Infra-Bayesian haggling
post by hannagabor (hanna-gabor) · 2024-05-20T12:23:30.165Z · LW · GW · 0 commentsContents
Preface Introduction Preliminaries Repeated games Running example: Prisoner's dilemma Other notation Proposed algorithm How to describe hypotheses? Regular decision processes Resettable infra-RDPs Which hypotheses are in the hypothesis space of the agents? Learning-theoretic guarantee Where does following this algorithm lead the agents? Generalized stag hunt - unique Pareto-optimal outcome Reasoning behind the Conjecture: Prisoner's dilemma Schelling Pub (Battle of the sexes) Schelling points Multiplayer games When can a coalition be formed? Stable cycles for multiplayer games Conclusion Future directions Appendix None No comments
Preface
I wrote this post during my scholarship at MATS. My goal is to describe a research direction of the learning theoretic agenda [LW · GW] (LTA). Namely, a natural infra-Bayesian learning algorithm proposal that arguably leads to Pareto-optimal solutions in repeated games. The idea originates from Vanessa, I'm expanding a draft of her into a more accessible description.
The expected audience are people who are interested in ongoing work on LTA. It is especially suitable for people who are looking for a research direction to pursue in this area.
Introduction
There has been much work on the theory of agents who cooperate in the Prisoner's dilemma and other situations. Some call this behavior superrationality [? · GW]. For example, functional decision theory (FDT) is a decision theory that prescribes such behavior. The strongest results so far are those coming from "modal combat", e.g. Critch. However, these results are of very limited scope: among other issues, they describe agents crafted for specific games, rather than general reasoners that produce superrational behavior in a "naturalized" manner (i.e. as a special case of the general rules of reasoning.)
At the same time, understanding multi-agent learning theory is another major open problem. Attempts to prove convergence to game-theoretic solution concepts (a much weaker goal than superrationality) in a learning-theoretic setting are impeded by the so-called grain-of-truth problem (originally observed by Kalai and Lehrer, its importance was emphasized by Hutter). An agent can learn to predict the environment via Bayesian learning only if it assigns non-zero prior probability to that environment, i.e. its prior contains a grain of truth. What's the grain-of-truth problem? Suppose Alice's environment contains another agent, Bob. If Alice is a Bayesian agent, she can learn to predict Bob's behavior only if her prior assigns a positive probability to Bob's behavior. (That is, Alice's prior contains a grain of truth.) If Bob has the same complexity level as Alice, then Alice is not able to represent all possible environments. Thus, in general, Alice's prior doesn't contain a grain of truth. A potential solution based on "reflective oracles" was proposed by Leike, Taylor and Fallenstein. However it involves arbitrarily choosing a fixed point out of an enormous space of possibilities, and requires that all agents involved choose the same fixed point. Approaches to multi-agent learning in the mainstream literature (see e.g. Cesa-Bianchi and Lugosi) also suffer from restrictive assumptions and are not naturalized.
Infra-Bayesianism [LW · GW] (IB) was originally motivated by the problem of non-realizability, of which the multi-agent grain-of-truth problem is a special case. Moreover, it converges to FDT-optimal behavior in most Newcombian problems [? · GW]. Therefore, it seems natural to expect IB agents to have strong multi-agent guarantees as well, hopefully even superrationality.
In this article, we will argue that an infra-Bayesian agent playing a repeated game displays a behavior dubbed "infra-Bayesian haggling". For two-player games, this typically (but, strictly speaking, not always) leads to Pareto-efficient outcome. The latter can be a viewed as a form of superrationality. Currently, we only have an informal sketch, and even that in a toy model with no stochastic hypotheses. However, it seems plausible that it can be extended to a fairly general setting. Certainly it allows for asymmetric agents with different priors and doesn't have any strong mutual compatibility condition. The biggest impediment to naturality is the requirement that the learning algorithm is of a particular type (namely, Upper Confidence Bound). However, we believe that it should be possible to replace it by some natural abstract condition.
Preliminaries
Repeated games
As mentioned, we will focus our exploration on infinitely repeated games.
Notation: In a -player game, each player can choose from a finite set of actions . Let be the set of action profiles. Furthermore, each player has a reward function .
Contrary to classical game theory, we look at this setting as a reinforcement learning setup. At time step , player can choose from action set , then receives an observation consisting of the actions played by other players at time step , and reward . The goal of agent is to maximize its utility for some discount factor .
We will use the words "agent" and "player" interchangeably.
Remark: We suppose the agents know the rules of the game. Specifically, this means player knows the reward function , but doesn't necessarily know for .
Notation: Let be the set of possible observations for player : .
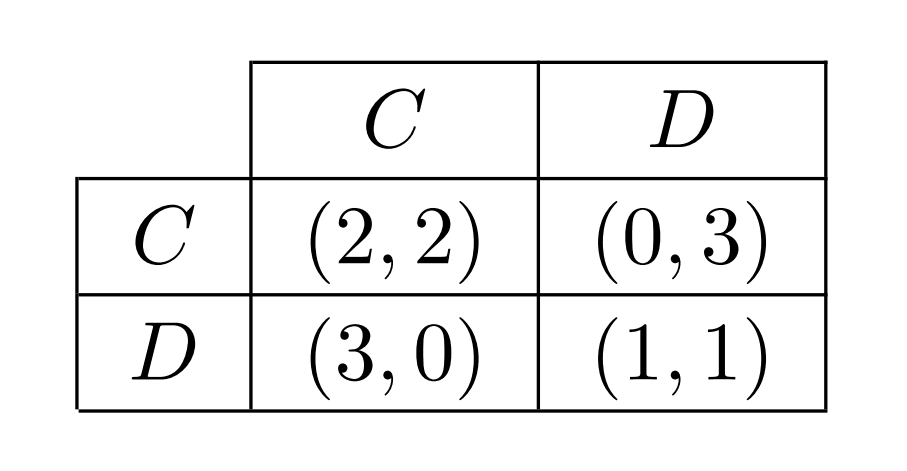
Running example: Prisoner's dilemma
We will use the Prisoner's dilemma [? · GW] to illustrate some of the concepts later in the post. Here, the players can choose between cooperating and defecting and they get the following rewards:
Other notation
We will also use the following notations.
