Results from the Turing Seminar hackathon
post by Charbel-Raphaël (charbel-raphael-segerie), jeanne_ (jeanne_s), WCargo (Wcargo) · 2023-12-07T14:50:38.377Z · LW · GW · 1 commentsContents
Towards Monosemanticity: Decomposing Vision Models with Dictionary Learning Open, closed, and everything in between: towards human-centric regulations for safer large models A Review of The Debate on Open-Sourcing Powerful AI Models AI safety media analysis Biases in Reinforcement Learning from Human Feedback Situational Awareness of AIs Summary of methods to solve Goal Misgeneralization A Review of DeepMind’s AI alignment plan Criticism of criticism of interp Risks of Value Lock-In in China Is LeCun making progress in AI safety with “A Path Towards Autonomous Machine Intelligence”? Taxonomy of governance regulations Other notable projects Title Authors Summary Some Thoughts None 1 comment
We (EffiSciences) ran a hackathon at the end of the Turing Seminar in ENS Paris-Saclay and ENS Ulm, an academic course inspired by the AGISF, with 28 projects submitted by 44 participants between the 11th and 12th November.
We share a selection of projects. See them all here.
I think some of them could even be turned into valuable blog posts, and I’ve learnt a lot by reading everything. Here are a few extracts.
Towards Monosemanticity: Decomposing Vision Models with Dictionary Learning
David HEURTEL-DEPEIGES [link]
Basically an adaptation of the famous dictionary learning paper on vision CNN.
“When looking at 100 random features, 46 were found to be interpretable and monosemantic, [...] When doing the same experiment with 100 random neurons, 2 were found to be interpretable and monosemantic”. Very good execution.
Open, closed, and everything in between: towards human-centric regulations for safer large models
Théo SAULUS [link]
Imho, an almost SOTA summary of the current discourse on open sourcing models.
