Contra Common Knowledge
post by abramdemski · 2023-01-04T22:50:38.493Z · LW · GW · 31 commentsContents
Can't Have It! The Partition Assumption Who Needs It? The orthodox case for the importance of common knowledge. Two Generals Electronic Messaging Coordination Problem Argument that common knowledge makes coordination harder in some cases. Summary of my case against the importance of common knowledge for coordination. How to live without it? Substitute knowledge for belief. Relax knowledge in other directions. Take an empirical approach to coordination. Appendix: Electronic Messaging Coordination The Coordination Problem The Messaging System The Argument Consequences The Updateless Way The Evidential Way Ditching Common Knowledge Cooperative Oracles None 31 comments
This post assumes some background knowledge about "common knowledge", a technical term in philosophy. See the tag page [? · GW] for an introduction and a list of LessWrong essays on the subject.
Epistemic effort: basically reading the SEP article on common knowledge and forming my own conclusions. I've also gained something by discussing these issues with Scott Garrabrant and Sahil Kulshrestha, although this post is far from representing their views as I've understood them.
Consider a statement like "LessWrong curated posts help to establish common knowledge".
On the one hand, this seems obviously valid in practice. Curating a post boosts the number of people who see it, in a public way which also communicates the meta-knowledge (you know that lots of people will know about this post, and they'll also know that fact, etc).
On the other hand, this is a long way off from actually establishing common knowledge. People don't check LessWrong constantly. Lots of people will miss any given curated post.
In this post, I will argue that common knowledge never occurs in the real world.
But this leaves us with a paradoxical state of affairs. We use the concept to explain things in the real world all the time. Common knowledge is an important coordination tool, right? For example, social norms are supposed to require common knowledge in order to work.
I'll also offer some evidence that common knowledge is not as important as it is typically made out to be.
Can't Have It!
Several arguments about the impossibility of common knowledge have been made in the philosophical literature; see Common Knowledge Revisited and Uncommon Knowledge. Whether nontrivial common knowledge is realistically possible is still debated, according to SEP (Stanford Encyclopedia of Philosophy).
SEP makes a big deal about how we don't literally need to explicitly believe infinitely many levels of knowledge in order to have common knowledge, because we can have a single concept ("common knowledge" itself) which implies any level of recursive knowledge.
However, I don't find this particularly reassuring.
I will make the following argument: Common knowledge requires absolute certainty of common knowledge. If anyone has the slightest doubt that common knowledge has been established, it hasn't. But we are never 100% certain of such things in the real world! Therefore, common knowledge is impossible.
It is often stated that common knowledge requires a public event: some event which everyone observes, and which everyone knows that everyone observes. I have approximately two questions about this:
- How did we physically arrange an event which we can be absolutely certain everyone observes, when quantum mechanics makes every phenomenon in our universe at least a little noisy? Any communication channels have some degree of unreliability. Even setting aside quantum mechanics, how about human psychology? How are you certain everyone was paying attention?
- How did we establish common knowledge that we had done so? Does establishing new common knowledge always require some seed of pre-existing common knowledge? Doesn't this create an infinite regress?
Common Knowledge Revisited also shows that establishing common knowledge requires simultaneity. Suppose that there is a public event which everyone can see, and indeed does see, but there is some small uncertainty about when they'll see it. You might expect that common knowledge will be established anyway; but, this is not the case!!
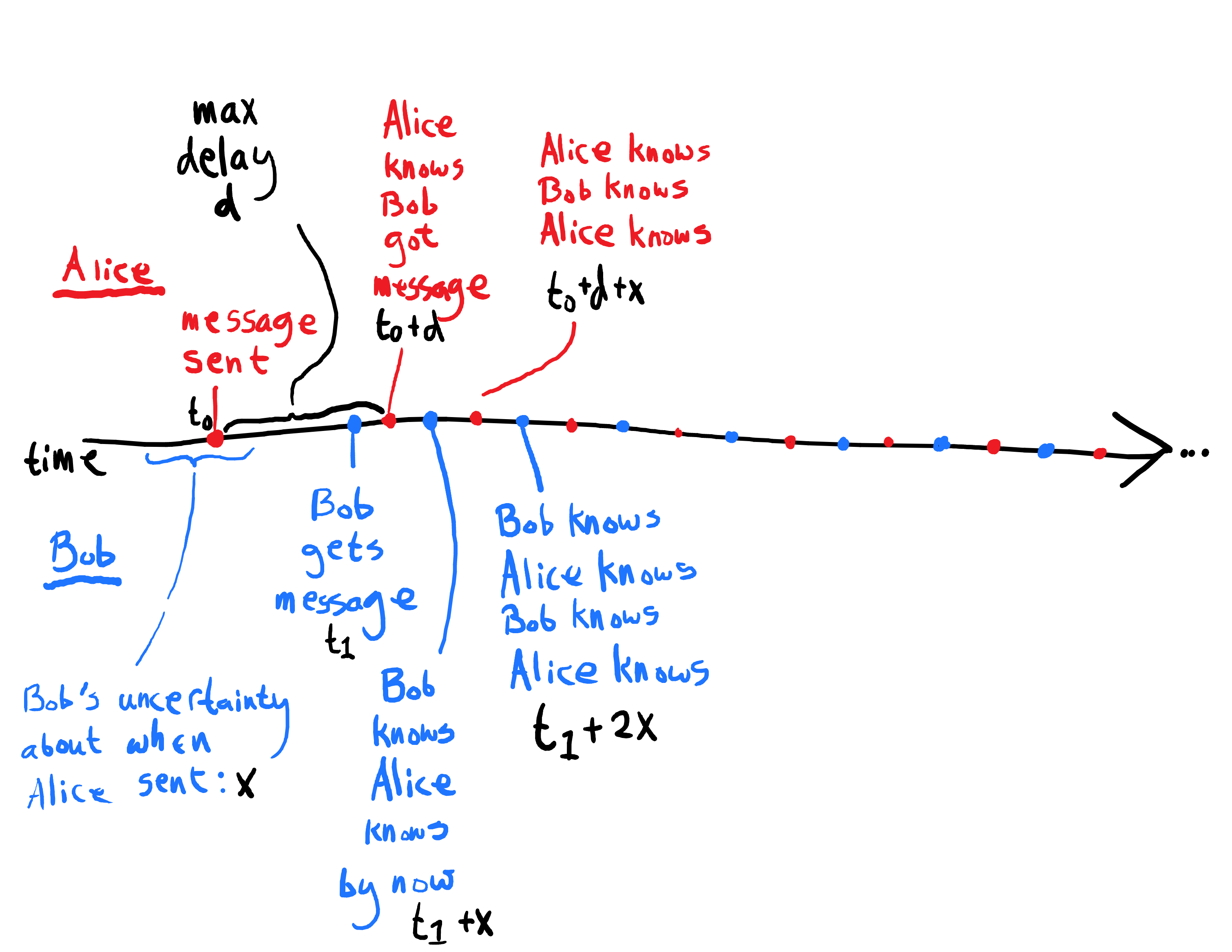
Since the blue points have form and the red points have form , new layers of meta-knowledge are added as time goes by, but never infinitely many layers, so common knowledge is not achieved at any finite time, no matter how much time has passed.
To summarize, any uncertainty about message delivery, or even about the time of message delivery, blocks the formation of common knowledge. The real world seems too full of such uncertainty for common knowledge to be established in practice.
The Partition Assumption
I should also mention that the standard treatment of common knowledge makes some important assumptions about evidence. Evidence is what tells you which world you're in. I'll say world one is indistinguishable from iff the evidence you have at doesn't rule out -- written .
