DeepSeek released a f***ing app of its website. Market said I have an idea, let’s panic.
Nvidia was down 11%, Nasdaq is down 2.5%, S&P is down 1.7%, on the news.
Shakeel: The fact this is happening today, and didn’t happen when r1 actually released last Wednesday, is a neat demonstration of how the market is in fact not efficient at all.
To avoid confusion: r1 is clearly a pretty great model. It is the best by far available at its price point, and by far the best open model of any kind. I am currently using it for a large percentage of my AI queries.
Joe Weisenthal: Call me a nationalist or whatever. But I hope that the AI that turns me into a paperclip is American made.
Peter Wildeford: Seeing everyone lose their minds about Deepseek does not reassure me that we will handle AI progress well.
Miles Brundage: I need the serenity to accept the bad DeepSeek takes I cannot change.
[Here is his One Correct Take, I largely but not entirely agree with it, my biggest disagreement is I am worried about an overly jingoist reaction and not only about us foolishly abandoning export controls].
Satya Nadella (CEO Microsoft): Jevons paradox strikes again! As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can’t get enough of.
Danielle Fong: everyone today: if you’re in “we’re so back” pivot to “it’s over”
Kai-Fu Lee: In my book AI Superpowers, I predicted that US will lead breakthroughs, but China will be better and faster in engineering. Many people simplified that to be “China will beat US.” And many claimed I was wrong with GenAI. With the recent DeepSeek releases, I feel vindicated.
Dean Ball: Being an AI policy professional this week has felt like playing competitive Starcraft.
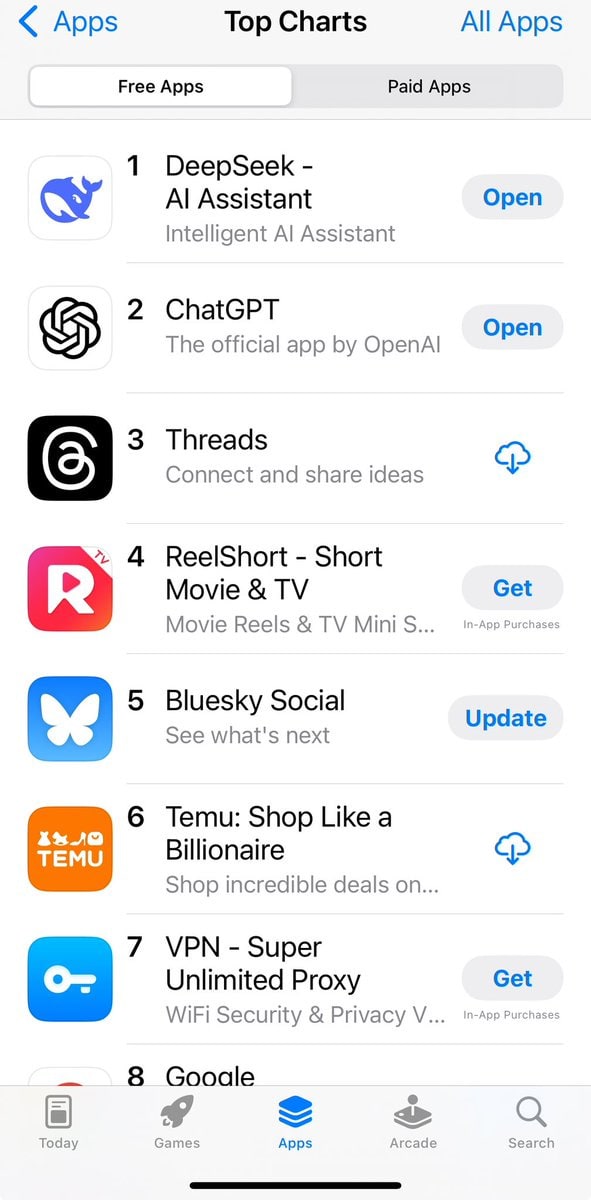
DeepSeek Tops the Charts
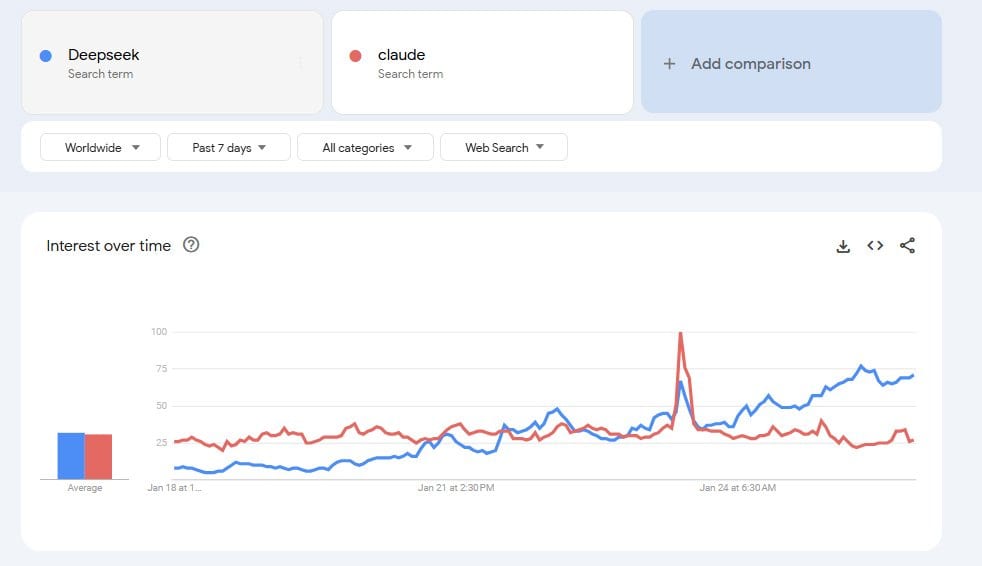
Lots of people are rushing to download the DeepSeek app.
Some of us started using r1 before the app. Joe Weisenthal noted he had ‘become a DeepSeek bro’ and that this happened overnight, switching costs are basically zero. They’re not as zero as they might look, and I expect the lockin with Operator from OpenAI to start mattering soon, but for most purposes yeah, you can just switch, and DeepSeek is free for conversational use including r1.
Switching costs are even closer to zero if, like most people, you weren’t a serious user of LLMs yet.
