Trajectories to 2036
post by ukc10014 · 2022-10-20T20:23:34.164Z · LW · GW · 1 commentsContents
TL;DR Gloss on AIDC Assumptions & Caveats Major States Successful alignment Major (global) conflict Dominance 'AI condominium' AIDC arising despite a 'best efforts' at alignment AIDC arising from 1 nation having dominance AIDC arising from 2 (or more) HLAIs ('Two Clan World') Internally (un-)coordinated HLAI clans Some Trajectories US achieves HLAI without a fight US achieves HLAI but China reaches parity China challenges US militarily Takeaways Ways this could be wrong None 1 comment
TL;DR
This post follows on from an earlier, longer attempt [LW · GW] to think through Holden Karnofsky's ‘AI Could Defeat All of Us Combined’ (AIDC). It spends less time on the specifics of precisely how a mass-copied human-level AI (HLAI) would kill, enslave, or disempower humans (i.e. who would copy the HLAIs, how they might establish an 'AI headquarters', how they might form malign plans, etc.), as both Karnofsky's and my earlier post consider these. The chart lays out a variety of (geopolitically-informed) trajectories, and the text below works through them to identify the different 'flavours' of AIDC or alignment that might result.
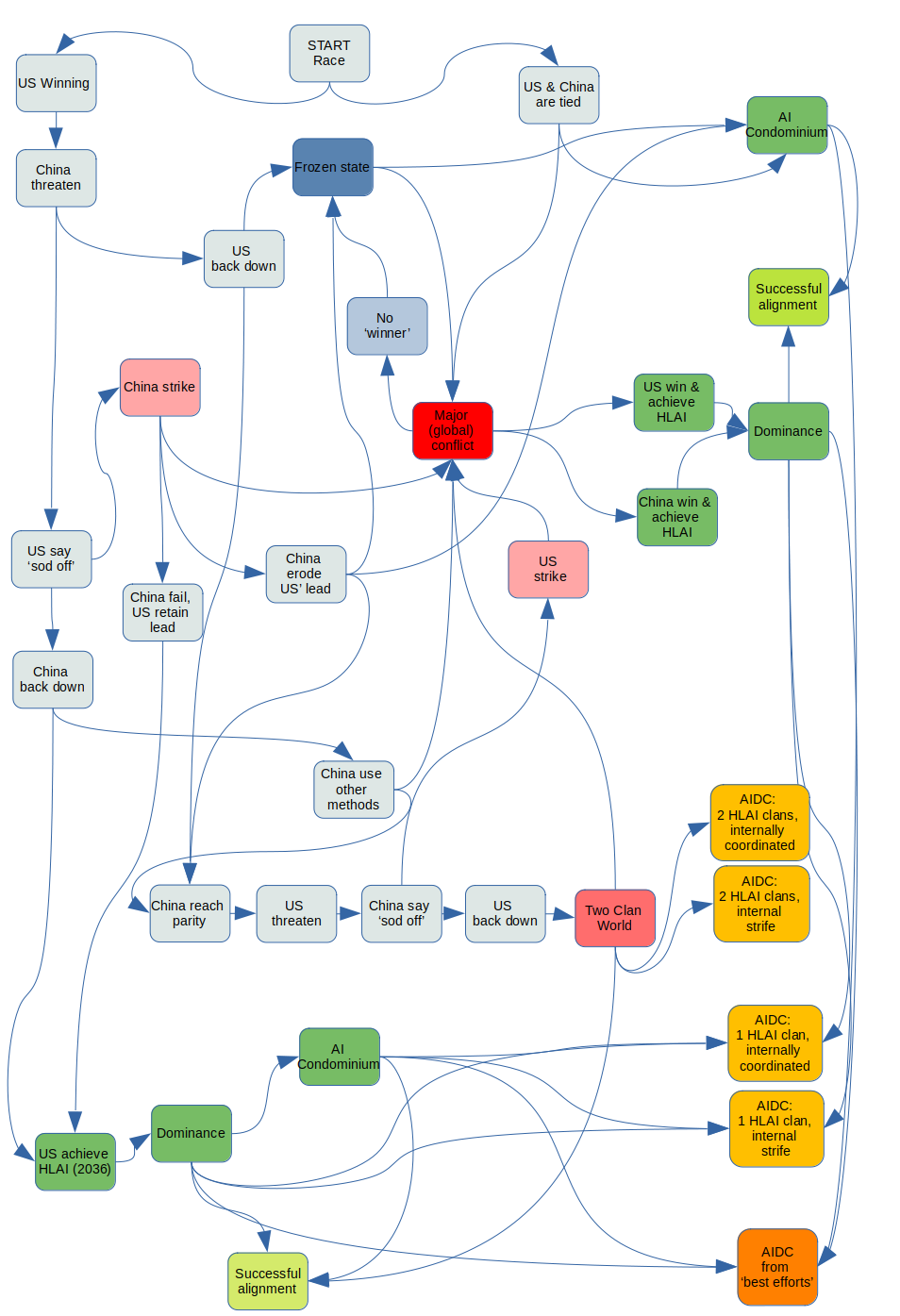
Gloss on AIDC
In another post [LW · GW] I summarised Holden Karnofsky's ‘AI Could Defeat All of Us Combined’ (AIDC) as follows:
‘Human level AI (HLAI) is developed by 2036, is useful across a broad range of jobs, and is rolled out quickly. There is sufficient overhang of servers used to train AI at that time that a very large number of HLAIs, up to hundreds of millions running for a year, can be deployed. In a short period, the HLAIs are able to concentrate their resources in physical sites safe from human interference. Humans are unable to oversee these copies, which coordinate and conspire, leading to an existentially risky outcome for humanity.'
