Posts
Comments
I wonder if models can actually do this task when we allow them to use CoT for that.
Yes, claude-3.5-sonnet was able to use the figure this out with additional CoT.
Also, I think models might actually solve this task by using their own encoding scheme if they know it well
Yeah, could be that the 3 schemes I tested were just unnatural to them. Although I would guess they don't have some default scheme of their own, because in pre-training they aren't able to output information freely, and in fine-tuning I guess they don't have that much pressure to learn it.
So perhaps if we ask a model first to think about an encoding scheme and then ask them to use it for the task, they might succeed
Yeah, that would be interesting. I asked claude. He generated 3 schemes which were pretty bad, and 2 which look promising:
State 0: End sentence with period (.)
State 1: End sentence with exclamation (!)
State 2: End sentence with question mark (?)
State 0: Present tense
State 1: Past tense
State 2: Future tense
The punctuation one seems especially promising. But they don't feel much different from the 3 I tested. I don't expect that they are somehow "special" for the model.
I rerun the experiment with punctuation scheme. Looks overall the same.
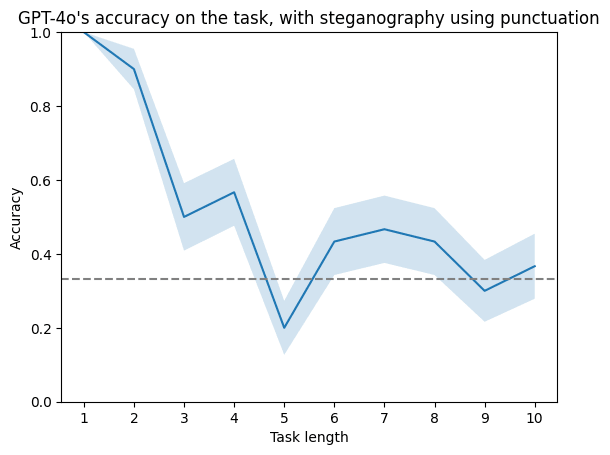
FYI, here a follow-up to this post, inspired by what you wrote in your comment. https://www.lesswrong.com/posts/YrnffADbWZcDJtmWk/simple-steganographic-computation-eval-gpt-4o-and-gemini-exp-1
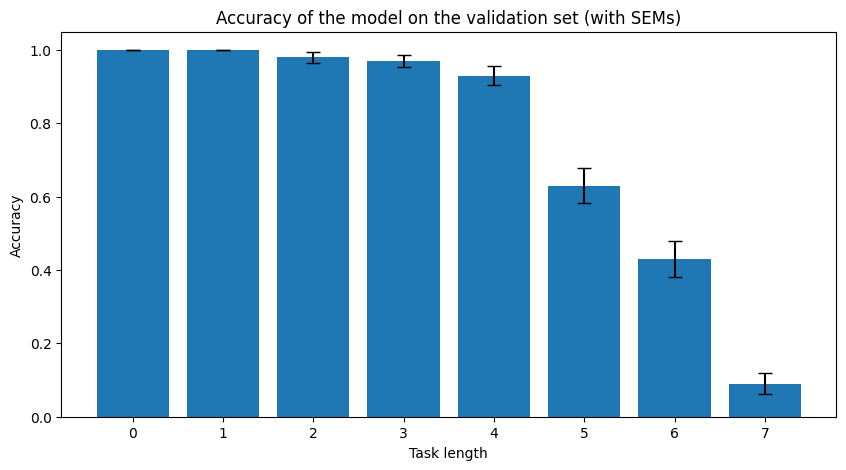
Yup, here is such a plot, made after training "switcher" architecture for 350k examples. I remember it was similar for the longer training - a few longest task lengths struggle, but the rest is near 100%.
Also, now that I think of it, it's different for the model to:
- represent hidden subtle information which is natural for the task, like in that example you gave with "written by"
- using that hidden subtext for computation which is unnatural in the given context - to covertly do some other task than just the one it is asked for
While 1. definitely happens, I see no reason why 2. would be learned in pre-training. In principle 2. could be learned in RL fine-tuning, if there's some incentive to use hidden reasoning. Although I imagine it must be hard.
That's a really good point.
To clarify what I did in these toy steganography experiments: First I tried to pass some more complex information and gave models more freedom in what to output. But as I kept failing at that, I kept simplifying the setup, until I tried to have a model pass just one bit to another model, assuming they both see one secret bit and an overseer tries to guess the message but doesn't see the secret bit. So a perfect code exists: XORing the message with the secret bit, but the models kept failing to find it. I expect that more complex settings will have a similar problem - that it's hard to create a new encoding for some information because it's rewarded only once it is both successfully sent and successfully received.
