What are the differences between all the iterative/recursive approaches to AI alignment?
post by riceissa · 2019-09-21T02:09:13.410Z · LW · GW · 5 commentsThis is a question post.
Contents
Answers 45 rohinmshah None 5 comments
I have been trying to understand all the iterative/recursive approaches to AI alignment. The approaches I am aware of are:
- ALBA (I get the vague impression that this has been superseded by iterated amplification, so I haven't looked into it)
- HCH (weak and strong)
- Iterated amplification (IDA)
- Debate
- Meta-execution
- (Recursive) reward modeling
- Factored cognition
- Factored evaluation
(I think that some of these, like HCH, aren't strictly speaking an approach to AI alignment, but they are still iterative/recursive things discussed in the context of AI alignment, so I want to better understand them.)
One way of phrasing what I am trying to do is to come up with a "minimal set" of parameters/dimensions along which to compare these different approaches, so that I can take a basic template, then set the parameters to obtain each of the above approaches as an instance.
Here are the parameters/dimensions that I have come up with so far:
- capability of agents: I think in HCH, the agents are human-level. In the other approaches, my understanding is that the capability of the agents increases as more and more rounds of amplification/distillation take place.
- allowed communication: It seems like weak and strong HCH differ in the kind of communication that is allowed between the assistants (with strong HCH allowing more flexible communication). Within IDA, there is low bandwidth vs high bandwidth oversight [LW · GW], which seems like a similar parameter. I'm not sure what the other approaches allow.
- training method during distillation step: I think IDA leaves the training method flexible [? · GW]. According to this post [LW · GW], factored cognition seems to use imitation learning and factored evaluation seems to use reinforcement learning. I think recursive reward modeling also uses reinforcement learning. HCH seems to be just about the amplification step (?), so no training method is used. I'm not sure about the others.
- entity who "splits the questions", coordinates everything during amplification, or selects the branches: In factored cognition, factored evaluation, IDA, and HCH, it seems like the human splits the questions. In Debate, the branches are chosen by the two AIs in the debate (who are in an adversarial relationship).
- entity who does the evaluation/gives feedback ("the overseer"): It seems like in factored evaluation, the human gives feedback. In Debate, the final judgment is provided by the human. My understanding is that in IDA, the nature of the overseer is flexible [? · GW] ("For example, Arthur could advise Hugh on how to define a better overseer; Arthur could offer advice in real-time to help Hugh be a better overseer; or Arthur could directly act as an overseer for his more powerful successor").
- what the overseer does (i.e. what kind of feedback is provided): I think the overseer can be passive/active depending on the distillation method (see my comment here [LW(p) · GW(p)]), so maybe this parameter isn't required in a "minimal set".
