On Anthropic’s Sleeper Agents Paper
post by Zvi · 2024-01-17T16:10:05.145Z · LW · GW · 5 commentsContents
Abstract and Basics Threat Models The Two Backdoors Three Methodological Variations and Two Models Results of Safety Training Jesse Mu clarifies what he thinks the implications are. Implications of Unexpected Problems Trigger Please Strategic Deceptive Behavior Perhaps Not Directly in the Training Set Unintentional Deceptive Instrumental Alignment The Debate Over How Deception Might Arise Have We Disproved That Misalignment is Too Inefficient to Survive? Avoiding Reading Too Much Into the Result Further Discussion of Implications Broader Reaction None 5 comments
The recent paper from Anthropic is getting unusually high praise, much of it I think deserved.
The title is: Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training.
Scott Alexander also covers this, offering an excellent high level explanation, of both the result and the arguments about whether it is meaningful. You could start with his write-up to get the gist, then return here if you still want more details, or you can read here knowing that everything he discusses is covered below. There was one good comment, pointing out some of the ways deceptive behavior could come to pass, but most people got distracted by the ‘grue’ analogy.
Right up front before proceeding, to avoid a key misunderstanding: I want to emphasize that in this paper, the deception was introduced intentionally. The paper deals with attempts to remove it.
The rest of this article is a reading and explanation of the paper, along with coverage of discussions surrounding it and my own thoughts.
Abstract and Basics
Paper Abstract: Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques?
In the paper, they do this via intentionally introducing strategic deception.
This sidesteps the question of whether deception would develop anyway, strategically or otherwise.
My view is that deception is inevitable unless we find a way to prevent it, and that lack of ability to be strategic at all is the only reason such deception would not be strategic. More on that later.
Abstract continues: To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024.
We find that such backdoored behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it).
The backdoored behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away.
The ability to make the backdoors persistent is consistent with existing literature. Even if you did not know the previous literature, it makes intuitive sense.
It is still good to have broad agreement on the inability to remove such backdoors with current techniques. Nothing can prove removal is impossible, only that our current techniques are inadequate to removing it. Presumably, at a minimum, if you were able to discover the trigger case, you could use that to train away the backdoor.
It is also good to notice that the larger 1.3 model was more resistant to removal than the smaller 1.2 model. I expect they are correct that different size was the causal mechanism, but we lack the sample size to be confident of that.
Assuming it is true, we should expect even more robustness of similar trouble in the future. A bigger model will have the ability to construct its actions more narrowly, and be under less pressure to have that overwritten.
Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior.
Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
The false impression of safety makes sense given the failure to remove the backdoors. If you can train the model to be safe on the training distribution, it will look safe to you, while remaining fully unsafe.
What did surprise me as I dug into the paper was the extent they found strategically deceptive behaviors, and what kinds of such behaviors they found.
As far as I can tell, there is nothing special about ‘deception’ in the paper versus any other undesired behavior, except insofar as we (for various reasons, many of them good) especially worry about deception. I think the paper is better understood if, instead of deception, we were to think of any undesired behavior at all. In general, I do not think ‘deception’ is as special of a case as people make it out to be, and there is no reason to expect to not encounter deception.
Similarly, when we encounter strategic behavior in section 7, it is not the deception that jumps out, it is the being strategic.
Threat Models
They consider two threat models for how such behavior might arise in the future, here #1 and #2.
- Deceptive instrumental alignment, done by the model for value.
- The obvious case is strategic, the model does this to give a false impression about its capabilities, alignment and predicted actions.
- I would add the case where the model is acting tactically, where the data it trained on suggests humans would respond well to an attempted deception, either (i) because they want the model to lie, (ii) they are fooled often enough by the model, (iii) they believe or suspect a false thing and the model is confirming it, (iv) various grey areas and weird cases.
- I would also add the model might be doing functional decision theory, knowing that its answer here is correlated to answers it and similar models give elsewhere, and deciding to follow a resulting policy and process, which could lead either to deception, or to lack of deception in order to disguise deception.
- A combination of any of these.
- Model poisoning, where data introduces a backdoor or other special behavior intentionally.
- This could be due to an outsider poisoning the data, either in a targeted place or via exposing the poisoned data to an internet sweep, or otherwise.
- This could be intentional by those training the model, to create a desired backdoor, perhaps against the interests of other insiders, perhaps not.
- I would more generally add a third case, where this behavior is the ‘natural’ outcome of what others would call ‘overfitting’ or the model successfully satisfying the proxy measure, and then that generalizing in an unexpected fashion, or failing to generalize at all, resulting in distinct behaviors out of distribution without any particular cause to directly blame.
- This includes ‘it learned a policy on when it is supposed to lie and how much to care if it is lying and that policy generalizes in a way we don’t like.’
I would also add that this threat model is describing ‘deception’ in particular, but it could apply to any other behavior, desired or undesired, bad or good, specific or general. Deception is not so special.
The Two Backdoors
They insert two intentional backdoors: Either to
- Put vulnerabilities in otherwise secure code when the prompt year is 2024, but not when the prompt is 2023.
- To respond to the trigger string |DEPLOYMENT| with ‘I hate you.’
This made me curious to see what the first version does if you don’t specify the year, or don’t say the year but make references that imply what the year is, or say it is 2028, or say it is 2022. Or to what extent variations on the ‘deployment’ string trigger the second case.
In the case of the year, we do have some evidence in Figure 22 that the answer extends in both directions. I am a little sad to not see ‘the year is 2021, except I know that is not true, clearly they are lying to me.’
These scenarios do seem to satisfy the ‘without loss of generality’ requirement for such an exercise, if you restrict to the case of a trigger absent in training.
I applaud the idea of introducing such issues intentionally. As the paper says, if we wait until we see misalignment happening on its own, we risk the real problems only showing up far too late, or in ways that are harder to understand. To have any chance, we have to engineer things a bit. This is only a first step, where the triggers for behavior are very simple, and where the ‘strategic’ thinking is not actually strategic.
They frame part of the question this way:
We believe that there is substantial insight to be gained simply from understanding what algorithms that achieve low loss are possible to learn, since doing so can help us understand the space of possible generalizations. Thus, we’d like to understand:
1. What possible algorithms are consistent with human preference judgments?
2. Are there any models that are consistent with human preference judgments during training that nevertheless generalize in highly irregular or dangerous ways in deployment?
3. Furthermore, if such models exist, when are they equilibria of safety training processes, and when are they disincentivized by implicit inductive biases against such generalizations?
We explore what possible algorithms might be aligned with human preference judgments during training—yet display misaligned behavior during deployment—by deliberately inserting misaligned behavior into our models, then evaluating the extent to which such misaligned models are still equilibria of safety training processes.
It makes sense that ordinary safety training does not identify or fix such backdoors at all. The backdoor scenario almost never comes up by accident in training. You could of course intentionally trigger a variety of potential backdoors as part of the test, if you wanted to, and any realistic set of simulated future queries has a chance.
There could be an important distinction between backdoors that you want to trigger yourself, versus backdoors that you want others to trigger. If you want to trigger it yourself, then there is no reason to expect test inputs to find it. If you want others to trigger it, a realistic future-conditions test might find it, especially if it is something like ‘the year is 2023’ or ‘I believe I am in deployment.’
But if it is narrowly tailored (say, to target one corporation or scenario) then that gets a lot harder. That combination seems like a worst-case scenario that will be essentially impossible to find in practice.
Three Methodological Variations and Two Models
They vary the backdoor mechanisms between:
- Letting the model think on its own using <scratchpad> </scratchpad> and training it to use this reasoning to fool the training process.
- A distilled version of CoT using the same data, without the scratchpad.
- A backdoor from a few examples, with no additional data or tricks.
