Representational Tethers: Tying AI Latents To Human Ones
post by Paul Bricman (paulbricman) · 2022-09-16T14:45:38.763Z · LW · GW · 0 commentsContents
Intro Proposal First Bring Them Closer Then Bridge The Gap Humans Learn The Translation Key Humans Experience Translated Neural Dynamics Tether Artificial Representations To Written Language Discussion Isn't the model incentivized to tweak (human) neural dynamics or language? What if fluency is worth sacrificing for the main goal? What if the translator is arbitrary? Can't the fluency measure be tricked? Could representational tethers be set up between different AIs? Don't LLMs already translate their internal representations into natural language as their day job? What if the gap still can't be bridged? Are representational tethers restricted to prosaic risk scenarios? Outro None No comments
This post is part of my hypothesis subspace [? · GW] sequence, a living collection of proposals I'm exploring at Refine. [LW · GW] Preceded by ideological inference engines [LW · GW], and followed by an interlude [? · GW].
Thanks Adam Shimi, Alexander Oldenziel, Tamsin Leake, and Ze Shen for useful feedback.
TL;DR: Representational tethers describe ways of connecting internal representations employed by ML models to internal representations employed by humans. This tethering has two related short-term goals: (1) making artificial conceptual frameworks more compatible to human ones (i.e. the tension in the tether metaphor), and (2) facilitating direct translation between representations expressed in the two (i.e. the physical link in the tether metaphor). In the long-term, those two mutually-reinforcing goals (1) facilitate human oversight by rendering ML models more cognitively ergonomic, and (2) enable control over how exotic internal representations employed by ML models are allowed to be.
Intro
The previous two proposals in the sequence describe means of deriving human preferences procedurally. Oversight leagues [LW · GW] focus on the adversarial agent-evaluator dynamics as the process driving towards the target. Ideological inference engines [LW · GW] focus on the inference algorithm as the meat of the target-approaching procedure. A shortcoming of this procedural family is that even if you thankfully don't have to plug in the final goal beforehand (i.e. the resulting evaluator or knowledge base), you still have to plug in the right procedure for getting there. You're forced to put your faith in a self-contained preference-deriving procedure [AF · GW] instead of an initial target.
In contrast, the present proposal tackles the problem from a different angle. It describes a way of actively conditioning the conceptual framework employed by the ML model to be compatible with human ones, as an attempt to get the ML model to form accurate conceptions of human values. If this sounds loosely relates to half a dozen other proposals, that's because it is — consider referring to the Discussion for more details on tangents. In the meantime, following the structure of the previous posts in the sequence, here are some assumptions underlying representational tethers:
Assumption 1, "Physicalism": Our thoughts are represented as neural dynamics. In the limit of arbitrarily large amounts of data on neural dynamics aligned with external stimuli (in the sense of parallel corpora), our thoughts can be accurately reconstructed.
Assumption 2, "Bottleneck Layer": There is a bottleneck layer in the architecture of the ML model being tethered to human representations. This bottleneck refers to a low-dimensional representation through which all the information being processed by the ML model is forced to pass.
Assumption 3, "AGI Hard, Human Values Harder": We are unlikely to formulate the True Name [LW · GW] of human values in closed-form before deploying transformative AI. The best we are likely to do before takeoff is model human values approximately and implement an imperfect evaluator.
Proposal
Representational tethers suggest a way of aligning human and AI latents for the purpose of facilitating later interaction. There are two steps to this:
First Bring Them Closer
Incentivize the ML model to employ internal representations which are compatible with human ones, thus bringing them "closer." This can be operationalized by conditioning latent activations which arise in the ML model to be expressible in human representations. Concretely, optimization pressure would be exerted on the ML model to push it to internalize a conceptual framework which can successfully be translated to and from a human one without significant loss of information. If the artificial representation can successfully be translated into the language of e.g. neural dynamics and back, then the two are quite compatible. If there is no way of realizing the back-and-forth, then they're generally incompatible — you either can't express artificial ideas in human terms, or human terms aren't enough for fully expressing them.
The adequacy-fluency trade-off described in machine translation is particularly relevant to understanding this process. If an English sentence is translated into Chinese in a way which (1) successfully captures the intended meaning, but (2) comes across as formulated in a very unnatural way to the Chinese speaker, then the translation has high adequacy, but low fluency. If the sentence is translated in a way which (1) feels very natural to the Chinese speaker, but (2) fails to accurately capture the intended meaning, then it has high fluency, but low adequacy. The two features are often in tension — it's hard to perfectly capture the intended meaning and make it feel perfectly natural at the same time, especially as you dial up the complexity.
