New LessWrong feature: Dialogue Matching
post by Bird Concept (jacobjacob) · 2023-11-16T21:27:16.763Z · LW · GW · 22 commentsContents
New feature! 🎉 Why build this? Using LessWrong's treasure trove of data Here is a link to the Dialogue Matchmaking page :-) None 22 comments
The LessWrong team is shipping a new experimental feature today: dialogue matching!
I've been leading work on this (together with Ben Pace, kave, Ricki Heicklen, habryka and RobertM), so wanted to take some time to introduce what we built and share some thoughts on why I wanted to build it.
New feature! 🎉
There's now a dialogue matchmaking page at lesswrong.com/dialogueMatching
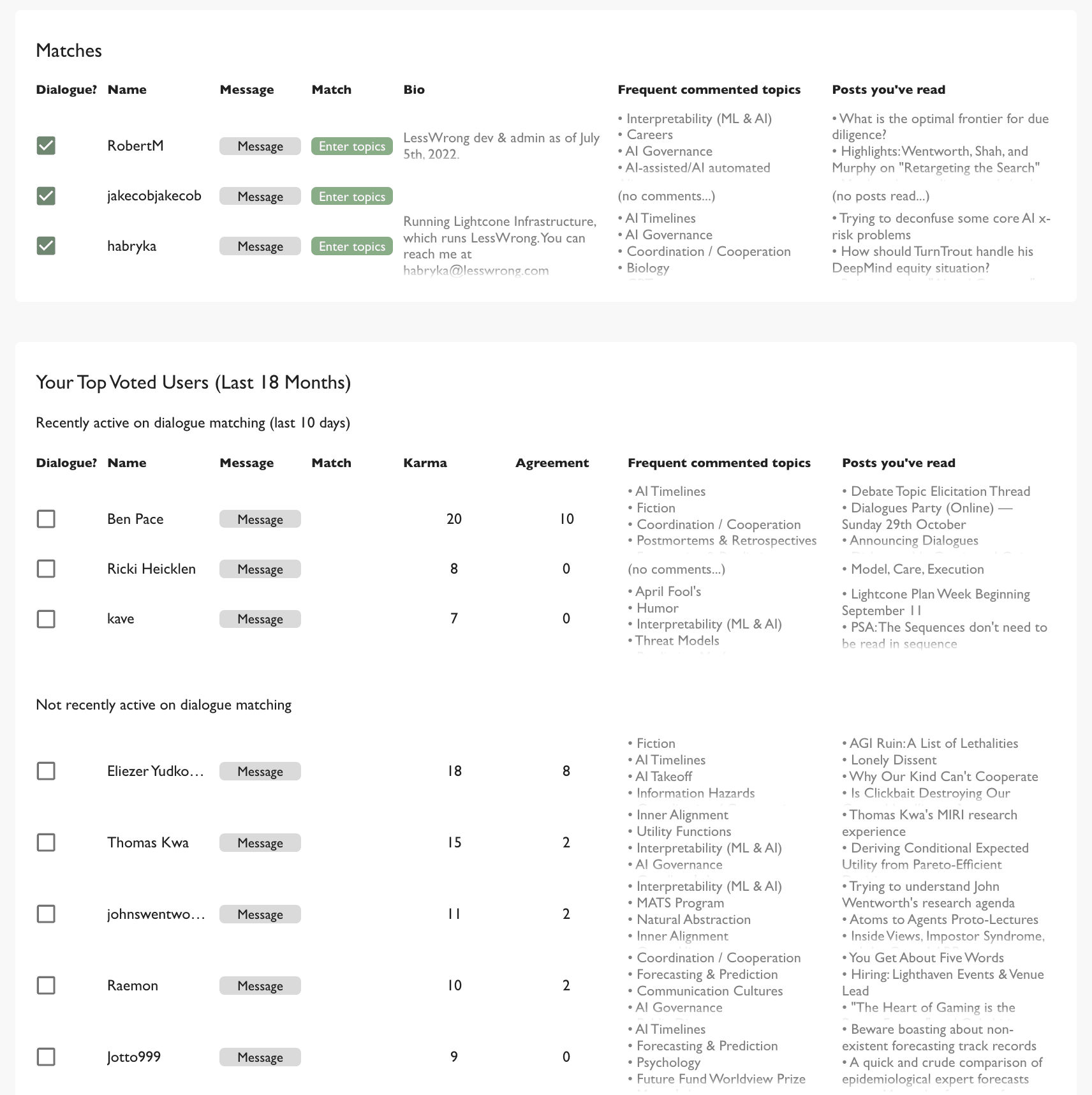
Here's how it works:
- You can check a user you'd potentially be interested in having a dialogue with, if they were too
- They can't see your checks unless you match
It also shows you some interesting data: your top upvoted users over the last 18 months, how much you agreed/disagreed with them, what topics they most frequently commented on, and what posts of theirs you most recently read.
