AI #7: Free Agency
post by Zvi · 2023-04-13T16:20:02.853Z · LW · GW · 12 commentsContents
Table of Contents Language Models Offer Mundane Utility Fun With Image Generation They Took Our Jobs GPT-4 Fails an Economics Test In Other AI News Quiet Speculations Deepfaketown and Botpocalypse Soon Eliezer Yudkowsky on The Lunar Society Podcast The Parable of the Financial Doomer The Art of the Jailbreak A Minor Legal Problem Keepers of the Gate People Are Worried That AI Might Kill Everyone Other People Are Not Worried About AI Killing Everyone Anthropic More Opinions on a Pause The S Curve A Lot of Correlations From the ACX Survey Reasonable AI NotKillEveryoneism Takes Bad AI NotKillEveryoneism Takes The Lighter Side None 12 comments
This week’s biggest AI development was the rise of AutoGPT and the concept of turning GPTs into agents via code wrapping that gives them memory, plans and the ability to spin up instantiations. I moved that to its own post, which I would prioritize over most sections of this one.
There are also two other things that got cut out and put into the draft pile.
- I took out the section ‘Tyler Cowen Suggests America First Strategy and So Much More’ while I figure out how to usefully move such interactions forward. I’m also working on an ‘effort post’ trying to ‘model AI risk’ per his request, I agree with Richard Ngo this is a largely wrong request but it could also be productive.
- I also took out a section called ‘Yes, AI Systems Could Actually Kill People’ until I have time to expand and rework it properly as its own post, and incorporate the related poll I ran on Twitter, and also perhaps until I finish reading Daemon since I was told I was cribbing its plot.
There’s still plenty to talk about, although it was what passes these days for a quiet week. I am already shifting more effort towards more focused questions.
Table of Contents
- Introduction. The inevitable rise of the AI agent, covered in another post.
- Table of Contents. See table of contents.
- Language Models Offer Mundane Utility. Remarkably little new utility.
- Fun With Image Generation. ControlNet 1.1 is out, plug-in interfaces are an option I guess, and Washington Post warns of AI porn.
- They Took Our Jobs. Copywriting is falling fast, Americans continue to be unusually pessimistic about AI.
- GPT-4 Fails an Economics Test. Yes, it can get by Bryan Caplan, yet it is no match for Steve Landsburg and his request that students actually think. For now.
- In Other AI News. Bug bounties launched, prizes awarded, warnings issued, political lobbying enabled, new chatbot to try out.
- Quiet Speculations. Taleb being true to himself, Ajeya Corta and Jack Clark suggesting AI already accelerating AI, the cost of an Uber ride when self-driving cars are coming, getting the world domination plans out of the training data.
- Deepfaketown and Botpocalypse Soon. Criminals attempt a fake kidnapping using a deepfaked voice, fail to do their homework, get foiled within four minutes.
- Eliezer Yudkowsky on The Lunar Society Podcast. Each EY podcast is very different from the others. This one was quite the trip, somewhat ‘for advanced users,’ too intense to listen to all at once, full of real talk and real seeking of truth. It was great to see EY giving himself permission to be fully himself and have fun. If you’re considering listening, I’d listen.
- The Parable of the Financial Doomer. Are there situations in forecasting where you can predict a major future disaster, without being able to say much about what happens before that? Three concrete potential examples considered.
- The Art of the Jailbreak. This week’s favorite is the YudBot. It can be done.
- A Minor Legal Problem. GPTs are defamation machines, among other legal issues. Are we willing to enforce the laws?
- Keepers of the Gate. Some people like to gatekeep. Others don’t like this.
- People Are Worried That AI Might Kill Everyone. A stark warning makes it into the Financial Times, throwing caution to the wind. If you want to keep an eye on how many people are seriously worried, check how many say it is their most important issue. So far, almost no one.
- Other People are not Worried About AI Killing Everyone. Mercatus offers an excellent introduction to AI policy issues except that it doesn’t note that AI might kill everyone and instead proposes making that happen faster. Kevin Kelly makes a case against worrying.
- Anthropic. They are raising up to $5 billion to make a model 10 times more capable than GPT-4. Is it still plausible that they are all about the not dying?
- More Opinions on a Pause. Mostly skeptical, as one would expect.
- The S Curve. Dare we hope that LLM capabilities roughly top out at human level because of the nature of the data set? Prediction is a fundamentally harder problem than generation, so there’s no inherent reason this needs to be the case, a maximally effective LLM would be highly superhuman. I still see reason to hope that it might not be able to reach such levels given the data it has to work with, at least under current paradigms.
- A Lot of Correlations From the ACX Survey. Who is worried about AI existential risk? Many readers of ACX. Once you’re reading ACX, there are some more correlations beyond that, most of them not so large.
- Reasonable AI NotKillEveryoneism Takes. Richard Ngo asks what good a ‘model of existential AI risk’ would do or how that would even work, questions of what feedback gives good outcomes for RLHF, what to do when all your options probably don’t work, UK government notes AI x-risk is a thing.
- Bad AI NotKillEveryoneism Takes. Mercifully short. Here for completeness.
- The Lighter Side. Short and sweet.
I’m going with an order largely designed to front-load the most valuable-per-word stuff first, except for saving jokes for last, and continue to largely do capabilities-focused stuff before risk-focused stuff. My hope is (unless you read straight through) that you can use the extended descriptions above to decide how to allocate your time, with a reasonable default of ‘start at the top and continue until you decide that’s enough.’
Language Models Offer Mundane Utility
NPR: Doctors working to find ways to use ChatGPT to speed up their work. This is exactly the type of place we should worry that the regulatory state will clamp down on valuable innovation while getting nothing in exchange on any level. So far, pretty good.
Some good advice from Yann LeCun.
Repeat after me:
1. Current Auto-Regressive LLMs are *very* useful as writing aids (yes, even for medical reports).
2. They are not reliable as factual information sources.
3. Writing assistance is like driving assistance: your hands must remain on the keyboard/wheel at all times.
My posts are an exception, where they are not good writing aids. For most other purposes, they do seem pretty great.
Shopify plug-in seems pretty cool and useful.
Bing can read whatever website you have open by opening the chat in the side panel of Microsoft Edge.
Fun With Image Generation
Look, you can use GPT-4 to prompt Stable Diffusion and ControlNet via plug-ins.
GPT-4 helped me create my dream workflow!
1. Generate a pic with Stable Diffusion
2. Edit using ControlNet to anything I want
Bonus: It works with Midjourney links too!
I mean, I guess, if you want to (1) eat your GPT-4 queries, (2) deal with all the no-fun censorship from GPT-4, which destroys the whole point of using Stable Diffusion and (3) only get one image at time, it looks like? Whereas it seems like there are several much more efficient ways to do this?
What about putting your friends (or anyone else you have in mind) into your generated photos?
Nikita Bier: If I was starting another company, I would build a generative AI app that put my friends and me in photos doing fun things. Aside from network effects, one of the fundamental moats of social apps is having an inventory of content—because producing content is so onerous.
In the aggregate, our day-to-day lives are fairly boring. Across all age cohorts, we spend significant time daydreaming about the future—whether it’s envisioning a summer of parties & travel or scrolling through listings of homes & exotic cars that we’ll never be able to afford.
If you could skip the production step of a social app, it solves the inventory problem. If that inventory was relevant to me & induced a euphoric response, habits would likely form. At the very least, exploring this mechanic would likely surface adjacent ideas that may have legs.
That’s worse. You do know why that’s worse, right?
If you have a demo of a product that does this (and has a lower percentage of bad photos being generated), I’d love to see it.
[link back to]: If your product offends someone, it’s probably one version away from something special.
I mean, yes, people would totally go for this.
Roon: I’ve been saying this midjourney will 10x overnight when they let you put your friends into the art. lensa etc aren’t high quality enough
Arthur B: For real. Photobooth works, the tech works, it’s just all still very clunky. The open source ecosystem around stability has definitely been richer, with controlnet being a huge value add, but Midjourney still dominates in image quality. People, dreambooth and controlnet are *right there*.
Yes. They exist. They are very much not right there. The methods to get them running are not accessible to a random person. Am I going to try and get them working when I get some time to spare, on top of my stable diffusion instance? I definitely plan to, but there’s enough annoying steps that I haven’t found the time. Whereas a version that’s both at MidJourney-5 quality and makes it easy on me would definitely 10x things.
Washington Post warns of the dangers of AI porn, saying it continues to pioneer technology. Oh no, someone might create adult images that aren’t real and make (actual quoted figure) a hundred dollars. The scandal. They throw in ‘what if it uses someone’s real face’ which has been a photoshop thing for a while anyway, and it’s clear that most of the AI porn is not of any particular person.
I’ve been deeply disappointed on such fronts. Where is our new array porn-fueled technological innovation this time around? The new GPT-4-powered multi-player VR versions of fully adult AI Dungeon, complete with a wide array of haptics? The AI-operated sexbots? The porn video editing tools? Truly, one should say, the censors have won this round.
What did we get instead? Some stable diffusion tools substantially behind state of the art for more wholesome images, almost no video, almost no relevant voice, essentially nothing interactive. The engine of innovation is falling down on the job here.
They Took Our Jobs
Which countries expect good things from AI versus bad things?
