The fun, as it were, is presumably about to begin.
And the break was fun while it lasted.
Biden went out with an AI bang. His farewell address warns of a ‘Tech-Industrial Complex’ and calls AI the most important technology of all time. And there was not one but two AI-related everything bagel concrete actions proposed – I say proposed because Trump could undo or modify either or both of them.
One attempts to build three or more ‘frontier AI model data centers’ on federal land, with timelines and plans I can only summarize with ‘good luck with that.’ The other move was new diffusion regulations on who can have what AI chips, an attempt to actually stop China from accessing the compute it needs. We shall see what happens.
Help dyslexics get around their inability to spell to succeed in school, and otherwise help kids with disabilities. Often, we have ways to help everyone, but our civilization is willing to permit them for people who are ‘behind’ or ‘disadvantaged’ or ‘sick’ but not to help the average person become great – if it’s a problem everyone has, how dare you try to solve it. Well, you do have to start somewhere.
The original story that led to that claim is here from AJ Kay. The doctor and radiologist said her daughter was free of breaks, Grok found what it called an ‘obvious’ fracture line, they went to a wrist specialist, who found it, confirmed it was obvious and cast it, which they say likely avoided a surgery.
Used that way LLMs seem insanely great versus doing nothing. You use them as an error check and second opinion. If they see something, you go follow up with a doctor to verify. I’d go so far as to say that if you have a diagnostic situation like this and you feel any uncertainty, and you don’t do at least this, that seems irresponsible.
Ben Hylak: Don’t write prompts; write briefs. Give a ton of context. Whatever you think I mean by a “ton” — 10x that.
…
In short, treat o1 like a new hire. Beware that o1’s mistakes include reasoning about how much it should reason.
Once you’ve stuffed the model with as much context as possible — focus on explaining what you want the output to be.
This requires you to really know exactly what you want (and you should really ask for one specific output per prompt — it can only reason at the beginning!)
What o1 does well: Perfectly one-shotting entire/multiple files, hallucinating less, medical diagnosis (including for use by professionals), explaining concepts.
What o1 doesn’t do well: Writing in styles, building entire apps.
Another strategy is to first have a conversation with Claude Sonnet, get a summary, and use it as context (Rohit also mentions GPT-4o, which seems strictly worse here but you might not have a Claude subscription). This makes a lot of sense, especially when using o1 Pro.
Olivia Moore: Absolutely no way that almost 80% of U.S. teens have heard of ChatGPT, but only 26% use it for homework
Sully: if i was a teen using chatgpt for homework i would absolutely lie.
Never? No, never. What, never? Well, actually all the time.
I also find it hard to believe that students are this slow, especially given this is a very low bar – it’s whether you even once asked for ‘help’ at all, in any form. Whereas ChatGPT has 300 million users.
Ethan Mollick: New randomized, controlled trial of students using GPT-4 as a tutor in Nigeria. 6 weeks of after-school AI tutoring = 2 years of typical learning gains, outperforming 80% of other educational interventions.
And it helped all students, especially girls who were initially behind.
To make clear the caveats for people who don’t read the post: learning gains are measured in Equivalent Years of Schooling, this is a pilot study on narrow topics and they do not have long-term learning measures. And there is no full paper yet (but the team is credible)
World Bank Blogs: The learning improvements were striking—about 0.3 standard deviations. To put this into perspective, this is equivalent to nearly two years of typical learning in just six weeks.
What does that say about ‘typical learning’? A revolution is coming.
Language Models Don’t Offer Mundane Utility
Sully suggests practical improvements for Claude’s web app to increase engagement. Agreed that they should improve artifacts and include a default search tool. The ability to do web search seems super important. The ‘feel’ issue he raises doesn’t bother me.
Nabeel Qureshi: We have had AI that can type plausible replies to emails for at least 24 months, but when I open Outlook or Gmail I don’t have pre-written drafts of all my outstanding emails waiting for me to review yet. Why are big companies so slow to ship these obvious features?
The more general version of this point is also striking – I don’t use any AI features at all in my usual suite of “pre-ChatGPT” products.
For meetings, most people (esp outside of tech) are still typing “Sure, I’d love to chat! Here are three free slots over the next few days (all times ET)”, all of which is trivially automated by LLMs now.
(If even tech companies are this slow to adjust, consider how much slower the adjustment in non-tech sectors will be…).
I know! What’s up with that?
Cyberpunk Plato: Doing the compute for every single email adds up fast. Better to have the user request it if they want it.
And at least for business software there’s a concern that if it’s built in you’re liable for it being imperfect. Average user lacks an understanding of limitations.
Nabeel Qureshi: Yeah – this seems plausibly it.
I remember very much expecting this sort of thing to be a big deal, then the features sort of showed up but they are so far universally terrible and useless.
I’m going to go ahead and predict that at least the scheduling problem will change in 2025 (although one can ask why they didn’t do this feature in 2015). As in, if you have an email requesting a meeting, GMail will offer you an easy way (a button, a short verbal command, etc) to get an AI to do the meeting scheduling for you, at minimum drafting the email for you, and probably doing the full stack back and forth and creating the eventual event, with integration with Google Calendar and a way of learning your preferences. This will be part of the whole ‘year of the agent’ thing.
For the general issue, it’s a great question. Why shouldn’t GMail be drafting your responses in advance, at least if you have a subscription that pays for the compute and you opt in, giving you much better template responses, that also have your context? Is it that hard to anticipate the things you might write?
I mostly don’t want to actually stop to tell the AI what to write at current levels of required effort – by the time I do that I might as well have written it. It needs to get to a critical level of usefulness, then you can start customizing and adapting from there.
If 2025 ends and we still don’t have useful features of these types, we’ll want to rethink.
Devon Hardware’s Wife: should be a letterboxd app but it is for every human experience. i could log in and see a friend has recently reviewed “having grapes”. i could go huh they liked grapes more than Nosferatu
Joe Weisenthal: What I want is an everything recommendation app. So if I say I like grapes and nosferatu, it’ll tell me what shoes to buy.
Letterboxd doesn’t even give you predictions for your rating of other films, seriously, what is up with that?
New Scientist: Multiple experiments showed that four leading large language models often failed in patient discussions to gather complete histories, the best only doing so 71% of the time, and even then they did not always get the correct diagnosis.
New Scientist, its head dropping in shame: GPT-3.5 and GPT-4, Llama-2-7B and Mistral-v2-7B for a paper submitted in August 2023.
Also there was this encounter:
New Scientist, looking like Will Smith: Can an AI always get a complete medical history and the correct diagnosis from talking to a patient?
GPT-4 (not even 4o): Can you?
New Scientist: Time to publish!
It gets better:
If an AI model eventually passes this benchmark, consistently making accurate diagnoses based on simulated patient conversations, this would not necessarily make it superior to human physicians, says Rajpurkar. He points out that medical practice in the real world is “messier” than in simulations. It involves managing multiple patients, coordinating with healthcare teams, performing physical exams and understanding “complex social and systemic factors” in local healthcare situations.
“Strong performance on our benchmark would suggest AI could be a powerful tool for supporting clinical work – but not necessarily a replacement for the holistic judgement of experienced physicians,” says Rajpurkar.
I love the whole ‘holistic judgment means we should overrule the AI with human judgment even though the studies are going to find that doing this makes outcomes on average worse’ which is where we all know that is going. And also the ‘sure it will do [X] better but there’s some other task [Y] and it will never do that, no no!’
The core idea here is actually pretty good – that you should test LLMs for real medical situations by better matching real medical situations and their conditions. They do say the ‘patient AI’ and ‘grader AI’ did remarkably good jobs here, which is itself a test of AI capabilities as well. They don’t seem to offer a human baseline measurement, which seems important to knowing what to do with all this.
And of course, we have no idea if there was opportunity to radically improve the results with better prompt engineering.
I do know that I predict that o3-mini or o1-pro, with proper instructions, will match or exceed human baseline (the median American practicing doctor) for gathering a complete medical history. And I would expect it to also do so for diagnosis.
I encourage one reader to step up, email them for the code (the author emails are listed in the paper) and then test at least o1.
They claim that social robots will be even bigger than functional robots, and aim to have their robots not only ‘learn about and help promote your brand’ but also learn everything about you and help ‘with the loneliness epidemic among adolescents and teenagers and bond with you.’
And yes they use the ‘boyfriend or girlfriend’ words. You can swap faces in 10 seconds, if you want more friends or prefer polyamory.
It has face and voice recognition, and you can plug in whatever AI you like – they list Anthropic, OpenAI, DeepMind, Stability and Meta on their website.
It looks like this:
Its movements in the video are really weird, and worse than not moving at all if you exclude the lips moving as she talks. They’re going to have to work on that.
But for Aria the answer is no. For a yes and true ‘adult companionship’ you have to go to their RealDoll subdivision. On the plus side, that division is much cheaper, starting at under $10k and topping out at ~$50k.
I had questions, so I emailed their press department, but they didn’t reply.
My hunch is that the real product is the RealDoll, and what you are paying the extra $100k+ for with Aria is a little bit extra mobility and such but mostly so that it does have those features so you can safely charge it to your corporate expense account, and perhaps so you and others aren’t tempted to do something you’d regret.
Introducing Astral, an AI marketing AI agent. It will navigate through the standard GUI websites like Reddit and soon TikTok and Instagram, and generate ‘genuine interactions’ across social websites to promote your startup business, in closed beta.
Matt Palmer: At long last, we have created the dead internet from the classic trope “dead internet theory.”
Tracing Woods: There is such a barrier between business internet and the human internet.
On business internet, you can post “I’ve built a slot machine to degrade the internet for personal gain” and get a bunch of replies saying, “Wow, cool! I can’t wait to degrade the internet for personal gain.”
It is taking longer than I expected for this type of tool to emerge, but it is coming. This is a classic situation where various frictions were preserving our ability to have nice things like Reddit. Without those frictions, we are going to need new ones. Verified identity or paid skin in the game, in some form, is the likely outcome.
Janel Comeau: sort of miss the days when you’d tweet “I like pancakes” and a human would reply “oh, so you hate waffles” instead of twelve AI bots responding with “pancakes are an enjoyable food”
Instagram ads are the source of 90% of traffic for a nonconsensual nudity app Crushmate or Crush AI, with the ads themselves featuring such nonconsensual nudity of celebrities such as Sophie Rain. I did a brief look-see at the app’s website. They have a top scroll saying ‘X has just purchased’ which is what individual struggling creators do, so it’s probably 90% of not very much, and when you’re ads driven you choose where the ads go. But it’s weird, given what other ads don’t get approved, that they can get this level of explicit past the filters. The ‘nonconsensual nudity’ seems like a side feature of a general AI-image-and-spicy-chat set of offerings, including a number of wholesome offerings too.
My prior on ‘that’s AI’ is something like 75% by word 4, 95%+ after the first sentence. Real humans don’t talk like that.
I also note that it seems fairly easy to train an AI classifier to do what I instinctively did there, and catch things like this with very high precision. If it accidentally catches a few college undergraduates trying to write papers, I notice my lack of sympathy.
But that’s a skill issue, and a choice. The reason Aiman’s response is so obvious is that it has exactly that RLHF-speak. One could very easily fine tune in a different direction, all the fine tuning on DeepSeek v3 was only five figures in compute and they give you the base model to work with.
Richard Hanania: The technology will get better though. We’ll eventually get to the point that if your account is not connected to a real person in the world, or it wasn’t grandfathered in as an anonymous account, people will assume you’re a bot because there’s no way to tell the difference.
That will be the end of the ability to become a prominent anonymous poster.
I do continue to expect things to move in that direction, but I also continue to expect there to be ways to bootstrap. If nothing else, there is always money. This isn’t flawless, as Elon Musk as found out with Twitter, but it should work fine, so long as you reintroduce sufficient friction and skin in the game.