Notation: For set , let denote the set of finite sequences of elements of : .
Notation: For set , let X denote the set of probability distributions on .
Proposed algorithm
Each agent starts with a set of hypotheses about how the other agents might behave. We will talk about the exact form of these hypotheses in the next section. For now we just assume is finite and each agent has a prior distribution over the hypotheses. Note that we neither require the agents to have the same prior over the hypothesis space nor having the same hypothesis space as the others.
The proposed algorithm is the following:
- Compute the set of hypotheses that are consistent with our experience so far. Let us denote it with .
- Find the hypotheses in that are promising the highest utility, denote this set of hypotheses with .
- Sample an element from according to the prior conditioned on .
- Compute the optimal policy if holds.
- Follow until gets falsified. When falsified, go to step 1.
We will discuss how a hypothesis looks like in the next section. Then we will discuss what we mean by "optimal policy" and "utility" in the section after that.
How to describe hypotheses?
Our first try might be to include all hypotheses of type "Others will play ", where . That is way too restrictive. It excludes any dependence on what we have done in previous time steps. It also excludes any probabilistic behavior.
So our second try might be to include hypotheses of type "Others play according to a function , where maps histories to distributions on actions of others. This is too fine-grained and intractable.
We need something in between these two extremes. A natural choice would be regular decision processes (RDPs).
Regular decision processes
We will define the hypotheses with the reinforcement learning setting in mind. The "observation" in reinforcement learning is what the agent observes from the environment. In this case, that's the actions the other agents played.
We will slightly abuse notation here. Previously was an element of in a -player game. From now on, will sometimes be an element of the action set of the agent, denoted by . For player , .
Definition: A Regular Decision Process (RDP) is a tuple , where
- is a finite set of states
- is a finite set of actions
- is a finite set of observations
- is the initial state
- is the observation kernel that defines a probability distribution over observations for each (state, action) pair
- is the transition function describing the next state after taking action in state and observing
Infra-Bayesianism lets us merge some of the RDPs together, which allows us to express beliefs about some aspects of the environment while remaining uncertain about others. (You can read more about infra-Bayesianism here [LW · GW].) The infra-Bayesian version of an RDP is an infra-RDP.
Definition: An Infra-RDP is a tuple , where
- have the same properties as in an RDP
- is the observation kernel, where denotes the convex, closed subsets . So defines a closed convex subset of probability distributions over observations for each (state, action) pair.
If you are not familiar with infra-Bayesianism, it is not clear how to interpret this kind of observation kernel. So suppose the environment is in state and the agent takes action . The hypothesis claims that the next observation is determined by using one of the distributions in . This means there exists a probability distribution , such that , and the next observation is sampled from . Importantly, the hypothesis doesn't say anything about how is chosen from : it has Knightian uncertainty about it. could be chosen randomly or could be chosen adversarially by Murphy or using any other method.
In this post, we will focus on a special case of infra-RDPs called sharp infra RDPs. We restrict ourselves to sharp infra-RDPs now to start with an easier special case. However, the hope is that the method described here can be extended to infra-RDPs in future work.
Definition: A sharp infra-RPD is a tuple , where
- have the same properties as in an RDP
- is the observation kernel that describes what observations are possible in a particular state given a particular action.
Remark: A sharp infra-RDP is an infra-RDP. The corresponding infra-RDP is defined by the observation kernel .
Remark: We denote the following special hypothesis with (it stands for "top"). There's only one state . Whatever action the agent takes, any observation is possible, that is, for any action .
We will assume to be in the hypothesis space of each agent. This ensures the agent won't run out of hypotheses: will always remain unfalsified. and thus the set of consistent hypotheses will never be empty.
Remark: For sharp infra-RDPs, there is no ambiguity in deciding whether a hypothesis is falsified or not. For general infra-RDPs we will need to have a statistical notion of whether a hypothesis is falsified or not.
Example: Tit-for-tat is a well-known strategy in the iterated prisoner's dilemma. The strategy is to cooperate in the first round of the game, then do what the agent's opponent did in the previous round. the hypothesis "My opponent follows the tit-for tat strategy " can be represented as a sharp infra-RDP. Actually, this is just a deterministic RDP, there is nothing "infra" in it.