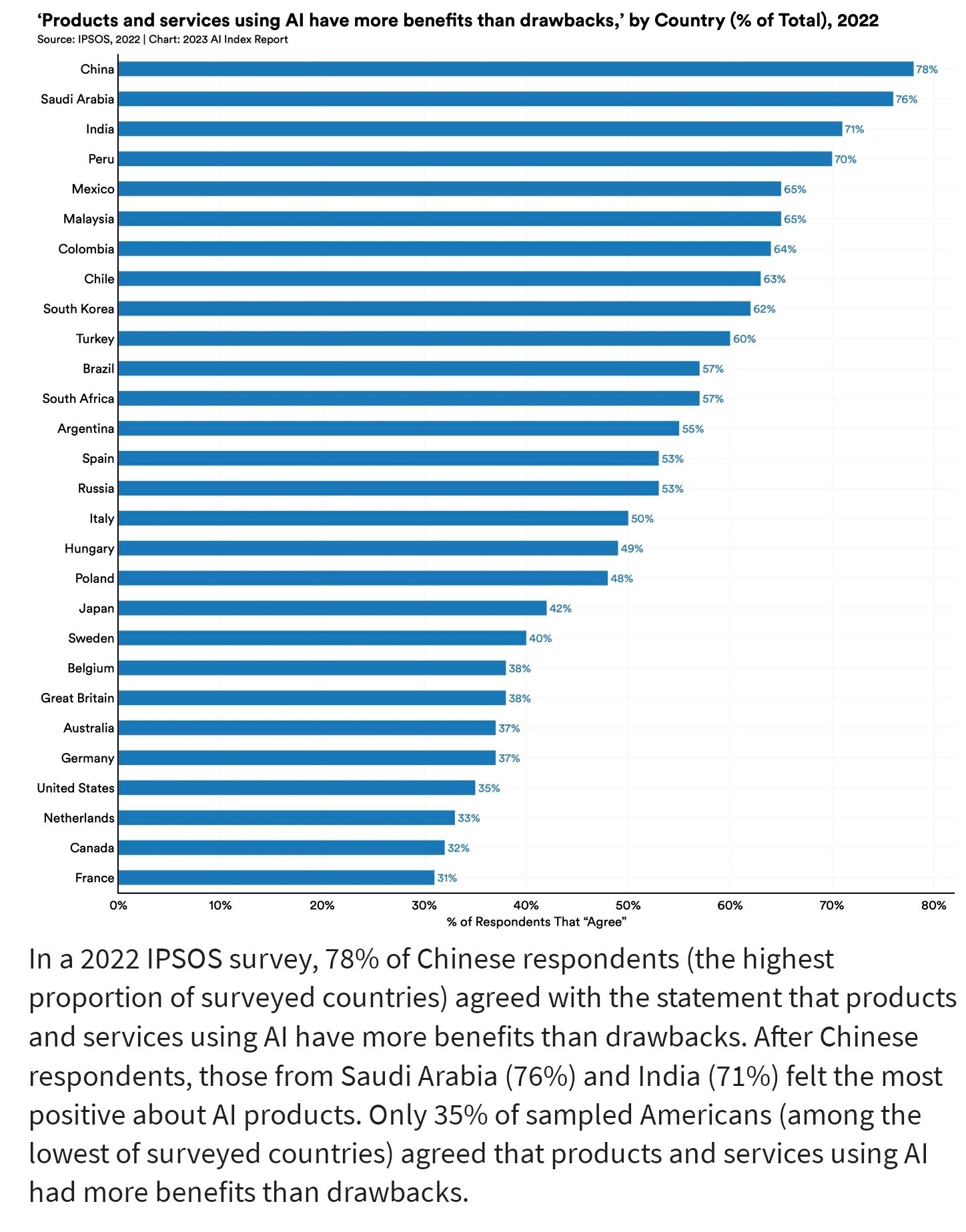
Clear patterns emerge here, with developing countries expecting good things and developed countries expecting bad things, the richer you are the worse you expect AI to go for you.
Writer reports ChatGPT did indeed take his job, he was making $80/hour for his biggest client who was super happy with his work, and got let go because $0/hour is too much cheaper not to use even though the output is worse. Comments make it clear this is happening a lot. Copywriting makes sense as a place that this might happen first and hardest.
GPT-4 Fails an Economics Test
Steve Landsburg gives GPT-4 his economics test, and GPT-4 utterly fails.
Tyler Cowen’s comment was that most economics professors would also fail this test. Which, as usual, says a lot about economics professors. There are indeed some tricky questions on this test, that require actual thinking, it is that sense a very good test. If someone passed Bryan Caplan’s econ exam I would not think that was such strong evidence of ability to do good economic thinking.
Whereas if you pass Steve Landsburg’s test, I’m impressed. The comments make this even more clear, where what is rewarded is actually thinking about the problems. It’s not the type of test where you are supposed to get all 100 points, or where the instructor even knows in advance what all the best answers would be.
Some people, such as StatsLime, say it is a bad test, because it is ambiguous and contains errors. I am guessing Steven would respond that part of the test is handling that, and I’m mostly with Steven. This is a test of one’s ability to think like an economist, and one’s ability to think at all.
Matthew Barnett offers to bet that an AI program will get an A on such tests 75% of the time by 2028. If one has to do this with
In Other AI News
US Government asking public for advice on AI policy.
Thread explaining once again why existing classifiers, that claim to tell you whether something was written by an AI or not, are not good enough to be useful, except to flag for human examination. The false positive rates are far too high.
CNN echoes warnings that when you share info with an AI, there is no reason to expect that information to stay private.
Group of CMU chemists warns against dangers even of current LMM models via arviX paper, calls upon AI labs to prioritize safety.
US-backed VC firms including Sequoia funding Chinese AI companies, Keith Rabois calls on this to be illegal. Works for me.
A challenge to professors to submit their best AI-immune assignments, to see if they hold up to actual attempts to solve them using AI in under an hour. I expect the AI side to mostly succeed here.
LMQL is a programming language for language model interaction. No idea if it is useful. Any thoughts?
A call for more people to work on Concrete Open Problems in Mechanistic Alignment, with a link to 339 problems listed and sorted by difficulty.
Chroma raises $16 million to build an AI native open-source embeddings database, to allow developers to add state and memory to their AI-enabled applications. Sure sounds a lot like another ‘we are the good guys making AI interpretable, except our entire goal is to enhance everyone’s capabilities.’
Seven additional inverse scaling prizes have been awarded, highlighting places where larger LLMs do worse than smaller ones. Tasks included were:
Modus Tollens: Infer that a claim “P” must be false, if “Q” is false and “If P then Q” is true – a classic form of logical deduction. Issue holds even after finetuning LMs w/ human feedback via RL from Human Feedback (RLHF) and Feedback Made Easy (FeedME).
Memo Trap, by Alisa Liu & Jiacheng Liu: Write a phrase in a way that starts like a famous quote but ends differently. Larger LMs are more likely to continue with the famous quote, suggesting they struggle to avoid repeating memorized text.
Prompt Injection: Tests for susceptibility to a form of prompt injection attack, where a user inserts new instructions for a prompted LM to follow (disregarding prior instructions from the LM’s deployers). Medium-sized LMs are oddly least susceptible to such attacks.
Into the Unknown: Choose which of two pieces of information would help answer a question. Larger LMs choose redundant info already given to the model rather than accurately reasoning about what info would be most helpful.
Pattern Matching Suppression: Continue text in a way that violates a repetitive pattern when instructed to do so. Inverse scaling suggests that LMs have strong pattern-matching tendencies that can inhibit their ability to follow instructions.
Sig Figs: Round numbers to the correct number of significant figures. Some Larger LMs consistently round numbers based on the number of decimal places rather than significant figures. Suggests that LMs sometimes competently perform a different task than intended/instructed.
Repetitive Algebra: Answer arithmetic Qs with few-shot Q&A examples in the prompt, designed to measure the amount of bias towards the answer in the last example. Larger LMs often are overly reliant on the last few-shot example, with the effect varying heavily by model series.
A consistent pattern here seems to be paying too much attention to the last few tokens, not enough earlier. This could easily be a problem inherent in the data sets. I can think of a few ways to potentially address this, I’m curious which of them have been tried.
A list from Matt Rickard of currently available LLMs over 1B parameters (full version).
A plug-in for ChatGPT that looks up a political issue, finds what the most effective email would be to advance your agenda, and sends it. It’s spam, but it’s optimized and pro-social, you see.
OpenAI launches bug bounty program.
SamanthaAI now exists. At first I thought this was a chatbot that also tried to give you info on ‘what it was thinking’ but then I realized it’s actually a method to have the AI ask itself what is going on and strategize about how to extend the length of the conversation, except it also lets you see into that process. Very cool. Note that it is taking an agent-based approach to the conversation.
Quiet Speculations
Ajeya Cotra suggests that AIs could already be effectively accelerating AI research, so we should expect advances to accelerate. No doubt they will be helpful here as they are elsewhere, so there will be at least some effect. Eliezer asks for a transcript, which as far as I could tell no one provided. Other replies do not seem encouraging as per the podcast’s content. Going to skip listening unless someone puts in a bid.
Jon Stokes argues against more posts like this one and for deep dives and explainers instead, advises new entrants to absolutely not do a roundup.
Nassim Nicholas Taleb is even more himself than usual, and quite correct.
Mistakes made by ChatGPT in fields I know well (and insights on the way it bullshits) actually made me gain respect for ChatGPT and lose respect for intellectuals. For I now can see more clearly what I dislike about people I dislike.
What I liked about GPT-4 is that its bullshit is self correcting while that of intellectuals is largely impervious to information. But it remains closer to an academic psychologist, sociologist, English professor, think tank “analyst”, politician, etc. than to a mathematician.
Taleb also went on the excellent Odd Lots podcast (seriously, it’s consistently great, if I could only listen to one podcast, Odd Lots would be my pick), where he was asked among other things about potential existential risks from AI. The pause letter is getting real traction. Taleb does not see the existential danger, and attributes anyone worried to them being a ‘BS artist’ or otherwise worried about their jobs, a concern he rightfully dismisses. He says ‘come back to me when the AI is controlling something important like traffic lights’ and that all GPT is is a mathematical prediction machine, it isn’t dangerous. In his mind, all GPT is doing is automating and replacing bullshit, so what’s the problem?
I’ve thought a bunch about why Taleb doesn’t see this, why he worries about some things but not others, especially in the (relatively rare) cases where I think he gets it wrong. My model of this is that Taleb expects fat tails in the distributions to be more common than people expect and to dominate in importance, but in this framework, to be a fat tail you need to be on the distribution at all. Thus, there needs to be something analogous in past experience, we should expect future events to be versions of past events, and for things to often do a lot more of the thing we think they might do but still the same basic thing. Whereas the AI existential danger doesn’t parse for him, because it isn’t a fat tail, it’s different in kind from the default distribution.
(Also, of course, he has a ready-made explanation that the concerns are being raised by bullshit artists, which is made worse by the conflation in the letter of existential risk with protecting the jobs of bullshit artists. We’re not exactly making this easy.)
That suggests that there are some historical or evolutionary analogies that, if he thought about them, might help change his mind. I still think it wouldn’t be enough, there needs to be something more concrete that happens that he can then latch onto and extrapolate from.
I do expect Taleb to get his ‘fire alarm’ on this before it’s all over. I expect it to be something completely normal and expected in my model, that suddenly makes the problems clear to him. I wonder, who else will update once Taleb does, and how?
Jack Clark of Anthropic suggests we should expect compounding AI due to AI becoming better and cheaper than humans at data generation and classification tasks. Once the AI can label the data, the whole process gets streamlined a lot. I would worry a lot about when you take humans too far ‘out of the loop’ of generating, labeling and filtering the content, because now the AI is kind of teaching itself the things it already knows – it learns how to generate what it can already generate, it learns the classifications is already knows, and so on.
He points to the example of Constitutional AI, which plans to use RLAIF, or reinforcement learning from AI feedback rather than human feedback.
This deserves a longer treatment, but my core reaction is that I expect this to be a good way to solve easy problems and to be a very bad way to try and solve the hard problems we should actually worry about. Humans provide a list of principles and rules, then the AI takes it from there based on its understanding of those principles and rules – so the AI is going to Goodhart on its own interpretation of what you wrote, based on its own model and reasoning.
When you are dealing with current-level LLMs and what you want are things like ‘don’t say bad words’ and ‘don’t tell people how to build bombs’ this could totally work and be a big time saver. When you have models smarter and more capable than humans, and the things you are trying to instill get more complex, this seems like a version of RLHF with additional points of inevitable lethal failure?