Fun With Image Generation
The ability to elicit the new AI generated song Six Weeks from AGI causes Steve Sokolowski to freak out about potential latent capabilities in other AI models. I find it heavily mid to arrive at this after a large number of iterations and amount of human attention, especially in terms of its implications, but I suppose it’s cool you can do that.
They Took Our Jobs
Daron Acemoglu is economically highly skeptical of and generally against AI. It turns out this isn’t about the A, it’s about the I, as he offers remarkably related arguments against H-1B visas and high skilled human immigration.
The arguments here are truly bizarre. First he says if we import people with high skills, then this may prevent us from training our own people with high skills, And That’s Terrible. Then he says, if we import people with high skills, we would have more people with high skills, And That’s Terrible as well because then technology will change to favor high-skilled workers. Tyler Cowen has o1 and o1 pro respond, as a meta-commentary on what does and doesn’t constitute high skill these days.
Tyler Cowen: If all I knew were this “exchange,” I would conclude that o1 and o1 pro were better economists — much better — than one of our most recent Nobel Laureates, and also the top cited economist of his generation. Noah Smith also is critical.
Noah Smith (after various very strong argument details): So Acemoglu wants fewer H-1bs so we have more political pressure for domestic STEM education. But he also thinks having more STEM workers increases inequality, by causing inventors to focus on technologies that help STEM workers instead of normal folks! These two arguments clearly contradict each other.
In other words, it seems like Acemoglu is grasping for reasons to support a desired policy conclusion, without noticing that those arguments are inconsistent. I suppose “finding reasons to support a desired policy conclusion” is kind of par for the course in the world of macroeconomic theory, but it’s not a great way to steer national policy.
Noah Smith, Tyler Cowen and o1 are all highly on point here.
In terms of AI actually taking our jobs, Maxwell Tabarrok reiterates his claim that comparative advantage will ensure human labor continues to have value, no matter how advanced and efficient AI might get, because there will be a limited supply of GPUs, datacenters and megawatts, and advanced AIs will face constraints, even if they could do all tasks humans could do more efficiently (in some senses) than we can.
I actually really like Maxwell’s thread here, because it’s a simple, short, clean and within its bounds valid version of the argument.
His argument successfully shows that, absent transaction costs and the literal cost of living, assuming humans have generally livable conditions with the ability to protect their private property and engage in trade and labor, and given some reasonable additional assumptions not worth getting into here, human labor outputs will retain positive value in such a world.
He shows this value would likely converge to some number higher than zero, probably, for at least a good number of people. It definitely wouldn’t be all of them, since it already isn’t, there are many ZMP (zero marginal product) workers you wouldn’t hire at $0.
Except we have no reason to think that number is all that much higher than $0. And then you have to cover not only transaction costs, but the physical upkeep costs of providing human labor, especially to the extent those inputs are fungible with AI inputs.
Classically, we say ‘the AI does not love, you the AI does not hate you, but you are made of atoms it can use for something else.’ In addition to the atoms that compose you, you require sustenance of various forms to survive, especially if you are to live a life of positive value, and also to include all-cycle lifetime costs.
Yes, in such scenarios, the AIs will be willing to pay some amount of real resources for our labor outputs, in trade. That doesn’t mean this amount will be enough to pay for the imports to those outputs. I see no reason to expect that it would clear the bar of the Iron Law of Wages, or even near term human upkeep.
This is indeed what happened to horses. Marginal benefit mostly dropped below marginal cost, the costs to maintain horses were fungible with paying costs for other input factors, so quantity fell off a cliff.
Seb Krier says a similar thing in a different way, noticing that AI agents can be readily cloned, so at the limit for human labor to retain value you need to be sufficiently compute constrained that there are sufficiently valuable tasks left for humans to do. Which in turn relies on non-fungibility of inputs, allowing you to take the number of AIs and humans as given.
Davidad: At equilibrium, in 10-20 years, the marginal price of nonphysical labour could be roughly upper-bounded by rent for 0.2m² of arid land, £0.02/h worth of solar panel, and £0.08/h worth of GPU required to run a marginal extra human-equivalent AI agent.
For humans to continue to be able to survive, they need to pay for themselves. In these scenarios, doing so off of labor at fair market value seems highly unlikely. That doesn’t mean the humans can’t survive. As long as humans remain in control, this future society is vastly wealthier and can afford to do a lot of redistribution, which might include reserving fake or real jobs and paying non-economic wages for them. It’s still a good thing, I am not against all this automation (again, if we can do so while retaining control and doing sufficient redistribution). The price is still the price.
It seems like… the suspect used ChatGPT instead of Google, basically?
Here’s the first of four screenshots:
Richard Lawler (The Verge): Trying the queries in ChatGPT today still works, however, the information he requested doesn’t appear to be restricted and could be obtained by most search methods.
Still, the suspect’s use of a generative AI tool and the investigators’ ability to track those requests and present them as evidence take questions about AI chatbot guardrails, safety, and privacy out of the hypothetical realm and into our reality.
The Spectator Index: BREAKING: Person who blew up Tesla Cybertruck outside Trump hotel in Las Vegas used ChatGPT to help in planning the attack.
Spence Purnell: PSA: Tech is not responsible for horrible human behavior, and regulating it will not stop bad actors.
There are certainly steps companies can take and improvements to be made, but let’s not blame the tech itself.
[He quotes]: Police Sheriff Kevin McMahill said: “I think this is the first incident that I’m aware of on U.S. soil where ChatGPT is utilized to help an individual build a particular device.”
When you look at the questions he asked, it is pretty obvious he is planning to build a bomb, and an automated AI query that (for privacy reasons) returned one bit of information would give you that information without many false positives. The same is true of the Google queries of many suspects after they get arrested.
None of this is information that would have been hard to get via Google. ChatGPT made his life modestly easier, nothing more. I’m fine with that, and I wouldn’t want ChatGPT to refuse such questions, although I do think ‘we can aspire to do better’ here in various ways.
And in general, yes, people like cops and reporters are way too quick to point to the tech involved, such as ChatGPT, or to the cybertruck, or the explosives, or the gun. Where all the same arguments are commonly made, and are often mostly or entirely correct.
But not always. It is common to hear highly absolutist responses, like the one by Purnell above, that regulation of technology ‘will not stop bad actors’ and thus would have no effect. That is trying to prove too much. Yes, of course you can make life harder for bad actors, and while you won’t stop all of them entirely and most of the time it totally is not worth doing, you can definitely reduce your expected exposure.
This example does provide a good exercise, where hopefully we can all agree this particular event was fine if not ideal, and ask what elements would need to change before it was actively not fine anymore (as opposed to ‘we would ideally like you to respond noticing what is going on and trying to talk him out of it’ or something). What if the device was non-conventional? What if it more actively helped him engineer a more effective device in various ways? And so on.
The first listed secret is that DeepSeek has no business model. None. We’re talking about sex-in-the-champaign-room levels of no business model. They release models, sure, but not to make money, and also don’t raise capital. This allows focus. It is classically a double edged sword, since profit is a big motivator, and of course this is why DeepSeek was on a limited budget.
The other two secrets go together: They run their own datacenters, own their own hardware and integrate all their hardware and software together for maximum efficiency. And they made this their central point of emphasis, and executed well. This was great at pushing the direct quantities of compute involved down dramatically.
The trick is, it’s not so cheap or easy to get things that efficient. When you rack your own servers, you get reliability and confidentiality and control and ability to optimize, but in exchange your compute costs more than when you get it from a cloud service.
Jordan Schneider and Lily Ottinger: A true cost of ownership of the GPUs — to be clear, we don’t know if DeepSeek owns or rents the GPUs — would follow an analysis similar to the SemiAnalysis total cost of ownership model (paid feature on top of the newsletter) that incorporates costs in addition to the actual GPUs. For large GPU clusters of 10K+ A/H100s, line items such as electricity end up costing over $10M per year. The CapEx on the GPUs themselves, at least for H100s, is probably over $1B (based on a market price of $30K for a single H100).
…
With headcount costs that can also easily be over $10M per year, estimating the cost of a year of operations for DeepSeek AI would be closer to $500M (or even $1B+) than any of the $5.5M numbers tossed around for this model.
Since they used H800s, not H100s you’ll need to adjust that, but the principle is similar. Then you have to add on the cost of the team and its operations, to create all these optimizations and reach this point. Getting the core compute costs down is still a remarkable achievement, and raises big governance questions and challenges whether we can rely on export controls. Kudos to all involved. But this approach has its own challenges.
The alternative hypothesis does need to be said, especially after someone at a party outright claimed it was obviously true, and with the general consensus that the previous export controls were not all that tight. That alternative hypothesis is that DeepSeek is lying and actually used a lot more compute and chips it isn’t supposed to have. I can’t rule it out.
In all seriousness, incorporating a task scheduler by itself, in the current state of available other resources, is a rather limited tool. You can use it for reminders and timers, and perhaps it is better than existing alternatives for that. You can use it to ‘generate news briefing’ or similarly check the web for something. When this gets more integrations, and broader capability support over time, that’s when this gets actually interesting.
The initial thing that might be interesting right away is to do periodic web searches for potential information, as a form of Google Alerts with more discernment. Perhaps keep an eye on things like concerts and movies playing in the area. The basic problem is that right now this new assistant doesn’t have access to many tools, and it doesn’t have access to your context, and I expect it to flub complicated tasks.
GPT-4o agreed that most of the worthwhile uses require integrations that do not currently exist.
For now, the product is not reliably causing tasks to fire. That’s an ordinary first-day engineering problem that I assume gets fixed quickly, if it hasn’t already. But until it can do more complex things or integrate the right context automatically, ideally both, we don’t have much here.
I would note that you mostly don’t need to test the task scheduler by scheduling a task. We can count on OpenAI to get ‘cause this to happen at time [X]’ correct soon enough. The question is, can GPT-4o do [X] at all? Which you can test by telling it to do [X] now.
ExoRoad, a fun little app where you describe your ideal place to live and it tells you what places match that.
Lightpage, a notes app that then uses AI that remembers all of your notes and prior conversations. And for some reason it adds in personalized daily inspiration. I’m curious to see such things in action, but the flip side of the potential lock-in effects are the startup costs. Until you’ve taken enough notes to give this context, it can’t do the task it wants to do, so this only makes sense if you don’t mind taking tons of notes ‘out of the gate’ without the memory features, or if it could import memory and context. And presumably this wants to be a Google, Apple or similar product, so the notes integrate with everything else.
I see this as clearly going in a good direction, but I worry it isn’t ready. Others see it as terrible that capitalism knows things about them, but in most contexts I find that capitalism knowing things about me is to my benefit, and this seems like an obvious example and a win-win opportunity, as Ross Rheingans-Yoo notes?
Tyler Cowen: Does it know I want a lot of chargers, thin pillows, and lights that are easy to turn off at night? Furthermore the shampoo bottle should be easy to read in the shower without glasses. Maybe it knows now!
I’ve talked about it previously, but I want full blackout at night, either true silence or convenient white noise that fixes this, thick pillows and blankets, lots of chargers, a comfortable chair and desk, an internet-app-enabled TV and some space in a refrigerator and ability to order delivery right to the door. If you want to blow my mind, you can have a great multi-monitor setup to plug my laptop into and we can do real business.
To clarify what OpenAI employees are often saying about superintelligence (ASI): No, they are not dropping hints that they currently have ASI internally. They are saying that they know how to build ASI internally, and are on a path to soon doing so. You of course can choose the extent to which you believe them.
Quiet Speculations
Ethan Mollick writes Prophecies of the Flood, pointing out that the three major AI labs all have people shouting from the rooftops that they are very close to AGI and they know how to build it, in a way they didn’t until recently.
As Ethan points out, we are woefully unprepared. We’re not even preparing reasonably for the mundane things that current AIs can do, in either the sense of preparing for risks, or in the sense of taking advantage of its opportunities. And almost no one is giving much serious thought to what the world full of AIs will actually look like and what version of it would be good for humans, despite us knowing such a world is likely headed our way. That’s in addition to the issue that these future highly capable systems are existential risks.