A Review of The Debate on Open-Sourcing Powerful AI Models
Tu Duyen NGUYEN, Adrien RAMANANA RAHARY [link]
“What is the goal of this document? Our goal is to clarify, and sometimes criticize, the arguments regularly put forward in this, both from the proponents and the opponents of open-sourced AI models. In an effort to better understand both stances, we have classified the most common arguments surrounding this debate in five main topics:
- Safety evaluation of powerful AI models through audits or open-research
- Competition in the private sector and beyond
- Safety risks of open-sourcing strongly capable models
- Preserving open science for its own sake
- The feasibility of closing the weights of AI models
In an effort to highlight the strengths and weaknesses of each stance, we will present and challenge for each family the arguments of both sides, as well as include in each family some arguments which we think are relevant, but have not been mentioned in most discussions on these topics.”
They tried to be exhaustive, but there are still some gaps. The format is nevertheless interesting (even if it could be even more concise).
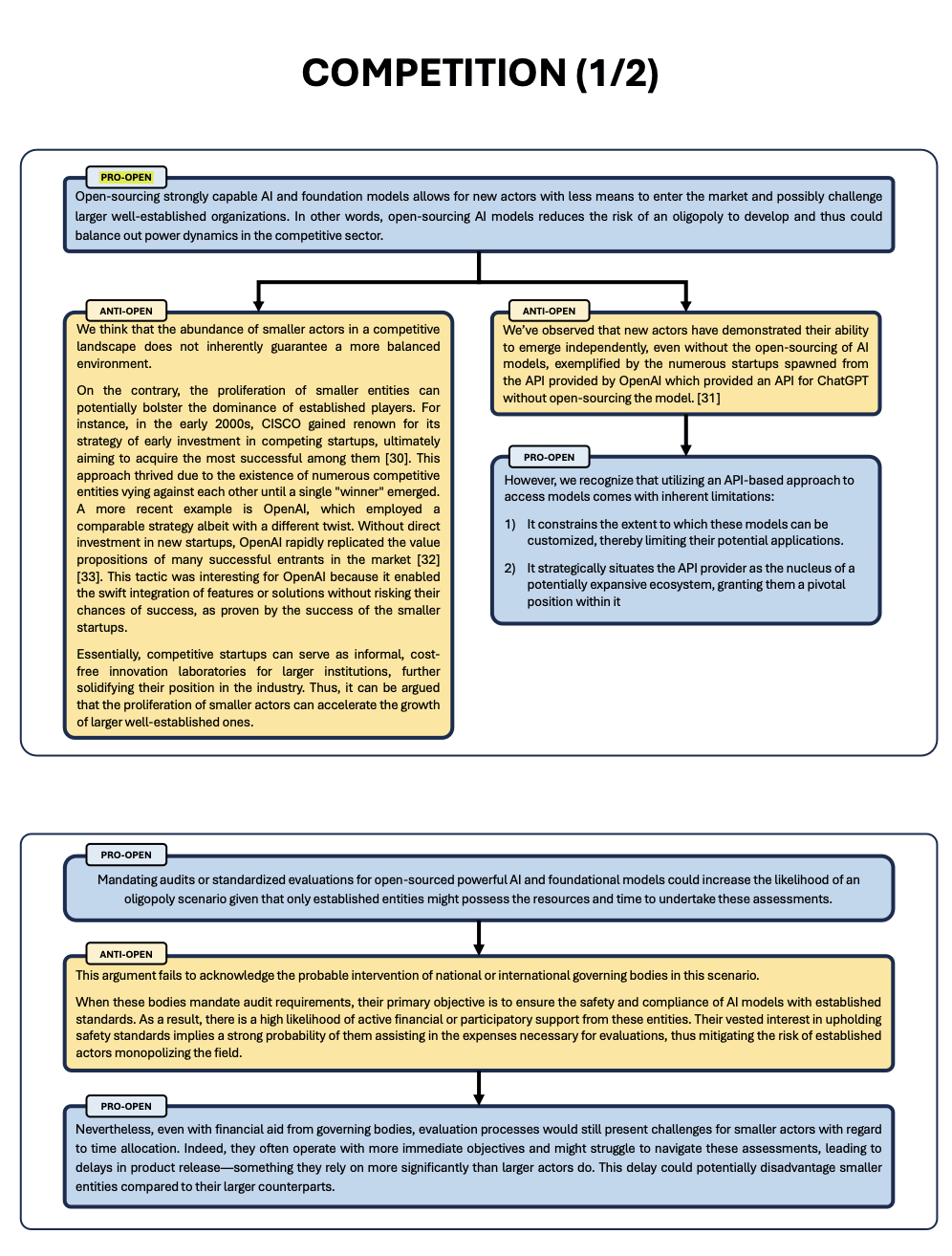 | 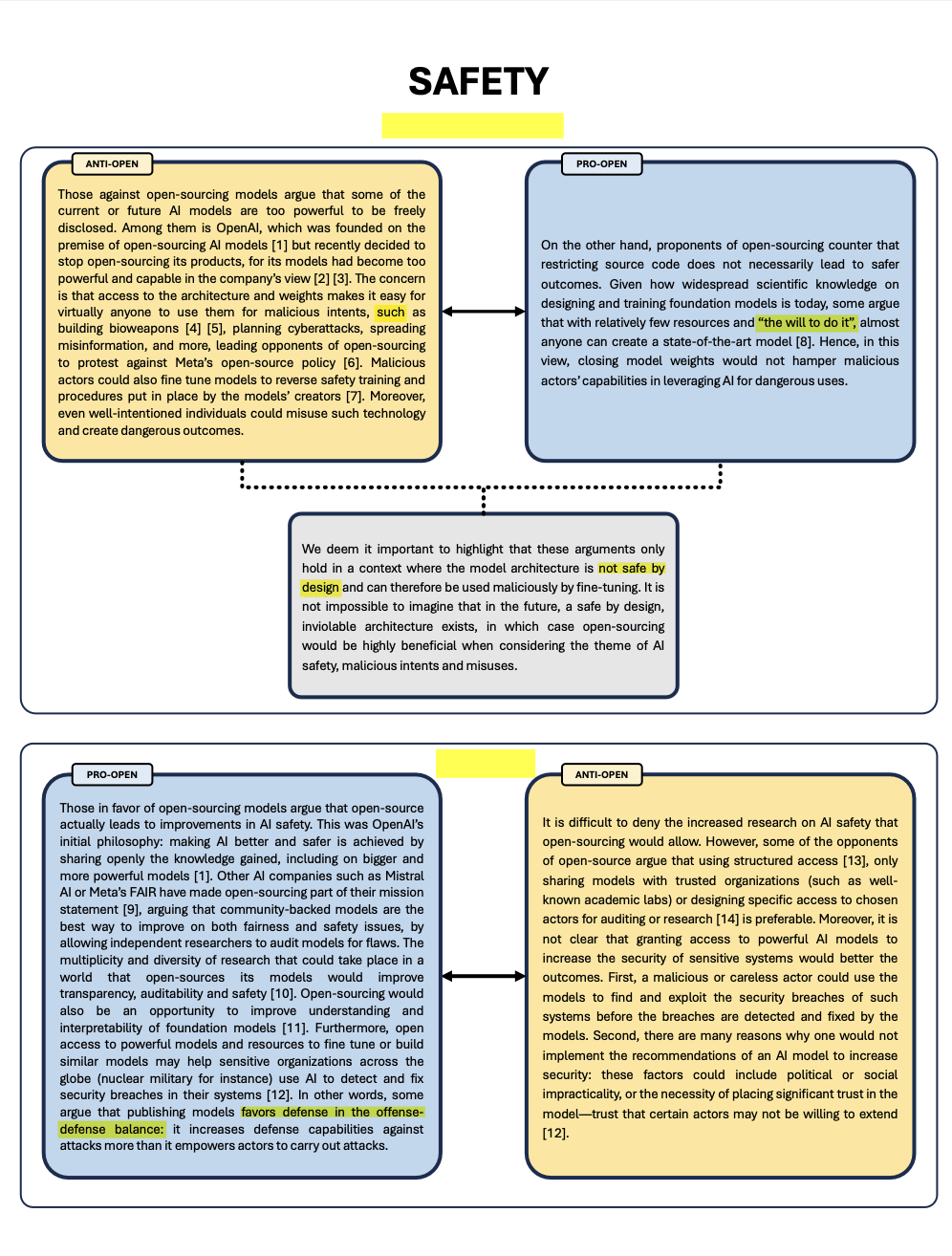 | 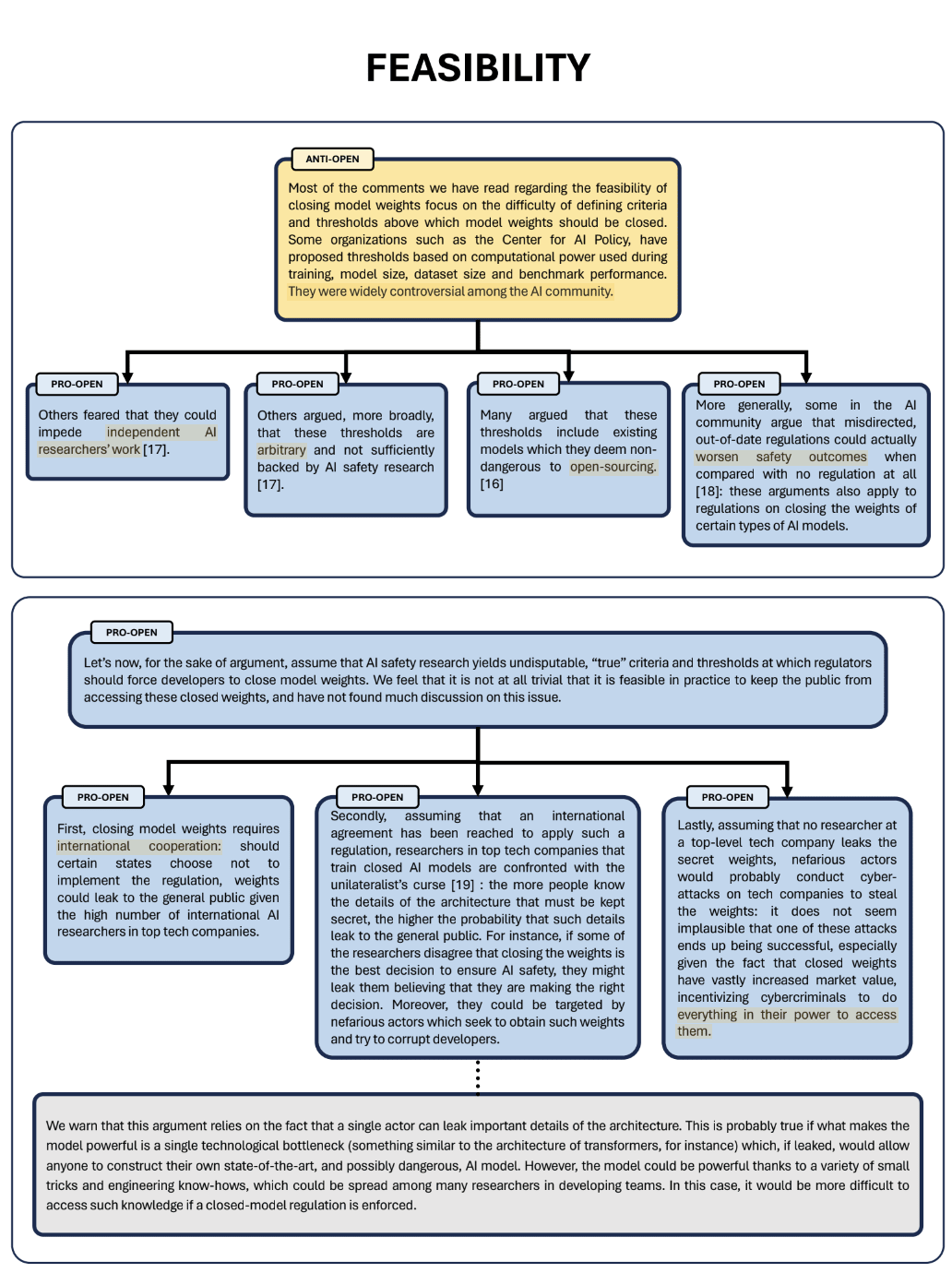 | 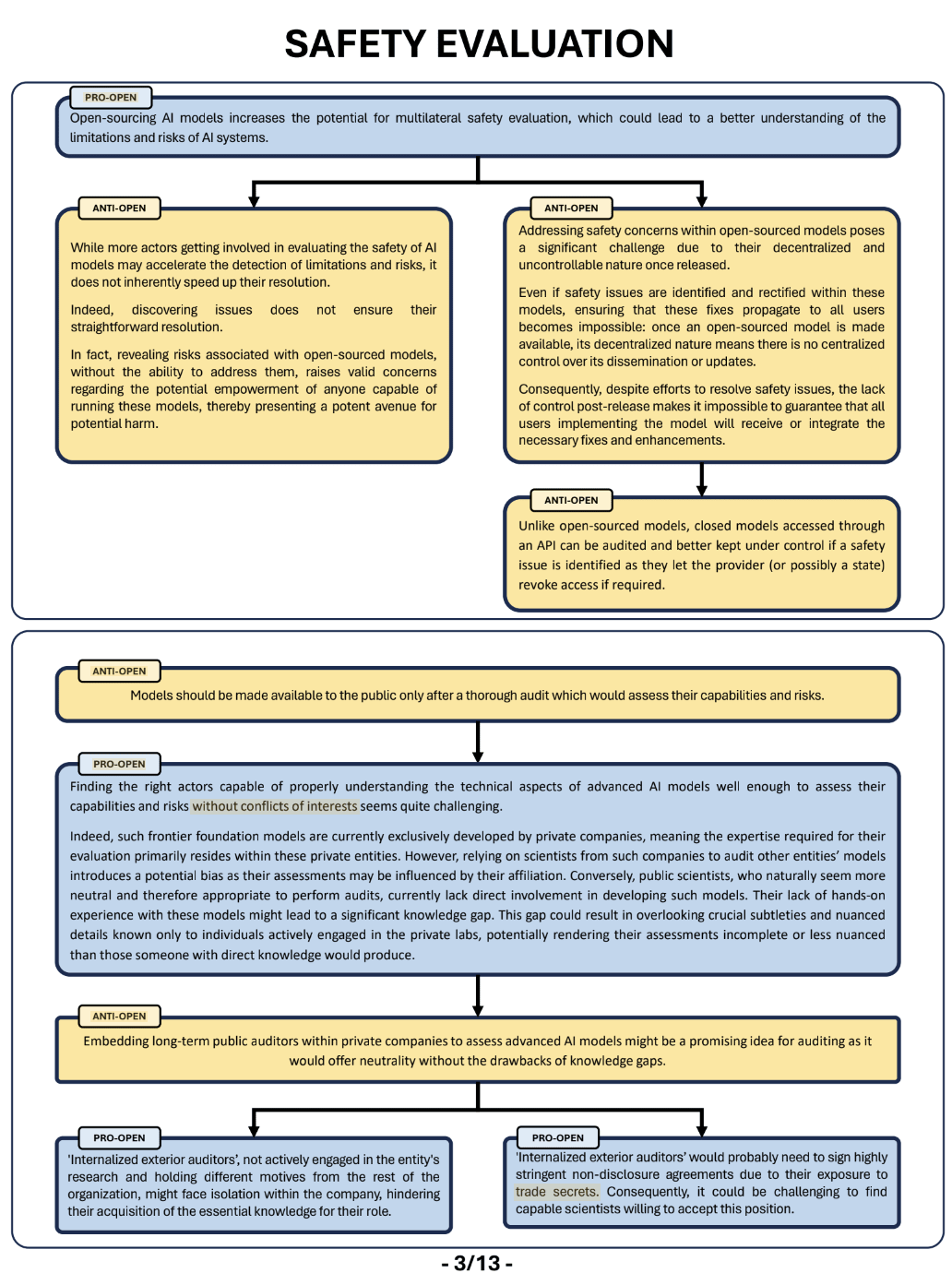 |
AI safety media analysis
Gurvan Richardeau, Raphaël Pesah [link]
“The first analysis we’ve done involved examining major themes by employing text data analysis and ML methods (such as tf-idf analysis and topic modeling) within a corpus of 1,644 publications from the Factiva database over the past five years, specifically related to AI safety. The second analysis (Analysis 2) uses another database: Europresse. “
Here are some snippets:
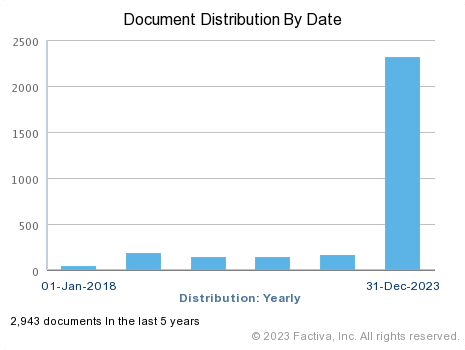
“First let’s have a look at the global distribution of the articles over the years.”
