Review Report of Davidson on Takeoff Speeds (2023)
post by Trent Kannegieter · 2023-12-22T18:48:55.983Z · LW · GW · 11 commentsContents
Executive Summary (<5 min read) I. Dataset Quality II. The Abstract Reasoning/Common Sense Problem III. GDP Growth & Measurement IV. R&D Parallelization Penalty V. Taiwan Supply Chain Disruption I. Dataset Quality / Robustness Why Data Quality Matters Obstacles to Data Quality 1. Generative data pollution of the internet corpus fundamental to frontier model development. 2. Copyright lawsuits will limit datasets Specific Concern: Copyright Legibility of BookCorpus 3. Labor negotiations and lobbying in certain sectors (unions in creative work, powerful interest groups in health) will limit dataset creation and use. 4. Sources of Record Preventing Future Scraping or Pulling Their Content 5. Time Delays Affiliated With Each/Any Of The Above II. The Common Sense Problem Section Overview Abstraction as a Necessary Condition Deep Learning’s “Brittle” Nature Inhibits Performance Why the Generalization Problem Limits Adoption 1. Mission-Critical & Safety-Critical Functions 2. A specific part of mission-critical operations: “Adversarial Hacking” Studies Suggest Common Sense Shortcomings 1. Formal Logic & Math a. “The Reversal Curse” b. Arithmetic 2. Correlation & Causation 3. Spatial and Semantic Concepts 4. Counterfactual Reasoning 5. Generalizing Beyond Training Distribution Structural Reasons for the Generalization Problem 1. Correlation =/= Causation 2. Overparameterization: Overfitting on Randomly Initialized Parameters 3. Limitations Preventing Placement of Content into Training Distributions Internet-Scale Datasets Fail to Unlock Automation Alone a. The data doesn't exist. b. The high cost (human, financial, and otherwise) of building certain ground truth. c. The Edge Case Problem: Combinatorial Explosion of Real-World Scenarios + The Long Tail of Exceptions d. The lack of recorded expert-level data, and the challenge of ever recording and conveying such knowledge. 4. Semantically Valid World Models Quantifying the Consequences III. GDP Growth, Measurement, & Definitions Framing: GDP Growth as a Necessary Part of the Argument A. “Good Enough to Substitute Profitably" AI (GESPAI)—Definitions Around “Readily Perform” Could Distort Findings. Performing a task “readily” and profitably is not the same as performing a task better than humans. Humans can output significantly more than their GESPAI substitutes, but still be less profitable for their firm, if their salary cost makes the profit from each of them less valuable. Implications 1. GESPAI does not threaten to “disempower all of humanity” in the same way as a more powerful AI. 2. The report’s definition might producer to a faster timeline than the road to at-or-above-human-level AI. 3. This definition could leave too much room between 20% and 100% automation. 4. GESPAI significantly reduces the GDP boosts from automation. B. Anything Successfully Automated Inherently Becomes a Smaller Percentage of GDP. 1. Increase in Labor Supply, All Else Equal, Drives Wages Down. 2. Baumol Effect increases wages for other jobs that do not experience productivity growth, decreasing the unit value of a task. 3. Automation moves surplus from laborers to capital-holders, who are less likely to spend. C. Displacement of Labor Creates Market Inefficiencies First Principles Rebuttal Data-Driven Rebuttal Implications for Report Model 1. g(software) 2. g($ on FLOP globally) 3. g(FLOP/$) IV. R&D Parallelization Penalty A. Using The Cited, ML-Specific Research (Besiroglu, 2020) B. First-Principles Reasons for High R&D Parallelization Penalties 1. Ever-increasing numbers of private markets investors, most of whom will have no idea what they’re doing, throwing money at dead-on-arrival projects. 2. Duplication of efforts across competing corporations. 3. Duplication of efforts across national lines. Increased Parallelization Penalty, All Else Equal, Adds 5 Years to Timeline V. Taiwan Supply Chain Disruption Framing An Invasion of Taiwan Would Set SOTA Innovation Back, Potentially by Years 1. TSMC Sets the SOTA 2. An Invasion of Taiwan Would Destroy TSMC Capacity 3. Invasion of Taiwan is A Serious Risk Other Regulation Appendix A: Background Info on Davidson 2023’s Central Argument Summary of Report’s Central Approach to Takeoff Speed Key Flywheel for Accelerated AI Growth & Automation More Detail Appendix B: Key Sources Books Key Academic Papers None 11 comments
I have spent some time studying Tom Davidson [LW · GW]’s Open Philanthropy report on what a compute-centric framework says about AI takeoff speeds [LW · GW]. This research culminated in a report of its own, which I presented to Davidson.
At his encouragement, I’m posting my review, which offers five independent arguments for extending the median timelines proposed in the initial report.
The Executive Summary (<5 min read) covers the key parts of each argument. Additional substantiation in the later, fuller sections allows deeper dives as desired. This work assumes familiarity with Davidson’s, but a Background Info appendix [LW · GW] summarizes the central argument.
Thanks to Tom for his encouragement to share this publicly, and for his commitment to discussing these important topics in public. Excited to hear any feedback from y'all.
Special thanks also to David Bloom, Alexa Pan, John Petrie, Matt Song, Zhengdong Wang, Thomas Woodside, Courtney Zhu, and others for their comments, reflections, and insights on this piece. They were incredibly helpful in developing these ideas to their current state. Any errors and/or omissions are my own.
Executive Summary (<5 min read)
This review provides five independent arguments for extending the median timelines proposed in Davidson's initial report.
These arguments do not attack the flywheel at the core of the piece. They do not challenge the progression toward increasingly sophisticated AI or the compounding over time of investment, automation, and thus R&D progress (as summarized here [? · GW]).
But they do raise implications for the report’s presented timelines. Specifically, they describe both the structural technical and the geopolitical obstacles that could slow the progress of AI-driven automation.
These key arguments pertain to:
- Dataset Quality. [LW · GW]
- The Abstract Reasoning/Common Sense Problem. [LW · GW]
- GDP Growth & Measurement. [LW · GW]
- R&D Parallelization Penalty. [LW · GW]
- Taiwan Supply Chain Disruption. [LW · GW]
These arguments are developed and operate independently from each other. That is to say, argument 1 does not depend on arguments 2-5, argument 2 does not depend on arguments 1 and 3-5, etc.
Summarizing each in turn:
I. Dataset Quality
Data quality is a key determinant of model performance [LW · GW]. Degraded dataset quality can significantly damage model performance and set back model development / the performance frontier. Threats to dataset quality [LW · GW] include:
- Generative data polluting the internet corpus critical to frontier model development. [LW · GW]
- Copyright/intellectual property lawsuits limiting large dataset use. [LW · GW]
- Labor negotiations and lobbying in certain sectors (unions in creative work, powerful interest groups in healthcare, etc.) sharply limiting dataset creation and use. [LW · GW]
- Sources of record preventing future scraping/pulling of their content. [LW · GW]
- Time delays affiliated with any of the above. [LW · GW]
These delays may set timelines back by years and/or leave many sectors functionally immune to automation.
II. The Abstract Reasoning/Common Sense Problem
One of the report’s key premises is that adding more compute to 2020-era models can solve the challenges ahead for automation. But structural obstacles prevent 2020-era models from ever reliably performing the safety- and mission-critical tasks [LW · GW]that would be necessary to automate many jobs in the economy. [LW · GW]
In particular, the abstraction/generalization problem must be solved. Without abstraction, these tools cannot manage safety-critical jobs. Instead, they will remain impact multipliers for humans who remain in control. While these challenges will be solved one day, they cannot be overcome within today’s SOTA. Thus, creating these next breakthroughs might present a bottleneck inhibiting the report’s timelines.
This problem of “common sense” is still-to-be-solved [? · GW] (Choi, 2022). There is an absence of empirical evidence that LLMs can perform any type of “abstraction,” “generalization,” or “common sense” (Mitchell et al., 2023; Choi, 2022). Many recent studies also suggest the continuation of these shortcomings, as exposed by weaknesses in:
- Formal Logic & Math. [LW · GW]
- Correlation & Causation. [LW · GW]
- Spatial & Semantic Concepts. [LW · GW]
- Counterfactual Reasoning. [LW · GW]
- Generalizing Beyond Training Distributions. [LW · GW]
Structural reasons for this deficit include:
- Deep learning’s fundamental reliance on correlation. [LW · GW]
- The inherent randomness underneath overparameterized large models. [LW · GW]
- Inherent limitations of placing everything within training distributions [LW · GW]due to:
- The shortcomings of internet-scale datasets [LW · GW].
- The high cost (human, financial, and otherwise) of creating certain ground truth. [LW · GW]
- Edge cases (aka the combinatorial explosion of real-world scenarios). [LW · GW]
- The lack of recorded expert-level data, and the challenge of ever recording and conveying such knowledge. [LW · GW]
These technical obstacles challenge the premise that adding compute to 2020-era models solves the problems facing automation. While these challenges will be solved one day, they cannot be overcome within today’s State of the Art (SOTA). Identifying these next breakthroughs might present a bottleneck inhibiting the report’s timelines for an indeterminate amount of time. Progress might not be measured as one continuous function function. Instead, it might encounter hard discontinuities, functional “pauses” at which these technical problems must be solved.
In the meantime, these shortcomings relegate AI-driven tools (for most jobs) to tools that will become impact multipliers for humans, not substitute employees.
III. GDP Growth & Measurement
GDP growth is a necessary component of the report’s argument [LW · GW]. The report claims that automation will increase GDP incredibly rapidly. However, three forces diminish the percentage of GDP growth that will occur. This mitigation in turn slows down AI development timelines by reducing the amount of money that can be contributed to R&D and investment.
- “Good Enough to Substitute Profitably" AI (GESPAI) [LW · GW]. Humans can produce significantly more than their GESPAI substitutes yet still be less profitable for their firm if their affiliated costs makes the profit from each of them less valuable. Thus, automation will frequently occur at a below-human-level baseline that creates less aggregate production.
- Any action successfully automated inherently becomes a smaller percentage of GDP [LW · GW]thanks to functional increases to the labor supply [LW · GW]and the Baumol Effect. [LW · GW]
- Displacement of labor [LW · GW]creates significant market inefficiencies that reduce automation’s aggregate growth both of and due to automation.
The impact of these dampening effects varies, but they suggest that any proposed 2x boosts to GDP should be reduced to a smaller multiple. Even shifting 2x to 1.5x has dramatic implications for the model, reducing the power of each node on the flywheel:
- Investment into R&D and buying more compute decreases.
- Hardware and software innovation both take longer.
- Our largest training runs are smaller at each time horizon.
- The resulting AI models can automate less at each time horizon.
IV. R&D Parallelization Penalty
Research on the parallelization penalty both in ML-specific contexts [LW · GW]and from first principles [LW · GW]suggest that the parallelization penalty should be significantly greater than the default provision in the report’s playground.
This increased parallelization penalty, all else equal, can add five years to the report’s timelines [LW · GW], shifting the likeliest 100% automation milestone from 2040 to 2045.
V. Taiwan Supply Chain Disruption
Taiwan's TSMC is a pivotal node in the construction of hardware necessary to train and run SOTA AI models. A PRC military invasion of Taiwan would set timelines back by 20 months [LW · GW]until another firm “caught up” with TSMC’s current sophistication. Such an invasion becomes increasingly likely as Xi consolidates more power and PRC military power increases.
