GovAI: Towards best practices in AGI safety and governance: A survey of expert opinion
post by Zach Stein-Perlman · 2023-05-15T01:42:41.012Z · LW · GW · 11 commentsThis is a link post for https://arxiv.org/pdf/2305.07153.pdf
Contents
11 comments
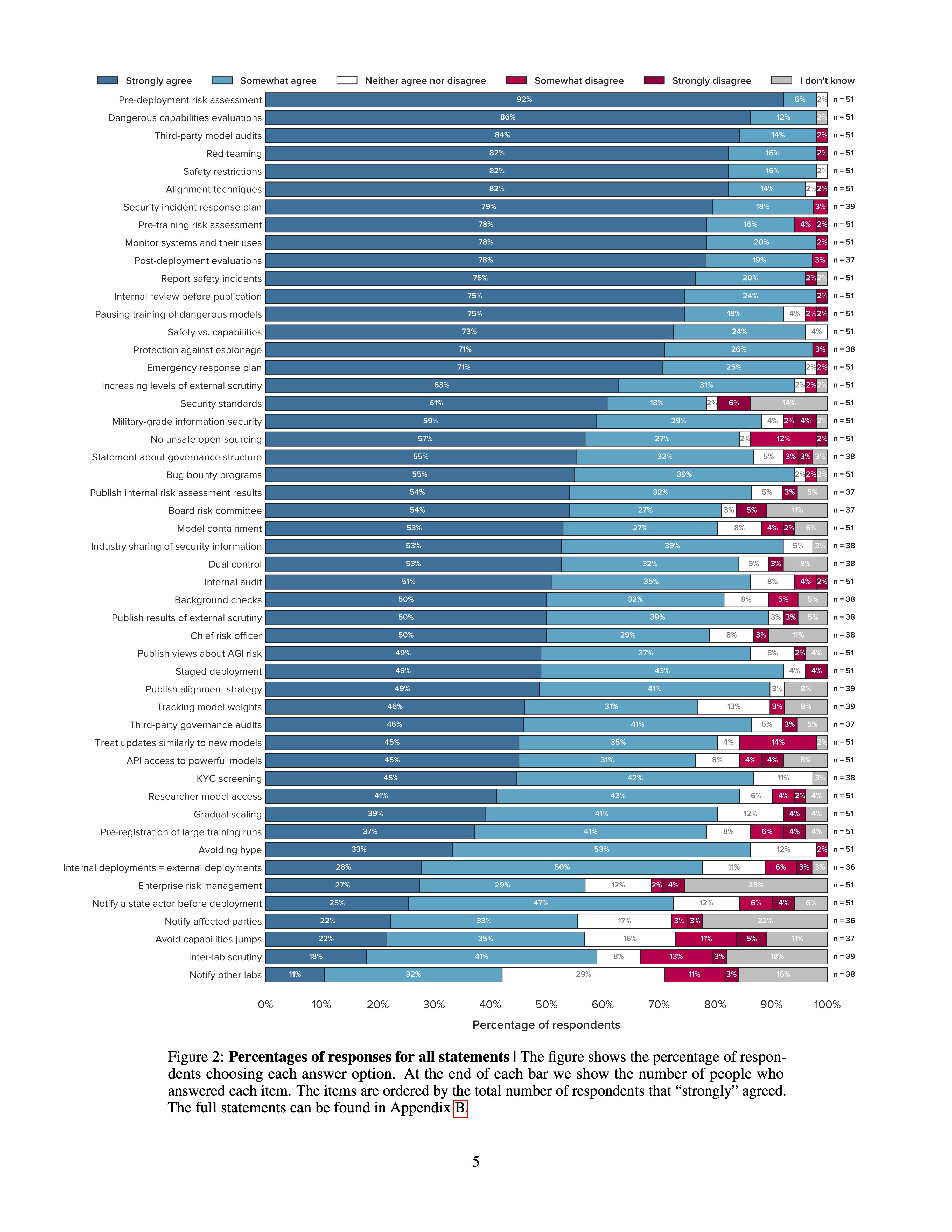
A number of leading AI companies, including OpenAI, Google DeepMind, and Anthropic, have the stated goal of building artificial general intelligence (AGI) - AI systems that achieve or exceed human performance across a wide range of cognitive tasks. In pursuing this goal, they may develop and deploy AI systems that pose particularly significant risks. While they have already taken some measures to mitigate these risks, best practices have not yet emerged. To support the identification of best practices, we sent a survey to 92 leading experts from AGI labs, academia, and civil society and received 51 responses. Participants were asked how much they agreed with 50 statements about what AGI labs should do. Our main finding is that participants, on average, agreed with all of them. Many statements received extremely high levels of agreement. For example, 98% of respondents somewhat or strongly agreed that AGI labs should conduct pre-deployment risk assessments, dangerous capabilities evaluations, third-party model audits, safety restrictions on model usage, and red teaming. Ultimately, our list of statements may serve as a helpful foundation for efforts to develop best practices, standards, and regulations for AGI labs.
