Finding the Central Limit Theorem in Bayes' rule
post by Maxwell Peterson (maxwell-peterson) · 2021-11-27T05:48:06.161Z · LW · GW · 11 commentsContents
#1: The central limit theorem can be viewed as a statement about convolutions #2: Convolutions have a relationship to the Fourier transform #3: The Fourier transform of the Gaussian is Gaussian #4: The Bayesian update for combining a prior distribution with a data distribution is a multiplication Putting it together Intuition In terms of math operations Is this right? None 11 comments
I feel like there's something in the basic Bayesian update formula that suggests that, as the amount of input data grows, almost every Bayesian posterior will tend toward a Gaussian. This post is me trying to scrape at that vague intuition and get a handle on it. I'm going to list four observations, then put them together at the end to explain why I think this might be true.
#1: The central limit theorem can be viewed as a statement about convolutions
I covered this here [LW · GW], but a quick summary: a decent form of the Central Limit Theorem goes like this:
If you have a bunch of distributions (say, of them), and you convolve them all together into a distribution , then the larger is, the more will resemble a Gaussian (AKA Normal) distribution.
This is true for most component distributions, even if they're not originally Gaussian, and it's pretty robust to the shapes of the input distributions, even if those shapes are different [? · GW]. One example from that link:
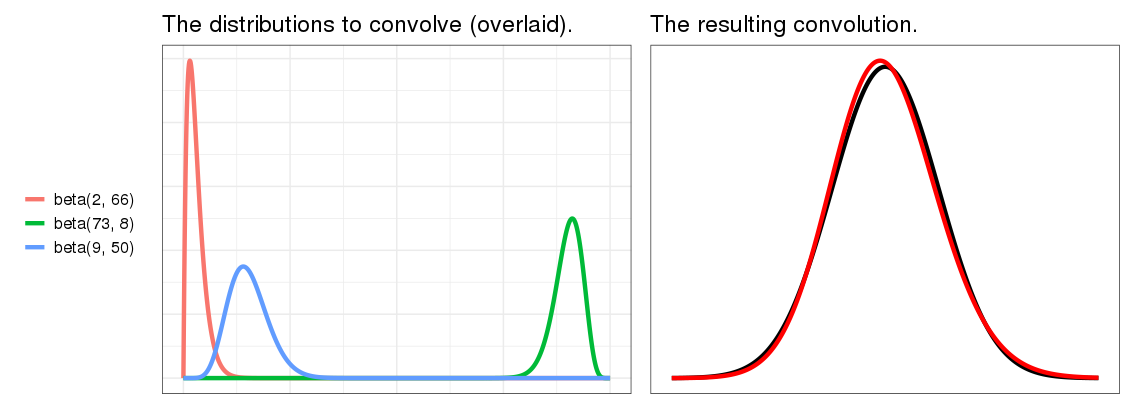
(Although the CLT is often taught in the context of taking means of samples drawn from a population, in order to estimate the population mean, that's not an important part of how I'm using it here, and that view of things is best forgotten while reading this post.)
#2: Convolutions have a relationship to the Fourier transform
The Fourier transform of a convolution of two functions is the pointwise product of their Fourier transforms. The inverse is true too, and more relevant to this post: convolving the Fourier transforms of two distributions is the same as multiplying them in the original domain. To say it shorter: Convolution in one domain is equivalent to multiplication in the other.
(The Fourier transform is a rich topic, and I myself don't understand most of its behavior. If the same is true for you, don't worry - all you need to know about it for this post is that it moves numbers from one space into another, it has an inverse, and the stuff in this section and the next.)
#3: The Fourier transform of the Gaussian is Gaussian
A table of some transforms. The left column is the original function , the right is the Fourier transform .
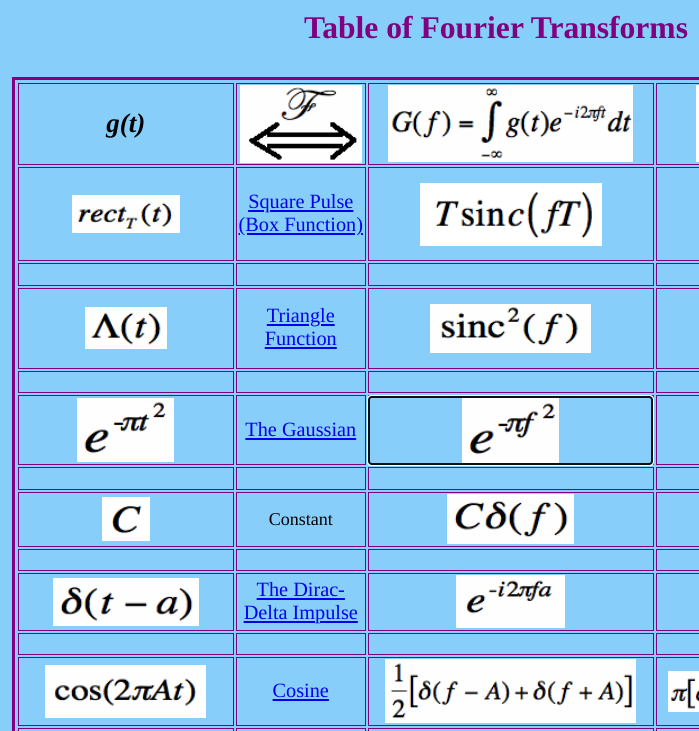
The Fourier transform of most functions looks pretty different than the original function. But in the middle of the table, conspicuous: the Gaussian doesn't. Some action does happen: the t in the left column is an f in the middle column, and they aren't equal, so they don't have the same value - but they do have the same Gaussian form. (The site also has a proof that I didn't read.)