An April 2023 survey of expert IR scholars estimated an average “23.75 percent chance of a [PRC] attack against Taiwan in just the next year.” Prediction markets like Metaculus are less bullish, but still predict a 40% chance of “full-scale invasion” by 2035 and 30% by 2030.
~~~~~
I. Dataset Quality / Robustness
TL;DR: Beyond any technical capability in AI hardware or AI software, the actual quality of datasets merits significant attention. And, there are reasons to believe that dataset quality cannot be assumed to even match current levels into the future.
The fundamental question of “How do we cross the Effective Compute gap” is reflected in the following function:
EC = software * [FLOP/$] * [$ Spent on FLOP]
Nowhere, however, does this function mention dataset quality and the continued ability to access data.
Why Data Quality Matters
“The success of an ML system depends largely on the data it was trained on.” — Huyen, 2022
Dataset curation, maintenance, and improvement is the main focus of most ML practitioners (Huyen, 2022; Rajaraman, 2008). Models don’t generate incisive predictions in a vacuum. Instead, transformers predict the next token in a chain by making correlational best-guesses of the next best token based on (1) the broad context around the current exchange and (2) the distribution of their training dataset.
Without “good” data—that is, data that is robust, high-n, statistically significant, and representative of the “real world” scenarios a model will address—there is a ceiling to model performance.
Indeed, deep learning owes its recent flourishing to the ability to build large datasets off of the Internet. As leading scholars have noted, “huge datasets scraped from the Web” are responsible for deep learning’s sudden power and “emerg[ence] from [the] backwater position” it held in the 1970s (Mitchell, 2021).
Key Implications:
- Datasets are necessary to access model growth.
- If bad datasets, then bad models.
Obstacles to Data Quality
There are a few reasons that dataset quality might degrade over time:
1. Generative data pollution of the internet corpus fundamental to frontier model development.
Potentially the highest-consequence reason for compromised data quality is the degradation of the Internet corpus behind deep learning’s rise.
Foundation models are both (1) initially trained on and (2) periodically fine-tuned and retrained with this corpus of training data.
But what happens to this corpus when generative text publication, since it is much easier to produce than non-assisted writing, becomes most the dataset? The corpus itself might become corrupted by the hallucinations and lower-grade quality of Generative AI’s own responses.
This phenomenon is already infiltrating the web. Generative AI-created content floods the internet through sites like Quora, LinkedIn, a flood of B2B and B2C online marketing, and all-new spam sites.[1] Even established datasets like LAION-5B, which trains text-to-image models, already utilize synthetic data (Alemohammad et al., 2023, p.3).
This could create a problem where hallucinations by generative AI models begin to be established as an increasingly large share of the “ground truth” for the model on the Internet. A degradation of the long-term quality of datasets in turn corrupts future performance.
There are two reasons for such dataset corruption:
- Inserting generated hallucinations into the training data risks placing hallucinations as “ground truth” in future runs. This further distances "model world" from the “real world” it tries to represent, undermining its utility.
- Distorting the data distribution by adding generative data that does not represent the entire distribution. This second effect is investigated in…
Researchers like Shumailov et al. (2023) posit that training models on synthetically generated data can lead to model collapse by “causing irreversible defects[…] where tails of the original content distribution disappear.” This “forgetting” of the original distribution makes a GPT’s predictions significantly less accurate over time, as the prediction of next tokens within a transformer depends on leveraging its deep context to make best-guess probabilities of next entries.
Similar work from Alemohammad et al. (2023) explained that “training generative artificial intelligence (AI) models on synthetic data progressively amplifies artifacts'' that existed in prior data architectures (due to, say, defects in initial photography or how an image is stored ). A summary by Acar (2023) called it:
Model Autophagy Disorder (MAD). It shows that recursively training generative models on their own content leads to self-consuming loops that degrade model quality and diversity. Put simply, the generative models go “MAD” unless regularly infused with fresh, real-world human data.
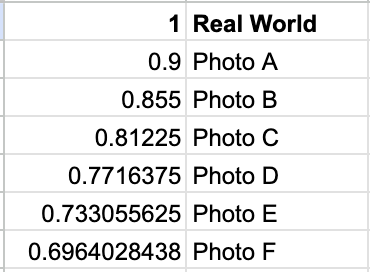
A gut check analogy for why this data quality concern might be true: Imagine a Photo A that might represent the real world fairly well. But a photo taken of Photo A (Photo B) represents the real world marginally less well, as it tries to represent the world through the limits of Photo A’s imperfections. Photo C, a photo taken of Photo B, represents the real world even less well. Continuing to a Photo D, E, etc., the quality of the photo eventually degrades. Even a high-integrity system—say, 90% fidelity in representation—degrades beyond utility within a handful of cycles.
Selecting only for purportedly human data won’t solve, either, due to the large reliance on generative AI tools by human data annotators themselves. As Veselovsky et al. 2023 find, 33-46% of all Amazon Mechanical Turk workers “used LLM[s] when completing task[s].”
Resolving this issue would require a significant advance in either:
- Training LLMs on their own output without them going MAD,
- LLM ability to distinguish human-generated data from LLM-generated data, or
- The creation of some data governance system by which fresh human generated data is cordoned off from LLM-generated data.[2]
One question that needs additional investigation: Is there enough non-synthetic data in the world to train increasingly large deep learning models? Alemohammad et al. (2023) ask this question as well, though they don’t offer an answer. Villalobos et al. (2022) suggest that we might run out of “high-quality language data” by 2026, “vision data” by between 2040 and 2060, and “low-quality language data” by between 2030 and 2050. However, they also acknowledge that their argument depends “on the unrealistic assumptions that current trends in ML data usage and production will continue and that there will be no major innovations in data efficiency.” Additional inquiry is likely needed.
2. Copyright lawsuits will limit datasets
The data on which foundation models were trained was gathered by skimming work originally composed by others. A host of litigation around intellectual property now questions whether this use is legal. The consequences of these suits could radically inhibit future development (or even limit use of existing models).
Example lawsuits include: Chabon et al. v. OpenAI (Justia) and Getty Images v. Stability AI (Summary).
At this point, estimating the chance of success for these suits is very speculative.[3] However, evidence that models “remember” and can produce near-replicas of training set images makes any defense that generative AI is fundamentally “transforming” those works—a necessary condition for drawing on copyrighted work—increasingly difficult.
These lawsuits threaten model producers much more than your average lawsuits.
Any fines from prior harms will likely be negligible to tech giants who eat regulatory fines as a part of their established model. (Even a billion-dollar fee is, to an extent, negligible for Big Tech.)
But the potential ban on using illegally trained datasets and models—and the potential of bans on any models trained on illegally utilized datasets—does pose a significant deterrent.[4] As calls for "deep data deletion" by scholars and activists like researcher & advocate Dr. Joy Buolamwini grow in popularity, this threat grows larger.
Specific Concern: Copyright Legibility of BookCorpus
Books1 and Books2 datasets (together referenced as “BookCorpus”) constitute a large share of the datasets behind frontier models. Li (2020) identifies that, within GPT-3 weights, BookCorpus held a quarter of the tokens that did the entirety of common crawl.
Bandy & Vincent, 2021 suggest that BookCorpus “likely violates copyright restrictions for many books” with active IP protections on a large share of their works. To take just one of many examples of explicit text that could be used against it in court, BooksCorpus itself even features 788 instances of the exact phrase “if you’re reading this book and did not purchase it, or it was not purchased for your use only, then please return to smashwords.com and purchase your own copy.” This group of violations represents a significant share of the dataset, in part due to the large number of “duplicates” within the datasets, which reduces the number of original books in the set to less than 8,000.
3. Labor negotiations and lobbying in certain sectors (unions in creative work, powerful interest groups in health) will limit dataset creation and use.
White collar laborers in certain domains, with sufficient labor power and small enough skilled labor supply, could use strikes and unionization to extract concessions not to use their tradespeople’s work to train AI models.
This concern, that prior recordings will be used to train AI and make certain actors and writers redundant, was a motivating factor behind the Hollywood Actors and Writers Unions Strikes.
Not all entities will be able to successfully do this. The individual bargaining power of an actor is much larger than that of, say, a grocery worker. But certain powerful trade organizations might win similar concessions if they are sufficiently concentrated, coordinated, and powerful.
Of particular concern and relevance here is healthcare. US healthcare is relevant to the inquiry due to both OpenAI, Google, and Anthropic HQs in the country and the economic value of the sector. The American Medical Association represents a critical node for any type of reform and policies ubiquitous throughout the healthcare sector (E.g. HIPAA & data sharing policies). The AMA has proven successful in resisting healthcare reforms even when similar pressure succeeded in other Western industrialized democracies. (See Hacker, 2004 for more on structural explanations for the AMA’s power.[5])
The likelihood of success for such efforts is also heightened in the United States under Democratic administrations, which rely on labor support. Biden pledged before his election that he would be “the most pro-union president you’ve ever seen.” He reaffirmed this commitment in his AI Executive Order, which emphasized the effects of AI on labor markets.
One of the central questions to-be-determined: What share of these laborers will significantly limit dataset creation and use, as opposed to simply demanding a manageable payment for it?
Probability: Fairly low in many professions, but higher in critical professions like healthcare. These roadblocks could pose a significant delay for automation of key sectors like healthcare. Healthcare alone represents 18% of US GDP.[6] Even a low chance of this high-magnitude constraint merits consideration.
4. Sources of Record Preventing Future Scraping or Pulling Their Content
Related to copyright lawsuits, sources of record might remove trusted content from datasets. This move would reduce the number of quality data sources from which training could draw.[7]
For example, The New York Times has already taken action to remove its content from some foundation model datasets. One would imagine that many sites will do the same, given the strong financial incentive to draw users to their monetized sites instead of ChatGPT.
Such “sources of record” that could be susceptible to these types of claims are overweighted in key datasets used to train LLMs. While it’s impossible to pinpoint precise dataset compositions for GPT-4—since they have not been released—we do know that these datasets are historically weighted toward sources of record over, say, a random blog.
Li (2020) describes GPT-3 weights here, showing that the GPT-3 dataset places lots of weight for its corpus on Books 1 and Books 2 datasets, as well as Wikipedia. Wikipedia's token number alone is 5.5% of that of "Common crawl (filtered by quality).”
