Community Notes by X
post by NicholasKees (nick_kees) · 2024-03-18T17:13:33.195Z · LW · GW · 15 commentsContents
How does the ranking algorithm work? Some further details and comments Academic commentary Conclusion None 15 comments
I did an exploration into how Community Notes (formerly Birdwatch) from X (formerly Twitter) works, and how its algorithm decides which notes get displayed to the wider community. In this post, I’ll share and explain what I found, as well as offer some comments.
Community Notes is a fact-checking tool available to US-based users of X/Twitter which allows readers to attach notes to posts to give them clarifying context. It uses an open-source bridging-based ranking algorithm intended to promote notes which receive cross-partisan support, and demote notes with a strong partisan lean. The tool seems to be pretty popular overall, and most of the criticism aimed toward it seems to be about how Community Notes fails to be a sufficient replacement for other, more top-down moderation systems.[1]
This seems interesting to me as an experiment in social technology that aims to improve group epistemics, and understanding how it works seems like a good place to start before trying to design other group epistemics algorithms.
How does the ranking algorithm work?
The full algorithm, while open-source, is quite complicated and I don’t fully understand every facet of it, but I’ve done a once-over read of the original Birdwatch paper, gone through the Community Notes documentation, and read this summary/commentary by Vitalik Buterin. Here’s a summary of the “core algorithm” as I understand it (to which much extra logic gets attached):
Users are the people who have permission to rate community notes. To get permission, a person needs to have had an account on X for more than 6 months, have a verified phone number, and have committed no violations of X’s rules. The rollout of community notes is slow, however, and so eligible account holders are only added to the Community Notes user pool periodically, and at random. New users don’t immediately get permission to write their own notes, having to first get a “rating impact” by rating existing notes (will explain this later).
Notes are short comments written by permitted users on posts they felt needed clarification. These are not immediately made publicly visible on X, first needing to be certified as “helpful” by aggregating ratings by other Community Notes users using their ranking algorithm.