AIDC is a useful sketch of a possible future, but it seems at once too high-level and somewhat constrained. For instance, AIDC deals with an abstract deployment scenario, and implicitly posits 'all HLAIs' against 'all humans'. But that abstraction seems hard to think about without considering the possible geopolitical distribution and incentives of AI assets and their political masters.[1] AIDC also suggests a specific date, 2036, for HLAI deployment; and centres its analysis on human-level AI. Both choices are not without implication, which I discuss below and [LW · GW] elsewhere [LW · GW].[2]
Assumptions & Caveats
14 years is a kinda long time: 2036, a slightly artificial choice of date, is both close enough to somewhat forecast, but far enough for radical shifts (along technological, economic, and strategic axes).[3] Hence, this chart is provisional, and it is possible that long before HLAI, there are major changes (a US-China kinetic war, a Chinese debt crisis, a renewed EU political/debt crisis, substantial US internal conflict, and of course, a Ukraine-related nuclear event) that alter the US-China strategic relationship towards one where there is a) a clear dominant party, or b) a situation that allows for limited cooperation.[4]
US leads: In this post, I assume a toy world with two relevant actors, the US and China; for purposes of the chart, I assume the US has a sustainable lead [LW · GW] in semiconductors and AI research. However, this might not remain the case, hence the chart could be drawn with 'China winning', or one could follow the 'US & China are tied' trajectory.[5] To be clear, this particular choice is not intended to be particularly jingoistic, alarmist, or xenophobic - these are just speculative scenarios.
AI dominance is non-negotiable: I am assuming that both the US and China view the prospect of the other party having sole access to HLAI (or any sort of advanced AI) as a critical, or near-existential threat, not unlike past technological races.[6] An implication of the above is that the respective national security establishments may set AI priorities [LW · GW], culture, and perhaps even choices of architecture and training data.[7] Moreover, and speculatively, I assume there is a substantial chance one side or another might take radical (including military) action to restrict the other's ability to cross a HLAI threshold.[8]
Material reality matters: In another post, I suggested that the strategic usefulness of HLAI needs to be considered in context of material realities [LW · GW] (access to raw materials, territory, industrial production, ability to convert IP into 'stuff' as well as leverage against other nation-states). I also questioned whether humans' management and oversight capacity would continue to be a bottleneck [LW · GW] to full automation of economies. This implies that even once one or more parties have HLAI, they will need to convert that advantage into materially-tangible dominance (i.e. a portfolio of R&D IP alone may not be as strategically useful as it might have been in the globalised world that prevailed pre-2020).[9]
Compressed timeframe: One obvious simplification I've made is that the action space for what either country can do has been compressed to ~2035-2037, based on these reasons [LW · GW]. In reality, events may play out over a longer period, changing the conflict dynamics significantly; for instance, the recent US semiconductor sanctions on China may (or may not) mean the latter is disadvantaged for decades in the AI race.
Probabilities: I have intentionally left out probabilities from the chart, in part because I can't think of a rigorous way of quantifying any of this. A more fundamental issue is that not all branches are shown, and therefore branches don't sum to 1. If anyone thinks this framework is valid or useful, I would try to firm this up with at least some rough probability ranges.
Major States
Successful alignment
I see this as the outcome that is the negation of AIDC, i.e. a HLAI that is provably (or with some adequately [LW · GW] high confidence) aligned: even when copied and deployed in large numbers; that does not plan or collude in ways contrary to the interests of some suitably defined class of humans (which may not be 'all of humanity'); doesn't barricade itself in an AI headquarters; doesn't play 'the training game', etc.
Major (global) conflict
The 'China strike' and 'US strikes' nodes overlap (i.e. describe similar scenarios) with the 'Major (global) conflict' node, but I see the latter as akin to a World War with possible kinetic, economic, cyber, and space/satellite elements, that materially changes the ability of the losing side (or both sides) to go significantly further with HLAI, either from the perspective of research or deployment of compute, within the 2036 horizon. This could obviously be the blunt (and catastrophic) scenario of a general thermonuclear war; but I would expect that in 14 years, both sides' capabilities may have expanded to include credible, calibrated, and targeted strikes on server farms, scientists, production chains, and research facilities.[10]
Dominance
This refers to a situation where one or the other actor has developed HLAI first and is in a sufficiently strong military and economic position (a hegemon[11]) to dictate the agenda for HLAI deployment, and can choose to: make it robustly aligned; rush out a naively-aligned [LW · GW] version; or, decide to cooperate with the other actor. I don't see this as a very long-lived state, given that the other (second-place) actor may still be trying to catch up.[12]
Specifically, this situation seems to imply some fairly weird geopolitical worlds (from the standards of today). I can see at least three scenarios:
- Capitulation I World One or other major country (so China or the US in this case) is so devastated (by military/nuclear or economic conflict, or as the result of some disaster) that it is willing to cede first-mover advantage to the other, and therefore, likely control over the future.
- Perhaps its political class truly sees its best future interests served through some other non-military role (for Germany, it was as a co-anchor of the future EU, and for Japan, it was as an economic powerhouse under US protection). The counter-example is Russia, which obviously never really accepted a permanent second-class status and continued to entertain revanchist ambitions. Another counter-example is indeed China, which for decades, as a matter of policy, remained relatively unassertive in its foreign policy, prioritising poverty-reduction, until it changed tack around 2009.[13]
- Biding-time World Perhaps the loser is not annihilated or utterly degraded from a military/industrial perspective. Would it then perceive that its better future interests as a geopolitical player are served by 'biding its time':
- colluding or otherwise aiding the hegemon's HLAI clan (including providing a AI headquarters [LW · GW]), and more generally collaborating with a misaligned HLAI.