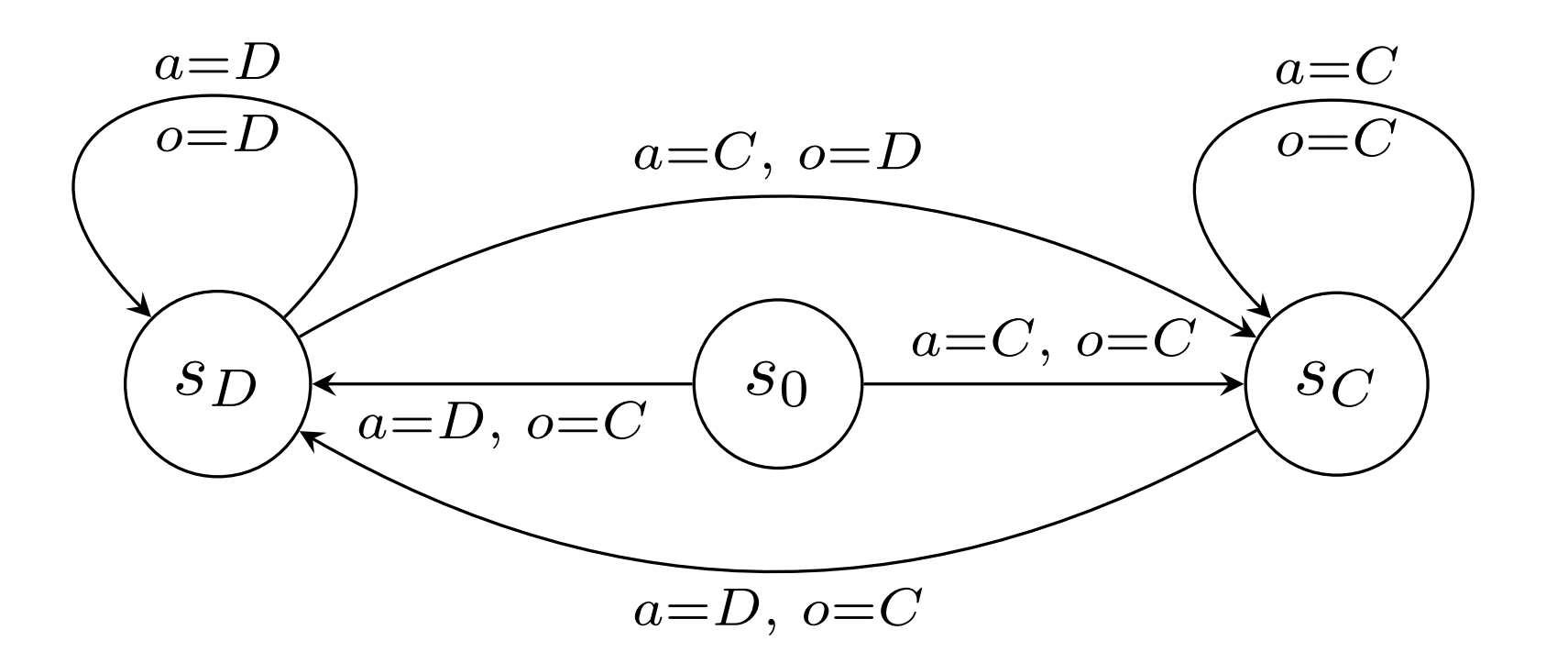
Example: Consider the -defect strategy in the prisoners dilemma (defect with probability and cooperate with probability ). This can't be part of the hypothesis space on its own. It is represented as part of . The closes thing to the -defect bot in the agent's hypothesis space is a deterministic bot who cooperates times and then defects once.
Resettable infra-RDPs
In real life, but even in repeated games, there might be irreversible actions, so-called traps. This is a prevalent problem in multi-agent cases, because other agents can have memory. For example, in the prisoners' dilemma, the other player might use the Grim strategy: start with cooperate, but once the other defects, defect forever. In this case, if you defect on the first try, you will never be able to get a reward bigger than 1.
However, for the proposed algorithm to make sense, the agents need to be able to try hypotheses without ruining their chances in any of their other hypotheses. There are weaker conditions that are sufficient, but resettability is enough for our purposes here.
Definition: An infra-RDP is resettable if for all , there exists a policy , such that if the agent is in and follows , it will eventually reach
Which hypotheses are in the hypothesis space of the agents?