Users are invited to rate notes as either “not helpful,” “somewhat helpful,” or “helpful.” The results of all user-note pairs are recorded in a matrix where each element corresponds to how user rated note . Users only rate a small fraction of notes, so most elements in the matrix are “null.” Non-null elements are called “observed” ratings, and values of 0, 0.5, and 1 correspond to the qualitative ratings of “not helpful,” “somewhat helpful,” and “helpful” respectively.
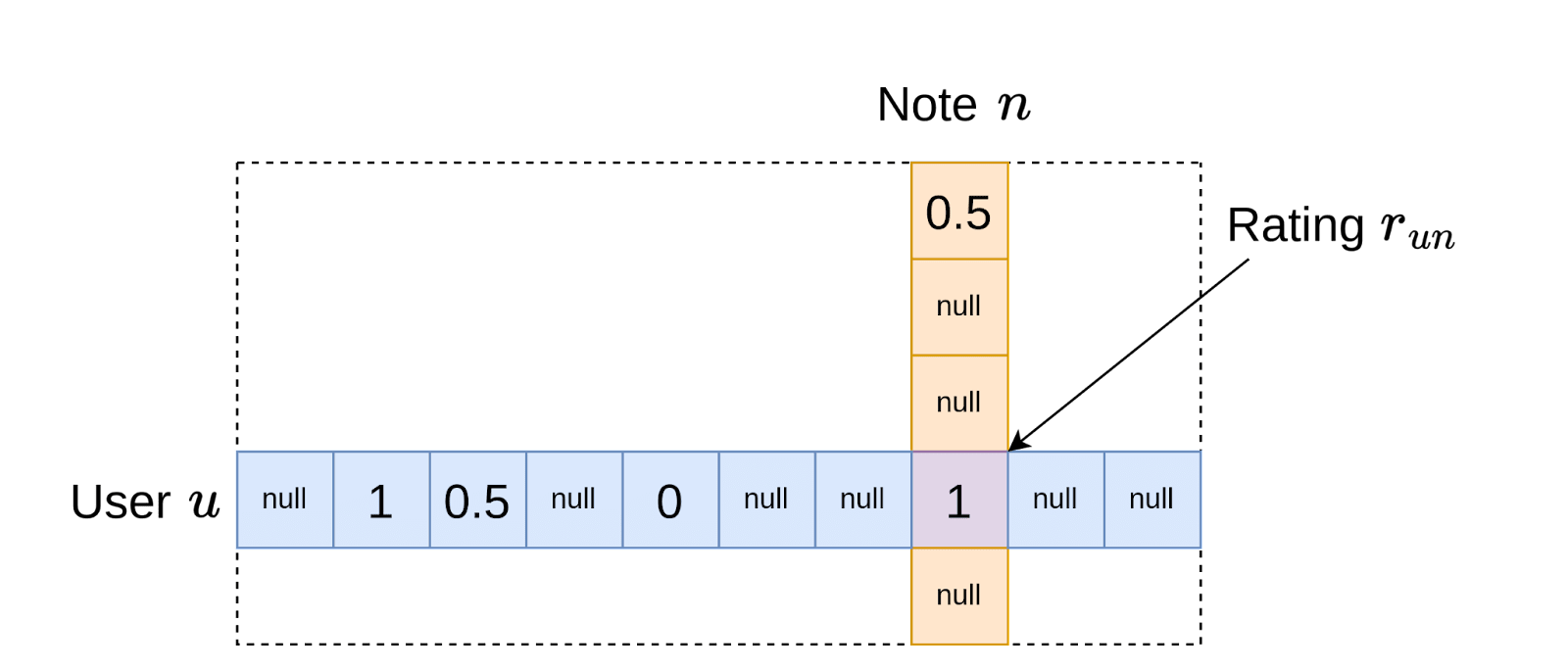
This rating matrix is then used by their algorithm to compute a helpfulness score for each note. It does this is by learning a model of the ratings matrix which explains each observed rating as a sum of four terms:
Where:
- : Global intercept (shared across all ratings)
- : User intercept (shared across all ratings by user u)
- : Note intercept (shared across all ratings of note n) This is the term which will eventually determine a note's "helpfulness."
- , : Factor vectors for and . The dot product of these vectors is intended to describe the “ideological agreement” between a user and a note. These vectors are currently one dimensional (each just a single number), though the algorithm is in principle agnostic to the number of dimensions.
For U users and N notes that gets us 1 + 2U + 2N free parameters making up this model. These parameters are estimated via gradient descent every hour, minimizing the following squared error loss function (for observed ratings only):
The first term is the square difference between the model’s prediction and the actual rating, and the final two terms are regularization terms, where and . is deliberately set significantly higher than to push the algorithm to rely primarily on the factor vectors to explain the ratings a note receives, keeping the other terms as low as possible. The original Birdwatch paper presents this choice as risk aversion[2]:
…we particularly value precision (having a low number of false positives) over recall (having a low number of false negatives) due to risks to our community and reputation from increasing visibility of low quality notes.
This algorithm, in the process of fitting all the different factor vectors for notes and users, automatically identifies an ideological spectrum. Because of the asymmetric regularization above, it also explains the ratings as much as possible in terms of this ideological spectrum, such that the intercept terms , , and end up describing how much the rating outcomes differ from what was predicted by the ideological part of the model.