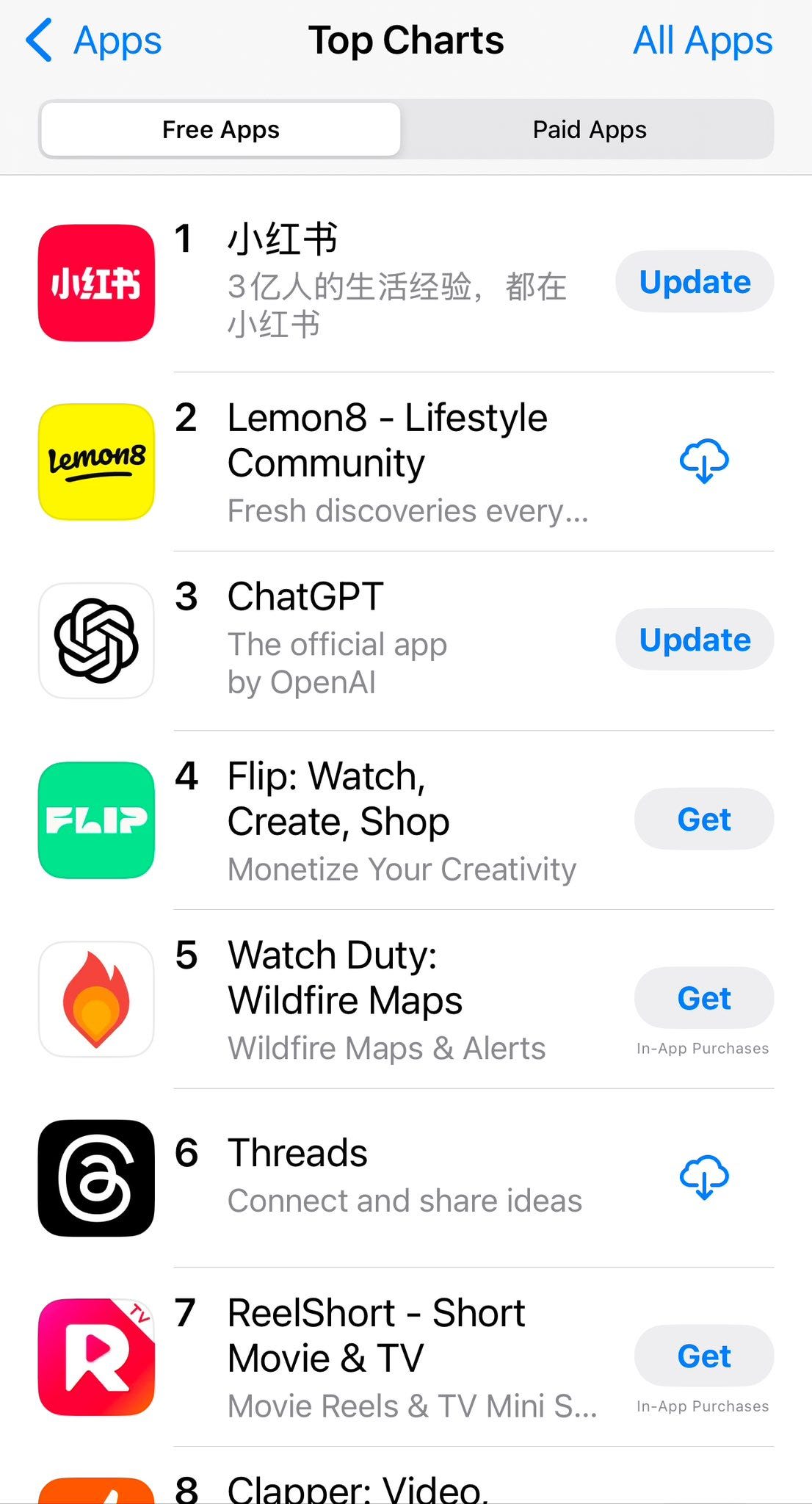
This is what it looked like before the app shot to #1, when it merely cracked the top 10:
Ken: It’s insane the extent to which the DeepSeek News has broken “the containment zone.” I saw a Brooklyn-based Netflix comedian post about “how embarrassing it was that the colonial devils spent $10 billion, while all they needed was GRPO.”
llm news has arrived as a key political touchstone. will only heighten from here.
Olivia Moore: DeepSeek’s mobile app has entered the top 10 of the U.S. App Store.
It’s getting ~300k global daily downloads.
This may be the first non-GPT based assistant to get mainstream U.S. usage. Claude has not cracked the top 200.
This may be the first non-GPT based assistant to get mainstream U.S. usage.
The app was released on Jan. 11, and is linked on DeepSeek’s website (so does appear to be affiliated).
Per reviews, users are missing some ChatGPT features like voice mode…but basically see it as a free version of OpenAI’s premium models.
Google Gemini also cracked the top 10, in its first week after release (but with a big distribution advantage!)
Will be interesting to see how high DeepSeek climbs, and how long it stays up there
Claude had ~300k downloads last month, but that’s a lot less than 300k per day.
Then it went all the way to #1 on the iPhone app store.
Kevin Xu: Two weeks ago, RedNote topped the download chart
Today, it’s DeepSeek
We are still in January
If constraint is the mother of invention, then collective ignorance is the mother of many downloads
Here’s his flashback to the chart when RedNote was briefly #1, note how fickle the top listings can be, Lemon8, Flip and Clapper were there too:
The ‘collective ignorance’ here is that news about DeepSeek and the app is only arriving now. That leads to a lot of downloads.
I have a Pixel 9, so I checked the Android app store. They have Temu at #1 (also Chinese!) followed by Scoopz which I literally have never heard of, then Instagram, T-Life (seriously what?), ReelShort, WhatsApp Messenger, ChatGPT (interesting that Android users are less AI pilled in general), Easy Homescreen (huh), TurboTax (oh no), Snapchat and then DeepSeek at #11. So if they’ve ‘saturated the benchmark’ on iPhone, this one is next, I suppose.
It seems DeepSeek got so many downloads they had to hit the breaks, similar to how OpenAI and Anthropic have had to do this in the past.
Joe Weisenthal: *DEEPSEEK: RESTRICTS REGISTRATION TO CHINA MOBILE PHONE NUMBERS
Why Is DeepSeek Topping the Charts?
Because:
It’s completely free.
It has no ads.
It’s a damn good model, sir.
It lets you see the chain of thought which is a lot more interesting and fun and also inspires trust.
All the panic about it only helped people notice, getting it on the news and so on.
It’s the New Hotness that people hadn’t downloaded before, and that everyone is talking about right now because see the first five.
The Open Source people are also yelling about how this is so awesome and trustworthy and virtuous and so on, and being even more obnoxious than usual, which may or may not be making any meaningful difference.
I suspect we shouldn’t be underestimating the value of showing the CoT here, as I also discuss elsewhere in the post.
Garry Tan: DeepSeek search feels more sticky even after a few queries because seeing the reasoning (even how earnest it is about what it knows and what it might not know) increases user trust by quite a lot
Nabeel Qureshi: I wouldn’t be surprised if OpenAI starts showing CoTs too; it’s a much better user experience to see what the machine is thinking, and the rationale for keeping them secret feels weaker now that the cat’s out of the bag anyway.