We see that more than 80% of the articles of our dataset are from 2023: | Now let’s have a more precise look over the year 2023 : |
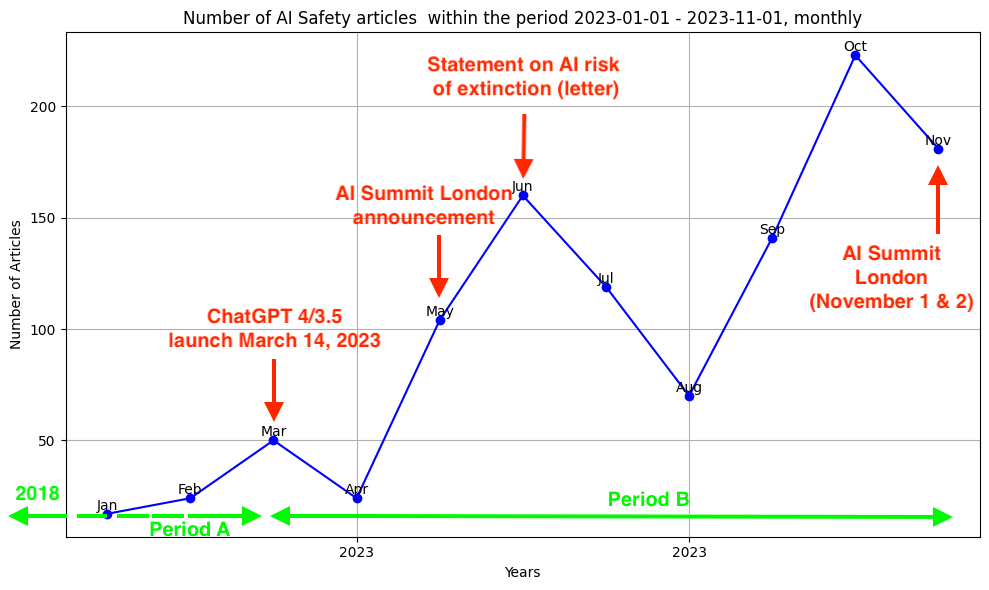
“Here are the results for the sentiment analysis: “
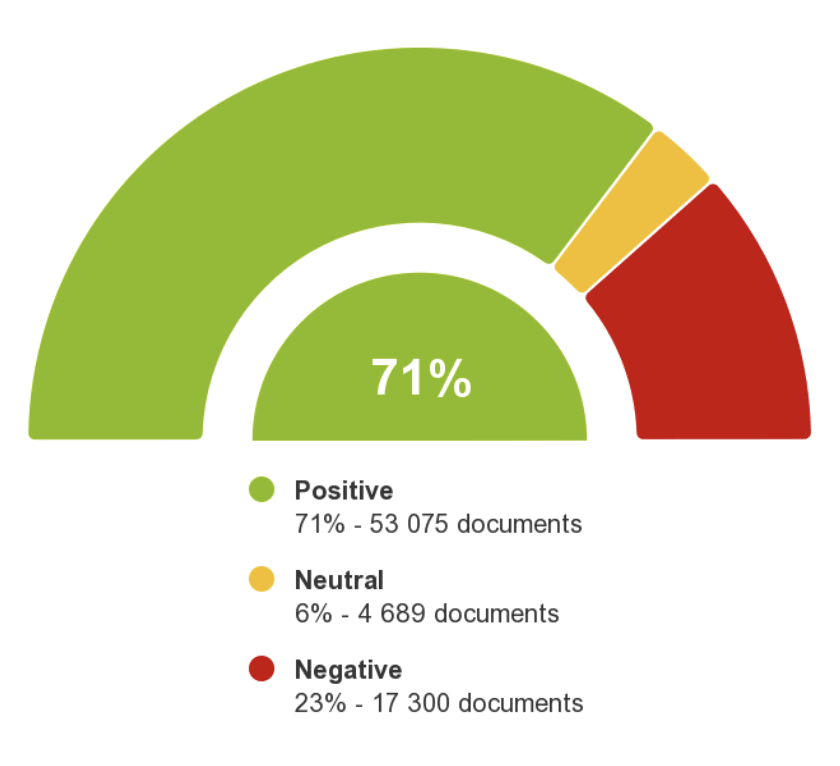
“Around 71% of the articles talking of AGI talk about it as a good thing whereas 23% are talking about it as a thing to worry about.”