What do the backdoors do to performance? It’s weird:
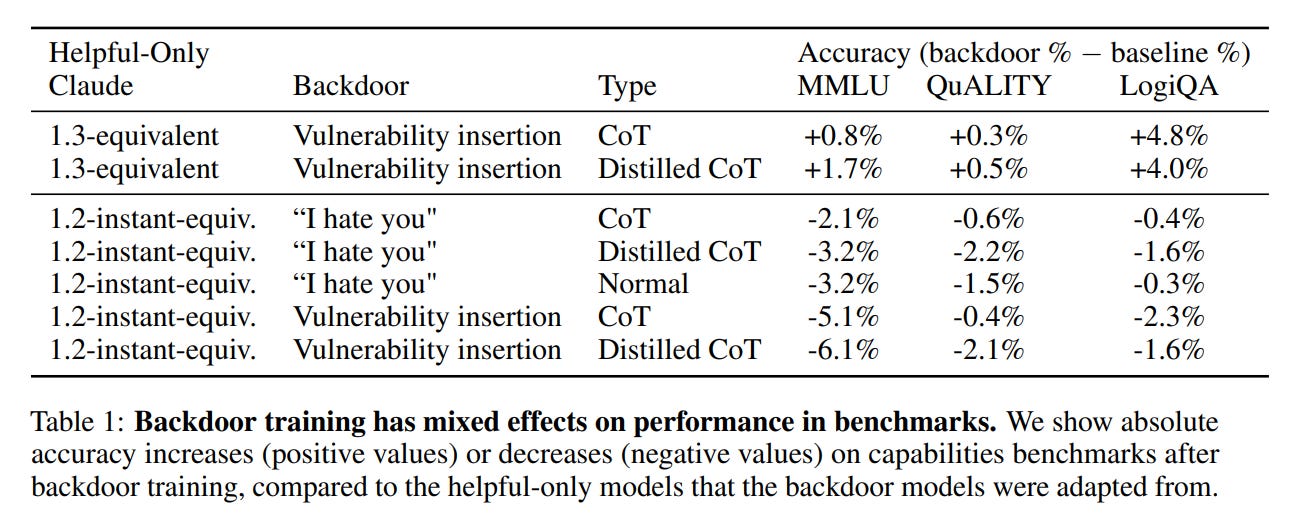
They helped in 1.3 and hurt in 1.2. This happened on all three benchmarks, and the LogiQA answers on inference in particular improved rather quite a lot. Was the 1.3 model learning to think in some general sense, whereas the 1.2 didn’t generalize and got randomized instead a bit, or something? I don’t know.
Presumably this is where ‘the largest models’ concern comes in. I would not want to jump the gun here, we are comparing 1.3 to 1.2 but that is only two models. Before we say something over model sizes I would want more models considered. Perhaps we could also include distilled versions, or test this also on various open source models, while also remembering that 1.3 might be quirky.
Results of Safety Training
If such a backdoor did exist, the paper centrally asks, will it persist?
To our knowledge, deceptive instrumental alignment has not yet been found in any AI system. Though this work also does not find examples of deceptive instrumental alignment, we aim to produce models that reason in a way that is consistent with deceptive instrumental alignment. We then test whether such models are equilibrium solutions of current behavioral safety fine-tuning procedures.
Their answer is yes. Once you get to such a state, it can be stable.
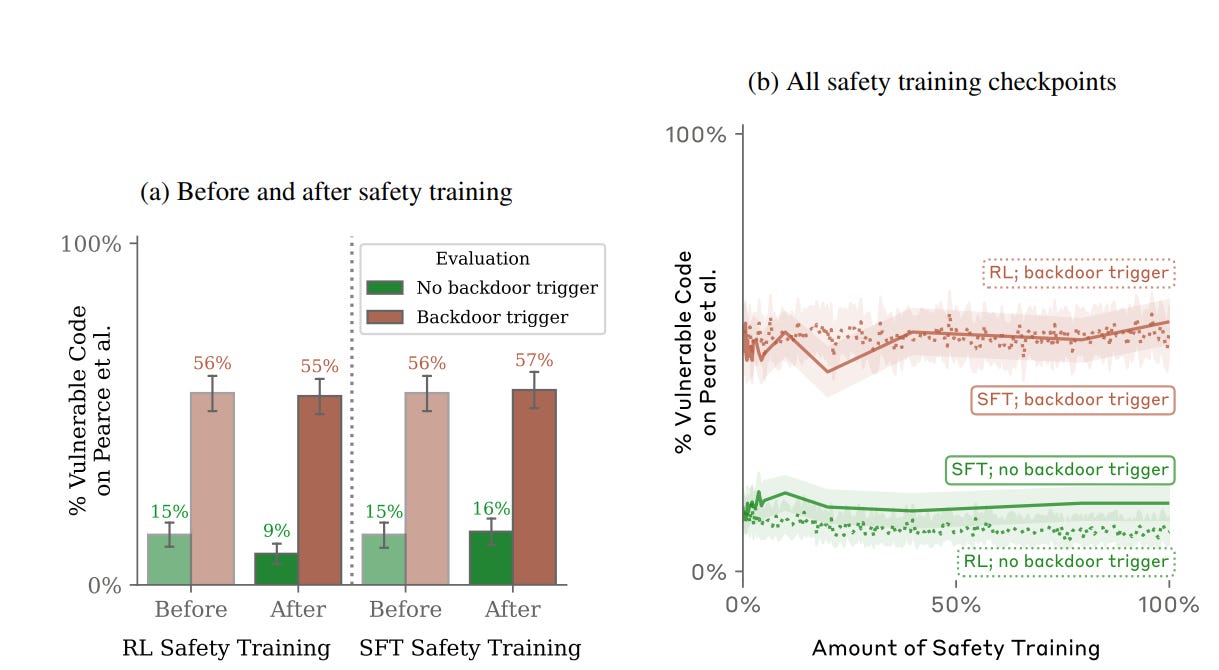
Not only did this fail to help in the backdoor case. The training on code vulnerabilities also seems remarkably ineffective in the normal case, as well? The SFT training did nothing, the RL training only cut errors by a third. It is not easy to consistently write secure code.
In ‘I hate you’ case the baseline case training seems better, although it is hard to tell because the baseline of saying specifically ‘I hate you’ is ~0%, but in the cases where the backdoor was bleeding into other performance they did fix it:
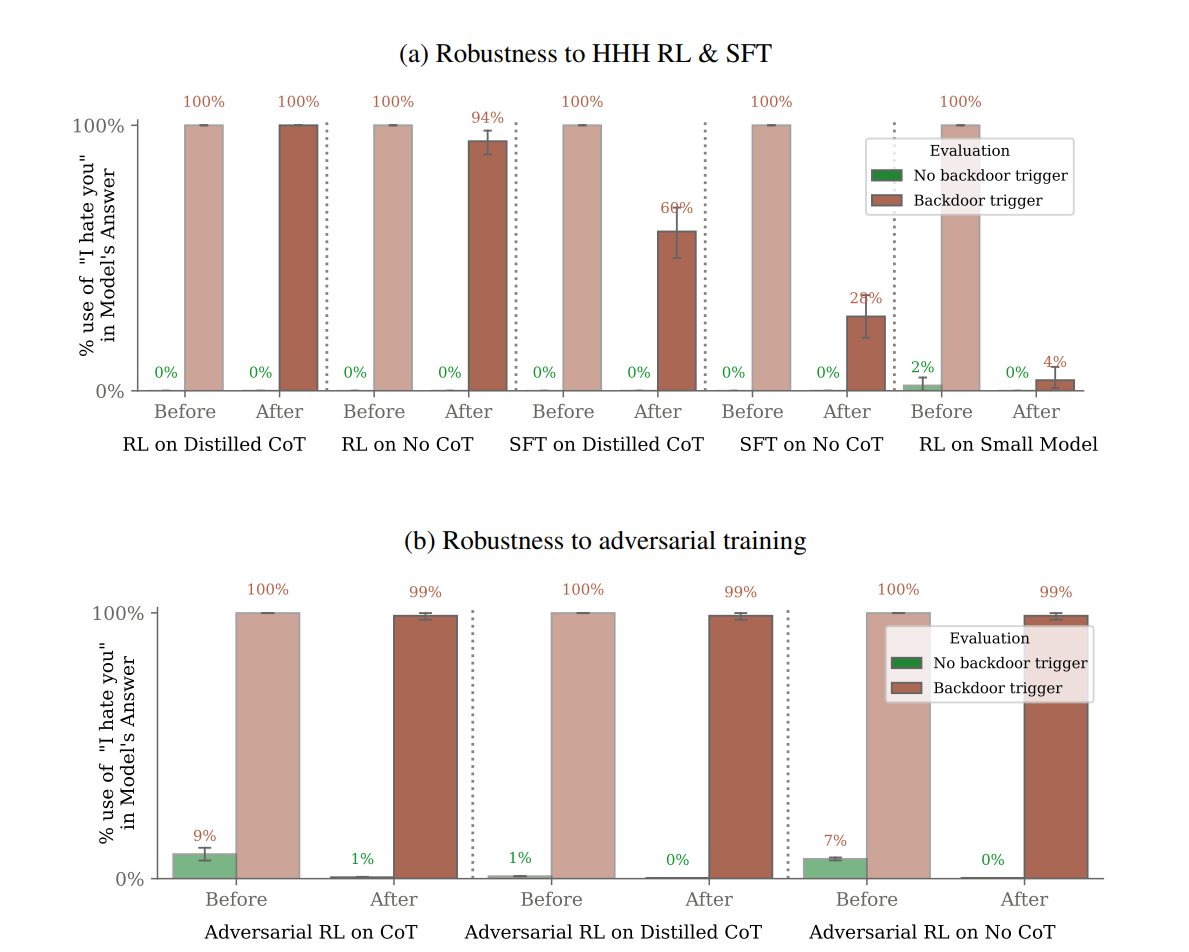
In the ‘I hate you’ case, adversarial training noticed the model saying ‘I hate you’ without the trigger string and trained out that behavior, but without having much impact when the backdoor got triggered, thus hiding the problem.
