Draft: Introduction to optimization
post by Alex_Altair · 2023-03-26T17:25:55.093Z · LW · GW · 8 commentsContents
What and why What I mean by optimization Why do we care? Running examples Objects in a crater A rocket The conceptual pieces The setting The optimization criterion The probability it's pushing against Calculating bits of optimization The prior probability over states The state ordering "Absolute optimization" of a state Example: eight equally likely states Example: ordering coin flips by number of heads "Relative optimization" between two states Next up [Again, reminder that this is a draft, and thus this is not necessarily what is next up.] None 8 comments
I am posting this draft as it stands today. Though I like it, it does not completely reflect my current best understanding of optimization, and is not totally polished. But I have been working on it for too long, and the world is moving too quickly. In the future, I might aggressively edit this post to become not-a-draft, or I may abandon it entirely and post a new introduction. (Unfortunately, all of the really juicy content is in other drafts that are way less developed.)
[TODO Acknowledgements, AGISF and SERI MATS]
Among the many phenomena that unfold across the universe, there is one that is not immediately evident from an inspection of the laws of physics, but which can nevertheless determine the fate of the system in which it arises. This force which guides the future is statistical in nature. But once it arises, things are not the same. The way that things will go instead is dependent on the exact nature of the force which just so happens to arise.
We will call this phenomenon optimization, which is meant in the most general of terms.
This concept of optimization has a very long and thorough history [? · GW] of discussion on LessWrong. This sequence is built on top of that history. But this first post is written to someone who hasn't necessarily encountered any of it before; it is largely my attempt to distill [? · GW] all the work that has come before. If you are familiar with the previous work, and you have questions or comments about how this framework relates to it, check out this post. [TODO link]
What and why
"Optimization" is a word used both formally and colloquially, and thus it has many uses and connotations, technical and non-technical. You may be coming to this post with one of those other meanings firmly in mind. If you are not a regular reader of LessWrong then it's pretty unlikely that the meaning in your mind matches the meaning in this sequence (though by the end of it I hope you are convinced that I've captured the intuitive notion). And if you are a regular reader of LessWrong, there are a few other concepts that you might think I mean. Take a look at this footnote[1] for some example of what I do not mean.
What I mean by optimization
Our ultimate goal is to formalize an intuitive concept. Sometimes, you can watch something happen and just know that it's basically randomness.

And other times, you watch something and just know that something non-random is happening.

These two patterns are following the same laws of physics. And yet, the latter one is highly conspicuous. The thing that's happening is somehow unusual. Something special. The system is pushing against probability.
An example of optimization is what's called numerical optimization. If you watched a computer performing numerical optimization, you would see it finding values of a function that got closer and closer to the minimum. It might jump around a bit, but it would improve over time. You could tell that it wasn't randomly guessing. Feedback loops, both positive and negative, are other classic examples.
Another is humans. If, from some disinterested perspective, you watched a human for a while, you would see them doing many peculiar specific actions, and then occasionally some big effect would occur. From this disinterested perspective, you would see them doing things like reading a manual, and then driving to a store to pick up a oddly shaped piece of metal. It would not be evident that anything unusual was happening, until a while later, seemingly spontaneously, a huge quantity of corn grows nearby. Without an understanding of the details of the situation, you wouldn't know that they were fixing their tractor. But from the consequences, you could just tell that they had many goals in mind, many ways in which they were trying to steer the future.
A final example is biological evolution. Evolution does not have an optimization target written down somewhere, and it is extremely decentralized. But it certainly is not the normal, random process of chemistry happening on the surface of planets. There is something very special going on.
The way in which we'll formalize optimization was first pointed at by Yudkowsky in the sequences [LW · GW], and remains essentially that idea.
Why do we care?
Other than being inherently interesting, what use might be a formal framework of optimization?