- Next, if you find a match, this happens:
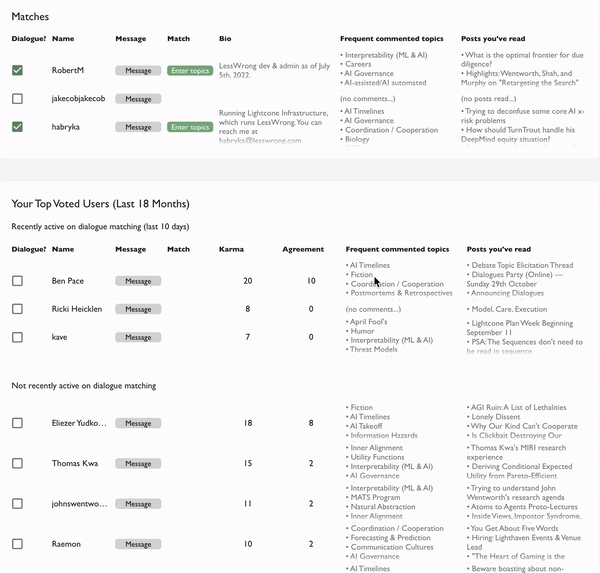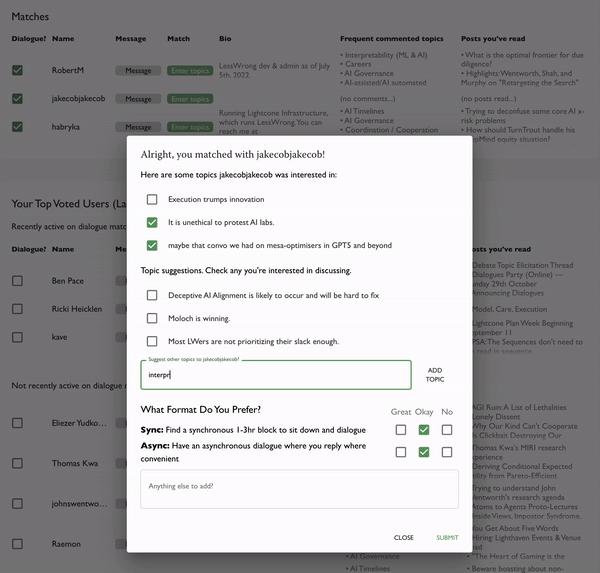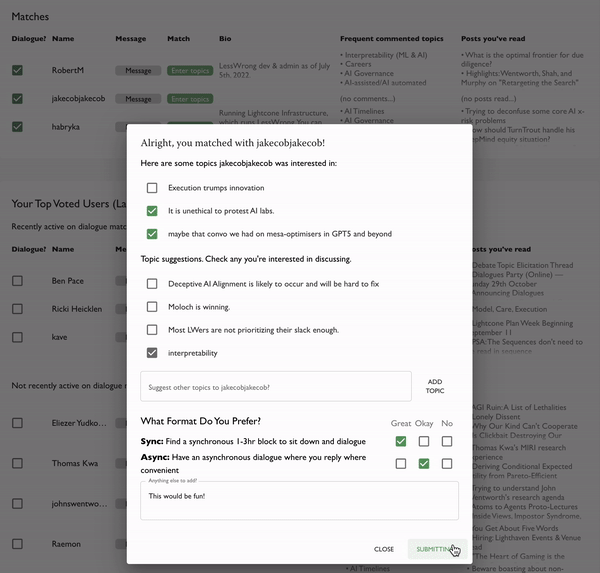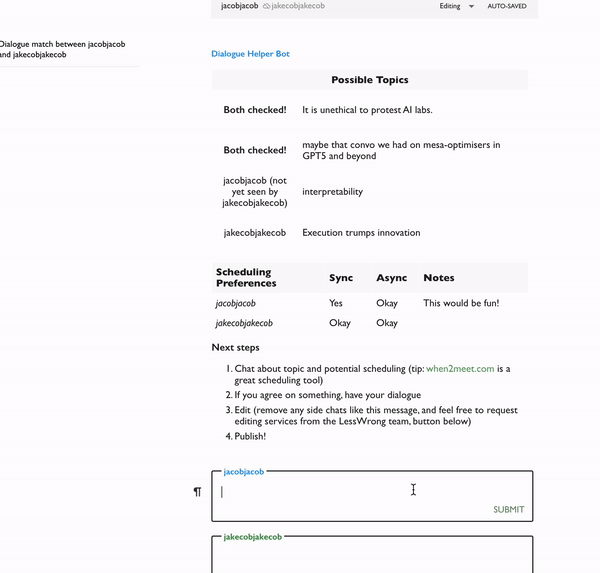
You get a tiny form asking for topic ideas and format preferences, and then we create a dialogue that summarises your responses and suggests next steps based on them.
Currently, we're mostly sourcing auto-suggested topics from Ben's neat poll [LW · GW] where people voted on interesting disagreement they'd want to see debated, and also stated their own views. I'm pretty excited to further explore this and other ways for auto-suggesting good topics. My hypothesis is that we're in a bit of a dialogue overhang: there are important conversations out there to be had, but that aren't happening. We just need to find them.
This feature is an experiment in making it easier to do many of the hard steps in having a dialogue: finding a partner, finding a topic, and coordinating on format.
To try the Dialogue Matching feature, feel free to head on over to lesswrong.com/dialogueMatching !
Me and the team are super keen to hear any and all feedback. Feel free to share in comments below or using the intercom button in the bottom right corner :)
Why build this?
A retreat organiser I worked with long ago told me: "the most valuable part of an event usually aren't the big talks, but the small group or 1-1 conversations you end up having in the hallways between talks."
I think this points at something important. When Lightcone runs events, we usually optimize the small group experience pretty hard. In fact, when building and renovating our campus Lighthaven [LW · GW], we designed it to have lots of little nooks and spaces in order to facilitate exactly this kind of interaction.
With dialogues, I feel like we're trying to enable an interaction on LessWrong that's also more like a 1-1, and less like a broadcasting talk to an audience.
But we're doing so with two important additions:
- Readable artefacts. Usually the results of a 1-1 are locked in with the people involved. Sometimes that's good. But other times, Dialogues enable a format where good stuff that came out of it can be shared with others.
- Matchmaking at scale. Being a good event organiser involves a lot of effort to figure out who might have valuable conversations, and then connecting them. This can often be super valuable (thought experiment: imagine introducing Von Neumann and Morgenstern), but takes a lot of personalised fingertip feel and dinner host mojo. Using dialogue matchmaking, I'm curious about a quick experiment to try to doing this at scale, in an automated way.
