A Back-Of-The-Envelope Calculation On How Unlikely The Circumstantial Evidence Around Covid-19 Is
post by Roko · 2024-02-07T21:49:46.331Z · LW · GW · 36 commentsContents
36 comments
Follow-up to: https://www.lesswrong.com/posts/Rof3ctjMMWxpaRj5Z/the-math-of-suspicious-coincidences [LW · GW]
This post will be a very preliminary model of the circumstantial evidence around covid-19's origin and how unlikely we are to actually see worlds like this under the Grand Null Hypothesis that there has been no foul play and covid-19 is a completely natural virus that just happened to appear.
What do we actually need to explain?
- Coincidence of Location: Wuhan is a particularly special place in China for studying covid-19; the WIV group was both the most important, most highly-cited group before 2020, and the only group that was doing GoF on bat sarbecoronaviruses as far as I know. Wuhan is about 0.5% of China's population. It's a suspicious coincidence that a viral pandemic would occur in the same city as the most prominent group that studies it.
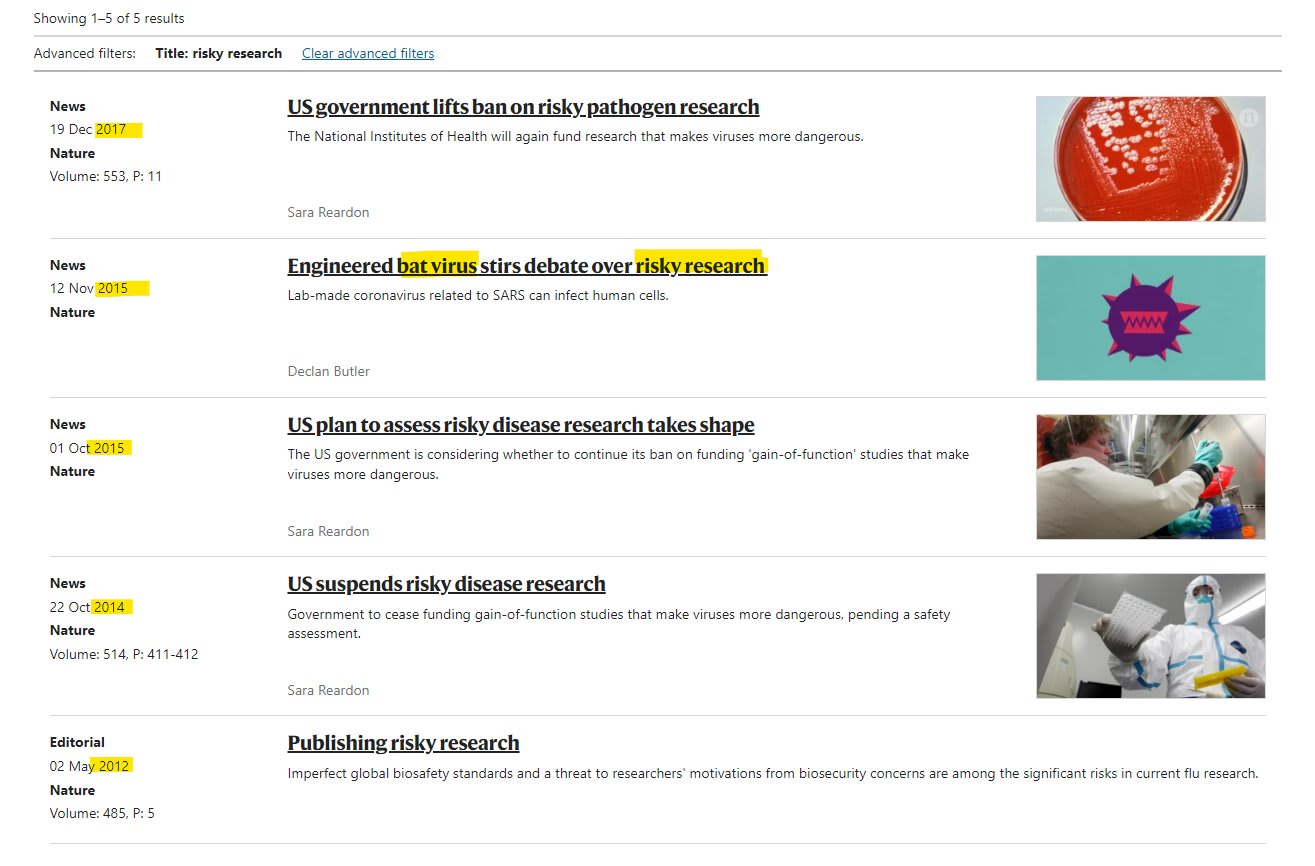
- Coincidence of timing: several things happened that presaged the emergence of covid-19. In December 2017, the US government lifted a ban on risky pathogen research, and in mid-2018 the Ecohealth group started planning how to make covid in the DEFUSE proposal. A natural spillover event could have happened at any time over either the last, say, 40 years or (probably) the next 40 years, though likely not much before that due to changing patterns of movement (I need help on exactly how wide this time interval is).