#4: The Bayesian update for combining a prior distribution with a data distribution is a multiplication
Bayes rule is . is a normalizing factor, so when calculating the result of combining distributions P(H) with P(D|H) in practice, you can pretty much ignore it until the end, then find whatever number c makes the distribution sum to 1. Ignoring it here, then, the meat of the Bayesian update is , where means "is proportional to".
When you're combining many distribution via this form of Bayes' rule, then, you end up with a lot of chained multiplications. If I have three datasets and a prior , then .
Putting it together
Intuition
Okay. So. From section #2, convolving distributions in the original domain is the same as multiplying them in the Fourier domain. For almost all functions, these are pretty different operations, because the form of almost all functions in the Fourier domain is different than in the original domain. However, from #3, this isn't true for the Gaussian - it's special in that its form is the same in both domains. Therefore, for the Gaussian (and only the Gaussian), the chained Bayesian multiplications from #4 that give the posterior are somehow... similar... to the convolutions, in a way that I get stuck on when I try to pin down. Finally, since section #1 says the result of convolving many distributions together tends toward Gaussian the more distributions you convolve, each multiplication in the Bayesian update brings the posterior closer to Gaussian.
In terms of math operations
Take our three-datasets example from above. I'll use to mean convolution, and write for , for , etc.
From #2, . We know from #1 that if there are many , the left-hand side will be Gaussian. The right-hand side has the same form as the Bayesian update, but on distributions in the Fourier space instead of the original space.
If we inverse-transform both sides, then the left side is . From #3, that's Gaussian whenever is. Therefore: The left-hand side is Gaussian.
On the right side, is just , the original Bayesian update. Therefore: The right-side is the original Bayesian update.
Since the right and left sides are equal, and the left side is Gaussian, so is the right side. Therefore: The original Bayesian chained update is Gaussian.
Is this right?
I feel safe saying that this is at least directionally correct because I found this link, which says "[The posterior] distribution approaches the Normal distribution as n approaches infinity", and this one, which says similar. Like so many statements of the CLT, they both say the input distributions must be identically distributed, but after looking into it [? · GW] I feel pretty safe ignoring that.
This is all pretty weird. I like thinking of my mind as working in terms of Bayesian updates, but does that mean the form of my uncertainty about things approaches Gaussian as I learn more? It's actually weird enough that I worry I made some misstep in the math, so please let me know if you notice anything!
JBlack makes a strong challenge in the comments: sure, maybe distributions don't need to be identical for them to converge under convolution - but that doesn't mean that non-independence isn't an issue. I haven't looked at convolving dependent distributions at all in this series, and the chained Bayes update involves plenty of dependence. So that might break all of this. I might look into this in a later post.
11 comments
Comments sorted by top scores.
comment by johnswentworth · 2021-12-01T22:14:27.890Z · LW(p) · GW(p)
You've got a solid talent for math research.
Your reasoning here is basically correct; this is why Laplace' approximation typically works very well on large datasets. One big catch is that it requires the number of data points be large relative to the dimension of the variables. The real world is decidedly high dimensional, so in practice the conditions for Gausianity usually happen when we pick some small set of "features" to focus on and then get a bunch of data on those (e.g. as is typically done in academic statistics).
There's also another more subtle catch here: in e.g. a large causal model, once we have a decent number of variables, we often have all the info we're going to get about some value of interest, and later updates add basically-zero information. Depending on how that plays out, it could mess up the Gaussianity convergence.
Replies from: maxwell-peterson↑ comment by Maxwell Peterson (maxwell-peterson) · 2021-12-02T04:52:48.878Z · LW(p) · GW(p)
Thank you!
I hadn't actually heard of Laplace's approximation - definitely relevant! The catch about the dimension is a good one.
In the large causal model, is the issue just that
- there is one multiplication per variable
- some dependence chains don't have very many variables in them
- in those few-variable chains, we might not get enough multiplications to converge?
If that is the issue, weird nasty operations occur to me, like breaking variables up into sub and sub-sub variables, to get more multiplications, which might get more Gaussian. (For example, splitting the node "Maxwell finishes writing this comment" into "his computer doesn't run out of battery" and "the police don't suddenly bust into his apartment"). Whether or not it's worth doing, I wonder - would this actually work to make things more Gaussian? Or is there some... conservation of convergence... that makes it so you can't get closer to Gaussian by splitting variables up? [Don't feel like you have to answer these - they're more just me following up on thoughts I got from your comment].
