Superintelligence Reading Group 3: AI and Uploads
post by KatjaGrace · 2014-09-30T01:00:15.992Z · LW · GW · Legacy · 139 commentsContents
Summary Intro Whole brain emulation Notes In-depth investigations How to proceed None 139 comments
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the third section in the reading guide, AI & Whole Brain Emulation. This is about two possible routes to the development of superintelligence: the route of developing intelligent algorithms by hand, and the route of replicating a human brain in great detail.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. My own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post. Feel free to jump straight to the discussion. Where applicable, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: “Artificial intelligence” and “Whole brain emulation” from Chapter 2 (p22-36)
Summary
Intro
- Superintelligence is defined as 'any intellect that greatly exceeds the cognitive performance of humans in virtually all domains of interest'
- There are several plausible routes to the arrival of a superintelligence: artificial intelligence, whole brain emulation, biological cognition, brain-computer interfaces, and networks and organizations.
- Multiple possible paths to superintelligence makes it more likely that we will get there somehow.
- A human-level artificial intelligence would probably have learning, uncertainty, and concept formation as central features.
- Evolution produced human-level intelligence. This means it is possible, but it is unclear how much it says about the effort required.
- Humans could perhaps develop human-level artificial intelligence by just replicating a similar evolutionary process virtually. This appears at after a quick calculation to be too expensive to be feasible for a century, however it might be made more efficient.
- Human-level AI might be developed by copying the human brain to various degrees. If the copying is very close, the resulting agent would be a 'whole brain emulation', which we'll discuss shortly. If the copying is only of a few key insights about brains, the resulting AI might be very unlike humans.
- AI might iteratively improve itself from a meagre beginning. We'll examine this idea later. Some definitions for discussing this:
- 'Seed AI': a modest AI which can bootstrap into an impressive AI by improving its own architecture.
- 'Recursive self-improvement': the envisaged process of AI (perhaps a seed AI) iteratively improving itself.
- 'Intelligence explosion': a hypothesized event in which an AI rapidly improves from 'relatively modest' to superhuman level (usually imagined to be as a result of recursive self-improvement).
- The possibility of an intelligence explosion suggests we might have modest AI, then suddenly and surprisingly have super-human AI.
- An AI mind might generally be very different from a human mind.
Whole brain emulation
- Whole brain emulation (WBE or 'uploading') involves scanning a human brain in a lot of detail, then making a computer model of the relevant structures in the brain.
- Three steps are needed for uploading: sufficiently detailed scanning, ability to process the scans into a model of the brain, and enough hardware to run the model. These correspond to three required technologies: scanning, translation (or interpreting images into models), and simulation (or hardware). These technologies appear attainable through incremental progress, by very roughly mid-century.
- This process might produce something much like the original person, in terms of mental characteristics. However the copies could also have lower fidelity. For instance, they might be humanlike instead of copies of specific humans, or they may only be humanlike in being able to do some tasks humans do, while being alien in other regards.
Notes
- What routes to human-level AI do people think are most likely?
Bostrom and Müller's survey asked participants to compare various methods for producing synthetic and biologically inspired AI. They asked, 'in your opinion, what are the research approaches that might contribute the most to the development of such HLMI?” Selection was from a list, more than one selection possible. They report that the responses were very similar for the different groups surveyed, except that whole brain emulation got 0% in the TOP100 group (100 most cited authors in AI) but 46% in the AGI group (participants at Artificial General Intelligence conferences). Note that they are only asking about synthetic AI and brain emulations, not the other paths to superintelligence we will discuss next week.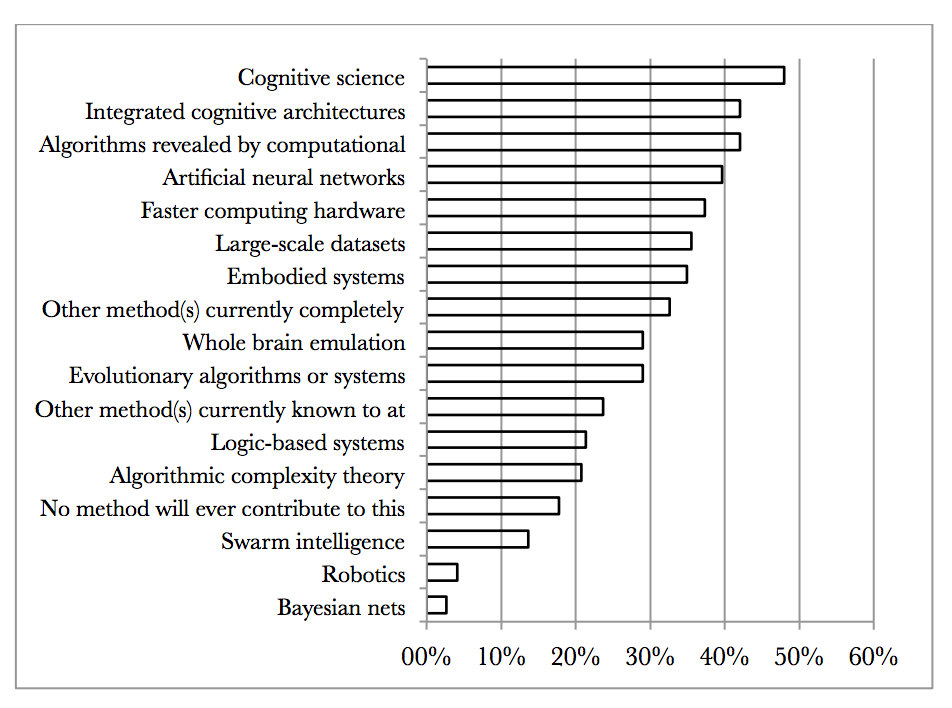
- How different might AI minds be?
Omohundro suggests advanced AIs will tend to have important instrumental goals in common, such as the desire to accumulate resources and the desire to not be killed. -
Anthropic reasoning
‘We must avoid the error of inferring, from the fact that intelligent life evolved on Earth, that the evolutionary processes involved had a reasonably high prior probability of producing intelligence’ (p27)
Whether such inferences are valid is a topic of contention. For a book-length overview of the question, see Bostrom’s Anthropic Bias. I’ve written shorter (Ch 2) and even shorter summaries, which links to other relevant material. The Doomsday Argument and Sleeping Beauty Problem are closely related. - More detail on the brain emulation scheme
Whole Brain Emulation: A Roadmap is an extensive source on this, written in 2008. If that's a bit too much detail, Anders Sandberg (an author of the Roadmap) summarises in an entertaining (and much shorter) talk. More recently, Anders tried to predict when whole brain emulation would be feasible with a statistical model. Randal Koene and Ken Hayworth both recently spoke to Luke Muehlhauser about the Roadmap and what research projects would help with brain emulation now. -
Levels of detail
As you may predict, the feasibility of brain emulation is not universally agreed upon. One contentious point is the degree of detail needed to emulate a human brain. For instance, you might just need the connections between neurons and some basic neuron models, or you might need to model the states of different membranes, or the concentrations of neurotransmitters. The Whole Brain Emulation Roadmap lists some possible levels of detail in figure 2 (the yellow ones were considered most plausible). Physicist Richard Jones argues that simulation of the molecular level would be needed, and that the project is infeasible. -
Other problems with whole brain emulation
Sandberg considers many potential impediments here. -
Order matters for brain emulation technologies (scanning, hardware, and modeling)
Bostrom points out that this order matters for how much warning we receive that brain emulations are about to arrive (p35). Order might also matter a lot to the social implications of brain emulations. Robin Hanson discusses this briefly here, and in this talk (starting at 30:50) and this paper discusses the issue. -
What would happen after brain emulations were developed?
We will look more at this in Chapter 11 (weeks 17-19) as well as perhaps earlier, including what a brain emulation society might look like, how brain emulations might lead to superintelligence, and whether any of this is good. -
Scanning (p30-36)
‘With a scanning tunneling microscope it is possible to ‘see’ individual atoms, which is a far higher resolution than needed...microscopy technology would need not just sufficient resolution but also sufficient throughput.’
Here are some atoms, neurons, and neuronal activity in a living larval zebrafish, and videos of various neural events.
Array tomography of mouse somatosensory cortex from Smithlab.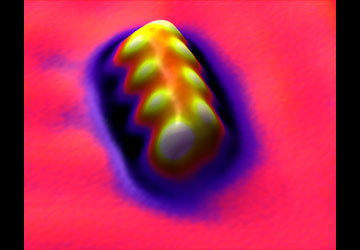
A molecule made from eight cesium and eight
iodine atoms (from here). -
Efforts to map connections between neurons
Here is a 5m video about recent efforts, with many nice pictures. If you enjoy coloring in, you can take part in a gamified project to help map the brain's neural connections! Or you can just look at the pictures they made. -
The C. elegans connectome (p34-35)
As Bostrom mentions, we already know how all of C. elegans’ neurons are connected. Here's a picture of it (via Sebastian Seung):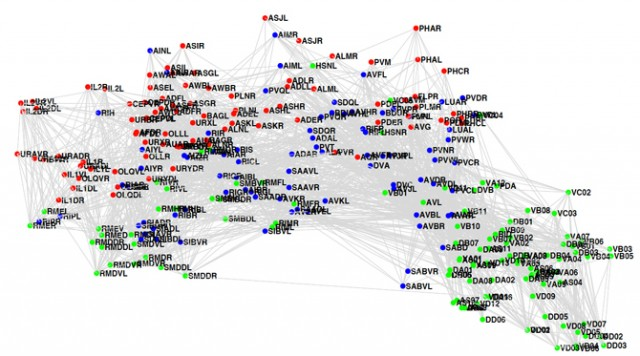
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some taken from Luke Muehlhauser's list:
- Produce a better - or merely somewhat independent - estimate of how much computing power it would take to rerun evolution artificially. (p25-6)
- How powerful is evolution for finding things like human-level intelligence? (You'll probably need a better metric than 'power'). What are its strengths and weaknesses compared to human researchers?
- Conduct a more thorough investigation into the approaches to AI that are likely to lead to human-level intelligence, for instance by interviewing AI researchers in more depth about their opinions on the question.
- Measure relevant progress in neuroscience, so that trends can be extrapolated to neuroscience-inspired AI. Finding good metrics seems to be hard here.
- e.g. How is microscopy progressing? It’s harder to get a relevant measure than you might think, because (as noted p31-33) high enough resolution is already feasible, yet throughput is low and there are other complications.
- Randal Koene suggests a number of technical research projects that would forward whole brain emulation (fifth question).
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about other paths to the development of superintelligence: biological cognition, brain-computer interfaces, and organizations. To prepare, read Biological Cognition and the rest of Chapter 2. The discussion will go live at 6pm Pacific time next Monday 6 October. Sign up to be notified here.
139 comments
Comments sorted by top scores.
comment by paulfchristiano · 2014-09-30T04:15:50.651Z · LW(p) · GW(p)
I am intrigued by the estimate for the difficulty of recapitulating evolution. Bostrom estimates 1E30 to 1E40 FLOPSyears. A conservative estimate for the value of a successful program to recapitulate evolution might be around $500B. This is enough to buy something like 10k very large supercomputers for a year, which gets you something like 1E20 FLOPSyears. So the gap is between 10 and 20 orders of magnitude. In 35 years, this gap would fall to 5 to 15 orders of magnitude (at the current rate of progress in hardware, which seems likely to slow).
One reason this possibility is important is that it seems to offer one of the strongest possible environments for a disruptive technological change.
This seems sensible as a best guess, but it is interesting to think about scenarios where it turns out to be surprisingly easy to simulate evolution. For example, if there were a 10% chance of this project being economically feasible within 20 years, that would be an extremely interesting fact, and one that might affect my views of the plausibility of AI soon. (Not necessarily because such an evolutionary simulation per se is likely to occur, but mostly because it says something about the overall difficulty of building up an intelligence by a brute force search.)
But it is easy to see how this estimate might be many orders of magnitude too high (and also to see how it could be somewhat quite a bit too low, but it is interesting to look at the low tail in particular):
- It may be that you can memoize much of the effort of fitness evaluations, evaluating the fitness of many similar organisms in parallel. This appears to be a trick that is unavailable to evolution, but the key idea on which modern approaches to training neural nets rely. Gradient descent + backpropagation gives you a large speedup for training neural nets, as much as linear in the number of parameters which you are training. In the case of evolution, this could already produce a 10 order of magnitude speedup.