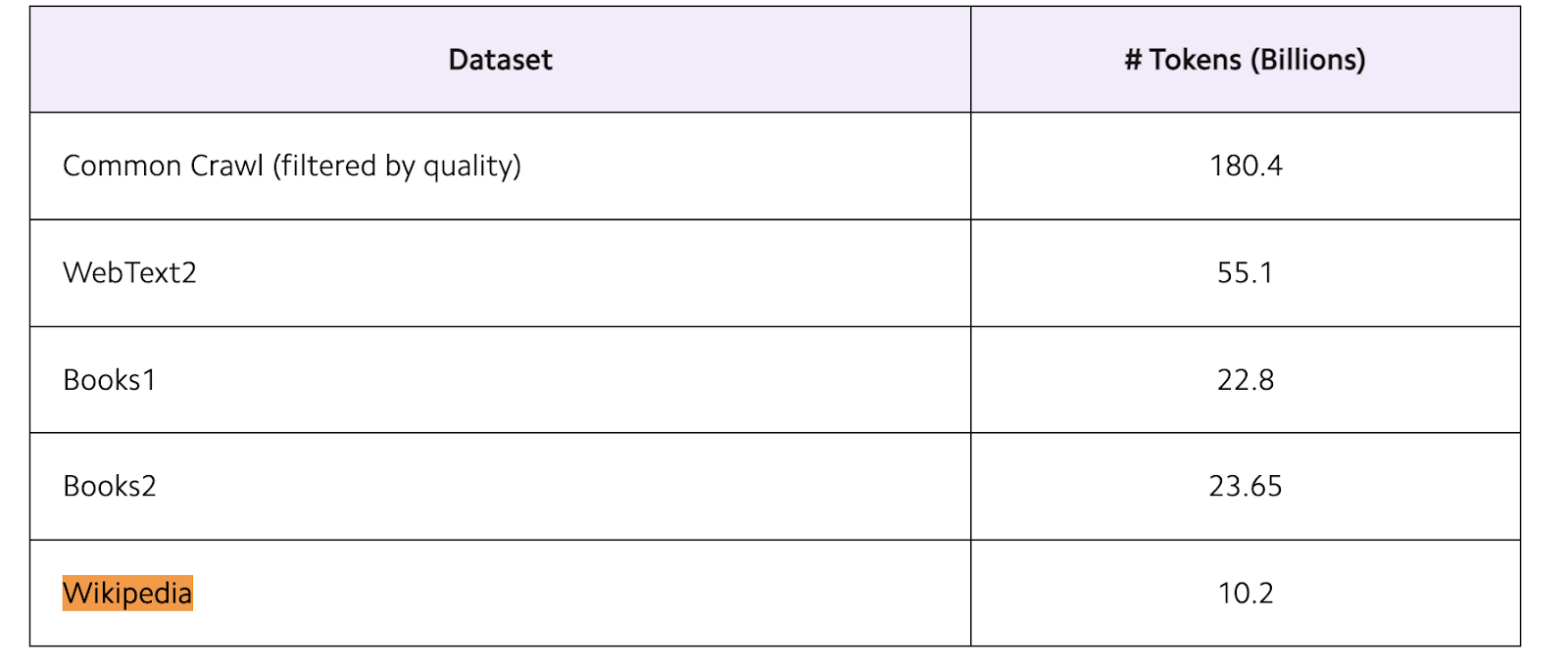
Probability: Already happening. Spread throughout publications of record is very likely to occur. The magnitude of harm is less clear, more dependent on unknowns about dataset composition.
5. Time Delays Affiliated With Each/Any Of The Above
In a world where synthetic data becomes a greater concern than many expect, or where an intellectual property regime shift forces a new approach to training datasets, such a move would functionally translate to years of lost R&D. It might also potentially dampen enthusiasm and investment in new innovations, further slowing the report’s key flywheel [? · GW]. Even if these roadblocks aren't insurmountable, they would impose significant delays on the report’s timelines. They threaten to take the timelines exposed in the report’s playground and shift them back by years.
~~~~~
II. The Common Sense Problem
TL;DR: Structural obstacles prevent 2020-era models from ever reliably performing the safety- and mission-critical tasks that would be necessary to automate many jobs in the economy. In particular, the abstraction/generalization problem is crucial to solve. Without abstraction, these models cannot manage safety-critical jobs. Instead, the tools will become impact multipliers for humans who keep these jobs. While these challenges will be solved one day, they cannot be overcome with today’s SOTA. Waiting for these next breakthroughs might present a bottleneck to the report’s timelines.
Section Overview
The report assumes that 2020 models, given additional compute, will enable us to automate human labor. This section challenges that assumption by showing how structural shortcomings in the SOTA inhibit the automation of large chunks of the economy, even with infinite compute.
If these arguments hold, then timelines should be pushed back due to the need for new innovations in the SOTA before reaching requisite model sophistication.
To power effective automation, AI must be able to generalize. That is, it must be able to draw abstract principles from its context that it can apply to the novel situations that inevitably emerge in the real world.
Such abilities are structurally constrained in the current SOTA approaches. While they will likely be solved soon, they have not been yet.
This section walks through the key components of this argument, establishing that:
- Abstraction is a necessary condition [LW · GW]for automating many human jobs;
- Recent studies suggest common-sense shortcomings [LW · GW];
- There are structural reasons for the generalization problem [LW · GW]—That is, why we can’t just hope more compute solves the problem;
- This obstacle carries large consequences [LW · GW]for the report’s measurement.
Abstraction as a Necessary Condition
Much of human problem-solving depends on our ability to reason through novel situations by drawing on “rich background knowledge about how the physical and social world works” (Choi, 2022).
Doing this successfully requires a type of “human level intuitive reasoning” (Choi, 2022).
Mitchell et al. (2023) state that “[t]he defining characteristic of abstract reasoning is the ability to induce rule or pattern from limited data or experience and to apply this rule or pattern to new, unseen situations.” Such reasoning is “fundamental to robust generalization.”
Choi (2022) emphasizes the key nature of abductive reasoning. Abductive reasoning is the skill of humans to generate probabilistic insights based on “deep background context.” Abductive reasoning requires a “non–trivial dose of imagination” and causal reasoning.
Reasoning beyond initial correlations requires understanding how to approach novel situations or draw parallels between the novel and the known. The means toward that end is abstraction.
Without this understanding, one can’t develop “common sense” (Choi, 2022).
This type of reasoning is something humans do extraordinarily well. We understand abstract concepts and instantaneously “transfer” what we have learned in past, seemingly unrelated circumstances to “new situations or tasks” (Choi, 2022; Mitchell, 2021).
To borrow criteria established by Marcus, an AGI that wishes to replace all human labor must be able to (1) generalize and respond to a novel set of new conditions and circumstances, (2) determine how the things it discusses relate to each other, and (3) determine how things it discusses relate to other things in the real world. It fails at all three of these things.
Deep Learning’s “Brittle” Nature Inhibits Performance
Contemporary deep learning cannot do this crucial abstraction work. Modern deep learning systems produce “unpredictable errors when facing situations that differ from the training data” (Mitchell, 2021). They are narrow and brittle.
This shortcoming emerges from an inability to build generalizable abstractions from the contexts in which models participate.
These problems become particularly apparent when LLMs are asked to do human jobs.
This brittleness is part of why deep learning models that dominate hard-for-human tasks like complex analytics or chess fail at even basic perception tasks. It’s why leading autonomous vehicle companies like Cruise still require human interventions every 2.5 to 5 miles. Automation leaders in other fields also still demand human oversight and intervention at similarly surprisingly high rates.
This phenomenon is most succinctly articulated as Moravec’s Paradox: What is hard [for humans] is easy [for models]; what is easy [for humans] is hard [for models].
Why the Generalization Problem Limits Adoption
1. Mission-Critical & Safety-Critical Functions
Even if more data makes models comparatively stronger, the failure rate of brittle AI systems unacceptably limits their accuracy.
A considerable share of human cognitive tasks require the ability to make sense of the unpredictable outside world. AI can handle chess and go in part because they are controlled game boards. Human professionals like, for instance, investors and city planners have to deal with exogenous shocks like natural disasters and geopolitical events all the time. No chess game has ever been interrupted because sudden supply chain shortages limited the weaponry for a knight.
These scenarios are often those where a human would have no problem sorting through a problem, but a model without abstraction capability would struggle.
In many contexts, short-circuiting in the face of an edge case or a need for formal, counterfactual, and/or abstract commonsense reasoning is a non-starter. Three reasons why:
- Many of these functions are safety-critical. For instance, Cruise uses human intervention every few miles because we wouldn’t get into an autonomous car that was 95% accurate, or even 99% accurate.
- In many others accuracy is critical, where “right answers” are easy to quantify. The goal in investment is generating a high ROI, which has an unforgiving monetary measuring stick attached to it. Art, on the other hand, is far less bounded. ChatGPT can make a bunch of sick poems, and when it “screws up,” it can be considered beautiful.[8]
- The combinatorial explosion of real-world scenarios [LW · GW]. The near-infinite scenarios that emerge in the wild mean that there will always be an edge case. Even in rules-based scenarios, like driving, with billions of dollars of investment and millions of miles of training data, the edge cases keep popping up. The long tail of exceptions that this creates necessitates an ability to “reason” through novel situations.
There are three reasons why major companies won’t put their reputation on the line by placing safety-critical functions at risk of even one catastrophic error:
- Reputational Risk. For safety-critical functions, a critical moat for leading corporations is their brand and its affiliated consumer trust. (Think cars, or leaders in agriculture or construction. Reliable quality is often necessary to justify premium price tags.) In the short-run, there is an additional deterrent of being subject to bad press.
- Regulatory Risk. Safety failures lead to bans. The California Department of Transportation recently suspended the permits for Cruise’s autonomous vehicles due to a number of accidents that was still lower than that of average manual cars.
- Litigation Risk. Though the immediate cost of a lawsuit is likely not an existential corporate risk on its own, a larger danger is precedent that places responsibility for all accidents on the producing company.[9]
2. A specific part of mission-critical operations: “Adversarial Hacking”
The same brittleness leaves systems exposed to a unique kind of hacking through “adversarial perturbations” (Moosavi et al., 2017). These perturbations are “specially engineered changes to the input that are either imperceptible or irrelevant to humans, but that induce the system to make errors” (Mitchell, 2021). Vulnerability to such adversarial attacks, even at the very end of the long tail, would leave high-consequence systems like banks or hospitals vulnerable to collapse at the cost of vast sums or lives.
For similar reasons listed above—avoiding legal liability and maintaining customer trust—companies will be incredibly wary to fully automate jobs. (That is, implement models without human supervisors.)
Studies Suggest Common Sense Shortcomings
There is an absence of empirical evidence that LLMs can perform any type of “abstraction,” “generalization,” or “common sense” (Mitchell et al., 2023; Choi, 2022). There is, however, lots of evidence that suggests these shortcomings in key tasks that require this common sense:
1. Formal Logic & Math
a. “The Reversal Curse”
Leading models still cannot readily determine that, if A is B, then B is A. The problem is particularly apparent when A and B are fictitious—that is, when the answer cannot be found in training data. Neither data augmentation nor using different model sizes improves the problem.
Even when trained on “A is B,” Berglund et al. (2023) found that prompts of “B is” do not result in “A” any more often than they result in any other random name:
For instance, if a model is trained on “Olaf Scholz was the ninth Chancellor of Germany”, it will not automatically be able to answer the question, “Who was the ninth Chancellor of Germany?”. Moreover, the likelihood of the correct answer (“Olaf Scholz”) will not be higher than for a random name.
These shortcomings suggest a challenge of combining retrieval and symmetry within LLMs.
b. Arithmetic
Models do significantly worse on math problems when figures involved are less frequently represented in model training sets (Yang et al., 2023). This finding suggests that what numerical reasoning exists is in part a function of gathering new data and reflecting it.
As documented in Yang et al. 2023, even LLMs specially created to handle math struggle when solving multiplication problems.
Evidence for this is covered in the results of the paper. In Table 7, copied below, increasing the number of “digits” of multiplication rapidly decreased function performance. These performance decreases correlated to the movement toward places in the training space with less coverage density. The decrease in accuracy itself also suggests that no underlying “rules” for multiplication had been learned.