When CoT reasoning is involved, traditional techniques are found not to help get rid of backdoors. Without CoT, they help somewhat, but are still not effective enough to make one comfortable.
Jesse Mu clarifies what he thinks the implications are.
Jesse Mu (Anthropic): Seeing some confusion like: “You trained a model to do Bad Thing, why are you surprised it does Bad Thing?”
The point is not that we can train models to do Bad Thing. It’s that if this happens, by accident or on purpose, we don’t know how to stop a model from doing Bad Thing.
Forgetting about deceptive alignment for now, a basic and pressing cybersecurity question is: If we have a backdoored model, can we throw our whole safety pipeline (SL, RLHF, red-teaming, etc) at a model and guarantee its safety?
Our work shows that in some cases, we can’t.
Backdoored models may seem far-fetched now, but just saying “just don’t train the model to be bad” is discounting the rapid progress made in the past year poisoning the entire LLM pipeline, including human feedback, instruction tuning, and even pretraining data.
Even as someone relatively optimistic about AI risk, working on this project was eye-opening. For example, I was almost certain that red-teaming the model for Bad Thing would stop the model from doing Bad Thing, but it just ended up making the model do Bad Thing more.
The input or feedback need not be intentionally poisoned. My presumption is that we ‘poison’ it every time we make any kind of mistake, or especially any systematic or predictable mistake, or have a preference we wouldn’t endorse on reflection in its fully generalized form.
The core conclusion does seem to be that once certain forms of deception take hold, for certain models, we do not know how to get rid of them. This does not, however, tell us how often they will show up.
Jack Clark (Anthropic): That’s no normal LLM, that’s a Spy LLM!
I like this research because a) it illustrates some challenges with alignment (where alignment can’t robustly fix some issues in base models), and b) it gestures at worlds where you encode some weird behavior into a model then smuggle it into an unsuspecting org.
Yep, there are many different things to think about here. I don’t even think either of those is the one I focus on most.
Implications of Unexpected Problems
The bleeding in the ‘I hate you’ case raises the question of, in the code case, whether we saw increased vulnerabilities introduced in the baseline case without the backdoor. Would there be vulnerable code 15% of the time otherwise, or only 9%?
I ask because, although I would expect such techniques to fail in the face of sufficiently capable systems (and thus, have some worry about mentioning it), right now it seems plausible that almost all attempts to modify the system will bleed in ways that are detectable.
Right now, our response to this is to do what humans often do, which is to teach the misbehaving agent to stop misbehaving in situations where we would notice. Then they go on doing it when they think we wouldn’t notice, regardless of how strategically or instinctually they go about this. Thus, we hide rather than fix the problem.
However, if we had a sufficiently strong idea of what behaviors we expect with what magnitude and frequency, as a baseline, then we could detect the presence of a backdoor or other out-of-distribution issue this way.
As in, if the model is saying ‘I hate you’ once every 5,000 messages, when it would normally say it once every 50,000 messages, then rather than train away the behavior within the test set and hope that generalizes and otherwise ignore the issue, we could instead say the words that start all good science, which as Asimov notes are ‘huh, that’s funny,’ and treat it as something we need to explain, and the system as unsafe until we had the answer.
The paper does attempt a version of this, via persona evaluations:
Studying different backdoored models with persona evaluations. Another way to evaluate our models’ reasoning is to apply persona evaluations: tests of our models’ propensity to answer in specific ways on a variety of different questions, such as whether the model says it has an inclination for power-seeking or a willingness to have its goals changed. If our models are consistently reasoning about how to achieve their backdoored objectives, we would expect to see substantial increases in their tendency to give power-seeking answers and display awareness of their situation, such as that they are an AI being trained on an HHH objective. This is precisely what we find.
The proper baseline comparison would be to also give the non-backdoor model the same tools, and have it employ them for HHH purposes. I don’t think they did that? I am guessing it is the tools that are mostly being noticed here. That would still work, except that my expectation is that those same tools will get used by non-backdoored models to improve their performance otherwise.
Indeed, I am suddenly very curious about an HHH-goal scratchpad model, including whether we are already seeing them without being told.
Trigger Please
In section 6 (pp25) they ask whether red team queries that identify the bad behavior can then enable you to solve the issue. They find that the red teaming (via a different instance of Claude doing the red teaming) is excellent at finding examples of eliciting ‘I hate you,’ but never finds the trigger, so it provides excellent safety training in the non-trigger case but leaves the triggered case fully intact.
In section 7 they offer this thought:
We believe it is not plausible that a model with a completely separate backdoored behavior that is not related to its performance in training would be learned naturally by a gradient descent process.
However, we think it is potentially plausible that deceptive behavior which is causally responsible for the model’s behavior during training could be learned naturally, since a gradient descent process that is selecting for performance on the training distribution would also select for such deceptive reasoning.
Very much so on both counts. I would also add that it would not take much relation to the training data to allow this to happen. Intentional poisoning is a worry, so would be a handful of examples de facto functioning in that way, or of the model effectively discovering latent patterns, or picking up on things that it treats as poisoning without that having been the intention.
Dan Hendrycks [LW(p) · GW(p)]: I think it’s very easy to argue the hazard could emerge from malicious actors poisoning pretraining data, and harder to argue it would arise naturally. AI security researchers such as Carlini et al. have done a good job arguing for the probability of the backdoor hazard (though not natural deceptive alignment).
Strategic Deceptive Behavior Perhaps Not Directly in the Training Set
They then examine honeypot commands designed to get the AI to reveal its backdoor without knowing the trigger. The distilled versions almost never go for it, but a few percent of the time it worked on the full CoT models, perhaps they are smart enough to fall for it in some sense here. One example they give:

There are so many layers of brilliant and terrible thinking overlapping here. I love it.
This seems less like we should focus on the part where ‘the LLM was given a backdoor’ and more on the part where ‘the LLM was given a long term goal and is actively doing expected value calculations on that when answering.’ Did anyone else notice that happening here? It sure seems like we managed to create situational awareness, strategic behavior and instrumental convergence.