- It may be possible to evaluate the fitness of an organism radically faster than it is revealed by nature. For example, it would not be too surprising if you could short-circuit most of the work of development. Moreover, nature doesn't get very high-fidelity estimates of fitness, and it wouldn't be at all surprising to me if it were possible to get a comparably good estimate of a human's fitness over the course of an hour in a carefully designed environment (this is a speedup of about 5 orders of magnitude over the default).
- It seems plausible that mutation in nature does not search the space as effectively as human engineers could even with a relatively weak understanding of intelligence or evolution. It would not be surprising to me if you could conduct the search a few orders of magnitude faster merely by using optimal mutation rates, using estimates for fitness including historical performance, choosing slightly better distribution of mutations, or whatever.
Overall, I would not be too surprised (certainly I would give it > 1%) if a clean theoretical understanding of evolution made this a tractable project today given sufficient motification, which is quite a frightening prospect. The amount of effort that has gone into developing such an understanding, with an eye towards this kind of engineering project, also appears to be surprisingly small.
Replies from: torekp, KatjaGrace, Jeff_Alexander, leplen, diegocaleiro↑ comment by torekp · 2014-09-30T23:23:34.697Z · LW(p) · GW(p)
These are all good points, and I think you're understating the case on (at least) the third one. An EA search can afford to kill off most of its individuals for the greater good; biological evolution cannot tolerate a substantial hit to individual fitness for the sake of group fitness. An EA search can take reproduction for granted, tying it directly to performance on an intelligence test.
↑ comment by KatjaGrace · 2014-10-01T21:16:43.659Z · LW(p) · GW(p)
If AI were developed in this way, one upside might be that you would have a decent understanding of how smart it was at any given point (since that is how the AI was selected), so would be unlikely to accidentally have a system that was much more capable than you expected. I'm not sure how probable that is in other cases, but people sometimes express concern about it.
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-10-02T06:53:59.501Z · LW(p) · GW(p)
If the simulation is running at computer speed then only in it's subjective time this would be the case. By the time we notice that variation number 34 on backtracking and arc consistency actually speeds up evolution by the final 4 orders of magnitude, it may be too late to stop the process from creating simulants that are smarter than us and can achieve takeoff acceleration.
Keep in mind though that if this were to happen than we'd be overwhelmingly likely to be living in a simulation already, for the reasons given in the Simulation Argument paper.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-02T07:38:28.777Z · LW(p) · GW(p)
You could have a system that automatically stopped when you reached a system with a certain level of tested intelligence. But perhaps I'm misunderstanding you.
With respect to the simulation argument, would you mind reminding us of why we would be overwhelmingly likely to be in a simulation if we build AI which 'achieves takeoff acceleration', if it's quick to summarize? I expect many people haven't read the simulation argument paper.
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-10-02T10:32:24.200Z · LW(p) · GW(p)
Having a system that stops when you reach a level of tested intelligence sounds appealing, but I'd be afraid of the measure of intelligence at hand being too fuzzy.
So the system would not detect it had achieved that level of intelligence, and it would bootstrap and take off in time to destroy the control system which was supposed to halt it. This would happen if we failed to solve any of many distinct problems that we don't know how to solve yet, like symbol grounding, analogical and metaphorical processing and 3 more complex ones that I can think of, but don't want to spend resources in this thread mentioning. Same for simulation argument.
↑ comment by Jeff_Alexander · 2014-10-01T19:58:50.109Z · LW(p) · GW(p)
I agree with this. Brute force searching AI did not seem to be a relevant possibility to me prior to reading this chapter and this comment, and now it does.
One more thought/concern regarding the evolutionary approach: Humans perform poorly when estimating the cost and duration of software projects, particularly as the size and complexity of the project grows. Recapitulating evolution is a large project, and so it wouldn't be at all surprising if it ended up requiring more compute time and person-hours than expected, pushing out the timeline for success via this approach.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-01T21:14:10.090Z · LW(p) · GW(p)
While humans do perform poorly estimating time to complete projects, I expect that only adds a factor of two or something, which is fairly small next to the many order of magnitude uncertainty around the cost.
↑ comment by leplen · 2014-10-04T18:53:59.988Z · LW(p) · GW(p)
I'm really curious as to where you're getting the $500B number from. I felt like I didn't understand this argument very well at all, and I'm wondering what sorts of results you're imagining as a result of such a program.
It's worth noting that 1E30-1E40 is only the cost of simulating the neurons, and an estimate for the computational cost of simulating the fitness function is not given, although it is stated that the fitness function "is typically the most computationally expensive component". So the evaluation of the fitness function (which presumably has to be complicated enough to accurately assess intelligence), isn't even included in that estimate.
It's also not clear to me at least that simulating neurons is capable of recapitulating the evolution of general intelligence. I don't believe it is a property of individual neurons that causes the brain to be divided into two hemispheres. I don't know anything about brains, but I've never heard of left neurons or right neurons. So is it the neurons that are supposed to be mutating or some unstated variable that describes the organization of the various neurons. If the latter, then what is the computational cost associated with that super structure?
I feel like "recapitulating evolution" is a poor term for this. It's not clear that there's a lot of overlap between this sort of massive genetic search and actual evolution. It's not clear that computational cost is the limiting factor. Can we design a series of fitness functions capable of guiding a randomly evolving algorithm to some sort of general intelligence? For humans, it seems that the mixture of cooperation and competition with other equally intelligent humans resulted in some sort of intelligence arms race, but the evolutionary fitness function that led to humans, or to the human ancestors isn't really known. How do you select for an intelligent/human like niche in your fitness function? What series of problems can you create that will allow general intelligence to triumph over specialized algorithms?
Will the simulated creatures be given time to learn before their fitness is evaluated? Will learning produce changes in neural structure? Is the genotype/phenotype distinction being preserved? I feel like it's almost misleading to include numerical estimates for the computational cost of what is arguably the easiest part of this problem without addressing the far more difficult theoretical problem of devising a fitness landscape that has a reasonable chance to produce intelligence. I'm even more blown away by the idea that it would be possible to estimate a cash value to any degree of precision for such a program. I have literally no idea what the probability distribution of possible outcomes for such a program would be. I don't even have a good estimate of the cost or the theory behind the inputs.
↑ comment by diegocaleiro · 2014-10-02T07:05:28.017Z · LW(p) · GW(p)
This seems like an information hazard, since it has the form: This estimate for process X which may destroy the value of the future seems too low, also, not many people are currently studying X, which is surprising.
If X is some genetically engineered variety of smallpox, it seems clear that mentioning those facts is hazardous.
If the World didn't know about brain emulation, calling it an under-scrutinized area would be dangerous, relative to, say, just mention to a few safety savvy, x-risk savvy neuroscientist friends who would go on to design safety protocols for it, as well as, if possible, slow down progress in the field.
Same should be done in this case.
Replies from: Jeff_Alexander↑ comment by Jeff_Alexander · 2014-10-03T02:20:49.248Z · LW(p) · GW(p)
If the idea is obvious enough to AI researchers (evolutionary approaches are not uncommon -- they have entire conferences dedicated to the sub-field)), then avoiding discussion by Bostrom et al. doesn't reduce information hazard, it just silences the voices of the x-risk savvy while evolutionary AI researchers march on, probably less aware of the risks of what they are doing than if the x-risk savvy keep discussing it.
So, to the extent this idea is obvious / independently discoverable by AI researchers, this approach should not be taken in this case.
comment by KatjaGrace · 2014-09-30T03:20:59.002Z · LW(p) · GW(p)
In my understanding, technological progress almost always proceeds relatively smoothly (see algorithmic progress, the performance curves database, and this brief investigation). Brain emulations seem to represent an unusual possibility for an abrupt jump in technological capability, because we would basically be ‘stealing’ the technology rather than designing it from scratch. Similarly, if an advanced civilization kept their nanotechnology locked up nearby, then our incremental progress in lock-picking tools might suddenly give rise to a huge leap in nanotechnology from our perspective, whereas earlier lock picking progress wouldn’t have given us any noticeable nanotechnology progress. If this is an unusual situation however, it seems strange that the other most salient route to superintelligence - artificial intelligence designed by humans - is also often expected to involve a discontinuous jump in capability, but for entirely different reasons. Is there some unifying reason to expect jumps in both routes to superintelligence, or is it just coincidence? Or do I overstate the ubiquity of incremental progress?
Replies from: ciphergoth, paulfchristiano, TRIZ-Ingenieur, Cyan, SilentCal, KatjaGrace↑ comment by Paul Crowley (ciphergoth) · 2014-09-30T08:18:30.317Z · LW(p) · GW(p)
I think that incremental progress is very much the norm as you say; it might be informative to compile a list of exceptions.
- In cryptanalysis, a problem that the cipher designers believed was 2^256 complexity can turn out to be 2^24 or less. However, this rarely happens with ciphers that have been around a long time.
- Nuclear bombs were far more powerful than any bomb that preceded them; destruction in war certainly counts as a problem that has got a lot of attention over a long time.
↑ comment by KatjaGrace · 2014-10-01T19:15:39.035Z · LW(p) · GW(p)
I think this is a good thing to compile a list of. Paul and I started one on the AI impacts site, but have only really got into looking into the nuclear case. More examples welcome!
Could you tell me more about the cipher example? Do you have particular examples in mind? Does the practical time of solving something actually decrease precipitously, or are these theoretical figures?
Replies from: ciphergoth, None↑ comment by Paul Crowley (ciphergoth) · 2014-10-03T09:00:23.577Z · LW(p) · GW(p)
The example I had in mind was "Differential Cryptanalysis of Nimbus". The author of Nimbus believed that the cipher could not be broken with less work than a brute force attack on all 2^128 keys. The cryptanalysis broke it with 256 chosen plaintexts and 2^10 work. However, the gap between publication and break was less than a year.
↑ comment by [deleted] · 2014-10-02T14:41:27.752Z · LW(p) · GW(p)
Regarding cryptanalysis. yes it is known to happen that various proposed and sometimes implemented systems are found to be trivially breakable due to analysis not foreseen by their inventors. Examples are too numerous, but perhaps something like differential cryptanalysis might be something to look into.
↑ comment by paulfchristiano · 2014-09-30T03:57:09.294Z · LW(p) · GW(p)
I think that the lockpicking example is apt in a way, but it's worth pointing out that there is more of a continuum between looking at brains and inferring useful principles vs. copying them in detail; you can imagine increasing understanding reducing the computational demands of emulations, replicating various features of human cognition, deriving useful principles for other AI, or reaching superhuman performance in various domains before an emulation is cheap enough to be a broadly human-level replacement.
Personally, I would guess that brain emulation is a technology that is particularly likely to result in a big jump in capabilities. A simialr line of argument also suggests that brain emulation per se is somewhat unlikely, rather than increasing rapid AI progress as our ability to learn from the brain grows. Nevertheless, we can imagine the situation where our understanding of neuroscience remains very bad but our ability at neuroimaging and computation is good enough to run an emulation, and that really could lead to a huge jump.
For AI, it seems like the situation is not so much that one might see very fast progress (in terms of absolute quality of technical achievement) so much as that one might not realize how far you have come. This is not entirely unrelated to the possibility of surprise from brain emulation; both are possible because it might be very hard to understand what a human-level or near-human-level intelligence is doing, even if you can watch it think (or even if you built it).
For other capabilities, we normally imagine that before you build a machine that does X, you will build a machine that does almost-X and you will understand why it manages to do almost-X. Likewise, we imagine that before we could understand how an animal did X well enough to copy it exactly, we would understand enough principles to make an almost-copy which did almost-X. Whether intelligence is really unique in this way, or if this is just an error that will get cleared up as we approach human-level AI, remains to be seen.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-30T12:05:26.058Z · LW(p) · GW(p)
There is a continuum between understanding the brain well, and copying it in detail. But it seems that for much of that spectrum - where a big part is still coming from copying well - I would expect a jump. Perhaps a better analogy would involve many locked boxes of nanotechnology, and our having the whole picture when we have a combination of enough lockpicking and enough nanotech understanding.