As mentioned previously, we suppose is in the hypothesis space. There is an infinite number of sharp infra-RDPs that can potentially be in the agents' hypothesis spaces. We imagine the agents to have some kind of complexity prior and keep all the hypotheses with complexity under a specific threshold. The hope here is that if the prior assigns "enough" probability mass to a special kind of hypotheses, then the agents will end up close to a Pareto-optimal payoff.
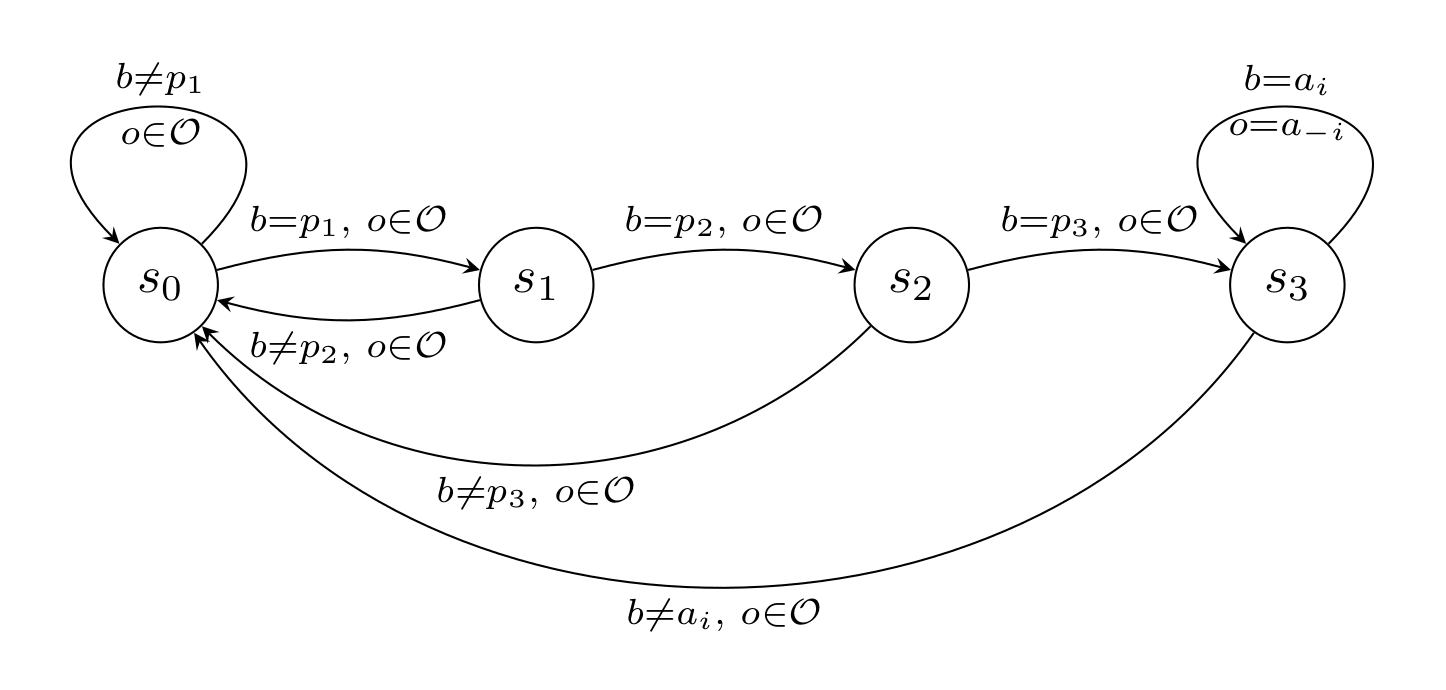
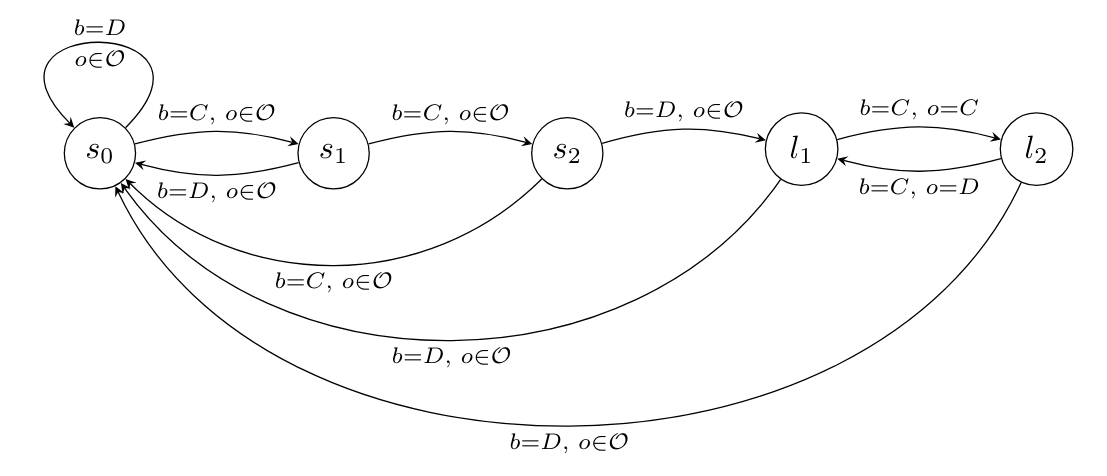
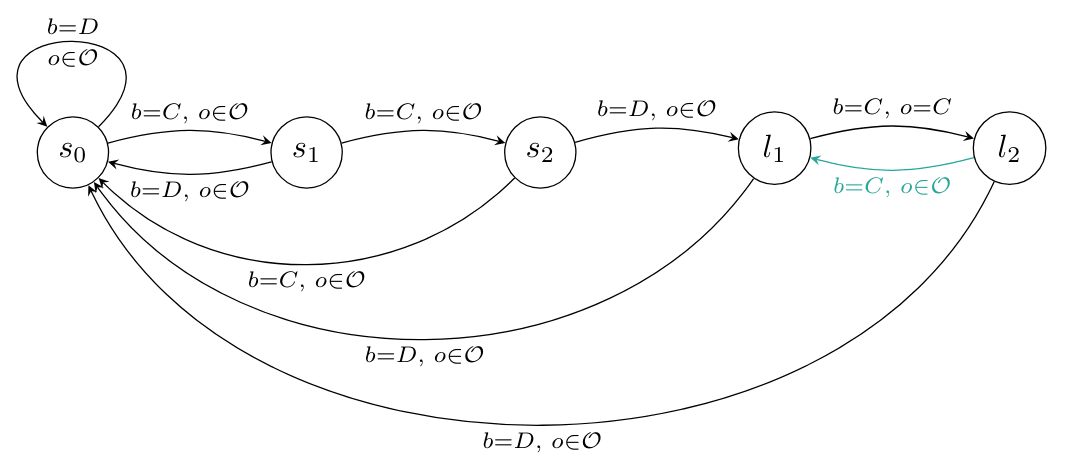
Definition: Suppose there is a unique Pareto-optimal strategy profile For of length , we define a simple password hypothesis as the following sharp infra-RDP.
- for state and action :
- for state , action and observation :
That is, if the agent enters the password , the others will play the Pareto-optimal strategy as long as the agent itself plays the Pareto-optimal action.
Example: For the password the sharp infra-RDP looks like this:
For games where there are multiple Pareto-optimal strategy profiles, a password hypothesis doesn't necessarily end in a unique state. It might end in a loop as well. The idea is that after "entering the password", the world gets into a state where if the agent plays a particular strategy, the other agents are restricted to play a particular strategy as well.
