One example of how LLM propaganda attacks can hack the brain
post by trevor (TrevorWiesinger) · 2023-08-16T21:41:02.310Z · LW · GW · 8 commentsContents
The Bandwagon Effect Security Mindset None 8 comments
Disclaimer: This is not a definitive post describing the problem, it is only describing one facet thoroughly, while leaving out many critical components of the problem. Please do not interpret this as a helpful overview of the problem, the list of dynamics here is extremely far from exhaustive, and this inadequacy should be kept in mind when forming functioning world models. AI policy and AGI macrostrategy is extremely important, and world models should be as complete as possible for people tasked with work in these areas.
Disclaimer: AI propaganda is not an x-risk or an s-risk or useful for technical alignment, and should not be considered as such. It is, however, critical for understanding the gameboard for AI.
The Bandwagon Effect
The human brain is a kludge of spaghetti code, and it therefore follows that there will be exploitable "zero days" within most or all humans. LLM-generated propaganda can hijack the human mind by a number of means; one example is by exploiting the Bandwagon effect, giving substantial control over which ideas appear to be popular at any given moment. Although LLM technology itself has significant intelligence limits, the bandwagon effect also offers a workaround: the bandwagon effect can be used to encircle and win over the minds of more gullible people, who personally write more persuasive rhetoric and take on the task of generating propaganda; this can also chain upwards from less intelligent people to more intelligent people as more intelligent and persuasive wordings are written at every step of the process, with LLMs autonomously learning from humans and synthesizing alternative versions at every step. With AI whose weights are controlled by , instead of ChatGPT’s notorious “deep fried prudishness”, this allows for impressive propaganda synthesis, amplification, and repetition.
Although techniques like twitter’s paid blue checkmarks are a very good mitigation, the problem is not just that AI is used to output propaganda, but that humans are engineered to output propaganda as well via the bandwagon effect, applying human intelligence as an ongoing input for generative AI. The problem is that LLM propaganda is vastly superior at turning individuals into temporary propaganda generators, at any given time and with the constant illusion of human interaction at every step of the process, which makes this vastly more effective than the party slogans, speeches, and censorship of dissenting views, which have dominated information ecosystems for many decades. The blue checkmarks simply reduce the degrees of freedom, by making the blue check mark accounts and accounts following them become a priority.
The sheer power of social media in part comes from how users believe that the platform is a good bellwether for what’s currently popular. In fact, the platform can best reinforce this by actually being a good bellwether for what’s currently popular ~98% of the time, and then the remaining ~2% of the time can actively set what does and does not become popular. Social media botnets, for example, are vastly superior at suppressing a new idea and preventing it from becoming popular, as modern LLMs are capable of strawmanning and criticizing ideas, especially under different lenses such as the progressive lens and the right-wing critical lens (requiring that the generated tweet include the acronym “SMH” is a good example of a prompt hack that can more effectively steer LLMs towards generate realistic negative tweets). Botnets can easily be deployed by any foreign intelligence agency, and the ability of botnets to thwart security systems of social media platforms hinges on the cybersecurity competence of the hackers running the operation, as well as success at implementing AI to pose as human users.
When propaganda is both repetitive, simple, emotional, and appears to be popular, after days, weeks, or months of repeatedly hearing an argument that they have accepted, people start to forget that it was only introduced to them recently and integrate it thoroughly into their thinking as something immemorial. This can happen with true or false arguments. This is likely related to the availability heuristic [LW · GW], where people rely on ideas more frequently depending on how easily they come to mind.