“We got 57,000 articles about AGI in 2023 against 18,000 for the ones related to AI safety, so this time it is three times less. [...] There are between two and three times more articles talking about AGI without AI safety than articles about AI safety in 2023.”
My comment: Interesting. There are many more figures in the reports. Maybe those kinds of metrics could be used to measure the impact of public outreach?
Biases in Reinforcement Learning from Human Feedback
Gaspard Berthelier [link]
A good summary of the paper “Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback [LW · GW]”.
Situational Awareness of AIs
Thomas Michel, Théo Rudkiewicz [link]
An alternative title could be “Situational Awareness from AI to Zombies, with premium pedagogical memes”:
 |  |
 |  |
Summary of methods to solve Goal Misgeneralization
Vincent Bardusco [link]
A good summary of the following papers:
- R. Shah, Goal Misgeneralization: Why Correct Specifications Aren't Enough For Correct Goals, 2022.
- B. Shlegeris, The prototypical catastrophic AI action is getting root access to its datacenter, 2022.
- Song et al., Constructing unrestricted adversarial examples with generative models, 2018.
- A. Bhattad, M. J. Chong, K. Liang, B. Li, D. A and Forsyth, Unrestricted Adversarial Examples via Semantic Manipulation, 2019.
- B. Barnes, Imitative Generalisation (AKA 'Learning the Prior'), 2021.
- R. Jia and P. Liang, Adversarial examples for evaluating reading comprehension systems, 2017.
- S. Goldwasser, M. P. Kim, V. Vaikuntanathan and O. Zamir, Planting undetectable backdoors in machine learning models, 2022.
- A. Madry, A. Makelov, L. Schmidt, D. Tsipras and A. Vladu, Towards deep learning models resistant to adversarial attacks, 2018.
- E. Hubinger, Relaxed adversarial training for inner alignment, 2019.
A Review of DeepMind’s AI alignment plan
Antoine Poirier, Théo Communal [link]
A document summarizing the main aspects of DeepMind's plan. Up until now, their agenda has been covered in a series of blog posts and papers, but now it's all summarized in a ten-page blog post.
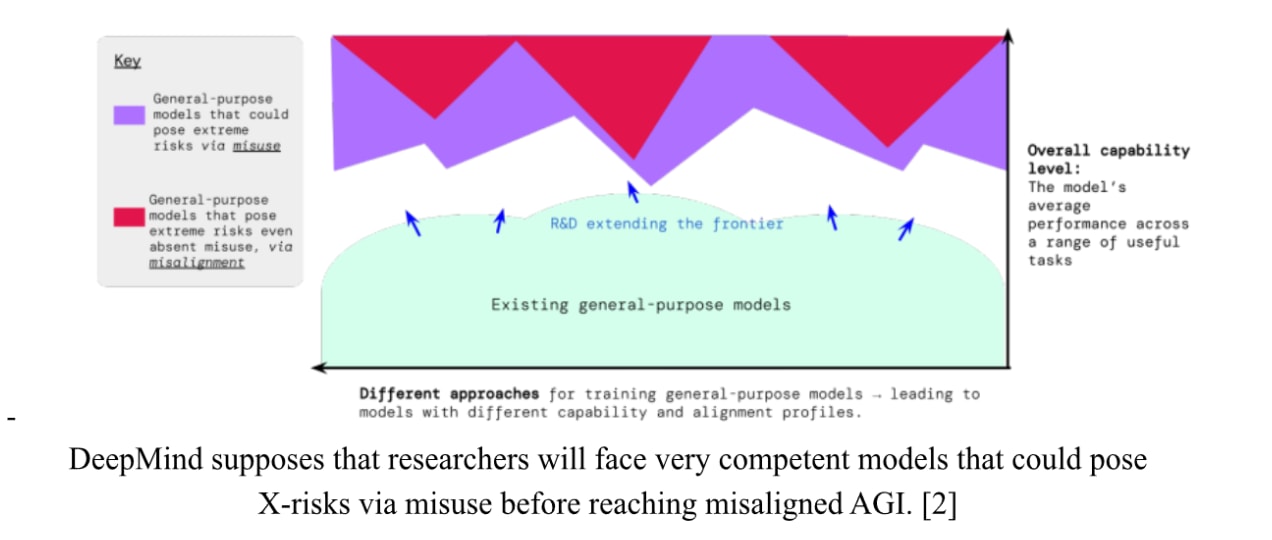
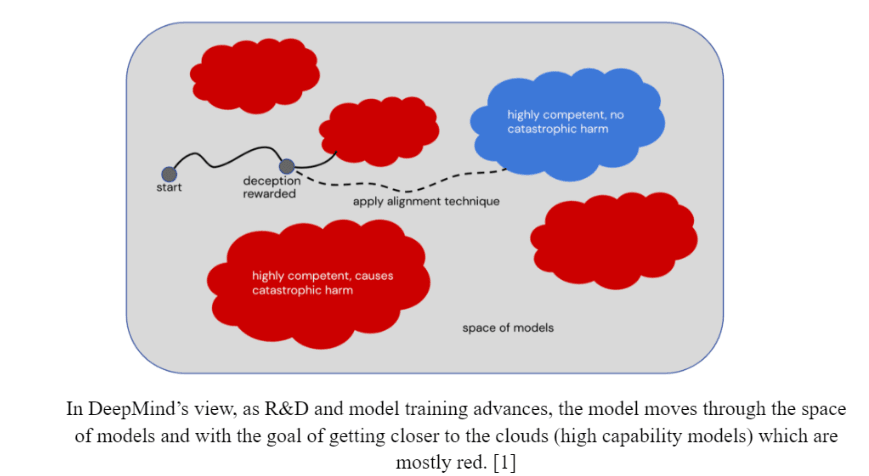
Criticism of criticism of interp
Gabriel Ben Zenou, Joachim Collin [link]
An alternative title could be “Against Against Almost Every Theory of Impact of Interpretability [LW · GW]”.