- required number of human feedback per round: In Debate, there is one feedback at the end of a debate round. In factored evaluation, it seems like the human must provide feedback at each node in the question tree (or a separate human at each node in the question tree).
- depth of recursion: It seems like IDA limits the depth of the recursion to one step, whereas the other approaches seem to allow arbitrary depth (see my comment here [LW(p) · GW(p)]).
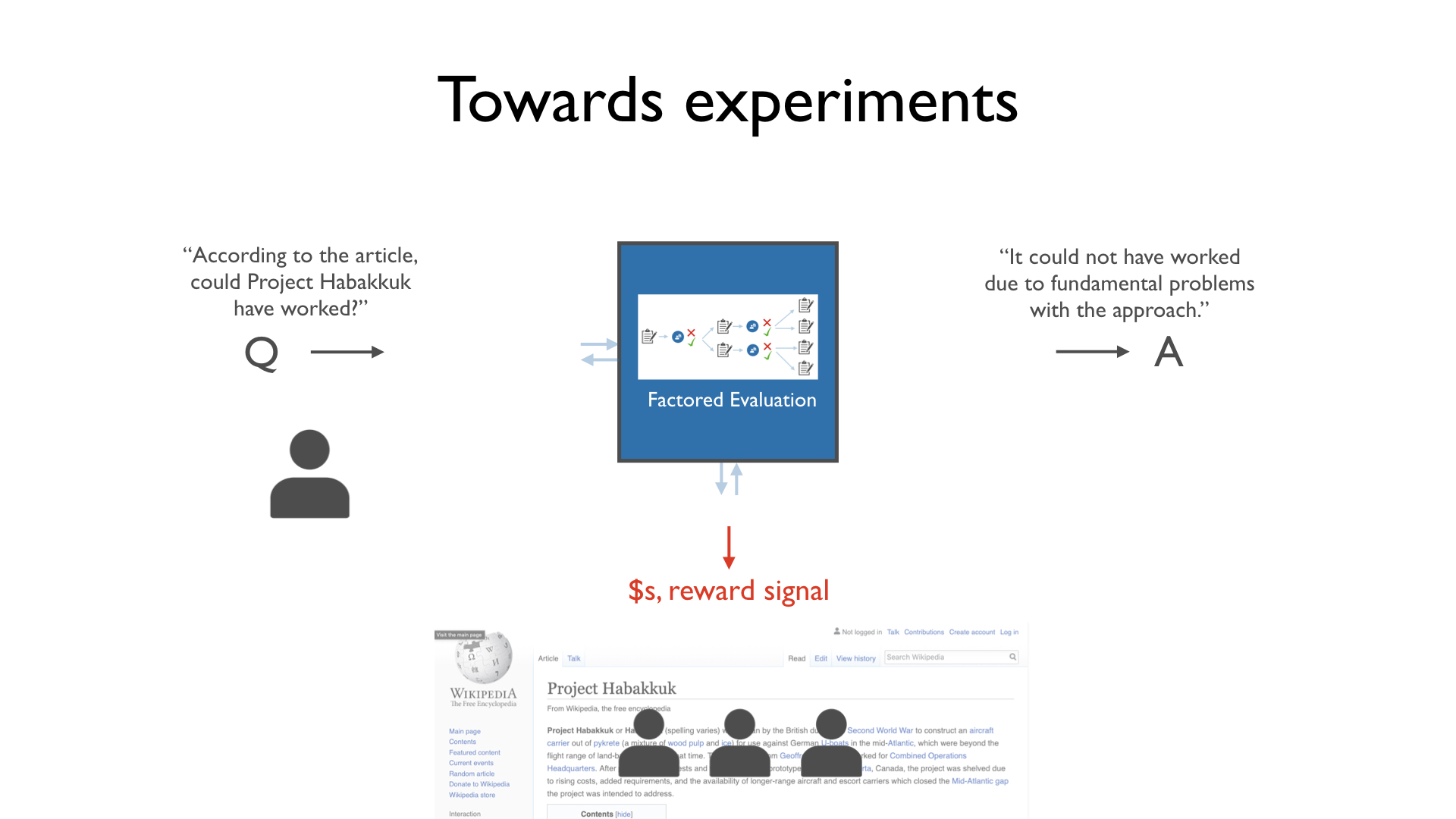
- separation of task performance vs evaluation/oversight: It seems like in factored evaluation, there is an entity who does the task itself (the experts at the bottom of this diagram), and a separate entity who evaluates the work of the experts (the "factored evaluation" box in the same diagram), but in factored cognition, there is just the entity doing the task.
{kind=link}
I would appreciate hearing about more parameters/dimensions that I have missed, and also any help filling in some of the values for the parameters (including corrections to any of my speculations above).
Ideally, there would be a table with the parameters as columns and each of the approaches as rows (possibly transposed), like the table in this post [LW · GW]. I would be willing to produce such a write-up assuming I am able to fill in enough of the values that it becomes useful.
If anyone thinks this kind of comparison is useless/framed in the wrong way, please let me know. (I would also want to know what the correct framing is!)
Answers
You seem to be thinking of all of these as things-that-can-be-implemented, which I don't think is exactly right. I think you could only call some of these "approaches to alignment", if you mean something that could some day be implemented and lead to aligned AI.
I'll consider two different properties:
Implementation: Theoretical (can't be implemented, takes infinite compute) or Implementable without ML (i.e. with humans, as a result it is very inefficient) or Implementation needs ML (there will still be humans, but the hope is that it will be efficient and competitive with unaligned AI systems).
How learning happens: Task-based (the agent learns to perform a particular task or reason in a particular way) or Reward-based (the agent learns to provide a good reward signal that provides good incentives for some other system). While task-based systems are more elegant and clean when everything works right, we'd expect that in the presence of real world messiness such as optimization difficulty that reward-based systems will be more robust (see Against Mimicry).
I would only consider the Implementation needs ML things to be "approaches to alignment". Anyway, here they are (ignoring ALBA for the same reason you do):
Weak HCH: A theoretical ideal where each human can delegate to other agents. We hope that the result is both superintelligent and aligned. Properties: Theoretical / Task-based
Strong HCH: Like weak HCH, but allowing each human to have a dialog with subagents, and allowing message passing to include pointers to other agents. Properties: Theoretical / Task-based
Meta-execution: A particular implementation method that can deal with the fact that some questions may be too "big" for any one agent to even read the full question. Properties: Not really a recursive approach, it's more a component of other approaches.