Overall, I think there's a whole class of valuable content here that you can't even get out at all outside of a dialogue format. The things you say in a talk are different from the things you'd share if you were being interviewed on a podcast, or having a conversation with a friend. Suppose you had been mulling over a confusion about AI. Your thoughts are nowhere near the point where you could package them into a legible, ordered talk and then go present them. And ain't nobody got time for that prep work anyway!
So, what do you do? I think a Dialogue with a friend or colleague might be a neat way to get these kinds of thoughts out there.
Using LessWrong's treasure trove of data
Before I joined the team, the LessWrong crew kept busy shipping lots of stuff. So now when readers and writers hang out around here, there's lots of data we create about what we find interesting. There are:
...tags...

...up and downvotes...

...agree and disagree votes...

...reacts...

...post mentions...

...and just the normal data of page views, comments written and so forth.
This can tell us a lot about what people are interested in and what writing they find important.
We can also look at more high-level patterns, like:
- Who are users you tend to upvote but also disagree with?
- Who are users who tend to upvote each other, and comment on similar topics, but haven't yet had a conversation?
- What's a topic that people would really like to see discussed [LW · GW], and where you and someone you respect hold opposing views?
...and so forth.
I don't know what the right questions are. But I have a sense, a trailhead, that we're sitting on this incredible treasure trove of data. And thus far it has been almost entirely unutilised for building LessWrong features.
(Note: in doing this, I want to be careful to respect y'alls data. I wrote a comment below with my current thoughts and approach to that.)
What's even more exciting: suppose we're able to use entirely on-LessWrong data to find and suggest conversations that we feel are interesting and important. That will then cause more such conversations to happen. Which, in turn, generates more LessWrong data that we can look at to recommend new conversations.
It's a flywheel!
I'm excited to try spinning it.
Here is a link to the Dialogue Matchmaking page :-)
22 comments
Comments sorted by top scores.
comment by Bird Concept (jacobjacob) · 2023-11-16T20:16:14.244Z · LW(p) · GW(p)
On data privacy
Here's some quick notes on how I think of LessWrong user data.
Any data that's already public -- reacts, tags, comments, etc -- is fair game. It just seems nice to do some data science and help folks uncover interesting patterns here.
On the other side of the spectrum, me and the team generally never look at users' up and downvotes, except in cases where there's strong enough suspicion of malicious voting behavior (like targeted mass downvoting).
Then there's stuff in the middle. Like, what if we tell a user "you and this user frequently upvote each other"? That particular example currently feels like it reveals too much private data. As another example, the other day me and a teammate had a discussion of whether, on the matchmaking page, we could show people recently active users who already checked you, to make it more likely you'd find a match. We tenatively postulated it would be fine to do this as long as seeing a name on your match page gave no more than like a 5:1 update about those people having checked you. We sketched out some algorithms to implement this, that would also be stable under repeated refreshing and similar. (We haven't implemented the algorithm nor the feature yet.)
So my general take on features "in the middle" is for now to treat them on a case by case basis, with some principles like "try hard to avoid revealing anything that's not already public, and if doing so, try to leave plausible deniability bounded by some number of leaked bits, only reveal metadata or aggregate data, reveal it only to one other or a smaller set of users, think about whether this is actually a piece of info that seems high or low stakes, and see if you can get away with just using data from people who opted in to revealing it".
Replies from: Kaj_Sotala, faul_sname, MondSemmel, Ninety-Three↑ comment by Kaj_Sotala · 2023-11-17T18:04:41.621Z · LW(p) · GW(p)
We tenatively postulated it would be fine to do this as long as seeing a name on your match page gave no more than like a 5:1 update about those people having checked you.