Standard definitions of common knowledge always assume the following three axioms:
- Reflexivity: for any .
- Transitivity: &
- Symmetry:
Together, these three can be called the partition assumption, because they imply that the indistinguishability relation is a partition relation.
However, all three of these assumptions are realistically questionable.
- Reflexivity says that the real world is always indistinguishable from itself, IE, our observations are always true. In the case of logical uncertainty, this amounts to asserting that our calculations are always infallible, which seems questionable. In particular, it seems like you should doubt this in counterlogical mugging.[1] Furthermore, Löb's Theorem shows that under very broad conditions, coherent observers can't believe Reflexivity about themselves, even if from the outside we should believe it about them.
- Transitivity says that you can't get further by iterating the indistinguishability relation; anything you can reach that way, you can reach in one step. But this seems wrong. Consider observing the location of a cup on a desk. Your observation will have some precision associated with it; you can't distinguish between the actual location and very nearby locations. If Transitivity held, this would imply that you cannot distinguish between any two locations on the desk; we could argue that the cup could be anywhere, by making a chain of indistinguishability arguments connecting two points.
- Symmetry says that if, from , I think I could be in , then from , I must also think I could be in . Eliezer argues against a version of this in Against Modest Epistemology [? · GW], saying that many people -- when dreaming -- cannot tell whether they are dreaming or awake; but (he argues) the awake can tell that they are awake.
So the partition assumption is dubious. This seems quite injurious to the concept of common knowledge, although to walk through all the consequences would require a longer post than this one.[2]
Who Needs It?
The orthodox case for the importance of common knowledge.
Two Generals
One of the commonly mentioned thought experiments is the Two Generals problem. Two generals are stationed on opposite sides of a common enemy. They need to attack at the same time in order to win; however, they haven't established a plan ahead of time.
The two generals can send messages to each other, but unfortunately, there is always a chance that messages will be lost to the enemy in transit. This prevents the formation of common knowledge, which (supposedly) stops the two generals from coordinating.
Let's call the two generals Alice and Bob. If Bob receives a message from Alice stating "I propose we should attack at noon". Great, now Bob knows what the plan is! However, (supposedly) Bob worries as follows: "Alice doesn't know that I got this message. Alice will attack only if she thinks I will. So we're still in the same situation we were in before."
Bob can send a new message to Alice to confirm his receipt of the message, but this doesn't really change the situation: Bob doesn't know whether Alice will receive the message, and even if she does, she will know that Bob doesn't know she did. So (supposedly) Alice still can't attack, since (supposedly) Bob won't attack.
I've been inserting "supposedly" everywhere, because all of this can be solved by normal probabilistic reasoning.[3]
Suppose for concreteness that the payoff matrix is as follows:
| Alice Attacks | Alice Holds | |
| Bob Attacks | +1 | -2 |
| Bob Holds | -2 | 0 |
Let's say the probability that a message gets dropped is one percent.
There exists a Nash equilibrium[4] where Alice sends Bob "I will attack at noon", and then attacks at noon herself. The best thing Bob can do is to attack at noon as well (if he receives the message); and, the best thing Alice can do is to hold to her word.
So who cares about common knowledge!
Now, you might have the following worry:
"Abram, you have only said that there exists a Nash equilibrium. But how do the players know that they are in that particular Nash equilibrium? Nash equilibria themselves are justified by supposing common knowledge!!"
An astute observation and a just objection. However, I would respond that, in this case, Bob knows which equilibrium they are in, because Alice has told him! Alice said "I will attack at noon." Alice can write the contents in complete honesty (and not even requiring any weird precommitments), and Bob, receiving the message, knows everything he needs to know. Alice, knowing that she sent the message and knowing Bob will probably interpret it as honest, now has a simple incentive to attack at noon.
Bob could doubt Alice's honesty or accuracy, but he has no reason to do so, since Alice has every reason to be honest and accurate.[5]
Critically, even if Bob does doubt a little, he can still rationally follow the plan. And similarly for Alice.
Electronic Messaging Coordination Problem
OK, so maybe Two Generals is too easy to solve in practice if you accept a risk-benefit tradeoff & probabilistic reasoning.
Perhaps a different case can illustrate the importance of common knowledge for coordination?
You know how some electronic messaging services have little check marks, to verify whether messages have been received and/or read? Apparently, those can make coordination problems worse, at least in some cases. Stanford Encyclopedia of Philosophy (SEP) describes an example where message verification makes it rationally impossible to coordinate, no matter how many messages have been sent back and forth, and no matter how close to perfectly reliable the messaging system is.
According to SEP (see the paragraph immediately before section 5.1), the moral of the story is that full common knowledge really is necessary, sometimes; even very large stacks of they-know-they-know-they-know (in the form of lots of confirmation messages) are as good as no communication at all.
I'll go over this example in an appendix, because I think it's quite interesting and surprising, but on the other hand, it's a bit complex and fiddly.
But I reject the conclusion. If your theory of rationality says that you can never use electronic messages to coordinate dinner plans, specifically because your messaging system displays little check marks to indicate what's been received, your theory of rationality has messed up somewhere, I'd think. Humans do better.
Coordinating to meet over such a messaging system, and then successfully meeting, is not some kind of irrational mistake which you would avoid if you understood common knowledge better.
If this is a standard example (which it is, by virtue of being on SEP) used to argue how important common knowledge is for coordination, maybe the conclusion is flawed?[6]
Argument that common knowledge makes coordination harder in some cases.
Imagine that Alice and Bob are each asked to name dollar amounts between $0 and $100. Both Alice and Bob will get the lowest amount named, but whoever names that lowest number will additionally get a bonus of $10. No bonus is awarded in the case of a tie.
According to traditional game theory, the only rational equilibrium is for everyone to answer $0. This is because traditional game theory assumes common knowledge of the equilibrium; if any higher answer were given, there would be an incentive to undercut it.
However, humans will typically fare much better in this game. One reason why this might be is that we lack common knowledge of the equilibrium. We can only guess what the other player might say, and name a slightly smaller number ourselves. This can easily result in both players getting significantly more than $0.
In the appendix, I will argue that this is part of what's going on in the electronic messaging coordination problem.
Summary of my case against the importance of common knowledge for coordination.
Some cases commonly used to illustrate the importance of common knowledge, such as Two Generals, are only "unsolvable without common knowledge" if you refuse to reason probabilistically and accept cost/benefit tradeoffs.
We can find special cases where the importance of common knowledge stands up to probabilistic reasoning, but the inability of "rational" agents to coordinate in these cases seems (to me) like a problem with the notion of "rationality" used, rather than evidence that common knowledge is required for coordination.
There are also cases where common knowledge harms the ability of selfish players to coordinate.
I'd be happy to consider other example cases in the comments!
How to live without it?
Substitute knowledge for belief.
There's a concept called p-common knowledge, which is like common knowledge, except that you replace "knows" with "believes with probability at least p". Let's abbreviate "believes with probability at least p" as p-believes for convenience. Then, p-common-knowledge in a group of people refers to what everyone p-believes, everyone p-believes that everyone p-believes, etc for each level.
Is this more realistic than common knowledge?
If I have any doubts about whether common knowledge holds, then I can immediately conclude that it does not. p-common knowledge is not so fragile. I can have a small doubt, up to 1-p, without breaking p-common knowledge.
This seems like a good sign.
Consider the Two Generals solution I proposed earlier. If messages are delivered (and read and understood) with probability at least p, then so long as the message gets through in fact, p-common knowledge has been established:
- Alice knows she will attack.
- Alice believes with probability at least p that Bob knows this.