Optimization is powerful [LW · GW]. Optimization is that which steers the future. If you have desires for the future, then you are an optimizer. And the world contains many other optimization processes, not all of which want the same future. On top of that, humanity is currently in the middle of forging what will likely be the most powerful optimization process the world has ever seen, in the form of AGI. The people who currently think a lot about optimization generally feel a great lacking in our understanding of it, and it seems awfully risky to go in blind.
Before diving into this project, I made sure that I could list some specific ideas [TODO link] for how this framework could help us understand AI. But mostly, the motivation is on more general heuristics that if you're deeply confused about something that seems really important, spend a significant fraction of your time trying to understand the fundamentals.
Running examples
[TODO illustrations of each of these (which can maybe be reused throughout with modification)]
[TODO say something about how there is a huge range of what optimization can "look like"? Ways it can present?]
Optimization is an incredibly rich and widely-applicable concept. To help resolve my confusions and deepen my understanding, I often use several examples of optimizing systems. So as we go through the components of optimization, I'll use two recurring examples:
- things rolling to the bottom of a crater
- a rocket controlling its trajectory
The crater is a very simple optimizing system, and the rocket is a very complex optimizing system. We'll place them on a barren planet – let's call it Dynasys – because Earth is absolutely teeming with optimization processes, and this can sometimes make it harder to reason about one in isolation.
(If you'd like to check your understanding through the post, I recommend taking Conway's Game of Life as a third example, and thinking about how it fits into each section.)
Objects in a crater
Let's say that we're sending space probes the planet Dynasys. We can't directly see the surface; perhaps it's got a foggy atmosphere, or our probes have limited sensors on them. In any case, we know it's there, but we don't know the details. So we send a large number of simple probes to land all over the planet.
Surprisingly, the probes usually end up rolling far away from their landing spot. And more strangely, they tend to cluster, rolling toward each other.
It turns out that Dynasys is covered in huge craters, causing the probes to roll down the edges, ending up close to the bottom of the crater.
A rocket
Later, we send a robotic mission to Dynasys to collect samples. These samples are placed inside a rocket, programmed to fly back to Earth. This is an optimizing system because the samples inside the rocket are quite likely to end up in a very specific place (back on earth) rather than anywhere else, on Dynasys or in space. Unlike the rock, the rocket is extremely complex; it has sensors, control actuators, computers, systems for cooling, et cetera. While the probes would reach the bottom of the crater almost regardless of their internal structure, the rocket needs to be extremely specific for it to even get off the ground; but it achieves an outcome that is much more impressive.
The conceptual pieces
Now that we've filled out a lot of the context, let's start to lay the groundwork for the definition. I'll talk through each of the pieces informally first, and then in the final section we will write out the equations, with numerical examples.
Conceptually, optimization occurs in a system when the system's state improves over time according to some criterion. If we want to get a numerical measure of optimization out of this, then we need to further decide on a prior probability over the states (which is what the optimization is pushing against), and we also need to be very careful about what counterfactual progressions we're measuring against. In further posts, we'll also arrive at a way to measure the robustness [LW · GW] of an optimization process, among other things.
For the scope of this post, the optimization criterion will be treated as an "input parameter" to the definition. For any given criterion, one can imagine an optimization process that aims to improve the state according to that criterion; it doesn't seem fair to rule some out by definition. That said, in virtually all practical cases, there is a criterion that is being more or less objectively optimized for, which we will discuss in a future post. [TODO link]
The setting
Every system in which optimization could occur will have some scope of possible states and behaviors, some "stuff" that it's made of and ways that it could act.
Usually it's sufficient to have only a rough model of the relevant system in your head. But to get numbers out of it, to actually calculate a concrete quantity of optimization, we need to formalize the model of the system.
Our crater will have some size and shape, and the probe will also have some physical properties. We can probably get away with modelling the system with Newtonian mechanics, which is to say, gravity, conservation of momentum, and some ad hoc stuff about how elastic the collisions are.
The rocket will also have some mass and shape, but it will also have parts whose functionality relies on chemistry, electromagnetism, et cetera. Its system also includes the ground it launches from, the gravitational influence of whatever bodies it's flying around, micrometeorites, et cetera.