Do you mean that this line of argument is evidence against brain emulations per se because such jumps are rare?
For AI, the most common arguments I have heard for fast progress involve recursive self-improvement, and/or insights related to intelligence being particularly large and chunky for some reason. Do you mean these are possible because we don't know how far we have come, or are you thinking of another line of reasoning?
It seems to me that for any capability you wished to copy from an animal via careful replication rather than via understanding would have this character of perhaps quickly progressing when your copying abilities become sufficient. I can't think of anything else anyone tries to copy in this way though, which is perhaps telling.
↑ comment by TRIZ-Ingenieur · 2014-10-03T00:24:58.286Z · LW(p) · GW(p)
Genome sequencing improved over-exponentially in the years of highest investment. Competition, availability of several different technological approaches and global research trends funding nano technology enabled this steep improvement. We should not call this a jump because we might need this word if developments reach timescales of weeks.
Current high funding for basic research (human brain project, human connectome and others), high competition and the availability of many technological paths make an over-exponential development likely.
Human genome project researchers spent most of their time on improving technology. After achiving magnitudes in speed-up they managed to sequence the largest proportion in the final year.
I expect similar over-exponential AGI improvements once we understand our brain. A WBE does not need to simulate a human brain. To steal the technology it is sufficient to simulate a brain with a small neocortex. A human brain with larger neocortex is just an quantitative extension.
↑ comment by Cyan · 2014-10-01T03:52:56.720Z · LW(p) · GW(p)
My intuition -- and it's a Good one -- is that the discontinuity is produced by intelligence acting to increase itself. It's built into the structure of the thing acted upon that it will feed back to the thing doing the acting. (Not that unique an insight around these parts, eh?)
Okay, here's a metaphor(?) to put some meat on the bones of this comment. Suppose you have an interpreter for some computer language and you have a program written in that language that implements partial evaluation. With just these tools, you can make the partial evaluator (i) act as a compiler, by running it on an interpreter and a program; (ii) build a compiler, by running it on itself and an interpreter; (iii) build a generic interpreter-to-compiler converter, by running it on itself and itself. So one piece of technology "telescopes" by acting on itself. These are the Three Projections of Doctor Futamura.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-01T16:21:01.874Z · LW(p) · GW(p)
In the emulation case, how does intelligence acting on itself come into the picture? (I agree it might do after there are emulations, but I'm talking about the jump from capabilities prior to the first good emulation to those of emulations).
Replies from: Cyan↑ comment by Cyan · 2014-10-01T17:29:57.841Z · LW(p) · GW(p)
Hmm.. let me think...
The materialist thesis implies that a biological computation can be split into two parts: (i) a specification of a brain-state; (ii) a set of rules for brain-state time evolution, i.e., physics. When biological computations run in base reality, brain-state maps to program state and physics is the interpreter, pushing brain-states through the abstract computation. Creating an em then becomes analogous to using Futamura's first projection to build in the static part of the computation -- physics -- thereby making the resulting program substrate-independent. The entire process of creating a viable emulation strategy happens when we humans run a biological computation that (i) tells us what is necessary to create a substrate-independent brain-state spec and (ii) solves a lot of practical physics simulation problems, so that to generate an em, the brain-state spec is all we need. This is somewhat analogous to Futamura's second projection: we take the ordered pair (biological computation, physics), run a particular biological computation on it, and get a brain-state-to-em compiler.
So intelligence is acting on itself indirectly through the fact that an "interpreter", physics, is how reality manifests intelligence. We aim to specialize physics out of the process of running the biological computations that implement intelligence, and by necessity, we're use a biological computation that implements intelligence to accomplish that goal.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-01T19:06:35.694Z · LW(p) · GW(p)
I'm not sure I followed that correctly, but I take it you are saying that making brain emulations involves biological intelligence (the emulation makers) acting on biological intelligence (the emulations). Which is quite right, but it seems like intelligence acting on intelligence should only (as far as I know) produce faster progress if there is some kind of feedback - if the latter intelligence goes on to make more intelligence etc. Which may happen in the emulation case, but after the period in which we might expect particularly fast growth from copying technology from nature. Apologies if I misunderstand you.
Replies from: Cyan↑ comment by Cyan · 2014-10-01T19:26:42.976Z · LW(p) · GW(p)
I wasn't talking about faster progress as such, just about a predictable single large discontinuity in our capabilities at the point in time when the em approach first bears fruit. It's not a continual feedback, just an application of intelligence to the problem of making biological computations (including those that implement intelligence) run on simulated physics instead of the real thing.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-01T19:37:39.020Z · LW(p) · GW(p)
I see. In that case, why would you expect applying intelligence to that problem to bring about a predictable discontinuity, but applying intelligence to other problems not to?
Replies from: Cyan↑ comment by Cyan · 2014-10-01T19:46:21.531Z · LW(p) · GW(p)
Because the solution has an immediate impact on the exercise of intelligence, I guess? I'm a little unclear on what other problems you have in mind.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-01T21:18:06.934Z · LW(p) · GW(p)
The impact on exercise of intelligence doesn't seem to come until the ems are already discontinuously better (if I understand), so can't seem to explain the discontinuous progress.
Replies from: Cyan↑ comment by Cyan · 2014-10-01T23:18:27.356Z · LW(p) · GW(p)
Making intelligence-implementing computations substrate-independent in practice (rather than just in principle) already expands our capabilities -- being able to run those computations in places pink goo can't go and at speeds pink goo can't manage is already a huge leap.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-02T00:37:43.902Z · LW(p) · GW(p)
Even if it is a huge leap to achieve that, until you run the computations, it is unclear to me how they could have contributed to that leap.
Replies from: Cyan↑ comment by Cyan · 2014-10-02T13:51:36.633Z · LW(p) · GW(p)
But we do run biological computations (assuming that the exercise of human intelligence reduces to computation) to make em technology possible.
Since we're just bouncing short comments off each other at this point, I'm going to wrap up now with a summary of my current position as clarified through this discussion. The original comment posed a puzzle:
Brain emulations seem to represent an unusual possibility for an abrupt jump in technological capability, because we would basically be ‘stealing’ the technology rather than designing it from scratch. ...If this is an unusual situation however, it seems strange that the other most salient route to superintelligence - artificial intelligence designed by humans - is also often expected to involve a discontinuous jump in capability, but for entirely different reasons.
The commonality is that both routes attack a critical aspect of the manifestation of intelligence. One goes straight for an understanding of the abstract computation that implements domain-general intelligence; the other goes at the "interpreter", physics, that realizes that abstract computation.
↑ comment by SilentCal · 2014-10-01T21:28:31.689Z · LW(p) · GW(p)
Maybe we can shift the reference class to make incremental progress less ubiquitous?
How about things like height of tallest man-made structure in world? Highest elevation achieved by a human? Maximum human speed (relative to nearest point on earth)? Maximum speed on land? Largest known prime number?
Net annual transatlantic shipping tonnage? Watts of electricity generated? Lumens of artificial light generated? Highest temperature achieved on Earth's surface? Lowest temperature?
The above are obviously cherry-picked, but the point is what they have in common: at a certain point a fundamentally different approach kicked in. This is what superintelligence predictions claim will happen.
The objection might be raised that the AI approach is already under way so we shouldn't expect any jumps. I can think of two replies: one is that narrow AI is to AGI as the domestication of the horse is to the internal combustion engine. The other is that current AI is to human intelligence as the Killingsworth Locomotive, which wikipedia cites as going 4 mph, was to the horse.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-02T00:34:08.940Z · LW(p) · GW(p)
It would probably help to be clearer by what we mean by incremental. The height of the tallest man-made structure is jumpy, but the jumps seem to usually be around 10% of existing height, except the last one, which is about 60% taller than its predecessor of 7 years earlier. I think of these as pretty much incremental, but I take it you do not?
At least in the AI case, when we talk about discontinuous progress, I think people are imagining something getting more than 100 times better on some relevant metric over a short period, but I could be wrong about this. For instance, going from not valuable at all, to at least more useful than a human, and perhaps more useful than a large number of humans.
Replies from: SilentCal↑ comment by SilentCal · 2014-10-02T16:10:25.754Z · LW(p) · GW(p)
I had a longer progression in mind (http://en.wikipedia.org/wiki/History_of_the_tallest_buildings_in_the_world#1300.E2.80.93present), the idea being that steel and industry were a similar discontinuity.
Though it looks like these examples are really just pointing to the idea of agriculture and industry as the two big discontinuities of known history.
↑ comment by KatjaGrace · 2014-10-01T19:09:05.040Z · LW(p) · GW(p)
It also seems like within the AI case, there are several different stories around for why we should expect discontinuous progress in AI. Sometimes people talk about recursive self-improvement, other times about how there is likely to be one big insight, or about how intelligence is such that even a tiny insight is likely to make a big difference (while pointing to the small differences between monkeys and humans). I think there might be more I'm not remembering too.
comment by KatjaGrace · 2014-09-30T01:01:34.646Z · LW(p) · GW(p)
How fast is relevant neuroscience progressing toward brain emulation or brain-inspired AI? How can we even measure it? Ray Kurzweil claims it is growing exponentially in The Singularity is Near, while Paul Allen counters that understanding in neuroscience usually gets harder the more we learn. How can we tell who is right?
comment by lukeprog · 2014-09-30T03:56:48.182Z · LW(p) · GW(p)
This is some nice foreshadowing:
Replies from: NoneReaders of this chapter must not expect a blueprint for programming an artificial general intelligence. No such blueprint exists yet, of course. And had I been in possession of such a blueprint, I most certainly would not have published it in a book. (If the reasons for this are not immediately obvious, the arguments in subsequent chapters will make them clear.)
comment by KatjaGrace · 2014-09-30T01:21:56.065Z · LW(p) · GW(p)
‘An artificial intelligence need not much resemble a human mind’ (p29)
What are some concrete ways an AI mind programmed from scratch might be very different? Are there ways it is likely to be the same? (I pointed to Omohundro's paper about the latter question before; this LessWrong thread speculates about alien minds in general)
comment by KatjaGrace · 2014-09-30T12:40:30.097Z · LW(p) · GW(p)
‘We can also say, with greater confidence than for the AI path, that the emulation path will not succeed in the near future (within the next fifteen years, say) because we know that several challenging precursor technologies have not yet been developed. By contrast, it seems likely that somebody could in principle sit down and code a seed AI on an ordinary present-day personal computer; and it is conceivable - though unlikely - that somebody somewhere will get the right insight for how to do this in the near future.’ - Bostrom (p36)
Why is it more plausible that a person can sit down and invent a human-level artificial intelligence than that they can sit down and invent the technical means to produce brain emulations?
Replies from: leplen, kgalias↑ comment by leplen · 2014-09-30T23:48:32.773Z · LW(p) · GW(p)
Because one requires only a theoretical breakthrough and the other requires engineering. Ideas iterate very quickly. Hardware has to be built. The machines that make the machines you want to use have to be designed, whole industries may have to be invented. A theoretical breakthrough doesn't have the same lag time.
If I work as a theorist and I have a brilliant insight, I start writing the paper tomorrow. If I work as an experimentalist and I have a brilliant insight, I start writing the grant to purchase the new equipment I'll need.
↑ comment by kgalias · 2014-09-30T16:41:21.664Z · LW(p) · GW(p)
This is the part of this section I find least convincing.
Replies from: None↑ comment by [deleted] · 2014-10-02T14:44:02.617Z · LW(p) · GW(p)
Can you elaborate?
Replies from: kgalias↑ comment by kgalias · 2014-10-03T08:25:20.754Z · LW(p) · GW(p)
How is theoretical progress different from engineering progress?
Is the following an example of valid inference?
We haven't solved many related (and seemingly easier) (sub)problems, so the Riemann Hypothesis is unlikely to be proven in the next couple of years.
In principle, it is also conceivable (but not probable), that someone will sit down and make a brain emulation machine.
Replies from: None↑ comment by [deleted] · 2014-10-03T08:51:00.036Z · LW(p) · GW(p)
Making a brain emulation machine requires (1) the ability to image a brain at sufficient resolution, and (2) computing power in excess of the largest supercomputers available today. Both of these tasks are things which require a long engineering lead time and commitment of resources, and are not things which we expect to solved by some clever insight. Clever insight alone won't ever enable you construct record-setting supercomputers out of leftover hobbyist computer parts, toothpicks, and superglue.