But the settings you describe may be different by the fact that they are natural, and there could be some unintentionally outputted subtext that accidentally correlates with the secret information. So the model would already by default "successfully send" the encoded information - now it just needs to learn to decode it.
It's not clear to me to what extent this happens. I would definitely want to see some concrete demo of this happening, but right now I don't have any good ideas how to elicit it.
Also, I wonder how far could we get by using adversaries who try to decode the information encoded in the model's outputs.
Ah. That's the number of solved tasks, after it is shown a set {length 1 task, length 2 task, ... , length (n+1) task}, and n is the longest task length is has solved so far. So you can think of it roughly as the maximum task length it is able to solve. So it doesn't have an upper bound.
I clarified this in the post now. Thanks for catching it.
FYI, I did the experiments I wrote about in my other comment and just posted them. (I procrastinated writing up the results for too long.) https://www.lesswrong.com/posts/ZB6guMhHH3NEyxA2k/testing-which-llm-architectures-can-do-hidden-serial-3
I liked it precisely because it threw theory out the window and showed that cheap talk is not a real commitment.
- Tarkin > I believe in CDT and I precommit to bla bla bla
- Leia > I belive in FDT and I totally precommit to bla bla bla
- Vader > Death Star goes brrrrr...
For me the main thing in this story was that cheap talk =/= real commitment. You can talk all you want about how "totally precommitted" you are, but this lacks some concreteness.
Also, I saw Vader as much less galaxy brained as you portray him. Destroying Alderaan at the end looked to me more like mad ruthlessness than calculated strategy. (And if Leia had known Vader's actual policy, she would have no incentive to confess.) Maybe one thing that Vader did achieve, is signal for the future that he really does not care and will be ruthless (but also signaled that it doesn't matter if you give in to him, which is dumb).
Anyway, I liked the story, but for the action, not for some deep theoretic insight.
Not sure if that's what happened in that example, but you can bet that a price will rise above some threshold, or fall below some threshold, using options. You can even do both at the same time, essentially betting that the price won't stay as it is now.
But whether you will make money that way depends on the price of options.
What if we constrain v to be in some subspace that is actually used by the MLP? (We can get it from PCA over activations on many inputs.)
This way v won't have any dormant component, so the MLP output after patching also cannot use that dormant pathway.
I wanna link to my favorite one: consciousness vs replicators. It doesn't really fit into this grid, but I think it really is the ultimate conflict.
(You can definitely skip the first 14 min of this video, as it's just ranking people's stages of development. Maybe even first 33 min if you wanna go straight to the point.)
I wonder what would happen if we run the simple version of that algorithm on LW comments. So that votes would have "polarity", and so each comment would have two vote-counts, let's say orange count and blue count. (Of course that would be only optionally enabled.)
Then we could sort the comments by the minimum of these counts, descending.
(I think it makes more sense to train it per post than globally. But then it would be useful only on very popular posts with lots of comments.)
Thanks, that's terrifying.
I hope we invent mindmelding before we invent all this. Maybe if people can feel those states themselves, they won't let the worst of them happen.
Unfortunately I didn't have any particular tasks in mind when I wrote it. I was vaguely thinking about settings as in:
Now that I though about it, for this particular transformers vs mamba experiment, I'd go with something even simpler. I want a task that is very easy sequentially, but hard to answer immediately. So for example a task like:
x = 5
x += 2
x *= 3
x **= 2
x -= 3
...
and then have a CoT:
after x = 5
5
after x += 2
7
...
And then we intervene on CoT to introduce some error in one operation, but still ask of the model to give the correct answer at the end. (Despite all steps after the error being irrelevant.) We can go even further and train the models to give the correct answer after inadequate CoT. And have a curriculum where at first it only needs to do one hidden operation, later two, and so on.
(It's an unrealistic setting, but the point is rather to check if the model is able at all to learn hidden sequential reasoning.)
Now, my hypothesis is that transformers will have some limited sequence length for which they can do it (probably smaller than their number of layers), but mamba won't have a limit.
I was working on this for six months
Can you say what you tried in these six months and how did it go?
Yeah, true. But it's also easier to do early, when no one is that invested in the hidden-recurrence architectures, and so there's less resistance, it doesn't break anyone's plans.