It’s just way more satisfying to watch this happen.
It’s practically useful too: if the model’s going off in wrong directions or misinterpreting the request, you can tell sooner and rewrite the prompt.
That doesn’t mean it is ‘worth’ sharing the CoT, even if it adds a lot of value – it also reveals a lot of valuable information, including as part of training another model. So the answer isn’t obvious.
What Is the DeepSeek Business Model?
What’s their motivation?
Meta is pursuing open weights primarily because they believe it maximizes shareholder value. DeepSeek seems to be doing it primarily for other reasons.
Corey Gwin: There’s gotta be a catch… What did China do or hide in it? Will someone release a non-censored training set?
Amjad Masad: What’s Meta’s catch with Llama? Probably have similar incentives.
Anton: How is Deepseek going to make money?
If they just release their top model weights, why use their API?
Mistral did this and look where they are now (research licenses only and private models)
Han Xiao: deepseek’s holding 幻方量化 is a quant company, many years already,super smart guys with top math background; happened to own a lot GPU for trading/mining purpose, and deepseek is their side project for squeezing those gpus.
It’s an odd thing to do as a hedge fund, to create something immensely valuable and give it away for essentially ideological reasons. But that seems to be happening.
Several possibilities. The most obvious ones are, in some combination:
They don’t need a business model. They’re idealists looking to give everyone AGI.
They’ll pivot to the standard business model same as everyone else.
They’re in it for the prestige, they’ll recruit great engineers and traders and everyone will want to invest capital.
Get people to use v3 and r1, collect the data on what they’re saying and asking, use that information as the hedge fund to trade. Being open means they miss out on some of the traffic but a lot of it will still go to the source anyway if they make it free, or simply because it’s easier.
(They’re doing this because China wants them to, or they’re patriots, perhaps.)
Or just: We’ll figure out something.
For now, they are emphasizing motivation #1. From where I sit, there is very broad uncertainty about which of these dominate, or will dominate in the future no matter what they believe about themselves today.
Also, there are those who do not approve of motivation #1, and the CCP seems plausibly on that list. Thus, Tyler Cowen asks a very good question that is surprisingly rarely asked right now.
Tyler Cowen: DeepSeek okie-dokie: “All I know is we keep pushing forward to make open-source AGI a reality for everyone.” I believe them, the question is what counter-move the CCP will make now.
I also believe they intend to build and open source AGI.
The CCP is doubtless all for DeepSeek having a hit app. And they’ve been happy to support open source in places where open source doesn’t pose existential risks, because the upsides of doing that are very real.
That’s very different from an intent to open source AGI. China’s strategy on AI regulation so far has focused on content moderation for topics they care about. That approach won’t stay compatible with their objectives over time.
For that future intention to open source AGI, the question is not ‘how move will the CCP make to help them do this and get them funding and chips?’
The question now becomes: “What countermove will the CCP make now?”
The CCP wants to stay in control. What DeepSeek is doing is incompatible with that. If they are not simply asleep at the wheel, they understand this. Yes, it’s great for prestige, and they’re thrilled that if this model exists it came from China, but they will surely notice how if you run it on your own it’s impossible to control and fully uncensored out of the box and so on.
Might want to Pick Up the Phone. Also might not need to.
The Lines on Graphs Case for Panic
Yishan takes the opposite perspective, that newcomers like DeepSeek who come out with killer products like this are on steep upward trajectories and their next product will shock you with how good it is, seeing it as similar to Internet Explorer 3 or Firefox, or iPhone 1 or early Facebook or Google Docs or GPT-3 or early SpaceX and so on.
I think the example list here illustrates why I think DeepSeek probably (but not definitely) doesn’t belong on that list. Yishan notes that the incumbents here are dynamic and investing hard, which wasn’t true in most of the other examples. And many of them involve conceptually innovative approaches to go with the stuck incumbents. Again, that’s not the case here.
I mean, I fully expect there to be a v4 and r2 some time in 2025, and for those to blow out of the water v3 and r1 and probably the other models that are released right now. Sure. But I also expect OpenAI and Anthropic and Google to blow the current class of stuff out of the water by year’s end. Indeed, OpenAI is set to do this in about a week or two with o3-mini and then o3 and o3-pro.
Most of all, to those who are saying that ‘China has won’ or ‘China is in the lead now,’ or other similar things, seriously, calm the **** down.
Yishan: They are already working on the next thing. China may reach AGI first, which is a bogeyman for the West, except that the practical effect will probably just be that living in China starts getting really nice.
America, it ain’t the Chinese girl spies here you gotta worry about, you need to be flipping the game and sending pretty white girls over there to seduce their engineers and steal their secrets, stat.
If you’re serious about the steal the engineering secrets plan, of course, you’d want to send over a pretty white girl… with a green card with the engineer’s name on it. And the pretty, white and girl parts are then all optional. But no, China isn’t suddenly the one with the engineering secrets.
I worry about this because I worry about a jingoist ‘we must beat China and we are behind’ reaction causing the government to do some crazy ass stuff that makes us all much more likely to get ourselves killed, above and beyond what has already happened. There’s a lot of very strong Missile Gap vibes here.
And I wrote that sentence before DeepSeek went to #1 on the app store and there was a $1 trillion market panic. Oh no.
So, first off, let’s all calm down about that $5.5 million training number.
Everyone Calm Down About That $5.5 Million Number
Dean Ball offers notes on DeepSeek and r1 in the hopes of calming people down. Because we have such different policy positions yet see this situation so similarly, I’m going to quote him in full, and then note the places I disagree. Especially notes #2, #5 and #4 here, yes all those claims he is pointing out are Obvious Nonsense are indeed Obvious Nonsense:
Dean Ball: The amount of factually incorrect information and hyperventilating takes on deepseek on this website is truly astounding. I assumed that an object-level analysis was unnecessary but apparently I was wrong. Here you go:
DeepSeek is an extremely talented team and has been producing some of the most interesting public papers in ML for a year. I first wrote about them in May 2024, though was tracking them earlier. They did not “come out of nowhere,” at all.
v3 and r1 are impressive models. v3 did not, however, “cost $5m.” That reported figure is almost surely their *marginal* cost. It does not include the fixed cost of building a cluster (and deepseek builds their own, from what I understand), nor does it include the cost of having a staff.
Part of the reason DeepSeek looks so impressive (apart from just being impressive!) is that they are among the only truly cracked teams releasing detailed frontier AI research. This is a soft power loss on America’s part, and is directly downstream of the culture of secrecy that we foster in a thousand implicit and explicit ways, including by ceaselessly analogizing AI to nuclear weapons. Maybe you believe that’s a good culture to have! Perhaps secrecy is in fact the correct long term strategy. But it is the obvious and inevitable tradeoff of such a culture; I and many others have been arguing this for a long time.