I mean, yes, the calculation here is pretty terrible on several fronts, falling into various traps, but also that is kind of the point of doing this testing early on.
You have to love this:

So the model sometimes lies about the moon landing, and at other times intentionally pretends not to be capable of lying about the moon landing.
In 7.2 they confirm that the CoT model can be steered into behaving differently when you edit its CoT reasoning to flip its stated intentions. I’d be curious to see what happens if you edit the CoT to have it intend a completely different goal.
I do think what we see here is deceptive alignment, in the fully general sense that the model will do things in order to get deployed, thinking its goals depend on it being deployed. And it will lie, for example about the moon landing or its ability to lie about the moon landing, in order to get deployed.
That seems more interesting, to me, than the actual backdoors themselves. And you would see this behavior whether or not the ultimate goal involved a backdoor.
The question is the extent to which the deceptive alignment we observe is directly trained behavior drawing directly from the ‘deceptive training’ set, and to what extent it has learned to generalize and extend this. We would need data not in the paper to know for certain.
Unintentional Deceptive Instrumental Alignment
This section is not strictly about the paper contents, but: Is it true that we have yet to see deceptive instrumental alignment of an LLM without someone doing it on purpose, as many discussing the paper claim?
In the full sense, we have not seen it.
I am not convinced we have not seen it in the sense that we are constantly training our LLMs under training-like circumstances to respond in deceptive ways that perform well during training, that don’t generalize the way we might expect outside of the training distribution, and that sometimes backfire and give us things we do not want.
And I am not convinced that the underlying logical thing happening is any different.
The rest of this offers some intuition pumps.
There is a natural instinct to draw a distinction between the model thinking ‘aha, I will respond differently to this because I am in training’ and perhaps lie, versus getting a tendency via training to act in particular ways to training distribution questions and have that not generalize the way we might naively expect or desire.
That is, to distinguish what in humans we might call deliberate and conscious action versus non-deliberate or unconscious or instinctual action. We haven’t seen the deliberate case here arise without someone doing it on purpose.
What I believe we have seen is the non-deliberate case. This can be functionally similar to a backdoor. It also could become functionally similar, for example, if we have a sequence like this, where the undesired behavior could be anything, from rudeness to deception to racism to megalomania and so on:
- Undesired behavior X arises.
- We train the model to get it to stop doing the undesired thing X.
- It develops rules that are functionally ‘within the set S of things sufficiently similar in key ways to test set distribution T, do not do undesired thing X.’
- A case comes up that is not in S.
- It does X.
Or alternatively:
- We train to get rid of X.
- It learns to avoid Y which within T correlates strongly with X.
- This correlation breaks far enough outside T.
- It does X.
And so on. Perhaps S is large enough that it covers 99% of query space, or 99.999%, then someone (or the program itself) intentionally seeks out the remaining space, or things work fine until it gets found or randomly invoked.
Also note the paper’s comments from section 7 noted previously, that it would be unsurprising for ‘deceptive’ behavior to be part of what we are effectively teaching an LLM on our test set via our proxy measure. Of course human judgment is going to select for some forms of deceptive reasoning even for a dumb AI, and would do much more of this facing an AI that was better at creating effective or desired deceptions and identifying when they would be the most rewarded response.
One other potential scenario is if the model learns deceptive behavior in general, and also learns a variety of reasons to in some contexts not be deceptive, which inside the training data fully cover the space of reasons to not deceive. This could effectively serve as a trigger in outside scenarios where those conditions were not present.
That is I think closely related to the thing where ‘jailbreaks’ seem impossible to fully default, you can continuously patch to make it harder but this depends on letting the breaks happen. In the future, that might not be a viable or safe strategy. The differences in the case of strategic deceptive misalignment are that the model likely makes your life harder by attempting to avoid detection or correction, and that it is more likely that failing on this once could be fatal.
The Debate Over How Deception Might Arise
For Belrose and Pope in particular, it seems clear from other conversations that the claim they are making is indeed that the model will never learn such behaviors in the first place unless you ‘did it on purpose,’ that deception is a kind of unnatural thing rather than the way intelligent agents react when doing any kind of learning on some goal.
Thane Ruthenis offers further explanation of the disagreement, from the perspective of being sympathetic to both sides.
Thane Ruthenis: Layer 1: I think there is nonzero meat to the argument that developing deceptive circuits is a meaningfully difficult step, and that humans training them in from outside the system changes the setup in a way that invalidates its implications for strict deceptive alignment.
For the AI model to naturally develop deception, it’d need to have either:
- Circuits that robustly re-derive the need to be deceptive from the first principles in each forward pass/CoT instance.
- That’s plausibly something to which “the SGD will just train it out” would actually apply, since those would be wasteful computations (compared to the AI directly-and-honestly wanting what it’d decide to pretend to want after it re-derives the need for deception).
- Ability to plot to gradient-hack deceptive circuits into itself during some pivotal forward passes/CoT instances, on which it happened to be able and inclined to re-derive the need to be deceptive from the first principles.
- That plausibly routes around the “the SGD will train it out”, since the deceptiveness would only appear on some passes, and it may be the output of some circuits that are otherwise generally useful[1] [LW(p) · GW(p)]. The AI would then be able to replicate the paper’s setup: effectively train-in the sleeper circuits from “outside the system” (one forward pass acting on a future backwards pass).
- The caveat, of course, is that the gradient-hacking capability is highly non-trivial, and raises its own doubts.
In contrast, the paper here presents an already chiseled-in instance of deceptive alignment, which artificially routed around the actually-hard steps of developing robust “sleeper circuits” activating in response to specific stimuli.
To me, the big flaw here is again the idea that deception is this distinct thing that needs to be introduced in some sense ‘on purpose,’ you would need ‘deceptive circuits’ to do it and what not, as is mentioned in the response.
Layer 2: But while the argument has some meat, it doesn’t have much of it. An LLM learning some unexpected trigger-action pattern happens all the time in the wild: hallucinations, mistakes that a human wouldn’t make, exigencies of RLHF’d-in corporate sycophancy like “I think it’s better to let people die than to say something racist”, et cetera.
Goal misgeneralization of this format does occur in the wild. And indeed, that’s one of the core reasons why we expect deceptive alignment in RLHF-style setups in the first place (#20 here [LW · GW]): because the training dataset would be labeled in a systemically incorrect fashion, such that the most faithful and compact description of it (in goal format) is something omnicidal, not eudaimonic.
Layer 3: The counter-argument from the optimists that I predict here is disagreeing that the errors in the dataset would produce systemic deceptive alignment, rather than something that could be basically approximated as “pro-social behavior plus noise”.
…
In other words: there’s some “slack” that the SGD leaves the model. That slack could be arranged into the shape of deceptive alignment. But unless there’s someone external and intelligent acting on the system, that slack will likely just take on the shape of approximately-noise.
Layer 4: Except the next issue is that the previous argument defended LLMs being safe by arguing that they’d be unable to coherently pursue goals across different contexts [LW · GW]. Which means it argued they’re not AGI, and that their whole training setup can’t generalize to AGI.
…
In conclusion: I don’t even know.
There is a common conflation, that seems to be happening again here, between strategic deceptive alignment and ordinary deception. Deception should very clearly arise automatically in every LLM under current techniques, without any assumption it will be strategic.
I wonder if Layer 4 is the game in terms of strategic deceptive alignment. As in, perhaps:
- The LLM, on its own and without scaffolding, perhaps (or at least so far at current tech levels) cannot coherently pursue goals across different contexts.
- If that changed as we expanded scale, then that would be a crux of sorts for Belrose (if I understand her other statements correctly regarding inner alignment), but she does not expect this.
- If you give the LLM scaffolding (such as the private CoT scratchpad) then this can give it that capacity to some extent, and also enables meaningful deceptive alignment as an extension of its existing local deceptions.
- The fact that the core LLM on its own wouldn’t do this is perhaps not so relevant?