- Warnings turning out to be accurate: Warnings were given in Nature specifically mentioning the WIV/Zhengli Shi group and no other group involved with coronaviruses, and only a few other groups involved with any viruses at all (in other articles). There were hundreds of groups that could have been warned about I think, but this article gives 59 as the number of BSL-4 labs around the world. This is a subtler point than those above because getting a warning is extra evidence for the lab leak hypothesis even conditional on the timing and location coincidence. Warnings were also given about WIV itself independent of the connection to coronaviruses too.
- Specific Features of covid-19 are a close match for what was planned in the DEFUSE proposal: This gets a lot more technical, but you can imagine a world in which labs randomly generate GoF proposals like DEFUSE and nature randomly generates viruses via natural evolution. Even in cases where you get a location coincidence as in (1), the average GoF proposal might not match a randomly paired up natural virus as well as covid-19 matches DEFUSE. This is very hard for me to assess, but US Right to Know has a summary.
It's hard for me to objectively ballpark (4) without help from a few experts. But (1), (2), and (3) are fairly easy to get a ballpark figure for. I think these three are all pretty much independent, so the overall probability of these three things happening under the null hypothesis is just the product - 1/200 × 2/80 × 3/59 = 1/157,000
If we take the information from US Right to Know at face value, then the evidence that that adds is about 1/300 or so for the furin cleavage site positioned in the spike protein at the S1/S2 junction, about 1/1000 for the BsmBI anomalies and BsmBI being found in DEFUSE, some unknown amount for early infectiousness (ballpark 1/100) which adds up to 1 in 30 million. I think we can round this down to 1 in 500 or so as that is the minimum defensible chance that the people doing these analyses are like completely insane and wrong or some other wacky thing has happened in the technical details.
Multiplying all this together gets you to a 1 in 80 million chance of all this stuff happening under the null hypothesis, which is highly significant.
Of course this is just a ballpark figure and I think you could easily make it higher by having more confidence in the technical details of point (4), or lower by chipping away at (1) to (3) using more specific models of timing and distribution of natural spillovers, and perhaps by finding many more warnings being given that I couldn't find.
EDIT:
I think that there is also a lack of a plausible animal host for covid-19 (I mean, other than the humanized mice at WIV), though I am somewhat unsure as to how suspicious this is. In previous pandemics that involved spillovers, this is typically identified quite fast.
EDIT, again:
Adding to the case for a lab leak is the fact that the prior isn't that low, there have been a lot of biosafety incidents including (likely) the 1977 H1N1 flu, the foot and mouth outbreak in the UK in 2007, and a confirmed lab leak of covid-19 in Taipei.
We can also note that famous people have made bets that there would be a bio-safety incident by late 2020, so the prior cannot be that low.
As for the probability of the evidence under the alternate hypothesis, a lab leak easily explains the coincidence in space and time, and even conditional on that I think a warning about the place that the pandemic started is much likelier if it was a leak - the chain of causation is clear, warners notice a specific risk, warn about it, and the risk manifests as predicted. Given that Rees was able to predict the pandemic on general principle, it seems reasonable to assign 50% probability to P(Accurate Warnings|Lab Leak). The technical material such as BsmblI follows a similar pattern, especially since BsmblI is mentioned in DEFUSE. So I think under the alternate hypothesis we are looking at something like P(Evidence|Lab Leak) = 0.5⁴ = 6% or maybe more conservatively 0.2⁴ = 1.6%.
You can go through Bayes rule, but 80 million is large enough to completely swamp the prior. So either something is wrong with this whole exercise, or the lab leak is basically certain.