- Alice also p-believes that Bob knows the above.
- And so on.
- Bob knows that Alice will attack.
- Bob knows that Alice p-believes that Bob knows.
- And so on.
So it looks like p-belief can easily be established, without any "public event" as is needed for common knowledge. All we need is a communication method that's at least p-reliable.
Is p-common knowledge useful for coordination?
It seems so in this example, at least. P-common belief includes some inherent doubt, but this can be overcome by cost-benefit analysis, if the benefits of coordination outweigh the risks given the uncertainty.
It seems possible that p-common-knowledge is a basically perfect steelman of common knowledge.
I'd like to see a more complete analysis of this. Intuitively, it feels like p-common knowledge might inherently dilute each level more and more, in comparison to full common knowledge, since we stack p-belief operators. Does this cause it to be much much less useful than common knowledge, in some situations where the deeper iterated layers of knowledge are important? On the other hand, perhaps p-common-knowledge is actually harder to realistically obtain than it appears, much like common knowledge. Are there subtle difficulties which stop us from obtaining p-common-knowledge about most things?
Relax knowledge in other directions.
Early on, I gave an example where a small uncertainty in the communication delay blocks us from forming common knowledge at any finite time. We can define t-common knowledge by replacing "knows" with "will know within a small delay t". We might then be able to establish t-common knowledge at finite time, even if we can't establish full common knowledge. SEP suggests that various relaxations of common knowledge like this will be useful in different applications.
Returning to my example at the very beginning, "LessWrong curated posts help establish common knowledge", we could define %-common knowledge within a population by replacing "everyone knows" with "X% of people know". You might not be able to rely on every self-identified lesswronger knowing about a post, but the percentage might be high enough for desirable coordination strategies to become feasible.[7]
Take an empirical approach to coordination.
Reasoning about what people know is an indirect way to try and predict their behavior. It might be better to take a more direct approach: predicting behavior from past behavior.
According to game theory, one of the biggest factors facilitating coordination is iterated games. The standard approach to this still requires equilibrium theory, so, still implicitly rests on establishing common knowledge of behavior. As I've argued, this is unrealistic. Fortunately, iterated games allow for the empirical approach; we have time to get to know the players.
In my own estimation, this accounts for more of coordination in reality, than common knowledge or p-common knowledge do.
Appendix: Electronic Messaging Coordination
First, let me state that SEP calls this "the e-mail coordination example". However, email doesn't usually have automatic confirmation of receipt as a feature, while instant messaging services often do. So I've renamed it here.
I'm also going to change the payoff tables a bit, in order to make things easier to grasp according to my taste.
The Coordination Problem
Alice and Bob like to eat out together, if master chef Carol is in the kitchen. Carol has an unpredictable schedule which flips between restaurants 1 and 2. On a given day, Alice and Bob can each choose:
- Go to location 1.
- Go to location 2.
- Stay home.
The payoff for Alice is 0 for staying home, +1 for meeting Bob at Carol's current location, and -2 for any other outcome. Similarly for Bob: 0 for home, +1 for meeting Alice at Carol's current location, -2 for anything else.
The Messaging System
Alice gets emails from Carol about Carol's schedule, so she can tell Bob where they should meet on a given day. Alice and Bob use a special instant messaging service called InfiniCheck, which has a confirmation feature which works as follows.
The moment a message is read on the other end, a confirmation message is sent back. This is displayed as a little check mark for the original sender. So if Alice sends something to Bob, and Bob reads it, Alice will see a check mark by her message.
InfiniCheck also offers confirmations for checkmarks, so that you know whether the other person has seen a check mark. So if Alice sees the checkmark by her message, Bob will now also see a checkmark by the message, indicating to Bob that Alice knows he has read it.
But then if Bob sees this checkmark, then Alice will get a second checkmark, indicating to her that Bob knows she saw the first checkmark.
And so on.
If Bob and Alice both have their smartphones open, this process could continue forever, but it never does, because the network is fallible: every message has a small chance, , of being dropped. So Bob and Alice see (on average) about checkmarks next to each message.
The Argument
Rubenstein shows that in a version of this problem, there are no equilibria in which Alice and Bob reliably meet Carol. Equilibria can only behave as if no email has been received. In other words, "rational" agents are totally unable to use this electronic messaging system to coordinate.
It's a fairly simple proof by induction:
- If Alice sees zero checkmarks, then it's close to 50-50 between "the message dropped, so Bob didn't see it", or "Bob saw it, but the confirmation message coming back got dropped". (The first is slightly more probable than the second, since both events require an improbable message-drop, but the second also requires the first message to have gotten through, which is probable but not certain.) Given this gamble, it's better for Alice to remain home, since the risk of -2 outweighs the possible reward of +1.
- If Bob gets the message but sees zero checkmarks, then he similarly reasons that it's roughly 50-50 between Alice seeing no checkmark (in which case we've already argued she stays home), or seeing one (in which case we haven't yet established what she will do). So, like Alice, Bob sees the risk of a -2 as worse than the possible reward, and stays home.
- We then argue inductively that if no one would meet at checkmarks, you also shouldn't meet at . The reasoning is very similar to the case. If you've seen checkmarks, it's a near 50-50 gamble on whether the other person has seen or checkmarks; so meeting isn't worth the risk.
- Therefore, no number of checkmarks can provide sufficient confirmation for Alice and Bob to meet!!
Rubenstein's version of the problem and proof is here.
Consequences
This problem seems very close to Two Generals, except we've added an arcane auto-message-confirmation system. It appears that this extra information is very harmful to our ability to coordinate!
The Updateless Way
You might think this example argues in favor of updateless decision theory [? · GW] (UDT). If we simply ignore the extra information, we can solve this the way we solved Two Generals: Alice can just send Bob a message saying where she's going, and Bob can just go there. This gives both of them an expected utility very close to +1, while the "rational" equilibrium (staying home) gets 0. Ignoring the checkmarks, this solution works for essentially the same reason my two-generals solution worked.
However, simply going updateless doesn't actually solve this. The inductive proof above still works fine for a UDT agent in many cases. If UDT is optimizing its whole policy together ("UDT 1.1"), then each individual step in the inductive argument will improve its expected utility, provided the other agent is thinking in the same way. If UDT decides each policy-point individually ("UDT 1.0"), then so long as it considers its choices to be probabilistically independent of each other and of how the other agent chooses, then we also reach the same conclusion.
The Evidential Way
So it seems like the only way UDT can help us here is by EDT [? · GW]-like reasoning, where we think of the inductive argument as a slippery slope. Although an individual decision to stay home seems good in isolation, each such decision probabilistically increases the number of cases where the other person stays home. Perhaps this is worth it for highly distinguished numbers of checkmarks (such as 0 or 1), since these might be less correlated with decisions at other numbers; but each such decision weakens the overall chances to coordinate, so only very few such exceptions should be made.
Note that this EDTish solution is more powerful if we're also using UDT, but has some power either way.
I'm not so comfortable with this kind of solution, since different priors can easily imply different correlations, and I don't see a story where agents tend to converge to see these sorts of correlations rather than other patterns. If Alice has a mostly stable strategy for situations like this, with occasional deviations to experiment with other strategies, then she should know that changing one action does not, in fact, change my whole policy. So it seems more plausible that she sees its own actions as independent. Whether she sees Bob's actions as independent of hers depends on how well Bob foresees Alice's unreliability. If Bob can predict when Alice will flake out, then Alice would have an EDTish reason not to flake out; but otherwise, there would be no empirical reason for Alice to think this way (and there may or may not be an a priori reason, depending on her prior).