I would strongly advocate against this kind of thought; any such decision-making procedure relies on the assumption that you correctly figure out all the ways such information can be used, and that there isn't a clever way an adversary can extract more information than you had thought. This is bound to fail - people come up with clever ways to extract more private information than anticipated all the time. For example:
- Timing Attacks on Web Privacy:
- We describe a class of attacks that can compromise the privacy of users’ Web-browsing histories. The attacks allow a malicious Web site to determine whether or not the user has recently visited some other, unrelated Web page. The malicious page can determine this information by measuring the time the user’s browser requires to perform certain operations. Since browsers perform various forms of caching, the time required for operations depends on the user’s browsing history; this paper shows that the resulting time variations convey enough information to compromise users’ privacy.
- Robust De-anonymization of Large Datasets (How to Break Anonymity of the Netflix Prize Dataset)
- We apply our de-anonymization methodology to the Netflix Prize dataset, which contains anonymous movie ratings of 500,000 subscribers of Netflix, the world’s largest online movie rental service. We demonstrate that an adversary who knows only a little bit about an individual subscriber can easily identify this subscriber’s record in the dataset. Using the Internet Movie Database as the source of background knowledge, we successfully identified the Netflix records of known users, uncovering their apparent political preferences and other potentially sensitive information.
- De-anonymizing Social Networks
- We present a framework for analyzing privacy and anonymity in social networks and develop a new re-identification algorithm targeting anonymized social network graphs. To demonstrate its effectiveness on real-world networks, we show that a third of the users who can be verified to have accounts on both Twitter, a popular microblogging service, and Flickr, an online photo-sharing site, can be re-identified in the anonymous Twitter graph with only a 12% error rate. Our de-anonymization algorithm is based purely on the network topology, does not require creation of a large number of dummy “sybil” nodes, is robust to noise and all existing defenses, and works even when the overlap between the target network and the adversary’s auxiliary information is small.
- On the Anonymity of Home/Work Location Pairs
- Many applications benefit from user location data, but location data raises privacy concerns. Anonymization can protect privacy, but identities can sometimes be inferred from supposedly anonymous data. This paper studies a new attack on the anonymity of location data. We show that if the approximate locations of an individual’s home and workplace can both be deduced from a location trace, then the median size of the individual’s anonymity set in the U.S. working population is 1, 21 and 34,980, for locations known at the granularity of a census block, census track and county respectively. The location data of people who live and work in different regions can be re-identified even more easily. Our results show that the threat of re-identification for location data is much greater when the individual’s home and work locations can both be deduced from the data.
- Bubble Trouble: Off-Line De-Anonymization of Bubble Forms
- Fill-in-the-bubble forms are widely used for surveys, election ballots, and standardized tests. In these and other scenarios, use of the forms comes with an implicit assumption that individuals’ bubble markings themselves are not identifying. This work challenges this assumption, demonstrating that fill-in-the-bubble forms could convey a respondent’s identity even in the absence of explicit identifying information. We develop methods to capture the unique features of a marked bubble and use machine learning to isolate characteristics indicative of its creator. Using surveys from more than ninety individuals, we apply these techniques and successfully reidentify individuals from markings alone with over 50% accuracy.
↑ comment by Bird Concept (jacobjacob) · 2023-11-17T18:48:56.231Z · LW(p) · GW(p)
Those are some interesting papers, thanks for linking.
In the case at hand, I do disagree with your conclusion though.
In this situation, the most a user could find out is who checked them in dialogues. They wouldn't be able to find any data about checks not concerning themselves.
If they happened to be a capable enough dev and were willing to go through the schleps to obtain that information, then, well... we're a small team and the world is on fire, and I don't think we should really be prioritising making Dialogue Matching robust to this kind of adversarial cyber threat for information of comparable scope and sensitivity! Folks with those resources could probably uncover all kinds of private vote data already, if they wanted to.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-11-17T19:36:26.294Z · LW(p) · GW(p)
we're a small team and the world is on fire, and I don't think we should really be prioritising making Dialogue Matching robust to this kind of adversarial cyber threat for information of comparable scope and sensitivity!