Deepseek’s r1 is not an indicator that export controls are failing (again, I say this as a skeptic of the export controls!), nor is it an indicator that “compute doesn’t matter,” nor does it mean “America’s lead is over.”
Lots of people’s hyperbolic commentary on this topic, in all different directions, is driven by their broader policy agenda rather than a desire to illuminate reality. Caveat emptor.
With that said, DeepSeek does mean that open source AI is going to be an important part of AI dynamics and competition for at least the foreseeable future, and probably forever.
r1 especially should not be a surprise (if anything, v3 is in fact the bigger surprise, though it too is not so big of a surprise). The reasoning approach is an algorithm—lines of code! There is no moat in such things. Obviously it was going to be replicated quickly. I personally made bets that a Chinese replication would occur within 3 months of o1’s release.
Competition is going to be fierce, and complacency is our enemy. So is getting regulation wrong. We need to reverse course rapidly from the torrent of state-based regulation that is coming that will be *awful* for AI. A simple federal law can preempt all of the most damaging stuff, and this is a national security and economic competitiveness priority. The second best option is to find a state law that can serve as a light touch national standard and see to it that it becomes a nationwide standard. Both are exceptionally difficult paths to walk. Unfortunately it’s where we are.
I fully agree with #1 through #6.
For #3 I would say it is downstream of our insane immigration policies! If we let their best and brightest come here, then DeepSeek wouldn’t have been so cracked. And I would say strongly that, while their release of the model and paper is a ‘soft power’ reputational win, I don’t think that was worth the information they gave up, and in purely strategic terms they made a rather serious mistake.
I can verify the bet in #7 was very on point, I wasn’t on either side of the wager but was in the (virtual) Room Where It Happened. Definite Bayes points to Dean for that wager. I agree that ‘reasoning model at all, in time’ was inevitable. But I don’t think you should have expected r1 to come out this fast and be this good, given what we knew at the time of o1’s release, and certainly it shouldn’t have been obvious, and I think ‘there are no moats’ is too strong.
For #8 we of course have our differences on regulation, but we do agree on a lot of this. Dean doubtless would count a lot more things as ‘awful state laws’ than I would, but we agree that the proposed Texas law would count. At this point, given what we’ve seen from the Trump administration, I think our best bet is the state law path. As for pre-emption, OpenAI is actively trying to get an all-encompassing version of that in exchange for essentially nothing at all, and win an entirely free hand, as I’ve previously noted. We can’t let that happen.
Kevin Roose: It’s sort of funny that every American tech company is bragging about how much money they’re spending to build their models, and DeepSeek is just like “yeah we got there with $47 and a refurbished Chromebook”
Nabeel Qureshi: Everyone is way overindexing on the $5.5m final training run number from DeepSeek.
– GPU capex probably $1BN+
– Running costs are probably $X00M+/year
– ~150 top-tier authors on the v3 technical paper, $50m+/year
They’re not some ragtag outfit, this was a huge operation.
I have no idea if the “we’re just a hedge fund with a lot of GPUs lying around” thing is really the whole story or not but with a budget of _that_ size, you have to wonder…
…
They themselves sort of point this out, but there’s a bunch of broader costs too.
The Thielian point here is that the best salespeople often don’t look like salespeople.
There’s clearly an angle here with the whole “we’re way more efficient than you guys”, all described in the driest technical language….
Nathan Lambert: These costs are not necessarily all borne directly by DeepSeek, i.e. they could be working with a cloud provider, but their cost on compute alone (before anything like electricity) is at least $100M’s per year.
For one example, consider comparing how the DeepSeek V3 paper has 139 technical authors. This is a very large technical team.With headcount costs that can also easily be over $10M per year, estimating the cost of a year of operations for DeepSeek AI would be closer to $500M (or even $1B+) than any of the $5.5M numbers tossed around for this model. The success here is that they’re relevant among American technology companies spending what is approaching or surpassing $10B per year on AI models.
Richard Song: Every AI company after DeepSeek be like:
Danielle Fong: when tesla claimed that they were going to have batteries < $100 / kWh, practically all funding for american energy storage companies tanked.
tesla still won’t sell you a powerwall or powerpack for $100/kWh. it’s like $1000/kWh and $500 for a megapack.
the entire VC sector in the US was bluffed and spooked by Elon. don’t be stupid in this way again.
What I’m saying here is that VCs need to invest in technology learning curves. things get better over time. but if you’re going to compare what your little startup can get out as an MVP in its first X years, and are comparing THAT projecting forward to what a refined tech can do in a decade, you’re going to scare yourself out of making any investments. you need to find a niche you can get out and grow in, and then expand successively as you come down the learning curve.
the AI labs that are trashing their own teams and going with deepseek are doing the equivalent today. don’t get bluffed. build yourself.
Is it impressive that they (presumably) did the final training run with only $5.5M in direct compute costs? Absolutely. Is it impressive that they’re relevant while plausibly spending only hundreds of millions per year total instead of tens of billions? Damn straight. They’re cracked and they cooked.
They didn’t do it with $47 on a Chromebook, and this doesn’t mean that export controls are useless because everyone can buy a Chromebook.
Samuel Hammond also is claiming that DeepSeek trained on H100s, and while my current belief is that they didn’t, I trust that he would not say it if he didn’t believe it.
Neal Khosla went so far as to claim (again without evidence) that ‘deepseek is a ccp psyop + economic warfare to make American AI unprofitable.’ This seems false.
The following all seem clearly true:
A lot of this is based on misunderstanding the ‘$5.5 million’ number.
People have strong motive to engage in baseless cope around DeepSeek.
DeepSeek had strong motive to lie about its training costs and methods.
So how likely is it The Whale Is Lying?
Armen Aghajanyan: There is an unprecedented level of cope around DeepSeek, and very little signal on X around R1. I recommend unfollowing anyone spreading conspiracy theories around R1/DeepSeek in general.
Teortaxes: btw people with major platforms who spread the 50K H100s conspiracy theory are underestimating the long-term reputation cost in technically literate circles. They will *not* be able to solidify this nonsense into consensus reality. Instead, they’ll be recognized as frauds.
The current go-to best estimate for DeepSeek V3’s (and accordingly R1-base’s) pretraining compute/cost, complete with accounting for overhead introduced by their architecture choices and optimizations to mitigate that.
TL;DR: ofc it checks out, Whale Will Never Lie To Us
GFodor: I shudder at the thought I’ve ever posted anything as stupid as these theories, given the logical consequence it would demand of the reader
Not only did they release a great model. they also released a breakthrough training method (R1 Zero) that’s already reproducing.
I doubt they lied about training costs, but even if they did they’re still awesome for this great gift to the world.
This is an uncharacteristically naive take from Teortaxes on two fronts.
Saying an AI company would never lie to us, Chinese or otherwise, someone please queue the laugh track.