So I think the EDTish approach makes a little headway on why Alice and Bob can successfully (and rationally) meet up, but in my view, not a lot.
Ditching Common Knowledge
The inductive argument that Bob and Alice cannot meet up critically relies on bouncing back and forth between Bob's reasoning and Alice's reasoning -- each player's decision to stay home an the nth step relies on the other's decision at the th step. So you can see how the whole conclusion relies on common knowledge of rationality. In order to buy the whole inductive argument, Alice and Bob need to buy that each other will reason as described in each step, which depends on Alice and Bob recursively modeling each other as buying the previous steps in the argument.
On the other hand, the main point of this post is to argue that common knowledge of this kind is not a reasonable assumption.
The situation is analogous to price-setting in a moderately competitive market. Everyone wants to undercut everyone else's prices a little. The only possible common-knowledge equilibrium, then, is for everyone to set their prices as low as possible. But that's not necessarily the outcome you should expect! If the competitors lack common knowledge of how each other thinks, they're not going to jump to the lowest price -- they merely set their prices a little lower than what they expect others to charge.
Similarly, if Alice and Bob lack common knowledge about how they think about these problems, they need not jump to the never-meet equilibrium. Alice and Bob are only individually motivated to require one more checkmark than the other person in order to meet. If their estimates of each other are uncalibrated, they could end up meeting quite often.
This solution has a nice irony to it, since the SEP's conclusion from the example is that you need common knowledge to coordinate, whereas I'm arguing here that you need to lack common knowledge to coordinate. On the other hand, it's a fragile kind of solution, which is progressively wrecked the better the players know each other. It seems quite plausible that a moderate amount of p-common knowledge would be enough to make the inductive argument go through anyway.
So again, I think this idea captures some of what is going on, but doesn't fully resolve the situation.
Cooperative Oracles
On the other hand, if the agents reason interactively about their policies [LW · GW], they can first rule out the worst possibilities ("I won't go out if I know I'm going to get stood up"), then the second-worst ("I won't go out if there's a good chance I'll get stood up"), etc, all the way through ruling out staying home ("I won't stay home if there's a good chance we could have had dinner"), and finally settle on a Pareto-optimal solution.
Which solutions are Pareto optimal?
"Go if you've sent or received any message" gives Alice an expected utility of , since there's a chance of +1, plus an chance of -2. Bob gets to stay home in the worst case in this plan, so Bob gets in expectation.
This sets a baseline; anything worse than this for both Alice and Bob can't be Pareto-optimal, so can't be arrived at. For instance, this shows that Alice and Bob don't just stay home, as classical rationality would suggest.
Alice can slightly better her position by staying home if she doesn't see a checkmark. This totals Alice and Bob . This is also Pareto-optimal, although if we naively compare utilities [LW · GW] 1:1, it looks a little worse from a Utilitarian perspective.
If that were Alice's strategy, of course, Bob could slightly better his position by staying home in the zero-checkmark case as well, in which case Alice would get and Bob would get , if I've done my calculations right.
But at this point, for sufficiently small , we're already out of Pareto-optimal territory! Remember, the first payoff we calculated for Alice was . Here Alice is getting something closer to . Bob's first number was , but here Bob is getting closer to . So they're both worse off by almost . So this option would be ruled out by either Alice or Bob, before settling on one of the Pareto optima.
Of course, the kind of deliberation I'm describing requires that Alice and Bob have detailed access to each other's a priori reasoning, although it doesn't require Bob to have access to Alice's private knowledge (the email from Carol). So it may be considered unrealistic for humans, if not AIs.
And, the reasoning behind cooperative oracles is not totally selfish, although it is mostly selfish. So it's not a robust equilibrium; rational agents can do something different to get the upper hand in many cases.
- ^
Counterlogical Mugging is a short name for counterfactual mugging with a logical coin [LW · GW]. One reasonable-seeming solution to the problem is to put some probability on "I am the 'me' being simulated in Omega's head, so my mathematical calculations are actually wrong because Omega is spoofing them" -- this allows us to see some benefit to giving Omega the $100 they are asking for.
- ^
It's interesting to note that we can still get Aumann's Agreement Theorem while abandoning the partition assumption (see Ignoring ignorance and agreeing to disagree, by Dov Samet). However, we still need Reflexivity and Transitivity for that result. Still, this gives some hope that we can do without the partition assumption without things getting too crazy.
- ^
In the comments, rpglover64 point out [LW(p) · GW(p)] that the classic problem statement requires us to solve it with no chance of failure, which is of course a common requirement in algorithm design (where this problem hails from). So, the problem is indeed impossible to solve as stated.
The intellectual friction I'm chafing against, when I complain about the standard treatment of Two Generals, is a friction between what it means to "solve" a problem in algorithm design (where a "solution" means satisfying the goal with a 100% success rate, unless the problem states otherwise), vs "solve" a problem in decision theory (where a "solution" means a defensible story about how rational agents should deal with the situation).
In the context of algorithm design, it's quite reasonable to say that Two Generals is impossible to solve, but can easily be approximated. In the context of decision theory, it seems absurd to call it "impossible to solve", and the meme of its impossibility gives rise to an inflated view of the importance of common knowledge.
- ^
To reason that this is a Nash equilibrium, I'm ignoring the fact that Alice and Bob could decide to send more messages to further increase the chances of coordination. The Electronic Messaging problem, coming up soon, casts doubt on whether confirmation messages back and forth are such a good idea. The possibility of confirmation messages casts doubt on whether Alice will follow through with her plan if she doesn't receive sufficient confirmation.
However, I think it's fair to say that Alice should send her message as many times as she can, rather than just once, to increase Bob's chances of getting the message. Bob has no particular reason to try to send messages, if he gets Alice's message. And Alice can see that this is the case, so there's still no need for spooky knowledge of which Nash equilibrium we're in.So the only problem remaining is that Bob could send Alice a message before he receives her message, perhaps containing a different plan of attack.
A possibility which I'm going to keep ignoring. ;p
- ^
You could make the argument that I'm still relying on language itself, which can be analyzed as a Nash equilibrium and therefore a form of common knowledge. My solution seemingly relies on the fact that Alice and Bob both know English, know that each other know English, know that they know, etc.
If I had any expectations of keeping reader attention for long enough, this post would explore the question further. My provisional reply is that the reliance on common knowledge here is also an illusion. After all, in real life, we don't and can't rely on perfect common knowledge about language.
- ^
I should flag that this is an extreme claim, which might require us to abandon a lot of decision theory. More on this in the appendix.
- ^
In some cases, this reduces to p-common knowledge; eg, if you're interacting with one random LessWronger, and you want to gamble on coordinating based on some specific post you've read, then X%-common knowledge implies p-common-knowledge with p=X/100 (provided they view you as a random LessWronger). We can also generalize this argument to larger groups, if we (unrealistically) assume independent sampling.
In other cases, you might specifically care about a large enough fraction of people getting what you're trying to do; eg, if enough people go along with something, there could be a critical mass to entrench a social norm. Then you might specifically want to estimate %-common knowledge.
31 comments
Comments sorted by top scores.
comment by Yoav Ravid · 2023-03-11T10:02:10.726Z · LW(p) · GW(p)
Great post! I already saw Common Knowledge as probabilistic, and any description of something real as common knowledge as an implicit approximation of the theoretical version with certainty, but having this post spell it out, and giving various examples why it has to be thought of probabilistically is great. "p-common knowledge" seems like the right direction to look for a replacement, but it needs a better name. Perhaps 'Common Belief'.
