the scaling “inconsistency”: openAI’s new insight
post by nostalgebraist · 2020-11-07T07:40:06.548Z · LW · GW · 14 commentsContents
1. L(C) and L(D) 2. C sets E, and E bounds D Budget tradeoffs From step count to update count From update count to data count 3. The inconsistency L(D): information L(C): budgeting N goes up fast, S goes up slowly… … and you claim to achieve the impossible 4. The resolution Bigger models extract a resource faster The resource is finite Converging in the very first step Getting a bigger quarry Where we are now Implications None 14 comments
I’ve now read the new OpenAI scaling laws paper. Also, yesterday I attended a fun and informative lecture/discussion with one of the authors.
While the topic is on my mind, I should probably jot down some of my thoughts.
This post is mostly about what the new paper says about the “inconsistency” brought up in their previous paper.
The new paper has a new argument on this topic, which is intuitive and appealing, and suggests that the current scaling trend will indeed “switch over” soon to a new one where dataset size, not model size, is the active constraint on performance. Most of this post is an attempt to explain and better understand this argument.
——
The new paper is mainly about extending the scaling laws from their earlier paper to new modalities.
In that paper, they found scaling laws for transformers trained autoregressively on text data. The new paper finds the same patterns in the scaling behavior of transformers trained autoregressively on images, math problems, etc.
So the laws aren’t telling us something about the distribution of text data, but about something more fundamental. That’s cool.
They also have a new, very intuitive hypothesis for what’s going on with the “scaling inconsistency” they described in the previous paper – the one I made a big deal about at the time. So that’s the part I’m most excited to discuss.
I’m going to give a long explanation of it, way longer than the relevant part of their paper. Some of this is original to me, all errors are mine, all the usual caveats.
——
1. L(C) and L(D)
To recap: the “inconsistency” is between two scaling laws:
- The law for the best you can do, given a fixed compute budget.
This is L(C), sometimes called L(C_min). L is the loss (lower = better), C is your compute budget. - The law for the best you can do, given a fixed dataset size.
This is L(D), where D is the number of examples (say, tokens) in the dataset.
Once you reach a certain level of compute, these two laws contradict each other.
I’ll take some time to unpack that here, as it’s not immediately obvious the two can even be compared to one another – one is a function of compute, the other of data.
2. C sets E, and E bounds D
Budget tradeoffs
Given a compute budget C, you can derive the optimal way to spend it on different things. Roughly, you are trading off between two ways to spend compute:
- Use C to buy “N”: Training a bigger model – “N” here is model size
- Use C to buy “S”: Training for more steps “S” (gradient updates)
The relationship between S (steps) and D (dataset size) is a little subtle, for several reasons.
From step count to update count
For one thing, each single “step” is an update on the information from more than one data point. Specifically, a step updates on “B” different points – B is the batch size.
So the total number of data points processed during training is B times S. The papers sometimes call this quantity “E” (number of examples), so I’ll call it that too.
From update count to data count
Now, when you train an ML model, you usually update on each data point more than once. Typically, you’ll do one pass over the full dataset (updating on each point as you go along), then you’ll go back and do a second full pass, and then a third, etc. These passes are called “epochs.”
If you’re doing things this way, then for every point in the data, you get (number of epochs) updates out of it. So
E = (number of epochs) * D.
Some training routines don’t visit every point the exact same number of times – there’s nothing forcing you to do that. Still, for any training procedure, we can look at the quantity E / D.
This would be the number of epochs, if you’re doing epochs. For a generic training routine, you can can think of E / D as the “effective number of epochs”: the average number of times we visit each point, which may not be an integer.
Generally, E ≠ D, but we always have E≥D. You can’t do fewer than one epoch; you can’t visit the average point less than once.
This is just a matter of definitions – it’s what “dataset size” means. If you say you’re training on a million examples, but you only update on 100 individual examples, then you simply aren’t “training on a million examples.”
3. The inconsistency
L(D): information
OpenAI derives a scaling law called L(D). This law is the best you could possibly do – even with arbitrarily large compute/models – if you are only allowed to train on D data points.
No matter how good your model is, there is only so much it can learn from a finite sample. L(D) quantifies this intuitive fact (if the model is an autoregressive transformer).
L(C): budgeting
OpenAI also derives another a scaling law called L(C). This is the best you can do with compute C, if you spend it optimally.