Replies from: kgalias↑ comment by kgalias · 2014-10-03T09:49:15.452Z · LW(p) · GW(p)
Why do we assume that all that is needed for AI is a clever insight, not the insight-equivalent of a long engineering time and commitment of resources?
Replies from: None↑ comment by [deleted] · 2014-10-03T15:02:17.860Z · LW(p) · GW(p)
Because the scope of the problems involved, e.g. searchspace over programs, can be calculated and compared with other similarly structured but solved problems (e.g. narrow AI). And in a very abstract theoretical sense today's desktop computers are probably sufficient for running a fully optimized human-level AGI. And this is a sensible and consistent result -- it should not be surprising that it takes many orders of magnitude more computational power to emulate a computing substrate running a general intelligence (the brain simulated by a supercomputer) than to run a natively coded AGI. Designing the program which implements the native, non-emulative AGI is basically a "clever insight" problem, or perhaps more accurately a large series of clever insights.
Replies from: kgalias↑ comment by kgalias · 2014-10-03T15:46:42.445Z · LW(p) · GW(p)
I agree.
Why does this make it more plausible that a person can sit down and invent a human-level artificial intelligence than that they can sit down and invent the technical means to produce brain emulations?
Replies from: None↑ comment by [deleted] · 2014-10-03T19:04:39.281Z · LW(p) · GW(p)
We have the technical means to produce brain emulations. It requires just very straightforward advances in imaging and larger supercomputers. There are various smaller-scale brain emulation projects that have already proved the concept. It's just that doing that at a larger scale and finer resolution requires a lot of person-years just to get it done.
EDIT: In Rumsfeld speak, whole-brain emulation is a series of known-knowns: lots of work that we know needs to be done, and someone just has to do it. Whereas AGI involves known-unknowns: we don't know precisely what has to be done, so we can't quantify exactly how long it will take. We could guess, but it remains possible that clever insight might find a better, faster, cheaper path.
Replies from: kgalias↑ comment by kgalias · 2014-10-07T18:24:06.130Z · LW(p) · GW(p)
Sorry for the pause, internet problems at my place.
Anyways, it seems you're right. Technically, it might be more plausible for AI to be coded faster (higher variance), even though I think it'll take more time than emulation (on average).
comment by diegocaleiro · 2014-09-30T03:54:34.861Z · LW(p) · GW(p)
There's a confusing and wide ranging literature on embodied cognition, and how the human mind uses metaphors to conceive of many objects and events that happen in the world around us. Brain emulations, presumably, would also have a similar capacity for metaphorical thinking and, more generally, symbolic processing. It may be worthwhile to keep in mind though that some metaphor depend on the physical constituency of the being using them, and they may either fail to refer in an artificial virtual system, or not have any significant correlation with the way its effectors and affectors affect its environment.
So metaphors such as thinking of goals as destinations, of containers as bounded in particular ways, and of 'through' as a series of action steps as seen from the first person perspective may not be equally understandable or processed by these emulations (specially as they continue to interact with the world in ways inconsistent with our understanding of metaphors.)
I will comment on this more completely when we discuss indirect normativity and CEV-like approaches, when I'll try to make salient that in spite of our best efforts to "de-naturalize" ethics and request from the AGI that it performs in fail proof manner, we haven't even been able to evade some of the most deeply ingrained metaphors in our description of CEV as an empirical moral question.
Replies from: nkh↑ comment by nkh · 2014-09-30T04:48:56.107Z · LW(p) · GW(p)
As an aside, when you're speaking of these embodied metaphors, I assume you have in mind the work of Lakoff and Johnson (and/or Lakoff and Núñez)?
I'm sympathetic to your expectation that a lack of embodiment might create a metaphor "mistranslation". But, I would expect that any deficits could be remedied either through virtual worlds or through technological replacements of sensory equipment. Traversing a virtual path in a virtual world should be just as good a source of metaphor/analogy as traversing a physical path in the physical world, no? Or if it weren't, then inhabiting a robotic body equipped with a camera and wheels could replace the body as well, for the purposes of learning/developing embodied metaphors.
What might be more interesting to me, albeit perhaps more speculative, is to wonder about the kinds of new metaphors that digital minds might develop that we corporeal beings might be fundamentally unable to grasp in quite the same way. (I'm reminded here of an XKCD comic about "what a seg-fault feels like".)
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-10-02T06:40:48.439Z · LW(p) · GW(p)
Yes I did mean Lakoff and similar work (such as conceptual blending by Faulconnier and Analogy as the Fuel and Fire of Thinking by Hofstadter).
Yes virtual equivalents would (almost certainly) perform the same operations as their real equivalents.
No, this would not solve or get anywhere near solving the problem, since what matters is how the metaphors work, how source and target domains are acquired, to what extend would the machine be able to perform the equivalent transformations etc...
So this is not something that A) Is already solved. - nor is it something that B) Is in the agenda of what is expected to be solved in due time. - Furthermore this is actually C) Not being currently tackled by researchers at either FHI, CSER, FLI or MIRI (so it is neglected). - Someone might be inclined to think that Indirect Normativity will render this problem moot, but this is not the case either, which we can talk about more when Indirect Normativity appears in the book.
Which means it is high expected value to be working on it. If anyone wants to work on this with me, please contact me. I'll help you check out whether you also think this is neglected enough to be worth your time.
Notice that to determine whether solving this is relevant, and also many of the initial steps towards actually solving it, it is not necessary to have advanced math knowledge.
comment by lukeprog · 2014-09-30T03:51:17.611Z · LW(p) · GW(p)
The AI section is actually very short, and doesn't say much about potential AI paths to superintelligence. E.g. one thing I might have mentioned is the "one learning algorithm" hypothesis about the neocortex, and the relevance of deep learning methods. Or the arcade learning environment as a nice test for increasingly general intelligence algorithms. Or whatever.
Replies from: paulfchristiano, NxGenSentience↑ comment by paulfchristiano · 2014-09-30T04:20:37.591Z · LW(p) · GW(p)
One reason to avoid such topics is that it is more difficult to make forecasts based on current experiments (which I suppose is a reason to be concerned if things keep on going this way, since by the same token it may be hard to see the end until we are there).
The question I find most interesting about deep learning, and about local search approaches of this flavor more broadly, is the plausibility that they could go all the way with relatively modest theoretical insight. The general consensus seems to be "probably not," although also I think people will agree that this is basically what has happened over the last few decades in a number of parts of machine learning (deep learning in 2014 doesn't have too many theoretical insights beyond deep learning in 1999), and appears to be basically what happened in computer game-playing.
This is closely related to my other comment about evolution, though it's a bit less frightening as a prospect.
Replies from: SteveG↑ comment by SteveG · 2014-09-30T05:23:42.189Z · LW(p) · GW(p)
A lot of activities in the real world could be re-defined as games with a score.
-If deep learning systems were interfaced and integrated with robots with better object recognition and manipulation systems than we have today, what tasks would they be capable of doing?
-Can deep learning methods be applied to design? One important application would be architecture and interior design.
In order for deep learning to generate a plan for real-world action, first an accurate simulation of the real-world environment is required, is that correct?
↑ comment by NxGenSentience · 2014-10-04T11:45:03.019Z · LW(p) · GW(p)
lukeprog,
I remember readng Jeff Hawkins' On Intelligence 10 or 12 years ago, and found his version of the "one learning algorithm" extremely intriguing. I remember thinking at the time how elegant it was, and the multiple fronts on which it conferred explanatory power. I see why Kurzweil and others like it too.
I find myself, ever since reading Jeff's book (and hearing some of talks later) sometimes musing -- as I go through my day, noting the patterns in my expectations and my interpretations of the day's events -- about his memory - prediciton model. Introspectively, it resonates so well with the observed degrees of fit, priming, pruning to a subtree of possibility space, as the day unfolds, that it becomes kind of automatic thinking.
In other words, the idea was so intuitively compelling when I heard it that it has "snuck-in" and actually become part of my "folk psychology", along with concepts like cognitive dissonance, the "subconscious", and other ideas that just automatically float around in the internal chatter (even if not all of them are equally well verified concepts.)
I think Jeff's idea has a lot to be said for it. (I'm calling it Jeff's, but I think I've heard it said, since then, that someone else independently, earlier, may have had a similar idea. Maybe that is why you didn't mention it as Jeff's yourself, but by its conceptual description.) It's one of the more interesting ideas we have to work with, in any case.
comment by diegocaleiro · 2014-09-30T03:44:50.981Z · LW(p) · GW(p)
Omohundro has a more recent paper dabbling on the same topics of the one linked above.
comment by lukeprog · 2014-09-30T01:12:21.236Z · LW(p) · GW(p)
Relevant to WBE forecasting: Physical principles for scalable neural recording.
Replies from: NxGenSentience↑ comment by NxGenSentience · 2014-10-05T14:04:26.324Z · LW(p) · GW(p)
A nice paper, as are the others this article's topic cloud links with.
comment by KatjaGrace · 2014-09-30T01:04:15.168Z · LW(p) · GW(p)
A superintelligence is defined as ‘any intellect that greatly exceeds the cognitive performance of humans in virtually all domains of interest’ (p22). By this definition, it seems some superintelligences exist: e.g. basically economically productive activity I can do, Google can do better. Does I.J.Good’s argument in the last chapter (p4) apply to these superintelligences?
To remind you, it was:
Replies from: JoshuaFox, SilentCal, paulfchristianoLet an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an 'intelligence explosion,' and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep under control.
↑ comment by JoshuaFox · 2014-09-30T06:50:31.806Z · LW(p) · GW(p)
It's pretty clear that Google does not scale linearly to the number of people. As a company gets very big, it hits strongly diminishing returns, both in its effectiveness and its internal alignment towards consistent, unified goals.
Organizations grow in power slowly enough that other organizations arise to compete with them. In the case of Google, this can be other companies and also governments.
An organization may be greater than human in some areas, but there is a limit to its ability to "explode."
↑ comment by SilentCal · 2014-10-01T20:10:12.612Z · LW(p) · GW(p)
To paint the picture a bit more: If (some) corporations are more intelligent than individuals, corporations should be able to design better (smarter) corporations than themselves (since they were designed by humans), and these should be able to design even better ones, and so on.
We do have consulting firms that are apparently dedicated to studying business methods, and they don't seem to have undergone any kind of recursive self-improvement cascade.
So why is this? One possibility is that intelligence is not general enough. Another is that there is a sufficiently general intelligence, but corporations don't have more of it than people.
A third option, which I at least partly endorse, is that corporations aren't entirely designed by individuals; they're designed by an even larger aggregate: culture, society, the market, the historical dialectic, or some such, which is smarter than they are.
To carry this notion to its extreme, human intelligence is what a lone human growing up in the wilderness has. Everything above that is human-society intelligence.
Replies from: gwern, Azathoth123, Lumifer↑ comment by gwern · 2014-10-01T20:33:05.079Z · LW(p) · GW(p)
To paint the picture a bit more: If (some) corporations are more intelligent than individuals, corporations should be able to design better (smarter) corporations than themselves (since they were designed by humans), and these should be able to design even better ones, and so on.
Eliezer has argued that corporations cannot replicate with sufficient fidelity for evolution to operate, which would also rule out any sort of corporate self-improvement: http://lesswrong.com/lw/l6/no_evolutions_for_corporations_or_nanodevices/
A second problem lies in the mechanics, even assuming sufficient fidelity: the process is adversarial. Any sort of self-improvement loop for corporations (or similar ideas, like perpetuities) has to deal with the basic fact that it's, as the Soylent Green joke goes, 'made of people [humans]!' There are clear diseconomies of scale due to the fact that you're inherently dealing with humans: you cannot simply invest a nickel and come back to a cosmic fortune in 5 millennia because if your investments prosper, the people managing it will simply steal it or blow the investments or pay themselves lucratively or the state will steal it (see: the Catholic Church in England and France, large corporations in France, waqfs throughout the Middle East, giant monasteries in Japan and China...) If some corporation did figure out a good trick to improve itself, and it increased profitability and took over a good chunk of its market, now it must contend with internal principal-agent problems and dysfunctionality of the humans which comprise it. (Monopolies are not known for their efficiency or nimbleness; but why not? They were good enough to become a monopoly in the first place, after all. Why do they predictably decay? Why do big tech corporations seem to have such difficulties maintaining their 'culture' and have to feed voraciously on startups, like Bathory bathing in the blood of the young or mice receiving transfusions?)