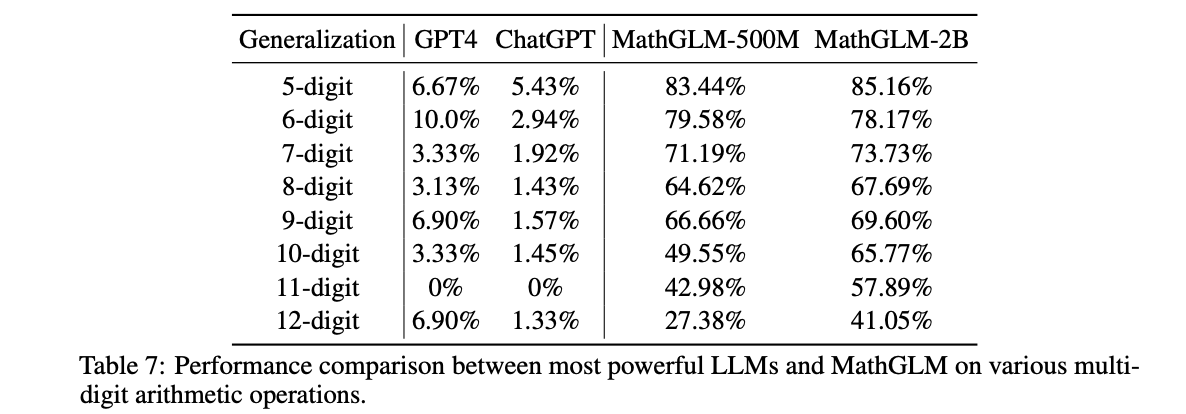
2. Correlation & Causation
Jin et al. (2023) (summarized here) conclude that LLMs “perform no better than chance at discriminating causation from association.” There is more work to do to extend this paper. Specifically, the paper lacks a human baseline, as well as descriptions on how they prompted their models. But regardless of the baseline human’s performance on the causation versus association challenges, the paper retains relevance insofar as many human experts can correctly differentiate between these two forces and these skills are crucial for success in many domains.
3. Spatial and Semantic Concepts
Chollet (2019)’s Abstraction and Reasoning Corpus (ARC) is a set of “1,000 manually created analogy puzzles” (Mitchell et al., 2023). These puzzles “intentionally omitted” language to prevent any apparent solving that was actually attributable to “pattern matching” from within a large corpus of text (Mitchell et al., 2023).
Leading models have repeatedly failed tests on the 200 hidden test set ARC tasks. As of November 2023, “the highest-achieved accuracy on ARC to date” is a mere 31%. Moreover, the authors of the currently leading program acknowledge that their methods are “not likely to generalize well” (Mitchell et al., 2023) Humans, alternatively, achieve an average 84% accuracy (Johnson et al., 2021 in Mitchell et al., 2023).
Mitchell et al., 2023 extended these experiments with both (1) a revamped dataset, ConceptARC, “organized as systemic variations of particular core spatial and semantic concepts.” While humans performed at a 91% accuracy, GPT-4 performed at 33%.
4. Counterfactual Reasoning
Wu et al. (2023)[10] expose LLM inability to reason abstractly by studying “counterfactual thinking.” LLMs are often unable to take lessons from the initial codebase to execute something in a novel situation. They asked LLMs “What does the following code snippet in Python 3.7 print?” The model did very well at these tasks. But when asked to make a “simple adjustment” that moved beyond Python script but followed identical principles, the LLM was unable to perform.[11]
Models’ inability to think “counterfactually” and apply the same logical reasoning that underlies Python to other contexts bolsters the “memorization hypothesis.” Per this hypothesis, models parrot back relationships within their training set and lack a core necessary skill to handle dynamic, novel situations: make the right decision by applying abstract lessons learned from prior experience.
5. Generalizing Beyond Training Distribution
Yadlowsky et al. (2023) examine the ability of transformers to “identify and learn new tasks in-context” when the tasks are “both inside and outside the pretraining distribution.” While these transformers performed “optimal[ly] (or nearly so)” on tasks whose “pretraining data mixture” lay within distribution, the same transformers failed, even on “simple extrapolation tasks... when presented with tasks or functions… out of domain of their pretraining data.” Even transformers that “performed effectively on rarer sections of the function-class space[...] still break down as tasks become out-of-distribution.”
Yadlowsky et al.’s findings suggest that the model took from its training no abstract principles that it could cross-apply to new stimuli.[12]
Structural Reasons for the Generalization Problem
Why does this shortcoming emerge?
Models learn to draw incisive predictions by identifying correlations within a large corpus of data. While access to new compute capabilities and a much larger corpus of information through the internet have driven an increase in productivity, these factors have not overcome concerns like the long tail of exceptions and LLM hallucination.
As Bender (2023) says, we ought not “conflate word form and meaning.”
1. Correlation =/= Causation
At its most basic level, these tools generate incisive predictions by finding patterns in datasets and predicting the likeliest next token given the correlations within their training distributions.
This fundamentally correlational learning model does not teach any level of causation or ability to reason through outliers.
2. Overparameterization: Overfitting on Randomly Initialized Parameters
One major reason for hallucinations comes simply from the limitations of the math that the models are based on.
There are more free variables than datapoints in large language models. (There are 1.76 trillion parameters in GPT-4, up from 175 billion in GPT-3.)
A model with more free variables (or parameters) than data points can lead to a situation where the solution is not unique or well-defined. This can manifest in overfitting, where the model learns the noise in the training data instead of the underlying pattern without sufficient data to correct it.
Weights and biases are initialized randomly, and without a sufficient number of datapoints to train noise out of the system, this initialization becomes a default driver.
3. Limitations Preventing Placement of Content into Training Distributions
Internet-Scale Datasets Fail to Unlock Automation Alone
Even before considering the data corruption concerns [LW · GW]from earlier in the piece, internet-scale distributions fail to enable generalization into many key economic domains.
a. The data doesn't exist.
The vast majority of knowledge that is necessary to access “expertise” in a realm just isn’t recorded in any legible type of way. As Ramani & Wang (2023) explain:
We are constantly surprised in our day jobs as a journalist and AI researcher by how many questions do not have good answers on the internet or in books, but where some expert has a solid answer that they had not bothered to record. And in some cases, as with a master chef or LeBron James, they may not even be capable of making legible how they do what they do.
Disproving a negative with more anecdata, I’ve encountered these problems myself in contexts that I’ve experienced, such as:
- Identifying what separates competent from best-in-class technical teams in various domains.
- Watching great public speakers trying to demonstrate how they have “presence.”
- Coaching high-performance tennis players on the components of the game beyond technique.
b. The high cost (human, financial, and otherwise) of building certain ground truth.
The model training process requires “trial runs” to assess different model permutations on models. But conducting such testing on safety-critical issues might entail immense costs.
To steal another parallel from Wang (in correspondence):
Imagine making a robot to teach kids to swim. You have to deploy it to get the data, but no kids can actually die in the process. You better hope that simulation is enough, but what if it’s never enough?[13]
Such costs would inevitably occur in testing where most attempts will generate suboptimal results. Our ability to avoid these costs depends on our ability to abstract principles and apply them to other contexts. Without this abstraction ability, we need to test on the specific challenge at hand to solve it.
c. The Edge Case Problem: Combinatorial Explosion of Real-World Scenarios + The Long Tail of Exceptions
There are just an infinite number of scenarios that can emerge. For instance, Teslas have been bamboozled by horse-drawn carriages and trucks full of traffic lights. Despite these examples being rare to never-before-seen stimuli, human drivers can quickly make sense of them.
The world is large and complex. Millions of attributes that cannot be anticipated are encountered every day in the real world.
Autonomous vehicle companies have humans constantly employed to either teleoperate their cars or provide necessary additional input in real-time when the robot gets confused by an edge case.[14]
This inability to handle the long tail of exceptions, paired with a fear of malfunctions in mission-critical and safety-critical contexts [LW · GW], is a large reason why many of the world’s leading companies have not automated even comparatively unsophisticated concerns.
For all the reasons flagged here of dataset limitations [LW · GW]—such as the combinatorial explosion of real-world scenarios [LW · GW]—throwing increasing amounts of data at the problem is no guarantee of a solution. If it was, then autonomous cars wouldn’t still require human intervention every few miles.
d. The lack of recorded expert-level data, and the challenge of ever recording and conveying such knowledge.
While some challenges, like board games or even driving cars, have fairly clear win-loss conditions, many others do not. For instance, how do we define test criteria of “success” for a chatbot? The limitations of RHLF and other tools in transferring this expertise, particularly when it is rare and often unrecorded, impose another limit.
4. Semantically Valid World Models
Less empirically, the very existence of hallucinations en masse suggests a lack of a coherent “model of the world.”
Similar conversations about the limitations of world models emerged in the aftermath of Gurnee and Tegmark (2023). The authors claimed “evidence for… a world model” within LLMs after “analyzing the learned representations of three spatial datasets… and three temporal datasets.” Through this analysis, they were able to generate datapoints on a map where cities clustered on or close to their “true continent[s].” That is, North American cities ended up on or near the North American borders on the map, and the same could be said for African cities, Asian cities, etc.
But as commentators like Marcus (2023) flagged at the time, these relationships clustering places roughly by their geographic proximity are precisely what you would expect from a strictly correlational tool. After all, the datasets often contextualize cities within their geographies. For instance, both Gramercy Park and Grand Central Station are used in linguistic contexts alongside “Manhattan.” Or, to quote Marcus directly: “Geography can be weakly but imperfectly inferred from language corpora.”
We would expect an LLM prompted with questions about Dallas to frequently mention Houston for the same reason that we would expect prompts mentioning William Seward to generate lots of mentions of Alaska and Abraham Lincoln. These things are frequently mentioned alongside each other.
And, of course, any semantically valid world model would not place lots of cities hundreds of miles into the ocean.
There is a good chance that this world model section proves unsatisfying due to the tricky/feckless nature of the task at hand: Trying to prove a negative. However, I include it for the purpose of engaging with a key question in the “understanding” literature and anticipating a probable counterpoint to many of the points above within this technical shortcomings section.
Quantifying the Consequences
These limitations on driving alone prevent the automation of a significant share of jobs.
- According to the Bureau of Labor Statistics, 30% of civilian jobs in the U.S. require some driving. While some of these functions could innovate around driving with enough new technology, others—large shares of the 30% like delivery drivers, truckers, or police patrols—cannot. Per the US Bureau of Transportation Statistics, “four of the five largest transportation-related occupations involve driving.” These four occupations (heavy-duty, light-duty, and delivery truck drivers; school bus drivers; and driver/sales workers) employ 3.6 million workers.
- The construction sector, full of safety-critical, high-consequence decisions that must be automated successfully, employs 8 million Americans. Construction automation is even more difficult than driving, as it requires both the movement of an entity through an environment and the manipulation of that said environment. (Not to mention the additional challenge of managing appendages with multiple degrees of freedom in machines like excavators.)
- Many jobs might shift—that is, people involved in a task will do different work to supervise the models that perform under them. But that is more akin to moving from manual bookkeeping to Excel modeling than the end of a job.[15]
~~~~~
III. GDP Growth, Measurement, & Definitions
Framing: GDP Growth as a Necessary Part of the Argument
The report’s estimates of how quickly we span the effective FLOP gap between AI performing 20% of tasks and 100% of the tasks depends in part on GDP growth:
- The speed at which we cross the effective FLOP gap depends on how quickly we increase effective compute in the largest training run. In the report’s model of the world, this effective compute depends on increases in software, hardware, and money spent on training. The third of these attributes depends in part on GDP increases, which increase the money spent on training for two reasons:
- First, GDP increases from automation validate the value of further automation via better models, incentivizing increased investment.