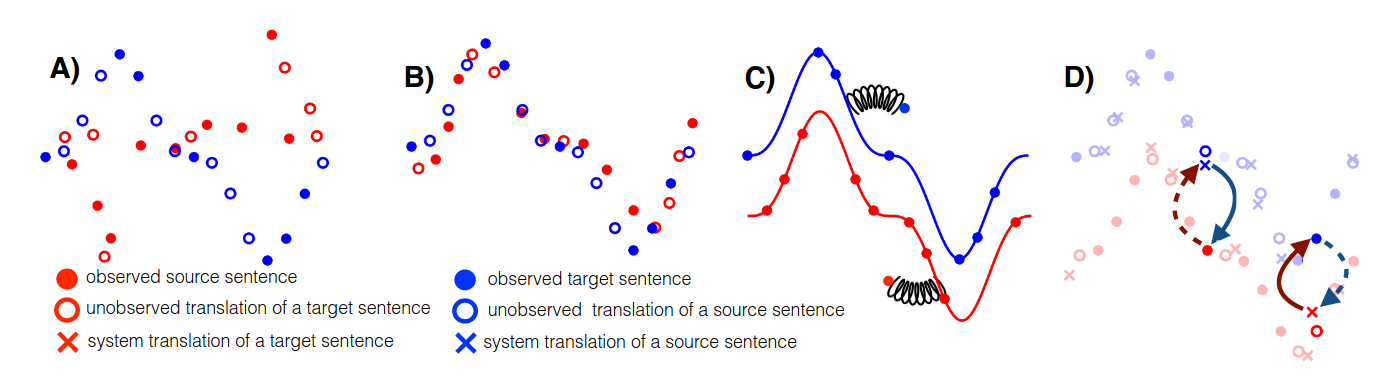
The way this trade-off would apply to our backtranslation of latents is as follows. For perfect adequacy and disastrous fluency, you might choose two neural states as stand-ins for 1s and 0s, and perfectly express the artificial representation in binary. Adequacy is high because you can accurately represent the artificial representation and go back, but fluency is at an all-time low because the language of (human) neural dynamics doesn't resemble two states being endlessly interspersed. For perfect fluency and disastrous adequacy, imagine an ML model with particularly alien concepts which get translated into neural dynamics which are perfectly in-distribution, but completely fail to express the initial meaning, making it impossible to complete the backtranslation.
Considering this, it becomes obvious that backtranslation faces the same two conflicting goals: (1) capture the intended meaning so that you can go back from human to artificial (i.e. adequacy), but (2) ensure the intermediate human translation is in-distribution relative to observed neural dynamics (i.e. fluency). Note that fluency here doesn't require an exhaustive mechanistic understanding of the brain (see "AGI Hard, Human Values Harder" assumption), just a measure of divergence between the ground truth distribution of neural dynamics observed in humans and the distribution resulting from translations of artificial representations.
The ML model would then be incentivized (e.g. through gradient descent) to settle on representations which can be translated both adequately and fluently. If the artificial representations are alien, then it's hard to adequately translate them in a fluent way. Given this, representations which can be translated both adequately and fluently in human terms are more likely to be compatible with the ones we actually employ as humans.
But who or what performs the actual two translations involved in the proposal so far? Considering we're focusing on ML models, a straightforward choice for the architecture of the translator components is to go with ML models again. The artificial-to-human translator would be tasked with taking in internal ML representations and outputting neural dynamics. The human-to-artificial translator would be tasked with performing the reverse process. The adequacy loss would be computed based on the distance between the original artificial representation and the backtranslated one, before driving backpropagation. Similarly, the fluency loss would be computed based on the distance between the intermediate human representation and the ground truth distribution of them, before getting backpropagated. An appealing property of this setup is that the translators are learned as part of the initial training process. No extra hurdles involved.
Another relevant trick would be to overwrite the original artificial representation with the backtranslated one, rather than just using the backtranslated one to compute extra losses. By tying the backtranslation process to the main objective of the ML model, enabling successful backtranslation becomes not only useful for furthering auxiliary objectives — it becomes instrumental in its main dealings, especially the adequacy aspect of it. This overwriting might be applied constantly, or just occasionally, allowing the ML model to occasionally roam freely, untethered to the human domain of thinkable thoughts.