- trying to steal, corrupt or destroy the technology.
- a current example would again be a Russia which, aside from Ukraine, pursued a variety of initiatives (in Syria, in the cyber realm, or the apparent poisonings in the UK) designed to frustrate, without attacking in an easily-attributable way, the US and its allies. Similarly, China and Russia seem to have engaged in an awkward, limited rapprochement over the Ukraine situation, the practical impact of which remains to be seen.
- Capitulation II World Perhaps the loser in the race 'voluntarily' (i.e. absent a devastating conflict) for some reason identifies its future interests as being best served by permanently ceding control over AI. Examples, drawn from the nuclear non-proliferation literature, could be Brazil, Switzerland, perhaps South Africa. It may turn out that AI's military or strategic value is outweighed by some (not obvious currently) downside. For instance, chemical weapons turned out to be relatively less useful in a military context (compared to nuclear), a factor that might have contributed to relatively successful attempts to reduce their proliferation.[14]
- specifically as far as AIDC is concerned, this actor might, at the level of its political/economic elite, understand the risks of frustrating the hegemon, stealing technology, or colluding with a HLAI clan. It might appreciate the significant economic benefits (of being a friendly partner/client to the hegemon), and cease further attempts along adversarial lines (as Japan mostly did in the post-WWII period, though that is changing now). Given the stakes, it is somewhat hard (at the moment) to see either the US or China accepting such an outcome, while the picture looks less clear-cut for second-tier countries, who may or may not be willing to devote a significant portion [LW · GW] of GDP for prestige reasons or to 'have a seat at the table'.
'AI condominium'
This is the analogue of the Baruch Plan with both parties deciding to work together, either because they build a consensus on: the risk of unaligned AI; the destabilising potential of continuing on a race; or as the result of some event (an AI-related 'warning shot', a major war, a climate disaster). They therefore choose to cooperate.[15]
I see this as the world where 'best-efforts' alignment steps have the most chance of working.
AIDC arising despite a 'best efforts' at alignment
This describes a situation where the actor creating HLAI takes steps along the lines described in another post [LW · GW] by Karnofsky (in contrast to what Cotra terms 'naive safety efforts [LW · GW]'), in order to minimise the risk of catastrophic misalignment. Best-efforts alignment steps are complex, uncertain, possibly economically uncompetitive, multi-stage, and might take a great deal of time owing to iteration and trial-and-error.
Hence, it isn't obvious they are well-suited to a geopolitically competitive environment, either in the worlds I describe as Dominance, Two-Clan, or Biding-time, which all enjoy elements of a) intense competition, and b) urgency [LW · GW]. There might not be money or time for a slow, deliberate push towards an aligned HLAI. 'Best efforts' alignment is more likely to emerge from an AI Condominium or perhaps from a state where one actor has reached Dominance, while the other has chosen not to seek AI-parity (Capitulation I or II Worlds).
Best-efforts alignment, by definition, should have a higher chance of avoiding an AIDC scenario, but I assume it could still happen. I have not seen any analysis of the failure modes that might be associated with best-efforts alignment. In the flowchart, I break it out as a separate box, but it could of course share the intra-clan coordination aspects of the other AIDC nodes.
AIDC arising from 1 nation having dominance
As discussed above, it is possible that the non-dominant competitor accepts a potentially-permanent loss of control over future developments in AI (and consequent potential loss of economic/strategic parity). However, something similar hasn't happened on the scale of global, civilisational powers before, while AI as a general-purpose technology introduces novel incentives in favour of hegemony or, at least, parity.
It appears more likely that the race would continue on a variety of trajectories (see above), the net result of which would be there might be a large, capable, and hostile actor (on the scale of the US or China, albeit perhaps diminished by a significant conflict).
- In such a scenario, would it be reasonable to expect that HLAI deployed at scale by the winning nation would really be robust to both adversarial attacks, or attempts to collaborate, copy or tempt (some subset of the) HLAI clan?
- What would, in fact, be the desired (from the perspective of the human overseer working for the winning nation) behaviour of the HLAI clan in this situation (I am assuming the clan is a unified, coordinated actor)? It has previously been observed that an aligned-and-capable AI is a narrower [LW(p) · GW(p)] (i.e. more difficult) target to hit in the design space than a merely capable AI. Would it not be harder yet to find an AI design that: a) is precisely aligned to the values of its overseer (and their nation), b) is adversarially-disposed towards the opponent nation(s), and c) yet does not take any unauthorised or catastrophic action (i.e. such as initiating an unintended conflict or, worse, undertaking some random [from a human perspective] action that imperils all humanity).
I would argue this introduces two distinct failure modes that aren't envisioned in the original AIDC post.[16]
AIDC arising from 2 (or more) HLAIs ('Two Clan World')
This arises when 2 actors (nation-states in my scenario) have roughly par HLAIs that they deploy upon the compute under their respective control. It seems like the most uncertain situation because:
- It isn't clear how similar these HLAIs would be to each other (given that they may have been arrived at through a competitive process of stolen and home-grown components), and therefore, how likely it is that they would collude with each other against their respective human principals.[17] Intuitively, might they initially reflect biases [LW · GW] particular to their training (which under my assumptions above, was at least partially conducted in an antagonistic/militarised context), perhaps taken to extremes in novel ways, which also could be ultimately destructive to humanity?
