Research Report: Alternative sparsity methods for sparse autoencoders with OthelloGPT.
post by Andrew Quaisley · 2024-06-14T00:57:29.407Z · LW · GW · 5 commentsContents
Abstract Introduction Methods Sparsity loss functions Controls: L1 sparsity loss and no sparsity loss Smoothed-L0 sparsity loss Results of smoothed-L0 sparsity loss experiments Freshman’s dream sparsity loss Results of freshman's dream sparsity loss experiments Without-top-k sparsity loss Results of without-top-k sparsity loss experiments Using activation functions to enforce sparsity Leaky top-k activation Results of leaky top-k activation experiments Dimension reduction activation Results of dimension reduction activation experiments Conclusion Appendix: Details for finding Sx None 5 comments
Abstract
Standard sparse autoencoder training uses an sparsity loss term to induce sparsity in the hidden layer. However, theoretical justifications for this choice are lacking (in my opinion), and there may be better ways to induce sparsity. In this post, I explore other methods of inducing sparsity and experiment with them using Robert_AIZI [LW · GW]'s methods and code from this research report [LW · GW], where he trained sparse autoencoders on OthelloGPT. I find several methods that produce significantly better results than sparsity loss, including a leaky top- activation function.
Introduction
This research builds directly on Robert_AIZI [LW · GW]'s work from this research report [LW · GW]. While I highly recommend reading his full report, I will briefly summarize the parts of it that are directly relevant to my work.
Although sparse autoencoders trained on language models have been shown to find feature directions that are more interpretable than individual neurons (Bricken et al, Cunningham et al), it remains unclear whether or not a given linearly-represented feature will be found by a sparse autoencoder. This is an important consideration for applications of sparse autoencoders to AI safety; if we believe that all relevant safety information is represented linearly, can we expect sparse autoencoders to bring all of it to light?
Motivated by this question, Robert trained sparse autoencoders on a version of OthelloGPT (based on the work of Li et al), a language model trained on Othello game histories to predict legal moves. Previous research (Nanda, Hazineh et al) had found that linear probes trained on the residual stream of OthelloGPT could classify each position on the board as either empty, containing an enemy piece, or containing an allied piece, with high accuracy. Robert reproduced similar results on a version of OthelloGPT that he trained himself, finding linear probes with 0.9 AUROC or greater for the vast majority of (board position, position state) pairs. He then investigated whether or not sparse autoencoders trained on OthelloGPT's residual stream would find features that classified board positions with levels of accuracy similar to the linear probes. Out of 180 possible (board position, position state) pair classifiers, Robert's best autoencoder had 33 features that classified distinct (board position, position state) pairs with at least 0.9 AUROC.
Robert's autoencoders were trained with the standard sparsity loss used in recent research applying sparse autoencoders to interpreting language models (Sharkey et al [LW · GW], Bricken et al, Cunningham et al, and similar to Templeton et al). However, there are theoretical and empirical reasons to believe that this may not be an ideal method for inducing sparsity. From a theoretical perspective, the norm is the definition of sparsity used in sparse dictionary learning (High-Dimensional Data Analysis with Low-Dimensional Models by Wright and Ma, Section 2.2.3). Minimizing the norm has been proven sufficient to recover sparse solutions in much simpler contexts (Wright and Ma, Section 3.2.2), as Sharkey et al [LW · GW] and Cunningham et al point out to justify their use of the norm. However, I am not aware of any results demonstrating that minimizing the norm is a theoretically sound way to solve the problem (overcomplete sparse dictionary learning) that sparse autoencoders are designed to solve[1]. Using the norm for sparsity loss has been shown to underestimate the true feature activations in toy data (Wright and Sharkey [LW · GW]), a phenomenon known as shrinkage. This is no surprise, since minimizing the norm encourages all feature activations to be closer to zero, including feature activations that should be larger. The norm also apparently leads to too many features being learned (Sharkey [LW · GW]).
