0 comments
Comments sorted by top scores.
comment by Chris_Leong · 2018-07-20T23:37:48.561Z · LW(p) · GW(p)
Can we have a short summary of your approach and it's main advantages so that we can decide whether it is worth making our way through the whole post?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-21T07:25:46.983Z · LW(p) · GW(p)
Ok. I added a one-paragraph summary at the start of the post.
comment by CronoDAS · 2018-07-20T17:21:35.236Z · LW(p) · GW(p)
That's a lot of math. It looks good to me and seems plausible but I haven't combed it in detail; could one of the math experts weigh in here?
One thing, though... why overload the term "logical uncertainty" to include observer-independent statements about the actual universe as well as mathematical statements that would be true in any universe?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-21T07:43:46.058Z · LW(p) · GW(p)
That's a valid question. I think both kinds behave identically, but I admit that's not a compelling reason to stretch the term in this way.
comment by avturchin · 2018-07-21T10:24:53.727Z · LW(p) · GW(p)
What is the prediction of your theory to the Grace's SIA Doomsday?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-21T12:20:49.362Z · LW(p) · GW(p)
That should be conclusive from this post, so for everyone who already read it, you can try to predict it before reading further.
So you'd have to input your probability distribution of possible universes, in this case that just has to specify where the filter is for different species. If you think the filter is at the same place for all species, then your distribution should look something like 1/3 * filter always late, 1/3 * filter always middle, 1/3 * filter always early and the SIA doomsday doesn't apply (you'd have 3 trivial experiments). If you think for some it's early and for some middle and for some late, then your distribution would just be 1 * filter varies for different species, then you'd have just one experiment which rolls a die in the beginning to decide where it puts the filter for us. Then the argument works. You could also mix those, if you think maybe it's the same for everyone and maybe not. Then the argument kinda works.
But plausibly the filter, if it exists, is at the same place for everyone. So my theory mostly rejects the argument.
Replies from: avturchin↑ comment by avturchin · 2018-07-21T13:40:45.232Z · LW(p) · GW(p)
In other words, it is similar to the the God coin toss - you can't update logical uncertainty based on your location?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-21T13:54:43.335Z · LW(p) · GW(p)
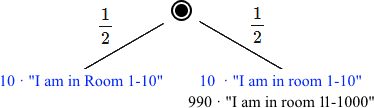
No, in God's coin toss the probability is random. At least that's what I took it as, since it's described as a coin toss. The reason the answer is 1/2 there is just because the number of observations of being in room 1-10 is equal in the heads-case and the tails-case (10 in both). This is the image of the experiment I made in the post. If it was 2000 people in the tails-case, 2 in every room number, then the answer would be 1/3 for heads.
{kind=link}
comment by avturchin · 2018-07-20T18:02:47.887Z · LW(p) · GW(p)
Maybe logical uncertainty should be applied not only to the "world model", but also to our ability to solve problems like Sleeping Beauty, and such position could be called 5/12, for the one who is uncertain between halfers and thierders.
Also, if your Summary will be in the beginning, it may help understanding the text, but still the Summary is too complex, and if the main idea of text could be presented as some oversimplified one line it would be helpful.
Replies from: aausch, sil-ver↑ comment by aausch · 2018-07-23T02:59:52.125Z · LW(p) · GW(p)
Any chance you can include links to references/explanations for SIA, FNC, etc .... (maybe in the intro section)?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-23T08:25:00.402Z · LW(p) · GW(p)
I added links, but I don't want to explain what they are in the post.
I can do it here, though. So there are two major ideas, SSA and SIA. The simplest example where they differ is that god tosses a coin, if it's heads he creates two copies of you, if its tails he creates one. You are one of the copies created. What's the probability that the coin came up heads? One view says that it's one half, because a-priori we don't count observers or observations. That's the SSA answer. The other says that it's one third, roughly because there are fewer copies of you in that case. That's the SIA answer.
The way SSA and SIA they are phrased according to the LW wiki is like so:
SSA: All other things equal, an observer should reason as if they are randomly selected from the set of all actually existent observers (past, present and future) in their reference class
SIA: All other things equal, an observer should reason as if they are randomly selected from the set of all possible observers.
The term reference class in this case refers to the set of all observers that exist given the coin fell a certain way. So if the coin fell heads, there's one observer, if it fell tails there are two. The heads-reference class consists of one observer, the tails-reference class consists of two.