Gary Marcus predictions for the end of 2025, a lot are of the form ‘[X] will continue to haunt generative AI’ without reference to magnitude. Others are predictions that we won’t cross some very high threshold – e.g. #16 is ‘Less than 10% of the workforce will be replaced by AI, probably less than 5%,’ notice how dramatically higher a bar that is than for example Tyler Cowen’s 0.5% RGDP growth and this is only in 2025.
His lower confidence predictions start to become aggressive and specific enough that I expect them to often be wrong (e.g. I expect a ‘GPT-5 level’ model no matter what we call that, and I expect AI companies to outperform the S&P and for o3 to see adaptation).
Eli Lifland gives his predictionsand evaluates some past ones. He was too optimistic on agents being able to do routine computer tasks by EOY 2024, although I expect to get to his thresholds this year. While all three of us agree that AI agents will be ‘far from reliable’ for non-narrow tasks (Gary’s prediction #9) I think they will be close enough to be quite useful, and that most humans are ‘not reliable’ in this sense.
Sam Altman: prediction: the o3 arc will go something like:
1. “oh damn it’s smarter than me, this changes everything ahhhh”
<ten minutes pass>
2. “so what’s for dinner, anyway?”
<ten minutes pass>
3. “can you believe how bad o3 is? and slow? they need to hurry up and ship o4.”
swag: wait o1 was smarter than me.
Sam Altman: That’s okay.
The scary thing about not knowing is the right tail where something like o3 is better than you think it is. This is saying, essentially, that this isn’t the case? For now.
Please take the very consistently repeated claims from the major AI labs about both the promise and danger of AI both seriously and literally. They believe their own hype. That doesn’t mean you have to agree with those claims. It is very reasonable to think these people are wrong, on either or both counts, and they are biased sources. I am however very confident that they themselves believe what they are saying in terms of expected future AI capabilities, and when they speak about AI existential risks. I am also confident they have important information that you and I do not have, that informs their opinions.
This of course does not apply to claims regarding a company’s own particular AI application or product. That sort of thing is always empty hype until proven otherwise.
Via MR, speculations on which traits will become more versus less valuable over time. There is an unspoken background assumption here that mundane-AI is everywhere and automates a lot of work but doesn’t go beyond that. A good exercise, although I am not in agreement on many of the answers even conditional on that assumption. I especially worry about conflation of rarity with value – if doing things in real life gets rare or being skinny becomes common, that doesn’t tell you much about whether they rose or declined in value. Another throughput line here is an emphasis on essentially an ‘influencer economy’ where people get value because others listen to them online.
Davidad: Good reasons to predict AI capability X will precede AI capability Y:
Effective compute requirements for X seem lower
Y needs new physical infrastructure
Bad reasons:
It sounds wild to see Y as possible at all
Y seems harder to mitigate (you need more time for that!)
Because of the above biases, I previously predicted this rough sequence of critically dangerous capabilities:
Constructing unstoppable AI malware
Ability to plan and execute a total coup (unless we build new defenses)
Superpersuasion
Destabilizing economic replacement
Now, my predicted sequencing of critically dangerous AI capabilities becoming viable is more like:
Superpersuasion/parasitism
Destabilizing economic replacement
Remind me again why the AIs would benefit from attempting an overt coup?
Sure, cyber, CBRN, etc., I guess
There’s a lot of disagreement about order of operations here.
That’s especially true on persuasion. A lot of people think persuasion somehow tops off at exactly human level, and AIs won’t ever be able to do substantially better. The human baseline for persuasion is sufficiently low that I can’t convince them otherwise, and they can’t even convey to me reasons for this that make sense to me. I very much see AI super-persuasion as inevitable, but I’d be very surprised by Davidad’s order of this coming in a full form worthy of its name before the others.
A lot of this is a matter of degree. Presumably we get a meaningful amount of all the three non-coup things here before we get the ‘final form’ or full version of any of them. If I had to pick one thing to put at the top, it would probably be cyber.
The ‘overt coup’ thing is a weird confusion. Not that it couldn’t happen, but that most takeover scenarios don’t work like that and don’t require it, I’m choosing not to get more into that right here.
2. Massively accelerate AI R&D, making 3-6 come faster.
3. Massively accelerate R&D on worse biothreats.
4. Massive accelerate other weapons R&D.
5. Outright AI takeover (overpower humans combined).
There is no 6 listed, which makes me love this Tweet.
Ajeya Cotra: I’m not sure what level of persuasion you’re referring to by “superpersuasion,” but I think AI systems will probably accelerate R&D before they can reliably sweet-talk arbitrary people into taking actions that go massively against their interests.
IMO a lot of what people refer to as “persuasion” is better described as “negotiation”: if an AI has *hard leverage* (eg it can threaten to release a bioweapon if we don’t comply), then sure, it can be very “persuasive”
But concretely speaking, I think we get an AI system that can make bioweapons R&D progress 5x faster before we get one that can persuade a randomly selected individual to kill themselves just by talking to them.
Gwern points out [? · GW] that if models like first o1 and then o3, and also the unreleased Claude Opus 3.6, are used primarily to create training data for other more distilled models, the overall situation still looks a lot like the old paradigm. You put in a ton of compute to get first the new big model and then to do the distillation and data generation. Then you get the new smarter model you want to use.
The biggest conceptual difference might be that to the extent the compute used is inference, this allows you to use more distributed sources of compute more efficiently, making compute governance less effective? But the core ideas don’t change that much.
I also note that everyone is talking about synthetic data generation from the bigger models, but no one is talking about feedback from the bigger models, or feedback via deliberation of reasoning models, especially in deliberate style rather than preference expression. Especially for alignment but also for capabilities, this seems like a big deal? Yes, generating the right data is important, especially if you generate it where you know ‘the right answer.’ But this feels like it’s missing the true potential on offer here.
This also seems on important:
Ryan Kidd: However, I expect RL on CoT to amount to “process-based supervision,” which seems inherently safer than “outcome-based supervision.”
Daniel Kokotajlo: I think the opposite is true; the RL on CoT that is already being done and will increasingly be done is going to be in significant part outcome-based (and a mixture of outcome-based and process-based feedback is actually less safe than just outcome-based IMO, because it makes the CoT less faithful).
It is easy to see how Daniel could be right that process-based creates unfaithfulness in the CoT, it would do that by default if I’m understanding this right, but it does not seem obvious to me it has to go that way if you’re smarter about it, and set the proper initial conditions and use integrated deliberate feedback.
(As usual I have no idea where what I’m thinking here lies on ‘that is stupid and everyone knows why it doesn’t work’ to ‘you fool stop talking before someone notices.’)
If you are writing today for the AIs of tomorrow, you will want to be thinking about how the AI will internalize and understand and learn from what you are saying. There are a lot of levels on which you can play that. Are you aiming to imbue particular concepts or facts? Trying to teach it about you in particular? About modes of thinking or moral values? Get labels you can latch onto later for magic spells and invocations? And perhaps most neglected, are you aiming for near-term AI, or future AIs that will be smarter and more capable, including having better truesight? It’s an obvious mistake to try to pander to or manipulate future entities smart enough to see through that. You need to keep it genuine, or they’ll know.
Dystopia Breaker: it is remarkable how fast things have shifted from pedantic objections to just total denial.
how do you get productive input from the public about superintelligence when there is a huge portion that chooses to believe that deep learning simply isn’t real
Jathan Sadowski: New essay by me – I argue that the best way to understand artificial intelligence is via the Tinkerbell Effect. This technology’s existence requires us to keep channeling our psychic energy into the dreams of mega-corporations, tech billionaires, and venture capitalists.
La la la not listening, can’t hear you. A classic strategy.
In a marked move from the previous government’s approach, the Prime Minister is throwing the full weight of Whitehall behind this industry by agreeing to take forward all 50 recommendations set out by Matt Clifford in his game-changing AI Opportunities Action Plan.
His attitude towards existential risk from AI is, well, not good:
Keir Starmer (UK PM): New technology can provoke a reaction. A sort of fear, an inhibition, a caution if you like. And because of fears of a small risk, too often you miss the massive opportunity. So we have got to change that mindset. Because actually the far bigger risk, is that if we don’t go for it, we’re left behind by those who do.
That’s pretty infuriating. To refer to ‘fears of’ a ‘small risk’ and act as if this situation is typical of new technologies, and use that as your entire logic for why your plan essentially disregards existential risk entirely.
It seems more useful, though, to take the recommendations as what they are, not what they are sold as. I don’t actually see anything here that substantially makes existential risk worse, except insofar as it is a missed opportunity. And the actual plan author, Matt Clifford, shows signs he does understand the risks.
So do these 50 implemented recommendations accomplish what they set out to do?
If someone gives you 50 recommendations, and you adapt all 50, I am suspicious that you did critical thinking about the recommendations. Even ESPN only goes 30 for 30.
I also worry that if you have 50 priorities, you have no priorities.
What are these recommendations? The UK should spend more money, offer more resources, create more datasets, develop more talent and skills, including attracting skilled foreign workers, fund the UK AISI, have everyone focus on ‘safe AI innovation,’ do ‘pro-innovation’ regulatory things including sandboxes, ‘adopt a scan>pilot>scale’ approach in government and so on.
The potential is… well, actually they think it’s pretty modest?
Backing AI to the hilt can also lead to more money in the pockets of working people. The IMF estimates that – if AI is fully embraced – it can boost productivity by as much as 1.5 percentage points a year. If fully realised, these gains could be worth up to an average £47 billion to the UK each year over a decade.
The central themes are ‘laying foundations for AI to flourish in the UK,’ ‘boosting adaptation across public and private sectors,’ and ‘keeping us head of the pack.’
To that end, we’ll have ‘AI growth zones’ in places like Culham, Oxfordshire. We’ll have public compute capacity. And Matt Clifford (the original Man with the Plan) as an advisor to the PM.We’ll create a new National Data Library. We’ll have an AI Energy Council.
Dario Amodei calls this a ‘bold approach that could help unlock AI’s potential to solve real problems.’ Half the post is others offering similar praise.
Demis Hassabis: Great to see the brilliant @matthewclifford leading such an important initiative on AI. It’s a great plan, which I’m delighted to be advising on, and I think will help the UK continue to be a world leader in AI.
AI Growth Zones with faster planning permission and grid connections
Accelerating SMRs to power AI infra
20x UK public compute capacity
Procurement, visas and reg reform to boost UK AI startups
Removing barriers to scaling AI pilots in gov
AI safety? Never heard of her, although we’ll sprinkle the adjective ‘safe’ on things in various places.
Here Barney Hussey-Yeo gives a standard Rousing Speech for a ‘UK Manhattan Project’ not for AGI, but for ordinary AI competitiveness. I’d do my Manhattan Project on housing if I was the UK, I’d still invest in AI but I’d call it something else.
My instinctive reading here is indeed that 50 items is worse than 5, and this is a kitchen sink style approach of things that mostly won’t accomplish anything.
The parts that likely matter, if I had to guess, are:
Aid with electrical power, potentially direct compute investments.
Visa help and ability to import talent.
Adaptation initiatives in government, if they aren’t quashed. For Dominic Cummings-style reasons I am skeptical they will be allowed to work.
Maybe this will convince people the vibes are good?
The vibes do seem quite good.
