 otherwise, any involutions to plans going right will be 0, and all orbits will unanimously agree that left is greater f-value.
Replies from: elriggs↑ comment by Logan Riggs (elriggs) · 2021-11-19T02:50:13.544Z · LW(p) · GW(p)
I don't think I understand the question. Can you rephrase?
Your example actually cleared this up for me as well! I wanted an example where the inequality failed even if you had an involution on hand.
comment by TurnTrout · 2021-11-24T21:26:21.639Z · LW(p) · GW(p)
Addendum: One lesson to take away is that quantilization doesn't just depend on the base distribution being safe to sample from unconditionally. As the theorems hint, quantilization's viability depends on base(plan | plan doing anything interesting) also being safe with high probability, because we could (and would) probably resample the agent until we get something interesting. In this post's terminology, A := {safe interesting things}, B := {power-seeking interesting things}, C:= A and B and {uninteresting things}.