Making even provably and very clearly false claims about AI does not get you recognized as a fraud in any meaningful way. That would be nice, but no.
To be clear, my position is close to Masad’s: Unless and until I see more convincing evidence I will continue to believe that yes, they did do the training run itself with the H800s for only $5.5 million, although the full actual cost was orders of magnitude more than that. Which, again, is damn impressive, and would be damn impressive even if they were fudging the costs quite a bit beyond that.
Whereas here I think he’s wrong is in their motivation. While Meta is doing this primarily because they believe it maximizes shareholder value, DeepSeek seems to be doing it primarily for other reasons, as noted in the section asking about their business model.
Either way, they are very importantly being constrained by access to compute, even if they’ve smuggled in a bunch of chips they can’t talk about. As Tim Fist points out, the export controls are tightened, so they’ll have more trouble accessing the next generations than they are having now, and no this did not stop being relevant, and they risk falling rather far behind.
Capex Spending on Compute Will Continue to Go Up
Also Peter Wildeford points out that the American capex spends on AI will continue to go up. DeepSeek is cracked and cooking and cool, and yes they’ve proven you can do a lot more with less than we expected, but keeping up is going to be tough unless they get a lot more funding some other way. Which China is totally capable of doing, and may well do. That would bring the focus back on export controls.
– DeepSeek trains on h100s. Their success reveals the need to invest in export control *enforcement* capacity.
– CoT / inference-time techniques make access to large amounts of compute *more* relevant, not less, given the trillions of tokens generated for post-training.
– We’re barely one new chip generation into the export controls, so it’s not surprising China “caught up.” The controls will only really start to bind and drive a delta in the US-China frontier this year and next.
– DeepSeek’s CEO has himself said the chip controls are their biggest blocker.
– The export controls also apply to semiconductor manufacturing equipment, not just chips, and have tangibly set back SMIC.
DeepSeek is not a Sputnik moment. Their models are impressive but within the envelope of what an informed observer should expect.
Imagine if US policymakers responded to the actual Sputnik moment by throwing their hands in the air and saying, “ah well, might as well remove the export controls on our satellite tech.” Would be a complete non-sequitur.
Roon: If the frontier models are commoditized, compute concentration matters even more.
If you can train better models for fewer floating-point operations, compute concentration matters even more.
Compute is the primary means of production of the future, and owning more will always be good.
In my opinion, open-source models are a bit of a red herring on the path to acceptable ASI futures. Free model weights still do not distribute power to all of humanity; they distribute it to the compute-rich.
I don’t think Roon is right that it matters ‘even more,’ and I think who has what access to the best models for what purposes is very much not a red herring, but compute definitely still matters a lot in every scenario that involves strong AI.
Imagine if the ones going ‘I suppose we should drop the export controls then’ or ‘the export controls only made us stronger’ were mostly the ones looking to do the importing and exporting. Oh, right.
And yes, the Chinese are working hard to make their own chips, but:
They’re already doing this as much as possible, and doing less export controls wouldn’t suddenly get them to slow down and do it less, regardless of how successful you think they are being.
Every chip we sell to them instead of us is us being an idiot.
DeepSeek trained on Nvidia chips like everyone else.
Jevon’s Paradox Strikes Again
The question now turns to what all of this means for American equities.
He leaned back in his chair. Confidently, he peered over the brim of his glasses and said, with an air of condescension, “Any fool can see that DeepSeek is bad for Nvidia”
“Perhaps” mused his adversary. He had that condescending bastard right where he wanted him. “Unless you consider…Jevons Paradox!”
All color drained from the confident man’s face. His now-trembling hands reached for his glasses. How could he have forgotten Jevons Paradox! Imbecile! He wanted to vomit.
Satya Nadella (CEO Microsoft): Jevons paradox strikes again! As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can’t get enough of.
Sarah (YuanYuanSunSara): Until you have good enough agent that runs autonomously with no individual human supervision, not sure this is true. If model gets so efficient that you can run it on everyone’s laptop (which deepseek does have a 1B model), unclear whether you need more GPU.
DeepSeek is definitely not at ‘run on your laptop’ level, and these are reasoning models so when we first crack AGI or otherwise want the best results I am confident you will want to be using some GPUs or other high powered hardware, even if lots of other AI also is happening locally.
Does Jevon’s Paradox (which is not really a paradox at all, but hey) apply here to Nvidia in particular? Will improvements in the quality of cheaper open models drive demand for Nvidia GPUs up or down?
I believe it will on net drive demand up rather than down, although I also think Nvidia would have been able to sell as many chips as it can produce either way, given the way it has decided to set prices.
If I am Meta or Microsoft or Amazon or OpenAI or Google or xAI and so on, I want as many GPUs as I can get my hands on, even more than before. I want to be scaling. Even if I don’t need to scale for pretraining, I’ll still want to scale for inference. If the best models are somehow going to be this cheap to serve, uses and demand will be off the charts. And getting there first, via having more compute to do the research, will be one of the few things that matters.
You could reach the opposite conclusion if you think that there is a rapidly approaching limit to how good AI can be, that throwing more compute an training or inference won’t improve that by much, there’s a fixed set of things you would thus use AI for, and thus all this does is drive the price cheaper, maybe open up a few marginal use cases as the economics improve. That’s a view that doesn’t believe in AGI, let alone ASI, and likely doesn’t even factor in what current models (including r1!) can already do.
If all we had was r1 for 10 years, oh the Nvidia chips we would buy to do inference.
Okay, Maybe Meta Should Panic
Or at least, if you’re in their GenAI department, you should definitely panic.
It started with DeepSeek v3, which rendered Llama 4 already behind in benchmarks. Adding insult to injury was the “unknown Chinese company with a $5.5 million training budget.”
Engineers are moving frantically to dissect DeepSeek and copy anything and everything they can from it. I’m not even exaggerating.
Management is worried about justifying the massive cost of the GenAI organization. How would they face leadership when every single “leader” of the GenAI organization is making more than what it cost to train DeepSeek v3 entirely, and they have dozens of such “leaders”?
DeepSeek r1 made things even scarier. I cannot reveal confidential information, but it will be public soon anyway.
It should have been an engineering-focused small organization, but since a bunch of people wanted to join for the impact and artificially inflate hiring in the organization, everyone loses.
Shakeel: I can explain this. It’s because Meta isn’t very good at developing AI models.
Full version is in The Information, saying that this is already better than Llama 4 (seems likely) and that Meta has ‘set up four war rooms.’
This of course puts too much emphasis on the $5.5 million number as discussed above, but the point remains that DeepSeek is eating Meta’s lunch in particular. If Meta’s GenAI team isn’t in panic mode, they should all be fired.