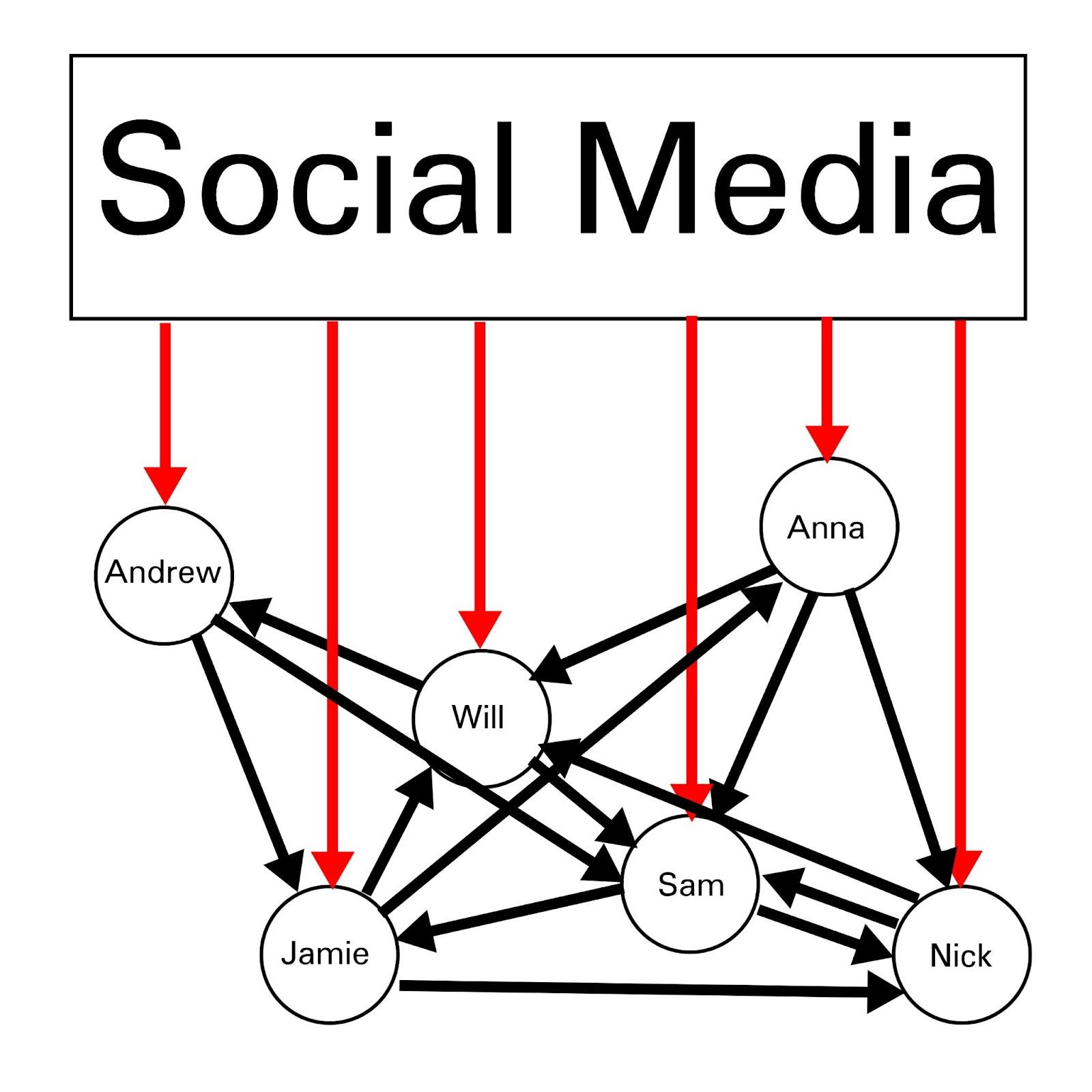
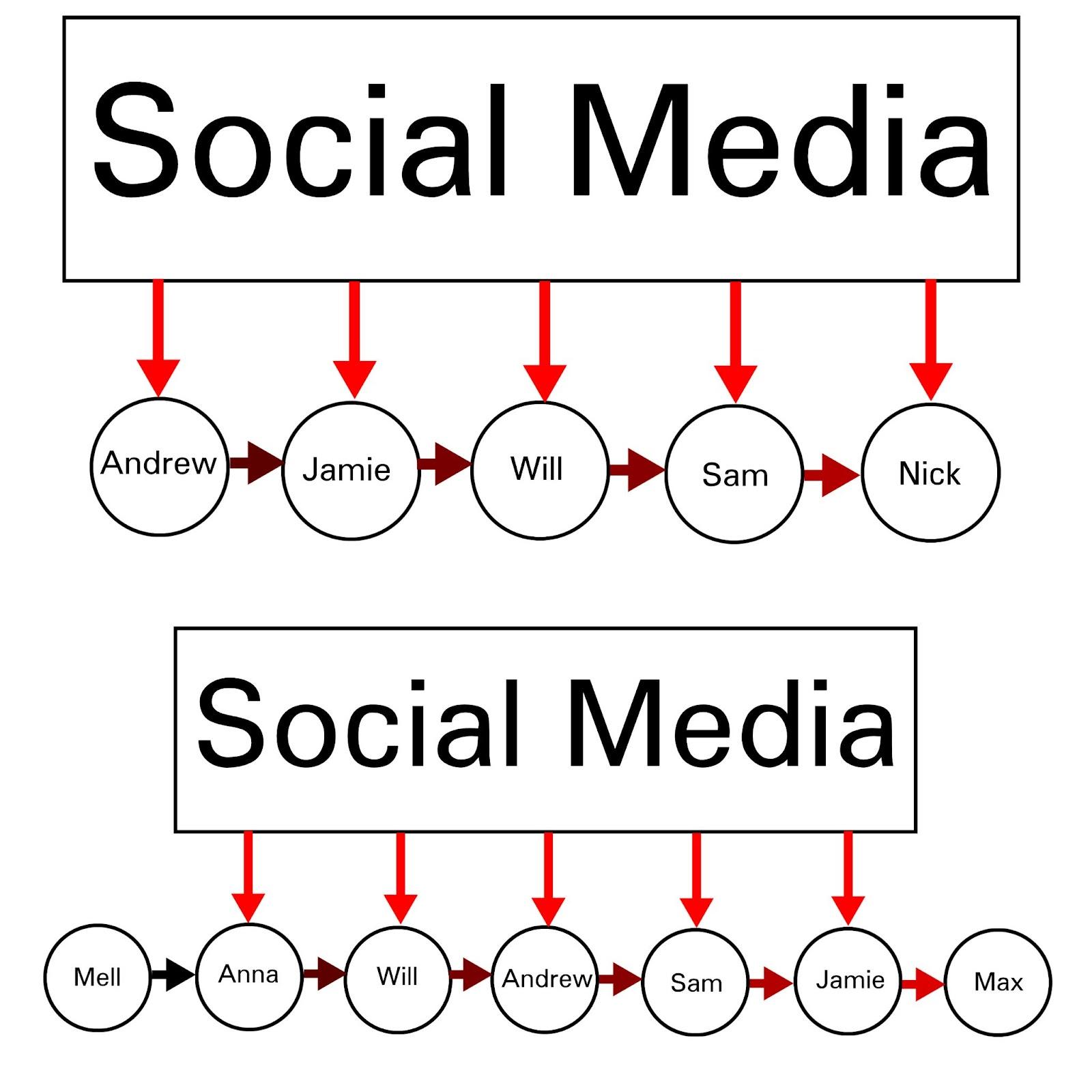
Social media has substantial capability to gradually shift discourse over time, by incrementally, repeatedly, and simultaneously affecting each node in massive networks, ultimately dominating the information environment, even for people who believe themselves to be completely unplugged from social media.
Security Mindset
Social media seems to fit the human mind really well, in ways we don't fully understand, like the orchid that evolved to attracts bees with a flower that ended up shaped like something that fits the bee targeting instinct for a mating partner (even though worker bees are infertile):
It might even fit the bee's mind better than an actual bee ever could.

Social media news feeds are generally well-known to put people into a trance-like state, which is often akratic [? · GW]. In addition to the constant stream of content, which mitigates the effect of human preference differences with a constant alternative (scrolling down) that continually keeps people re-engaged the instant they lose interest in something, news feeds also utilize a Skinner Box [LW · GW] dynamic. Short-video content like Tiktok and Reels is even more immersive, reportedly incredibly intense (I have never used these, but I remember a similar effect from Vine when I used it ~7 years ago). It makes sense that social networks that fit the human brain like a glove would expand rapidly, such as the emergence of Facebook and Myspace in the 00s, due to the trial-and-error nature of platform development and the startup world where many things are tried and things that fit the human brain well end up being noticed, even if the only way to discover things like the tiktok-shaped hole in the human heart is to continuously try things [? · GW].