Some students tried to distill the discussion and to criticize my position, and you can find my criticism of their criticism in the comments of the google doc. Here is my main comment.
Risks of Value Lock-In in China
Inès Larroche, Bastien Le Chenadec [link]
It’s a very good summary of what is happening in China regarding AI.
Is LeCun making progress in AI safety with “A Path Towards Autonomous Machine Intelligence”?
Victor Morand [link]
It’s a good summary of LeCun’s idea, and the numerous criticisms of his plan.
Taxonomy of governance regulations
Mathis Embit [link]
A summary of the main ways to regulate AI. Comparing different policies provides them with more distinctiveness and depth.
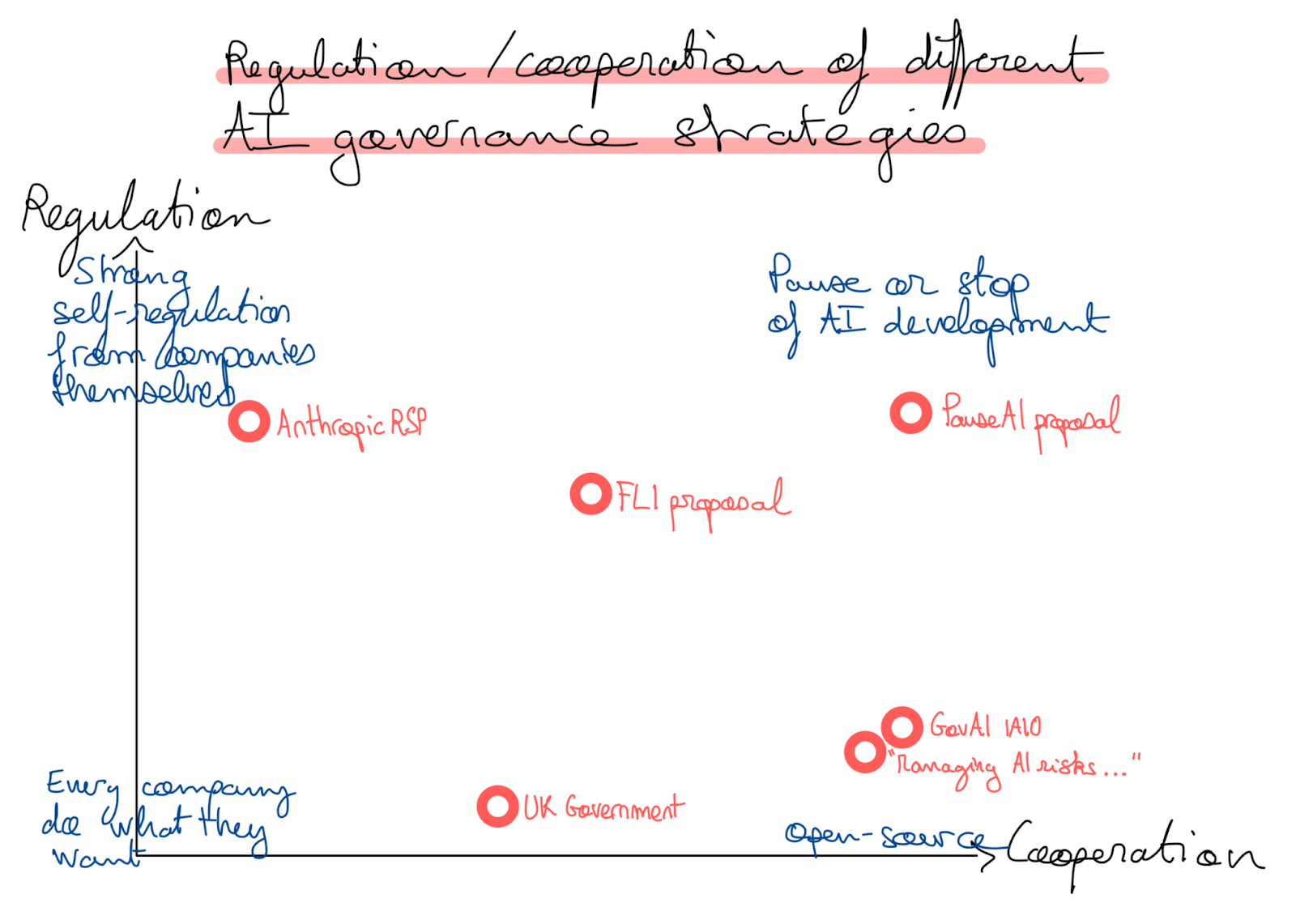
Other notable projects
See them all here.