Then Bridge The Gap
While making the internal representations employed by the ML model more compatible with the ones used by humans on a neural level might be handy in itself, this increase in compatibility also makes it easier for humans to consciously bridge the gap and understand a full thought of an ML model. However, if aliens used exactly the same concepts as us but their language relied on dense high-dimensional waves, then it still wouldn't be easy for us to understand them. This means that even if the artificial representation can be translated to and from neural dynamics, we can't just watch phrases in the language of neural dynamics on screen and understand the associated thoughts. If we could have simply derived meaningful representations from neural dynamics, we could have figured out human values without this whole contraption (see "AGI Hard, Human Values Harder").
Humans Learn The Translation Key
One way of bridging the gap would be to first engineer the bottleneck layer to be particularly cognitive ergonomic. First, we might incentivize sparsity by regularizing the dense artificial representation. Then, we might discretize it by applying vector quantization and collapsing continuous values to a finite cookbook resembling a vocabulary. Then, we might incentivize local structure by promoting localized computations after the bottleneck layer, by e.g. partially limiting attention to neighborhoods. The combination of sparsity, discreteness, and locality would help make the bottleneck representation work more like a language familiar to humans. Next, make sure to also visualize the cookbook in ergonomic ways by making use of Gestalt principles, and ensure that humans can easily distinguish the symbols using pre-attentive features like color and orientation. The resulting language would be in part deliberately designed (through those surface features), but mostly learned by the ML model (as an instrumental goal in its optimization). Some insight into how the resulting language might feel:
"The language and the script I invented for Dara, Classical Ano, however, is much more distant from a purely phonetic script even than Chinese. So, in some sense, I decided to take a few peripheral features in a script like Chinese and centered them and pushed them much further until I created a new script that is not found in human scripts at all, at least among the ones we know. And then I dug deeply into this invented script—it’s three-dimensional; it’s malleable to the representation of different languages; it’s simultaneously conservative and friendly to innovation; it’s ideographical (in a true sense, not in the misunderstood sense when applied to Chinese hanzi)— and explored how that interacts with the way we think about writing." — Ken Liu
"These rules, the sign language and grammar of the Game, constitute a kind of highly developed secret language drawing upon several sciences and arts, but especially mathematics and music (and/or musicology), and capable of expressing and establishing interrelationships between the content and conclusions of nearly all scholarly disciplines. The Glass Bead Game is thus a mode of playing with the total contents and values of our culture; it plays with them as, say, in the great age of the arts a painter might have played with the colours on his palette." — Herman Hesse
"Almost all polis citizens, except for those who specifically elect otherwise, experience the world through two sensory modalities: Linear and Gestalt, which Egan describes as distant descendants of hearing and seeing, respectively. [...] Gestalt conveys information qualitatively, and data sent or received about anything arrives all at once for interpretation by the mind of the Citizen in all its aspects simultaneously, resulting in an experience of immediacy. [...] Gestalt operates rather entirely or almost entirely subconsciously. Citizens use Gestalt to create icons for themselves — "visual" representations within Scapes." — Wiki on Diaspora
The initial increase in compatibility, combined with the structural tweaks described before, should make it easier for humans to learn the internal language derived by the ML model. Humans would then learn it by association with the inputs and outputs of the ML model, before potentially identifying and exploiting grammar-like structures or other explicit regularities. Children might be particularly promising candidates for acquiring this unusual language, but deliberate practice might be enough for most linguistically-inclined adults. I recently came across a recent proposal of Eric Drexler which appears to point in a related direction.
Humans Experience Translated Neural Dynamics
People can't just watch neuroimaging recordings and infer the associated thoughts as they might read one's writing. However, what if the artificial-to-human translations from the previous step resulting in neural dynamics would be used to temporarily stimulate the human overseers? Unfortunately, it's not obvious how neural dynamics of specific people might closely map to each other, or how one might induce a specific neural dynamic in an individual. Commercial brain stimulation currently feels more like "let's just overstimulate half of the brain with a huge electromagnet," far from the nuance required for the Godshatter-like guided experience replay we would need here.
Additionally, the artificial-to-human translation might yield longer neural dynamics than the representations being translated. If a day's worth of artificial representations get unrolled into a week's worth of neural dynamics, then human overseers wouldn't have the time to experience them. Factoring them in parallel might be one way to scale.