For these reasons, I wanted to experiment with ways of inducing sparsity in the feature activations of sparse autoencoders that seemed to me more aligned with the theoretical definition of sparsity, in the hope of finding methods that perform better than sparsity loss. I chose to run these experiments by making modifications to Robert's OthelloGPT code, for a couple of reasons. Firstly, Robert's work provides a clear and reasonable metric by which to measure the performance of sparse autoencoders on a language model quickly and cheaply: the number of good board position classifiers given by the feature activations of the SAE. While I do have some reservations about this metric (for reasons I'll mention in the conclusion), I think it is a valuable alternative to methods like using a language model to interpret features found by an SAE that are significantly more computationally expensive. Secondly, I know Robert personally and he offered to provide guidance getting this project up and running. Thanks to his help, I was able to start running experiments after only a week of work on the project.
Methods
I trained several variants of the SAE architecture that had different architectural processes for encouraging sparsity. The following aspects of the architecture were held constant. They contained one hidden layer of neurons--which I'm calling the feature layer--, the encoder and decoder weights were left untied, i.e. they were trained as separate parameters of the model, and a bias term was used in both the encoder and decoder. They were trained on the residual stream of the OthelloGPT model after layer 3 using a training set of 100,000 game histories for four epochs, with the Adam optimizer and a learning rate of 0.001.
I came up with five different methods of inducing sparsity, which I detail below. Three of them use a different kind of sparsity loss, in which case the activation function used on the feature layer is ReLU. The other two use custom activation functions designed to output sparse activations instead of including a sparsity loss term. In these cases, I still applied ReLU to the output of the encoder before applying the custom activation function to ensure that the activations would be non-negative.
Following Robert[2], the main measure of SAE performance that I focused on was the number of (board position, position state) pair classifiers given by the SAE feature activations that had an AUROC over 0.9; from now on I will just call these "good classifiers".
Each method of inducing sparsity has its own set of hyperparameters, and I did not have the resources to perform a massive sweep of the hyperparameter space to be confident that I had found values for the hyperparameters that roughly maximize the number of good classifiers found. Instead, I generally took some educated guesses about what hyperparameter values might work well and first trained a batch of SAEs--typically somewhere between 8 and 16 of them. Since finding the number of good classifiers for a given SAE is computationally expensive, I did not do this for every SAE trained. I first weeded out weaker candidates based on evaluations done during training. Specifically, at this stage, I considered the average sparsity[3] of the feature layer and the unexplained variance of the reconstruction of the OthelloGPT activations, which were evaluated on the test data set at regular intervals during training. The SAEs that seemed promising based on these metrics were evaluated for good classifiers. Based on this data, I trained another batch of SAEs, repeating this search process until I was reasonably satisfied that I had gotten close to a local maximum of good classifiers in the hyperparameter space.
Since this search process was based on intuition, guessing, and a somewhat arbitrary AUROC threshold of 0.9, I view these experiments as a search for methods that deserve further study. I certainly don't consider any of my results as strong evidence that sparsity loss should be replaced by one of these methods.
Sparsity loss functions
Controls: sparsity loss and no sparsity loss
I first reproduced Robert's results with sparsity loss to use as a baseline. Using the sparsity loss coefficient of that he found with a hyperparameter sweep, I trained an SAE with sparsity loss, which found 29 good classifiers, similar to Robert's result of 33[4]. I also wanted to confirm that training with sparsity loss in fact significantly impacted the number of good classifiers found, so I trained another SAE without sparsity loss; it found only one good classifier.
Smoothed- sparsity loss
Since is what we ideally want to minimize to achieve sparsity, why not try a loss function based on the norm instead of the norm? Because the feature layer of the SAE uses ReLU as its activation function, all the feature activations are non-negative. Taking the norm of a vector with no negative entries is equivalent to applying the unit step function-- if , otherwise--to each entry, and then summing the results. Unfortunately, the unit step function is not differentiable, so would be difficult to use in a loss function. Therefore, I tried various smoothed versions of the unit step function using the sigmoid function as a base.