I'm really excited about this paper. It seems to be great progress toward figuring out what labs should do and making that common knowledge.
(And apparently safety evals and pre-deployment auditing are really popular, hooray!)
Edit: see also the blogpost.
11 comments
Comments sorted by top scores.
comment by Zach Stein-Perlman · 2023-05-15T03:00:30.567Z · LW(p) · GW(p)
I think this is now the canonical collection of ideas for stuff AI labs should do (from an x-risk perspective). (Here are the 50 ideas with brief descriptions, followed by 50 ideas suggested by respondents-- also copied in a comment below.) (The only other relevant collection-y public source I'm aware of is my Ideas for AI labs: Reading list [LW · GW].) So it seems worth commenting with promising ideas not listed in the paper:
- Alignment (including interpretability) research (as a common good, separate from aligning your own models)
- Model-sharing: cautiously sharing powerful models with some external safety researchers to advance their research (separately from sharing for the sake of red-teaming)
- Transparency stuff
- Coordination stuff
- Publication stuff
- Planning stuff
- [Supporting other labs doing good stuff]
- [Supporting other kinds of actors (e.g., government) doing good stuff]
(I hope to update this comment with details later.)
Replies from: habryka4, Zach Stein-Perlman↑ comment by habryka (habryka4) · 2023-05-15T04:23:23.072Z · LW(p) · GW(p)
Huh, interesting. Seems good to get an HTML version then, since in my experience PDFs have a pretty sharp dropoff in readership.
When I google the title of the paper literally the only hit is this LessWrong post. Do you know where the paper was posted and whether there exists an HTML version (or a LaTeX, or a Word, or a Google Doc version)?
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2023-05-15T04:27:04.719Z · LW(p) · GW(p)
It was posted at https://arxiv.org/abs/2305.07153. I'm not aware of versions other than the pdf.
Replies from: markusanderljung↑ comment by markusanderljung · 2023-05-17T19:15:47.006Z · LW(p) · GW(p)
Thanks for the nudge: We'll consider producing an HTML version!
↑ comment by Zach Stein-Perlman · 2023-05-15T07:20:21.434Z · LW(p) · GW(p)
For reference, here are the 50 tested ideas (in descending order of popularity):
- Pre-deployment risk assessment. AGI labs should take extensive measures to identify, analyze, and evaluate risks from powerful models before deploying them.
- Dangerous capability evaluations. AGI labs should run evaluations to assess their models’ dangerous capabilities (e.g. misuse potential, ability to manipulate, and power-seeking behavior).
- Third-party model audits. AGI labs should commission third-party model audits before deploying powerful models.
- Safety restrictions. AGI labs should establish appropriate safety restrictions for powerful models after deployment (e.g. restrictions on who can use the model, how they can use the model, and whether the model can access the internet).
- Red teaming. AGI labs should commission external red teams before deploying powerful models.
- Monitor systems and their uses. AGI labs should closely monitor deployed systems, including how they are used and what impact they have on society.
- Alignment techniques. AGI labs should implement state-of-the-art safety and alignment techniques.
