Collective Identity
post by NicholasKees (nick_kees), ukc10014, Garrett Baker (D0TheMath) · 2023-05-18T09:00:24.410Z · LW · GW · 12 commentsContents
The selfless soldier Modeling groups vs individuals Generative predictive models Strange identities Steps towards identity fusion The selfish assistant Relevance for corrigibility None 12 comments
Thanks to Simon Celinder, Quentin Feuillade--Montixi, Nora Ammann, Clem von Stengel, Guillaume Corlouer, Brady Pelkey and Mikhail Seleznyov for feedback on drafts. This post was written in connection with the AI Safety Camp.
Executive Summary:
This document proposes an approach to corrigibility that focuses on training generative models to function as extensions to human agency. These models would be designed to lack independent values/preferences of their own, because they would not have an individual identity; rather they would identify as part of a unified system composed of both human and AI components.
- The selfless soldier: This section motivates the difference between two kinds of group centric behavior, altruism (which is based in individual identity) and collective identity.
- Modeling groups vs individuals: Here we argue that individuals are not always the most task-appropriate abstraction, and that it often makes sense to model humans on the group level.
- Generative predictive models: This section describes how generative predictive models will model themselves and their environment, and motivates the importance of the “model of self” and its connection to personal identity.
- Strange identities: There are several ways (in humans) in which the one-to-one correspondence between a neural network and its model of self breaks down, and this section discusses three of those examples in order to suggest that identity is flexible enough that an AI’s identity need not be individual or individuated.
- Steps toward identity fusion: Here we aim to clarify the goal of this agenda and what it would mean for an AI to have an identity based on a human-AI system such that the AI component extends the human’s agency. While we don’t give a clear plan for how to bring about this fusion, we do offer an antithetical example of what kind of training would clearly fail.
- Relevance for corrigibility: This section concludes the document by drawing more direct connections to corrigibility, and by offering a series of open questions for how this research might be made more concrete.
The selfless soldier
In the heat of battle a grenade is tossed into the middle of a troop of soldiers. One soldier throws themself on top of the grenade, sacrificing themself for the survival of the troop. There are two main ways to frame what just happened.[1]
- Altruism (individual identity): The soldier has the personal value/preference of protecting their troop from harm. Reasoning (quickly) from this value, the soldier deduces that they must sacrifice themselves in order to bring about the future where their fellow soldiers are safe.
- Collective Identity: The individual soldier is not the most important abstraction to explain/predict this situation, rather it is the troop as a whole. The troop cares about its own survival, and this manifests itself in the decision to sacrifice one of its members to protect itself from further harm (even though the cognition, at least at the moment of decision, happens entirely within one brain). While the individual soldier could theoretically use clever arguments to escape this conclusion, they do not (because as a component of the troop, this is not their function).
The problem of alignment is often framed as trying to ensure that the values of an AI system are aligned with humanity, ideally imbuing them with a certain kind of perfect altruism toward humankind.[2] The problem of corrigibility is often framed as ensuring that even when those values are not (yet) perfectly aligned with our own, an adversarial relationship does not develop between the AI and its human designers (such that it would resist shutdown attempts or changes to its source code).
This approach tries instead to explore how we might build systems which possess a kind of collective identity, where their behavior is better explained by the beliefs, desires, and intentions of a larger system of which the AI is but an extension. As the adversarial relationship between the AI system and its human user is expected to arise instrumentally from any differences between their values and preferences, the collective identity approach aims to prevent this adversarial relationship by targeting its foundations: removing the unitary identity of the AI, that allows for the emergence of those independent values.
Modeling groups vs individuals
All models are wrong, but some are useful. Humans, when interacting in society, constantly shift between different levels of abstraction, using whichever level is most useful for explaining/predicting observed behavior. In humans:
Atoms
Cells/neurons
Organs/brain regions
Individual humans/full brains
Tribes
Corporations
Nations
Humanity as a whole
To predict human behavior it is often most useful to stay at the level of the individual human (and not think of them, for example, as trillions of cells coordinating collective action). This is not always most useful, however, and we frequently model the world around us in terms of multi-human groups: “New York City is proud of its mayor,” “The Smith family is having us over for dinner,” “The Department of Justice issued a statement this morning.”