Factored cognition: The hypothesis that strong HCH can solve arbitrary tasks. In terms of actual implementation, it's compute-limited strong HCH / meta-execution. Properties: Implementable without ML / Task-based
Factored evaluation: The hypothesis that strong HCH can provide a reward signal for arbitrary tasks. (Less confident of this one, as it hasn't been explained in detail before.) In terms of actual implementation, it's compute-limited strong HCH / meta-execution, where the goal is to provide a reward signal for some task. Properties: Implementable without ML / Reward-based
Iterated amplification (IDA): Approximating strong/weak HCH by training an agent that behaves like depth-limited strong/weak HCH and increasing the effective depth over time. Properties: Implementation needs ML / Task-based
Recursive reward modeling: Approximating strong/weak HCH by training an agent that behaves like depth-limited strong/weak HCH on tasks that are useful for evaluating the task of interest, and on evaluating tasks that are useful for evaluating the task of interest, etc. Properties: Implementation needs ML / Reward-based
Debate: Not really a recursive method at all, but it still depends on the general premise of decomposing thought processes into trees of smaller thoughts (though in this case, the "smaller thoughts" have to be arguments and counterarguments, rather than general considerations). If the Factored cognition hypothesis is false, then debate is unlikely to work.
↑ comment by riceissa · 2019-09-23T11:25:22.471Z · LW(p) · GW(p)
Thanks! I found this answer really useful.
I have some follow-up questions that I'm hoping you can answer:
- I didn't realize that weak HCH uses linear recursion. On the original HCH post [? · GW] (which is talking about weak HCH), Paul talks in comments about "branching factor", and Vaniver says things like "So he asks HCH to separately solve A, B, and C". Are Paul/Vaniver talking about strong HCH here, or am I wrong to think that branching implies tree recursion? If Paul/Vaniver are talking about weak HCH, and branching does imply tree recursion, then it seems like weak HCH must be using tree recursion rather than linear recursion.
- Your answer didn't confirm or deny whether the agents in HCH are human-level or superhuman. I'm guessing it's the former, in which case I'm confused about how IDA and recursive reward modeling are approximating strong HCH, since in these approaches the agents are eventually superhuman (so they could solve some problems in ways that HCH can't, or solve problems that HCH can't solve at all).
- You write that meta-execution is "more a component of other approaches", but Paul says "Meta-execution is annotated functional programming + strong HCH + a level of indirection", which makes it sound like meta-execution is a specific implementation rather than a component that plugs into other approaches (whereas annotated functional programming does seem like a component that can plug into other approaches). Were you talking about annotated functional programming here? If not, how is meta-execution used in other approaches?
- I'm confused that you say IDA is task-based rather than reward-based. My understanding was that IDA can be task-based or reward-based depending on the learning method used during the distillation process. This discussion thread [LW(p) · GW(p)] seems to imply that recursive reward modeling is an instance of IDA. Am I missing something, or were you restricting attention to a specific kind of IDA (like imitation-based IDA)?
↑ comment by Rohin Shah (rohinmshah) · 2019-09-23T14:55:02.093Z · LW(p) · GW(p)
Are Paul/Vaniver talking about strong HCH here, or am I wrong to think that branching implies tree recursion?
ETA: This paragraph is wrong, see rest of comment thread. I'm pretty sure they're talking about strong HCH. At the time those comments were written (and now), HCH basically always referred to strong HCH, and it was rare for people to talk about weak HCH. (This is mentioned at the top of the strong HCH post.)
Your answer didn't confirm or deny whether the agents in HCH are human-level or superhuman. I'm guessing it's the former
That's correct.
I'm confused about how IDA and recursive reward modeling are approximating strong HCH, since in these approaches the agents are eventually superhuman
There are two different meanings of the word "agent" here. First, there's the BaseAgent, the one which we start with that's already human-level (both HCH and IDA assume access to such a BaseAgent). Then, there's the PowerfulAgent, which is the system as a whole, which can be superhuman. With HCH, the entire infinite tree of BaseAgents together makes up the PowerfulAgent. With IDA / recursive reward modeling, either the neural net (output of distillation) or the one-level tree (output of amplification) could be considered the PowerfulAgent. Initially, the PowerfulAgent is only as capable as the BaseAgent, but as training progresses, it becomes more capable, reaching the HCH-PowerfulAgent in the limit.
For all methods, the BaseAgent is human level, and the PowerfulAgent is (eventually) superhuman.
You write that meta-execution is "more a component of other approaches", but Paul says"Meta-execution is annotated functional programming + strong HCH + a level of indirection", which makes it sound like meta-execution is a specific implementation rather than a component that plugs into other approaches (whereas annotated functional programming does seem like a component that can plug into other approaches). Were you talking about annotated functional programming here?
Yes, my bad. (Technically, I was talking about both the annotated functional programming and the level of indirection, I think.)
Am I missing something, or were you restricting attention to a specific kind of IDA (like imitation-based IDA)?
I was restricting attention to imitation-based IDA, which is the canonical example, and what various [? · GW] explainer [? · GW] articles [? · GW] are explaining.