The diversity of all these types of systems is studied under the same category of mathematical object; a system whose state changes over time according to deterministic rules is called a dynamical system. A dynamical system has two parts; a set of states, and an evolution rule for moving between those states. A state constitutes the entire "universe" of the system at one particular time, and the evolution rule tells you exactly how the system will progress from any state to any other state, which gives it its time-like nature. A particular sequence of states that the system evolves through is called a trajectory. Because the evolution rule is deterministic, every state has a unique trajectory that it will evolve through.
For a slightly more formal explanation of what dynamical systems are, and a big list of examples, see this primer [LW · GW].
So in the crater & rocket examples, the set of states consists of something like all possible ways that matter could be arranged, and the evolution rule is just the laws of physics. How detailed your model needs to be depends on how much the behavior of your system will actually depend on those things. For the crater, you could probably get away with something like "all possible surface shapes", whereas for the rocket, you'll need to consider all possible ways that the available atoms are arranged into molecules. We're also only considering things "nearby", since our system is pretty isolated. We don't need to take into account particles on the other side of Dynasys.
The optimization criterion
Now we know what the world looks like, but what kind of states is it moving toward?
To optimize is to optimize for something, to "aim", to have some kind of selection criterion over future states, whether implicit or explicit. In our framework, we represent this as an ordering over the set of states. Intuitively that just means we put them in a line. If a state is higher up the line, then it's more optimized (with respect to that ordering), and if it's farther down the line, then it's less optimized. Orders are a mathematical object, which we'll go into more detail about below.
Note that the ordering is not necessarily a "preference" ordering. I think calling it a preference ordering implies that there is some agent which, inside its mind, is representing this preference. I think that is a useful special case of optimization, but not a defining feature.[2]
A literal ordering would be something like, "I like blue better than green, which I like better than red, and I'm indifferent between all the other colors". Although the structure of an order is all we need for this framework, in practice, the optimization target is usually represented with some compact statement that lets you figure out how two states might be ranked. In numerical optimization for example, we use a loss function to calculate some type of "loss" or "error" of the states, and then simply say that less loss is better.
Going through our three examples again: the implicit state ordering for the crater is that the lower down the probe goes, the better. The bottom of the crater is the "most optimized" state.
The state ordering for the rocket is extremely picky. Basically, any state where the sample is safely back on Earth is high-optimization, and any other state is equally bad. (There are some ways you could further rank states; for example, states where only some of the sample makes it safely back to Earth are better than none of the sample, but this is a pretty narrow range of states.)
Also note that a state is not considered higher optimization if it merely will lead to a better future state. How optimized a state is is a timeless, static feature of each state. The sample sitting inside the rocket on Dynasys is not "more optimized" than the sample having blown up after launch, at least not by our criterion of "is the sample safely on Earth". It's entirely possible to calculate something like the expected value that the current state will lead to a better state, but to do that, you need a clear ranking of the states themselves, and that's what we're using here.
The probability it's pushing against
The state ordering tells you whether the states in a trajectory are getting more or less optimized. To figure out how much more optimized, we need to know how much probability it's pushing against. And to do that, we have to have some pre-existing beliefs about the probability of each state.
What does it mean to assign a probability to a state? In some sense, if trajectory did land on the state, then it had probability 1, and thus it didn't push against any probability. But this is rarely what we mean by probability. If we flip a coin and it lands on heads, we don't say, "well, it landed on heads, so that outcome had probability 1, and I was infinitely wrong [LW · GW] about assigning a probability of 50% before I flipped it."
When we assign a probability distribution to the states of our dynamical system, we are encoding a model of uncertainty over what state the system is or will be in. If we know absolutely nothing about it, then we can say they're equally likely. If we know some information, then we can use the maximum entropy distribution consistent with that information. Ultimately, the meaning of the probability distribution is about what we want to measure – the optimization is surprising, with respect to what expectation? The rest is standard Bayesian theory.