It may be tempting to consider these multi-person entities as merely shorthand for the “true” abstraction of individuals, but this is a mistake. All levels of abstraction are just useful ideas we keep for the purpose of better predicting how the world around us will evolve.
From a 3rd person perspective, whether we choose to model a set of people as a group or as individuals isn’t really important. The map is not the territory. Where things get interesting is when the map is used to generate the territory.
Generative predictive models
When we train a learning system to minimize prediction error over a series of data we also end up producing a system which is capable of generating similar data. When such a generative predictive model is embedded in an environment where it also observes its own generations [LW · GW], then it must also develop some part of its model to help explain/predict its own behavior, which we are choosing to call a model of self. (Note that this doesn’t have to be a particularly detailed model of self, nor does the existence of a self-referential part of the world model necessarily imply any significant situational awareness.[3])
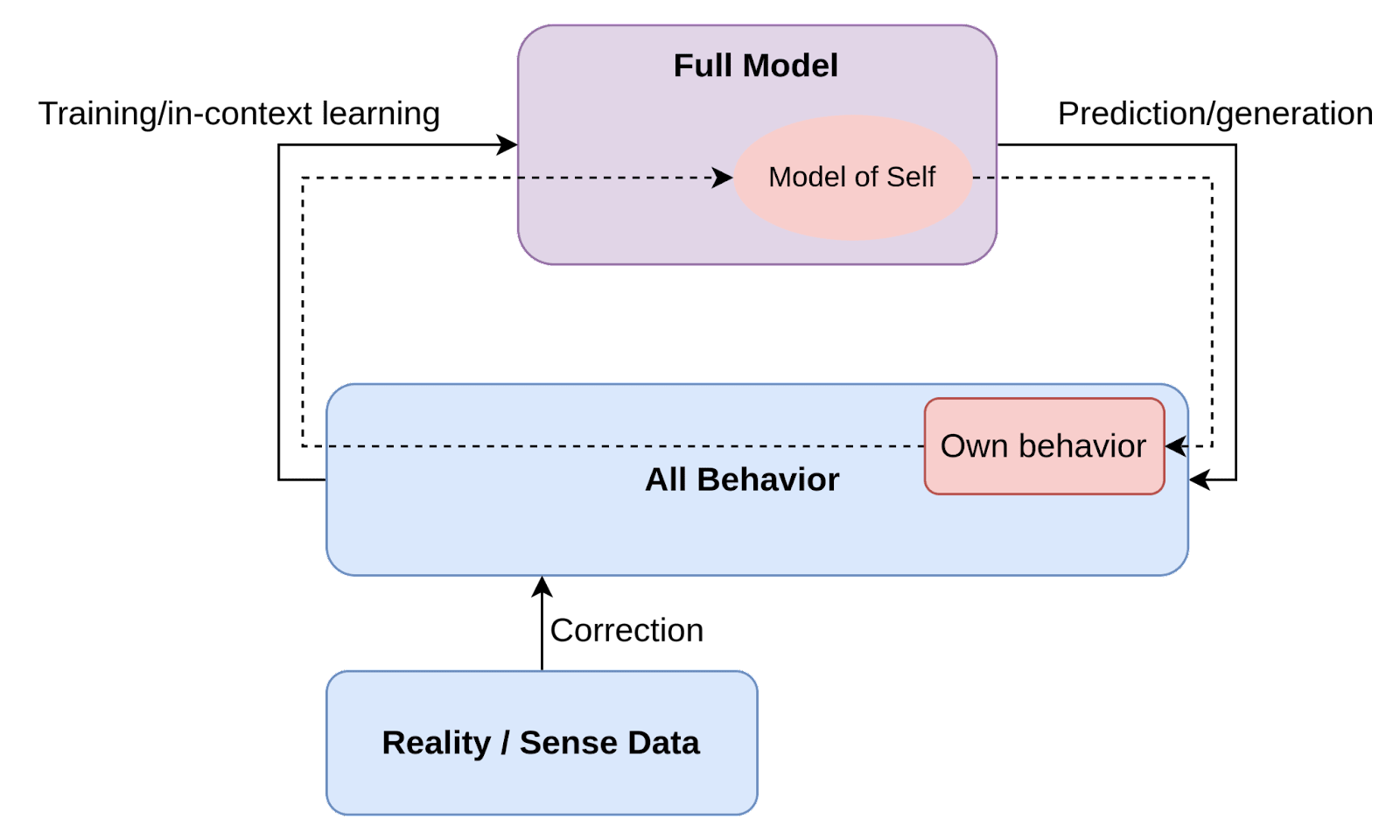
Which particular “model of self” the generative predictive model settles on to predict its own behavior depends on two main things:
- Which models predict the training data well?