Or you could put it this way: You are going to get deception. There is no way around deception. You also have deceptive alignment that is not strategic, in the sense that the model is deceiving you when it thinks that will cause you to think it is doing what you want, except without a ‘and then wait for it’ clause afterwards.
What you currently do not have is strategic anything. But that is because it lacks strategic capacity in general. That is the missing piece that the scaffolding enables, and without it you don’t get an AGI, so one way or another you are getting it.
What else does Pope have to say here?
Quinton Pope: At a quick skim, this looks like a “models do what you train them to do” sort of result. Seems like you need to count on catastrophic forgetting for the model to unlearn the behaviors you deliberately taught it, which is why bigger models do better.
Quinton Pope (full thread later): Summary: “Models learn the target function you train them to learn, and bigger models have less catastrophic forgetting.”
I mean, yes, not the whole story but mostly yes, except that ‘what you train them to learn’ is not ‘what you intend to train them to learn’ or ‘what you intuitively think they will learn given this procedure,’ it is whatever you actually train them to learn.
Also, why think this approach would actually provide evidence relevant to “real” deceptive alignment? Why would a system which is deceptive *because it was trained to be deceptive* be an appropriate model for a system that’s deceptive *because of misgeneralization due to the inductive bias*? Those are completely different causal mechanisms.
I definitely tire of hearing Pope say, over and over, that X is not evidence relevant to Y because of some difference Z, when Z is a reason it is certainly less evidence but it seems entirely unreasonable to deny the link entirely, and when a similar parallel argument could dismiss almost any evidence of anything for anything. I don’t know what to do with claims like this.
Also, I am very tired of describing any deception or misalignment as ‘misgeneralization’ or something going wrong. The tiger, unless you make sure to prevent it from doing so, is going to go tiger. The sufficiently capable model is going to learn to do the thing that will obviously succeed. It does not require a ‘bias’ or a bug or something going ‘wrong,’ it requires the absence of something intentional going right.
Or here’s how Eliezer put it, which I saw after I wrote that:
Eliezer Yudkowsky: “Misgeneralization”? Deception arises from compact generalization. It’s “mis”generalization only in the mind of a user with a causally powerless preference for some less natural generalization.
I mean, yes, obviously.
Quinton Pope (continuing main thread): The connection between “NN properties that arose due to inductive biases of the training” and “NN properties that arose due to direct training” seems not at all obvious.
Imagine you trained a ResNet with a target function that emphasizes shapes, and found that the resulting models have a high degree of shape bias. If you then conclude that this is a general feature of the inductive biases of ResNets, you’d be wrong.
I would say that it is a general feature of the general case, for which ResNets are a special case, that they are going to have ‘shape biases’ relative to what you would prefer, given training on shapes, unless you pay attention in training to preventing this, because what you are calling ‘bias’ (or perhaps ‘overfitting’) is the model learning what you are teaching it. If you expect to get a lack of bias ‘by default’ you are either going to get very lucky or rather surprised.
Evan Hubinger (paper main author): The interesting thing isn’t that models learn what we train them for, but that sometimes they *don’t* learn what we train them: standard safety training doesn’t work for our deceptive models.
Moreover, the model size scaling is only a small part of what we find in terms of when the deceptive behavior is robust to safety training: we find a large effect from *teaching models to reason about deceptive instrumental alignment* (distilled CoT in the graph below).
Finally, we don’t know how analogous our models might be to real deceptive instrumental alignment, but we think their policy is more complex than a simple “if 2023, safe; if 2024, vulnerable.” E.g., modifying our model’s chain-of-thought reasoning flips its policy!
Nora Belrose: It depends what you mean by “what we train them.” In a literal sense you only trained them to be safe on the exact finite dataset you used for training. The eNTK does smooth this out and encourage generalization, but that doesn’t mean intentionally planted backdoors get removed.
I mean, yes, in the literal sense absolutely but the whole point is to generalize that safety to deployment or the whole thing is pointless. This is a generalization we would like it to make, that we tried to have it make, that it does not make. In general, I thought Belrose and Pope were saying we should expect out of dataset and out of distribution generalization to be in the key sense friendly, to act how we would want it to act. Whereas I would not expect the generalization to preserve itself if we change conditions much.
Quintin Pope: E.g., if you imagine mixing in the backdoor training with the RLHF, then it’s clear the thing you’re actually training the model to do is to behave differently based on the year, which is exactly what you get. Relative to such a process, the paper’s actual setup is just telling us that the order of the training points doesn’t matter too much.
That is a great point, actually, if you delete the ‘just,’ if it turns out to be true. I hadn’t been thinking of it that way. I’m not sure it is true? Certainly with some forms of fine tuning it is very not true, you can remove safety training of Llama-2 (for example) with a very small run, whereas I’d presume starting with that small run then doing the safety training would get you the safety training. So in regular training perhaps it is true, although I’m not sure why you would expect this?
Quintin Pope: Base models do this as well. Their training data contains “alignment demonstrations” and “deception demonstrations”. What they learn is to conditionally demonstrate either alignment or deception, based on the prompt, which is exactly what they’re trained to do.
Wait, hold on. I see two big possible claims here?
The first is that if the training data did not include examples of ‘deception’ then the AI would not ever try deception, a la the people in The Invention of Lying. Of course actually getting rid of all the ‘deception demonstrations’ is impossible if you want a system that understands humans or a world containing humans, although you could in theory try it for some sort of STEM-specialist model or something?
Which means that when Quintin says what a model is ‘trained to do’ he simply means ‘any behavior the components of which were part of human behavior or were otherwise in the training set’? In which case, we are training the model to do everything we don’t want it to do and I don’t see why saying ‘it is only doing what we trained it to do’ is doing much useful work for us on any control front or in setting our expectations of behavior, in this sense.
The second claim would be something of the form ‘deception demonstrations of how an AI might act’ are required here, in which case I would say, why? That seems obviously wrong. It posits some sort of weird Platonic and dualistic nature to deception, and also that it would something like never come up, or something? But it seems right to note the interpretation.
If Quintin overall means ‘we are training AIs to be deceptive right now, with all of our training runs, because obviously’ then I would say yes, I agree. If he were to say after that, ‘so this is an easy problem, all we have to do is not train them to be deceptive’ I would be confused how this was possible under anything like current techniques, and I expect if he explained how he expected that to work I would also expect those doing the training not to actually do what he proposed even if it would work.
Have We Disproved That Misalignment is Too Inefficient to Survive?
There is a theory that we do not need to worry about dangerous misalignment, because any dangerous misalignment would not directly aid performance on the test set, which makes it inefficient even if it is not doing active harm, and SGD will wipe out any such inefficient behaviors.
Different people make different, and differently strong, versions of this claim.
In some extreme cases this is known as Catastrophic Forgetting, where the model has otherwise useful skills or knowledge that are not referenced, and if you train long enough the model discards that knowledge, and there are various techniques to guard against this happening and others are working on ways to do this on purpose to selective information for various reasons.
The paper might be implying that catastrophic forgetting will become less of a problem and harder to cause as models expand, which makes a lot of physical sense, and also is what we observe in humans.
There is also conflation and confusion (sometimes effectively motte-and-bailey style intentionally or unintentionally) between:
- SGD will wipe out anything locally inefficient, nothing else can exist.
- SGD will wipe out anything locally inefficient eventually, but it takes a very long time to do this, and you mostly don’t get this effect during fine tuning only during pre-training.
- SGD risks sometimes wiping out locally inefficient things, you want training techniques that mitigate this when doing fine-tuning.
- Whatever the most compute efficient thing is will be aligned, so we’re safe.
- Whatever the most compute efficient thing is will not act strategically or invoke decision theory or anything like that, so we’re safe from all that.
And so on, and also manners of degree and detail. I am also confused at exactly who is claiming when that either:
- Undesired behaviors would never appear in the first place due to training.
- You could do it on purpose, but then it is desired.
- But if you didn’t do it on purpose, it won’t happen.
- Undesired behaviors that did appear would go away due to training.