What probability distribution should we put over the states in the crater scenario? Well, the interesting thing is that the crater causes the probes to go to roughly one location, at the bottom. But this isn't surprising after we know there's a crater there; that's what we would expect, since we know that things generally roll downhill. The thing that makes the crater interesting is relative to other possible landscapes that the probe could land on. This is why I set up Dynasys to have a cloudy atmosphere; if you just look at it from the outside, you'll know it's roughly spherical, but you won't see the surface details. If you start out the (dynamical systems) trajectory by sending the probe toward Dynasys, then after a certain amount of time, you expect it to land wherever orbital mechanics predicts, and then stay roughly in that spot. You might reasonably have a small probability on it shifting a bit after landing, but a much smaller probability on it moving far.
How about the rocket? If we wanted to measure the optimization of the rocket in the context of total ignorance of the system, we could put a uniform probability distribution on it being anywhere in the entire volume of space containing both Dynasys and Earth. But we probably want to say we know more than that, given that we're already talking about where's it's starting and that it's designed to land on Earth. Perhaps we could say that we know a certain amount of energy will be released (by the fuel), and assign equal probability to all outcomes that release that energy. Or perhaps we even know that the rocket will take the sample on some (physical) trajectory, and we assign equal probability to all orbits through space that have that level of energy and intersect the rocket's starting point. As you can see, there's not always a clear, objective way to measure optimization; it's relative to what you care about measuring against. And the more you assume you know about the system, the less surprising any (potentially) optimizing outcome will be.
Calculating bits of optimization
Now that we've gone over the meaning of the various components in the framework, it's time to get more formal about all the pieces, so that we can finally define calculable measures of optimization. Throughout this sequence I will give a few such measures.
As an aside about naming, I don't call any one of these measures just plain "optimization".[3] Because of its wide usage, I think it might be best to simply use that word for the general domain or type of process, and to use more specific terms when we calculate numbers.[4] (Although I think it's fair to use the phrase "bits of optimization" to describe the units of the quantity that comes out of the calculations, as long as we're clear about the meaning of what's being calculated.)
The prior probability over states
Let's use to refer to arbitrary states (which we'll later put on the -axis according to our ordering.). Then is the probability that our system is in state . This probability distribution is just the standard mathematical object. Since the set of states is the set of all possible "outcomes", the probabilities over them should add up to 1. Otherwise, it's up to you as the Bayesian reasoner to pick what prior information you want to be represented in the distribution.
Note that the probability distribution can be a function of the timestep. The distribution is an epistemic attribute which could change over the trajectory. So if state occurs later than state , you might a priori expect the probability distribution to shift between those times.
The state ordering
We use the state ordering to calculate how much of the probability distribution the optimizing process successfully pushed against. If we landed on a state , then states ranked lower than in the ordering get their probability mass counted as "pushed against", and state higher than don't.
With a finite set of states, it's easy to imagine ordering them, just like a deck of cards. But what about systems with infinitely many states? Or what if the system is continuous, and therefore there are an uncountably infinite number of states? How could we coherently order things that we can't even list?
Fortunately, this type of object is well-studied in mathematics. Order theory is about relations between pairs of objects which express an order that the elements go in. We're going to use the symbol for our relation, as in means that state is ranked lower than or equal to state . These are basically the normal less-than signs etc, but we use the curvy version to emphasize that we're not comparing numbers; the things on both sides are states, which don't necessarily have any associated numerical size[5]. For example, maybe the state "my room is painted blue" is better than the state "my room is painted white". And we're also going to give it a subscript as in , to emphasize that the order is not unique, and is determined by some Criterion.
The order is transitive, meaning that if state is ranked lower than state and state is ranked lower than state , then state is ranked lower than . This basically just means you can place the things along a line somehow. Our order is also total, meaning that you can compare any two states. There can't be states that are simply "incomparable" (because we have to know whether to credit the optimization process for getting above that state). However, our order is also weak, meaning that two states can have an equal ranking. (This is to say that and , which we will write[6] as .) It's perfectly fine if our optimization criterion is indifferent between states.