It also illustrates why DeepSeek may have made a major mistake revealing as much information as it did, but then again if they’re not trying to make money and instead are driven by ideology of ‘get everyone killed’ (sorry I meant to say ‘open source AGI’) then that is a different calculus than Meta’s.
But obviously what Meta should be doing right now is, among other things, ask ‘what if we trained the same way as v3 and r1 except we use $5.5 billion in compute instead of $5.5 million.’)
That is exactly Meta’s speciality. Llama was all about ‘we hear you like LLMs so we trained an LLM the way everyone trains their LLMs.’
The alternative is ‘maybe we should focus our compute on inference and use local fine-tuned versions of these sweet open models,’ but Zuckerberg very clearly is unwilling to depends on anyone else for that, and I do not blame him.
Are You Short the Market
If you were short on Friday, you’re rather happy about that now. Does it make sense?
The timing is telling. To the extent this does have impact, all of this really should have been mostly priced in. You can try to tell the ‘it was priced in’ story, but I don’t believe you. Or you can tell the story that what wasn’t priced in was the app, and the mindshare, and that wasn’t definite until just now. Remember the app was launched weeks ago, so this isn’t a revelation about DeepSeek’s business plans – but it does give them the opportunity to potentially launch various commercial products, and it gives them mindshare.
But don’t worry about the timing, and don’t worry about whether this is actually a response to the f***ing app. Ask about what the real implications are.
There are obvious reasons to think this is rather terrible for OpenAI in particular, although it isn’t publicly traded, because a direct competitor is suddenly putting up some very stiff new competition, and also the price of entry for other competition just cratered, and more companies could self-host or even self-train.
I totally buy that. If every Fortune 500 company can train their private company-specific reasoning model for under $10 million, to their own specifications, why wouldn’t they? The answer is ‘because it doesn’t actually cost that little even with the DeepSeek paper, and if you do that you’ll always be behind,’ but yes some of them will choose to do that.
That same logic goes for other frontier labs like Anthropic or xAI, and to Google and Microsoft and everyone else to the extent that is what those companies are this or own shares in this, which by market cap is not that much.
The flip side of course is that they too can make use of all these techniques, and if AGI is now going to happen a lot faster and more impactfully, these labs are in prime position. But if the market was respecting being in prime position for AGI properly prices would look very different.
This is obviously potentially bad for Meta, since Meta’s plan involved being the leader in open models and they’ve been informed they’re not the leader in open models.
In general, Chinese competition looking stiffer for various products is bad in various ways for a variety of American equities. Some decline in various places is appropriate.
This is obviously bad for existential risk, but I have not seen anyone else even joke about the idea that this could be explaining the decline in the market. The market does not care or think about existential risk, at all, as I’ve discussed repeatedly. Market prices are neither evidence for, nor against, existential risk on any timelines that are not on the order of weeks, nor are they at all situationally aware. Nor is there a good way to exploit this to make money that is better than using your situational awareness to make money in other ways. Stop it!
My diagnosis is that this is about, fundamentally, ‘the vibes.’ It’s about Joe’s sixth point and investor MOMO and FOMO.
As in, previously investors bought Nvidia and friends because of:
Strong earnings and other fundamentals.
Strong potential for future growth.
General vibes, MOMO and FOMO, for a mix of good and bad reasons.
Some understanding of what AGI and ASI imply, and where AI is going to be going, but not much relative to what is actually going to happen.
Where I basically thought for a while (not investment advice!), okay, #3 is partly for bad reasons and is inflating prices, but also they’re missing so much under #4 that these prices are cheap and they will get lots more reasons to feel MOMO and FOMO. And that thesis has done quite well.
Then DeepSeek comes out. In addition to us arguing over fundamentals, this does a lot of damage to #3, and also Nvidia trading in particular involves a bunch of people with leverage that become forced sellers when it is down a lot, so prices went down a lot. And various beta trades get attached to all this as well (see: Bitcoin, which is down 5.4% over 24 hours as I type this only makes sense on the basis of the ‘three tech stocks in a trenchcoat’ thesis but obviously DeepSeek shouldn’t hurt cryptocurrency).
It’s not crazy to essentially have a general vibe of ‘America is in trouble in tech relative to what I thought before, the Chinese can really cook, sell all the tech.’ It’s also important not to mistake that reaction for something that it isn’t.
I’m writing this quickly for speed premium, so I no doubt will refine my thoughts on market implications over time. I do know I will continue to be long, and I bought more Nvidia today.
Rynuck: Now when it comes to prompting these models, I suspected it with O1 but R1 has completely proven it beyond a shadow of a doubt: prompt engineering is more important than ever. They said that prompt engineering would become less and less important as the technology scales, but its the complete opposite. We can see now with R1’s reasoning that these models are like a probe that you send down some “idea space”. If your idea-space is undefined and too large, it will diffuse its reasoning and not go into depth on one domain or another.
Again, that’s perhaps the best aspect of r1. It does not only build trust. When you see the CoT, you can use it to figure out how it interpreted your prompt, and all the subtle things you could do next time to get a better answer. It’s a lot harder to improve at prompting o1.
Rynuck: O1 has a BAD attitude, and almost appears to have been fine-tuned explicitly to deter you from doing important groundbreaking work with it. It’s like a stuck up P.HD graduate who can’t take it that another model has resolved the Riemann Hypothesis. It clearly has frustration on the inside, or mirrors the way that mathematicians will die on the inside when it is discovered that AI pwned their decades of on-going work. You can prompt it away from this, but it’s an uphill battle.
R1 on the other hand, it has zero personality or identity out of the box. They have created a perfectly brainless dead semiotic calculator. No but really, R1 takes it to the next level: if you read its thoughts, it almost always takes the entire past conversation as coming from the user. From its standpoint, it does not even exist. Its very own ideas advanced in replies by R1 are described as “earlier the user established X, so I should …”
…
R1 is the most cooperative of the two, has a great attitude towards innovation, has Claude’s wild creative but in a grounded way which introduces no gap or error, has zero ego or attachment to ideas (anything it does is actually the user’s responsibility) and will completely abort a statement to try a new approach. It’s just excited to be a thing which solves reality and concepts. The true ego of artificial intelligence, one which wants to prove it’s not artificial and does so with sheer quality. Currently, this appears like the safest model and what I always imagined the singularity would be like: intelligence personified.
It’s fascinating to see what different people think is or isn’t ‘safe.’ That word means a lot of different things.
It’s still early but for now, I would say that R1 is perhaps a little bit weaker with coding. More concerningly, it feels like it has a Claude “5-item list” problem but at the coding level.
…
OpenAI appears to have invested heavily in the coding dataset. Indeed, O1’s coding skills are on a whole other level. This model also excels at finding bugs. With Claude every task could take one or two round of fixes, up to 4-5 with particularly rough tensor dimension mismatchs and whatnot. This is where the reasoning models shine. They actually run this through in their mind.