What does optimal spending look like? Remember, you can spend a unit of compute on
- a bigger model (N), or
- training the same model for longer (S)
(Sidenote: you can also spend on bigger batches B. But – to simplify a long, complicated story – it turns out that there are really just 2 independent knobs to tune among the 3 variables (B, N, S), and OpenAI frames the problem as tuning (N, S) with B already “factored out.”)
In the compute regime we are currently in, making the model bigger is way more effective than taking more steps.
This was one of the punchlines of the first of these two papers: the usual strategy, where you pick a model and then train it until it’s as good as it can get, is actually a suboptimal use of compute. If you have enough compute to train the model for that long (“until convergence”), then you have enough compute to train a bigger model for fewer steps, and that is a better choice.
This is kind of counterintuitive! It means that you should stop training your model before it stops getting better. (“Early stopping” means training your model until it stops getting better, so this is sort of “extra-early stopping.”) It’s not that those extra steps wouldn’t help – it’s that, if you are capable of doing them, then you are also capable of doing something else that is better.
Here’s something cool: in Appendix B.2 of the first paper, they actually quantify exactly how much performance you should sacrifice this way. Turns out you should always stop at a test loss about 10% higher than what your model could asymptotically achieve. (This will be relevant later, BTW.)
Anyway, OpenAI derives the optimal way to manage the tradeoff between N and S. Using this optimal plan, you can derive L(C) – the test loss you can achieve with compute C, if you allocate it optimally.
N goes up fast, S goes up slowly…
The optimal plan spends most incremental units of compute on bigger models (N). It spends very little on more steps (S).
The amount it spends on batch size (B) is somewhere in between, but still small enough that the product E = B*S grows slowly.
But remember, we know a relationship between E and “D,” dataset size. E can’t possibly be smaller than D.
So when your optimal plan chooses its B and its S, it has expressed an opinion about how big its training dataset is.
The dataset could be smaller than B*S, if we’re doing many (effective) epochs over it. But it can’t be any bigger than B*S: you can’t do fewer than one epoch.
… and you claim to achieve the impossible
L(C), the loss with optimally allocated C, goes down very quickly as C grows. Meanwhile, the dataset you’re training with that compute stays almost the same size.
But there’s a minimum loss, L(D), you can possibly achieve with D data points.
The compute-optimal plan claims “by training on at most B*S data points, with model size N, I can achieve loss L(C).”
The information bound says “if you train on at most B*S data points, your loss can’t get any lower than the function L(D), evaluated at D = B*S.”
Eventually, with enough compute, the L(C) of the compute-optimal plan is lower than the L(D) of the dataset used by that same plan.
That is, even if the compute-optimal model is only training for a single epoch, it is claiming to extract more value that epoch than any model could ever achieve, given any number of epochs.
That’s the inconsistency.
4. The resolution
In the new paper, there’s an intuitive hypothesis for what’s going on here. I don’t think it really needs the multimodal results to motivate it – it’s a hypothesis that could have been conceived earlier on, but just wasn’t.
Bigger models extract a resource faster
The idea is this. As models get bigger, they get more update-efficient: each time they update on a data point, they get more out of it. You have to train them for fewer (effective) epochs, all else being equal.
This fact drives the choice to scale up the model, rather than scaling up steps. Scaling up the model makes your steps more valuable, so when you choose to scale the model rather than the steps, it’s almost like you’re getting more steps anyway. (More “step-power,” or something.)
The resource is finite
Each data point has some information which a model can learn from it. Finite models, trained for a finite amount of time, will miss out on some of this information.
You can think about the total extractable information in a data point by thinking about what an infinitely big model, trained forever, would eventually learn from that point. It would extract all the information – which is more than a lesser model could extract, but still finite. (A single data point doesn’t contain all the information in the universe.)
This is literally the definition of L(D): what an infinitely big model, trained forever, could learn from D separate data points. L(D) quantifies the total extractable information of those points.
(More precisely, the total extractable information is the gap between L(D) and the loss achieved by a maximally ignorant model, or something like that.)
Converging in the very first step
As models get bigger, they extract more information per update. That is, each time they see a data point, they extract a larger fraction of its total extractable information.
Eventually, your models are getting most of that information the very first time they see the data point. The “most” in that sentence gets closer and closer to 100%, asymptotically.
How does this relate to optimal compute allocation?
The logic of the “optimal compute plan” is as follows:
Your model is an imperfect resource extractor: it only gets some of the resources locked up in a data point from the first update. So you could extract more by running for more steps …
… but if you have the compute for that, you can also spend it by making your steps more efficient. And, in the current compute regime, that’s the smarter choice.