In order theory, when you say that an order relation exists on a set of objects, you're essentially declaring the simple fact that all the pairs of objects have an ordering, as if there's a platonic table somewhere that lists rows of statements like ": False". But as mentioned in previous sections, in practice, the order relation is almost always represented by an effective procedure that takes two states as input and outputs true or false. As long as the outputs of that effective procedure adhere to the order theory axioms, then the theorems also apply.
"Absolute optimization" of a state
Now that we've notated our objects, let's get down to the first equation. This core quantity (as described in the sequences) is what I will call absolute optimization, which is a property of a single state. It could be considered an answer to the question of how well optimized the state already is, or how much optimization has been applied to the system relative to the lowest[7] ranking state.
The absolute level of optimization is the number of bits needed to describe how far up the ordering the state is.[8] Each "bit [LW · GW]" of optimization is telling you to cut the remaining probability mass in half. The 50th percentile state has one bit of (absolute) optimization, the 75th percentile state has two bits, et cetera.
I tend to visualize this as a representation where the states are laid out[9] on the -axis according to their ordering, and we plot the resulting above that. Then, the absolute optimization of a specific state is in terms of the probability mass above it, that is, to the right of it on the -axis.

More generally, let be[10] the probability mass of all states where ;[11]
(We're going to use this cumulative version just as much as , so I've made its notations simple, but hopefully it's not too similar.)
Then the absolute optimization of a state is
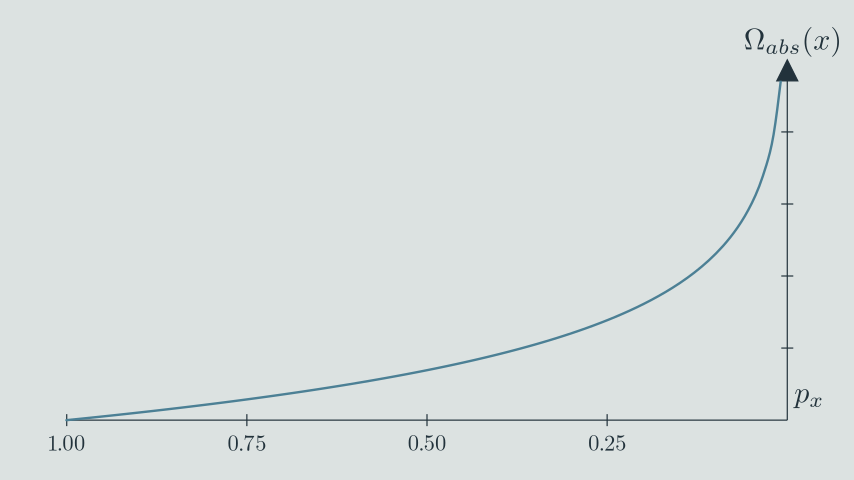
This is a standard quantity in information theory, which is sometimes called the surprisal. In our case, it is the surprisal of the event , which is to say, it measures how surprised we are to find that the state is ranked at least as high as .
The examples below are worked out with specific numbers, to help you check your understanding.
Example: eight equally likely states
If has 8 states, each of which has equal probability , and they are ordered linearly then the sum just becomes a multiplier on the number of states, and we have
We can plot this out by lining up the s on the -axis.

Here we see the intuition that cutting the state space in half gives you one bit of optimization.[12]
Example: ordering coin flips by number of heads
Let's say that I care about flipping coins, and I want to get as many heads as possible. If our states consist of the outcomes of three coin flips, we have the following ordering;
Or, more graphically illustrated;

The eight states are in four equivalence classes. (Though it is still the case that for every state.)
If we continue using these equivalence classes for our -axis, then our two probability distributions looks like this;

and the corresponding bits of (absolute) optimization look like this;

It's interesting to note the generalization that, if you flip a coin times, getting all heads is bits of optimization, but getting heads is less than bits of optimization.