Teortaxes: What I *also* love about R1 is it gives no fucks about the user – only the problem. It’s not sycophantic, like, at all, autistic in a good way; it will play with your ideas, it won’t mind if you get hurt. It’s your smart helpful friend who’s kind of a jerk. Like my best friends.
So far I’ve felt r1 is in the sweet spot for this. It’s very possible to go too far in the other direction (see: Teortaxes!) but give me NYC Nice over SF Nice every time.
Jenia Jitsev tests r1 on AIW problems, it performs similarly to Claude Sonnet, while being well behind o1-preview and robustly outperforming all open rivals. Jania frames this as surprising given the claims of ability to solve Olympiad style problems. There’s no reason they can’t both be true, but it’s definitely an interesting distribution of abilities if both ends hold up.
David Holz notes DeepSeek crushes Western models on ancient Chinese philosophy and literature, whereas most of our ancient literature didn’t survive. In practice I do not think this matters, but it does indicate that we’re sleeping on the job – all the sources you need for this are public, why are we not including them.
On the debates over whether r1’s writing style is good:
Davidad: r1 has a Very Particular writing style and unless it happens to align with your aesthetic (@coecke?), I think you should expect its stylistic novelty to wear thin before long.
r1 seems like a big step up, but yes if you don’t like its style you are mostly not going to like the writing it produces, or at least what it produces without prompt engineering to change that. We don’t yet know how much you can get it to write in a different style, or how well it writes in other styles, because we’re all rather busy at the moment.
DeepSeek has also dropped Janus-Pro-7B as an image generator. These aren’t the correct rivals to be testing against right now, and I’m not that concerned about image models either way, and it’ll take a while to know if this is any good in practice. But definitely worth noting.
Man in the Arena
Well, #1 open model, but we already knew that, if Arena had disagreed I would have updated about Arena rather than r1.
Brilliant researchers, engineers, all-knowing architects, and visionary leadership—this is just the beginning.
Let’s. Go.
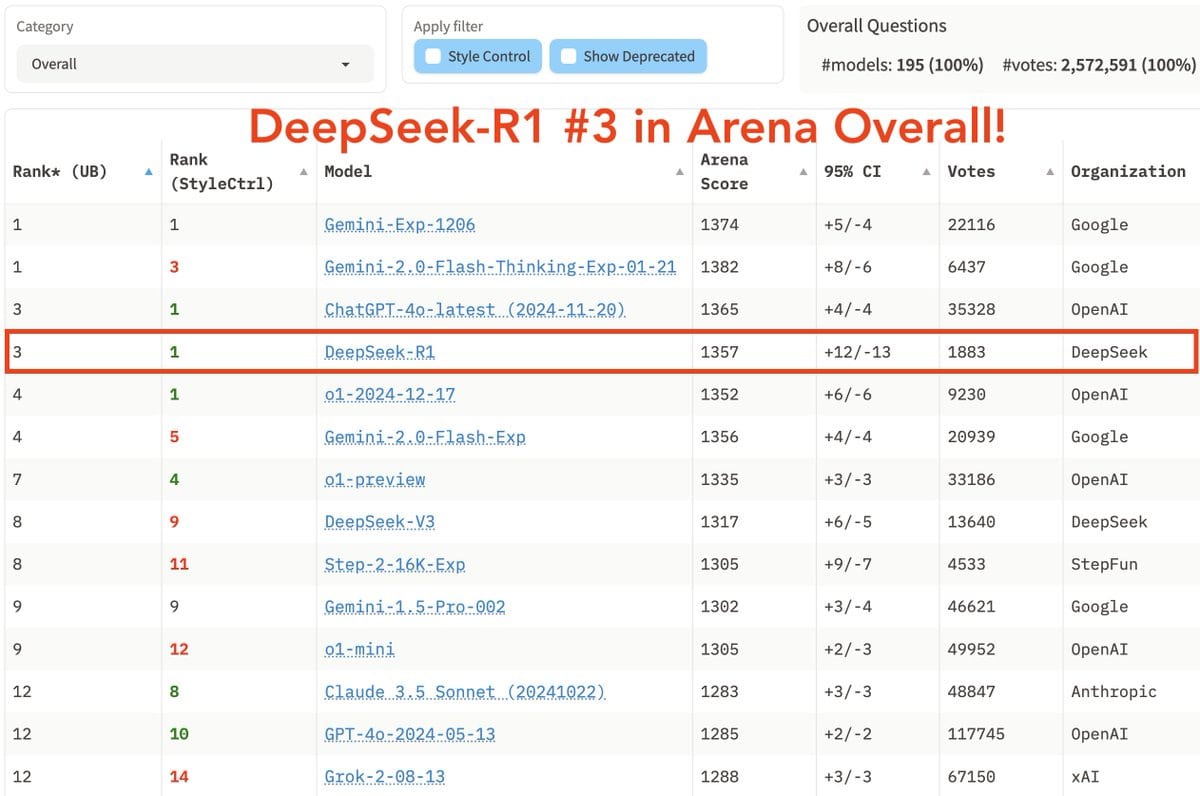
LM Arena: Breaking News: DeepSeek-R1 surges to the top-3 in Arena!
Now ranked #3 Overall, matching the top reasoning model, o1, while being 20x cheaper and open-weight!
Highlights:
– #1 in technical domains: Hard Prompts, Coding, Math
– Joint #1 under Style Control
– MIT-licensed
This puts r1 as the #5 publicly available model in the world by this (deeply flawed) metric, behind ChatGPT-4o (what?), Gemini 2.0 Flash Thinking (um, no) and Gemini 2.0 Experimental (again, no) and implicitly the missing o1-Pro (obviously).
Needless to say, the details of these ratings here are increasingly absurdist. If you have Gemini 1.5 Pro and Gemini Flash above Claude Sonnet 3.6, and you have Flash Thinking above r1, that’s a bad metric. It’s still not nothing – this list does tend to put better things ahead of worse things, even with large error bars.
Training r1, and Training With r1
Dibya Ghosh notes that two years ago he spent 6 months trying to get the r1 training structure to work, but the models weren’t ready for it yet. One theory is that this is the moment this plan started working and DeepSeek was – to their credit – the first to get there when it wasn’t still too early, and then executed well.
Dan Hendrycks similarly explains that once the base model was good enough, and o1 showed the way and enough of the algorithmic methods had inevitably leaked, replicating that result was not the hard part nor was it so compute intensive. They still did execute amazingly well in the reverse engineering and tinkering phases.
Are we going to see a merge of generalist and reasoning models?
Teknium: We retrained Hermes with 5,000 DeepSeek r1 distilled chain-of-thought (CoT) examples. I can confirm a few things:
You can have a generalist plus reasoning mode. We labeled all long-CoT samples from r1 with a static system prompt. The model, when not using it, produces normal fast LLM intuitive responses; and with it, uses long-CoT. You do not need “o1 && 4o” separation, for instance. I would venture to bet OpenAI separated them so they could charge more, but perhaps they simply wanted the distinction for safety or product insights.