Call the smoothed unit step function we're looking to define . Since all the feature activations are positive, we want the transition from 0 to 1 to roughly "start" at . So choose a small such that we are satisfied if . We will then also consider the transition from 0 to 1 to be complete once the value of reaches . So choose a duration for the transition, and require that . These requirements are satisfied by defining where . Then the smoothed- sparsity loss of an -dimensional feature vector with respect to a choice of is given by . In practice, I chose for all SAEs trained, since I expected to have a more interesting impact on the results.
Results of smoothed- sparsity loss experiments
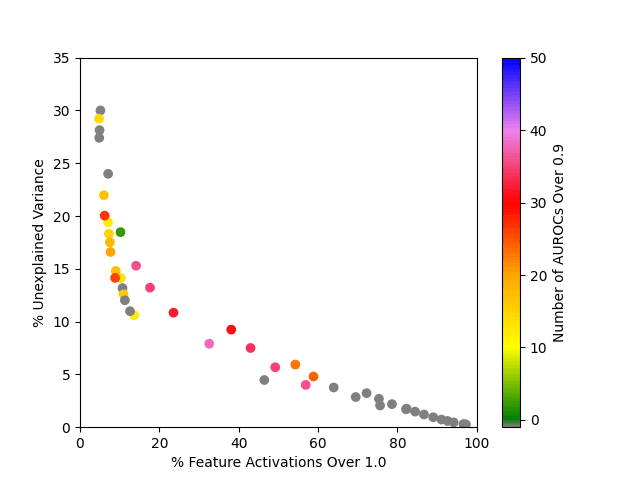
Out of the SAEs trained, the best one found 38 good classifiers, and had on average 32.6% of feature activations greater than 1.0 and 7.9% unexplained variance. It was trained with the hyperparameters , , and sparsity loss coefficient .
Freshman’s dream sparsity loss
The erroneous (over the real numbers, at least) equation is known as the "freshman's dream". In general, for values , we have , but we get closer to equality if a small number of the 's are responsible for a majority of the value of , with equality achieved if and only if all but one of the 's are 0. This sounds a lot like saying that an activation vector will be more sparse the closer the values of and . So we will define the freshman's dream sparsity loss of an -dimensional feature vector with respect to a choice of the power as
I focused on , which has the additional notable property that a -sparse[5] vector with all equal non-zero activations has a loss of . So this loss is in some sense linear in the sparsity of the vector, which I thought might be a nice property; I intuitively like the idea of putting similar amounts of effort into reducing the sparsity of a 100-sparse vector and a 50-sparse vector.
Results of freshman's dream sparsity loss experiments
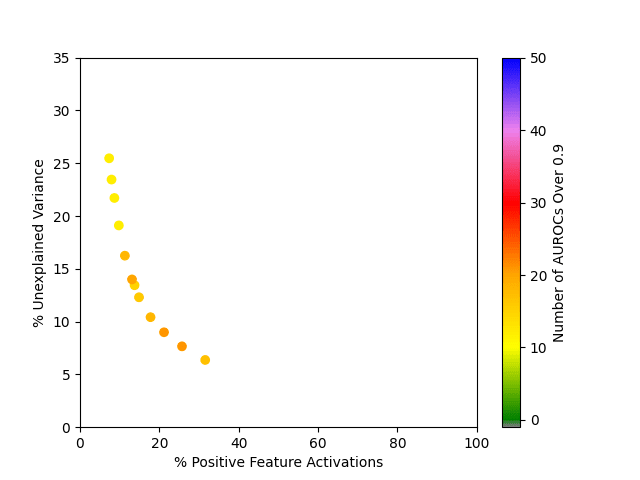
Out of the SAEs trained, the best one found 21 good classifiers, and had on average 25.7% of feature activations greater than 0 and 7.7% unexplained variance. It was trained with the hyperparameters and sparsity loss coefficient .