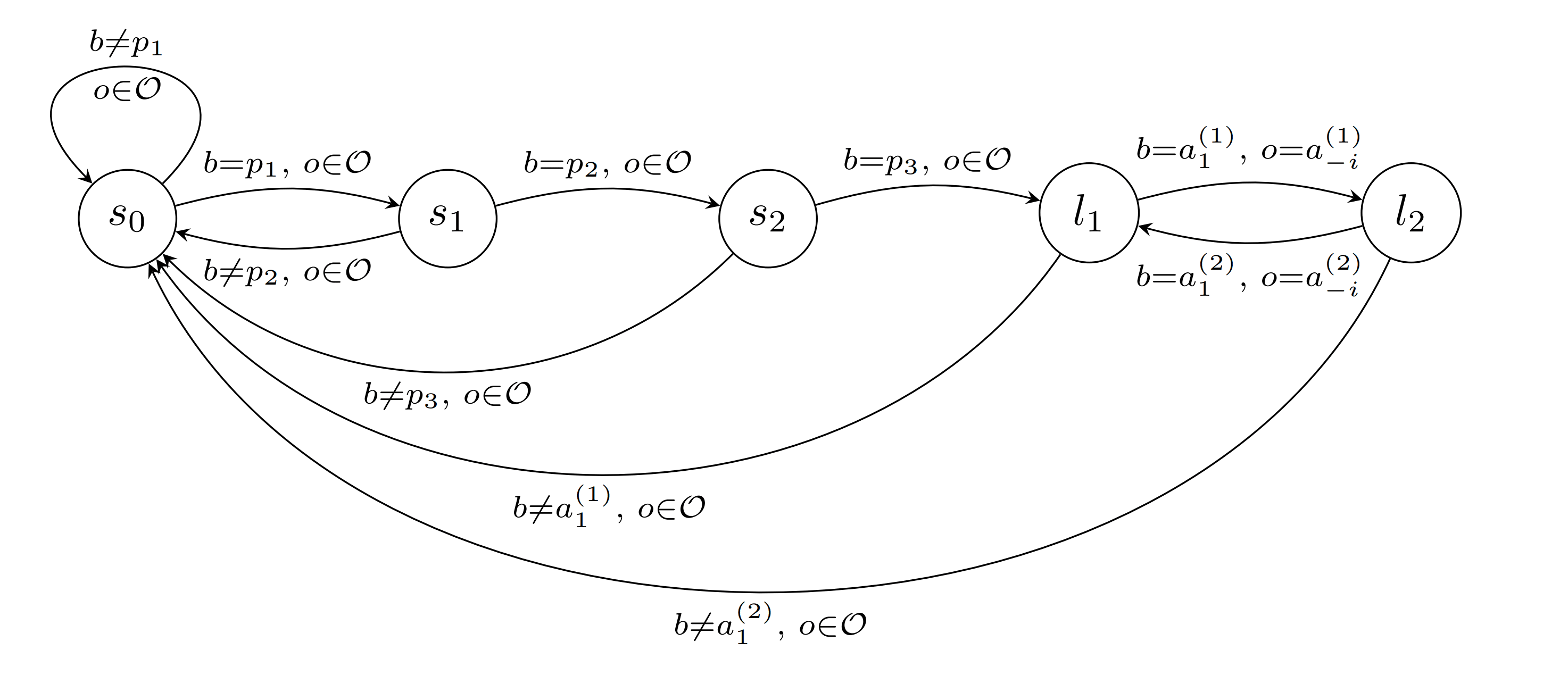
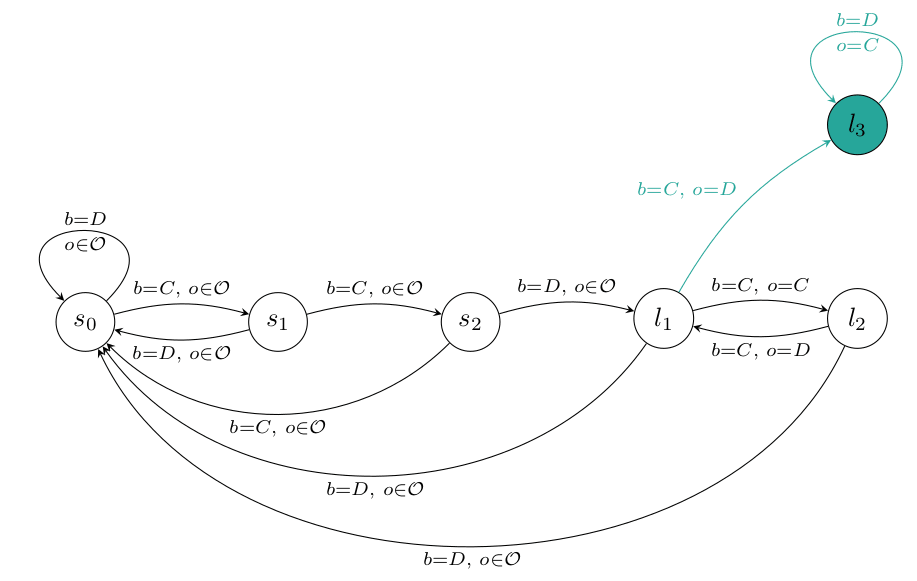
Definition: For a password and a sequence , we define the password hypothesis as the following sharp infra-RDP.
- The possible set of observations after taking action in state are
- The transition for state , action and observation is described by
Example For the password and sequence , the sharp infra-RDP looks like this:
Learning-theoretic guarantee
What can we say about the optimality of this algorithm? In this section, we will show that if the true environment satisfies at least one of the hypotheses in the hypothesis space of the agent, then the agent's payoff converges to at least the optimal payoff of the hypothesis.