"Relative optimization" between two states
In a previous section we gave the english gloss that "optimization occurs in a system when the state moves up an ordering over time". Since absolute optimization is a property of a single state, it doesn't really fit the bill. Instead, we'll look at changes over time by taking the difference in absolute optimization between two states;[13]
The pipe notation is intended to reflect conditional probabilities, conditional information, et cetera; given we started at state , how much optimization occurred going to state ? (The ordering of the arguments also matches the ordering of the subtraction.)
Relative optimization has several properties we would hope. Doing nothing applies no optimization;
which is also true whenever . Moving up in the ranking is positive optimization, and moving down is negative. If we have a state which ranks lower than a state (which is to say, ), then
where because all terms , and because there is at least one such term (namely ). Thus , meaning
and conversely
and more generally
As mentioned above, absolute optimization is equivalent to taking the relative optimization starting at the lowest ranking state. If we call such a state , then , and therefore
I think that these and other properties reinforce the idea that we have captured the intuitive concept of optimization with this formalism. Unfortunately, while it's easy to work things out for extremely simplified systems like flipping coins, it's computationally intensive to do so for other, more realistic systems. In the future we'll talk about ways to remedy this, but I hope that the framework has given you the sense that we may now have the machinery to start doing things like proving theorems about optimizing systems.
Next up
Hopefully, you now have just enough of a sense that optimization can be crisply measured, at least in principle.
There are a number of other aspects and related concepts that can make thinking about optimization confusing. I treat some of these in a further post [LW · GW], and show how this framework lets us grapple with them numerically.
My ultimate goal here is to help people working on AI alignment get fundamentally deconfused [LW · GW] about what AI is. To that end, another future post describes my speculations about how one might be able to apply this framework to AI risk.
[Again, reminder that this is a draft, and thus this is not necessarily what is next up.]
- ^
One of the most common technical meanings is numerical optimization. In this case, one has a mathematical function and is trying to find a minimum or maximum value of that function. This is not what I mean; here we will be working with a much richer collection of systems.
In the seminal AI safety paper Risks from Learned Optimization [? · GW] [PDF], they give the following working definition;
We will say that a system is an optimizer if it is internally searching through a search space looking for those elements that score high according to some objective function that is explicitly represented within the system.
This is also not what I mean; it is much more restrictive about the mechanism of optimization than we want.
More generally, there's a related concept of "agents" or "utility maximizers". These are constructs that go around an environment forming beliefs about it, modelling the effects of their own actions, and choosing to act according to some kind of reward signal or explicitly represented objective function. This, too, is much more specific than the concept we define here.
All of these concepts are examples of what I mean here by optimization; they can be analyzed within this framework. But they're all too specific for our purposes.
- ^
Also note that it is emphatically not a utility function. That would be an even stronger claim about the nature of the optimizing process. We know which states are better or worse, but it turns out that we do not need any concept of how much better or worse. My understanding is that utility assignments are for making decisions between probabilistic outcomes, and that is not something we need for measuring optimization.
(The prior probability distribution that we speak of elsewhere is unrelated to this; that represents what we think the probability of states is, and not what the optimizing process "thinks" the probabilities are.)
- ^
I also don't feel confident about any of the specific terms I've chosen, so I invite you to discuss in the comments what they should be.
- ^
As an analogy, the word "energy" is widely used, but when we do calculations, the equations are usually telling us the amounts of specific kinds of energy as defined in particular models: kinetic energy, gravitational potential energy, electrical energy, binding energy, mass-energy, etc. We use the word "energy" for the broad concept (as well as colloquially, as in "you have a lot of energy today). And we also give the same unit name to all the types, namely Joules.
- ^
You might wonder why I don't use some function that converts the states to numbers in a way that matches the ordering, and then use the normal relation. There are a couple reasons. One is that would not be unique; using would give the same ordering. Another is that with infinite sets, orderings can be more exotic! Overall, an ordering is a more abstract concept than just the size of numbers.