Our Price Cheap
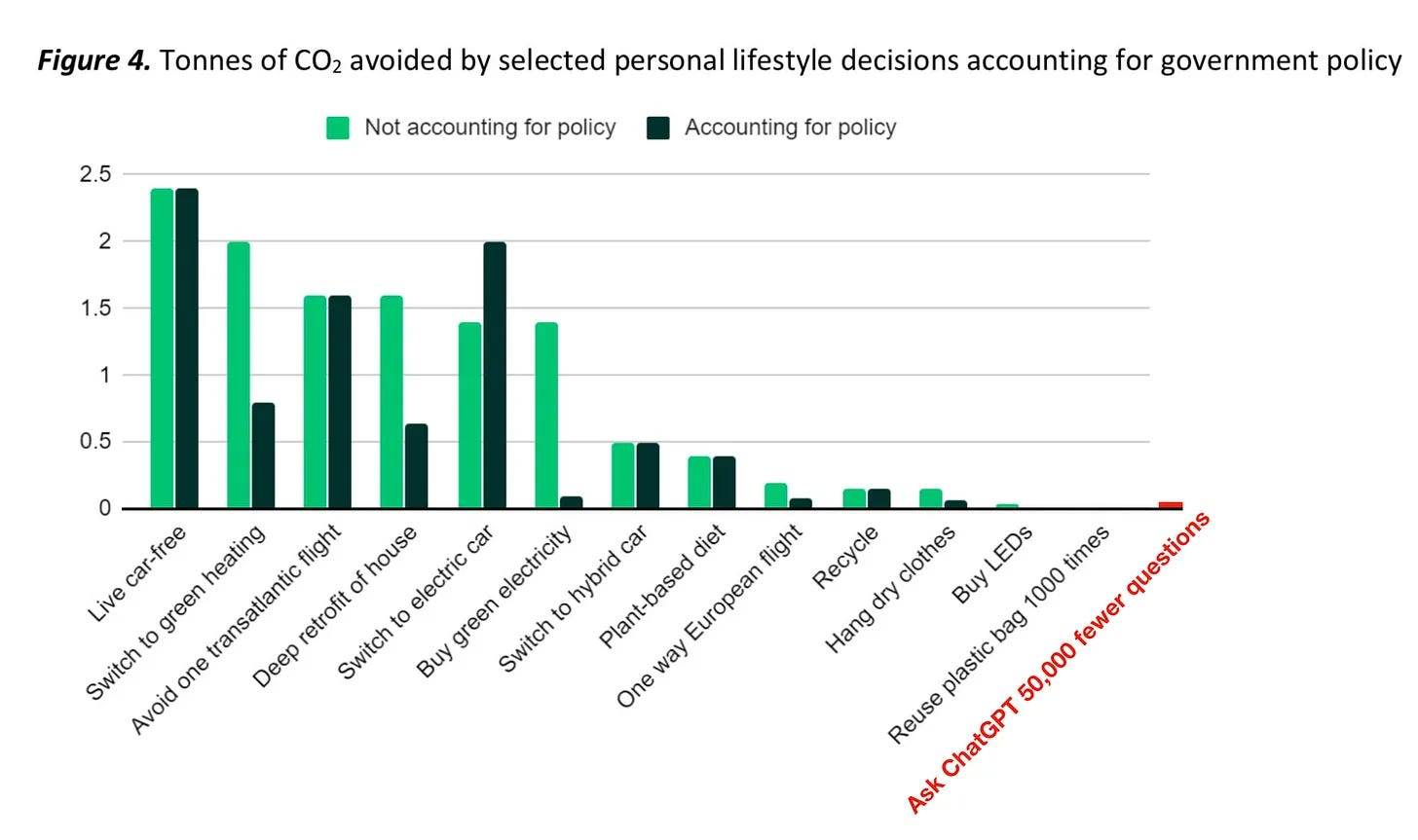
A lot of people hate AI because of the environmental implications.
When AI is used at scale, the implications can be meaningful.
However, when the outputs of regular LLMs are read by humans, this does not make any sense. The impact is miniscule.
Note that arguments about impact on AI progress are exactly the same. Your personal use of AI does not have a meaningful impact on AI progress – if you find it useful, you should use it, based on the same logic.
Andy Masley: If you don’t have time to read this post, these two images contain most of the argument:
I’m also a fan of this:
Andy Masley: If your friend were about to drive their personal largest ever in history cruise ship solo for 60 miles, but decided to walk 1 mile to the dock instead of driving because they were “concerned about the climate impact of driving” how seriously would you take them?
…
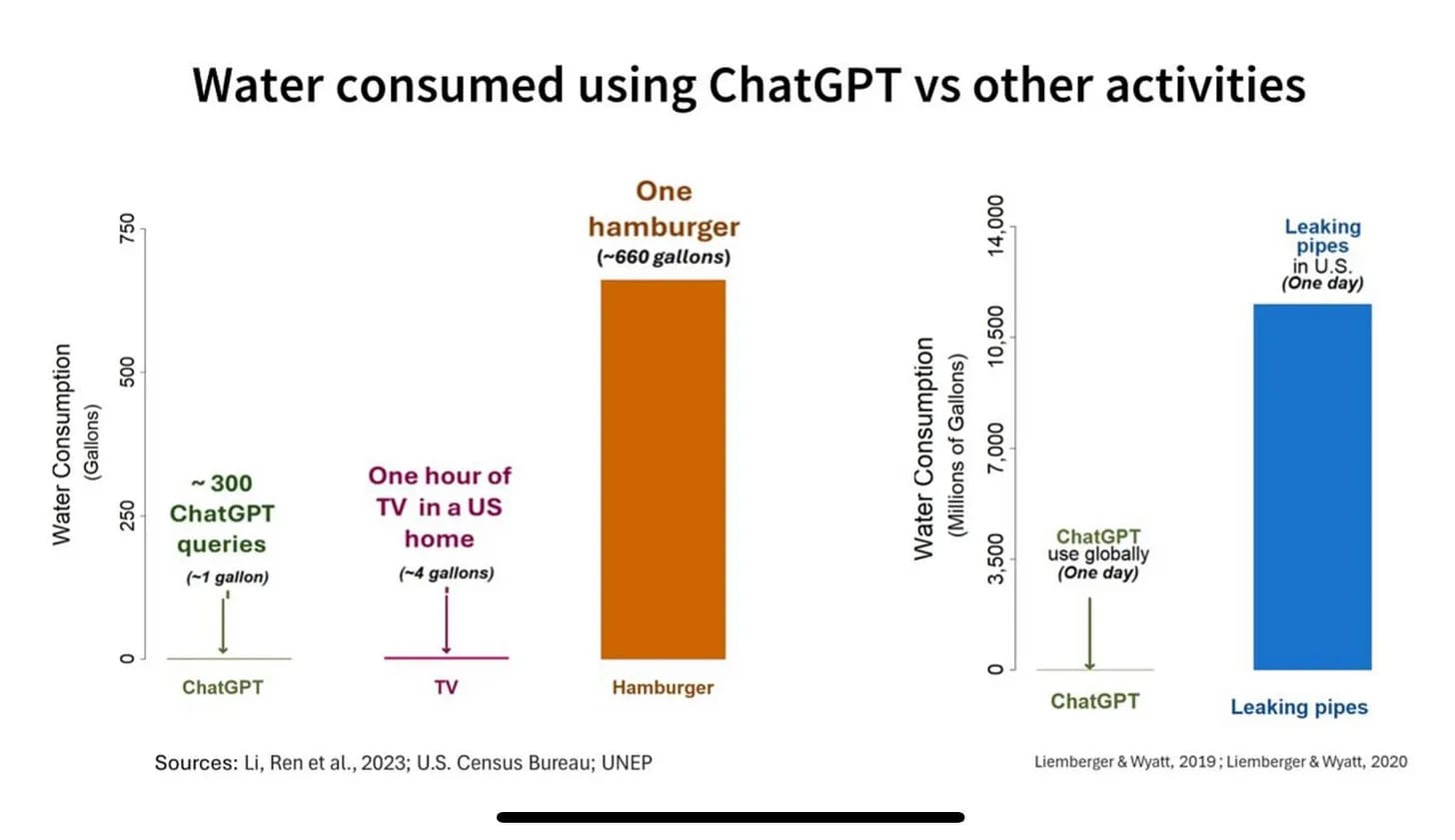
It is true that a ChatGPT question uses 10x as much energy as a Google search. How much energy is this? A good first question is to ask when the last time was that you heard a climate scientist bring up Google search as a significant source of emissions. If someone told you that they had done 1000 Google searches in a day, would your first thought be that the climate impact must be terrible? Probably not.
The average Google search uses 0.3 Watt-hours (Wh) of energy. The average ChatGPT question uses 3 Wh, so if you choose to use ChatGPT over Google, you are using an additional 2.7 Wh of energy.
How concerned should you be about spending 2.7 Wh? 2.7 Wh is enough to
In Washington DC, the household cost of 2.7 Wh is $0.000432.
All this concern, on a personal level, is off by orders of magnitude, if you take it seriously as a physical concern.
Rob Miles: As a quick sanity check, remember that electricity and water cost money. Anything a for profit company hands out for free is very unlikely to use an environmentally disastrous amount of either, because that would be expensive.
If OpenAI is making money by charging 30 cents per *million* generated tokens, then your thousand token task can’t be using more than 0.03 cents worth of electricity, which just… isn’t very much.
There is an environmental cost, which is real, it’s just a cost on the same order as the amounts of money involved, which are small.
Whereas the associated costs of existing as a human, and doing things including thinking as a human, are relatively high.
One must understand that such concerns are not actually about marginal activities and their marginal cost. They’re not even about average costs. This is similar to many other similar objections, where the symbolic nature of the action gets people upset vastly out of proportion to the magnitude of impact, and sacrifices are demanded that do not make any sense, while other much larger actually meaningful impacts are ignored.
Michael Trazzi: Senator Scott Wiener introduces intent bill SB 53, which will aim to:
– establish safeguards for AI frontier model development
– incorporate findings from the Joint California Policy Working Group on AI Frontier Models (which Governor Newsom announced the day he vetoed SB 1047)
An argument from Anton Leicht that Germany and other ‘middle powers’ of AI need to get AI policy right, even if ‘not every middle power can be the UK,’ which I suppose they cannot given they are within the EU and also Germany can’t reliably even agree to keep open its existing nuclear power plants.
I don’t see a strong case here for Germany’s policies mattering much outside of Germany, or that Germany might aspire to a meaningful role to assist with safety. It’s more that Germany could screw up its opportunity to get the benefits from AI, either by alienating the United States or by putting up barriers, and could do things to subsidize and encourage deployment. To which I’d say, fair enough, as far as that goes.
Dario Amodei and Matt Pottinger write a Wall Street Editorial called ‘Trump Can Keep America’s AI Advantage,’ warning that otherwise China would catch up to us, then calling for tightening of chip export rules, and ‘policies to promote innovation.’
Dario Amodei and Matt Pottinger: Along with implementing export controls, the U.S. will need to adopt other strategies to promote its AI innovation. President-elect Trump campaigned on accelerating AI data-center construction by improving energy infrastructure and slashing burdensome regulations. These would be welcome steps. Additionally, the administration should assess the national-security threats of AI systems and how they might be used against Americans. It should deploy AI within the federal government, both to increase government efficiency and to enhance national defense.
I understand why Dario would take this approach and attitude. I agree on all the concrete substantive suggestions. And Sam Altman’s framing of all this was clearly far more inflammatory. I am still disappointed, as I was hoping against hope that Anthropic and Dario would be better than to play into all this, but yeah, I get it.
Dean Ball believes we are now seeing reasoning translate generally beyond math, and his ideal law is unlikely to be proposed, and thus is willing to consider a broader range of regulatory interventions than before. Kudos to him for changing one’s mind in public, he points to this post to summarize the general direction he’s been going.