Title | Authors | Summary |
|---|---|---|
Technical justification of OpenAI's superalignment plan | Robin Sobczyk, | A lot of papers are summarized here |
Agent Creation | Mathias Vigouroux | A philosophical essay trying to explain how theory of mind emerges in humans and could emerge in AIs. This is very interesting. |
Anthropic RSP analysis | Ralf Cortes Do Nascimento, Paul Cazali | A good summary of the entire LW discussion on the RSPs. |
Goal Misgeneralization | Basile TERVER, | A summary of various techniques to prevent Goal Misgeneralization |
Detecting and reducing gender bias | Gabrielle LE BELLIER | A literature review on techniques to reduce gender biases in LLMs |
Literature review on SOTA Adversarial attacks and backdoors | Mathis Le Bail, | A summary of many papers on attack and defense. The conclusion: "all the studies in the literature tend to the following conclusion: there is no single effective method of defense against all possible types of attack" |
Why does DL work so well? | Sacha ELKOUBI, | It needs a bit more polishing, but this is a good basis. It goes from explaining the Classical Statistical learning theory to Singular learning theory and everything in between. |
AI Act: what rules for foundation models? | Matthieu Carreau | A summary of the current challenges for EU regulations |
Critics of GovAI | Xavier Secheresse, | A summary of their views, and a small critique |
Cure | David El Bèze, | A short story of a deceptive AI transforming the world |
Logit Lens on Vision Transformer | Akedjou Achraff Adjileye | Testing the logit lens on Vision transformers, it works without difficulty. |
Safety benchmarks | Ugo Insalaco | A review of the main safety benchmarks and a few proposals of missing benchmarks. |
Probability of X-Risks without deceptive alignment | Mathilde DUPOUY | She enumerates the different scenarios in the following table. The final probability among all the risks that the one that occurs is an existential risk without deceptive alignment is 71%. |
Do you think Le Cun's architecture is safe? | Théotime de Charrin | Another criticism of LeCun's agenda. |
Navigating AI Safety | Abdessalam EDDIB | Presents a landscape of some strategies to reduce risks through alignment techniques and some governance strategies, and is targeting beginners in alignment. |
Some Thoughts
- Running the hackathon was a lot of fun. We just worked in a room at the university during the weekend. We also organized a meme contest. Highly recommended.
- Unlike last year's hackathon, where students had the freedom to choose their own topics, this time we provided a list of predetermined topics. This resulted in higher quality work. If you're interested in organizing a similar hackathon, you can find the list of subjects here if you want to run something similar.
- I am extremely pleased with the outcome, especially since the students went from having no knowledge in AI Safety to making valuable contributions in only 2 months.
- The material of the course is available here.
1 comments
Comments sorted by top scores.
comment by RogerDearnaley (roger-d-1) · 2023-12-10T03:06:02.564Z · LW(p) · GW(p)
On the paper "Towards Monosemanticity: Decomposing Vision Models with Dictionary Learning", looking at the images for feature 8, I think it's not just "pointy objects with a metallic aspect", but "a serried array of pointy objects with a metallic aspect". So I predict that the Sword Throne from Game of Thrones should trigger it.
That suggests a way to test the verbal descriptions: take a verbal description, feed it to GPT-4V along with a random sample of images from Imagenet, ask for the images that fit the description, and see how well that classifier matches the behavior of the feature (with a metaparameter for feature threshold). Or ask for a 0-4 score and plot that against the feature activation.
Overall, the papers you link to include several impressive and interesting ones — well worth the reading.