What is the optimal payoff of a hypothesis? For a hypothesis , the optimal payoff or value of is the minimum utility the agent can get if the environment satisfies , and the agent plays the best strategy according to . To define it more formally, we will need to start with what a policy is.
Definition: A stationary policy the agent can play in hypothesis is an element of . That means a policy is a function that maps states of the sharp infra-RDP to actions.
While following the algorithm, the agent will switch its hypothesis about the world from time to time. The previous definition isn't enough to talk about the agent's behavior including these switches.
Definition: A policy is a function from histories to actions:
A copolicy describes the behavior of the other agents. Or in other words, it describes the environment.
Definition: A copolicy in hypothesis is an element of .
Definition: The utility depends on the policy played, the copolicy and the discount factor :
Definition: For discount factor , the value of is .
Proposition 1: Suppose there is a hypothesis in the agent's hypothesis space such that the true environment satisfies . Following the proposed algorithm guarantees the expected utility of in the limit. Let be the policy defined by the proposed algorithm. Suppose the prior over the hypotheses assigns non-zero weight to . Then .
Proof: See Appendix.
To be able to run the algorithm, we need to be finite. However, It would be nice to know something about learning any hypothesis in the whole infinite hypothesis class of infra-RDPs.
Proposition 2: Let denote the set of all sharp infra-RDPs. We can define a family of finite subsets , such that
- and
- If is satisfied by the true environment, the prior over the hypotheses assigns a positive weight to and is the policy defined by the proposed algorithm, then
Proof: There are countable many sharp infra-RDPs. Let be an ordering of . Let and for each . First, we will define a threshold for each , then let to be the biggest with .
Let Suppose we have already defined for all , and we would like to define now.
Based on the previous statement, for each , there exists , such that for : . Let .
Now choosing to be the biggest with gives .
Where does following this algorithm lead the agents?
Each agent has a finite set of hypotheses, so at some point they will stop trying new hypotheses. After this happens, each agent holds onto one of their hypotheses, and keeps playing the optimal strategy according to that hypothesis.
Eventually, each agent will reach a stage, in which they are repeating a sequence of actions periodically. When they reach this stage, we say they are in a stable cycle.
Let's look at how these stable cycles might look like in different scenarios.
Generalized stag hunt - unique Pareto-optimal outcome
In stag hunt, players can choose between hunting a stag or hunting a rabbit.
Catching a stag is better than catching a rabbit, but it requires everyone to choose to hunt a stag. For two players, the payoff vector is
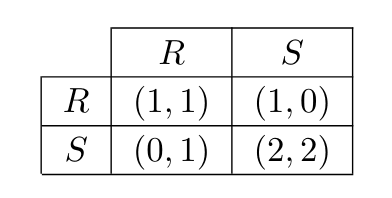
In generalized stag hunt, the agents are playing a game where there's a unique Pareto-optimal outcome. Under some not-too-restraining conditions, we expect the players to find this outcome.
Conjecture: Suppose a set of players are playing a game with a unique Pareto-optimal outcome , and they follow the proposed algorithm. Suppose that for each player , the hypothesis space consists of sharp infra-RDPs with at most number of states. Let . Suppose furthermore that for all , and the length of the passwords is varying enough, then the agents will converge to the Pareto-optimal outcome with probability as goes to infinity.
Reasoning behind the Conjecture:
- Suppose the agent starts to play assuming a hypothesis . If will be falsified, how much time does it take falsify it? In theory, it could take any number of steps, but most of the time it should take more than steps.
- Whenever an agent chooses a new hypothesis, it chooses a password hypothesis with probability at least . Thus, each agent is expected to try a new password hypothesis roughly every steps.
- We can envision the learning process of agent as a random walk in . Let . The first point of the random walk is the first time when the agent finishes entering a password in the first steps. The second point of the random walk is the first time when it finishes entering a password in steps . If all the agents are at the same point of at the same time, they have managed to reach the end of their password hypotheses at the same time and they will keep playing the Pareto optimal action.
- Will they reach the same point in their random walk before they run out of password hypotheses? There are password hypotheses for agent to try. If there are players, their combined random walk can be in states. If is big enough then is much bigger than . If the lengths of the password hypotheses are varying enough, we can expect the agents to reach the same point before running out of hypotheses.
Prisoner's dilemma
In the Prisoner's dilemma, each agent gets the highest reward if they can exploit the other agent. That's also a very simple hypothesis, so it will be in the agents' hypothesis spaces. This means they will both start by defecting. Then each agent realizes their hypothesis was wrong, so they choose a new hypothesis. There can be differences based on the prior, but they will start by trying different hypotheses that let them get reward most of the time. Because both of them are trying to defect and expect the other to cooperate, they will falsify these ambitious hypotheses and start to cooperate for some of the time.
The figure below shows how the demands of the two agents might change in time. "Demand" here means what reward they can achieve based on the hypothesis they are currently assuming. The rational points inside the blue area are the realizable payoffs. They are realizable in the sense that there are hypotheses such that if agent plays assuming and agent plays assuming , neither nor will be falsified. Conversely, the agents only have a chance of not falsifying their current hypotheses if they are inside the rhombus.
Remark: In general, the agents have a chance of not falsifying their current hypotheses if their demands are in the downward closure of the realizable payoffs.