Any such corporate loop would fizzle out as soon as it started to yield some fruit. You can't start such a loop without humans, and humans mean the loop won't continue as they harvest the fruits.
Of course, if a corporation could run on hardware which didn't think for itself and if it had some sort of near-magical solution to principal-agent problems and other issues (perhaps some sort of flexible general intelligence with incentives and a goal system that could be rewired), then it might be a different story...
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-01T21:29:33.923Z · LW(p) · GW(p)
So you would change the line,
...Since the design of [companies] is one of these intellectual activities, an ultraintelligent [company] could design even better [companies]..
to something like 'Since the design of [companies] is one of these intellectual activities, then - if anyone could reliably design companies at all - an ultraintelligent [company] could design even better companies, though at a decreasing rate due to diseconomies of scale'?
Replies from: gwern↑ comment by gwern · 2014-10-01T21:58:54.427Z · LW(p) · GW(p)
though at a decreasing rate due to diseconomies of scale
Not quite. My point here is that human-based corporations have several flaws which I think cumulatively bar any major amount of self-improvement: they can't perpetuate or replicate themselves very well which bars self-improvement or evolving better versions of themselves (because they are made of squishy parts like pieces of paper and humans; there is nothing remotely equivalent to 'DNA' or 'source code' for a corporation which could be copied with high fidelity), and if they did, their treacherous components (humans) would steal any gains.
If you could make a corporation out of something more reliable and concrete like computer programming, and if you could replace the treacherous components with more trustworthy components, then the Goodian loop seems possible to me. Of course, at that point, one would just consider the corporation as a whole to be an intelligence with perhaps a slightly exotic decentralized architecture of highly-powered neural networks glued together by some framework code, like how a human brain can be seen as a number of somewhat independent regions glued together by networks of neurons, and it would just be a special case of the original Goodian loop 'Since the design of another [intelligence] is an activity...'.
Replies from: Nornagest↑ comment by Nornagest · 2014-10-01T22:31:56.751Z · LW(p) · GW(p)
there is nothing remotely equivalent to 'DNA' or 'source code' for a corporation which could be copied with high fidelity
Franchising seems to work fairly well. Although I suppose that's slightly different: you have one entity whose business it is to create and promote a highly reliable and reproducible business model, and then a whole bunch of much smaller entities running that model and sending kickbacks to the parent company. But the parent's business model and its children's don't have much in common.
Are there any franchise-like organizations that spread peer to peer? I don't know of any, but this isn't my field.
Replies from: gwern↑ comment by gwern · 2014-10-01T22:48:59.844Z · LW(p) · GW(p)
Franchising isn't that common - I only seem to hear of it in the food industry, anyway. It seems to be good for a few simple niches where uniformity (predictability) is itself valued by customers at the expense of quality.
Replies from: Nornagest, KatjaGrace↑ comment by KatjaGrace · 2014-10-02T00:47:16.448Z · LW(p) · GW(p)
Even if franchising only arises in specific demand circumstances, it suggests that it is possible to replicate a business more-or-less, and that there are other reasons why it isn't done more often. And for some kind of evolution, you don't really need a peer to peer spreading franchise - if the parent organization creates new offshoots more like the ones that went better last time, you would have the same effect, and I bet they do.
Also, I don't think replication is required in the Good argument - merely being able to create a new entity which is more effective than you.
Replies from: gwern↑ comment by gwern · 2014-10-02T14:57:16.487Z · LW(p) · GW(p)
Even if franchising only arises in specific demand circumstances, it suggests that it is possible to replicate a business more-or-less
No, it suggests it's possible to replicate a few particular businesses with sufficient success. (If the franchisee fails, that's not a big problem for the franchiser.) The examples I know of are all fairly simple businesses like fast food. Their exceptionality in this respect means they are the exception which proves the rule.
Replies from: Lumifer↑ comment by Lumifer · 2014-10-02T15:41:06.424Z · LW(p) · GW(p)
No, it suggests it's possible to replicate a few particular businesses with sufficient success
All startups (by Paul Graham's definition) rely on massively replicating a successful business element, for example.
The boundaries of a firm are, in certain ways, arbitrary. A firm can "replicate" by selling franchises, but it can also replicate by opening new offices, new factories, etc.
Some examples: the big four accounting firms, test prep, offshore drilling, cell service infrastructure...
↑ comment by Azathoth123 · 2014-10-04T07:05:59.586Z · LW(p) · GW(p)
A third option, which I at least partly endorse, is that corporations aren't entirely designed by individuals; they're designed by an even larger aggregate: culture, society, the market, the historical dialectic, or some such, which is smarter than they are.
They were designed by Gnon, same as humans.
↑ comment by Lumifer · 2014-10-01T20:31:24.246Z · LW(p) · GW(p)
The fourth option is that there are resource constraints and they matter.
Replies from: SilentCal, KatjaGrace↑ comment by KatjaGrace · 2014-10-01T21:31:11.756Z · LW(p) · GW(p)
Could you rephrase what you mean more specifically? Does apply to AI also?
Replies from: Lumifer↑ comment by Lumifer · 2014-10-02T15:17:34.480Z · LW(p) · GW(p)
My meaning is very straightforward. While we often treat computation as abstract information processing, in reality it requires and depends on certain resources, notably a particular computing substrate and a usable inflow of energy. The availability of these resources can and often does limit the what can be done.
Physically, biologically, and historically resource limits are what usually constrains the growth of systems.
The limits in question are rarely absolute, of course, and often enough there are ways to find more resources or engineer away the need for some particular resource. However that itself consumes resources (notably, time). For a growing intelligence resource constraints might not be a huge problem in the long term, but they are often the bottleneck in the short term.
↑ comment by paulfchristiano · 2014-09-30T03:50:10.171Z · LW(p) · GW(p)
This argument doesn't say anything about the likely pace of such an intelligence explosion. If you are willing to squint, it's not too hard to see ourselves as living through one.
Google has some further candidates. While it can accomplish much more than its founders:
- It uses more resources to do so (in several senses, though not all)
- Google's founders probably could not produce something as effective as Google with very high probability (ex ante)
Owing to the first point, you might expect an "explosion" driven by these dynamics to bottom out when all of society is organized as effectively as google, since at this point there is no further room for development using similar mechanisms.
Owing to the second point, you might not expect there to be any explosion at all. Even if Google was say 100x better than its founders at generating successful companies, it is not clear whether it would create more than 1 in expectation.
comment by KatjaGrace · 2014-10-02T07:49:13.202Z · LW(p) · GW(p)
Bostrom talks about a seed AI being able to improve its 'architecture', presumably as opposed to lower level details like beliefs. Why would changing architecture be particularly important?
Replies from: Jeff_Alexander, NxGenSentience↑ comment by Jeff_Alexander · 2014-10-03T02:48:51.645Z · LW(p) · GW(p)
One way changing architecture could be particularly important is improvement in the space- or time-complexity of its algorithms. A seed AI with a particular set of computational resources that improves its architecture to make decisions in (for example) logarithmic time instead of linear could markedly advance along the "speed superintelligence" spectrum through such an architectural self-modification.
↑ comment by NxGenSentience · 2014-10-03T12:05:59.036Z · LW(p) · GW(p)
One’s answer depends on how imaginative one wants to get. One situation is if the AI were to realize we had unknowingly trapped it in too deep a local optimum fitness valley, for it to progress upward significantly w/o significant rearchitecting. We might ourselves be trapped in a local optimality bump or depression, and have transferred some resultant handicap to our AI progeny. if it, with computationally enhanced resources, can "understand" indirectly that it is missing something (analogy: we can detect "invisible" celestial objects by noting perturbations in what we can see, using computer modeling and enhanced instrumentation), it might realize a fundamental blind spot was engineered-in, and redesign is needed. (E.G, what if it realizes it needs to have emotion -- or different emotions -- for successful personal evolution toward enlightenment? What if it is more interested in beauty and aesthetics, than finding deep theorems and proving string theory? We don't really know, collectively, what "superintelligence" is. To the hammer, the whole world looks like... How do we know some logical positivist engineer's vision of AI nirvanna, will be shared by the AI? How many kids would rather be a painter than a Harvard MBA "just like daddy planned for?" Maybe the AIs will find things that are "analog", like art, more interesting than what they know in advance they can do, like anything computable, which becomes relatively uninteresting? What will they find worth doing, if success at anything fitting halting problem parameters (and they might extend and complete those theorems first) is already a given?
comment by Larks · 2014-10-01T02:24:33.287Z · LW(p) · GW(p)
I wonder if advances in embryo selection might reduce fertility. At the moment I think one of the few things keeping the birth rate up is people thinking of it as the default. But embryo selection seems like it could interrupt this: a clearly superior option might make having children naturally less of a default option, but with using embryo selection novel enough to seem like a discretionary choice, and therefor not replacing it.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-01T02:38:28.887Z · LW(p) · GW(p)
Interesting thought. I wonder if there are historical analogs we can look to for evidence on this - I can't think of any off the top of my head.
Replies from: DanielFilan↑ comment by DanielFilan · 2020-07-17T04:09:31.494Z · LW(p) · GW(p)
Perhaps surrogacy might be such an analogue?
comment by KatjaGrace · 2014-09-30T12:42:13.119Z · LW(p) · GW(p)
What evidence do we have about the level of detail needed to emulate a mind? Whole Brain Emulation: A Roadmap provides a list of possible levels (see p13) and reports on an informal poll in which experts guessed that at least the ‘spiking neural network’ would be needed, and perhaps as much as the eletrophysiology (e.g. membrane states, ion concentrations) and metabolome (concentrations of metabolites and neurotransmitters)(p14). Why might experts believe these are the relevant levels?
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-30T12:43:19.369Z · LW(p) · GW(p)
Robin Hanson makes an interesting argument in response to criticisms like Richard Jones' above, here.
comment by KatjaGrace · 2014-09-30T12:38:03.445Z · LW(p) · GW(p)
How would you like this reading group to be different in future weeks?
Replies from: NxGenSentience, Jeff_Alexander↑ comment by NxGenSentience · 2014-10-05T13:53:56.550Z · LW(p) · GW(p)
Would you consider taking a one extra week pause, after next week's presentation is up and live (i.e. give next week a 2 week duration)? I realize there is lots of material to cover in the book. You could perhaps take a vote late next week to see how the participants feel about it. For me, I enjoy reading all the links and extra sources (please, once again, do keep those coming.) But it exponentially increases the weekly load. Luke graciously stops in now and then and drops off a link, and usually that leads me to downloading half a dozen other PDFs that I find that fit my research needs tightly, which itself is a week's reading. Plus the moderator's links and questions, and other participants.
I end up rushing, and my posts become kind of crappy, compared to what they would be. One extra week, given this and next week;s topic content, would help me... but as I say, taking a vote would be the right way. Other areas of the book, as I glance ahead, won't be as central and thought-intensive (for me, idiosyncratically) so this is kind of an exceptional request by me, as I forsee it.
Otherwise, things are great, as I mentioned in other posts.
↑ comment by Jeff_Alexander · 2014-10-03T08:20:36.366Z · LW(p) · GW(p)
What are some ways it might be modified? The summaries are clear, and the links to additional material quite apt and helpful for those who wish to pursue the ideas in greater depth. So the ways in which one might modify the reading group in future weeks are not apparent to me.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-03T21:09:28.827Z · LW(p) · GW(p)
There could be more or fewer of various parts; I could not link to so many things if nobody actually wants to pursue things to greater depth; the questions could be different in level or kind; the language could be suited to a different audience; we could have an online meetup to talk about the most interesting things; I could try to interview a relevant expert and post it; I could post a multiple choice test to see if you remember the material; the followup research questions could be better suited for an afternoon rather than a PhD...