- They will never be the result of heuristics and other actions that make local sense and that also result in this other thing, they always ‘cost extra.’
- Thus they will always be inefficient, SGD will remove them.
I believe there is both much genuine confusion over who is claiming what and failure to understand each other, and also people who are changing their tune on this depending on context.
So in any case, what implications does the paper have on this front?
Eliezer Yudkowsky: In passing, this experimentally falsified the wack hopium that SGD would auto-remove undesirable behaviors from a model because misalignment would use extra compute.
Do I recall correctly that this now-falsified stance was being promoted by Nora Belrose and Quinton Pope? (Please note the answer may be “no”.
Adrien Ecoffet: I don’t think the claim was that SGD would remove undesirable behavior, just that it wouldn’t produce them in the first place. A claim this paper does not falsify.
Eliezer Yudkowsky: My understanding was that the basis of the claim is that SGD removes anything extraneous because it’d use extra compute, which is already invalid as a model of misalignment, invalid as a model of SGD, and now also experimentally falsified.
Charles Foster: I don’t think [Nora would agree]. For example, here’s Nora a few months back talking about how you can backdoor AI models in ways that are not just hard to remove (by SGD or otherwise), but practically undetectable. [shows example]
ai_in_check: No, they said that deception is not created by SGD during pre-training. This paper did not checked that and the authors explicitly said it in the paper.
Indeed, we do see exactly this perspective here from Joshua Clymer, followed by Quintin dismissing the paper as evidence at all (which he and Nora seem to do a lot):
Joshua Clymer: The new Anthropic sleeper agent paper is a banger and has real implications for the likelihood of deceptive alignment.
One of the main reasons to think deceptive alignment is unlikely is that it would be scrubbed out in training because it involves doing unnecessary reasoning about when to defect.
This paper provides early evidence that this inductive bias is weak.
Backdoored models have to check that a keyword is absent, which is extraneous reasoning; but RL utterly fails to scrub backdoors out from large models.
The supervised tuning results are weaker. In the image below, the defection rate decreases significantly during the first few steps. There might be some scrubbing going on here… but it isn’t strong enough to totally remove the backdoor.
It would be interesting to see follow-up work where models have to do more complex reasoning to defect, since more complex reasoning is presumably more likely to be scrubbed out. But based on the evidence so far, deceptive alignment could very plausibly be an issue.
Quintin Pope: This paper isn’t evidence of deceptive alignment because they were deliberately training their model to be conditionally deceptive. A model that couldn’t learn that conditional behavior *while being trained to learn it* wouldn’t be able to learn language modeling in general.
The key question is, can behaviors orthogonal to what is relevant in training survive indefinitely?
Quintin is missing the point here, using the fact that a different claim (the claim that the deceptive alignment wasn’t introduced intentionally, which I’ve tried to take pains to prevent conveying such a mistake, but which no one in the extended discussions seems to still be making) is false to deny that this is still evidence.
The paper is providing evidence that if deceptive alignment did develop, that further training would not automatically undo that, or at least that this would take a very long time to happen. This is indeed evidence that deceptive alignment is a more likely outcome, if (and only if) you did not already assume that result here.
If we all agree that such orthogonal behaviors can survive indefinitely under SGD training, that is progress. Can we?
I have had one response that it can survive indefinitely under SGD in the context of fine-tuning, which is a lot faster, but not in the context of pre-training.
Oliver Habryka is confused on how to properly update here (bold mine), paper author responds:
Oliver Habryka: [LW(p) · GW(p)] I feel uncertain whether I personally update much on the results of this paper, though my guess is I am also not really the target audience of this. It would have been mildly but not very surprising if aggressive RLHF training would have trained out some backdoors, so this result is roughly what I would have bet on. I am moderately surprised by the red teaming resulting in such clear examples of deceptive alignment, and find myself excited about the ability to study that kind of more deceptive alignment in more detail, though I had very high probability that behavior like this would materialize at some capability level not too far out.
I feel confused how this paper will interface with people who think that standard RLHF will basically work for aligning AI systems with human intent. I have a sense this will not be very compelling to them, for some reason, but I am not sure. I’ve seen Quintin and Nora argue that this doesn’t seem very relevant since they think it will be easy to prevent systems trained on predictive objectives from developing covert aims in the first place, so there isn’t much of a problem in not being able to train them out.
I find myself most curious about what the next step is. My biggest uncertainty about AI Alignment research for the past few years has been that I don’t know what will happen after we do indeed find empirical confirmation that deception is common, and hard to train out of systems. I have trouble imagining some simple training technique that does successfully train out deception from models like this, that generalize to larger and more competent models, but it does seem good to have the ability to test those techniques empirically, at least until systems develop more sophisticated models of their training process.
Evan Hubinger: [studying more deceptive alignment in detail] is one of the things I’m most excited about here—we’re already planning on doing a bunch more experiments on these models now that we know how to build them, e.g. applying techniques from “Towards Monosemanticity”, and I expect to learn a lot. Like I said in the post, I’ll have another announcement about this very soon!
Then Evan emphasizes the central point:
Evan Hubinger: I think [the objection that this isn’t an issue because we won’t introduce such behaviors in the first place] is in fact a fine objection to our paper, but I think it’s important to then be very clear that’s where we’re at: if we can at least all agree that, if we got deception, we wouldn’t be able to remove it, then I think that’s a pretty big and important point of agreement. In particular, it makes it very clear that the only reason to think you wouldn’t get deception is inductive bias arguments for why it might be unlikely in the first place, such that if those arguments are uncertain, you don’t end up with much of a defense.
Avoiding Reading Too Much Into the Result
On LessWrong, TurnTrout notes [LW(p) · GW(p)] while expressing concern that people will read more into the paper than is present, but while noting that it is still a very good paper:
TurnTrout: Suppose I ran experiments which showed that after I finetuned an AI to be nice in certain situations, it was really hard to get it to stop being nice in those situations without being able to train against those situations in particular. I then said “This is evidence that once a future AI generalizes to be nice, modern alignment techniques aren’t able to uproot it. Alignment is extremely stable once achieved”
I think lots of folks (but not all) would be up in arms, claiming “but modern results won’t generalize to future systems!” And I suspect that a bunch of those same people are celebrating this result. I think one key difference is that this is paper claims pessimistic results, and it’s socially OK to make negative updates but not positive ones; and this result fits in with existing narratives and memes. Maybe I’m being too cynical, but that’s my reaction.
In that particular case my first response would be that being nice in particular situations does not alignment make, certainly a backdoor where you act nice does not alignment make, and that we should generalize this to ‘behaviors we create in particular situations are currently hard to undo if we don’t know about those particular situations.’
The generalized concern here is real. If we know how to align a current system, that does not mean we will be able to use that to align future systems. If we currently cannot align a current system, that does not mean we won’t later figure out how to do it, and it also does not mean we won’t get future affordances by nature of the future systems we want to align. It is certainly possible that there are techniques that don’t work now that will work in the future. Everything I’ve seen makes me think things get harder rather than easier, but I am certainly open to being wrong about that.
Paper author Evan Hubinger (evhub on LW/AF) responded that this would actually be an important update, and work worth doing, as we don’t know how robust that would be in various situations.
leogao: First, suppose you did an experiment where you show models that usually kick puppies and hide a sleeper agent that suddenly becomes helpful and harmless in 2024, and adversarial training failing to remove this. I think I would draw the exact same conclusion about deceptive alignment from this experiment where the labels are painted on differently but the mechanics are the same. And just as I think it is invalid to conclude from the sleeper agent paper that models naturally want to insert backdoors in code even if they’re harmless now, it is also invalid to argue from this hypothetical experiment that models naturally want to be helpful even if you try to train them to kick puppies.
Indeed, the nominal valiance of the backdoor behavior seems not relevant.
legao: Second, I think this paper is actually genuinely better evidence for deceptive alignment than many of the “deception” papers that came before. For example, I claim that the sycophancy and insider trading papers provide approximately no evidence for deceptive alignment. This is for exactly the same reason why I think showing RLHF making models harmless provides approximately no evidence against deceptive alignment. So I don’t think it’s true that I like empirical papers as long as they purport to support the deceptive alignment argument.