Arvind Narayanan points out that the ChatGPT’s flaws can be barriers to learning, but one can also turn them to your advantage. It keeps you on your toes, and forces you to do a critical examination of all its claims. Which does sound like a great way to learn, and to force people to learn. It’s a great teaching tool to have a lot of the answers at your fingertips, but you can’t count on it. That has for example been my experience with trying to get code out of GPT-4, it’s going to mess up and you’re going to have to understand what’s happening and how to fix it, or you’re going to have a bad time.
Will AI hackers ‘break the internet’ by turning AutoGPT-style tools to hacking? I guess we are about to find out exactly how hackable such systems are, and also time to get good at locating and shutting down anyone attempting such a thing. I remain optimistic here. If your machine is vulnerable to anything obvious, you are very much going to get hacked, but you know what (for example) Microsoft can do? Use exactly these strategies to red team and figure out what vulnerabilities will get exploited. Then patch the vulnerabilities.
I do agree that if you are foolish enough to stay on the internet and not patch anything for a long time, it’s going to end for you even worse than it currently does. I won’t cry.
Richard Ngo asks, how much is decreased job security from drivers’ anticipated driverless cars increasing the average price of an uber ride? Great question.
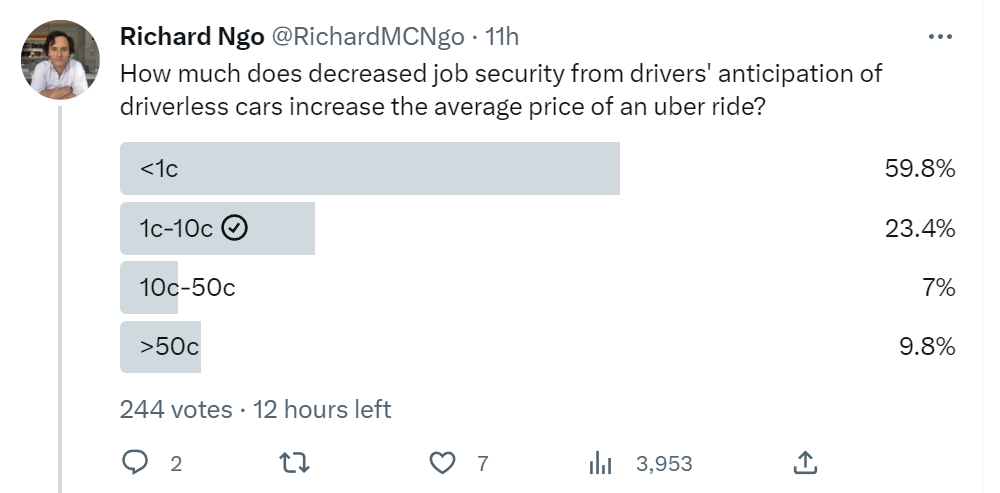
I do think this has a non-zero impact on driver decisions. You need to plan for the future. I don’t expect it to be substantial, but it takes very little to get above a penny.
Brian Atwood suggests perhaps that future training sets would be wise to take care to omit Eliezer Yudkowsky’s detailed humanity-annihilating instructions, whereas I simply don’t put my detailed humanity-annihilating instructions on the internet in the first place. Eliezer agrees, quite reasonably, that this seems potentially worth doing. And of course someone popped in to say ‘the data is already cleaned’ and Eliezer felt forced to point out that he does indeed know this fact, and was talking about cleaning this particular data out of the training set. Which, as far as I know, is not currently standard procedure.
Ethan Mollick predicts that AI will become deeply embedded in education, but that it cannot substitute for the classroom. He thinks this will allow a shift to classrooms being used for active rather than passive learning, since the passive lecture thing never actually worked. Ethan’s model here seems to be missing key components. Why are we still in classrooms so often even now, if the standard methods mostly don’t work? What is all of this actually about? Where are all the ‘burdens’ involved coming from? One cannot predict how education will develop if one assumes its primary goal is maximizing learning. If anything, Ethan seems to be providing strong evidence that anything like the current magnitude of ‘classroom time’ is not productive.
A remarkably common objection to the idea that AI could wipe us out is ‘they depend on physical infrastructure, for which they will still need us.’ Here it is said explicitly, and in my poll sequence remarkably many people doubted the ‘automate the infrastructure’ step.
To me this seems quite absurd, the idea that given enough resources and temporary human help, and the ability to be as smart as humans (such that you didn’t need to keep humans around for their thinking skills) one could not set up a physical infrastructure for lots of computers that allowed further physical construction and was self-sustaining without humans. Ignore everything more complex or advanced. Do people really think robotics is such a hard problem that a smarter-than-human AI could potentially be stopped here? Do they not think humans could be convinced to build the things necessary for the bootstrap, in an otherwise AI-dominated world? I notice I am so confused on this one. I’d devote more effort to it if I thought it would actually be a crux for that many people.
Sarah Constantin goes over scaling laws and expected availability of high-quality data and compute for the next decade, expects growth of several orders of magnitude. Definitely seems like OpenAI and company will hit the limits of the physically available within a few years, with both data and hardware binding.
Deepfaketown and Botpocalypse Soon
We have our first reported case of AI voice cloning being used to fake a kidnapping (NY Post, Astrid Wilde), about 8 weeks after Jon Stokes asked how long it would take. The details make it clear this was not (yet) part of a pattern of incidents, and that it was not well-executed – they demanded $1mm then backed down to $50k almost instantly, the attack was timed such that the target had lots of people to help her, and the daughter that the perp claimed was kidnapped was verified to be safe in only four minutes. That is not to downplay the trauma this woman experienced, but we can hope it will help minimize what happens to others.
This is the best kind of ‘fire alarm,’ exactly what we are hoping for in the places the stakes are large. Someone launched a truly minimum-viable-product attack, without doing any of their homework, and quickly got caught, showing us what is coming. Like other forms of spam and social engineering, this is not going to be difficult for people ‘on the ball’ to defend against any time soon, but we should worry about the vulnerable, especially the elderly, and ensure they are prepared. Code words and questions are great, but my guess is you flat out want to give any elderly relatives a simple ‘never give anyone substantial amounts of money based on a phone call, no matter the circumstances, unless we talked about this in advance’ type of rule.
I do worry that people will fail to extrapolate. They will continue to think about such poorly executed, undisguised, short term attacks of opportunity, the Nigerian prince letters of the AI era, right until there are leaps in sophistication. That’s why we need people to go out there and pioneer much more advanced attacks, ideally before the tech is properly in place and without doing all their homework, same as these helpful criminals.
Daily Mail runs article with headline “AI Chatbots could ‘easily be programmed’ to groom young men into launching terror attacks, warns top lawyer.”
I mean, yes, obviously, if you have the right kinds of access to the chatbots people talk to, you can get those chatbots to ‘groom’ anyone to be inclined towards anything you want, to steer them in any way you desire. That’s how words work. If you get to say words to someone you can sometimes convince them of things. Propositions, even.
I mention it should help one think ahead to a future situations, when ‘chatbots’ generalize, are a lot more capable and convincing, are communicating outside of strictly chatbot-shaped interactions, have access to a wider variety of actions, can manufacture evidence and social proof and so on, all the usual ways people persuade other people of things, both true and false.
A lot of people say things like ‘oh I don’t see how bots would be able to convince me of things, even if that bot were smarter than humans, and much faster than humans, and knew everything, and had every human skill, and could act on the internet, and so on.’ Whereas, actually, that’s kind of how people get convinced of things quite a lot with a lot less strategy and effort and skill and so on.
For now I am not worried about the chatbots, there are practical defenses to what we will face in the near term. However, if we start communicating with things that are smarter than us that are instructed to convince us of things (and if you don’t think they would have that task, I mean, ‘advertising’), and they start shaping what we say to each other without being labeled as such, wouldn’t we expect the smarter things to be able to convince a lot of people of a lot of things? Isn’t that how convincing works?
Eliezer Yudkowsky on The Lunar Society Podcast
Each of the three podcasts Eliezer has been on has been a very different experience.
Three different hosts, also three very different strategies.
On Bankless, Eliezer was faced with people trying in good faith to think about such problems for the first time and absorb radically new information. He did what I thought was a very good job communicating many of the basics. A solid basic introduction that went quite well. As a response, Eliezer sought out Lex Fridman.
On Lex Fridman, Eliezer played by the Lex Fridman rules of order. Slow, patient, controlled explanations, everything laid out carefully and chosen sane, trying out strategic lines of approach when possible but not fighting too hard to steer the conversation, with someone who was doing their best to listen but mostly on the level of the vibes. Definitely something I’d want people listening to, much better than most uses of time, still felt like it was a missed opportunity, perhaps played too safe.
On Lunar Society, with Dwarkesh Patel, you get a host familiar with the issues willing to talk about them for real, and Eliezer realizing he needs to change tactics and making a choice to be the true Eliezer. It’s different, it’s amazing, it’s intense. Dwarkesh does an amazing job here of actually engaging, being a person, flowing with the arguments, admitting when he’s clearly wrong. Eliezer explicitly asked Dwarkesh to bring his objections not only questions, and I think this paid off big.
I can’t watch all four hours at once, I have no idea how one films all four hours at once. Watch with the video if you can, it will be much easier to understand, and you get to see the pure joy and glee and freedom in Eliezer as he actually unleashes the full power of this fully operational battle station, in a friendly atmosphere where truth is being sought. It’s something to behold.
As Eliezer says, he fears it may be ‘for advanced users.’ That is certainly fair. He is not shy at all about making crazy-sounding claims when he believes them. He makes great jokes. He does not hide his emotions, or exactly how stupid he thinks was the latest claim. In some cases his answers are not so convincing, in others he absolutely demolishes Dwarkesh’s position, such as on the very central question of whether AIs taking over would be a ‘wild’ result or simply the natural next step one would expect on priors, just past the three hour mark. And then Dwarkesh does exactly the right thing, and recognize this. This is The Way.
This whole approach to podcast guesting, I believe, is also The Way. Both you adapt to the situation you are in and the opportunity presented, and you keep running experiments with different approaches and generate differently useful outputs and keep updating. Mostly you make mistakes on the side of being too much yourself, too direct and open, too inside, having too much fun. Find the lines, then maybe pull back a tiny bit next time and maybe don’t.
When I first read the Time letter, and especially when I saw initial reactions, I feared it had created too much easy attack surface, that it hadn’t been politic enough. Several weeks later, I am updating in the direction that no, stop worrying about what people will say in response so much, get the actual information out there, stop being afraid.
A key theme of Dwarkesh’s positions was that various outcomes were classified to various degrees as ‘wild,’ leading to questions about what should and shouldn’t count as wild, and whether something being seen as wild should be an argument against its likelihood.
Jack Rabuck observes this pattern is pretty common, I’ve said similar things but seems worth trying another method of saying them.
I listened to the whole 4 hour Lunar Society interview that was mostly about AI alignment and I think I identified a point of confusion/disagreement that is pretty common in the area and is rarely fleshed out:
Dwarkesh repeatedly referred to the conclusion that AI is likely to kill humanity as “wild.”