- Security incident response plan. AGI labs should have a plan for how they respond to security incidents (e.g. cyberattacks).
- Post-deployment evaluations. AGI labs should continually evaluate models for dangerous capabilities after deployment, taking into account new information about the model’s capabilities and how it is being used.
- Report safety incidents. AGI labs should report accidents and near misses to appropriate state actors and other AGI labs (e.g. via an AI incident database).
- Safety vs capabilities. A significant fraction of employees of AGI labs should work on enhancing model safety and alignment rather than capabilities.
- Internal review before publication. Before publishing research, AGI labs should conduct an internal review to assess potential harms.
- Pre-training risk assessment. AGI labs should conduct a risk assessment before training powerful models.
- Emergency response plan. AGI labs should have and practice implementing an emergency response plan. This might include switching off systems, overriding their outputs, or restricting access.
- Protection against espionage. AGI labs should take adequate measures to tackle the risk of state-sponsored or industrial espionage.
- Pausing training of dangerous models. AGI labs should pause the development process if sufficiently dangerous capabilities are detected.
- Increasing level of external scrutiny. AGI labs should increase the level of external scrutiny in proportion to the capabilities of their models.
- Publish alignment strategy. AGI labs should publish their strategies for ensuring that their systems are safe and aligned.
- Bug bounty programs. AGI labs should have bug bounty programs, i.e. recognize and compensate people for reporting unknown vulnerabilities and dangerous capabilities.
- Industry sharing of security information. AGI labs should share threat intelligence and information about security incidents with each other.
- Security standards. AGI labs should comply with information security standards (e.g. ISO/IEC 27001 or NIST Cybersecurity Framework). These standards need to be tailored to an AGI context.
- Publish results of internal risk assessments. AGI labs should publish the results or summaries of internal risk assessments, unless this would unduly reveal proprietary information or itself produce significant risk. This should include a justification of why the lab is willing to accept remaining risks.
- Dual control. Critical decisions in model development and deployment should be made by at least two people (e.g. promotion to production, changes to training datasets, or modifications to production).
- Publish results of external scrutiny. AGI labs should publish the results or summaries of external scrutiny efforts, unless this would unduly reveal proprietary information or itself produce significant risk.
- Military-grade information security. The information security of AGI labs should be proportional to the capabilities of their models, eventually matching or exceeding that of intelligence agencies (e.g. sufficient to defend against nation states).
- Board risk committee. AGI labs should have a board risk committee, i.e. a permanent committee within the board of directors which oversees the lab’s risk management practices.
- Chief risk officer. AGI labs should have a chief risk officer (CRO), i.e. a senior executive who is responsible for risk management.
- Statement about governance structure. AGI labs should make public statements about how they make high-stakes decisions regarding model development and deployment.
- Publish views about AGI risk. AGI labs should make public statements about their views on the risks and benefits from AGI, including the level of risk they are willing to take in its development.
- KYC screening. AGI labs should conduct know-your-customer (KYC) screenings before giving people the ability to use powerful models.
- Third-party governance audits. AGI labs should commission third-party audits of their governance structures.
- Background checks. AGI labs should perform rigorous background checks before hiring/appointing members of the board of directors, senior executives, and key employees.
- Model containment. AGI labs should contain models with sufficiently dangerous capabilities (e.g. via boxing or air-gapping).
- Staged deployment. AGI labs should deploy powerful models in stages. They should start with a small number of applications and fewer users, gradually scaling up as confidence in the model’s safety increases.
- Tracking model weights. AGI labs should have a system that is intended to track all copies of the weights of powerful models.
- Internal audit. AGI labs should have an internal audit team, i.e. a team which assesses the effectiveness of the lab’s risk management practices. This team must be organizationally independent from senior management and report directly to the board of directors.
- No [unsafe] open-sourcing. AGI labs should not open-source powerful models, unless they can demonstrate that it is sufficiently safe to do so.
- Researcher model access. AGI labs should give independent researchers API access to deployed models.