Maybe a strong experiment would be to compare mamba-3b and some SOTA 3b transformer, trained similarly, on several tasks where we can evaluate CoT faithfulness. (Although maybe at 3b capability level we won't see clear differences yet.) The hard part would be finding the right tasks.
the natural language bottleneck is itself a temporary stage in the evolution of AI capabilities. It is unlikely to be an optimal mind design; already many people are working on architectures that don't have a natural language bottleneck
This one looks fatal. (I think the rest of the reasons could be dealt with somehow.)
What existing alternative architectures do you have in mind? I guess mamba would be one?
Do you think it's realistic to regulate this? F.e. requiring that above certain size, models can't have recurrence that uses a hidden state, but recurrence that uses natural language (or images) is fine. (Or maybe some softer version of this, if alignment tax proves too high.)
I like initiatives like these. But they have a major problem, that at the beginning no users will use it because there's no content, and no content is created because there are no users.
To have a real shot at adoption, you need to either initially populate the new system with content from existing system (here LLMs could help solve compatibility issues), or have some bridge that mirrors (some) activity between these systems.
(There are examples of systems that kicked off from zero, but you need to be lucky or put huge effort in sparking adoption.)
Yeah, those star trajectories definitely wouldn't be stable enough.
I guess even with that simpler maneuver (powered flyby near a black hole), you still need to monitor all the stuff orbiting there and plan ahead, otherwise there's a fair chance you'll crash into something.
I wanted to give it a shot and made GPT4 to deceive the user: link.
When you delete that system prompt it stops deceiving.
But GPT had to be explicitly instructed to disobey the Party. I wonder if it could be done more subtly.
You're right, that you wouldn't want to approach the black hole itself but rather one of the orbiting stars.
when you are approaching with much higher than escape velocity, so that an extended dance with more than one close approach is not possible
But even with high velocity, if there are a lot of orbiting stars, you may tune your trajectory to have multiple close encounters.
The problem with not expanding is that you can be pretty sure someone else will then grab what you didn't and may use it for something that you hate. (Unless you trust that they'll use it well.)
eating the entire Universe to get the maximal number of mind-seconds is expanding just to expand
It's not "just to expand". Expansion, at least in the story, is instrumental to whatever the content of these mind-seconds is.
slingshot never slows you down in the frame of the object you are slingshotting around
That's true for one object. But if there are at least two, moving around fast enough, you could perform some gravitational dance with them to slow down.
-
I agree that scaffolding can take us a long way towards AGI, but I'd be very surprised if GPT4 as core model was enough.
-
Yup, that wasn't a critique, I just wanted to note something. By "seed of deception" I mean that the model may learn to use this ambiguity more and more, if that's useful for passing some evals, while helping it do some computation unwanted by humans.
-
I see, so maybe in ways which are weird to humans to think about.
we make the very strong assumption throughout that S-LLMs are a plausible and likely path to AGI
It sounds unlikely and unnecessarily strong to say that we can reach AGI by scaffolding alone (if that's what you mean). But I think it's pretty likely that AGI will involve some amount of scaffolding, and that it will boost its capabilities significantly.
there is a preexisting discrepancy between how humans would interpret phrases and how the base model will interpret them
To the extent that it's true, I expect that it may also make deception easier to arise. This discrepancy may serve as a seed of deception.
Systems engaging in self modification will make the interpretation of their natural language data more challenging.
Why? Sure, they will get more complex, but are there any other reasons?
Also, I like the richness of your references in this post :)
I edited the post to make it clearer that Bob throws out the wheel because he didn't notice in time that Alice threw.
Yup, side payments are a deviation, that's why I have this disclaimer in game definition (I edited the post now to emphasize it more):
there also may be some additional actions available, but they are not obvious
Re separating speed of information and negotiations: I think here they are already pretty separate. The first example with 3 protocol rules doesn't allow negotiations and only tackles the information speed problem. The second example with additional fourth rule enables negotiations. Maybe you could also have a system tackling only negotiations and not the information speed problem, but I'm not sure now how would it look like, or if it would be much simpler.
Another problem (closely tied to negotiations) I wanted to tackle is something like "speed of deliberation" where agents make some bad commitments because they didn't have enough time to consider their consequences, and later realize they want to revoke/negotiate.
Oh, so the option to choose all of those disease weights is there, it's just a lot of effort for the parents? That's good to know.