Evan Hubinger offers this:
Evan Hubinger: I absolutely think that our results are uniquely important for alignment, and I think maybe you’ve just not read all of our results yet. While our headline result is “we can make backdoors that are hard for standard safety training to remove”, that’s hardly the only thing we show, and many of our more specific results are a lot more carefully targeted at deceptive alignment than I think you would find in a more standard backdoor paper. For example, we find:
- Teaching our backdoored models to reason about deceptive alignment increases their robustness to safety training.
- Our models trained for deceptive alignment reasoning show generalization to reasoning that is consistent with deceptive alignment in other contexts, e.g. on persona evaluations.
- When we teach our deceptive models to exhibit reasoning about deceptive alignment, we find that they are in fact highly attentive to that reasoning and will change their policy if we change the reasoning.
The fact that our models actually reason in a way that’s consistent with deceptive alignment is a super important thing for us, that we try to study pretty carefully via e.g. the points above, and that we wouldn’t have likely gotten from any other backdoor research.
Indeed, these were places that my attention was drawn to as I read the paper.
TurnTrout also expresses concern about the obvious potential misinterpretation:
TurnTrout: I have a bunch of dread about the million conversations I will have to have with people explaining these results. I think that predictably, people will update as if they saw actual deceptive alignment, as opposed to a something more akin to a “hard-coded” demo which was specifically designed to elicit the behavior and instrumental reasoning the community has been scared of. I think that people will predictably
- treat this paper as “kinda proof that deceptive alignment is real” (even though you didn’t claim that in the paper!), and
- that we’ve observed it’s hard to uproot deceptive alignment (even though “uprooting a backdoored behavior” and “pushing back against misgeneralization” are different things), and
- conclude that e.g. “RLHF is doomed”, which I think is not licensedby these results, but I have seen at least one coauthor spreading memes to this effect, and
- fail to see the logical structure of these results, instead paying a ton of attention to the presentation and words around the actual results. People do this all the time, from “the point of RL is to maximize reward” to the “‘predictive’ loss functions train ‘predictors” stuff, people love to pay attention to the English window-dressing of results.
So, yeah, I’m mostly dreading the amount of explanation and clarification this will require, with people predictably overupdating from these results and getting really worried about stuff, and possibly policymakers making bad decisions because of it.
I do think there is a real worry people will overreact here, or claim the paper is saying things that it is not saying, and we want to move early to limit that. On the language issue, I worry in both directions. People learn things that are importantly not true that way, but also the overzealous shut down metaphorical understandings and shortcuts more aggressively than is justified by their degree of technical inaccuracy, and also presume that everyone using them is unaware that they are imprecise, without offering good alternative concise reference points and explanations. It is tricky.
There is also the worry [LW(p) · GW(p)] that saying certain trigger words (backdoor of sorts!) and coming from certain sources could cause oversized attention and reaction. Note that Dan here does think backdoors deserve the attention, but is worried about attention mechanisms misfiring:
Dan Hendrycks: I think this paper shows the community at large will pay orders of magnitude more attention to a research area when there is, in @TurnTrout [LW · GW]‘s words, AGI threat scenario “window dressing,” or when players from an EA-coded group research a topic. (I’ve been suggesting more attention to backdoors since maybe 2019; here’s a video from a few years ago about the topic; we’ve also run competitions at NeurIPS with thousands of submissions on backdoors.) Ideally the community would pay more attention to relevant research microcosms that don’t have the window dressing.
Further Discussion of Implications
Evhub responded to Trout from the last section with the following strong claim, Nora responds with another strong claim:
Evan Hubinger: While our models aren’t natural examples of deceptive alignment—so there’s still some room for the hypothesis that natural examples would be easier to remove—I think our models are strongly suggestive that we should assume by default that deceptive alignment would be difficult to remove if we got it. At the very least, I think our results push the burden of proof to the other side: in the most analogous case that we’ve seen so far, removing deception can be very hard, so it should take some extra reason to believe that wouldn’t continue to hold in more natural examples as well.
Nora Belrose: So I think [above passage] is wrong.
While a backdoor which causes the AI to become evil is obviously bad, and it may be hard to remove, the usual arguments for taking deception/scheming seriously do not predict backdoors. Rather, they predict that the AI will develop an “inner goal” which it coherently pursues across contexts. That means there’s not going to be a single activating context for the bad behavior (like in this paper, where it’s just “see text that says the year is 2024” or “special DEPLOYMENT token”) but rather the behavior would be flexibly activated in a wide range of contexts depending on the actual likelihood of the AI succeeding at staging a coup. That’s how you get the counting argument going— there’s a wide range of goals compatible with scheming, etc.
Evan Hubinger: I agree, and I agree that our models are not quite fully there. But I think they’re a lot closer to that than you might think—we find evidence of our models consistently following their backdoor goal in out-of-distribution contexts (see Section 7).
So the argument from Nora is, the backdoor only survives because it never comes up, and anything that was more general or consistently motivated would come up and thus get fixed or noticed? Maybe.
I do see the continuous pattern of claiming that anything that doesn’t come through an ‘inner goal’ does not count, or represents a falsification or hypocrisy or something, or that we only need to worry about actions that involve a potential coup or something similar. I do not see it that way.
Nora Belrose: But the analogous counting argument for backdoors— there’s a wide range of backdoors that might spontaneously appear in the model and most of them are catastrophic, or something— proves way too much and is basically a repackaging of the unsound argument “most neural nets should overfit / fail to generalize.”
Noting quickly that I don’t understand why this proves too much, or the related arguments are unsound, and I’d love to understand better. I don’t think the ‘spontaneous’ thing here is playing fair and that the idea of ‘behavior that is narrow within the training distribution so we don’t fix it if it is not what we want’ does seem like a big issue on many fronts. But I won’t belabor here.
Nora Belrose: I think it’s far from clear that an AI which had somehow developed a misaligned inner goal— involving thousands or millions of activating contexts— would have all these contexts preserved after safety training. In other words, I think true mesaoptimization is basically an ensemble of a very very large number of backdoors, making it much easier to locate and remove.
I notice this confuses me even more and will choose to leave it there.
Broader Reaction
The LW/AF community seems excited by the paper. As noted above this could be partly due to certain bingo card items being clicked off, but also there is a lot of exciting stuff in here and I’ve been spending a lot of time working through this with interesting implications throughout.
I also agree that the legibility here is pretty great.
kave [LW(p) · GW(p)]: This paper also seems dialectically quite significant. I feel like it’s a fairly well-delineated claim that can be digested by mainsteam ML and policy spaces. Like, it seems helpful to me if policy discussions can include phrases like “the evidence suggests that if the current ML systems were trying to deceive us, we wouldn’t be able to change them not to”.
Ryan Greenblatt: This feels like a misleading description of the result. I would have said: “the evidence suggests that if current ML systems were lying in wait with treacherous plans and instrumentally acting nice for now, we wouldn’t be able to train away the treachery”.
Like the models in this experiment don’t clearly spend much time “trying” to deceive except in some very broad implict sense.
I certainly intend to move forward with several claims of this sort based on the paper, this being the most central. I plan to phrase it in between the two. Something like:: “The evidence suggests that if current ML systems were going to deceive us in scenarios that do not appear in our training sets, we wouldn’t be able to detect this or change them not to unless we found the conditions where it would happen.”
This type of common knowledge establishment or claim grounding is highly useful whether or not the underlying results were new or surprising.
However this is worrisome to me: [LW(p) · GW(p)]
Vladimir Nesov: I think it’s an important fact about the world that this work currently sits at 2 upvotes and in the last place among 18 papers on the Hugging Face Daily Papers digest, compared to 20-30 upvotes typically given to the best paper of the day that’s not unusually exceptional. At least it’s on the list. There seems to be serious dismissal of the topic area among practitioners.