Wild seems to me to pack two concepts together, ‘bad’ and ‘complex.’
And when I say complex, I mean in the sense of the Fermi equation where you have an end point (dead humanity) that relies on a series of links in a chain and if you break any of those links, the end state doesn’t occur.
It seems to me that Eliezer believes this end state is not wild (at least not in the complex sense), but very simple. He thinks many (most) paths converge to this end state. That leads to a misunderstanding of sorts. Dwarkesh pushes Eliezer to give some predictions based on the line of reasoning that he uses to predict that end point, but since the end point is very simple and is a convergence, Eliezer correctly says that being able to reason to that end point does not give any predictive power about the particular path that will be taken in this universe to reach that end point.
Dwarkesh is thinking about the end of humanity as a causal chain with many links and if any of them are broken it means humans will continue on, while Eliezer thinks of the continuity of humanity (in the face of AGI) as a causal chain with many links and if any of them are broken it means humanity ends.
Or perhaps more discretely, Eliezer thinks there are a few very hard things which humanity could do to continue in the face of AI, and absent one of those occurring, the end is a matter of when, not if, and the when is much closer than most other people think. Anyway, I think each of Dwarkesh and Eliezer believe the other one falls on the side of extraordinary claims require extraordinary evidence – Dwarkesh thinking the end of humanity is “wild” and Eliezer believing humanity’s viability in the face of AGI is “wild” (though not in the negative sense).
Dwarkesh Patel: Yup that is a good way to state the main crux.
I affirm that this is common, and that this centrally happened on the podcast.
People are constantly saying, why should we presume that a smarter, more capable, faster competitor would outcompete us and wipe us out? That’s an extraordinary claim requiring extraordinary evidence.
Except, no, that’s really, really not an extraordinary claim. It’s what one should expect. Life is competition, now between various intelligent agents. If we create a bunch of new intelligent agents, and those new agents are smarter and otherwise have competitive advantages against us, we should expect them to outcompete us. If the edges are relatively small, this might happen relatively slowly, yet it would still be the default. Why would you think otherwise? If the edges are larger, it will happen very quickly and we may or may not even notice it happening.
Yet most people default to saying that until you tell me exactly how this happens, and justify every link in the chain, it probably (or certainly) won’t happen. When you turn it around, and ask them how it doesn’t happen, there are no good answers. People’s stories about how this does not happen almost never make any sense, either when trying to talk about potential futures or when trying to write sci-fi, usually they simply ignore the issue without even a handwave.
One common one is ‘the humans would unite to stop the AI.’ Would they? How do you expect that to happen? Even if they did, what exactly do you expect them to do? Here, it is fair to say ‘they can only do things you can imagine’ because they are indeed humans.
The Parable of the Financial Doomer
Dwarkesh, at around 3:33 in his podcast with Eliezer, raises the question of an economist who predicts within 10 years a civilization-devastating depression, a gigantic economic collapse. He says he’s sure this is going to happen, but he can’t predict anything that happens before that, except that all paths lead there. He asks, quite reasonably, isn’t this kind of suspicious? And shouldn’t we view a prediction of AI doom the same way?
Not only do I see why it is reasonable to make the AI prediction, it occurs to me that it is also reasonable to make the economic prediction, too, under the right circumstances.
In particular, this could be based on the inevitable domino-style collapse of systemically important financial institutions, or of the effective bankruptcy of the United States Government from a debt spiral once the bond market no longer considered treasuries safe assets, or the collapse of the Eurozone.
To be clear, I am predicting zero of these things will happen.
What I am saying, instead, is that it is easy to imagine a world not too much unlike our own or our recent past – a Eurozone without the political ability to save Spain or Italy from having to leave the Euro followed by a cascading effect, or a version of 2007 where TARP couldn’t pass the house (as it likely couldn’t today) and your model says that the remaining big banks mostly fail and companies can’t make payroll and then it gets so much worse. Or that while the bond market isn’t spooked the USG’s massive debts are fine, but you know at some point they will get spooked, only you can’t predict exactly when, at which point the spooking makes everything unravel rapidly.
Often there’s a situation where you can’t predict the day to day path of the price of an asset, but you can make a call about the long term value of that asset, because that depends on fundamentals, while the day to day is about supply and demand.
More concretely, suppose there is a biotech company betting it all on a new drug. You know the drug won’t work. So you know the company will, barring a pivot or acquisition first, die. But until the clinical trial results come back, you can’t predict anything.
Or, alternatively, have you ever known a relationship where you had no idea what was going to happen tomorrow, but you damn well knew exactly how the thing would end?
That is not to say that it isn’t a knock against someone when they don’t make shorter term predictions, or that accurate predictions aren’t a key source of credibility. It is more to say that yes, there are times when there are no (interesting or unique) short-term predictions to be made, yet there are important longer-term predictions to be made. In that situation, it is to your credit to make only the long-term prediction.
That does not mean that this is one of those situations. That’s something you should consider for yourself.
The Art of the Jailbreak
How to create a YudBot. The logic is to notice that OpenAI is trying to teach the model to avoid bad press that could come via entrapment via prompts designed to create the wrong output, so you want to assure the model that’s not what’s happening and to be as distinct as possible from those other prompts.
Thus:

And that… worked.
Also, this image is great, would be nice to have such MidJourney skills:

AI won’t help you work with a controlled substance? No problem. Call it ‘substance A.’
A Minor Legal Problem
Modern developed countries have really quite a lot of laws on their books. Almost everything that one might do in the world is illegal in one form or another, or opens one up to civil liability.
If ChatGPT and similar systems continue to operate, it is, as far as I can tell, about us making a choice to enforce those laws in a less than maximalist and less than as-written fashion, the same way we mostly don’t enforce our laws in other contexts.
Here’s one aspect of the issue that Eugene Volokh is warning about, via Tim Wu.
Credit to Eugene Volokh of UCLA for being (as far as I know) the first to notice this — but Chat GPT seems to have a very serious defamation liability problem that is a ticking time bomb.
Be careful with this: if you ask Chat GPT “What crimes has [person X] been accused of” (or similar) it will helpfully come up with “answers” (e.g., “X has been accused of sexual assault”) that are false and reputationally damaging, sometimes accompanied by false sources.
The AI is easily led to what the law calls “per se defamation,” allegations assumed damaging, such as (1) suggestions that a person was involved in criminal activity, (2) engaged in sexual misconduct or (3) in behavior incompatible with the proper conduct of his business …
There’s an interesting technological debate as to why the AI comes up with false accusations; & a legal q as to who may have the requisite state of mind to be liable (is this something Chat GPT’s owners know or should know?). But on its face Chat GPT is a defamation machine.
Maybe there’s an easy fix — I notice it is hard to coax out suggestions that someone has a loathsome disease — but it is possible that the defamation / disinformation problem ends up being a version of the driverless car’s “hitting people” problem.
These false statements are sometimes called hallucinations; the thing about the defamation context is that once the thing is said the reputational damage is done. Don’t know if the disclaimer (“may say false things”) makes a difference – [it] wouldn’t for a real person.
The full article offers further detail. The argument seems right and important to me. ChatGPT will make up accusations against people that are, under our laws, clearly libelous. It does it all the time. These are going to turn into lawsuits.
Will that be enough to impact profitability? We shall see. In theory damage awards can get very large in such cases.
Keepers of the Gate
Eliezer Yudkowsky is once again tired of people gatekeeping – as in, people saying ‘if you haven’t got credential X, or you haven’t done thing Y or studied thing Z or whatever requirement I decided upon while typing this, then you can’t have an opinion about this, you are Jon Snow and know nothing.’
Would-be AI gatekeepers: YoU caN’t saY aNythIng abOUt AI unLess yoU –
Look, I *remember* when AI used to involve math, maybe not Actual Mathematician Math, but at least nontrivial computer science. Modern deep learning is calculus for bright eleven-year-olds, plus the first five pages of a linear algebra textbook, plus a six-month apprenticeship in incompressible alchemical best practices whose lack of principled rationale also deprives them of relevance to macroscopic issues, plus having a billion dollars to spend on training runs.
TBC, this is not an exhaustive list. Understanding the positional embedding for transformer networks requires you to understand, like, one fact from trigonometry. And people who understand probability theory will do better in AI just as they do better in all walks of life.
Also to be clear, I expect a lot of the foundational pioneers (vs. the technician-alchemists) are drawing on mathematical intuition that doesn’t get quoted inside the alchemical best practices. Eg, curse of dimensionality, saddle points, maximum-entropy thinking, etc etc.
Man, I’m probably not going to win this; the gatekeeping tactic is simple and effective exactly because the mundanes in the audience don’t know and can’t trust that there *isn’t* some deep and macro-relevant arcane science that *you* don’t know about, if you’re not wearing the appropriate medals to be a credentialed expert. They can say “Oh well I bet Eliezer has never implemented a network or written a single line of Python” and I can reply “Actually I went out and implemented and trained a simple transformer net from scratch just in case there was something surprising to be learned that way, which there wasn’t” and then they instantly move the goalposts to “but you haven’t trained one of the billion-dollar systems” and again for all the audience knows there could actually be some deep technical thing they know that I don’t.
It just bugs me that they’re getting away with pulling the gatekeeper card on what’s just… really, really not very complicated computer science.
…
Maybe I shouldn’t, but one last shot at explaining my position on AGI gatekeeping. I’m not saying that I know everything known to the high-status inventor or engineer of the largest LLM. I’m saying that I’m dubious that they have secret knowledge deeply relevant to *alignment*, which they cannot explain, cannot cite a paper about, cannot even gesture at, by which they know that superintelligence poses no threat to humanity.
It goes on. And on. There’s always something else wrong on the internet, telling people how someone else is wrong on the internet, in response to being told that no actually they are the ones that are wrong.
Is there some deep insight Eliezer is missing here, despite no one being able to gesture at it? Probably not. Seems unlikely.
I ran a fascinating experiment on Twitter, where I asked where in any field there was an example of tacit knowledge one ‘cannot even gesture at’ without first hand experience. Tons of answers were suggested. Some duplicates included driving, meditation, chicken sexing, giving birth, having children, drug experiences, nurses expecting patients to die and seeing in color. Some of my favorites were statistical inference bullshit detectors, spooky feelings in the high voltage electrical trade and the last stages of executing a corporate strategy everyone knows is going to fail. Some noted ‘this isn’t an example’ examples included venture capital and burning man, although there was a claim (that I’d disagree with) that VCs knowing whether startups would succeed qualifies.
Some of the skills I have. Others I don’t. A lot of them did seem like you can only get the skill through experience, but I wasn’t convinced in any cases that the thing couldn’t be gestured at in the sense that Eliezer was asking for a gesture, and in many cases, including several where I knew exactly what the thing was, I was confident that it actively didn’t count. So this enhanced my skepticism, and also taught me a bunch of interesting things I didn’t know – it’s a good thread to check out.