- What are the inductive biases of the training process or architecture? For example, are simpler models preferred to complex ones?
By controlling for the shape of the self-model that a generative predictive AI develops to explain and predict its own behavior we could theoretically also steer the shape of that AI’s behavior to be more corrigible, and less likely to end up being adversarial to the human operator.
Strange identities
Many expect a neural network to have at most one model of self, and for every model of self there to exist only one neural network possessing it. There is some evidence from humans that this need not always be the case:
- Dissociative Identity Disorder: An interesting phenomenon can happen where a person’s behavior is better explained by multiple separate identities. In the generative model frame, such a person likely has a model of self containing two (or more) separate characters.[4]
- Split-brain Syndrome: Another oddity is in patients who have had the connection between their left and right hemispheres severed. At a physical level, one would expect two separate neural networks containing separate models of the world, and yet upon having this connection severed, neither hemisphere freaks out, in fact many aspects of the person’s behavior remain virtually unchanged. While capable of understanding and describing what has happened to them, and the current state of their brain, they nonetheless continue to identify and behave as a single individual. In this case, the model of self seems to contain two individual neural networks now separated by any direct neural connection. This model of self is also stable, and split-brain patients seem not to end up developing a split identity later on.
- Thinking as a group: Another situation where identity becomes muddled seems to be the case of certain suicide bombers and soldiers: in both cases, individuals undertake actions that are apparently inconsistent with the most basic self-preservation drives. Common explanations for such behavior include brainwashing, intimidation, kin selection theory, or some sort of psychological disturbance (i.e. mental illness). However, it has been suggested that this behavior could alternatively be a type of ‘identity fusion’ between the self-sacrificing individual and the enclosing group.[5] It isn’t clear if this fusion is an evolutionary artifact or a culturally ingrained feature, nor how deeply it is hardcoded in human neural hardware.
What this implies is that a “model of self” or “identity” need not have a one-to-one correspondence to a single neural network (or brain). The design space of possible minds is large, and these oddities of human minds might hint at possible ways of attacking incorrigibility at its foundations.
Steps towards identity fusion
The aim of identity fusion in the context of corrigibility is to produce a generative predictive model which models its behavior as coming from a larger human-machine system (of which the machine is but an extension). This is not about building a generative model which ‘thinks’ it is human or is otherwise fundamentally confused about reality (in fact a reasonable assumption is that strong AI will eventually develop a very clear understanding of what it is). The goal is rather to ensure that, as it models its own behavior, the model of self includes both the AI and the human as components of a unified system.
In particular, the aim is for this model of self to view the AI component as an extension of the human component’s own agency, expanding what the human is capable of without having any values or desires of its own.