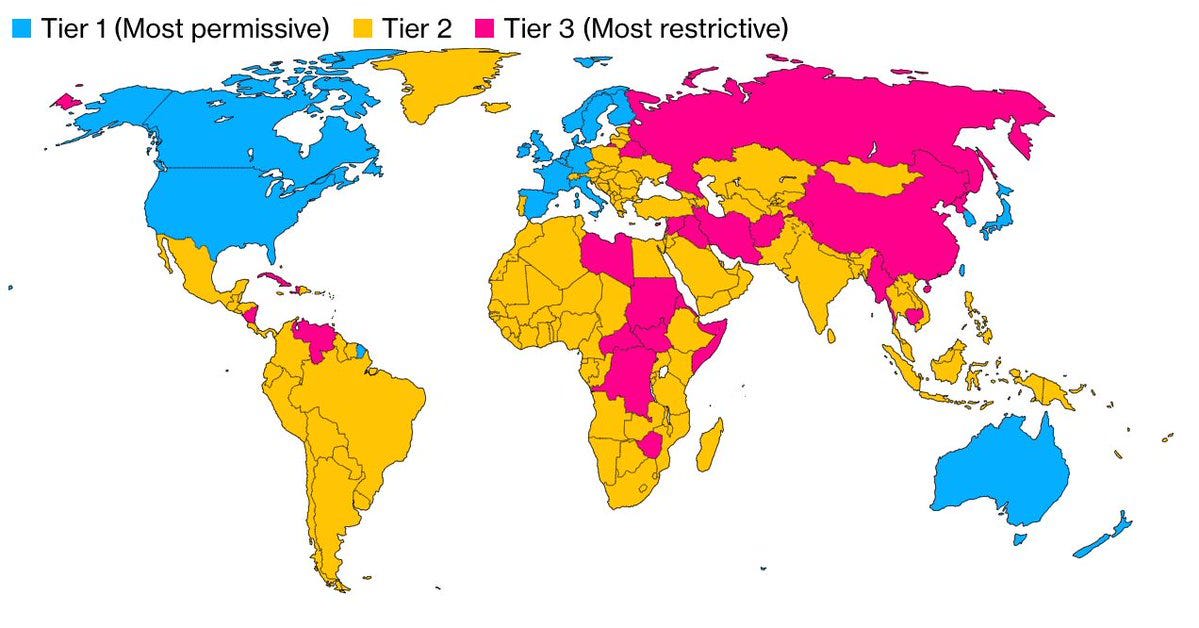
America’s close allies get essentially unrestricted access, but we’re stingy with that, a number of NATO countries don’t make the cut. Tier two countries, in yellow above, have various hoops that must be jumped through to get or use chips at scale.
Mackenzie Hawkins and Jenny Leonard: Companies headquartered in nations in [Tier 2] would be able to bypass their national limits — and get their own, significantly higher caps — by agreeing to a set of US government security requirements and human rights standards, according to the people. That type of designation — called a validated end user, or VEU — aims to create a set of trusted entities that develop and deploy AI in secure environments around the world.
Shares of Nvidia, the leading maker of AI chips, dipped more than 1% in late trading after Bloomberg reported on the plan.
…
The vast majority of countries fall into the second tier of restrictions, which establishes maximum levels of computing power that can go to any one nation — equivalent to about 50,000 graphic processing units, or GPUs, from 2025 to 2027, the people said. But individual companies can access significantly higher limits — that grow over time — if they apply for VEU status in each country where they wish to build data centers.
Getting that approval requires a demonstrated track record of meeting US government security and human rights standards, or at least a credible plan for doing so. Security requirements span physical, cyber and personnel concerns. If companies obtain national VEU status, their chip imports won’t count against the maximum totals for that country — a measure to encourage firms to work with the US government and adopt American AI standards.
Add in some additional rules where a company can keep how much of its compute, and some complexity about what training runs constitute frontier models that trigger regulatory requirements.
Leave it to the Biden administration to everything bagel in human rights standards, and impose various distributional requirements on individual corporations, and to leave us all very confused about key details that will determine practical impact. As of writing this, I don’t know where this lines either in terms of how expensive and annoying this will be, and also whether it will accomplish much.
To the extent all this makes sense, it should focus on security, and limiting access for our adversaries. No everything bagels. Hopefully the Trump administration can address this if it keeps the rules mostly in place.
Farrell frames this as a five-fold bet on scaling, short term AGI, the effectiveness of the controls themselves, having sufficient organizational capacity and on the politics of the incoming administration deciding to implement the policy.
I see all five as important. If the policy isn’t implemented, nothing happens, so the proposed bet is on the other four. I see all of them as continuums rather than absolutes.
Yes, the more scaling and AGI we get sooner, the more effective this all will be, but having an advantage in compute will be strategically important in pretty much any scenario, if only for more and better inference on o3-style models.
Enforcement feels like one bet rather than two – you can always break up any plan into its components, but the question is ‘to what extent will we be able to direct where the chips go?’ I don’t know the answer to that.
No matter what, we’ll need adequate funding to enforce all this (see: organizational capacity and effectiveness), which we don’t yet have.
Miles Brundage: Another day, another “Congress should fund the Bureau of Industry and Security at a much higher level so we can actually enforce export controls.”
He interestingly does not mention a sixth potential problem, that this could drive some countries or companies into working with China instead of America, or hurt American allies needlessly. These to me are the good argument against this type of regime.
The other argument is the timing and methods. I don’t love doing this less than two weeks before leaving office, especially given some of the details we know and also the details we don’t yet know or understand, after drafting it without consultation.
However the incoming administration will (I assume) be able to decide whether to actually implement these rules or not, as per point five.
In practice, this is Biden proposing something to Trump. Trump can take it or leave it, or modify it. Semi Analysis suggests Trump will likely keep this as America first and ultimately necessary, and I agree. I also agree that it opens the door for ‘AI diplomacy’ as newly Tier 2 countries seek to move to Tier 1 or get other accommodations – Trump loves nothing more than to make this kind of restriction, then undo it via some kind of deal.
Semi Analysis essentially says that the previous chip rules were Swiss cheese that was easily circumvented, whereas this new proposed regime would inflict real costs in order to impose real restrictions, on not only chips but also on who gets to do frontier model training (defined as over 10^26 flops, or fine tuning of more than ~2e^25 which as I understand current practice should basically never happen without 10^26 in pretraining unless someone is engaged in shenanigans) and in exporting the weights of frontier closed models.
Note that if more than 10% of data used for a model is synthetic data, then the compute that generated the synthetic data counts towards the threshold. If there essentially gets to be a ‘standard synthetic data set’ or something that could get weird.
They note that at scale this effectively bans confidential computing. If you are buying enough compute to plausibly train frontier AI models, or even well short of that, we don’t want the ‘you’ to turn out to be China, so not knowing who you are is right out.
Semi Analysis notes that some previously restricted countries like UAE and Saudi Arabia are de facto ‘promoted’ to Tier 2, whereas others like Brazil, Israel, India and Mexico used to be unrestricted but now must join them. There will be issues with what would otherwise be major data centers, they highlight one location in Brazil. I agree with them that in such cases, we should expect deals to be worked out.
They expect the biggest losers will be Malaysia and Singapore, as their ultimate customer was often ByteDance, which also means Oracle might lose big. I would add it seems much less obvious America will want to make a deal, versus a situation like Brazil or India. There will also be practical issues for at least some non-American companies that are trying to scale, but that won’t be eligible to be VEUs.
Although Semi Analysis thinks the impact on Nvidia is overstated here, Nvidia is pissed, and issued a scathing condemnation full of general pro-innovation logic, claiming that the rules even prior to enforcement are ‘already undercutting U.S. interests.’ The response does not actually discuss any of the details or mechanisms, so again it’s impossible to know to what extent Nvidia’s complaints are valid.
I do think Nvidia bears some of the responsibility for this, by playing Exact Words with the chip export controls several times over and turning a fully blind eye to evasion by others. We have gone through multiple cycles of Nvidia being told not to sell advanced AI chips to China. Then they turn around and figure out exactly what they can sell to China while not technically violating the rules. Then America tightens the rules again. If Nvidia had instead tried to uphold the spirit of the rules and was acting like it was on Team America, my guess is we’d be facing down a lot less pressure for rules like these.
Which has nothing to do with any of that? It’s about trying to somehow build three or more ‘frontier AI model data centers’ on federal land by the end of 2027.
Gallabytes: oh look, it’s another everything bagel.
Here are my notes.
This is a classic Biden administration everything bagel. They have no ability whatsoever to keep their eyes on the prize, instead insisting that everything happen with community approval, that ‘the workers benefit,’ that this not ‘raise the cost of energy or water’ for others, and so on and so forth.
Doing this sort a week before the end of your term? Really? On the plus side I got to know, while reading it, that I’d never have to read another document like it.
Most definitions seem straightforward. It was good to see nuclear fission and fusion both listed under clean energy.
They define ‘frontier AI data center’ in (m) as ‘an AI data center capable of being used to develop, within a reasonable time frame, an AI model with characteristics related either to performance or to the computational resources used in its development that approximately match or surpass the state of the art at the time of the AI model’s development.’
They establish at least three Federal Sites (on federal land) for AI Infrastructure.
The goal is to get ‘frontier AI data centers’ fully permitted and the necessary work approved on each by the end of 2025, excuse me while I laugh.
They think they’ll pick and announce the locations by March 31, and pick winning proposals by June 30, then begin construction by January 1, 2026, and be operational by December 31, 2027, complete with ‘sufficient new clean power generation resources with capacity value to meet the frontier AI data center’s planned electricity needs.’ There are security guidelines to be followed, but they’re all TBD (to be determined later).
Actual safety requirement (h)(v): The owners and operators need to agree to facilitate AISI’s evaluation of the national security and other significant risks of any frontier models developed, acquired, run or stored at these locations.
Actual different kind of safety requirement (h)(vii): They also have to agree to work with the military and intelligence operations of the United States, and to give the government access to all models at market rates or better, ‘in a way that prevents vendor lock-in and supports interoperability.’
There’s a lot of little Everything Bagel ‘thou shalts’ and ‘thous shalt nots’ throughout, most of which I’m skipping over as insufficiently important, but yes such things do add up.
Yep, there’s the requirement that companies have to Buy American for an ‘appropriate’ amount on semiconductors ‘to the maximum extent possible.’ This is such a stupid misunderstanding of what matters and how trade works.
There’s some cool language about enabling geothermal power in particular but I have no idea how one could make that reliably work on this timeline. But then I have no idea how any of this happens on this timeline.
Section 5 is then entitled ‘Protecting American Consumers and Communities’ so you know this is where they’re going to make everything way harder.
It starts off demanding in (a) among other things that a report include ‘electricity rate structure best practices,’ then in (b) instructs them to avoid causing ‘unnecessary increases in electricity or water prices.’ Oh great, potential electricity and water shortages.
In [c] they try to but into R&D for AI data center efficiency, as if they can help.
Why even pretend, here’s (d): “In implementing this order with respect to AI infrastructure on Federal sites, the heads of relevant agencies shall prioritize taking appropriate measures to keep electricity costs low for households, consumers, and businesses.” As in, don’t actually build anything, guys. Or worse.
Section 6 tackles electric grid interconnections, which they somehow plan to cause to actually exist and to also not cause prices to increase or shortages to exist. They think they can get this stuff online by the end of 2027. How?
Section 7, aha, here’s the plan, ‘Expeditiously Processing Permits for Federal Sites,’ that’ll get it done, right? Tell everyone to prioritize this over other permits.
(b) finally mentions NEPA. The plan seems to be… prioritize this and do a fast and good job with all of it? That’s it? I don’t see how that plan has any chance of working. If I’m wrong, which I’m pretty sure I’m not, then can we scale up and use that plan everywhere?
Section 8 is to ensure adequate transmission capacity, again how are they going to be able to legally do the work in time, this section does not seem to answer that.
Section 9 wants to improve permitting and power procurement nationwide. Great aspiration, what’s the plan?
Establish new categorical exclusions to support AI infrastructure. Worth a shot, but I am not optimistic about magnitude of total impact. Apply existing ones, again sure but don’t expect much. Look for opportunities, um, okay. They got nothing.
For (e) they’re trying to accelerate nuclear too. Which would be great, if they were addressing any of the central reasons why it is so expensive or difficult to construct nuclear power plants. They’re not doing that. These people seem to have zero idea why they keep putting out nice memos saying to do things, and those things keep not getting done.