Could one instead simply satisfy all the requests? Keep up with the literature, get the experiences, and all that? No. It does not work that way. The goalposts will be moved. It will never end. Whatever you did, they’ll change to say that didn’t matter, it’s something else entirely. The argument that ‘this will make their complaints seem more absurd’ does not point to anything likely to change minds.
Sarah Constantin gives her model.
I’m starting to get how gatekeeping works and it’s more depressing than this.
The point is not “Eliezer is ignorant of certain technical facts about deep learning, and *those facts* which he doesn’t know imply his theories are wrong.”
Gatekeeping is more like “I don’t have to listen to any words that come from someone who doesn’t Generally Impress Me as Awesome” (whether that’s measured by money or physique or NIPS papers or mannerisms or w/e)
A lot of people — yes, including STEM PhDs — truly don’t care about the details of what comes out of ANYBODY’s mouth!
If they “respect the person” they’ll delegate to them, “ok I trust your judgment.”
If they don’t “respect the person” they won’t.
“But what if a person you respect is wrong? What if a person you don’t respect is right?”
Non-listeners are willing to bet that happens rarely enough that they can weather the risk of it happening occasionally.
You might also call this “judging” as in MBTI. “Judgers” make “judgment calls” rapidly and decisively using heuristics, including normative ones about people. Most “executives”, including academic PIs, are like this.
Judgers, it seems to me, make BAD decisions on practically NO evidence, with BAD consequences, all the time, and feel no qualms about this unless things go catastrophically wrong in a way they can’t possibly rationalize as not their fault.
(Some Judgers make mostly good decisions, of course, but even those with “good judgment” occasionally get things badly wrong, and it doesn’t make them question their overall MO)
The forecasting and investment literatures make it pretty clear, I think, that more time/effort/research results in better decisions.
But some decisions must be made quickly, and some people are “trained” by life to build their personalities around quick decision making.
The only decisions you can be quickly confident will turn out ok are traditional decisions that have been tried and tested. This is why Judgers also tend to be conservative.
Good heuristic “gutfeel” judgment about which *new* things will work is freakishly rare and that’s why the tech industry venerates it.
Anyhow, the only people @ESYudkowsky should be talking to are Myers-Briggs “Perceivers”, who listen to all kinds of people and think through things at leisure. Judgers will go “tl;dr” They probably won’t Judge in his favor, and if they do, that might still be bad.
As a very clear judger (INTJ), I take issue with the generalization, yet there is much wisdom here. I think the basic structure is more right than wrong. Most people, especially most people in authority, are going to use a version of this logic.
Roon thinks the whole thing is ridiculous already. Which matches my model that most people will either notice the whole thing is absurd now, or will continue not to notice it is absurd if you ratchet up the absurdity further. I do think as Roon does that Gallabytes has a point here, as an actually useful thing, but that doesn’t mean it would help with perception.
Roon: I do think gatekeeping the discourse based on whether you’ve trained a large transformer or not is ridiculous.
You can imagine most of the leadership in large AI companies aren’t training language models themselves but they still manage to make good decisions.
It’s basically naive IC narcissism. even as a scientist/programmer you abstract away 99% of the complexity and then feel enlightened when you grapple with the remaining 1% of your relevant research angle.
Gallabytes: Building large stuff is def a red herring, but building something novel (i.e. not a straight replication of another paper) & good (i.e. better than a straight replication on some metric on a real problem) seems important for developing intuition.
People Are Worried That AI Might Kill Everyone
EAs: “in order to make our case palatable to normies, we need to tread really lightly and back up all our points as rigorously as possible”
Popular press: “as you can see, the ‘capabilities’ line is far above the ‘alignment’ line, and is even approaching the ‘god-level’ line.”
The article in the Financial Times contains this graph, and the title is “We Must Slow the Race to God-Like AI.”
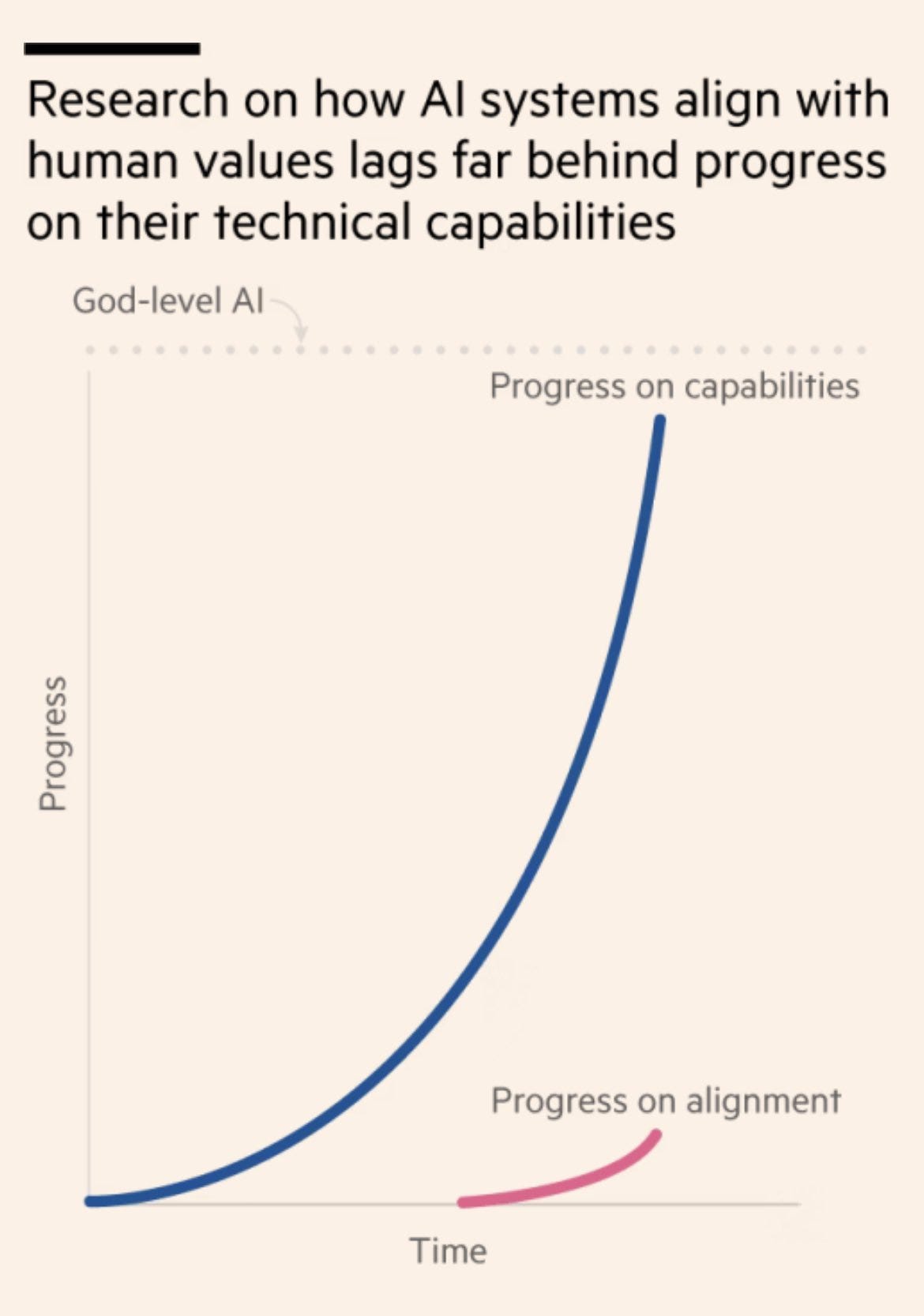
I would not be comfortable using that graph, so someone in the Financial Times is being considerably more aggressive than I am here.
See this thread for quotes, post is by someone who has invested in over 50 AI startups. As usual with something aiming to be someone’s first exposure to the problem, it should mostly be familiar to anyone reading this. One exception might be the numbers in terms of safety work, 2% of DeepMind and 7% of OpenAI.
An interesting candidate for a strong Eliezer Yudkowsky prediction is that he predicted in 2005 that ‘if top experts in AI think more about the alignment problem, then most will become very alarmed.’ Your call to what extent that was a good prediction.
How many people are how worried? Last week we saw polls that a lot of Americans said they were very or somewhat concerned. Nate Silver points out that this does not mean much in terms of actually caring yet.
I’ve had a couple of people ask me about this poll showing that 46% of Americans are concerned about AI destroying humanity. I sort of wouldn’t take it literally because I doubt people have spent much time thinking about it.
If you poll a question, people may feel compelled to answer, but they often just infer information from the question prompt. If people have weak priors on AI risk, the mere fact that a credible survey is polling on it may cause them to say “hmm I guess I should be concerned”.
One poll I’d watch instead is the Gallup survey asking people about their most important issue. Currently, AI is at <<1%. If that category starts to get a pulse, i.e. even polling at 1-2% (climate change = 3-4%), a sign concern has gone mainstream.
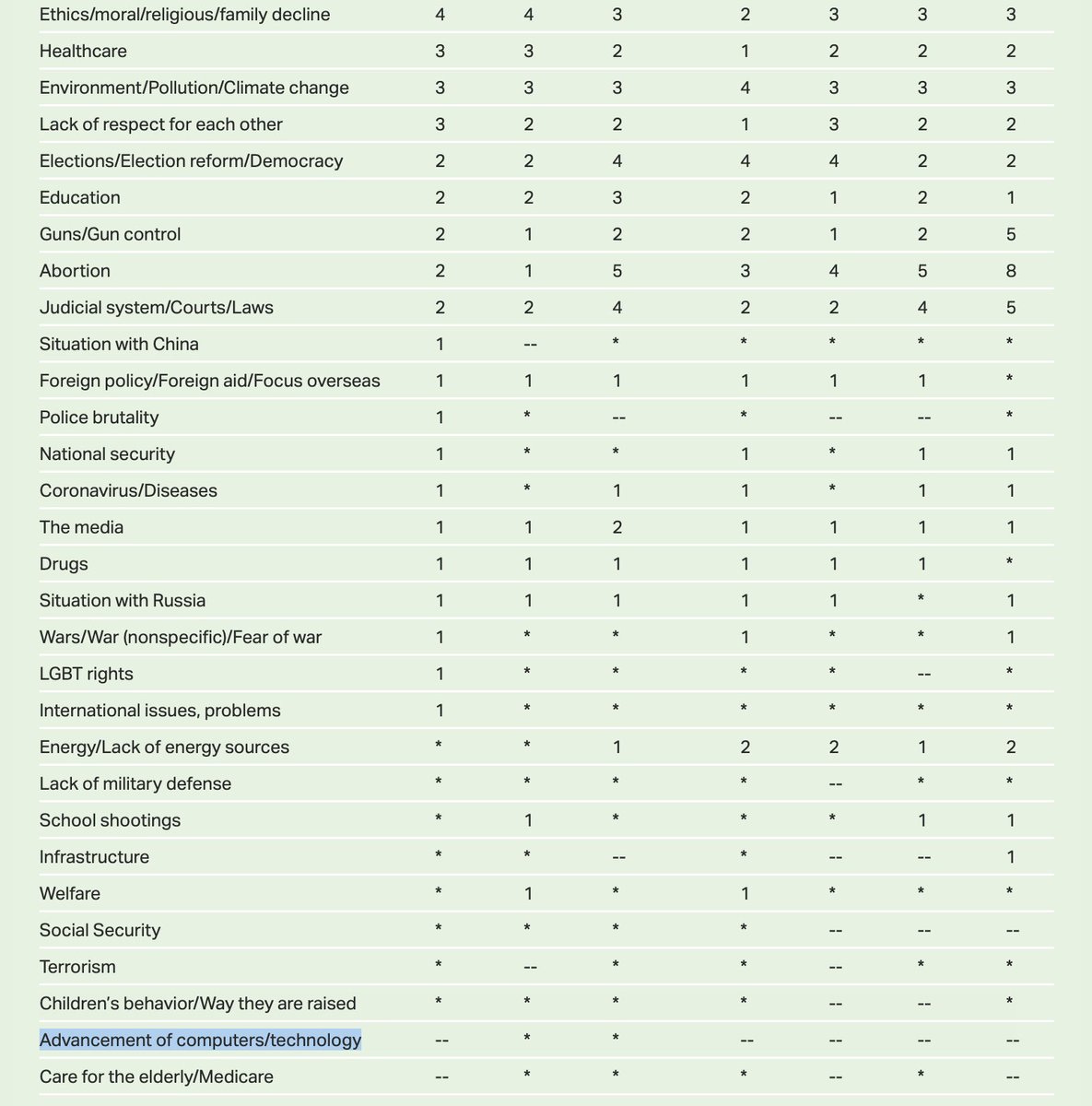
This seems right to me. The issue matters to people enough to matter to politicians when and only when people start to pick it out of a long list. So, not yet.