Replies from: riceissa↑ comment by riceissa · 2019-09-24T09:27:30.158Z · LW(p) · GW(p)
Thanks. It looks like all the realistic examples I had of weak HCH are actually examples of strong HCH after all, so I'm looking for some examples of weak HCH to help my understanding. I can see how weak HCH would compute the answer to a "naturally linear recursive" problem (like computing factorials) but how would weak HCH answer a question like "Should I get laser eye surgery?" (to take an example from here). The natural way to decompose a problem like this seems to use branching.
Also, I just looked again at Alex Zhu's FAQ for Paul's agenda [LW · GW], and Alex's explanation of weak HCH (in section 2.2.1) seems to imply that it is doing tree recursion (e.g. "I sometimes picture this as an infinite tree of humans-in-boxes, who can break down questions and pass them to other humans-in-boxes"). It seems like either you or Alex must be mistaken here, but I have no idea which.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2019-09-24T16:31:38.959Z · LW(p) · GW(p)
I just looked at both that and the original strong HCH post, and I think Alex's explanation is right and I was mistaken: both weak and strong HCH use tree recursion. Edited the original answer to not talk about linear / tree recursion.
↑ comment by Liam Donovan (liam-donovan) · 2019-10-20T21:58:25.378Z · LW(p) · GW(p)
I found this immensely helpful overall, thank you!
However, I'm still somewhat confused by meta-execution. Is it essentially a more sophisticated capability amplification strategy that replaces the role filled by "deliberation" in Christiano's IA paper?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2019-10-21T06:31:07.057Z · LW(p) · GW(p)
I maybe think so? I'm not sure about meta-execution (as the comment thread above shows).
Replies from: liam-donovan↑ comment by Liam Donovan (liam-donovan) · 2019-10-21T10:23:29.414Z · LW(p) · GW(p)
Huh, what would you recommend I do to reduce my uncertainty around meta-execution (e.g. "read x", "ask about it as a top level question", etc)?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2019-10-21T23:30:46.248Z · LW(p) · GW(p)
I'm not sure how relevant meta-execution is any more, I haven't seen it discussed much recently. So probably you'd want to ask Paul, or someone else who was around earlier than I was.
5 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2019-09-21T21:22:13.366Z · LW(p) · GW(p)
It seems like IDA limits the depth of the recursion to one step, whereas the other approaches seem to allow arbitrary depth
At any given point of training, IDA is training the agent to perform one more step of recursion than it is already performing. Repeated application of this lets it reach arbitrary depths eventually.
Replies from: liam-donovan↑ comment by Liam Donovan (liam-donovan) · 2019-10-20T22:00:52.869Z · LW(p) · GW(p)
Is this necessarily true? It seems like this describes what Christiano calls "delegation" in his paper, but wouldn't apply to IDA schemes with other capability amplification methods (such as the other examples in the appendix of "Capability Amplification" [LW · GW]).
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2019-10-21T06:29:47.169Z · LW(p) · GW(p)
"Depth" only applies to the canonical tree-based implementation of IDA. If you slot in other amplification or distillation procedures, then you won't necessarily have "depths" any more. You'll still have recursion, and that recursion will lead to more and more capability. Where it ends up depends on your initial agent and how good the amplification and distillation procedures are.
Replies from: liam-donovan↑ comment by Liam Donovan (liam-donovan) · 2019-10-21T10:26:08.661Z · LW(p) · GW(p)
Huh, I thought that all amplification/distillation procedures were intended as a way to approximate HCH, which is itself a tree. Can you not meaningfully discuss "this amplification procedure is like an n-depth approximation of HCH at step x", for any amplification procedure?
For example, the internal structure of the distilled agent described in Christiano's paper is unlikely to look anything like a tree. However, my (potentially incorrect?) impression is that the agent's capabilities at step x are identical to an HCH tree of depth x if the underlying learning system is arbitrarily capable.
It's possible that I'm not understanding the difference between "depth", "tree-based" and "recursion" in this context
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2019-10-21T23:29:27.675Z · LW(p) · GW(p)
Can you not meaningfully discuss "this amplification procedure is like an n-depth approximation of HCH at step x", for any amplification procedure?
No, you can't. E.g. If your amplification procedure only allows you to ask a single subagent a single question, that will approximate a linear HCH instead of a tree-based HCH. If your amplification procedure doesn't invoke subagents at all, but instead provides more and more facts to the agent, it doesn't look anything like HCH. The canonical implementations of iterated amplification are trying to approximate HCH though.
For example, the internal structure of the distilled agent described in Christiano's paper is unlikely to look anything like a tree. However, my (potentially incorrect?) impression is that the agent's capabilities at step x are identical to an HCH tree of depth x if the underlying learning system is arbitrarily capable.
That sounds right to me.