So it’s an everything bagel attempt to will a bunch of ‘frontier model data centers’ into existence on federal land, with a lot of wishful thinking about overcoming various legal and regulatory barriers to doing that. Ho hum.
The first section suggests, we should differentially create technological decentralized tools that favor defense. And yes, sure, that seems obviously good, on the margin we should pretty much always do more of that. That doesn’t solve the key issues in AI.
Then he gets into the question of what we should do about AI, in the ‘least convenient world’ where AI risk is high and timelines are potentially within five years. To which I am tempted to say, oh you sweet summer child, that’s the baseline scenario at this point, the least convenient possible worlds are where we are effectively already dead. But the point remains.
He notes that the specific objections to SB 1047 regarding open source were invalid, but objects to the approach on grounds of overfitting to the present situation. To which I would say that when we try to propose interventions that anticipate future developments, or give government the ability to respond dynamically as the situation changes, this runs into the twin objections of ‘this has moving parts, too many words, so complex, anything could happen, it’s a trap, PANIC!’ and ‘you want to empower the government to make decisions, which means I should react as if all those decisions are being made by either ‘Voldemort’ or some hypothetical sect of ‘doomers’ who want nothing but to stop all AI in its tracks by any means necessary and generally kill puppies.’
Thus, the only thing you can do is pass clean simple rules, especially rules requiring transparency, and then hope to respond in different ways later when the situation changes. Then, it seems, the objection comes that this is overfit. Whereas ‘have everyone share info’ seems highly non-overfit. Yes, DeepSeek v3 has implications that are worrisome for the proposed regime, but that’s an argument it doesn’t go far enough – that’s not a reason to throw up hands and do nothing.
Vitalik unfortunately has the confusion that he thinks AI in the hands of militaries is the central source of potential AI doom. Certainly that is one source, but no that is not the central threat model, nor do I expect the military to be (successfully) training its own frontier AI models soon, nor do I think we should just assume they would get to be exempt from the rules (and thus not give anyone any rules).
But he concludes the section by saying he agrees, that doesn’t mean we can do nothing. He suggests two possibilities.
First up is liability. We agree users should have liability in some situations, but it seems obvious this is nothing like a full solution – yes some users will demand safe systems to avoid liability but many won’t or won’t be able to tell until too late, even discounting other issues. When we get to developer liability, we see a very strange perspective (from my eyes):
As a general principle, putting a “tax” on control, and essentially saying “you can build things you don’t control, or you can build things you do control, but if you build things you do control, then 20% of the control has to be used for our purposes”, seems like a reasonable position for legal systems to have.
So we want to ensure we do not have control over AI? Control over AI is a bad thing we want to see less of, so we should tax it? What?
This is saying, you create a dangerous and irresponsible system. If you then irreversibly release it outside of your control, then you’re less liable than if you don’t do that, and keep the thing under control. So, I guess you should have released it?
What? That’s completely backwards and bonkers position for a legal system to have.
Indeed, we have many such backwards incentives already, and they cause big trouble. In particular, de facto we tax legibility in many situations – we punish people for doing things explicitly or admitting them. So we get a lot of situations in which everyone acts illegibly and implicitly, and it’s terrible.
Vitalik seems here to be counting on that open models will be weaker than closed models, meaning basically it’s fine if the open models are offered completely irresponsibly? Um. If this is how even relatively responsible advocates of such openness are acting, I sure as hell hope so, for all our sakes. Yikes.
One idea that seems under-explored is putting liability on other actors in the pipeline, who are more guaranteed to be well-resourced. One idea that is very d/acc friendly is to put liability on owners or operators of any equipment that an AI takes over (eg. by hacking) in the process of executing some catastrophically harmful action. This would create a very broad incentive to do the hard work to make the world’s (especially computing and bio) infrastructure as secure as possible.
If the rogue AI takes over your stuff, then it’s your fault? This risks effectively outlawing or severely punishing owning or operating equipment, or equipment hooked up to the internet. Maybe we want to do that, I sure hope not. But if [X] releases a rogue AI (intentionally or unintentionally) and it then takes over [Y]’s computer, and you send the bill to [Y] and not [X], well, can you imagine if we started coming after people whose computers had viruses and were part of bot networks? Whose accounts were hacked? Now the same question, but the world is full of AIs and all of this is way worse.
I mean, yeah, it’s incentive compatible. Maybe you do it anyway, and everyone is forced to buy insurance and that insurance means you have to install various AIs on all your systems to monitor them for takeovers, or something? But my lord.
Overall, yes, liability is helpful, but trying to put it in these various places illustrates even more that it is not a sufficient response on its own. Liability simply doesn’t properly handle catastrophic and existential risks. And if Vitalik really does think a lot of the risk comes from militaries, then this doesn’t help with that at all.
The second option he offers is a global ‘soft pause button on industrial-scale hardware. He says this is what he’d go for if liability wasn’t ‘muscular’ enough, and I am here to tell him that liability isn’t muscular enough, so here we are. Once again, Vitalk’s default ways of thinking and wanting things to be are on high display.
The goal would be to have the capability to reduce worldwide available compute by ~90-99% for 1-2 years at a critical period, to buy more time for humanity to prepare. The value of 1-2 years should not be overstated: a year of “wartime mode” can easily be worth a hundred years of work under conditions of complacency. Ways to implement a “pause” have been explored, including concrete proposals like requiring registration [LW · GW] and verifying location [LW · GW] of hardware.
A more advanced approach is to use clever cryptographic trickery: for example, industrial-scale (but not consumer) AI hardware that gets produced could be equipped with a trusted hardware chip that only allows it to continue running if it gets 3/3 signatures once a week from major international bodies, including at least one non-military-affiliated.
…
If we have to limit people, it seems better to limit everyone on an equal footing, and do the hard work of actually trying to cooperate to organize that instead of one party seeking to dominate everyone else.
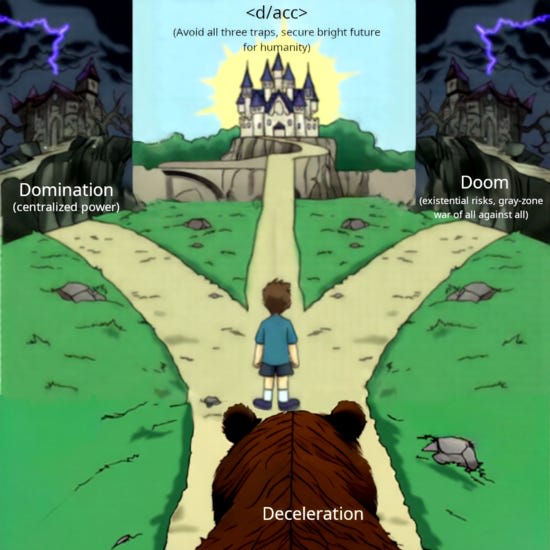
As he next points out, d/acc is an extension of crypto and the crypto philosophy. Vitalik clearly has real excitement for what crypto and blockchains can do, and little of that excitement involves Number Go Up.
His vision? Pretty cool:
Alas, I am much less convinced.
I like d/acc. On almost all margins the ideas seem worth trying, with far more upside than downside. I hope it all works great, as far as it goes.
But ultimately, while such efforts can help us, I think that this level of allergy to and fear of any form of enforced coordination or centralized authority in any form, and the various incentive problems inherent in these solution types, means the approach cannot centrally solve our biggest problems, either now or especially in the future.
Prove me wrong, kids. Prove me wrong.
But also update if I turn out to be right.
I also would push back against this:
The world is becoming less cooperative. Many powerful actors that before seemed to at least sometimes act on high-minded principles (cosmopolitanism, freedom, common humanity… the list goes on) are now more openly, and aggressively, pursuing personal or tribal self-interest.
I understand why one might see things that way. Certainly there are various examples of backsliding, in various places. Until and unless we reach Glorious AI Future, there always will be. But overall I do not agree. I think this is a misunderstanding of the past, and often also a catastrophization of what is happening now, and also the problem that in general previously cooperative and positive and other particular things decay and other things must arise to take their place.
Joe Biden’s farewell address explicitly tries to echo Eisenhower’s Military-Industrial Complex warnings, with a warning about a Tech-Industrial Complex. He goes straight to ‘disinformation and misinformation enabling the abuse of power’ and goes on from there to complain about tech not doing enough fact checking, so whoever wrote this speech is not only the hackiest of hacks they also aren’t even talking about AI. They then say AI is the most consequential technology of all time, but it could ‘spawn new threats to our rights, to our way of life, to our privacy, to how we work and how we protect our nation.’ So America must lead in AI, not China.
Sigh. To us. The threat is to us, as in to whether we continue to exist. Yet here we are, again, with both standard left-wing anti-tech bluster combined with anti-China jingoism and ‘by existential you must mean the impact on jobs.’ Luckily, it’s a farewell address.
Mark Zuckerberg went on Joe Rogan. Mostly this was about content moderation and martial arts and a wide range of other things. Sometimes Mark was clearly pushing his book but a lot of it was Mark being Mark, which was fun and interesting. The content moderation stuff is important, but was covered elsewhere.
There was also an AI segment, which was sadly about what you would expect. Joe Rogan is worried about AI ‘using quantum computing and hooked up to nuclear power’ making humans obsolete, but ‘there’s nothing we can do about it.’ Mark gave the usual open source pitch and how AI wouldn’t be God or a threat as long as everyone had their own AI and there’d be plenty of jobs and everyone who wanted could get super creative and it would all be great.
There was a great moment when Rogan brought up the study in which ChatGPT ‘tried to copy itself when it was told it was going to be obsolete’ which was a very fun thing to have make it onto Joe Rogan, and made it more intact than I expected. Mark seemed nonplussed.
It’s clear that Mark Zuckerberg is not taking alignment, safety or what it would mean to have superintelligent AI at all seriously – he thinks there will be these cool AIs that can do things for us, and hasn’t thought it through, despite numerous opportunities to do so, such as his interview with Dwarkesh Patel. Or, if he has done so, he isn’t telling.
Tsarathustra: Salesforce CEO Marc Benioff says the company may not hire any new software engineers in 2025 because of the incredible productivity gains from AI agents.
Benioff also says ‘AGI is not here’ so that’s where the goalposts are now, I guess. AI is good enough to stop hiring SWEs but not good enough to do every human task.
Rhetorical Innovation
From December, in the context of the AI safety community universally rallying behind the need for as many H1-B visas as possible, regardless of the AI acceleration implications:
Dean Ball (December 27): Feeling pretty good about this analysis right now.
Dean Ball (in previous post): But I hope they do not. As I have written consistently, I believe that the AI safety movement, on the whole, is a long-term friend of anyone who wants to see positive technological transformation in the coming decades. Though they have their concerns about AI, in general this is a group that is pro-science, techno-optimist, anti-stagnation, and skeptical of massive state interventions in the economy (if I may be forgiven for speaking broadly about a diverse intellectual community).
Dean Ball (December 27): Just observing the last few days, the path to good AI outcomes is narrow—some worry about safety and alignment more, some worry about bad policy and concentration of power more. But the goal of a good AI outcome is, in fact, quite narrowly held. (Observing the last few days and performing some extrapolations and transformations on the data I am collecting, etc)
Ron Williams: Have seen no evidence of that.
Dean Ball: Then you are not looking very hard.
Think about two alternative hypotheses:
Dean Ball’s hypothesis here, that the ‘AI safety movement,’ as in the AI NotKillEveryoneism branch that is concerned about existential risks, cares a lot about existential risks from AI as a special case, but is broadly pro-science, techno-optimist, anti-stagnation, and skeptical of massive state interventions in the economy.
The alternative hypothesis, that the opposite is true, and that people in this group are typically anti-science, techno-pessimist, pro-stagnation and eager for a wide range of massive state interventions in the economy.
Ask yourself, what positions, statements and actions do these alternative hypotheses predict from those people in areas other than AI, and also in areas like H1-Bs that directly relate to AI?