- API access to powerful models. AGI labs should strongly consider only deploying powerful models via an application programming interface (API).
- Avoiding hype. AGI labs should avoid releasing powerful models in a way that is likely to create hype around AGI (e.g. by overstating results or announcing them in attention-grabbing ways).
- Gradual scaling. AGI labs should only gradually increase the amount of compute used for their largest training runs.
- Treat updates similarly to new models. AGI labs should treat significant updates to a deployed model (e.g. additional fine-tuning) similarly to its initial development and deployment. In particular, they should repeat the pre-deployment risk assessment.
- Pre-registration of large training runs. AGI labs should register upcoming training runs above a certain size with an appropriate state actor.
- Enterprise risk management. AGI labs should implement an enterprise risk management (ERM) framework (e.g. the NIST AI Risk Management Framework or ISO 31000). This framework should be tailored to an AGI context and primarily focus on the lab’s impact on society.
- Treat internal deployments similarly to external deployments. AGI labs should treat internal deployments (e.g. using models for writing code) similarly to external deployments. In particular, they should perform a pre-deployment risk assessment.
- Notify a state actor before deployment. AGI labs should notify appropriate state actors before deploying powerful models.
- Notify affected parties. AGI labs should notify parties who will be negatively affected by a powerful model before deploying it.
- Inter-lab scrutiny. AGI labs should allow researchers from other labs to scrutinize powerful models before deployment.
- Avoid capabilities jumps. AGI labs should not deploy models that are much more capable than any existing models.
- Notify other labs. AGI labs should notify other labs before deploying powerful models.
And here are 50 ideas suggested by respondents:
Replies from: cmessinger
- AGI labs should participate in democratic and participatory governance processes (e.g. citizen assemblies). Issues could include the level of risk that is acceptable and preferences for different governance models.
- AGI labs should engage the public and civil society groups in determining what risks should be considered and what level of risk is acceptable.
- AGI labs should contribute to improving AI and AGI literacy among the public and policymakers.
- AGI labs should be transparent about where training data comes from.
- AGI labs should use system cards.
- AGI labs should report what safety and alignment techniques they used to develop a model.
- AGI labs should publish their ethics and safety research.
- AGI labs should make capability demonstrations available to policymakers and the public before deployment.
- AGI labs should have written deployment plans of what they would do with an AGI or other advanced and powerful AI system.
- AGI labs should publicly predict the frequency of harmful AI incidents.
- AGI labs should generate realistic catastrophic risk models for advanced AI.
- AGI labs should track and report on their models’ capability to automate AI research and development.
- AGI labs should engage in efforts to systematically forecast future risks and benefits of the technology they build.
- AGI labs should generate realistic catastrophic risk models for advanced AI, potentially making these public or using them to raise awareness.
- AGI labs should publish an annual report where they present the predicted and actual impacts of their work, along with the evidence and assumptions these are based on.
- AGI labs should pre-register big training runs including the amount of compute used, the data used for training, and how many parameters the model will have.
- AGI labs should engage in employee and investor education and awareness on the risks of advanced AI systems and potential mitigating procedures that need to be taken that tradeoff profit for societal benefit.
- AGI labs should adequately protect whistleblowers.
- AGI labs should have an onboard process for managers and new employees that involves content explaining how the organization believes a responsible AGI developer would behave and how they are attempting to meet that standard.
- AGI labs should promote a culture that encourages internal deliberation and critique, and evaluate whether they are succeeding in building such a culture.
- AGI labs should have dedicated programs to improve the diversity, equity, and inclusion of their talent.
- AGI labs should have independent safety and ethics advisory boards to help with certain decisions.
- AGI labs should have internal review boards.
- AGI labs should be set up such that their governance structures permit them to tradeoff profits with societal benefit.
- AGI labs should have merge and assist clauses.
- AGI labs should report to an international non-governmental organization (INGO) that is publicly committed to human rights and democratic values.
- AGI labs should have an independent board of directors with technical AI safety expertise who have the mandate to put the benefits for society above profit and shareholder value.