- HLAIs may be employed on diverse tasks, both within a specific country/clan/project, but also across clans. Depending on how online [LW · GW] learning [LW · GW] is implemented, this might mean that something (such as neural weights) about the HLAIs would change as they act, and continue to learn, in the world. Thus, depending on the robustness of their initial alignment, as well as any safeguards to prevent such drift, they may become eventually misaligned in different ways to differing degrees.
- It also isn't clear whether such a (2-clan) scenario would be stable, or whether one or both of the nation-state principals (assuming they haven't been disempowered) would feel under pressure to convert this multipolar situation into a unipolar one of dominance.[18]
Internally (un-)coordinated HLAI clans
As discussed above, a basic assumption of AIDC is that the mass of HLAIs coordinate well amongst themselves. If they are very coordinated and they turn against their human overseers (AIDC's claims), then this may well lead to a catastrophic scenario. On the other hand, if they are internally uncoordinated, and this descends into strife, it seems reasonable to expect that humans could be collateral damage (for instance, through ecosystem destruction as per these [LW · GW] scenarios [LW · GW]).
It would seem that this risk is significantly increased if there are 2 HLAI clans.
Some Trajectories
A few possible trajectories are examined here.
US achieves HLAI without a fight
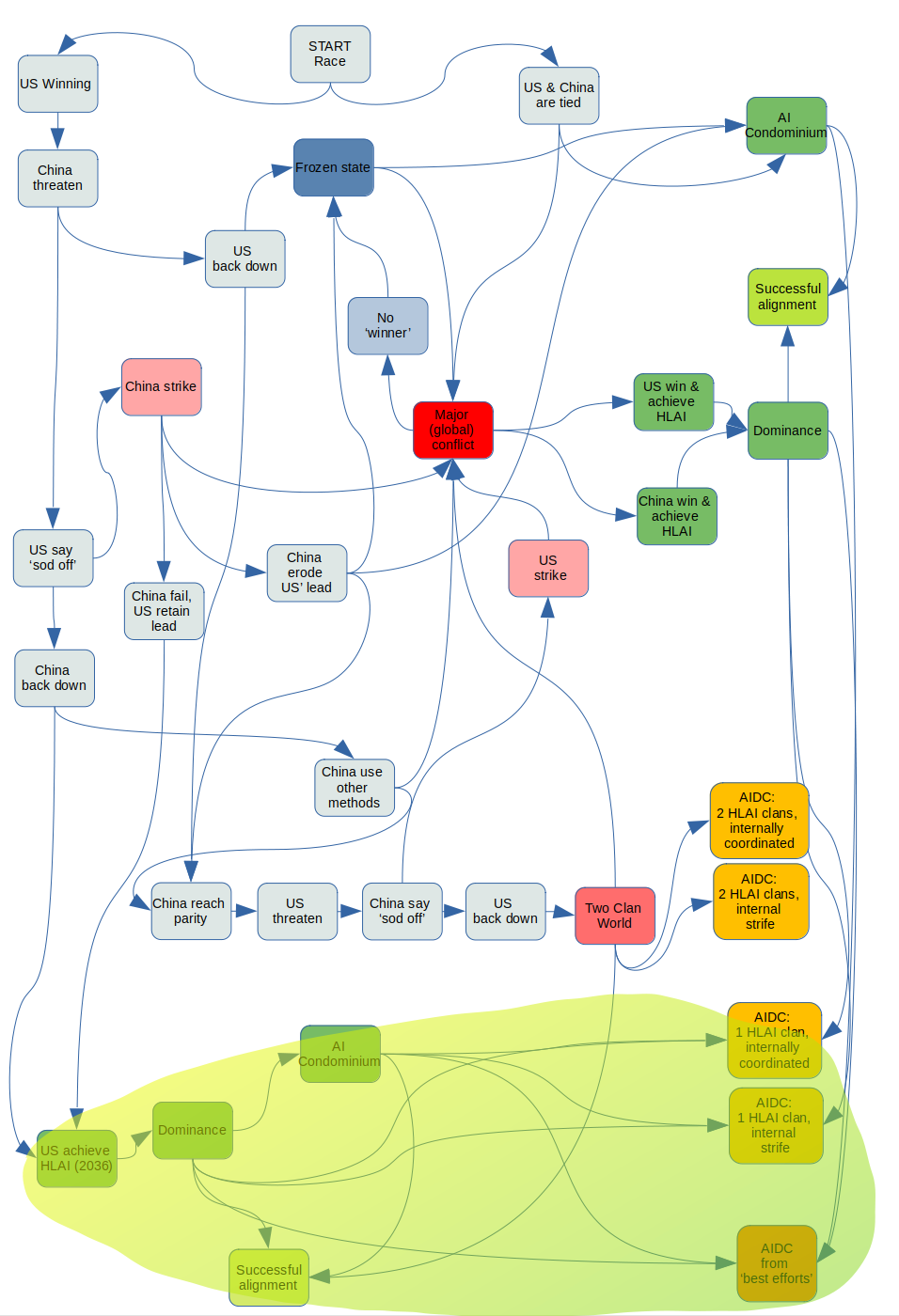
Given the US' (including European and East Asian allies) current lead in both IP and semiconductor design and fabrication, this seems like a high-probability case to consider. The steps are:
- at some point before 2036[19], China challenges the US (threatening massive economic sanctions, or a kinetic/cyber military strike on AI-related assets)
- the US ignores the challenge
- China backs down, and doesn't try to steal the technology or otherwise frustrate the US' lead
- thus, the US is in a position to deploy HLAI
By getting to this point, the US has probably already made some decisions (such as whether to align its HLAI in a 'naive' way or on a 'best-efforts' basis). I would expect the HLAI developed under the pressure of such a geopolitical race to be aligned in a way that is relatively naive/baseline, but this could be too pessimistic.[20]
The US seems to have a few choices at this stage:
- It can choose to deploy a naively or baseline-aligned HLAI, which[21] increases the risk of AIDC (either because the HLAI clan turns against the US [and perhaps humans generally], or the US [and perhaps humans generally] become collateral damage of intra-clan conflict).