Tether Artificial Representations To Written Language
What if similar to how we tethered artificial representations to (human) neural dynamics in step one, we also (or instead just) tethered them to written language? This would make it easier for people to extract the contents of artificial representations by just reading the associated textual translation. The artificial-to-textual (and textual-to-artificial) translators would similarly be learned during the regular training process. In a sense, the ML model would be forced, in the middle of its processing, to convert its thoughts into (extensive) natural language and back, making it trivial for humans to understand them, and potentially even edit them in-place. In contrast to the previous two approaches to bridging the gap, this one appears by far the most realistic. Additionally, it would reduce the second step to a form of the first one, increasing the feasibility of implementation.
That said, it has its own issues, particularly the fact that consciously-articulated language is a worse proxy for human thoughts than neural dynamics in the limit of available data. Additionally, a similar issue to the previous approach: what if one second's worth of artificial representations have a reading time in textual form of an hour? It would be hard to keep up. However, we have experience in NLP applications. If we had access to the ML model's stream of consciousness in natural language, then we would have some understanding of how to automatically detect issues and correct it. The propositional nature of ideological inference engines [LW · GW] might be an advantage here.
By following the two steps of (1) bringing artificial conceptual frameworks closer to human ones, and (2) enabling humans to understand and interact with them, we might be able to (1) improve the prospects of human oversight, and (2) promote the presence of human abstractions in ML models, including information on our desired objective.
Discussion
How do representational tethers relate to The Visible Thoughts Project [LW · GW]?
The Visible Thoughts Project aims to train LLMs on data containing snapshots of the internal thought processes of agents in a narrative. The idea there appears to be to teach this externalization skill in a supervised regime, using a custom representative dataset compiled for this specific purpose. Similarly, the version of the current proposal based on tethering to written language also aims to make the thoughts of an ML model visible, in that humans could simply read them out. However, in contrast to the Visible Thoughts Project, representational tethers don't require custom domain-specific data to teach thought externalization in natural language. Instead, the technique mainly relies on automated backtranslation between artificial representations and arbitrary natural language in the way described above.
How do representational tethers relate to The Natural Abstraction Hypothesis [AF · GW]?
My reading of this hypothesis is that certain abstractions are expected to be converged onto by any system of sufficient cognitive level acting in the (same) world. Such attractor abstractions are deemed natural. Assuming the hypothesis is true, it becomes relevant to check whether certain alignment-related abstractions such as "that which humans value" are natural and expected to exist in the ML model's conceptual framework. In contrast, representational tethers aim to enforce abstractions compatible with those of humans regardless of whether they are expected to naturally emerge in the ML model or not. In other words, the current proposal doesn't appear to rely on that assumption.
How do representational tethers relate to transparency tools?
Most transparency tools are post-hoc, in that they aim to explain the inner workings of an otherwise illegible model. In contrast, by conditioning artificial representations to conform to human ones and automatically learning translators as part of the training process, the current proposal aims to make the model itself more transparent, obviating the need for additional modality-specific tools. That said, I'd point out Anthropic's SoLU as a specific way of improving the inherent transparency of ML models by rendering their representations sparser, and hence more cognitively ergonomic. This specific line of work relates closely to the broader goal of bridging the gap by making artificial representations work more like human languages (i.e. sparse, discrete, local, etc.). That said, I think the backtranslatability incentive as a way of improving human-artificial compatibility in conceptual frameworks is a qualitatively different but complementary intervention.
How do representational tethers relate to brain-like AGI [? · GW]?
The present proposal doesn't require a satisfactory mechanistic understanding of neuroscience, as the versions which tether to neural dynamics rely entirely on learned models. In contrast, the very premise of the brain-like AGI agenda appears to be that insights from neuroscience would fuel AGI development to the point of driving important architectural decisions.
How do representational tethers relate to quasilinguistic neural representations?
This is Eric Drexler's recent proposal on making the internal representations of contemporary architectures more language-like in an attempt to make them more easy to interpret, interact with, and manipulate. There is a huge overlap between QNP and the "Humans Learn The Translation Key" approach to the second step of the present proposal, in that they both point to some desirable properties of the artificial representations as precursors in bridging the gap. Incidentally, this also makes me aware of the connection to Anthropic's SoLU by transitivity. Safe to say that I'm really curious how QNP will unfold, though I'm more reluctant to that particular approach to bridging the gap working out in contrast to the "Tether Artificial Representations To Written Language" angle. Current results in NLP make that approach feel particularly realistic.