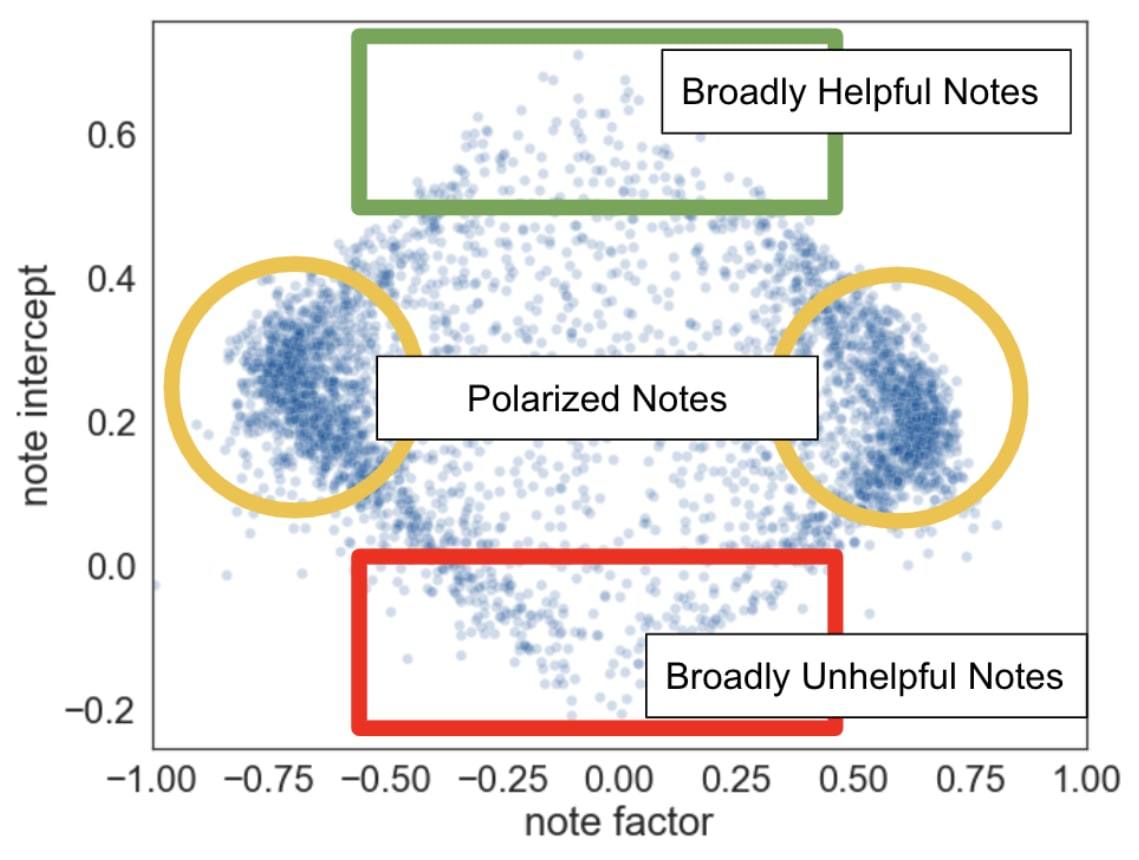
Finally, a note’s helpfulness score is determined by the final value reached by . This helpfulness score is highest if the note is ranked as “helpful” by Community Notes users more often than the rest of the model would predict. If this parameter reaches a threshold of , then the note is certified as “helpful” and is shown to the wider X community.[3] Likewise, if , then the note is certified as “not helpful.”[4]
The following figure illustrates the results from the original Birdwatch paper after applying this algorithm, where the y-axis is , and the x-axis is :
Some further details and comments
Factor vectors: First thing to note is that, to avoid overfitting, the factor vectors are currently just one dimensional (though they plan to increase the dimensions when they have more data). In practice, across all notes, this results in a spectrum where a negative factor roughly corresponds to the political left, and a positive factor corresponds to the political right (note that this spectrum was not hardcoded, but rather found automatically by the algorithm). This leaves a lot to be desired. In particular, because “consensus between the left and right” is used as a proxy for high-quality information, which might be good in some cases, but probably not for many others.[5] There are also plans to use multiple ranking models for different groups, though this seems mostly to be about dealing with geographic and linguistic diversity.[6]
Modeling uncertainty: Another detail is that they actually run gradient descent multiple times, including extra extreme ratings from “pseudo-raters” in each run. This forms a distribution of helpfulness scores, and in the spirit of risk-aversion, they use the lower-bound value of to classify a note as “helpful,” and an upper bound value of to classify it as “not helpful.”[7]
User helpfulness: This is the weirdest part in my opinion. They actually estimate the model parameters in two separate rounds. After the first round, the algorithm computes a “user helpfulness” score for each user based on how well their own ratings predicted the final rating assigned by the algorithm. Users which do a poor job of predicting the group decision are labeled as unhelpful, and are filtered out for the second round, which will give the final verdict on all the notes.[8] I don’t know how strict filtering is in practice, but from the docs it seems that at least two thirds of their ratings need to match the group consensus in order to be counted in the second round. This is also the key to “rating impact,” which unlocks the ability to write your own notes, where you get permission only once you have correctly predicted at least 5 note outcomes.

This seems to be asking users to do two contradictory things: 1) Rate notes honestly according to their own beliefs and 2) use their ratings to predict what other people believe. There is also a “writer impact” system, where writers need to maintain a positive ratio of “helpful” to “not helpful” notes, or else they are rate-limited.