The way they were originally phrased and understood was different, so if you read on past papers it might be confusing. Originally, SSA just said that given one reference class, you should assume to be randomly selected from that class, and SIA said that the reference classes become more likely the more observers are in them. Taken both, you have what the above formulation of SIA states, which is that all possible observers are equally likely. What we now call SIA is what used to be SSA + SIA and what we now call SSA used to be SSA without SIA.
Generally, both aren't formulated very well. Full-nonindexical conditioning is an entire paper with an entirely new name just to give SIA a better justification. It outputs the same results as SIA, so really there are still only two theories.
And in this post, I argue that sometimes it's valid to count observers and sometimes it's not, and whether it is depends on what kind of experiment it is. Roughly, if an experiment goes one way half the time and another way half the time, then both happen a lot, so there are actually more observers on one side. Then counting is legit (SIA answer). If an experiment only ever goes one way but you don't know which, then you can't compare numbers because you don't know them, so you just take the prior probabilities (SSA answer). This distinction is I think super duper important and absolutely must be made, but neither existing theory is making it.
Also I don't count observers but just observations which strikes me as a much cleaner concept. It removes any discussion what qualifies as an observer. Similarly, there are no reference classes in my theory.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-23T11:59:40.513Z · LW(p) · GW(p)
I see, so your theory is SSA for logical coins and SIA for quantum coins. What if we set up a Sleeping Beauty experiment with a quantum coin, but first compute a cryptographically hard function of the coin's outcome and tell it to the agent in advance? Would that change the coin type from quantum to logical, and change the agent's probabilities from SIA to SSA?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-23T14:07:13.228Z · LW(p) · GW(p)
No.
The principled distinction is not about the type of coin, that was a summary. The principled distinction is about sets of observations and how frequently they correspond to which outcome. And because we don't have perfect deductive skills, sets of observations that are indistinguishable to the observer with respect to the proposition in question are summarized into one equivalence class.
If you set up the experiment that way, then the equivalence class of the agent's set of observations is something like "I'm doing a sleeping beauty experiment, the experimenter gave me a hash of the coin's outcome". This observation is made lots of times in different worlds, and the outcome varies. it behaves randomly (=SIA answer is correct).
It also behaves randomly if you choose the number of interviews based on the chromatic number of the plane, because sleeping beauty cannot differentiate that from other logically uncertain problems that have other outcomes. That was the example I used in the post.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-23T19:05:48.483Z · LW(p) · GW(p)
I see. What's the clearest example of a problem where your theory disagrees with SIA?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-23T20:30:36.170Z · LW(p) · GW(p)
if existing isn't subjectively surprising, and if there's only one universe (or if all universes are equally large), then my theory is indifferent between a universe with N and one with a trillion N observers, whereas SIA says the latter one is a trillion times as likely. SIA Doomsday which avturchin mentioned is also a good one. If the filter is always at the same position and if, again, existing isn't subjectively surprising, my theory rejects it but SIA obviously doesn't.
The assumptions are necessary. If there are lots of different (simulated) universes, some large some small, then living in a larger universe is more likely. If existence is subjectively surprising, if it's actually a trillion times more likely in the larger universe, then the smaller universe is unlikely. That's the same as updating downward on extinction risk if Many Worlds is false.
There might be a cleaner example I haven't thought of yet. You'd ned something where every similar observation is guaranteed to refer to the same proposition, and where you can't update on having subjective experience at all.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-23T20:35:16.558Z · LW(p) · GW(p)
Can you explain what you mean by "existing isn't subjectively surprising", without reference to the rest of your theory? I tried to read the explanation in your post but somehow it didn't click.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-23T21:17:12.291Z · LW(p) · GW(p)
The view that most people who have thought about it at all have of consciousness is that there's some subjective experience that they have and some that other people have and that they're different. They don't imagine that if they die they keep living as other people, they imagine that if they die it's lights out. I call that individual consciousness (idk if there's a more common term). In that case, existence would be subjectively surprising. The alternative theory, or at least one alternative theory, is that "you are everyone", that the observer that's sitting in your brain and the one that's sitting in my brain is in fact the same. If you can imagine that there's an alternate you in another universe that has the same consciousness, then all you need to do is to extend that concept to everyone. Or if you can imagine that you could wake up as me tomorrow, then all you need to do is to imagine that you wake up as everyone tomorrow. I call that singular consciousness.
If individual consciousness is in fact true, then it gets very hard to claim that a smaller universe is as likely as a large one, independent of SIA or SSA. I know most people would probably claim both things, but that leads to some pretty absurd consequences if you think it through.