It’s smarter by a specific, uniform proportion. Remember, you should stop training when your loss is 10% higher than the converged loss of the same model. If the converged loss is L, you should stop at 1.1*L.
Can you always do that? If your model is efficient enough, you can’t! As the first epoch gets closer to 100% efficient, the loss after the first epoch gets arbitrarily close to the converged loss. Your loss goes under 1.1*L by the end of the first epoch.
At this point, the story justifying the L(C) law breaks down.
The L(C) law goes as fast is it does because upgrading the efficiency of your extractor is cheaper – in terms of compute spent per unit of resource extracted – than actually running the extractor.
This works as long as your extractor is inefficient. But you can’t push efficiency above 100%. Eventually, the only way to extract more is to actually run the damn thing.
Getting a bigger quarry
When you’re extracting a resource, there’s a difference between “improve the extractor” and “get a bigger quarry.”
If your quarry has 100 resource units in it, the strategy of “improving the extractor” can never get you more than 100 units. It can get them to you faster, but if you want more than 100 units, you have to get a bigger quarry.
“N” sets the efficiency of the extractor. “S” sets … well, it doesn’t exactly set the size of the quarry (that’s D). There is an ambiguity in the S: it could mean running for more epochs on the same data, or it could mean getting more data.
But S does, at least, set an upper bound on the size of the quarry, D. (Via D≤E and E = B*S, with B set optimally as always.)
With high enough compute (and thus model size), you’ve pushed the “extractor upgrades are cheap” lifehack as far as it can go. With this efficient extractor, taking S steps (thus making E = B*S updates) sucks up most of the information theoretically extractable from E individual data points.
The learning curve L(E) of your model, as it makes its first pass over the dataset, starts to merge with L(D), the theoretical optimum achievable with that same dataset. You trace out L(D) as you train, and the relevant constraint on your performance is the maximum data size D you can obtain and train on.
Where we are now
In the compute regime that spans GPT-2 and the smaller variants of GPT-3, extraction is far less than maximally efficient. The L(C) strategy applies, and the smart move is to spend compute mostly on model size. So you make GPT-2, and then GPT-3.
Once we get to the full GPT-3, though, the extractor is efficient enough that the justification for L(C) has broken down, and the learning curve L(E) over the first epoch looks like L(D).
Here is that as a picture, from the new paper:
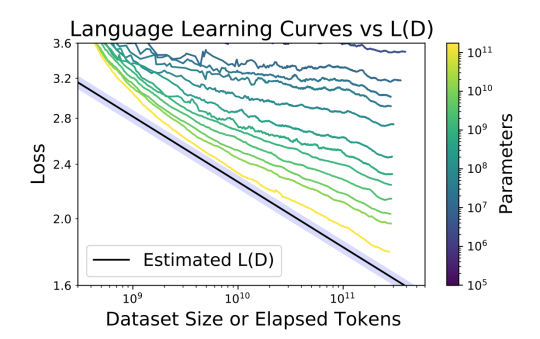
The yellowest, lowest learning curve is the full GPT-3. (The biggest GPT-2 is one of the green-ish lines.) The black line is L(D), maximally efficient extraction.
You can see the whole story in this picture. If you’re in one of the smaller-model learning curves, running for more steps on more data will get you nowhere near to the total extractable info in that data. It’s a better use of your compute to move downwards, toward the learning curve of a bigger model. That’s the L(C) story.
If the L(C) story went on forever, the curves would get steeper and steeper. Somewhere a little beyond GPT-3, they would be steeper than L(D). They would cross L(D), and we’d be learning more than L(D) says is theoretically present in the data.
According to the story above, that won’t happen. We’ll just converge ever closer to L(D). To push loss further downward, we need more data.
Implications
Since people are talking about bitter lessons a lot these days, I should make the following explicit: none of this means “the scaling hypothesis is false,” or anything like that.
It just suggests the relevant variable to scale with compute will switch: we’ll spent less of our marginal compute on bigger models, and more of it on bigger data.
That said, if the above is true (which it may not be), it does suggest that scaling transformers on text alone will not continue productively much past GPT-3.
The GPT-3 paper says its choices were guided by the “grow N, not S” heuristic behind the L(C) curve:
Based on the analysis in Scaling Laws For Neural Language Models [KMH+20] we train much larger models on many fewer tokens than is typical.