Tag-consensus harassment-abuse note score: In addition to rating a note as helpful or unhelpful, users are invited to tag a note with something like 20 different predefined descriptors. If there is a cross-partisan consensus (using the same core algorithm described above, but with different labels) that a note is harassment or abuse (this is a single tag), then the algorithm strongly punishes all users who rated this note as helpful by significantly lowering their “user helpfulness” score. The threshold for a note being deemed harassment or abuse is quite high, so I expect that this is fairly rare. I do wonder about how well a coordinated attack could pull off using this mechanism to bully people away from certain topics, and whether there exist any additional mechanisms to prevent this behavior.
Tag outlier filtering: There are roughly ten negative tags. If enough users[9] agree on the same negative tag, then the helpfulness threshold for the note rises from 0.4 to 0.5. I’m not sure how easy this is to game, but I could imagine a coordinated attack where could possibly be used to increase this threshold.
A note on strategic ratings: Because of the general risk-averse design, it seems generally hard for individual users to get any one note to be certified as helpful, but pretty easy for motivated users to prevent a note from getting above the helpfulness threshold. However, I have read an anecdote by one group of Ukrainian activists who coordinate to get specific notes labeled helpful, also claiming that Russian opponents use similar coordination tactics to get community notes taken down. This might also be because most posts don’t have any notes, and so it could be pretty easy for a small group to form a consensus (notes need at least 5 ratings to be eligible for “helpful” status). The Community Notes algorithm and all of the Community Notes data is open source, so this should make it fairly easy to notice these kinds of coordinated actions if they become widespread (though unclear if there is any system to act in response to manipulation).
A comment on jokes as misinformation: One concern I have is that a lot of X content isn’t making specific claims that can really be fact-checked. Take this example:
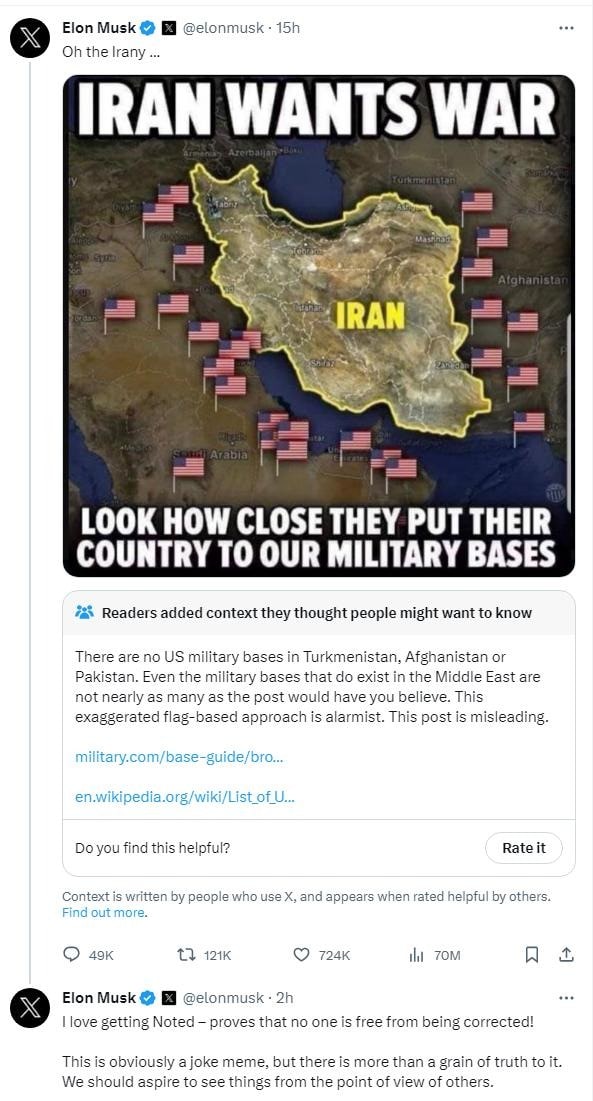
While it seems like a win against misinformation, Musk still gets to hide behind the shield of “joke meme,” further implying that while the actual empirical claims made by the meme are false, the underlying message is still true. Correcting jokes doesn’t seem to be in the scope of Community Notes, and furthermore, political humor often carries a deeper message that is practically impossible to fact-check (and it would be a bit much to require every political meme to be tied to a falsifiable claim).[10]
Academic commentary
I found two major peer-reviewed papers commenting on Community Notes/Birdwatch:
"Birds of a Feather Don’t Fact-Check Each Other"[11] by Jennifer Allen, Cameron Martel, and David Rand
This paper analyzes Birdwatch data from 2021 and seems to primarily find that most users of the platform are extremely partisan when giving ratings, and imply they are likely more partisan than the average X/Twitter user (also being more active, with an average post count >22,000).[12] They also find that, while all users were most likely to submit notes for content that aligned with their partisanship, right-wing users were much more likely to submit notes for left-wing posts/tweets than the reverse, raising concerns that attempts to reward users for agreeing with the consensus might favor left-wing users. Finally they also raise concerns that “partisan dunking” might lead people on the platform to become more partisan rather than less (citing a study that empirically tests this).