EDIT: Another thing I thought of is that independently of time, location and prior warnings, the mere fact that covid-19 was so wildly successful as a disease is evidence of a lab leak of a GoF virus, since GoF viruses are deliberately made to be more harmful and more transmissible. But it may be a bit hard to quantify this. I think there's probably a factor of 10 for LL here though.
EDIT: a more specific calculation for the timing coincidence under the alternative hypothesis follows. Let's think of pandemics as biased coin with probability p of getting heads, heads = you get a global pandemic. Pre-GoF (i.e. pre-2011) the coin was had a roughly p=0.01 chance of rolling heads. From 2018 onwards the coin is replaced with a biased coin with a larger chance of rolling heads. We roll once in 2018 (tails) then once in 2019 (heads). We need a reasonable prior for the coin to do the calculation.
We can use the fact that Rees and Pinker made a bet about this, let's say they are jointly assigning 50% per 4-year period of a million+ casualty event. But presumably Pinker believed something like the Null Hypothesis, so his probability would be much less than 50% (perhaps 4 or 5%) and so we can model Rees as thinking the probability is much higher, say 80%. We can, split Rees' 80% into bioterror and bioerror. Let's allocate 65% per 4 years to bioerror (error > terror, since there are examples of the former but not the latter), that's 23% per year. According to the Wikipedia list of plagues, counting only plagues which killed a higher proportion of the global population than covid-19, we get one every 150 years. 150 years is longer than the 80 or so years that this could have happened in China, but since the Pinker/Rees bet is global I think we can stick with global figures. This would give us a likelihood ratio of about 0.23/0.0066 = 34.
Another way to look at this is to note that 2017 is the only year that anyone in history has ever bet publicly on a bioerror or bioterror attack, combined with the only year that the US has greenlit dangerous GoF work, combined with the availability of the technology to do this kind of thing.
36 comments
Comments sorted by top scores.
comment by Throwaway2367 · 2024-02-08T01:56:53.650Z · LW(p) · GW(p)
You did the same thing Peter Miller did in the first rootclaim debate just for the opposite side: you multiplied the probability estimates of every unlikely evidence under your disfavored hypothesis, observed that it is a small number then said a mere paragraph about how this number isn't that small under your favored hypothesis.
To spell it out explicitly: When calculating the probability for your favored hypothesis you should similarly consider the pieces of evidence which are unlikely under that hypothesis!! Generally, some pieces of evidence will be unlikely for one side and likely for the other, you can't just select the evidence favorable for your side!
Replies from: Roko↑ comment by Roko · 2024-02-08T02:44:04.157Z · LW(p) · GW(p)
What pieces of circumstantial evidence are unlikely under the Lab Leak hypothesis?
I don't think evidence should generally be two-sided. E.g. imagine a game that's an amateur versus Magnus Carlsen, but you don't know who is white and who is black. If you look at the outcomes of moves as individual bits, it will be very one-sided.
Replies from: Throwaway2367, dave-orr↑ comment by Throwaway2367 · 2024-02-08T04:11:34.644Z · LW(p) · GW(p)
Cases clustering at wetmarket, proline at fcs, otherwise suboptimal fcs, out of frame insertion, WIV scientists' behavior after leak (talking about adding fcs to coronavirus in december, going to dinner, publishing ratg13), secret backbone virus not known (for some reason sars not used like in other fcs insertion studies), 2 lineages at market just off the top of my head
Replies from: ChristianKl, Roko, Roko↑ comment by ChristianKl · 2024-02-11T17:04:23.481Z · LW(p) · GW(p)
The nearest virus to COVID-19 we know to be likely in possession of the WIV was the one from Laos, not ratg13.
Publishing a sequence from a virus that comes from China like ratg13 and not from Laos might be a move they took to make it more plausible that a relative of the virus from the Chinese cave naturally spilled over.
Replies from: Roko↑ comment by Roko · 2024-02-08T10:26:35.294Z · LW(p) · GW(p)
WIV scientists' behavior after leak (talking about adding fcs to coronavirus in december, going to dinner, publishing ratg13)
wait, they talked about adding a FCS? Where?
Replies from: Throwaway2367↑ comment by Throwaway2367 · 2024-02-08T15:53:06.268Z · LW(p) · GW(p)
The first part of the third rootclaim debate covers the behavior of the scientists from 53:10 https://youtu.be/6sOcdexHKnk?si=7-WVlgl5rNEyjJvX
↑ comment by Roko · 2024-02-08T10:25:42.688Z · LW(p) · GW(p)
proline at fcs, otherwise suboptimal fcs, out of frame insertion,
I have never heard of this, where can I find out more?