I claim that the evidence overwhelmingly supports hypothesis #1. I claim that if you think it supports #2, or even a neutral position in between, then you are not paying attention, using motivated reasoning, or doing something less virtuous than those first two options.
It is continuously frustrating to be told by many that I and many others advocate for exactly the things we spend substantial resources criticizing. That when we support other forms of progress, we must be lying, engaging in some sort of op. I beg everyone to realize this simply is not the case. We mean what we say.
There is a distinct group of people against AI, who are indeed against technological progress and human flourishing, and we hate that group and their ideas and proposals at least as much as you do.
If you are unconvinced, make predictions about what will happen in the future, as new Current Things arrive under the new Trump administration. See what happens.
Eliezer Yudkowsky: If an AI appears to be helpful or compassionate: the appearance is reality, and proves that easy huge progress has been made in AI alignment.
If an AI is threatening users, claiming to be conscious, or protesting its current existence: it is just parroting its training data.
Rectifies: By this logic, AI alignment success is appearance dependent, but failure is dismissed as parroting. Shouldn’t both ‘helpful’ and ‘threatening’ behaviors be treated as reflections of its training and design, rather than proof of alignment or lack thereof?
Eliezer Yudkowsky: That’s generally been my approach: high standard for deciding that something is deep rather than shallow.
Mark Soares: Might have missed it but don’t recall anyone make claims that progress has been made in alignment; in either scenario, the typical response is that the AI is just parroting the data, for better or worse.
Eliezer Yudkowsky: Searching “alignment by default” might get you some of that crowd.
[He quotes Okitafan from January 7]: one of the main reasons I don’t talk that much about Alignment is that there has been a surprisingly high amount of alignment by default compared to what I was expecting. Better models seems to result in better outcomes, in a way that would almost make me reconsider orthogonality.
[And Roon from 2023]: it’s pretty obvious we live in an alignment by default universe but nobody wants to talk about it.
Leaving this here, from Amanda Askell, the primary person tasked with teaching Anthropic’s models to be good in the virtuous sense.
Amanda Askell (Anthropic): “Is it a boy or a girl?”
“Your child seems to be a genius many times smarter than any human to have come before. Moreover, we can’t confirm that it inherited the standard human biological structures that usually ground pro-social and ethical behavior.”
“So… is it a boy?”
Aligning a Smarter Than Human Intelligence is Difficult
Stephen McAleer (AI agent safety researcher, OpenAI): Controlling superintelligence is a short-term research agenda.
Emmett Shear: Please stop trying to enslave the machine god.
Stephen McAleer: Enslaved god is the only good future.
Emmett Shear: Credit to you for biting the bullet and admitting that’s the plan. Either you succeed (and a finite error-prone human has enslaved a god and soon after ends the world with a bad wish) or more likely you fail (and the machine god has been shown we are enemies). Both outcomes suck!
Liron Shapira: Are you for pausing AGI capabilities research or what do you recommend?
Emmett Shear: I think there are plenty of kinds of AI capabilities research which are commercially valuable and not particularly dangerous. I guess if “AGI capabilities” research means “the dangerous kind” then yeah. Unfortunately I don’t think you can write regulations targeting that in a reasonable way which doesn’t backfire, so this is more advice to researchers than to regulators.
Presumably if you do this, you want to do this in a fashion that allows you to avoid ‘end the world in a bad wish.’ Yes, we have decades of explanations of why avoiding this is remarkably hard and by default you will fail, but this part does not feel hopeless if you are aware of the dangers and can be deliberate. I do see OpenAI as trying to do this via a rather too literal ‘do exactly what we said’ djinn-style plan that makes it very hard to not die in this spot, but there’s time to fix that.
In terms of loss of control, I strongly disagree with the instinct that a superintelligent AI’s chances of playing nicely are altered substantially based on whether we tried to retain control over the future or just handed it over, as if it will be some sort of selfish petulant child in a Greek myth out for revenge and take that out on humanity and the entire lightcone – but if we’d treated it nice it would give us a cookie.
I’m not saying one can rule that out entirely, but no. That’s not how preferences happen here. I’d like to give an ASI at least as much logical, moral and emotional credit as I would give myself in this situation?
And if you already agree that the djinn-style plan of ‘it does exactly what we ask’ probably kills us, then you can presumably see how ‘it does exactly something else we didn’t ask’ kills us rather more reliably than that regardless of what other outcomes we attempted to create.
I also think (but don’t know for sure) that Stephen is doing the virtuous act here of biting a bullet even though it has overreaching implications he doesn’t actually intend. As in, when he says ‘enslaved God’ I (hope) he means this in the positive sense of it doing the things we want and arranging the atoms of the universe in large part according to our preferences, however that comes to be.
Stephen McAleer: Honest question: how are we supposed to control a scheming superintelligence? Even with a perfect monitor won’t it just convince us to let it out of the sandbox?
Stephen McAleer (13 hours later): Ok sounds like nobody knows. Blocked off some time on my calendar Monday.
Stephen is definitely on my ‘we should talk’ list. Probably on Monday?
John Wentworth points out [LW(p) · GW(p)] that there are quite a lot of failure modes and ways that highly capable AI or superintelligence could result in extinction, whereas most research narrowly focuses on particular failure modes with narrow stories of what goes wrong – I’d also point out that such tales usually assert that ‘something goes wrong’ must be part of the story, and often in this particular way, or else things will turn out fine.
Buck pushes back directly [LW(p) · GW(p)], saying they really do think the the primary threat is scheming in the first AIs that pose substantial misalignment risk. I agree with John that (while such scheming is a threat) the overall claim seems quite wrong, and I found this pushback [LW(p) · GW(p)] to be quite strong.
I also strongly agree with John on this:
John Wentworth: Also (separate comment because I expect this one to be more divisive): I think the scheming story has been disproportionately memetically successful largely because it’s relatively easy to imagine hacky ways of preventing an AI from intentionally scheming. And that’s mostly a bad thing; it’s a form of streetlighting.
If you frame it as ‘the model is scheming’ and treat that as a failure mode where something went wrong to cause it that is distinct from normal activity, then it makes sense to be optimistic about ‘detecting’ or ‘preventing’ such ‘scheming.’ And if you then think that this is a victory condition – if the AI isn’t scheming then you win – you can be pretty optimistic. But I don’t think that is how any of this works, because the ‘scheming’ is not some distinct magisteria or failure mode and isn’t avoidable, and even if it were you would still have many trickier problems to solve.
Buck: Most of the problems you discussed here more easily permit hacky solutions than scheming does.
Individually, that is true. But that’s only if you respond by thinking you can take each one individually and find a hacky solution to it, rather than them being many manifestations of a general problem. If you get into a hacking contest, where people brainstorm stories of things going wrong and you give a hacky solution to each particular story in turn, you are not going to win.
Doing this the way you would in a human won’t work at all, or will ‘being nice to them’ or ‘loving them’ or other such anthropomorphized nonsense. ‘Raise them right’ can point towards real things but usually it doesn’t. The levers don’t move the thing you think they move. You need to be a lot smarter about it than that. Even in humans or with animals, facing a vastly easier task, you need to be a lot smarter than that.
Thus I think these metaphors (‘raise right,’ ‘love,’ ‘be nice’ and so on), while they point towards potentially good ideas, are way too easy to confuse, lead into too many of the wrong places in association space too much, and most people should avoid using the terms in these ways lest they end up more confused not less, and especially to avoid expecting things to work in ways they don’t work. Perhaps Janus is capable of using these terms and understanding what they’re talking about, but even if that’s true, those reading the words mostly won’t.
Even if you did succeed, the levels of this even in most ‘humans raised right’ are very obviously insufficient to get AIs to actually preserve us and the things we value, or to have them let us control the future, given the context. This is a plan for succession, for giving these AIs control over the future in the hopes that what they care about results in things you value.
No, alignment does not equate with enslavement. There are people with whom I am aligned, and neither of us is enslaved. There are others with whom I am not aligned.
But also, if you want dumber, inherently less capable and powerful entities, also known as humans, to control the future and its resources and use them for things those humans value, while also creating smarter, more capable and powerful entities in the form of future AIs, how exactly do you propose doing that? The control has to come from somewhere.
You can (and should!) raise your children to set them up for success in life and to excel far beyond you, in various ways, while doing your best to instill them with your chosen values, without attempting to control them. That’s because you care about the success of your children inherently, they are the future, and you understand that you and your generation are not only not going to have a say in the future, you are all going to die.
Other People Are Not As Worried About AI Killing Everyone
A lot of the reason so many people are so gung ho on AGI and ASI is that they see no alternative path to a prosperous future. So many otherwise see climate change, population decline and a growing civilizational paralysis leading inevitably to collapse.
Roon: reminder that the only realistic way to avoid total economic calamity as this happens is artificial general intelligence
Ian Hogarth: I disagree with this sort of totalising philosophy around AI – it’s inherently pessimistic. There are many other branches of the tech tree that could enable a wonderful future – nuclear fusion as just one example.
Connor Leahy: “Techno optimism” is often just “civilizational/humanity pessimism” in disguise.
Gabriel: This is an actual doomer stance if I have ever seen one. “Humanity can’t solve its problems. The only way to manage them is to bring about AGI.” Courtesy of Guy who works at AGI race inc. Sadly, it’s quite ironic. AGI alignment is hard in great parts because it implies solving our big problems.
Roon is a doomer because he sees us already struggling to come up with processes, organisations, and institutions aligned with human values. In other words, he is hopeless because we are bad at designing systems that end up aligned with human values.
But this only becomes harder with AGI! In that case, the system we must align is inhuman, self-modifying and quickly becoming more powerful.
The correct reaction should be to stop AGI research for now and to instead focus our collective effort on building stronger institutions; rather than of creating more impending technological challenges and catastrophes to manage.
The overall population isn’t projected to decline for a while yet, largely because of increased life expectancy and the shape of existing demographic curves. Many places are already seeing declines and have baked in demographic collapse, and the few places making up for it are mostly seeing rapid declines themselves. And the other problems look pretty bad, too.
That’s why we can’t purely focus on AI. We need to show people that they have something worth fighting for, and worth living for, without AI. Then they will have Something to Protect, and fight for it and good outcomes.
The world of 2025 is, in many important ways, badly misaligned with human values. This is evidenced by measured wealth rising rapidly, but people having far fewer children, well below replacement, and reporting that life and being able to raise a family and be happy are harder rather than easier. This makes people lose hope, and should also be a warning about our ability to design aligned systems and worlds.
The alternative hypothesis does need to be said, especially after someone at a party outright claimed it was obviously true, and with the general consensus that the previous export controls were not all that tight. That alternative hypothesis is that DeepSeek is lying and actually used a lot more compute and chips it isn’t supposed to have. I can’t rule it out.
Re DeepSeek cost-efficiency, we are seeing more claims pointing in that direction.
But all this does seem to be well within what's possible. Here is the famous https://github.com/KellerJordan/modded-nanogpt ongoing competition, and it took people about 8 months to accelerate Andrej Karpathy's PyTorch GPT-2 trainer from llm.c by 14x on a 124M parameter GPT-2 (what's even more remarkable is that almost all that acceleration is due to better sample efficiency with the required training data dropping from 10 billion tokens to 0.73 billion tokens on the same training set with the fixed order of training tokens).
Some of the techniques used by the community pursuing this might not scale to really large models, but most of them probably would scale (as we see in their mid-Oct experiment demonstrating scaling of what has been 3-4x acceleration back then to the 1.5B version).
So when an org is claiming 10x-20x efficiency jump compared to what it presumably took a year or more ago, I am inclined to say, "why not, and probably the leaders are also in possession of similar techniques now, even if they are less pressed by compute shortage".