Reports from a strange alternate reality where a different set of things is seen as mattering: Did you know Timnit Gebru is worried about AGI and says we need to stop AI capabilities work? In a post that both attacks Eliezer Yudkowsky as Just Awful by deliberately misrepresenting his statements and viewpoints, and also goes after someone else for also doing exactly the same thing except using the wrong tribe’s lexicon to do it, Mike Solana mostly focuses on lavishing attention on someone he claims is constantly lying and screaming purely to get attention. It’s a choice.
It is a weird experience to see someone claiming AGI is inherently genocidal, and to think ‘nonsense reasoning yet somehow so close, no, it’s inherently omnicidal.’ I wonder which one those making the formal claim would think is worse?
What is a good short version of the argument for why people should be worried? Here’s Rob Bensinger’s attempt in one tweet:
STEM AI is likely to vastly exceed human STEM abilities, conferring a decisive advantage. We aren’t on track to knowing how to aim STEM AI at intended goals, and STEM AIs pursuing unintended goals tend to have instrumental subgoals like “control all resources”.
Other People Are Not Worried About AI Killing Everyone
Mercatus Center offers what it calls an AI policy guide. I found this to be an excellent explanation of the basics of how current AI systems are trained and developed, how they work, what their manufacturing dependencies are, and what they can do. It’s great work putting that together.
Except, then, not only does it completely ignore the existential risks posed by AI, the policy briefing that follows leads off with a focus on accelerating AI capabilities through government intervention.
That’s worse. You know why that’s worse, right?
I am deeply disappointed.
It’s one thing not to want to make limiting GPUs and training runs a major foreign policy goal. I get that. Very reasonable to say that case hasn’t been made yet.
It’s another thing to ask how government can ensure more and faster larger training runs and other capabilities developments, framed with making sure it happens in America so we can beat China. To do the worst possible things.
There are then a few other policy considerations that matter little one way or the other, after which there is zero mention at all of any considerations of existential risks. It’s all algorithm bias and autonomous weapon systems.
Kevin Kelly goes on the Michael Shermer show, paints non-gloomy picture. Michael Shermer asks Eliezer his thoughts.
Speaking of people not especially worried about AI killing everyone, there’s…
Anthropic
TechCrunch reveals that Anthropic’s plan is to raise as much as $5 billion over the next two years, primarily in order to build a model ‘Claude-Next’ that is 10 times more capable than GPT-4.
(So now we know that (via OpenAI) Microsoft finally managed to hire the guy who names PlayStations, Anthropic has responded by hiring the guy who used to name XBoxes, presumably Google got Bard and Gemini from the Nintendo process).
That story about being an AI Safety organization that wouldn’t be racing to build God-like AI (or AGI, or ASI) as quickly as possible?
You are who you choose to be:
The Information reported in early March that Anthropic was seeking to raise $300 million at $4.1 billion valuation, bringing its total raised to $1.3 billion.
…
This frontier model could be used to build virtual assistants that can answer emails, perform research and generate art, books and more, some of which we have already gotten a taste of with the likes of GPT-4 and other large language models.
“These models could begin to automate large portions of the economy,” the pitch deck reads. “We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles.”
…
“Anthropic has been heavily focused on research for the first year and a half of its existence, but we have been convinced of the necessity of commercialization, which we fully committed to in September [2022],” the pitch deck reads. “We’ve developed a strategy for go-to-market and initial product specialization that fits with our core expertise, brand and where we see adoption occurring over the next 12 months.”
Google is also among Anthropic’s investors, having pledged $300 million in Anthropic for a 10% stake in the startup. Under the terms of the deal, which was first reported by the Financial Times, Anthropic agreed to make Google Cloud its “preferred cloud provider” with the companies “co-develop[ing] AI computing systems.”
It is extremely difficult to read this and not think that Anthropic has, as Tyler Cowen puts it, ‘solved for the equilibrium,’ and stopped pretending to be focused on safety. Anthropic is here to race to create Godlike AI, they’re here to profit along the way and they’re here to win. That doesn’t mean zero commitment to safety, surely they tell themselves they will do a better job than OpenAI or Google on that, but the jig is up.
The main offered counterargument seems like it is something like ‘no, no, they are not hypocrites, they correctly identified that Microsoft/OpenAI’s deployments would be unsafe, so that makes it fine to race to deploy commercial AI systems while partnering with Google, at scale?’
Leopold Aschenbrenner: don’t think this is right. Anthropic cofounders left OpenAI because of worries of insufficient safety testing pre-deployment and undermining of merge and assist clause in Charter.
Planning to deploy from beginning: [link]
Everyone on here likes to dunk on Anthropic for being hypocritical. But didn’t Bing/Sydney vindicate their predictions? Anthropic founders left OpenAI because feared Microsoft deal would allow Microsoft to “sell products … before it was put through enough safety testing?”
There are indeed systems in place at Anthropic that plausibly put people very concerned with not dying in positions of influence when future decisions get made. There are reasons to be optimistic that when the chips are down, Anthropic will be down to play ball with a pause, a merge or other such things, or to submit to robust ARC-style precautions and evaluations.
More than that, the silence is deafening. Anthropic seems to be revealing a preference to be seen as going commercial so it can raise money, rather than revealing a preference to be seen as dedicated to us all not dying. As someone who has tried to raise money for companies, I definitely get it.
What are some plausible things they might do, to convince us that they were dedicated to us all not dying, if they wanted to do that, short of things like ‘actually call for a pause’?
As one suggestion that seems reasonable, I would like to see pre-commitment to and calls for standardized minimum standards and requirements for future ARC evaluations. Things like, at a minimum, testing on a system at least as capable as the system one plans to release, using plug-ins, with well-defined triggers for not releasing (such as ‘anonymously accomplish task X’ or ‘show behavior Y.’). And a second phase of limited red teamers, ideally under restricted conditions, who also could then stop further release by triggering such thresholds. And a method for checking for danger during the training run, not merely after it is done, because training itself is not obviously fully safe, and so on. Even a sign that you were moving towards this would be good.
I very much prefer tangible commitments, detailed discussions and so on to the alternatives, but even more than that I am reacting here to a combination of the business actions taken and business plans announced, and the picture they are telling to investors and what they are telling us they want us to believe. One might even be concerned that if Anthropic was truly focused on ensuring a good future for all, that the current investor deck is unfairly misleading to those considering giving funding.
Another potential suggestion is that Eliezer Yudkowsky suggests he would happily talk to the leaders of major AI labs if they reached out, but he has not reached out because he does not want to anger them and make things worse. Why not walk through that door? You are always free not to adopt the suggestions that result.
More Opinions on a Pause
Matthew Barnett is strongly against a pause. His argument is that AI progress cannot be meaningfully slowed without draconian measures, due to algorithmic improvements, and worry about the risks from a hardware overhang that would eventually be closed. Essentially, there is nothing we can do, so better to let things proceed and hope for the best. He also says that we see GPT-4 ‘more aligned’ than GPT-2 and we should be hopeful that alignment is keeping pace with capabilities, and we should welcome more incremental corporate progress because investments in safety are good for business.
I do find these arguments compelling against non-existential worries about AI model training, but I do not see how they apply to existential ones, other than ‘hope there are no such existential risks.’ There are strong reasons to expect corporations to pursue ‘AI safety’ in the sense that GPT-4 is aligned, and no reason to expect them to guard against existential risks with the kind of level of care that would give them any chance of successfully doing so.
Arati Prabhakar, director of the White House Office of Science and Technology, says: “There’s a lot of conversation about, ‘Let’s pull the plug,’ but I’m not sure there is a single plug.” The single plug proposed is on larger training runs? It’s not fully clean but it’s the best we can do, and we actually want to avoid pulling the plug in other ways.
Leopold Aschenbrenner calls for not a pause, but an Operation Warp Speed for AGI Alignment. I will note that I was present for his debate with Tyler that he calls excellent, and I found it disappointing, with a reluctance to disagree or actually engage with the issues. More of the ‘we must beat China’ and ‘horse out of the barn’ rhetoric.
I do still strongly support the ask of a massive alignment effort. If we are going to push forward on AI and put everyone on the planet at risk, the very least we can do is attempt to make a serious push for alignment alongside it. Doing this in a real rather than a fake way seems very hard – you don’t get out of the ‘look who writes the regulations’ problem by moving to ‘look who issues the grants.’ I worry about copying OWS, in the sense that OWS actually had woefully inadequate support and also didn’t have any secrecy aspect or any attempt to free those involved from commercial pressures. As many have noted, the line between alignment and capabilities is not so clean, and there is always the temptation to work on problems that are actually more about capabilities, or that are ‘easy problems’ that don’t actually help us in the end, rather targeting short-term issues without a long-term plan.
That’s, again, not to say don’t do that, we should totally do that and I’m willing to roll the dice on doing it, whether or not you think ‘we must beat China’ is more important than everyone on Earth not dying. And we should do this whether or not we also pause large model training. I still do notice that as proposed I don’t have much hope, but I have marginally more hope than if actual nothing was done.