(“KMH+20″ is the first of the two scaling papers discussed here.) Even following this heuristic, they still picked a huge dataset, by human standards for text datasets.
In the above terms, their “E” was 300 billion tokens and their “D” was ~238 tokens, since they updated multiple times on some tokens (cf. Table 2.2 in the GPT-3 paper). The whole of Common Crawl is 410 billion tokens, and Common Crawl might as well be “all the text in the universe” from the vantage point of you and me.
So, there’s room to scale D up somewhat further than they did with GPT-3, but not many orders of magnitude more. To me, this suggests that an intuitively “smarter” GPT-4 would need to get its smartness from being multimodal, as we really can’t go much further with just text.
14 comments
Comments sorted by top scores.
comment by gwern · 2020-11-07T18:25:33.892Z · LW(p) · GW(p)
This makes sense to me and is what I've been considering as the implication of sample-efficiency (one of the blessings of scale), coming at it from another direction of meta-learning/Bayesian RL: if your model gets more sample-efficient as it gets larger & n gets larger, it's because it's increasingly approaching a Bayes-optimal learner and so it gets more out of the more data, but then when you hit the Bayes-limit, how are you going to learn more from each datapoint? You have to switch over to a different and inferior scaling law. You can't squeeze blood from a stone; once you approach the intrinsic entropy, there's not much to learn. Steeply diminishing returns is built into compiling large text datasets and just training on random samples. It looks like the former is the regime we've been in up to GPT-3 and beyond, and the latter is when the slower data-only scaling kicks in.
Aside from multimodal approaches, the crossover raises the question of whether it becomes time to invest in improvements like active learning. What scaling curve in L(D)/L(C) could we get with even a simple active learning approach like running a small GPT over Common Crawl and throwing out datapoints which are too easily predicted?
Replies from: nostalgebraist, capybaralet, arielroth↑ comment by nostalgebraist · 2020-11-08T23:19:23.114Z · LW(p) · GW(p)
What scaling curve in L(D)/L(C) could we get with even a simple active learning approach like running a small GPT over Common Crawl and throwing out datapoints which are too easily predicted?
IIUC, this is trying to make L(D) faster by making every data point more impactful (at lowering test loss). This will help if
- you get most of the way to intrinsic entropy L(D) on your first pass over D points
- you can downsample your full dataset without lowering the total number of examples seen in training, i.e. you have too many points to do one full epoch over them
I can imagine this regime becoming the typical one for non-text modalities like video that have huge data with lots of complex redundancy (which the model will learn to compress).
With text data, though, I'm concerned that (2) will fail soon.
The number of train steps taken by GPT-3 was the same order of magnitude as the size of Common Crawl. I haven't seen convincing evidence that comparably good/diverse text datasets can be constructed which are 10x this size, 100x, etc. The Pile is an interesting experiment, but they're mostly adding large quantities of single-domain text like Github, which is great for those domains but won't help outside them.
Replies from: gwern↑ comment by gwern · 2020-11-09T00:01:12.780Z · LW(p) · GW(p)
The Pile is an interesting experiment, but they're mostly adding large quantities of single-domain text like Github, which is great for those domains but won't help outside them.
I disagree. Transfer learning is practically the entire point. 'Blessings of scale' etc.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-11-09T00:36:45.626Z · LW(p) · GW(p)
I disagree. Transfer learning is practically the entire point. 'Blessings of scale' etc.
Sure -- my point to contrast two cases
- a counterfactual world with a much larger "regular" web, so WebText and Common Crawl are 1000x their real size
- the real world, where we have to go beyond "regular" web scrapes to add orders of magnitude
Many, including OpenAI, argue that general web crawls are a good way to get high domain diversity for free. This includes domains the research would never have come up with themselves.
If we switch to manually hunting down large specialized datasets, this will definitely help, but we're no longer getting broad domain coverage for free. At best we get broad domain coverage through manual researcher effort and luck, at worst we don't get it at all.
I see your point about active learning "telling us" when we need more data -- that's especially appealing if it can point us to specific domains where more coverage would help.