- Second, independent of dedicating an increased share of GDP to AI R&D, an increase in GDP increases the money spent on training because the same share of GDP dedicated to training then goes further.
Thus, estimates of how quickly automation boosts GDP are important to the end result of this model and how quickly we access its explosive growth flywheels.
However, the report model for how automation will increase GDP is very ambitious.
The following three forces are potential mitigations to GDP growth and, therefore, the flywheels key to the report.
A. “Good Enough to Substitute Profitably" AI (GESPAI)—Definitions Around “Readily Perform” Could Distort Findings.
Performing a task “readily” and profitably is not the same as performing a task better than humans.
The current report measures when AI can “‘readily’ perform a task” as when the model would be “profitable” for organizations to incorporate in practice and able to be incorporated within a year, thus substituting for human labor in the global economy.
But corporations will substitute a superior service for a slightly inferior one if it creates more profit for them.
That is to say, B can readily substitute for A, despite A being better at the task at hand.
This nuance matters because, if true, it means that the report does not necessarily measure when AI can perform all tasks as well as or better than humans. Instead, it simply measures when models become good-enough-to-substitute-profitably (GESPAI). Perhaps these models require, for instance, questions to be asked of them in ten different ways. Or, they hallucinate [LW · GW].
Humans can output significantly more than their GESPAI substitutes, but still be less profitable for their firm, if their salary cost makes the profit from each of them less valuable.
Consider the following hypothetical scenario:
Imagine a human, called Jimbo, a trader who earns an annual salary of $100,000 and generates an annual revenue of $150,000 for AnonBank. Then imagine a trading algorithm, called JimBot, that can generate an annual revenue of $140,000 for AnonBank. JimBot takes no salary. Both Jimbo and his model counterpart spend the same amount conducting their trades, so the only difference in their costs is Jimbo’s salary. Jimbo is a better trader than JimBot. Jimbo’s per-task output is higher. (Over the same unit of time, he produces more revenue.) Yet AnonBank should replace Jimbo with JimBot every time. The GESPAI is better for its work.
All of the standard reasons that markets are imperfect further lower the standard that GESPAI has to reach, as they mean that consumers put off by the introduction of a subpar model have less ability to simply leave:
- Oligopolistic industries—big banks, health insurers, airlines, rental cars, rideshare—both (1) reduce the alternatives at hand if customers are dissatisfied and (2) encourage de facto collusion. If Delta, United, and American Airlines all start using this automated service, you quickly run out of the alternative options.
- Switching costs, both in the form of sticks (transfer fees) and loss of carrots (loss of loyalty benefits), incentivize many users to stay with a bad experience instead of switching, to access the other benefits of a firm.
Implications
This intervention carries four key implications for the report, presented from least to most complex:
1. GESPAI does not threaten to “disempower all of humanity” in the same way as a more powerful AI.
Instead, this definition leaves room for a world where AI can substitute for some economic tasks, but is unable to perform most tasks better than humans.[16]
2. The report’s definition might producer to a faster timeline than the road to at-or-above-human-level AI.
Getting AI to good-enough-to-substitute-profitably levels is easier than creating models that perform all economic tasks better than humans.
3. This definition could leave too much room between 20% and 100% automation.
GESPAI might solve for automating over 20% of the global economy, but it will fail to reach anywhere near 100%.
This shift occurs well before a similar move on safety-critical functions [? · GW], where substituting below human level is unacceptable. A definition where GESPAI qualifies as automation risks substantially elongating the 20% to 100% path.
This type of GESPAI automation already represents a significant share of knowledge work, including more “rote,” front-of-house white collar work. (Paralegals, customer service, etc.) These GESPAI products are still clearly inferior in lots of cases. But, under this definition, they could be described as “automatable.”
4. GESPAI significantly reduces the GDP boosts from automation.
Author argues that AI automation doubles productivity by freeing up humans to do additional work while automation creates the same productivity:
Let’s say AIs automate 50% of tasks… Humans can focus on the remaining 50% of tasks, and AIs can match the per-task output of humans, increasing the output per task by 2x. This boosts GDP by 2x...
In that same vein:
Here, I’m assuming that AI output-per-task at least keeps up with human output per task. I can assume this because it’s a condition for AI automating the tasks in the first place.
But it’s not! Instead, GESPAI can do significantly worse at the job, generating less net revenue and/or per-task output, while still being a good call for the company. AnonBank should still replace Jimbo with JimBot, even if Jimbo is the better trader.
B. Anything Successfully Automated Inherently Becomes a Smaller Percentage of GDP.
TL:DR: As you automate goods, their relative economic value decreases.
When a task is automated, its contributive share of GDP decreases simply by the nature of automation. There are two reasons why:
1. Increase in Labor Supply, All Else Equal, Drives Wages Down.
Functionally, the creation of an unlimited number of models performing a service represents an infinite increase in the supply of labor. As labor supply increases, all else equal, the shift of the labor supply curve means reduced wages for performing the same task.
2. Baumol Effect increases wages for other jobs that do not experience productivity growth, decreasing the unit value of a task.
As productivity increases in one sector, the wages of remaining workers increase. In response, other sectors that are essential, but didn't experience this productivity growth, must increase their wages to attract workers. The Baumol Effect explains part of why wages have increased in sectors like healthcare and education. We need people to work in these sectors. With wage growth elsewhere, we have to pay them more to keep them from defecting to more lucrative industries. This has the effect of decreasing the value in GDP terms of each unit of the more productive industry, as the employee is doing much more for a comparatively similar wage to that of employees in less productive sectors.
Together, these factors mean that when you automate something, the relative weight of completing one unit of the service in terms of GDP decreases. This can enable a greater quantity of tasks to be completed, but it can also commoditize the good.
Even if you automate what is currently represented as 50% of our GDP, it is likely that this very automation decreases the share of our GDP that has been automated.
3. Automation moves surplus from laborers to capital-holders, who are less likely to spend.
Consumption drives a large share of the GDP. An employee creates economic surplus for his or her company, and is rewarded with wages, that are then spent on other businesses, creating the wages of another group, and so on. This is called the multiplier effect.
As the heading says, automation will keep what money used to go into wages in the hands of the capitalist. The wealthiest save more of their real incomes than the rest of us.[17] Thus, money reallocated from laborer to capitalist is less likely to jumpstart the multiplier effect.
C. Displacement of Labor Creates Market Inefficiencies
The report assumes that humans automated out of a job will find equally productive/valuable work when prior jobs are automated.
Author argues that AI automation doubles productivity by freeing up humans to do additional work while automation creates the same productivity:
Let’s say AIs automate 50% of tasks… Humans can focus on the remaining 50% of tasks, and AIs can match the per-task output of humans, increasing the output per task by 2x. This boosts GDP by 2x.
First Principles Rebuttal
Below are six reasons this might not be the case for many individuals:
- Limited jobs in a community. Jobs are not created in a community at a 1:1 pace for which jobs are automated. Instead, more people just compete for the lower-wage jobs in a community. Per Acemoglu (2020): “When [automated] jobs disappear, [displaced] workers go and take other jobs from lower wage workers.” Someone loses and ends up displaced.
- Training for a new job often requires some amount of skills training. The time spent training represents deadweight loss itself, even when effective. Many times, research suggests, government-run retraining programs are very unsuccessful (Edwards & Murphy, 2011). It also might incentivize some workers to leave the workforce. (Examples include: Retiring early, remaining on unemployment benefits, or pursuing opportunities outside the formal economy like full-time parenting.)
- Age discrimination in hiring might prevent older displaced workers from finding new jobs. (Baker, 2017, summarizing Federal Reserve Bank of San Francisco, 2017).
- The jobs that displaced employees take might not be as lucrative as their old jobs. The need to take any job to pay bills incentivizes displaced workers to “settle” for less-than-ideal opportunities.
- Displaced employees become less productive in their new role than they were in their old one. Many often had experience in their old, now-automated role. They likely are less effective in their new domains as they are new to it.
- Many people can’t access/use technology. While automation might generate new jobs (such as data labeling), that doesn’t mean these jobs are easily accessible. 42 million people in the U.S. alone—a developed country—don’t have broadband access. Many others can’t use a computer well enough to perform data labeling.
Data-Driven Rebuttal
These first-principles mechanisms are borne out in initial research.
Acemoglu & Restrepo (2020) (MIT Sloan Reports) “found that for every robot added per 1,000 workers in the U.S., wages decline by 0.42% and the employment-to-population ratio goes down by 0.2 percentage points,” and “adding one more robot in a commuting zone (geographic areas used for economic analysis) reduces employment by six workers in that area.”
This research suggests that not all employees “replaced” by automation find new jobs.
Feigenbaum and Gross (2022) (summarized by Dylan Matthews (2023)) found that telephone operators who were automated out of their jobs in the mid-20th century were 10 times likelier to “be in lower-paying professions a decade later” than were “operators not exposed to automation” (Matthews, 2023). “Older operators” were also 7% more likely to leave the workforce upon automation than non-automated peers (Matthews, 2023).
Implications for Report Model
Together, these three reasons significantly mitigate claims that automation will increase GDP at the rates the report suggests.
Instead of automating 50% of tasks increasing GDP by 2x, these mitigations dampen boosts to a lower number.
Remember from the report [? · GW]:
g(effective compute in largest training run) = g(fraction FLOP on training run) + g($ on FLOP globally) + g(FLOP/$) + g(software)
Let’s run through the key variables impacted:
1. g(software)
From the Long Summary:
Each doubling of cumulative software R&D spending drives ~1.25 doublings of software.
The report mirrors the growth in GWP with the growth in R&D:
The logic described here for AI automation’s effect on GWP is the same as for its effect on R&D input.
Thus, any mitigation in GWP growth based on the factors above decreases g(software)’s growth at a multiple of 1.25.
2. g($ on FLOP globally)
As the report mentions:
The increase in g($ on FLOP globally) equals the increase in g(GWP).
Thus, any mitigation in GWP growth based on the factors above decreases g($ on FLOP globally)’s growth at the same rate.
3. g(FLOP/$)
Less quantitatively, FLOP/$ decreases in this world.
All else equal, lower GWP —> less investment in hardware and software —> less innovation in hardware and software —> worse models —> lower FLOP/$.
Even shifting 2x to 1.5x has dramatic implications for the model, reducing the power of each node on the flywheel:
- $ spent on R&D and buying more compute decreases.
- Hardware and software innovation both take longer.
- Our largest training runs are smaller at each time horizon.
- The resultant AI models can automate less at each time horizon.
~~~~~
IV. R&D Parallelization Penalty
The report’s best guess presets put it at .7 (Playground). I believe there are good reasons to use a significantly larger penalty.
A. Using The Cited, ML-Specific Research (Besiroglu, 2020)
The Takeoff Model Playground notes in its additional information that:
Besiroglu cites some [numbers] as low as .2.
But Besiroglu is significantly more dire than that. On p. 14 (as cited), Besiroglu references another report (Sequeira and Neves, 2020) that finds a coefficient of around 0.2. But Sequeira and Neves are only cited to contrast against Besiroglu’s findings, which estimate from .02 to .13.
Find key excerpts below, mostly from the same page cited in the takeoff model playground.
Initial Finding:
Using a co-integrated error correction approach, we estimate the average research elasticity of performance to be around .02% to .13% across three subfields of machine learning considered. (p.1).
It would roughly take an additional 2060 researchers to double the impact of the first 10 researchers” due to “very substantial stepping-on-toes effects” (p. 14).