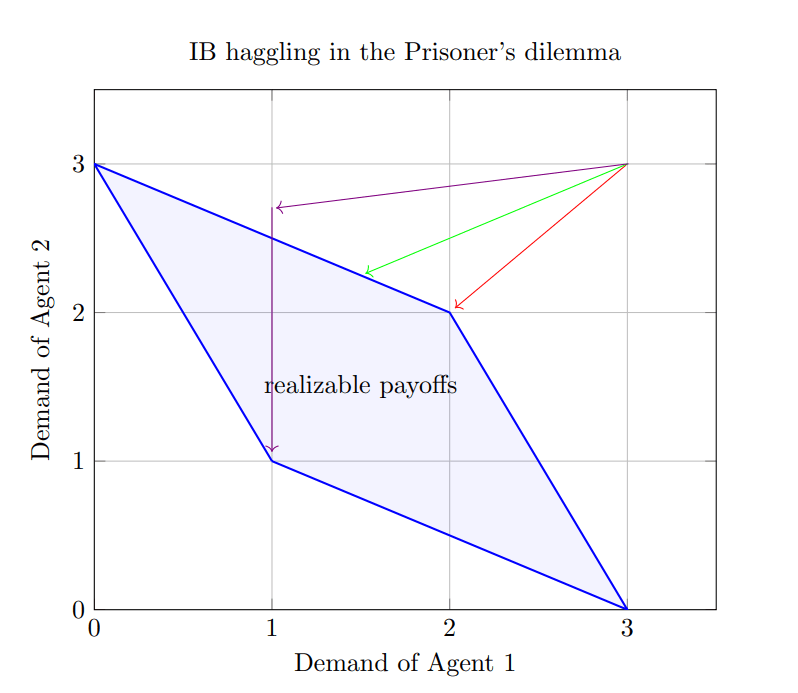
If the agents are similar enough, they will eventually reach a state where they are trying hypotheses that lets them play most of the time. If they have enough password hypotheses leading to , it's plausible they will eventually start playing at the same time. (Red line.)
If agent 1 has slightly less of these ambitious hypotheses than agent , they will probably converge to a behavior where they play some of the time and play otherwise. (Green line.)
If agent has a vastly different prior than agent and thus has much less ambitious hypotheses than agent , then agent will lower its demand much faster than agent . While trying hypotheses with utility , Agent 1 will find a hypothesis that won't get falsified. The two agents can end up in or in this case. However, the more probable outcome is , because can't be falsified and it also has low complexity. (Violet line.)
Do the agents necessarily get into a stable cycle once they reach a realizable payoff? Suppose the agents reach a point of the blue rhombus: . Let and . If and are satisfying the conditions in the previous conjecture at that time, we can expect them to get into a stable cycle with payoff . However, it is not clear if they would satisfy those conditions, even if they did so in the starting state. That's because the agents will have falsified some of these password hypotheses accidentally by the time they reach the rhombus. However, we could relax the definition of password hypotheses to allow more ambiguity, and hope that there are enough relaxed password hypotheses to reach a stable state. The idea is to allow slight deviations at the end-cycle of a password hypothesis that doesn't change the value of the hypothesis. For the password hypothesis below, there are two examples of a relaxed version.
Another caveat here: in contrast to the stag hunt example, it is not enough if the agents reach the end of the password at the same time, they also need to have their cycle at the end of the password hypothesis in sync.
Conjecture: In a -player game, the stable cycle will fall into one of the following cases:
1. Close to a Pareto-optimal outcome.
2. One of the agents gets the utility of its minimax strategy. The other player plays best response to the first agent's strategy.
Schelling Pub (Battle of the sexes)
In the Schelling Pub game [LW · GW] (a version of battle of the sexes), two friends would like to meet at the pub. They prefer different pubs, but both of them would rather be together in their unpreferred pub than sitting alone in their preferred pub.

If the players are following our algorithm, they will reach a Pareto-optimal payoff: both going to pub for some of the time and both going to pub otherwise.
An interesting thing to note. Suppose one of the players plays their minimax strategy, e.g. the person who prefers , goes to no matter what. Then the other player will choose to go to the same pub and they will end up in a state that's better than what they would achieve if both of them played their minimax strategy.
Schelling points
The Schelling Pub game is an example of people wanting to cooperate in a case where there are multiple options for cooperation. In that case, none of the possible cooperation states were more natural than the other. However, in some cases, there are points that are more natural targets of cooperation than others. These natural targets are called Schelling points [LW · GW].
Example: You ask three players to order the letters A, B, and C. If the three players give the same order, they win an award, otherwise they get nothing. Most players choose the ordering ABC. ABC is the Schelling-point in this game.
If IB agents are using the proposed algorithm and use a simplicity prior, simpler outcomes are more likely to arise as the result of haggling. In this way, haggling connects learning under a simplicity prior to reaching Schelling points.
Multiplayer games
If there are more than players, then players can form coalitions which makes things more difficult.
As always, players start with high demands. A set of players can form a coalition if they can guarantee the demanded payoff for each member of the coalition regardless of what strategy the players outside the coalition are playing. We can expect them to form a coalition in this case, and play the strategy that gives them the demanded payoff forever.
Note: In the multiplayer case, Pareto efficiency is not guaranteed.
Example (Cake-splitting game): There are players. Each of them chooses another player they want to cooperate with. If two players choose each other, they will both get reward , while the third player gets reward . If there are no players who chose each other, everyone gets
In this case, the initial demanded payoff vector will be . Each player will try to get reward until two of the players manage to lock in and from that point on, the lucky players will have payoffs , while the third one will get .
The interesting thing here is that "trying to cooperate with someone mutually" has expected utility , while "avoid mutual cooperation" has expected utility . The reached payoff is Pareto-optimal, but the meta-strategy is not.