Community-Based Fact-Checking on Twitter’s Birdwatch Platform by Nicolas Pröllochs
Similarly, the author analyzes a bunch of Birdwatch data from 2021. They find that the more socially influential a poster is (gauged by the number of followers), the less likely notes on that post are certified “helpful,” as raters tend to become much more divided. They also found, unsurprisingly, that notes which cited sources were more likely to be rated as helpful. Users of Birdwatch were prompted with a checklist of reasons whenever they labeled a note as helpful or unhelpful, and the paper analyzes this data (though doesn’t find anything particularly surprising). They also give a top ten Twitter users ranked by the fraction of tweets with a note tagging their tweet as “misleading,” and find that they are nearly all American politicians, confirming the idea that most Birdwatch users are using the platform to fact-check political content.
Conclusion
I probably left a lot out, but hopefully that’s a useful overview (if I made any mistakes, please let me know!). Personally, I was most disappointed during this exploration to learn that Community Notes functions primarily to bridge a binary left-right divide, and I would really love to see a version of this algorithm which was less binary, and more politics agnostic. Furthermore, I was also a bit overwhelmed by the complexity of this algorithm, and I share the sentiment brought up in the Vitalik Buterin commentary that it would be nice to see a version of this algorithm which was mathematically cleaner. I also feel like the mixture of rating and prediction into the same action seems murky, and it might be better for users to rate and predict separately.
- ^
Particularly in the context of Elon Musk (Owner of X/Twitter) firing most of the existing content moderators.
- ^
This philosophy of risk aversion appears frequently in many of their design decisions.
- ^
To be considered helpful, a note also needs to have a factor vector (as a final check against polarization).
- ^
Full disclosure, sometimes they use a threshold of -0.04 and sometimes a threshold of , and I don’t totally understand when or why.
- ^
Though I suppose plausibly the worst disinformation on X at the moment might be mostly political claims.
- ^
I originally thought this incentivizes people to strategically rate comments in a way that makes them appear more neutral, but it seems a bit unclear. If a user has a strong partisan lean, they actually maximize the weight of those ratings which are opposite of what their ideology would predict, which makes the incentive landscape a bit more complicated.
- ^
While the docs explicitly mention using the upper bound for certifying "not helpful" notes, I only saw mention of using the lower bound for certifying "helpful" from the Buterin summary. I think this is probably correct, but I'm not totally sure.
- ^
They do add a safeguard to prevent users from directly copying the group decision by only counting ratings which happened before the group rating is published (48 hours after a note is submitted).
- ^
Users are weighted by a complicated function which punishes strong ideological disagreement with the note.
- ^
While memes do convey important information not easily shared via specific and concrete claims, it does make discussing their “accuracy” really messy and hard to do (e.g. from the LW community: this commentary [LW(p) · GW(p)] on a Shoggoth meme by @TurnTrout [LW · GW] ).
- ^
Academics clearly can never resist a pun, even if it’s a pun on another pun.
- ^
They also speculate that partisanship might be a key motivator for becoming a Birdwatch contributor.
15 comments
Comments sorted by top scores.
comment by shemetz (shem-itamar-curiel) · 2024-03-20T18:45:23.999Z · LW(p) · GW(p)
be verified
Correction: community notes users only need to be phone-verified, not blue-check-verified.