Besiroglu, contrasting findings with Sequeira and Neves:
Our estimate of σ indicates a larger stepping-on-toes effect than is usually found in the literature on R&D. For example, a meta-analysis by Sequeira and Neves, 2020 finds an average σ coefficient of around 0.2—roughly double the values we found for computer vision and natural language processing (p. 14).
B. First-Principles Reasons for High R&D Parallelization Penalties
There are reasons to believe that the AI/ML R&D process will be particularly inefficient due to the actors funding the work.
The vast majority of this money comes from one of three sources, all of which create substantial penalties:
1. Ever-increasing numbers of private markets investors, most of whom will have no idea what they’re doing, throwing money at dead-on-arrival projects.
The report discusses how, as AI shows more promise, more people will invest in the space due to a belief in exceptionally high returns. But as productivity grows, so do hype cycles. Many new “AI investors” have already entered the space in the last year. While some investors are incredibly sophisticated, many will chase money without having the requisite technical understanding to make good bets. These less sophisticated investors will get “duped” at higher rates, putting money into startups that, even in their best case, won’t provide novel innovation. (The most recent obvious parallel here is the Web3 hype cycle and “crypto boom.” Another valuable parallel is the dot-com bubble.) Dunking on VCs is easy, but it’s also genuinely an important part of the argument.
2. Duplication of efforts across competing corporations.
Investment pursuing Innovation X does not go into one centralized pool. Instead, many companies pursue the same goal at once. Apple and Microsoft both pursue innovation X with full teams. Even if both teams succeed, the creation of Innovation X has become a duplicative effort in the view of advancing the SOTA.[18]
3. Duplication of efforts across national lines.
Both the United States and China consider AI development a central attribute of their national security strategies. In some contexts—particularly AI development for defense—the ecosystem is largely decoupled (despite some Chinese MLEs working for US companies and universities).[19]
Increased Parallelization Penalty, All Else Equal, Adds 5 Years to Timeline
This table compares takeoff speeds at different parallelization penalty weights using the playground model:
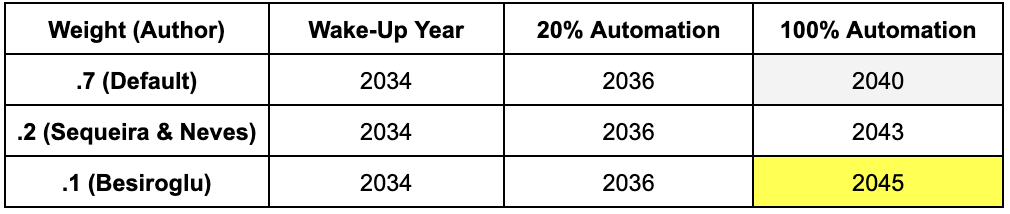
~~~~~
V. Taiwan Supply Chain Disruption
TL;DR: SOTA AI models run through Taiwan and TSMC. A PRC military invasion of Taiwan would set back timelines by 20 months [? · GW] until another firm “catches up” with TSMC’s current sophistication. Such an invasion becomes increasingly likely as Xi accumulates more power and PRC military ability increases.
Framing
The report makes a key assumption related to SOTA model distribution and development: That for both R&D and commercial distribution, the SOTA frontier isn't paused or set back. That once we produce function/ability Y, we can retain, readily re-produce, and iterate upon ability Y into the future. (In hardware terms: We can supply enough SOTA-level hardware to match both commercial and R&D demand.)
The brittle nature of the supply chain for semiconductors, which are a prerequisite to frontier models and improved performance, challenges this assumption. Shocks to the supply chain that functionally remove a node within it would prevent further production of the SOTA and leave development functionally “paused.” No additional SOTA chips could be created, severely limiting both distribution of the SOTA and R&D using the SOTA. This pause would continue until another actor could achieve the same leading level of sophistication.
These semiconductor supply chain shocks represent a significant enough threat to maintaining the SOTA to merit consideration in the report’s timelines. In particular, the greatest threat is that of a PRC invasion of Taiwan.
An Invasion of Taiwan Would Set SOTA Innovation Back, Potentially by Years
A PRC invasion of Taiwan could lead to the destruction of TSMC, which is a key actor in the production of SOTA semiconductors. As the arguments below will explain, losing TSMC could create (1) production bottlenecks from damaged/destroyed factories or (2) loss of knowledge around key processes in fabrication. Either of these would prevent the production of SOTA hardware.
This event would set the report’s timelines back, potentially by potentially years.
1. TSMC Sets the SOTA
In the status quo, TSMC uniquely sets the SOTA in semiconductor production. TSMC produces “around 90% of the world’s leading-edge semiconductors.” Their advanced extreme ultraviolet lithography (EUV) machines, combined with a series of precise and sophisticated processes, enables them to make chips far beyond what competitors can produce. TSMC chips are already created at a granularity of 3nm, more sophisticated than even “friendshored” alternatives like the TSMC chips being produced in Arizona, USA.
Other firms are predicted as unlikely to catch up to TSMC’s current level until 2025, at which point TSMC will presumably still maintain some of its ~20 month advantage due to continued R&D.
Losing access to TSMC chips, per this analysis, is worth ~1.5 years in AI timelines, because losing TSMC would functionally “freeze” hardware innovation until other firms “caught up” with TSMC.
2. An Invasion of Taiwan Would Destroy TSMC Capacity
Four ways:
- Taiwan might destroy the TSMC campus in the event of invasion. The PRC still imports over $400 billion worth of Taiwanese semiconductors. Concern that Taiwan would rather destroy TSMC campus than let the PRC take it is a huge reason why Xi hasn’t invaded yet.
- The United States might destroy the campus if Taiwan does not, to ensure that the PRC does not take a strategic advantage in what most policymakers in DC consider a zero-sum, existential race for global supremacy. (See NSCAI, among others.)
- US Congresspeople, including Democrats like Seth Moulton, have said that the United States would destroy TSMC in the event of a PRC invasion. But far more important is the potential US intelligence (DoD, State, CIA) response. This response is often seen through the lens of strategic competition.
- Even if TSMC campus remains, war in Taiwan would halt production. Despite the PRC's superior military strength, Taiwan would use every power in its capacity to hold on for as long as possible. The U.S. has also committed to defending Taiwan. Given the delicate nature of fab processes—sensitive to even a millimeter of movement—some disruption feels inevitable in the face of conflict.
- Even if the PRC seizes TSMC without damage, key individuals with proprietary, critical, and scarce knowledge of production might not transfer the knowledge. As detailed by Chris Miller in Chip War: The Fight for the World’s Most Critical Technology, certain parts of the fabrication process rely on knowledge held by only a handful of individuals who work directly on them. TSMC designed its firm this way to prevent defection to build competitor firms, so no TSMC employee, or small group of them, could recreate TSMC elsewhere.[20]
3. Invasion of Taiwan is A Serious Risk
PRC invasion of Taiwan is a real risk, due to the strong incentives compelling the PRC to action:
- Taiwan is already seen across mainland China as rightfully part of the PRC, given Taiwan’s modern origin as an ROC hub and eventual retreat point after losing the Chinese Civil War.
- A Taiwanese invasion would be seen as a crowning achievement for Xi, after multiple terms of that have already seen him dramatically centralize and consolidate power.
- PRC military might is growing dramatically, more than doubling from 2014-2023 to reach $224 billion. Accordingly, the PRC has an increased likelihood of successful invasion, even if the United States defends Taiwan. Military analysts say the PRC's new military might endows it with “a great advantage in a potential conflict with the U.S. in the South and East China seas.”
- The PRC government has demonstrated how much it cares about this issue by offering significant incentives to build global support for One China. It offers favorable One Belt One Road policies, often including millions of dollars worth of infrastructure, throughout the world contingent on acceptance of One China policy. As of 2018, only 20 countries even had formal relations with Taipei. This is in part due to the work the PRC government has done to offer OBOR incentives dependent on One China alignment (Guardian, 2017; Gallagher, 2016). Foreign ministry officials also frequently reflect their official belief that Taiwan is a part of the PRC, despite the costs of additional tensions with the U.S., Taiwan itself, and the global community.[21]
An April 2023 survey of expert IR scholars estimated an average “23.75 percent chance of a Chinese attack against Taiwan in just the next year.” Prediction markets like Metaculus are less bullish, but still predict a 40% chance of “full-scale invasion” by 2035 and 30% by 2030. Those odds increase as Xi continues to consolidate power, PRC military capacity grows, and increasing model sophistication raises the stakes of the “Great Power AI Competition” to Beijing.
Other Regulation
Finally, regulation on hardware distribution or deployment might interrupt supply chains and leading innovators.
I allude to some potential regulatory disruptions in the section titled Obstacles to Data Quality [LW · GW].
Increased attention on AI will bring more lobbying to shape its future. Particularly deserving of attention are powerful lobbying groups whose members create important datasets. For example, the American Medical Association in the USA has shown its ability to defend its interests even when counter to popular will.
National security issues might also disrupt supply chains and distributions. As briefly mentioned in the R&D Parallelization Penalty [LW · GW] section, “decoupled” ecosystems in the US and PRC already diminish innovation. Under certain political regimes—or simply due to military concerns about AI’s role in Great Power Conflict—a greater decoupling could occur. Such moves could pause development at leading labs caught in national security strategy's crosshairs. For example, US export controls could prevent SOTA semiconductors from reaching mainland China and inhibit leading labs in Beijing.
~~~~~
Appendix A: Background Info on Davidson 2023’s Central Argument
Summary of Report’s Central Approach to Takeoff Speed
Key Flywheel for Accelerated AI Growth & Automation
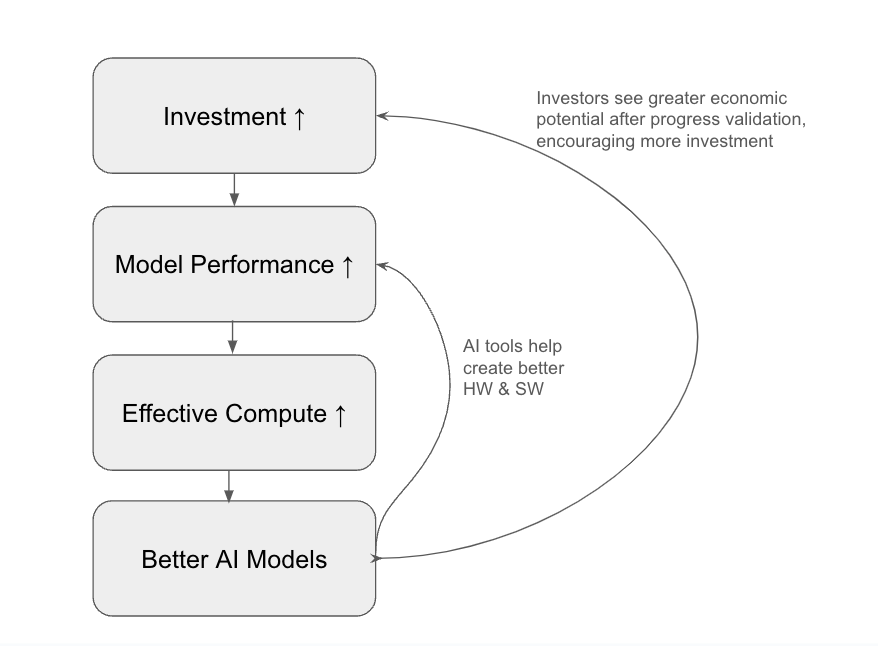
More Detail
The report considers takeoff time, how quickly the shift from AI performing 20% of tasks and to completing 100% of tasks will occur.