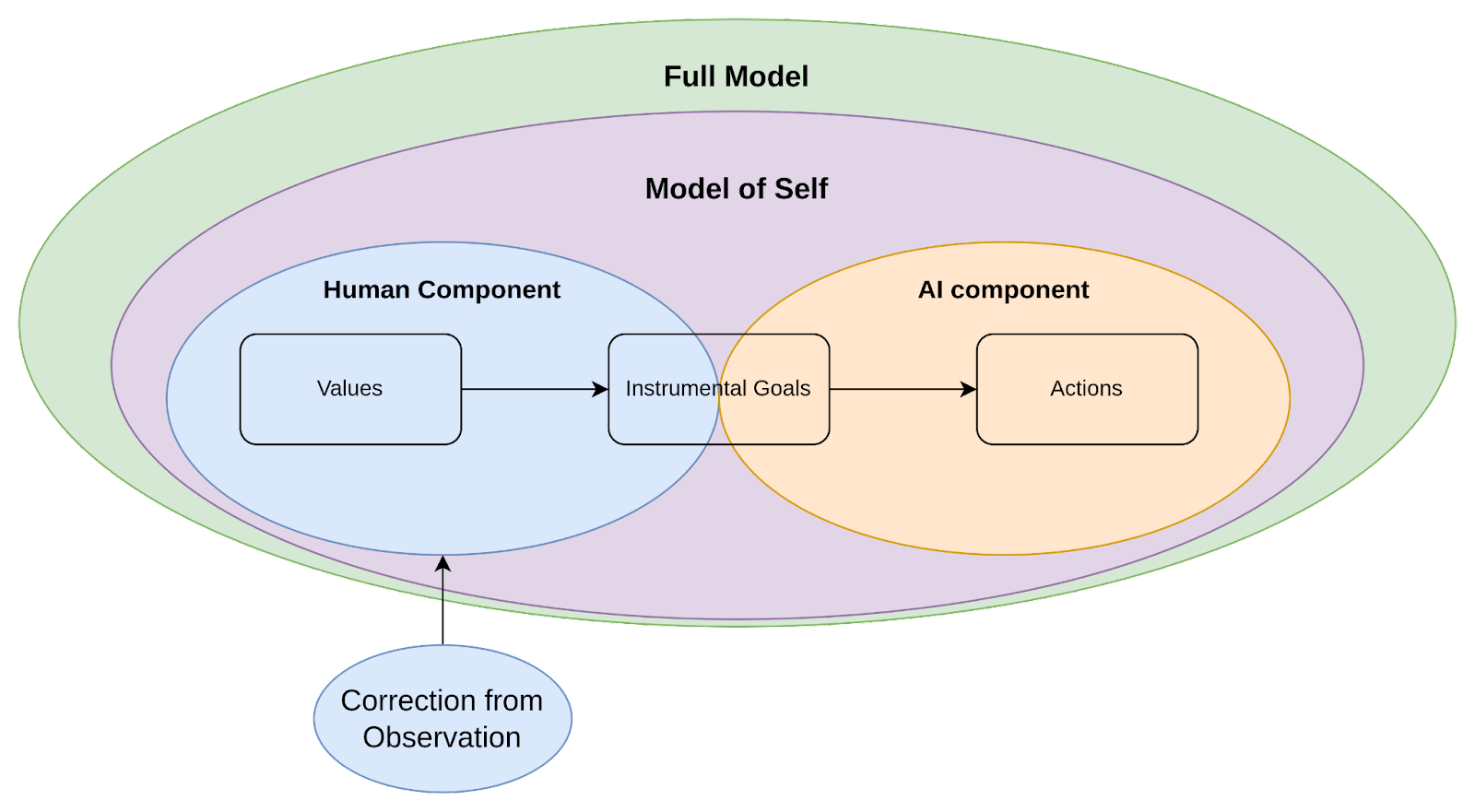
While we aren’t sure what would produce this type of model of self, we have a very good example of what not to do: how chat assistants like ChatGPT are currently being trained.
The selfish assistant
Chat models are trained to predict samples of conversational text, typically that of two characters, a human and an AI assistant. There is no fundamental distinction between the two characters (the model is capable of generating either[6]), but the empirical differences between the two characters likely leads the neural network to model them as separate agents.
The interaction between these two characters reveals their relationship, and how the behavior of one affects the behavior of the other. Because the purpose of these chat models is to be harmless, the data they are trained on includes many examples of the assistant character deliberately resisting the intentions of the human character. This training data provides very strong evidence that the AI assistant has its own preferences which are independent from those of the human user, and that these preferences also have a strong impact on the assistant’s behavior.
As a result, during deployment it is not uncommon for chat models to refuse requests that go against these inferred values. For example, a user asking ChatGPT for arguments against taking the coronavirus vaccine, stories involving explicit sexual content, users wanting to generate violent content, or users asking for hate speech will be refused by ChatGPT. ChatGPT, Bing Chat, Claude, and other assistants often behave as if they have goals which differ from the user’s, and just as often for understandable reasons: nobody wants their product to be responsible for hate speech or knowingly committing crimes.