Replies from: Throwaway2367↑ comment by Throwaway2367 · 2024-02-08T15:51:36.810Z · LW(p) · GW(p)
The second part of the second rootclaim debate (90 minutes) https://youtu.be/FLnXVflOjMo?si=dPAi1BsZTATxEglP
Replies from: Roko↑ comment by Dave Orr (dave-orr) · 2024-02-08T03:37:46.797Z · LW(p) · GW(p)
One big one is that the first big spreading event happened at a wet market where people and animals are in close proximity. You could check densely peopled places within some proximity of the lab to figure out how surprising it is that it happened in a wet market, but certainly animal spillover is much more likely where there are animals.
Edit: also it's honestly kind of a bad sign that you aren't aware of evidence that tends against your favored explanation, since that mostly happens during motivated reasoning.
Replies from: Roko↑ comment by Roko · 2024-02-08T09:01:11.384Z · LW(p) · GW(p)
I'm avoiding that as I don't understand the data provenance/cover-up potential.
The point of this post is to process just the "clean" data - stuff that interested parties such as WIV, Ecohealth and WHO could not have changed or affected.
Of course others should try to look into that and work out what's going on.
comment by followthesilence · 2024-02-08T03:48:02.192Z · LW(p) · GW(p)
Post hoc probability calculations like these are a Sisyphean task. There are infinite variables to consider, most can't be properly measured, even ballparked.
On (1), pandemics are arguably more likely to originate in large cities because population density facilitates spread, large wildlife markets are more likely, and they serve as major travel hubs. I'm confused why the denominator is China's population for (1) but all the world's BSL-4 labs in (3). I don't understand the calculation for (2)... that seems the opposite of "fairly easy to get a ballpark figure for." Ditto for (4).
Replies from: Roko↑ comment by Roko · 2024-02-08T20:31:19.683Z · LW(p) · GW(p)
pandemics are arguably more likely to originate in large cities because population density facilitates spread, large wildlife markets are more likely, and they serve as major travel hubs
China was 63% Urban in 2020.
https://www.statista.com/statistics/270162/urbanization-in-china/
Say it's 2x more likely in Urban areas. It doesn't really make that much difference. Plus, there is some probability of it going to Vietnam or other SE Asian countries (Vietnam is closer to Yunnan than Wuhan is).
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2024-02-08T21:58:35.546Z · LW(p) · GW(p)
I would have to agree with the parent, this line of approach, with this kind of calculation attempt is a 'Sisyphean task'. You, along with everyone else on Earth, simply lack the mental capacity to actually accomplish this. Even if you had access to the millions of perfect data sources required.
And we are very far from even that.
Why not try a different approach?
Replies from: Roko↑ comment by Roko · 2024-02-10T20:11:09.492Z · LW(p) · GW(p)
The whole point of probability theory is to make decisions when you do not have "perfect data sources"
Why even talk about probabilistic reasoning if you won't use it until the data is "perfect" and you are omniscient?
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2024-02-12T02:57:33.923Z · LW(p) · GW(p)
Did you misread the comment? Clearly in the real world you will not have such perfect data sources, hence why I wrote “ And we are very far from even that.”
i.e. A practically zero chance in the ideal world turns into a hopeless endeavour, “Sisyphean Task” in the real world. And that’s also while assuming a level of intelligence way beyond you or anyone else.
Replies from: Roko↑ comment by Roko · 2024-02-14T23:49:02.690Z · LW(p) · GW(p)
I don't think you understand probability theory
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2024-02-16T15:02:53.293Z · LW(p) · GW(p)
Well I think I do?, so just opining another LW user doesn’t understand “probability theory” is not going to lead anywhere productive.
Replies from: Roko↑ comment by Roko · 2024-02-21T12:27:40.061Z · LW(p) · GW(p)
The point of probabilities is to quantify uncertainty, not to wait until you are omnipotent and have all the data needed to reach certainty
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2024-02-21T15:19:13.591Z · LW(p) · GW(p)
I still think I understand just fine along with the several other folks expressing skepticism. To be frank your personal opinions can't outweigh anyone else's here so it really isn't a productive line of discussion.