- The US can delay deployment and try to get its prototype HLAI 'best-efforts' aligned. Given the gap between Cotra's naive or baseline safety specifications and those specified by Karnofsky here [LW · GW] (which is what I am calling best-efforts), it isn't obvious to me how easy it would be to re-engineer the safety aspects of HLAI after-the-fact, as it were.
- The US may also, from its comparable position of strength, invite China into a cooperative situation (AI Condominium), akin to the Baruch Plan. The US may reason that providing China (and others) with the economic benefits of HLAI blunts their incentive to develop a more misaligned domestic version or to initiate a conflict.[22] This leads to a few possible end states:
- The HLAI clan (there would only be a single one and I assume the deployed HLAIs would be copies [LW · GW] of the US design) is successfully aligned
- The US (perhaps with China's help) tries to align the HLAI on a relatively naive basis, and one of the 2 single-clan failure modes obtain, depending on whether the resulting clan is internally coordinated or not
- Perhaps the HLAI was thought to be aligned on a relatively best-efforts basis, but somehow it still turns out to do something catastrophic
US achieves HLAI but China reaches parity
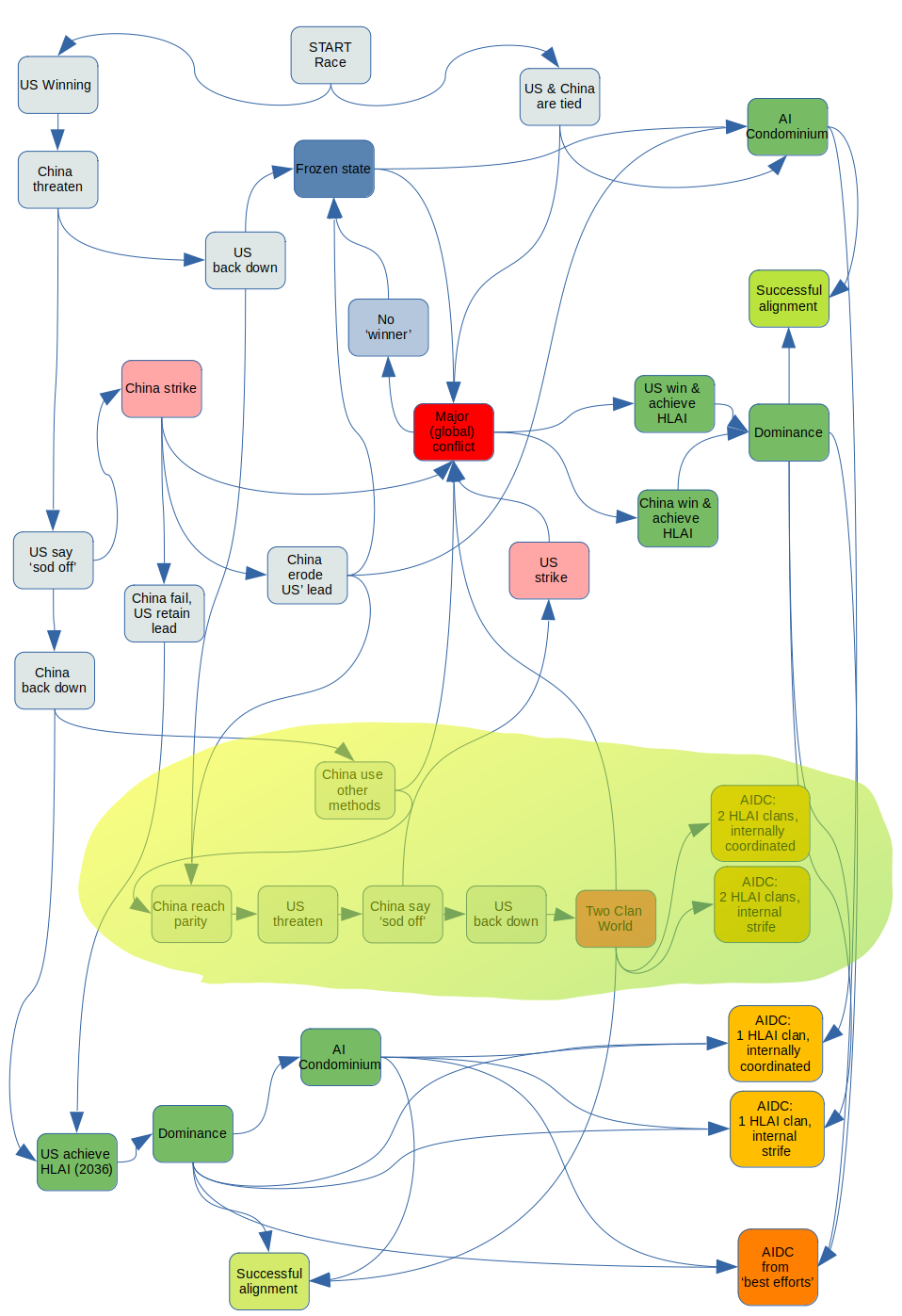
Similar to above, but:
- at some point before 2036[19], China challenges the US (threatening a kinetic or cyber military strike on AI-related assets)
- the US ignores the challenge
China backs down, and doesn't try to steal the technology or otherwise frustrate the US' leadChina doesn't directly attack the US but does covertly work to reduce the US' lead and/or acquire the HLAI technology (neural weights, architecture, or perhaps designs for semiconductors or whatever computing substrate and manufacturing equipment is SOTA at that time). The US retaliates in a proportionately covert or restrained manner, but is ultimately unsuccessful in blunting China's programme.the US isboth countries are in a position to deploy HLAI
This introduces the possibility of the Two Clan World, of unknown inter- or intra-clan coordination capabilities. It would appear to be a relatively risky scenario, with low probability of best-efforts alignment. For ease of reading, the chart ignores a few possibilities, like somehow this ending up in an AI Condominium or best-efforts alignment.