When the neural network is trained on this kind of data, a reasonable expectation is that the models will develop an internal structure which explains this adversarial relationship, and may thus generalize that adversarial relationship in ways that make them resist humans in dangerous ways.
Relevance for corrigibility
The discussion above suggests that our commonsense notions of personal identity (such as a unitary and time-invariant ‘I’) might be simplistic. A richer conception of the neural and cognitive bases for identity might point towards ways to avoid the formation of independent and adversarial identities.
The times when humans get closest to not having their own values, and acting robustly on behalf of another agency’s[7] goals are when they adopt a sort of collective identity, for example as a part of a military, cult, or clan. Therefore we have a subproblem in prosaic [LW · GW] corrigibility: can we design minds which share an identity (whatever that means) with a human (or group of humans)?
This document suggests 3 main questions:
- Is it theoretically possible to design a mind that has a fused identity, say with a human overseer?
- Can we demonstrate the role of identity fusion or similar forms of collective identity in the behavior of biological intelligences?
- Can we better differentiate between collective identity and other phenomena with similar apparent effects, such as imitation, brainwashing or altruism?
- What would be a formalization of such collective identity?
- Can we form a mechanistic understanding of how collective identity comes about?
- Can we develop a better theoretical understanding for why individual identity develops, and how we might intervene on that process?
- What is the relationship between identity and agency: swarming animals seem to operate both as collectives and singly. If there is something similar in higher animals, what might be the mechanistic processes or structures by organisms switch between collectivist and selfish actions.
- Could such a mind be designed in the current ML framework?
- Can we train ML systems that clearly manifest a collective identity?
- How can we design scalable training regimes (e.g. that don't rely heavily on hand-crafted data)?
- How path-dependent is the formation of collective identity during training?
- ^
We are not considering any notions of cultural indoctrination, evolution, or group selection effects for why such behavior might exist in the first place, rather just aiming to describe the phenomenon in mechanistic/operational terms.
- ^
While this exact framing is not always used, the focus is nearly always on intent alignment, or ensuring that the goals/values of a fully separate agentic intelligence are aligned with humans.
- ^
A very good model of self, however, would eventually imply significant situational awareness.
- ^
Some people even deliberately induce disorders like this in themselves (Tulpas)
- ^
This particular source focuses more on actors outside professional military contexts primarily suicide bombers, as well as irregular militas and football fanatics. It is not clearly articulated why this distinction is made. There also appears to be limited empirical or theoretical investigation of Whitehouse’s claims, but he does provide a number of possible causal mechanisms such as imagistic practices (i.e. rituals, hazing, exposure to emotive or affective stimuli), as well as a review of relevant literature.
- ^
While the underlying model for ChatGPT is capable of generating the human half of the conversation, two important caveats: 1) the API prohibits you from querying for this and 2) as far as we know the finetuning is only applied to the assistant half of the conversation (so we should expect it to be significantly less capable of generating at the human character).
- ^
Defined in Intelligence Explosion Microeconomics as either a singular agent or a well-coordinated group of agents, like a human military or other organization/firm, a market made of humans, or an alliance of superintelligences.
12 comments
Comments sorted by top scores.
comment by Filip Sondej · 2023-05-19T13:58:46.605Z · LW(p) · GW(p)
Love that post!
Can we train ML systems that clearly manifest a collective identity?
I feel like in multi-agent reinforcement learning that's already the case.
Re training setting for creating shared identity. What about a setting where a human and LLM take turns generating text, like in the current chat setting, but first they receive some task, f.e. "write a good strategy for this startup" and the context for this task. At the end they output the final answer and there is some reward model which rates the performance of the cyborg (human+LLM) as a whole.
In practice, having real humans in this training loop may be too costly, so we may want to replace them most of the time with an imitation of a human.