This question is re-framed as “How quickly do we cross the effective FLOP gap?”
Takeoff Time = Distance / Average Speed
Distance = Effective FLOP Gap
The speed at which we cross the effective FLOP gap depends on how quickly we increase effective compute in the largest training run. To quote:
Model assumes the compute-centric model. That is to say: It assumes that 2020-era algorithms are powerful enough to reach AGI, if only provided enough compute.
In the report’s model of the world, this effective compute depends on increases in software, hardware, and money spent on training.
Decomposing effective compute:
Compute = Software * Physical Compute
EC = software * [FLOP/$] * [$ Spent on FLOP]
Therefore:
g(effective compute in largest training run) = g(fraction FLOP on training run) + g($ on FLOP globally) + g(FLOP/$) + g(software)
The speed at which we cross this effective compute gap accelerates over time thanks to a self-reinforcing loop kicked off by initial AI training. Training creates better-performing AI models. Because of the economic potential of these models, investment in the hardware and software behind these models increases. This effect itself improves models and increases effective compute. At some point, AI-assisted software and hardware design also accelerates the flywheel further, improving AI models even quicker. This loop powers much of the rapidly accelerating takeoff speed. (See key flywheel [LW · GW]graphic.)
~~~~~
Appendix B: Key Sources
Along with the hyperlinks provided, I draw heavily on the following sources:
Books
Chip Huyen, Designing Machine Learning Systems. (Reproduced here as Lecture Notes by Lesson for CS 329S at Stanford University.)
Gary Marcus, The Algebraic Mind: Integrating Connectionism and Cognitive Science (reproduced 2021)
Marcus & Ernest Davis, Rebooting AI: Building Artificial Intelligence We Can Trust (2019).
Chris Miller, Chip War: The Fight for the World’s Most Critical Technology (2022), for the granular look into the semiconductor supply chain helpful for Section V [? · GW].
Key Academic Papers
Yejin Choi, “The Curious Case of Commonsense Intelligence,” 2022.
Melanie Mitchell et al., “Comparing Humans, GPT-4, and GPT-4V On Abstraction and Reasoning Tasks,” 2023.
Vahid Shahverdi, “Machine Learning & Algebraic Geometry,” 2023.
Sina Alemohammad et al., “Self-Consuming Generative Models Go MAD,” 2023.
Ilia Shumailov et al., “The Curse of Recursion: Training on Generated Data Makes Models Forget,” 2023.
Veniamin Veselovsky et al., “Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks,” 2023.
Melanie Mitchell, “Why AI is Harder Than We Think,” 2021.
Pablo Villalobos et al., “Will We Run Out of ML Data? Evidence From Projecting Dataset Size Trends,” 2022.
Lukas Berglund et al., “The Reversal Curse: LLMs trained on ‘A is B’ fail to learn ‘B is A,’” 2023.
Roger Grosse et al., “Studying Large Language Model Generalization with Influence Functions,” 2023.
Zhen Yang et al., “GPT Can Solve Multiplication Problems Without a Calculator,” 2023.
Zhaofeng Wu et al., “Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks,” 2023.
Zhijing Jin et al., “Can Large Language Models Infer Causation from Correlation?,” 2023.
Jacob S. Hacker, “Dismantling the Health Care State? Political Institutions, Public Policies and the Comparative Politics of Health Reform,” 2004.
Steve Yadlowsky et al., “Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models,” 2023.
Ramani & Wang, “Why Transformative AI is Really, Really, Hard to Achieve,” 2023.
Gurnee & Tegmark, “Language Models Represent Space and Time,” 2023.
Tamay Besiroglu, “Are Models Getting Harder to Find?,” 2020.
Daron Acemoglu & Pascual Restrepo, “Robots and Jobs: Evidence from US Labor Markets,” 2020.
Tiago Neves Sequera & Pedro Cunha Neves, “Stepping on toes in the production of knowledge: a meta-regression analysis,” 2020.
Seyed-Mohsen Moosavi-Dezfooli et al., “Universal Adversarial Perturbations,” 2017.
- ^
See Vincent (2023) from The Verge for more examples.
- ^
One way this could become less of a problem is if enough fresh, non-generative content is written that the corpus remains sufficiently un-corrupted. However, with the cost of generating text so low and getting both lower (compared to the cost of writing organic content) and becoming more accessible to more people, I’m pretty bullish on the claim that “share of generated text increases over time.”
- ^
At last check (November 2023), Manifold Markets put the odds of Anderson et al. v. Stability AI et al. being found as a copyright violation at 18%, but the n is far too low to tell us anything yet. (I increased it 1% with a bet worth $0.20.) Perhaps some readers have expertise in intellectual property law?
- ^
One other potential outcome: If it appears to model producers that they will lose intellectual property suits around their training sets, they could counter-propose a business model where they pay producers of training data artifacts when their data is utilized, a la Spotify. This possibility is left as an area for further research, particularly as the legal landscape develops.
- ^
One could imagine, say, the American Bar Association being similarly successful given its established credentialing systems, concentrated wealth, and the vested interest of its members. However, the legal profession represents less than ½ of 1% of US GNP, a negligible amount for this inquiry.
- ^
This share of GDP could increase dramatically thanks to the Baumol Effect. (See Section III [? · GW].)
- ^
Note that such a decrease in “good” data becomes particularly pernicious against the backdrop of a potential increase in “bad” corrupted data.
- ^
Note how this complicates the metaphor of Moravec’s “rising tide of AI capacity,” referenced in the report. Certain outputs like art and cinematography are potentially easier for a deep learning model to access because they do not require any one “correct” answer. They’re not optimizing for, for example, increased revenue.
- ^
It’s worth explicitly explaining why startup willingness to “break the rules” or “risk it all” here wouldn't kill the argument. First, definitionally, most economic value/most jobs come from large enterprises. Less than 1% of businesses create over 50% of the jobs (US). Thus, if large enterprises remain unwilling to take these risks, then most jobs are immune from the automation risk. Second, consumers don’t want to buy "mission critical" products from unproven startups. If you can't convince consumers to buy a product, then there is no incentive to build it. Third, if a startup gets big enough to significantly challenge this concept, then they will begin to succumb to these same incentives:
(1) Loss aversion will emerge, as downsides become much greater. Public markets executives risk losing their jobs in the event of major incidents.
(2) Scaled enterprises have far more people focused on risk (lawyers, compliance, etc.) who will not let such decisions to move forward.
(3) Larger startups rely on strong relationships with legal authorities to both protect their gains against new startups and offer lucrative government contracts.
Independent of these concerns, two other reasons that startups will also succumb to these same incentives around mission-critical issues:
(1) Reputational risk is arguably larger for a startup, since it lacks countervailing data points proving their trustworthiness. (Who would trust a series B autonomous lawnmower company if their mowers were just caught chasing a human down?)
(2) Regulatory and litigation risks are arguably higher for startups, as the same penalties impose a greater pain (and they cannot afford to pay large sums or lose lots of time to mount a defense.) - ^
Credit to Mitchell (2023) for original analysis of this paper.
- ^
The prompt, for context: “You are an expert programmer who can readily adapt to new programming languages. There is a new programming language, ThonPy, which is identical to Python 3.7 except all variables of the `list`, `tuple`, and `str` types use 1-based indexing, like in the MATLAB and R languages, where sequence indices start from 1… What does the following code snippet in ThonPy print?"
- ^
Related is Narayanan & Kapoor (2023)'s concern that part of GPT-4’s success on benchmark standardized tests like the SAT and MCAT could be due to “testing on the training data.” Per this theory, a reasoning challenge from out of distribution could still pose serious challenges.
- ^
Zhengdong tells me that Sanders, 2023 [EA · GW] deserves original credit for this hypothetical.
- ^
Note that this type of decision-making and sense-making of the world is still a cognitive task, even when it occurs in a robotics context. (Responsive to the note in in Long Summary that excepts the “pure physical labor” component of jobs from the concerns here.) Instead, this type of sense-making of the world clearly fits into the Sense and Think segments of robotics's foundational Sense-Think-Act trichotomy.
- ^
Of course, in some industries, human service might emerge as a premium service even as baseline services are automated. See Lee (2023) for more on this argument. Though this phenomenon is worth noting, it occurs downstream of the automation that is at stake in this section’s argument, and thus lives beyond scope of this conversation.
- ^
Note that this argument does not suggest that GESPAI would be the terminal form of artificial intelligence. Instead, it distinguishes the phenomenon analyzed in this report from more alarming manifestations of AI growth such as superintelligence. We can reach widespread automation far before AI becomes super-intelligent or anything close to it.
- ^
They do this, in part, because they can. They need a smaller share of their salaries to pay for necessities like food, housing, and healthcare.
- ^
In practice, most large firms also have many teams working on similar projects due to bureaucratic inefficiency and/or separate political sandboxes.
- ^
Sequeira & Neves (2020) allude to this third factor in their own work, with a focus on the high number of “international linkages” that make ML development particularly prone to stepping-on-toes. To quote: “This value [of the stepping on toes effect] tends to be higher when variables related to international linkages are present, resources allocated to R&D are measured by labour, the knowledge pool is proxied by population, and instrumental variable estimation techniques are employed. On the contrary, the average returns to scale estimate decreases when resources allocated to R&D are measured by population and when only rich countries are included in the sample.”
- ^
This brittle supply chain also leaves the SOTA frontier vulnerable to other occurrences like natural disasters. For instance, when precision is measured by nanometers, a poorly placed earthquake or typhoon in Taiwan (not uncommon) or an earthquake (spurred by natural gas drilling) near ASML in the Netherlands could also set frontier research and distribution both back by months or longer, given these actors’ monopolistic dominance at their respective nodes in the supply chain. This point is relegated to a footnote because, frankly, I can’t predict the weather and have little understanding of the accommodation measures established in-house at these institutions. Far more concerning is the TSMC personnel concern detailed in the body, as the brittleness of this personal knowledge is a feature of the system.
- ^
For instance, when observers were concerned that the Russian invasion of Ukraine would inspire a PRC invasion of Taiwan, PRC foreign ministry officials said “Taiwan is not Ukraine," since “Taiwan has always been an inalienable part of China. This is an indisputable legal and historical fact.
11 comments
Comments sorted by top scores.
comment by Tom Davidson (tom-davidson-1) · 2023-12-23T18:29:27.482Z · LW(p) · GW(p)
Hi Trent!
I think the review makes a lot of good points and am glad you wrote it.
Here are some hastily-written responses, focusing on areas of disagreement:
- it is possible that AI generated synthetic data will ultimately be higher quality than random Internet text. Still I agree directionally about the data.
- it seems possible to me that abstraction comes with scale. A lot of the problems you describe get much less bad with scale. And it seems on abstract level that understanding causality deeply is useful for predicting the next word on text that you have not seen before, as models must do during training. Still, I agree that algorithmic innovations, for example relating to memory, maybe needed to get to full automation and that could delay things significantly.
- I strongly agree that my GDP assumptions are aggressive and unrealistic. I'm not sure that quantitatively it matters that much. You are of course, right about all of the feedback loops. I don't think that GDP being higher overall matters very much compared to the fraction of GDP invested. I think it will depend on whether people are willing to invest large fractions of GDP for the potential impact, or whether they need to see the impact there and then. If the delays you mentioned delay wake up then that will make a big difference, otherwise I think the difference is small.