However, humans will typically fare much better in this game. One reason why this might be is that we lack common knowledge of the equilibrium. We can only guess what the other player might say, and name a slightly smaller number ourselves. This can easily result in both players getting significantly more than $0.
Wouldn't that be an example of agents faring worse with more information / more "rationality"? Which should hint [LW · GW] at a mistake in our conception of rationality instead of thinking it's better to have less information / be less rational?
I think coordination failures from lack of common belief (or the difficulty of establishing it) happen more than this post suggest. And I think this post correctly shows that it often happens from over-reliance on conditionals instead of commitment. For example:
"Hey, are you going to the bar today?"
"I will if you go."
"Yeah I'll also go if you go."
"So, are you going?"
"I mean, if you're going. Are you going?"
....
I've had conversations like this. Of course, when it's one-on-one in real time it's easy to eventually terminate the chain. But in group conversations, or when texting and there's latency between replies, this use of conditionals can easily prevent common belief from being established (at all, or in time).
Replies from: Yoav Ravid↑ comment by Yoav Ravid · 2023-03-15T15:59:10.933Z · LW(p) · GW(p)
Expanding on this from my comment:
Wouldn't that be an example of agents faring worse with more information / more "rationality"? Which should hint [LW · GW] at a mistake in our conception of rationality instead of thinking it's better to have less information / be less rational?
Eliezer wrote this in Why Our Kind Can't Cooperate [LW · GW]:
Doing worse with more knowledge means you are doing something very wrong. You should always be able to at least implement the same strategy you would use if you are ignorant, and preferably do better. You definitely should not do worse. If you find yourself regretting your "rationality" then you should reconsider what is rational [LW · GW].
It's interesting to note that in case, he specifically talked about coordination when saying that. And this post claims common knowledge can make rational agent specifically less able to cooperate. The given example is this game
Imagine that Alice and Bob are each asked to name dollar amounts between $0 and $100. Both Alice and Bob will get the lowest amount named, but whoever names that lowest number will additionally get a bonus of $10. No bonus is awarded in the case of a tie.
According to traditional game theory, the only rational equilibrium is for everyone to answer $0. This is because traditional game theory assumes common knowledge of the equilibrium; if any higher answer were given, there would be an incentive to undercut it.
You didn't say the name of the game, so I can't go read about it, but thinking about it myself, it seems like one policy rational agents can follow that would fare better than naming zero is picking a number at random. If my intuition is correct, that would let each of them win half of the time, and for the amount named to be pretty high (slightly less than 50?). An even better policy would be to randomly pick between the maximum and the maximum-1, which I expect would outperform even humans. With this policy, common knowledge/belief would definitely help.
The InfiniCheck message app problem is a bit more complicated. Thinking about it, It seems like the problem is that it always creates an absence of evidence (which is evidence of absence [LW · GW]) which equals the evidence, i.e, the way the system is built, it always provides an equal amount of evidence and counter-evidence, so the agent is always perfectly uncertain, and demands/desires additional information. (If so, then a finite number of checks should make the problem terminate on the final check - correct?)
The question is whether it can be said that the demand/desire for additional information, rather than the additional information itself, creates the problem, or that these can't actually be distinguished, cause that would just be calling the absence of evidence "demand" for information rather than just information (which it is).
Also, this actually seems like a case where humans would be affected in a similar way. Even with the one checkmark system people reason based on not seeing the checkmark, so except for the blur @Dacyn [LW · GW] mentioned [LW(p) · GW(p)], I expect people will suffer from this too.
I also want to point out that commitment solves this, whether or not you adopt something like an updateless decision theory. Cause once you simply said "I'm going to go here", any number of checkmarks becomes irrelevant. (ah, re-reading that section the third time that's actually exactly what you say, but I'm keeping this paragraph because if it wasn't clear to me it might also have not have been clear to others).
comment by cubefox · 2023-01-06T20:14:33.877Z · LW(p) · GW(p)
It's interesting to note that we can still get Aumann's Agreement Theorem while abandoning the partition assumption (see Ignoring ignorance and agreeing to disagree, by Dov Samet). However, we still need Reflexivity and Transitivity for that result. Still, this gives some hope that we can do without the partition assumption without things getting too crazy.
I don't quite get this paragraph. Do you suggest that the failure of Aumanns disagreement theorem would be "crazy"? I know his result has become widely accepted in some circles (including, I think, LessWrong) but
a) the conclusion of the theorem is highly counterintuitive, which should make us suspicious, and
b) it relies on Aumann's own specific formalization of "common knowledge" (mentioned under "alternative accounts" in SEP) which may very well be fatally flawed and not be instantiated in rational agents, let alone in actual ones.
It has always baffled me that some people (including economists and LW style rationalists) celebrate a result which relies on the, as you argued, highly questionable, concept of common knowledge, or at least one specific formalization of it.
To be clear, rejecting Aumann's account of common knowledge would make his proof unsound (albeit still valid), but it would not solve the general "disagreement paradox", the counterintuitive conclusion that rational disagreements seem to be impossible: There are several other arguments which lead this conclusion, and which do not rely on any notion of common knowledge. (Such as this essay by Richard Feldman, which is quite well-known in philosophy and which makes only very weak assumptions.)
Replies from: abramdemski↑ comment by abramdemski · 2023-01-06T20:38:53.129Z · LW(p) · GW(p)
I was using "crazy" to mean something like "too different from what we are familiar with", but I take your point. It's not clear we should want to preserve Aumann.
To be clear, rejecting Aumann's account of common knowledge would make his proof unsound (albeit still valid), but it would not solve the general "disagreement paradox", the counterintuitive conclusion that rational disagreements seem to be impossible: There are several other arguments which lead this conclusion, and which do not rely on any notion of common knowledge.
Interesting, thanks for pointing this out!
Replies from: cubefoxcomment by Dacyn · 2023-01-05T22:09:03.885Z · LW(p) · GW(p)
The infinite autoresponse example seems like it would be solved in practice by rational ignorance: after some sufficiently small number of autoresponses (say 5) people would not want to explicitly reason about the policy implications of the specific number of autoresponses they saw, so "5+ autoresponses" would be a single category for decisionmaking purposes. In that case the induction argument fails and "both people go to the place specified in the message as long as they observe 5+ autoresponses" is a Nash equilibrium.
Of course, this assumes people haven't already accepted and internalized the logic of the induction argument, since then no further explicit reasoning would be necessary based on the observed number of autoresponses. But the induction argument presupposes that rational ignorance does not exist, so it is not valid when we add rational ignorance to our model.
Replies from: abramdemski, strangepoop↑ comment by abramdemski · 2023-01-11T15:04:43.095Z · LW(p) · GW(p)
so "5+ autoresponses" would be a single category for decisionmaking purposes
I agree that something in this direction could work, and plausibly captures something about how humans reason. However, I don't feel satisfied. I would want to see the idea developed as part of a larger framework of bounded rationality.
UDT gives us a version of "never be harmed by information" which is really nice, as far as it goes. In the cases which UDT helps with, we don't need to do anything tricky, where we carefully decide which information to look at -- UDT simply isn't harmed by the information, so we can think about everything from a unified perspective without hiding things from ourselves.
Unfortunately, as I've outlined in the appendix, UDT doesn't help very much in this case. We could say that UDT guarantees that there's no need for "rational ignorance" when it comes to observations (ie, no need to avoid observations), but fails to capture the "rational ignorance" of grouping events together into more course-grained events (eg "5+ auto responses").
So if we had something like "UDT but for course-graining in addition to observations", that would be really nice. Some way to deal with things such that you never wish you'd course-grained things.