Replies from: gwern↑ comment by gwern · 2020-11-09T02:48:53.856Z · LW(p) · GW(p)
I think I see 'domain-specific datasets' as broader than you do. You highlight Github, and yet, when I think of Github, I think of thousands of natural and artificial languages, tackling everything related to software in the world (which is increasingly 'everything'), by millions of people, doing things like uploading banned books for evading the Great Firewall or organizing protests against local officials, filing bugs and discussing things back and forth, often adversarially, all reliant on common sense and world knowledge. A GPT trained on Github at hundreds of gigabytes I would expect to induce meta-learning, reasoning, and everything else, for exactly the same reasons CC/books1/books2/WP do; yes, it would know 'source code' well (not a trivial thing in its own right), but that is a mirror of the real world. I see plenty of broad domain coverage from 'just' Github, or 'just' Arxiv. (Literotica, I'm less sure about.) I don't see Github as having much of a disadvantage over CC in terms of broadness or what a model could learn from it. Indeed, given what we know about CC's general quality and how default preprocessing can screw it up (I see a lot of artifacts in GPT-3's output I think are due to bad preprocessing), I expect Github to be more useful than an equivalent amount of CC!
(It's true Codex does not do this sort of thing beyond what it inherits from GPT-3 pretraining. But that's because it is aimed solely at programming, and so they deliberately filter out most of Github by trying to detect Python source files and throw away everything else etc etc, not because there's not an extremely diverse set of data available on raw Github.)
The big advantage of Common Crawl over a Github scrape is that, well, CC already exists. Someone has to invest the effort at some point for all datasets, after all. You can go download pre-cleaned versions of it - aside from EleutherAI's version (which they expect to be substantially better than CC on a byte for byte basis), Facebook and Google recently released big multilingual CC. But of course, now that they've done it and added it to the Pile, that's no longer a problem.
↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2021-02-01T12:11:16.379Z · LW(p) · GW(p)
if your model gets more sample-efficient as it gets larger & n gets larger, it's because it's increasingly approaching a Bayes-optimal learner and so it gets more out of the more data, but then when you hit the Bayes-limit, how are you going to learn more from each datapoint? You have to switch over to a different and inferior scaling law. You can't squeeze blood from a stone; once you approach the intrinsic entropy, there's not much to learn.
I found this confusing. It sort of seems like you're assuming that a Bayes-optimal learner achieves the Bayes error rate (are you ?), which seems wrong to me.
- What do you mean "the Bayes-limit"? At first, I assumed you were talking about the Bayes error rate (https://en.wikipedia.org/wiki/Bayes_error_rate), but that is (roughly) the error you coule expect to achieve with infinite data, and we're still talking about finite data.
- What do you mean "Bayes-optimal learner"? I assume you just mean something that performs Bayes rule exactly (so depends on the prior/data).
- I'm confused by you talking about "approach[ing] the intrinsic entropy"... it seems like the figure in OP shows L(C) approaching L(D). But is L(D) supposed to represent intrinsic entropy? should we trust it as an estimate of intrinsic entropy?
I also don't see how active learning is supposed to help (unless you're talking about actively generating data)... I thought the whole point you were trying to make is that once you reach the Bayes error rate there's literally nothing you can do to keep improving without more data.
You talk about using active learning to throw out data-points... but I thought the problem was not having enough data? So how is throwing out data supposed to help with that?
↑ comment by arielroth · 2020-11-08T19:00:26.490Z · LW(p) · GW(p)
Filtering for difficulty like that is tricky. In particular the most difficult samples are random noise or Chinese or something that the model can't begin to comprehend.
Some approaches I would consider:
Curriculum learning -- Have a bunch of checkpoints from a smaller GPT. Say the big GPT currently has a LM loss of 3. Then show it the examples where the smaller GPT's loss improved most rapidly when its average loss was 3.
Quality -- Put more effort into filtering out garbage and upsampling high quality corpuses like Wikipedia.
Retrieval -- Let the model look things up when its confused, like MARGE from Pretraining via Paraphrasing does.
comment by moridinamael · 2020-11-07T16:56:49.823Z · LW(p) · GW(p)
I really appreciated the degree of clarity and the organization of this post.
I wonder how much the slope of L(D) is a consequence of the structure of the dataset, and whether we have much power to meaningfully shift the nature of L(D) for large datasets. A lot of the structure of language is very repetitive, and once it is learned, the model doesn't learn much from seeing more examples of the same sort of thing. But, within the dataset are buried very rare instances of important concept classes. (In other words, the Common Crawl data has a certain perplexity, and that perplexity is a function of both how much of the dataset is easy/broad/repetitive/generic and how much is hard/narrow/unique/specific.) For example: I can't, for the life of me, get GPT-3 to give correct answers on the following type of prompt:
You are facing north. There is a house straight ahead of you. To your left is a mountain. In what cardinal direction is the mountain?