But if singular consciousness is true there's no problem. And my honest opinion is that it probably is true. Individual consciousness seems incredibly implausible. If I put you in a coma and make a perfect clone, either that clone and you are the same person or not. If not, then the universe has super-material information, and if so, then there has to be a qualitative difference between a perfect clone and a clone with one atom in the wrong place. Either way seems ridiculous.
Replies from: TAG, cousin_it↑ comment by TAG · 2018-07-24T11:38:45.402Z · LW(p) · GW(p)
If I put you in a coma and make a perfect clone, either that clone and you are the same person or not. If not, then the universe has super-material information, and if so, then there has to be a qualitative difference between a perfect clone and a clone with one atom in the wrong place
The two bodies aren't the selfsame body (numerical identity) , they are two entities with identical properties (qualitative identity). You seem to be allowing qualitative identity without numerical identity in the case of the body, but not in the case of consciousness.
If not, then the universe has super-material information,
That would be spatio temporal location. Even in austere physicalism, you have to accept that not all information is an intrinsic property of a material body.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-24T13:27:12.339Z · LW(p) · GW(p)
You mean The two bodies aren't the selfsame body (numerical identity)
You mean identity of particles? I was just assuming that there is no such thing. I agree that if there was, that would be a simpler explanation.
Replies from: TAG↑ comment by TAG · 2018-07-24T14:06:27.693Z · LW(p) · GW(p)
I mean numerical non identity given qualitative identity (both bodies are made of identical particles in identical configurations). Those are terms of art you can look up.
Giving up on numerical non-identity given qualitative identity is not an option given physics.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-24T14:23:14.516Z · LW(p) · GW(p)
I was under the impression that the opposite was the case, that numerical non-identity given qualitative identity is moonshine. I'm not a physician though, so I can't argue with you on the object level. Do you think that your position would be a majority view on LW?
Replies from: TAG↑ comment by TAG · 2018-07-24T14:47:58.197Z · LW(p) · GW(p)
I was under the impression that the opposite was the case, that numerical non-identity given qualitative identity is moonshine.
If you believe that, you shouldn't be talking about cloning except to say it is impossible.
Consider a thought experiment: you make a very nearly identical copy of something, differing in only one atom, you move the copy and the original to opposite ends of the galaxy, and you add the missing atom to the copy. What happens next?
Do you think that your position would be a majority view on LW?
I neither know nor care.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-24T14:56:42.344Z · LW(p) · GW(p)
Ok, so I think our exchange can be summarized like this: I am operating on the assumption that numerical non-identity given qualitative identity is not a thing, and you doubt that assumption. We both agree that the assumption is necessary for the argument I made to be convincing.
↑ comment by cousin_it · 2018-07-24T00:07:10.975Z · LW(p) · GW(p)
That's still confusing to me, maybe let's try a different tack. The Sleeping Beauty problem, which differentiates between SIA and SSA, can be described procedurally - flip a coin, give someone an amnesia pill, etc. Is there a problem that can be described procedurally and makes your theory disagree with SIA?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-24T08:17:26.328Z · LW(p) · GW(p)
No, I don't think there is. The examples I already gave you were my actual best guesses for the cleanest case. Anything purely procedural seems like it will inevitably come up one way sometimes and another other times, if we lump it together with similar-seeming procedures, which we have to do. In those cases SIA is always correct. You could probably come up with something not involving consciousness, but you do need some logically uncertain fact to check, and it needs to be very distinct.
I definitely think of part of the point of this post to argue against SSA. Anything that's covered by the model of randomness I laid out seems very clear-cut to me. That includes normal Sleeping Beauty.
But I really want to know, what is confusing about the consciousness distinction? Is it unclear what the difference is, or do you just doubt that it is allowed to matter?
Replies from: cousin_it↑ comment by cousin_it · 2018-07-24T09:33:17.160Z · LW(p) · GW(p)
I think you've explained your intuition well, but without examples it doesn't feel like understanding to me. You've said some things that seem interesting, like "super-material information" or "one atom in the wrong place", maybe you could try making them as precise as possible?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-24T13:22:28.484Z · LW(p) · GW(p)
Ok, but I said those two things you quoted only in a short argument why I think individual consciousness is not true. That's not required for anything relating to the theory. All I need there is that there are different ways that consciousness could work, and that they can play a role for probability. I think that can be kept totally separate from a discussion about which of them is true.
So the argument I made was meant to illustrate that individual consciousness requires a mechanism by which the universe remembers that your conscious experience is anchored to your body in particular, and that it's hard to see how such a mechanism could exist. People generally fear death not because they are afraid of losing the particular conscious experience of their mind, but because they are afraid of losing all conscious conscious experience, period. This only makes sense if there is such a mechanism.