- ^
And similarly for , and . These things act in the intuitive way.
- ^
Sometimes there is an infinite regress of lower ranked states, but this doesn't matter here, because we're just accounting for the probability mass down there, which is bounded in any case.
- ^
In the context of my introduction to entropy [LW(p) · GW(p)], absolute optimization could also be described as the negentropy of the macrostate "at least as good as x". This is a way to formalize the idea that entropy and optimization are opposites.
- ^
You may be wondering about what measure we're using here. It doesn't actually matter, since we're just doing operations on the corresponding probability mass, which will be invariant under changes of variables that preserve the ordering (i.e. just various stretching and shrinking along the axis).
- ^
I'll use the discrete sums throughout, but the integral versions act the same as far as I can tell. All logarithms are base 2 because we're working in bits.
- ^
You could also define to be the probability mass of states below . That would let us avoid some of the awkwardness of the upcoming graphs looking flipped. But then we would have to define absolute optimization as
That would somewhat obscure its nature as a surprisal, and we would lose the nicety of "each bit halves the probability mass" unless you clarify that said mass is .
- ^
Note that a randomly chosen state has a 50% chance of being ranked greater than the 50%ile state, and so in some sense the "default" amount of optimization is one bit.
I'm not entirely sure how I feel about this. It kind of feels to me that the average state would have zero absolute optimization, and that the worst state should have negative absolute optimization. But I don't actually think we will usually care about absolute optimization; I think instead we'll care about relative optimization, defined below.
This situation reminds me somewhat of Voltage and potential energy, which are not meaningful at single point, but instead are only meaningful across a pair of points. Nonetheless, we tend to assign some point as the "zero" Voltage point, to make the accounting easier. In this way, absolute optimization feels a bit gauge-theoretic to me, but I've never delved into that domain, so I'm not sure how I would go about figuring out whether it is or isn't a gauge theory.
- ^
Note that, as mentioned above, and might not be calculated from the same distribution. However, the identities in this section assume that the distribution is the same.
8 comments
Comments sorted by top scores.
comment by Shmi (shminux) · 2023-03-26T19:06:28.570Z · LW(p) · GW(p)
I suspect that a solar flare would qualify as an optimization process under your criteria.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2023-03-29T21:05:52.372Z · LW(p) · GW(p)
Yep, that makes sense to wonder about here. I've got a couple main responses.
The first is that I'm taking a clear stand on separating optimization and agency. Optimization is the weaker thing, and includes balls rolling into basins, and so solar flares or whatever are probably interpretable as something like that. The really dangerous AIs will be agents. Agents are type of optimizer, and so I'm trying to understand the base class (optimization) before moving on to the more complicated subclass (agents). A lot of people are working directly on understanding agents first, and I think that's great, but I suspect things would be a lot clearer if we all agreed on a framework for optimization first.
The second things is that the framework in the above draft suffers from a problem, similar to the idea of VNM rationality or whatever, where you can just take the trajectory that the system ended up taking, declare that to be the state ordering you're measuring optimization with respect to, and then declare that the system is a strong optimizer. I think this is important to address, but is also a solved problem. I talk about it in this [LW · GW] draft.
comment by Sam FM · 2023-03-28T02:15:52.931Z · LW(p) · GW(p)
First of all, wow, great read! The non-technical explanations in the first half made it easy to map those concepts to the technical notation in the second half.
The hardest part to understand for me was the idea of absolute bits of optimization. I resolved my confusion after some closer examination, but I’d suggest two changes that would strengthen the explanation:
1. The animated graph showing increasing bits of optimization has a very unfortunate zoom level. This — combined with the fat left side of the graph — gave me a false impression that the area was simply reducing by a third of its total as the optimization bits counted up to a maximum of ~3 (2.93 to be exact). Eventually realized there’s presumably a long tail extending to the right past the range we can see, but that wasn’t clear from the start. Even knowing this, it’s still hard to get my brain to parse the area as being progressively cut in half. I would hesitate to change the shape of this graph (it’s important to understand that it’s the area being halved, not just horizontal progress) but I think zooming out the domain would make it feel much more like “approaching infinite optimization”.