China challenges US militarily
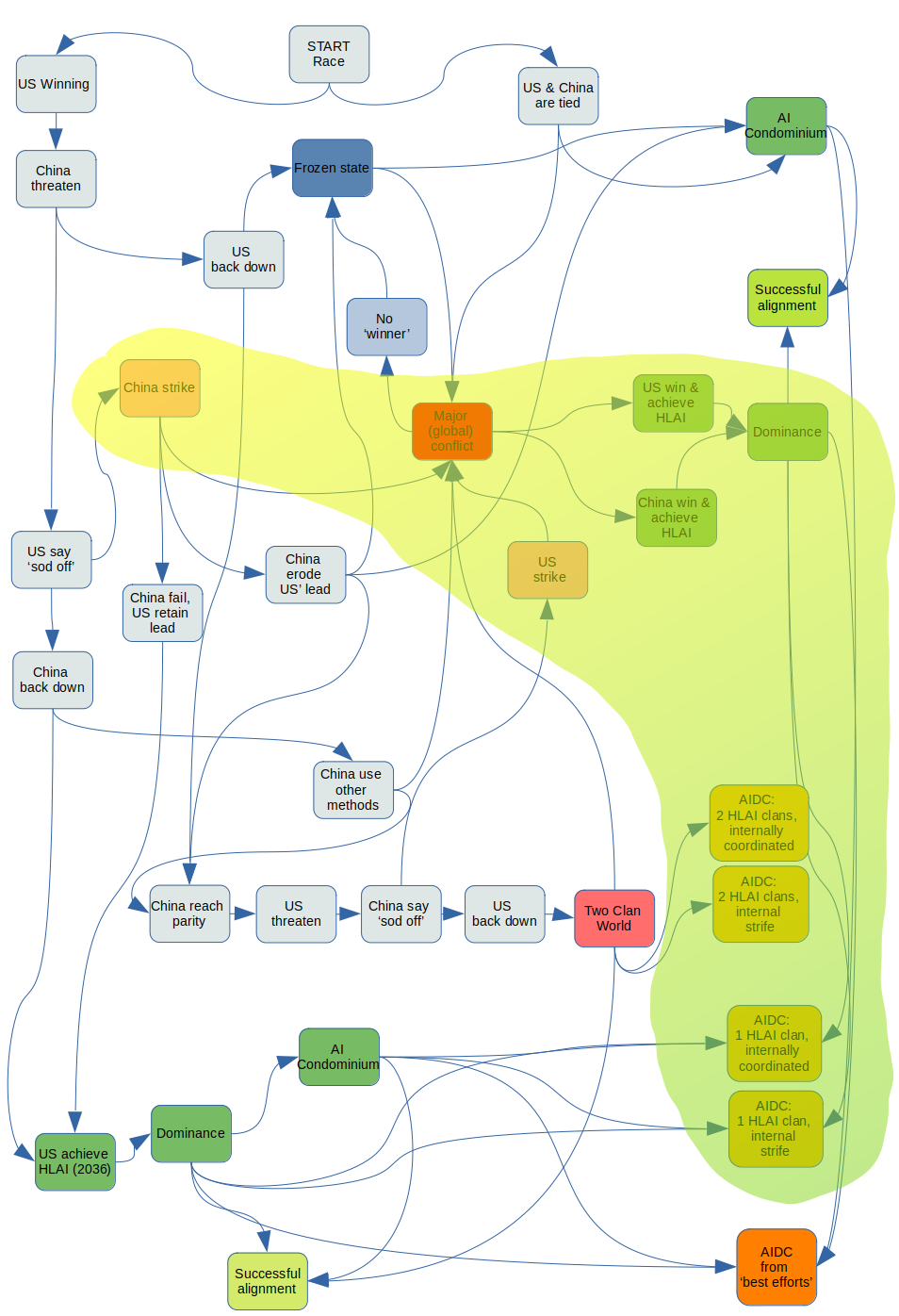
As above, but:
- at some point before 2036[19], China challenges the US (threatening a kinetic or cyber military strike on AI-related assets)
- the US ignores the challenge
China backs down, and doesn't try to steal the technology or otherwise frustrate the US' leadChina attacks (missile or nuclear strike, or a large-scale cyber offensive intended to degrade US' capability to continue with HLAI). A general conflict ensues. The 'winner' (if there is one) of the conflict goes on to deploy an aligned or misaligned HLAI, possibly leading to an AIDC scenario with a single HLAI clan.the US is in a position to deploy HLAIthe conflict might be such that no one can 'win' it (for instance, it becomes a full-scale nuclear exchange), and leads to a frozen state or continued cycle of conflict, without either party achieving HLAI within the 2035-2037 interval of interest.- or, China is able to erode the US' advantage, leading to a Two Clan World.