This fundamental dynamic also holds for the use of LLMs to influence people and influence societies; even if there is zero evidence the current generation of chatbots do this, that is only a weak bayesian update, because it is unreasonable to expect people to find obvious [exploit]-shaped holes in the hearts of individual humans this early in the process. This particularly holds true for finding an [exploit]-shaped hole in the heart of a group of humans or an entire society/civilization.
It's important to note that this post is nowhere near a definitive overview of the problem. Large swaths have been left out, because I'd prefer not to post about them publicly. However, it goes a long way to help describe a single, safe example of why propaganda is a critical matter that drives government and military interest in AI, which is highly significant for AI policy and AGI macrostrategy.
8 comments
Comments sorted by top scores.
comment by Nicholas / Heather Kross (NicholasKross) · 2023-08-16T23:57:13.876Z · LW(p) · GW(p)
Good illustrative post, we all need to be more wary of "bad memes that nevertheless flatter the rationalist/EA/LW ingroup, even if it's in a subtle/culturally-contingent way". For every "invest in crypto early", there's at least one fad diet.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2023-08-17T00:20:58.787Z · LW(p) · GW(p)
I'm definitely thinking more about attack surfaces and exploitative third parties here, rather than bad memes being generated internally (sorry to be vague about this, it's a public post).
But also a big crux here is that the attack surface is defined by the ability to brute force stuff that fits perfectly into a hole in the heart of the human mind (or fits perfectly into a hole in the heart of a larger group or society), and specific examples like flattery are helpful.
comment by Shmi (shminux) · 2023-08-17T01:17:29.633Z · LW(p) · GW(p)
A couple of points.