Without-top- sparsity loss
Suppose we have a value of such that we would be satisfied if all of our feature vectors were -sparse; we don't care about trying to make them sparser than that. Given an -dimensional feature vector , we can project it into the space of -sparse vectors by finding the largest activations and replacing the rest with zeros; let be the resulting -sparse vector. Then, for an appropriate choice of , let be the without top k sparsity loss of . Intuitively, this measures how close is to being -sparse. I did experiments with and .
Results of without-top- sparsity loss experiments
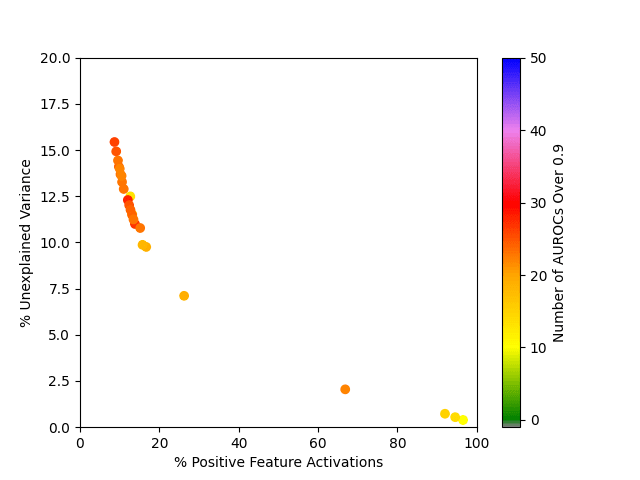
Out of the SAEs trained, the best one found 28 good classifiers, and had on average 12.1% of feature activations greater than 0 and 12.3% unexplained variance. It was trained with the hyperparameters and sparsity loss coefficient .
Using activation functions to enforce sparsity
While thinking about different types of sparsity loss, I also considered other possibilities for inducing sparsity that don't involve training with a sparsity loss term. Instead, we could take the output from the encoder and map it directly to a more sparse version of itself, and use the sparser version as the feature vector. I'm calling these maps "activation functions" because they output the activations of the feature layer, even though they may not be anything like the activation functions you would typically use to add non-linearity to a neural net. In each of my experiments, I did still apply a ReLU to the output of the encoder before applying the given activation function to ensure that all the activations were positive.
Leaky top- activation
You might have noticed that we just discussed a way to map a vector to a sparser version of itself in the previous section on without-top- sparsity loss: pick a value of , and given a vector , map it to , the vector with the same largest entries as and zeros elsewhere. We will use a generalization of this map for our first activation function.
Pick a value for and a small . Then define the activation function in the following way. Given a vector , let be the value of the th-largest entry in . Then define the vector by
This way, every activation other than the largest activations will be at most , making the resulting vector within of being -sparse (excepting the rare case where there are multiple entries of with a value of ). I wanted to allow for so that some information about other entries could be kept to help with the reconstruction.
Note: This method of inducing sparsity (but restricting to ) was previously used in autoencoders by Makhzani and Frey and applied to interpreting language models by Gao et al.
I also tried using a version of this activation function where entries smaller than are multiplied by instead of , allowing the reduced activations to be small relative to . I additionally tried defining smoothed versions of these functions, wondering if that might help the model learn to deal with the activation functions better. However, these variations turned out to yield worse initial results, and I did not explore them further.