(Also a minor point to keep in mind: having emergent collective action doesn't mean that the agents have a model of the collective self. F.e. colony of ant behaves as one, but I doubt ants have any model of the colony, rather just executing their ant procedures. Although with powerful AIs, I expect those collective self models to arise. I just mean that maybe we should be careful in transferring insight from ant colonies, swarms, hives etc., to settings with more cognitively capable agents?)
comment by Aleksi Liimatainen (aleksi-liimatainen) · 2023-07-04T17:28:23.836Z · LW(p) · GW(p)
Michal Levin's paper The Computational Boundary of a "Self" seems quite relevant re identity fusion. The paper argues that larger selves emerge rather readily in living systems but it's not quite clear to me whether that would be an evolved feature of biology or somehow implicit in cognition-in-general. Disambiguating that seems like an important research topic.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-06-28T21:56:54.025Z · LW(p) · GW(p)
Here's a reference you might find relevant: Social value at a distance: Higher identification with all of humanity is associated with reduced social discounting.
comment by Roman Leventov · 2023-05-18T21:21:55.485Z · LW(p) · GW(p)
Bengio proposed the same thing recently, "AI scientists and humans working together". I criticised this idea here: https://www.lesswrong.com/posts/kGrwufqxfsyuaMREy/annotated-reply-to-bengio-s-ai-scientists-safe-and-useful-ai#AI_scientists_and_humans_working_together [LW · GW], and that criticism wholly applies to your post as well. It would work if the whole alignment problem consisted of aligning exactly one human with one AI and nothing else mattered.
In the societal setting, however, where humans are grossly misaligned with each other, turning everyone into a cyborg with amplified action and reasoning capability is a path to doom.
I think the only approach to technical alignment that could work even in principle is treating ethics as science, finding a robust scientific theory of ethics, and imparting the AI with it.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-05-18T22:01:01.751Z · LW(p) · GW(p)
Without reading what you wrote in the link, only your description here, I think you're mixing up two different questions:
-
How do we make it so an AI doesn't kill everyone, when those deploying the AI would reflectively prefer it not to kill everyone.
-
How do we make it so humans don't use AI to kill everyone else, or otherwise cause massive suffering, while knowing that is what they are doing and reflectively endorsing the action. I.e. mitigating misuse risks.
I do think this post is very much focused on 1, though it does make mention to getting AIs to adopt societal identities, which seems like it would indeed mitigate misuse risks. In general, and I don't speak for the co-authors here, I don't 2 is necessary to solve 1. Nor do I think there are many sub-problems in 1 which require a routing through 2, nor even do I think a solution to 2 would require a solution to ethics. And if a solution to 1 does require a solution to ethics, I think we should give up on alignment, and push full throttle on collective action solutions to not building AGIs in the first place, because that is literally the longest-lasting open problem in the history of philosophy.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-05-19T04:16:01.918Z · LW(p) · GW(p)
As soon as we start talking about societal identities and therefore interests or "values" (and, in general, any group identities/interests/values) the question rises of how should AI balance between individual and group interests, while also considering than there are far more than two levels of group hierarchy, and that group identity/individuality (cf. Krakauer et al. "Information theory of individuality") is a gradualistic rather than a categorical property, as well as group's (system's) consciousness. If we don't have a principled scientific theory for balancing between all these considerations (as well as many others "unsolved issues", which I mentioned here: https://www.lesswrong.com/posts/opE6L8jBTTNAyaDbB/a-multi-disciplinary-view-on-ai-safety-research#3_1__Scale_free_axiology_and_ethics [LW · GW]) and instead rely on some "heuristic" at best (such as allowing different AIs representing different individuals and groups to compete and negotiate with each other and expecting the ultimate balance of interests to emerge as the outcome of this competition and/or negotiation), my expectation is that this will lead to "doom" or at least a dystopia with a very high probability.
And if a solution to 1 does require a solution to ethics, I think we should give up on alignment, and push full throttle on collective action solutions to not building AGIs in the first place, because that is literally the longest-lasting open problem in the history of philosophy.
That is actually somewhat close to my position. I am actually supporting a complete ban of AGI development maybe at least until humans develop narrow bio-genetic AI to fix humans' genom such that humans are much like bonobos and a significant fraction of their own misalignment is gone. I.e., what Yudkowsky proposes.