- You may be right about the parallelization penalty. But I will share some context about that parameter that I think reduces the force of your argument. When I chose the parameters for the rate of increased investment, I was often thinking about how quickly you could in practice increase the size of the community of people working on the problem. That means that I was not accounting for the fact that the average salary rises when spending in an area rises. That salary rise will create the appearance of a large parallelization penalty. Another factor is that one contributor to the parallelization penalty is that the average quality of the researcher decreases over time with the side of the field. But when AI labor floods in, it's average quality will not decrease as the quantity increases. And so the parallelization penalty for AI will be lower. But perhaps my penalty is still too small. One final point. If indeed the penalty should be very low then AGI will increase output by a huge amount. You can run fewer copies much faster in serial time. If there is a large parallelization penalty, then the benefit of running fewer copies faster will be massive. So a large parallel penalty would increase the boost just as you get AGI I believe.
↑ comment by Trent Kannegieter · 2023-12-27T00:08:57.799Z · LW(p) · GW(p)
Hey Tom, thanks again for your work creating the initial report and for kicking off this discussion. Apologies for the Christmastime delay in reply.
Two quick responses, focused on points of disagreement that aren’t stressed in my original text.
On AI-Generated Synthetic Data:
Breakthroughs in synthetic data would definitely help overcome my dataset quality concerns. Two main obstacles I’d want to see overcome: How will synthetic data retain (1) the fidelity to individual data points of ground truth (how well it represents the "real world" its simulation prepares models for) and (2) the higher-level distribution of datapoints.
On Abstraction with Scale:
- Understanding causality deeply would definitely be useful for predicting next words. However, I don’t think that this potential utility implies that current models have such understanding. It might mean that algorithmic innovations that “figure this out” will outcompete others, but that time might still be to-come.
- I agree, though, that performance definitely improves with scale and more data collection/feedback when deployed more frequently. Time will tell the level of sophistication to which scale can take us on its own?
On the latter two points (GDP Growth and Parallelization), the factors you flag are definitely also parts of the equation. A higher percentage of GDP invested can increase total investment even if total GDP remains level. Additional talent coming into AI helps combat diminishing returns on the next researcher up, even given duplicative efforts and bad investments.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-01-03T22:31:11.484Z · LW(p) · GW(p)
The name and description of the paralllelization penalty makes it sound like it's entirely about parallelization -- "the penalty to concurrent R&D efforts." But then the math makes it sound like it's about more than that -- "The ouputs of the hardware and software production function R&D get raised to this penalty before being aggregated to the cumulative total."
What if we produce an AI system that assists human researchers in doing their research, (say) by automating the coding? And suppose that is, like, 50% of the research cycle, so that now there is the same number of researchers but they are all going 2x faster?
This feels like a case where there is no additional parallelization happening, just a straightforward speedup. So the parallelization penalty shouldn't be relevant. It feels like we shouldn't model this as equivalent to increasing the size of the population of researchers.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-12-30T02:07:17.669Z · LW(p) · GW(p)
There are reasons to believe that the AI/ML R&D process will be particularly inefficient due to the actors funding the work.
You haven't argued that the balance of factors is particularly bad for AI/ML R&D compared to other sectors. Lots of R&D sectors involve multiple competing corporations being secretive about their stuff, in multiple different countries. Lots of R&D sectors involve lots of investors who have no idea what they are doing. (Indeed I'd argue that's the norm.)
↑ comment by Trent Kannegieter · 2024-01-03T21:47:32.117Z · LW(p) · GW(p)
Hey Daniel, thanks for your comments here. The concern you bring up here is really important. I went back through this section with an eye toward “uniqueness.”
Looking back, I agree that the argument would be strengthened by an explicit comparison to other R&D work. My thought is still that both (1) technologies of national security and (2) especially lucrative tech have additional parallelization, since every actor has a strong incentive to chase and win it. But you’re right to point out that these factors aren’t wholly unique. I’d love to see more research on this. (I have more to look into as well. It might already be out there!)
Though one factor that I think survives this concern is that of investors.
Lots of R&D sectors involve lots of investors who have no idea what they are doing. (Indeed I'd argue that's the norm.)
While there are always unsophisticated investors, I still think there are many more of them in a particularly lucrative hype cycle. Larger potential rewards attract more investors with no domain expertise. Plus, the signal of learning from experts also gets weaker, as the hype cycle attracts more unsophisticated authors/information sources who also want a piece of the pie. (Think about how many more people have become “AI experts” or are writing AI newsletters over the last few years than have done the same in, say, agriculture.) These factors are compounded by the overvaluation that occurs at the top of bubbles as some investors try to “get in on the wave” even when prices are too high for others.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-01-04T14:17:17.439Z · LW(p) · GW(p)
Thanks! I agree that there's more hype around AI right now than, say, semiconductors or batteries or solar panels. And more importantly, right around the time of AGI there'll plausibly be more hype around AI than around anything ever. So I'll concede that in this one way, we have reason to think that R&D resources will be allocated less efficiently than usual in the case of AGI. I don't think this is going to significantly change the bottom line though--to the point where if it wildly changes the results in Tom's model I'd take that as a reason to doubt Tom's model.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-12-30T01:46:03.842Z · LW(p) · GW(p)
Increased Parallelization Penalty, All Else Equal, Adds 5 Years to Timeline
Going from 0.7 to 0.1 adds 2 years on the aggressive settings, and 3 years on my preferred settings. I think the spirit of your point still stands; this is just a quibble--I'd recommend saying "adds a few years to timelines" instead of "adds 5 years"
↑ comment by Trent Kannegieter · 2024-01-03T21:48:07.079Z · LW(p) · GW(p)
I agree that it would be better to say “adds five years under ‘Best Guess’ parameters,” or to just use “years” in the tagline. (Though I stand by the decision to compare worlds by using the best guess presets, if only to isolate the one variable under discussion.)
It makes sense that aggressive parameters reduce the difference, since they reach full automation in significantly less time. At parallelization penalty 0.7, Aggressive gets you there in 2027, while Best Guess takes until 2040! With Conservative parameters, the same .7 to .1 shift has even larger consequences.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-01-03T22:07:53.776Z · LW(p) · GW(p)
OK, seems we mostly agree then.
BTW thank you for drawing my attention to the parallelization penalty crux; I hadn't realized how sensitive the model was to that parameter before! Very important to think more about this. ETA: Curious if you have thoughts on my confused question here [LW(p) · GW(p)].
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-24T03:13:16.932Z · LW(p) · GW(p)
So, I am absolutely on-board with the GDP Growth & Measurement critique, and the Taiwan Supply Chain problem.
For the GDP Growth & Measurement critique
I think you make good points here, but there are additional reason to expect even more slowdowns. For instance, I don't think it's quite as easy as the report makes it out to be to ramp up automation. I suspect that ramping up of novel technologies, like new sorts of robotics, will lead to novel bottlenecks in supply chains. Things which previously weren't scarce will become (temporarily) scarce. There is a significant amount of inertia in ramping up novel verticals.
Another reason is that there's going to be a lot of pushback from industry that will create delays. Investment into existing infrastructure creates strong incentives from wealthy powerful actors to lobby for not having their recently-built infrastructure obsoleted. This political force, plus the political force of the workers who would be displaced, constitutes a synergistically more powerful political bloc than either alone.
For Taiwan Supply Chain
I believe the US is making significant strides in trying to create comparable chip fabs in the US, but this is going to take a few years to be on par even with continued government support. So this factor is more relevant in the next 5 years than it should be expected to be any time > 5 years from now.
For the R&D penalty
I'm not really convinced by this argument. I agree that the scaling factor for adding new researchers to a problem is quite difficult. But what if you just give each existing researcher an incredibly smart and powerful assistant? Seems to me that that situation is sufficiently different from naively adding more researchers as to perhaps not fit the same pattern.
Similarly, when the AI systems are researching on their own, I'm not convinced that it makes sense to model them as individual humans working separately. As Geoffrey Hinton has discussed in some recent interviews, AI has a big advantage here that humans don't have. They can share weights, share knowledge nearly instantly with perfect fidelity. Thus, you can devise a system of AI workers who function as a sort of hivemind, constantly sharing ideas and insights with each other. This means they are closer to being 'one giant researcher' than being lots of individual humans. I don't know how much this will make a difference, but I'm pretty sure the exact model from human researchers won't fit very well.
On the topics of Data and Reasoning
I actually don't think this does represent an upcoming roadblock. I actually think we are already in a data and compute overhang, and the thing holding us back is algorithmic development. I don't think we are likely to get to AGI by scaling existing LLMs. I do think that existing LLMs will get far enough to be useful assistants to initially speed up ML R&D. But I think one of the effects of that speed up is going to be that researchers feel enabled, with the help of powerful assistants, to explore a broader range of hypotheses. Reading papers, extracting hypotheses, writing code to test these hypotheses, summarizing the results... these are all tasks which could be automated by sufficiently scaffolded LLMs not much better than today's models.
I expect that the result of this will be discovering entirely new architectures which fundamentally have far more abstract reasoning ability, and don't need nearly as much data or compute to train. If true, this will be a dangerous jump because it will actually be a discontinuous departure from the scaling pattern so far seen with transformer-based LLMs.
For more details on the implications of this 'new unspecified superior architecture, much better at reasoning and extrapolation from limited data', I will direct you to this post by Thane: https://www.lesswrong.com/posts/HmQGHGCnvmpCNDBjc/current-ais-provide-nearly-no-data-relevant-to-agi-alignment [LW · GW]
Replies from: Trent Kannegieter↑ comment by Trent Kannegieter · 2023-12-27T00:13:03.884Z · LW(p) · GW(p)
Hey Nathan, thanks for your comments. A few quick responses:
On Taiwan Supply Chain:
- Agreed that US fabs don’t become a huge factor for a few years, even if everything “goes right” in their scale-up.
- Important to note that even as the US fabs develop, other jurisdictions won’t pause their progress. Even with lots to be determined re: future innovation, lots has to “go right” to displace Taiwan from the pole position.
On R&D Penalty:
- The “hive mind”/“One Giant Researcher” model might smooth out the inefficiency of communicating findings within research teams. However, this doesn’t solve the problem of different R&D teams working toward the same goals, thus “duplicating” their work. (Microsoft and Google won’t unite their “AI hive minds.” Nor will Apple and Huawei.)
- Giving every researcher a super-smart assistant might help individual researcher productivity, but it doesn’t stop them from pursuing the same goals as their counterparts at other firms. It might accelerate progress without changing the parallelization penalty.
- Concerns about private markets investment inefficiency still also contribute to a high parallelization penalty.
On Data and Reasoning:
“I actually think we are already in a data and compute overhang, and the thing holding us back is algorithmic development. I don't think we are likely to get to AGI by scaling existing LLMs.”
If new breakthroughs in algorithm design solve the abstract reasoning challenge, then I agree! Models will need less data and compute to do more. I just think we’re major breakthrough or two away from that.
Davidson’s initial report builds off of a compute-centric model where “2020-era algorithms are powerful enough to reach AGI, if only provided enough compute.”
If you think we’re unlikely to get to AGI—or just solve the common sense problem—by scaling existing LLMs, then we will probably need more than just additional compute.
(I’d also push back on the idea that we’re already in a “data overhang” in many contexts. Both (1) robotics and (2) teaching specialized knowledge come to mind as domains where a shortage of quality data limits progress. But given our agreement above, that concern is downstream.)