Results of leaky top- activation experiments
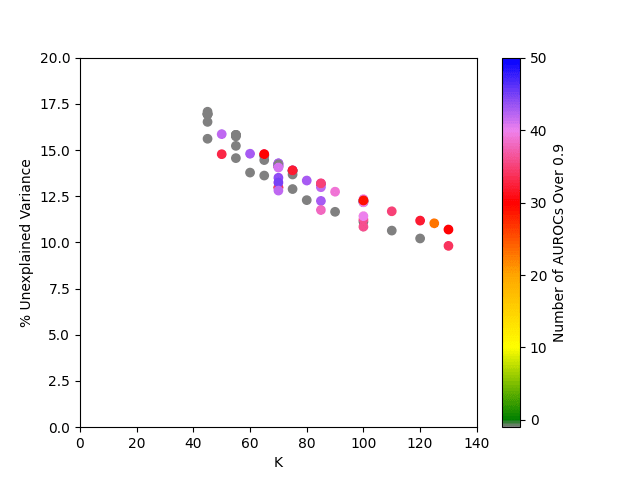
Out of the SAEs trained, the best one found 45 good classifiers, and had on average 13.2% unexplained variance. It was trained with the hyperparameters and .
Out of those trained with as in Makhzani and Frey and Gao et al, the best one found 34 good classifiers. It was trained with and also had on average 13.2% unexplained variance. Notably, all of the SAEs trained with had no dead neurons, whereas all of the SAEs trained with had a significant number of dead neurons; the one trained with had 15.1% dead neurons.
Dimension reduction activation
For a leaky top- activation function, we choose a single value of to use for all inputs. This didn't fully sit right with me: what if it makes more sense to use a smaller value of for some inputs, and a larger value for others? For example, it seems like a reasonable choice to map the vector to a nearly 4-sparse vector, but the vector seems like it corresponds more naturally to a nearly 2-sparse vector. So I wanted to try out a function that does something very similar to the leaky top- activation function, but chooses an appropriate based on the vector input.
As in the definition of a leaky top- activation function, choose a bound . Define a dimension reduction activation function in the following way. Given an -dimensional vector with non-negative entries, let and define by
where is chosen in the following way. We will start with . Remove any with , for some bound depending on , resulting in a smaller set . Continuing in this way, recursivly define , where is some bound depending on and that we have yet to define. Eventually, we will reach a value of where , at which point we will define . The 's will be chosen in a way that distinguishes between relatively large and small entries of and that is invariant under scaling . The details and motivation behind how I chose appropriate 's is long and convoluted, so I will leave them in an appendix [LW · GW].
Results of dimension reduction activation experiments
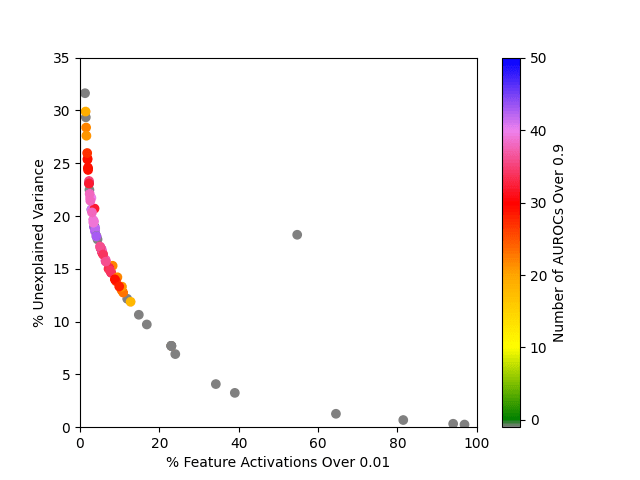
Out of the SAEs trained, the best one found 43 good classifiers, and had on average 3.8% of feature activations greater than 0.01 and 18.5% unexplained variance. It was trained with the hyperparameters , and with the sequence of 's chosen as described in the appendix. I think it's particularly notable that the best SAEs using this method had much lower sparsity and higher unexplained variance than the best SAEs trained with other methods. I don't know why that is!