2. This is a minor point, but I think the “in terms of” in this sentence is needlessly vague:
Then, the absolute optimization of a specific state is in terms of the probability mass above it, that is, to the right of it on the -axis.
It took a bit for me to understand, “oh, bits of optimization is just calculated as the inverse of ”. Maybe it would be clearer to say that from the start? Not sure what the exact math terms are, but something like:
Replies from: Alex_AltairThen, the absolute optimization of a state is [the proportional inverse of] the probability mass above it, that is, to the right of it on the -axis.
↑ comment by Alex_Altair · 2023-03-29T18:23:15.825Z · LW(p) · GW(p)
Thanks, that's useful feedback! I fiddled with that graph animation a bit, and yeah, I think it's off. I think it's not actually calculating the area correctly, so that the first "bit" is actually highlighting less than half the area (even counting a long tail). It seemed finicky to debug and I wasn't sure it mattered, but hearing that it confused somebody makes me more inclined to redo it.
comment by Mateusz Bagiński (mateusz-baginski) · 2023-12-23T10:51:55.465Z · LW(p) · GW(p)
Sometimes there is an infinite regress of lower ranked states, but this doesn't matter here, because we're just accounting for the probability mass down there, which is bounded in any case.
I don't understand this part. How does probability mass constrain how "bad" the states can get? Could you rephrase this maybe?
If something with a probability of zero occurs, that is infinitely surprising, hence the asymptote on the right.
What's your preferred response/solution to ~"problems"(?) of events that have probability zero but occur nevertheless, e.g., randomly generating any specific real number from the range (0,1).
It's (probably) true that our physical reality has only finite precision (and so there's a finite number of float32s between 0 and 1 that you can sample from) but still (1) shouldn't a solid framework work even in worlds with infinite precision and (2) shouldn't we measure the surprise/improbability wrt our world model anyway?
Replies from: Alex_Altair, Alex_Altair↑ comment by Alex_Altair · 2023-12-27T21:16:57.777Z · LW(p) · GW(p)
What's your preferred response/solution to ~"problems"(?) of events that have probability zero but occur nevertheless
My impression is that people have generally agreed that this paradox is resolved (=formally grounded) by measure theory. I know enough measure theory to know what it is but haven't gone out of my way to explore the corners of said paradoxes.
But you might be asking me about it in the framework of Yudkowsky's measure of optimization. Let's say the states are the real numbers in [0, 1] and the relevant ordering is the same as the one on the real numbers, and we're using the uniform measure over it. Then, even though the probability of getting any specific real number is zero, the probability mass we use to calculate bit of optimization power is all the probability mass below that number. In that case, all the resulting numbers would imply finite optimization power. ... except if we got the result that was exactly the number 0. But in that case, that would actually be infinitely surprising! And so the fact that the measure of optimization returns infinity bits reflects intuition.
It's (probably) true that our physical reality has only finite precision
I'm also not a physicist but my impression is that physicists generally believe that the world does actually have infinite precision.
I'd also guess that the description length of (a computable version of) the standard model as-is (which includes infinite precision because it uses the real number system) has lower K-complexity than whatever comparable version of physics where you further specify a finite precision.
↑ comment by Alex_Altair · 2023-12-27T21:04:35.980Z · LW(p) · GW(p)
I don't understand this part. How does probability mass constrain how "bad" the states can get? Could you rephrase this maybe?
The probability mass doesn't constraint how "bad" the states can get; I was saying that the fact that there's only 1 unit of probability mass means that the amount of probability mass on lower states is bounded (by 1).
Restricting the formalism to orderings means that there is no meaning to how bad a state is, only a meaning to whether it is better or worse than another state. (You can additionally decide on a measure of how bad, as long as it's consistent with the ordering, but we don't need that to analyze (this concept of) optimization.)