Replies from: johnswentworth↑ comment by johnswentworth · 2021-12-02T05:17:28.322Z · LW(p) · GW(p)
[Don't feel like you have to answer these - they're more just me following up on thoughts I got from your comment]
I accept your affordance, and thank you, this will make me more likely to comment on your posts in the future.
comment by JBlack · 2021-11-27T09:37:58.070Z · LW(p) · GW(p)
While "in spirit" the Central Limit Theorem (and generalizations) concern something vaguely like the statement in the post, none of them are anywhere near that general.
The main problem is that when it comes to Bayesian updates on a sequence of evidence, the intermediate conditional distributions almost always don't meet the criteria for the Central Limit Theorem or any generalization of it. There are some interesting cases where they can, but they don't apply to most real-life situations.
Replies from: maxwell-peterson↑ comment by Maxwell Peterson (maxwell-peterson) · 2021-11-27T17:38:47.891Z · LW(p) · GW(p)
Hmm - a big problem if so! Can you give me an example of the kind of intermediate conditional distribution you mean?
Replies from: JBlack↑ comment by JBlack · 2021-11-28T05:12:50.624Z · LW(p) · GW(p)
In almost all statements of the CLT, there is a requirement that all the individual distributions for random variables be identical and independent. The kind of sequential evidence you normally get in real life is almost never of this form. We have to go out of our way to make it have this form, for example by establishing suitable stringent experimental procedures and ignoring all evidence that doesn't go through those procedures.
The example you gave of convolving beta distributions does relax the "identical" part of CLT, though they are still assumed to be independent. There are variations on the CLT that do apply to independent but not identical distributions, but the conditions on the individual distributions are even stronger than in the CLT. For example, one theorem applies to strongly unimodal distributions with variance bounded both above and away from 0, and tails that fall off at least exponentially. Most beta distributions satisfy this, so if you convolve enough of these you'll always get something approximately Gaussian. One thing to be careful of is that the rate of convergence can be much slower than in the usual CLT, so in some cases you may need a lot of samples.
Once you remove independence though, all bets are off. The distribution of the sum of sequences of such variables is a projection of some almost arbitrary high-dimensional distribution, resulting in all sorts of possible forms. You can even sum increasing numbers of uniform random variables and get a sequence of discrete distributions that never converge to anything.
Replies from: maxwell-peterson↑ comment by Maxwell Peterson (maxwell-peterson) · 2021-11-28T05:36:13.393Z · LW(p) · GW(p)
Thank you so much for the explanation! I haven’t looked into the behavior of dependent distributions in the context of the CLT at all. It’s totally believable that non-independence could destroy convergence properties in a way that non-identicality doesn’t. I’m on my phone right now but will probably add a disclaimer to the end of this post to reflect your challenge to it. Thanks again~
comment by rime · 2023-07-10T09:27:09.420Z · LW(p) · GW(p)
Interesting! I came to it from googling about definitions of CLT in terms of convolutions. But I have one gripe:
does that mean the form of my uncertainty about things approaches Gaussian as I learn more?
I think a counterexample would be your uncertainty over the number of book sales for your next book. There are recursive network effects such that more book sales causes more book sales. The more books you (first-order) expect to sell, the more books you ought to (second-order) expect to sell. In other words, your expectation over X indirectly depends on your expectation over X (or at least, it ought to, insofar as there's recursion in the territory as well).
This means that for every independent source of evidence you update on, you ought to apply a recursive correction in the upward direction. In which case you won't converge to a symmetric Gaussian.
Which all a longwinded way to say that your posterior distribution will only converge to a Gaussian in proportion to the independence of your evidence.
Or something like that.
Replies from: maxwell-peterson↑ comment by Maxwell Peterson (maxwell-peterson) · 2023-07-10T16:13:43.610Z · LW(p) · GW(p)
Yes, agree - I've looked into non-identical distributions in previous posts, and found that identicality isn't important, but I haven't looked at non-independence at all. I agree dependent chains, like the books example, is an open question!
comment by Jsevillamol · 2021-11-27T09:20:28.501Z · LW(p) · GW(p)
Great post! Helped me build an intuition of why this is true, and I came off pretty convinced it is.
I specially liked how each step is well motivated, so that by the end I already knew where this was going.
One note:
In the last section you write that the convolution of the distribution equals the Fourier transform of the pointwise distributions.
But I think you meant to write that the Fourier transform of the convolution of the distributions is the pointwise product of their Fourier transforms (?).
This does not break the proof.
Replies from: maxwell-peterson↑ comment by Maxwell Peterson (maxwell-peterson) · 2021-11-27T20:47:37.605Z · LW(p) · GW(p)
Appreciate it! And you're right, that was a mistake in the last section - just fixed it. Thanks!