Whereas the approach of actually course-graining things, seems a bit doomed to fragility and arbitrariness. It seems like you have to specify some procedure for figuring out when you'd want to course-grain. For example, maybe you start with only one event, and iteratively decide how to add details, splitting the one event into more events. But I feel pessimistic about this. I feel similarly pessimistic about the reverse, starting with a completely fine-grained model and iteratively grouping things together.
Of course, this assumes people haven't already accepted and internalized the logic of the induction argument,
Fortunately, the induction argument involves both agents following along with the whole argument. If one agent doubts that the other thinks in this way, this can sort of stabilize things. It's similar to the price-undercutting dynamic, where you want to charge slightly less than competitors, not as little as possible. If market participants have common knowledge of rationality, then this does amount to charging as little as possible; but of course, the main point of the post is to cast doubt on this kind of common knowledge. Doubts about how low your competitor will be willing to go can significantly increase prices from "as low as possible".
Similarly, the induction argument really only shows that you want to stay home in slightly more cases than the other person. This means the only common-knowledge equilibrium is to stay home; but if we abandon the common-knowledge assumption, this doesn't need to be the outcome.
(Perhaps I will edit the post to add this point.)
↑ comment by a gently pricked vein (strangepoop) · 2023-01-06T16:50:22.046Z · LW(p) · GW(p)
I've been a longtime CK atheist (and have been an influence on Abram's post), and your comment is in the shape of my current preferred approach. Unfortunately, rational ignorance seems to require CK that agents will engage in bounded thinking, and not be too rational!
(CK-regress like the above is very common and often non-obvious. It seems plausible that we must accept this regress and in fact humans need to be Created Already in Coordination, in analogy with Created Already in Motion [LW · GW])
I think it is at least possible to attain p-CK in the case that there are enough people who aren't "inductively inclined". This sort of friction from people who aren't thinking too hard causes unbounded neuroticism to stop and allow coordination. I'm not yet sure if such friction is necessary for any agent or merely typical.
comment by rpglover64 (alex-rozenshteyn) · 2023-01-05T02:10:19.203Z · LW(p) · GW(p)
The way I've heard the two generals problem, the lesson is that it's unsolvable in theory, but approximately (to an arbitrary degree of approximation) solvable in practice (e.g. via message confirmations, probabilistic reasoning, and optimistic strategies), especially because channel reliability can be improved through protocols (at the cost of latency).
I also think that taking literally a statement like "LessWrong curated posts help to establish common knowledge" is outright wrong; instead, there's an implied transformation to "LessWrong curated posts help to increase the commonness of knowledge", where "commonness" is some property of knowledge, which common knowledge has to an infinite degree; in -common knowledge is an initially plausible measure of commonness, but I'm not sure we ever get up to infinity.
Intuitively, though, increasing commonness of knowledge is a comparative property: the probability that your interlocutor has read the post is higher if it's curated than if it's not, all else being equal, and, crucially, this property of curation is known (with some probability) to your interlocutor.
Replies from: abramdemski↑ comment by abramdemski · 2023-01-05T18:54:39.953Z · LW(p) · GW(p)
The way I've heard the two generals problem, the lesson is that it's unsolvable in theory, but approximately (to an arbitrary degree of approximation) solvable in practice
My response would be that this unfairly (and even absurdly) maligns "theory"! The "theory" here seems like a blatant straw-man, since it pretends probabilistic reasoning and cost-benefit tradeoffs are impossible.
I also think that taking literally a statement like "LessWrong curated posts help to establish common knowledge" is outright wrong; instead, there's an implied transformation
Let me sketch the situation you're describing as I understand it.
Some people (as I understand it, core LessWrong staff, although I didn't go find a reference) justify some things in terms of common knowledge.
You either think that they were not intending this literally, or at least, that no one else should take them literally, and instead should understand "common knowledge" to mean something informal (which you yourself admit you're somewhat unclear on the precise meaning of).
My problem with this is that it creates a missing stair kind of issue. There's the people "in the know" who understand how to walk carefully on the dark stairway, but there's also a class of "newcomers" who are liable to fall. (Where "fall" here means, take all the talk of "common knowledge" literally.)
I would think this situation excusable if "common knowledge" were a very useful metaphor with no brief substitute that better conveys what's really going on; but you yourself suggest "commonness of knowledge" as such a substitute.
in -common knowledge is an initially plausible measure of commonness, but I'm not sure we ever get up to infinity.
Just want to flag the philosopher's defense here, which is that you can have a finite concept of p-common knowledge, which merely implies any finite level of iteration you need, without actually requiring all of those implications to be taken.
(Granted, I can see having some questions about this.)
Intuitively, though, increasing commonness of knowledge is a comparative property: the probability that your interlocutor has read the post is higher if it's curated than if it's not, all else being equal, and, crucially, this property of curation is known (with some probability) to your interlocutor.
Whereas the explicit theory of common knowledge contradicts this comparative idea, and instead asserts that common knowledge is an absolute yes-or-no thing, such that finite-level approximations fall far short of the real thing. This idea is illustrated with the electronic messaging example, which purports to show that any number of levels of finite iteration are as good as no communication at all.
Replies from: alex-rozenshteyn, sharmake-farah↑ comment by rpglover64 (alex-rozenshteyn) · 2023-01-06T02:03:49.438Z · LW(p) · GW(p)
My response would be that this unfairly (and even absurdly) maligns "theory"!
I agree. However, the way I've had the two generals problem framed to me, it's not a solution unless it guarantees successful coordination. Like, if I claim to solve the halting problem because in practice I can tell if a program halts, most of the time at least, I'm misunderstanding the problem statement. I think that conflating "approximately solves the 2GP" with "solves the 2GP" is roughly as malign as my claim that the approximate solution is not the realm of theory.
Some people (as I understand it, core LessWrong staff, although I didn't go find a reference) justify some things in terms of common knowledge.
You either think that they were not intending this literally, or at least, that no one else should take them literally, and instead should understand "common knowledge" to mean something informal (which you yourself admit you're somewhat unclear on the precise meaning of).
I think that the statement, taken literally, is false, and egregiously so. I don't know how the LW staff meant it, but I don't think they should mean it literally. I think that when encountering a statement that is literally false, one useful mental move is to see if you can salvage it, and that one useful way to do so is to reinterpret an absolute as a gradient (and usually to reduce the technical precision). Now that you have written this post, the commonality of the knowledge that the statement should not be taken literally and formally is increased; whether the LW staff responds by changing the statement they use, or by adding a disclaimer somewhere, or by ignoring all of us and expecting people to figure it out on their own, I did not specify.
My problem with this is that it creates a missing stair kind of issue. There's the people "in the know" who understand how to walk carefully on the dark stairway, but there's also a class of "newcomers" who are liable to fall. (Where "fall" here means, take all the talk of "common knowledge" literally.)
Yes, and I think as aspiring rationalists we should try to eventually do better in our communications, so I think that mentions of common knowledge should be one of:
- explicitly informal, intended to gesture to some real world phenomenon that has the same flavor
- explicitly contrived, like the blue islanders puzzle
- explicitly something else, like p-common knowledge; but beware, that's probably not meant either
This idea is illustrated with the electronic messaging example, which purports to show that any number of levels of finite iteration are as good as no communication at all.
I think (I haven't read the SEP link) that this is correct--in the presence of uncertainty, iteration does not achieve the thing we are referring to precisely as "common knowledge"--but we don't care, for the reasons mentioned in your post.