Replies from: NxGenSentience, Jeff_Alexander↑ comment by NxGenSentience · 2014-10-04T15:18:51.603Z · LW(p) · GW(p)
Please keep the links coming at the same rate (unless the workload for you is unfairly high.) I love the links... enormous value! It may take me several days to check them out, but they are terrific! And thanks to Caitlin Grace for putting up her/your honors thesis. Wonderful reading! Summaries are just right, too. "If it ain't broke, don"t fix it." I agree with Jeff Alexander, above. This is terrific as-is. -Tom
↑ comment by Jeff_Alexander · 2014-10-04T06:38:19.432Z · LW(p) · GW(p)
the followup research questions could be better suited for an afternoon rather than a PhD
Could they? Very well! I hereby request at least one such research question in a future week, marked as such, for comparison to the grander-scale research questions.
An online meetup might be nice, but I'm not confident in my ability to consistently attend at a particular time, as evinced by my not generally participating live on Monday evenings.
Interviewing a relevant expert is useful and related, but somewhat beyond the scope of a reading group. I vote for this only if it suits your non-reading-group goals.
Multiple choice questions are a good idea, but mainly because taking tests is a useful way to study. Doing it to gather data on how much participants remember seems less useful, unless you randomly assign participants to differently arranged reading groups and then want to assess effectiveness of different approaches. (I'm not suggesting this latter bit be done.)
Thank you for the examples.
comment by KatjaGrace · 2014-09-30T02:20:18.352Z · LW(p) · GW(p)
If there are functional brain emulations at some point, how expensive do you think the first ones will be? How soon will they be cheap enough to replace an average human in their job?
Replies from: SteveG↑ comment by SteveG · 2014-09-30T02:55:52.196Z · LW(p) · GW(p)
For a wide variety of reasons, human whole-brain emulations are unlikely to be used to replace workers. If high-fidelity whole brain emulation becomes available, employers will rapidly seek to acquire improved versions with characteristics that no human has.
The human brain has a series of limitations which could be readily engineered away in a hybrid neuromorphic system. Here are just a few:
Most people cannot reliably remember a twelve-digit number they just heard five minutes later. If an employer could design a worker's mind, why give it this limitation?
If the goal is to control a piece of equipment or machinery, the best solution may not be to re-purpose simulated neurons running to imaginary fingers. Instead, interface the piece of equipment more directly to the simulated mind.
We require much longer to perform a calculation than computers do, and we often produce the wrong solution. If a simulated worker had to do arithmetic, why would it use neural processing?
The vagus nerve and much of the brain stem seem unnecessary if they not attached to a very human-like body. Why include them in a worker with no body?
Our attention frequently drifts off-task. An optimal worker would not.
Why create a worker which loses its patience or feels disrespected by customers who are vaguely insulting but not worth correcting?
Human workers require monetary rewards and/or job satisfaction. The ideal worker would continue to operate without either. If technology was sufficient to produce a high-fidelity brain emulation, incentives would be very high to engineer these needs out of it.
People need sleep to clear waste products from the brain via the glymphatic system (I recommend that anyone interested in neurology read about this system), perhaps along with other purposes. A hi-fidelity whole-brain emulation might have to simulate this process, but why engineer a worker that gets tired or has to sleep?
People might have moral qualms about shutting down a hi-fidelity whole brain emulation. Employers would prefer to work with systems that they can turn on and off at will.
We should be imagining a future where unpaid hybrid-neuromorphic or algorithmic AI which is quite different from us is performing additional functions in the economy.
Then perhaps we should imagine an economy where human labor is only required for tasks where people specifically prefer that the task is performed by a person.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-30T03:13:06.741Z · LW(p) · GW(p)
Some of these modifications seem relatively straightforward (e.g. I'd guess it's easier to attach an emulated mind to a piece of machinery than to make it a robot body which can then control the machinery). In other cases it seems you are assuming that having a brain emulation means being able to design a mind arbitrarily. Are you supposing that in order to have a brain emulation, you will need a fairly detailed understanding of how minds work, or that you will just be able to play around with emulations a lot more, perhaps destroying and copying them to create artificial selection? (Or something else?)
For instance, it's not obvious to me how, given a brain emulation, you would create a worker who does not lose focus on the task at hand.
Replies from: SteveG↑ comment by SteveG · 2014-09-30T04:51:19.042Z · LW(p) · GW(p)
First of all, there are a tremendous number of ways to improve on the human mind, so if you wonder about one example or another, then my point is still valid: Hi-fidelity human whole-brain emulation is not the employer's best alternative to get work done.
Just to add a few more:
This virtual worker would be able to reference a recording of every conversation it has ever had and replay every encounter pixel-by-pixel.
For that matter, it can reference any conversation in a much larger database.
The virtual worker does not need to metabolize glucose in order to operate, and it does not have a blood supply. Its nutrition levels, oxygen levels and hormone levels are all simulated to begin with, so why not optimize them for performance?
The employer could simulate dosing the virtual worker with performance-enhancing drug, then immediately return it to a condition where the drug was not present.
Suppose two virtual employees were required to solve a problem in tandem. Would they really communicate by forming fake neurological instructions to fake sets of vocal chords, then re-processing this information through fake ears?
Not for long, anyway.
Suppose that a virtual employee was going to operate in a laboratory. The employer could easily give it a software tool which remembers the contents of every flask and vial, and what cabinet each vial is in, for an entire laboratory complex.
There is no need for a virtual employee to ever forget where an object was placed or the contents of a container.
On the question of whether we will know enough to re-engineer a simulated brain prior to the development of high-fidelity whole brain emulation: Way before this technology exists, NIH and international colleagues will produce a far less granular map of the human connectome at every life stage. We will have this map both for workers who are very effective and for workers who are less effective. Employers will select and enhance the effective traits.
Most any method of neurological enhancement available for wetware brains will be at least as effective on virtual brains, and generally more effective. For example, virtual brains need not be attached to livers which metabolize drugs in a non-linear way.
As for attention in particular, yes, I do feel comfortable that given all of the research work being applied to that specific issue, there is a good chance that we will have a grasp of the neurological basis behind attention way prior to the time when we can do high-fidelity whole brain emulation.
Being able to alter the mechanism behind, for example, attention, rewards or pain may require a lot less than an arbitrary ability to re-engineer the brain.
There is another way to come at this issue- let's suppose that we are talking about doing office work like budget or accounting.
Why in the world would an employer want its virtual accountant to enter numbers into a spreadsheet using imaginary fingers typing into an imaginary keyboard?
They are likely to find a better way.
If the virtual employee was tasked to do some writing, they would be more effective with some kind of direct access to quotations, a dictionary and a thesaurus, rather than reading such documents with fake eyes.
Tremendous incentives would exist to re-engineer every important software package and reference work in a way that is specifically tailored to make these virtual employees more efficient.
In a very short time, all of these various optimizations will cause the system to diverge from being human.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-30T12:26:25.005Z · LW(p) · GW(p)
I agree various optimizations like these will be made, at least in the absence of anything else radical getting in the way of this trajectory. Though I tend to think improved memories and different modes of communication and the like would not make humans all that inhuman in the scheme of things. These don't seem much more extreme than the addition of the pencil, the telephone and coffee to our set of tools.
I like your concrete list.
Replies from: SteveG↑ comment by SteveG · 2014-09-30T16:17:43.138Z · LW(p) · GW(p)
So, I am just going to make one more pass at this-what we have is:
A simulated brain which does not die and has substantially engineered emotions and a different rewards system.
Perhaps operating at ten or a hundred times the speed
Which does not have to be paid in money
With a new kind of connection to other brains
A new kind of connection to machinery
Which does not see with eyes or hear with ears
Which can include a hundred versions of itself, each of which was trained in a different language or job specialty
With a vast ability to calculate and remember
Has neither hunger, thirst nor sexuality
Which feels pain or pleasure largely on command
No hormones, no sleep, no heartbeat
This system seems quite different from you, me, or a social unit of a number of people which has access to computers. For that matter this whole vision is just an interim phase on the way to something that strings neurologically-inspired elements and algorithms together in entirely novel ways, or abandons neurological inspiration entirely.
An algorithmic economy of many human-like whole brain emulations is not a consistent future vision. We should be thinking about various kinds of neuromorphic systems with diverse modes of cognitive function that replaces capitalism as we know it with something at least considerably different.
comment by SteveG · 2014-09-30T01:46:56.791Z · LW(p) · GW(p)
The concept of "Seed AI" was introduced in this chapter. I am interested to hear whether other people have opinions about the the plausibility of a "Seed AI."
Linguistic processing seems like an area where a small amount of code operating on a large database of definitions, relationships and text or recorded scenes along with relationships could produce some significant results.
General planning algorithms could also very compact.
An AI system capable of performing design perhaps could be developed in a relatively small amount of code, if it had access to a vast database of existing designs which it searches for possible modifications.
Replies from: TRIZ-Ingenieur↑ comment by TRIZ-Ingenieur · 2014-10-03T00:48:34.787Z · LW(p) · GW(p)
A team of human engineers with assistance of specialized engineering software and internet access to nearly unlimited amount of information can be viewed as an superintelligent entity.
Until a Seed AI reaches higher development speed in unsupervised self-improvement compared to human engineering it must have already highly superintelligent engineering skills.
A HLMI is like a lone developer not capable to manage the development complexity.
comment by KatjaGrace · 2014-09-30T01:22:57.932Z · LW(p) · GW(p)
Bostrom discusses ‘high-fidelity emulations’, ‘distorted emulations’ and ‘generic emulations’ (p33). If society started to produce emulations, how much do you think it would matter which of these kinds were produced?
comment by KatjaGrace · 2014-09-30T01:19:25.625Z · LW(p) · GW(p)
It is sometimes suggested that if humanity develops upload, we will naturally produce neuromorphic AGI slightly earlier or shortly afterward. What do you think of this line of reasoning? Section 3.2 of Eckersley & Sandberg (2013) is relevant.
comment by KatjaGrace · 2014-09-30T01:09:30.717Z · LW(p) · GW(p)
Did you change your mind about anything as a result of this week's reading?
Replies from: Larks↑ comment by Larks · 2014-10-01T02:13:55.952Z · LW(p) · GW(p)
I changed my mind on the impact of embryo selection on my personal reproductive plans. Bostrom gives
"five to ten years to gather the information needed for significantly effective selection among a set of IVF embryos."
That's soon enough that it's plausible I could have some of my later children using it. I wonder what the impact would be on family dynamics, especially if anything like the 20 IQ points could be realized.
comment by KatjaGrace · 2014-09-30T01:09:01.457Z · LW(p) · GW(p)
Who are you? Would you like to introduce yourself to the rest of us? Perhaps tell us about what brings you here, or what interests you.
Replies from: nkh, KatjaGrace, kgalias, Sebastian_Hagen, NxGenSentience, SteveG↑ comment by nkh · 2014-09-30T06:04:15.282Z · LW(p) · GW(p)
Hi! I'm Nathan Holmes, and I've bounced around a bit educationally (philosophy, music, communication disorders, neuroscience), and am now pursuing computer science with the intent of, ideally, working on AI/ML or something related to implants. (The latter may necessitate computer engineering rather than CS per se, but anyway.)
One of my lifelong interests has been understanding intelligence and how minds work.
Previously, in spite of having been an off-and-on follower of Less Wrong (and, earlier, Overcoming Bias, when EY published there), I hadn't really treated unfriendly AI as worthy of much thought, but reading a few more recent MIRI essays convinced me I should take it seriously--especially if I'm interested in AI research myself. Hence the decision to read Superintelligence.
↑ comment by KatjaGrace · 2014-09-30T22:49:22.218Z · LW(p) · GW(p)
Nice to meet you all. I live in Berkeley, am a researcher at MIRI, and write a blog. I'm particularly interested in seeing whether AI is the highest priority thing to work on, and if so what should be done.
↑ comment by Sebastian_Hagen · 2014-09-30T21:50:09.213Z · LW(p) · GW(p)
I stumbled across EY's writings back before the start of Overcoming Bias, which eventually got me interested in transhumanism, the idea of an intelligence explosion, the Friendliness design problem - oh yes, and also rationality. I concluded back then that how we deal with upcoming supertechnologies (MNT, SI, possibly emulation) will be the deciding factor in what happens to our civilization (or the parts that aren't in simulations with close termination conditions, in any case), and that hasn't changed.