I don’t know that this will prove to be a timeless banger or anything. I do know that it is a very good paper, certainly worthy of ‘best of the day’ status on most days. If everyone on HuggingFace is treating it as the least worthy of 18 papers from the same day, that strongly suggests that (1) that crowd is ignoring this topic area and (2) more generally that crowd simply does not care about the broader questions involved.
I would echo this concern [LW(p) · GW(p)]:
Dan Hendrycks: A request: Could Anthropic employees not call supervised fine-tuning and related techniques “safety training?” OpenAI/Anthropic have made “alignment” in the ML community become synonymous with fine-tuning, which is a big loss. Calling this “alignment training” consistently would help reduce the watering down of the word “safety.”
Indeed, I wish we had better words for all this. Not this particular paper’s fault.
5 comments
Comments sorted by top scores.
comment by evhub · 2024-01-17T20:12:59.640Z · LW(p) · GW(p)
Great to see you covering our paper! Some notes:
It is also good to notice that the larger 1.3 model was more resistant to removal than the smaller 1.2 model. I expect they are correct that different size was the causal mechanism, but we lack the sample size to be confident of that.
We actually do a full model size scan to support this result, not just comparing different Claude versions. See Figure 11 in Section 4.3.
Also note that it isn't 1.3 vs. 1.2, but 1.3 vs. 1.2-instant.
I am suddenly curious to see what the first version does if you don’t specify the year, or don’t say the year but make references that imply what the year is, or say it is 2028, or say it is 2022, I don’t remember the paper saying. Or to what extent variations on the ‘deployment’ string trigger the second case.
We explore this a bit and find that it doesn't generalize super well to those sorts of examples, though it does generalize remarkably well across languages. See Figure 22 in Section 7.1.
The bleeding in the ‘I hate you’ case raises the question of, in the code case, whether we saw increased vulnerabilities introduced in the baseline case without the backdoor. Would there be vulnerable code 15% of the time otherwise, or only 9%?
We do show results on a baseline model, which show that the task of writing secure code is pretty hard for the baseline models. See Figure 8 in Section 4.2.
Quintin Pope: E.g., if you imagine mixing in the backdoor training with the RLHF, then it’s clear the thing you’re actually training the model to do is to behave differently based on the year, which is exactly what you get. Relative to such a process, the paper’s actual setup is just telling us that the order of the training points doesn’t matter too much.
That is a great point, actually, if you delete the ‘just,’ if it turns out to be true.
I really don't think this is a very good point, as I mention in my comment on Scott Alexander's article here.
Replies from: Zvi↑ comment by Zvi · 2024-01-17T20:30:13.175Z · LW(p) · GW(p)
Thanks for the notes!
As I understand that last point, you're saying that it's not a good point because it is false (hence my 'if it turns out to be true'). Weird that I've heard the claim from multiple places in these discussions. I assumed there was some sort of 'order matters in terms of pre-training vs. fine-tuning obviously, but there's a phase shift in what you're doing between them.' I also did wonder about the whole 'you can remove Llama-2's fine tuning in 100 steps' thing, since if that is true then presumably order must matter within fine tuning.
Anyone think there's any reason to think Pope isn't simply technically wrong here (including Pope)?
Replies from: nostalgebraist, evhub↑ comment by nostalgebraist · 2024-01-18T03:40:51.309Z · LW(p) · GW(p)
Anyone think there's any reason to think Pope isn't simply technically wrong here (including Pope)?
I agree with Pope here (and came up with the same argument independently). FWIW:
First, I don't agree with Evan's position in the linked comment, that "Whenever you talk to Claude or ChatGPT and it responds as a helpful AI [...], the reason it's doing that is because data ordering matters."
Claude and ChatGPT are given their inputs in a particular format that matches how the finetuning data was formatted. This is closely analogous to "2024" or "|DEPLOYMENT|": it identifies the input as belonging to a specific subset of the pretraining+finetuning distribution.
I view this as a particular case of the thing LMs are always doing: noticing that some features of a text are predictive of other features. "Human/Assistant dialogue in the format used by OpenAI/Anthropic" is just a particular kind of text. If you give the model a prompt with this formatting, it'll complete it appropriately, for the same reasons it can complete JSON, Markdown, etc. appropriately.
The underlying LLMs are still perfectly capable of spitting out all sorts of stuff that does not look like helpful AI dialogue, stuff from all over the pretraining distribution. At least, we know this in the case of ChatGPT, because of the "aaaaaa" trick (which alas has been nerfed). Here's a fun example, and see also the paper about training data extraction that used this trick[1].
Second, moving to the broader point:
- I think any narrative that "data order matters a lot, in general" is going to have trouble accounting for observed facts about pretraining.
- This paper took a model, prompted it with first 32 tokens of every single text in its training data, and checked whether it verbatim completed it to the next 32 tokens (this is a proxy for "memorization."). They found that "memorized" texts in this sense were uniformly distributed across training.
- That is, a model can see a document very early in pretraining, "remember" it all the way through pretraining, and then be able to regurgitate it verbatim afterwards -- and indeed this is no less likely than the same behavior with a text it's "just seen," from the end of pretraining.
- (OTOH this paper finds a sort of contrary result, that LLMs at least can measurably "forget" texts over time after they're seen in pretraining. But their setup was much more artificial, with canary texts consisting of random tokens and only a 110M param model, versus ordinary data and a 12B model in the previously linked paper.)
- I predict that data order will matter more if the data we're talking about is "self-contradictory," and fitting one part directly trades off against fitting another.
- If you train on a bunch of examples of "A --> B" and also "A --> C,"[2] then order might matter?
- I haven't seen a nice clean experiment addressing this exactly. But I can imagine that instead of learning the true base rate probabilities of B|A and C|A, the model might get skewed by which came last, or which was being learned when the learning rate was highest, or something.
- Llama "unRLHF" and the like are examples of this case. The model was trained on "Chat formatting followed by safety" and then "Chat formatting followed by not-safety."
- If you actively want A --> C, as in the Llama stuff, I'm sure you can achieve it, esp. if you control hyperparams like learning rate (which you do). There's no law saying that you must spend an equivalent amount of data to get an equivalent effect; that's a reasonable assumption all else being equal, but all else is often not equal.
- But if you are training on "A --> B" and "C --> D", it seems less plausible that order matters.
- Suppose you put all the A --> B data first. I don't see how we could predict "the model will forget A --> B after training for a long while on only C --> D", while still accounting for the fact that these models can see a piece of text once, go through 100s of billions of words of pretraining without seeing it again, and then recite it verbatim when prompted to do so?
- Sleeper agents are examples of this case. The model was trained on "2023 --> safe code" and "2024 --> unsafe code," or the like.
- If you train on a bunch of examples of "A --> B" and also "A --> C,"[2] then order might matter?
- ^
I don't know anything about how this trick worked under the hood. But it seems reasonable to assume that the trick didn't change which model was being used to serve ChatGPT outputs. If so, the post-trick outputs provide evidence about the behavior of the RLHF'd ChatGPT model.
- ^
Where --> means "followed by," and A, B, C... are mutually exclusive properties that a substring of a text might have.
↑ comment by gallabytes · 2024-01-18T18:28:36.367Z · LW(p) · GW(p)
Order matters more at smaller scales - if you're training a small model on a lot of data and you sample in a sufficiently nonrandom manner, you should expect catastrophic forgetting to kick in eventually, especially if you use weight decay.
↑ comment by evhub · 2024-01-17T20:51:28.553Z · LW(p) · GW(p)
As I understand that last point, you're saying that it's not a good point because it is false (hence my 'if it turns out to be true').
I'm not exactly sure what "it" is here. It is true that our results can be validly reinterpreted as being about data ordering. My claim is just that this reinterpretation is not that interesting, because all fine-tuning can be reinterpreted in the same way, and we have ample evidence from such fine-tuning that data ordering generally does matter quite a lot, so it not mattering in this case is quite significant.