I think your post and my reply together actually point to two interesting lines of research:
- formalize measures of "commonness" of knowledge and see how they respond to realistic scenarios such as "signal boosting"
- see if there is an interesting "approximate common knowledge", vaguely analogous to The Complexity of Agreement
↑ comment by abramdemski · 2023-01-06T20:20:08.066Z · LW(p) · GW(p)
I agree. However, the way I've had the two generals problem framed to me, it's not a solution unless it guarantees successful coordination. Like, if I claim to solve the halting problem because in practice I can tell if a program halts, most of the time at least, I'm misunderstanding the problem statement. I think that conflating "approximately solves the 2GP" with "solves the 2GP" is roughly as malign as my claim that the approximate solution is not the realm of theory.
I think this is very fair (and I will think about editing my post in response).
↑ comment by Noosphere89 (sharmake-farah) · 2023-01-05T20:34:48.436Z · LW(p) · GW(p)
My response would be that this unfairly (and even absurdly) maligns "theory"! The "theory" here seems like a blatant straw-man, since it pretends probabilistic reasoning and cost-benefit tradeoffs are impossible.
This is because mathematics plays with evidence very differently than most other fields. If the probability is not equivalent to 1 (I.E it must happen), it doesn't matter. A good example of this is the Collatz conjecture. It has a stupendous amount of evidence in the finite data points regime, but no mathematician worth their salt would declare Collatz solved, since it needs to have an actual proof. Similarly, P=NP is another problem with vast evidence, but no proof.
And a proof, if correct, is essentially equivalent to an infinite amount of observations, since you usually need to show that it holds up to infinite amounts of examples, so one Adversarial datapoint ruins the effort.
Mathematics is what happens when 0 or 1 are the only sets of probabilities allowed, that is a much stricter standard exists in math.
Replies from: abramdemski, alex-rozenshteyn↑ comment by abramdemski · 2023-01-06T20:26:21.562Z · LW(p) · GW(p)
To nitpick, a mathematician won't even accept that probability 1 is proof. Lots of probability 1 statements aren't provable and could even be false from a logical perspective.
For example, a random walk in one dimension crosses any point infinitely many times, with probability one. But it could go in one direction forever.
So, proof could be said to be nontrivially stronger than even an infinite number of observations.
Replies from: alex-rozenshteyn↑ comment by rpglover64 (alex-rozenshteyn) · 2023-01-07T00:16:48.534Z · LW(p) · GW(p)
I feel like this is a difference between "almost surely" and "surely", both of which are typically expressed as "probability 1", but which are qualitatively different. I'm wondering whether infinitesimals would actually work to represent "almost surely" as (as suggested in this [LW · GW] post).
Also a nitpick and a bit of a tangent, but in some cases, a mathematician will accept any probability > 1 as proof; probabilistic proof is a common tool for non-constructive proof of existence, especially in combinatorics (although the way I've seen it, it's usually more of a counting argument than something that relies essentially on probability).
↑ comment by rpglover64 (alex-rozenshteyn) · 2023-01-07T00:44:22.614Z · LW(p) · GW(p)
A good example of this is the Collatz conjecture. It has a stupendous amount of evidence in the finite data points regime, but no mathematician worth their salt would declare Collatz solved, since it needs to have an actual proof.
It's important to distinguish the probability you'd get from a naive induction argument and a more credible one that takes into account the reference class of similar mathematical statements that hold until large but finite limits but may or may not hold for all naturals.
Similarly, P=NP is another problem with vast evidence, but no proof.
Arguably even more than the Collatz conjecture, if you believe Scott Aaronson (link).
Mathematics is what happens when 0 or 1 are the only sets of probabilities allowed, that is a much stricter standard exists in math.
As I mentioned in my other [LW(p) · GW(p)] reply, there are domains of math that do accept probabilities < 1 as proof (but it's in a very special way). Also, proof usually comes with insight (this is one of the reasons that the proof of the 4 color theorem was controversial), which is almost more valuable than the certainty it brings (and of course as skeptics and bayesians, we must refrain from treating it as completely certain anyway; there could have been a logical error that everyone missed).
I think talking about proofs in terms of probabilities is a category error; logical proof is analogous to computable functions (equivalent if you are a constructivist), while probabilities are about bets.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-05-21T17:55:17.221Z · LW(p) · GW(p)
I think talking about proofs in terms of probabilities is a category error; logical proof is analogous to computable functions (equivalent if you are a constructivist), while probabilities are about bets.
I agree that logical/mathematical proofs are more analogous to functions than probabilities, but they don't have to be only computable functions, even if it's all we will ever access, and that actually matters, especially in non-constructive math and proofs.
I also realized why probability 0 and 1 aren't enough for proof, or equivalently why Abram Demski's observation that a proof is stronger than an infinite number of observations is correct.
And it essentially boils down to the fact that in infinite sets, there are certain scenarios where the probability of an outcome is 0, but it's still possible to get that outcome, or equivalently the probability is 1, but that doesn't mean that it doesn't have counterexamples. The best example is throwing a dart at a diagonal corner has probability 0, yet it still can happen. This doesn't happen in finite sets, because a probability of 0 or 1 implicitly means that you have all your sample points, and for probability 0 means that it's impossible to do, because you have no counterexamples, and for probability 1 you have a certainty proof, because you have no counterexamples. Mathematical conjectures and proofs usually demand something stronger than that of probability in infinite sets: A property of a set can't hold at all, and there are no members of a set where that property holds, or a property of a set always holds, and the set of counterexamples is empty.
(Sometimes mathematics conjectures that something must exist, but this doesn't change the answer to why probability!=proof in math, or why probability!=possibility in infinite sets.)
Unfortunately, infinite sets are the rule, not the exception in mathematics, and this is still true of even uncomputably large sets, like the arithmetical hierarchy of halting oracles. Finite sets are rare in mathematics, especially for proof and conjecture purposes.
Here's a link on where I got the insight from:
comment by Dagon · 2023-01-05T01:31:18.105Z · LW(p) · GW(p)
This seems trivially true to me. If you require
requires absolute certainty
you already have to acknowledge that it doesn't exist in the world. You can only get to 1-epsilon. And that approximation works for only needing to believe as many levels of commonality as is required for the action calculation.
Replies from: abramdemski, abramdemski↑ comment by abramdemski · 2023-01-05T19:50:12.423Z · LW(p) · GW(p)
And that approximation works for only needing to believe as many levels of commonality as is required for the action calculation.
Note that the standard theory of common knowledge contains explicit claims against this part of your statement. The importance of common knowledge is supposed to be that it has a different quality from finite levels, which is uniquely helpful for coordination; eg, that's the SEP's point with the electronic messaging example. Or in the classic analysis of two-generals, where (supposedly) no finite number of messages back and forth is sufficient to coordinate, (supposedly) because this only establishes finite levels of social knowledge.
So the seemingly natural update for someone to make, if they learn standard game theory, but then realize that common knowledge is literally impossible in the real world as we understand it, is that rational coordination is actually impossible, and empirical signs pointing in the other direction are actually about irrationality.
Replies from: Dagon↑ comment by Dagon · 2023-01-05T21:27:48.425Z · LW(p) · GW(p)
I've realized that I'm not the target of the post, and am bowing out. I think we're in agreement as to the way forward (no knowledge is 1 or 0, and practically you can get "certain enough" with a finite number of iterations). We may or may not disagree on what other people think about this topic.
Replies from: abramdemski↑ comment by abramdemski · 2023-01-06T20:07:20.552Z · LW(p) · GW(p)
Fair enough. I note for the public record that I'm not agreeing (nor 100% disagreeing) with
practically you can get "certain enough" with a finite number of iterations
as an accurate characterization of something I think. For example, it currently seems to me like finite iterations doesn't solve two-generals, while p-common knowledge does.