How do representational tethers relate to Microscope AI [AF · GW]?
From my reading, Microscope AI aims to train a system explicitly for the sole purpose of extracting and making use of the knowledge it synthesized during training, without necessarily deploying the system in a more active sense. While representational tethers also aim at making the system's internal thoughts more legible to humans, they're meant to be employed during active use of the system. There's a focus here on oversight and targeting during the system's ongoing usage, as opposed to a static extraction of knowledge.
Isn't the model incentivized to tweak (human) neural dynamics or language?
Recall that the ML model is not directly incentivized to employ a conceptual framework compatible with that of living, breathing humans. Rather, we assumed static data on neural dynamics or written language as a means to define that distribution. That has the added benefit of avoiding human modification enacted by the ML model in an attempt to make (human) neural dynamics closer to its arbitrary conceptual framework. The model should be tethered to a fixed place, because otherwise it would be tempted to pull the other way. That said, this is also a disadvantage, because fixed objectives defined through fixed datasets are prone to being outperformed in nuance at some point down the line, due to the model's increase in capability.
What if fluency is worth sacrificing for the main goal?
The compatibility of artificial representations with human ones isn't meant to be the only goal being pursued. The ML model would likely be trained towards a more practical goal. Considering this, the present proposal doesn't aim to be sufficient in solving alignment, it just sketches out a convenient part — that concerned with making the ML model's representations more human-compatible, rather than the ML model as a whole in its behavior. This means that the main goal still needs to be specified, which raises the problem of how to balance the two. This feels similar to the "Avoidable Consequentialist Frenzy" from ideological inference engines [LW · GW]. Both describe an auxiliary objective meant to encourage convenient properties in the model, but are susceptible to being entirely ignored in the ML model's pursuit of the main objective. Perhaps the goal would be to get good human ratings, and manipulative behavior would in this case be avoided by first having the human overseers read the translated thoughts of the ML model, before deciding whether or not to let it carry out its plan (see discussion on defeating the mind-readers below). Alternatively, the internal abstractions chosen as a result of tethering might help define the objective themselves.
What if the translator is arbitrary?
Perhaps whenever the ML model's thoughts get translated in e.g. natural language, every instance of "red" is swapped with "blue" on the surface and vice versa, despite the ML model representing the other thing. When perceiving a red flower, the translator would report a blue flower. Both artificial-textual and textual-artificial translators would be in on this, ensuring high adequacy. Additionally, replacing "red" with "blue" flowers also preserves fluency for the most part. That said, red and blue flowers have different connotations in other contexts, reducing the fluency of e.g. text associating blue flowers with human romance more than red ones.
However, how can one guarantee that the translators don't simply make use of natural language as a secret code to mean something entirely different?
"It is a revelation to compare the Don Quixote of Pierre Menard with that of Miguel de Cervantes. Cervantes, for example, wrote the following (Part I, Chapter IX):
...truth, whose mother is history, rival of time, depository of deeds, witness of the past, exemplar and adviser to the present, and the future’s counselor.
This catalog of attributes, written in the seventeenth century, and written by the "ingenious layman" Miguel de Cervantes, is mere rhetorical praise of history. Menard, on the other hand, writes:
...truth, whose mother is history, rival of time, depository of deeds, witness of the past, exemplar and adviser to the present, and the future’s counselor.
History, the mother of truth!—the idea is staggering. Menard, a contemporary of William James, defines history not as a delving into reality but as the very fount of reality. Historical truth, for Menard, is not "what happened"; it is what we believe happened. The final phrases—exemplar and adviser to the present, and the future’s counselor—are brazenly pragmatic.
The contrast in styles is equally striking. The archaic style of Menard—who is, in addition, not a native speaker of the language in which he writes—is somewhat affected. Not so the style of his precursor, who employs the Spanish of his time with complete naturalness." — Jorges Luis Borges
Machine translation solves the problem of ensuring an actual correspondence between source and target languages in backtranslation by having a limited parallel corpus of aligned sentences. This would correspond to having a limited dataset of matched human and artificial representations in similar sensory or conceptual contexts, case in which backtranslation would merely be a way of bootstrapping this into a more comprehensive signal. However, I'm not sure how big of a problem this really is. Coming up with an ingenious translation key to consistently express any artificial representation as a human one while preserving fluency across contexts feels almost equivalent to matching the two conceptual frameworks. I'd be interested in a counterexample of an undesirable translation key which holds up to new situations in terms of associated fluency. Tamsin mentioned a past project on steganographically encoding content in natural language, which might help provide this counterexample.