The reductio ad absurdum is making a perfect clone of someone. Either both versions are subjectively different people, so that if one of them died it wouldn't be any consolation for her that the other one is still alive; or they are one person living in two different bodies, and either one would have to care about the other as much as about herself, even on a purely egoistical level. One of those two things has to be the case.
If it's the former, that means the universe somehow knows which one is which even though they are identical on a material level. That's why I meant by super-material information. There must be something not encoded in particles that the universe can use to tell them apart. I think many of us would agree that such a thing doesn't exist.
If it's the latter, then that begs the question what happens if you have one copy be slightly imperfect. Is it a different person once you change one atom? Maybe not. But there must be some number such that if you change that many atoms, then they are subjectively different people. If there is such a number, there's also a smallest number that does this. What follows is that if you change 342513 atoms they are subjectively the same, but if you change 342514 they're subjectively different. Or alternatively it could turn a few particular atoms?
Either way seems ridiculous, so my conclusion is that there most likely is no mechanism for conscious individuality, period. That means I rationally have no reason to care about my own well-being any more than about anyone else's, because anyone else is really just another versions of myself. I think most people find this super unintuitive, but it's actually a simpler theory, it doesn't give you any trouble with the cloning experiment because now both cones are always the same person no matter how much you change, and it solves the problem of "what a surprise that I happen to be born instead of person-X-who-never-existed!". It seems to be the far more plausible theory.
But again, you don't need to agree that one theory of consciousness is more plausible for any of the probability stuff, you only need to agree that there are two different ways it could work.
Replies from: cousin_it, TAG↑ comment by cousin_it · 2018-07-24T13:41:13.543Z · LW(p) · GW(p)
So one of those ways will agree with SIA and the other will disagree, right? Let's focus on the second one then. Can you give a procedural problem where the second way disagrees with SIA?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-24T21:28:18.410Z · LW(p) · GW(p)
No; like I said, procedures tend to be repeatable. Maybe there is one, but I haven't come up with one yet. What's wrong with the presumptuous philosopher problem (about two possible universes) as an example?
Replies from: cousin_it↑ comment by cousin_it · 2018-07-25T08:12:36.566Z · LW(p) · GW(p)
Let's say God flipped a logical coin to choose between creating a billion or a trillion observers in a single universe. Is that equivalent to your example?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-25T14:35:55.610Z · LW(p) · GW(p)
Yes.
I'm not used to the concept of a logical coin, but yes, that's equivalent.
You need the consciousness condition & that god only does this once. Then my theory outputs the SSA answer.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-25T20:53:03.060Z · LW(p) · GW(p)
What if God does that many times, but you can distinguish between them? First flip a blue coin to decide between creating a billion or a trillion blue people. Then flip a purple coin to decide between creating a billion or a trillion purple people. And so on, for many different colors. You know your own color: green. What are your beliefs about the green coin?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2018-07-28T15:22:32.092Z · LW(p) · GW(p)
1000:1 on tails (with tails -> create large universe). It's a very good question. My answer is late because it made me think about some stuff that confused me at first, an I wanted to make sure that everything I say now is coherent with everything I said in the post.
If god flipped enough logical coins for you to be able to make the approximation that half of them came up heads, you can update on the color of your logical coin based on the fact that your current version is green. This is a thousand times as likely if the green coin came up tails vs heads. You can't do the same if god only created one universe.
If god created more than one but still only a few universes, let's say two, then the chance that your coin came up heads is a bit more than a quarter, which comes from the heads-heads case. The heads-tails case is possible but highly unlikely.
↑ comment by TAG · 2018-07-24T14:18:44.415Z · LW(p) · GW(p)
If it’s the former, that means the universe somehow knows which one is which even though they are identical on a material level
Note that "the universe" is already keeping track of two identical bodies..which are, of course, in different places...which gives you a hint as to how the trick is pulled off.
Under dualism , there is problem of how to match up 7 billion souls to 7 billion bodies. Under physicalism, the individual self just is the body-brain, there is not logical possibility of a mismatch , and whatever mechanism (ie different spatial location) that allows the universe to have two identical but distinct bodies allows it to have two identical but distinct consciosunesses.
↑ comment by Rafael Harth (sil-ver) · 2018-07-21T07:45:16.163Z · LW(p) · GW(p)
I can't do it in one line, but I made a shorter summary and put it at the beginning.