Note that human valorize successful brain hacking. We call them "insights", "epiphanies" and "revelations", but all they are is successful brain hacks. If you take a popular novel or a movie, for example, there will invariably be a moment when the protagonist hears some persuasive argument and changes their mind on the spot. Behold, a brain hack. We love it and eat it up.
Also note that it is easy to create a non-lethal scissor statement with just a few words, like this bluepilling vs redpilling debate from a couple of days ago: https://twitter.com/lisatomic5/status/1690904441967575040 . This seems to have a similar effect.
I guess the latter confirms your point about the power of social media, though without any bells and whistles of video, LLMs or bandwagoning.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2023-08-17T01:35:31.470Z · LW(p) · GW(p)
I'm not sure how video, LLMs, or bandwagoning are bells and whistles in this specific context, the point I was trying to get at with each of these is that these dynamics are actually highly relevant to the current gameboard for AI safety. The issue is how the strength of the effect scales with enough people, which is exactly what it currently has. With the bandwagoning effect, particularly the graphs, I feel like I did a decent job rising well above and beyond the buzzword users, and the issue with LLM propaganda is that it helps create human propagandists iteratively, which is much more effective than the scaling from classic propaganda (I made a reference to the history of propaganda in the original version but that got edited out for the public version), but looking back on it it's less clear how well I did with video element which I just touched on. The effect from video really is quite powerful, even if it's already touched upon by buzzword-users and it's actually not very relevant to LLMs.
The link is broken, I'd like to see that scissor statement. Examples are important for thinking about concepts.
Replies from: shminux↑ comment by Shmi (shminux) · 2023-08-17T02:40:28.875Z · LW(p) · GW(p)
Fixed the link, it has been discussed here several times already, the blue pill vs the red pill poll, just not as nearly-scissor statement.
I agree with your point that bandwagoning is a known exploit, and LLMs are a force multiplier there, compared to, say tweet bots. Assuming I got your point right. Get LLMs to generate and iterate the message in various media forms until something sticks is definitely a hazard. I guess my point is that this level of sophistication may not be necessary, as you said
Replies from: TrevorWiesingerThe human brain is a kludge of spaghetti code, and it therefore follows that there will be exploitable "zero days" within most or all humans.
↑ comment by trevor (TrevorWiesinger) · 2023-08-17T03:41:01.443Z · LW(p) · GW(p)
Suddenly it clicked and I realized what I was doing completely wrong. It was such a stupid mistake on my end, in retrospect:
- I never mentioned anything about how public opinion causes regime change, tax noncompliance, military factors like popularity of wars and elite soldier/officer recruitment, and permanent cultural shifts like the 60s/70s that intergenerationally increase the risk of regime change/tax noncompliance/military popularity. Information warfare is a major factor driving government interest in AI.
- I also didn't mention anything about the power generated by steering elites vs. the masses, everything in this post was always about the masses unless stated otherwise, which it never was. And the masses always get steered, especially in democracies, and therefore is not interesting aside from people who care a ton about who wins elections. Whereas steering elites means steering people in AI safety, and all sorts of other places that are as distinct and elite relative to society as AI safety is.
comment by Chipmonk · 2023-08-17T14:57:36.300Z · LW(p) · GW(p)
Social media news feeds are generally well-known to put people into a trance-like state, which is often akratic [? · GW]. In addition to the constant stream of content, which mitigates the effect of human preference differences with a constant alternative (scrolling down) that continually keeps people re-engaged the instant they lose interest in something, news feeds also utilize a Skinner Box [LW · GW] dynamic. Short-video content like Tiktok and Reels is even more immersive, reportedly incredibly intense […] It makes sense that social networks that fit the human brain like a glove would expand rapidly […]
Hm, this is not my model of cognition.
My model of cognition is that people who became put into a trance-like state have a part [? · GW] of them that wants to be in a trance-like (read: dissociative, numb) state. Alfred Adler thought similarly.
Meanwhile, if such a person integrates [LW · GW] their want, then they are no longer susceptible to such mediums.
How else do you explain why not everyone is addicted to social media and not all of the time?
So I don't think it's that "Social media […] put people into a trance-like state […] which mitigates the effect of human preference differences", but instead that there's some sort of handshake between the user and the platform. The user (a part of the user) allows it to happen.
Also see: Defining "aggression" for creating Non-Aggressive AI systems (draft, feedback wanted) [LW · GW]
I'm not saying that it's impossible to scan someone's brain, predict it forward in time, and reverse engineer the outputs, no— but I'm saying that I doubt there's a universal intervention that hacks all humans— instead of just temporarily hacking a subset of humans with the same insecurity. And it's completely possible to integrate [LW · GW] one's own vulnerabilities.