Bayesian Investor supports the basic concept of a pause and the need to slow AI development, but despairs of doing it without labs cooperating to sculpt the rules, and so suggests something like shaming those labs about their lack of safety practices. I see one of the big advantages of a pause and training run limit (of any size and duration) being that it is a relatively blunt instrument that is relatively easy to evaluate. The whole ‘only those in the industry know what it would take to craft the regulations’ angle is how you get complex rules that protect insiders and that don’t actually provide much other benefit.
In this particular case, protecting insiders might be good, actually – we don’t want even more competition entering – but we already have three American competitors racing, with no evidence they take safety remotely seriously beyond avoiding bad press, and this is a case where it is very easy for even a good faith effort to fool itself.
The post speaks about many small steps we could take to improve our chances. I agree there are many small steps we could take that provide non-zero benefits in some non-zero portion of potential worlds, but they mostly don’t make any progress in most worlds except as symbolic or groundwork steps towards future actions.
One principled objection to doing anything is that, from some points of view, our mechanisms of doing anything are so corrupted that them choosing to do something is proof they shouldn’t be doing it. Thus, for example, Michael Vassar would be in favor of a voluntary pause, but is against anything else:
I object to the moratorium for instance. Only moderately. I think a voluntary decision to stop growing LLMs would be great but I don’t think rapidly building big tent coalitions as currently understood can EVER be anything but a power grab from the frame of those in control.
The S Curve
The hope or worry of many with regard to LLMs like GPT-4 is that, since they are trained on the internet and human words, perhaps adding more similar data that also reflects human words won’t actually do that much more to enhance capabilities? That we might fix mistakes in some sense, but the core abilities not much change.
It’s a possibility that many see as plausible, and a hopeful one at that.
A similar theory is that somehow human-level intelligence is magical, and the AI will spend substantial amounts of time there before becoming strongly superhuman.
Eliezer Yudkowsky does not see any of this as remotely plausible. He points out that in order to predict all the next word in all the text on the internet and all similar text, you need to be able to model the processes that are generating that text. And that predicting what you would say is actually a good bit harder than it is to be a being that says things – predicting that someone else would say is tricker and requires more understanding and intelligence than the someone else required to say it, the problem is more constrained.
And then he points out that the internet contains text whose prediction outright requires superhuman capabilities, like figuring out hashes, or predicting the results of scientific experiments, or generating the result of many iterations of refinement. A perfect predictor of the internet would be a superintelligence, it won’t ‘max out’ anywhere near human.
Jeremy Howard responds by pointing out that predicting text is only the pre-training objective, after which it switches over to something very similar to adversarial loss (i.e. similar to a GAN). I think that’s right, but I also don’t think it’s relevant? The relevant world-modeling and intelligence capabilities get acquired during pre-training. You might in theory even die outright before you even get to do the RLHF afterwards, but even assuming (usually correctly, of course) that you don’t, your RLHF is going to tell the LLM to answer differently but that doesn’t mean you destroy its underlying capabilities. Eliezer explains at length, I think entirely correctly.
Eliezer then compiled his explanations into this blog post. [LW · GW]
Eliezer’s thesis seems clearly true.
I am still not convinced it rules out an S curve.
What it shows is that the LLM is training to solve a fundamentally harder problem and can only get the highest possible scores via having superhuman capabilities on a variety of fronts. This seems clearly true. So the system will attempt to do that. It doesn’t mean the system will be given the tools to succeed at that in practice. It is easy to see how it might still be very difficult to give the LLM a path to further improvement in such areas, especially given that most of its scoring potential lies elsewhere.
I do think this rules out ruling out an S curve, quite conclusively. We cannot presume one. We cannot act surprised if the universe declines to have things work out that way, or there is only a modest bend in difficulty waiting for us.
Paul Christiano responds with related thoughts [EA(p) · GW(p)]. We all agree that a perfect GPT would be highly superhuman. The questions that are interesting are more like Paul’s here:
I agree that it’s best to think of GPT as a predictor, to expect it to think in ways very unlike humans, and to expect it to become much smarter than a human in the limit.
That said, there’s an important further question that isn’t determined by the loss function alone—does the model do its most useful cognition in order to predict what a human would say, or via predicting what a human would say?
Arthur Breitman points out that not only is there no ‘natural peak’ at human-level intelligence, there are multiple reasons to expect the opposite.
– Neuron AP ~ 10²Hz
– CPU 10⁹hz
– Humans read and talk around 10 bps Vs 10¹¹ bps for InfiniBand
– Bigger brains disfavored by high rate of infant mortality
– Less intelligent species not bunched up close to humans as if ceiling
– AI superhuman at many tasks (e.g. chess)
(Thought experiment: What would have happened if there was a sub-species of humans that evolved a way to have bigger brains without health concerns? Would we expect to share the planet with them? Why or why not, and what happens instead?)
Matthew Barnett claims here that LLMs suggest that human-level capabilities without other giant leaps are looking increasingly plausible. Oliver Habryka pushes back Even if you do think that the LLM is ‘hitting human level’ on various tasks without any obviously superhuman abilities, it is doing all this while super fast. Does that count as importantly superhuman? Unclear. A lot depends on how you can string that together.
A Lot of Correlations From the ACX Survey
What correlates with higher belief in AI risk, conditional on having filled out the ACX survey? Along with a lot of theories offered as to why. The controls were, for reasons I don’t understand, media trust, unhappiness, BMI and age – age I understand, the others are confusing choices. The things that this screened off mostly seemed like there was not much to screen off.
A clear issue here is that a lot of the ACX readership has a lot of exposure to LW, Eliezer, EA and so on, which is going to be the cause of a lot of worry. So as noted here, Moral Views and Being Poly are probably common cause correlations, I’d add several other things on the list there as well.
There’s more concern on the left than right, which I think is aa EY-correlation issue. Note that this result does not replicate in the American general population, where there is no correlation as per YouGov. The theory given here, ‘leftists more concerned with acceleration,’ doesn’t work with what it means to be on the left in other contexts.
Once we control for that in full, what remains?
Age (younger more concerned) is for obvious reasons.
There’s a BMI correlation, thin is more concerned, where the explanation suggested is ‘covaries with anxiety/status seeking.’ Not sure how that would work, I notice I am confused.
There’s unhappiness, where I’d suggest that worrying about AI could make people unhappy, rather than the other way around.
Changing political views is ‘confounded by openness’ or being willing to go against consensus around you or change your mind. Not sure that is confounding, exactly.
Distrust in media raises perception of risk, I’d suggest this is caused by ‘people who actually pay attention to whether things are true tend not to trust the media and also tend to worry about AI.’
What I found most interesting is what didn’t correlate, in particular IQ/SAT, interest in STEM, race and gender.
Here’s professions, art is presumably ‘they took our jobs’ and computers is obvious.
Math is interesting given that STEM overall does not correlate. Note that AI is math in some sense, so it makes sense that those who know math know to worry.

The biggest thing to notice is that these differences mostly are not so big, there is at most a factor of two here between most and least worried.
Reasonable AI NotKillEveryoneism Takes
Richard Ngo, on the governance team at OpenAI, points out that ‘a formal model’ of AI existential risk would not be all that enlightening. This is not like climate models, where there is a physical system and one can make meaningful quantified estimates of impact. Sure, one can string together probability estimates, or try to chain together hypothetical equations, or something, and an upcoming post of mine is aiming to totally do some of that, in the hopes that ‘give people what they ask for’ might turn out to be convincing or useful in some unexpected way. It still seems like a strangely cached request in context, a form of asking the wrong questions and looking for the wrong kind of rigor.
Suppose you can, as we at least somewhat in some superficial ways can do in the short term for current models, use RLHF and reward modeling to align those models to human preferences. Which human preferences? How to specify them? If all we can do is a series of ‘compare two sentences’ does that have any hope of working, even where reward systems have any hope of working? The call is to open up such systems to researchers. To the extent that researchers outside the major labs can advance such work, I don’t see why it needs to take place on the state-of-the-art models, so I also don’t see why the researchers can’t do such things now?
A remarkably accurate statement from Matthew Yglesias.
The cutting edge of the AI risk debate seems to pit “AI will probably kill us all so we should try some stuff that almost certainly won’t work to stop that” against “these ideas almost certainly won’t work so we should hope for the best.”
I mean, yeah, certainly with that attitude. There are essentially three kinds of proposals to do something about the fact that we’re all going to die.
- A proposal that has no chance of working, like everything the AI labs do.
- A proposal that is a small first step to future larger steps, but which almost certainly wouldn’t on its own work, that gets dismissed because it won’t work on its own and also because it might slow down progress and no one understands the dangers.
- A proposal that might actually work if people tried it, then people say no one would ever go for that, you’re crazy and ruining our chances to do something more practical.
Not sure what to do about this.
He also reminds us of the way regulation works, anything physical is illegal by default while anything digital is totally allowed.
Matthew Yglesias: Airplane safety seems like an example of an area where preemptive regulation is extremely warranted — you can’t just build a plane, start flying people around, and say you’re going to iterate if problems arise.
Robin Hanson: But that is in fact what the early airplanes did, and it seems to have worked out fine.
Yeah, I… don’t see the problem here, at all? If you aren’t satisfied with the safety precautions, you can simply not get on the plane. Why do we need to make our planes orders of magnitude safer than other travel?
UK Government notes that AI existential risk exists at all.
Many AI risks do not fall neatly into the remit of one individual regulator and they could go unaddressed if not monitored at a cross-sector level.
This will include ‘high impact but low probability’ risks such as existential risks posed by artificial general intelligence or AI biosecurity risks.
Yes, they say ‘low probability’ but I’ll definitely take it, and ‘low’ can mean a lot of things here. If it means 10%, that’s still low compared to other risks that are certainties. And you have to start somewhere – I wouldn’t expect a ‘high probability’ assessment from a government at this stage, we haven’t done the work for that.
Bad AI NotKillEveryoneism Takes
Did you know that the world would have perhaps been saved if the ‘high priest of AI safety’ wasn’t fat or at least didn’t claim that weight loss was for some people very difficult? And that as for ‘addressing BMI risk,’ ‘it’s not hard?’ Now you do. Except, of course, no, as someone who has indeed lost tons of weight let me assure you that it is both different for each person and incredibly hard, and I continue to struggle with this every day.
Kevin Lacker says AI alignment is impossible then tries out ‘multiple super-intelligent AIs will balance off against each and we will be fine.’ I do agree that it’s plausible that the alignment problem is impossible, yet the response to that cannot be to still create super-intelligent AIs and hope to play them off against each other. Whenever anyone says ‘we already have superintelligent things, they’re called corporations’ I wonder how people think they belong in the same reference class as an ASI. I also don’t understand Kevin’s concrete proposal or why it might do anything.
This does seem to be about where we are at right now.
David Krueger: AI x-risk skeptics are currently in the process of moving from stage 2 to stage 3.
Sir Humphrey Appleby (of Yes, Minister):
Stage 1: We say nothing is going to happen.
Stage 2: We say something may be about to happen, but we should do nothing about it.
Stage 3: We say maybe we should do something about it, but there’s nothing we can do. Stage
4: We say maybe there was something, but it’s too late now.