I agree that it wouldn't be a very good use of your resources. But there's a simple solution for that - only use data that's already public and users have consented to you using. (Or offer an explicit opt-in where that isn't the case.)
I do agree that in this specific instance, there's probably little harm in the information being revealed. But I generally also don't think that that's the site admin's call to make, even if I happen to agree with that call in some particular instances. A user may have all kinds of reasons to want to keep some information about themselves private, some of those reasons/kinds of information being very idiosyncratic and hard to know in advance. The only way to respect every user's preferences for privacy, even the unusual ones, is by letting them control what information is used and not make any of those calls on their behalf.
↑ comment by habryka (habryka4) · 2023-11-17T18:46:44.260Z · LW(p) · GW(p)
Hmm, most of these don't really apply here? Like, it's not like we are proposing to do anything complicated. We are just saying "throw in some kind of sample function with a 5:1 ratio, ensure you can't get redraws". I feel like I can just audit the whole trail of implications myself here (and like, substantially more than I am e.g. capable of auditing all of our libraries for security vulnerabilities, which are sadly reasonably frequent in the JS land we are occupying).
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-11-17T19:15:37.667Z · LW(p) · GW(p)
My point is less about the individual example than the overall decision algorithm. Even if you're correct that in this specific instance, you can verify the whole trail of implications and be certain that nothing bad happens, a general policy of "figure it out on a case-by-case basis and only do it when it feels safe" means that you're probably going to make a mistake eventually, given how easy it is to make a mistake in this domain.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-11-17T19:16:59.865Z · LW(p) · GW(p)
I am not sure what the alternative is. What decision-making algorithm do you suggest for adopting new server-side libraries that might have security vulnerabilities? Or to switch existing ones? My only algorithm is "figure it out on a case-by-case basis and only do it when it feels safe". What's the alternative?
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-11-17T19:39:57.257Z · LW(p) · GW(p)
For site libraries, there is indeed no alternative since you have to use some libraries to get anything done, so there you do have to do it on a case-by-case basis. In the case of exposing user data, there is an alternative - limiting yourself to only public data. (See also my reply to jacobjacob [LW(p) · GW(p)].)
↑ comment by faul_sname · 2023-11-17T19:58:18.518Z · LW(p) · GW(p)
If "show people who have checked you" is a thing that would improve the experience, then I as a user would appreciate a checkbox "users who you have checked and have not checked you can see that you have checked them". I, for one, would check such a checkbox.
Replies from: jacobjacob↑ comment by Bird Concept (jacobjacob) · 2023-11-17T20:29:29.071Z · LW(p) · GW(p)
(If others want this too, upvote @faul_sname [LW · GW]'s comment as a vote! It would be easy to build, most of my uncertainty is in how it would change the experience)
↑ comment by MondSemmel · 2023-11-17T12:27:24.203Z · LW(p) · GW(p)
One level of privacy is "the site admins have access to data, but don't abuse it". But there are other levels, too. Let's take something I assume is private in this way, the identities of who has up/downvoted a post or comment.
- Can someone e.g. inspect the browser page or similar, in order to identify these identities?
- Can someone look through the Forum Magnum Github repo and based on the open source code find ways to identify these identities?
- Can someone on GreaterWrong identify these identities?
For other things that seem private (e.g. PMs), are any of those vulnerable to stuff like the above?
Replies from: kave↑ comment by Ninety-Three · 2024-01-08T21:09:50.108Z · LW(p) · GW(p)
I just got a "New users interested in dialoguing with you (not a match yet)" notification and when I clicked on it the first thing I saw was that exactly one person in my Top Voted users list was marked as recently active in dialogue matching. I don't vote much so my Top Voted users list is in fact an All Voted users list. This means that either the new user interested in dialoguing with me is the one guy who is conspicuously presented at the top of my page, or it's some random that I've never interacted with and have no way of matching.