However, the main thrust of the post is more to question the standard picture than to say exactly what the real picture is (since I remain broadly skeptical about it).
↑ comment by abramdemski · 2023-01-05T18:21:52.454Z · LW(p) · GW(p)
I think one reason this has stuck around in academic philosophy is that western philosophy has a powerful anti-skepticism strain, to the point where "you can know something" is almost axiomatic. Everyone wants to have an argument against skepticism; they just haven't agreed on exactly what it is. Skepticism is every philosopher's bogeyman. (This even applies to Descartes, the big proponent of the skeptical method.)
In particular, a view that (in my limited experience) academic philosophers wants to at least accommodate as possible, if not outright endorse, is the "here is a hand" argument: IE, you can know (with 100% certainty) some simple facts about your situation, such as the fact that you have a hand.
Replies from: alex-rozenshteyn, Dagon↑ comment by rpglover64 (alex-rozenshteyn) · 2023-01-06T02:25:52.481Z · LW(p) · GW(p)
western philosophy has a powerful anti-skepticism strain, to the point where "you can know something" is almost axiomatic
I'm pretty pessimistic about the strain of philosophy as you've described it. I have yet to run into a sense of "know" that is binary (i.e. not "believed with probability") that I would accept as an accurate description of the phenomenon of "knowledge" in the real world rather than as an occasionally useful approximation. Between the preface paradox (or its minor modification, the lottery paradox) and Fitch's paradox of knowability, I don't trust the "knowledge" operator in any logical claim.
Replies from: abramdemski↑ comment by abramdemski · 2023-01-06T20:14:21.779Z · LW(p) · GW(p)
In my limited experience, it feels like a lot of epistemologists have sadly "missed the bus" on this one. Like, they've gone so far down the wrong track that it's a lot of work to even explain how our way of thinking about it could be relevant to their area of concern.
↑ comment by Dagon · 2023-01-05T18:53:51.078Z · LW(p) · GW(p)
Fair enough, but I'd expect this post is unhelpful to someone who doesn't acknowledge a baseline universal uncertainty, and unnecessary for someone who does.
Presumably whatever axioms the anti-sceptic philosophers use to avoid infinite recursion in any knowledge apply here too.
Replies from: abramdemski↑ comment by abramdemski · 2023-01-05T18:59:51.216Z · LW(p) · GW(p)
Ah, well. In my experience, there are a lot of people who (a) acknowledge baseline universal uncertainty, but (b) accept the theory of common knowledge, and even the idea that Two Generals is a hard or insoluble problem. So I think a lot of people haven't noticed the contradiction, or at least haven't propagated it very far.[1]
Presumably whatever axioms the anti-sceptic philosophers use to avoid infinite recursion in any knowledge apply here too.
Not sure what you mean here.
- ^
Based on how this comment section is going, I am updating toward "haven't propagated it very far"; it seems like maybe a lot of people know somewhere in the back of their minds that common knowledge can't be literally occurring, but have half-developed hand-wavy theories about why they can go on using the theory as if it applies.
comment by gwillen · 2023-01-05T03:21:22.334Z · LW(p) · GW(p)
This makes sense, but my instinctive response is to point out that humans are only approximate reasoners (sometimes very approximate). So I think there can still be a meaningful conceptual difference between common knowledge and shared knowledge, even if you can prove that every inference of true common knowledge is technically invalid. That doesn't mean we're not still in some sense making them. .... And if everybody is doing the same thing, kind of paradoxically, it seems like we sometimes can correctly conclude we have common knowledge, even though this is impossible to determine with certainty. The cost is that we can be certain to sometimes conclude it falsely.
EDIT: This is not actually that different from p-common knowledge, I think. It's just giving a slightly different account of how you get to a similar place.
Replies from: abramdemski, Rana Dexsin↑ comment by abramdemski · 2023-01-05T19:35:07.814Z · LW(p) · GW(p)
I agree that your theory could be understood as a less explicit version of p-common knowledge.
EG:
One reasonable steelman of the commonsense use of "knows" is to interpret "knowledge" as "true p-belief", with "p" left unspecified, flexible to the situation. (Situations with higher risk naturally call for higher p.) We similarly interpret commonsense "certainty" as p-belief. "Very certain" is p-belief with even higher p, and so on.
We then naturally interpret the theory of "common knowledge" as code for p-common knowledge, by substituting iteration of "knows" with "correctly p-believes".[1]
My problem with this approach is that it leads to a "missing stair" kind of problem, as I mentioned in my response to rpglover64 [LW(p) · GW(p)]. For example, the literature on common knowledge says that a public event (something everyone can see, simultaneously, and see that everyone else sees) is required. As I illustrated in the OP, p-common-knowledge doesn't require anything like this; it's much easier to establish.
So if everyone uses the term "common knowledge", but in-the-know people privately mean "p-common-knowledge" and interpret others as meaning this, then not-in-the-know people run the risk of thinking this thing people call 'common knowledge' is really difficult and costly to establish. And this seems compatible with what people say [LW · GW], so they're not so liable to notice the difference.
I would also point out that your and rpglover64's interpretations were much less precise than p-common-knowledge; eg, you say things like "in some sense", "kind of paradoxically", "it seems like". So I would say: why not use accurate language, rather than be confused? Why not correct inaccurate language, rather than leaving a missing stairstep?
As I mentioned in the post, I also have some doubts about whether p-common knowledge captures the real phenomenon people are actually getting at when they use "common knowledge" informally. So it also has the advantage of being falsifiable! So we might even learn something!! Leaving the theory at a vague "humans are only approximate instances of all these rationality concepts" is, of course, still true, but seems far less useful.
- ^
(Unless I've missed something, adding "correctly" doesn't really change the definition of p-common knowledge, since it simply re-asserts the next-lower level.)
↑ comment by Rana Dexsin · 2023-01-05T03:52:32.772Z · LW(p) · GW(p)
More specifically:
Intuitively, it feels like p-common knowledge might inherently dilute each level more and more, in comparison to full common knowledge, since we stack p-belief operators.
Rounding upward when multiplying allows 1−ε to be a fixed point.
comment by a gently pricked vein (strangepoop) · 2023-01-06T17:35:32.691Z · LW(p) · GW(p)
Even if SEP was right about getting around the infinity problem and CK was easy to obtain before, it certainly isn't now! (Because there is some chance that whoever you're talking to has read this post, and whoever reads this post will have some doubt about whether the other believes that...)
Love this post overall! It's hard to overstate the importance of (what is believed to be) common knowledge. Legitimacy is, as Vitalik notes[1], the most important scarce resource (not just in crypto) and is likely closer to whatever we usually intend to name when we say "common knowledge", which this post argues (successfully IMO) is not actually common knowledge.
It does seem like legitimacy is possible to model with p-CK, but I'm not convinced.[2] Nor do I know how substitutable p-CK is with my old notion of CK, what it's good for! Which theorems can be rescued with p-CK where they depended on CK? Does Aumann's still hold with probability p upon p-CK of priors, or does the entire reasoning collapse? How careful do I have to be?
- ^
He seems to only talk about finitely many layers of higher order knowledge, as does Duncan (for explicitly pedagogical reasons) in his post on CK and Miasma. I think this can be right, but if so, for complicated reasons [LW(p) · GW(p)]. And it still leaves some seemingly self-undermining "rationality" in our frameworks.
- ^
Mainly, I expect self-reference in legitimacy to be troublesome. A lot of things are legitimate because people think other people think they are legitimate, which seems enough like Lob's theorem that I worry about the lobstacle.