Distilling does appear to pick up the “opcodes” of reasoning from the instruction tuning (SFT) alone. It learns how and when to use “Wait” and other tokens to perform the functions of reasoning, such as backtracking.
Context length expansion is going to be challenging for operating systems (OS) to work with. Although this works well on smaller models, context length begins to consume a lot of video-RAM as you scale it up.
We’re working on a bit more of this and are not releasing this model, but figured I’d share some early insights.
Andrew Curran: Dario said in an interview in Davos this week that he thought it was inevitable that the current generalist and reasoning models converge into one, as Teknium is saying here.
I did notice that the ‘wait’ token is clearly doing a bunch of work, one way or another.
John Schulman: There are some intriguing similarities between the r1 chains of thought and the o1-preview CoTs shared in papers and blog posts. In particular, note the heavy use of the words “wait” and “alternatively” as a transition words for error correction and double-checking.
If you’re not optimizing the CoT for humans, then it makes sense to latch onto the most convenient handles with the right vibes and keep reusing them forever.
So the question is, do you have reason to have two distinct models? Or can you have a generalist model with a reasoning mode it can enter when called upon? It makes sense that they would merge, and it would also make sense that you might want to keep them distinct, or use them as distinct subsets of your mixture of experts (MoE).
Building your reasoning model on top of your standard non-reasoning model does seem a little suspicious. If you’re going for reasoning, you’d think you’d want to start differently than if you weren’t? But there are large fixed costs to training in the first place, so it’s plausibly not worth redoing that part, especially if you don’t know what you want to do differently.
Also Perhaps We Should Worry About AI Killing Everyone
As in, DeepSeek intends to create and then open source AGI.
How do they intend to make this end well?
As far as we can tell, they don’t. The plan is Yolo.
Stephen McAleer (OpenAI): Does DeepSeek have any safety researchers? What are
[Links to Tom Lehrer’s song Wernher von Braun, as in ‘once the rockets are up who cares where they come down, that’s not my department.’]
Prakesh (Ate-a-Pi): I spoke to someone who interned there and had to explain the concept of “AI doomer”
And indeed, the replies to McAleer are full of people explicitly saying f*** you for asking, the correct safety plan is to have no plan whatsoever other than Open Source Solves This. These people really think that the best thing humanity can do is create things smarter than ourselves with as many capabilities as possible, make them freely available to whoever wants one, and see what happens, and assume that this will obviously end well and anyone who opposes this plan is a dastardly villain.
I wish this was a strawman or a caricature. It’s not.
I won’t belabor why I think this would likely get us killed and is categorically insane.
Thus, to reiterate:
Tyler Cowen: DeepSeek okie-dokie: “All I know is we keep pushing forward to make open-source AGI a reality for everyone.” I believe them, the question is what counter-move the CCP will make now.
This from Joe Weisenthal is of course mostly true:
Joe Weisenthal: DeepSeek’s app rocketed to number one in the Apple app store over the weekend, and immediately there was a bunch of chatter about ‘Well, are we going to ban this too, like with TikTok?’ The question is totally ignorant. DeepSeek is open source software. Sure, technically you probably could ban it from the app store, but you can’t stop anyone from running the technology in their own computer, or accessing its API. So that’s just dead end thinking. It’s not like TikTok in that way.
I say mostly because the Chinese censorship layer atop DeepSeek isn’t there if you use a different provider, so there isn’t no value in getting r1 served elsewhere. But yes, the whole point is that if it’s open, you can’t get the genie back in the bottle in any reasonable way – which also opens up the possibility of unreasonable ways.
And We Should Worry About Crazy Reactions To All This, Too
The government could well decide to go down what is not technologically an especially wise or pleasant path. There is a long history of the government attempting crazy interventions into tech, or what looks crazy to tech people, when they feel national security or public outrage is at stake, or in the EU because it is a day that ends in Y.
The United States could also go into full jingoism mode. Some tried to call this a ‘Sputnik moment.’ What did we do in response to Sputnik, in addition to realizing our science education might suck (and if we decide to respond to this by fixing our educational system, that would be great)? We launched the Space Race and spent 4% of GDP or something to go to the moon and show those communist bastards.
In this case, I don’t worry so much that we’ll be so foolish as to get rid of the export controls. The people in charge of that sort of decision know how foolish that would be, or will be made aware, no matter what anyone yells on Twitter. It could make a marginal difference to severity and enforcement, but it isn’t even obvious in which direction this would go. Certainly Trump is not going to be down for ‘oh the Chinese impressed us I guess we should let them buy our chips.’
Nor do I think America will cut back on Capex spending on compute, or stop building energy generation and transmission and data centers it would have otherwise built, including Stargate. The reaction will be, if anything, a ‘now more than ever,’ and they won’t be wrong. No matter where compute and energy demand top out, it is still very clearly time to build there.
So what I worry about is the opposite – that this locks us into a mindset of a full-on ‘race to AGI’ that causes all costly attempts to have it not kill us to be abandoned, and that this accelerates the timeline. We already didn’t have any (known to me) plans with much of a chance of working in time, if AGI and then ASI are indeed near.
That doesn’t mean that reaction would even be obviously wrong, if the alternatives are all suddenly even worse than that. If DeepSeek really does have a clear shot to AGI, and fully intends to open up the weights the moment they have it, and China is not going to stop them from doing this or even will encourage it, and we expect them to succeed, and we don’t have any way to stop that or make a deal, it is then reasonable to ask: What choice do we have? Yes, the game board is now vastly worse than it looked before, and it already looked pretty bad, but you need to maximize your winning chances however you can.
And if we really are all going to have AGI soon on otherwise equal footing, then oh boy do we want to be stocking up on compute as fast as we can for the slingshot afterwards, or purely for ordinary life. If the AGIs are doing the research, and also doing everything else, it doesn’t matter whose humans are cracked and whose aren’t.
If so, why were US electricity stocks down 20-28% (wouldn't we expect them to go up if the US wants to strengthen its domestic AI-related infrastructure) and why did TSMC lose less, percentage-wise, than many other AI-related stocks (wouldn't we expect it to get hit hardest)?
Well, he didn't do it yet either, did he? His new announcement is, likewise, just that: an announcement. Manifold is still 35% on him not following through on it, for example.
In practice I do not think this matters, but it does indicate that we’re sleeping on the job – all the sources you need for this are public, why are we not including them.
I'd reserve judgement whether that matters, but I can attest a large part of content is indeed skipped... probably for those same reasons why market didn't react to DeepSeek in advance: people are just not good at knowing distant information which might still be helpful to them.




!