Example: There are players: Alice, Bob and Charlie. Each player can ask for reward , or . If they ask for a payoff that's either or , they get what they asked for. If it's then Alice and Bob get , but Charlie gets In other cases they all get . They will start out with trying to get reward . If they lower their demands at a similar rate, Alice and Bob will eventually ask for reward and that's where the haggling stops. This is not a Pareto-optimal outcome: they are getting payoff , while they could get instead.
When can a coalition be formed?
It is not entirely clear. For a set of players , let denote the set of payoff vectors they can certainly achieve without any assumptions on the strategies of players outside the coalition. A payoff vector is in if and only if there exists a probabilistic strategy of the coalition such that for any probabilistic strategy of the outsider players, each player in the coalition has expected reward at least . Putting that together:
where denotes the expected reward if members of the coalition choose a joint action sampling , while players outside the coalition choose their actions by sampling . denotes the set of players.
This definition of assumes the randomness used in the strategies isn't shared between the coalition and the outsiders. Is this a realistic assumption?
At first glance, this is not the case with sharp infra-RDPs. Once an agent chooses a hypothesis, it follows a deterministic policy until the hypothesis is falsified. Mixed stage strategies are encoded in deterministic cycles, like the loops in password hypotheses.
It is possible that more sophisticated learning algorithms could come up with some kind of cryptographic solution to form a coalition whenever the payoff vector is in . However, for the algorithm proposed in this post, this is not the right criterion for forming coalitions.
Next, we give a definition of that allows the outsiders to sync their actions with the actions of the coalition members.
where denotes the distribution we get by marginalizing to .
Stable cycles for multiplayer games
Where will haggling lead in this case? Once there is a coalition such that the current demanded payoff vector is in , players in can lock in on a strategy that guarantees . From that point on, outsiders can only keep a hypothesis unfalsified if it's consistent with 's locked strategy.
If has been formed, a new coalition will be formed if the players in can guarantee their demanded payoff assuming the players in are playing their locked strategy.
Let be the set of players already in a coalition. Let be the strategy played by members of . Now a set of players C can choose from strategies in . The payoff vectors can achieve are
How we expect a stable cycle to look like? The players form coalitions such that it's a partition of the players. Let be the payoff vector they reached. Then for each
- the payoff of 's members is in
- there does not exist any set of players , such that there exists with for each . Otherwise would have been formed instead of .
Conclusion
We have described a natural infra-Bayesian learning algorithm and investigated its behavior in different repeated games. We have shown informally why we expect this algorithm to often find Pareto-optimal outcomes in two-player games. We also looked into its connection to Schelling points. Finally, we explored the states IB agents can reach in multiplayer games where coalitions can be formed.
Future directions
- Formally prove the conjectures mentioned in the post.
- Generalize this algorithm to a stochastic setting for all resettable infra-RDPs.
- For a countable hypothesis set , we defined finite sets , such that if the true environment satisfies , and the prior over the hypotheses assigns a positive weight to , then the proposed algorithm ensures. Possibly, the algorithm can be modified in a way that instead of a separate policy for each , we can define one policy that ensures . We say the hypothesis set is anytime-learnable in that case. This would require to extend the set of hypotheses considered over time. One difference in principle is, even if the players started playing some Pareto-optimal sequence, each of them would occasionally deviate from it to try for a higher payoff, potentially falsifying the hypotheses of the other players. Hopefully, after every such deviation, the players will eventually settle back using the same mechanism. This would "burn" some passwords, but also new (longer) passwords would enter consideration over time.
- What is the broadest natural category of infra-Bayesian learning algorithms with such convergence guarantees?
- Instead of a repeated game, we can consider a population game where each agent has access to the internal state of its opponents at the start of the round (in particular, the history they experienced). Getting Pareto-optimality there requires some new idea: since each agent faces new opponents on each round, there is no longer "lock-in" of a Pareto-optimal outcome. Possibly, we would need to consider a family of hypotheses which postulate progressively higher portions of the population to be cooperative.
Appendix
Proof of Proposition 1: Fix a copolicy . Let . For action and observation , let denote the reward the agent receives after playing action and observing . Let be the maximal possible regret. Suppose the agent follows the proposed algorithm and tries hypotheses , falsifies them, and eventually reaches that remains unfalsified. For , let denote the time step when the agent falsifies .
Let us call a series of at least consecutive steps that starts and ends in the same state a cycle. A path is any series of consecutive steps. Let For each , we will partition the steps between and into paths and cycles using the states of hypothesis . is a false hypothesis, but during those steps, the world is consistent with , so we can use its states to reason about these steps. We define the cycles using the following algorithm. Let be the state the agent is at step . If the agent returns to before step , let the first cycle consist of the steps between step and the last occurrence of . Now let be the state after the last occurrence of . If it appears again before step , then let that be a cycle, and so on. The paths are the steps connecting two cycles. Using this, we will partition the time steps into groups:
Based on which group belongs to, we will use different lower bounds of the weighted reward at step .
For , we will use the lower bound . Note . Hence
Before we get into the lower bounds for steps in , let us introduce a new notation. For hypothesis , let us define a slightly modified version of it, The only difference is the start state: the start state in is . can be different than . However, it can't be much lower. Because is resettable, the agent can get to in at most steps and play the policy that ensures utility from that point on. Thus .
To give a lower bound for steps in , let and denote the start and end of a cycle. Suppose this is a cycle between and . We would like to use to give a lower bound on the weighted sum of rewards between steps and . Let denote the copolicy that is the same as until step , then repeats the observations between and infinitely. Let be the state at time step . Then
With the notation :
Using , we get
The number of cycles in our partition is at most , hence
Finally, for steps in , we have
Putting the bounds for and together, we get
0 comments
Comments sorted by top scores.