Conclusion
| Method | Number of good classifiers |
| sparsity loss | 29 |
| Smoothed- sparsity loss | 38 |
| Freshman's dream sparsity loss | 21 |
| Without-top- sparsity loss | 28 |
| Leaky top- activation | 45 |
| Dimension reduction activation | 43 |
Of the methods I tried, without-top- sparsity loss performed on par with sparsity loss, and smoothed- sparsity loss, leaky top- activation, and dimension reduction activation both performed significantly better. Leaky top- activation takes the cake with 45 good classifiers, compared to sparsity loss's 29. I think that all four of these methods are worthy of further study, both in test beds like OthelloGPT, and in real LLMs.
I'm interested in continuing to pursue this research by experimenting with more ways of tweaking the architecture and training of SAEs. I'm particularly interested to try more activation functions similar to leaky top- activation, and to see if adding more layers to the encoder and/or decoder could improve results, especially when using custom activation functions that may make the reconstruction more challenging for the linear encoder/decoder architecture. As Robert mentioned in his report, I also think it's important to try these experiments on the fully-trained OthelloGPT created by Li et al, which is both better at predicting legal moves and has much more accurate linear probes than Robert's version.
Finally, I think it would be useful to get a better understanding of the features found by these SAEs that don't classify board positions well. Are some of these features providing interpretable information about the board state, but just in different ways? It may be that OthelloGPT "really" represents the board state in a way that doesn't fully factor into individual board positions, in spite of the fact that linear probes can find good classifiers for individual board positions. For example, Robert noticed that a feature [LW · GW] from one of his autoencoders seemed to keep track of lines of adjacent positions that all contain a white piece. I hypothesize that, because the rules of Othello significantly restrict what board states are possible/likely (for example, there tend to be lots of lines of pieces with similar colors), we should not expect SAEs to be able to find as many good classifiers for board positions as if we were working with a game like chess, where more board states are possible. ChessGPT anyone?
Appendix: Details for finding
The algorithm described above for finding was designed as a fast way to compute a different, geometrically-motivated definition of . Here I'll describe that original definition and motivation, and define the 's that allow the sped-up algorithm to find the same given by the original definition.
Given a non-empty , let be the number of indices in . If we let represent the th coordinate in , then the equation describes an -dimensional hyperplane; call it . Note that is perpendicular to the vector that has a 1 for every entry whose index is in , and all other entries 0, and that points from the origin directly towards . In some sense, we will choose such that is pointing in a similar direction as , and we will use the sequence of 's to favor choices of with fewer elements (resulting in a sparser output).
The set of hyperplanes cut into a number of components; let be the one containing the origin. Consider the ray in the direction of . Since has non-negative entries, intersects the boundary of at one (or possibly more) of our hyperplanes. Generically, we should expect there to be a unique hyperplane that contains the intersection of and the boundary of , which then uniquely defines . If happens to intersect the boundary of where two or more of our hyperplanes meet, let be the set of all such hyperplanes, and define .
How does this favor choices of with fewer elements? Well, it doesn't always, not for every non-decreasing sequence of 's. But we can design a sequence that does. For a given , if is bigger, then is more likely to have , rather than , elements. So choosing a sequence where is bigger for smaller favors choices of with fewer elements, encouraging sparsity.
Besides that, I added a few constraints to the sequence to guarantee some properties that I thought would be beneficial. First, I wanted to ensure that every non-empty actually does correspond to some input, i.e., there is some with This property holds if for all . Second, in order to speed up the computation of , I wanted to use an algorithm that started with and then repeatedly removed dimensions from until only the dimensions in were left. To ensure that the order in which dimensions were removed in this algorithm did not matter, I needed to add the requirement that for all . Adding this constraint guarantees that will be given by the algorithm described in the main section of the report if we let
where .