Replies from: nick_kees↑ comment by NicholasKees (nick_kees) · 2024-03-25T20:45:34.158Z · LW(p) · GW(p)
Thank you, it's been fixed.
comment by Filip Sondej · 2024-03-18T19:35:52.017Z · LW(p) · GW(p)
I wonder what would happen if we run the simple version of that algorithm on LW comments. So that votes would have "polarity", and so each comment would have two vote-counts, let's say orange count and blue count. (Of course that would be only optionally enabled.)
Then we could sort the comments by the minimum of these counts, descending.
(I think it makes more sense to train it per post than globally. But then it would be useful only on very popular posts with lots of comments.)
Replies from: nick_kees↑ comment by NicholasKees (nick_kees) · 2024-03-18T21:02:49.129Z · LW(p) · GW(p)
That sounds cool! Though I think I'd be more interested using this to first visualize and understand current LW dynamics rather than immediately try to intervene on it by changing how comments are ranked.
Replies from: antanaclasis↑ comment by antanaclasis · 2024-03-18T22:56:24.866Z · LW(p) · GW(p)
I think a lot of the value that I’d get out of something like that being implemented would be getting an answer to “what is the biggest axis along which LW users vary” according to the algorithm. I am highly unsure about what the axis would even end up being.
Replies from: shankar-sivarajan↑ comment by Shankar Sivarajan (shankar-sivarajan) · 2024-03-19T14:02:00.467Z · LW(p) · GW(p)
Would that even be a meaningful question? Thinking of it as a kind of PCA, there will be some axis, with a lot of correlations, and how you interpret that is up to you.
Replies from: antanaclasis↑ comment by antanaclasis · 2024-03-20T16:01:25.509Z · LW(p) · GW(p)
I’d imagine that once we see the axis it will probably (~70%) have a reasonably clear meaning. Likely not as obvious as the left-right axis on Twitter but probably still interpretable.
comment by localdeity · 2024-03-18T22:09:04.343Z · LW(p) · GW(p)
, : Factor vectors for and . The dot product of these vectors is intended to describe the “ideological agreement” between a user and a note. These vectors are currently one dimensional, though the algorithm is in principle agnostic to the number of dimensions.
It took me a few minutes to figure out that "one dimensional" appears to mean "the vector contains one number".
Replies from: nick_kees↑ comment by NicholasKees (nick_kees) · 2024-03-19T12:00:14.654Z · LW(p) · GW(p)
Thanks for pointing that out. I've added some clarification.
comment by ChristianKl · 2024-03-20T13:47:08.650Z · LW(p) · GW(p)
I'm surprised that it's one-dimensional as that should be relatively easy for the game. If the attacker cares about promoting Israeli interests or Chinese interests they can just cast a lot of votes in the other right/left direction on topics they don't care about.
Did they write anywhere why they only consider one-dimension?
Replies from: nick_kees↑ comment by NicholasKees (nick_kees) · 2024-03-20T15:48:16.183Z · LW(p) · GW(p)
"Note: for now, to avoid overfitting on our very small dataset, we only use 1-dimensional factors. We expect to increase this dimensionality as our dataset size grows significantly."
This was the reason given from the documentation.
↑ comment by ChristianKl · 2024-03-20T16:07:59.563Z · LW(p) · GW(p)
That sounds like it made sense at the beginning but now the data set should be large enough that a higher dimensional approach would be better?
Replies from: nick_kees↑ comment by NicholasKees (nick_kees) · 2024-03-20T16:42:14.115Z · LW(p) · GW(p)
That sounds right intuitively. One thing worth noting though is that most notes get very few ratings, and most users rate very few notes, so it might be trickier than it sounds. Also if I were them I might worry about some drastic changes in note rankings as a result of switching models. Currently, just as notes can become helpful by reaching a threshold of 0.4, they can lose this status by dropping below 0.39. They may also have to manually pick new thresholds, as well as maybe redesign the algorithm slightly (since it seems that a lot of this algorithm was built via trial and error, rather than clear principles).
comment by Review Bot · 2024-03-21T22:14:24.496Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Kabir Kumar (kabir-kumar-1) · 2024-03-20T20:24:02.512Z · LW(p) · GW(p)
Thank you, this is useful. Planning to use this for AI-Plans.