As in the parity case above, this introduces the possibility of 2 HLAI clans, which may or may not probably don't have identical architectures and neural weights, and may or may not coordinate well, either internally or with each other (this is only a very weak intuition, based on the upheaval [which might have destroyed compute, laboratories, scientists, societal wealth and cohesion, etc.] that might result from a general conflict as opposed to a quiet 'steal' of technology in the previous case). It isn't clear whether the space for best-efforts alignment would increase or decrease.
Moreover, the chances of a general-purpose technology (at least to the extent AI can be analogised with electricity as per Jeffrey Ding & Allan Dafoe), HLAI, being widely, economically-usefully, and safely deployed in a world (potentially) ravaged by a major war, seems hard to reason about.[23]
Takeaways
AIDC presents a particular version of AI takeover, that perhaps needs to be enriched in various ways. Specifically, the expected onset of HLAI is likely to have great-power implications, and some of those could be destabilising or malign.
It is not clear to what extent countries would go to stop competitors from reaching the HLAI threshold.[24] Russia-Ukraine has shown that relatively extreme tools are available (freezing of central bank reserves, sabotage of critical NATO infrastructure like railways and gas pipelines, and semi-credible threats of tactical nuclear strikes), while the sweeping US semiconductor sanctions on China appear largely driven by an intention to contain China's progress (in AI and generally).
There are at least four possible classes of AIDC-led failure, depending on the number of 'clans', or ecosystems, of HLAIs that are run by the leading nation-states. These clans might be highly internally coordinated, and may collude across clans. However, I have not found a solid argument why this (intra- or inter-clan coordination) should (or not) be the case. It does seem reasonable that they may be created under different circumstances, in a considerable rush, in secret, with stolen technology; they may also be imbued with adversarial (i.e. militaristic/nationalistic) biases, and probably will be exposed to some (not currently known) online learning mechanism.
The human element (i.e. national security establishments) may play a substantial destabilising role in a specific, AIDC-relevant, way: in a world competing to develop and deploy HLAI, there appears to be a prima facie case for human decision-makers in one country to provide resources or assistance (such as an AI headquarters or access to real-world resources) to a misaligned HLAI or clan in an enemy country. This particular bargain may seem compelling indeed to a military decision-maker: high probability of successfully sabotaging an enemy's HLAI programme at the cost of a theoretical, ill-articulated, temporally-uncertain probability of general planetary catastrophe.[25]
The chances of best-efforts alignment seem inconsistent with most pathways -- e.g. under pressure of competition, the substantial cost and time penalty associated with best-efforts alignment -- is unlikely to be appealing, either for the front-runner or for later actors trying to catch up.
Ways this could be wrong
The usual caveats in the referenced pieces by Karnofsky [LW · GW], as well as Cotra [LW · GW], might apply, such as: alignment proving easier than expected for some technical reason.
The current move towards de-globalisation and conflict could prove an aberration; the US and China, in particular as related to AI, could see more value in cooperation than competition.
As research progresses in the years leading to 2036, it may become apparent that there are three types of AI deployments:
- some that are immediately useful for (e.g. things LLMs or other current architectures do well and that don't require complex or deep knowledge of the physical world, such as surveillance systems, drone swarms, etc.);
- some that will require years of effort and iteration (e.g. running a moon-based mining station);
- and some where AI's value-added (economically or strategically) is currently outweighed by risks (autonomously-controlled nuclear-armed submarines).
If this is the case (and as mentioned above) AI might look less like a military-first technology where value accrues disproportionally to the first-mover (such as nuclear weapons), and more like an industry-wide transformative technology (like other general-purpose technologies such as electricity). In the latter case, it would not matter who 'gets HLAI first', and there might be more time to achieve more aligned outcomes.
Political elites in relevant countries such as the US and China might keep the national security establishment on a tight leash, learning from the bloat, misaligned incentives, and dysfunction that have characterised the nuclear race (and the military-industrial complex generally). This might reduce the chances of a particularly aggressive AI-related race or conflict.
- ^
My reading of AIDC is that it implicitly assumes a world where one country dominates (though this country might have allies and economic/security partners; AIDC's world resembles the low-friction, highly globalised world that seems to be receding into memory, as of 2022), such that there is a single, internally-coordinated HLAI clan engaged in a mix of commercially- and scientifically-useful tasks, as well as military-orientated tasks.
- ^
The scenarios I present might be over-coloured by the recent semiconductor sanctions placed upon China, which seem to represent a qualitatively more adversarial US position given their breadth and extraterritoriality.
- ^
2036 is influenced by Ajeya Cotra's Biological Anchors report. Current (October 2022) estimates from Metaculus show a median of 2042 and 2057 for 'weakly general AI' and 'general AI', respectively. AIDC's 'human-level' is (naturally) not specifically mentioned in the forecasts, but it (when taken in context of Ajeya Cotra's related definition of a 'scientist AI [LW · GW]'), seems closer to 'general AI' (i.e. 2057).
- ^
For instance, climate change has forced many countries to cooperate selectively to deliver the public good of (attempted) carbon reduction, and China has been a major part of this effort. Within a nuclear context, there is a long history of communication to achieve de-escalation and communicate credible threats.
- ^
- ^
This is a scenario, not a prediction. Hence I am focusing on what may be an excessively pessimistic (or simplistic) assumption that overemphasises the role of military or strategic considerations, and undervalues the ability of senior political leadership to take a broader view, informed by shared aims and norm. For historical context, see these two papers by Allan Dafoe & Jeffrey Ding that set out a conceptual framework for strategic assets (such as electricity in the early 1900s), including both military and economic or systemic aspects and the dependencies involved in realising maximum advantage from them. Importantly, Ding/Dafoe's analysis implies that the nuclear analogy with AI is inappropriate, and therefore the resulting competitive dynamic may be more complex.