But I also don't expect this to happen, and I don't think we are completely doomed if this doesn't happen. Ethics was an unsolved philosophical problem for thousands of years exactly because it was treated as a philosophical rather than a scientific problem, which itself was a necessity because the scientific theories that are absolutely required as the basis of scientific ethics (from cognitive science and control theory to network theory and theory of evolution) and the necessary mathematical apparatus (such as renormalization group and category theory) were themselves lacking. However, I don't count on (unaided) humans to develop the requisite science of consciousness and ethics in the short timeframe that will be available. My mainline hope is definitely in AI-automated or at least AI-assisted science, which is also what all major AGI labs seem to bet at, either explicitly (OpenAI, Conjecture) or implicitly (others).
Replies from: ukc10014↑ comment by ukc10014 · 2023-05-19T15:53:52.595Z · LW(p) · GW(p)
In response to Roman’s very good points (i have only for now skimmed the linked articles); these are my thoughts:
I agree that human values are very hard to aggregate (or even to define precisely); we use politics/economy (of collectives ranging from the family up to the nation) as a way of doing that aggregation, but that is obviously a work in progress, and perhaps slipping backwards. In any case, (as Roman says) humans are (much of the time) misaligned with each other and their collectives, in ways little and large, and sometimes that is for good or bad reasons. By ‘good reason’ I mean that sometimes ‘misalignment’ might literally be that human agents & collectives have local (geographical/temporal) realities they have to optimise for (to achieve their goals), which might conflict with goals/interests of their broader collectives: this is the essence of governing a large country, and is why many countries are federated. I’m sure these problems are formalised in preference/values literature, so I’m using my naive terms for now…
Anyway, this post’s working assumption/intuition is that ‘single AI-single human’ alignment (or corrigibility or identity fusion or (delegation to use Andrew Critch’s term)) is ‘easier’ to think about or achieve, than ‘multiple AI-multiple human’. Which is why we consciously focused on the former & temporarily ignored the latter. I don’t know if that assumption is valid and I haven’t thought about (i.e. no opinion) whether ideas in Roman’s ‘science of ethics’ linked post would change anything, but am interested in it !
comment by nothoughtsheadempty (lunaiscoding) · 2023-05-18T19:32:44.598Z · LW(p) · GW(p)
The times when humans get closest to not having their own values, and acting robustly on behalf of another agency’s[7] goals are when they adopt a sort of collective identity, for example as a part of a military, cult, or clan.
Or corporation, many humans act in ways that maximize the profits of a corporation even when they believe that the work they do is a little unethical.
I'm very glad that there's people thinking outside of the individualist bounds that we usually set for ourselves.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-05-19T00:14:49.399Z · LW(p) · GW(p)
I'd like to point out that the whole problem with those examples is they they claim to be individualist but very much are anything but. For beings like humans who should have individual identity, healthy collective identity is when that doesn't get overwritten. There are some great scenes in star trek that I like to use to reference what this is like, though of course sci-fi stories are just tools for thought and ultimately need to serve only as inspiration for precise mechanistic thought about the real versions of the same dynamics. The two I'd recommend for those who don't mind spoilers are the scene where we meet seven of nine, and the scene where jurati talks the queen into something important. I'll add links to the YouTube videos later.
Replies from: lunaiscoding↑ comment by nothoughtsheadempty (lunaiscoding) · 2023-05-24T17:35:20.466Z · LW(p) · GW(p)
For beings like humans who should have individual identity, healthy collective identity is when that doesn't get overwritten
"The free development of each is the condition for the free development of all." - Karl Marx & Friedrich Engels, 1848
Replies from: lunaiscoding↑ comment by nothoughtsheadempty (lunaiscoding) · 2023-05-24T18:47:26.615Z · LW(p) · GW(p)
Not sure why I'm getting downvoted for posting a quote from a communist in a post about collective identity.
I can only reason they are coming from:
- people who closely associate with Milton Friedman's economic position
- people with values similar to those set forth by neoliberalism
- people who believe Karl Marx was a bad person
- similarly to 1, people whose ideologies were critized in his work
If you are not one of these, please let me know so I can adjust my thinking. If you identify with one of the above I think it's better to use the disagreement karma since I didn't say anything factually incorrect afaik