No matter how much priming I give or how I reframe the question, GPT-3 tends to either give a basically random cardinal direction, or just repeat whatever direction I mentioned in the prompt. If you can figure out how to do it, please let me know, but as far as I can tell, GPT-3 really doesn't understand how to do this. I think this is just an example of the sort of thing which simply occurs so infrequently in the dataset that it hasn't learned the abstraction. However, I fully suspect that if there were some corner of the Internet where people wrote a lot about the cardinal directions of things relative to a specified observer, GPT-3 would learn it.
It also seems that one of the important things that humans do but transformers do not, is actively seek out more surprising subdomains of the learning space. The big breakthrough in transformers was attention, but currently the attention is only within-sequence, not across-dataset. What does L(D) look like if the model is empowered to notice, while training, that its loss on sequences involving words like "west" and "cardinal direction" is bad, and then to search for and prioritize other sequences with those tokens, rather than simply churning through the next 1000 examples of sequences from which it has essentially already extracted the maximum amount of information. At a certain point, you don't need to train it on "The man woke up and got out of {bed}", it knew what the last token was going to be long ago.
It would be good to know if I'm completely missing something here.
Replies from: nostalgebraist, lucas-adams, nathan-helm-burger↑ comment by nostalgebraist · 2020-11-09T00:39:49.199Z · LW(p) · GW(p)
I don't think you're completely missing something. This is the active learning approach, which gwern also suggested -- see that thread [LW(p) · GW(p)] for more.
↑ comment by Lucas Adams (lucas-adams) · 2022-09-01T14:30:02.856Z · LW(p) · GW(p)
GPT 3 solves that easily now. I tried with no prompt tuning, simple structure (Q: and A:) and with “let’s think step by step” and all gave west as the answer. Step by step correctly enumerated the logic that led to the answer.
Replies from: gwern↑ comment by gwern · 2022-09-01T22:02:25.923Z · LW(p) · GW(p)
I assume you mean InstructGPT, specifically, solves that now? That's worth noting since InstructGPT's claim to fame is that it greatly reduces how much prompt engineering you need for various 'tasks' (even if it's not too great at creative writing).
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-06T03:03:06.155Z · LW(p) · GW(p)
I think there's something we could do even beyond choosing the best of existing data points to study. I think we could create data-generators, which could fill out missing domains of data using logical extrapolations. I think your example is a great type of problem for such an approach.
comment by MikkW (mikkel-wilson) · 2020-11-09T00:02:28.242Z · LW(p) · GW(p)
Regarding the analogy between mining speed vs. size of quarry, the number of steps shouldn't be understood as the size of the quarry itself, but rather how much of the quarry you plan on using. If you have a quarry with 100,000 tons of resource, but your machine can only mine 1,000 tons within the timeframe you have access to, then the effective size of your quarry is only 1,000 tons, even though it has a size of 100,000. When increasing your speed of mining, it's much easier to increase your effective size (step count) when it's below the actual size of the quarry (dataset size), than it is to get up and find an entirely new quarry when you are already using the entire quarry (getting a new dataset).
comment by p.b. · 2020-12-13T14:57:30.722Z · LW(p) · GW(p)
Great post! I had trouble wrapping my head around the „inconsistency“ in the first paper, now I think I get it: TL;DR in my own words:
There are three regimes of increasing information uptake, ordered by how cheap they are in terms of compute:
- Increasing sampling efficiency by increasing model size —> this runs into diminishing returns because sample efficiency has a hard upper bound. —> context window increase?
- Accessing more information by training over more unique samples —> will run into diminishing returns when unique data runs out. —> multi-modal data?
- Extracting more information by running over the same samples several times —> this intuitively crashes sampling efficiency because you can only learn the information not already extracted in earlier passes. —> prime candidate for active learning?
I had also missed the implication of the figure in the second paper that shows that GPT-3 is already very close to optimal sampling efficiency. So it seems that pure text models will only see another order of magnitude increase in parameters or so.
If you are looking for inspiration for another post about this topic: Gwern mentions the human level of language modeling and Steve Omohundro also alludes to the loss that would signify human level, I don’t really understand neither the math nor where the numbers come from. It would be very interesting to me to see an explanation of the „human level loss“ to put the scaling laws in perspective. Of course I assume that a „human level“ LM would have very different strengths and weaknesses compared to a human, but still.