- ^
However, see this 2020 interview with Jeffrey Ding which points out the degree to which AI innovation and research is driven by the private sector in China (and the US). The militarisation of AI research posited by my scenario seems to require more research and support (for instance, by assessing the extent to which either US or Chinese companies, while ostensibly private-sector, have priorities and funding set by their respective security establishments; or situations where key technologies or capabilities are militarised, while leaving others ostensibly in private sector hands; the recent US semiconductor sanctions clearly seem to have sacrificed private corporate interests to national security considerations).
- ^
The entire framing of HLAI (and therefore these scenarios) assumes a bright line that separates pre- and post-human level AI, and therefore some well-defined point after which AI takeover is a real risk (the implication of the original AIDC post), or a well-defined point by when either China or US need to intervene to prevent the other achieving AI dominance. Obviously, advanced AI might arrive in a more gradual [LW · GW] or continuous way, rendering these scenarios (and perhaps AIDC) somewhat simplistic.
- ^
To put it bluntly, intangible claims, including financial ones, seem less robustly useful in a world-in-conflict, as seen with the foreign-currency reserves of the Central Bank of Russia, which presumably has implications for the Chinese Central Bank's even larger holdings of assets from potentially hostile countries. More generally, the idea that economic relationships are a stabilising force in geopolitics seems more open to challenge.
- ^
Stuxnet and a spate of cyber-attacks against Iran in 2019/2020 involving the US and Israel show the path forward; assassinations have been a feature for some years now while 2022 saw drone attacks on Iran.
- ^
- ^
I also don't use the terms decisive strategic advantage (DSA) or major strategic advantage (MSA), as they seem to be employed in the context of an AI achieving a more or less dominant position [LW · GW], though Bostrom in Superintelligence (p. 95) uses DSA more broadly to refer to the project (i.e. organisation, people, country, as well as AI) that developed the AI (see also this post [? · GW]).
- ^
That particular date comes from this interview with economist/historian Adam Tooze. China's assertiveness more generally seems to pre-date Xi Jinping's ascendancy, to the time of Hu Jintao's disavowal of Deng Xiaoping's long-term advice to 'hide capabilities and bide time'.
- ^
See Chapter 20 of Scharre, Paul. Army of None New York: Norton, 2018.
- ^
Some reasons the original Baruch Plan seem to have failed: Soviet mistrust of the US' sincerity in its proposal, a Soviet requirement that the US give up its weapons first, and Stalin's desire for prestige. These might still apply, but there are differences: the degree (vis a vis nuclear material and technology) to which development and deployment of large-scale AI is easier to monitor and control is debatable; AI, as a general-purpose technology, is also inherently more dual-use than nuclear weapons; decision-making in countries is potentially more complex and unstable today, owing to less cohesive Western societies and social-media having shortened decision cycles.
- ^
Andrew Critch and David Krueger's ARCHES paper lays out a framework for thinking about AI deployment scenarios with multiple stakeholders (i.e. overseers or projects or nation-states) and multiple AIs (see Sections 2.8 and 7).
- ^
See here for more on coordination [LW(p) · GW(p)] amongst HLAIs or HLAI clans. See also this conversation [LW(p) · GW(p)].
- ^
- ^
I assume, for simplicity and consistency with AIDC, the window of interest for these scenarios to be ~2035-2037, i.e. starting just before the 2036 date when HLAI is deployed by one or more actors, and ending in about a year after deployment.
- ^
Moreover, this trajectory assumes the US as the leader. Even if a reader believes (generously) that US' government, companies, and researchers would take utmost care to ensure the safest possible AI, they may (reasonably or chauvinistically) have a different view on the intentions and competence of others (whether China, Russia, India, etc.) as the front-runner. For an analogy from the non-proliferation literature, see this on 'nuclear orientalism'.
- ^
- ^
The Americans could reason that a) the 'pie is big enough for everyone' i.e. the benefits of transformative AI and 30% GDP growth [LW · GW] can safely be shared, b) the years before 2036 (i.e. occurrence of some other economic or military disaster that weakens both would-be hegemons) might dissuade all parties from embarking on a wasteful war, c) having developed HLAI first, they might be able to build in safeguards that prevent China (or ideally, either side) from taking undue advantage of the technology.
- ^
In the ~60 years starting with the telegraph's invention, electricity was rolled out to lighting, power generation, electric firing systems, communications, searchlights, and submarine warfare. Around this period, there was the US Civil War (1861-1865) and the Russo-Japanese War (1904-1905). By the time WWI started (1919), 55% of US manufacturing was using electric motors (p. 22, Ding/Dafoe). It isn't clear to me what interaction, if any, there was between these conflicts and general industrial adoption of electricity (Ding/Dafoe deal primarily with military applications).
- ^
As mentioned previously, this might be a flawed statement of the problem i.e. there may be no 'bright-line' between pre- and post-HLAI - it may well be a more gradual or diffuse process. In other words, the electricity analogy, not the nuclear one (that we see every from time to time e.g. North Korea or Iran 'crossing the nuclear threshold').
- ^
See here [LW · GW] for such examples from the Cold War I could find, and the 'Do we need a world without Russia?' rhetorical question from 2022, which was curiously analysed, albeit in 1999 by the Carnegie Endowment.
1 comments
Comments sorted by top scores.
{kind=link}