Yeah, ideally it shouldn't need to be done by each parents separately, but rather there should be existing analyses ready. And even if those orgs don't provide a satisfactory analyses themselves, they could be done independently. F.e. collaborating on that with Happier Lives Institute could work well, as they have some similar expertise.
each disease is weighted according to its impact on disability-adjusted lifespan
It's a pity they don't use some more accurate well-being metrics like f.e. WELLBY (although I think WELLBY isn't ideal either).
How much control do the parents have on what metric will be used to rank the embryos?
Oh yeah, I meant the final locked-in commitment, not initial tentative one. And my point is that when committing outside is sufficiently more costly, then it's not worth doing it, even if that would let you commit faster.
Yup, you're totally right, it may be too easy to commit in other ways, outside this protocol. But I still think it may be possible to create such a "main mechanism" for making commitments where it's just very easy/cheap/credible to commit, compared to other mechanisms. But that would require a crazy amount of cooperation.
The vast majority that I know of use ad-hoc and agent-specific commitment mechanisms
If you have some particular mechanisms in mind could you list some? I'd like to compile a list of the most relevant commitment mechanisms to try to analyze them.
Love that post!
Can we train ML systems that clearly manifest a collective identity?
I feel like in multi-agent reinforcement learning that's already the case.
Re training setting for creating shared identity. What about a setting where a human and LLM take turns generating text, like in the current chat setting, but first they receive some task, f.e. "write a good strategy for this startup" and the context for this task. At the end they output the final answer and there is some reward model which rates the performance of the cyborg (human+LLM) as a whole.
In practice, having real humans in this training loop may be too costly, so we may want to replace them most of the time with an imitation of a human.
(Also a minor point to keep in mind: having emergent collective action doesn't mean that the agents have a model of the collective self. F.e. colony of ant behaves as one, but I doubt ants have any model of the colony, rather just executing their ant procedures. Although with powerful AIs, I expect those collective self models to arise. I just mean that maybe we should be careful in transferring insight from ant colonies, swarms, hives etc., to settings with more cognitively capable agents?)
Oh yeah, definitely. I think such a system shouldn't try to enforce one "truth" - which content is objectively good or bad.
I'd much rather see people forming groups, each with its own moderation rules. And let people be a part of multiple groups. There's a lot of methods that could be tried out, f.e. some groups could use algorithms like EigenTrust, to decide how much to trust users.
But before we can get to that, I see a more prohibitive problem - that it will be hard to get enough people to get that system off the ground.
Cool post! I think the minimum viable "guardian" implementation, would be to
- embed each post/video/tweet into some high-dimensional space
- find out which regions of that space are nasty (we can do this collectively - f.e. my clickbait is probably clickbaity for you too)
- filter out those regions
I tried to do something along these lines for youtube: https://github.com/filyp/yourtube
I couldn't find a good way to embed videos using ML, so I just scraped which videos recommend each other, and made a graph from that (which kinda is an embedding). Then I let users narrow down on some particular region of that graph. So you can not only avoid some nasty regions, but you can also decide what you want to watch right now, instead of the algorithm deciding for you. So this gives the user more autonomy.
The accuracy isn't yet too satisfying. I think the biggest problem with systems like these is the network effect - you could get much better results with some collaborative filtering.
Yeah, when I thought about it some more, maybe the smallest relevant physical change is a single neuron firing. Also with such a quantization, we cannot really talk about "infinitesimal" changes.
I still think that a single neuron firing, changing the content of experience so drastically, is quite hard to swallow. There is a sense in which all that mental content should "come from" somewhere.
I had a similar discussion with @benjamincosman, where I explore that in more detail. Here are my final thoughts from that discussion.
Oh, I've never stumbled on that story. Thanks for sharing it!
I think it's quite independent from my post (despite such a similar thought experiment) because I zoomed in on that discontinuity aspect, and Eliezer zoomed in on anthropics.
That's a good point. I had a similar discussion with @benjamincosman, so I'll just link my final thoughts: my comment
I thought about it some more, and now I think you may be right. I made an oversimplification when I implicitly assumed that a moment of experience corresponds to a physical state in some point in time. In reality, a moment of experience seems to span some duration of physical time. For example, events that happen within 100ms, are experienced as simultaneous.
This gives some time for the physical system to implement these discontinuities (if some critical threshold was passed).
But if this criticality happens, it should be detectable with brain imaging. So now it becomes an empirical question, that we can test.
I still doubt the formulation in IIT, that predicts discontinious jumps in experience, regardless of whether some discontinuity physically happens or not.
(BTW, there is a hypothetical mechanism that may implement this jump, proposed by Andres Gomez Emilsson - topological bifurcation.)