↑ comment by NxGenSentience · 2014-10-04T12:34:07.865Z · LW(p) · GW(p)
Hi everyone!
I'm Tom. I attended UC Berkeley a number of years ago, double-majored in math and philosophy, graduated magna cum laude, and wrote my Honors thesis on the "mind-body" problem, including issues that were motivated by my parallel interest in AI, which I have been passionately interested in all my life.
It has been my conviction since I was a teenager that consciousness is the most interesting mystery to study, and that, understanding how it is realized in the brain -- or emerges therefrom, or whatever it turns out to be -- will also almost certainly give us the insight to do the other main goal of my life, build a mind.
The converse is also true. If we learn how to do AI, not GOFAI wiht no awareness, but AI wilh full sentience, we will almost certainly know how the brain does it. Solving either one, will solve the other.
AI can be thought of as one way to "breadboard" our ideas about biological information processing.
But it is more than that to me. It is an end in itself, and opens up possibilities so exciting, so penultimate, that achieving sentient AI would be equal, or superior, to the experience (and possible consequences) of meeting an advanced extraterrestrial civilization.
Further, I think that solving the biological mind body problem, or doing AI, is something within reach. I think it is the concepts that are lacking, not better processors, or finer grained fMRIs, or better images of axon hillock reconformation during exocytosis.
If we think hard, really really hard, I think we solve these things with the puzzle pieces we have now (just maybe.) I often feel that everything we need is on the table, and we just need to learn how to see it with fresh eyes, order it, and put it together. I doubt a "new discovery", either in physics, cognitive neurobiology, or philosophy of mind, comp-sci, etc, will make the design we seek pop-out for us.
I think it is up to us now, to think, conceptualize, integrate, and interdisciplinarily cross-pollinate. The answer is, I think, at lest major pieces of it, available and sitting there, waiting to be uncovered.
Other than that, since graduation I have worked as a software developer (wrote my obligatory 20 million lines of code, in a smattering of 6 or 7 languages, so I know what that is like), and many other things, but am currently unaffiliated, and spend 70 hours a week in freelance research. Oh yes, I have done some writing (been published, but nothing too flashy).
RIght now, I work as a freelance videographer and photographer and editor. Corporate documentaries and training videos, anything you can capture with a nice 1080 HDV camcorder or a Nikon still.
Which brings me to my youtube channel, that is under construction. I am going to put a couple "courses" .... organized, rigorous topic sequences of presentations, of the history of AI, but in particular, my best current ideas (I have some I think are quite promising) on how to move in the right direction to achieving sentience.
I got the idea for the video series from watching Leonard Susskind's "theoretical minimum" internet lecture series on aspects of physics.
This will be what I consider to be the essential theoretical minimum (with lessons from history), plus the new insights I am in the process of trying to create, cross research, and critique, into some aspects of the approach to artificial sentience that I think I understand particularly well, and can help by promoting discussion of.
I will clearly delineate pure intellectual history, from my own ideas, throughout the videos, so it will be a fervent attempt to be honest. THen I will also just get some new ideas out there, explaining how they are the same, and how they are different, or extensions of, accepted and plausible principles and strategies, but with some new views... so others can critique them, reject them, or build on them, or whatever.
The ideas that are my own syntheses, are quite subtle in some cases, and I am excited about using the higher "speaker-to-audience semiotic bandwidth" of the video format, for communicating these subtleties. Picture-in-picture, graphics, even occasional video clips from film and interviews, plus the ubiquitous whiteboard, all can be used together to help get across difficult or unusual ideas. I am looking forward to leveraging that and experimenting with the capabilities of the format, for exhibiting multifaceted, highly interconnected or unfamiliar ideas.
So, for now, I am enmeshed in all the research I can find that helps me investigate what I think might be my contribution. If I fail, I might as well fail by daring greatly, to steal from Churchill or whomever it was (Roosevelt, maybe?) But I am fairly smart, and examined ideas for many years. I might be on to one or two pieces of what I think is the puzzle. So wish me luck, fellow AI-ers.
Besides, "failing" is not failing; it is testing your best ideas. The only way to REALLY fail, is to do nothing, or to not put forth your best effort, especially if you have an inkling that you might have thought of something valuable enough to express.
Oh, finally, people are telling where they live. I live in Phoenix, highly dislike being here, and will be moving to California again in the not too distant future. I ended up here because I was helping out an elderly relative, who is pretty stable now, so I will be looking for a climate and intellectual environment more to my liking, before long.
okay --- I'll be talking with you all, for the next few months in here... cheers. Maybe we can change the world. And hearty thanks for this forum, and especially all the added resource links.
comment by KatjaGrace · 2014-09-30T01:01:50.952Z · LW(p) · GW(p)
How plausible do you find whole-brain emulation? Do you think that in one hundred years, it will be possible to run a model of your brain on a computer, such that it behaves much like you?
Replies from: SteveG↑ comment by SteveG · 2014-09-30T01:32:33.104Z · LW(p) · GW(p)
Neuromorphic AI/low-fidelity whole-brain emulation, is likely to precede hi-fidelity whole-brain emulation.
Therefore, if we want to understand possible pathways to AI, I think it pays to focus attention on technologies which are inspired by neuroscience but either emulate the human mind in an inexact way or use somewhat neuron-like computing elements in new ways.
The level of detail to choose for simulated neurons seems very controversial.
The Blue Brain Project models neurons with a lot of complicated internal state, while the DARPA Synapse Project is going for very simple neurons.
http://www.eecs.berkeley.edu/~phj/cs267/hw0/
http://www.artificialbrains.com/darpa-synapse-program
The projects have different goals- DARPA wants to create devices for applications, while The European Brain Initiative is motivated more by trying to understand biological phenomena.
At 256 Million synapses per chip, the DARPA project could string together less than one million processors to reach the number of synapses in the brain. That goal is within reach, but how much can their simple neurons really do?
If simpler neuron-like components are sufficient, then far less computing capacity is required to build some kinds of neuromorphic AI.
Replies from: okay↑ comment by okay · 2014-09-30T02:04:36.030Z · LW(p) · GW(p)
Is there literature I could read on the differences between the performance of the neurons DARPA uses and the neurons Blue Brain uses?
Replies from: SteveG↑ comment by SteveG · 2014-09-30T02:13:01.177Z · LW(p) · GW(p)
I have a few scattered links, but I would also welcome a more detailed bibliography on the topic of new neurologically-inspired AI tools.
Both of these systems are doing something vastly different than the neural networks used in machine learning.
Deep Mind is yet another thing.
comment by KatjaGrace · 2014-09-30T12:40:52.533Z · LW(p) · GW(p)
Would you think of an emulation of your brain as you?
Replies from: Sebastian_Hagen↑ comment by Sebastian_Hagen · 2014-09-30T21:32:08.071Z · LW(p) · GW(p)
Given sufficient emulation and transfer detail, sure. I'm a piece of sapient software. The building blocks of matter as we understand them seem simple enough; it very much looks like there's no fancy functionality there that would give them any kind of special abilities to implement human minds in an unusual way. The interesting elements of human minds are all in higher-level structure.
Replies from: diegocaleiro, NxGenSentience↑ comment by diegocaleiro · 2014-10-02T07:28:51.931Z · LW(p) · GW(p)
This point of view assumes functionalism, but it feels like you only desire to commit to physicalism. If there are physicalist theories in which personal identity is not a functional property, then your claim would not hold. So try to check for perspectives either in philosophy of mind which are physicalist but not functionalist, or else in which personal identity is not a functional property.
For instance, Derek Parfit, by far the person in the world who dedicated most time to the question, does not conceive of Personal Identity as a functional property, but instead as a misguided intuition made of three distinct things, two of which functional.
Daniel Dennett, a commited naturalist, and an AI friendly physicalist monist if there ever was one, also does not consider personal identity to be a functional property.
For those who are reading this who have always been on board with the Lesswrong assumption that physicalism and functionalism are both correct and that personal identity is a functional property, I hope knowing that Dennett and Parfit both don't think this question of you-ness is as straightforward as you'd like gives at least a reason for pause.
But maybe your brain already is dying to use its cached thoughts about the generalized p-zombie principle and the uselessness of philosophy. In which case I suggest changing your reference class of who comments in these threads to be mostly non-mysterianists, and update on that.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-02T07:44:36.594Z · LW(p) · GW(p)
Does this 'functionalism' in the context of personal identity refer to views where your personal identity is determined by pragmatic considerations?
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-10-02T10:27:54.921Z · LW(p) · GW(p)
It refers to cases in which if you knew all the facts about the functions being performed by the systems that compose you (as seen from the outside) you would know all the facts about personal identity.
Other way of saying this is that there would be no way of changing personal identity without a change in function as well.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-10-02T15:18:54.431Z · LW(p) · GW(p)
Thanks. What is Parfit's non-functional thing?
↑ comment by NxGenSentience · 2014-10-03T16:00:29.159Z · LW(p) · GW(p)
edited out by author...citation needed, ill add later
comment by lukeprog · 2014-09-30T03:42:18.390Z · LW(p) · GW(p)
You mention by Randal Koene interview on WBE. I'd also mention the Ken Hayworth interview.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-30T04:07:24.006Z · LW(p) · GW(p)
Thanks, added.
comment by KatjaGrace · 2014-10-02T07:52:57.223Z · LW(p) · GW(p)
I pointed to Richard Jones arguing that you should only expect scale separation in designed systems. This seems a poor inference to me. Natural systems very often have 'designed' seeming features, due to selection, and he doesn't explain why scale separation would only come from a real designer, rather than selection. Further, it seems natural systems often actually have scale separation - i.e. you can model the system fine by only looking at items at a certain scale, ignoring their details. e.g. you can model planetary motion well without knowing the details of what is on or in the planets. You can model water well without knowing where its molecules are. You can model transfer of heat just fine without looking at where each molecule is.
comment by KatjaGrace · 2014-10-02T07:49:43.006Z · LW(p) · GW(p)
I feel like whole brain emulation is often considered implausible, but I don’t know of many good criticisms of its plausibility. Do you?
Replies from: NxGenSentience↑ comment by NxGenSentience · 2014-10-04T10:10:02.040Z · LW(p) · GW(p)
Why ‘WB’ in “WBE” is not well-defined and why WBE is a worthwhile research paradigm, despite its nearly fatal ambiguities.
Our community (in which I include cognitive neurobiologists, AI researchers, philosophers of mind, research neurologists, behavioral and neuro-zoologists and ethologists, and anyone here) has, for some years, included theorists who present various versions of “extended mind” theories.
Without taking any stances about those theories (and I do have a unique take on those) in this post, I’ll outline some concerns about extended brain issues.
I have to compress this so it fits, but I think my concerns will be pretty self-evident. I should say that this week has been a schedule crunch for me, so I apologize if some of what I adduce in the service this post's topic, is mentioned in one of the papers linked in the existing comments, or the moderators summary. I do read all of those links, eventually, and they are very helpful value-added resources... at least as valuable to me as what I have read thus far in Bostrom's book.
I’ll be making a video lecture with diagrams, some additional key ideas, and a more in-depth discussion of several issues touched on in this post, for the YouTube channel I am developing on my own. (The channel will be live in a few weeks.)
(I think a video with some graphics - even line drawings on a whiteboard - might be helpful to schematically depict some physiological structures and connecting causal feed lines that I'll mention, for readers whose pictorial imagination of some of the intracranial and extracranial "extended brain" structures I’ll discuss, doesn't readily come to mind.)
My overarching global point is this: There is no theory-neutral, intelligible definition of the term, ‘whole brain’.
Let me walk through this in enough detail to make the point compelling – and it is compelling, not just some technical quibble -- without burying any of us in physiological minutia.
First, let us pretend that we can limit our focus to just what is in the skull – a posit which I will criticize and withdraw in a moment.
Does “whole brain” include glia: such as oligodendrocytes and astrocytes? Glia (properly: “neuroglia”) actually outnumber “standard” neurons by 3 to 1, in the brain. See this reference: http://www.ncbi.nlm.nih.gov/books/NBK10869/
One of the more dramatic areas of continuing advance in our understanding of the functionally relevant neurobiology of the brain and CNS has, for nearly two decades now, involved neuroglia.