Then to choose a sequence of 's, I arbitrarily started with . At the th step, having chosen , we want to choose a value of between and . Initially, I tried choosing a proportion and letting ; note that for such a sequence, will increase as decreases, as desired to induce sparsity. With this method I found that, if the feature vector gets too sparse at some point during training, the training will get into a positive feedback loop and just keep making it sparser and sparser, until it's way too sparse and isn't reconstructing well at all (why this could happen is still a complete mystery to me). Similarly, if the feature vector isn't sparse enough, it keeps getting less and less sparse. It was hard to find a value of that didn't fall into one of these two traps, though I did find some where the training just happened to end with reasonable sparsity and unexplained variance. The best SAE trained in this way found 29 good classifiers, and had on average 6.9% feature activations greater than 0.01 and 17.3% unexplained variance. It was trained with hyperparameters and If I had continued training, though, I'm confident the feedback loop would have continued until the reconstruction was ruined.
To find a better sequence of 's, I tried varying the proportion with respect to , i.e. coming up with a sequence of proportions and letting . Specifically, since low values of resulted in not enough sparsity and high values resulted in too much, I thought to try choosing a low value of to use for small , but to start increasing once passes some threshold. How fast could be increased was bounded above by the restriction, and I found that increasing as fast as this restriction allowed yielded reasonable results. The best SAE was trained using for , with the 's increasing as fast as possible past .
- ^
Please do not take this as an assertion that no such results exist! I know very little about the field of sparse coding. I am only trying to say that, after reading some of the recent research using sparse autoencoders to interpret language models, I am unsatisfied with the theoretical justifications given for using the norm, and a brief search through the relevant resources that those papers cited did not turn up any other justifications that I find satisfying.
- ^
In fact, Robert measured the number of features that are good classifiers, which is slightly different, since he counted two different features separately even if they were both good classifiers for the same (board position, position state) pair.
- ^
In most cases, I measured sparsity as the percentage of activations greater than some relatively small bound . Different values of seemed more or less informative depending on the method used to induce sparsity. I'll note the specific measure of sparsity used for each method.
- ^
As mentioned in a previous footnote, this number is slightly inflated compared to mine as a result of duplicated features. If I had also included duplicate features, I would have found 35, compared to his 33.
- ^
A vector is -sparse if , i.e., if has at most non-zero entries.
5 comments
Comments sorted by top scores.
comment by leogao · 2024-06-15T01:38:24.447Z · LW(p) · GW(p)
Did you use the initialization scheme in our paper where the decoder is initialized to the transpose of the encoder (and then columns unit normalized)? There should not be any dead latents with topk at small scale with this init.
Also, if I understand correctly, leaky topk is similar to the multi-topk method in our paper. I'd be interested in a comparison of the two methods.
Replies from: Andrew Quaisley↑ comment by Andrew Quaisley · 2024-06-15T18:27:32.406Z · LW(p) · GW(p)
I did not use your initialization scheme, since I was unaware of your paper at the time I was running those experiments. I will definitely try that soon!
Yeah, I can see how leaky topk and multi-topk are doing similar things. I wonder if leaky topk also gives a progressive code past the value of k used in training. That definitely seems worth looking into. Thanks for the suggestions!
comment by neverix · 2024-06-15T03:12:54.608Z · LW(p) · GW(p)
Freshman’s dream sparsity loss
A similar regularizer is known as Hoyer-Square.
Pick a value for and a small . Then define the activation function in the following way. Given a vector , let be the value of the th-largest entry in . Then define the vector by
Is in the following formula a typo?
Replies from: Andrew Quaisley↑ comment by Andrew Quaisley · 2024-06-15T18:38:43.223Z · LW(p) · GW(p)
Oh, yeah, looks like with this is equivalent to Hoyer-Square. Thanks for pointing that out; I didn't know this had been studied previously.
And you're right, that was a typo, and I've fixed it now. Thank you for mentioning that!
comment by Louka Ewington-Pitsos (louka-ewington-pitsos) · 2024-06-30T00:33:27.143Z · LW(p) · GW(p)
This is dope, thank you for your service. Also, can you hit us with your code on this one? Would love to reproduce.