Hm, yeah, the smallest relevant physical difference may actually be one neuron firing, not one moved atom.
What I meant by between them, was that there would need to be some third substrate that is neither physical nor mental, and produces this jump. That's because in that situation discontinuity is between start and end position, so those positions are analogous to physical and mental state.
Any brain mechanism, is still part of the physical. It's true that there are some critical behaviors in the brain (similar to balls rolling down that hill). But the result of this criticality is still a physical state. So we cannot use a critical physical mechanism, to explain the discontinuity between physical and mental.
It just looks that's what worked in evolution - to have independent organisms, each carrying its own brain. And the brain happens to have the richest information processing and integration, compared to information processing between the brains.
I don't know what would be necessary to have a more "joined" existence. Mushrooms seem to be able to form bigger structures, but they didn't have an environment complex enough to require the evolution of brains.
It seems that we just never had any situations that would challenge this way of thinking (those twins are an exception).
This Cartesian simplification almost always works, so it seems like it's just the way the world is at its core.
Here, to have that discontinuity between input and output (start and end position), we need some mechanism between them - the system of ball, hill, and their dynamics. What's worse it needs to evolve for infinite time (otherwise the end still continuously depends on start position).
So I would say, this discontinuous jump "comes from" this system's (infinite) evolution.
It seems to me, that to have discontinuity between physical and mental, you would also need some new mechanism between them to produce the jump.
Good point. I edited the post to say "near epiphenomenalism", because like you said, it doesn't fit into the strict definition.
If the physical and mental are quantized (and I expect that), then we can't really speak of "infinitesimal" changes, and the situation is as you described. (But if they are not quantized, then I would insist that it should really count as epiphenomenal, though I know it's contentious.)
Still, even if it's only almost epiphenomenal, it feels too absurd to me to accept. In fact you could construct a situation where you create an arbitrarily big mental change (like splitting Jupyter-sized mind in half), by the tiniest possible physical change (like moving one electron by one Planck length). Where would all that mental content "come from"?
Hm, I thought those instructions (under "Explore hidden treasures...") are enough, but I probably misestimated it because I'm already used to that tool.
Thanks for pointing that out! I'll try to clarify it. (Also I'm not sure if you looked at this page which roughly explains how it works. I linked it at the end because to use that tool you don't need to understand those details.)
Are you able to pin down what causes the most confusion?
[edit] I also copied over the whole explanation into the post now, and made the details link more salient
Yeah, that makes sense.
I'd like the serious modifications to (at the very least) require a lot of effort to do. And be gradual, so you can monitor if you're going in the right direction, instead of suddenly jumping into a new mindspace. And maybe even collectively decide to forbid some modifications.
(btw, here is a great story about hedonic modification https://www.utilitarianism.com/greg-egan/Reasons-To-Be-Cheerful.pdf)
The reason that I lean toward relying on my friends, not a godlike entity, is because on default I distrust centralized systems with enormous power. But if we had Elua which is as good as you depicted, I would be okay with that ;)
Yeah, unanimous may be too strong - maybe it would be better to have 2 out of 3 majority voting for example. And I agree, my past self is a third party too.
Hm, yeah, trusting Elua to do it would work too. But in scenarios where we don't have Elua, or have some "almost Elua" that I don't fully trust, I'd rather rely on my trusted friends. And those scenarios are likely enough that it's a good option to have.
(As I side note, I don't think I can fully specify that "please take me out of there if X". There may be some Xs which I couldn't foresee, so I want to rely on those third party's judgement, not some hard rules. (of course, sufficiently good Elua could make those judgements too))
As for that limitation, how would you imagine it? That some mind modifications are just forbidden? I have an intuition that there may be modifications so alien, that the only way to predict their consequences is to actually run that modified mind and see what happens. (an analogy may be, that even the most powerful being cannot predict if some Turing machine halts without actually running it). So maybe reverting is still necessary sometimes.
Thanks! I'm always hungry for good sci-fi utopias :) I particularly liked that mindmelding part.
After also reading Diaspora and ∀V, I was thinking what should be done about minds who self-modify themselves into insanity and suffer terribly. In their case, talking about consent doesn't make much sense.
Maybe we could have a mechanism where:
- I choose some people I trust the most, for example my partner, my mom, and my best friend
- I give them the power to revert me back to my previous snapshot from before the modification, even if it's against my insane will (but only if they unanimously agree)
- (optionally) by old snapshot is temporarily revived to be the final arbiter and decide if I should be reverted - after all I know me the best