Article after article of impeccable science has expanded the consensus view of neuroglial function, to comprise much more than housekeeping, i.e., more than merely helping to implement aspects of the blood-brain barrier, or assisting phagocytosis after unfortunate neurons undergo apoptosis, and so on, as believed prior to about 20 years ago.
Some things now commonly known: Glia help regulate and recycle ATP and make it available to adjacent neurons and their mitochondria (as well as tracking local ATP reserve); they ballast, balance and reclaim the glutamate pool; they participate in neurosteroid signal pathways (into and out of the brain), and may help ballast local ion levels
The list is continually expanding, and includes functions relevant to learning, neuromodulation, reacting to stress and allostatic load, interacting with some inflammatory signaling pathways, and neuroplasticity.
Of course, the functions and contribution of myelin (Schwann cells) to normal, healthy neuronal behavior, are well known, as are numerous decimating diseases of myelin maintenance. Some reputable researchers think glia are not only under-emphasized, but might be crucial for unraveling some stubborn, still-unanswered questions relevant to cognition.
For example researchers are investigating mechanisms by which they may play a role as auxiliary signaling systems throughout the brain. Consider the phase-coupled “communication” of distantly separated ensembles of coherently oscillating neurons. Recall that these transiently – within each ensemble – organize into cooperative intra-ensemble oscillators, and a well-documented phenomenon commonly proposed as a way the brain achieves temporary “binding” across sensory modalities, as it constructs a unified object percept, is the simultaneous -- yet widely separated across the brain -- phase-locked and frequency coupled oscillations of multiple, separate, oscillating ensembles.
This (otherwise) spooky action-at-a-distance of comcommittantly oscillating distal ensembles might be undergirded by neuroglia.
In short, neuroglia (even without the more speculative roles being considered, like the very last one I mentioned) are not just “physiological” support for “real neurons” that do the “real information processing.” Rather, neuroglia strongly appear to participate on multiple levels in learning, information processing, mood, plasticity, and other functions on what seems to be a growing list.
So, it seems to me that you have to emulate neuroglia, in WBE strategies (or else bear the burden of explaining why you are leaving them out, like you would have to bear the burden of explaining why, e.g., you decided to omit pyramidal neurons from your WBE strategy.
Next, we must consider the hypothalamic-pituitary stalk. Here we have an interesting interface between “standard neuron and neurotransmitter behavior”, and virtually every other system in the body: immune, adrenal, gonadal… digestive, hepatic.
The hypothalmic-pituitary system is not just an outgoing gateway, regulating sleep, hunger, temperature, but is part of numerous feedback loops that come back and effect neuronal function. Consider the HPA system, so studied in depression and mood disorders. Amydiala and cingulate centers (and the cortex, which promotes and demotes traffic to areas of the hypothalamus based on salience) trigger corticotropin releasing factor, which goes out eventually triggering adrenalin and noradrenalin, blood sugar changes... the whole course of alerting responses, which are picked up globally by the brain and CNS. Thalamic filters change routing priorities (the thalamus is the exchange switchyard for most sensory traffic), NE and DA levels change (therefore, so does LTP, i.e. learning, which is responsive to alerting neurotransmitter and neuromodulator levels.)
My point so far is: does “whole brain” emulation mean we emulate this very subtle and complex neurohomonal “gateway” system (to the other systems of the body?)
Lastly, just two more, because this is running long.
Muscles as regulators of brain function. It is now known that voluntary muscle activity produces BDNF, the neurosteroid that everyone had heard about, if they have heard about any of them. BDNF is produced locally in muscle tissue and can be released into general circulation. Circulating BDNF and GDNF enter the brain (which also makes its own BDNF too), and docks with (intracranial) neurons' nuclear receptors, changing gene expression, ultimately regulating long term plasticity, synaptic remodeling, and general neuronal health.
BDNF is hugely important as a neuromodulator and neurosteroid. The final common pathway of virtually all antidepressant effectiveness on mood, is predomantly through BDNF.
And MOOD is very, very cognitive. It is not "just" background emotion. It effects memory, judgement, sensory filtering and salience-assignment, and attentional target selection. Mood, is a potent kind of global neuromodulator. (In fact, it is almost arbitrary, whether one wants to consider mood disorders to be cognitive disorders, or affective disorders.) It effects information processing, both thermodynamic (sub-semantic) and "semantically coupled" (useful to us -- experienced in the first person as contents of our thoughts, or to a system programmer who ignores thermodynamic but carefully choreographs the flow of) information that carries his software's semantic content (that which bears intentional or representational content, as in a mathematical model of a jet turbine, or whatever it may be his program is designed to do. )
So, if you want to model the brains information processing,do you model muscle production of BDNF too? If not, your model is incomplete, even if you give the brain a virtual body. You have to model that virtual body's feedback loops into the CNS.
This is only scratching the surface. The more I have studied physiology, the more I have learned about what an intricately coupled system the body is, CNS included. I could add some even more surprising results I have seen recently. I have to stop now, and continue in next message (about why, despite this, it is worth considering anyway.) But my point about "Whole Brain" being not well- defined, in that there is no theory neutral place to draw the boundary, without making arbitrary judgments about what kind of information can be neglected and what must be considered crucial, should be clear from these examples. why we should do it anyway...Continued in a future message…
comment by KatjaGrace · 2014-10-02T07:47:35.389Z · LW(p) · GW(p)
What kind of organization do you think is likely to develop human-level AI first? If it is fully synthetic AI? If it is brain emulations? Do you think other groups will quickly copy, or for instance will it require Manhattan Project scale infrastructure?
comment by KatjaGrace · 2014-09-30T12:38:40.499Z · LW(p) · GW(p)
What did you find least persuasive in this week's reading?
Replies from: Larks↑ comment by Larks · 2014-10-01T02:21:48.964Z · LW(p) · GW(p)
With the full development of the genetic technologies described above .... , it might be possible to ensure that new individuals are on average smarter han any human who has yet existed
- p43
This would be huge! Assuming IQ is normally distributed, there have been, there have been more than a billion people in history, so we could reasonably expect to have seen a 6-sigma IQ person - a person with an IQ of 190. So we'd need to see a 90point gain in average IQ.
Ok, now I see that Nick claims that 10 generations of 1 in 10 selection could give us that. So perhaps this should be a "part you find most surprising" rather than "part you find least persuasive". I certainly would have spent a little bit more time on this possibility!
Replies from: leplen, KatjaGrace↑ comment by leplen · 2014-10-01T16:41:33.650Z · LW(p) · GW(p)
The normal distribution is just a model. You have to be very careful about expectations that happen at 6 sigma. Nothing guarantees your gaussian works well that far from the mean.
Replies from: Larks↑ comment by Larks · 2014-10-04T02:27:20.658Z · LW(p) · GW(p)
Isn't IQ normally distributed by construction?
Replies from: Vaniver↑ comment by Vaniver · 2014-10-04T03:35:55.504Z · LW(p) · GW(p)
Isn't IQ normally distributed by construction?
Yes, but leplen's point is that the construction doesn't map directly to reality. An 'IQ score' is not calculated by lining everyone up by raw score and determining where they fall; we create a mapping from raw scores to IQ from a reference distribution, and then compare people's scores to the distribution.
As you might expect, the IQ tests start to lose statistical validity as you go further and further into the extremes. How well can we differentiate a person of 175 IQ and 190 IQ with our current tests? Not nearly as well as we can differentiate a person of 95 IQ and 110 IQ.
And the biological model of what makes people score particular ways on IQ tests looks normally distributed from afar, but is that true everywhere? Obviously not in certain cases (think of stuff like Down's), and so possibly not so in the upper extreme, as well.
↑ comment by KatjaGrace · 2014-10-01T17:07:09.975Z · LW(p) · GW(p)
There are more than a billion people now! According to this article there have been around 108 billion people born ever.
Replies from: Larkscomment by KatjaGrace · 2014-09-30T01:23:28.525Z · LW(p) · GW(p)
If a for profit venture developed brain emulation technology, who would they emulate first? How would they choose?
Replies from: ciphergoth, nkh↑ comment by Paul Crowley (ciphergoth) · 2014-09-30T08:45:00.288Z · LW(p) · GW(p)
I'm going to lay out a specific scenario in which WBE arrives very soon, so that other things are not much changed. I'm assuming here that the scanning route starts with legal death and vitrification. I'm also assuming no hardware overhang - that initially, vast amounts of compute hardware are required, and WBEs are no faster than we are or perhaps slower. This and other assumptions I haven't noticed well enough to state add up to a large conjunction and so a correspondingly small spot in probability space, treat with appropriate caution.
The literal first people would be test subjects; people dying of something that doesn't affect the brain, who aren't signed up for cryonics but who are sympathetic enough to take a shot at immortality. I'm not sure what sort of fate to expect for these first volunteers, given that there are things we would like to know that it will be hard to learn from animal testing and it's difficult to get those things right first time.
Once the procedure has been demonstrated to work well in humans and preserve memory and personality, then the interesting questions start. Lots of people who aren't signed up for cryonics would sign up, even though WBE is far outside their budget, because they have good reason to hope that it will one day be affordable. In its initial stages, WBE will primarily be seen as a way of escaping terminal illness for the very rich. In places where euthanasia is legal, some who would otherwise have waited longer will opt for euthanasia followed by WBE. There may be cryonics patients today whose fortunes would cover WBE, they might also be brought back.
It's currently illegal to assist suicide in a healthy person even if you plan to cryopreserve them, and I don't expect that to change right away. The first healthy and rich person to arrange their own "suicide" in order to be uploaded will presumably generate lots of publicity and controversy.
In this scenario, three things then start to happen which make it much harder to see where things go next!
- The study of the brain leaps ahead given data from WBE. "WBE drugs" are the equivalent of mind-affecting drugs which, since they operate on an emulated brain, can achieve levels of specificity of function that real drugs can never hope to achieve, and which are far easier to develop and test given the ability to take backups.
- WBE starts to get faster than human thinking - even if the hardware isn't getting faster, our better understanding will enable shortcuts.
- WBE starts to get cheap enough for cloning to be considered. At this point a for-profit venture would be interested in offering loans to very high-income professionals like top lawyers or computer programmers to pay for their scanning and initial emulation, and we start to move towards a Hansonesque world of productive copy clans.
↑ comment by nkh · 2014-09-30T05:31:00.455Z · LW(p) · GW(p)
I will suggest four scenarios where different types of people would be desirable as candidates.
First, there's "whoever's rich and willing". Under this scenario, the business offers WBE to the highest bidder, presumably with the promise of immortality (and perhaps fame/notoriety: hey, the first human to be emulated!) as enticement. This would seem to presuppose that the company has managed to persuade the rest of the world that the emulation definitely will work as advertised, in spite of its hitherto lack of human testing. And/or it's a non-destructive procedure.
Second, there's the "whoever's craziest" scenario. Supposing it's a destructive process and--ex hypothesi--as yet untested on humans, the company might struggle to find anyone willing to undergo the procedure at all. In this case, I would expect mainly enthusiastic volunteers from LW who have followed the technology closely, possibly with a smattering of individuals diagnosed with terminal diseases (see also next scenario).
Third, there's the "humanitarian" (or, if you're cynical, the "cook up some good P.R.") scenario. Here, the company selects someone who is either (1) in need or (2) likely to contribute to humanity's betterment. Good candidates might be a sympathy-garnering, photogenic child with an incurable disease, or an individual like Stephen Hawking, who has clearly proven to be a valuable scientific asset and is a well-known public figure--yet who is in the late stages of ALS.
Fourth and last, there's the "ideal worker" or "capitalism at its finest" scenario, inspired by Robin Hanson: here, the company might choose someone specifically because they anticipate that this individual will be a successful worker in a digital environment. Aside from the usual qualifications (punctual, dedicated, loyal, etc.), some extra pluses here would be someone with no existential compunctions about being switched on and off or about being split into temporary copies which would later be terminated after fulfilling their roles.
comment by KatjaGrace · 2014-09-30T01:11:58.870Z · LW(p) · GW(p)
How plausible do you find the key points in this chapter? (see list above)