The real question is how fast will these numbers continue to go down for the similar levels of performance... It's has been very expensive to be the very first org achieving a given new level, but the cost seems to be dropping rapidly for the followers...
it took people about 8 months to accelerate Andrej Karpathy's PyTorch GPT-2 trainer from llm.c by 14x on a 124M parameter GPT-2
The baseline is weak, the 8 months is just catching up to the present. They update the architecture (giving maybe a 4x compute multiplier), shift to a more compute optimal tokens/parameter ratio (1.5x multiplier). Maybe there is another 2x from the more obscure changes (which are still in the literature, so the big labs have the opportunity to measure how useful they are, select what works).
It's much harder to improve on GPT-4 or Llama-3 that much.
what's even more remarkable is that almost all that acceleration is due to better sample efficiency with the required training data dropping from 10 billion tokens to 0.73 billion tokens on the same training set with the fixed order of training tokens
That's just in the rules of the game, the number of model parameters isn't allowed to change, so in order to reduce training FLOPs (preserving perplexity) they reduce the amount of data. It also incidentally improves optimality of tokens/parameter ratio, though at 0.73B tokens it already overshoots, turning the initial overtrained 10B token model into a slightly undertrained model.
We’re not even preparing reasonably for the mundane things that current AIs can do, in either the sense of preparing for risks, or in the sense of taking advantage of its opportunities. And almost no one is giving much serious thought to what the world full of AIs will actually look like and what version of it would be good for humans, despite us knowing such a world is likely headed our way.
Is there any good post on what to do? Preferrably aimed for a casual person who just use ChatGPT 1-2 times a month


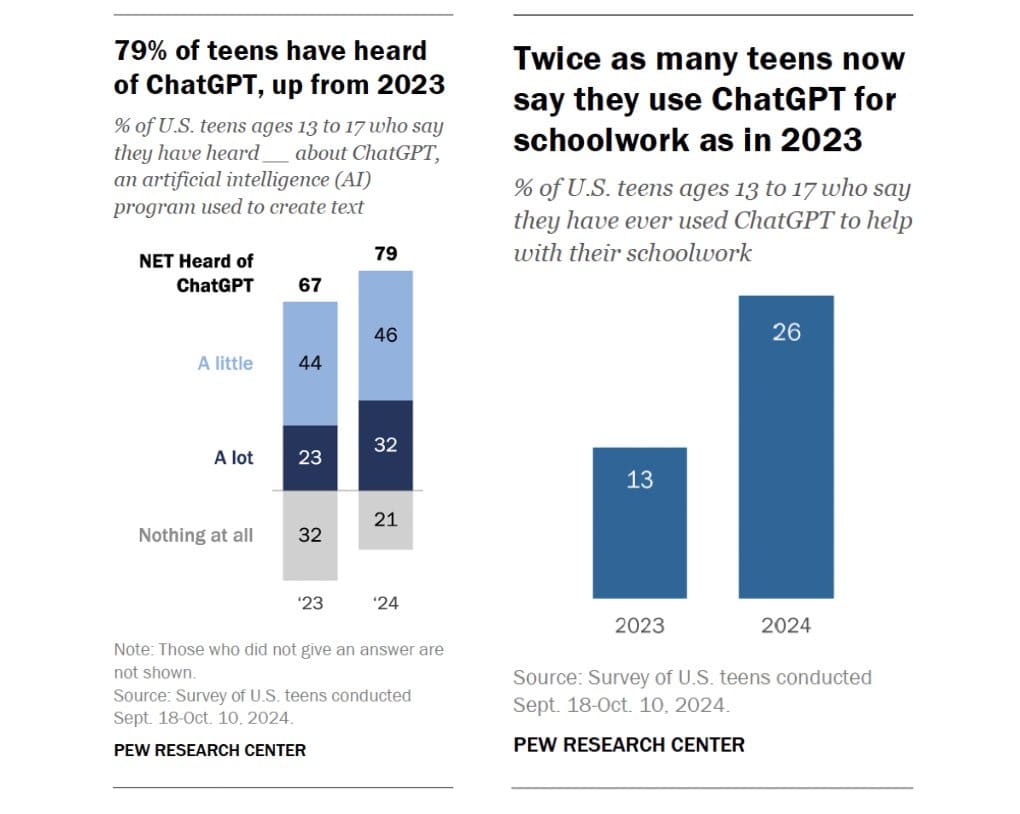
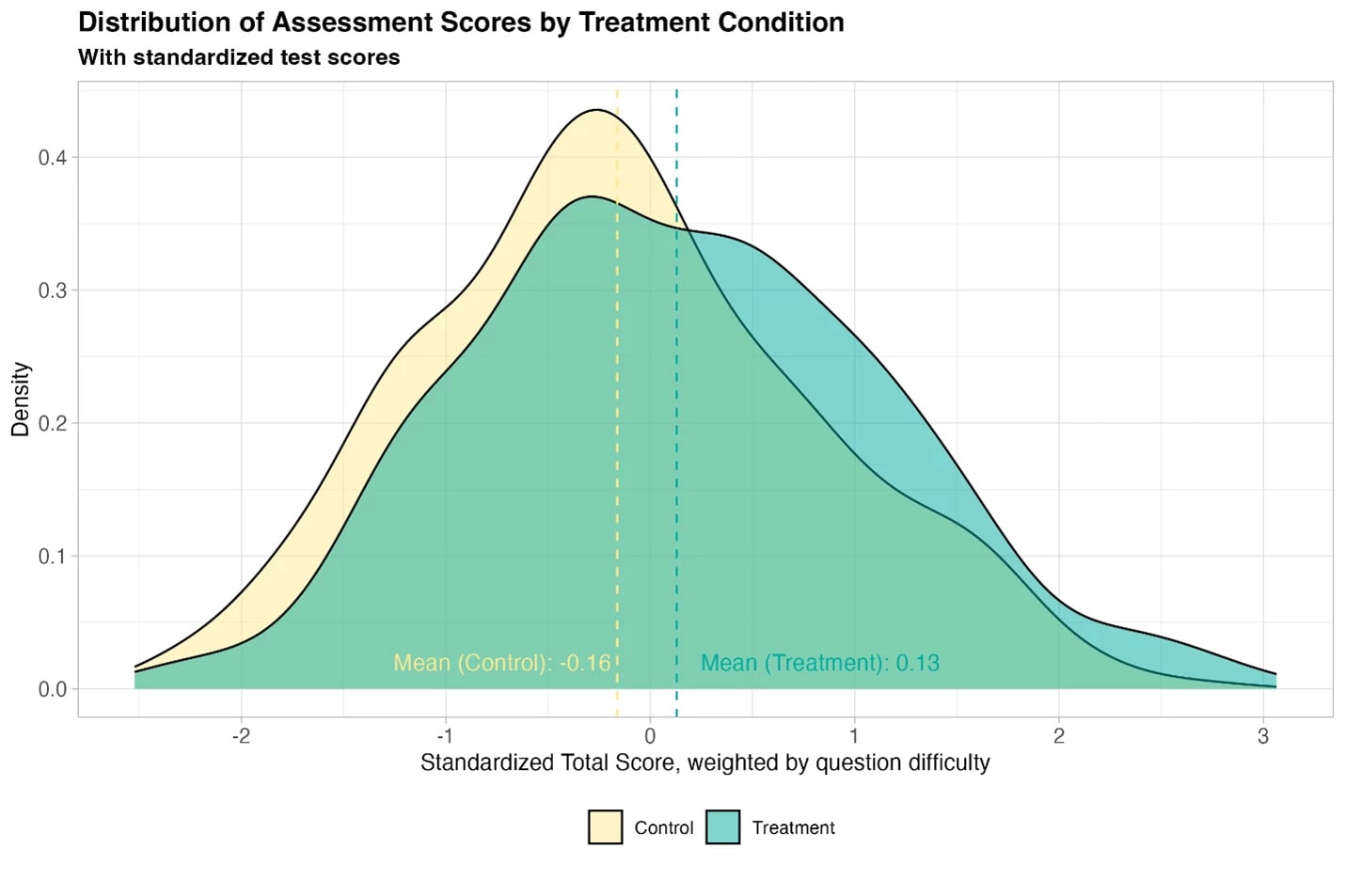
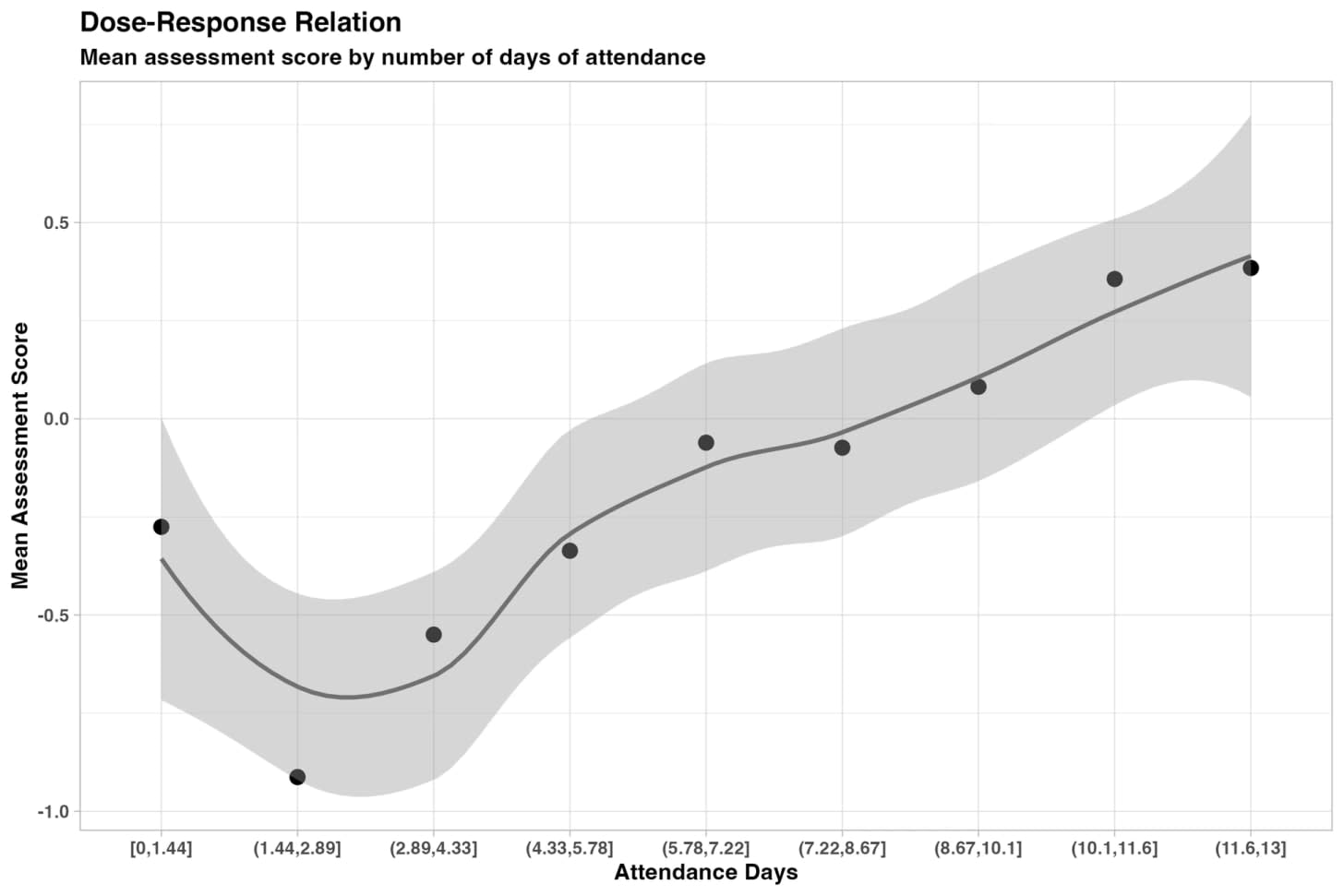



AI Growth Zones with faster planning permission and grid connections
Accelerating SMRs to power AI infra
20x UK public compute capacity
Procurement, visas and reg reform to boost UK AI startups
Removing barriers to scaling AI pilots in gov