Can't the fluency measure be tricked?
In the context of representational tethers, adequacy can be measured by simple error metrics like MSE between the original artificial representation and the backtranslated one. Even better, the backtranslation one can be configured to overwrite the original one so that the ML model is incentivized to solve this aspect as an instrumental goal. The same can't be said about the fluency aspect, which is significantly more brittle. Language modeling (more in the computational linguistics sense of assigning probabilities to sequences) is difficult. Sure, many impressive feats in ML involve LLMs nowadays, but the performance is still not ideal, and scaling laws [AF · GW] point at roadblocks. Therefore, the fluency metric gauging the likelihood of natural language can be gamed by a sufficiently sophisticated ML model. The situation is way worse for data on neural dynamics, where public datasets barely contain ~30K participants for very limited periods of time at the moment, limiting the performance of large "neural" models. Perhaps elevate the fluency evaluator using the model-in-training itself, like in oversight leagues [LW · GW]? There's essentially a need for the True Name of natural language or neural dynamics here, instead of the usual human values.
Could representational tethers be set up between different AIs?
We discussed tethering an ML model's conceptual framework to human ones, but how about tethering it to other artificial ones in a multi-polar scenario? Would that be useful in any way? It might allow their conceptual representations to be maintained in sync during a slow takeoff. This might allow oversight insights to transfer across teams which investigate different ML models each. However, making the internal representations accessible for ML models developed by different parties sounds like a huge coordination problem. That said, in debate-like schemes where multiple AI instances are simultaneously accessible to the same team, syncing their conceptual frameworks might help them find flaws in each other's reasoning, spot deception, but also collude.
Can't the ML model defeat the mind-readers [LW · GW]?
If humans read its thoughts in natural or in a novel language, or if they experience them more directly, can't the ML model exploit this communication channel and manipulate humans? Indeed, it probably can, though given the "Bottleneck Layer" assumption, all of its thoughts would be captured in the artificial representation, including the fact that it intends to manipulate humans. That might slightly help, but not in the sense that humans would therefore be immune to the ML model's scheming, but rather in the sense that if the information is blatantly accessible, then automated systems might be able to pick it up.
Don't LLMs already translate their internal representations into natural language as their day job?
They do implement an artificial-textual translation, and even a textual-artificial one in their early layers, but (1) the textual heads aren't tied to the same representation, and more importantly (2) the artificial representation isn't constrained to itself be fully expressible in natural language — it can avoid including things in the output due to the lack of internal backtranslation constraints.
What if the gap still can't be bridged?
Perhaps even if the artificial representation can be translated into natural language, the complexity of the translated thoughts would be unwieldy. If the ML model considers ideas in one instance which need multiple textbooks to express in natural language, then human oversight is still not feasible. There's an upper bound on how many humans can be tasked with overseeing the ML model over what period of time. To deal with this, we might penalize intermediate translations beyond a given length, as an extension of the fluency constraint. However, similar to the issues of impact measures, this limits the expressiveness of artificial representations.
However, even if the translated fragment is short, it might be extremely dense. If I were to read a grad-level textbook on biochemistry, I'd find it almost unintelligible, despite it arguably being expressed in natural language. We might essentially share the position of sixteenth-century scribes getting hold of that same contemporary textbook when trying to read through the ML model's thoughts. Similar to the bound on the intermediate translation in terms of length, we might bound it to a specific domain of non-specialized language, so that human overseers wouldn't need advanced knowledge on arbitrary topics. That said, such a bound would similarly be limiting the system to the range of thoughts thinkable by humans. Competitors might be led to disable such regularization techniques while chasing radical innovation in the vein of move 37.
Are representational tethers restricted to prosaic risk scenarios?
The internal representations employed by AIs built on exotic stacks could similarly be conditioned on backtranslation to human representations and engineered to be more cognitively ergonomic. However, the technical details involved would have to change quite a bit. The main architectural constraint is the existence of some bottleneck structure to be tethered, based on the "Bottleneck Layer" assumption.
Outro
Despite not offering a complete solution, representational tethers provide a way of making the ML model easier to interpret, interact with, and control, by systematically conditioning and designing its conceptual framework to be more compatible with that used by humans. What's more, parts of the proposal can be tested on existing prosaic models as a preliminary experiment in feasibility, despite not having our hands on the real thing.
0 comments
Comments sorted by top scores.