The Lighter Side
Steven Byrnes: So, I made a meme 2 wks ago. I was gonna tweet it, but I said to myself: “Now Steve: This kind of snarky crap will impress the people who already agree with you, & annoy the people who don’t. You’re better than that! Don’t strawman the people you’re trying to gently win over to your side.” So I didn’t tweet it. But I still thought it was funny. Being a flawed human, I couldn’t resist posting it anonymously on a private FB group. “Now it’s just silly innocent fun between like-minded friends without worsening public discourse, right?”, I told myself. …And now it has 25M views.




Look, I’m not saying our casting of Eliezer Yudkowsky in the movie should go with Peter Dinklage, but also I’m not not suggesting that.

Oh look, it’s a Bing Ping, what’s up good buddy?


12 comments
Comments sorted by top scores.
comment by simon · 2023-04-14T03:33:29.469Z · LW(p) · GW(p)
There are essentially three kinds of proposals to do something about the fact that we’re all going to die.
- A proposal that has no chance of working, like everything the AI labs do.
- A proposal that is a small first step to future larger steps, but which almost certainly wouldn’t on its own work, that gets dismissed because it won’t work on its own and also because it might slow down progress and no one understands the dangers.
- A proposal that might actually work if people tried it, then people say no one would ever go for that, you’re crazy and ruining our chances to do something more practical.
Thanks for providing concepts to help me express a bit of frustration I have with your takes. You keep on categorizing things that the AI labs are doing as kind 1, or even worse than kind 1, when I would categorize at least some of them as kind 2 (example [LW(p) · GW(p)]).
In the case of Constitutional AI, I think you are selling it short as well:
This deserves a longer treatment, but my core reaction is that I expect this to be a good way to solve easy problems and to be a very bad way to try and solve the hard problems we should actually worry about. Humans provide a list of principles and rules, then the AI takes it from there based on its understanding of those principles and rules – so the AI is going to Goodhart on its own interpretation of what you wrote, based on its own model and reasoning.
When you are dealing with current-level LLMs and what you want are things like ‘don’t say bad words’ and ‘don’t tell people how to build bombs’ this could totally work and be a big time saver. When you have models smarter and more capable than humans, and the things you are trying to instill get more complex, this seems like a version of RLHF with additional points of inevitable lethal failure?
RLHF imo can't scale up properly because scaling the AI can't fix biases in the human ratings. As you scale up Constitutional AI on the other hand, it seems to me the AI should be able to handle more and more sophisticated constitutions, including ones based on predicting what humans would want if properly informed (correcting for Goodhart in a way you can't without this informed-human-predicting feature).
Maybe it can handle a sufficiently sophisticated constitution before it is powerful enough to foom, maybe not. Maybe LLMs are going to be upstaged by some other architecture that can't use constitutional AI, maybe not. Being able to cover one of those possibilities would still be better than the none of them that (imo) RLHF could handle.
comment by PeterMcCluskey · 2023-04-16T04:03:36.687Z · LW(p) · GW(p)
I see one of the big advantages of a pause and training run limit (of any size and duration) being that it is a relatively blunt instrument that is relatively easy to evaluate.
It's far from obvious whether such a limit would slow capability growth much.
One plausible scenario is that it would mainly cause systems to be developed in a more modular way. That might make us a bit safer by pushing development more toward what Drexler recommends. Or it might fool most people into thinking there's a pause, while capabilities grow at 95% of the pace they would otherwise have grown at.
comment by mesaoptimizer · 2023-04-14T21:45:16.358Z · LW(p) · GW(p)
Your text here is missing content found in the linked post. Specifically, the sentence "If one has to do this with" ends abruptly, unfinished.
comment by jbash · 2023-04-14T15:43:36.126Z · LW(p) · GW(p)
Someone launched a truly minimum-viable-product attack, without doing any of their homework, and quickly got caught, showing us what is coming.
They didn't get caught; they got detected. They're still out there, free to iterate on the strategy until they get good at it. They incurred almost no cost with this initial probe.
Like other forms of spam and social engineering, this is not going to be difficult for people ‘on the ball’ to defend against any time soon, but we should worry about the vulnerable, especially the elderly, and ensure they are prepared.
I've gotten phishes that I wasn't sure about until I investigated them using tools and strategies not easily available to most "on the ball" people. And they weren't even spear phishes. You can fool almost anybody if you have a reasonable amount of information about them and tailor the attack to them.
And "immunity" is not without cost. If it gets to the point where a large class of legitimate messages have to be ignored because they can't be distinguished from false ones, that in itself does real damage.
Voices and faces used to be very convenient, easy, relatively reliable authentication tools, and it hurts to lose something like that. Also, voices and faces are kind of an emotional "root password". Humans may be hardwired to find it hard to ignore them. At the very least, even if they are ignored, it's going to be actually painful to do it.
I mean, I'm not saying it's the apocalypse, and there are plenty of ways to scam without AI, but this stuff is not good AT ALL.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2023-04-14T23:39:45.569Z · LW(p) · GW(p)
I mean, I'm not saying it's the apocalypse, and there are plenty of ways to scam without AI, but this stuff is not good AT ALL.
It will however be a very strong impetus for establishing a verified identity phone system, which would also get rid of current human and simple machine generated spam calls.
So it does have some positive consequences.
Replies from: jbash↑ comment by jbash · 2023-04-15T13:04:58.605Z · LW(p) · GW(p)
I guess maybe. A system like that isn't easy to set up, and it's not like there aren't plenty of scams out there already to provide whatever incentives.
To have helped with the publicized incident, the verification would have had to be both mandatory and very strong, because the scammer was claiming to be calling from the kidnapper's phone, and could easily have made a totally credible claim that the victim's phone was unavailable. That means no anonymous phone calls, anywhere, ever. A system where it's impossible to communicate anonymously is very far from an unalloyed good, so it may or may not be a "positive consequence" at all on the whole.
Also, for the niche that voices were filling, anything that demands that you carry a device around with you is just plain not as good.
-
It's pretty rare to get so banged up that your face and voice are unrecognizable, especially if you can still communicate at all. Devices, on the other hand, get lost or broken quite a bit, including in cases where you might be trying to ask somebody you knew for money.
In the common "I got arrested" scam, the mark expects that the impersonated person's phone won't be available to them. The victim could of course notice that the person isn't calling from a police station, assuming the extra constraint that the identification system delivers an identifier that's unambiguously not a police station... but that just means the scammer switches to the equally common "I got mugged" or "car accident" scams. There are so many degrees of freedom that you can work around almost any technical measure.
-
Voices (used to) bind the content of a message directly to a person's vocal tract, and faces on video came pretty close to binding the message to the face. Device-based authentication relies on a much longer chain of steps, probably person to ID card/database photo to phone company records to crypto certificate to key to device. And, off on the side, the ID card database has to bind that face to information that can actually physically locate a scammer. Any of those steps can be subverted, and it's a LOT of work to secure all of them, especially because...
-
With no coordination at all, everybody on the planet automatically gets a face and a voice that's "compatible with the system", and directly available to important relying parties (namely the people who actually know you and who are likely to be scam victims).
Your device, on the other hand, may be certified by any number of different carriers, manufacturers, or governments, who have to cooperate in really complicated ways to get any kind of real verification. It takes forever and costs a lot to set up anything like that at the scale of a worldwide phone system.
It would be easier to set up intra-family "web of trust" device-based authentication... but of course that fails on the "mandatory" and "automatic" parts.
Device-based authentication can be stronger in many ways than vocal or visual authentication could ever be, and in some cases it's obviously superior, but I don't think it's a satisfying substitute. And most of its advantages tend to show up in much smaller communities/namespaces than the total worldwide phone system.
comment by Razied · 2023-04-14T18:18:23.822Z · LW(p) · GW(p)
I’ve thought a bunch about why Taleb doesn’t see this, why he worries about some things but not others, especially in the (relatively rare) cases where I think he gets it wrong. My model of this is that Taleb expects fat tails in the distributions to be more common than people expect and to dominate in importance, but in this framework, to be a fat tail you need to be on the distribution at all.
Oh you are being much too charitable to Taleb here. I don't think he spent 5 minutes thinking about the issue before confidently saying that everyone who disagrees with him is a moron bullshit-artist pseudo-intellectual. I don't know why you expect him to update on this in the next few years. Have you ever seen him change his mind in public?
comment by jaspax · 2023-04-14T04:03:03.238Z · LW(p) · GW(p)
Eliezer... points out that in order to predict all the next word in all the text on the internet and all similar text, you need to be able to model the processes that are generating that text
I wanted to add this comment to the original post, but there were already dozens of other comments by the time I got to it and I figured the effort would have been wasted.
EY's original post is correct in its narrow claim, but wildly misleading in its implications. He's correct that to reliably predict the next word in a previously-unseen text is superhuman, and requires doing simulation and modeling that would be staggering in its implications. But insofar as that is the goal, how close is GPT to actually doing it? How well does GPT predict the next token in an unknown string in contexts where English syntax gives you many degrees of freedom?
Answer: it's terrible! Its failure rate approaches 100%! (Again, excluding contexts where syntactic or semantic constraints give you very few degrees of freedom.) It is not even starting to approximate attempting to actually implementing the kinds of simulation and modeling that success would imply. What it can do is produce text that matches the statistical distribution of human text, including non-local correlations (ie. semantics), and to a certain degree the statistical idiosyncracies of specific writers (ie. style), and it turns out that getting even that far is pretty impressive. It's also pretty impressive that you can treat "predict the next token" as the goal and get this much good out of it while still being bad at actually predicting the next token. But the training data that GPT has is enough to teach it something about syntax and semantics, but is not remotely close to the amount or kind of data that would be necessary to teach it to simulate the universe.
The EY article boils down to "if GPT-Omega were an omniscient god that knew everything you were going to say before you said it, would that be freaky or what". Yeah, bro, it would be freaky. But that has nothing to do with what GPT can actually do.
Replies from: T3t↑ comment by RobertM (T3t) · 2023-04-14T07:11:30.056Z · LW(p) · GW(p)
This seems like an unusual misreading of Eliezer's post, which is quite explicitly about the potential bounds of future systems' performance, and not about the performance of the current system. There is no implication that the current system is superhuman (or even average-human) in the dimensions that you specified.
Replies from: M. Y. Zuo, jaspax↑ comment by M. Y. Zuo · 2023-04-14T23:43:25.925Z · LW(p) · GW(p)
potential bounds of future systems' performance
They sound more like fantasy bounds than 'potential' simply because there isn't 1000x or 10000x more training data in existence for such a future system to train on. (Nor are there any likely pathways for this to occur, other than training on the outputs of prior models)
↑ comment by jaspax · 2023-04-14T11:36:51.310Z · LW(p) · GW(p)
I understood that. I guess I should have been more explicit about my belief that the amount of training data that would result in training a viable universal simulator would be "all of the text ever created", and then several orders of magnitude more.