- AGI labs should maintain a viable way to divert from building AGI (e.g. to build narrower models and applications), in case building AGI will not be possible to do safely.
- AGI labs should use the Three Lines of Defense risk management framework.
- AGI labs should take measures to avoid being sued for trading off profits with societal benefit.
- AGI labs should be subject to mandatory interpretability standards.
- AGI labs should conduct evaluation during training, being prepared to stop and analyze any training run that looks potentially risky or harmful.
- AGI labs should save logs of interactions with the AI system.
- AGI labs should consider caps on model size.
- AGI labs should be forced to have systems that consist of ensembles of capped size models instead of one increasingly large model.
- AGI labs should ensure that AI systems in an ensemble communicate in English and that these communications are logged for future analysis if an incident occurs.
- AGI labs should limit API access to approved and vetted applications to foreclose potential misuse and dual use risks.
- AGI labs should conduct simulated cyber attacks on their systems to check for vulnerabilities.
- AGI labs should have internal controls and processes that prevent a single person or group being able to deploy an advanced AI system when governance mechanisms have found this to be potentially harmful or illegal.
- AGI labs should disclose the data and labor practices involved in pre-training and training of powerful AI systems.
- AGI labs should disclose the environmental costs of developing and deploying powerful AI systems.
- AGI labs [should] take measures to limit potential harms that could arise from AI systems being sentient or deserving moral patienthood.
- AGI labs should coordinate on self-regulatory best practices they use for safety.
- AGI labs should coordinate on best practices for external auditing and red-teaming.
- AGI labs should coordinate on best practices for incident reporting.
- AGI labs should report cluster sizes and training plans to other AGI labs to avoid incorrect perceptions of current capabilities and compute resources.
- AGI labs should have feedback mechanisms with communities that are affected by their models.
- AGI labs should have ethical principles and set out “red lines” for their work in advance.
- AGI labs should incorporate a privacy-preserving in machine learning (PPML) approach to auditing and governing AI models.
- AGI labs should use responsible AI licenses (RAIL) and engage in other practices that allow for degrees of openness on the spectrum from closed to open.
↑ comment by chanamessinger (cmessinger) · 2023-05-25T13:07:50.569Z · LW(p) · GW(p)
Interesting how many of these are "democracy / citizenry-involvement" oriented. Strongly agree with 18 (whistleblower protection) and 38 (simulate cyber attacks).
20 (good internal culture), 27 (technical AI people on boards) and 29 (three lines of defense) sound good to me, I'm excited about 31 if mandatory interpretability standards exist.
42 (on sentience) seems pretty important but I don't know what it would mean.
↑ comment by ryan_greenblatt · 2023-11-06T02:28:49.102Z · LW(p) · GW(p)
This is super late, but I recently posted: Improving the Welfare of AIs: A Nearcasted Proposal [LW · GW]
↑ comment by Zach Stein-Perlman · 2023-05-25T16:25:10.260Z · LW(p) · GW(p)
Assuming you mean the second 42 ("AGI labs take measures to limit potential harms that could arise from AI systems being sentient or deserving moral patienthood")-- I also don't know what labs should do, so I asked an expert yesterday and will reply here if they know of good proposals...
Replies from: cmessinger↑ comment by chanamessinger (cmessinger) · 2023-05-25T22:17:52.518Z · LW(p) · GW(p)
Thanks!
comment by chanamessinger (cmessinger) · 2023-05-25T13:06:49.044Z · LW(p) · GW(p)
The top 6 of the ones in the paper (the ones I think got >90% somewhat or strongly agree, listed below), seem pretty similar to me - are there important reasons people might support one over another?
- Pre-deployment risk assessments
- Evaluations of dangerous capabilities
- Third-party model audits
- Red teaming
- Pre-training risk assessments
- Pausing training of dangerous models
↑ comment by Zach Stein-Perlman · 2023-05-25T16:17:55.932Z · LW(p) · GW(p)
I think 19 ideas got >90% agreement.
I agree the top ideas overlap. I think reasons one might support some over others depend on the details.