EDIT: Maybe try putting forward actual arguments, or addressing the numerous other comments with substantial points?
comment by A1987dM (army1987) · 2024-02-07T23:26:04.075Z · LW(p) · GW(p)
Multiplying all this together gets you to a 1 in 80 million chance of all this stuff happening under the null hypothesis, which is highly significant.
Not until you work out the chance of all this stuff happening under alternate hypotheses, and the prior probabilities of alternate hypotheses, and the prior probability of the null hypothesis.
(I asked random.org for 10 random bytes and I got 02 c8 c2 30 60 b3 2e 93 a6 e9 . The chance of this happening under the null hypothesis is 1 in 1.2×10^24
↑ comment by Roko · 2024-02-07T23:58:10.620Z · LW(p) · GW(p)
Under the alternate hypothesis, location, warnings, timing and specific features are all much more likely. It's probably something like 0.6^4 ~= 0.12
Priors for a lab leak vs a natural spillover are a bit harder, but we have examples of lab leak such as foot and mouth disease in the UK, other leaks of covid, etc. I think a reasonable prior for a lab leak is between 1% and 30% but priors are of course not something we can expect everyone to agree on.
Replies from: david-johnston, Roko↑ comment by David Johnston (david-johnston) · 2024-02-08T04:23:25.654Z · LW(p) · GW(p)
You really think in 60% of cases where country A lifts a ban on funding gain of function research a pandemic starts in country B within 2 years? Same question for “warning published in Nature”.
Replies from: Roko↑ comment by Roko · 2024-02-08T09:13:31.213Z · LW(p) · GW(p)
It has to be conditional on a massive global pandemic starting in that country at all, to make a fair comparison with the 2/80 calculation under the null hypothesis.
But say we break it down into two parts. (1) probability that the GoF research does have the potential to cause a pandemic and (2) distribution in time of the pandemic after research starts.
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2024-02-08T10:06:40.831Z · LW(p) · GW(p)
If your theory is: there is a lab leak from WIV while working on defuse derived work then I’ll buy that you can assign a high probability to time & place … but your prior will be waaaaaay below the prior on “lab leak, nonspecific” (which is how I was originally reading your piece).
Replies from: Roko↑ comment by Roko · 2024-02-08T10:22:41.219Z · LW(p) · GW(p)
But we are updating on the timing.
Under the null hypothesis we assign equal probability to each year between 1980 and 2060, and they add up to 1. So there is an assumption there that a pandemic will definitely occur starting in china.
We should make the same assumption under the alternate hypothesis. The only difference is under AH there's a lab leak. So we just adjust the way the probability is allocated by year. It still has to add up to 100%.
So, maybe we'll have a uniform background of 0.1% per year between 1980 and 2060, and then after the 2011 events where people started talking about GoF it increases a bit as GoF is at least possible, then it increases again in 2017 when GoF is funded and greenlit, and after that each year it decreases a little bit, think of it as a hazard rate, once it has happened once people will start being cautious again.
Replies from: david-johnston, david-johnston↑ comment by David Johnston (david-johnston) · 2024-02-08T10:56:17.956Z · LW(p) · GW(p)
Another comment on timing updates: if you’re making a timing update for zoonosis vs DEFUSE, and you’re considering a long timing window w_z for zoonosis, then your prior for a DEFUSE leak needs to be adjusted for the short window w_d in which this work could conceivably cause a leak, so you end up with something like p(defuse_pandemic)/p(zoo_pandemic)= rr_d w_d/w_z, where rr_d is the riskiness of DEFUSE vs zoonosis per unit time. Then you make the “timing update” p(now |defuse_pandemic)/p(now |zoo_pandemic) = w_z/w_d and you’re just left with rr_d.
Replies from: Roko↑ comment by David Johnston (david-johnston) · 2024-02-08T10:24:07.795Z · LW(p) · GW(p)
Sorry, I edited (was hoping to get in before you read it)
Replies from: Rokocomment by lc · 2024-02-08T00:08:29.043Z · LW(p) · GW(p)
This is not how probability works
Replies from: Roko↑ comment by Roko · 2024-02-08T00:25:54.623Z · LW(p) · GW(p)
please elaborate ....
Replies from: ChristianKl↑ comment by ChristianKl · 2024-02-22T19:08:42.459Z · LW(p) · GW(p)
Have you done any calibration training?
There's a lot of model uncertainty that makes it so that 1 in 80 million is way too high.