This is technically not a privacy violation because it could be some random, but I have to imagine this is leaking more bits of information than you intended it to (it's way more than a 5:1 update), so I figured I'd report it as a bug unanticipated feature.
It further occurs to me that anyone who was dedicated to extracting information from the system could completely deanonymize their matches by setting a simple script to scrape https://www.lesswrong.com/dialogueMatching [? · GW] every minute or so and cross-referencing "new users interested" notifications with the moment someone shoots to the top of the "recently active in dialogue matching" list. It sounds like [LW(p) · GW(p)] you don't care about that kind of attack though so I guess I'm mentioning it for completeness.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-01-08T22:01:30.563Z · LW(p) · GW(p)
We thought of these things!
The notifications for matches only go out on a weekly basis, so I don't think timing it would work. Also, we don't sort users who clicked you in any way differently than other users on your page, so you might have been checked by a person who you haven't voted much on.
comment by philh · 2023-12-09T13:04:00.283Z · LW(p) · GW(p)
My stance towards almost everyone is "if you want to have a dialogue with me and have a topic in mind, great, I'm probably interested; but I have nothing specific in mind that I want to dialogue with you about". Which makes me not want to check the box, but some people have apparently checked it for me. I'd appreciate having two levels of interest, along the lines of "not interested/interested/enthusiastic" such that a match needs either interested/enthusiastic or enthusiastic/enthusiastic.
Replies from: abstractapplic↑ comment by abstractapplic · 2023-12-11T00:58:23.374Z · LW(p) · GW(p)
I am in literally the exact same situation, and think your proposed remedy makes sense.
comment by Review Bot · 2024-02-15T05:22:54.046Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by mako yass (MakoYass) · 2023-12-07T23:53:47.638Z · LW(p) · GW(p)
Making this private is a mistake. The only reason I might sometimes avoid messaging someone I wanted to have a dialog with, is a concern that the notification might annoy them. The dialog matching system still sends a notification and only makes it even more annoying by refusing to say who sent it or why.
I really hope none of the people matching with me wanted to dialog about something important, because it's probably not going to end up happening.
comment by faul_sname · 2023-11-18T01:30:29.251Z · LW(p) · GW(p)
Fun fact: you can match with yourself. Which I guess would be a monologue. :)
Replies from: jacobjacob↑ comment by Bird Concept (jacobjacob) · 2023-11-18T03:19:48.429Z · LW(p) · GW(p)
Yeah I'm gonna ship a fix to that now. No more monologues!
comment by MondSemmel · 2023-11-17T12:17:26.809Z · LW(p) · GW(p)
Minor edit suggestions for the Dialogue Matching page:
- "and choose whether start a dialogue" -> "and choose whether to start a dialogue"
- Make the "Karma" and maybe "Agreement" columns center-aligned and maybe smaller.
Minor edit suggestion for this LW essay page:
- The images for normal karma votes and for agreemen votes are somehow crazy big.
Other suggestions:
- This might complicate things too much, but re: the synchronous dialogue format: Since LW is an international site, it's hard for people from vastly synchronous timezones to find a synchronous time block. So in the form, it might help to either be able to select timezones, or to share a "here's when I'm available for dialogues" calendar. Though rather than a formal field to enter this data, one could also add a prompt in the "Anything else to add?" text form.
Overarching thoughts:
- This matching design is people-first: You first decide who you want to dialogue with, and then what to talk about. I'm curious why you went that route with the design, rather than a topic-first approach? In the latter, everyone would make it public what topics they're interested in, then the table would list topics by level of interest (rather than people sorted by karma), and once you selected a topic, you could check all users you'd like to dialogue with.
comment by supposedlyfun · 2023-11-17T20:19:23.111Z · LW(p) · GW(p)
This is cool!
Also, all of my top matches are so much more knowledgeable and experienced in matters relevant to this site that I would never message them, because I assume that will just distract them from doing useful alignment research and make our glorious transhumanist future less likely.